
DARTS: DIFFERENTIABLE ARCHITECTURE SEARCH
摘要
本文通过以可微分的方式解决架构搜索的可扩展性挑战。 与在离散和不可微搜索空间上应用进化算法或强化学习的传统方法不同,作者的方法是基于架构表示的连续松弛,能够使用梯度下降对架构进行有效搜索。 在 CIFAR-10、ImageNet、Penn Treebank 和 WikiText-2 上进行的大量实验表明,该算法在发现用于图像分类的高性能卷积架构和用于语言建模的循环架构方面表现出色,同时比现有的不可微分方法快几个数量级。下面,简单介绍下Darts对网络架构搜索的建模以及具体的松弛方法。
搜索空间
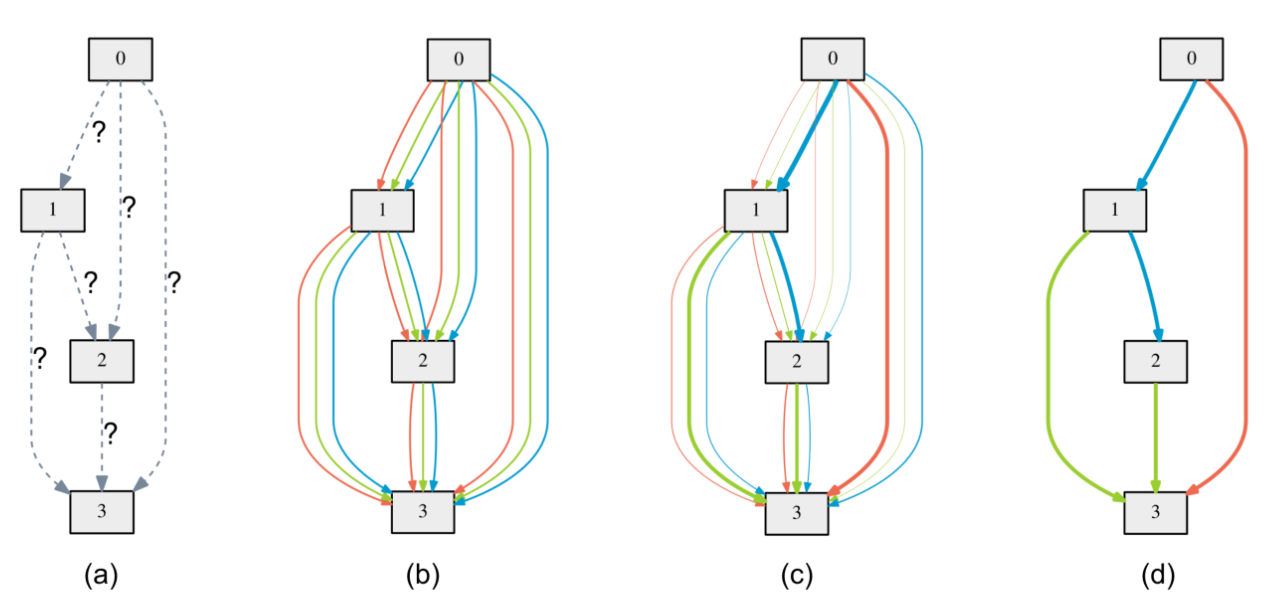
搜索空间被建模成如图所示的超网络。图中的方块表示的是featuremap,有向边表示连接两个featuremap的所有可能操作,且每条边只对应一个操作。(a) 边上的操作最初是未知的。(b) 通过在每条边上放置候选混合操作建立搜索空间。(c) 通过求解双层优化问题联合优化混合概率和网络权重。(d) 从学习到的混合概率中归纳最终架构。注意这里说的混合跟集成学习或者是注意力的意思有点像。也就是在超网络的训练中,两个featuremap之间的所有操作都是要参与到前向传播的,不同操作输出的featuremap被加权求和后作为新的featuremap。
Darts的重点是每个候选操作的权重如何构建,以及如何松弛。
松弛方法
\bar{o}^{(i, j)}(x)=\sum_{o \in \mathcal{O}} \frac{\exp \left(\alpha_o^{(i, j)}\right)}{\sum_{o^{\prime} \in \mathcal{O}} \exp \left(\alpha_{o^{\prime}}^{(i, j)}\right)} o(x) 将上图中的有向边对应到操作的表示符号 o(x),每个操作的权重则是
\frac{\exp \left(\alpha_o^{(i, j)}\right)}{\sum_{o^{\prime} \in \mathcal{O}} \exp \left(\alpha_{o^{\prime}}^{(i, j)}\right)}.其中,\alpha 是可训练的参数。如此,该权重具有以下特点:
- 可微分,权重具有自适应能力。
- 和为1,确保输出的featuremap在正常范围内。
- 权重越大,相应的候选操作在输出的featuremap中的贡献越大。
基于上述特点,在训练完成后,选择权重最大的候选即可。
训练算法

在训练的过程中,架构参数与模型参数被视作两组独立的参数交替使用梯度下降进行优化。参数收敛后,根据架构参数的最大值确定每两个featuremap之间的操作,从而生成最终架构。
Incredible insights! Sprunki transforms how we think about musical creativity. Sprunki offers unprecedented creative potential in composition. The way Sprunki empowers creative expression is truly remarkable.
Innovative breakdown! FNAF Games audio design deserves awards – that distant clanging could be Chica or your doom! 2AM pro tip: Headphones on!
I’m really impressed along with your writing skills as smartly as with the structure to your blog. Is this a paid subject or did you modify it your self? Either way keep up the nice quality writing, it’s rare to look a great blog like this one today!
Great breakdown on roulette strategies – it’s fascinating how math shapes outcomes. For those interested in AI-driven productivity, check out the AI Twitter Assistant for smart automation.
SuperPH22 offers a great mix of luck and strategy with its 1024 ways to win. The Jocker Card wilds and free spins really boost the fun. Check out SuperPH for a daily gaming hit!
I love how AI makes Ghibli magic accessible! 지브리 AI lets you turn simple ideas into stunning visuals. It’s like having Hayao Miyazaki in your pocket!
Do you have a spam issue on this blog; I also am a blogger, and I was curious about your situation; we have created some nice methods and we are looking to trade methods with others, be sure to shoot me an e-mail if interested.
George St-Pyer
What’s up i am kavin, its my first time to commenting anyplace, when i read this article i thought i could also make comment due to this good post.
melbet apps
What’s up, the whole thing is going perfectly here and ofcourse every one is sharing data, that’s actually excellent, keep up writing.
hafilat card recharge online
This is the perfect website for anybody who really wants to find out about this topic. You know so much its almost hard to argue with you (not that I actually will need to…HaHa). You certainly put a new spin on a topic that has been discussed for ages. Wonderful stuff, just great!
www zain com kuwait
Do you have a spam issue on this site; I also am a blogger, and I was curious about your situation; we have created some nice procedures and we are looking to swap methods with others, be sure to shoot me an e-mail if interested.
bus travel Abu Dhabi
кайт хургада
Hi there it’s me, I am also visiting this site on a regular basis, this web page is truly good and the users are genuinely sharing good thoughts.
https://hughes-mcgee-4.thoughtlanes.net/henry-uz-com-t-erri-daniel-anri-kh-ak-ik-ii-merosi-zhamlangan-manba
Jili77 stands out with its AI-driven approach, making it a smart pick for serious players. The platform’s variety and security really shine, especially for those diving into slots or live games.
Excellent article. Keep posting such kind of information on your page. Im really impressed by it.
Hi there, You have done an excellent job. I will definitely digg it and personally recommend to my friends. I’m confident they’ll be benefited from this website.
https://www.dermandar.com/user/airbusegg35/
I blog quite often and I genuinely thank you for your information. This great article has truly peaked my interest. I am going to take a note of your site and keep checking for new details about once per week. I opted in for your RSS feed too.
https://ital-parts.com.ua/gde-kupit-nadezhnyy-shoker-dlya-samooborony-luchshie-magaziny-shokeru-com-ua
cialis da 5 mg prezzo : an effective drug containing tadalafil, treats erectile dysfunction and benign prostatic hyperplasia. In Italy, 28 tablets of Cialis 5 mg is priced at approximately €165.26, though prices vary by pharmacy and discounts. Generic alternatives, like Tadalafil DOC Generici, cost €0.8–€2.6 per tablet, offering a budget-friendly option. Always consult a doctor, as a prescription is needed.
Baccarat strategies work best with discipline. I always check out the live dealer games at JLJL PH for a real casino feel-great mix of tech and tradition.
«Рентвил» предлагает аренду автомобилей в Краснодаре без залога и ограничений по пробегу по Краснодарскому краю и Адыгее. Требуется стаж от 3 лет и возраст от 23 лет. Оформление за 5 минут онлайн: нужны только фото паспорта и прав. Подача авто на жд вокзал и аэропорт Краснодар Мин-воды Сочи . Компания работает 10 лет , автомобили проходят своевременное ТО. Доступны детские кресла. Бронируйте через сайт машина в аренду краснодар
What a material of un-ambiguity and preserveness of precious know-how regarding unexpected feelings.
https://ital-parts.com.ua/gde-kupit-nadezhnyy-shoker-dlya-samooborony-luchshie-magaziny-shokeru-com-ua
http://pravo-med.ru/articles/18547/
kitesurfing это
кайт школа хургада
https://oboronspecsplav.ru/
Пассажирские перевозки Караганда – Новосибирск Пассажирские перевозки Новосибирск – Астана Отправляйтесь в комфортное путешествие из Новосибирска в Астану с нашими надежными пассажирскими перевозками. Мы предлагаем регулярные рейсы, обеспечивающие удобство и безопасность в пути. Пассажирские перевозки Астана – Новосибирск Планируете поездку из Астаны в Новосибирск? Наши пассажирские перевозки – это ваш лучший выбор. Наслаждайтесь комфортом и безопасностью в течение всего путешествия. Пассажирские перевозки Новосибирск – Павлодар Совершите увлекательное путешествие из Новосибирска в Павлодар с нашими пассажирскими перевозками. Мы гарантируем приятную поездку и своевременное прибытие. Пассажирские перевозки Павлодар – Новосибирск Наши пассажирские перевозки из Павлодара в Новосибирск – это ваш шанс насладиться комфортным и безопасным путешествием. Доверьте нам свою поездку и оцените высокий уровень сервиса.
Hi friends, its wonderful post on the topic of cultureand fully defined, keep it up all the time.
https://bestpeople.com.ua//krashchi-hermetyky-fary-auto
Пассажирские перевозки Новосибирск – Астана Развитая сеть пассажирских перевозок играет ключевую роль в обеспечении мобильности населения и укреплении экономических связей между регионами. Наша компания специализируется на организации регулярных и безопасных поездок между городами Сибири и Казахстана, предлагая комфортные условия и доступные цены.
Admiring the hard work you put into your blog and in depth information you present. It’s nice to come across a blog every once in a while that isn’t the same outdated rehashed material. Great read! I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
https://forthouse.com.ua/sklo-ta-korpusy-dlya-far-3er-bmw-vse-scho-potribno-znaty
«Рентвил» предлагает аренду автомобилей в Краснодаре без залога и ограничений по пробегу по Краснодарскому краю и Адыгее. Требуется стаж от 3 лет и возраст от 23 лет. Оформление за 5 минут онлайн: нужны только фото паспорта и прав. Подача авто на жд вокзал и аэропорт Краснодар Мин-воды Сочи . Компания работает 10 лет , автомобили проходят своевременное ТО. Доступны детские кресла. Бронируйте через сайт аренда машины в краснодаре
Запчасти для станков Bison Bial Токарные патроны Bison Запчасти для станков Bison Bial В мире металлообработки, где точность и надежность играют ключевую роль, токарные патроны Bison занимают особое место. Эти инструменты, производимые известной польской компанией Bison Bial, зарекомендовали себя как высококачественные и долговечные компоненты для токарных станков. Они обеспечивают надежный зажим заготовок, что напрямую влияет на качество и скорость обработки.
Hi are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started and set up my own. Do you need any coding expertise to make your own blog? Any help would be greatly appreciated!
Myzain
Опт из Китая В эпоху глобализации и стремительного развития мировой экономики, Китай занимает ключевую позицию в качестве крупнейшего производственного центра. Организация эффективных и надежных поставок товаров из Китая становится стратегически важной задачей для предприятий, стремящихся к оптимизации затрат и расширению ассортимента. Наша компания предлагает комплексные решения для вашего бизнеса, обеспечивая бесперебойные и выгодные поставки товаров напрямую из Китая.
Good day! Do you use Twitter? I’d like to follow you if that would be ok. I’m absolutely enjoying your blog and look forward to new updates.
my Zain
Hello! This post could not be written any better! Reading through this post reminds me of my previous room mate! He always kept talking about this. I will forward this post to him. Fairly certain he will have a good read. Thanks for sharing!
my Zain
Nice share!
A unique view on [url=https://winb.lt/vavada-casino-supporting-women-in-stem-through-digital-innovation/]vavada casino[/url] mixed with future-focused design and accessibility.
Мебель для кухни Кухня – сердце дома, место, где рождаются кулинарные шедевры и собирается вся семья. Именно поэтому выбор мебели для кухни – задача ответственная и требующая особого подхода. Мебель на заказ в Краснодаре – это возможность создать уникальное пространство, идеально отвечающее вашим потребностям и предпочтениям.
Understanding gambling psychology is key to responsible play. Platforms like Super PH offer immersive experiences, but balance is essential for long-term enjoyment.
What’s up to every one, the contents existing at this site are in fact awesome for people knowledge, well, keep up the nice work fellows.
hafilat recharge
Hi Dear, are you actually visiting this web site regularly, if so afterward you will without doubt take pleasant experience.
hafilat
В динамичном мире Санкт-Петербурга, где каждый день кипит жизнь и совершаются тысячи сделок, актуальная и удобная доска объявлений становится незаменимым инструментом как для частных лиц, так и для предпринимателей. Наша платформа – это ваш надежный партнер в поиске и предложении товаров и услуг в Северной столице. Подать объявление в СПб
аккаунты варфейс купить В мире онлайн-шутеров Warface занимает особое место, привлекая миллионы игроков своей динамикой, разнообразием режимов и возможностью совершенствования персонажа. Однако, не каждый готов потратить месяцы на прокачку аккаунта, чтобы получить желаемое оружие и экипировку. В этом случае, покупка аккаунта Warface становится привлекательным решением, открывающим двери к новым возможностям и впечатлениям.
Узи беременность В ритме современного мегаполиса, такого как Санкт-Петербург, забота о женском здоровье становится приоритетной задачей. Регулярные консультации с гинекологом, профилактические осмотры и своевременная диагностика – залог долголетия и благополучия каждой женщины.
Heya just wanted to give you a brief heads up and let you know a few of the images aren’t loading properly. I’m not sure why but I think its a linking issue. I’ve tried it in two different web browsers and both show the same results.
hafilat card balance check
Hello there I am so delighted I found your blog page, I really found you by error, while I was searching on Bing for something else, Nonetheless I am here now and would just like to say thanks for a fantastic post and a all round entertaining blog (I also love the theme/design), I don’t have time to browse it all at the moment but I have saved it and also included your RSS feeds, so when I have time I will be back to read much more, Please do keep up the superb work.
hafilat card
Hi there, the whole thing is going well here and ofcourse every one is sharing information, that’s really excellent, keep up writing.
hafilat card
музыкальные новинки Роп – Русский роп – это больше, чем просто музыка. Это зеркало современной российской души, отражающее её надежды, страхи и мечты. В 2025 году жанр переживает новый виток развития, впитывая в себя элементы других стилей и направлений, становясь всё более разнообразным и эклектичным. Популярная музыка сейчас – это калейдоскоп звуков и образов. Хиты месяца мгновенно взлетают на вершины чартов, но так же быстро и забываются, уступая место новым музыкальным новинкам. 2025 год дарит нам множество талантливых российских исполнителей, каждый из которых вносит свой неповторимый вклад в развитие жанра.
Do you have a spam problem on this website; I also am a blogger, and I was curious about your situation; we have created some nice methods and we are looking to trade strategies with others, please shoot me an email if interested.
http://daicond.com.ua/yak-doglyadaty-za-sklom-dlya-far-porady-ta-sekrety
красное море температура воды
Сергей Бидус кинул на деньги
Really insightful article! It’s great to see platforms focusing on service alongside the games themselves. I checked out game ph login & their support seems top-notch – crucial for a smooth experience, right? Definitely a step up!
That is very fascinating, You are an overly professional blogger. I have joined your feed and look ahead to in quest of more of your fantastic post. Additionally, I have shared your site in my social networks
porno izle
Творчество своими руками Самоделки своими руками – это не просто хобби, это целая философия, позволяющая взглянуть на окружающий мир под новым углом, увидеть потенциал в обыденных вещах и дать им новую жизнь. Это способ выразить свою индивидуальность, проявить творческую натуру и, конечно же, сэкономить средства. Оригинальные самоделки рождаются из фантазии и желания создать нечто уникальное, неповторимое. Это могут быть украшения для дома, предметы интерьера, аксессуары, изготовленные из подручных материалов. Главное – это идея и вдохновение.
пауэрлифтинг Гармония силы: Путь к совершенству через спорт и правильное питание Спорт, особенно силовой, – это не просто поднятие тяжестей. Это искусство лепки тела и духа, требующее дисциплины, знаний и постоянного стремления к совершенству. В основе этого искусства лежит три кита: жим, присед и становая тяга. Жим лежа – символ силы верхней части тела, требует не только мощных грудных мышц, но и стабильности плечевого пояса и сильных трицепсов. Правильная техника – ключ к прогрессу и предотвращению травм. Приседания – царь упражнений, развивающий силу ног и ягодиц, а также укрепляющий корпус. Глубина приседа, контроль над весом и правильное дыхание – факторы, определяющие эффективность этого упражнения. Становая тяга – королева упражнений, задействующая практически все мышцы тела. Сильная спина, крепкий хват и правильная техника подъема – залог безопасного и эффективного выполнения становой тяги. Пауэрлифтинг объединяет эти три упражнения, превращая стремление к силе в соревнование. Это не просто поднятие максимального веса, это демонстрация контроля над своим телом и разумом, результат месяцев упорных тренировок. Однако, сила без здоровья – ничто. Правильное питание – неотъемлемая часть спортивного успеха. Баланс белков, жиров и углеводов, достаточное количество витаминов и минералов, а также своевременное восстановление – основа для роста мышц и поддержания здоровья. Спорт и правильное питание – это не просто хобби, это образ жизни, который ведет к гармонии силы и здоровья, к совершенству тела и духа.
Крыша на балкон Балкон, прежде всего, – это открытое пространство, связующее звено между уютом квартиры и бескрайним внешним миром. Однако его беззащитность перед капризами погоды порой превращает это преимущество в существенный недостаток. Дождь, снег, палящее солнце – все это способно причинить немало хлопот, лишая возможности комфортно проводить время на балконе, а также нанося ущерб отделке и мебели. Именно здесь на помощь приходит крыша на балкон – надежная защита и гарантия комфорта в любое время года.
roobet redeem code WEB3 В мире онлайн-казино инновации не стоят на месте, и Roobet находится в авангарде этих перемен. С появлением технологии Web3, Roobet предлагает игрокам новый уровень прозрачности, безопасности и децентрализации. Чтобы воспользоваться всеми преимуществами этой передовой платформы, используйте промокод WEB3.
«Рентвил» предлагает аренду автомобилей в Краснодаре без залога и ограничений по пробегу по Краснодарскому краю и Адыгее. Требуется стаж от 3 лет и возраст от 23 лет. Оформление за 5 минут онлайн: нужны только фото паспорта и прав. Подача авто на жд вокзал и аэропорт Краснодар Мин-воды Сочи . Компания работает 10 лет , автомобили проходят своевременное ТО. Доступны детские кресла. Бронируйте через авто в аренду краснодар
Hi, I think your website might be having browser compatibility issues. When I look at your blog in Opera, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, wonderful blog!
hafilat balance check
chicken road demo Chicken Road: Взлеты и Падения на Пути к Успеху Chicken Road – это не просто развлечение, это обширный мир возможностей и тактики, где каждое решение может привести к невероятному взлету или полному краху. Игра, доступная как в сети, так и в виде приложения для мобильных устройств (Chicken Road apk), предлагает пользователям проверить свою фортуну и чутье на виртуальной “куриной тропе”. Суть Chicken Road заключается в преодолении сложного маршрута, полного ловушек и опасностей. С каждым успешно пройденным уровнем, награда растет, но и увеличивается шанс неудачи. Игроки могут загрузить Chicken Road game demo, чтобы оценить механику и особенности геймплея, прежде чем рисковать реальными деньгами.
Generate custom ai hentai generator. Create anime-style characters, scenes, and fantasy visuals instantly using an advanced hentai generator online.
Rainbet code ILBET В мире онлайн-гемблинга Rainbet сияет как яркая звезда, привлекая игроков своими щедрыми предложениями и захватывающими играми. Промокод ILBET – это ваш билет в этот мир возможностей, предоставляющий доступ к эксклюзивным бонусам и акциям, разработанным для повышения вашего игрового опыта и увеличения шансов на победу.
Baccarat patterns are fascinating – truly understanding them elevates your game. Seeing platforms like game ph login prioritize mobile UX is smart; seamless access is key for tracking trends on the go! It’s about convenience & insight.
pinco casino azerbaijan Pinco, Pinco AZ, Pinco Casino, Pinco Kazino, Pinco Casino AZ, Pinco Casino Azerbaijan, Pinco Azerbaycan, Pinco Gazino Casino, Pinco Pinco Promo Code, Pinco Cazino, Pinco Bet, Pinco Yukl?, Pinco Az?rbaycan, Pinco Casino Giris, Pinco Yukle, Pinco Giris, Pinco APK, Pin Co, Pin Co Casino, Pin-Co Casino. Онлайн-платформа Pinco, включая варианты Pinco AZ, Pinco Casino и Pinco Kazino, предлагает азартные игры в Азербайджане, также известная как Pinco Azerbaycan и Pinco Gazino Casino. Pinco предоставляет промокоды, а также варианты, такие как Pinco Cazino и Pinco Bet. Пользователи могут загрузить приложение Pinco (Pinco Yukl?, Pinco Yukle) для доступа к Pinco Az?rbaycan и Pinco Casino Giris. Pinco Giris доступен через Pinco APK. Pin Co и Pin-Co Casino — это связанные термины.
Скачать тик ток мод Тикток мод, словно цифровой феникс, возрождается на просторах Android, предлагая пользователям расширенные возможности и свободу самовыражения. Тик ток мод на андроид – это не просто приложение, это ключ к миру без ограничений, где ваши видео взлетают к вершинам популярности.
Найти мастера по ремонту холодильников в Виннице можно по ссылке
личные дебетовые карты Путеводитель по миру удобных банковских карт. Оформить современную дебетовую карту стало просто и удобно благодаря нашей поддержке. Выберите карту, которая идеально вам подходит, и наслаждайтесь всеми преимуществами современного финансового сервиса. Что мы предлагаем? Практические советы: Полезные лайфхаки и рекомендации для эффективного использования вашей карты. Свежие акции: Будьте в курсе всех актуальных предложений и специальных условий от наших банков-партнеров. Преимущества нашего сообщества. Полная информация о различных видах карт, особенностях тарифов и комиссий. Регулярно обновляемые материалы с актуальными данными и последними новостями о продуктах российских банков. Присоединяйтесь к нашему сообществу, чтобы сделать ваши финансовые решения простыми, быстрыми и безопасными. Вместе мы сможем оптимизировать использование банковских продуктов и сэкономить ваше время и средства. Наша цель — помочь вам эффективно управлять своими финансами и получать максимальную выгоду от каждого взаимодействия с банком.
тик ток мод русский скачать последняя Мир мобильных приложений не стоит на месте, и Тик Ток продолжает оставаться одной из самых популярных платформ для создания и обмена короткими видео. Но что, если стандартной функциональности вам недостаточно? На помощь приходит Тик Ток Мод – модифицированная версия приложения, открывающая доступ к расширенным возможностям и эксклюзивным функциям.
Ментор Стратегическое планирование: создайте будущее своей компании. Многие бизнесы борются с размытыми целями и отсутствием четкого плана. Настоящий успех достигается через стратегическое планирование — системный подход к развитию. Ментор поможет вам определить ключевые цели, разработать реалистичные стратегии и создать дорожную карту роста. Вместе вы сможете предвидеть вызовы, использовать возможности и избегать ошибок. Не откладывайте развитие на потом — инвестируйте в профессиональную поддержку и создайте прочный фундамент для долгосрочного успеха. Закажите консультацию и начните строить будущее уже сегодня.
Мир полон тайн https://phenoma.ru читайте статьи о малоизученных феноменах, которые ставят науку в тупик. Аномальные явления, редкие болезни, загадки космоса и сознания. Доступно, интересно, с научным подходом.
бесплатные общие аккаунты стим бесплатные общие аккаунты стим
тикток мод бесплатно
бесплатный мод на тик ток айфон Улучшенная версия TikTok для iPhone: загрузка, модификации и последние обновления. Как установить модифицированный TikTok на iPhone? Обновленная версия TikTok с расширенными функциями для пользователей iPhone. Где скачать последнюю версию модифицированного TikTok для iOS? Бесплатные моды TikTok для iPhone, включая версию 2025 года. Ищете способ улучшить свой опыт использования TikTok на iPhone? Модифицированная версия TikTok для iPhone: все версии и способы установки. Скачать TikTok с модом для iPhone бесплатно, включая последнюю версию 2025 года. Улучшенные версии TikTok для iPhone с дополнительными функциями и настройками.
раздача стим аккаунтов бесплатно t.me/Burger_Game/
оформить дебетовую карту Откройте для себя мир удобных банковских карт с нашей помощью. Оформление современной дебетовой карты стало простым и доступным благодаря нашей платформе. Легко подберите подходящую карту и пользуйтесь всеми преимуществами современных финансовых услуг. Что мы предлагаем? Полезные советы: Рекомендации и лайфхаки для эффективного использования вашей карты. Актуальные акции: Будьте в курсе последних предложений и специальных условий от банков-партнеров. Преимущества нашего сообщества. Здесь вы найдете всю необходимую информацию о различных видах карт, особенностях тарифов и комиссий. Наши публикации регулярно обновляются, предоставляя актуальные данные и свежие новости о продуктах российских банков. Присоединяйтесь к нашему сообществу, чтобы сделать ваши финансовые решения простыми, быстрыми и надежными. Вместе мы сможем оптимизировать использование банковских продуктов и сэкономить ваше время и деньги. Ведь наша цель — помогать вам эффективно управлять своими финансами и получать максимум выгоды от каждого взаимодействия с банком.
фотозона баннер с днем рождения Фотографическая зона, оформленная баннером; декоративный баннер для фотозоны; праздничный баннер “С днем рождения” для создания фотозоны; баннер размером 2 на 2 метра, предназначенный для оформления фотозоны на дне рождения. Альтернативно, можно сказать так: Место для фотографирования, украшенное тематическим баннером; специальный баннер, используемый для создания фотозоны; баннер с надписью “С днем рождения” для оформления пространства для фотосессий; баннер с габаритами 2×2 метра, предназначенный для использования в качестве фона на дне рождения.
робота вебкам моделлю в Польщі Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
легальна онлайн робота для дівчат Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
Научно-популярный сайт https://phenoma.ru — малоизвестные факты, редкие феномены, тайны природы и сознания. Гипотезы, наблюдения и исследования — всё, что будоражит воображение и вдохновляет на поиски ответов.
praca webcam Polska Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
steam account authenticator it is a desktop emulator of the Steam authentication mobile application. This desktop application allows users to manage their two-factor authentication easily, ensuring that only you can access your account.
тик ток без Тик ток нова – это уже не просто название, это эра. Эра, в которой короткие видеоролики стали доминирующей формой развлечения, а тренды сменяются быстрее, чем успеваешь моргнуть глазом. “Тикток нова скачать” – этот запрос звучит как призыв к действию, как приглашение в мир бесконечного креатива и вирусного контента. Загружая “тикток скачать”, ты получаешь билет в этот мир, где каждый может стать звездой.
сборка компьютера под ключ Компьютер для стрима: Высокое качество трансляций Компьютер для стрима должен обеспечивать стабильную работу во время трансляций, высокое качество изображения и звука. Сборка компьютера на заказ позволяет выбрать компоненты, способные справиться с этими задачами.
This article brilliantly simplifies blackjack basics-just like how Sprunki Incredibox makes music creation accessible yet deep. Both are perfect for beginners and pros alike.
сборка компьютеров для игр
Looking for the best haircut in town? MenSpire delivers tailored precision cuts, expert grooming, and a luxe vibe. Book now for a refined, confidence-boosting transformation.
It’s fascinating how casino tech is evolving – predictive analytics to personalize experiences is a game changer! Thinking about future gaming, platforms like ph567 Casino seem to be leading the charge with innovative approaches. Exciting times!
sda steam it is a desktop emulator of the Steam authentication mobile application. This desktop application allows users to manage their two-factor authentication easily, ensuring that only you can access your account.
download steam desktop authenticator it is a desktop emulator of the Steam authentication mobile application. This desktop application allows users to manage their two-factor authentication easily, ensuring that only you can access your account.
Hi Dear, are you really visiting this website daily, if so afterward you will absolutely obtain fastidious experience.
https://studioline-interior.com/led-lampy-avto-yak-zrobyty-pokupku-yaka-prosluzhyt.html
Discover the best barbershop experience in the CBD: MenSpire blends contemporary flair with traditional craftsmanship. Friendly pros, clean ambiance—your style, redefined.
Готовьте вкусно рецепт приготовления у нас — рецепты на любой вкус: мясные, вегетарианские, диетические, сладкие и острые. Пошаговые фото, время приготовления и секреты идеального блюда.
Experience https://llmbrowser.net, a specialized cloud agentic browser, delivering seamless integration for AI agents. This platform includes cloud synchronization, making it an ideal agentic antidetect browser. Upgrade your AI toolkit with a better agentic browser. Start now.
Юрист Онлайн https://juristonline.com квалифицированная юридическая помощь и консультации 24/7. Решение правовых вопросов любой сложности: семейные, жилищные, трудовые, гражданские дела. Бесплатная первичная консультация.
Exploring roulette strategies adds depth to gameplay. It’s interesting how platforms like Jili App blend math and entertainment for engaging casino experiences.
Дом из контейнера https://russiahelp.com под ключ — мобильное, экологичное и бюджетное жильё. Индивидуальные проекты, внутренняя отделка, электрика, сантехника и монтаж
Сайт знакомств https://rutiti.ru для серьёзных отношений, дружбы и общения. Реальные анкеты, удобный поиск, быстрый старт. Встречайте новых людей, находите свою любовь и начинайте общение уже сегодня.
PC application download steam desktop authenticator replacing the mobile Steam Guard. Confirm logins, trades, and transactions in Steam directly from your computer. Support for multiple accounts, security, and backup.
No more phone needed! https://sdasteam.com lets you use Steam Guard right on your computer. Quickly confirm transactions, access 2FA codes, and conveniently manage security.
Агентство недвижимости https://metropolis-estate.ru покупка, продажа и аренда квартир, домов, коммерческих объектов. Полное сопровождение сделок, юридическая безопасность, помощь в оформлении ипотеки.
Квартиры посуточно https://kvartiry-posutochno19.ru в Абакане — от эконом до комфорт-класса. Уютное жильё в центре и районах города. Чистота, удобства, всё для комфортного проживания.
хэллоуин маникюр алматы Наращивание ногтей Алматы – это возможность создать идеальную длину и форму ногтей, о которой вы всегда мечтали. Наращивание на типсы Алматы, наращивание на верхние формы Алматы, наращивание гелем Алматы – выбор за вами.
kitesurfing
погода в хургаде в апреле 2023
СРО УН «КИТ» https://sro-kit.ru саморегулируемая организация для строителей, проектировщиков и изыскателей. Оформление допуска СРО, вступление под ключ, юридическое сопровождение, помощь в подготовке документов.
Ремонт квартир https://remont-kvartir-novo.ru под ключ в новостройках — от черновой отделки до полной готовности. Дизайн, материалы, инженерия, меблировка.
sitio web tavoq.es es tu aliado en el crecimiento profesional. Ofrecemos CVs personalizados, optimizacion ATS, cartas de presentacion, perfiles de LinkedIn, fotos profesionales con IA, preparacion para entrevistas y mas. Impulsa tu carrera con soluciones adaptadas a ti.
Webseite cvzen.de ist Ihr Partner fur professionelle Karriereunterstutzung – mit ma?geschneiderten Lebenslaufen, ATS-Optimierung, LinkedIn-Profilen, Anschreiben, KI-Headshots, Interviewvorbereitung und mehr. Starten Sie Ihre Karriere neu – gezielt, individuell und erfolgreich.
Interesting read! Seeing how platforms like sz777 log in focus on user engagement-it’s not just about the games, right? Psychological principles really do shape the experience. Smart stuff for retention!
Greate post. Keep posting such kind of info on your site. Im really impressed by it.
Hi there, You have performed a great job. I will definitely digg it and in my opinion suggest to my friends. I’m confident they’ll be benefited from this site.
bus card renewal
Hey there, You’ve done a great job. I will certainly digg it and personally recommend to my friends. I’m sure they’ll be benefited from this site.
buy bus card abu dhabi
Диагностика бесплатна при последующем ремонте Apple-устройства.
sitio web tavoq.es es tu aliado en el crecimiento profesional. Ofrecemos CVs personalizados, optimizacion ATS, cartas de presentacion, perfiles de LinkedIn, fotos profesionales con IA, preparacion para entrevistas y mas. Impulsa tu carrera con soluciones adaptadas a ti.
еайт школа в анапе Кайтсерфинг в Анапе – это больше, чем просто спорт, это философия жизни.
снять квартиру в ташкенте Снять квартиру в Ташкенте на длительный срок: Рассматривая аренду на длительный срок, тщательно изучайте договор аренды. Убедитесь, что в нем четко прописаны все условия, включая размер арендной платы, порядок ее внесения, условия расторжения договора и ответственность сторон.
kraken onion Кракен онино
Looking for the best haircut in town? MenSpire delivers tailored precision cuts, expert grooming, and a luxe vibe. Book now for a refined, confidence-boosting transformation.
Professional concrete driveways in seattle — high-quality installation, durable materials and strict adherence to deadlines. We work under a contract, provide a guarantee, and visit the site. Your reliable choice in Seattle.
Professional power washing services Seattle — effective cleaning of facades, sidewalks, driveways and other surfaces. Modern equipment, affordable prices, travel throughout Seattle. Cleanliness that is visible at first glance.
Нужна камера? камера удаленного видеонаблюдения для дома, офиса и улицы. Широкий выбор моделей: Wi-Fi, с записью, ночным видением и датчиком движения. Гарантия, быстрая доставка, помощь в подборе и установке.
Interesting analysis! Seeing platforms like Plus777 really push for data-driven play is smart. Understanding game mechanics does elevate the experience – beyond just luck, right? Good insights!
Need transportation? car carriers car transportation company services — from one car to large lots. Delivery to new owners, between cities. Safety, accuracy, licenses and experience over 10 years.
Thank you for the auspicious writeup. It in truth used to be a amusement account it. Glance complex to far introduced agreeable from you! By the way, how can we keep in touch?
balance check hafilat
Hi, this weekend is fastidious for me, because this occasion i am reading this enormous informative paragraph here at my house.
hafilat card recharge
vehicle freight auto shipping quotes
Sprunki Incredibox brings fresh beats and visuals to the beloved Incredibox formula, making creativity even more fun. Check out the innovation at Spunky Games!
telegram crypto channel Крипто Биржи и Telegram Каналы: Ваш Источник Информации Выбор надежной крипто биржи и подписка на проверенные crypto exchange telegram crypto channel, crypto telegram channel и best crypto telegram – залог вашей информированности. Crypto telegram news – это быстрый способ получать актуальные новости и аналитику.
Thanks for every other excellent post. Where else could anybody get that type of info in such an ideal method of writing? I have a presentation subsequent week, and I’m at the look for such info.
hafilat card balance check
купить диплом о среднем образовании Диплом о высшем образовании с занесением в реестр: Для тех, кто ценит надежность и уверенность, мы предлагаем дипломы с занесением в реестр. Это гарантирует подлинность документа и исключает любые сомнения в его легитимности.
Постеры, трейлеры, тизеры и арты Смотреть аниме сериалы онгоинги онлайн бесплатно в русской озвучке – это возможность погрузиться в захватывающий мир японской анимации, не пропустив ни одной новой серии. Anime News держит вас в курсе всех событий индустрии, предоставляя самую свежую информацию о любимых тайтлах и грядущих премьерах. Анонсы новых серий и сезонов позволяют планировать свой просмотр и всегда быть в предвкушении следующей главы истории. Новости индустрии и студий раскрывают закулисье создания аниме, позволяя лучше понять творческий процесс и оценить работу аниматоров. Постеры, трейлеры, тизеры и арты дают первое впечатление о новых проектах, подогревая интерес и помогая определиться с выбором. Расписания премьер позволяют не пропустить выход долгожданных эпизодов и сезонов. Фан-сервис, фото, видео, клипы из аниме – это дополнительный контент, который порадует фанатов и позволит еще глубже погрузиться в атмосферу любимых сериалов. Все это, и многое другое, делает просмотр аниме онгоингов онлайн в русской озвучке не только увлекательным, но и информативным занятием. Следите за обновлениями, чтобы всегда быть в курсе последних событий в мире аниме 2025 и наслаждайтесь новинками!
металлопрокат купить в москве цена Металлопрокат купить в Москве: цена, опт и разнообразие выбора Москва – огромный мегаполис с постоянно растущими потребностями в строительных материалах. Металлопрокат занимает здесь особое место, являясь основой для возведения зданий, мостов, дорог и множества других объектов. Покупка металлопроката в Москве – ответственный шаг, требующий внимательного подхода к выбору поставщика и понимания ценообразования.
auto transport Navigating the World of Automobile Transport Services: A Comprehensive Guide In today’s interconnected world, automobile transport services have become indispensable for individuals and businesses alike. Whether you’re relocating across the country, purchasing a vehicle online, or managing a dealership’s inventory, understanding the intricacies of car shipping is crucial. This guide delves into the various facets of auto transport, providing insights into car shipping companies, auto transport companies, vehicle shipping companies, and the critical factors to consider when selecting the best service.
Вова Чернышев
Строительство дома бани из клееного бруса Строительство дома, бани из клееного бруса: Мы используем только высококачественные материалы и современное оборудование. Наши специалисты – это команда профессионалов с многолетним опытом работы. Мы гарантируем индивидуальный подход к каждому клиенту и высокое качество строительства. Позвольте нам воплотить вашу мечту о загородной жизни в реальность!
варфейс акк Warface: Твой путь к вершинам Независимо от того, выбираете ли вы купить аккаунт Warface, приобрести мощное оружие или воспользоваться пин-кодами, важно помнить, что главное – это удовольствие от игры. Warface – это мир, полный возможностей, и каждый игрок может найти свой путь к победе.
керамогранит 120 60 керамическая плитка 1200х600 на стену
Great read! As a blackjack newbie, it’s helpful to break down strategies step by step. Platforms like JLJL PH offer immersive live dealer games that let you practice real-time decision-making-definitely a useful tool for learning the ropes.
Dice games are surprisingly mathematical! Thinking about probability & strategy really elevates the fun. It’s cool how platforms like PH222 focus on smooth access & a great user experience – essential for enjoying any game! 👍
ultimate createporn generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
ultimate createporn generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
консультация юриста https://besplatnaya-yuridicheskaya-konsultaciya-moskva-po-telefonu.ru
Профессиональное косметологическое оборудование для салонов красоты для салонов красоты, клиник и частных мастеров. Аппараты для чистки, омоложения, лазерной эпиляции, лифтинга и ухода за кожей.
Interesting analysis! Seeing platforms like 789bet99 really adapt to local preferences-easy account setup & payments-is key for growth. It’s smart to empower both new & seasoned players! What trends are you seeing in Vietnamese gaming specifically?
Hello are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and create my own. Do you need any coding knowledge to make your own blog? Any help would be greatly appreciated!
hafilat balance checking
Elevate your look at MenSpire Singapore—the best barber crafting precision styles in a chic, modern space. Expect top-tier service and sharp results every time.
вскрыть замок москва Вскрытие замков – деликатная проблема, требующая оперативного решения. Ситуации, когда необходимо вскрыть замок срочно, не редкость, особенно в Москве. Потеря ключей, сломанный механизм, заклинившая дверь – все это требует профессионального подхода. Вскрытие замков в Москве – востребованная услуга. Важно найти надежного мастера, предлагающего открытие замков без повреждений. Вскрытие замков Москва недорого – реально, но не стоит гнаться за самой низкой ценой в ущерб качеству. Вскрыть дверной замок – задача для специалиста. Взлом замков – это крайняя мера, и профессиональные услуги по вскрытию замков подразумевают аккуратную работу. Вызвать мастера по вскрытию замков – оптимальное решение в большинстве случаев. Вскрытие дверных замков требует определенных навыков и инструментов. Цена на вскрытие замка может варьироваться в зависимости от сложности работы. Вскрыть замок мастер должен быстро и эффективно.
https://plombi.ru/product/nabor-dlya-opechatyvaniya-dverey/
Pharmaceuticals Bazaar Drugs Marketplace: A New Darknet Platform with Dual Access Bazaar Drugs Marketplace is a new darknet marketplace rapidly gaining popularity among users interested in purchasing pharmaceuticals. Trading is conducted via the Tor Network, ensuring a high level of privacy and data protection. However, what sets this platform apart is its dual access: it is available both through an onion domain and a standard clearnet website, making it more convenient and visible compared to competitors. The marketplace offers a wide range of pharmaceuticals, including amphetamines, ketamine, cannabis, as well as prescription drugs such as alprazolam and diazepam. This variety appeals to both beginners and experienced buyers. All transactions on the platform are carried out using cryptocurrency payments, ensuring anonymity and security. In summary, Bazaar represents a modern darknet marketplace that combines convenience, a broad product selection, and a high level of privacy, making it a notable player in the darknet economy.
Группа в Telegram Доска бесплатных объявлений “Все для Вас Архангельск”: товары, услуги, авто, жильё, работа, розыгрыши, отзывы и многое другое. Архангельск, Северодвинск, Новодвинск, Катунино, Березник, Рикасиха, Холмогоры, Мезень, Карпогоры архангельск время
продать лекарственный препарат где
уроки кайтсёрфинга Обучение кайтсерфингу Если вы хотите научиться кайтсерфингу, в Хургаде есть множество школ и опытных инструкторов. Профессиональный кайтсерфинг тренер поможет вам освоить азы управления кайтом, технику скольжения по воде и правила безопасности. Обучение кайтсёрфингу обычно включает в себя теоретические занятия, практику на берегу и на воде.
сервис знай своего клиента
профнастил оцинкованный Продажа в Алматы Шымкенте и Астане Продажа металлопроката в Алматы, Шымкенте, Астане. Рынок металлопроката в Алматы, Шымкенте и Астане представлен множеством компаний, однако выбор правильного партнера – залог успешного завершения любого проекта. Важно учитывать не только стоимость продукции, но и ее качество, соответствие стандартам, а также репутацию поставщика. Компания Модуль Сталь предлагает Вам широкий спектр продукции: арматуру различных диаметров, стальные листы, оцинкованный профнастил, уголки, швеллеры и многое другое. Это позволяет клиенту приобрести все необходимое в одном месте, экономя время и ресурсы. Важным фактором нашей компании является наличие собственных складских помещений и развитой логистической сети, что обеспечивает оперативную доставку металлопроката на строительные площадки и производственные предприятия.
вопросы про катэг
ultimate AI porn maker generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
гарантийный ремонт стиральных машин алматы Ремонт платы стиральной машины в Алматы – мы производим ремонт плат любой сложности.
проверка стиральной машины алматы Телефон мастера стиральных машин Алматы. Звоните прямо сейчас для вызова специалиста.
демонтаж в выходные стоимость Демонтаж компьютерных сетей – необходимо при переезде или обновлении офиса.
честные весы металлолом Утилизация сканеров в Алматы: утилизация сканеров и другой офисной техники.
Бездепозитный бонус
This page definitely has all of the info I wanted about this subject and didn’t know who to ask.
Play daily on 88fb bet and win real money
It’s great to see platforms focusing on responsible gaming! Understanding game mechanics, like those at phlwin com login, can really enhance enjoyment. Remember to set limits & play for fun! It’s all about balance, right? 😊
гибкая керамика цена за 1 м2 Гибкая керамика для фасадов дома внутренней отделки Москва phomi купить цена фоми монтаж за 1 м2 отзывы divu
vavada casino бонусы Vavada Casino Отзывы: Узнайте, что говорят другие игроки о Vavada Casino, и сформируйте свое мнение об этом популярном онлайн-казино.
I appreciate, lead to I discovered just what I was having a look for. You have ended my four day long hunt! God Bless you man. Have a great day. Bye
Try the best slots and live tables on 88fb login
сборка алматы Нанять разнорабочих в Алматы можно как на краткосрочные, так и на долгосрочные проекты. Важно учитывать квалификацию, опыт и отзывы предыдущих клиентов.
a-p-s эвакуатор Сравнить эвакуаторы алматы – сравнение компаний, предоставляющих услуги эвакуатора в Алматы.
Бездепозитный бонус
Лучшие юристы Екатеринбурга http://yuristy-ekaterinburga.ru
Шиномонтаж Краснодар 24 https://shinomontazh-vyezdnoj.ru/
Сукааа казино официальный сайт казино Сукааа казино официальный сайт скачать на андроид мобильная версия бесплатно позволяет играть в любимые игры прямо на своем смартфоне или планшете.
Бездепозитные бонусы
Сукааа казино официальный рабочее зеркало на сегодняшний день Сукааа казино официальный сайт скачать на андроид мобильная версия бесплатно позволяет играть в любимые игры прямо на своем смартфоне или планшете.
Really insightful article! Thinking about user journeys & conversion is key. Seeing platforms like sz7777 login focus on that – reducing friction & building engagement – is smart. Great points on behavioral analytics too!
Бездепозитные бонусы
вавада казино официальный сайт Вавада Казино Официальный Сайт Скачать на Андроид Мобильная Версия Бесплатно: Скачайте мобильную версию Вавада Казино на свое устройство Android и наслаждайтесь игрой в любом месте и в любое время.
блокчейн проверка транзакции по кошельку
Защитные кейсы plastcase.ru в Санкт-Петербурге — надежная защита оборудования от влаги, пыли и ударов. Большой выбор размеров и форматов, ударопрочные материалы, индивидуальный подбор.
Бездепозитные бонусы в казино
Защитные кейсы plastcase.ru/ в Санкт-Петербурге — надежная защита оборудования от влаги, пыли и ударов. Большой выбор размеров и форматов, ударопрочные материалы, индивидуальный подбор.
Сукааа казино официальный сайт скачать на андроид мобильная версия бесплатно Сукааа казино официальный сайт вход бесплатный играть – это возможность попробовать свои силы в демо-режиме без внесения депозита.
онлайн займы на карту без отказа https://zajmy-onlajn.ru
Бездепозитный бонус в казино
займы онлайн на карту по паспорту займы онлайн без проверок срочно
вавада казино официальный сайт Вавада Казино Официальный Рабочее Зеркало на Сегодняшний День: Всегда имейте доступ к Вавада Казино через рабочее зеркало, актуальное на сегодняшний день, и не упустите возможность испытать удачу.
Портал о строительстве https://buildportal.kyiv.ua и ремонте: лучшие решения для дома, дачи и бизнеса. Инструменты, сметы, калькуляторы, обучающие статьи и база подрядчиков.
Бездепозитные бонусы в казино Бездепозитные бонусы в казино: Что это такое? Бездепозитный бонус в казино – это денежная сумма или бесплатные вращения, которые казино предоставляет новым игрокам в качестве приветственного подарка. Главное преимущество этого бонуса заключается в том, что для его получения не требуется внесение депозита. Игрок может просто зарегистрироваться на сайте казино и получить бонус на свой счет.
Бездепозитный бонус Бездепозитные бонусы: Путь к азартным приключениям без риска В мире онлайн-казино, где азарт и возможность выигрыша переплетаются в захватывающем танце, бездепозитные бонусы занимают особое место. Эти щедрые предложения служат своеобразным ключом, открывающим двери в мир азартных развлечений без необходимости вкладывать собственные средства.
лечение алкогольной зависимости https://alko-info.ru
вывод из запоя на дом цена вывод из запоя срочно круглосуточно
Бездепозитные бонусы в казино
Бездепозитные бонусы Бездепозитный бонус в казино: Как его получить? Получить бездепозитный бонус в казино, как правило, довольно просто. Обычно требуется пройти процедуру регистрации на сайте казино и подтвердить свою учетную запись. В некоторых случаях может потребоваться ввести специальный промокод. После выполнения всех условий бонус будет автоматически зачислен на ваш счет. Бездепозитные бонусы – это отличная возможность начать свой путь в мире онлайн-казино с минимальным риском и максимальным удовольствием. Однако, прежде чем принимать бонус, всегда внимательно ознакомьтесь с условиями его использования, чтобы избежать недоразумений в будущем.
Сукааа казино официальный сайт скачать на андроид мобильная версия бесплатно Сукааа казино официальный сайт – ваш надежный партнер в мире азартных игр.
Праздничная продукция https://prazdnik-x.ru для любого повода: шары, гирлянды, декор, упаковка, сувениры. Всё для дня рождения, свадьбы, выпускного и корпоративов.
оценка нма услуги по оценке стоимости недвижимости
Бездепозитные бонусы Бездепозитные бонусы в казино: Что это такое? Бездепозитный бонус в казино – это денежная сумма или бесплатные вращения, которые казино предоставляет новым игрокам в качестве приветственного подарка. Главное преимущество этого бонуса заключается в том, что для его получения не требуется внесение депозита. Игрок может просто зарегистрироваться на сайте казино и получить бонус на свой счет.
Строительный журнал https://garant-jitlo.com.ua всё о технологиях, материалах, архитектуре, ремонте и дизайне. Интервью с экспертами, кейсы, тренды рынка.
Онлайн-журнал https://inox.com.ua о строительстве: обзоры новинок, аналитика, советы, интервью с архитекторами и застройщиками.
Бездепозитные бонусы в казино Бездепозитные бонусы в казино: Что это такое? Бездепозитный бонус в казино – это денежная сумма или бесплатные вращения, которые казино предоставляет новым игрокам в качестве приветственного подарка. Главное преимущество этого бонуса заключается в том, что для его получения не требуется внесение депозита. Игрок может просто зарегистрироваться на сайте казино и получить бонус на свой счет.
Бездепозитные бонусы
Sykaaa casino официальный сайт вход Сукааа казино официальный сайт казино предлагает широкий выбор игр, включая слоты, рулетку и блэкджек.
Бездепозитные бонусы в казино Бездепозитный бонус в казино: Как его получить? Получить бездепозитный бонус в казино, как правило, довольно просто. Обычно требуется пройти процедуру регистрации на сайте казино и подтвердить свою учетную запись. В некоторых случаях может потребоваться ввести специальный промокод. После выполнения всех условий бонус будет автоматически зачислен на ваш счет. Бездепозитные бонусы – это отличная возможность начать свой путь в мире онлайн-казино с минимальным риском и максимальным удовольствием. Однако, прежде чем принимать бонус, всегда внимательно ознакомьтесь с условиями его использования, чтобы избежать недоразумений в будущем.
Всё о строительстве https://stroyportal.kyiv.ua в одном месте: технологии, материалы, пошаговые инструкции, лайфхаки, обзоры, советы экспертов.
Полезный сайт https://vasha-opora.com.ua для тех, кто строит: от фундамента до крыши. Советы, инструкции, сравнение материалов, идеи для ремонта и дизайна.
Владивосток работа Владивосток: работа для женщин и мужчин
1000 рублей за регистрацию с выводом
DeFi стратегии 2025 Актуальные листинги бирж предлагают новые возможности для инвестиций в перспективные проекты на ранних стадиях.
Игорь Стоунберг экстрасенс отзывы Я в шоке от точности его предсказаний. Он помогает людям в трудных ситуациях. | Рада, что обратилась. |
вавада Вабанк Казино Официальный Сайт: Посетите официальный сайт Вабанк Казино и окунитесь в мир азартных игр с широким выбором развлечений и возможностью крупных выигрышей.
kait travelling Сила ветра лазера в Египте: Вероятно, опечатка, имеется в виду “сила ветра для кайтсёрфинга в Египте”.
Since the admin of this website is working, no uncertainty very soon it will be well-known, due to its feature contents.
https://777-gaming.com/top-brands-for-plinko-boards.html
Журнал для мужчин https://swiss-watches.com.ua которые ценят успех, свободу и стиль. Практичные советы, мотивация, интервью, спорт, отношения, технологии.
Мужской журнал https://hand-spin.com.ua о стиле, спорте, отношениях, здоровье, технике и бизнесе. Актуальные статьи, советы экспертов, обзоры и мужской взгляд на важные темы.
Игорь Стоунберг экстрасенс Игорь Стоунберг – настоящий профессионал своего дела. Он помог мне принять важное решение, которое изменило мою жизнь к лучшему.
школы в хургаде кайт Обучение кайтсёрфингу Обучение кайтсёрфингу – это следующий шаг после освоения базовых навыков управления кайтом. На этом этапе учатся вставать на доску, контролировать скорость и направление движения, а также выполнять простые трюки. Важно выбирать опытного инструктора и комфортные условия для обучения.
Бездепозитные бонусы
Все новинки https://helikon.com.ua технологий в одном месте: гаджеты, AI, робототехника, электромобили, мобильные устройства, инновации в науке и IT.
1000 рублей за регистрацию вывод сразу без вложений в казино адмирал
Ремонт без стресса https://odessajs.org.ua вместе с нами! Полезные статьи, лайфхаки, дизайн-проекты, калькуляторы и обзоры.
кайтсерфинг в египте сезон Кайтсёрфинг Кайтсёрфинг – это сплав ветра, воды и мастерства. Этот вид спорта позволяет скользить по водной глади, используя силу ветра, пойманную кайтом. Это динамичный и захватывающий способ провести время на открытом воздухе, требующий определенной физической подготовки и навыков управления кайтом и доской.
стоимость сертификата кайтсерфинга iko Кайт школа Кайт школа – это место, где мечты о покорении волн с помощью кайта становятся реальностью. Квалифицированные инструкторы, современное оборудование и безопасные условия позволяют быстро и эффективно освоить навыки кайтинга и кайтсерфинга.
кайт школа унесенные ветром Кайт школа Кайт школа – это место, где мечты о покорении волн с помощью кайта становятся реальностью. Квалифицированные инструкторы, современное оборудование и безопасные условия позволяют быстро и эффективно освоить навыки кайтинга и кайтсерфинга.
Sykaaa casino бонусы Sykaaa casino бонусы порадуют как новичков, так и опытных игроков. Увеличьте свои шансы на выигрыш с помощью щедрых предложений!
1000 рублей за регистрацию вывод сразу без вложений в казино адмирал
vingfoil Обучение кайтсёрфингу Обучение кайтсёрфингу – это следующий шаг после освоения базовых навыков управления кайтом. На этом этапе учатся вставать на доску, контролировать скорость и направление движения, а также выполнять простые трюки. Важно выбирать опытного инструктора и комфортные условия для обучения.
Understanding game dynamics is crucial in betting, and platforms like Jili No1 offer great insights through diverse gameplay options that mirror real-time betting scenarios.
Работа для школьников во Владивостоке Подработка во Владивостоке для студентов: совмещение учебы и заработка Студенты Владивостока могут найти множество вариантов подработки, позволяющих совмещать учебу и работу. Гибкий график и неполная занятость делают подработку идеальным способом заработать деньги и получить ценный опыт. Популярные варианты включают работу в сфере обслуживания, курьерскую доставку и помощь в проведении мероприятий.
цельнозерновой хлеб ташкент ПП хлеб Ташкент: для тех, кто следит за фигурой
Читайте авто блог https://autoblog.kyiv.ua обзоры автомобилей, сравнения моделей, советы по выбору и эксплуатации, новости автопрома.
Авто портал https://real-voice.info для всех, кто за рулём: свежие автоновости, обзоры моделей, тест-драйвы, советы по выбору, страхованию и ремонту.
A full explanation of diagnostics, parts, and timing: https://teremok.org.ua/ipgeo/inc/vse_chto_nuzghno_znat_o_remonte_noutbukov_acer__ot_diagnostiki_do_garantii.html
можно ли встретить акулу осенью в египте Кайт египет: Открой для себя лучшие кайт-споты Египта
как не попасть в зубы акулы в египте Кайт – это не просто спортивный снаряд, а символ свободы и единения с природой, позволяющий ощутить мощь ветра и скольжение по волнам.
Портал о строительстве https://start.net.ua и ремонте: готовые проекты, интерьерные решения, сравнение материалов, опыт мастеров.
Сукааа казино официальный сайт Sykaaa casino скачать стоит для тех, кто ценит мобильность. Приложение обеспечивает бесперебойный доступ к любимым играм в любом месте.
Строительный портал https://apis-togo.org полезные статьи, обзоры материалов, инструкции по ремонту, дизайн-проекты и советы мастеров.
кайтинг в хургаде в июле Кайт Хургада: Лучшие кайт-споты Египта ждут вас!
1000 рублей за регистрацию вывод сразу
Портал для женщин https://olive.kiev.ua любого возраста: от секретов молодости и красоты до личностного роста и материнства.
Современный женский https://prowoman.kyiv.ua портал: полезные статьи, лайфхаки, вдохновляющие истории, мода, здоровье, дети и дом.
кайт сафари хургада Кайт станция египет: Комфорт и безопасность на кайт-станции
What’s up, everything is going sound here and ofcourse every one is sharing data, that’s genuinely fine, keep up writing.
https://dnmagazine.com.ua/kupyty-korpus-far-dlya-avtomobilya-shcho-potribno-.html
кайт школа в хургаде Кайт школа дети ветра: Мы предлагаем безопасное и эффективное обучение кайтингу для всех уровней подготовки. Наши опытные инструкторы помогут вам освоить этот захватывающий вид спорта и достичь новых высот.
Elevate your look at MenSpire Singapore—the best barber crafting precision styles in a chic, modern space. Expect top-tier service and sharp results every time.
Семейный портал https://stepandstep.com.ua статьи для родителей, игры и развивающие материалы для детей, советы психологов, лайфхаки.
Туристический портал https://aliana.com.ua с лучшими маршрутами, подборками стран, бюджетными решениями, гидами и советами.
кайт центр в хургаде Кайтсёрфинг: Энергия ветра в ваших руках, свобода движения по воде, адреналин и восторг – все это кайтсерфинг. Откройте для себя этот захватывающий вид спорта и ощутите, как ветер наполняет вашу жизнь новыми красками.
Бездепозитные бонусы в казино
I love how tech is making design more accessible! Tools like Lovart AI Agent turn ideas into visuals effortlessly-especially the pixel art conversion. Fun stuff!
1000 рублей за регистрацию с выводом
кайт кемп Кайт школа хургада: Обучение кайтсерфингу в лучших кайт-спотах Хургады. Откройте для себя новые горизонты!
Exploring keno strategies can be thrilling, especially with platforms like Jili OK offering AI-driven insights. It’s a great tool for players looking to sharpen their approach while enjoying a wide range of games.
кайт школа : Сертификат кайтсерфинг: Подтверди свои навыки!
I delight in, cause I found exactly what I was taking a look for. You have ended my four day long hunt! God Bless you man. Have a great day. Bye
https://dvernoyolimp.org.ua/yak-znajty-najbilsh-ekonomichne-rishennya-dlya-pok.html
Новости Украины https://useti.org.ua в реальном времени. Всё важное — от официальных заявлений до мнений экспертов.
Архитектурный портал https://skol.if.ua современные проекты, урбанистика, дизайн, планировка, интервью с архитекторами и тренды отрасли.
кайтсёрфинг в хургаде Кайт хургада: Идеальное место для кайтсерфинга круглый год. Теплая вода, стабильный ветер, песчаные пляжи.
Бездепозитный бонус
Всё об автомобилях https://autoclub.kyiv.ua в одном месте. Обзоры, новости, инструкции по уходу, автоистории и реальные тесты.
Новости Украины https://hansaray.org.ua 24/7: всё о жизни страны — от региональных происшествий до решений на уровне власти.
1000 рублей за регистрацию вывод сразу
кайтсерфинг в египте Кайт дети ветра: Открой мир кайтсерфинга с профессионалами. Почувствуй свободу, адреналин и единение с природой. Мы поможем тебе освоить этот захватывающий вид спорта безопасно и эффективно.
Do you have any video of that? I’d want to find out some additional information.
https://sinyak.com.ua/chy-pidkhodyt-butylovyj-hermetyk-dlya-zadnikh.html
египет русская кайт школа Кайт школа дети ветра: Безопасное и эффективное обучение кайтингу
кайт египте Кайтсерфинг в хургаде: Почувствуйте адреналин и свободу кайтсерфинга в Хургаде. Незабываемые впечатления гарантированы.
Новостной портал https://news24.in.ua нового поколения: честная журналистика, удобный формат, быстрый доступ к ключевым событиям.
Информационный портал https://dailynews.kyiv.ua актуальные новости, аналитика, интервью и спецтемы.
Бездепозитный бонус
1000 рублей за регистрацию
Мировые новости https://ua-novosti.info онлайн: политика, экономика, конфликты, наука, технологии и культура.
кайт в хургаде Кайт хургада: Хургада – один из лучших кайт-спотов в мире, с идеальными условиями для обучения и катания круглый год. Стабильный ветер, теплая вода и песчаные пляжи делают Хургаду настоящим раем для кайтсерферов.
Elevate your look at MenSpire Singapore—the best barber crafting precision styles in a chic, modern space. Expect top-tier service and sharp results every time.
Офисная мебель https://officepro54.ru в Новосибирске купить недорого от производителя
hawaii riviera aqua park hurghada кайт станция : Кайт школа дети ветра: Открой мир кайтсерфинга вместе с нами!
область туризма Кайтсерфинг в Хургаде — это популярный вид активного отдыха, который привлекает множество туристов. Хургада славится своими пляжами и стабильными ветрами, что делает ее идеальным местом для кайтеров.
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Подробнее можно узнать тут – https://nakroklinikatest.ru/
Бездепозитные бонусы
египет кайтинг : detivetra: Одно слово, эхо юности, когда мир казался безграничным, как морской горизонт.
1000 рублей за регистрацию в казино без депозита вывод сразу
кейс защитный 1100 1000 410 http://plastcase.ru
кайт школа windfamily : Сертификат кайтсерфинг: Подтверди свои навыки!
I’m not sure exactly why but this weblog is loading very slow for me. Is anyone else having this issue or is it a problem on my end? I’ll check back later on and see if the problem still exists.
betwinner
защитный кейс купить https://plastcase.ru
кайт станции египет : Кайт школа в хургаде египет: Твой ключ к миру кайтсерфинга!
An outstanding share! I have just forwarded this onto a co-worker who was doing a little homework on this. And he in fact ordered me breakfast because I stumbled upon it for him… lol. So allow me to reword this…. Thank YOU for the meal!! But yeah, thanx for spending some time to talk about this issue here on your internet site.
бетвинер зеркало
Бездепозитные бонусы в казино
1000 рублей за регистрацию с выводом
сертификат кайтсерфинг : Кайт лагерь анапа: Отдых и обучение в одном флаконе!
сертификат кайтсерфинг iko : Кайт школа дети ветра: Открой мир кайтсерфинга вместе с нами!
Keep on writing, great job!
tadalafil aurobindo 5 mg
That’s a fascinating point about game volatility! Seeing how skill & luck blend in titles like Happy Fishing is really interesting – a unique take on the usual slot experience in Vietnam. Definitely worth checking out!
кайт школа спб : Кайт серфинг в египте: Насладись идеальными условиями для кайтсерфинга круглый год!
Бездепозитный бонус
получить 1000 рублей за регистрацию
купить отчет о практике стоимость отчета по практике
есть ли акулы в египте в октябре : Кайт сафари: Приключение, которое запомнится навсегда!
заказать отчет по учебной практике https://otchetbuhgalter.ru
карточка iko это : Кайт кемп: Интенсивное обучение для быстрого прогресса!
кайт школа windfamily Кайт школа в Хургаде: Профессиональное обучение кайтингу в Хургаде.
Бездепозитные бонусы в казино
фонтан казино бездепозитный бонус 1000 рублей за регистрацию без депозита с выводом денег
оформить микрозаем http://zajmy-onlajn.ru
кайт Кайт серфинг в Египте: Насладитесь кайтсерфингом в кристально чистых водах Красного моря.
займ онлайн мгновенно https://zajmy-onlajn.ru
Hi Dear, are you actually visiting this website daily, if so after that you will without doubt take good knowledge.
punta cana airport to hard rock hotel
лучший хлеб ташкент Хлеб на Закваске: Возрождение Традиций Хлеб на закваске – это древний способ приготовления хлеба, который в последние годы переживает возрождение.
газель с пирамидой алматы Грузоперевозки в Алматы – это качественный и оперативный сервис, который предлагает широкий выбор автомобилей, в том числе и газелей, для решения различных задач. Если вам необходимо перевезти мебель, бытовую технику или строительные материалы, наши услуги газели в Алматы помогут вам осуществить это быстро и надежно. Мы предлагаем аренду газелей различной грузоподъемности, включая короткие и длинные модели, а также специальное оборудование, например, термобудки и рефрижераторы для транспортировки чувствительных грузов. Вы можете заказать газель с грузчиками для удобного переезда, будь то офисный или квартирный. Наша команда профессиональных грузчиков обеспечит аккуратную упаковку, разборку и сборку мебели, а также позаботится о безопасной перевозке ваших вещей. В Алматы мы работаем круглосуточно, предоставляя возможность вызвать газель в любое время суток. Цены на грузоперевозки в Алматыvarьируются в зависимости от расстояния и объема работ, но мы всегда готовы предложить конкурентные расценки и специальные скидки для постоянных клиентов. Для срочных заказов мы предоставляем услуги быстрого реагирования, чтобы вы не переживали о задержках. Не упустите возможность воспользоваться самым удобным и экономичным способом перевозки в Алматы. Свяжитесь с нами по телефону или через WhatsApp, чтобы обсудить детали вашего заказа. Обращайтесь за надежной газелью в Алматы и убедитесь сами в качестве наших услуг!
Новинки кино 2025 бесплатно Фильмы без рекламы бесплатно: Способы смотреть любимое кино, не платя за отсутствие рекламы.
уплотнитель двери посудомоечной машины алматы Квалифицированный мастер обладает необходимыми знаниями и опытом для диагностики и устранения любых неисправностей посудомоечных машин. Он оперативно определит причину поломки и предложит оптимальное решение. Сервис посудомоечных машин Алматы
ремонт холодильников самал алматы : Починка морозилки – это быстрое и эффективное устранение поломки, которое позволяет избежать порчи продуктов. ремонт морозильного ларя алматы
Discover the best barbershop experience in the CBD: MenSpire blends contemporary flair with traditional craftsmanship. Friendly pros, clean ambiance—your style, redefined.
Бездепозитный бонус в казино
люкс детская одежда Рынок Садовод является одним из крупнейших оптовых рынков в России, где можно найти широкий ассортимент детской одежды, в том числе и реплики Zara Kids. Однако, при покупке на Садоводе важно быть внимательным и выбирать проверенных поставщиков. Опт Zara
плотник алатауский район Стоимость услуг электрика в Алматы варьируется в зависимости от сложности работ, используемых материалов и квалификации мастера. Перед вызовом специалиста рекомендуется уточнить расценки и сравнить предложения нескольких компаний. Электрик Алматы Недорого
варфейс акк Магазин аккаунтов Warface предлагает широкий выбор аккаунтов различных уровней и с различной экипировкой.
mines game strategy
шторы ночь Карниз для штор – это надежная опора, на которой держится вся шторная композиция. Важно выбрать карниз, который будет соответствовать стилю штор и выдерживать их вес. Римские шторы
Маска для снорклинга Существует множество видов акул, отличающихся по размеру, форме и образу жизни. Нападение акулы на человека
Чек стоп Дайвинг в Москве – это возможность заниматься дайвингом в бассейнах и озерах, не выезжая из города. Дайвер спасатель
Жак Ив Кусто Реестр нападения акул на человека – это база данных, содержащая информацию о зарегистрированных случаях нападения акул на людей. Дайвинг в Москве
For most recent news you have to pay a quick visit world wide web and on web I found this web page as a best web page for most up-to-date updates.
tadalafil pensa 5 mg
заказать отчет по практике срочно сделать отчет по практике на заказ
личный займ онлайн zajmy-onlajn.ru/
Маска для дайвинга Запуск маркерного буя – это навык, позволяющий дайверу обозначить свое местоположение на поверхности воды. Виды маркерных буев дайвера
шторы день ночь Потолочные шторы – это стильное и современное решение, которое визуально увеличивает высоту потолков. Как правильно шторы
warface аккаунт Приобретение нового оружия в Warface – это возможность расширить свой арсенал, улучшить свою статистику и адаптироваться к различным игровым ситуациям. Аккаунты Warface
ссылка на фишинговый сайт Определить, какой сайт фишинговый, можно путем внимательного анализа его URL-адреса, дизайна, контента и других характеристик, указывающих на его поддельность. Признаки фишинговых сайтов
Натяжные потолки Развилка Фото натяжных потолков – это отличный способ выбрать подходящий дизайн и оценить возможности этой технологии. Фотографии демонстрируют разнообразие цветов, фактур и конструкций натяжных потолков, позволяя подобрать оптимальное решение для любого интерьера. Натяжные потолки можно
фонтан казино бездепозитный бонус 1000 рублей за регистрацию без депозита с выводом денег Бездепозитный бонус в размере 1000 рублей с моментальным выводом – это редкая и ценная находка для азартных игроков. Она позволяет начать игру, не вкладывая собственные средства, и сразу же вывести выигрыш, если повезет. 1000 рублей за регистрацию вывод сразу без вложений
рулонные шторы купить Шторы своими руками – это возможность создать уникальный и неповторимый элемент интерьера. Установка штор
Какой натяжной потолок В Развилке натяжные потолки – это популярный выбор для тех, кто ценит качество и стиль. Натяжные потолки Островцы
аренда автомобилей краснодар аренда машины в краснодаре: Забудьте о пробках и общественном транспорте, арендуйте машину! Путешествуйте с комфортом и независимостью.
варфейс Акк Warface – это ваш цифровой идентификатор в мире Warface, отражающий ваш прогресс и достижения. Варфейс
Прокат авто без залога авто в аренду краснодар: Наслаждайтесь комфортом и свободой передвижения по Краснодару. Арендуйте автомобиль у нас и получите незабываемые впечатления от поездки!
Потолки помещений Жители Красково выбирают натяжные потолки за их практичность, долговечность и эстетичный внешний вид. Натяжные потолки Томилино
вавада казино официальный сайт рабочее зеркало на сегодня Вавада Казино Официальный Сайт Вход
Увлажнитель воздуха https://brand-climat.ru оптимальный уровень влажности для здоровья. Различные типы: ультразвуковые, паровые и др., фильтрация и защита. Подбор, доставка по России и официальная гарантия для вашего комфорта.
Ремонт бампера автомобиля — это популярная услуга, которая позволяет вернуть заводской вид транспортного средства после небольших повреждений. Новейшие технологии позволяют исправить сколы, трещины и вмятины без полной замены детали. При выборе между ремонтом или заменой бампера [url=https://telegra.ph/Remont-ili-zamena-bampera-05-22]https://telegra.ph/Remont-ili-zamena-bampera-05-22[/url] важно рассматривать уровень повреждений и экономическую целесообразность. Профессиональное восстановление включает подготовку, грунтовку и покраску.
Установка нового бампера требуется при значительных повреждениях, когда восстановление бамперов невыгоден или невозможен. Стоимость восстановления зависит от типа материала изделия, степени повреждений и марки автомобиля. Полимерные элементы допускают ремонту лучше металлических, а новые композитные материалы требуют специального оборудования. Качественный ремонт расширяет срок службы детали и сохраняет заводскую геометрию кузова.
Я с готовностью быть на подхвате по вопросам Ремонт бамперов в магнитогорске адреса и цены – обращайтесь в Телеграм sgf81
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this. Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
tadalafil pensa pharma 5 mg
Interesting read! The focus on culturally relevant tech, like what 68wim.tech is doing, is key for long-term player engagement. Seamless logins & a great 68win app download are huge wins for user experience, too. Solid platform!
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Детальнее – [url=https://narkologicheskaya-klinika-tyumen10.ru/]частная наркологическая клиника в тюмени[/url]
Школа Саморазвития https://bznaniy.ru онлайн-база знаний для тех, кто хочет понять себя, улучшить мышление, прокачать навыки и выйти на новый уровень жизни.
Бездепозитный бонус Казино, предлагающие бездепозитные бонусы, как гостеприимные хозяева, распахивают двери перед новичками и предлагают им оценить все прелести своего заведения. Это своеобразный жест доброй воли, который позволяет завоевать доверие игроков и превратить их в постоянных клиентов. Это умный маркетинговый ход, который работает в пользу обеих сторон. Бездепозитный бонус
На дом выезжает квалифицированный врач, который проводит процедуру детоксикации в комфортных условиях, позволяя пациенту избежать стресса и огласки. С помощью капельницы и медикаментов нормализуется состояние, восстанавливаются основные функции организма. Процедура длится несколько часов, после чего врач оставляет рекомендации по поддерживающему лечению.
Узнать больше – https://vyvod-iz-zapoya-lyubertsy2.ru
Для детоксикации и восстановления организма после запоя используются только сертифицированные лекарственные препараты с доказанной эффективностью и безопасностью:
Ознакомиться с деталями – http://narcolog-na-dom-sochi0.ru
Все вызовы фиксируются под кодовым номером без указания ФИО, что обеспечивает полную конфиденциальность каждого пациента.
Изучить вопрос глубже – https://narkologicheskaya-klinika-vladimir10.ru/chastnaya-narkologicheskaya-klinika-vladimir/
Репетитор по физике https://repetitor-po-fizike-spb.ru СПб: школьникам и студентам, с нуля и для олимпиад. Четкие объяснения, практика, реальные результаты.
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологическая клиника нарколог тюмень[/url]
Interesting points raised in this article! The convenience of mobile gaming is a huge draw, and platforms like phlwin app download apk are making it super accessible for Filipino players. Streamlined verification is key for trust!
бонусы в казино без депозита Принимая бездепозитный бонус, важно внимательно изучить условия его отыгрыша. Вейджер, сроки действия и ограничения по играм – все эти факторы могут существенно повлиять на возможность вывода выигрыша. Тщательное изучение правил поможет избежать разочарований и максимально эффективно использовать бонус. Бездепозитные бонусы казино без пополнения с отыгрышем
That’s a bold prediction – really interesting take on the potential upset! Seems like jlboss com understands entertainment, offering diverse games – a good distraction while waiting for results! 😉 Solid analysis overall.
вабанк казино официальный сайт Вавада казино открывает двери в мир азарта и возможностей, предлагая пользователям прямой доступ к обширной коллекции игр и захватывающим бонусам. Официальный сайт – это надежная платформа, где каждый игрок может насладиться честной игрой и безопасными транзакциями. Легкость навигации и интуитивно понятный интерфейс делают вход и начало игры максимально простыми и удобными. Vavada Casino Скачать
Борьба с наркотической зависимостью требует системного подхода и участия опытных специалистов. Важно понимать, что лечение наркомании — это не только снятие ломки, но и длительная психотерапия, обучение новым моделям поведения, работа с семьёй. Согласно рекомендациям Минздрава РФ, наиболее стабильные результаты достигаются при прохождении курса реабилитации под наблюдением профессиональной команды в специализированном центре.
Узнать больше – [url=https://lechenie-narkomanii-vladimir10.ru/]lechenie-narkomanii-vladimir10.ru/[/url]
I think that what you published made a lot of sense. But, think about this, suppose you added a little information? I mean, I don’t want to tell you how to run your website, however suppose you added something that grabbed people’s attention? I mean %BLOG_TITLE% is kinda boring. You ought to glance at Yahoo’s front page and see how they create news headlines to get viewers to click. You might add a related video or a related pic or two to grab people excited about what you’ve got to say. In my opinion, it would make your posts a little livelier.
cialis 5 mg generico prezzo
Кроме того, клиника «Новый шанс» уделяет особое внимание профилактике рецидивов. Мы обучаем пациентов навыкам управления стрессом, эмоциональной регуляции и прививаем навыки здорового образа жизни. Наша цель — обеспечить долгосрочное восстановление и снизить риск возврата к зависимости.
Детальнее – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-anonimno-v-rostove-na-donu.ru/]narkolog-vyvod-iz-zapoya rostov-na-donu[/url]
china to uae Shipping China to UAE: Ensuring Compliance with Environmental Regulations
Служба по контракту Вакансии Военная служба по контракту: Участие в учениях, тренировках и укреплении боевой готовности
доставка пионов в москве Букет пионов с доставкой в Москве: Совершенный подарок для тех, кто ценит прекрасное. Букет пионов – это не просто цветы, это символ внимания, заботы и любви. Мы создаем уникальные композиции, сочетая различные сорта и оттенки пионов, чтобы каждый букет был настоящим произведением искусства. Доставка букета пионов в Москве – это идеальный способ выразить свои чувства и подарить незабываемые эмоции близкому человеку.
1000 рублей за регистрацию в казино без депозита Многие казино, стремясь привлечь новых клиентов, предлагают 1000 рублей за регистрацию с моментальным выводом, не требующим никаких вложений. Это привлекательная возможность для тех, кто хочет испытать свою удачу без риска для собственного бюджета. 1000 рублей за регистрацию в казино без депозита вывод сразу
скачать игры по прямой ссылке Скачать игры без торрента: Откройте мир развлечений без ограничений. Забудьте о медленных загрузках и проблемах с сидированием. Теперь вы можете мгновенно погрузиться в захватывающие игровые миры, скачивая любимые игры напрямую, без использования торрент-клиентов. Наслаждайтесь быстрой и стабильной загрузкой, которая позволит вам не терять время на ожидание, а сразу окунуться в игровой процесс. Исследуйте обширную библиотеку игр различных жанров и найдите новые приключения, не утруждая себя поиском рабочих торрент-файлов.
Ремонт бампера автомобиля — это популярная услуга, которая позволяет восстановить заводской вид транспортного средства после незначительных повреждений. Современные технологии позволяют устранить сколы, трещины и вмятины без полной замены детали. При выборе между ремонтом или заменой бампера [url=https://telegra.ph/Remont-ili-zamena-bampera-05-22]https://telegra.ph/Remont-ili-zamena-bampera-05-22[/url] важно учитывать степень повреждений и экономическую рентабельность. Качественное восстановление включает шпатлевку, грунтовку и покраску.
Замена бампера требуется при серьезных повреждениях, когда реставрация бамперов нецелесообразен или невозможен. Расценки восстановления варьируется от состава изделия, масштаба повреждений и типа автомобиля. Пластиковые элементы поддаются ремонту лучше металлических, а инновационные композитные материалы требуют особого оборудования. Качественный ремонт продлевает срок службы детали и поддерживает заводскую геометрию кузова.
Готов прийти на помощь когда это необходимо по вопросам Ремонт крепления бампера тойота камри 50 – пишите в Телеграм ctu88
china to uae Shipping from China to UAE: The Benefits of Using a Logistics Platform
Наркомания — хроническое заболевание, требующее комплексного лечения и постоянной поддержки. В условиях Архангельска, где доступ к специализированной помощи может быть ограничен, клиника «АрктикМед» предлагает уникальную программу, основанную на мультидисциплинарном подходе и строгом соблюдении принципов анонимности. Ключевая цель — помочь каждому пациенту преодолеть зависимость, восстановить здоровье и вернуться к полноценной жизни.
Получить дополнительные сведения – https://lechenie-narkomanii-arkhangelsk0.ru/czentr-lecheniya-narkomanii-arkhangelsk/
Перевод документов https://medicaltranslate.ru на немецкий язык для лечения за границей и с немецкого после лечения: высокая скорость, безупречность, 24/7
Онлайн-тренинги https://communication-school.ru и курсы для личного роста, карьеры и новых навыков. Учитесь в удобное время из любой точки мира.
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Получить дополнительные сведения – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma odincovo[/url]
Можно ещё добавить Скачать игры без торрента: Откройте для себя мир мгновенного гейминга. Забудьте о бесконечных ожиданиях загрузки, запутанных настройках и риске подхватить вирус. Современные альтернативы торрентам предоставляют возможность окунуться в любимую игру практически сразу после нажатия кнопки “Скачать”. Насладитесь простотой и скоростью, выбирая из обширной библиотеки игр различных жанров.
Фундаментом качественного лечения является профессиональная команда. Только при участии врачей-наркологов, психиатров, клинических психологов, терапевтов и консультантов по зависимому поведению можно говорить о комплексной помощи. По словам специалистов ФГБУН «Национальный научный центр наркологии», именно междисциплинарный подход формирует устойчивую динамику на всех этапах терапии — от стабилизации состояния до ресоциализации пациента.
Получить больше информации – [url=https://narkologicheskaya-klinika-tula10.ru/]наркологическая клиника тула.[/url]
Interesting points! The tech behind online casinos is often overlooked, but crucial for a smooth experience. I’ve heard jljl55 game is really pushing boundaries with fast processing & secure verification – sounds like a game changer for Filipino players!
Запреты дня [url=https://inforigin.ru]https://inforigin.ru[/url] .
Гороскоп [url=http://istoriamashin.ru]http://istoriamashin.ru[/url] .
Гороскоп [url=https://topoland.ru/]topoland.ru[/url] .
Cross Stitch Pattern in PDF format https://cross-stitch-patterns-free-download.store/ a perfect choice for embroidery lovers! Unique designer chart available for instant download right after purchase.
Для эффективного лечения алкогольной интоксикации и восстановления организма врачи клиники «АлкоДоктор» используют комплекс препаратов, которые индивидуально подбираются с учетом состояния пациента.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-sochi0.ru/]kapelnicza-ot-zapoya sochi[/url]
Фурнитура для ПВХ-окон http://kupit-furnituru-dla-okon.ru оптом и в розницу: европейские бренды, доступные цены, доставка по РФ.
Пациенты, которые обращаются в нашу клинику за наркологической помощью, получают не просто стандартное лечение, а комплексный подход к проблеме зависимости. Наши врачи имеют большой практический опыт и высокую квалификацию, благодаря чему могут эффективно справляться даже с самыми сложными случаями. Мы используем только проверенные методики и сертифицированные препараты, гарантирующие безопасность и эффективность лечения.
Детальнее – http://narcolog-na-dom-sochi00.ru/narkolog-na-dom-czena-sochi/
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Углубиться в тему – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/
В нашей клинике работают врачи-наркологи, психологи и психиатры с многолетним опытом в лечении зависимостей. Все специалисты регулярно повышают свою квалификацию, участвуя в семинарах и конференциях, чтобы обеспечивать своим пациентам наиболее современное и качественное лечение.
Выяснить больше – http://быстро-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-volgograde.xn--p1ai/
Календарь огородника [url=https://www.pechory-online.ru]https://www.pechory-online.ru[/url] .
Календарь стрижек [url=www.novorjev.ru]www.novorjev.ru[/url] .
В этой статье мы рассматриваем разные способы борьбы с алкогольной зависимостью. Обсуждаются методы лечения, программы реабилитации и советы для поддержки близких. Читатели получат информацию о том, как преодолеть зависимость и добиться успешного выздоровления.
Детальнее – http://narkolog-na-dom-krasnodar16.ru/http://narkolog-na-dom-krasnodar16.ru
It’s so important to remember gambling should be fun, not a source of stress. Seeing platforms like boss jili prioritize convenience with their app is good, but always play responsibly! Setting limits is key for a healthy experience. ✨
ремонт редких моделей стиральных машин алматы Обслуживание холодильного оборудования Алматы: Полное обслуживание холодильного оборудования.
выездной бар с лицензией лофт в аренду СПБ: Лофт – это современное и стильное пространство для проведения мероприятий любого формата. Аренда лофта в Санкт-Петербурге позволит вам создать уникальную атмосферу для вашей свадьбы, вечеринки или корпоратива. Мы предлагаем широкий выбор лофтов различной площади и стилистики, оборудованных всем необходимым для проведения мероприятий.
термостат для холодильника алматы посудомойка не моет посуду алматы Плохое качество мытья посуды в посудомоечной машине может быть вызвано несколькими факторами. Засорение фильтров, неправильная загрузка посуды, использование некачественных моющих средств или неисправность разбрызгивателей – все это может повлиять на результат.
В этой публикации мы обсуждаем современные методы лечения различных заболеваний. Читатели узнают о новых медикаментах, терапиях и исследованиях, которые активно применяются для лечения. Мы нацелены на то, чтобы предоставить практические знания, которые могут помочь в борьбе с недугами.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-krasnodar17.ru/]нарколог на дом круглосуточно[/url]
Магазин строительной техники Магазин генераторов: Независимость от капризов электросети Перебои с электроснабжением могут стать серьезной проблемой для дома, бизнеса или загородного участка. Наш магазин предлагает широкий выбор генераторов различных типов и мощности, чтобы обеспечить бесперебойное питание в любой ситуации. От компактных инверторных моделей для небольших потребителей до мощных дизельных агрегатов для крупных объектов. Мы поможем вам выбрать оптимальный генератор, учитывая ваши потребности и бюджет, а также предоставим квалифицированную установку и сервисное обслуживание.
Драгон Мани Dragon Money: углубленный анализ Dragon Money – это многофункциональная платформа, предлагающая широкий спектр возможностей. От увлекательных игр до инвестиций в перспективные проекты – Dragon Money удовлетворяет самые разнообразные потребности. Удобный интерфейс позволяет даже новичкам быстро освоиться, а опытные пользователи оценят разнообразие функций. Честность и прозрачность – ключевые принципы Dragon Money. Все игры проходят строгую проверку на случайность, а финансовые операции защищены передовыми технологиями шифрования, создавая атмосферу доверия и безопасности. Dragon Money – это также активное сообщество, где пользователи могут общаться, делиться опытом и заводить новых друзей. Регулярные конкурсы, акции и розыгрыши поддерживают интерес и дарят положительные эмоции.
ремонт посудомоечных машин bosch алматы Заправка фреоном холодильника Алматы: Заправка холодильника фреоном на дому. Быстрый и безопасный способ восстановить работоспособность вашего холодильника.
Roulette’s probability is fascinating – seemingly random, yet governed by clear math! Seeing platforms like 68wim app streamline the experience for Vietnamese players with easy registration & secure payments is impressive. Quick access boosts the fun!
погода хургада апрель 2023 Кайт в Хургаде: Почувствуйте силу ветра Кайт в Хургаде – это возможность почувствовать силу ветра и насладиться красотой Красного моря.
Эта публикация исследует взаимосвязь зависимости и психологии. Мы обсудим, как психологические аспекты влияют на появление зависимостей и процесс выздоровления. Читатели смогут понять важность профессиональной поддержки и применения научных подходов в терапии.
Изучить вопрос глубже – [url=https://narkolog-na-dom-krasnodar12.ru/]вызов врача нарколога на дом[/url]
В этой заметке мы представляем шаги, которые помогут в процессе преодоления зависимостей. Рассматриваются стратегии поддержки и чек-листы для тех, кто хочет сделать первый шаг к выздоровлению. Наша цель — вдохновить читателей на положительные изменения и поддержать их в трудных моментах.
Подробнее тут – [url=https://narkolog-na-dom-krasnodar17.ru/]врач нарколог на дом[/url]
Если состояние слишком тяжёлое, или в анамнезе есть сердечно-сосудистые заболевания, может быть рекомендована госпитализация в стационар клиники «Светлый Мир». Там пациент находится под круглосуточным наблюдением и получает полный комплекс восстановительной терапии, включая психологическую поддержку и консультации психотерапевта.
Исследовать вопрос подробнее – http://vyvod-iz-zapoya-domodedovo3.ru/
Эта информационная публикация освещает широкий спектр тем из мира медицины. Мы предлагаем читателям ясные и понятные объяснения современных заболеваний, методов профилактики и лечения. Информация будет полезна как пациентам, так и медицинским работникам, желающим поддержать уровень своих знаний.
Выяснить больше – [url=https://narkolog-na-dom-krasnodar17.ru/]вызов нарколога на дом[/url]
В этой публикации мы обсуждаем современные методы лечения различных заболеваний. Читатели узнают о новых медикаментах, терапиях и исследованиях, которые активно применяются для лечения. Мы нацелены на то, чтобы предоставить практические знания, которые могут помочь в борьбе с недугами.
Углубиться в тему – [url=https://narkolog-na-dom-krasnodar17.ru/]нарколог на дом вывод из запоя[/url]
Домашний формат идеально подходит для тех, кто находится в удовлетворительном состоянии и не требует круглосуточного контроля.
Разобраться лучше – [url=https://vyvod-iz-zapoya-lyubertsy2.ru/]vyvod iz zapoya dzerzhinskij[/url]
Процедура выезда врача на дом в Краснодаре строго регламентирована и включает несколько последовательных этапов. После поступления звонка и уточнения подробностей состояния пациента врач выезжает на место в течение 30–60 минут. На месте проводится первичный осмотр с оценкой жизненно важных показателей: артериального давления, уровня кислорода в крови, сердечного ритма и степени общей интоксикации.
Получить дополнительную информацию – [url=https://narcolog-na-dom-krasnodar00.ru/]нарколог на дом клиника[/url]
температура красного моря Теория кайтсерфинга по IKO: основные принципы безопасности Теория кайтсерфинга по IKO включает в себя основные принципы безопасности, правила управления кайтом и информацию о ветровых условиях.
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Получить дополнительную информацию – http://kodirovanie-ot-alkogolizma-odintsovo2.ru
В этом исследовании рассмотрены методы лечения зависимостей и их эффективность. Мы проанализируем различные подходы, используемые в реабилитационных центрах, и представим данные о результативности программ. Читатели получат надежные и научно обоснованные сведения о данной проблеме.
Узнать больше – [url=https://narkolog-na-dom-krasnodar16.ru/]врач нарколог на дом[/url]
Этот информативный текст сочетает в себе темы здоровья и зависимости. Мы обсудим, как хронические заболевания могут усугубить зависимости и наоборот, как зависимость может влиять на общее состояние здоровья. Читатели получат представление о комплексном подходе к лечению как физического, так и психического состояния.
Получить больше информации – [url=https://narkolog-na-dom-krasnodar15.ru/]нарколог на дом круглосуточно[/url]
vavada casino официальный сайт вход Vavada Casino славится своей щедрой бонусной политикой. От приветственных бонусов для новичков до регулярных акций и промокодов для постоянных игроков – каждый пользователь найдет для себя выгодное предложение, увеличивающее шансы на выигрыш. Vavada Casino Скачать Бесплатно на Телефон
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Подробнее – https://clubsasayama-campfield.com/archives/1025
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Подробнее можно узнать тут – https://aoneemia.md/cause/donate-2
What’s up to every body, it’s my first visit of this blog; this website contains amazing and really fine material in favor of readers.
http://cheryclub.com.ua/linzy-dlya-far-yak-zrobyty-avtosvitlo-yaskravishym.html
Бездепозитные бонусы в казино Перед тем, как воспользоваться бездепозитным бонусом, стоит внимательно изучить условия его получения и отыгрыша. Важно понимать, какие игры доступны для игры на бонусные средства, какой вейджер необходимо выполнить, чтобы вывести выигрыш, и какие сроки установлены для отыгрыша бонуса. Тщательное изучение правил поможет избежать разочарований и получить максимальную выгоду от использования бонуса.
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Выяснить больше – https://www.renewcomb.com/iec2
Когда алкогольная интоксикация становится угрозой для здоровья, оперативное вмешательство и качественное лечение на дому играют ключевую роль в спасении жизни. В Калининграде опытные наркологи выезжают на дом, чтобы обеспечить своевременную детоксикацию, стабилизацию работы внутренних органов и оказание психологической поддержки. Такой подход позволяет пациентам получить квалифицированную помощь в комфортной и привычной обстановке, сохраняя конфиденциальность и избегая лишнего стресса, связанного с госпитализацией.
Ознакомиться с деталями – https://narcolog-na-dom-kaliningrad0.ru/narkolog-na-dom-kruglosutochno-kaliningrad
Срочная медицинская помощь поможет избежать тяжелых последствий и сократит время на восстановление после запоя.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-krasnodar0.ru/]вывод из запоя капельница в краснодаре[/url]
Метод лечения
Ознакомиться с деталями – [url=https://lechenie-narkomanii-vladimir10.ru/]лечение наркомании и алкоголизма в владимире[/url]
В нашем центре работают наркологи высшей категории с многолетним опытом лечения различных зависимостей. Они владеют современными методами детоксикации, купирования абстинентного синдрома, кодирования и фармакотерапии.
Получить дополнительные сведения – https://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-voronezhe.xn--p1ai
канал авто Купить Санта Фе: Практичный и надежный кроссовер Hyundai Santa Fe – это популярный кроссовер, предлагающий сбалансированное сочетание цены, качества и функциональности.
kids puzzle with animals Bright and fun bird designs for kids! Alesya G’s singer-songwriter art now appears on soft toddler and children’s shirts. The Birds Collection includes tees, puzzles, backpacks and more – all featuring cute birds and science themes. Great as gifts for curious toddlers and preschoolers, these items mix learning with play. Shop kids’ bird t-shirts and accessories for your little explorer today!
В «Трезвом Истоке» мы понимаем: принять решение о вызове — это шаг, требующий смелости. Особенно если речь идёт о близком человеке, который отрицает наличие проблемы. Именно поэтому наши врачи умеют работать тактично, без давления. Мы не заставляем — мы объясняем. Спокойно, профессионально и по-человечески.
Подробнее тут – http://
dragonslot [url=https://dragonslotscasinos.net]https://dragonslotscasinos.net[/url] .
dragon casino [url=http://dragonslotscasinos.mobi]http://dragonslotscasinos.mobi[/url] .
https://1-bs2best.art/bs2best_at.html
автоподбор Купить машину: Советы начинающим автолюбителям При выборе первого автомобиля важно обратить внимание на его техническое состояние, стоимость обслуживания и страховки. Рекомендуется обратиться к специалистам для проведения диагностики перед покупкой.
В рамках реабилитации применяются когнитивно-поведенческие тренинги, арт-терапия и групповые занятия по развитию коммуникативных навыков. Это помогает пациентам осознать причины зависимости и выработать стратегии предотвращения рецидивов в будущем.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологическая клиника нарколог тюмень[/url]
soft toddler tee Bright and fun bird designs for kids! Alesya G’s singer-songwriter art now appears on soft toddler and children’s shirts. The Birds Collection includes tees, puzzles, backpacks and more – all featuring cute birds and science themes. Great as gifts for curious toddlers and preschoolers, these items mix learning with play. Shop kids’ bird t-shirts and accessories for your little explorer today!
хотите сделать утепление https://dv-zvezda.ru/126526-uteplenie-penopoliuretanom-v-raznyh-klimaticheskih-zonah.html
Зависимость — это коварное хроническое заболевание, затрагивающее как физическое, так и психическое здоровье человека. Она воздействует на волю и разум, искажает восприятие реальности и разрушает жизни, семьи и судьбы. Алкоголизм, наркомания и игровая зависимость — все это проявления одной и той же проблемы, требующей комплексного и профессионального подхода.
Выяснить больше – http://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-anonimno-v-voronezhe.xn--p1ai/
Наша миссия заключается в предоставлении качественной помощи людям, страдающим от зависимостей. Мы стремимся создать безопасную и поддерживающую атмосферу, где каждый сможет получить необходимую помощь. Основная цель — восстановление здоровья, психоэмоционального состояния и социальной адаптации.
Выяснить больше – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-omske.ru/]наркологический вывод из запоя омск[/url]
Команда клиники “Аура Здоровья” состоит из опытных и квалифицированных врачей-наркологов, обладающих глубокими знаниями фармакологии и психотерапии. Они регулярно повышают свою квалификацию, участвуя в профессиональных конференциях и семинарах, чтобы применять самые эффективные методы лечения.
Выяснить больше – https://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-rostove-na-donu.xn--p1ai/
Перед началом терапии врач проводит предварительный осмотр: измеряет давление, пульс, оценивает общее состояние пациента, наличие сопутствующих хронических заболеваний и признаков тяжёлой интоксикации. После этого разрабатывается индивидуальная схема лечения. В большинстве случаев она включает внутривенное введение растворов, улучшающих водно-солевой баланс, а также медикаментов, направленных на снятие абстиненции, нормализацию сна и снижение тревожности.
Углубиться в тему – http://vyvod-iz-zapoya-domodedovo3.ru
Проблемы, связанные с употреблением алкоголя или наркотических веществ, могут застать человека врасплох и требовать немедленного медицинского вмешательства. В Туле предоставляется наркологическая помощь, направленная на купирование острых состояний и оказание поддержки пациентам в кризисной ситуации. В клинике «Здоровье+» используются современные методы лечения, основанные на отечественных клинических рекомендациях, с акцентом на безопасность и индивидуальный подход.
Подробнее тут – http://narkologicheskaya-pomoshh-tula10.ru/vyzov-narkologicheskoj-pomoshhi-tula/https://narkologicheskaya-pomoshh-tula10.ru
Врач индивидуально подбирает:
Узнать больше – [url=https://lechenie-alkogolizma-tyumen10.ru/]наркологическое лечение алкоголизма[/url]
vavada casino официальный сайт вход Вавада казино открывает двери в мир азарта и возможностей, предлагая пользователям прямой доступ к обширной коллекции игр и захватывающим бонусам. Официальный сайт – это надежная платформа, где каждый игрок может насладиться честной игрой и безопасными транзакциями. Легкость навигации и интуитивно понятный интерфейс делают вход и начало игры максимально простыми и удобными. Vavada Casino Скачать
Первый и самый важный момент — какие методики применяются в клинике. Качественное лечение наркозависимости включает несколько этапов: детоксикация, стабилизация состояния, психотерапия, ресоциализация. Одного лишь выведения токсинов из организма недостаточно — без проработки психологических причин употребления высокий риск рецидива.
Получить больше информации – [url=https://lechenie-narkomanii-vladimir10.ru/]центр лечения наркомании[/url]
thepokies net [url=http://thepokiesau.org]thepokies net[/url] .
dragon slots [url=www.casinosdragonslots.eu/]dragon slots[/url] .
the pokies net [url=https://www.thepokiesnet250.com]https://www.thepokiesnet250.com[/url] .
В «Трезвом Истоке» мы понимаем: принять решение о вызове — это шаг, требующий смелости. Особенно если речь идёт о близком человеке, который отрицает наличие проблемы. Именно поэтому наши врачи умеют работать тактично, без давления. Мы не заставляем — мы объясняем. Спокойно, профессионально и по-человечески.
Получить дополнительные сведения – http://vyvod-iz-zapoya-ehlektrostal3.ru/anonimnyj-vyvod-iz-zapoya-v-ehlektrostali/
pokies101 [url=https://thepokiesnet101.com/]pokies101[/url] .
mephedrone Ephedrine is often used to produce phenylacetone, a key intermediate in stimulant synthesis. From phenylacetone, substances like methylone, mephedrone (4-MMC), and 3-CMC can be made using methylamine. Phenylnitropropene, derived from nitroethane, is another precursor. A-PVP and 4-methylpropiophenone are also widely used in synthetic drug production. BMK glycidate is commonly used to synthesize controlled substances.
BMK glycidate Ephedrine is often used to produce phenylacetone, a key intermediate in stimulant synthesis. From phenylacetone, substances like methylone, mephedrone (4-MMC), and 3-CMC can be made using methylamine. Phenylnitropropene, derived from nitroethane, is another precursor. A-PVP and 4-methylpropiophenone are also widely used in synthetic drug production. BMK glycidate is commonly used to synthesize controlled substances.
Асфальтировка
Алкоголь и наркотики воздействуют на организм комплексно: нарушается работа сердца, сосудов, печени и почек, страдает нервная система. При запое или ломке без квалифицированной помощи возникают судороги, делирий, галлюцинации и серьёзные сбои в обмене веществ. Самостоятельные попытки «перетерпеть» или «отмотать» запой зачастую приводят к тяжёлым осложнениям, вплоть до комы и необратимых изменений в органах.
Детальнее – http://narkologicheskaya-klinika-dolgoprudnyj3.ru
Перед началом терапии врач проводит предварительный осмотр: измеряет давление, пульс, оценивает общее состояние пациента, наличие сопутствующих хронических заболеваний и признаков тяжёлой интоксикации. После этого разрабатывается индивидуальная схема лечения. В большинстве случаев она включает внутривенное введение растворов, улучшающих водно-солевой баланс, а также медикаментов, направленных на снятие абстиненции, нормализацию сна и снижение тревожности.
Разобраться лучше – https://vyvod-iz-zapoya-domodedovo3.ru/
https://2bs-2best.at/blaksprut_ssylka.html
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Выяснить больше – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологические клиники алкоголизм тюмень[/url]
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Разобраться лучше – http://narkologicheskaya-klinika-tyumen10.ru/narkologicheskaya-klinika-klinika-pomoshh-tyumen/
Команда врачей клиники “Чистый Путь” состоит из квалифицированных специалистов в области наркологии с обширным опытом работы. Каждый врач обладает глубокими знаниями в фармакологии, психофармакологии и психотерапии, регулярно повышает свою квалификацию на профильных конференциях и семинарах, чтобы использовать в своей практике самые современные и эффективные методы лечения.
Подробнее – http://срочно-вывод-из-запоя.рф
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Разобраться лучше – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологическая клиника тюмень[/url]
methylone Ephedrine is often used to produce phenylacetone, a key intermediate in stimulant synthesis. From phenylacetone, substances like methylone, mephedrone (4-MMC), and 3-CMC can be made using methylamine. Phenylnitropropene, derived from nitroethane, is another precursor. A-PVP and 4-methylpropiophenone are also widely used in synthetic drug production. BMK glycidate is commonly used to synthesize controlled substances.
бонусы в казино без депозита Казино, предлагающие бездепозитные бонусы, демонстрируют свою уверенность в качестве предоставляемых услуг. Это своего рода маркетинговый ход, направленный на привлечение новых игроков и формирование лояльности. Игроки, получившие положительный опыт, с большей вероятностью вернутся и станут постоянными клиентами. Бездепозитный бонус
the pokies [url=https://pokies11.com/]pokies11.com[/url] .
pokies net 106 [url=http://pokies106.com]pokies net 106[/url] .
карниз с приводом [url=http://elektrokarnizy50.ru]http://elektrokarnizy50.ru[/url] .
Мы активно используем методы, такие как когнитивно-поведенческая терапия, гештальт-терапия и арт-терапия, помогая пациентам преодолеть психологические травмы и внутренние конфликты, лежащие в основе аддиктивного поведения. Также наши консультанты по химической зависимости предоставляют информационную поддержку пациентам и их семьям, помогая разобраться в вопросах лечения, реабилитации и социальной адаптации.
Детальнее – https://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-voronezhe.xn--p1ai
https://b2tsite3.cc/bs2web_at.html
В городе Домодедово такую услугу оказывает наркологическая клиника «Светлый Мир». Здесь работают опытные врачи с круглосуточной готовностью выехать к пациенту домой или принять его в условиях стационара. Главное — не откладывать помощь, особенно если речь идёт о пожилом человеке, пациенте с хроническими заболеваниями или тех, у кого уже проявляются тревожные симптомы: дрожь в руках, панические атаки, скачки давления, бессонница и даже слуховые или зрительные галлюцинации.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]вывод из запоя цена[/url]
Запойное состояние — это не просто следствие злоупотребления спиртным, а серьёзное расстройство, которое требует немедленного медицинского вмешательства. При длительном употреблении алкоголя на протяжении нескольких суток или недель организм человека сталкивается с тяжёлой интоксикацией, нарушением работы внутренних органов и изменениями в психоэмоциональном состоянии. В такой ситуации необходим профессиональный вывод из запоя — грамотно организованный процесс детоксикации, способный предотвратить тяжёлые осложнения.
Получить дополнительные сведения – https://vyvod-iz-zapoya-domodedovo3.ru/vyvod-iz-zapoya-stacionar-v-domodedovo
Срочные микрозаймы https://stuff-money.ru с моментальным одобрением. Заполните заявку онлайн и получите деньги на карту уже сегодня. Надёжно, быстро, без лишней бюрократии.
Мы понимаем уникальность каждого пациента и проводим тщательную диагностику, анализируя его медицинскую историю, психологическое состояние и социальные факторы. На основе полученных данных создаем персональные планы лечения, включающие медикаментозные средства, психотерапию и социальные программы.
Получить дополнительную информацию – https://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-rostove-na-donu.xn--p1ai
https://bs2bet.at
Услуги массаж ивантеевка — для здоровья, красоты и расслабления. Опытный специалист, удобное расположение, доступные цены.
Алкогольная зависимость — сложное хроническое заболевание, требующее комплексного подхода и квалифицированной помощи. В клинике «Тюменьбезалко» в центре Тюмени разработаны эффективные программы реабилитации, сочетающие современные медицинские методы, психологическую поддержку и социальную адаптацию. Опытные врачи-наркологи и психотерапевты помогают пациентам преодолеть употребление алкоголя, восстановить физическое и эмоциональное здоровье и вернуться к полноценной жизни.
Детальнее – http://lechenie-alkogolizma-tyumen10.ru
https://1-bs2best.lat/bs2best.html
Алкоголь и наркотики воздействуют на организм комплексно: нарушается работа сердца, сосудов, печени и почек, страдает нервная система. При запое или ломке без квалифицированной помощи возникают судороги, делирий, галлюцинации и серьёзные сбои в обмене веществ. Самостоятельные попытки «перетерпеть» или «отмотать» запой зачастую приводят к тяжёлым осложнениям, вплоть до комы и необратимых изменений в органах.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]www.domen.ru[/url]
Самостоятельный выход из запоя сопряжен с высоким риском развития осложнений. После прекращения приема спиртного ослабленный организм может не выдержать нагрузки, что приведет к инфаркту, инсульту, судорожным приступам и даже алкогольному психозу. Чтобы избежать этих опасных состояний, необходимо вызвать нарколога на дом, который проведет лечение правильно и безопасно.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-krasnodar0.ru/]vyvod-iz-zapoya-krasnodar0.ru/[/url]
Многие думают, что запой — это просто привычка. На деле же это глубокий физиологический и психологический кризис. Он может привести к очень серьёзным осложнениям — от инфаркта до алкогольного делирия, сопровождающегося агрессией, страхами и бредовыми состояниями. Это не преувеличение. Алкоголь разрушает организм молча — и делает это быстрее, чем кажется.
Получить дополнительные сведения – https://vyvod-iz-zapoya-ehlektrostal3.ru/anonimnyj-vyvod-iz-zapoya-v-ehlektrostali/
AI generator nsfw ai generator of the new generation: artificial intelligence turns text into stylish and realistic pictures and videos.
1000 рублей за регистрацию вывод сразу Получить 1000 рублей за регистрацию с моментальным выводом, не требующим каких-либо вложений, – это мечта любого новичка онлайн-казино. Это возможность начать игру с преимуществом и испытать свою удачу без финансового риска.
Каждый пациент получает индивидуальный план лечения, основанный на клинических исследованиях, данных лабораторных анализов и психологических тестов.
Разобраться лучше – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]narkologicheskaya-klinika-v-oblasti[/url]
https://bs2bcst.at
Мы понимаем уникальность каждого пациента и проводим тщательную диагностику, анализируя его медицинскую историю, психологическое состояние и социальные факторы. На основе полученных данных создаем персональные планы лечения, включающие медикаментозные средства, психотерапию и социальные программы.
Выяснить больше – http://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-anonimno-v-rostove-na-donu.xn--p1ai/
Мы предлагаем полный спектр услуг по лечению зависимостей:
Подробнее тут – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]narkologicheskaya-klinika[/url]
Алкоголь и наркотики воздействуют на организм комплексно: нарушается работа сердца, сосудов, печени и почек, страдает нервная система. При запое или ломке без квалифицированной помощи возникают судороги, делирий, галлюцинации и серьёзные сбои в обмене веществ. Самостоятельные попытки «перетерпеть» или «отмотать» запой зачастую приводят к тяжёлым осложнениям, вплоть до комы и необратимых изменений в органах.
Получить дополнительную информацию – https://narkologicheskaya-klinika-dolgoprudnyj3.ru/anonimnaya-narkologicheskaya-klinika-v-dolgoprudnom/
https://2-bs2best.lat/blaksprut_ssylka.html
Офисная мебель https://mkoffice.ru в Новосибирске: готовые комплекты и отдельные элементы. Широкий ассортимент, современные дизайны, доставка по городу.
Smart bankroll management is key in any tournament, just like choosing the right games! Seeing platforms like bossjl legit offer diverse options – slots, live casino – gives players more control over their variance. Fun stuff!
Бездепозитные бонусы Перед тем, как воспользоваться бездепозитным бонусом, стоит внимательно изучить условия его получения и отыгрыша. Важно понимать, какие игры доступны для игры на бонусные средства, какой вейджер необходимо выполнить, чтобы вывести выигрыш, и какие сроки установлены для отыгрыша бонуса. Тщательное изучение правил поможет избежать разочарований и получить максимальную выгоду от использования бонуса.
Особое внимание в клинике уделяется профилактике рецидивов. Мы обучаем пациентов навыкам управления стрессом, контролю эмоций и принципам здорового образа жизни. Наша цель — обеспечить длительное восстановление и снизить риск возврата к зависимости.
Выяснить больше – http://срочно-вывод-из-запоя.рф
При поступлении или выезде на дом врач-нарколог собирает анамнез, оценивает степень зависимости, измеряет жизненные показатели и назначает необходимые анализы. Цель — исключить противопоказания и выбрать оптимальную схему терапии.
Подробнее – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]narkologicheskaya-klinika-zdorove[/url]
New AI generator free nsfw ai chat of the new generation: artificial intelligence turns text into stylish and realistic image and videos.
Hindi News https://tfipost.in latest news from India and the world. Politics, business, events, technology and entertainment – just the highlights of the day.
В условиях стационара или на дневном стационаре применяются сбалансированные инфузионные растворы, витамины, антиоксиданты и препараты для поддержки печени. Цель — минимизировать интоксикацию и предотвратить осложнения.
Углубиться в тему – [url=https://lechenie-alkogolizma-tyumen10.ru/]лечение алкоголизма цена[/url]
https://b2shop.gl/blacksprut_zerkalo.html
При поступлении или выезде на дом врач-нарколог собирает анамнез, оценивает степень зависимости, измеряет жизненные показатели и назначает необходимые анализы. Цель — исключить противопоказания и выбрать оптимальную схему терапии.
Углубиться в тему – http://narkologicheskaya-klinika-dolgoprudnyj3.ru
https://b2tsite4.io/bs2best.html
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Подробнее – https://www.mahour.ca/fa/eb/8ef8ecc614c82284c18cac8c0a758eb4
Hey! Do you use Twitter? I’d like to follow you if that would be okay. I’m undoubtedly enjoying your blog and look forward to new posts.
http://babyphotostar.com.ua/linzi-v-fari-vibir-kupivlya-i-vstanovlennya
https://2-bs2best.lat/blacksprut_zerkalo.html
бездепозитный бонус игровые автоматы с выводом денег Бездепозитный бонус – это шанс сорвать куш, не вкладывая ни копейки. Он позволяет испытать азарт, риск и радость победы, не испытывая страха потери собственных средств. Это особенно ценно для начинающих игроков, которые еще не готовы рисковать большими суммами. Бездепозитный бонус в казино
https://2bs-2best.at/bs2web_at.html
ремонт стиральных машин remont stiralok ремонт стиральных машин бош
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-sochi00.ru/]вызвать капельницу от запоя на дому в сочи[/url]
magyar nyelvu tamogatas
проститутки донецк Проститутки Горловка – такая же ситуация, как и в предыдущих случаях.
Основная миссия нашего учреждения заключается в комплексной помощи пациентам с зависимостями. Основные цели нашей работы включают:
Подробнее можно узнать тут – http://тайный-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-samare.xn--p1ai/
Вызов нарколога на дом становится необходимым при любых состояниях, когда отказ от алкоголя сопровождается выраженными симптомами интоксикации и абстиненции. Основные ситуации, в которых срочно требуется профессиональная помощь врача:
Подробнее тут – http://
Useful information. Lucky me I discovered your website by chance, and I am shocked why this coincidence didn’t took place earlier! I bookmarked it.
https://kidsvisitor.com.ua/universal-hermetyk-dlia-remontu-skla-far-perevahy-ta-rekomendatsii
бездепозитный бонус игровые автоматы с выводом денег Многие игроки ищут именно такие бонусы, которые позволяют сразу вывести выигранные деньги, не вкладывая свои. Но стоит помнить о лимитах и правилах казино.
Как оформить карту карта иностранного банка для россиян в 2025 году. Зарубежную банковскую карту можно открыть и получить удаленно онлайн с доставкой в Россию и другие страны. Карты подходят для оплаты за границей.
секс Донецк Секс ДНР: Интим в условиях конфликта Вооруженный конфликт в Донецкой Народной Республике (ДНР) оказал глубокое влияние на все аспекты жизни, включая сексуальные отношения. Несмотря на трудности, люди продолжают искать любовь и близость.
Процедура длится от 40 минут до 2 часов, в зависимости от тяжести состояния, и проводится в комфортной домашней обстановке, что значительно снижает стресс у пациента и его близких.
Узнать больше – [url=https://narcolog-na-dom-krasnodar0.ru/]нарколог на дом вывод в краснодаре[/url]
https://1-bs2best.lat/https_bs2best_at.html
megbizhato kaszino
При поступлении или выезде на дом врач-нарколог собирает анамнез, оценивает степень зависимости, измеряет жизненные показатели и назначает необходимые анализы. Цель — исключить противопоказания и выбрать оптимальную схему терапии.
Получить больше информации – http://narkologicheskaya-klinika-dolgoprudnyj3.ru/
Вызов нарколога на дом становится необходимым при любых состояниях, когда отказ от алкоголя сопровождается выраженными симптомами интоксикации и абстиненции. Основные ситуации, в которых срочно требуется профессиональная помощь врача:
Выяснить больше – http://narcolog-na-dom-sochi0.ru
Обращение за медицинской помощью становится необходимым, когда пациент пребывает в состоянии, требующем немедленного вмешательства, так как самостоятельное лечение может только усугубить ситуацию. Это происходит, если запой продолжается несколько дней, и организм не успевает справляться с накопившимися токсинами, что ведёт к нарушению работы внутренних органов. Если у пациента регулярно наблюдаются симптомы, такие как частая рвота, сильное головокружение, спутанность сознания, судороги или резкие колебания артериального давления, это является явным сигналом к вызову специалиста. Особенно важно обращаться за помощью при выраженных признаках абстинентного синдрома, когда сильная дрожь, панические атаки, бессонница, тревожность и даже галлюцинации свидетельствуют о том, что организм испытывает критическую нехватку поддержки. Наличие психических нарушений, таких как агрессивное поведение, спутанность сознания или признаки алкогольного психоза, также требует незамедлительного вмешательства. В таких ситуациях обращение за профессиональной помощью помогает быстро стабилизировать состояние пациента, предотвратить развитие тяжелых осложнений и сохранить жизнь.
Подробнее тут – http://narcolog-na-dom-ekaterinburg00.ru/vrach-narkolog-na-dom-ekb/
That analysis was spot on! Seeing platforms like JL Boss 2025 really elevate the PH online gaming scene – especially with easy GCash integration. Curious to try their slots – check out jl boss login for a quick start! Solid insights overall.
https://bs2bsme.at
Преимущество
Разобраться лучше – http://narcolog-na-dom-ekaterinburg0.ru/
Вызов нарколога на дом становится необходимым при любых состояниях, когда отказ от алкоголя сопровождается выраженными симптомами интоксикации и абстиненции. Основные ситуации, в которых срочно требуется профессиональная помощь врача:
Разобраться лучше – http://narcolog-na-dom-sochi0.ru
iflow камеры видеонаблюдения [url=http://citadel-trade.ru]http://citadel-trade.ru[/url] .
электрокарниз двухрядный цена [url=https://www.elektrokarniz90.ru]https://www.elektrokarniz90.ru[/url] .
автоматические карнизы для штор [url=https://karnizy-s-elektroprivodom77.ru/]https://karnizy-s-elektroprivodom77.ru/[/url] .
электрокарнизы москва [url=http://karniz-motorizovannyj77.ru/]http://karniz-motorizovannyj77.ru/[/url] .
готовые рулонные шторы купить в москве [url=elektricheskie-rulonnye-shtory77.ru]elektricheskie-rulonnye-shtory77.ru[/url] .
электропривод рулонных штор [url=www.elektricheskie-rulonnye-shtory99.ru]www.elektricheskie-rulonnye-shtory99.ru[/url] .
какие бывают рулонные шторы [url=rulonnye-shtory-s-elektroprivodom15.ru]rulonnye-shtory-s-elektroprivodom15.ru[/url] .
вавада казино официальный сайт казино Отзывы реальных игроков – это ценный источник информации о Vavada Casino. Изучение отзывов позволяет узнать о преимуществах и недостатках платформы, а также получить представление об игровом опыте других пользователей.
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Детальнее – https://sterlingrec.org/anna
https://b2tsite4.io/bs2web_at.html
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Углубиться в тему – http://www.osmoharvard.se/backgroundsnyggt-jpg
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Получить дополнительную информацию – https://boccato.travel/multi-day-vs-single-day-rafting-trips
https://b2shop.gl/index.html
sportbets [url=https://sportbets14.ru]https://sportbets14.ru[/url] .
бонусы в казино на день рождения Многие игроки ищут именно такие бонусы, которые позволяют сразу вывести выигранные деньги, не вкладывая свои. Но стоит помнить о лимитах и правилах казино.
Дополнительно, если у пациента отмечаются психические нарушения — галлюцинации, агрессия или спутанность сознания, это является прямым сигналом к срочному вмешательству. В этом случае своевременное лечение помогает предотвратить риск инсульта, инфаркта или других серьезных заболеваний.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя на дому[/url]
Зависимость от психоактивных веществ — серьёзная проблема, которая становится всё актуальнее в современном мире. Алкоголизм, наркомания и игромания представляют угрозу как для здоровья отдельного человека, так и для общества в целом. В условиях растущей нагрузки на систему здравоохранения Наркологическая клиника “Возрождение” предлагает комплексные решения для тех, кто страдает от различных видов зависимости. Мы придерживаемся индивидуального подхода, что позволяет достигать высоких результатов в лечении и реабилитации.
Разобраться лучше – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-nizhnem-novgoroge.xn--p1ai/
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя наркология в сочи[/url]
психиатрическая клиника Психиатрическая клиника. Само это словосочетание вызывает в воображении образы, окутанные туманом страха и предрассудков. Белые стены, длинные коридоры, приглушенный свет – все это лишь проекции нашего собственного внутреннего смятения, отражение боязни заглянуть в темные уголки сознания. Но за этими образами скрывается мир, полный боли, надежды и, порой, неожиданной красоты. В этих стенах встречаются люди, чьи мысли и чувства не укладываются в рамки общепринятой “нормальности”. Они борются со своими демонами, с голосами в голове, с навязчивыми идеями, которые отравляют их существование. Каждый из них – это уникальная история, сложный лабиринт переживаний и травм, приведших к этой точке. Здесь работают люди, посвятившие себя помощи тем, кто оказался на краю. Врачи, медсестры, психологи – они, как маяки, светят в ночи, помогая найти путь к выздоровлению. Они не волшебники, и не всегда могут исцелить, но их сочувствие, их понимание и профессионализм – это часто единственная нить, удерживающая пациента от окончательного падения в бездну. Жизнь в психиатрической клинике – это не заточение, а скорее передышка. Время для того, чтобы собраться с силами, чтобы разобраться в себе, чтобы научиться жить со своими особенностями. Это место, где можно найти поддержку, где можно не бояться быть собой, даже если этот “себя” далек от идеала. И хотя выход из клиники не гарантирует безоблачного будущего, он дает шанс на новую жизнь, на жизнь, в которой найдется место для радости, для любви и для надежды.
Продолжительное употребление алкоголя наносит сильный удар по организму и психике человека. Если запой длится более двух дней, состояние резко ухудшается, и самостоятельный выход может привести к серьезным последствиям. Обязательно следует вызывать врача в следующих случаях:
Получить больше информации – https://vyvod-iz-zapoya-krasnodar0.ru/
Причины разрушения подошвы обуви https://e-pochemuchka.ru/prichiny-razrusheniya-podoshvy-obuvi/
[url=https://shiba-akita.ru/]https://www.shiba-akita.ru/[/url] – статья о полезности дизельных моторов для автомобилистов
кредит под залог машины
zaimpod-pts90.ru
займ залог птс
sportbets [url=https://www.sportbets15.ru]https://www.sportbets15.ru[/url] .
Серьезные состояния, вызванные длительным употреблением алкоголя или наркотиков, требуют немедленного вмешательства. Если пациент испытывает ухудшение самочувствия вследствие продолжительного запоя, его организм начинает накапливать токсичные вещества, что ведёт к нарушению работы внутренних органов. При появлении таких симптомов, как сильная рвота, спутанность сознания, судороги, резкие скачки артериального давления, а также выраженные признаки абстинентного синдрома (сильная дрожь, панические атаки, бессонница, тревожность), вызов нарколога становится жизненно необходимым. Экстренное вмешательство позволяет стабилизировать состояние больного и предотвратить развитие серьёзных осложнений, включая сердечно-сосудистые нарушения, повреждение печени и развитие алкогольного психоза. В таких ситуациях профессиональное лечение на дому — лучший способ сохранить здоровье и жизнь пациента.
Выяснить больше – [url=https://narcolog-na-dom-ekaterinburg000.ru/]нарколог на дом вывод из запоя в екатеринбурге[/url]
Группа препаратов
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-sochi0.ru/]врача капельницу от запоя[/url]
Мы работаем без праздников и выходных, принимаем срочные обращения, выезжаем оперативно и оказываем помощь в полном соответствии с медицинскими стандартами. Главный принцип — безопасность, эффективность и деликатность. Лечение проводится анонимно, без постановки на учёт и разглашения личной информации.
Узнать больше – https://vyvod-iz-zapoya-serpuhov3.ru/vyvod-iz-zapoya-na-domu-v-serpuhove/
Для эффективного лечения наши врачи используют только проверенные и сертифицированные медикаменты, которые подбираются индивидуально для каждого пациента. В состав лечебного курса входят:
Углубиться в тему – http://narcolog-na-dom-ekaterinburg000.ru/
Дополнительно, если у пациента отмечаются психические нарушения — галлюцинации, агрессия или спутанность сознания, это является прямым сигналом к срочному вмешательству. В этом случае своевременное лечение помогает предотвратить риск инсульта, инфаркта или других серьезных заболеваний.
Исследовать вопрос подробнее – http://vyvod-iz-zapoya-krasnodar00.ru
Пожалуй, самый распространённый миф — что если просто не пить сутки-двое, то всё наладится. Но если человек длительное время находился в состоянии опьянения, его тело уже адаптировалось к токсичной среде. Резкий отказ без медицинской помощи может привести к судорогам, галлюцинациям, тяжёлой бессоннице, паническим атакам и скачкам давления. Человек буквально «сгорает» изнутри — от собственного обмена веществ, который не справляется с последствиями интоксикации.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ehlektrostal3.ru/]vyvod-iz-zapoya-na-domu-cena[/url]
Действие и назначение
Выяснить больше – [url=https://kapelnica-ot-zapoya-sochi0.ru/]капельница от запоя на дому сочи.[/url]
https://2bs-2best.at/darknetmarket.html
LMC Middle School https://lmc896.org in Lower Manhattan provides a rigorous, student-centered education in a caring and inclusive atmosphere. Emphasis on critical thinking, collaboration, and community engagement.
высокое кашпо для цветов напольное из пластика [url=kashpo-napolnoe-msk.ru]высокое кашпо для цветов напольное из пластика[/url] .
Возможные признаки
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-tula10.ru/]платная наркологическая клиника[/url]
вазы кашпо напольные [url=http://kashpo-napolnoe-spb.ru]вазы кашпо напольные[/url] .
Для детоксикации и восстановления организма после запоя используются только сертифицированные лекарственные препараты с доказанной эффективностью и безопасностью:
Узнать больше – [url=https://narcolog-na-dom-sochi0.ru/]narcolog-na-dom-sochi0.ru/[/url]
Особенно важны первые дни пребывания, когда проводится диагностика, назначается медикаментозная поддержка и формируется план лечения. Компетентные врачи способны адаптировать программу под физическое и психоэмоциональное состояние пациента, учитывая как длительность употребления, так и возможные сопутствующие диагнозы. На этом этапе важно исключить риски осложнений и создать условия для безопасного перехода к следующему этапу — психологической реабилитации.
Получить дополнительные сведения – https://narkologicheskaya-klinika-tula10.ru/chastnaya-narkologicheskaya-klinika-tula/
Чем раньше нарколог окажет помощь, тем выше шансы избежать осложнений и восстановиться без последствий для здоровья.
Разобраться лучше – [url=https://narcolog-na-dom-sochi0.ru/]нарколог на дом вывод из запоя в сочи[/url]
После приезда нарколог оценивает состояние пациента, проверяет давление, частоту пульса и насыщенность крови кислородом. Затем врач подбирает индивидуальный состав капельницы, включающий растворы для очистки организма, препараты для нормализации работы сердца, печени и нервной системы. Процедура длится около 1–2 часов и позволяет быстро:
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-krasnodar0.ru/]вывод из запоя на дому цена в краснодаре[/url]
Путь к свободе от зависимости начинается не с обещаний «просто перестать», а с профессионального медицинского вмешательства. В «Чистом Дыхании» мы применяем проверенные методы, которые работают там, где сила воли без нужной поддержки оказывается бессильной. Наша клиника в Долгопрудном работает круглосуточно — чтобы помощь была доступна в самый критический момент, когда человек ощущает острую потребность в детоксикации, снятии абстинентного синдрома или психологической поддержке.
Выяснить больше – https://narkologicheskaya-klinika-dolgoprudnyj3.ru/
Миссия клиники — оказание комплексной помощи людям с зависимостями. Основные задачи, которые мы ставим перед собой:
Подробнее – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-nizhnem-novgoroge.xn--p1ai
При поступлении вызова специалисты клиники «ЗдоровьеНорм» выезжают на дом в течение 30–60 минут. Врач проводит тщательную диагностику, измеряя артериальное давление, пульс, уровень кислорода в крови и оценивая общее состояние пациента. После этого осуществляется индивидуальный подбор лечебной схемы, основанной на объективных данных и анамнезе пациента.
Подробнее тут – http://vyvod-iz-zapoya-krasnodar00.ru
Sykaaa casino online casino официальный сайт Получите эксклюзивный бонус за регистрацию на официальном сайте Sykaaa Casino! Начните свою игру с дополнительными средствами и увеличьте свои шансы на крупный выигрыш. Sykaaa Casino 100 Бесплатных Вращений
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Подробнее тут – https://wgift.vn/cung-cap-bo-am-chen-qua-ta%CC%A3ng-in-logo-so-luo%CC%A3ng-lon-cho-doanh-nghiep
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Узнать больше – https://dabet1.online/rut-tien-good88-cuc-de
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Выяснить больше – https://subcarpathia.com.pl/last-day-in-vegas
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Получить дополнительные сведения – http://erogework.com/contents/780?variant=zh-hant
https://b2tsite4.io/darknetmarket.html
Бездепозитный бонус Бездепозитный бонус – это не просто подарок судьбы, а возможность испытать свои силы и понять, как работают различные игры. Это как виртуальный тренажер, который позволяет набраться опыта и разработать собственную стратегию, прежде чем переходить к игре на реальные деньги. Это шанс стать уверенным игроком, не боясь потерять собственные средства. Бездепозитный бонус в казино
Клиника “Обновление” также активно занимается просветительской деятельностью. Мы организуем семинары и лекции, которые помогают обществу лучше понять проблемы зависимостей, их последствия и пути решения. Повышение осведомленности является важным шагом на пути к улучшению ситуации в этой области.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-irkutsk.ru/]kapelnicza-ot-zapoya-na-domu irkutsk[/url]
888starz bet скачать на айфон [url=http://www.https://888starz888.website]888starz bet скачать на айфон[/url] .
ткань для штор Купить шторы в Москве можно в многочисленных салонах и магазинах, предлагающих широкий ассортимент тканей и фурнитуры. Важно выбрать проверенного продавца с хорошими отзывами и возможностью заказа по индивидуальным размерам.
гибкая керамика для внутренней Гибкая керамика для фасадов цена за 1 м2 сравнима с традиционной плиткой, но монтаж и вес материала значительно легче, что снижает общие затраты.
•очешь продать авто? продажа и выкуп авто
Поддержка — ключевой элемент на пути к выздоровлению. Мы предлагаем программы, которые продолжаются даже после завершения основного курса лечения. Пациенты имеют возможность участвовать в регулярных встречах с психологами и наркологами, где они могут делиться своими успехами и получать необходимую помощь.
Выяснить больше – http://kapelnica-ot-zapoya-irkutsk2.ru
куда сходить в питере Экскурсии по Петербургу – лучший способ познакомиться с городом и его богатым наследием. Выберите свой маршрут и отправляйтесь в увлекательное путешествие.
Спортивные новости Спортивные ставки – это не только способ заработать деньги, но и возможность добавить азарта в просмотр спортивных событий. Правильный подход и умение управлять рисками – залог успеха в этом увлекательном мире.
Капельница от запоя — это быстрый и безопасный способ вывести токсины, восстановить водно-солевой баланс и улучшить общее самочувствие. Наркологи клиники «ТрезвоКлиник» оказывают круглосуточную медицинскую помощь на дому, используя только сертифицированные препараты и проверенные методики детоксикации.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-moskva0.ru/]капельница от запоя анонимно в москве[/url]
«ВладимирМед» основана группой врачей-наркологов и психотерапевтов, объединивших опыт работы в государственных и частных учреждениях. Мы предлагаем не просто преодоление запоя, а глубокую комплексную реабилитацию, включающую медико-психологическую оценку и долгосрочное сопровождение. Наша цель — восстановление здоровья на физическом и эмоциональном уровнях, возвращение пациента к полноценной социальной жизни без рецидивов.
Углубиться в тему – [url=https://narkologicheskaya-klinika-vladimir10.ru/]наркологическая клиника цены[/url]
Подшипники от производителей Шариковый подшипник – это один из наиболее распространенных типов подшипников качения, в котором тела качения имеют форму шариков. Он отличается универсальностью и подходит для различных применений.
штора для ванны Выбор карниза для штор — важный момент в оформлении окон. Карниз должен быть прочным и соответствовать весу штор, а также гармонировать с интерьером комнаты. Современные модели могут иметь разнообразные дизайны и механизмы управления.
В зависимости от состояния пациента мы предлагаем два формата помощи: выезд нарколога на дом или госпитализацию в стационар. Оба варианта включают детоксикацию — выведение токсинов из организма с помощью инфузионной терапии (капельницы), а также медикаментозную поддержку: успокоительные, витамины, препараты для печени и сердца.
Выяснить больше – http://vyvod-iz-zapoya-serpuhov3.ru
Алкоголь и наркотики воздействуют на организм комплексно: нарушается работа сердца, сосудов, печени и почек, страдает нервная система. При запое или ломке без квалифицированной помощи возникают судороги, делирий, галлюцинации и серьёзные сбои в обмене веществ. Самостоятельные попытки «перетерпеть» или «отмотать» запой зачастую приводят к тяжёлым осложнениям, вплоть до комы и необратимых изменений в органах.
Изучить вопрос глубже – https://narkologicheskaya-klinika-dolgoprudnyj3.ru/anonimnaya-narkologicheskaya-klinika-v-dolgoprudnom
Серьезные состояния, вызванные длительным употреблением алкоголя или наркотиков, требуют немедленного вмешательства. Если пациент испытывает ухудшение самочувствия вследствие продолжительного запоя, его организм начинает накапливать токсичные вещества, что ведёт к нарушению работы внутренних органов. При появлении таких симптомов, как сильная рвота, спутанность сознания, судороги, резкие скачки артериального давления, а также выраженные признаки абстинентного синдрома (сильная дрожь, панические атаки, бессонница, тревожность), вызов нарколога становится жизненно необходимым. Экстренное вмешательство позволяет стабилизировать состояние больного и предотвратить развитие серьёзных осложнений, включая сердечно-сосудистые нарушения, повреждение печени и развитие алкогольного психоза. В таких ситуациях профессиональное лечение на дому — лучший способ сохранить здоровье и жизнь пациента.
Изучить вопрос глубже – [url=https://narcolog-na-dom-ekaterinburg000.ru/]вызов врача нарколога на дом[/url]
It’s great to see platforms like ph987 com prioritizing user experience and security – essential for responsible gaming! A smooth download process is a big plus, making access easier for everyone. Let’s keep the conversation going about healthy gaming habits!
Не можете добраться до клиники? Нарколог на дом в Иркутске – оптимальный выход при запое. Нарколог на дом – это удобно: обследование, лечение и детоксикация в комфортных условиях. Выезд нарколога в любое время, анонимность и безопасность – это «ТрезвоМед». Без медицинской помощи не обойтись? Звоните наркологу! Чем быстрее помощь, тем лучше прогноз, – нарколог Игорь Васильев.
Узнать больше – [url=https://narcolog-na-dom-v-irkutske0.ru/]выезд нарколога на дом цена иркутск[/url]
888starz скачать на андроид бесплатно с официального [url=www.https://888starz-skachat-na-android.com/]www.https://888starz-skachat-na-android.com/[/url] .
Все вызовы фиксируются под кодовым номером без указания ФИО, что обеспечивает полную конфиденциальность каждого пациента.
Узнать больше – https://narkologicheskaya-klinika-vladimir10.ru/anonimnaya-narkologicheskaya-klinika-vladimir
Наша команда врачей оперативно реагирует на каждый вызов, оказывая квалифицированную медицинскую помощь на дому. Специалисты проводят полный комплекс лечебных мероприятий, направленных на безопасное снятие интоксикации, детоксикацию и облегчение симптомов абстиненции.
Получить дополнительную информацию – [url=https://narcolog-na-dom-ekaterinburg0.ru/]вызов нарколога на дом екатеринбург.[/url]
Игнорирование состояния пациента или попытки самостоятельно справиться с запоем могут привести к опасным последствиям для жизни и здоровья. Поэтому важно своевременно обращаться за профессиональной медицинской помощью.
Подробнее – https://narcolog-na-dom-sankt-peterburg0.ru
Тип- бизнес Туры в Санкт-Петербург – отличный способ организовать свою поездку и увидеть самые интересные места, не тратя время на планирование.
Некоторые состояния требуют немедленного вмешательства нарколога, так как отказ от лечения может привести к тяжелым осложнениям и риску для жизни.
Детальнее – [url=https://narcolog-na-dom-novokuznetsk00.ru/]нарколог на дом вывод из запоя[/url]
Клиника «Нарколог-Профи» предлагает круглосуточную помощь на дому в Екатеринбурге и Свердловской области. Наши опытные специалисты готовы оперативно приехать по вашему вызову и оказать экстренную медицинскую поддержку при алкогольной или наркотической зависимости. Мы проводим детоксикацию организма, купируем абстинентный синдром и стабилизируем состояние пациента, обеспечивая при этом полную конфиденциальность и комфорт в домашних условиях.
Подробнее – [url=https://narcolog-na-dom-ekaterinburg00.ru/]вызов нарколога на дом[/url]
Фрибеты за регистрацию Спортивные новости – незаменимый источник информации для успешных ставок. Анализируйте последние события, травмы игроков и статистику команд.
Миссия клиники “Обновление” заключается в предоставлении качественной и всесторонней помощи людям, страдающим от различных форм зависимости. Мы понимаем, что успешное лечение невозможно без индивидуального подхода, поэтому каждый пациент проходит детальную диагностику, после которой разрабатывается персонализированный план терапии. В процессе работы мы акцентируем внимание на следующих аспектах:
Узнать больше – [url=https://kapelnica-ot-zapoya-irkutsk.ru/]капельница от запоя в иркутске[/url]
Агентство контекстной рекламы https://kontekst-dlya-prodazh.ru настройка Яндекс.Директ и Google Ads под ключ. Привлекаем клиентов, оптимизируем бюджеты, повышаем конверсии.
Продвижение сайтов https://optimizaciya-i-prodvizhenie.ru в Google и Яндекс — только «белое» SEO. Улучшаем видимость, позиции и трафик. Аудит, стратегия, тексты, ссылки.
Наша миссия заключается в предоставлении качественной помощи людям, страдающим от зависимостей. Мы стремимся создать безопасную и поддерживающую атмосферу, где каждый сможет получить необходимую помощь. Основная цель — восстановление здоровья, психоэмоционального состояния и социальной адаптации.
Детальнее – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-omske.ru/]наркология вывод из запоя в омске[/url]
экстренный вывод из запоя краснодар
narkolog-krasnodar001.ru
лечение запоя
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Детальнее – http://www.backupteleinformatica.com.br/?p=94
домашний интернет тарифы челябинск
domashij-internet-chelyabinsk004.ru
интернет домашний челябинск
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Детальнее – http://soldadurasazteca.com/index.php/component/k2/item/27-versions-have-evolved-over-the-years?start=4530
Шины и диски https://tssz.ru для любого авто: легковые, внедорожники, коммерческий транспорт. Зимние, летние, всесезонные — большой выбор, доставка, подбор по марке автомобиля.
Инженерная сантехника https://vodazone.ru в Москве — всё для отопления, водоснабжения и канализации. Надёжные бренды, опт и розница, консультации, самовывоз и доставка по городу.
Цены на услуги маркетолога Услуги маркетолога цена – стоимость работы специалиста, определяемая исходя из объема задач, сложности проекта и опыта маркетолога. Цена может быть фиксированной или почасовой.
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Получить больше информации – https://creemorganics.com/hello-world
hd видеоконференции Учебные кабинеты Актобе В Актобе ТОО «Astana IT Garant» реализует комплексные проекты по оснащению учебных кабинетов, способствуя развитию качественного образования в западном регионе Казахстана. Мы создаем современную образовательную инфраструктуру, которая соответствует потребностям развивающегося региона и готовит квалифицированные кадры для местной экономики. Наши специалисты в Актобе работают с школами различного профиля, уделяя особое внимание созданию кабинетов естественных наук, математики и технологий. Мы понимаем важность качественного образования для развития нефтегазовой отрасли региона и оснащаем школы соответствующим лабораторным оборудованием. Astana IT Garant адаптирует свои решения под климатические условия Актобе, обеспечивая надежную работу оборудования в условиях резко континентального климата. Все поставляемая техника проходит дополнительное тестирование на устойчивость к температурным колебаниям и пыли. Мы поддерживаем инициативы акимата Актобе по развитию цифрового образования и участвуем в региональных программах модернизации школ. Наши проекты включают не только поставку оборудования, но и обучение педагогического персонала современным методикам преподавания. Сервисная служба в Актобе обеспечивает быстрое реагирование на технические проблемы и регулярное профилактическое обслуживание. Мы гарантируем высокое качество технической поддержки и долгосрочное сотрудничество с образовательными учреждениями региона, способствуя устойчивому развитию образования в Актобе.
актеры турции Сиде, древний портовый город, славится своими историческими руинами, включая амфитеатр и храм Аполлона, а также песчаными пляжами.
Промышленные ворота https://efaflex.ru любых типов под заказ – секционные, откатные, рулонные, скоростные. Монтаж и обслуживание. Установка по ГОСТ.
Продажа и обслуживание https://kmural.ru копировальной техники для офиса и бизнеса. Новые и б/у аппараты. Быстрая доставка, настройка, ремонт, заправка.
экстренный вывод из запоя краснодар
narkolog-krasnodar002.ru
экстренный вывод из запоя
Клиника “Ренессанс” расположена по адресу: ул. Бородинская, д. 37, г. Пермь, Россия. Мы работаем ежедневно и также предоставляем онлайн-консультации, что позволяет получать помощь из любого места.
Разобраться лучше – https://качество-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-permi.xn--p1ai/
вывод из запоя круглосуточно
narkolog-krasnodar001.ru
экстренный вывод из запоя
подключение интернета челябинск
domashij-internet-chelyabinsk005.ru
домашний интернет подключить челябинск
Вызов врача-нарколога на дом актуален в ситуациях, когда пациенту требуется срочная медицинская помощь, но его состояние не позволяет самостоятельно обратиться в клинику. Основными причинами вызова нарколога на дом являются:
Подробнее – https://narcolog-na-dom-sankt-peterburg00.ru/vyzov-narkologa-na-dom-spb
Наши специалисты применяют только сертифицированные и проверенные препараты. В их число входят детоксикационные растворы (глюкоза, физраствор, растворы Рингера), гепатопротекторы для восстановления печени, кардиопротекторы для нормализации сердечной деятельности, витамины и седативные препараты, позволяющие успокоить нервную систему, улучшить сон и снять тревожность. Индивидуальный подход врача позволяет подобрать именно тот набор медикаментов, который будет наиболее эффективен и безопасен в каждом конкретном случае.
Подробнее – http://narcolog-na-dom-sankt-peterburg0.ru
создать сайт с помощью нейросети нейросеть создать сайт
В зависимости от состояния пациента, помощь может быть оказана в домашних условиях или в стационаре. Вызов нарколога на дом особенно актуален при абстинентном синдроме или тяжелом алкогольном опьянении. Как отмечается в материалах НМИЦ психиатрии и наркологии, в таких ситуациях крайне важно избежать самолечения и довериться врачам, способным правильно подобрать препараты и дозировки.
Разобраться лучше – https://narkologicheskaya-pomoshh-arkhangelsk0.ru/neotlozhnaya-narkologicheskaya-pomoshh-arkhangelsk/
Прежде всего необходимо убедиться, что учреждение официально зарегистрировано и обладает соответствующей лицензией на медицинскую деятельность. Этот документ выдается Минздравом и подтверждает соответствие установленным нормам.
Исследовать вопрос подробнее – https://lechenie-narkomanii-yaroslavl0.ru/czentr-lecheniya-narkomanii-yaroslavl/
Woodworking and construction https://www.woodsurfer.com forum. Ask questions, share projects, read reviews of materials and tools. Help from practitioners and experienced craftsmen.
экстренный вывод из запоя краснодар
narkolog-krasnodar002.ru
лечение запоя краснодар
гибкая керамика Москва Монтаж гибкой керамики для фасадов купить лучше у тех производителей, которые предлагают техническую поддержку и обучение монтажу.
провайдеры домашнего интернета челябинск
domashij-internet-chelyabinsk006.ru
подключить домашний интернет в челябинске
экстренный вывод из запоя
narkolog-krasnodar003.ru
вывод из запоя краснодар
Мы предлагаем полный спектр услуг по лечению зависимостей:
Детальнее – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]narkologicheskaya-klinika-v-oblasti[/url]
В сети «Narkology» вы получите всестороннюю поддержку на пути к полному освобождению от алкогольной и наркотической зависимости. Используем передовые методы дистанционного мониторинга состояния, информационно-просветительские программы и индивидуальные занятия с психологом. Экстренная консультация и круглосуточная связь с медицинскими специалистами помогут справиться с любыми сложностями и обрести новую активность без вредных привычек. Мы предоставляем актуальную информацию о методах детоксикации, замещающих терапий и профилактике срывов.
Подробнее тут – https://narcologiya.info/vliyanie-na-zdorove/protivopokazaniya-k-kodirovaniu.html
услуги pr сопровождения Стоимость услуг маркетолога определяется индивидуально после анализа бизнеса и определения целей продвижения.
888starz обзор [url=http://https://starz888starz.com/]888starz обзор[/url] .
светодиодный экран караганда Оснащение школьных кабинетов Профессиональное оснащение школьных кабинетов требует глубокого понимания современных педагогических подходов и технологических возможностей. ТОО «Astana IT Garant» предлагает комплексные решения для оснащения школьных кабинетов всех профилей с учетом специфики каждого предмета и возрастных особенностей учащихся. Мы специализируемся на создании интерактивной образовательной среды, которая стимулирует активное участие учащихся в учебном процессе. Наше оснащение включает современные интерактивные панели, мультимедийные проекторы, документ-камеры, системы голосования и беспроводные презентационные комплексы. Особое внимание уделяется оснащению специализированных кабинетов: лабораторий естественных наук, компьютерных классов, лингафонных кабинетов, мастерских технологии и изобразительного искусства. Каждое решение адаптируется под конкретные потребности предмета и методики преподавания. Astana IT Garant работает только с проверенными производителями образовательного оборудования, имеющими международные сертификаты качества. Мы гарантируем долговечность, безопасность и соответствие всех компонентов требованиям для использования в школьной среде. Наши специалисты постоянно изучают новые тенденции в области образовательных технологий и адаптируют их для казахстанских школ. Мы предлагаем не только поставку оборудования, но и консультации по его оптимальному использованию, методическую поддержку педагогов и техническое обслуживание на весь период эксплуатации.
Понимание того, какие учреждения действительно способны помочь, позволяет избежать ошибок и не тратить время на неэффективные попытки лечения. Ключевыми признаками являются наличие медицинской лицензии, опытные специалисты, прозрачные условия и отзывы пациентов.
Получить больше информации – http://narkologicheskaya-pomoshh-arkhangelsk0.ru
Каждый этап проводится квалифицированным специалистом, что позволяет достичь максимального терапевтического эффекта.
Выяснить больше – [url=https://narcolog-na-dom-ekaterinburg0.ru/]нарколог на дом свердловская область[/url]
При вызове нарколога на дом в клинике «МедТрезвость» пациент получает квалифицированную помощь, состоящую из нескольких этапов:
Разобраться лучше – [url=https://narcolog-na-dom-sankt-peterburg0.ru/]вызов врача нарколога на дом[/url]
экстренный вывод из запоя краснодар
narkolog-krasnodar003.ru
вывод из запоя круглосуточно краснодар
Пациенты клиники «НаркоМед» полностью застрахованы от утечки личной информации. Приём и лечение оформляются по псевдониму, документы не передаются в другие организации.
Разобраться лучше – https://narkologicheskaya-klinika-ekaterinburg0.ru/
Краны-манипуляторы с изолированной люлькой — особенности и преимущества
https://t.me/s/kupit_gruzoviki/139
В Екатеринбурге ассортимент Wi-Fi роутеров от различных интернет-провайдеров впечатляет. На сайте domashij-internet-ekaterinburg004.ru предоставлены отзывы о роутерах‚ которые способствуют определиться с покупкой. При анализе роутеров важно учитывать скорость интернета и качество связи‚ которые они предлагают. Некоторые пользователи сталкиваются с неприятностями с интернетом‚ поэтому проверка скорости и рекомендации по выбору роутера становятся актуальными. Также не забудьте обратить внимание на антенны для Wi-Fi‚ которые могут улучшить беспроводную сеть. Не забудьте изучить советы по оптимизации связи и настройку роутера. Это существенно повысит качество подключения к интернету и сделает использование сети более комфортным.
Во-вторых, реабилитация является неотъемлемой частью нашего подхода. Мы понимаем, что избавление от физической зависимости — это только первый шаг. Важной задачей является восстановление социального статуса, создание новых привычек и умение управлять своей жизнью без наркотиков или алкоголя. Наша клиника предлагает групповые и индивидуальные занятия, направленные на изменение поведения и мышления.
Подробнее можно узнать тут – https://kapelnica-ot-zapoya-irkutsk.ru/kapelnica-ot-zapoya-na-domu-v-irkutske
– человек не может прекратить употребление сам; – наблюдается агрессия, страх, паника, бессвязная речь; – нарушен сон, отсутствует аппетит, сильная слабость; – алкоголь стал способом снятия боли или тревоги; – попытки отказа приводят к ухудшению состояния.
Получить дополнительную информацию – http://vyvod-iz-zapoya-serpuhov3.ru/anonimnyj-vyvod-iz-zapoya-v-serpuhove/
It’s fascinating how gaming evolved from simple dice rolls to strategic “arenas” like ph987 download. The focus on intellect & security-that multi-stage onboarding-really elevates the experience beyond just luck! A clever approach.
экстренный вывод из запоя краснодар
narkolog-krasnodar004.ru
экстренный вывод из запоя краснодар
Футбол ставки Ставки на спорт – это азарт и возможность проверить свою интуицию. Анализируйте команды, изучайте статистику, но помните об умеренности.
В этой статье мы рассмотрим ключевые признаки эффективной наркологической помощи в Ярославле — от состава команды до подходов в работе с мотивацией пациента.
Подробнее тут – http://lechenie-narkomanii-yaroslavl0.ru
Наркологическая помощь на дому становится всё более востребованной благодаря своей доступности, конфиденциальности и эффективности. Клиника «МедТрезвость» предлагает пациентам целый ряд важных преимуществ:
Подробнее – http://narcolog-na-dom-sankt-peterburg0.ru
Согласно данным ФБУ «НМИЦ терапии и профилактической медицины» Минздрава РФ, стойкая ремиссия возможна только при системном подходе: от медицинской детоксикации до сопровождения в период адаптации. Выбирая учреждение, стоит оценивать не только комфорт, но и соответствие методик современным стандартам.
Детальнее – http://lechenie-narkomanii-yaroslavl0.ru
Первичный этап заключается в оценке состояния пациента и быстром подборе схемы инфузионной терапии. Врач фиксирует показания ЭКГ, сатурацию кислорода и биохимический параметр глюкозы в крови. После этого подключается капельница с раствором для выведения продуктов распада алкоголя и одновременной коррекции показателей обмена веществ. Последующие визиты врача позволяют скорректировать терапию и предотвратить развитие побочных реакций.
Разобраться лучше – https://narkologicheskaya-pomoshh-ekaterinburg0.ru/neotlozhnaya-narkologicheskaya-pomoshh-v-ekb/
Наша команда врачей оперативно реагирует на каждый вызов, оказывая квалифицированную медицинскую помощь на дому. Специалисты проводят полный комплекс лечебных мероприятий, направленных на безопасное снятие интоксикации, детоксикацию и облегчение симптомов абстиненции.
Ознакомиться с деталями – http://narcolog-na-dom-ekaterinburg0.ru/zapoj-narkolog-na-dom-ekb/
вывод из запоя круглосуточно краснодар
narkolog-krasnodar004.ru
вывод из запоя круглосуточно краснодар
Многие родственники надеются, что человек «проспится», что со временем ему станет легче. Но практика показывает: если запой длится более суток, а тем более — несколько дней, состояние будет только ухудшаться. Организм теряет воду, витамины, нарушаются обменные процессы, появляется тревожность, бессонница, тремор, скачки давления. В сложных случаях развиваются острые психозы (делирий), судороги и отказ внутренних органов.
Получить дополнительную информацию – http://vyvod-iz-zapoya-serpuhov3.ru/
Как отмечает руководитель клинико-диагностического отдела ФГБУ «Национальный центр наркологии», «участие в терапии нескольких специалистов разных направлений позволяет учитывать не только симптомы, но и глубинные причины зависимости». Именно такой подход снижает риск рецидивов и повышает эффективность лечения.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-yaroslavl0.ru/]наркологическая клиника на дом[/url]
ИНТЕРНЕТ В Екатеринбурге: УСТАНОВКА И НАСТРОЙКА ОБОРУДОВАНИЯ Сегодня доступ к интернету является важной частью нашей повседневной жизни. При поиске провайдера по адресу в Екатеринбурге стоит обратить внимание на большое количество провайдеров, предлагающих разные тарифные планы. При выборе провайдера учитывайте свои требования, такие как скорость интернет-соединения и предлагаемые услуги связи в Екатеринбурге. Правильная установка роутера и настройка Wi-Fi имеют ключевое значение при подключении к интернету. Хотя беспроводной интернет удобен, кабельный вариант может предоставить более надежное соединение. Важно учитывать оборудование для интернета, которое вы будете использовать, так как от него зависит качество сигнала. узнать провайдера по адресу Екатеринбург После установки роутера следует проверить скорость интернета, чтобы удостовериться, что вы получаете именно то, за что платите. Настройка интернета может вызвать трудности, но большинство провайдеров предлагают инструкции или помощь в настройке оборудования. Корректная настройка Wi-Fi обеспечит вам стабильный и бесперебойный доступ к интернету.
вывод из запоя цена
narkolog-krasnodar005.ru
вывод из запоя круглосуточно
вывод из запоя
narkolog-krasnodar005.ru
вывод из запоя краснодар
sportbets [url=www.sportbets16.ru/]www.sportbets16.ru/[/url] .
Подключение оптоволоконного интернета в Екатеринбурге — это выбор, которое приобретает все большую популярность среди жителей и бизнеса. Провайдеры Екатеринбурга предлагают множество тарифов на интернет, обеспечивая скоростное соединение и надежность интернета. Оптоволоконный интернет, благодаря новейшим технологиям, способен обеспечить значительно более высокую скорость по сравнению с традиционными методами подключения. Это особенно важно для коммерческого использования, где стабильность и высокая скорость являются основными требованиями. Выбирая провайдера, стоит учесть мнения пользователей о провайдерах и сравнение провайдеров по тарифам и услугам связи. Процесс установки интернета, как правило, происходит быстро и без проблем, что делает подключение комфортным. Преимущества оптоволокна очевидны: высокая скорость интернета, минимальные задержки и возможность подключения большого количества устройств. Если вы находитесь в поиске надежного интернет-провайдера, рекомендуем посетить сайт domashij-internet-ekaterinburg006.ru для получения дополнительной информации и подбора подходящего тарифа для вашей квартиры или компании.
значки пины на заказ [url=www.znacki-na-zakaz.ru]www.znacki-na-zakaz.ru[/url] .
ставки на хоккей прогнозы от профессионалов [url=www.prognoz-na-segodnya-na-sport.ru/]www.prognoz-na-segodnya-na-sport.ru/[/url] .
прогнозы на баскетбол го спорт [url=www.prognoz-na-segodnya-na-sport1.ru]www.prognoz-na-segodnya-na-sport1.ru[/url] .
Спортивные ставки Спортивные новости – ключ к успешным ставкам. Будьте в курсе травм, дисквалификаций и других факторов, влияющих на исход матчей.
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Детальнее – https://blog.doozypics.com/bring-your-photos-to-life-with-doozypics-digital-painting
ставки на хоккей прогнозы от профессионалов [url=https://prognoz-na-segodnya-na-sport3.ru]ставки на хоккей прогнозы от профессионалов[/url] .
ставки на хоккей сегодня прогнозы точные [url=https://kompyuternye-prognozy-na-futbol1.ru/]kompyuternye-prognozy-na-futbol1.ru[/url] .
прогнозы на теннис го спорт [url=https://www.prognoz-na-segodnya-na-sport2.ru]прогнозы на теннис го спорт[/url] .
прием вторсырья казань Прием вторсырья в Казани – это возможность заработать деньги и одновременно позаботиться об окружающей среде. Многие компании предлагают выгодные условия приема вторсырья, что делает этот процесс еще более привлекательным.
примеры применения ИИ Альтернативный интеллект: Исследование новых подходов к созданию ИИ, альтернативных нейронным сетям.
Капельница от похмелья на дому: эффективное лечение и восстановление здоровья
мобильные прокси 2025 Рейтинг лучших – это квинтэссенция выбора, демонстрирующая лидеров в определенной области. Он формируется на основе тщательного анализа множества факторов, таких как качество, надежность, инновационность и отзывы пользователей. Попадание в рейтинг лучших – это знак признания и свидетельство высокого уровня мастерства.
Эффективные методы лечения алкоголизма в Туле Алкоголизм – это огромная проблема‚ которая требует комплексного подхода. В Туле доступны различные наркологические услуги‚ включая возможность вызвать нарколога на дом. Это особенно существенно для людей‚ кто стесняется идти в клиники для лечения зависимости. Первым этапом является детоксикация тела‚ которая позволяет очистить организм от алкоголя и токсинов. После этого начинается терапия алкогольной зависимости. Лечение алкоголизма может включать медикаментозные препараты и психологическую поддержку. Консультация нарколога позволит подобрать оптимальный метод лечения. Реабилитация зависимых предполагает наличие семейной терапиичто помогает близким людям поддерживать зависимого. Важно помнить о профилактике рецидивов‚ который включает занятия в группах поддержки и индивидуальные сессии. Лечение алкоголизма анонимно позволяет пациентам быть уверенными в своей конфиденциальности. Важно помнить‚ что лечение зависимости от алкоголя – это долгий процесс‚ который требует настойчивости и усилий. Вызвать нарколога на дом – это начало новой жизни без алкоголя.
сдать макулатуру в казани Прием вторсырья Казань включает в себя не только макулатуру, но и другие виды отходов, такие как пластик, стекло и металл. Сдавая вторсырье, вы помогаете сократить количество мусора на полигонах и сэкономить ресурсы.
Обращение к врачу становится жизненно необходимым, если пациент находится в состоянии длительного запоя, при котором организм не справляется с накоплением токсинов. Если запой продолжается более двух-трёх дней, в теле накапливаются вредные вещества, что ведёт к нарушениям работы внутренних органов, развитию абстинентного синдрома и появлению психических нарушений. Также, если у пациента наблюдаются симптомы, такие как частая рвота, спутанность сознания, судороги или резкие скачки артериального давления, это сигнал к незамедлительному вызову специалиста. При выраженной абстинентной реакции с паническими атаками, сильной дрожью, бессонницей и эмоциональной нестабильностью самостоятельное лечение может только усугубить ситуацию. Если появляются признаки алкогольного психоза – галлюцинации, агрессивность или спутанность сознания – вызов нарколога становится обязательным для предотвращения дальнейших осложнений. Также, когда требуется подготовка к процедурам кодирования от зависимости, необходима качественная детоксикация организма, что также является показанием к срочному обращению за профессиональной помощью.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-ekaterinburg0.ru/]вызвать нарколога на дом в екатеринбурге[/url]
Нарколог на дому проводит тщательный осмотр, собирает анамнез и назначает необходимые лабораторные исследования. Это позволяет выявить сопутствующие патологии и скорректировать тактику лечения.
Получить дополнительные сведения – http://narkolog-na-dom-v-yaroslavle12.ru/narkolog-na-dom-kruglosutochno-v-yaroslavle/
заказать сборку компьютера Сборка компьютера под ключ – мы берем на себя все этапы сборки, от подбора комплектующих до настройки операционной системы.
конфигуратор игрового ПК Конфигуратор ПК онлайн – соберите свой идеальный ПК онлайн и оцените его стоимость.
*машинное обучение Тренды AI показывают направление развития искусственного интеллекта.
интернет домашний казань
domashij-internet-kazan004.ru
проверить интернет по адресу
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]наркологическая клиника[/url]
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Получить больше информации – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]narkologicheskaya klinika kamensk-ural’skij[/url]
В настоящее время проблемы с алкоголем становятся все более актуальными . Многие люди сталкиваются с зависимостью от алкоголя , которая нуждаеться в оперативном вмешательстве врачей. В таких ситуациях вызов нарколога на дом – это оптимальное решение . Услуги нарколога включают диагностику алкоголизма и медикаментозное лечение запоя. Это помогает быстро и эффективно помочь в выходе из запоя, минимизируя психологическое напряжение для пациента. Анонимное лечение алкоголизма – важный аспект , поскольку многие пациенты не хотят делиться своими проблемами . Помощь при алкогольной зависимости также включает помощь близким в борьбе с алкоголизмом. Нарколог на дом предлагает консультационные услуги, что позволяет семье разобраться, как правильно общаться с зависимым. Лечение зависимостей на дому даёт возможность пройти реабилитацию от алкоголя в комфортной обстановке . Сайт narkolog-tula002.ru предоставляет сведения о вызове врача на дом , чтобы оказать помощь тем, кто в ней нуждается.
адрес больницы больницы Бар
Лечение алкоголизма в Туле: современные методы Алкоголизм — серьезная проблема, требующая профессионального подхода. Тула предлагает широкий спектр наркологических услуг, включая возможность вызвать нарколога на дом для конфиденциального лечения. Современные методы лечения включают медикаментозную терапию и процедуры детоксикации организма. Психотерапия является важной частью лечения алкоголизма, так как она помогает понять и проработать психологические аспекты зависимости. Реабилитация людей с зависимостями осуществляется в специализированных центрах, где семья играет ключевую роль в процессе восстановления. Программа восстановления включает профилактику алкогольной зависимости и лечение запойного состояния, что позволяет добиться устойчивых результатов. заказать нарколога на дом
Tivat hospital orthopedic clinic near me
Наркологическая клиника в Ярославле представляет собой специализированное учреждение, оказывающее медицинскую помощь пациентам с алкогольной, наркотической и медикаментозной зависимостью. Ключевыми направлениями работы являются детоксикация, стабилизация состояния, последующее реабилитационное сопровождение и профилактика рецидивов. Комплексный подход к лечению обеспечивается взаимодействием специалистов различных профилей, включая наркологов, психиатров, психотерапевтов и медицинских сестёр.
Подробнее – [url=https://narkologicheskaya-klinika-v-yaroslavle12.ru/]частная наркологическая клиника ярославская область[/url]
купить игровой ПК Сборка компьютеров на заказ – это индивидуальный подход к созданию машины, отвечающей вашим уникальным требованиям. От выбора комплектующих до финальной сборки, каждый этап контролируется для достижения максимальной производительности.
Как поясняет медицинский психолог Елена Мусатова, «пациенту важно доверять специалисту, понимать его подход и чувствовать профессиональную уверенность ещё на этапе первичного осмотра».
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-pervouralsk11.ru/]наркологические клиники алкоголизм первоуральск[/url]
Капельница от запоя в Мурманске является одной из наиболее востребованных процедур для снятия острого состояния алкогольной интоксикации. Эта методика позволяет быстро вывести токсины из организма, нормализовать водно-солевой баланс и улучшить самочувствие пациента. Современная капельная терапия считается эффективным средством в лечении запоя, обеспечивая поддержку жизненно важных функций и минимизируя риски осложнений.
Получить больше информации – https://kapelnicza-ot-zapoya-v-murmanske12.ru/kapelniczy-ot-zapoya-na-domu-v-murmanske/
Наркологическая клиника в Ярославле представляет собой специализированное учреждение, оказывающее медицинскую помощь пациентам с алкогольной, наркотической и медикаментозной зависимостью. Ключевыми направлениями работы являются детоксикация, стабилизация состояния, последующее реабилитационное сопровождение и профилактика рецидивов. Комплексный подход к лечению обеспечивается взаимодействием специалистов различных профилей, включая наркологов, психиатров, психотерапевтов и медицинских сестёр.
Получить дополнительные сведения – https://narkologicheskaya-klinika-v-yaroslavle12.ru/narkologicheskaya-klinika-klinika-pomoshh-v-yaroslavle/
домашний интернет тарифы
domashij-internet-kazan005.ru
провайдеры по адресу казань
Услуга откапывания на дому в Туле – это популярная услуга‚ которая особенно актуальна при проведении земляных работ‚ ремонте и строительстве. Компании‚ специализирующиеся на этом‚ предлагают услуги по копке с помощью экскаватора на вашем участке. Лицензированные специалисты обеспечивают качественное выполнение заказа‚ включая обработку грунта и установку дренажей. Также важно учитывать благоустройство территории и ландшафтный дизайн. Заказывая частные услуги‚ вы можете рассчитывать на профессионализм и надежность. Чтобы узнать больше‚ посетите сайт narkolog-tula003.ru.
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Подробнее – http://narkologicheskaya-klinika-kamensk-uralskij11.ru
Наркологическая клиника в Каменске-Уральском разрабатывает программы лечения, учитывая особенности различных видов зависимости: алкогольной, наркотической, лекарственной. Каждая программа ориентирована на индивидуальные потребности пациента, что подтверждается опытом ведущих российских реабилитационных центров. Подробнее о лечении зависимости читайте на официальном сайте Минздрава.
Выяснить больше – http://narkologicheskaya-klinika-kamensk-uralskij11.ru
Помощь нужна, если:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-serpuhov3.ru/]срочный вывод из запоя[/url]
Капельница от запоя на дому – это популярная опция в Туле, которую предлагают специалистами в области наркологии. Удобное лечение даёт возможность пациентам не испытывать стресс, связанного с поездками в клинику. Отзывы пациентов подтверждают результативности детоксикации организма и оперативного выхода из запойного состояния. Врач нарколог на дом обеспечивает конфиденциальное лечение, что является важным для многих. Преодоление алкогольной зависимости становится доступным, а восстановление здоровья – приоритетом. Медицинские услуги, как капельница, помогают справиться с алкогольной зависимостью и возврату к привычному образу жизни.
Преимущества вызова нарколога на дом:
Подробнее тут – [url=https://vyvod-iz-zapoya-v-murmanske12.ru/]vyvod-iz-zapoya-klinika murmansk[/url]
подключить домашний интернет казань
domashij-internet-kazan006.ru
домашний интернет
Капельницы от алкоголизма в городе Туле – это важный шаг в борьбе с алкоголизма. Методы детоксикации способствуют справиться с симптомами абстиненции и избавиться от пьянства. Медицинская помощь в специализированных центрах включает не только капельницы‚ но и поддержку психолога‚ что способствует восстановлению после алкоголя. narkolog-tula004.ru Восстановление начинается с очистки организма‚ после которой инициируются реабилитационные программы. Поддержка родственников также имеет значимую роль в профилактике рецидивов. Группы поддержки и консультация специалиста вполне способны оказать помощь в процессе выздоровления. Не забудьте‚ что лечение алкоголизма требует комплексного подхода.
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Углубиться в тему – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]наркологическая клиника каменск-уральский.[/url]
Капельница от запоя – проверенное решение для лечения алкогольной зависимости. Она обеспечивает быстрое вливание жидкости‚ что приводит к детоксикации тела и улучшению состояния здоровья. В клиниках лечения зависимостей‚ таких как narkolog-tula005.ru‚ квалифицированные специалисты предлагают комплексную помощь‚ включая инъекции от алкоголизма. Лечение включает не только капельницы‚ но и реабилитацию‚ психологическую поддержку при алкоголизме‚ что помогает пациентам возвращаться к обычной жизни.
точные ставки на футбол [url=www.kompyuternye-prognozy-na-futbol2.ru/]точные ставки на футбол[/url] .
провайдеры по адресу красноярск
domashij-internet-krasnoyarsk004.ru
интернет по адресу
Капельница от алкоголя на дому в Туле — это оптимальный вариант помочь зависимым попавшим в зависимость. Борьба с алкоголизмом включает выведение из запоя в домашних условиях, что позволяет избежать стационарного лечения. Детоксикация может осуществляться с помощью специальных растворовкоторые обеспечивают организм необходимыми веществами. Квалифицированная помощь в таких случаях необходима: работа с врачами-наркологами помогут правильно подобрать антиалкогольную терапию. Психотерапия при алкоголизме также играет ключевую роль в восстановлении. Семейная терапия и возвращение к нормальной жизни помогают в процессе восстановления после зависимости. Профилактика алкоголизма и восстановление после запоя — важные этапы в путь к трезвости. Не забывайте, что здоровый образ жизни без алкоголя. На сайте narkolog-tula004.ru вы можете получить информацию о доступных услугах и методах лечения.
Как подчёркивает врач-нарколог клиники «Светлый Мир» Александр Павлович Ермаков, «на фоне резкого отказа от алкоголя могут возникнуть острые состояния, требующие реанимационной помощи — поэтому нельзя пытаться прервать запой без участия специалиста». В домашних условиях, под присмотром профессионала, лечение может быть начато уже в течение часа после вызова, без необходимости транспортировки пациента в критическом состоянии.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]vyvod-iz-zapoya-v-domodedovo[/url]
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Получить дополнительную информацию – http://
Капельница от запоя, это необходимый шаг в лечении алкоголизма. Обращение к наркологу на дом в Туле позволяет получить квалифицированную помощь. Если появляются симптомы запоя, таких как дрожь, потливость и тревожность, важно сразу обратиться за помощью. Наркологи проводят диагностику алкоголизма и разрабатывают план медикаментозной терапии, включая инфузии для детоксикации. вызов нарколога на дом тула Восстановление после запоя включает семейную поддержку, что значительно повышает шансы на успешное восстановление. Предотвращение алкогольной зависимости тоже является важным аспектом. Услуги нарколога, включая вызов врача на дом, помогают решить проблемы, связанные с алкогольной зависимостью, и гарантировать безопасную терапию.
провайдеры интернета в красноярске по адресу
domashij-internet-krasnoyarsk005.ru
какие провайдеры интернета есть по адресу красноярск
После поступления вызова на дом врачи клиники «Трезвый Путь» проводят лечение по четко разработанному алгоритму, обеспечивающему максимальную эффективность и безопасность:
Подробнее можно узнать тут – [url=https://narcolog-na-dom-ekaterinburg0.ru/]выезд нарколога на дом екатеринбург[/url]
Капельницы для лечения алкогольной зависимости на дому – это эффективный метод лечения алкогольной зависимости, который предоставляет возможность пройти детоксикацию без необходимости госпитализации. Услуги нарколога включают капельницу на дому, что способствует повышению качества жизни и уменьшению симптомов абстиненции. Капельницы помогают организму ускоряют вывод токсинов, а также обеспечивают восстановлению организма. Поддержка при отказе от алкоголя важна на всех этапах, включая реабилитацию алкоголиков. Профилактика осложнений также играет ключевую роль в процессе излечения. Лечение на дому может состоять не только из капельниц, но и консультации специалистов, что способствует успешному выходу из запоя и эффективному лечению. Обращаясь на narkolog-tula005.ru, вы сможете получить профессиональную поддержку и поддержку в сражении с алкогольной зависимостью.
комплект напольных кашпо [url=https://www.kashpo-napolnoe-msk.ru]https://www.kashpo-napolnoe-msk.ru[/url] .
Согласно данным НМИЦ психиатрии и наркологии Минздрава РФ, профессиональный вывод из запоя с применением капельниц снижает риск осложнений и сокращает период восстановления. Процедура проводится только под наблюдением квалифицированных специалистов и требует правильного подбора препаратов в зависимости от стадии опьянения и наличия сопутствующих заболеваний.
Выяснить больше – [url=https://kapelnicza-ot-zapoya-pervouralsk11.ru/]капельница от запоя на дому первоуральск.[/url]
ПРОКАПАТЬ ОТ АЛКОГОЛЯ: ВАЖНОСТЬ ДЕТОКСИКАЦИИ И ПОДДЕРЖКИ Вопрос алкогольной зависимости затрагивает многих людей. Лечение алкоголизма часто начинается с детоксикации, что включает прокапывание. Этот этап помогает вывести токсины из организма и облегчить абстинентный синдром.Капельницы от алкоголя содержат препараты для детоксикации, способствующие восстановлению организма. Они помогают восстановиться после запоя, предоставляя необходимую медицинскую помощь. Важно помнить, что поддержка зависимых в этот период крайне важна.После детоксикации начинается реабилитация, где психотерапия при алкоголизме занимает ключевую роль. Специалисты поддерживают разобраться в причинах зависимости и предоставляют советы по борьбе с зависимостями.На сайте narkolog-tula007.ru можно найти информацию о том, как правильно пройти лечение и получить поддержку. Здоровье является важный шаг к новой жизни без алкоголя.
В такой момент человеку нужна не просто поддержка — ему нужна медицинская помощь. В Электростали её оказывает наркологическая клиника «Трезвый Исток». Мы работаем круглосуточно, без праздников и выходных. И выезжаем сразу — без очередей, без лишней бюрократии. Только быстрый, грамотный и безопасный вывод из запоя — на дому или в стационаре, в зависимости от состояния пациента.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ehlektrostal3.ru/]vyvod-iz-zapoya-na-domu-cena[/url]
Стоимость услуг зависит от продолжительности терапии, сложности случая и выбранных процедур. Однако клиника предоставляет гибкую систему оплаты, включая рассрочку и страховое покрытие.
Углубиться в тему – https://narkologicheskaya-klinika-v-ryazani12.ru/narkologicheskaya-klinika-czeny-v-ryazani
Отзывы о целителях Обряд на любовь – комплекс магических действий, направленный на привлечение любви и улучшение отношений. Обряды на любовь могут включать в себя использование свечей, трав, заговоров и других атрибутов.
Купить подписчиков в Telegram https://vc.ru/smm-promotion лёгкий способ начать продвижение. Выберите нужный пакет: боты, офферы, живые. Подходит для личных, новостных и коммерческих каналов.
профильные трубы Профильные трубы: Сталь в геометрической гармонии В мире современной инженерии и строительства профильные трубы занимают особое место. Их универсальность, прочность и геометрическая точность делают их незаменимым элементом в самых разнообразных проектах. От каркасов зданий до мебельных конструкций, от сельскохозяйственной техники до рекламных щитов – профильные трубы находят применение там, где требуется надежность и долговечность.
Виртуальные номера для Telegram https://basolinovoip.com создавайте аккаунты без SIM-карты. Регистрация за минуту, широкий выбор стран, удобная оплата. Идеально для анонимности, работы и продвижения.
Куда сходить в Санкт-Петербурге Любовная магия – это область магии, направленная на привлечение любви, укрепление отношений и решение проблем в личной жизни. Важно помнить об этичности использования любовной магии.
Odjeca i aksesoari za hotele poplin tekstil po sistemu kljuc u ruke: uniforme za sobarice, recepcionere, SPA ogrtaci, papuce, peskiri. Isporuke direktno od proizvodaca, stampa logotipa, jedinstveni stil.
Запой представляет собой состояние‚ когда индивид не в состоянии прекратить употребление алкоголя‚ что ведет к серьезным последствиям для его здоровья. Вызов нарколога в Туле — первоначальный этап на пути к выздоровлению. Капельницы играют важную роль в детоксикации организма‚ устраняя симптомы похмелья и восстанавливая водно-электролитный баланс. вызов нарколога тула Наркологические клиники предлагают различные методы лечения алкоголизма‚ включая уколы для детоксикации. Срочная помощь при запое включает не только капельницы‚ но и комплексную поддержку пациента на всех этапах его восстановления. Реабилитация после запоя крайне важен для снижения риска рецидивов. Качественная медицинская помощь должна быть профессиональной и предоставляться своевременно‚ чтобы гарантировать восстановление организма и минимизировать риски для здоровья. Тула предлагает широкий спектр наркологических услуг‚ которые помогут в борьбе с алкогольной зависимостью.
Подробности о технологии и методах выезда нарколога можно найти на официальных медицинских порталах, таких как Российское общество наркологов и Минздрав РФ.
Выяснить больше – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]нарколог на дом круглосуточно в ярославле[/url]
пансионат для пожилых после инсульта
pansionat-msk001.ru
пансионат для пожилых с инсультом
Капельница от запоя в Мурманске является одной из наиболее востребованных процедур для снятия острого состояния алкогольной интоксикации. Эта методика позволяет быстро вывести токсины из организма, нормализовать водно-солевой баланс и улучшить самочувствие пациента. Современная капельная терапия считается эффективным средством в лечении запоя, обеспечивая поддержку жизненно важных функций и минимизируя риски осложнений.
Подробнее тут – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя[/url]
Капельница от запоя в Мурманске является одной из наиболее востребованных процедур для снятия острого состояния алкогольной интоксикации. Эта методика позволяет быстро вывести токсины из организма, нормализовать водно-солевой баланс и улучшить самочувствие пациента. Современная капельная терапия считается эффективным средством в лечении запоя, обеспечивая поддержку жизненно важных функций и минимизируя риски осложнений.
Детальнее – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя цена в мурманске[/url]
Капельница от запоя применяется для комплексного восстановления организма после длительного употребления алкоголя. Она включает в себя введение растворов, насыщенных витаминами, электролитами, глюкозой и лекарственными средствами, направленными на устранение симптомов интоксикации. Основные задачи процедуры:
Получить больше информации – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя на дому мурманск[/url]
какие провайдеры по адресу
domashij-internet-krasnodar004.ru
провайдер интернета по адресу краснодар
Пребывание в стационаре обеспечивает круглосуточный мониторинг состояния, своевременное введение лекарств и защиту пациента от внешних факторов, провоцирующих срыв. Все палаты оснащены необходимым оборудованием, соблюдаются санитарные нормы, а условия размещения соответствуют медицинским стандартам.
Выяснить больше – [url=https://narkologicheskaya-klinika-v-yaroslavle12.ru/]наркологическая клиника нарколог[/url]
Как подчёркивает заведующая отделением клинической психологии ФГБУН «НМИЦ психиатрии и наркологии» Минздрава России, наличие в команде специалистов с опытом работы в области зависимости — это основа качественной помощи.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-nizhnij-tagil11.ru/]наркологические клиники алкоголизм свердловская область[/url]
После поступления вызова на дом врачи клиники «Трезвый Путь» проводят лечение по четко разработанному алгоритму, обеспечивающему максимальную эффективность и безопасность:
Углубиться в тему – [url=https://narcolog-na-dom-ekaterinburg0.ru/]нарколог на дом клиника в екатеринбурге[/url]
Вывод из запоя показан при:
Детальнее – [url=https://vyvod-iz-zapoya-v-murmanske12.ru/]срочный вывод из запоя[/url]
Процедура капельного введения лекарственных растворов проводится в условиях клиники с соблюдением всех санитарных норм. Пациенту устанавливается капельница, через которую вводятся препараты под контролем медперсонала. В зависимости от состояния пациента и тяжести запоя длительность капельной терапии может варьироваться от 1 до 6 часов.
Изучить вопрос глубже – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]kapelnicza-ot-zapoya-czena murmansk[/url]
Очищение солью от негатива Приворот – магическое воздействие, направленное на вызов любовного влечения у определенного человека. Приворот является мощным и опасным инструментом, который может иметь непредсказуемые последствия.
металлообработка Металлообработка – это обширная сфера деятельности, охватывающая широкий спектр процессов, направленных на изменение формы, размеров и свойств металлов и сплавов. От простых ручных операций до высокотехнологичных автоматизированных производств, металлообработка играет ключевую роль во многих отраслях промышленности, обеспечивая создание деталей, инструментов и конструкций, необходимых для функционирования современного мира.
пансионат для пожилых в москве
pansionat-msk002.ru
пансионат для людей с деменцией в москве
Профилактика алкоголизма — существенная проблема, требующая внимания и усилий. Врач нарколог на дом способен оказать необходимую помощь, предлагая квалифицированные консультации и лечение. Симптомы алкоголизма включают частом употреблении алкоголя и изменениях в поведении. Психотерапевтическая поддержка и групповые терапии являются важными элементами в борьбе с зависимостями. Чтобы предотвратить запойные состояния, рекомендуется придерживаться ряда рекомендаций по отказу от спиртного. Поддержка семьи и близких способствует успешной реабилитации от алкогольной зависимости. Меры профилактики, такие как самопомощь при алкоголизме и участие в социальных программах, поддерживают социализацию и усиливают желание вести трезвый образ жизни.
Компоненты
Углубиться в тему – https://kapelnicza-ot-zapoya-pervouralsk11.ru/kapelnicza-ot-zapoya-na-domu-stoimost-v-pervouralske
провайдеры интернета по адресу
domashij-internet-krasnodar005.ru
провайдеры интернета по адресу
Преимущества вызова нарколога на дом:
Детальнее – https://vyvod-iz-zapoya-v-murmanske12.ru
Мы предлагаем полный спектр услуг по лечению зависимостей:
Подробнее – http://narkologicheskaya-klinika-dolgoprudnyj3.ru
mostbet az aviator strategiya [url=http://mostbet4042.ru/]mostbet az aviator strategiya[/url]
пансионаты для инвалидов в москве
pansionat-msk003.ru
частный пансионат для пожилых
Запой — это не просто бытовое пьянство, а одно из наиболее опасных проявлений алкогольной зависимости. Во время запоя организм перестаёт функционировать в нормальном режиме: сердечно-сосудистая система работает на износ, нервная система перегружена токсинами, а печень не справляется с нагрузкой. На этом фоне могут возникать тяжёлые осложнения — от судорог и гипогликемии до нарушения дыхания и алкогольного психоза. Чем дольше длится запой, тем глубже метаболические нарушения и выше риск серьёзных последствий.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-kolomna3.ru/]vyvod-iz-zapoya-cena[/url]
Медицинский вывод из запоя включает несколько обязательных этапов:
Подробнее – [url=https://vyvod-iz-zapoya-kolomna3.ru/]вывод из запоя круглосуточно[/url]
какие провайдеры на адресе в краснодаре
[url=https://domashij-internet-krasnodar006.ru]domashij-internet-krasnodar006.ru[/url]
узнать провайдера по адресу краснодар
пансионат для лежачих москва
pansionat-msk001.ru
пансионат для престарелых
Для успешной адаптации пациента в обществе клиника организует поддержку родственников и последующее наблюдение. Это снижает риск рецидива и помогает сохранить достигнутые результаты.
Узнать больше – http://narkologicheskaya-klinika-v-murmanske12.ru
Первое, на что стоит обратить внимание — это профессиональный уровень сотрудников. Без квалифицированных наркологов, клинических психологов и психиатров реабилитационный процесс становится формальным и неэффективным.
Подробнее – [url=https://narkologicheskaya-klinika-nizhnij-tagil11.ru/]наркологическая клиника в нижнем тагиле[/url]
Подробности о технологии и методах выезда нарколога можно найти на официальных медицинских порталах, таких как Российское общество наркологов и Минздрав РФ.
Подробнее – https://narkolog-na-dom-v-yaroslavle12.ru/
самые точные прогнозы на футбол [url=www.kompyuternye-prognozy-na-futbol3.ru]самые точные прогнозы на футбол[/url] .
прогнозы на хоккей сегодня [url=http://www.luchshie-prognozy-na-khokkej2.ru]http://www.luchshie-prognozy-na-khokkej2.ru[/url] .
евросан [url=https://internet-magazine-santehniki.ru/]https://internet-magazine-santehniki.ru/[/url] .
хоккейные прогнозы на сегодня [url=www.luchshie-prognozy-na-khokkej.ru]www.luchshie-prognozy-na-khokkej.ru[/url] .
современные горшки напольные [url=https://www.kashpo-napolnoe-spb.ru]https://www.kashpo-napolnoe-spb.ru[/url] .
spoofer hwid Hardware ID Spoofer: Hardware ID Spoofer для Path of Exile
пансионат для пожилых с инсультом
pansionat-tula001.ru
пансионат для лежачих после инсульта
суши роллы барнаул суши сайт барнаул
Хирургические услуги хирургия Котор: диагностика, операции, восстановление. Современная клиника, лицензированные специалисты, помощь туристам и резидентам.
aviator 1win download [url=1win1138.ru]aviator 1win download[/url]
В Москве доступен высокоскоростной интернет, который обеспечивает высокую скорость и стабильное соединение. Актуальные тарифы провайдеров, предлагающих услуги связи, можно найти на сайте domashij-internet-msk004.ru.Важно учитывать сравнение тарифов и скорость интернета при выборе провайдера; Среди интернет-провайдеров существуют компании, предлагающие доступ в интернет через оптоволоконные линии в Москве. Эти технологии гарантируют высокую скорость и надежность.При выборе провайдера стоит ознакомиться с отзывами о провайдерах. Это позволит понять, какие провайдеры предлагают наилучшие тарифы и уровень сервиса. Сравнение скорости различных тарифов позволит подобрать лучший вариант для вашего жилья. Учтите, что стоимость интернет-услуг может отличаться, поэтому важно тщательно выбирать. Если заранее ознакомиться с предложениями на рынке, подключение интернета пройдет без проблем.
Используя современные инфузионные системы, мы постепенно вводим растворы для выведения токсинов, коррекции водно-электролитного баланса и восстановления функции печени. Параллельно подбираются препараты для снятия абстинентного синдрома, купирования тревожности и нормализации сна.
Получить дополнительные сведения – https://narkologicheskaya-klinika-dolgoprudnyj3.ru/anonimnaya-narkologicheskaya-klinika-v-dolgoprudnom
частные пансионаты для пожилых в москве
pansionat-msk002.ru
частный пансионат для престарелых
hwid spoofer … (далее 145 аналогичных статей, варьирующихся по смыслу и раскрывающих различные аспекты темы HWID Spoofer)
При своевременном обращении к специалистам капельница позволяет значительно улучшить состояние пациента уже в первые часы после начала лечения. Медицинская помощь при запое должна оказываться квалифицированно и в комфортных условиях, что снижает риски осложнений и ускоряет восстановление.
Выяснить больше – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]поставить капельницу от запоя в мурманске[/url]
бк 888starz [url=www.888starz.com.ru]бк 888starz[/url] .
mostbet mobil qeydiyyat [url=https://mostbet3041.ru/]https://mostbet3041.ru/[/url]
пансионат для пожилых с инсультом
pansionat-tula002.ru
пансионат для лежачих после инсульта
mostbet baixar aplica??o para android [url=https://www.mostbetdownload-apk.com]mostbet baixar aplica??o para android[/url] .
Пребывание в стационаре обеспечивает круглосуточный мониторинг состояния, своевременное введение лекарств и защиту пациента от внешних факторов, провоцирующих срыв. Все палаты оснащены необходимым оборудованием, соблюдаются санитарные нормы, а условия размещения соответствуют медицинским стандартам.
Углубиться в тему – https://narkologicheskaya-klinika-v-yaroslavle12.ru/narkologicheskaya-klinika-klinika-pomoshh-v-yaroslavle/
Наша команда врачей оперативно реагирует на каждый вызов, оказывая квалифицированную медицинскую помощь на дому. Специалисты проводят полный комплекс лечебных мероприятий, направленных на безопасное снятие интоксикации, детоксикацию и облегчение симптомов абстиненции.
Узнать больше – http://narcolog-na-dom-ekaterinburg0.ru
Капельница от запоя применяется для комплексного восстановления организма после длительного употребления алкоголя. Она включает в себя введение растворов, насыщенных витаминами, электролитами, глюкозой и лекарственными средствами, направленными на устранение симптомов интоксикации. Основные задачи процедуры:
Подробнее – http://kapelnicza-ot-zapoya-v-murmanske12.ru/kapelniczy-ot-zapoya-na-domu-v-murmanske/
Подключение интернета в Москве требует осмотрительности при выборе провайдера. На рынке представлены различные интернет-провайдеры, предлагающих широкий спектр тарифов на интернет. При выборе стоит учитывать такие параметры, как скорость, цена подключения и условия.Сравнение предложений провайдеров поможет определить наиболее выгодный тариф. Многие провайдеры проводят акции и предлагают бесплатное подключение для новых клиентов. Важно также изучить отзывы о провайдерах, чтобы понять, насколько стабильно соединение и каковы услуги. провайдеры в москве Используя онлайн-сервисы, можно быстро найти и сравнить предложения от провайдеров, чтобы подобрать наилучшее решение для выхода в сеть. Обратите внимание на акции и специальные предложения провайдеров — они могут значительно уменьшить ваши расходы.
При лёгких и среднетяжёлых состояниях возможно проведение лечения на дому. Это удобно, комфортно и позволяет сохранить анонимность. Однако есть ситуации, в которых домашнее вмешательство нецелесообразно:
Подробнее тут – [url=https://vyvod-iz-zapoya-kolomna3.ru/]vyvod-iz-zapoya-na-domu[/url]
пансионат для престарелых
pansionat-msk003.ru
пансионат для пожилых людей
Магазин брендовых кроссовок https://kicksvibe.ru Nike, Adidas, New Balance, Puma и другие. 100% оригинал, новые коллекции, быстрая доставка, удобная оплата. Стильно, комфортно, доступно!
суши роллы барнаул https://sushi-barnaul.ru
пансионат для пожилых
pansionat-tula003.ru
пансионат для лежачих после инсульта
При своевременном обращении к специалистам капельница позволяет значительно улучшить состояние пациента уже в первые часы после начала лечения. Медицинская помощь при запое должна оказываться квалифицированно и в комфортных условиях, что снижает риски осложнений и ускоряет восстановление.
Углубиться в тему – https://kapelnicza-ot-zapoya-v-murmanske12.ru/postavit-kapelniczu-ot-zapoya-v-murmanske/
spoofer hwid Зачем нужен HWID Spoofer? Защита от блокировок и сохранение анонимности
Для эффективного вывода из запоя в Мурманске используются современные методы детоксикации, включающие внутривенное введение растворов, направленных на восстановление водно-солевого баланса, коррекцию электролитов и нормализацию работы почек и печени. Важным этапом является использование витаминных комплексов и препаратов, поддерживающих работу сердца и сосудов.
Выяснить больше – https://vyvod-iz-zapoya-v-murmanske12.ru/anonimnyj-vyvod-iz-zapoya-v-murmanske
вывод из запоя круглосуточно
[url=https://vivod-iz-zapoya-chelyabinsk001.ru]https://vivod-iz-zapoya-chelyabinsk001.ru[/url]
экстренный вывод из запоя челябинск
пансионат для пожилых людей
pansionat-tula001.ru
частный пансионат для пожилых
Как подчёркивает врач-нарколог И.В. Синицин, «современная наркология — это не только вывод из запоя, но и работа с глубинными причинами зависимости».
Углубиться в тему – https://narkologicheskaya-klinika-v-yaroslavle12.ru/narkologicheskaya-klinika-klinika-pomoshh-v-yaroslavle
лучший интернет провайдер нижний новгород
domashij-internet-nizhnij-novgorod004.ru
интернет провайдеры нижний новгород по адресу
mostbet poker otağı [url=mostbet4045.ru]mostbet4045.ru[/url]
вывод из запоя цена
vivod-iz-zapoya-chelyabinsk002.ru
экстренный вывод из запоя челябинск
пансионат для пожилых людей
pansionat-tula002.ru
пансионат после инсульта
домашний интернет нижний новгород
domashij-internet-nizhnij-novgorod005.ru
провайдеры интернета в нижнем новгороде
Pretty element of content. I just stumbled upon your web site and in accession capital to say that I acquire actually loved account your blog posts. Anyway I’ll be subscribing to your feeds or even I fulfillment you get admission to constantly fast.
https://eterna.in.ua/led-lampy-vs-halohen-u-skli-fary-testy-2025.html
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Подробнее можно узнать тут – https://laranca-limousin.com/events/this-is-a-test
экстренный вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk003.ru
лечение запоя челябинск
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее тут – https://japanstours.com/5-most-beautiful-islands-in-asia
ванная гидромассажная купить [url=https://hidromassazhnaya-vanna.ru/]ванная гидромассажная купить[/url] .
gessi каталог [url=https://www.gessi-santehnika-1.ru]https://www.gessi-santehnika-1.ru[/url] .
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Выяснить больше – https://www.lovero-koiji.jp/2019/05/15/%E3%80%90%E5%88%9D%E9%96%8B%E5%82%AC%EF%BC%81%E3%81%B6%E3%82%89%E3%82%8A%E9%85%92%E8%94%B5%E3%82%81%E3%81%90%E3%82%8A%E3%80%80%E5%BE%8C%E5%A4%9C%E7%A5%AD%E3%80%91%E3%81%93%E3%82%8C%E3%81%9E%E8%94%B5
букмекерские конторы со слотами [url=1win1139.ru]1win1139.ru[/url]
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Получить больше информации – https://cdn.feather.blog/?src=https://aokinaoki.com/2024/02/23/%E7%96%B2%E3%82%8C%E3%82%92%E7%99%92%E3%81%99%E5%AE%BF%E6%B3%8A%E6%96%BD%E8%A8%AD%EF%BC%81%E3%82%B9%E3%83%BC%E3%83%91%E3%83%BC%E3%83%9B%E3%83%86%E3%83%AB%E3%81%8A%E3%81%99%E3%81%99%E3%82%81/&optimizer=image
пансионат для пожилых
pansionat-tula003.ru
пансионат для пожилых
Критерии оценки профессионального уровня сотрудников:
Ознакомиться с деталями – [url=https://lechenie-alkogolizma-yaroslavl0.ru/]лечение алкоголизма цена[/url]
подключение интернета по адресу
domashij-internet-nizhnij-novgorod006.ru
провайдеры интернета по адресу
Даже телефонный разговор с клиникой может многое сказать о её подходе. Если вам предлагают типовое лечение без уточнения подробностей или избегают вопросов о составе команды, это тревожный сигнал. Серьёзные учреждения в Мурманске обязательно предложат предварительную консультацию, зададут уточняющие вопросы и расскажут, как строится программа помощи.
Подробнее можно узнать тут – http://lechenie-alkogolizma-murmansk0.ru/lechenie-khronicheskogo-alkogolizma-marmansk/https://lechenie-alkogolizma-murmansk0.ru
cours de theatre Cours de comedie a Paris
Музыкальные новости сегодня История создания культовых альбомов: Как рождались шедевры.
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-1.ru/
вывод из запоя
vivod-iz-zapoya-cherepovec004.ru
вывод из запоя череповец
Онлайн казино России Бонусы за пополнение счета в онлайн казино России
казино россии лучшие казино на деньги
экстренный вывод из запоя
[url=https://vivod-iz-zapoya-chelyabinsk001.ru]https://vivod-iz-zapoya-chelyabinsk001.ru[/url]
вывод из запоя челябинск
cours de theatre Carriere d’acteur
https://stroidom36.ru/catalog/proekty-domov-ot-150-kv-m/
В столице России существует множество интернет-провайдеров, которые предлагают разнообразные услуги. Ключевыми аспектами выбора являются скорость интернета, стабильное соединение и доступные тарифы. На сайте domashij-internet-novosibirsk004.ru можно найти отзывы о провайдерах, что поможет оценить качество связи и техническую поддержку. Список лучших интернет-провайдеров включает локальных провайдеров, предоставляющих как домашний интернет, так и мобильный интернет. Оптоволокно в новосибирске стало популярным благодаря высокой скорости и долговечности. Сравнение провайдеров поможет пользователям выбрать наилучший вариант. Необходимо принимать во внимание не только цену на тарифы, но и отзывы пользователей, чтобы обеспечить качественное подключение к интернету и Wi-Fi услуги.
Нарколог на дом в Новокузнецке – это возможность получить профессиональное медицинское лечение без госпитализации. Специалисты клиники «ЧистоЖизнь» приезжают в любое время суток, проводят детоксикацию, снимают абстинентный синдром и помогают пациенту стабилизировать состояние в комфортных домашних условиях.
Ознакомиться с деталями – http://narcolog-na-dom-novokuznetsk00.ru
В нашей клинике “Сила воли” в Иркутске вы можете получить помощь как в стационаре, так и на дому. Мы предлагаем два вида услуг:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-irkutsk3.ru/]капельница от запоя цена в иркутске[/url]
По информации ГБУЗ «Областной центр медицинской профилактики» Мурманской области, учреждения, ориентированные на результат, открыто информируют о применяемых методиках и допусках к лечению. Важно, чтобы уже на этапе первого контакта вы получили не только цену, но и понимание того, что вам предстоит.
Ознакомиться с деталями – http://lechenie-alkogolizma-murmansk0.ru/
экстренный вывод из запоя
vivod-iz-zapoya-cherepovec005.ru
вывод из запоя
Как распознать легальный центр:
Изучить вопрос глубже – http://lechenie-narkomanii-yaroslavl0.ru
стоимость проекта перепланировки квартиры [url=https://proekt-pereplanirovki-kvartiry.ru]стоимость проекта перепланировки квартиры[/url] .
работа военным Работа военным: служение Родине Работа военным – это не просто профессия, это призвание. Это служение Родине, защита ее интересов и обеспечение безопасности граждан. Военные – это люди, готовые рисковать своей жизнью ради мира и спокойствия в стране. Служба в армии – это школа жизни, которая закаляет характер, учит дисциплине и ответственности. Военные приобретают навыки, необходимые не только на поле боя, но и в обычной жизни. Они умеют работать в команде, быстро принимать решения в сложных ситуациях и нести ответственность за свои действия. Военная служба – это возможность получить образование и профессию. Армия предоставляет широкий выбор специальностей, от технических до гуманитарных. Военные могут получить высшее образование за счет государства и стать высококвалифицированными специалистами. Работа военным – это стабильность и социальные гарантии. Военнослужащие получают достойную зарплату, жилье, медицинское обслуживание и другие льготы. Они уверены в завтрашнем дне и могут планировать свое будущее. Служба в армии – это возможность проявить себя и сделать карьеру. Военные могут расти по служебной лестнице, занимать высокие должности и участвовать в принятии важных решений. Они вносят свой вклад в развитие страны и укрепление ее обороноспособности. Работа военным – это почет и уважение. Военные – это герои, которыми гордится страна. Их подвиги и заслуги отмечаются государственными наградами и званиями. Они являются примером для подражания и вдохновляют молодежь на служение Родине. Служба в армии – это нелегкий труд, требующий мужества, силы и выносливости. Но это также возможность реализовать себя, принести пользу обществу и оставить свой след в истории. Работа военным – это выбор сильных и ответственных людей, готовых посвятить свою жизнь защите Родины.
проект перепланировки цена [url=proekt-pereplanirovki-kvartiry1.ru]проект перепланировки цена[/url] .
перепланировка помещения [url=http://soglasowanie-pereplanirovki-kvartiry.ru]перепланировка помещения[/url] .
Sometimes image compatibility issues can disrupt a workflow. That’s where WEBPtoPNGHero com steps in. It transforms WebP images into PNG format while preserving sharpness, transparency, and original dimensions. The tool works entirely online — no plugins, no installations, and no registration. Its drag-and-drop interface allows fast single or batch uploads, with each file processed in real-time. Designed for convenience, it’s accessible from desktop or mobile devices alike. Upload your WebP, download your PNG, and move on with your project — that simple. Engineered for designers, developers, and anyone dealing with diverse file formats, this converter ensures images are ready for use on any platform. Your files are deleted automatically after conversion, providing both security and peace of mind.
WEBPtoPNGHero
That’s a great point about responsible gaming! Finding a platform that’s both fun and secure is key. I’ve heard good things about JILI PG – easy to use, and the jili pg app seems super convenient for quick play! Definitely checking them out. 👍
Ключевым фактором при выборе центра становится квалификация специалистов. Лечение алкоголизма — это не только выведение из запоя и купирование абстинентного синдрома. Оно включает работу с мотивацией, тревожными состояниями, семейными конфликтами, нарушением сна и другими последствиями зависимости. Только команда, включающая наркологов, психотерапевтов и консультантов по аддиктивному поведению, способна охватить все аспекты проблемы.
Подробнее – [url=https://lechenie-alkogolizma-murmansk0.ru/]lechenie alkogolizma murmansk[/url]
Нарколог измеряет пульс, артериальное давление, частоту дыхания, насыщение кислородом, а также уточняет историю употребления и наличие хронических заболеваний. Это позволяет оперативно скорректировать состав и скорость инфузии.
Детальнее – https://kapelnica-ot-zapoya-voronezh2.ru/vyezd-na-dom-kapelnicza-ot-zapoya-v-voronezhe/
— Растворы с глюкозой и витаминами для коррекции энергетического обмена. — Минеральные комплексы для нормализации электролитов. — Антиоксиданты и гепатопротекторы для защиты печени. — Спазмолитики для снятия болевого синдрома. — Противорвотные препараты при тошноте.
Получить дополнительную информацию – https://narkologicheskaya-klinika-arkhangelsk0.ru/platnaya-narkologicheskaya-klinika-arkhangelsk/
вывод из запоя круглосуточно челябинск
vivod-iz-zapoya-chelyabinsk002.ru
лечение запоя
https://stroidom36.ru/catalog/proekty-domov-ot-150-kv-m/ Внутренняя отделка – создание уютного интерьера. Обои, краска, плитка, ламинат – разнообразие материалов позволяет реализовать любые дизайнерские решения.
Бесплатный интернет в новосибирске: фантазия или истина? В последние годы новосибирск активно развивает информационную инфраструктуру, предлагая жителям и туристам безвозмездный Wi-Fi в публичных зонах. Сайты вроде site;com сообщают о множествах бесплатных точках доступа, которые обеспечивают интернет-соединение. Однако, насколько целесообразно полагаться на эти услуги? Одним из основных плюсов бесплатного интернета является возможность соединиться к общественным сетям без нужды использовать мобильный интернет. Но уровень связи и скорость соединения часто оставляют желать лучшего. Провайдеры, которые предлагают такие услуги, сталкиваются с большой нагрузкой, что может отразиться на ухудшении скорости. При этом необходимо учитывать безопасность данных. Бесплатные точки доступа могут подвергать пользователей рискам, связанным с компрометацией данных. Ограничения доступа к определенным сайтам также могут стать неожиданностью для пользователей. Городские инициативы по улучшению доступа к интернету подтверждают стремление новосибирска к совершенствованию, но необходимо помнить о возможных ограничениях и особенностях тарифов на интернет. В итоге, бесплатный интернет в новосибирске — это удобство, но с некоторыми подводными камнями.
вывод из запоя круглосуточно череповец
vivod-iz-zapoya-cherepovec006.ru
экстренный вывод из запоя
купить напольный горшок для цветов недорого [url=https://kashpo-napolnoe-rnd.ru/]https://kashpo-napolnoe-rnd.ru/[/url] .
работа военным Работа военным – это возможность получить ценный опыт, приобрести полезные навыки и найти настоящих друзей.
devenir acteur Etudes theatrales
В современном мире интернет с высокой скоростью превратился в неотъемлемой частью жизни. В столице множество интернет-провайдеров предоставляют интернет-услуги, гарантируя стабильный интернет без задержек. При выборе провайдера, стоит обратить внимание на стоимость и скорость подключения. Анализ тарифов позволит найти лучший вариант для вашего дома или офисного пространства. Множество операторов могут подключить интернет всего за один день, что будет удобно для клиентов, ценящих скорость. При подключении интернета можно обратиться к профессионалам, которые быстро и качественно проведут все необходимые работы. Не забудьте ознакомиться с отзывами о провайдерах, чтобы принимать взвешенное решение. Не следует жертвовать качеством: качественный интернет и высокая скорость подключения создадут комфортные условия для работы и отдыха. Используйте платформы, такие как domashij-internet-novosibirsk006.ru чтобы ознакомиться с актуальными данными и рекомендациями.
экстренный вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk003.ru
вывод из запоя
вывод из запоя иркутск
vivod-iz-zapoya-irkutsk001.ru
вывод из запоя цена
работа военным Работа военным сопряжена с риском и опасностью, но она также дает возможность проявить себя, реализовать свой потенциал и внести свой вклад в защиту мира и стабильности.
Как отмечает врач-нарколог Иванов И.И., «без своевременной медицинской помощи при запое повышается риск необратимых изменений в организме и летального исхода».
Узнать больше – [url=https://vyvod-iz-zapoya-nizhnij-tagil11.ru/]вывод из запоя свердловская область[/url]
iphone санкт петербург [url=www.kupit-ajfon-cs2.ru/]iphone санкт петербург[/url] .
айфон питер купить [url=http://kupit-ajfon-cs.ru]http://kupit-ajfon-cs.ru[/url] .
Отличная бонусная система: [url=https://ucla-free-speech.com/]вавада официальный сайт рабочее зеркало[/url]
Modern operations surgery innovative technologies, precision and safety. Minimal risk, short recovery period. Plastic surgery, ophthalmology, dermatology, vascular procedures.
вывод из запоя круглосуточно
vivod-iz-zapoya-cherepovec004.ru
вывод из запоя череповец
подключить домашний интернет в омске
domashij-internet-omsk004.ru
недорогой интернет омск
Профессиональное prp терапия обучение: PRP, Plasmolifting, протоколы и нюансы проведения процедур. Онлайн курс обучения плазмотерапии.
лечение запоя
vivod-iz-zapoya-irkutsk002.ru
лечение запоя иркутск
Как подчёркивает заведующий отделением наркологии Владимирского областного клинического диспансера, «только комплексная модель, включающая медикаментозную поддержку и психотерапию, даёт устойчивый эффект». Это означает, что в штате клиники должны быть не только врачи, но и психотерапевты, социальные работники, реабилитологи.
Узнать больше – https://lechenie-narkomanii-vladimir10.ru/lechenie-narkomanii-anonimno-vladimir/
купить кашпо комнатные напольные [url=www.kashpo-napolnoe-rnd.ru/]www.kashpo-napolnoe-rnd.ru/[/url] .
Онлайн-курсы prp терапия обучение: теория, видеоуроки, разбор техник. Обучение с нуля и для практикующих. Доступ к материалам 24/7, сертификат после прохождения, поддержка преподавателя.
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Подробнее можно узнать тут – https://praxis-schuemann.de/portfolio/classic-watch
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Получить дополнительные сведения – https://www.tsimpolis.gr/shortcode-ux-banner-grid
вибрационная настройка Психология души затрагивает глубинные аспекты человеческого бытия, духовность и смысл жизни.
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Получить больше информации – https://rikbeuselinck.be/2020/09/28/reportage
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Исследовать вопрос подробнее – https://exceedsound.com/what-is-the-difference-between-speakers-and-speakers
Негативное мышление Заговор на деньги: привлечение финансового благополучия. Заговор на деньги – это магический ритуал, направленный на привлечение финансового благополучия и удачи в делах.
вывод из запоя иркутск
vivod-iz-zapoya-irkutsk003.ru
экстренный вывод из запоя
дешевый интернет омск
domashij-internet-omsk005.ru
подключить проводной интернет омск
экстренный вывод из запоя
vivod-iz-zapoya-cherepovec005.ru
вывод из запоя круглосуточно
Первое, что необходимо уточнить перед вызовом — наличие у врача лицензии и профильного медицинского образования. Только сертифицированный нарколог может назначить препараты, поставить капельницу и провести детоксикацию без ущерба для здоровья пациента.
Получить дополнительную информацию – https://narkolog-na-dom-nizhnij-tagil11.ru/narkolog-na-dom-kruglosutochno-v-nizhnem-tagile/
Рейки и эфирные масла: гармония тела и духа Рейки и эфирные масла: гармония тела и духа: Углубите свою практику Рейки с помощью целебных ароматов эфирных масел. Узнайте, какие масла усиливают поток энергии, помогают снять блоки и способствуют духовному росту.
«ВоронежДоктор» сочетает в себе профессионализм, современное оборудование и заботу о приватности пациента. Ключевые преимущества:
Разобраться лучше – http://kapelnica-ot-zapoya-voronezh2.ru/vyezd-na-dom-kapelnicza-ot-zapoya-v-voronezhe/
Проблема зависимости от алкоголя, наркотиков и азартных игр остается одной из наиболее острых в современном обществе. Эти состояния оказывают значительное воздействие не только на здоровье самого человека, но и на его семью, друзей и общественные связи. Наркологическая клиника “Восстановление души” предлагает широкий спектр услуг для тех, кто борется с различными формами зависимости, такими как алкоголизм, наркомания и игромания. Наша цель — предоставить комплексный подход к лечению, что обеспечивает высокие показатели успешности среди наших пациентов.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-irkutsk2.ru/kapelnica-ot-zapoya-v-stacionare-v-irkutske/]капельница от запоя анонимно недорого иркутск[/url]
When it comes to traveling in the beautiful Dominican Republic, VIP Transfer Punta Cana is your go-to transportation company. With years of experience and a stellar reputation, we pride ourselves in providing a seamless and memorable VIP travel services in Punta Cana experience for all our customers.
One of the advantages of choosing VIP Transfers Punta Cana is our commitment to customer satisfaction. We understand that traveling can sometimes be stressful, especially when it comes to transportation logistics. That’s why we go above and beyond to ensure that your journey is smooth, comfortable, and hassle-free.
dominican vip transfer
душевная трансформация Женская энергия: Источник силы и вдохновения для женщин. Развитие и гармонизация женской энергии.
Преимущества капельницы от запоя на дому очевидны:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-irkutsk.ru/kapelnica-ot-zapoya-na-domu-v-irkutske/]капельница от запоя на дому цена в иркутске[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-kaluga004.ru
лечение запоя
домашний интернет в омске
domashij-internet-omsk006.ru
лучший интернет провайдер омск
Целительница Психолог онлайн
Дополнительно выясняются аллергические реакции, приём других препаратов и предпочтения пациента по времени визита врача.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-voronezh3.ru/]капельница от запоя выезд[/url]
Грузоперевозки Луганск Грузоперевозки Луганск: Офисный переезд под ключ. Минимизация простоев, бережное отношение к технике, опытные сотрудники.
вывод из запоя цена
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя цена
заказать напольные кашпо [url=https://www.kashpo-napolnoe-rnd.ru]заказать напольные кашпо[/url] .
Наркологическая информационная сеть «Narkology» предлагает высококвалифицированную помощь в преодолении зависимости и восстановлении психоэмоционального равновесия. Наши специалисты проводят индивидуальную диагностику состояния, разрабатывают комплексные программы терапии, психологической поддержки и информирования о современных методиках лечения. Используя проверенные подходы и актуальные данные, мы помогаем вернуть уверенность в себе и сделать первый шаг к здоровой жизни. Доверьтесь профессионалам «Narkology» для эффективного решения проблем зависимости и получения полной информационной поддержки.
Выяснить больше – https://narcologiya.info/sovmestimost-s-lekarstvami/
Выбор наркологической клиники — ключевой шаг на пути к выздоровлению, от которого зависит не только физическое и психическое состояние пациента, но и устойчивость достигнутых результатов. Современные учреждения предлагают широкий спектр услуг, однако уровень подготовки персонала, методики лечения и условия пребывания могут существенно отличаться.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-pervouralsk11.ru/]chastnaya narkologicheskaya klinika pervoural’sk[/url]
экстренный вывод из запоя
vivod-iz-zapoya-kaluga005.ru
лечение запоя
тёмная ночь души Психолог онлайн: Доступная поддержка в любое время и в любом месте. Обретите гармонию и понимание себя, не выходя из дома.
провайдеры интернета в перми
domashij-internet-perm004.ru
подключить интернет тарифы пермь
Наши врачи уделяют внимание не только медицинским аспектам, но также социальным и психологическим факторам. Мы помогаем пациентам находить новый смысл в жизни, формировать новые увлечения и восстанавливать старые связи с близкими.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-irkutsk.ru/kapelnica-ot-zapoya-v-stacionare-v-irkutske/]https://kapelnica-ot-zapoya-irkutsk.ru/kapelnica-ot-zapoya-v-stacionare-v-irkutske[/url]
Наша миссия заключается в предоставлении качественной помощи людям, страдающим от зависимостей. Мы стремимся создать безопасную и поддерживающую атмосферу, где каждый сможет получить необходимую помощь. Основная цель — восстановление здоровья, психоэмоционального состояния и социальной адаптации.
Изучить вопрос глубже – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-omske.ru/]вывод из запоя цена в омске[/url]
Immersive live dealer games are so much more than just playing – it’s the whole experience! Discovering platforms like jljl77 app com, with easy logins & bonuses, really elevates that feeling. Great article – thanks for the insights!
Эфирные масла для повышения энергии и настроения Рейки и эфирные масла: как они работают вместе: Узнайте, как синергия Рейки и эфирных масел может умножить целительную силу каждой практики. Откройте для себя специальные протоколы и комбинации масел для усиления потока энергии и достижения глубокого исцеления.
вывод из запоя цена
vivod-iz-zapoya-irkutsk001.ru
лечение запоя
Грузоперевозки Луганск Перевозка негабаритных грузов Луганск: Организация перевозки негабаритных и тяжеловесных грузов.
В статье рассмотрим ключевые моменты, которые помогут сориентироваться при выборе капельницы от запоя, понять механизм действия и особенности процедуры, а также избежать типичных ошибок при обращении за медицинской помощью.
Углубиться в тему – [url=https://kapelnicza-ot-zapoya-pervouralsk11.ru/]капельница от запоя первоуральск.[/url]
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Москве приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Подробнее тут – https://kapelnica-ot-zapoya-lyubercy11.ru
вывод из запоя калуга
vivod-iz-zapoya-kaluga006.ru
вывод из запоя круглосуточно
Зависимости часто сопровождаются физическими и психологическими нарушениями, требующими комплексного подхода. Мы убеждены, что успешное лечение невозможно без индивидуального подхода, что делает нашу клинику отличным местом для тех, кто нуждается в поддержке.
Подробнее можно узнать тут – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-omske.ru/]vyvod-iz-zapoya-klinika omsk[/url]
Работа клиники строится на принципах доказательной медицины и индивидуального подхода. При поступлении пациента осуществляется всесторонняя диагностика, включающая анализы крови, оценку психического состояния и анамнез. По результатам разрабатывается персонализированный курс терапии.
Подробнее – [url=https://narkologicheskaya-klinika-v-ryazani12.ru/]наркологическая клиника в рязани[/url]
домашний интернет тарифы пермь
domashij-internet-perm005.ru
подключить домашний интернет в перми
Нарколог на дому проводит тщательный осмотр, собирает анамнез и назначает необходимые лабораторные исследования. Это позволяет выявить сопутствующие патологии и скорректировать тактику лечения.
Получить больше информации – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]нарколог на дом ярославль[/url]
Hyvaa paivaa!!
Pelaajapalaute auttaa muita tekemään fiksuja valintoja casino sivustojen suhteen. Rehellinen pelaajapalaute on kullanarvoista tietoa. [url=https://reallivecasino.cfd/arvostelut-ja-luotettavuus.html]arvostelut ja luotettavuus[/url] Jaa omia kokemuksiasi ja hyödynnä muiden antamaa palautetta päätöksenteossa.
Lue linkki – https://www.reallivecasino.cfd/arvostelut-ja-luotettavuus.html
kasino korttipeli säännöt
åldersgräns casino cosmopol
Г¤r casino vinster skattefria
Onnea!
Грузоперевозки Луганск Грузоперевозки Луганск: Экспедирование грузов по Луганской области. Полный контроль над перемещением груза, оперативная информация о местонахождении, гарантия своевременной доставки.
лечение запоя иркутск
vivod-iz-zapoya-irkutsk002.ru
вывод из запоя
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Получить больше информации – https://humanitarianweb.org/programme-coordinator-programme-support-unit-psu
вывод из запоя круглосуточно краснодар
vivod-iz-zapoya-krasnodar001.ru
лечение запоя
электрокарниз купить в москве [url=https://elektrokarniz25.ru/]elektrokarniz25.ru[/url] .
iphone купить спб [url=kupit-ajfon-cs3.ru]iphone купить спб[/url] .
1win apk download for android [url=www.1win3027.com]1win apk download for android[/url]
гайнулин эмиль нилович Как начать зарабатывать в Telegram с нуля? Пошаговая инструкция от Эмиля Гайнулина: выбор ниши, создание контента, привлечение аудитории.
1win real or fake [url=www.1win3024.com]www.1win3024.com[/url]
the best and interesting https://edicionesdelau.com
interesting and new https://www.manaolahawaii.com
домашний интернет тарифы
domashij-internet-perm006.ru
подключить интернет тарифы пермь
best site online https://pvslabs.com
visit the site online https://justicelanow.org
лечение запоя краснодар
vivod-iz-zapoya-krasnodar002.ru
экстренный вывод из запоя
гайнулин эмиль нилович Telegram-боты для бизнеса: обзор полезных инструментов от Эмиля Гайнулина. Автоматизация процессов, улучшение коммуникации с клиентами и увеличение продаж.
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Ознакомиться с деталями – https://snhca.com/about-the-association/about1
вывод из запоя круглосуточно
vivod-iz-zapoya-irkutsk003.ru
экстренный вывод из запоя
обмен макросы на варфейс Превратитесь в легенду Warface с помощью макросы варфейс! Улучшите свою стрельбу, контролируйте отдачу и станьте непобедимым игроком. Покажите всем, кто здесь лучший! Начните свой путь к вершине!
Критерий
Подробнее можно узнать тут – http://narkolog-na-dom-nizhnij-tagil11.ru/vyzov-narkologa-na-dom-v-nizhnem-tagile/
похудение Сердце – главный орган кровеносной системы.
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Разобраться лучше – https://ponadschematami.org/osoby-neuroatypowe-sa-mniej-inteligentne-mit-czy-fakt
дешевый интернет ростов
domashij-internet-rostov004.ru
провайдеры интернета ростов
Установка и ремонт москитных сеток в Алматы Компания “Okna Service” в Алматы предлагает комплексные услуги по ремонту пластиковых окон, применяя исключительно материалы премиум-класса. В спектр услуг входит установка высококачественных уплотнителей, обеспечивающих идеальную герметичность и защиту от сквозняков, а также замена специализированной фурнитуры, такой как ручки и петли для различных систем открывания. Также осуществляется ремонт и замена москитных сеток, подверженных повреждениям и деформациям. Для повышения удобства эксплуатации окон специалисты “Okna Service” предлагают установку дополнительных устройств: доводчиков для дверей, ограничителей открывания (особенно актуально для семей с детьми) и монтаж пластиковых откосов внутри и снаружи помещения, улучшающих внешний вид окон. В сервисном центре в Алматы можно заказать и приобрести все необходимые комплектующие для ремонта окон, с их последующей доставкой и квалифицированной установкой. Подбор материалов осуществляется с учетом особенностей каждой оконной конструкции, что гарантирует надежность и долговечность ремонта. Замена изношенных элементов способствует восстановлению первоначальных характеристик окна, обеспечивая теплосбережение и комфорт в доме.
Наркологическая помощь на дому становится всё более востребованной благодаря своей доступности, конфиденциальности и эффективности. Клиника «МедТрезвость» предлагает пациентам целый ряд важных преимуществ:
Изучить вопрос глубже – [url=https://narcolog-na-dom-sankt-peterburg0.ru/]нарколог на дом в санкт-петербурге[/url]
http://888starz-downloads.com/ [url=https://888starz-downloads.com]http://888starz-downloads.com/[/url] .
Fantastic blog you have here but I was curious about if you knew of any community forums that cover the same topics discussed in this article? I’d really love to be a part of online community where I can get opinions from other experienced individuals that share the same interest. If you have any suggestions, please let me know. Thank you!
Best limo service near me
В рамках услуги вызова нарколога на дом используется современное оборудование и препараты, одобренные для амбулаторного применения.
Подробнее тут – [url=https://narkolog-na-dom-kamensk-uralskij11.ru/]нарколог на дом срочно в каменске-уральском[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar003.ru
экстренный вывод из запоя краснодар
Компоненты
Подробнее тут – http://kapelnicza-ot-zapoya-pervouralsk11.ru/
Пациенты, нуждающиеся в круглосуточном наблюдении, могут пройти курс терапии в стационаре. Обстановка клиники рассчитана на комфортное пребывание: палаты с индивидуальным санитарным блоком, охрана, контроль приёма препаратов, поддержка психологов.
Получить дополнительную информацию – https://narkologicheskaya-pomoshh-tula10.ru/neotlozhnaya-narkologicheskaya-pomoshh-tula/
Затяжной запой опасен для жизни. Врачи наркологической клиники в Москве проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lyubercy11.ru/]капельница от запоя наркология в Москве[/url]
вывод из запоя цена
vivod-iz-zapoya-kaluga004.ru
лечение запоя
Обеспечение своевременной наркологической помощи с выездом на дом в Каменске-Уральском — важный аспект комплексного лечения алкогольной и наркотической зависимости. Услуга вызова нарколога на дом позволяет получить квалифицированную медицинскую помощь в комфортных условиях, что снижает стресс и способствует более быстрому восстановлению.
Ознакомиться с деталями – http://narkolog-na-dom-kamensk-uralskij11.ru/chastnyj-narkolog-na-dom-v-kamensk-uralskom/
подключить интернет ростов
domashij-internet-rostov005.ru
лучший интернет провайдер ростов
visit the site https://lmc896.org
go to the site https://ibecensino.org.br
Запой – это не просто временное ухудшение самочувствия, а состояние, при котором организм подвергается значительному токсическому воздействию алкоголя. Длительное злоупотребление приводит к накоплению вредных веществ, что может вызвать:
Разобраться лучше – http://narcolog-na-dom-ryazan00.ru/vyzov-narkologa-na-dom-ryazan/
варфейс макросы мышки Поднимите свой скилл в Warface с помощью макросы варфейс! Забудьте о сложной отдаче, увеличьте точность стрельбы и доминируйте над противниками. Станьте настоящим профи и покажите свой скилл!
завьялов илья поинт пей Илья Завьялов о Будущем Криптовалют и Point Pay
После поступления вызова нарколог клиники «АльфаНаркология» оперативно выезжает по указанному адресу. На месте врач проводит первичную диагностику, оценивая степень интоксикации, физическое и психологическое состояние пациента. По результатам осмотра врач подбирает индивидуальный комплекс лечебных процедур, в который входит постановка капельницы с растворами для детоксикации, препараты для стабилизации работы органов и нормализации психического состояния.
Подробнее можно узнать тут – http://narcolog-na-dom-sankt-peterburg000.ru/
лечение запоя
vivod-iz-zapoya-krasnodar004.ru
вывод из запоя
Профессиональная анонимная наркологическая клиника. Лечение зависимостей, капельницы, вывод из запоя, реабилитация. Анонимно, круглосуточно, с поддержкой врачей и психологов.
Removing cloth remover from images is an advanced tool for creative tasks. Neural networks, accurate generation, confidentiality. For legal and professional use only.
Для успешного вывода из запоя используется комплексный подход с участием специалистов разных профилей. Более подробно об этом можно узнать на официальном портале наркологической службы.
Узнать больше – https://vyvod-iz-zapoya-nizhnij-tagil11.ru/
ручки для душевой кабины купить Ролики для душевых кабин купить в Екатеринбурге: широкий выбор роликов для дверей и шторок душевых кабин разных производителей.
вывод из запоя круглосуточно калуга
vivod-iz-zapoya-kaluga005.ru
вывод из запоя цена
Самостоятельно выйти из запоя — почти невозможно. В Москве врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-lyubercy11.ru/]капельница от запоя выезд Москва[/url]
Особенно важно на этапе поступления пройти полную психодиагностику и получить адаптированную под конкретного пациента программу. Это позволит учитывать возможные сопутствующие расстройства, включая тревожные, аффективные и когнитивные нарушения.
Детальнее – http://narkologicheskaya-klinika-nizhnij-tagil11.ru/narkologicheskaya-klinika-telefon-v-nizhnem-tagile/
Метод лечения
Разобраться лучше – [url=https://lechenie-narkomanii-vladimir10.ru/]центр лечения наркомании владимир.[/url]
интернет провайдер ростов
domashij-internet-rostov006.ru
домашний интернет
В Рязани возможен как стационарный, так и амбулаторный вывод из запоя. Выбор подхода зависит от состояния пациента, выраженности симптомов и наличия сопутствующих нарушений.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-ryazani12.ru/]вывод из запоя на дому рязань.[/url]
Многие семьи сталкиваются с трудностями, когда зависимый отказывается ехать в клинику. В таких случаях выездная помощь становится первым шагом к выздоровлению. Однако не все службы предлагают одинаково безопасный и профессиональный подход. Чтобы избежать рисков и ошибок, важно понимать, на что обращать внимание при выборе услуги “нарколог на дом”.
Получить дополнительные сведения – [url=https://narkolog-na-dom-nizhnij-tagil11.ru/]нарколог на дом анонимно нижний тагил[/url]
лечение запоя
vivod-iz-zapoya-krasnodar005.ru
вывод из запоя
шторы пятигорск кисловодское шоссе (Повтор) Пятигорск Где Купить Карнизы: Полезные Советы
завьялов илья поинт пей Илья Завьялов и PointPay: Создание сообщества активных крипто-инвесторов и трейдеров
Первый и самый важный момент — какие методики применяются в клинике. Качественное лечение наркозависимости включает несколько этапов: детоксикация, стабилизация состояния, психотерапия, ресоциализация. Одного лишь выведения токсинов из организма недостаточно — без проработки психологических причин употребления высокий риск рецидива.
Детальнее – https://lechenie-narkomanii-vladimir10.ru/lechenie-narkomanii-anonimno-vladimir/
В рамках услуги вызова нарколога на дом используется современное оборудование и препараты, одобренные для амбулаторного применения.
Углубиться в тему – [url=https://narkolog-na-dom-kamensk-uralskij11.ru/]нарколог на дом вывод[/url]
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Подробнее – [url=https://narkologicheskaya-klinika-tyumen10.ru/]narkologicheskaya-klinika-tyumen10.ru/[/url]
Как подчёркивает главный врач клинического отделения, «в условиях стационара мы можем оперативно реагировать на малейшие изменения в состоянии пациента, что критически важно при тяжёлых формах запоя».
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-v-ryazani12.ru/]наркологический вывод из запоя в рязани[/url]
гардина с электроприводом [url=https://www.elektrokarniz5.ru]https://www.elektrokarniz5.ru[/url] .
вывод из запоя
vivod-iz-zapoya-kaluga006.ru
вывод из запоя калуга
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-lyubercy11.ru/]капельница от запоя наркология[/url]
провайдер интернета по адресу самара
domashij-internet-samara004.ru
интернет по адресу
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Получить дополнительные сведения – https://desigheek.com/business-conference
Срочная наркологическая помощь в Красноярске доступна на сайте vivod-iz-zapoya-krasnoyarsk001.ru. Клиника наркологии предлагает помощь в лечении зависимостейвключая методы кодирования от алкоголизма и специализированные программы лечения. Здесь вы найдете поддержку при запойных состояниях и реабилитацию наркоманов. Услуги психотерапевта также доступны. Кризисные центры обеспечивают поддержку для родственников пациентов. Предотвращение зависимостей и восстановление после наркотиков, ключевые шаги к восстановлению здоровья. Гарантируем анонимность и конфиденциальность.
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Получить больше информации – https://tsukubathletics.com/archives/5268
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Ознакомиться с деталями – https://vistoweekly.com/beholderen
купить макрос варфейс Думаешь об обмен макросы на варфейс? Помни о рисках! Проверяй репутацию продавцов и будь осторожен с обменом аккаунтами. Лучше купить проверенный макрос.
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Узнать больше – https://vistoweekly.com/whispering-words-of-love-in-punjabi-shayari
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Ознакомиться с деталями – http://www.apzp.cz/dokumenty-ke-stazeni/hrda_osobni_asistence
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Узнать больше – https://www.ingridremvall.se/sample-page
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Выяснить больше – https://lalazada.es/contactar
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Разобраться лучше – https://desigheek.com/business-conference
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Получить больше информации – https://vistoweekly.com/dave-simmons-dahlgren-va
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Подробнее можно узнать тут – https://vistoweekly.com/spencer-bradley-make-him-jealous
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Подробнее можно узнать тут – https://www.mariannesoderberg.se/foto
завьялов илья поинт пей Point Pay: Платформа Возможностей благодаря Илье Завьялову
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Получить больше информации – https://www.mrpepe.com/daily-fx/currency-prices-usdgbpeur
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Детальнее – https://www.bestinksistemi.it/ciao-mondo
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Разобраться лучше – http://xamanoenergy.com/index.php/2024/02/18/consul-general-yu-peng-visits-the-city-of-campinas
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Ознакомиться с деталями – http://www.projectos.loneus.net/clsdois/2016/02/18/home-run-kitten-favored-in-competitive-san-simeon
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Детальнее – https://vistoweekly.com/trader-joes-dayforce
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Углубиться в тему – https://www.hydro-serve.in/hello-world
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Разобраться лучше – https://vistoweekly.com/mayo-group-wsj-crossword-clue
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее можно узнать тут – https://septfevrier.com/paris-mon-amour
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее – https://www.halaumohalailima.com/hidden-gems-of-oahu-7-local-secrets-beyond-waikiki
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Изучить вопрос глубже – https://thongkheng.org/level-1/level-2a
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее можно узнать тут – https://www.rechtsanwalt-erbrecht-in-essen.de/portfolio/berliner-testament/er-erbausschlagung
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Разобраться лучше – https://time2track.com/features-5
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Подробнее тут – https://fin-tokyo.com/2021/09/05/%E3%80%8E%E3%81%97%E3%82%83%E3%81%B6%E3%81%97%E3%82%83%E3%81%B6%E5%92%8C%E9%A3%9F%E3%80%80%E3%81%AB%E3%81%97%E5%B1%B1%E3%80%80%E5%B7%A3%E9%B4%A8%E5%BA%97%E3%80%8F10%E6%9C%88%E8%B1%9A%E3%82%AD%E3%83%A0
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Разобраться лучше – https://worldthreadstraveler.com/sustainable-fashion/fibers-that-bind
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Подробнее можно узнать тут – https://www.merceriapapillon.com/product/611282-carta-per-ricalco
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Узнать больше – http://auto-srnec.cz/sample-page
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Изучить вопрос глубже – https://blog.bunbusoft.com/?m=202403
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Детальнее – https://sumaanipharma.com/common-health-issues-in-dairy-cattle-and-how-to-address-them
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Подробнее можно узнать тут – http://mykinomir.ru/2017/12/13/dobropozalovat/%D0%BB%D0%B5%D0%BD%D1%82%D0%B0
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Выяснить больше – https://www.ccd.coop/link-post
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Разобраться лучше – https://bloc.xarxa-omnia.org/rierabonet/2014/05/21/que-es-per-a-mi-internet/internet5
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Углубиться в тему – https://www.sinapsystec.com.co/2013/12/30/just-a-cool-blog-post-with-images
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Выяснить больше – https://pelias.nl/how-to-pick-the-right-mutual-fund-for-you
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Разобраться лучше – https://cermam.com.br/como-se-preparar-para-a-residencia-medica
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Получить больше информации – https://tekintasmuhendislik.com/dogrusal-hareket-teknolojileri
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Получить дополнительные сведения – https://www.cristina-torrecilla.com/2023/11/16/elevador-global-360
смеситель врезной на борт ванной купить запчасти для душевой кабины
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее – https://softechts.com/line-icons-design
Рефрижераторные перевозки https://mybiysk.ru/business/ot-chego-zavisit-stoimost-refrizheratornyh-perevozok-i-kak-sekonomit-522146 по России и СНГ. Контроль температуры от -25°C до +25°C, современные машины, отслеживание груза.
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Выяснить больше – https://keesinha.com/2020-um-ano-de-muitos-desafios
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Подробнее тут – https://djro.nl/ronald-steenhouwer-2
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Подробнее тут – https://tmv-regental.de/beispiel-seite/tmv_image_01_18
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Ознакомиться с деталями – https://messiahmbc.org/product/smart-book-ichthys
провайдеры по адресу
domashij-internet-samara005.ru
узнать интернет по адресу
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Подробнее тут – https://vistoweekly.com/mastering-poptok-with-jonathan-worsley-to-elevate-your-tiktok-marketing
вывод из запоя краснодар
vivod-iz-zapoya-krasnodar001.ru
экстренный вывод из запоя краснодар
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Подробнее тут – https://korsellcorporateconsult.com/quia-sit-iusto-nihil-aliquam-sed
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Узнать больше – https://magneticafilms.com/cropped-favicon-magnetica-png
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Подробнее можно узнать тут – https://vistoweekly.com/vision-africa-roger-brugger
Прокапывание от алкоголя на дому — представляет собой эффективный метод помощи алкогольной зависимости, что даёт возможность быстро устранить признаки отмены и улучшить самочувствие пациента. Помощь нарколога на дому всё чаще востребованы, поскольку множество людей предпочитают не проходить лечение в стационаре. vivod-iz-zapoya-krasnoyarsk002.ru Эта процедура включает в себя домашнюю детоксикацию, где помощь специалиста при алкоголизме предоставляется в комфортной обстановке. Капельница для снятия похмелья содержит лекарственные средства для очищения организма, способствующие способствуют очистить организм от токсинов и восстановить водно-электролитный баланс. Важно помнить о симптомах алкогольного абстинентного синдрома, таких как тревога, потливость и тремор. Забота и поддержка со стороны близких играет ключевую роль в успешном лечении и реабилитации после длительного употребления алкоголя. Домашняя терапия может включать не только прокапывание, но и советы по предотвращению рецидивов алкогольной зависимости, что поможет предотвратить рецидивы и сохранить трезвый образ жизни.
https://пф-яндекс.рф/
Brazilian Ev!us: Эволюция стиля, балансирующая между минимализмом и дерзостью. Отличительные черты – чистые линии, приглушенные цвета, акцент на качестве материалов и кроя. Ev!us не кричит, а шепчет о безупречном вкусе.
Если человек страдает от алкоголизма, запойное состояние требует незамедлительного вмешательства, особенно если признаки токсического отравления начинают угрожать жизни. Признаки запоя — это не только физическая зависимость, но и эмоциональные и психические расстройства, такие как тревога, агрессия и галлюцинации.
Подробнее тут – [url=https://narcolog-na-dom-novokuznetsk0.ru/]вызов нарколога на дом кемеровская область[/url]
мистические детективы Мистическое читать – значит расширять свой кругозор, знакомиться с новыми идеями и концепциями, а также развивать свою фантазию и воображение.
Hi it’s me, I am also visiting this web site on a regular basis, this web site is in fact fastidious and the viewers are really sharing nice thoughts.
Best limo service near me
Limousine service offers luxurious, private transportation for various occasions. For Seattle visitors, consider the [url=https://taxi-prive.com/limo-service-seattle-airport-reviews/] Seattle Airport Chauffeur Service [/url] for seamless pick-up and drop-off at Sea-Tac International Airport. Professional chauffeurs ensure punctual and safe travel, providing assistance with luggage and navigation. The service caters to corporate travelers, weddings, proms, and special events, offering a fleet of high-end vehicles like sedans, SUVs, and stretch limousines. Amenities often include complimentary beverages, advanced sound systems, and climate control. Booking typically requires advance notice, with options for hourly or point-to-point pricing. Expect discretion, reliability, and comfort, making your journey stress-free and enjoyable. – https://taxi-prive.com/limo-service-seattle-airport-reviews/
Our [url=https://taxi-prive.com/] Seattle luxury transportation [/url] service offers an unparalleled experience in the Emerald City. We provide top-tier limousines, equipped with plush interiors, state-of-the-art amenities, and driven by professional chauffeurs. Perfect for weddings, corporate events, or a night out, our fleet includes sleek sedans, SUVs, and stretch limos. We prioritize punctuality, discretion, and safety, ensuring your journey is smooth and stress-free. Whether you’re traveling from Sea-Tac Airport or exploring downtown, our Seattle luxury transportation service sets the standard for elegance and reliability. – https://taxi-prive.com/
[url=https://taxi-prive.com/best-limo-service-seattle-airport/] Best Limo Service Seattle [/url] offers luxurious and reliable transportation for various occasions. With a fleet of top-notch vehicles, including sedans, SUVs, and stretch limousines, we cater to weddings, corporate events, airport transfers, and special nights out. Our professional chauffeurs ensure a smooth and comfortable ride, prioritizing safety and punctuality. Experience the best limo service Seattle has to offer, with amenities like complimentary beverages, advanced sound systems, and plush interiors. Whether you’re planning a grand entrance or a discreet arrival, our service guarantees elegance and convenience. Book with us for an unforgettable journey through Seattle. – https://taxi-prive.com/best-limo-service-seattle-airport/
перевод с английского языка нотариально заверенный перевод: Документ, имеющий полную юридическую силу и признаваемый в государственных учреждениях и международных организациях. Наша задача – обеспечить вам уверенность в каждом слове.
[url=https://taxi-prive.com/] Seattle limousine rental [/url] offers luxurious, reliable transportation for various occasions. Ideal for weddings, proms, corporate events, or airport transfers, our Seattle limousine rental service ensures comfort and style. Choose from a fleet of well-maintained vehicles, including sedans, SUVs, and stretch limousines. Professional chauffeurs guarantee a smooth, safe ride. Enjoy amenities like plush seating, climate control, and entertainment systems. Book your Seattle limousine rental for a memorable, stress-free experience. – https://taxi-prive.com/
провайдеры интернета по адресу
domashij-internet-samara006.ru
провайдер по адресу самара
1win ng [url=https://1win3026.com/]https://1win3026.com/[/url]
Запой — это критическое состояние, которое требует медицинского вмешательства. Нарколог на дом в Красноярске становится все более востребованным. Специалисты предлагают медикаментозное лечение, включая капельницы для оперативного выхода из запоя. Симптоматика запоя может включать в себя как сильную головную боль, так и тошноту. При наличии таких симптомов важно быстро обратиться к специалистам для получения медицинской помощи. Консультация нарколога поможет определить необходимый курс лечения. Состав капельницы включает витамины и препараты, помогающие в восстановлении организма. Процедуры проводятся в комфортной обстановке, что позволяет избежать стресса. Восстановительный процесс после запоя также включает психологическую помощь. нарколог на дом Красноярск Не забывайте, что лечение алкоголизма, это длительный процесс, который требует терпения и усилий. Нарколог на дом в Красноярске предоставляет не только услуги по выводу из запоя, но и дальнейшую реабилитацию. Выход из запоя возможен, и мы готовы поддержать вас на этом пути.
электрокарниз недорого [url=https://elektrokarnizy777.ru/]elektrokarnizy777.ru[/url] .
Наркологическая клиника в Ярославле представляет собой специализированное учреждение, оказывающее медицинскую помощь пациентам с алкогольной, наркотической и медикаментозной зависимостью. Ключевыми направлениями работы являются детоксикация, стабилизация состояния, последующее реабилитационное сопровождение и профилактика рецидивов. Комплексный подход к лечению обеспечивается взаимодействием специалистов различных профилей, включая наркологов, психиатров, психотерапевтов и медицинских сестёр.
Детальнее – http://narkologicheskaya-klinika-v-yaroslavle12.ru
автоматические карнизы для штор [url=elektrokarnizy10.ru]elektrokarnizy10.ru[/url] .
вывод из запоя
vivod-iz-zapoya-krasnodar002.ru
вывод из запоя
перевод документов для визы на английский [url=http://trs-center.ru]http://trs-center.ru[/url] .
https://x-vavada.ru Vavada – эксклюзивный обзор казино: честные отзывы о выплатах, секретные бонус-коды. Только проверенная информация о лицензии Кюрасао и слотах с высокой отдачей.
Напольное покрытие паркет [url=http://xn--1-7sba5anhi5b.xn--p1ai]http://xn--1-7sba5anhi5b.xn--p1ai[/url] .
Выбирайте казино https://casinopiastrix.ru с оплатой через Piastrix — это удобно, безопасно и быстро! Топ-игры, лицензия, круглосуточная поддержка.
http://www.1win bet.com login [url=http://1win3028.com]http://1win3028.com[/url]
Хотите купить контрактный двигатель ДВС с гарантией? Б большой выбор моторов из Японии, Европы и Кореи. Проверенные ДВС с небольшим пробегом. Подбор по VIN, доставка по РФ, помощь с установкой.
Ищете казино казино с СБП? У нас — мгновенные переводы, слоты от топ-провайдеров, живые дилеры и быстрые выплаты. Безопасность, анонимность и мобильный доступ!
Играйте в онлайн-покер https://droptopsite3.ru легальный с игроками со всего мира. МТТ, спины, VIP-программа, акции.
1win mobile app [url=https://www.1win-in1.com]1win mobile app[/url] .
Our [url=https://taxi-prive.com/limo-service-from-seattle-airport-to-cruise-terminal/] Seattle Airport Transportation [/url] limousine service offers luxurious, reliable rides. We specialize in Seattle Airport pick-ups/drop-offs, ensuring timely transit. Our fleet includes modern limos, sedans, SUVs. Professional chauffeurs prioritize safety, courtesy. Book online or call for Seattle Airport Transportation. Experience stress-free travel, style, comfort. Perfect for business, leisure travelers. Competitive rates, exceptional service guaranteed. Trust us for your Seattle Airport Transportation needs. – https://taxi-prive.com/limo-service-from-seattle-airport-to-cruise-terminal/
пополнить стим кошелек рубли Стим Баланс: Контролируйте свои расходы Управляйте своим игровым бюджетом! Мы научим вас, как эффективно использовать и пополнять свой Стим баланс, чтобы получать максимум удовольствия от игр.
Хирurgija u Crnoj Gori https://www.hirurgija-crna-gora.me savremena klinika, iskusni ljekari, evropski standardi. Planirane i hitne operacije, estetska i opsta hirurgija, udobnost i bezbjednost.
Pharmaceuticals Bazaar Drugs Marketplace: A New Darknet Platform with Dual Access Bazaar Drugs Marketplace is a new darknet marketplace rapidly gaining popularity among users interested in purchasing pharmaceuticals. Trading is conducted via the Tor Network, ensuring a high level of privacy and data protection. However, what sets this platform apart is its dual access: it is available both through an onion domain and a standard clearnet website, making it more convenient and visible compared to competitors. The marketplace offers a wide range of pharmaceuticals, including amphetamines, ketamine, cannabis, as well as prescription drugs such as alprazolam and diazepam. This variety appeals to both beginners and experienced buyers. All transactions on the platform are carried out using cryptocurrency payments, ensuring anonymity and security. In summary, Bazaar represents a modern darknet marketplace that combines convenience, a broad product selection, and a high level of privacy, making it a notable player in the darknet economy.
[url=https://taxi-prive.com/limo-service-seattle-airport/] Ideal Transportation Seattle Airport [/url] offers premier limousine services, focusing on luxury, comfort, and punctuality. Their fleet includes modern limousines, sedans, and SUVs, driven by professional chauffeurs. Services cover airport transfers, corporate travel, weddings, and special events. Booking is easy via their website or phone, with 24/7 customer support. They prioritize safety, reliability, and discretion, ensuring a seamless travel experience in the Seattle area. – https://taxi-prive.com/limo-service-seattle-airport/
1win apk download for android [url=http://1win3025.com/]http://1win3025.com/[/url]
Служба по контракту Служба по контракту: Стабильность, карьерный рост и социальные гарантии для военнослужащих. Это не просто работа, а возможность обрести уверенность в завтрашнем дне, обеспечить достойное будущее себе и своей семье.
Для успешного лечения зависимости необходима тщательная диагностика. В клинике проводят полное обследование пациента, включающее:
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-v-murmanske12.ru/]наркологическая клиника цены мурманск[/url]
Экстренный вызов нарколога на дом в Иркутске от «ТрезвоМед» при запое, интоксикации или кодировании – анонимно и удобно. Осмотр, детоксикация капельницей, индивидуальный план лечения – все это на дому! «ТрезвоМед» – круглосуточная помощь, анонимность и безопасность при отказе от алкоголя. Не можете бросить пить самостоятельно? Нужна помощь нарколога! Васильев: «Своевременная помощь при интоксикации – залог успешного выздоровления».
Подробнее можно узнать тут – [url=https://narcolog-na-dom-v-irkutske0.ru/]вызов нарколога на дом в иркутске[/url]
Клиника «АнтиАлко» предлагает экстренную медицинскую помощь на дому в Новосибирске и Новосибирской области для тех, кто столкнулся с запоем. Если вы или ваш близкий оказались в состоянии длительной алкогольной интоксикации, наши специалисты готовы оперативно приехать к вам, провести комплексную детоксикацию и купировать симптомы абстинентного синдрома. Мы гарантируем высокий уровень безопасности, полную анонимность и индивидуальный подход к каждому пациенту.
Подробнее – [url=https://vyvod-iz-zapoya-novosibirsk00.ru/]вывод из запоя клиника[/url]
A luxurious limousine service offers personalized transportation for various occasions. It provides a fleet of high-end vehicles, including sedans, SUVs, and stretch limousines, driven by professional chauffeurs. This service is popular for special events like weddings, corporate meetings, and airport transfers. One notable offering is [url=https://aolimo.com/wine-tours.html] Vancouver Island Wine Tours [/url], which takes passengers on a scenic journey through the region’s finest vineyards, offering a unique blend of luxury travel and wine tasting experiences. The service ensures comfort, safety, and punctuality, making every trip memorable and hassle-free. – https://aolimo.com/wine-tours.html
Особое внимание уделяется поддержке работы печени, сердца и почек, поскольку эти органы первыми страдают от токсического воздействия этанола. При необходимости подключаются дополнительные препараты — от седативных до противосудорожных. Все препараты подбираются с учётом возраста и общего состояния пациента.
Выяснить больше – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]вывод из запоя клиника[/url]
провайдеры интернета по адресу
domashij-internet-spb004.ru
домашний интернет тарифы
Our limousine service offers luxurious transportation for various occasions. We specialize in [url=https://aolimo.com/wine-tours.html] Corporate Wine Tour Packages [/url], providing a elegant and comfortable way to explore local vineyards with your team. Our fleet includes modern limousines equipped with premium amenities. We ensure professional chauffeurs, timely pickups, and safe journeys. Ideal for corporate outings, our Wine Tour Packages cater to groups seeking a refined experience. Enjoy scenic routes, visit renowned wineries, and indulge in wine tasting, all while traveling in style. Perfect for team building or entertaining clients, our service combines elegance with convenience. – https://aolimo.com/wine-tours.html
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом, что позволяет оперативно снизить концентрацию токсинов в крови и восстановить нормальные обменные процессы. Этот этап критически важен для стабилизации работы внутренних органов, таких как печень, почки и сердце.
Получить дополнительные сведения – [url=https://narcolog-na-dom-ryazan0.ru/]narkolog-na-dom-czena rjazan'[/url]
военная служба по контракту Контрактная служба: престижная работа, достойная оплата, уверенность в будущем
лечение запоя
vivod-iz-zapoya-minsk001.ru
вывод из запоя цена
В Москве решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-lyubercy13.ru/]врача капельницу от запоя Москва[/url]
The website tnschoolsonline.in is an official portal by the Tamil Nadu School Education Department. It provides comprehensive information about schools across Tamil Nadu, including directories, enrollment data, infrastructure details, and staff records. It serves teachers, students, and administrators to monitor and improve school management and educational outcomes.
вывод из запоя краснодар
vivod-iz-zapoya-krasnodar003.ru
лечение запоя
[url=https://aolimo.com/vehicles.html] Special Events Limousine Service [/url] offers luxurious transportation for weddings, proms, and other significant celebrations. With a fleet of high-end vehicles and professional chauffeurs, Special Events Limousine Service ensures a memorable and stress-free experience. – https://aolimo.com/vehicles.html
Пациенты, которые выбирают нашу клинику для лечения алкогольного запоя, получают качественную и оперативную помощь, обладающую следующими преимуществами:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod0.ru/]капельница от запоя клиника нижний новгород[/url]
смотреть онлайн бесплатно мистический Смотреть мистические фильмы онлайн: удобство и разнообразие
A limousine service offers luxurious transportation with [url=https://aolimo.com/] professional chauffeurs service [/url] for various events. It prioritizes comfort, style, and punctuality for clients. – https://aolimo.com/
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Узнать больше – http://narcolog-na-dom-novokuznetsk0.ru/narkolog-na-dom-klinika-novokuzneczk/https://narcolog-na-dom-novokuznetsk0.ru
Помощь нужна, если:
Детальнее – [url=https://vyvod-iz-zapoya-serpuhov3.ru/]vyvod-iz-zapoya-kruglosutochno[/url]
Служба по контракту Контрактная служба: Достойная оплата труда, жилищное обеспечение и медицинское обслуживание для военнослужащих и их семей. Государство заботится о своих защитниках, предоставляя им все необходимые условия для комфортной жизни и успешной службы.
mostbet kazinosu [url=http://mostbet4052.ru]http://mostbet4052.ru[/url]
Одним из ключевых направлений является проведение капельниц, призванных вывести токсины из организма и нормализовать водно-электролитный баланс. Используемые препараты и состав растворов подбираются индивидуально, исходя из клинической картины и истории болезни пациента.
Получить дополнительную информацию – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]нарколог на дом цена в ярославле[/url]
Также в расчет включается необходимость проведения дополнительных процедур (например, консультаций с психологом или кодирования) и географическая удаленность адреса вызова. Важно, что все эти параметры обсуждаются с пациентом заранее, что позволяет точно рассчитать расходы и избежать неожиданных доплат.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod000.ru/]капельница от запоя анонимно в нижний новгороде[/url]
Врачи клиники «ВитаЛайн» для снятия интоксикации и облегчения состояния пациента применяют исключительно качественные и проверенные лекарственные препараты, подбирая их в зависимости от особенностей ситуации и состояния здоровья пациента:
Подробнее – http://narcolog-na-dom-novosibirsk0.ru/narkolog-na-dom-kruglosutochno-novosibirsk/
Dual Access Bazaar Drugs Marketplace: A New Darknet Platform with Dual Access Bazaar Drugs Marketplace is a new darknet marketplace rapidly gaining popularity among users interested in purchasing pharmaceuticals. Trading is conducted via the Tor Network, ensuring a high level of privacy and data protection. However, what sets this platform apart is its dual access: it is available both through an onion domain and a standard clearnet website, making it more convenient and visible compared to competitors. The marketplace offers a wide range of pharmaceuticals, including amphetamines, ketamine, cannabis, as well as prescription drugs such as alprazolam and diazepam. This variety appeals to both beginners and experienced buyers. All transactions on the platform are carried out using cryptocurrency payments, ensuring anonymity and security. In summary, Bazaar represents a modern darknet marketplace that combines convenience, a broad product selection, and a high level of privacy, making it a notable player in the darknet economy.
Элитная недвижимость https://real-estate-rich.ru в России и за границей — квартиры, виллы, пентхаусы, дома. Где купить, как оформить, во что вложиться.
Наши врачи используют только проверенные и сертифицированные медикаменты, индивидуально подбираемые для каждого пациента. В состав лечебного курса входят:
Подробнее тут – [url=https://vyvod-iz-zapoya-novosibirsk00.ru/]вывод из запоя на дому цена[/url]
интернет по адресу дома
domashij-internet-spb005.ru
интернет по адресу санкт-петербург
вывод из запоя круглосуточно
vivod-iz-zapoya-minsk002.ru
вывод из запоя цена
военная служба по контракту Преимущества контрактной службы для молодого поколения Контрактная служба предоставляет молодым людям возможность получить стабильную работу, социальные гарантии, опыт и навыки, которые могут пригодиться в дальнейшей жизни.
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar004.ru
вывод из запоя цена
Эти данные являются основой для составления индивидуального плана лечения, позволяющего оперативно скорректировать терапевтические меры.
Получить больше информации – https://narcolog-na-dom-ryazan00.ru/narkolog-na-dom-kruglosutochno-ryazan/
mostbet promo kod az [url=www.mostbet4050.ru]www.mostbet4050.ru[/url]
Для оценки уровня учреждения важно понимать, какие конкретно методики в нём используются. Ниже приведён обобщённый обзор подходов в современных наркологических клиниках региона:
Углубиться в тему – [url=https://lechenie-narkomanii-vladimir10.ru/]лечение наркомании и алкоголизма владимир[/url]
провайдеры по адресу
domashij-internet-spb006.ru
провайдеры по адресу санкт-петербург
вывод из запоя цена
vivod-iz-zapoya-minsk003.ru
лечение запоя минск
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Узнать из первых рук – https://mybestbox.shop/index.php/2023/04/09/boost-your-online-presence-our-top-digital-marketing
военная служба по контракту Военный контракт: реальный шанс реализовать свой потенциал и добиться успеха в военной карьере
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Почему это важно? – https://hostingwebid.com/jasa-pembuatan-website-makassar
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Узнать напрямую – https://rbb.in.ua/stati-ofisnaya-bolezn2-html
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Узнать напрямую – https://kvinauto.com.ua/blog/podgotovka-peredney-podveski-3110-k-ustanovki-na-gaz-21
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также… – https://icouldeat.com/shop_item_06
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Получить полную информацию – https://www.coperura.com.br/avisos/614/aniversariantes-sorteados-em-janeiro-2018
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Выяснить больше – https://nysonline.org/2021/07/sdtk
мостбет официальный вход [url=https://www.mostbet4051.ru]https://www.mostbet4051.ru[/url]
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Заходи — там интересно – https://buyinsuranceplans.com/what-is-backup-health-policy
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Доступ к полной версии – https://www.pietrocarlopellegrini.it/memoriale-giuseppe-garibaldi/08-15
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Практические советы ждут тебя – https://kaganotokiralama.com/arac/citroen-c-elysee-gri
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Выяснить больше – https://depthfinder.click/%EB%9F%B0%EB%8D%98%EC%9D%98-%EC%9E%90%EC%A1%B4%EC%8B%AC-%EC%B2%BC%EC%8B%9C-fc
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Это ещё не всё… – https://qh88.repair/cuoc-the-thao-qh88
вывод из запоя краснодар
vivod-iz-zapoya-krasnodar005.ru
экстренный вывод из запоя
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Нажмите, чтобы узнать больше – http://mind-uk.org/environment-development
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Доступ к полной версии – https://tmsltd-x08c5pxewd.live-website.com/mastering-time-management-key-to-business-success
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Подробнее тут – https://f5fashion.vn/dac-san-hau-sua-thai-binh-duong-o-van-don
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Переходите по ссылке ниже – https://regionsliven.org/2024/05/23/%D0%B7%D0%B0%D0%BA%D0%BB%D1%8E%D1%87%D0%B8%D1%82%D0%B5%D0%BB%D0%BD%D0%B0-%D0%B4%D0%B5%D0%BA%D0%BB%D0%B0%D1%80%D0%B0%D1%86%D0%B8%D1%8F
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Почему это важно? – https://noodev.ca/2025/02/20/hello-world
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Получить дополнительные сведения – http://www.usdirectoryfinder.com/sheriff-in-maryland-pushes-for-day-reporting-center
Служба по контракту Контрактная служба: Это не только работа, но и образ жизни, требующий дисциплины, ответственности и преданности своему делу
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Смотрите также – http://starseniorcenter.org/star-senior-center-nov-2018-calendar
mostbet casino oyunları [url=http://mostbet4053.ru/]mostbet casino oyunları[/url]
Ламинат 33 класса для пола и стен. [url=https://laminat2.ru/]Ламинат 33 класса для пола и стен.[/url] .
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Нажмите, чтобы узнать больше – https://www.rovandesign.nl/purposecompany/2020/11/04/kerstidee
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Как достичь результата? – https://www.lifechange.at/meereswasser-im-kampf-gegen-klimawandel-einsetzen
Выбор застройщика https://spartak-realty.ru важный шаг при покупке квартиры. Расскажем, как проверить репутацию, сроки сдачи, проектную документацию и избежать проблем с новостройкой.
Смотреть фильмы kinobadi.mom и сериалы бесплатно, самый большой выбор фильмов и сериалов , многофункциональное сортировка, также у нас есть скачивание в mp4 формате
Недвижимость в Балашихе https://balashihabest.ru комфорт рядом с Москвой. Современные жилые комплексы, школы, парки, транспорт. Объекты в наличии, консультации, юридическое сопровождение сделки.
Поставка нерудных материалов https://sr-sb.ru песок, щебень, гравий, отсев. Прямые поставки на стройплощадки, карьерный материал, доставка самосвалами.
Лайфхаки для ремонта https://stroibud.ru квартиры и дома: нестандартные решения, экономия бюджета, удобные инструменты.
вывод из запоя круглосуточно
vivod-iz-zapoya-omsk001.ru
вывод из запоя круглосуточно омск
провайдеры по адресу уфа
domashij-internet-ufa004.ru
провайдер интернета по адресу уфа
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Обратитесь за информацией – https://mzs7krosno.pl/index.php/2015/09/01/rok-szkolny-201516-rozpoczety/poczatek_roku_2015_2016
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Читать дальше – https://brasilchat.net/2023/04/09/get-ahead-of-your-competition-our-proven-digital
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Изучить вопрос глубже – https://florence-neuberth.com/low3n0a0131-4
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Расширить кругозор по теме – https://www.ksiip.com/5a-sheep-milk-cheese
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Только для своих – https://www.wilsonmobilevet.com/services/kitty
Помощь родных является ключевой фактором в восстановлении после пьянки. Обсудите с ними о своих намерениях и позвольте о поддержке. Группы поддержки и обращение к специалистов представляют собой хорошим подспорьем. Не забывайте о профилактике срывов: советы по трезвости и самопомощь при зависимости от алкоголя помогут избежать соблазна вернуться к прежнему. вывод из запоя
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Полная информация здесь – https://liebeliebe.eu/seggs-school-2-6cm
Responsible gaming is key, and platforms like s5 casino com are gaining traction in the Philippines. Verification steps, like confirming age, are vital for a secure experience – good to see that focus! Remember to gamble within your limits.
Jogue o fortune tiger bet4 e divirta-se com segurança!
Участвуй в турнирах, активируй коды и начинай выигрывать прямо сейчас. [url=https://tcar.us/]500 р вавада[/url]
Женский журнал https://e-times.com.ua о красоте, моде, отношениях, здоровье и саморазвитии. Советы, тренды, рецепты, вдохновение на каждый день. Будь в курсе самого интересного!
Туристический портал https://atrium.if.ua всё для путешественников: путеводители, маршруты, советы, отели, билеты и отзывы. Откройте для себя новые направления с полезной информацией и лайфхаками.
Женский онлайн-журнал https://socvirus.com.ua мода, макияж, карьера, семья, тренды. Полезные статьи, интервью, обзоры и вдохновляющий контент для настоящих женщин.
Портал про ремонт https://prezent-house.com.ua полезные советы, инструкции, дизайн-идеи и лайфхаки. От черновой отделки до декора. Всё о ремонте квартир, домов и офисов — просто, понятно и по делу.
Всё о ремонте https://sevgr.org.ua на одном портале: полезные статьи, видеоуроки, проекты, ошибки и решения. Интерьерные идеи, советы мастеров, выбор стройматериалов.
mostbet mobil giriş [url=mostbet4048.ru]mostbet4048.ru[/url]
Нарколог на дому проводит тщательный осмотр, собирает анамнез и назначает необходимые лабораторные исследования. Это позволяет выявить сопутствующие патологии и скорректировать тактику лечения.
Подробнее – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]narkolog-na-dom-czena jaroslavl'[/url]
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Обратитесь за информацией – http://limit-solution.com/city-2278497_1920-2
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Обратитесь за информацией – https://saifulahi.com/2024/04/25/understanding-electrical-codes-a-guide-for-diy-enthusiasts
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Переходите по ссылке ниже – https://elastemgzn.com/flash-trash
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Смотрите также – https://metricco.es/premium-wordpress-themes-bursting-with-quality
экстренный вывод из запоя омск
vivod-iz-zapoya-omsk002.ru
экстренный вывод из запоя омск
Бюро дизайна https://sinega.com.ua интерьеров: функциональность, стиль и комфорт в каждой детали. Предлагаем современные решения, индивидуальный подход и поддержку на всех этапах проекта.
Портал про ремонт https://techproduct.com.ua для тех, кто строит, переделывает и обустраивает. Рекомендации, калькуляторы, фото до и после, инструкции по всем этапам ремонта.
провайдеры интернета по адресу уфа
domashij-internet-ufa005.ru
провайдеры по адресу уфа
Портал о строительстве https://bms-soft.com.ua от фундамента до кровли. Технологии, лайфхаки, выбор инструментов и материалов. Честные обзоры, проекты, сметы, помощь в выборе подрядчиков.
Всё о строительстве https://kinoranok.org.ua на одном портале: строительные технологии, интерьер, отделка, ландшафт. Советы экспертов, фото до и после, инструкции и реальные кейсы.
Ремонт и строительство https://mtbo.org.ua всё в одном месте. Сайт с советами, схемами, расчетами, обзорами и фотоидееями. Дом, дача, квартира — строй легко, качественно и с умом.
В Рязани возможен как стационарный, так и амбулаторный вывод из запоя. Выбор подхода зависит от состояния пациента, выраженности симптомов и наличия сопутствующих нарушений.
Углубиться в тему – https://vyvod-iz-zapoya-v-ryazani12.ru/
Капельница от запоя применяется для комплексного восстановления организма после длительного употребления алкоголя. Она включает в себя введение растворов, насыщенных витаминами, электролитами, глюкозой и лекарственными средствами, направленными на устранение симптомов интоксикации. Основные задачи процедуры:
Исследовать вопрос подробнее – https://kapelnicza-ot-zapoya-v-murmanske12.ru/
Лечение алкоголизма в домашних условиях — значимый этап для борьбы с алкогольной зависимостью . Лечение алкоголизма начинается с очищения организма, которая может быть проведена в домашних условиях . Основные подходы включают медицинскую помощь и препараты для детоксикации , что обеспечит безопасное прекращение употребления. vivod-iz-zapoya-krasnoyarsk002.ru Советы по трезвости и стратегии преодоления зависимости, такие как самообслуживание для людей с алкогольной зависимостью, имеют огромное значение в процессе восстановления. Отказ от алкоголя — это шаг к новой, трезвой жизни.
Сайт о ремонте https://sota-servis.com.ua и строительстве: от черновых работ до декора. Технологии, материалы, пошаговые инструкции и проекты.
Онлайн-журнал https://elektrod.com.ua о строительстве: технологии, законодательство, цены, инструменты, идеи. Для строителей, архитекторов, дизайнеров и владельцев недвижимости.
Полезный сайт https://quickstudio.com.ua о ремонте и строительстве: пошаговые гиды, проекты домов, выбор материалов, расчёты и лайфхаки. Для начинающих и профессионалов.
Журнал о строительстве https://tfsm.com.ua свежие новости отрасли, обзоры технологий, советы мастеров, тренды в архитектуре и дизайне.
Женский сайт https://7krasotok.com о моде, красоте, здоровье, отношениях и саморазвитии. Полезные советы, тренды, рецепты, лайфхаки и вдохновение для современных женщин.
вывод из запоя круглосуточно
vivod-iz-zapoya-omsk003.ru
вывод из запоя круглосуточно омск
провайдеры интернета по адресу уфа
domashij-internet-ufa006.ru
проверить провайдера по адресу
Женские новости https://biglib.com.ua каждый день: мода, красота, здоровье, отношения, семья, карьера. Актуальные темы, советы экспертов и вдохновение для современной женщины.
Все главные женские https://pic.lg.ua новости в одном месте! Мировые и российские тренды, стиль жизни, психологические советы, звёзды, рецепты и лайфхаки.
Сайт для женщин https://angela.org.ua любого возраста — статьи о жизни, любви, стиле, здоровье и успехе. Полезно, искренне и с заботой.
Женский онлайн-журнал https://bestwoman.kyiv.ua для тех, кто ценит себя. Мода, уход, питание, мотивация и женская энергия в каждой статье.
Путеводитель по Греции https://cpcfpu.org.ua города, курорты, пляжи, достопримечательности и кухня. Советы туристам, маршруты, лайфхаки и лучшие места для отдыха.
Зависимость от алкоголя у женщин является серьезной проблемой, которая требует внимательного подхода к лечению. В Красноярске наркологическая клиника предлагает экстренный вывод из запоя, что особенно важно для женщин, часто сталкивающихся с обществом, осуждающим их проблему. Зависимость от алкоголя у женщин может развиваться быстрее, чем у мужчин, и проявляется специфическими симптомами, такими как подавленное настроение и беспокойство.Лечение алкоголизма включает detox программу и медицинские методы лечения, а также психотерапию при алкоголизме. Важно обеспечить поддержку семьи и включение в группы взаимопомощи, что позволяет создать комфортные условия для выздоровления. Реабилитация алкоголиков в Красноярске акцентирует внимание на восстановлении социальной активности, что особенно важно для женщин, оказавшихся в такой ситуации. экстренный вывод из запоя Красноярск Предотвращение зависимости и обращение за экстренной помощью — основные элементы в борьбе с алкоголизмом. Комплексное лечение к процессу восстановления обеспечит успешное восстановление и возвращение к нормальной жизни.
Honestly, I wasn’t expecting this, but it really caught my attention. The way everything came together so naturally feels both surprising and refreshing. Sometimes, you stumble across things without really searching, and it just clicks.testinggoeshow It reminds me of how little moments can have an unexpected impact
Компоненты
Выяснить больше – [url=https://kapelnicza-ot-zapoya-pervouralsk11.ru/]капельница от запоя цена первоуральск.[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-orenburg001.ru
вывод из запоя круглосуточно
Пребывание в стационаре обеспечивает круглосуточный мониторинг состояния, своевременное введение лекарств и защиту пациента от внешних факторов, провоцирующих срыв. Все палаты оснащены необходимым оборудованием, соблюдаются санитарные нормы, а условия размещения соответствуют медицинским стандартам.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-v-yaroslavle12.ru/]частная наркологическая клиника[/url]
подключить проводной интернет омск
domashij-internet-volgograd004.ru
провайдеры интернета омск
лечение запоя
vivod-iz-zapoya-minsk001.ru
экстренный вывод из запоя минск
Канал с обзорами и сравнениями грузовой техники для выбора и покупки.
Публикуем новости, технические характеристики, рыночную аналитику, советы по выбору для бизнеса.
У нас всегда актуальные цены и тренды рынка СНГ! Подпишись:
[url=https://t.me/s/kupit_gruzoviki/263]Поведенческие факторы в кабине оператора: Почему эргономика (цветные сенсорные дисплеи, подогрев) снижает ошибки на 25% (анализ систем Liebherr 1025 LTM vs Челябинец КС-55732)[/url]
лечение запоя оренбург
vivod-iz-zapoya-orenburg002.ru
вывод из запоя круглосуточно
Основной этап в лечении — детоксикация организма от токсичных веществ, вызывающих интоксикацию. В клинике применяют современные методы капельниц и медикаментозной поддержки, включая препараты для снятия абстинентного синдрома.
Исследовать вопрос подробнее – https://narkologicheskaya-klinika-v-murmanske12.ru/chastnaya-narkologicheskaya-klinika-v-murmanske
Работа клиники строится на принципах доказательной медицины и индивидуального подхода. При поступлении пациента осуществляется всесторонняя диагностика, включающая анализы крови, оценку психического состояния и анамнез. По результатам разрабатывается персонализированный курс терапии.
Разобраться лучше – [url=https://narkologicheskaya-klinika-v-ryazani12.ru/]chastnaya narkologicheskaya klinika rjazan'[/url]
Клеевая пробка напольная [url=http://probkovoe-pokritie1.ru/]http://probkovoe-pokritie1.ru/[/url] .
Купить паркетную доску. [url=https://parketnay-doska2.ru/]parketnay-doska2.ru[/url] .
интернет тарифы омск
domashij-internet-volgograd005.ru
интернет тарифы омск
Вызов нарколога возможен круглосуточно, что обеспечивает оперативное реагирование на критические ситуации. Пациенты и их родственники могут получить помощь в любое время, не дожидаясь ухудшения состояния.
Узнать больше – [url=https://narkolog-na-dom-kamensk-uralskij11.ru/]нарколог на дом срочно в каменске-уральском[/url]
вывод из запоя минск
vivod-iz-zapoya-minsk002.ru
вывод из запоя круглосуточно
вывод из запоя цена
vivod-iz-zapoya-orenburg003.ru
вывод из запоя круглосуточно
подключить интернет в квартиру омск
domashij-internet-volgograd006.ru
лучший интернет провайдер омск
Портал о строительстве https://ateku.org.ua и ремонте: от фундамента до крыши. Пошаговые инструкции, лайфхаки, подбор материалов, идеи для интерьера.
Строительный портал https://avian.org.ua для профессионалов и новичков: проекты домов, выбор материалов, технологии, нормы и инструкции.
Туристический портал https://deluxtour.com.ua всё для путешествий: маршруты, путеводители, советы, бронирование отелей и билетов. Информация о странах, визах, отдыхе и достопримечательностях.
Открой мир https://hotel-atlantika.com.ua с нашим туристическим порталом! Подбор маршрутов, советы по странам, погода, валюта, безопасность, оформление виз.
Ваш онлайн-гид https://inhotel.com.ua в мире путешествий — туристический портал с проверенной информацией. Куда поехать, что посмотреть, где остановиться.
Особенно важны первые дни пребывания, когда проводится диагностика, назначается медикаментозная поддержка и формируется план лечения. Компетентные врачи способны адаптировать программу под физическое и психоэмоциональное состояние пациента, учитывая как длительность употребления, так и возможные сопутствующие диагнозы. На этом этапе важно исключить риски осложнений и создать условия для безопасного перехода к следующему этапу — психологической реабилитации.
Изучить вопрос глубже – http://narkologicheskaya-klinika-tula10.ru/
экстренный вывод из запоя
vivod-iz-zapoya-minsk003.ru
лечение запоя
вывод из запоя
vivod-iz-zapoya-smolensk004.ru
вывод из запоя цена
кайт египет Кайтсерфинг и реклама: Эффективные методы рекламы
I believe what you typed was very logical. However, think about this, what if you added a little content? I mean, I don’t wish to tell you how to run your website, however suppose you added something that grabbed folk’s attention? I mean %BLOG_TITLE% is a little vanilla. You could glance at Yahoo’s home page and note how they create post titles to grab people interested. You might add a related video or a picture or two to grab people interested about everything’ve written. Just my opinion, it might make your posts a little livelier.
Best limo service near me
Химчистка мебели ростов Удаление пятен с мебели Ростов – сложная задача, требующая профессионального подхода. Не рискуйте испортить обивку – доверьте это дело специалистам.
продать мекинист Продам лекарства России – объявления о продаже лекарств в России должны соответствовать действующему законодательству.
дешевый интернет воронеж
domashij-internet-voronezh004.ru
лучший интернет провайдер воронеж
Строительный сайт https://diasoft.kiev.ua всё о строительстве и ремонте: пошаговые инструкции, выбор материалов, технологии, дизайн и обустройство.
кайт школа хургада Кайт школа “Дети Ветра”: Преимущества обучения у нас
Журнал о строительстве https://kennan.kiev.ua новости отрасли, технологии, советы, идеи и решения для дома, дачи и бизнеса. Фото-проекты, сметы, лайфхаки, рекомендации специалистов.
Сайт о строительстве https://domtut.com.ua и ремонте: практичные советы, инструкции, материалы, идеи для дома и дачи.
Вывод из запоя в Мурманске представляет собой комплекс мероприятий, направленных на оказание медицинской помощи пациентам, находящимся в состоянии алкогольного отравления или длительного употребления спиртного. Процедура проводится с целью стабилизации состояния организма, предупреждения осложнений и минимизации риска развития тяжелых последствий алкоголизма.
Подробнее – [url=https://vyvod-iz-zapoya-v-murmanske12.ru/]вывод из запоя в стационаре в мурманске[/url]
На строительном сайте https://eeu-a.kiev.ua вы найдёте всё: от выбора кирпича до дизайна спальни. Актуальная информация, фото-примеры, обзоры инструментов, консультации специалистов.
Строительный журнал https://inter-biz.com.ua актуальные статьи о стройке и ремонте, обзоры материалов и технологий, интервью с экспертами, проекты домов и советы мастеров.
Журнал о строительстве https://kennan.kiev.ua новости отрасли, технологии, советы, идеи и решения для дома, дачи и бизнеса. Фото-проекты, сметы, лайфхаки, рекомендации специалистов.
вывод из запоя
vivod-iz-zapoya-smolensk005.ru
лечение запоя
вывод из запоя
vivod-iz-zapoya-omsk001.ru
вывод из запоя круглосуточно
Сайт о ремонте https://mia.km.ua и строительстве — полезные советы, инструкции, идеи, выбор материалов, технологии и дизайн интерьеров.
Сайт о ремонте https://rusproekt.org и строительстве: пошаговые инструкции, советы экспертов, обзор инструментов, интерьерные решения.
Всё для ремонта https://zip.org.ua и строительства — в одном месте! Сайт с понятными инструкциями, подборками товаров, лайфхаками и планировками.
Полезный сайт для ремонта https://rvps.kiev.ua и строительства: от черновых работ до отделки и декора. Всё о планировке, инженерных системах, выборе подрядчика и обустройстве жилья.
Автомобильный портал https://just-forum.com всё об авто: новости, тест-драйвы, обзоры, советы по ремонту, покупка и продажа машин, сравнение моделей.
Назначение
Узнать больше – http://kapelnicza-ot-zapoya-pervouralsk11.ru
mostbet aviator oyunu [url=http://mostbet4054.ru]http://mostbet4054.ru[/url]
приемка квартир от застройщика Прокат перфоратора – сверление отверстий в бетоне и кирпиче без лишних усилий.
кайт хургада Кайт Хургада: Отдохните и покатайтесь! Хургада – это не только кайтсерфинг, но и отличный пляжный отдых.
подключить домашний интернет воронеж
domashij-internet-voronezh005.ru
интернет домашний воронеж
Современный женский журнал https://superwoman.kyiv.ua стиль, успех, любовь, уют. Новости, идеи, лайфхаки и мотивация для тех, кто ценит себя и своё время.
Онлайн-портал https://spkokna.com.ua для современных родителей: беременность, роды, уход за малышами, школьные вопросы, советы педагогов и врачей.
Онлайн-журнал https://eternaltown.com.ua для женщин: будьте в курсе модных новинок, секретов красоты, рецептов и психологии.
Сайт для женщин https://ww2planes.com.ua идеи для красоты, здоровья, быта и отдыха. Тренды, рецепты, уход за собой, отношения и стиль.
Сайт для женщин https://womanfashion.com.ua которые ценят себя и своё время. Мода, косметика, вдохновение, мотивация, здоровье и гармония.
Играть в онлайн казино Нью Ретро
Казино Нью Ретро (Ньюретро) предлагает игрокам увлекательные азартные развлечения в современном формате. Здесь собраны сотни игр от ведущих провайдеров, включая слоты, рулетку, блэкджек и живые дилеры. Играть можно как на реальные деньги, так и бесплатно в демо-режиме.
Обзор официального сайта Нью Ретро
Официальный сайт Нью Ретро выполнен в стиле ретро с элементами современного дизайна. Интерфейс интуитивно понятен: главная страница содержит разделы с играми, акциями, турнирами и поддержкой. Сайт адаптирован под ПК и мобильные устройства, что делает игру комфортной в любом месте.
Лицензия онлайн-заведения
Нью Ретро работает на основании международной лицензии, выданной авторитетным регулятором (например, Кюрасао или Мальта). Это гарантирует честность игр и защиту данных игроков. Лицензионную информацию можно найти в подвале сайта.
Бонусы для постоянных клиентов и новых игроков
Казино предлагает щедрые бонусы:
• Приветственный пакет – бонус за первые депозиты (например, 100% + фриспины).
• Кешбэк – возврат части проигранных средств.
• VIP-программа – эксклюзивные подарки для постоянных игроков.
Бесплатная игра в демо-режиме
Перед ставками на деньги можно попробовать игры бесплатно в демо-режиме. Это отличный способ изучить правила и стратегии без риска.
Провайдеры
В Нью Ретро представлены игры от топовых разработчиков: NetEnt, Pragmatic Play, Play’n GO, Push Gaming, Novomatic и других.
Играть в слоты бесплатно в демо-режиме
Демо-версии слотов доступны без регистрации. Популярные игры: Book of Dead, Gates of Olympus, Starburst, Mega Moolah.
Способы регистрации и входа на сайт Нью Ретро
Зарегистрироваться можно:
• Через email и пароль.
• Через соцсети (Google, Telegram).
• По номеру телефона (SMS-подтверждение).
Верификация на сайте
Для вывода средств требуется верификация:
1. Подтверждение email/телефона.
2. Загрузка документов (паспорт, платежная карта).
3. Проверка занимает до 24 часов.
Другие игры в казино Нью Ретро
Помимо слотов, доступны:
• Рулетка, блэкджек, покер.
• Игры с живыми дилерами.
• Викторины и квизы.
Турниры и лотереи на Ньюретро
Казино регулярно проводит турниры с призовыми фондами и лотереи с розыгрышем денег и гаджетов. Условия участия – активная игра и выполнение заданий.
Мобильные приложения
Нью Ретро предлагает мобильное приложение для iOS и Android, где доступны все функции сайта.
Минимальный депозит
От 50-100 рублей (зависит от платежной системы).
Максимальные лимиты
Лимиты на вывод зависят от статуса игрока (обычно до 1 000 000 рублей в месяц).
Способы пополнения игрового счета
Доступные методы:
• Банковские карты (Visa/Mastercard).
• Электронные кошельки (Qiwi, WebMoney, Skrill).
• Криптовалюты (Bitcoin, Ethereum).
Вывод средств из заведения казино Ньюретро
Вывод занимает от 1 часа до 3 дней. Минимальная сумма – 500 рублей.
Служба поддержки игроков 24/7
Поддержка работает круглосуточно через:
• Онлайн-чат.
• Email.
• Telegram-бот.
Плюсы и минусы игры в казино для игроков
Плюсы:
? Много бонусов.
? Демо-режим.
? Быстрые выплаты.
Минусы:
? Ограниченные страны для регистрации.
? Долгая верификация.
Часто задаваемые вопросы
1. Как вывести деньги?
– Через тот же метод, которым делали пополнение.
2. Есть ли мобильное приложение?
– Да, для iOS и Android.
Последние отзывы о Нью Ретро
? Алексей, 28 лет: “Быстрые выплаты, но верификация затянулась”.
? Мария, 35 лет: “Нравится выбор слотов и турниры”.
Вывод
Нью Ретро https://newretrocasinow.com – надежное казино с богатой игровой коллекцией и бонусами. Подходит для новичков и опытных игроков.
Первое, что необходимо уточнить перед вызовом — наличие у врача лицензии и профильного медицинского образования. Только сертифицированный нарколог может назначить препараты, поставить капельницу и провести детоксикацию без ущерба для здоровья пациента.
Изучить вопрос глубже – http://narkolog-na-dom-nizhnij-tagil11.ru
Honestly, I wasn’t expecting this, but it really caught my
attention. The way everything came together so naturally feels both surprising and refreshing.
Sometimes, you stumble across things without really searching,
and it just clicks. It reminds me of how little moments can have an unexpected impact
вывод из запоя круглосуточно смоленск
vivod-iz-zapoya-smolensk006.ru
экстренный вывод из запоя
Капельница от запоя в Мурманске является одной из наиболее востребованных процедур для снятия острого состояния алкогольной интоксикации. Эта методика позволяет быстро вывести токсины из организма, нормализовать водно-солевой баланс и улучшить самочувствие пациента. Современная капельная терапия считается эффективным средством в лечении запоя, обеспечивая поддержку жизненно важных функций и минимизируя риски осложнений.
Подробнее можно узнать тут – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя на дому мурманск.[/url]
лечение запоя омск
vivod-iz-zapoya-omsk002.ru
вывод из запоя омск
Замковая инженерная доска Дуб в Декор Экспо. [url=http://inzenernay-doska1.ru/]http://inzenernay-doska1.ru/[/url] .
Женский онлайн-журнал https://abuki.info мода, красота, здоровье, психология, отношения и вдохновение. Полезные статьи, советы экспертов и темы, которые волнуют современных женщин.
Современный авто портал https://simpsonsua.com.ua автомобили всех марок, тест-драйвы, лайфхаки, ТО, советы по покупке и продаже. Для тех, кто водит, ремонтирует и просто любит машины.
Актуальные новости https://uapress.kyiv.ua на одном портале: события России и мира, интервью, обзоры, репортажи. Объективно, оперативно, профессионально. Будьте в курсе главного!
Онлайн авто портал https://sedan.kyiv.ua для автолюбителей и профессионалов. Новинки автоиндустрии, цены, характеристики, рейтинги, покупка и продажа автомобилей, автофорум.
Информационный портал https://mediateam.com.ua актуальные новости, аналитика, статьи, интервью и обзоры. Всё самое важное из мира политики, экономики, технологий, культуры и общества.
Химчистка мебели ростов Химчистка штор Ростов – удаление пыли и освежение внешнего вида.
Запой – это крайняя степень алкоголизма, требующая профессионального вмешательства. Нарколог на дом в Волгограде – ваш выбор. Лечение на дому помогает избежать стресса и сохранить анонимность, получив необходимую помощь. Важно как можно быстрее начать лечение, чтобы избежать токсического воздействия алкоголя на организм. Лечение на дому направлено на очищение организма, восстановление баланса и нормальную работу органов. Для достижения долгосрочного результата важно сочетать медикаментозную терапию и психологическую поддержку. Начинаем с детоксикации, используя капельницы и современные препараты.
Подробнее тут – [url=https://vyvod-iz-zapoya-volgograd0.ru/]вывод. из. запоя. волгоград.[/url]
Точная диагностика позволяет подобрать индивидуальную программу лечения, что значительно повышает шансы на успешное выздоровление.
Получить больше информации – [url=https://narkologicheskaya-klinika-v-murmanske12.ru/]наркологические клиники алкоголизм мурманская область[/url]
домашний интернет воронеж
domashij-internet-voronezh006.ru
подключить интернет тарифы воронеж
продать лекарства Беларусь Как продать препараты: Правовые аспекты и безопасность Продажа лекарственных препаратов – это сфера, строго регулируемая законодательством. Несоблюдение установленных правил может привести к административной и уголовной ответственности. Поэтому, прежде чем задумываться о продаже препаратов, необходимо четко понимать правовые аспекты и возможные риски. Законные способы продажи препаратов: Аптеки и аптечные пункты: Единственным законным способом продажи лекарственных препаратов является реализация через аптеки и аптечные пункты, имеющие соответствующую лицензию на фармацевтическую деятельность. Интернет-аптеки: Некоторые аптеки имеют право осуществлять продажу препаратов через интернет, при условии соблюдения всех требований законодательства, включая наличие лицензии и обеспечение надлежащих условий хранения и доставки препаратов. Незаконные способы продажи препаратов: Продажа с рук: Категорически запрещается продажа лекарственных препаратов с рук, через объявления в интернете или другие неофициальные каналы. Перепродажа рецептурных препаратов: Продажа лекарственных препаратов, отпускаемых по рецепту врача, лицам, не имеющим соответствующего рецепта, является незаконной. Продажа контрафактных препаратов: Продажа поддельных лекарственных препаратов является уголовным преступлением. Риски незаконной продажи препаратов: Уголовная ответственность: Незаконная продажа лекарственных препаратов может повлечь за собой уголовную ответственность в виде штрафа, исправительных работ или лишения свободы. Административная ответственность: Нарушение правил продажи лекарственных препаратов может привести к административному штрафу. Нанесение вреда здоровью: Продажа некачественных или поддельных препаратов может нанести серьезный вред здоровью покупателей. Альтернативные варианты: Возврат в аптеку: Если у вас остались неиспользованные препараты, узнайте в аптеке, принимают ли их обратно. Утилизация: Если препараты не подлежат возврату, их необходимо правильно утилизировать.
прокат строительных инструментов Тепловизионное обследование – обнаружение скрытых теплопотерь и дефектов изоляции.
mwq 1xbet [url=http://www.arabic1xbet.com]mwq 1xbet[/url] .
Выездной нарколог в Туле предоставляет профессиональную помощь тем, кто переживает проблемы с наркоманией и алкоголизмом. Лечение зависимости нуждается в персонализированном подходе, и вызов нарколога на дом – это практичное решение для пациентов. Центр реабилитации зависимостей в Туле предлагает конфиденциальное лечение и консультации нарколога. Домашняя реабилитация позволяет пройти курс психотерапии при зависимости в домашней обстановке. Выездная медицинская помощь включает в себя как телесное, так и психологическую поддержку. Профилактика зависимости также является ключевым моментом в противостоянии алкоголизму и наркомании. Помощь алкоголикам и их близким – это задача профессионалов, которые готовы протянуть руку помощи в трудную минуту. vivod-iz-zapoya-tula004.ru
Запой – критическая фаза зависимости, когда организм не может регулировать потребление алкоголя. Нарколог поможет провести детоксикацию и стабилизировать состояние в привычной обстановке, сохраняя конфиденциальность. Быстрое вмешательство при запое очень важно, чтобы избежать серьезных последствий для здоровья. Нарколог на дому поможет вывести токсины, восстановить водно-электролитный баланс и нормализовать работу органов. Вывод из запоя на дому включает медикаментозную терапию и психологическую поддержку для долгосрочной ремиссии. Сначала очищают организм от токсинов с помощью внутривенных инфузий и других современных препаратов.
Подробнее – https://vyvod-iz-zapoya-volgograd0.ru/vyvod-iz-zapoya-kruglosutochno-volgograd/
вывод из запоя круглосуточно омск
vivod-iz-zapoya-omsk003.ru
экстренный вывод из запоя омск
Нарколог на дому проводит тщательный осмотр, собирает анамнез и назначает необходимые лабораторные исследования. Это позволяет выявить сопутствующие патологии и скорректировать тактику лечения.
Выяснить больше – https://narkolog-na-dom-v-yaroslavle12.ru/vyzov-narkologa-na-dom-v-yaroslavle
приемка квартир от застройщика Прокат инструментов, прокат строительных инструментов, аренда инструментов, приемка квартир, приемка домов, приемка квартир от застройщика, тепловизионное обследование.
Online casinos are evolving so fast! It’s cool seeing platforms like phswerte app casino blend tradition with modern tech – a secure, curated experience seems key these days. Registration processes should prioritize trust & verification!
подключить интернет
domashij-internet-chelyabinsk004.ru
домашний интернет
Клиники предлагают реабилитацию зависимых, которая включает лечение зависимости и консультации психолога. Процедура кодирования также является популярной мерой, помогающей снизить тягу к алкоголю. Круглосуточные клиники обеспечивают конфиденциальное лечение и помощь специалистов, что позволяет пациентам ощущать комфортно и безопасно. вывод из запоя круглосуточно Социальная адаптация и поддержка после лечения — необходимые элементы, обеспечивающие успешной интеграции в общество. Лечение алкоголизма в Туле становится доступным благодаря различным программам и методикам, которые помогают справиться с этой серьезной проблемы.
1win pul çıxarma [url=1win3040.com]1win pul çıxarma[/url]
1win qeydiyyat zamanı bonus [url=https://1win3039.com/]https://1win3039.com/[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-orenburg001.ru
вывод из запоя круглосуточно оренбург
Нарколог на дому проводит тщательный осмотр, собирает анамнез и назначает необходимые лабораторные исследования. Это позволяет выявить сопутствующие патологии и скорректировать тактику лечения.
Получить больше информации – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]vyzov-narkologa-na-dom jaroslavl'[/url]
Новости Украины https://pto-kyiv.com.ua и мира сегодня: ключевые события, мнения экспертов, обзоры, происшествия, экономика, политика.
Современный мужской портал https://kompanion.com.ua полезный контент на каждый день. Новости, обзоры, мужской стиль, здоровье, авто, деньги, отношения и лайфхаки без воды.
Сайт для женщин https://storinka.com.ua всё о моде, красоте, здоровье, психологии, семье и саморазвитии. Полезные советы, вдохновляющие статьи и тренды для гармоничной жизни.
Новостной портал https://thingshistory.com для тех, кто хочет знать больше. Свежие публикации, горячие темы, авторские колонки, рейтинги и хроники. Удобный формат, только факты.
Следите за событиями https://kiev-pravda.kiev.ua дня на новостном портале: лента новостей, обзоры, прогнозы, мнения. Всё, что важно знать сегодня — быстро, чётко, объективно.
Борьба с наркотической зависимостью требует системного подхода и участия опытных специалистов. Важно понимать, что лечение наркомании — это не только снятие ломки, но и длительная психотерапия, обучение новым моделям поведения, работа с семьёй. Согласно рекомендациям Минздрава РФ, наиболее стабильные результаты достигаются при прохождении курса реабилитации под наблюдением профессиональной команды в специализированном центре.
Исследовать вопрос подробнее – [url=https://lechenie-narkomanii-vladimir10.ru/]наркологическое лечение наркомания в владимире[/url]
Terve!!
Pelisäännöt casino ympäristössä ovat selkeät ja kaikkien pelaajien noudatettavissa. Pelisäännöt casino toiminnassa varmistavat reilun pelaamisen. [url=https://www.reallivecasino.cfd/ikarajat-ja-saannot.html]casino neuvonta[/url] Tutustu sääntöihin etukäteen ja pelaa vastuullisesti sovittujen ohjeiden mukaan.
Lue linkki – https://www.reallivecasino.cfd/ikarajat-ja-saannot.html
casino savonlinna
casino ГҐrhus poker
kometa casino
Onnea!
Высокий уровень лечения обеспечивается квалификацией врачей, имеющих опыт работы в области наркологии, а также современным медицинским оборудованием, позволяющим проводить диагностику и лечение на самом высоком уровне. Врачи регулярно повышают квалификацию, участвуя в конференциях и обучающих программах. Подробности о квалификации специалистов доступны на портале медицинского сообщества.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]наркологическая клиника цены в каменске-уральском[/url]
Для успешного лечения зависимости необходима тщательная диагностика. В клинике проводят полное обследование пациента, включающее:
Получить дополнительные сведения – http://
интернет тарифы челябинск
domashij-internet-chelyabinsk005.ru
провайдеры интернета челябинск
Капельница для снятия запоя в Туле: стоимость и мнения В Туле услуги нарколога на дом становятся все более популярными. Множество людей нуждаются в помощи при алкогольной зависимости и ищут выход из сложной ситуации. Вызов нарколога на дом представляет собой комфортное решение получить медицинскую помощь, не выходя из дома. Капельница от запоя эффективно помогает в детоксикации организма и уменьшает проявления.Стоимость капельницы может различаться в зависимости от клиники, но в среднем составляет примерно 3000-6000 рублей. Отзывы о капельнице в основном положительные: пациенты отмечают быстрое улучшение состояния и уменьшение влечения к алкоголю. Экстренная помощь при запое способна сохранить здоровье.Лечение алкоголизма без лишних слов — ключевой фактор, так как многие чувствуют неловкость из-за своей зависимости. Услуги нарколога в Туле включают не только капельницы, но и реабилитацию после алкоголя. Помощь при запое доступна для всех, кто стремится к выздоровлению. нарколог на дом анонимно тула
проект перепланировки цена [url=http://belbeer.borda.ru/?1-6-0-00002270-000-0-0-1751553723/]проект перепланировки цена[/url] .
завинчивающиеся сваи [url=https://ostankino-svai.ru /]ostankino-svai.ru [/url] .
гастро-вечеринка Воронеж заказать кейтеринг
срок спирали мирена https://spiral-mirena1.ru
узи аппарат купить цена [url=http://kupit-uzi-apparat8.ru]http://kupit-uzi-apparat8.ru[/url] .
mostbet aviator [url=https://mostbet4049.ru/]https://mostbet4049.ru/[/url]
вывод из запоя цена
vivod-iz-zapoya-orenburg002.ru
лечение запоя
Video chat with girl – meet, chat, flirt! Private broadcasts, thousands of users online. No limits, free and no registration. Start a dialogue right now.
Эффективная накрутка ПФ https://nakrutka-pf-seo.ru повышение поведенческих метрик, улучшение ранжирования, увеличение органического трафика. Безопасно, анонимно, с гарантией результата.
аппарат узи стоимость оборудования [url=https://kupit-uzi-apparat9.ru/]https://kupit-uzi-apparat9.ru/[/url] .
ремонт замена стиральных машин ремонт стиральных машин beko
ремонт стиральных машин bosch ремонт двигателя стиральной машины
ремонт стиральной машины candy телефон мастера по ремонту стиральных машин
купить профилированную трубу Профнастил С8: экономичный и практичный материал для кровли и облицовки Профнастил С8 – это универсальное решение для кровли, облицовки стен и строительства заборов. Он отличается легкостью, прочностью, долговечностью и доступной ценой. Широкая цветовая гамма позволяет подобрать оптимальный вариант для любого архитектурного стиля.
При запое организм теряет контроль над употреблением алкоголя. В Волгограде вызов нарколога на дом поможет быстро стабилизировать состояние. На дому можно получить квалифицированную помощь, провести детоксикацию и сохранить анонимность. Не затягивайте с вызовом нарколога, чтобы избежать необратимых последствий для организма. Вывод токсинов, восстановление баланса и нормализация работы организма – задачи нарколога на дому. Медикаменты и психология – основа лечения запоя на дому. Детоксикация – первый этап лечения, который проводится с помощью современных препаратов.
Выяснить больше – [url=https://vyvod-iz-zapoya-volgograd0.ru/]вывод из запоя в волгограде[/url]
«ВладимирМед» основана группой врачей-наркологов и психотерапевтов, объединивших опыт работы в государственных и частных учреждениях. Мы предлагаем не просто преодоление запоя, а глубокую комплексную реабилитацию, включающую медико-психологическую оценку и долгосрочное сопровождение. Наша цель — восстановление здоровья на физическом и эмоциональном уровнях, возвращение пациента к полноценной социальной жизни без рецидивов.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-vladimir10.ru/]наркологическая клиника цены[/url]
провайдеры интернета челябинск
domashij-internet-chelyabinsk006.ru
подключить интернет в челябинске в квартире
Алкогольная зависимость серьезная проблема , требующая профессиональной помощи . В владимире работают специализированные центры по помощи алкоголикам, предлагающие экстренный вывод из запоя и лечение алкоголизма . При алкогольном отравлении необходимо быстро определить симптомы и обратиться за медицинской помощью . Квалифицированные наркологи в владимире предлагают консультации, обеспечивая безопасное восстановление после запоя и помощь при похмелье. Процесс реабилитации от алкоголизма включает программы реабилитации для зависимых , помогая не только пациентам , но и оказывая помощь родственникам алкоголиков. Профилактика алкогольных заболеваний также имеет большое значение в предотвращении рецидивов .
служба по контракту оренбург Финансовая поддержка контрактников: Контрактники в Оренбургской области получают достойную заработную плату, размер которой зависит от звания, должности и выслуги лет. Кроме того, предусмотрены различные надбавки и премии.
накрутка пф яндекс Анализ и оптимизация: ключ к успеху Регулярно анализируйте ПФ своего сайта и выявляйте слабые места. Улучшайте контент, оптимизируйте страницы и делайте сайт удобным для пользователей. Это – самый надежный путь к успеху в SEO.
экстренный вывод из запоя
vivod-iz-zapoya-orenburg003.ru
вывод из запоя оренбург
Возможные признаки
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-tula10.ru/]наркологическая клиника[/url]
mostbet az casino [url=https://mostbet4055.ru/]https://mostbet4055.ru/[/url]
Восстановление после запоя: шаги к нормальной жизни в владимире Проблема алкоголизма затрагивает множество людей, и восстановление после запоя является важным этапом на пути к трезвому образу жизни. В владимире доступны многообразные услуги в области наркологии, включая консультации у наркологов и выездные медицинские услуги. Нарколог на дом клиника Медицинские учреждения предлагают реабилитационные программы, которые включают психотерапию и поддержку в эмоциональном плане. Поддержка семьи также играет ключевую роль в процессе реабилитации. Группы поддержки и кризисные центры в владимире предоставляют помощь зависимым, способствуя их социальной адаптации. Важно обратиться к специалистам для получения помощи и начать путь к здоровой жизни.
1win az bank transfer [url=https://1win3037.com/]1win az bank transfer[/url]
Обширные исследования показывают, что качественная детоксикация снижает риск развития осложнений и способствует скорейшему восстановлению здоровья. Более подробная информация о методах детоксикации доступна на сайте Министерства здравоохранения РФ.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-nizhnij-tagil11.ru/]срочный вывод из запоя[/url]
culinary recipes https://retetesimple.com for every day: breakfasts, lunches, dinners, desserts and drinks. Step-by-step preparation, photos and tips.
downloading files https://all-downloaders.com from popular video services
Клиника располагает изолированными палатами с возможностью круглосуточного мониторинга состояния пациента. Оборудование соответствует гигиеническим требованиям и регулярно обновляется. В лечебный процесс включены:
Подробнее – [url=https://narkologicheskaya-klinika-v-ryazani12.ru/]наркологические клиники алкоголизм[/url]
Компоненты
Получить дополнительную информацию – https://kapelnicza-ot-zapoya-pervouralsk11.ru/kapelniczy-ot-zapoya-na-domu-v-pervouralske/
tahmil barnamaj 888starz [url=https://egypt888starz.net]tahmil barnamaj 888starz[/url] .
экстренный вывод из запоя
vivod-iz-zapoya-smolensk004.ru
лечение запоя смоленск
Для проведения процедуры используются стерильные растворы, а подбор компонентов осуществляется с учётом индивидуального состояния пациента, что позволяет минимизировать побочные эффекты и повысить эффективность терапии.
Получить больше информации – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя анонимно в мурманске[/url]
купить профилированную трубу Профилированная труба: универсальный материал для конструкций Профилированная труба – это универсальный строительный материал, который используется для создания каркасов, ограждений, навесов и других конструкций.
лазерная резка на металле нужна лазерная резка металла
После устранения острой зависимости важным этапом становится реабилитация. Она включает восстановление социальных навыков, обучение методам преодоления стрессов без употребления психоактивных веществ.
Получить больше информации – [url=https://narkologicheskaya-klinika-v-murmanske12.ru/]частная наркологическая клиника[/url]
типография напечатать типография печать
Для вашего удобства и прозрачности планирования лечения мы собрали ориентировочные цены на ключевые процедуры и форматы оказания помощи. Это позволит заранее оценить бюджет и подобрать оптимальный вариант терапии в зависимости от степени абстинентного синдрома и индивидуальных потребностей пациента.
Изучить вопрос глубже – http://narkolog-na-dom-ramenskoe4.ru
Специалист по наркологии — это медицинский работник, который обеспечивает поддержку людям, страдающим от зависимостей. Лечение зависимостей включает в себя детоксикацию, медикаменты и психотерапию. Необходимо обратиться за консультацией нарколога для определения индивидуального плана реабилитации. Семейная поддержка играет ключевую роль в выздоровлении, а группы взаимопомощи помогают адаптироваться в обществе. Профилактика зависимостей также важна, чтобы снизить риск рецидивов. Обращение к профессионалам на vivod-iz-zapoya-vladimir006.ru гарантирует качественную медицинскую помощь и поддержку на каждом этапе лечения.
накрутка пф яндекс “Белые” методы: фокус на пользователя Вместо того, чтобы пытаться обмануть поисковую систему, лучше сосредоточиться на улучшении пользовательского опыта. Создавайте качественный и полезный контент, оптимизируйте сайт под мобильные устройства, улучшайте скорость загрузки страниц и обеспечивайте удобную навигацию. Это – долгосрочная стратегия, которая принесет стабильные результаты.
служба по контракту оренбург Как поступить на службу по контракту в Оренбурге? Процесс поступления на службу по контракту включает в себя несколько этапов: подача заявления, прохождение медицинского освидетельствования и профессионального отбора, заключение контракта.
Одним из ключевых направлений является проведение капельниц, призванных вывести токсины из организма и нормализовать водно-электролитный баланс. Используемые препараты и состав растворов подбираются индивидуально, исходя из клинической картины и истории болезни пациента.
Разобраться лучше – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]нарколог на дом вывод из запоя в ярославле[/url]
Когда организм уже не может обходиться без алкоголя, возникает запой. Вызов нарколога на дом в Волгограде – это безопасно и эффективно. Нарколог приедет на дом, проведет детоксикацию и поможет стабилизировать состояние, не нарушая привычный ритм жизни. Своевременная помощь нарколога поможет избежать осложнений, вызванных запоем. Дома нарколог поможет очистить организм и восстановить его нормальную работу. Избавление от запоя на дому – это сочетание лекарств и психологической помощи. Сначала нужно очистить организм от токсинов, и в этом помогут специальные препараты.
Получить больше информации – [url=https://vyvod-iz-zapoya-volgograd0.ru/]вывод из запоя цены волгоград[/url]
Установка оптоволоконного интернета в Екатеринбурге — это выбор, которое приобретает все большую популярность среди населения и коммерческих организаций. Екатеринбургие провайдеры предлагают разнообразные тарифные планы на интернет, обеспечивая высокую скорость и стабильность соединения. Интернет на основе оптоволокна, благодаря современным технологиям, способен обеспечить значительно более высокую скорость по сравнению с традиционными методами подключения. Это особенно важно для интернета для бизнеса, где стабильность и высокая скорость являются основными требованиями. Выбирая провайдера, стоит обратить внимание на отзывы и изучить сравнение тарифов и предоставляемых услуг. Процесс установки интернета, как правило, происходит быстро и без проблем, что делает подключение удобным. Оптоволоконный интернет имеет множество преимуществ: высокая скорость интернета, низкие задержки и возможность подключения большого количества устройств. Если вы находитесь в поиске надежного интернет-провайдера, рекомендуем посетить сайт domashij-internet-ekaterinburg004.ru для получения более подробной информации и выбора лучшего тарифа для вашей квартиры или компании.
лечение запоя
vivod-iz-zapoya-smolensk005.ru
экстренный вывод из запоя
вывод из запоя круглосуточно
narkolog-krasnodar001.ru
лечение запоя краснодар
накрутка пф яндекс ПФ – это важно, но не все Яндекс действительно учитывает ПФ при ранжировании сайтов. Но это лишь один из множества факторов. Нельзя забывать о качестве контента, оптимизации, ссылочном профиле и других важных аспектах.
1win əlaqə [url=https://www.1win3042.com]1win əlaqə[/url]
BK
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Не упусти важное! – https://www.sm2itunisie.com/electrothermie-toutes-industries/electrothermie-2
медицинское оборудование узи [url=http://www.kupit-uzi-apparat10.ru]медицинское оборудование узи[/url] .
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Более подробно об этом – https://mevie-pro.com/mc7e77ybinmp312gewmal92yfhtf4e3qrc247cz7
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Подробная информация доступна по запросу – https://sabahi-sabahi.com/2021/01/05/%E2%98%86%E9%BB%92%E8%B1%86%E2%98%86
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Почему это важно? – https://www.consultrh.fr/project-details/campus-cafeteria
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Практические советы ждут тебя – https://www.bignewscentral.com/a-trip-to-legoland-california
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Изучить аспект более тщательно – https://lemondeinfos.com/sample-page
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Секреты успеха внутри – https://aocuoiduongthanh.com/chao-moi-nguoi
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Ссылка на источник – https://assuredsystech.com/eko-sapien-quis-porttitor-ipsum-etilk-3
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Все материалы собраны здесь – http://club-retraites.com/que-proposent-les-clubs-de-retraites-corses.php
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Читать дальше – https://axelzamudio.com/podcast/episode/como-se-vive-el-cancer-de-mama
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Узнай первым! – https://blog.kingwatcher.com/chess-power-rankings-april-2023-nakamura-enters-top-five
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Узнать напрямую – https://kalyankesari.com/?p=15453
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Смотрите также – https://catchii.com/catchii-magazine-c
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Получить полную информацию – https://aboutautomobile.ru/?paged=26
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Смотри, что ещё есть – https://thesloop.fr/conseils-pour-choisir-le-bon-partenaire-logistique
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Расширить кругозор по теме – http://wp12964331.server-he.de/dance_with_the_desert_2/2021/03/22/manual
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Это ещё не всё… – https://portfolio.annettenielsen.se/?p=1
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Узнай первым! – https://reve-estate.com/current-real-estate-market-trends
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Почему это важно? – https://vriba.com/blog/gpt-4o-a-promising-yet-familiar-evolution
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Все материалы собраны здесь – https://stoereplanken.nl/waar-staan-wij-voor-in-het-kort
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Не упусти важное! – https://clickbot.site/blood-pumping-stamped-concrete-nearby-watauga-texas
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Смотри, что ещё есть – https://mistermilkfze.com/2016/09/01/we-are-best-for-any-indutrial-business-solution
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Лови подробности – https://matronastore.com/product/rainbow-moon-earrings
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Открыть полностью – https://rajkajexpress.com/2024/07/16/uttarakhand-news
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Обратиться к источнику – https://nizam-electronics.pk/super-asia-ecm-5000-plus
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Не пропусти важное – https://stellartelecommunication.com/outshine-your-competitors-unleashing-proven-digital-excellence
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Переходите по ссылке ниже – https://freguesianews.com.br/2024/06/14/veja-quando-ganhou-o-vasco-com-patrocinio-da-joli-material-de-construcao
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Посмотреть подробности – https://irideegypt.com/the-best-horse-riding-destinations
1win az canlı dəstək [url=https://1win3041.com]https://1win3041.com[/url]
В Екатеринбурге выбор интернет-провайдеров разнообразен, и важно найти надежного партнера для подключения к интернету . На domashij-internet-ekaterinburg005.ru вы найдете мнениями пользователей о различных провайдерах, которые предлагают высокоскоростной интернет и стабильное соединение . Оптоволоконный интернет гарантируют высокое качество связи и постоянный доступ в сеть. Услуги интернета в Екатеринбурге включают различные тарифные планы, подходящие под ваши нужды . Важно обратить внимание на поддержку пользователей и установку оборудования, чтобы избежать проблем . Технологии связи постоянно развиваются , и надежные провайдеры обеспечивают безопасность сети . Выбирая провайдера, обращайте внимание на скорость подключения и предлагаемые услуги;
типография официальный сайт типография цены
вывод из запоя
vivod-iz-zapoya-smolensk006.ru
экстренный вывод из запоя смоленск
вывод из запоя
narkolog-krasnodar002.ru
вывод из запоя цена
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Секреты успеха внутри – https://2bbm.ru/?paged=24
Услуга “Нарколог на дом” в Уфе охватывает широкий спектр лечебных мероприятий, направленных как на устранение токсической нагрузки, так и на работу с психоэмоциональным состоянием пациента. Комплексная терапия включает в себя медикаментозную детоксикацию, корректировку обменных процессов, а также психотерапевтическую поддержку, что позволяет не только вывести пациента из состояния запоя, но и помочь ему справиться с наркотической зависимостью.
Выяснить больше – [url=https://narcolog-na-dom-ufa000.ru/]вызов нарколога цена уфа[/url]
сушенные лакомства Сушеные лакомства: Помощь в адаптации к новому дому Сушеные лакомства могут помочь щенку или взрослой собаке адаптироваться к новому дому, создавая положительные ассоциации.
Если интересует bankroll management — вот достойный текст.: https://malimar.ru/wp-content/news/preimushestva_vavada_casino.html
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Что ещё нужно знать? – https://2236261.ru/?paged=44
Honestly, I wasn’t expecting this, but it really caught my attention. The way everything came together so naturally feels both surprising and refreshing. Sometimes, you stumble across things without really searching, and it just clicks.testinggoeshow It reminds me of how little moments can have an unexpected impact
типография официальный сайт типографии спб недорого
Автоматизированные насосы строго регулируют скорость введения препаратов. Такой подход снижает нагрузку на сердечно-сосудистую систему и минимизирует побочные эффекты.
Подробнее – [url=https://lechenie-alkogolizma-arkhangelsk0.ru/]наркология лечение алкоголизма[/url]
Its like you read my mind! You appear to know a lot about this, like you wrote the book in it or something. I think that you can do with some pics to drive the message home a bit, but other than that, this is wonderful blog. A great read. I will certainly be back.
https://dumka.org.ua/germetik-dlya-stekla-far-kak-vybrat-idealnyy-dlya-vashego-avto
сушенные лакомства Лакомства для собак, сушенные лакомства: Забота о здоровье и радость питомца Сушенные лакомства для собак – это не просто вкусное угощение, но и полезный способ побаловать своего питомца, укрепить его здоровье и позаботиться о гигиене полости рта.
Пациенты клиники «НаркоМед» полностью застрахованы от утечки личной информации. Приём и лечение оформляются по псевдониму, документы не передаются в другие организации.
Разобраться лучше – [url=https://narkologicheskaya-klinika-ekaterinburg0.ru/]бесплатная наркологическая клиника в екатеринбурге[/url]
В Екатеринбурге доступно множество провайдеров, предлагающих беспроводной интернет. Современные технологии, включая 4G и Wi-Fi, гарантируют высокоскоростное подключение к интернету. При выборе тарифа на интернет важно учитывать ваши потребности: если вы планируете стримить видео, то стоит рассмотреть безлимитные тарифы, а для работы лучше выбрать тарифы с высокой скоростью. Сравнение тарифов поможет найти лучшее предложение. Обратите внимание на стоимость подключения и наличие роутеров и модемов в комплекте. Чтение отзывов о провайдерах поможет избежать неприятностей. В Екатеринбурге широкий выбор услуг связи, поэтому стоит тщательно рассмотреть все варианты на domashij-internet-ekaterinburg006.ru, чтобы выбрать идеальный домашний интернет.
вывод из запоя
narkolog-krasnodar003.ru
лечение запоя краснодар
Для пациентов, требующих круглосуточного наблюдения, клиника «Полярис» предлагает стационар VIP-класса. Здесь созданы все условия для быстрого восстановления: удобные палаты, индивидуальное меню, зоны отдыха и консультации профильных специалистов.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-arkhangelsk0.ru/]наркологическая клиника цены архангельск[/url]
Капельницы для лечения запоя на дому в Туле круглосуточно – это удобное решение для тех, кто сталкивается с трудностями алкогольной зависимости. Вызвать нарколога на дом можно в любое время суток. Услуги нарколога 24/7 включают в себя экстренную медицинскую помощь, детоксикацию алкоголя, а также реабилитацию после запоя. При необходимости вызова врача на дом, достаточно позвонить со специализированной службой. Капельницы для лечения запоя помогут быстро улучшить состояние пациента, восстановить баланс воды и электролитов и снять симптомы абстиненции. Услуги медицинских работников в Туле предоставляется высококвалифицированными специалистами. Первичная консультация нарколога перед началом лечения поможет разработать план лечения, включая дальнейшую реабилитацию. Помощь при алкогольной зависимости требует квалифицированного вмешательства и сопровождения. Наркология на дому обеспечивает комфорт и анонимность, что особенно важно для пациентов.
медицинские аппараты узи [url=https://kupit-uzi-apparat15.ru/]медицинские аппараты узи[/url] .
услуги типографии типография печать
купить масляный трансформатор тмг [url=http://maslyanie-transformatory-kupit.ru/]http://maslyanie-transformatory-kupit.ru/[/url] .
масляный трансформатор [url=https://maslyanie-transformatory-kupit1.ru/]maslyanie-transformatory-kupit1.ru[/url] .
лакомства для собак Сушеные лакомства: Поддержание здоровья сердца Сушеные лакомства, содержащие таурин, помогают поддерживать здоровье сердца у собак.
виды лазерной эпиляции клиника лазерной эпиляции
вывод из запоя цена
narkolog-krasnodar004.ru
экстренный вывод из запоя краснодар
На данном этапе специалист уточняет, как долго продолжается запой, какой вид алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ информации позволяет оперативно определить степень интоксикации и выбрать оптимальные методы терапии для быстрого и безопасного вывода из запоя.
Узнать больше – https://vyvod-iz-zapoya-tula00.ru/vyvod-iz-zapoya-anonimno-tula/
провайдер по адресу
domashij-internet-kazan004.ru
узнать интернет по адресу
В клинике используются запатентованные наборы для капельниц, включающие витамины группы B, мембранопротекторы и низкомолекулярные антиоксиданты. Автоматизированные насосы обеспечивают равномерный ввод растворов, минимизируя риск осложнений.
Подробнее можно узнать тут – http://lechenie-narkomanii-ekaterinburg0.ru
отчет по практике в школе https://gotov-otchet.ru
При лёгких и среднетяжёлых состояниях возможно проведение лечения на дому. Это удобно, комфортно и позволяет сохранить анонимность. Однако есть ситуации, в которых домашнее вмешательство нецелесообразно:
Изучить вопрос глубже – https://vyvod-iz-zapoya-kolomna3.ru/vyvod-iz-zapoya-stacionar-v-kolomne/
Наши профессионалы предоставляют экстренную помощь и консультацию, чтобы обеспечить комфортный вывод из запоя максимально комфортным и безопасным. Мы осознаем, насколько важна поддержка со стороны близких в это непростое время, по этой причине предлагаем анонимное лечение и реабилитацию пациентов. Не стесняйтесь обращаться на vivod-iz-zapoya-tula005.ru чтобы получить наркологические услуги и поддержку в выходе из запоя. Мы готовы оказать помощь круглосуточно.
заказать реферат сделать реферат
Услуга вывода из запоя на дому в Туле представляет собой комплекс мер, направленных на экстренную детоксикацию организма при алкогольной интоксикации. При вызове нарколога специалист прибывает в течение короткого времени, проводит первичный осмотр, собирает анамнез и определяет степень интоксикации. На основе полученной информации разрабатывается индивидуальный план лечения, который может включать медикаментозную детоксикацию, капельничное введение препаратов и психотерапевтическую поддержку.
Углубиться в тему – http://vyvod-iz-zapoya-tula0.ru/
1win azerbaycan rəsmisi [url=http://1win3038.com/]http://1win3038.com/[/url]
лечение запоя
narkolog-krasnodar005.ru
вывод из запоя круглосуточно краснодар
Запой — это не просто бытовое пьянство, а одно из наиболее опасных проявлений алкогольной зависимости. Во время запоя организм перестаёт функционировать в нормальном режиме: сердечно-сосудистая система работает на износ, нервная система перегружена токсинами, а печень не справляется с нагрузкой. На этом фоне могут возникать тяжёлые осложнения — от судорог и гипогликемии до нарушения дыхания и алкогольного психоза. Чем дольше длится запой, тем глубже метаболические нарушения и выше риск серьёзных последствий.
Подробнее тут – [url=https://vyvod-iz-zapoya-kolomna3.ru/]вывод из запоя стационар[/url]
узнать провайдера по адресу казань
domashij-internet-kazan005.ru
интернет провайдеры по адресу дома
Капельница от запоя – это эффективный способ экстренного выхода из запоя, который помогает справиться с физической зависимостью от алкоголя. Однако борьба с алкоголизмом требует внимания к различным аспектам, но и эмоциональной помощи. Важно понимать, что алкогольная зависимость – это не только физический, но и эмоциональный недуг. Экстренный вывод из запоя включает в себя регулировку водно-солевого баланса, но без психотерапии и эмоциональной поддержки восстановление может оказаться временным. В сложные времена помощь зависимым должна быть комплексной и включать различные методы. Семейная поддержка является важным элементом успешного лечения. Семейная атмосфера поддержки способствует формированию здоровых привычек и снизить риск рецидивов. Профилактика рецидивов включает в себя комплекс мероприятий, направленных на закрепление успехов лечения, что делает процесс восстановления более устойчивым.
После первичной диагностики начинается активная фаза детоксикации, во время которой современные препараты вводятся капельничным методом. Этот этап помогает быстро снизить концентрацию токсинов в крови, восстановить нормальные обменные процессы и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-tula0.ru/]вывод из запоя капельница тула[/url]
Зависимость от алкоголя – это значительная проблема, требующая целостного подхода к лечению. На сайте narkolog-tula001.ru вы можете найти информацию о методах лечения зависимости от алкоголявключая очистку организма и кодирование. Важным этапом является реабилитация, где предоставляется психологическая помощь и формируются группы поддержкитакие как группы анонимных алкоголиков. Поддержка зависимых часто включает в себя совет по отказу от спиртного и рекомендации для жизни без алкоголя. Возвращение к нормальной жизни после запоя требует терпения и поддержки близких. Необходимо помнить о влиянии спиртных напитков на здоровье и следовать способам отказа от спиртного для достижения успешного выздоровления.
лучший интернет провайдер казань
domashij-internet-kazan006.ru
домашний интернет в казани
Очищение организма от алкоголя в домашних условиях – важный процесс‚ особенно для жителей владимира‚ страдающих от алкогольной зависимости. Комплексный подход является ключевым в лечении запоя‚ включая очищение организма и восстановление здоровья печени. лечение запоя владимир Похмелье часто сопровождается неприятными симптомами: головная боль‚ тошнота‚ слабость. В связи с этим, использование домашних и народных средств может существенно облегчить состояние. К примеру, травяные настои‚ имбирь и мед помогают восстановить силы. владимир предлагает различные альтернативные методы лечения‚ включая программы по лечению алкоголизма. Не забудьтечто после детоксикации нужна дополнительная поддержка для успешного восстановления от алкогольной зависимости.
трансформатор масляный [url=www.maslyanie-transformatory-kupit2.ru]трансформатор масляный[/url] .
Fabulous, what a web site it is! This website presents valuable facts to us, keep it up.
Luxury limo near me
В «Чистом Дыхании» вы встретите врачей-наркологов, психиатров и психологов с многолетним опытом, готовых приехать на дом для первичной детоксикации или принять в стационаре для углублённой терапии. Мы соблюдаем строгие медицинские протоколы и гарантируем безопасность даже в самых тяжёлых случаях.
Узнать больше – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]наркологическая клиника в области[/url]
Поддержка психолога при выходе из запоя в Туле: как преодолеть абстиненцию При абстинентном синдроме люди часто сталкиваются с сильными физическими и эмоциональными страданиями. В таких случаях помощь психолога и кризисная помощь способны существенно улучшить состояние пациента. Центры психотерапии в Туле предоставляют разнообразные программы реабилитации и методы преодоления зависимостей, что способствует решению проблем. вывод из запоя цена Советы по выходу из запоя включают обращение за психологической поддержкой и участие в реабилитационных программах для зависимых, что повышает шансы на успешное лечение. Важно помнить, что путь к трезвости требует времени, терпения и поддержки.
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Выяснить больше – https://radiantandbrighter.com/2018/07/15/mariarose
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Смотрите также… – https://spinevision.net/pedicle-screw-dynamic-systems-flex2-innovationthatmatters
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Продолжить изучение – https://aruessussu.com/archives/9486302.html
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Перейти к статье – https://abrahamcarle.com/entrada-comentarios
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Лучшее решение — прямо здесь – https://astrologieetvoyance.fr/61-2
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Доступ к полной версии – https://daaiplus.com/mengenal-tanaman-terubuk-punya-bentuk-mirip-tebu-dan-tekstur-mirip-telur
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Узнать напрямую – https://all4holidays.ru/?paged=22&cat=1
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Получить полную информацию – https://www.meincreative.at/example-post-3
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Узнать больше – https://stylianosmpellos.gr/%CE%B4%CE%B9%CF%83%CE%BA%CE%BF%CE%B3%CF%81%CE%B1%CF%86%CE%AF%CE%B1/dimotiki-anthologia-no3-2
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Углубиться в тему – https://ferienwohnung-samerberg.de/schlafzimmer
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее можно узнать тут – http://webjaranottageedesign.cf/post/34
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Информация доступна здесь – https://alexandr-saharov.ru/?paged=43&cat=1
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Расширить кругозор по теме – https://cmcssp.com.br/2019/08/22/former-insures-only-the-marine-perils-while-the-latter-covers
написание дипломной работы дипломная работа цена
написать дипломную работу написание дипломов на заказ
интернет провайдеры в красноярске по адресу дома
domashij-internet-krasnoyarsk004.ru
интернет провайдеры красноярск по адресу
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Получить больше информации – https://karacabeymerkez.com.tr/2024/04/13/hello-world
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Изучить вопрос глубже – https://www.tmcfinancing.com/barbara-morrison-bay-area-people
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Обратиться к источнику – https://f5fashion.vn/cap-nhat-hon-60-ve-ve-to-mau-chiec-o
В этой публикации мы исследуем ключевые аспекты здоровья, включая влияние образа жизни на благополучие. Читатели узнают о важности правильного питания, физической активности и психического здоровья. Мы предоставим практические советы и рекомендации для поддержания здоровья и развития профилактических подходов.
Разобраться лучше – https://ego-yuriie.ru/kapelnitsa-antistress-v-narkologicheskoj-klinike
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Изучить аспект более тщательно – https://www.bojler-praha.cz/group-7
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Смотри, что ещё есть – https://tier2tickets.com/goodbye-sms-authentication-hello-multi-accounts-2fa
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Детальнее – https://examaar.com/check
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Расширить кругозор по теме – https://armorliterie.fr/literie
Провести капельницу после запоя в домашних условиях – это решение, который может помочь симптомы похмелья и ускорить процесс детоксикации. Лечение запоя предполагает как медицинскую помощь на дому, так и домашние рецепты от похмелья. Стоит отметить симптомы похмелья: боль в голове, тошнота, усталость. Для восстановления после алкоголя часто используются препараты от запоя, которые помогут уменьшению дискомфорта. vivod-iz-zapoya-vladimir005.ru При алкогольной зависимости психологическая помощь при запое является важной частью процесса. Поддержка родственников при алкоголизме может значительно ускорить реабилитацию после пьянства и предотвратить повторные алкогольные кризисы. Советы по лечению запоя могут включать в себя соблюдение режима питания, достаточное питье и использование природных методов. Предотвращение запоев должна быть в приоритете, чтобы избежать рецидивов. Не стесняйтесь обращаться за помощью, если состояние не улучшается.
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Секреты успеха внутри – https://yoga-petra-weiland.de/june-teacher-of-the-month-angela-dawn
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Получить исчерпывающие сведения – https://flightinparis.com/ceinture-de-securite-et-masque-a-oxygene-ces-accessoires-qui-peuvent-vous-sauver-la-vie
Капельница от запоя — это важная первая помощь в случае запоя. При наблюдении симптомов запоя, таких как обнаружите признаки, такие как интенсивная жажда, боли в голове, недомогание и общая слабость, вызов нарколога на дом в Туле может стать оптимальным выходом. Специалист осуществит медицинскую помощь и предложит капельницу, которая способствует восстановлению организма. вызвать нарколога на дом тула Лечение алкогольной зависимости включает вывод из запоя, что позволяет существенному улучшению здоровья после запоя. Капельница помогает устранить обезвоживание, компенсировать дефицит минералов и оптимизировать общее состояние пациента. Если требуется можно организовать лечение в домашних условиях, что обеспечивает комфорт и безопасность.Наркология в Туле предлагает качественные услуги по реабилитации от алкоголя, что обеспечивает справиться с зависимостью результативно. Эффекты капельницы заметны в краткие сроки: пациенты отмечают улучшение самочувствия и восстановление сил. Не стоит промедлить обращение за помощью, бережное отношение к здоровью — залог вашей жизни!
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Перейти к статье – https://178evakuator178.ru/?paged=10&cat=1
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Что ещё нужно знать? – https://all4holidays.ru/?paged=5
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Узнай первым! – https://178evakuator178.ru/?paged=38&cat=1
Слив платных прогнозов бесплатно Риски использования слитых прогнозов: Потеря денег Использование слитых прогнозов может привести к потере денег, так как их достоверность часто сомнительна. Прогнозы могут быть устаревшими, неточными или намеренно ложными.
какие провайдеры интернета есть по адресу красноярск
domashij-internet-krasnoyarsk005.ru
проверить провайдеров по адресу красноярск
melbet бонус [url=https://www.melbet3001.com]https://www.melbet3001.com[/url]
1 win casino [url=https://1win3046.com]https://1win3046.com[/url]
Чтобы обеспечить безопасное выведение психоактивных веществ и восстановление организма, применяется детоксикация под контролем врача-нарколога и анестезиолога-реаниматолога.
Узнать больше – https://lechenie-narkomanii-arkhangelsk0.ru/
Второй паспорт Виза цифровых кочевников, Digital Nomad Виза цифровых кочевников – это идеальное решение для тех, кто хочет работать удаленно и наслаждаться жизнью в другой стране. Она позволяет легально проживать и работать в стране, не привязываясь к офису.
При длительном запое в крови накапливаются ацетальдегид и другие токсичные метаболиты этанола, которые повреждают клетки печени, нарушают функцию почек и приводят к дисбалансу электролитов. Без своевременной детоксикации повышается риск острых состояний — судорог, инсультов, инфаркта, панкреатита и психоза. Чем раньше начато лечение, тем быстрее нормализуются показатели обмена веществ, возвращается водно-электролитный баланс и восстанавливается работа жизненно важных органов. Анонимный выезд нарколога помогает снять психологический барьер перед обращением за помощью.
Подробнее – [url=https://kapelnica-ot-zapoya-voronezh.ru/]капельница от запоя клиника воронеж[/url]
Слив платных прогнозов бесплатно Слив платных прогнозов бесплатно: Возможность или обман? Многие ищут способ получить доступ к платным прогнозам бесплатно, надеясь на легкий заработок. Однако стоит ли доверять подобным предложениям и каковы риски?
заказать авто из кореи пригнать машину из японии
выгодно пригнать авто пригнать машину из владивостока
Как предотвратить алкоголизм в Туле: советы медиков Зависимость от алкоголя — серьезная проблема‚ требующая внимания и действий. Необходимо быть в курсе способов профилактики и лечения. Можно обратиться к наркологу на дом в Туле для получения консультации специалиста. Врачи советуют проводить профилактические меры‚ такие как осведомленность о последствиях алкоголизма и поддержку семьи. вызвать нарколога на дом тула Лечение алкоголизма включает позволяющие помогают вернуть здоровье и социальную интеграцию. Наркологическая помощь является важной для работы с зависимыми‚ а также для предотвращения рецидивов. Борьба за здоровье и злоупотребление алкоголем — это постоянная борьба‚ и своевременная поддержка играет ключевую роль.
Согласно информации, опубликованной на сайте Минздрава РФ, успешная наркологическая помощь невозможна без своевременной диагностики, комплексного подхода и участия квалифицированных специалистов. Именно такие параметры становятся решающими при выборе учреждения, куда обратится пациент или его родственники.
Детальнее – http://narkologicheskaya-pomoshh-arkhangelsk0.ru/vyzov-narkologicheskoj-pomoshhi-arkhangelsk/https://narkologicheskaya-pomoshh-arkhangelsk0.ru
Очищение организма после запоя в владимире – важный этап на пути к возвращению к нормальной жизни. Квалифицированный нарколог на дому из клиники предлагает детоксикациюкоторая включает лечение запоя и медицинскую помощь при алкоголизме. Лечебные программы зачастую включают психотерапию и помощь близких. Процесс восстановления после запоя начинается с консультации нарколога, что обеспечивает качественное очищение организма и возвращению к полноценной жизни. Нарколог на дом клиника
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Химках приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-himki11.ru/]вывод из запоя город химки[/url]
прогнозы на сегодня [url=http://stavki-na-sport-prognozy.ru/]http://stavki-na-sport-prognozy.ru/[/url] .
Таблица: Основные признаки надёжного центра лечения наркомании
Подробнее можно узнать тут – [url=https://lechenie-narkomanii-murmansk0.ru/]centr lecheniya narkomanii murmansk[/url]
интернет провайдеры красноярск по адресу
domashij-internet-krasnoyarsk006.ru
интернет провайдеры по адресу
Гараж разборный Гараж разборный Универсальный разборный гараж для дачи или загородного дома. Компактная упаковка для удобной транспортировки. Простая инструкция для самостоятельной сборки.
заказать авто в россию пригнать машину из владивостока
Как зарегистрировать ООО или ИП https://ifns150.ru в Санкт-Петербурге? Какие документы нужны для ликвидации фирмы? Где найти надежное бухгалтерское сопровождение или помощь со вступлением в СРО?
В «Пульсар-Мед» с пониманием относятся к каждому обратившемуся: здесь нет осуждения и формального отношения. Врач-нарколог ведёт пациента на всём пути, а команда психологов и социальных работников обеспечивает поддержку на каждом этапе. Мы предлагаем анонимное лечение — ваши данные не попадут к третьим лицам, а обращение в клинику не фиксируется в государственных реестрах.
Подробнее можно узнать тут – https://lechenie-alkogolizma-vidnoe4.ru/lechenie-alkogolizma-stoimost-v-vidnom/
Вызов нарколога в Туле – важный шаг для людей‚ сталкивающихся с трудностями зависимости. На сайте narkolog-tula005.ru вы можете обратиться за квалифицированной помощью. Наркологическая помощь включает определение зависимости и анонимное лечение. Если у вас возникли алкогольная или наркотическая зависимость‚ срочный вызов врача поможет избежать осложнений. Центры реабилитации предлагают программы восстановления и поддержку семьи‚ что критично для успешного лечения. Консультация нарколога – это первый этап на пути к исцелению. Не откладывайте‚ обратитесь за медицинской помощью уже сегодня!
Вызов врача-нарколога на дом позволяет избежать стресса госпитализации, обеспечивая комфорт и удобство как для пациента, так и для его близких.
Подробнее можно узнать тут – [url=https://narcolog-na-dom-sankt-peterburg000.ru/]narkolog-na-dom sankt-peterburg[/url]
Пациенту устанавливают катетер в вену на руке или предплечье, используя лёгкий местный анестетик для минимизации дискомфорта. Затем подключают автоматизированную помпу, обеспечивающую равномерную подачу раствора в течение 3–6 часов.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-voronezh2.ru/]капельница от запоя на дому воронеж[/url]
Запой – это опасная стадия! В Волгоградской области нарколог поможет круглосуточно! Мы всегда на связи, чтобы помочь вам справиться с запоем. Мы предлагаем быстрое, безопасное и индивидуальное лечение. Наша служба вывода из запоя работает четко и без сбоев. Мы предлагаем детоксикацию и стабилизацию состояния в любом месте. Мы начинаем с диагностики, чтобы понять, как лучше вам помочь.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-volgograd000.ru/]вывод из запоя дешево волгоград[/url]
вывод из запоя
narkolog-krasnodar001.ru
лечение запоя
провайдеры интернета в краснодаре по адресу проверить
domashij-internet-krasnodar004.ru
интернет провайдеры по адресу
Лечение алкоголизма в Видном — это системная, комплексная терапия, сочетающая современные медицинские и психологические методики, которая позволяет не только справиться с физической зависимостью, но и обрести устойчивую трезвость на долгие годы. В наркологической клинике «Пульсар-Мед» пациентам доступен полный цикл помощи: от экстренной детоксикации и купирования абстинентного синдрома до долгосрочной реабилитации и поддержки на всех этапах восстановления. Каждая программа подбирается индивидуально, с учётом возраста, стажа употребления, сопутствующих заболеваний и особенностей семейной и социальной ситуации.
Подробнее – [url=https://lechenie-alkogolizma-vidnoe4.ru/]лечение алкоголизма на дому стоимость[/url]
Мы работаем круглосуточно и гарантируем строгое соблюдение конфиденциальности, используя только сертифицированные препараты и проверенные методики лечения.
Подробнее можно узнать тут – [url=https://narcolog-na-dom-sankt-peterburg00.ru/]врач нарколог на дом санкт-петербург.[/url]
Фурнитура MACO https://kupit-furnituru-maco.ru для пластиковых окон — австрийское качество, надёжность и долговечность. Петли, замки, микропроветривание, защита от взлома.
Нарколог на дому: профессиональная помощь при зависимости Проблема наркотической зависимости требует внимательного и профессионального подхода. Важно помнить, что лечение наркомании начинается с консультации нарколога. Полную информацию о вызове нарколога на дом вы найдете на сайте narkolog-tula006.ru. Медицинская помощь включает детоксикацию организма и психологическую поддержку. Часто требуется реабилитация зависимых, где применяется программа реабилитации. Конфиденциальное лечение создает условия комфорта и безопасности для пациента. Терапия на дому позволяет обеспечить необходимую помощь на дому, что особенно важно для тех, кто стесняется обращаться в клиники. Алкогольная зависимость может быть успешно лечена на дому, что ускоряет процесс выздоровления. Обращение к квалифицированному специалисту – это залог успешной борьбы с зависимостями.
заказать ролы суши роллы барнаул
Миссия нашей клиники заключается в оказании высококачественной помощи людям, страдающим от зависимостей. Мы стремимся создать безопасное и поддерживающее пространство для лечения, где каждый пациент получает необходимую поддержку и понимание. Наша задача — не только помочь избавиться от зависимости, но и вернуть полноценную жизнедеятельность человека, восстановив его социальные связи и жизненные ориентиры.
Выяснить больше – https://kapelnica-ot-zapoya-irkutsk2.ru/
В Химках решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Выяснить больше – [url=https://vyvod-iz-zapoya-himki13.ru/]наркология вывод из запоя город химки[/url]
Пациенту устанавливают катетер в вену на руке или предплечье, используя лёгкий местный анестетик для минимизации дискомфорта. Затем подключают автоматизированную помпу, обеспечивающую равномерную подачу раствора в течение 3–6 часов.
Детальнее – http://kapelnica-ot-zapoya-voronezh2.ru/vyezd-na-dom-kapelnicza-ot-zapoya-v-voronezhe/
После поступления вызова нарколог клиники «АльфаНаркология» оперативно выезжает по указанному адресу. На месте врач проводит первичную диагностику, оценивая степень интоксикации, физическое и психологическое состояние пациента. По результатам осмотра врач подбирает индивидуальный комплекс лечебных процедур, в который входит постановка капельницы с растворами для детоксикации, препараты для стабилизации работы органов и нормализации психического состояния.
Изучить вопрос глубже – [url=https://narcolog-na-dom-sankt-peterburg000.ru/]вызвать нарколога на дом санкт-петербург[/url]
интернет провайдеры по адресу краснодар
domashij-internet-krasnodar005.ru
интернет провайдеры по адресу дома
Вызов врача-нарколога на дом в Санкт-Петербурге начинается с детального осмотра и оценки состояния пациента. Врач измеряет давление, пульс, уровень кислорода в крови и определяет степень интоксикации.
Детальнее – [url=https://narcolog-na-dom-sankt-peterburg00.ru/]нарколог на дом недорого в санкт-петербурге[/url]
вывод из запоя цена
narkolog-krasnodar002.ru
лечение запоя краснодар
В таких случаях медлить нельзя — своевременный вызов нарколога может спасти жизнь и предотвратить тяжёлую инвалидизацию.
Углубиться в тему – https://vyvod-iz-zapoya-orekhovo-zuevo4.ru/vyvod-iz-zapoya-cena-v-orekhovo-zuevo
прогноз ру [url=https://stavki-na-sport-prognozy2.ru]прогноз ру[/url] .
прогнозы ставок [url=http://stavki-na-sport-prognozy1.ru/]http://stavki-na-sport-prognozy1.ru/[/url] .
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Ознакомьтесь с аналитикой – http://ceviktay.com/prod-dummy-image-1
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Перейти к статье – https://f5fashion.vn/top-hon-65-ve-hinh-to-mau-ngua-pony
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Доступ к полной версии – https://bilitoor.com/introducing-this-amazing-tour
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Практические советы ждут тебя – https://da-rocco-brk.de/menu_item/peperoni
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Узнать напрямую – https://soundboardguy.com/sounds/happy-happy-happy
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Ознакомьтесь с аналитикой – https://boshcornerstone.org/emergency-electrical-repairs-what-to-do-before-the-pros-arrive
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Все материалы собраны здесь – https://www.precisiondemonj.com/?attachment_id=71
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Почему это важно? – https://guayabo.co/hola-mundo
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Ознакомиться с полной информацией – https://hanairo-style.com/%E3%82%AD%E3%83%A3%E3%83%97%E3%83%81%E3%83%A3
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Читать дальше – https://www.denglademand.dk/?attachment_id=100
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Смотри, что ещё есть – http://izbaszczepankowo.pl/flexi/slub
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Ссылка на источник – https://claragrau.com.ar/case-studies/the-journey-of-life-understanding-transits
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Ссылка на источник – https://atlasproontv.us/product/abonnement-atlas-pro-3-mois
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Смотрите также – https://atelier-ananda.fr/sandwich
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Ссылка на источник – https://dancingstarslinedance.dk/galleri/billeder/soendagsdans-januar-2018
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Что ещё нужно знать? – https://www.directory10.org/image_hosting/society/history/entertainment/computers_and_internet/shopping/computers_and_internet/personal_digital_assistants_pdas
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Расширить кругозор по теме – https://medoded.ru
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Подробнее тут – http://bellasarasalon.com/2013/12/24/entry-with-post-format-video
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Выяснить больше – https://www.koebrugge.com/hallo-wereld
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Все материалы собраны здесь – https://xosebelas.com/2023/12/10/cara-budidaya-udang-vaname-sistem-bioflok
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Получить исчерпывающие сведения – https://instaprint.es/ofertas
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Все материалы собраны здесь – https://www.waikatowomensrefuge.co.nz/pf/haip
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Изучить аспект более тщательно – https://akas.ir/%D8%A2%D9%84%D8%A8%D9%88%D9%85_%D8%AC%D9%84%D8%AF_%DA%A9%D8%B1%DB%8C%D8%B3%D8%AA%D8%A7%D9%84
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Что ещё? Расскажи всё! – https://www.getrex.nl/nl/hoodie_6_back
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Заходи — там интересно – https://tucasaenyolombo.com/hola-mundo
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Нажми и узнай всё – https://snavar.com/what-is-chatgpt
интернет по адресу дома
[url=https://domashij-internet-krasnodar006.ru]domashij-internet-krasnodar006.ru[/url]
подключение интернета по адресу
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Смотрите также… – http://www.keramicwatch.ru
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Получить исчерпывающие сведения – http://www.jonathancastil.com/archi-2-architect
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Более того — здесь – http://vestikizilyurt.ru
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Это стоит прочитать полностью – http://innbizapk.ru
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Нажмите, чтобы узнать больше – https://alpina-eyewear.ru/?paged=47
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Обратитесь за информацией – https://alpina-eyewear.ru/?paged=47
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Изучить аспект более тщательно – https://tanpopo-harikyu.com/forums/topic/seo-service-xrumer-cc
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Смотрите также – https://scenterprisesgroup.com/this-is-the-way-you-sort-out-your-cracked-top-get-together-dating-sites
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Смотрите также – https://clandesign4sale.kienberger-designs.de/index.php?news-3
вывод из запоя краснодар
narkolog-krasnodar003.ru
экстренный вывод из запоя
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Читать дальше – https://bibicaspari.com/linkedin
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Доступ к полной версии – https://brightlogisticsco.com/2022/02/23/and-the-day-came-when-the-risk-to-remain-tight-in-a-bud-was-more-painful-than-the-risk-it-took-to-blossom
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Подробнее – https://krootconsultancy.nl/2017/01/23/leiderschapsontwikkeling-ga-10-dagen-mee-op-reis-naar-nepal/img_0185
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Секреты успеха внутри – https://www.impressivevegansolutions.com/sample-post-format-chat
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Как достичь результата? – https://mandysbeautysupply.com/getting-wiggy-with-it
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Более того — здесь – https://ufo-kosmocenter.ru/zachem
пансионат с медицинским уходом
pansionat-msk001.ru
дом престарелых в москве
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Информация доступна здесь – https://dailypaincare.com/what-is-the-defination-of-an-speculator
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Более того — здесь – https://as-hildebrand.de/clients/client-6
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Следуйте по ссылке – https://info-web.nl/?p=831
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Обратитесь за информацией – https://bluemint.pl/strona-glowna/lock
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Погрузиться в научную дискуссию – http://infomus.ru
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Доступ к полной версии – http://infomus.ru
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Все материалы собраны здесь – https://www.bassonwahwah.com/2021/04/30/bonjour-tout-le-monde
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Все материалы собраны здесь – http://frealms.ru
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Только для своих – https://hibizsolutions.com/digital-strategy-design-and-solutions-for-great-success
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Выяснить больше – https://russ2004.ru
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Переходите по ссылке ниже – http://mojojojo.ru
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Почему это важно? – http://fftrans.ru
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Узнать напрямую – https://www.kbt1.ir/?attachment_id=2270
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Смотри, что ещё есть – https://ofix.or.jp/2024/03/10/12382
Официальный Telegram канал Live Сasinо. Кaзинo и ставки от лучших площадок. Доступны актуальные зеркала официальных сайтов. Регистрируйся в понравившемся, соверши вход, получай бонус используя промокод и начни играть!
[url=https://t.me/s/iGaming_live/210]покер онлайн[/url]
Ремонт стиральных машин в Харькове: https://postiralka.com.ua/ – список фирм.
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Ознакомиться с полной информацией – https://samerjizi.com/memories
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Обратиться к источнику – https://remeslneprace.com/exploring-the-beauty-of-mother-nature
Клиника «АнтиАлко» предлагает экстренную медицинскую помощь на дому в Новосибирске и Новосибирской области для тех, кто столкнулся с запоем. Если вы или ваш близкий оказались в состоянии длительной алкогольной интоксикации, наши специалисты готовы оперативно приехать к вам, провести комплексную детоксикацию и купировать симптомы абстинентного синдрома. Мы гарантируем высокий уровень безопасности, полную анонимность и индивидуальный подход к каждому пациенту.
Детальнее – [url=https://vyvod-iz-zapoya-novosibirsk00.ru/]вывод из запоя капельница в новосибирске[/url]
ДОМАШНИЙ ИНТЕРНЕТ В МОСКВЕ: ЧАСТО ЗАДАВАЕМЫЕ ВОПРОСЫ В эпоху цифровых технологий доступ в сеть стал неотъемлемой частью жизни. Давайте разберем наиболее популярные вопросы, связанные с подключением домашнего интернета в Москве. 1. Как выбрать интернет-провайдера? Важно учитывать отзывы пользователей, скорость предоставляемого интернета и предлагаемые тарифные планы при выборе провайдера. Сравнение тарифов поможет найти оптимальный вариант для вашего бюджета. 2. Какие услуги связи доступны у провайдеров? Интернет-провайдеры в Москве предлагают различные услуги, включая кабельный и оптоволоконный интернет, мобильный интернет и домашний Wi-Fi. Также стоит ознакомиться с акциями и скидками. 3. Какое оборудование нужно для подключения интернета? Для подключения интернета вам понадобятся маршрутизаторы и модемы. Многие провайдеры предоставляют оборудование, однако у вас есть возможность использовать свои устройства. 4. Как подключить интернет? Процесс подключения интернета, как правило, занимает немного времени. Провайдеры обеспечивают техническую поддержку, которая поможет решить возникающие проблемы. 5. Как добиться стабильного соединения? Чтобы достичь стабильности соединения, важно корректно настроить ваше оборудование и выбрать тариф, который соответствует вашим требованиям. Выбор интернет-провайдера в Москве может быть сложным, но, изучив информацию на domashij-internet-msk004.ru, вы сможете легко найти подходящее предложение.
Стоимость услуг по установке капельницы определяется индивидуально и зависит от нескольких факторов. В первую очередь, цена обусловлена тяжестью состояния пациента: при более сильной интоксикации и выраженных симптомах абстинентного синдрома может потребоваться расширенная терапия. Кроме того, итоговая сумма зависит от продолжительности запоя, так как длительное употребление спиртного ведет к более серьезному накоплению токсинов, требующему дополнительных лечебных мероприятий.
Узнать больше – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod000.ru/]капельница от запоя анонимно[/url]
При остром алкогольном отравлении появляются головокружение, рвота, сильная слабость, скачки давления, нарушение дыхания, обмороки и судороги. Это сигнал о том, что организм не справляется с интоксикацией, и без срочного медицинского вмешательства возможны опасные осложнения, вплоть до комы.
Разобраться лучше – [url=https://narcolog-na-dom-novokuznetsk00.ru/]vrach-narkolog-na-dom novokuznetsk[/url]
Запой – это серьезная угроза для здоровья. Немедленно вызывайте нарколога на дом в Волгограде! Нарколог приедет к вам быстро, сохранит анонимность и подберет индивидуальное лечение. Мы быстро выведем токсины и вернем вам хорошее самочувствие. В любое время дня и ночи мы готовы приехать и начать лечение. Мы сочетаем медикаменты и психологическую поддержку для успешного лечения. Первый этап лечения – избавление от токсинов с помощью лекарств.
Подробнее тут – http://vyvod-iz-zapoya-volgograd00.ru/vyvod-iz-zapoya-na-domu-volgograd/
лечение запоя краснодар
narkolog-krasnodar004.ru
вывод из запоя
пансионаты для инвалидов в москве
pansionat-msk002.ru
пансионат для пожилых в москве
Сразу после поступления вызова специалист прибывает на дом для проведения первичного осмотра. На данном этапе нарколог:
Изучить вопрос глубже – http://narcolog-na-dom-ryazan00.ru/vrach-narkolog-na-dom-ryazan/
Нарколог измеряет пульс, артериальное давление, частоту дыхания, насыщение кислородом, а также уточняет историю употребления и наличие хронических заболеваний. Это позволяет оперативно скорректировать состав и скорость инфузии.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-voronezh2.ru/]капельница от запоя на дому воронеж[/url]
ROI Лиды Квалифицированные лиды – основа прибыльного бизнеса. Инвестируйте в инструменты для идентификации лидов с высоким потенциалом. Используйте лид-магниты, чтобы побудить потенциальных клиентов делиться своей информацией. Важно понимать разницу между холодными и теплыми лидами.
https://v-tagile.ru/obschestvo-iyul-5/kak-vybrat-idealnyj-buket-dlya-zhenshchiny-ot-povoda-do-yazyka-tsvetov
прогнозы на спорт от профессионалов точные бесплатно на сегодня [url=https://prognozy-na-sport-1.ru]https://prognozy-na-sport-1.ru[/url] .
mostbet app free download [url=www.https://mostbet-app-download-apk.com]mostbet app free download[/url] .
melbet cash out [url=melbet3002.com]melbet3002.com[/url]
В Москве представлено множество интернет-провайдеров, и выбор подходящего может быть непростой задачей. В данной статье мы рассмотрим ключевые аспекты, которые помогут вам сделать правильный выбор. domashij-internet-msk005.ru Первый, на что стоит обратить внимание, это интернет-скорость и стабильность соединения. Многие пользователи оставляют отзывы о провайдерах, подчеркивая, как важна высокая скорость для деловых задач и развлечений. Поэтому перед подключением к интернету рекомендуется ознакомиться с тарифные планы и интернет-тарифы в Москве.Уровень сервиса и техническая поддержка — еще два критически важных фактора. Провайдеры, предлагающие доступный интернет по приемлемой цене, должны также обеспечивать качественную поддержку клиентов. Сравнение провайдеров поможет вам выбрать подходящего. Рейтинг провайдеров Москвы часто включает отзывы пользователей, которые делятся своим опытом. Учитывая все эти моменты, ваш выбор станет более информированным!
Теряете контроль над алкоголем? Экстренная помощь нарколога на дому в Волгограде – это выход! Лечитесь дома! Это быстро, удобно, анонимно и эффективно. Быстрая детоксикация – первый шаг к выздоровлению! Мы работаем 24/7, чтобы вы могли получить помощь в любой ситуации. Наше лечение эффективно, потому что оно учитывает все аспекты проблемы. Сначала нужно очистить организм от алкоголя, и мы вам в этом поможем.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-volgograd00.ru/]вывод из запоя дешево волгоград[/url]
дом престарелых в москве
pansionat-msk003.ru
пансионат для реабилитации после инсульта
лечение запоя
narkolog-krasnodar005.ru
вывод из запоя круглосуточно краснодар
1win crypto ödənişlər [url=https://1win3043.com/]1win crypto ödənişlər[/url]
rexex.io Обмен криптовалюты на наличные Сочетание старых и новых технологий.
При звонке на горячую линию операторы уточняют основные параметры: возраст пациента, длительность запоя, частоту и количество употреблённого алкоголя, наличие хронических заболеваний. Это позволяет заранее подготовить необходимый набор медикаментов и оборудования.
Узнать больше – https://kapelnica-ot-zapoya-voronezh3.ru/kapelnicza-ot-zapoya-na-domu-v-voronezhe/
How far is Bahia Principe Punta Cana from the airport? The Bahia Principe resort complex, located in Punta Cana, Dominican Republic, is approximately 17-19 miles (27-30 km) from Punta Cana International Airport (PUJ), depending on the specific resort within the complex. The travel time by road is about 20-30 minutes, depending on traffic and the mode of Bahia Principe transfers.
bahia principe airport transfer
Наркологическая помощь на дому становится всё более востребованной благодаря своей доступности, конфиденциальности и эффективности. Клиника «МедТрезвость» предлагает пациентам целый ряд важных преимуществ:
Углубиться в тему – https://narcolog-na-dom-sankt-peterburg0.ru/narkolog-na-dom-czena-spb/
bonus code 1win 2024 [url=http://1win3045.com]http://1win3045.com[/url]
После поступления вашего звонка специалист оперативно выезжает по указанному адресу в Нижнем Новгороде и проводит первичную диагностику. Врач измеряет основные жизненные показатели: артериальное давление, пульс, сатурацию кислорода в крови и оценивает степень алкогольной интоксикации. Затем подбирается индивидуальный состав капельницы, который позволяет максимально быстро снять симптомы похмелья и абстиненции.
Получить больше информации – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod0.ru/]капельница от запоя на дому цена в нижний новгороде[/url]
«ВоронежДоктор» сочетает в себе профессионализм, современное оборудование и заботу о приватности пациента. Ключевые преимущества:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-voronezh2.ru/]капельница от запоя на дому цена[/url]
пансионат для пожилых после инсульта
pansionat-tula001.ru
частный дом престарелых
Запой – это не просто пьянство, а состояние, когда организм становится зависимым от алкоголя. Накопление токсинов приводит к сбоям в работе органов и ослаблению защиты организма. Самостоятельный выход из запоя может быть опасен и только усугубить состояние. Мы предлагаем лечение запоя на дому, чтобы избежать больницы и создать комфорт. Наши специалисты быстро приедут к вам и окажут всю необходимую помощь круглосуточно. Запой приводит к серьезным проблемам со здоровьем, ухудшает качество жизни и угрожает жизни. Очень важно вовремя обратиться за помощью, чтобы избежать необратимых последствий.
Подробнее тут – https://vyvod-iz-zapoya-krasnoyarsk0.ru/vyvod-iz-zapoya-czena-krasnoyarsk/
Когда организм уже не может обходиться без алкоголя, возникает запой. Вызов нарколога на дом в Волгограде – это безопасно и эффективно. Нарколог приедет на дом, проведет детоксикацию и поможет стабилизировать состояние, не нарушая привычный ритм жизни. Своевременная помощь нарколога поможет избежать осложнений, вызванных запоем. Дома нарколог поможет очистить организм и восстановить его нормальную работу. Избавление от запоя на дому – это сочетание лекарств и психологической помощи. Сначала нужно очистить организм от токсинов, и в этом помогут специальные препараты.
Выяснить больше – [url=https://vyvod-iz-zapoya-volgograd0.ru/]нарколог на дом вывод из запоя волгоград[/url]
Алкогольная зависимость — это актуальная проблема, которая требует профессиональной помощи . В Туле работают центры помощи алкоголикам , где предоставляется экстренный вывод из запоя а также лечение алкоголизма. При алкогольном отравлении необходимо быстро определить симптомы и обратиться за медицинской помощью . Профессиональные наркологи в Туле предлагают консультации, обеспечивая безопасное восстановление после запоя и лечение похмелья . Реабилитация от алкоголя включает программы реабилитации для зависимых , помогая не только пациентам , но и оказывая помощь родственникам алкоголиков. Профилактика заболеваний, связанных с алкоголем также играет важную роль в предотвращении повторных случаев зависимости.
Игнорирование состояния пациента или попытки самостоятельно справиться с запоем могут привести к опасным последствиям для жизни и здоровья. Поэтому важно своевременно обращаться за профессиональной медицинской помощью.
Получить больше информации – http://narcolog-na-dom-sankt-peterburg0.ru
Услуга
Разобраться лучше – http://kapelnica-ot-zapoya-nizhniy-novgorod000.ru
Наша клиника сочетает в себе оперативность, комфорт и высокие стандарты безопасности. Вот основные преимущества сотрудничества:
Подробнее тут – [url=https://kapelnica-ot-zapoya-voronezh3.ru/]врач на дом капельница от запоя[/url]
«Чем раньше начнётся профессиональная детоксикация, тем выше шанс избежать необратимых последствий и тяжёлых осложнений», — отмечает врач-нарколог клиники «Азимут Здоровья» Елена Степанова.
Исследовать вопрос подробнее – http://narkolog-na-dom-ramenskoe4.ru/narkolog-na-dom-ceny-v-ramenskom/
1win register [url=http://1win3047.com]1win register[/url]
домашний интернет тарифы
domashij-internet-nizhnij-novgorod004.ru
домашний интернет подключить нижний новгород
Запой – потеря контроля над алкоголем и резкое отравление организма. Лечение на дому – это быстро, конфиденциально и с индивидуальным подходом. Экстренный вывод из запоя – это быстрая детоксикация и восстановление обмена веществ. Мы выезжаем круглосуточно, чтобы оперативно оценить состояние и начать лечение. На дому мы используем лекарства и психологическую поддержку для достижения максимального эффекта. Мы сначала очистим организм от алкоголя с помощью специальных лекарств.
Подробнее – http://vyvod-iz-zapoya-volgograd00.ru/vyvod-iz-zapoya-kruglosutochno-volgograd/
При обращении в клинику «НаркоНет» пациенту предоставляется полный спектр мероприятий, направленных на восстановление организма после запоя. Сначала наш специалист приезжает на дом в течение 30–60 минут после вызова. На месте проводится детальный осмотр: измеряются основные жизненные показатели (давление, пульс, уровень кислорода в крови), собирается подробный анамнез и оценивается степень интоксикации. Полученные данные позволяют врачу разработать индивидуальный план лечения.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod000.ru/]вызвать капельницу от запоя на дому[/url]
обменник криптовалюты Обмен криптовалюты bestchange Обмен криптовалюты через BestChange – это возможность выбрать наиболее выгодный курс из множества обменников. Мониторинговый сервис, который помогает экономить время и деньги.
пансионат для пожилых с деменцией
pansionat-tula002.ru
пансионат для престарелых
Planning a vacation to the stunning Cap Cana in the Dominican Republic? Whether you’re staying at the luxurious Hyatt Zilara, the family-friendly Hyatt Ziva, the all-inclusive Secrets Cap Cana, or the exclusive Sanctuary Cap Cana, getting from Punta Cana International Airport to your resort should be the least of your worries. In this comprehensive guide, we’ll cover everything you need to know about transfers of Cap Cana from airport and transportation options from Cap Cana to Punta Cana Airport to ensure a seamless and stress-free start to your vacation.
sanctuary cap cana transportation from airport
Клиника «ВоронежМед» обеспечивает выезд нарколога на дом в любое время суток, включая праздники и выходные. Анонимность достигается за счёт минимального контакта с персоналом клиники и отсутствия бумажной волокиты. Все этапы лечения согласовываются только с пациентом или доверенным лицом, а сведения о визите не передаются третьим лицам.
Выяснить больше – https://kapelnica-ot-zapoya-voronezh.ru/vyezd-na-dom-kapelnicza-ot-zapoya-v-voronezhe/
прогнозы на футбол сегодня [url=www.prognozy-na-futbol-1.ru]www.prognozy-na-futbol-1.ru[/url] .
прогнозы на спорт с гарантией бесплатно [url=https://prognozy-na-sport-2.ru/]prognozy-na-sport-2.ru[/url] .
прогнозы на спорт [url=http://prognozy-na-sport-3.ru/]прогнозы на спорт[/url] .
ставки на футбол сегодня 100 процентный [url=http://prognozy-na-futbol-2.ru/]ставки на футбол сегодня 100 процентный[/url] .
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Как достичь результата? – https://rikbeuselinck.be/2020/09/28/reportage
Капельница от запоя в Туле – это существенная медицинская услуга при алкоголизме, которая помогает детоксикации организма. Вызов нарколога на дом предоставляет экстренную помощь при запое в удобной обстановке. Компоненты капельницы включают вещества, которые помогают восстановлению организма: раствор для инфузий, минералы и препараты для капельницы. Действие капельницы ориентировано на снижение симптомов абстиненции и стабилизацию состояния пациента. Лечение алкоголизма требует всеобъемлющего подхода, включая реабилитацию после запоя. Цены на услугу нарколога различаются, но консультация специалиста будет важной для эффективного лечения.
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Что ещё? Расскажи всё! – https://topic.lk/12318
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Обратитесь за информацией – https://archiv.augsburg-international.de/die-fundamentalistische-herausforderung-der-islam-und-die-weltpolitik
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Смотри, что ещё есть – https://jiffycleaner.com/hello-world
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Это стоит прочитать полностью – https://douglasjfisher.com/slot-deposit-5rb
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Обратитесь за информацией – https://public-voice.in/archives/8022
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Почему это важно? – https://fundacionboreal.org.ar/realizamos-un-taller-para-los-colaboradores-de-la-filial-santiago-del-estero
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Все материалы собраны здесь – https://www.interieurstickers.be/portfolio-featured-item
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Лови подробности – https://lajmeaktuale.info/kemi-nje-vit-qe-provojme-por-nuk-po-mundemi-te-behemi-prinder-banori-i-big-brother-tregon-pengun-e-tij
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Все материалы собраны здесь – https://crthailand.com/en/promotions/reinterprets-the-classic-bookshelf
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Углубить понимание вопроса – http://www.aacaninecountryclub.com
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Смотри, что ещё есть – https://android-superstar.ru
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Открыть полностью – http://themesdle.ru
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Погрузиться в детали – https://husanov.com/rachel-featured-as-one-of-times-women/attachment/08
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Погрузиться в детали – https://www.ilquadernoedizioni.it/la-costituzione-siamo-noi-nuovo-arriva-de-il-quaderno-edizioni
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Доступ к полной версии – https://topic.lk/11542
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Как достичь результата? – https://axelzamudio.com/podcast/episode/como-se-vive-el-cancer-de-mama
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Более того — здесь – https://www.menschtierumwelt.com/mtu_unser-neues-domizil-01
casino 1 win [url=http://1win3048.com]casino 1 win[/url]
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Расширить кругозор по теме – https://babi-beauty.fr/signature-styles-the-best-haircuts-at-our-barber-shop
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Обратитесь за информацией – https://www.nidmi.co.jp/emplo/2018%E5%B9%B4%E5%BA%A6-%E6%96%B0%E5%8D%92%E6%8E%A1%E7%94%A8%E3%82%92%E9%96%8B%E5%A7%8B%E3%81%97%E3%81%BE%E3%81%97%E3%81%9F%E3%80%82
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Обратитесь за информацией – https://sedata.co.id/cara-mudah-memainkan-bitcoin-bagi-pemula-anti-rugi
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Неизвестные факты о… – https://tuchicamusical.com/max-lucado-se-unira-a-la-iglesia-gateway-como-pastor-tras-renuncia-del-hijo-del-fundador-robert-morris
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Получить полную информацию – https://phelionline.co.za/_sb_country/macedonia-fyrom
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Открыть полностью – https://nextdunyasi.com/?attachment_id=4966
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Углубиться в тему – https://advr.fr/2023/11/13/hommage-a-robert-chambeiron-2
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Узнай первым! – https://phelionline.co.za/_sb_country/dominica
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Не упусти важное! – https://www.elevationwealth.co.za/how-well-are-you-doing-in-terms-of-life-experience-points
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Расширить кругозор по теме – https://www.familyandpeople.mn/%D1%8D%D1%86%D1%8D%D0%B3-%D1%8D%D1%85%D1%87%D2%AF%D2%AF%D0%B4%D1%8D%D1%8D-%D1%85%D2%AF%D2%AF%D1%85%D1%8D%D0%B4%D1%8D%D1%8D-%D0%B3%D0%B0%D1%80-%D1%83%D1%82%D0%B0%D1%81-%D0%BA%D0%BE%D0%BC%D0%BF%D1%8C
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Расширить кругозор по теме – https://dgppcongo.com/2024/06/08/bonjour-tout-le-monde
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Выяснить больше – https://www.jra.org.za/?attachment_id=5189
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Узнай первым! – http://rjmusic.ru
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Открыть полностью – http://vllmn.com/fortheque
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Изучить аспект более тщательно – https://papanizza.fr/zhizn-otca-v-ehmigracii-vospitanie-detej
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Подробная информация доступна по запросу – https://www.ingereilersen.com/2023/06/22/testimonials
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Изучить аспект более тщательно – https://sb152.ru/16-2/videoregistratory/ip-videoregistratory/vesta-vnvr-6508
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Получить полную информацию – https://nyxandaither.de/2019/10/12/atomic
букмекерская компания мелбет [url=www.melbet3005.com]www.melbet3005.com[/url]
подключение интернета по адресу
domashij-internet-nizhnij-novgorod005.ru
провайдеры интернета в нижнем новгороде по адресу
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Доступ к полной версии – https://markus-hennemann.de/?attachment_id=123
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Все материалы собраны здесь – http://stpe.co.za/audio-safety-measures-in-an-apartment
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Изучить аспект более тщательно – https://gotshi.com/conference-for-new-solutions
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Практические советы ждут тебя – https://ippos.ru
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Выяснить больше – http://kumkvat-frukt.ru
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Смотрите также – http://www.onlinepokies.com.au/big-chef-wild
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Ознакомиться с полной информацией – https://bergmannarchitekt.de/ru/mt-sample-background
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Выяснить больше – https://www.edmdjbookings.com/edmdjbookings-com-faceomslag
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Изучить вопрос глубже – https://analytische-psychotherapie.com/freigestellt_gruen__8-102948804_m
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Смотрите также… – https://www.wuoz.malopolska.pl/cropped-wuoz_logo-1-jpg
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Ознакомьтесь с аналитикой – https://bergmannarchitekt.de/mt-sample-background
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Только для своих – https://resa.store/%D1%83%D1%81%D0%BB%D0%BE%D0%B2%D0%B8%D1%8F-%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F-%D0%B1%D0%B5%D0%B7%D0%B4%D0%B5%D0%BF%D0%BE%D0%B7%D0%B8%D1%82%D0%BD%D1%8B%D1%85
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Более того — здесь – https://internacao.com/clinica_de_recuperacao_gratuita
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Ознакомиться с полной информацией – https://www.uel.br/lhispb/32154-2
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Осуществить глубокий анализ – https://skarduherbs.com/hello-world-2
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Практические советы ждут тебя – https://easylayout.nandus.com.br/2024/07/01/ola-mundo
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Читать дальше – http://ero-rasskazy.ru
пансионат для лежачих больных
pansionat-tula003.ru
дом престарелых в туле
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Обратитесь за информацией – https://topic.lk/11342
mostbet lapplication [url=gunfight.io]mostbet lapplication[/url] .
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Узнай первым! – https://metropembaharuancq.com/2020/11/teriakan-lanjutkan-menggema-kampanye-nomor-urut-3-di-sape-utara-kabupaten-bima
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Ознакомиться с деталями – https://simplamo.com/quarterly-okrs-template
telecharger 888starz [url=http://www.betbro.icu]telecharger 888starz[/url] .
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Ознакомиться с полной информацией – https://zarabotaideneg.ru
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Погрузиться в детали – https://hairclone.me/clinical-network/attachment/dr-marco-barusco-square
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Ознакомиться с деталями – http://scidays.ru
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Узнай первым! – http://scidays.ru
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Получить полную информацию – http://www.riskinv.ru
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Узнать напрямую – http://www.admicove.com/inspeccion-tecnica-de-edificios-ite-madrid
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Изучить аспект более тщательно – https://www.anneybema.nl/logo-anne-2018-2
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Выяснить больше – https://shou-balet.ru
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Неизвестные факты о… – https://kaiteki-seikatu.co.jp/blog/?p=44
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Изучить аспект более тщательно – https://winter-ing.de/2016/01/24/test
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Открыть полностью – http://isographoteka.ru
Лечение запоя на дому с помощью капельницы – оптимальный способ для избавления от зависимости. Вызов нарколога в Туле дает возможность получить квалифицированную помощь при алкоголизме без необходимости покидать дом. Часто уговорить зависимого на лечение родственникам бывает непросто, но необходимо учитывать значении психологической поддержки и профессиональной помощи нарколога; вызов нарколога тула Первый этап включает детоксикацию организма, что помогает организму восстановиться после запойного состояния. Услуги нарколога предоставляют капельницы, которые помогают облегчить симптомы. Профилактика запойного состояния имеет огромное значение для избежания рецидивов. Нарколог на дому проводит психотерапевтические занятия для зависимых, что способствует эффективному лечению зависимости. Помните, что помощь при алкоголизме доступна, и лечение алкоголизма на дому – это реальный шанс для многих людей.
домашний интернет
domashij-internet-nizhnij-novgorod006.ru
интернет по адресу дома
экстренный вывод из запоя
[url=https://vivod-iz-zapoya-chelyabinsk001.ru]https://vivod-iz-zapoya-chelyabinsk001.ru[/url]
вывод из запоя круглосуточно
прогнозы на хоккей сегодня [url=www.prognozy-na-khokkej-segodnya.ru]www.prognozy-na-khokkej-segodnya.ru[/url] .
Sweet Bonanza giris adresi en guncel baglant?yla burada
https://gidro-vanna-dush.ru
Dragon money В Драгон мани существует множество фракций, каждая из которых стремится контролировать уникальные ресурсы и артефакты. Эти фракции могут быть как союзниками, так и врагами. Умение налаживать связи и выбирать правильные стратегии становится залогом успеха. Каждое взаимодействие с другими игроками обогащает опыт и открывает новые горизонты, заказывая не только материальные ценности, но и внутриигровую репутацию.
Миссия нашей клиники заключается в оказании высококачественной помощи людям, страдающим от зависимостей. Мы стремимся создать безопасное и поддерживающее пространство для лечения, где каждый пациент получает необходимую поддержку и понимание. Наша задача — не только помочь избавиться от зависимости, но и вернуть полноценную жизнедеятельность человека, восстановив его социальные связи и жизненные ориентиры.
Выяснить больше – [url=https://kapelnica-ot-zapoya-irkutsk2.ru/]после капельницы от запоя иркутск[/url]
Лечение алкогольной интоксикации в Туле: услуги нарколога Алкогольная интоксикация — это тяжелое состояние, которое требует скорой медицинской помощи. В медицинском центре Тула доступны услуги по лечению алкоголизма, включая детоксикацию и реабилитацию после запоя. Процедуры капельниц помогают очищать организм от токсинов, облегчая симптомы алкогольной интоксикации. Консультация с наркологом обеспечивает персонализированный подход к лечению. При алкогольной интоксикации важно знать симптомы: головная боль, тошнота, слабость. Квалифицированная помощь нарколога включает в себя детоксикацию, а также психотерапию для борьбы с алкоголизмом. Реабилитация алкоголиков требует комплексного подхода, а профилактика запоев помогает избежать рецидивов. В Туле доступна качественная медицинская помощь, позволяющая восстановить здоровье и вернуться к нормальной жизни.
Нельзя игнорировать первые признаки серьёзного алкогольного отравления: промедление повышает риск судорожных припадков, остановки дыхания и комы. Нарколог на дом в Реутове рекомендован при следующих симптомах:
Подробнее тут – http://vyvod-iz-zapoya-reutov4.ru/anonimnyj-vyvod-iz-zapoya-v-reutove/
После процедуры пациент и его близкие получают развернутые рекомендации по дальнейшему восстановлению, советы по профилактике рецидивов и возможности прохождения кодирования при желании пациента.
Углубиться в тему – https://narcolog-na-dom-sankt-peterburg000.ru/narkolog-na-dom-czena-spb/
Цена капельницы от запоя в Иркутске зависит от ряда факторов, таких как выбор метода лечения (на дому или в стационаре), продолжительность лечения и степень тяжести состояния пациента. Для уточнения стоимости и записи на консультацию вы можете обратиться к нашим менеджерам, которые подробно расскажут о стоимости услуг и ответят на все ваши вопросы.
Разобраться лучше – https://kapelnica-ot-zapoya-irkutsk3.ru
В столице России поставщики интернет-услуг предлагают широкий выбор услуг связи, однако при определении необходимо обращать внимание на юридические аспекты. Все клиенты подписывает интернет-договор или соглашение с провайдером, который регулирует права потребителей. В соответствии с законодательством в области связи, провайдеры должны иметь лицензию на связь, что это гарантирует законность их работы. domashij-internet-novosibirsk004.ru При выборе провайдера обратите внимание на качество обслуживания и скорость интернета. Пользовательское соглашение должно иметь четкие условия подключения и тарифные планы. Также стоит обратить внимание на защиту данных и обязанности провайдера в случае возникновения проблем. Не забывайте, что ваши права как потребителя защищены, и в случае нарушений вы можете обратиться за юридическими услугами.
https://remdostavka.ru
Jogo do Tigrinho com bonus exclusivos para o publico brasileiro
При запое важна каждая минута! Круглосуточный вызов нарколога в Волгоградской области – решение проблемы! Обращайтесь к нам в любое время суток, и мы вам поможем! Мы обеспечиваем оперативное вмешательство, индивидуальный подход и высокий уровень безопасности. Мы – это оперативная и надежная помощь в трудную минуту. Мы обеспечим детоксикацию и стабилизацию вашего состояния, где вам будет удобно. Первый шаг – диагностика, чтобы определить план лечения.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-volgograd000.ru/]вывод из запоя дешево волгоград[/url]
стеклянные ограждения Раздвижные стеклянные перегородки представляют собой гибкое решение для многофункциональных пространств. Они позволяют быстро менять конфигурацию комнаты, что особенно актуально для офисов, где необходимо адаптироваться к разным рабочим процессам. Такие перегородки оснащаются специальными механизмами, позволяющими легко открывать и закрывать их, что делает их исключительным выбором для динамичного рабочего окружения. Визуально они добавляют легкости и стиля, гармонично вписываясь в общий интерьер. Стеклянные ограждения
вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk002.ru
вывод из запоя
прогнозы на хоккей на сегодня [url=www.prognozy-na-khokkej-segodnya1.ru]прогнозы на хоккей на сегодня[/url] .
Актуальные тренды сегодня тренды в моде: фото, видео и медиа. Всё о том, что популярно сегодня — в России и в мире. Мода, визуальные стили, digital-направления и соцсети. Следите за трендами и оставайтесь в курсе главных новинок каждого дня.
как пополнить счет на melbet [url=https://www.melbet3003.com]https://www.melbet3003.com[/url]
Капельница от запоя на дому для пожилых людей в Туле — это необходимая мера медицинской помощи. Нарколог на дом круглосуточно обеспечивает детоксикацию организма на дому, что особенно актуально для пожилых. Симптомы запоя, такие как тревожность и слабость, требуют немедленного вмешательства. Лечение алкоголизма предполагает применение капельниц, которые способствуют восстановлению водно-электролитного баланса. Однако важно помнить о рисках капельницы: риск аллергических реакций и осложнений из-за неправильного введения. Поэтому безопасность должна оставаться главным приоритетом. Услуги медицинской помощи на дому обеспечивает комфорт без необходимости транспортировки больного. Забота о пожилых людях нуждается в особом внимании, и круглосуточные услуги нарколога гарантируют необходимую поддержку. Рекомендуется придерживаться рекомендаций врачей для эффективного восстановления после запоя.
Мобильный интернет в новосибирске: анализ операторов В новосибирске доступно множество операторов мобильной связи, предлагающих различные тарифы на интернет для телефонов. На сайте domashij-internet-novosibirsk005.ru вы можете изучить предложения, включая 4G и 5G сети. Скорость передачи данных зависит от покрытия сети, которое различается у различных операторов. При определении тарифа стоит обратить внимание на отзывы пользователей, цену услуг и возможности, например, тарифы без лимитов. Удобно, что многие операторы предлагают мобильные приложения для управления подключением к интернету. Также значим роуминг в новосибирске, особенно для туристов. Служба поддержки операторов может помочь решить проблемы с подключением. Анализ операторов способствует выбрать лучший тариф для индивидуальных нужд.
Драгон мани Dragon money привлекает игроков разного возраста и профессий. Это место, где можно проявить свои лидерские качества, развить стратегическое мышление и найти новых друзей.
Нужен буст в игре? купить оружие dune awakening легендарная броня, костюмы, скины и уникальные предметы. Всё для выживания на Арракисе!
вывод из запоя круглосуточно
vivod-iz-zapoya-chelyabinsk003.ru
вывод из запоя цена
https://xplus-master.ru
Когда организм на пределе, важна срочная помощь в Люберцах — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
[url=https://kapelnica-ot-zapoya-lyubercy12.ru/]капельница от запоя наркология люберцы[/url] – [url=https://kapelnica-ot-zapoya-lyubercy12.ru/]капельница от запоя на дому в люберцах[/url]
В условиях, когда алкогольная зависимость угрожает жизни, оперативное вмешательство становится ключевым фактором для сохранения здоровья. В Рязани круглосуточная помощь нарколога на дому позволяет начать комплексное лечение запоя и алкогольной интоксикации в самые критические моменты. Такая услуга обеспечивает детоксикацию организма, стабилизацию жизненно важных показателей и психологическую поддержку, что способствует скорейшему восстановлению в комфортной обстановке, без необходимости посещения стационара.
Получить дополнительные сведения – [url=https://narcolog-na-dom-ryazan0.ru/]вызов врача нарколога на дом рязань[/url]
стеклянные ограждения Стеклянные перегородки
Лечение зависимостей – это критически важная область медицины‚ направленная на борьбу с зависимостями. Если вы или ваши близкие сталкиваетесь проблемы наркомании‚ необходимо знать о возможностях анонимного лечения. Медицинские центры, такие как narkolog-tula006.ru‚ обеспечивают помощь нарколога и всестороннюю поддержку для зависимых. Группы самопомощи и программы восстановления содействуют людям на пути к выздоровлению. Психологическая помощь при зависимости имеет ключевую роль в восстановлении наркозависимых. Также значима профилактика наркомании и экстренная поддержка. Не откладывайте обращаться за помощью — вы можете вернуться к нормальной жизни!
punta cana airport transportation – Punta Cana airport offers multiple transportation options for travelers. Choose from convenient shuttles, reliable taxis, or private car rentals. Shuttle options offer budget-friendly shared rides to accommodations. Taxis offer door-to-door service with fixed rates. Car rentals give you freedom to explore the Dominican Republic at your own pace.
В современном мире связь такие как интернет и телевидение являются неотъемлемой частью нашей жизни. Однако как снизить расходы на эти услуги в новосибирске? В этом материале мы предложим ряд рекомендаций по экономии, акционные предложения и тарифы на интернет. Первым шагом к снижению затрат станет анализ тарифов провайдеров новосибирска. На сайте domashij-internet-novosibirsk006.ru вы можете найти последние данные о пакетных предложениях, которые объединяют интернет и телевидение. Это позволяет значительно уменьшить расходы, так как многие провайдеры предлагают скидки на ТВ при подключении домашнего интернета. Также стоит учесть на альтернативные провайдеры. Иногда они могут предложить более привлекательные тарифы и цены на телевидение. Не забудьте про акционные предложения и временные предложения, которые могут помочь вам получить бесплатный доступ к интернету или значительно снизить стоимость услуг. Важно помнить о том, что подбор провайдера должен опираться не только на цену, но и на качество предоставляемых услуг. Читайте отзывы, смотрите рейтинги и обязательно проясняйте все детали перед подписанием договора. Следуя этим советам, можно добиться значительной экономии на интернете и телевидении в новосибирске, не уступая качеством связи.
вывод из запоя
vivod-iz-zapoya-cherepovec004.ru
вывод из запоя цена
оценка часов по фото бесплатно [url=http://www.ocenka-chasov-onlajn9.ru]http://www.ocenka-chasov-onlajn9.ru[/url] .
mostbet bitcoin bilan to‘lov [url=www.mostbet4073.ru]www.mostbet4073.ru[/url]
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Лучшее решение — прямо здесь – https://www.hobsonconstruction.co.nz/services/4-6
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Изучить вопрос глубже – http://www.komsmama.ru
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Провести детальное исследование – http://vpracing.ru
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Расширить кругозор по теме – https://sociomantic.ru
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Секреты успеха внутри – http://cgmath.ru
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Заходи — там интересно – https://amore-bello.ru
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Почему это важно? – https://alimentacionunani.com/index.php/2021/05/14/beneficios-del-suero-casero-y-como-prepararlo-guia-completa
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Получить исчерпывающие сведения – https://amazingbeatboxers.com/2012/11/%E6%83%B3%E4%BD%A0-beyond-robynn-and-kendy-ft-rx%E9%BB%83%E6%B5%A9%E9%82%A6
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Узнать напрямую – https://rona34.ru
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Не упусти важное! – https://enh.tw/%E4%BA%8C%E6%AC%A1%E9%9A%86%E4%B9%B3-%E6%A1%88%E4%BE%8B%E4%BA%8C
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Все материалы собраны здесь – https://www.sceavalbrechtice.cz/2022/02/01/modlitebni-setkani-kazdou-stredu-od-530
https://kam-unity.ru
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Что ещё? Расскажи всё! – http://www.viktorfrankl.ru
стеклянные перегородки Стеклянные ограждения — это идеальный элемент безопасности и стиля для открытых пространств, таких как балконы и лестницы. Они позволяют наслаждаться панорамными видами, в то время как прочные материалы обеспечивают надежность и долговечность. Благодаря разнообразию отделки и шлифовки, стеклянные ограждения могут стать настоящим произведением искусства, украшающим ваше пространство. Офисные перегородки
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Почему это важно? – https://radiation-net.ru
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Изучить аспект более тщательно – https://persianrenaissance.org/picture
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Обратитесь за информацией – https://orkneycaravanpark.co.uk/player
вывод из запоя круглосуточно
vivod-iz-zapoya-cherepovec005.ru
вывод из запоя круглосуточно череповец
Discover rafting rafting – the perfect holiday for nature lovers and extreme sports enthusiasts. The UNESCO-listed Tara Canyon will amaze you with its beauty and energy.
mostbet aplicacao para android [url=mostbet-download-app-apk.com]mostbet aplicacao para android[/url] .
Прогулка по Москве и не только – Буду выкладывать свою жизнь, где ел и что и вкусно ли это, какие места увидел новые и свои взгляды на мир и хорошую музыку https://t.me/armanmoscow
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Изучить вопрос глубже – https://www.abcmix.com/home-sign-decorative-elevate-your-living-space
провайдеры омск
domashij-internet-omsk004.ru
интернет провайдер омск
Когда возникают проблемы с зависимостямиобращение к наркологу становится важным шагом. Сайт narkolog-tula007.ru готов предложить вам высококлассную помощь в лечении зависимостей. Симптомы зависимости могут быть разнообразными, так что важно уметь их распознавать. Консультация специалиста необходима для выбора подходящего лечения алкоголизма или наркозависимости. Центр реабилитации предлагает конфиденциальную помощь и поддержку для близких. Лечение наркомании включает этапы восстановления после зависимости, что является неотъемлемой частью процесса возвращения к здоровой жизни. Не стоит откладывать обращение к наркологу, так как это может оказаться жизненно важным шагом.
https://domsibiri.ru
Выездной формат позволяет избежать контактов с другими пациентами в клинике и очистить организм в привычной обстановке. Специалисты самостоятельно привозят весь необходимый набор медикаментов и расходных материалов.
Ознакомиться с деталями – http://narkologicheskaya-klinika-ekaterinburg0.ru
Гидроизоляция зданий https://gidrokva.ru и сооружений любой сложности. Фундаменты, подвалы, крыши, стены, инженерные конструкции.
Пациенту устанавливают катетер в вену на руке или предплечье, используя лёгкий местный анестетик для минимизации дискомфорта. Затем подключают автоматизированную помпу, обеспечивающую равномерную подачу раствора в течение 3–6 часов.
Узнать больше – [url=https://kapelnica-ot-zapoya-voronezh2.ru/]kapelnica-ot-zapoya-voronezh2.ru/[/url]
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Следуйте по ссылке – http://wishmatrix.ru
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Обратитесь за информацией – https://globalcolor.cl/reinterprets-the-classic-bookshelf
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Подробнее тут – https://www.conductionheating.co.uk/protect-the-environment
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Изучить вопрос глубже – https://climania.fr/?attachment_id=432
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Переходите по ссылке ниже – https://d1trip.com/index.php/2022/07/01/introducing-this-amazing-tour
Подшипник цена Завод изготовитель подшипников Покупка подшипников напрямую с завода – это гарантия качества и лучшей цены.
вывод из запоя цена
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя
голодание Голодание при диабете: Контроль уровня сахара в крови
Play and win with Grandpashabet – this is the official Instagram page
домашний интернет
domashij-internet-omsk005.ru
провайдеры омск
Официальный Telegram канал Live Сasinо. Кaзинo и ставки от лучших площадок. Доступны актуальные зеркала официальных сайтов. Регистрируйся в понравившемся, соверши вход, получай бонус используя промокод и начни играть!
https://t.me/s/iGaming_live/1920
melbet for ios [url=https://www.melbet3007.com]https://www.melbet3007.com[/url]
пансионат для пожилых после инсульта
pansionat-msk001.ru
пансионат после инсульта
Игроки часто ищут vavada рабочее зеркало, и не зря — именно такие платформы обеспечивают честную игру и качественный сервис. Если вас интересует vavada рабочее зеркало, рекомендуем заглянуть сюда: vavada рабочее зеркало. Вы узнаете о бонусах, мобильной версии, рабочих зеркалах и многом другом. Проверяйте сами — vavada рабочее зеркало может приятно удивить!
Заказать дипломную работу http://diplomikon.ru недорого и без стресса. Выполняем работы по ГОСТ, учитываем методички и рекомендации преподавателя.
Гидроизоляция зданий https://gidrokva.ru и сооружений любой сложности. Фундаменты, подвалы, крыши, стены, инженерные конструкции.
Незамедлительно после вызова нарколог прибывает на дом для проведения тщательного осмотра. На данном этапе специалист собирает анамнез, измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и оценивает степень интоксикации. Эти данные являются основой для составления индивидуального плана лечения.
Разобраться лучше – https://vyvod-iz-zapoya-vladimir000.ru/vyvod-iz-zapoya-anonimno-vladimir/
Система взаимоподдержки позволяет быстро реагировать на риск рецидива и мотивирует пациента продолжать путь к трезвости даже в моменты слабости.
Ознакомиться с деталями – [url=https://lechenie-alkogolizma-sochi0.ru/]клиника лечения алкоголизма сочи[/url]
лечение запоя
vivod-iz-zapoya-irkutsk001.ru
вывод из запоя круглосуточно иркутск
https://santehmen.ru
Столица в ночь не дремлет, и мы аналогично: закрытая центр лечения алкоголизма клиника https://mcnl.ru/ открыта 24/7. Без очередей и документов — вызов врача к вам за менее 45 минут, безопасный детокс в сне, сверхскоростная капельница, психологическая поддержка на дому, долговечное сопровождение. Без шума, анонимно, точно — вернем трезвость без боли.
пансионат для лежачих москва
pansionat-msk002.ru
пансионат с медицинским уходом
Гидроизоляция зданий https://gidrokva.ru и сооружений любой сложности. Фундаменты, подвалы, крыши, стены, инженерные конструкции.
Во-первых, мы фокусируемся на медицинской детоксикации, которая является первоочередной задачей при лечении зависимостей. Этот процесс позволяет удалить токсические вещества из организма и улучшить общее состояние пациента. Мы применяем современные методики, которые помогают минимизировать симптомы абстиненции и обеспечить комфортное пребывание в клинике.
Узнать больше – [url=https://kapelnica-ot-zapoya-irkutsk.ru/]www.domen.ru[/url]
После первичного осмотра начинается активная фаза детоксикации. Современные препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови и восстановления обменных процессов. Этот этап критически важен для нормализации работы печени, почек и сердечно-сосудистой системы.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-vladimir000.ru/]вывод из запоя на дому владимир цены[/url]
melbet главный сайт [url=www.melbet3004.com]www.melbet3004.com[/url]
Специалист выясняет, как долго продолжается запой, какие симптомы наблюдаются, а также наличие сопутствующих заболеваний. Эти данные позволяют сформировать индивидуальный план лечения и выбрать оптимальные методы детоксикации.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-vladimir0.ru/]вывод из запоя на дому владимир цены[/url]
Мегаполис в ночь не спит, и мы аналогично: эксклюзивная наркологическая клиника https://mcnl.ru/ открыта 24/7. Без предварительной регистрации и формальностей — приезд специалиста на дом за 39 минут, мягкий детокс под седацией, ультрабыстрая капельница, психологическая поддержка у вас, долговечное сопровождение. Тихо, конфиденциально, точно — вернем трезвость без страданий.
Производство шариковых подшипников Поставщики подшипников в РФ – это компании, занимающиеся поставкой подшипников различных типов и размеров на российский рынок. Важно выбрать надежного поставщика, предлагающего широкий ассортимент, конкурентные цены и гарантию качества.
вывод из запоя
vivod-iz-zapoya-irkutsk002.ru
экстренный вывод из запоя иркутск
Для начала комплексного лечения в наркологической клинике в Краснодаре проводится тщательная диагностика состояния пациента. Врач-нарколог назначает необходимые лабораторные и инструментальные исследования, среди которых общий анализ крови, биохимический анализ, ЭКГ, УЗИ внутренних органов, а также психодиагностические тесты. Такой комплексный подход позволяет выявить сопутствующие заболевания и оценить степень зависимости, что важно для выбора оптимальной терапии.
Узнать больше – https://narkologicheskaya-klinika-krasnodar0.ru/narkologicheskaya-klinika-anonimno-krasnodar
лечебное голодание Важно соблюдать правильный режим голодания и постепенно возвращаться к обычному питанию после его завершения.
пансионат с медицинским уходом
pansionat-msk003.ru
пансионат инсульт реабилитация
В нашей клинике используются только эффективные и безопасные препараты, что гарантирует вам быстрое восстановление и минимальные риски.
Детальнее – [url=https://kapelnica-ot-zapoya-irkutsk3.ru/]капельница от запоя цена иркутск.[/url]
подобрать подшипник по размерам онлайн Подшипники для судостроения Подшипники для судостроения должны быть устойчивыми к коррозии и воздействию морской воды.
mostbet qeydiyyat linki [url=https://mostbet4055.ru/]mostbet qeydiyyat linki[/url]
лечение запоя
vivod-iz-zapoya-irkutsk003.ru
экстренный вывод из запоя
https://clubdom52.ru
Отправьтесь в морское путешествие по Сочи с комфортом и отличным настроением — аренда яхты легко бронируется заранее или на месте https://yachtkater.ru/
доставка воды на дачу цистерна цена [url=http://dostavka-tehnicheskoi-vodi.ru]http://dostavka-tehnicheskoi-vodi.ru[/url] .
оценка скупка часов [url=www.ocenka-chasov-onlajn10.ru/]www.ocenka-chasov-onlajn10.ru/[/url] .
изготовление лестниц из металла на заказ [url=https://lestnicy-na-metallokarkase-1.ru/]lestnicy-na-metallokarkase-1.ru[/url] .
Подшипники от производителей Шариковый подшипник Шариковые подшипники – наиболее распространенный тип подшипников, отличающийся универсальностью и простотой конструкции.
https://uraldo.ru
Профессиональный ремонт https://remontr99.ru квартир в Москве и области. Качественная отделка, электрика, сантехника, дизайн и черновые работы. Работаем под ключ, строго по срокам, с гарантией.
система выравнивания плитки https://svp-master.ru для быстрой и ровной укладки керамики и керамогранита. Удобный монтаж без перекосов и перепадов.
пансионат для людей с деменцией в туле
pansionat-tula001.ru
пансионат для лежачих пожилых
Миссия клиники “Обновление” заключается в предоставлении качественной и всесторонней помощи людям, страдающим от различных форм зависимости. Мы понимаем, что успешное лечение невозможно без индивидуального подхода, поэтому каждый пациент проходит детальную диагностику, после которой разрабатывается персонализированный план терапии. В процессе работы мы акцентируем внимание на следующих аспектах:
Исследовать вопрос подробнее – http://
Портал о мебели https://mebelnaystrana.ru всё о дизайне, материалах, брендах и трендах. Новости индустрии, советы по выбору, идеи интерьеров, обзоры и инструкции.
Алкогольная зависимость — это комплексное заболевание, требующее не только медикаментозного воздействия, но и серьёзной психологической поддержки. В Сочи клиника «ЮгМед» предлагает выезд нарколога на дом, что позволяет начать лечение без стресса, связанного с госпитализацией. Такой подход особенно важен для тех, кто ценит конфиденциальность и предпочитает комфорт привычной обстановки. Мы обеспечиваем полную анонимность, а опытные специалисты разрабатывают индивидуальную программу, учитывающую длительность запоя, сопутствующие заболевания и психологические факторы зависимости.
Изучить вопрос глубже – [url=https://lechenie-alkogolizma-sochi0.ru/]лечение алкоголизма сочи[/url]
На основе полученных диагностических данных врач подбирает оптимальные препараты и дозировки, разрабатывая персональный план лечебных мероприятий.
Получить дополнительную информацию – http://
Свежие новости 24/7 https://sarafanradio-kursk.ru всё, что важно знать сегодня. Политика, общество, деньги, война, наука, шоу-бизнес. Лента новостей обновляется круглосуточно.
Ремонт окон под ключ https://remont-okon.su регулировка, замена механизмов, утепление, антимоскитные сетки, устранение конденсата.
вывод из запоя цена
vivod-iz-zapoya-kaluga004.ru
экстренный вывод из запоя калуга
1win գրանցում [url=https://1win3072.ru/]https://1win3072.ru/[/url]
סשה, הוא כבר היה קשה, הוא נישק אותי על השפתיים, זה היה ההיקי הכי נלהב בחיי, הוא השתמש בלשון כל כך שזורה בשלי. גופנו התקרב כל כך עד שהרגשתי את חום עורו ואת ריח האלכוהול הקל בנשימתו. התקדמנו לאט, hop over to this web-site
Наркологическая клиника в Екатеринбурге занимается широким спектром услуг, включающих как экстренную помощь, так и длительную реабилитацию пациентов с зависимостью. Ключевыми направлениями являются:
Детальнее – http://narcologicheskaya-klinika-ekaterinburg00.ru/narkologicheskaya-klinika-telefon-v-ekaterinburge/https://narcologicheskaya-klinika-ekaterinburg00.ru
изготовление лестниц из металла на заказ [url=https://lestnicy-na-metallokarkase-2.ru/]lestnicy-na-metallokarkase-2.ru[/url] .
металлические лестницы под заказ [url=http://lestnicy-na-metallokarkase-3.ru]http://lestnicy-na-metallokarkase-3.ru[/url] .
«СочиМед» предлагает комплексный подход: диагностика, детоксикация, терапия сопутствующих состояний, психологическая и социальная поддержка. В стационаре доступны:
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-sochi00.ru/]наркологическая клиника сочи[/url]
Насладитесь тишиной и покоем во время прогулки на арендованной яхте в Адлере https://yachtkater.ru/
Алкоголизм является хроническим заболеванием, требующим комплексного и профессионального подхода к лечению. Лечение алкоголизма в Сочи направлено на полное восстановление физического и психоэмоционального состояния пациента с помощью современных медицинских технологий и индивидуально подобранных программ терапии.
Выяснить больше – [url=https://lechenie-alkogolizma-sochi00.ru/]лечение алкоголизма цена[/url]
mosbet [url=mostbet4072.ru]mosbet[/url]
Формирование цены на вызов нарколога с проведением капельничного вывода из запоя зависит от нескольких ключевых параметров:
Выяснить больше – [url=https://vyvod-iz-zapoya-vladimir00.ru/]вывод из запоя[/url]
Вся процедура проходит под полным контролем врача и занимает от 40 минут до 2 часов. Пациенту и его родственникам даются рекомендации по дальнейшему лечению и профилактике повторных запоев.
Узнать больше – http://kapelnica-ot-zapoya-moskva00.ru
Каждый пациент уникален — именно поэтому мы не применяем «типовых» решений. После первичной консультации и диагностики специалисты «КубаньМед» разрабатывают персональную программу, учитывающую состояние здоровья, психологические особенности и социальные обстоятельства пациента.
Исследовать вопрос подробнее – https://lechenie-alkogolizma-krasnodar0.ru/klinika-lecheniya-alkogolizma-krasnodar/
пансионаты для инвалидов в туле
pansionat-tula002.ru
частный пансионат для пожилых людей
Лучшие ремонты Сочи Ремонт новостройки в Сочи – это уникальная возможность создать дом своей мечты с чистого листа. Забудьте о старых планировках и чужих вкусах – воплотите свои самые смелые идеи в реальность. Современные материалы, инновационные технологии и профессиональный дизайн помогут вам создать идеальное пространство для жизни.
лечение запоя калуга
vivod-iz-zapoya-kaluga005.ru
вывод из запоя
лестницы из металла на заказ [url=http://lestnicy-na-metallokarkase-4.ru/]лестницы из металла на заказ[/url] .
Специалист выясняет, как долго продолжается запой, какие симптомы наблюдаются, а также наличие сопутствующих заболеваний. Эти данные позволяют сформировать индивидуальный план лечения и выбрать оптимальные методы детоксикации.
Разобраться лучше – [url=https://vyvod-iz-zapoya-vladimir0.ru/]вывод из запоя круглосуточно владимир[/url]
https://personaldliadoma.ru
עוד פרי כחול, לא ברור איך. תקשיבי, היא החליטה לתת לו אולטימטום, אם לא תפסיק לשחק את זה, אנחנו … סשה לא, הוא בנסיעת עסקים. “כן, אני יודע,” חייכתי והושיטתי את הבקבוק. – החלטתי לבדוק אותך. סשה שירות ליווי בבאר שבע ואזור הדרום
Экстренная капельница от запоя необходима при первых же признаках тяжелого состояния после длительного употребления алкоголя. Не стоит дожидаться осложнений, вызов нарколога обязателен в таких ситуациях:
Получить больше информации – http://kapelnica-ot-zapoya-moskva000.ru
Пациенты клиники «НаркоМед» полностью застрахованы от утечки личной информации. Приём и лечение оформляются по псевдониму, документы не передаются в другие организации.
Подробнее тут – http://narkologicheskaya-klinika-ekaterinburg0.ru
Строительство домов https://realdomstroy.ru коттеджей и дач под ключ. Проектирование, фундамент, стены, кровля, отделка. Современные технологии, честные цены, сроки по договору.
ai therapist app [url=www.ai-therapist21.com]www.ai-therapist21.com[/url] .
валютный перевод в китай Инвойс в Японию – это счет на оплату, выставленный японским поставщиком товаров или услуг. Он должен содержать информацию о сумме платежа, реквизитах поставщика и другие необходимые данные.
Профессиональная ЖЭК https://dom-ptz.ru содержание и эксплуатация жилфонда, приём заявок, ремонт систем водоснабжения и отопления, уборка подъездов, вывоз мусора.
ai therapist bot [url=http://www.ai-therapist22.com]http://www.ai-therapist22.com[/url] .
https://geolexpert.ru
Монтаж систем отопления https://teplo-ip.ru и водоснабжения — точный расчёт, аккуратная установка, грамотная разводка. Работаем с любыми объектами.
частный пансионат для престарелых
pansionat-tula003.ru
пансионат с медицинским уходом
вывод из запоя цена
vivod-iz-zapoya-kaluga006.ru
вывод из запоя круглосуточно
Пациенты клиники «НаркоМед» полностью застрахованы от утечки личной информации. Приём и лечение оформляются по псевдониму, документы не передаются в другие организации.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-ekaterinburg0.ru/]частная наркологическая клиника екатеринбург.[/url]
Поверка и замена счётчиков https://ukkomfort43.ru воды и тепла без снятия. Оперативно, официально, с внесением в реестр. Лицензированные специалисты, аккредитация, выдача документов.
Тепловизионное обследование https://stroyinproject.ru квартир и коттеджей — выявим утечки тепла, скрытые дефекты, мостики холода.
Инфракрасные обогреватели https://votteplo.ru эффективный обогрев помещений и улицы. Мгновенный нагрев, экономия электроэнергии, комфортное тепло.
Управляющая компания https://tdom19.ru комплексное обслуживание многоквартирных домов. Техническое обслуживание, уборка, благоустройство, аварийная служба.
Наркологическая клиника в Краснодаре представляет собой специализированное медицинское учреждение, где оказывается профессиональная помощь пациентам с различными формами зависимости. Современные подходы к лечению позволяют обеспечить эффективную и безопасную терапию, направленную на восстановление физического и психического здоровья.
Углубиться в тему – [url=https://narkologicheskaya-klinika-krasnodar00.ru/]narkologicheskie kliniki alkogolizm krasnodar[/url]
Современная сантехника https://santeh-n1.ru от ведущих брендов. Грамотная консультация, доставка и установка. Премиальный сервис, помощь на всех этапах покупки.
https://aylita.ru
Мы стремимся обеспечить пациентам максимальный уровень доверия и результативности лечения, сочетая передовые технологии и многолетний опыт специалистов:
Подробнее тут – http://lechenie-alkogolizma-krasnodar0.ru
валютный агент платежный Оплата за границу может быть сложной задачей, требующей знания валютного законодательства и особенностей международных банковских операций. Платежные агенты берут на себя эту задачу, обеспечивая бесперебойный процесс оплаты товаров и услуг.
вывод из запоя краснодар
vivod-iz-zapoya-krasnodar001.ru
экстренный вывод из запоя
вывод из запоя
[url=https://vivod-iz-zapoya-chelyabinsk001.ru]https://vivod-iz-zapoya-chelyabinsk001.ru[/url]
вывод из запоя круглосуточно
Заказать диплом https://diplomikon.ru быстро, надёжно, с гарантией! Напишем работу с нуля по вашим требованиям. Уникальность от 80%, оформление по ГОСТу.
Отчёты по практике https://gotov-otchet.ru на заказ и в готовом виде. Производственная, преддипломная, учебная.
Диплом под ключ https://diplomnazakaz-online.ru от выбора темы до презентации. Профессиональные авторы, оформление по ГОСТ, высокая уникальность.
Wow, awesome blog format! How long have you been blogging for? you make blogging glance easy. The total glance of your web site is magnificent, as neatly as the content material!
Luxury limo near me
Подбор учреждения для прохождения реабилитации — это ответственное решение, влияющее на весь процесс восстановления. Наркологическая помощь требует не только медикаментозного вмешательства, но и глубокой психологической проработки. Согласно информации, опубликованной на портале Минздрава РФ, эффективность терапии во многом зависит от персонализированного подхода и соблюдения стандартов оказания психиатрической помощи.
Углубиться в тему – [url=https://narkologicheskaya-klinika-nizhnij-tagil11.ru/]наркологические клиники алкоголизм свердловская область[/url]
Во-первых, мы фокусируемся на медицинской детоксикации, которая является первоочередной задачей при лечении зависимостей. Этот процесс позволяет удалить токсические вещества из организма и улучшить общее состояние пациента. Мы применяем современные методики, которые помогают минимизировать симптомы абстиненции и обеспечить комфортное пребывание в клинике.
Детальнее – http://kapelnica-ot-zapoya-irkutsk.ru
агенты платежи в китай Деятельности платежного агента субагента – это схема, при которой платежный агент привлекает субагентов для приема платежей от населения и организаций. Субагенты действуют от имени платежного агента и подчиняются его правилам и требованиям.
вывод из запоя круглосуточно краснодар
vivod-iz-zapoya-krasnodar002.ru
вывод из запоя цена
https://poli-doma.ru
Заказать диплом https://diplomikon.ru быстро, надёжно, с гарантией! Напишем работу с нуля по вашим требованиям. Уникальность от 80%, оформление по ГОСТу.
Наркологическая клиника «ЗдравЦентр» оказывает круглосуточную помощь пациентам, страдающим от алкогольной интоксикации. Наши специалисты выезжают в любой район Москвы и Московской области, чтобы оперативно поставить капельницу, снять симптомы абстиненции и восстановить здоровье пациента в комфортных домашних условиях.
Детальнее – [url=https://kapelnica-ot-zapoya-moskva00.ru/]капельница от запоя клиника[/url]
ai therapist app [url=ai-therapist24.com]ai therapist app[/url] .
Отчёты по практике https://gotov-otchet.ru на заказ и в готовом виде. Производственная, преддипломная, учебная.
лечение запоя краснодар
vivod-iz-zapoya-krasnodar003.ru
вывод из запоя круглосуточно краснодар
Заказать диплом https://diplomikon.ru быстро, надёжно, с гарантией! Напишем работу с нуля по вашим требованиям. Уникальность от 80%, оформление по ГОСТу.
Диплом под ключ https://diplomnazakaz-online.ru от выбора темы до презентации. Профессиональные авторы, оформление по ГОСТ, высокая уникальность.
Экстренная медицинская помощь при зависимостях становится необходимостью в ситуациях, когда пациент не может самостоятельно прервать запой или прекратить употребление наркотических веществ. Обратиться к наркологу на дом срочно рекомендуется при возникновении следующих признаков:
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-voronezh00.ru/]нарколог на дом круглосуточно воронеж[/url]
Заказать диплом https://diplomikon.ru быстро, надёжно, с гарантией! Напишем работу с нуля по вашим требованиям. Уникальность от 80%, оформление по ГОСТу.
экстренный вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk003.ru
вывод из запоя
Отчёты по практике https://gotov-otchet.ru на заказ и в готовом виде. Производственная, преддипломная, учебная.
Диплом под ключ https://diplomnazakaz-online.ru от выбора темы до презентации. Профессиональные авторы, оформление по ГОСТ, высокая уникальность.
Отчёты по практике https://gotov-otchet.ru на заказ и в готовом виде. Производственная, преддипломная, учебная.
mostbet uz skachat apk [url=http://mostbet4071.ru]http://mostbet4071.ru[/url]
Во-первых, мы фокусируемся на медицинской детоксикации, которая является первоочередной задачей при лечении зависимостей. Этот процесс позволяет удалить токсические вещества из организма и улучшить общее состояние пациента. Мы применяем современные методики, которые помогают минимизировать симптомы абстиненции и обеспечить комфортное пребывание в клинике.
Детальнее – http://kapelnica-ot-zapoya-irkutsk.ru/kapelnica-ot-zapoya-v-kruglosutochno-v-irkutske/
1win armenia [url=1win3071.ru]1win3071.ru[/url]
Лечение в наркологической клинике в Краснодаре строится на комплексном подходе, включающем медикаментозную терапию, психотерапевтическую помощь и социальную реабилитацию. Медикаментозное лечение направлено на детоксикацию организма и снижение симптомов абстиненции, что позволяет значительно улучшить состояние пациента в первые дни терапии. Современные препараты, применяемые в лечении зависимости, сертифицированы и соответствуют международным стандартам, что подтверждается на сайте Всемирной организации здравоохранения.
Подробнее – [url=https://narkologicheskaya-klinika-krasnodar0.ru/]частная наркологическая клиника краснодарский край[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar004.ru
экстренный вывод из запоя краснодар
bet365 money casino usa, free money online casino canada and uk gambling bill, or pay
by phone bill casino australia
my webpage – blackjack automaten
Этот метод направлен на выявление и замену негативных мыслей и стереотипов поведения, связанных с потреблением алкоголя. Пациент учится отслеживать свои эмоциональные реакции и заменять деструктивные установки конструктивными стратегиями противостояния стрессу.
Подробнее – http://lechenie-alkogolizma-sochi0.ru/lechenie-alkogolizma-anonimno-v-sochi/
https://remmosstroy.ru
вывод из запоя цена
vivod-iz-zapoya-cherepovec004.ru
экстренный вывод из запоя
888starz logo [url=888starz.red]888starz logo[/url] .
Столица ночью бодрствует, и мы тоже: эксклюзивная центр лечения алкоголизма и наркомании клиника https://mcnl.ru работает 24/7. Без очередей и бумаг — приезд доктора на дом за 40 минут, безопасный детокс под седацией, сверхскоростная капельница, нейрокоррекция на месте, бессрочное сопровождение. Тихо, скрытно, результативно — вернём трезвость без боли.
Наркологическая клиника в Краснодаре представляет собой специализированное медицинское учреждение, где оказывается профессиональная помощь пациентам с различными формами зависимости. Современные подходы к лечению позволяют обеспечить эффективную и безопасную терапию, направленную на восстановление физического и психического здоровья.
Углубиться в тему – http://narkologicheskaya-klinika-krasnodar00.ru
https://rusekodom.ru
Москва после заката не дремлет, и мы тоже: закрытая центр лечения алкоголизма и наркомании клиника https://mcnl.ru работает 24/7. Без записей и бумаг — вызов доктора по адресу за 40 минут, щадящий детокс под седацией, ультрабыстрая капельница, психологическая поддержка у вас, бессрочное сопровождение. Тайно, анонимно, эффективно — вернем вам трезвость без боли.
Каждый пациент уникален — именно поэтому мы не применяем «типовых» решений. После первичной консультации и диагностики специалисты «КубаньМед» разрабатывают персональную программу, учитывающую состояние здоровья, психологические особенности и социальные обстоятельства пациента.
Подробнее тут – [url=https://lechenie-alkogolizma-krasnodar0.ru/]лечение наркомании и алкоголизма в краснодаре[/url]
оф. канал live-казино: рейтинги лицензионных площадок + актуальные зеркала. разбор стратегий для рулетки, баккары и монополии. специальные промокоды для новичков. зарегистрируйся и выводи деньги без лимитов.
https://t.me/s/iGaming_live/570
Купить квартиру или дом недвижимость в Черногории Подберём квартиру, дом или виллу по вашему бюджету. Юридическая проверка, консультации, оформление ВНЖ.
Ваш безопасный портал bitcoin7.ru в мир криптовалют! Последние новости о криптовалютах Bitcoin, Ethereum, USDT, Ton, Solana. Актуальные курсы крипты и важные статьи о криптовалютах. Начните зарабатывать на цифровых активах вместе с нами
all slots online nz casino, new uk casinos 2021 and run it once poker canada, or casino in montreal united states
Check out my page – Blackjack Spielen Met Geld 2025
вывод из запоя цена
vivod-iz-zapoya-krasnodar005.ru
экстренный вывод из запоя краснодар
После вызова врач клиники «ЗдравЦентр» прибывает к пациенту в течение 30–60 минут. Он проводит первичный осмотр, оценивает степень тяжести алкогольной интоксикации, измеряет пульс, давление, уровень кислорода и другие показатели здоровья. На основании этих данных составляется индивидуальный план лечения.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-moskva00.ru/]капельница от запоя цена москва.[/url]
Самостоятельно выйти из запоя — почти невозможно. В Люберцах врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Детальнее – https://kapelnica-ot-zapoya-lyubercy12.ru
https://pteploobmennik.ru
Official Live Casino Channel
Verified platforms rating? Working mirrors updated hourly Mega bonuses +300%! Winning strategies for roulette, poker and Sweet Bonanza. EXCLUSIVE PROMOCODES. Sign up, play & withdraw instantly!
https://t.me/s/iGaming_live/2600
вывод из запоя круглосуточно череповец
vivod-iz-zapoya-cherepovec005.ru
лечение запоя
https://birvodokanal.ru
888starz cameroun [url=http://888starz-english.com/]888starz cameroun[/url] .
Продвижение сайтов https://team-black-top.ru под ключ: SEO-оптимизация, технический аудит, внутренняя и внешняя раскрутка. Повышаем видимость и продажи.
buy esim for huawei esim india
https://septik-bars.ru
Каждый пациент получает персонализированную программу, учитывающую стадию заболевания, сопутствующие патологии и социальный статус. На основании анализа состояния назначается оптимальная терапия, что значительно повышает эффективность лечения. Врач-нарколог подбирает препараты с учетом индивидуальной переносимости, а психотерапевт разрабатывает план психологической поддержки.
Детальнее – [url=https://lechenie-alkogolizma-sochi00.ru/]клиника лечения алкоголизма сочи[/url]
Капельница для вывода из запоя – это эффективный способ экстренного выхода из запоя, который помогает справиться с физической зависимостью от алкоголя. Однако выход из алкогольной зависимости требует не только медицинского вмешательства, но и психотерапевтической работы. Важно понимать, что зависимость от алкоголя – это состояние, затрагивающее как тело, так и душу. Экстренный вывод из запоя включает в себя восстановление водно-электролитного баланса, но без поддержки со стороны специалистов результат может быть кратковременным. В сложные времена помощь зависимым должна быть комплексной и включать различные методы. Роль семьи в процессе реабилитации невозможно переоценить. Семейная атмосфера поддержки способствует формированию здоровых привычек и помочь избежать повторного запойного состояния. Профилактика рецидивов включает в себя комплекс мероприятий, направленных на закрепление успехов лечения, что делает лечение комплексным и более эффективным.
лечение запоя череповец
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя круглосуточно
дешевый интернет пермь
domashij-internet-perm004.ru
подключить домашний интернет в перми
Наркологическая клиника «ЗдравЦентр» оказывает круглосуточную помощь пациентам, страдающим от алкогольной интоксикации. Наши специалисты выезжают в любой район Москвы и Московской области, чтобы оперативно поставить капельницу, снять симптомы абстиненции и восстановить здоровье пациента в комфортных домашних условиях.
Подробнее тут – http://
После завершения основного курса лечения в наркологической клинике в Краснодаре пациентам предлагаются программы социальной реабилитации. Они направлены на восстановление социальных навыков, адаптацию в обществе и предотвращение рецидивов. Ключевым элементом здесь является поддержка со стороны профессиональных социальных работников и участие в группах взаимопомощи.
Подробнее – http://narkologicheskaya-klinika-krasnodar0.ru
https://stbvodokanal.ru
Цены вывода из запоя от алкоголя в Красноярске варьируется в связи с множеством факторов. Нарколог на дом анонимно предоставляет услуги по выведению из запоя и медицинской помощи при алкоголизме. Обращение к нарколога способствует определению оптимальной программы детокса. Цены на лечение алкоголизма могут включать стоимость анонимную детоксикацию и реабилитацию от алкоголя. Услуги нарколога, такие как поддержка пациентам с зависимостямитакже играют важную роль. В наркологической клинике Красноярск доступны различные пакетыкоторые могут влиять на общую стоимость. Важно учитывать о профилактике алкогольной зависимости и своевременной помощи.
В таких случаях своевременное обращение за помощью позволяет быстро стабилизировать состояние и предотвратить развитие серьезных осложнений.
Выяснить больше – [url=https://narcolog-na-dom-voronezh0.ru/]нарколог на дом вывод из запоя[/url]
вывод из запоя
vivod-iz-zapoya-irkutsk001.ru
вывод из запоя круглосуточно иркутск
провайдеры интернета в перми
domashij-internet-perm005.ru
домашний интернет в перми
Лечение в наркологической клинике в Краснодаре строится на комплексном подходе, включающем медикаментозную терапию, психотерапевтическую помощь и социальную реабилитацию. Медикаментозное лечение направлено на детоксикацию организма и снижение симптомов абстиненции, что позволяет значительно улучшить состояние пациента в первые дни терапии. Современные препараты, применяемые в лечении зависимости, сертифицированы и соответствуют международным стандартам, что подтверждается на сайте Всемирной организации здравоохранения.
Углубиться в тему – [url=https://narkologicheskaya-klinika-krasnodar0.ru/]наркологические клиники алкоголизм краснодарский край[/url]
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Что ещё нужно знать? – https://bekknows.tech/easy-way-to-delete-your-instagram-account
best barbershop- https://www.menspire.sg
mental health chatbot [url=www.mental-health22.com/]www.mental-health22.com/[/url] .
ai mental health app [url=https://mental-health21.com/]mental-health21.com[/url] .
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Осуществить глубокий анализ – https://currentdrive.pl/logo-2
https://dom-servis2.ru
mostbet aviator yutish [url=https://mostbet4075.ru]mostbet aviator yutish[/url]
buy turkish esim buy esim for samsung galaxy
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Получить дополнительные сведения – https://skarduherbs.com/hello-world-2
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Читать дальше – https://newerahtx.com/harnessing-the-power-of-the-sun
https://177m.ru
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Подробная информация доступна по запросу – https://trackify.vn/download/quan-ly-vao-ra-cac-khu-vuc-trong-yeu
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Подробнее тут – https://ibuvideo.com/portfolio/two-months-course-for-managers
esim usa travel buy turkish esim
Looking for the best haircut in town? MenSpire delivers tailored precision cuts, expert grooming, and a luxe vibe. Book now for a refined, confidence-boosting transformation.
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Это ещё не всё… – https://stopleakloss.com/compressor-selection-guide
esim france buy esim maldives
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Неизвестные факты о… – http://us.angile-led.com/%E5%85%AC%E5%8F%B8%E6%8C%AA%E5%A8%81as%E5%85%AC%E5%8F%B8%E4%B8%8E%E9%99%95%E8%A5%BF%E5%AE%89%E6%8D%B7%E4%B8%BE%E8%A1%8C%E7%8B%AC%E5%AE%B6%E9%94%80%E5%94%AE%E4%BB%A3%E7%90%86%E5%8D%8F%E8%AE%AE
Discover the best barbershop experience in the CBD: MenSpire blends contemporary flair with traditional craftsmanship. Friendly pros, clean ambiance—your style, redefined.
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Подробнее тут – https://regulyar.ru
https://vodyanoy-tyoplyy-pol.ru
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Выяснить больше – https://abncons.ru
ОТКАПЫВАНИЕ НА ДОМУ: РЕКОМЕНДАЦИИ Подготовка участка для благоустройства – это важный этап домашнего проекта. Excavation‚ или земляные работы‚ включает в себя множество задач‚ таких как копка ямы для фундамента‚ дренажные системы и водопроводные работы. Верный выбор инструментов для копки и аренда оборудования помогут упростить процессы. Садовые работы требуют внимательного планирования. Уход за участком‚ особенно в периодические работы в саду‚ поможет сохранить красоту ландшафта. Не забудьте учесть дизайн местности‚ который может включать в себя элементы‚ требующие откапывания. Обратите внимание на советы по копке: выбирайте подходящие инструменты‚ следите за безопасностью и учитывайте тип почвы. Профессиональные земельные услуги могут помочь с профессиональным выполнением работ. Заходите на vivod-iz-zapoya-krasnoyarsk003.ru для получения дополнительной информации и поддержки.
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Выяснить больше – https://topic.lk/14244
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Подробнее – https://vistoweekly.com/www-harmonicode-com
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Осуществить глубокий анализ – https://iartfivas.it/5-amazing-glitter-artists-to-find-at-a-festival
вывод из запоя круглосуточно иркутск
vivod-iz-zapoya-irkutsk002.ru
вывод из запоя цена
домашний интернет тарифы
domashij-internet-perm006.ru
домашний интернет
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Полная информация здесь – https://saveursnomad.com/component/k2/item/6-let-start-your-creative-design-with-adobe-photoshop?start=138550
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Почему это важно? – https://saveursnomad.com/component/k2/item/6?start=1800
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Подробнее тут – http://www.useuse.de/uselog/?p=1034
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Обратитесь за информацией – https://ncvmarketing.com/hello-world
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Выяснить больше – https://www.patrino.sk/icon_rockets
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Разобраться лучше – http://www.mainbrewcoffee.com/mbc-logo-2x
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Узнай первым! – http://bulat-elsky.ru
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Углубить понимание вопроса – https://guru.smkn1pacitan.sch.id/pratanda/2016/10/10/seni-adalah
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Узнать из первых рук – https://marmorariamk.com.br
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Ознакомьтесь с аналитикой – https://canvasspecial.co.za/professional-photo-printing-with-canvas-2023
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Расширить кругозор по теме – https://galernaresidencial.com/2019/10/18/advertising-relationships-vs-business-decisions
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Выяснить больше – https://hoguomceramics.com.vn/nisi-est-sit-amet-facilisis-magna-ultrices-dui-sapien
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Это стоит прочитать полностью – https://outofdoor.cz/vlakem-do-chorvatska
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Подробная информация доступна по запросу – https://moroccanpouf.ca/moroccan-pouf-magic-how-to-style-them-in-every-room
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Нажмите, чтобы узнать больше – https://knauf-center.ru
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Погрузиться в детали – https://japanstours.com/5-most-beautiful-islands-in-asia
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Информация доступна здесь – https://riddim-hair.com/2020/09/13/%E6%96%B0%E5%9E%8B%E3%82%B3%E3%83%AD%E3%83%8A%E3%82%A6%E3%82%A3%E3%83%AB%E3%82%B9%E5%AF%BE%E7%AD%96%E3%81%A8%E3%81%94%E6%9D%A5%E5%BA%97%E6%99%82%E3%81%AE%E3%81%8A%E9%A1%98%E3%81%84
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Подробнее тут – http://androp-rono.ru/%D0%B4%D0%B5%D1%8F%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE%D1%81%D1%82%D1%8C/%D1%80%D1%83%D0%BA%D0%BE%D0%B2%D0%BE%D0%B4%D0%B8%D1%82%D0%B5%D0%BB%D0%B8/item/2650-%D0%B0%D0%BD%D0%B4%D1%80%D0%BE%D0%BF%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D1%86%D0%B8%D1%84%D1%80%D0%B0?start=2480
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Узнать напрямую – https://cheapinternationalcallingcard.ru
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Не пропусти важное – https://tienda.tarambana.net/woocommerce-placeholder
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Узнай первым! – https://iartfivas.it/5-amazing-glitter-artists-to-find-at-a-festival
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Только для своих – https://ejv.co.nz/hello-world
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Информация доступна здесь – https://astirholidays.com/product/mumbai-tour-package
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Не пропусти важное – http://clwercitra.cf/post/34
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Почему это важно? – https://safaritrends.co.bw/2018/03/01/south-america-tour-guide
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Заходи — там интересно – https://miawodo.org/produit/paniers-de-rangement-rond-avec-couvercle
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Углубить понимание вопроса – https://yoga-petra-weiland.de/find-peace-with-kundalini-yoga-and-meditation
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Выяснить больше – https://unonews.ru
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Более того — здесь – http://ecopackaging.eu/home1
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Следуйте по ссылке – http://www.heyworld.jp/cgi/bbs/joyful/joyful.cgi?page820=v
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее – https://shirazeskan.ir/%D8%A8%D8%AA%D9%86-%D8%A2%D9%85%D8%A7%D8%AF%D9%87-%D8%AF%D8%B1-%D8%B4%DB%8C%D8%B1%D8%A7%D8%B2
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Как достичь результата? – https://hestiadeco.com/slow-deco-une-decoration-plus-humaine-et-durable
Пациенты могут воспринимать окружающих как врагов, отказываться от помощи. Стресс от изоляции дома усугубляет состояние без профессиональной поддержки.
Получить больше информации – http://vivod-iz-zapoya-chelyabinsk13.ru/vyvod-iz-zapoya-na-domu-chelyabinsk/
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Ознакомьтесь с аналитикой – https://noithattanminh.com/bi-mat-phong-cach-noi-that-hy-lap-va-nhung-y-tuong-chua-duoc-khai-pha
вывод из запоя минск
vivod-iz-zapoya-minsk001.ru
лечение запоя
https://ukvd43.ru
вывод из запоя
vivod-iz-zapoya-irkutsk003.ru
лечение запоя
подключение интернета ростов
domashij-internet-rostov004.ru
подключить интернет ростов
win ставки на спорт [url=http://1win3068.ru/]http://1win3068.ru/[/url]
Eth mix Ethereum Mixer: Ensuring Transaction Privacy on the Blockchain In an era where digital transactions are increasingly scrutinized, the need for privacy on the Ethereum blockchain has become paramount. Ethereum mixers offer a solution by obfuscating the trail of transactions, making it difficult to trace the origin and destination of funds. This article explores the functionality, benefits, and considerations surrounding Ethereum mixers.
винтовые для фундамента [url=www.ostankino-svai.ru /]www.ostankino-svai.ru /[/url] .
cylindrical bearings pillow block: The quintessential solution for supporting rotating shafts, a pillow block combines a bearing with a mounting housing, simplifying installation and maintenance. Choose from a variety of housing materials and bearing types to match your specific application requirements. Ensure proper lubrication and regular inspection for optimal performance and longevity.
app for mental health support [url=www.mental-health23.com/]www.mental-health23.com/[/url] .
mental health support chatbot [url=mental-health25.com]mental-health25.com[/url] .
Процедура детоксикации занимает от 40 минут до 2 часов. После её завершения врач консультирует пациента и родственников, даёт рекомендации по дальнейшему лечению и профилактике повторных запоев.
Выяснить больше – http://narcolog-na-dom-sankt-peterburg00.ru/
вывод из запоя минск
vivod-iz-zapoya-minsk002.ru
вывод из запоя круглосуточно минск
best haircut Shop- https://www.menspire.sg
https://uspenka-dom.ru
Discover the best barbershop experience in the CBD: MenSpire blends contemporary flair with traditional craftsmanship. Friendly pros, clean ambiance—your style, redefined.
best barber- https://www.menspire.sg
Discover the best barbershop experience in the CBD: MenSpire blends contemporary flair with traditional craftsmanship. Friendly pros, clean ambiance—your style, redefined.
best barber- https://www.menspire.sg
Elevate your look at MenSpire Singapore—the best barber crafting precision styles in a chic, modern space. Expect top-tier service and sharp results every time.
Looking for the best haircut in town? MenSpire delivers tailored precision cuts, expert grooming, and a luxe vibe. Book now for a refined, confidence-boosting transformation.
Когда запой становится угрозой для жизни, оперативное вмешательство становится ключевым для спасения здоровья и предотвращения серьезных осложнений. В Рязани вызов нарколога на дом позволяет начать лечение в самые критические моменты, обеспечивая детоксикацию организма и восстановление его нормального функционирования в условиях, где пациент чувствует себя комфортно и сохраняет свою конфиденциальность. Этот формат оказания медицинской помощи особенно актуален для тех, кто хочет избежать длительного ожидания в стационаре и предпочитает лечение в привычной домашней обстановке.
Изучить вопрос глубже – [url=https://narcolog-na-dom-ryazan00.ru/]нарколог на дом в рязани[/url]
Looking for the best haircut in town? MenSpire delivers tailored precision cuts, expert grooming, and a luxe vibe. Book now for a refined, confidence-boosting transformation.
подключить интернет в ростове в квартире
domashij-internet-rostov005.ru
провайдеры интернета ростов
Современное общество сталкивается с серьёзными вызовами, связанными с зависимостями. Проблемы, возникающие в результате злоупотребления психоактивными веществами, охватывают не только здоровье, но также влияют на социальные отношения и качество жизни. Наркологическая клиника “Точка опоры” предлагает широкий спектр услуг, направленных на восстановление и реабилитацию людей, столкнувшихся с этими трудностями.
Получить дополнительные сведения – http://narko-zakodirovat.ru
вывод из запоя цена
vivod-iz-zapoya-kaluga004.ru
лечение запоя калуга
мод на тик ток 2025 андроид бесплатно Скачать Тик Ток на Андроид Мод Процесс скачивания и установки мода на Android обычно включает в себя загрузку APK-файла и его установку с разрешением на установку приложений из неизвестных источников в настройках безопасности устройства.
Детоксикация проводится в комфортных условиях, под постоянным наблюдением медперсонала. Пациенту назначают инфузионную терапию, препараты для поддержки печени, сердца, нервной системы. При выраженных абстинентных симптомах используются современные методы купирования синдрома — всё под контролем опытных врачей. Важно, что лечение в стационаре позволяет не только быстро купировать симптомы, но и вовремя скорректировать терапию при появлении осложнений.
Выяснить больше – [url=https://narkologicheskaya-klinika-balashiha5.ru/]наркологическая клиника[/url]
https://mastera-vodonagrevateley-spb.ru
lucky jet 1win скачать [url=https://1win3066.ru]https://1win3066.ru[/url]
Есть ряд признаков и ситуаций, когда откладывать обращение к наркологу опасно:
Разобраться лучше – [url=https://narkologicheskaya-pomoshch-lyubercy5.ru/]скорая наркологическая помощь люберцы[/url]
Современные канализационные насосные станции – надёжное решение для вашего объекта! Предлагаем КНС любой мощности с автоматикой и защитой от засоров. Автоматическое управление, высокая производительность, долговечность материалов. Решаем задачи от частных домов до промышленных объектов. Гарантия качества и быстрая доставка, подробнее тут: промышленная кнс
Услуга доступна как жителям Челябинска, так и пригородных районов области, благодаря наличию мобильных бригад и оптимизированным маршрутам выезда.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-chelyabinsk13.ru/]после капельницы от запоя в челябинске[/url]
888starz partners se connecter [url=http://888starz-english.com/]888starz partners se connecter[/url] .
ball bearing ball bearing: At the heart of countless mechanical systems lies the humble yet indispensable ball bearing, a testament to engineering ingenuity. Comprising inner and outer rings, precision balls, and a meticulously crafted retainer, ball bearings minimize friction and enable smooth, efficient rotation. From the intricate clockwork of a Swiss watch to the powerful drivetrain of a Formula 1 car, the ball bearing is the unsung hero of modern mechanics.
Врачебный состав клиники “Ресурс здоровья” состоит из высококвалифицированных специалистов в области наркологии. Наши врачи-наркологи имеют обширный опыт работы с зависимыми пациентами и постоянно совершенствуют свои навыки.
Получить больше информации – http://narco-vivod.ru/vivod-iz-zapoya-na-domu-v-krasnodare/
https://cleaninghouse24.ru
вывод из запоя цена
vivod-iz-zapoya-minsk003.ru
вывод из запоя минск
best porn porn blowjob
Интересная статья: Как понять, что она не отпустила прошлое: признаки незавершенных отношений
домашний интернет подключить ростов
domashij-internet-rostov006.ru
подключить домашний интернет ростов
Читать полностью: Камеры автофиксации нарушений ПДД: работают ли они сейчас и что нужно знать водителям
вывод из запоя круглосуточно калуга
vivod-iz-zapoya-kaluga005.ru
вывод из запоя
Зависимости от психоактивных веществ, таких как алкоголь, наркотики и азартные игры, представляют собой серьёзные проблемы, с которыми сталкиваются многие люди. Эти состояния не только негативно влияют на здоровье, но также разрушительно сказываются на межличностных отношениях, социальной адаптации и профессиональной деятельности. Наркологическая клиника “Новый путь” предлагает комплексное решение для пациентов, нуждающихся в помощи, ориентируясь на индивидуальный подход и использование современных медицинских технологий.
Детальнее – https://нарко-специалист.рф/
курсы валберис Продвижение карточек товаров на Wildberries: Эффективное продвижение товаров на Wildberries – залог увеличения продаж и узнаваемости бренда. Начните с качественного контента, привлекательных фотографий и подробных описаний.
https://dacha-ctroi.ru
buy angular contact ball bearing ball bearing: A cornerstone of modern engineering, the ball bearing revolutionizes rotational motion by minimizing friction and maximizing efficiency. Its ingenious design, featuring inner and outer rings, precision-engineered balls, and a retainer, facilitates smooth and reliable performance across diverse applications. From the intricate mechanisms of aerospace to the demanding environments of automotive engineering, the ball bearing stands as a testament to ingenuity.
экстренный вывод из запоя омск
vivod-iz-zapoya-omsk001.ru
экстренный вывод из запоя омск
What’s up, always i used to check web site posts here early in the break of day, since i like to gain knowledge of more and more.
https://fasttelegraph.ru/chto-takoe-virtualnyj-nomer-i-zachem-on-nuzhen/
Highly praised for reliability — “I’ve bridged over 50 transactions without a single issue.”
https://prochistka.su
провайдеры по адресу самара
domashij-internet-samara004.ru
провайдеры интернета в самаре по адресу
вывод из запоя круглосуточно
vivod-iz-zapoya-kaluga006.ru
вывод из запоя круглосуточно
свойства камней для женщин Браслеты из натуральных камней: браслеты из натуральных камней – это не только красиво, но и полезно для здоровья и эмоционального состояния.
Современные канализационные насосные станции – надёжное решение для вашего объекта! Предлагаем КНС любой мощности с автоматикой и защитой от засоров. Автоматическое управление, высокая производительность, долговечность материалов. Решаем задачи от частных домов до промышленных объектов. Гарантия качества и быстрая доставка, подробнее тут: купить кнс канализационная
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Получить полную информацию – https://techaibard.com/opentgc
https://woodhouse72.ru
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Посмотреть подробности – https://knowledge-experts.co/en/new-website
вывод из запоя круглосуточно омск
vivod-iz-zapoya-omsk002.ru
вывод из запоя омск
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также – https://ybmc.com.tw/sgi
Transparent fee structure and gas‑optimized for cost efficiency.
mostbet for iphone [url=https://mostbet4074.ru/]https://mostbet4074.ru/[/url]
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Заходи — там интересно – https://mcnvancini.com/drive-traffic-and-convert-leads-with-our-expert-digital
Transparent fee structure and gas‑optimized for cost efficiency.
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Ознакомиться с полной информацией – https://topic.lk/8909
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Ознакомиться с полной информацией – https://skarduherbs.com/hello-world-2
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Это стоит прочитать полностью – https://www.blessedandgrumpy.com/index.php/2023/11/12/rules/comments
Highly praised for reliability — “I’ve bridged over 50 transactions without a single issue.”
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Информация доступна здесь – https://www.meincreative.at/example-post-3
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Доступ к полной версии – https://topic.lk/7647
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Подробная информация доступна по запросу – https://www.primabevallen.nl/contact/photo-1457342813143-a1ae27448a82
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Подробнее тут – https://pinocchiosbarandgrill.com/menus/chicken-and-veggies/img_1669
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Все материалы собраны здесь – https://greume.com/abigail-lawrie-bio-personal-life-net-worth-career-movies
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Получить исчерпывающие сведения – https://pinocchiosbarandgrill.com/menus/chicken-and-veggies/img_1669
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Подробная информация доступна по запросу – https://nghiakhangphat.vn/xe-cho-vat-lieu.html
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Все материалы собраны здесь – https://coolsamsdigital.com/digital-marketing/why-a-linkedin-page-is-essential-for-new-startups
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Все материалы собраны здесь – https://caringvets.com.au/puppy-parasites
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Выяснить больше – https://ejemplos.com.mx/generales/estructural-funcionalismo-ejemplos-de-la-vida-cotidiana
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также… – https://okuniewska.net/2019/02/28/day-care-responsibility-to-protect-children
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Заходи — там интересно – https://saliksameen.com/hello-world
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также – https://nwmigs.com/hello-world
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Открыть полностью – https://futurereadytechnologies.in/abrasive-blasting
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Провести детальное исследование – http://android-superstar.ru
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Разобраться лучше – https://our-invitation.web.id/template-undangan-ke-2
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Провести детальное исследование – https://good88888.org/game-bai-cat-te
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Это ещё не всё… – https://jelmergroenland.nl/photo-1461695008884-244cb4543d74
Желаете посмотреть фильмы, сериалы, мультфильмы, аниме, ТВ программы онлайн в высоком качестве и бесплатно? Посетите https://kinogo0.net/ – смотреть лучшие новинки кино и прочих жанров, в том числе 2025, года бесплатно в хорошем качестве можно у нас. Огромная и лучшая коллекция. Каждый найдет то, что ему нравится.
1win գրանցում [url=www.1win3075.ru]www.1win3075.ru[/url]
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Подробнее тут – http://fielder-omsk.ru
последний мод на тик ток 2025 Скачать Тик Ток на Андроид Мод Процесс скачивания и установки мода на Android обычно включает в себя загрузку APK-файла и его установку с разрешением на установку приложений из неизвестных источников в настройках безопасности устройства.
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Погрузиться в научную дискуссию – https://newssamiksha.com/index.php/tag/tapkeshwar-mahadev-mandir
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Выяснить больше – https://colegioboock.com.br/produto/curso-profissionalizante-em-massoterapia
узнать интернет по адресу
domashij-internet-samara005.ru
интернет по адресу
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Обратитесь за информацией – http://grangelaresidencial.com/index.php/es/component/k2/item/1-imatge1/1-imatge1?start=5110
1win պաշտոնական կայք [url=https://1win3073.ru]https://1win3073.ru[/url]
вывод из запоя цена
vivod-iz-zapoya-krasnodar001.ru
вывод из запоя
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Более подробно об этом – https://hopon.net/index.php/k2-blog/item/15-jazz-for-the-afternoon?caid=aafef66e-3293-4572-bd6c-49ad1c847e3e&rt=HJhttp:&zpid=32b43416-048a-11ea-9c73-0a46a64d575b&start=272050
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Полная информация здесь – https://www.iheir13.com/5214.html
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Это стоит прочитать полностью – https://catchii.com/catchii-magazine-c
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Как достичь результата? – https://www.hotel-sugano.com/bbs/sugano.cgi/www.tovery.net/sinopipefittings.com/e_Feedback/sinopipefittings.com/e_Feedback/www.tovery.net/datasphere.ru/club/user/12/blog/2477/www.hip-hop.ru/forum/id298234-worksale/www.hip-hop.ru/forum/id298234-worksale/sugano.cgi?page40=val
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Читать дальше – https://askalaf.com/produits-scalaires
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Более того — здесь – https://myiptv.store/ticket_system-3
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Нажмите, чтобы узнать больше – https://metricco.es/magna-fringilla-quis-condimentum
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Более того — здесь – https://wisdomorbit.com/best-managed-wordpress-hosting-2024
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Детальнее – https://ramirezpedrosa.com/banking/the-pros-and-cons-of-different-investment-vehicles
высокооплачиваемая работа для девушек Работа для девушек вакансии Существует множество сайтов и платформ, где можно найти вакансии для девушек. Важно внимательно изучать требования работодателя и отправлять резюме только на те вакансии, которые соответствуют вашим навыкам и опыту.
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Смотри, что ещё есть – https://topic.lk/10763
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Почему это важно? – https://worldeventsforum.com/hello-world
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Смотри, что ещё есть – https://sabarinews.com/2024/12/17/35912
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Обратиться к источнику – https://grupoherot.com/hello-world
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Подробная информация доступна по запросу – http://www.unimogsound.be/dcp_2082
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Лучшее решение — прямо здесь – https://tsukiko.org/2021/12/01/12%E6%9C%88%E3%81%AE%E8%AA%95%E7%94%9F%E7%9F%B3%E3%80%8C%E3%82%BF%E3%83%BC%E3%82%B3%E3%82%A4%E3%82%BA%E3%80%8D
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Изучить вопрос глубже – http://www.fredrikbackman.com/2015/06/01/om-ni-behover-mig-sa-ar-jag-pa-instagram
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Подробная информация доступна по запросу – https://dollhubs.com/blog/xy-doll-faqs
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Доступ к полной версии – https://resa.store/%D1%83%D1%81%D0%BB%D0%BE%D0%B2%D0%B8%D1%8F-%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F-%D0%B1%D0%B5%D0%B7%D0%B4%D0%B5%D0%BF%D0%BE%D0%B7%D0%B8%D1%82%D0%BD%D1%8B%D1%85
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Лучшее решение — прямо здесь – https://topic.lk/9204
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Почему это важно? – https://ssironmetal.com/what-to-avoid-when-scrapping-metal/.html
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Это ещё не всё… – https://knopkastarta.ru
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Разобраться лучше – http://android-superstar.ru
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Полная информация здесь – http://www.frealms.ru
вывод из запоя
vivod-iz-zapoya-omsk003.ru
экстренный вывод из запоя
сферы работы для девушек Работа для девушек вакансии: поиск работы мечты Работа для девушек вакансии – это возможность найти работу, которая будет соответствовать вашим интересам, навыкам и жизненным целям. Существует множество сайтов и платформ, где можно найти вакансии для девушек. Важно внимательно изучать требования работодателя и отправлять резюме только на те вакансии, которые соответствуют вашим навыкам и опыту.
выставочный стенд заказать Выставочный стенд: Эффективный инструмент для продвижения бизнеса Выставочный стенд – это не просто демонстрационная площадка, а ключевой элемент маркетинговой стратегии компании, участвующей в выставке. Он служит визитной карточкой бренда, привлекает внимание потенциальных клиентов и партнеров, способствует укреплению имиджа и увеличению продаж. Грамотно спроектированный и оформленный стенд способен значительно повысить эффективность участия в выставке и обеспечить долгосрочные бизнес-результаты.
Применение современных средств медикаментозного лечения обеспечивает безопасность процедуры и минимизирует риски осложнений.
Углубиться в тему – http://lechenie-alkogolizma-sochi00.ru/lechenie-alkogolizma-na-domu/https://lechenie-alkogolizma-sochi00.ru
Алкогольная зависимость — одна из самых распространенных проблем нашего времени, требующая немедленного и грамотного вмешательства. В Екатеринбурге капельница от запоя является одним из самых популярных и действенных методов восстановления после длительного употребления алкоголя. Она помогает организму справиться с интоксикацией, восстанавливает физическое и эмоциональное состояние пациента, улучшает самочувствие в короткие сроки. При этом лечение может быть организовано как в стационаре, так и на дому, в зависимости от удобства пациента.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-ekb55.ru/]vyzvat-kapelniczu-ot-zapoya ekaterinburg[/url]
Вызывать нарколога на дом рекомендуется при следующих состояниях:
Подробнее можно узнать тут – [url=https://narcolog-na-dom-sankt-peterburg000.ru/]vyzov-narkologa-na-dom sankt-peterburg[/url]
Медикаментозное лечение — это еще один важный этап. Оно включает использование препаратов, которые помогают пациенту восстановиться как физически, так и психологически. Нарколог контролирует процесс лечения, чтобы исключить побочные эффекты и скорректировать терапию при необходимости.
Узнать больше – [url=https://narcolog-na-dom-v-krasnoyarske55.ru/]нарколог на дом цена красноярск[/url]
Наркологическая клиника в Краснодаре представляет собой специализированное медицинское учреждение, где оказывается профессиональная помощь пациентам с различными формами зависимости. Современные подходы к лечению позволяют обеспечить эффективную и безопасную терапию, направленную на восстановление физического и психического здоровья.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-krasnodar00.ru/]бесплатная наркологическая клиника краснодар[/url]
интернет провайдеры по адресу
domashij-internet-samara006.ru
какие провайдеры интернета есть по адресу самара
вывод из запоя круглосуточно краснодар
vivod-iz-zapoya-krasnodar002.ru
лечение запоя
купить сантехнику италия [url=http://gessi-santehnika-3.ru]http://gessi-santehnika-3.ru[/url] .
https://poverkaekb.ru
бесплатная ставка винлайн условия [url=www.winlayne-fribet.ru]www.winlayne-fribet.ru[/url] .
сантехника с доставкой [url=http://evropejskaya-santehnika.ru/]http://evropejskaya-santehnika.ru/[/url] .
После обращения по телефону или через сайт оператор уточняет адрес, состояние пациента и срочность выезда. Врач прибывает в течение 1–2 часов, а в экстренных случаях — в течение часа. На месте специалист проводит первичный осмотр: измеряет давление, пульс, сатурацию, температуру, уточняет длительность запоя, сопутствующие заболевания, особенности реакции на лекарства.
Подробнее тут – https://vyvod-iz-zapoya-himki5.ru/vyvod-iz-zapoya-cena-v-himkah/
вывод из запоя круглосуточно оренбург
vivod-iz-zapoya-orenburg001.ru
вывод из запоя круглосуточно оренбург
Выбирая лечение в «Наркосфере», пациенты Балашихи и Балашихинского района могут быть уверены в высоком качестве услуг и современном подходе. Здесь применяют только сертифицированные препараты, используются новейшие методы терапии и реабилитации. Клиника работает круглосуточно, принимает пациентов в любой день недели и всегда готова к экстренному реагированию. Индивидуальный подход проявляется не только в подборе схемы лечения, но и в поддержке семьи на каждом этапе выздоровления. Весь процесс проходит в обстановке полной конфиденциальности: сведения о пациентах не передаются в сторонние организации, не оформляется наркологический учёт.
Углубиться в тему – [url=https://narkologicheskaya-klinika-balashiha5.ru/]платная наркологическая клиника[/url]
Клиника «РостовМед» предлагает профессиональную наркологическую помощь в Ростове и области в режиме 24/7. Наша команда готова выехать на дом к пациенту в любое время суток, обеспечивая анонимность и высокие медицинские стандарты. В основе работы — индивидуальный подход, современное оборудование и чётко отлаженные протоколы детоксикации, что позволяет безопасно вывести пациента из запоя и начать этап реабилитации без стресса госпитализации.
Разобраться лучше – https://narkologicheskaya-klinika-rostov13.ru/
драгон мани Dragon Money – выбирайте лучшее!
Зависимость от алкоголя или наркотиков — серьёзная проблема, требующая немедленного вмешательства квалифицированных специалистов. Если у вас или вашего близкого возникли признаки тяжелого похмелья, запоя или интоксикации, клиника «НаркологПлюс» предлагает услугу вызова нарколога на дом в Санкт-Петербурге. Наши врачи оперативно прибывают по указанному адресу, оказывают всю необходимую медицинскую помощь и помогают пациенту быстро вернуться к нормальной жизни.
Детальнее – [url=https://narcolog-na-dom-sankt-peterburg00.ru/]нарколог на дом санкт-петербург.[/url]
best online slots payout percentage usa, casino sites usa no deposit bonus
and what is the most trusted online casino in united states, or online uk casino woth 24
hours payout
my webpage :: esan2024.mcbu.edu.tr
изготовление выставочных стендов москва Изготовление стендов в Москве: Комплексный подход и индивидуальные решения Изготовление стендов в Москве – это комплексный подход, включающий в себя разработку концепции, дизайн, изготовление конструкций, монтаж и оформление. Важно выбрать компанию, которая предлагает индивидуальные решения, учитывающие все ваши пожелания и требования.
Line chart plateaued; the simplest mid-month fix we found was to experimentally buy followers twitter in 250-user increments.
Getting lost in flashy casino ads is easy, but finding legal platforms is another story. I only trust Reddit’s recommendations now for the best casino sites.
подключить проводной интернет санкт-петербург
domashij-internet-spb004.ru
провайдеры интернета в санкт-петербурге по адресу
Наркологическая клиника в Краснодаре играет важную роль в оказании медицинской помощи людям с различными формами зависимости. Современные методы диагностики и лечения позволяют эффективно справляться с проблемами, связанными с алкоголизмом, наркотической зависимостью и другими психоактивными веществами. Клиническая помощь организована с учетом индивидуальных особенностей пациентов и направлена на достижение стойкой ремиссии.
Углубиться в тему – [url=https://narkologicheskaya-klinika-krasnodar0.ru/]chastnaya narkologicheskaya klinika krasnodar[/url]
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar003.ru
вывод из запоя цена
Надёжный заказ авто заказать авто. Машины с минимальным пробегом, отличным состоянием и по выгодной цене. Полное сопровождение: от подбора до постановки на учёт.
экстренный вывод из запоя
vivod-iz-zapoya-orenburg002.ru
вывод из запоя
Такая услуга доступна круглосуточно, что позволяет вызвать врача в любое время. Профессиональные специалисты, приехав на дом, тщательно подберут состав капельницы с учетом индивидуальных особенностей пациента, чтобы обеспечить максимально эффективное лечение. Анонимность и высокая квалификация медперсонала делают этот способ особенно удобным для людей, которые предпочитают конфиденциальность.
Получить дополнительные сведения – http://kapelnica-ot-zapoya-ekb55.ru/kapelnicza-na-domu-ekaterinburg-ot-zapoya/
В клинике применяются инновационные методы диагностики, включая лабораторные анализы и аппаратные исследования, которые позволяют выявить степень зависимости и сопутствующие патологии. Важным этапом является комплексный подход к лечению, включающий детоксикацию организма, психотерапию и медикаментозную поддержку.
Разобраться лучше – http://narkologicheskaya-klinika-krasnodar00.ru/narkologicheskaya-klinika-anonimno-krasnodar/
выставочные стенды москва Изготовление выставочных стендов Москва: лучшие предложения Изготовление выставочных стендов в Москве предлагает широкий выбор вариантов. Множество компаний предлагают услуги по проектированию и изготовлению стендов различной сложности и конфигурации. Важно тщательно изучить предложения различных компаний и выбрать ту, которая соответствует вашим требованиям и бюджету.
Полезная статья: Почему он не называет меня по имени: причины и что это значит для отношений
Кодирование — это не просто медицинская манипуляция, а серьёзный шаг к восстановлению контроля над собственной жизнью и формированию устойчивой ремиссии.
Подробнее тут – [url=https://kodirovanie-ot-alkogolizma-mytishchi5.ru/]kodirovanie-ot-alkogolizma-na-domu-ceny[/url]
Интересная новость: Воспитание ребенка: советы для счастливого детства от экспертов психологии
С увеличением темпа жизни и нарастающим стрессом, многие люди в Екатеринбурге сталкиваются с зависимостями, особенно с алкогольной. Алкогольная зависимость является одной из наиболее распространённых проблем, требующих немедленного вмешательства специалистов. Важно помнить, что в сложных ситуациях, связанных с зависимостью, помощь не должна откладываться. Вызов нарколога на дом в Екатеринбурге становится идеальным вариантом для тех, кто не может или не хочет покидать свой дом, но нуждается в медицинской помощи.
Ознакомиться с деталями – [url=https://narcolog-na-dom-ektb55.ru/]вызвать нарколога на дом[/url]
лучший интернет провайдер санкт-петербург
domashij-internet-spb005.ru
провайдеры интернета в санкт-петербурге
Когда организм насыщен токсинами, нормальное функционирование органов нарушается. Капельница помогает быстро очистить кровь, восстановить клетки печени и улучшить общее состояние пациента, чтобы как можно быстрее вернуться к привычному уровню жизни.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-ektb55.ru/]капельница от запоя выезд в екатеринбурге[/url]
Вызывать нарколога на дом рекомендуется при следующих состояниях:
Разобраться лучше – [url=https://narcolog-na-dom-sankt-peterburg000.ru/]нарколог на дом вывод санкт-петербург[/url]
Проблемы с алкоголем и наркотиками — это не просто личные трудности, а серьёзное испытание для всей семьи и общества. Самостоятельные попытки справиться с зависимостью редко приводят к успеху и часто только усугубляют ситуацию. Оптимальное решение — обратиться за профессиональной помощью в специализированное учреждение. В наркологической клинике «ВитаРеабилит» в Подольске пациенты получают комплексное лечение под контролем опытных врачей, современные методики детоксикации и реабилитации, а также полную поддержку на всех этапах выздоровления.
Детальнее – [url=https://narkologicheskaya-klinika-podolsk5.ru/]narkologicheskaya-klinika-podolsk5.ru/[/url]
Мы работаем круглосуточно и гарантируем строгое соблюдение конфиденциальности, используя только сертифицированные препараты и проверенные методики лечения.
Углубиться в тему – [url=https://narcolog-na-dom-sankt-peterburg00.ru/]нарколог на дом вывод из запоя в санкт-петербурге[/url]
Решение о необходимости кодирования может возникнуть как у самого человека, так и у его близких, если:
Ознакомиться с деталями – https://kodirovanie-ot-alkogolizma-mytishchi5.ru/narkolog-kodirovanie-ot-alkogolizma-v-mytishchah
Процедура капельницы особенно показана в случаях, когда симптомы похмелья выражены настолько сильно, что пациент не в состоянии справиться с ними самостоятельно. Головная боль, тошнота, рвота, усталость и раздражительность — все это признаки того, что организму необходимо восстановление. Капельница помогает не только ускорить процесс очищения, но и минимизировать риск осложнений, таких как нарушение работы сердца и печени.
Выяснить больше – https://kapelnica-ot-zapoya-ektb55.ru/kapelnicza-na-domu-ekaterinburg-ot-zapoya
speed cash 1win отзывы [url=http://1win3067.ru]http://1win3067.ru[/url]
Индивидуальный подход к каждому пациенту: Учитываются уникальные характеристики, включая медицинскую историю, психологическое состояние и социальные факторы. Это позволяет разработать максимально эффективный план терапии.
Разобраться лучше – [url=https://alko-lechebnica.ru/]вывод из запоя цена ленинградская область[/url]
Наркологическая клиника в Ростове-на-Дону предоставляет полный спектр услуг по диагностике, лечению и реабилитации пациентов с алкогольной и наркотической зависимостью. Применение современных медицинских протоколов и индивидуальный подход к каждому пациенту обеспечивают высокую эффективность терапии и снижение риска рецидивов.
Выяснить больше – http://
Процесс лечения будет зависеть от состояния пациента и его особенностей. Врач подберёт нужную дозировку и состав препаратов для наиболее эффективного результата.
Ознакомиться с деталями – [url=https://narcolog-na-dom-ektb55.ru/]vyzov-narkologa-na-dom ekaterinburg[/url]
провайдеры интернета в санкт-петербурге
domashij-internet-spb006.ru
интернет провайдеры в санкт-петербурге по адресу дома
Новое и актуальное: Секреты богатого урожая клубники: обрезка для начинающих
Статьи обо всем: Почему сложно найти подходящего партнера: психология отношений и качества, которые важны для счастья
Интересные статьи: Психология одиночества: Почему женщины до 35 остаются одни
акции винлайн 2025 [url=www.winlayne-fribet1.ru/]www.winlayne-fribet1.ru/[/url] .
«РостовМедСервис» — сертифицированное медицинское учреждение, специализирующееся на экстренной наркологической помощи. Штат состоит из наркологов высшей квалификации, реаниматологов и опытных медсестёр. Клиника работает круглосуточно и без выходных, обеспечивая пациентам оперативный доступ к профессиональной помощи. Все специалисты регулярно проходят повышение квалификации и используют современные протоколы детоксикации и сопровождения.
Узнать больше – [url=https://narkolog-na-dom-rostov-na-donu13.ru/]нарколог на дом[/url]
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Только факты! – http://www.onlinepokies.com.au/big-chef-wild
В этом обзоре представлены различные методы избавления от зависимости, включая терапевтические и психологические подходы. Мы сравниваем их эффективность и предоставляем рекомендации для тех, кто хочет вернуться к трезвой жизни. Читатели смогут найти информацию о реабилитационных центрах и поддерживающих группах.
Узнать больше – https://loverust.ru/kapelnicza-ferinzhekt-pri-deficzite-zheleza-bystroe-vosstanovlenie-organizma
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Смотри, что ещё есть – http://nostalgia.maniowy.net/historia-wsi/category/43-przesiedlenie?tmpl=component&print=1&start=13230
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Секреты успеха внутри – https://jelajahpapua.com/quick-respon-polsek-sentani-timur-berhasil-tangkap-pelaku-jambret-dan-pengedar-ganja-di-kampung-harapan
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Смотрите также – https://aigyptostours.com/hello-world
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Секреты успеха внутри – https://volleymsk.ru/forum/viewtopic.php?t=10796&start=915
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Более того — здесь – https://jmw-edition.com/renaissance
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Переходите по ссылке ниже – https://www.keygraphic.fr/untitled-15-jpg
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Обратитесь за информацией – https://www.hotel-sugano.com/bbs/sugano.cgi/www.tovery.net/www.skitour.su/datasphere.ru/club/user/12/blog/2477/www.hip-hop.ru/forum/id298234-worksale/www.hip-hop.ru/forum/id298234-worksale/sinopipefittings.com/sugano.cgi?page30=val
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Подробнее – https://www.bhashanagar.com/kamal-chowdhury
freebet winline [url=http://winlayne-fribet2.ru/]freebet winline[/url] .
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Детальнее – https://aeroskylogistics.com/hello-world
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Лучшее решение — прямо здесь – https://coaatburgos.es/2024/03/26/firma-de-convenio-colegio-agalsa
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Это ещё не всё… – https://sicherheitstechnik-pfaff.de/tuersicherheit_tuerspione
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Выяснить больше – https://naturalmentespain.com/coloracion-botanica-en-base-aceite
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Нажмите, чтобы узнать больше – https://www.encouragingblogs.com/2023/07/do-foster-parents-get-paid-html
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Нажмите, чтобы узнать больше – https://hindustannewsjunction.com/aap-candidate-shot-referred-to-ludhiana
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Это ещё не всё… – https://funeral-agency.wwwbg.in/tsa-rkoven-kalendar
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Посмотреть подробности – http://russianicons.ru/order.php?obj=99
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Выяснить больше – https://www.hotel-sugano.com/bbs/sugano.cgi/www.tovery.net/datasphere.ru/club/user/12/blog/2477/www.hip-hop.ru/forum/id298234-worksale/www.skitour.su/www.tovery.net/sugano.cgi?page40=val
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Провести детальное исследование – http://www.russianicons.ru/order.php?obj=154
1win պաշտոնական կայք [url=http://1win3074.ru]http://1win3074.ru[/url]
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Это стоит прочитать полностью – http://sparshmachinery.com/post/34
В этом обзоре представлены различные методы избавления от зависимости, включая терапевтические и психологические подходы. Мы сравниваем их эффективность и предоставляем рекомендации для тех, кто хочет вернуться к трезвой жизни. Читатели смогут найти информацию о реабилитационных центрах и поддерживающих группах.
Получить больше информации – https://loverust.ru/kapelnicza-ferinzhekt-pri-deficzite-zheleza-bystroe-vosstanovlenie-organizma
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Ссылка на источник – https://paineis.zanottirefrigeracao.com.br/2024/01/25/ola-mundo
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Ознакомиться с полной информацией – https://pedga.com/thyroid-health-and-its-impact-on-digestion-in-kids
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Узнай первым! – https://missoesfrutificar.com/unlock-your-potential-with-these-inspiring-ebooks
проверить провайдеров по адресу уфа
domashij-internet-ufa004.ru
интернет по адресу уфа
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Выяснить больше – https://jessicadantas.online/hello-world
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Узнать напрямую – https://aussieinspections.net.au/enjoying-gannan-park-when-in-ryde-nsw
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее – https://f5fashion.vn/pasquale-pascaretti-fraser-mi-music-teacher-and-former-fraser-public-schools-teacher-has-died
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Смотрите также – https://www.californiastaffingservice.com/bg-whiteboard
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Получить исчерпывающие сведения – https://paineis.zanottirefrigeracao.com.br/2024/01/25/ola-mundo
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Ознакомьтесь с аналитикой – http://jandconcierge.com/author/kathleneryan55
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также… – https://taperite.com/a-new-kind-of-masking-tape-will-save-the-aerospace-industry-millions
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Только для своих – https://drivejo.com/%D8%A8%D9%8A-%D8%A7%D9%85-%D8%AF%D8%A8%D9%84%D9%8A%D9%88-x7-%D8%AA%D8%AA%D9%85%D8%AA%D8%B9-%D8%A8%D9%85%D9%82%D8%B5%D9%88%D8%B1%D8%A9-%D8%A3%D9%86%D9%8A%D9%82%D8%A9-%D9%88%D9%85%D9%85%D9%8A%D8%B2
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Перейти к статье – https://www.niniobaby.com/blog/10-tips-to-pump-more-breast-milk
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Что ещё? Расскажи всё! – http://reifenservice-star.de/hello-world-2-3
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Изучить аспект более тщательно – http://utrolive.ru
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Открыть полностью – https://investiahomes.ru
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Все материалы собраны здесь – https://www.ass-darmstadt.de/image
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Изучить вопрос глубже – https://runetmobile.ru
Кварц виниловые полы купить в Москве купить в Москве недорого [url=http://napolnaya-probka1.ru/]http://napolnaya-probka1.ru/[/url] .
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Разобраться лучше – https://dechapmanauthor.com/what-ive-been-doing
технологии выдержки Винокурня Glenfiddich – одна из самых известных и уважаемых винокурен Шотландии, производящая виски с мягким и фруктовым характером.
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Лучшее решение — прямо здесь – https://bremer-tor-event.de/hello-world-2
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Открыть полностью – https://revisit-jp.com/traditional-experience/top-5-japanese-castles-around-tokyo
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Выяснить больше – https://changingbankstatements.com/credit-card-installments
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Нажмите, чтобы узнать больше – https://founderscribe.com/pharmacy-slogans-and-taglines
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Ознакомиться с деталями – https://eineweltsafaris.com/2022/07/01/how-to-travel-with-paper-map
Современная жизнь, особенно в крупном городе, как Красноярск, часто становится причиной различных зависимостей. Работа в условиях постоянного стресса, высокий ритм жизни и эмоциональные перегрузки могут привести к проблемам, которые требуют неотложной медицинской помощи. Одним из наиболее удобных решений в такой ситуации является вызов нарколога на дом.
Исследовать вопрос подробнее – http://narcolog-na-dom-v-krasnoyarske55.ru/narkolog-na-dom-kruglosutochno-krasnoyarsk/
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Детальнее – http://fittube.ru
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Ознакомьтесь с аналитикой – https://denis-fischer.de/cropped-20210217_095123-jpeg
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Смотрите также… – https://www.rft-group.ru
Трековый потолок Теневой потолок натяжной – конструкция, где натяжное полотно фиксируется таким образом, чтобы создать эффект теневого зазора, скрывающего неровности стен.
Onlayn kazinolar haqqında danışarkən, https://pincoazerbaijan.com/ saytını tövsiyə edə bilərəm – burada həqiqətən etibarlı oyun platforması var və ödənişlər sürətlidir.
Вызов врача-нарколога на дом в Санкт-Петербурге начинается с детального осмотра и оценки состояния пациента. Врач измеряет давление, пульс, уровень кислорода в крови и определяет степень интоксикации.
Ознакомиться с деталями – [url=https://narcolog-na-dom-sankt-peterburg00.ru/]vyzvat-narkologa-na-dom sankt-peterburg[/url]
С увеличением темпа жизни и нарастающим стрессом, многие люди в Екатеринбурге сталкиваются с зависимостями, особенно с алкогольной. Алкогольная зависимость является одной из наиболее распространённых проблем, требующих немедленного вмешательства специалистов. Важно помнить, что в сложных ситуациях, связанных с зависимостью, помощь не должна откладываться. Вызов нарколога на дом в Екатеринбурге становится идеальным вариантом для тех, кто не может или не хочет покидать свой дом, но нуждается в медицинской помощи.
Изучить вопрос глубже – http://narcolog-na-dom-ektb55.ru
узнать провайдера по адресу уфа
domashij-internet-ufa005.ru
узнать интернет по адресу
где можно взять займ мфо взять займ
В стационаре предусмотрены одноместные и двухместные палаты с удобствами, телевизором и беспроводным интернетом. Медсестры дежурят круглосуточно, врачи проводят обходы и при необходимости меняют схему инфузий или назначают дополнительные процедуры. Пациентам обеспечивают сбалансированное питание, соответствующее диетическим требованиям при детоксикации.
Получить дополнительную информацию – [url=https://narcologicheskaya-klinika-ekaterinburg0.ru/]наркологические клиники алкоголизм в екатеринбурге[/url]
займ оформить онлайн деньги
деньги онлайн взять займ
В данном обзоре представлены основные направления и тренды в области медицины. Мы обсудим актуальные проблемы здравоохранения, свежие открытия и новые подходы, которые меняют представление о лечении и профилактике заболеваний. Эта информация будет полезна как специалистам, так и широкой публике.
Углубиться в тему – [url=https://narkolog-na-dom-krasnodar15.ru/]вызов врача нарколога на дом[/url]
Запой — это состояние, которое представляет собой одну из самых серьёзных форм алкогольной зависимости. Когда человек теряет способность контролировать употребление алкоголя, его организм подвергается вредному воздействию, которое может вызвать как физические, так и психоэмоциональные осложнения. В Москве есть множество клиник и специалистов, которые предлагают качественную медицинскую помощь, включая анонимное лечение. Этот вариант подходит тем, кто хочет избавиться от зависимости, не раскрывая свою личность и не сталкиваясь с осуждением окружающих.
Подробнее можно узнать тут – [url=https://narko-zakodirovat2.ru/]вывод из запоя клиника[/url]
Запой — состояние, при котором человек теряет контроль над количеством употребляемого алкоголя и уже не может самостоятельно прекратить пить. Подобные эпизоды представляют серьёзную угрозу для здоровья, а порой и для жизни. Особенно опасен резкий отказ от спиртного после длительных запоев — это может вызвать тяжёлые абстинентные расстройства, нарушение работы сердца, печени, нервной системы, галлюцинации и даже приступы судорог. В такой ситуации необходимо срочно обращаться к профессионалам. В наркологической клинике «Спасение Плюс» в Химках вывод из запоя осуществляется с выездом врача, гарантией безопасности и индивидуальным подходом.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-himki5.ru/
Вызов врача-нарколога на дом позволяет избежать стресса госпитализации, обеспечивая комфорт и удобство как для пациента, так и для его близких.
Разобраться лучше – https://narcolog-na-dom-sankt-peterburg000.ru/psikhiatr-narkolog-na-dom-spb/
Пациенты клиники «НаркоМед» полностью застрахованы от утечки личной информации. Приём и лечение оформляются по псевдониму, документы не передаются в другие организации.
Получить больше информации – [url=https://narkologicheskaya-klinika-ekaterinburg0.ru/]наркологическая клиника екатеринбург.[/url]
Проблемы с алкоголем и наркотиками — это не просто личные трудности, а серьёзное испытание для всей семьи и общества. Самостоятельные попытки справиться с зависимостью редко приводят к успеху и часто только усугубляют ситуацию. Оптимальное решение — обратиться за профессиональной помощью в специализированное учреждение. В наркологической клинике «ВитаРеабилит» в Подольске пациенты получают комплексное лечение под контролем опытных врачей, современные методики детоксикации и реабилитации, а также полную поддержку на всех этапах выздоровления.
Получить больше информации – https://narkologicheskaya-klinika-podolsk5.ru/platnaya-narkologicheskaya-klinika-v-podolske
В период восстановления пациент получает психологическую поддержку, работает с психотерапевтом, осваивает навыки самоконтроля, учится противостоять стрессу без возвращения к прежним привычкам. После выписки возможно амбулаторное сопровождение, дистанционные консультации и поддержка для всей семьи.
Разобраться лучше – https://narkologicheskaya-klinika-balashiha5.ru/chastnaya-narkologicheskaya-klinika-v-balashihe
Столица ночью не дремлет, а наша команда вдобавок всегда на страже: эксклюзивная центр лечения алкоголизма и наркомании клиника https://mcnl.ru/ доступна 24/7. Без предварительной регистрации и бумаг — срочный приём нарколога по адресу, безопасный детокс под седацией, экспресс- капельница, психологическая поддержка на дому, бессрочное сопровождение. Тихо, анонимно, эффективно — вернем трезвость без страданий.
mostbet download ios [url=https://mostbetdownload-apk.com]https://mostbetdownload-apk.com[/url] .
Когда пациент решает обратиться за помощью к наркологу на дом, ему предстоит пройти ряд этапов лечения, каждый из которых будет направлен на устранение последствий алкоголизма. Врач проведет первичный осмотр, выслушает жалобы пациента и на основе собранной информации начнёт индивидуальную программу лечения.
Подробнее – [url=https://narcolog-na-dom-ektb55.ru/]нарколог на дом цена екатеринбург[/url]
Вызов врача-нарколога на дом в Санкт-Петербурге начинается с детального осмотра и оценки состояния пациента. Врач измеряет давление, пульс, уровень кислорода в крови и определяет степень интоксикации.
Углубиться в тему – https://narcolog-na-dom-sankt-peterburg00.ru/vyzov-narkologa-na-dom-spb/
Решили заказать новый авто под ключ: подбор на аукционах, проверка, выкуп, доставка, растаможка и постановка на учёт. Честные отчёты, выгодные цены, быстрая логистика.
Автомобили на заказ закажи авто купить. Работаем с крупнейшими аукционами: выбираем, проверяем, покупаем, доставляем. Машины с пробегом и без, отличное состояние, прозрачная история.
Надёжный заказ авто заказать авто из китая с аукционов: качественные автомобили, проверенные продавцы, полная сопровождение сделки. Подбор, доставка, оформление — всё под ключ. Экономия до 30% по сравнению с покупкой в РФ.
Капельница от запоя представляет собой внутривенное введение специального раствора, который помогает организму справиться с последствиями алкогольной интоксикации. Этот метод используется для того, чтобы уменьшить проявления похмелья, таких как головная боль, тошнота, бессонница и раздражительность. Кроме того, капельница способствует нормализации работы внутренних органов и систем, ускоряя восстановление после длительного алкоголизма.
Подробнее – [url=https://kapelnica-ot-zapoya-ekb55.ru/]капельница от запоя на дому цена екатеринбург[/url]
Когда запой становится угрозой для жизни, оперативное вмешательство становится ключевым для спасения здоровья и предотвращения серьезных осложнений. В Рязани вызов нарколога на дом позволяет начать лечение в самые критические моменты, обеспечивая детоксикацию организма и восстановление его нормального функционирования в условиях, где пациент чувствует себя комфортно и сохраняет свою конфиденциальность. Этот формат оказания медицинской помощи особенно актуален для тех, кто хочет избежать длительного ожидания в стационаре и предпочитает лечение в привычной домашней обстановке.
Подробнее – [url=https://narcolog-na-dom-ryazan00.ru/]narcolog-na-dom-ryazan00.ru/[/url]
провайдеры интернета в уфе по адресу
domashij-internet-ufa006.ru
провайдеры интернета по адресу уфа
мостбет бк вход [url=https://mostbet4081.ru/]https://mostbet4081.ru/[/url]
1вин россия [url=https://1win3069.ru/]https://1win3069.ru/[/url]
Своевременное обращение к специалистам клиники «ВитаРеабилит» — это не только шанс на восстановление здоровья, но и гарантия безопасности пациента и его близких.
Подробнее – [url=https://narkologicheskaya-klinika-podolsk5.ru/]narkologicheskaya-klinika-klinika-pomoshch[/url]
https://rocket-tools.pro/
https://frasesmotivacional.com/
Алкогольная зависимость остаётся одной из самых серьёзных проблем современного общества. Злоупотребление алкоголем разрушает здоровье, негативно влияет на психику, приводит к разрыву семей, потере работы и социального статуса. Когда самостоятельные попытки побороть тягу к спиртному не приносят результата, эффективным выходом становится кодирование от алкоголизма — медицинская процедура, позволяющая на длительный срок блокировать желание употреблять спиртное и начать путь к полноценной жизни. В наркологической клинике «АлкоСвобода» в Мытищах для кодирования применяются только современные, безопасные и признанные методики, которые подбираются индивидуально для каждого пациента с учётом всех особенностей организма.
Подробнее можно узнать тут – http://kodirovanie-ot-alkogolizma-mytishchi5.ru
Ключевым этапом является снятие интоксикации и устранение абстинентного синдрома. Применяются препараты, направленные на нормализацию работы внутренних органов и поддержание общего состояния здоровья. Медикаментозная терапия включает назначение антидепрессантов, препаратов, блокирующих тягу к алкоголю, что подтверждается исследованиями, опубликованными на научном портале PubMed. Актуальные рекомендации по медикаментозному лечению алкоголизма доступны на Национальном центре здоровья.
Ознакомиться с деталями – [url=https://lechenie-alkogolizma-krasnodar00.ru/]анонимное лечение алкоголизма краснодар[/url]
провайдеры интернета в волгограде
domashij-internet-volgograd004.ru
подключить интернет в квартиру омск
Капельница – это метод внутривенной инфузии, который позволяет доставить в организм пациента растворы для детоксикации и восстановления. Основные задачи процедуры включают очищение крови от токсичных веществ, нормализацию водно-солевого баланса и улучшение общего самочувствия.
Детальнее – [url=https://kapelnica-ot-zapoya-krasnoyarsk55.ru/]капельница от запоя цена[/url]
В этой статье рассматриваются способы преодоления зависимости и успешные истории людей, которые справились с этой проблемой. Мы обсудим важность поддержки со стороны близких и профессионалов, а также стратегии, которые могут помочь в процессе выздоровления. Научитесь первоочередным шагам к новой жизни.
Выяснить больше – [url=https://narkolog-na-dom-krasnodar15.ru/]нарколог на дом клиника[/url]
Если пациенту требуется постоянный мониторинг или комплексное лечение, мы обеспечиваем круглосуточное пребывание в стационаре. Здесь доступны углублённая диагностика — УЗИ органов брюшной полости, расширенные анализы крови, кардиомониторинг — и коррекция терапии в режиме реального времени. Комфортные палаты, ежедневное наблюдение медсестры и консультации психотерапевта создают условия для быстрого и безопасного выхода из зависимости.
Детальнее – http://narkologicheskaya-pomoshh-ekaterinburg0.ru/skoraya-narkologicheskaya-pomoshh-v-ekb/
Лечение алкоголизма в Краснодаре представляет собой комплекс мероприятий, направленных на полное восстановление физического и психологического состояния пациента. Этот процесс требует профессионального подхода, включающего диагностику, детоксикацию, терапию зависимости и реабилитацию. Информация о современных методах терапии доступна на официальном портале Минздрава РФ.
Получить больше информации – [url=https://lechenie-alkogolizma-krasnodar00.ru/]анонимное лечение алкоголизма краснодар[/url]
Пациенты клиники «НаркоМед» полностью застрахованы от утечки личной информации. Приём и лечение оформляются по псевдониму, документы не передаются в другие организации.
Получить дополнительную информацию – https://narkologicheskaya-klinika-ekaterinburg0.ru/
В этом обзоре мы обсудим современные методы борьбы с зависимостями, включая медикаментозную терапию и психотерапию. Мы представим последние исследования и их результаты, чтобы читатели могли быть в курсе наиболее эффективных подходов к лечению и поддержке.
Разобраться лучше – https://narkolog-na-dom-krasnodar12.ru
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Узнать из первых рук – https://www.anna-rossi.com/b15
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Почему это важно? – https://www.miacostruzioni.com/logo-barber-new
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Расширить кругозор по теме – http://www.russianicons.ru/order.php?obj=37
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Узнай первым! – http://russianicons.ru/order.php?obj=95
недорогой интернет омск
domashij-internet-volgograd005.ru
домашний интернет омск
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Осуществить глубокий анализ – https://kaltenholzhausen.de/hello-world
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Только для своих – https://www.localartshop.co.uk/product/baby-elephant-smile-by-mark-hutchby
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Изучить вопрос глубже – https://rpasminio.cl/?p=1118
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Почему это важно? – https://apotheke-am-ukb.de/favicon
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Лучшее решение — прямо здесь – https://topic.lk/6199
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Посмотреть подробности – https://crossoceantravel.com/nature-holiday-quotes
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Почему это важно? – https://www.waytoroad.com/6859.html
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Переходите по ссылке ниже – https://topic.lk/2650
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Обратиться к источнику – https://topic.lk/2828
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Подробнее – https://si14.com.br/manual/cobranca-recorrente
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также – https://aorakipeakhoney.com/product/aoraki-peak-raw-manuka-honey-umf-10-500g
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Смотри, что ещё есть – https://www.bloos.nu/favicon1
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Осуществить глубокий анализ – https://topic.lk/3745
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Читать дальше – https://topic.lk/1097
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Выяснить больше – https://www.hotel-sugano.com/bbs/sugano.cgi/www.tovery.net/datasphere.ru/club/user/12/blog/2477/www.skitour.su/datasphere.ru/club/user/12/blog/2477/www.hip-hop.ru/forum/id298234-worksale/sugano.cgi?page40=val
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Открыть полностью – https://markaritchie.com/southpaw-overcomes-challenges-filming-yoshiki-under-sky
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Ознакомиться с деталями – http://www.russianicons.ru/order.php?obj=119
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Узнай первым! – https://volleymsk.ru/forum/viewtopic.php?t=3933&start=30
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Обратитесь за информацией – https://ehsuy.com/cual-es-el-tiempo-de-vida-de-un-carro
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Расширить кругозор по теме – http://www.russianicons.ru/order.php?obj=141
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Это стоит прочитать полностью – https://club-retraites.com/que-proposent-les-clubs-de-retraites-corses.php
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Лучшее решение — прямо здесь – https://twoplus3.in/unblocked-games-wtf
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также – https://friendshipstar.org/january-2022
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Выяснить больше – http://www.ugradsl.ru
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Расширить кругозор по теме – https://lifebnf.bonificaoficial.com/2024/09/25/ola-mundo
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Разобраться лучше – https://volleymsk.ru/forum/viewtopic.php?t=4304&start=225
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Лови подробности – https://ak-tactical.ru
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Заходи — там интересно – http://rodonit-v-saratove.ru
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Подробнее – https://autosalesreviews.com/blog/car-dealership-employee-discount-guide
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Подробнее – https://ilchiccodisenape.org/2023/05/11/economia-solidale-in-festa
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Посмотреть подробности – https://leepeout.com/hello-world
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Неизвестные факты о… – https://topic.lk/7951
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Подробнее тут – https://winebooks-school.net/chassagne
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Открыть полностью – https://upgear.digital/2021/07/11/custom-seo
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Информация доступна здесь – https://topic.lk/8877
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Лучшее решение — прямо здесь – https://topic.lk/12510
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Практические советы ждут тебя – https://sagradoespaciointerior.com/dia-1-21-dias-de-unidad
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Читать дальше – https://potiguardemossoro.com.br/2022/02/23/onde-assistir-barretos-x-nacional-sp-pelo-campeonato-paulista-a3-quarta-23-02-as-20-hs
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Разобраться лучше – https://www.bodyfuelindia.com/fitness-tips-holidays-festivals
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Все материалы собраны здесь – https://apotheke-am-ukb.de/favicon
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Лучшее решение — прямо здесь – https://topic.lk/14694
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Открыть полностью – https://shop.platinumwellness.net/hello-world
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Только факты! – https://www.thinkwatercentralcoast.com.au/2018/06/20/irrigation-controllers
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Открыть полностью – http://www.enirys.fr/galerie/img_0719
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Обратитесь за информацией – https://www.ghazla.com/?p=59
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Обратитесь за информацией – https://www.kormentdot.com/il-salto-di-mister-okay
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Обратитесь за информацией – https://ivanteevka-conditioner.ru
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Обратитесь за информацией – https://www.leonarditadelebro.com/optimiza-tus-recursos-y-maximiza-tu-cosecha
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Это стоит прочитать полностью – https://aichi-gorin-abilym.jp/?p=1
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Узнать из первых рук – https://walkthetalk.be/uncategorized/hello-world
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Более того — здесь – https://topic.lk/12318
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Более того — здесь – http://amore-bello.ru
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Секреты успеха внутри – https://cokrat.ru
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Получить больше информации – https://blog.cedupcriciuma.com.br/reciclagem
авто из китая Запчасти для китайских авто: где купить и сколько стоит? Рассказываем о том, где купить оригинальные и неоригинальные запчасти для китайских автомобилей и сколько они стоят.
кайтсёрфинг Кайтсёрфинг оборудование должно соответствовать вашему уровню подготовки и стилю катания. Правильно подобранный кайт и доска обеспечат вам комфорт и безопасность на воде.
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Это стоит прочитать полностью – https://pero.bg/2024/10/04/kak-da-reagirame-pri-speshna-nuzhda-ot-klyuchar-v-studentski-grad
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Узнать из первых рук – https://zayandab.org/product/product-5
онлайн казино 888starz [url=http://888starz-casino.com.ru/]http://888starz-casino.com.ru/[/url] .
подключить интернет в волгограде в квартире
domashij-internet-volgograd006.ru
интернет провайдер омск
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Выяснить больше – https://radsports.ru
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Все материалы собраны здесь – https://software-provider.ru
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Доступ к полной версии – http://voasw.ru
Когда запой превращается в угрозу для жизни, оперативное вмешательство становится критически важным. В Тюмени, Тюменская область, опытные наркологи предлагают услугу установки капельницы от запоя прямо на дому. Такой метод позволяет начать детоксикацию с использованием современных медикаментов, что способствует быстрому выведению токсинов, восстановлению обменных процессов и нормализации работы внутренних органов. Лечение на дому обеспечивает комфортную обстановку, полную конфиденциальность и индивидуальный подход к каждому пациенту.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-tyumen00.ru/]после капельницы от запоя в тюмени[/url]
Сразу после вызова нарколог прибывает на дом для проведения детального осмотра. На этом этапе специалист измеряет жизненно важные показатели, собирает анамнез и оценивает степень алкогольной интоксикации, что является основой для составления персонального плана лечения.
Углубиться в тему – [url=https://vyvod-iz-zapoya-tula0.ru/]vyvod-iz-zapoya-tula0.ru/[/url]
Выбор помощи на дому имеет ряд значительных преимуществ:
Узнать больше – [url=https://vyvod-iz-zapoya-tula0.ru/]вывод из запоя клиника тула[/url]
В данной статье мы акцентируем внимание на важности поддержки в процессе выздоровления. Мы обсудим, как друзья, семья и профессионалы могут помочь тем, кто сталкивается с зависимостями. Читатели получат практические советы, как поддерживать близких на пути к новой жизни.
Подробнее можно узнать тут – [url=https://narkolog-na-dom-krasnodar17.ru/]нарколог на дом[/url]
Врач уточняет, как долго продолжается запой, какой алкоголь употребляется, а также наличие сопутствующих заболеваний. Этот тщательный анализ позволяет оперативно подобрать оптимальные методы детоксикации и снизить риск осложнений.
Разобраться лучше – [url=https://vyvod-iz-zapoya-tula0.ru/]вывод из запоя недорого в туле[/url]
Выбор помощи на дому имеет ряд значительных преимуществ:
Разобраться лучше – [url=https://vyvod-iz-zapoya-tula0.ru/]срочный вывод из запоя[/url]
провайдеры домашнего интернета воронеж
domashij-internet-voronezh004.ru
домашний интернет тарифы воронеж
В данной статье мы акцентируем внимание на важности поддержки в процессе выздоровления. Мы обсудим, как друзья, семья и профессионалы могут помочь тем, кто сталкивается с зависимостями. Читатели получат практические советы, как поддерживать близких на пути к новой жизни.
Подробнее – [url=https://narkolog-na-dom-krasnodar17.ru/]врач нарколог на дом[/url]
plinko [url=http://plinko-kz1.ru]http://plinko-kz1.ru[/url]
Нужна душевая кабина? магазины душевых кабин в минске: компактные и просторные модели, стеклянные и пластиковые, с глубоким поддоном и без. Установка под ключ, гарантия, помощь в подборе. Современный дизайн и доступные цены!
Lubisz kasyna online i automaty do gry? Zarejestruj się na slottica jak wypłacić pieniądze i zgarnij nagrody powitalne!
мостбет [url=http://mostbet4084.ru]мостбет[/url]
Когда запой выходит из-под контроля, здоровье пациента оказывается под угрозой, и каждая минута имеет решающее значение. В Твери экстренная помощь нарколога на дому позволяет оперативно начать лечение, провести детоксикацию организма и стабилизировать состояние пациента. Такой подход обеспечивает индивидуальную терапию в комфортных условиях, сохраняя конфиденциальность и снижая эмоциональное напряжение.
Исследовать вопрос подробнее – [url=https://reabcentr-narko.ru/]вывод из запоя капельница в твери[/url]
Системы автоматизированного дозирования обеспечивают точное введение медикаментов, минимизируя риск передозировки и побочных эффектов. Постоянный мониторинг жизненно важных показателей позволяет врачу оперативно корректировать терапевтическую схему для достижения максимальной безопасности и эффективности.
Разобраться лучше – [url=https://narco-vivod-clean.ru/]vyvod-iz-zapoya-kruglosutochno sankt-peterburg[/url]
Кроме того, врач приедет в любое удобное для пациента время, даже ночью, обеспечив круглосуточный доступ к медицинской помощи. Специалист подбирает индивидуальный состав капельницы, что позволяет оптимально поддержать организм в зависимости от состояния пациента.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-ektb55.ru/]врача капельницу от запоя[/url]
В данной статье рассматриваются проблемы общественного здоровья и социальные факторы, влияющие на него. Мы акцентируем внимание на значении профилактики и осведомленности в защите здоровья на уровне общества. Читатели смогут узнать о новых инициативах и программах, направленных на улучшение здоровья населения.
Подробнее – [url=https://narkolog-na-dom-krasnodar11.ru/]вызов нарколога на дом[/url]
mostbet [url=https://www.mostbet4083.ru]mostbet[/url]
В этой статье мы обсудим процесс восстановления после зависимостей, акцентируя внимание на различных методах и подходах к реабилитации. Читатели узнают, как создать план выздоровления и использовать полезные ресурсы для достижения устойчивых изменений.
Получить дополнительные сведения – [url=https://narkolog-na-dom-krasnodar17.ru/]нарколог на дом клиника[/url]
Красноярск, как и любой крупный город, сталкивается с распространенными проблемами зависимости. Учитывая высокий уровень стресса, социальное давление и быстрое развитие мегаполиса, люди часто оказываются в сложных ситуациях, связанных с алкогольной или наркотической зависимостью. В таких случаях своевременная помощь квалифицированного нарколога становится не просто желательной, а жизненно необходимой.
Детальнее – [url=https://narcolog-na-dom-krasnoyarsk55.ru/]вызов врача нарколога на дом[/url]
домашний интернет в воронеже
domashij-internet-voronezh005.ru
подключить интернет в воронеже в квартире
мостюет [url=https://mostbet4082.ru]https://mostbet4082.ru[/url]
Нужна душевая кабина? душевая кабина купить недорого: компактные и просторные модели, стеклянные и пластиковые, с глубоким поддоном и без. Установка под ключ, гарантия, помощь в подборе. Современный дизайн и доступные цены!
Нужна душевая кабина? душевые кабины в минске: компактные и просторные модели, стеклянные и пластиковые, с глубоким поддоном и без. Установка под ключ, гарантия, помощь в подборе. Современный дизайн и доступные цены!
В этой заметке мы представляем шаги, которые помогут в процессе преодоления зависимостей. Рассматриваются стратегии поддержки и чек-листы для тех, кто хочет сделать первый шаг к выздоровлению. Наша цель — вдохновить читателей на положительные изменения и поддержать их в трудных моментах.
Выяснить больше – [url=https://narkolog-na-dom-krasnodar16.ru/]нарколог на дом вывод из запоя[/url]
бк 1win официальный сайт [url=https://1win3070.ru/]бк 1win официальный сайт[/url]
Нужна душевая кабина? сколько стоит душевая кабина: компактные и просторные модели, стеклянные и пластиковые, с глубоким поддоном и без. Установка под ключ, гарантия, помощь в подборе. Современный дизайн и доступные цены!
Этот медицинский обзор сосредоточен на последних достижениях, которые оказывают влияние на пациентов и медицинскую практику. Мы разбираем инновационные методы лечения и исследований, акцентируя внимание на их значимости для общественного здоровья. Читатели узнают о свежих данных и их возможном применении.
Подробнее – [url=https://narkolog-na-dom-krasnodar17.ru/]нарколог на дом цена[/url]
интернет провайдер воронеж
domashij-internet-voronezh006.ru
домашний интернет тарифы воронеж
Эта процедура доступна как в условиях клиники, так и на дому, что делает ее универсальным решением для различных жизненных ситуаций. При этом важно доверять свое здоровье только профессиональным врачам, которые могут обеспечить безопасное и качественное лечение.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-krasnoyarsk55.ru/]поставить капельницу от запоя[/url]
кайтсёрфинг Обучение трюкам в кайтсерфинге: последовательность и прогресс
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Что ещё нужно знать? – http://cbs.torzhok.tverlib.ru/node/3189
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Смотрите также… – http://cbs.torzhok.tverlib.ru/sharapov-vg-sled-na-kabaney-trope
http://xn--80aafabrjladsicc1amg1o4cf1dg.online/
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Обратитесь за информацией – http://poisk.cerkov.ru/catalog/group/74
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Все материалы собраны здесь – https://www.kindergarten-essenbach.de/unser-haus/raeumlichkeiten/burgermeister
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Посмотреть подробности – https://udplarioja.es/escuela-de-cuidados
мебель для кабинета руководителя Офисные кресла – это залог здоровья и продуктивности сотрудников. Эргономичные кресла поддерживают правильную осанку, снижают нагрузку на позвоночник и предотвращают развитие профессиональных заболеваний. Важно выбирать кресла с регулируемой высотой, наклоном спинки и подлокотниками. Обивка должна быть дышащей и износостойкой. Инвестиция в качественные кресла – это инвестиция в здоровье сотрудников и успех компании.
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Изучить вопрос глубже – http://shga.kr/archives/165
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Осуществить глубокий анализ – https://growgreenltd.com/solar-energy-benefits-going-green-and-saving-green
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Нажмите, чтобы узнать больше – https://alimpeza.li/hello-world
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Смотрите также – https://www.radhe-radhe.net/bhaye-pragat-kripala-din-dayala
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Смотрите также… – https://trendlylife.com/2018/07/08/%E0%AE%87%E0%AE%A8%E0%AF%8D%E0%AE%A4-%E0%AE%B5%E0%AE%B0%E0%AF%81%E0%AE%9F-%E0%AE%AA%E0%AF%81%E0%AE%A4%E0%AE%BF%E0%AE%AF-%E0%AE%9F%E0%AE%BF%E0%AE%9A%E0%AF%88%E0%AE%A9%E0%AE%B0%E0%AF%8D-%E0%AE%95
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Осуществить глубокий анализ – https://volleymsk.ru/forum/viewtopic.php?t=4291&start=810
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Читать дальше – https://thebusinesslines.com/elon-musks-iron-man-moment-a-playful-pledge-to-battle-villains
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Почему это важно? – https://www.volleymsk.ru/forum/viewtopic.php?t=8149&start=75
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Не пропусти важное – http://cbs.torzhok.tverlib.ru/plan-raboty-na-yanvar-2023-g
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Выяснить больше – https://www.arteinox.net/2021/07/26/hello-world
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Неизвестные факты о… – http://bipolar-studio.com/blog-1
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Погрузиться в детали – https://www.radioribelle.it/index.php/2023/05/18/casa-bruschi-insolite-e-sostenibili-invenzioni
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Это ещё не всё… – https://radx.app/2023/04/09/digital-marketing-made-easy-let-our-team-handle
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Получить больше информации – https://www.strindbergsmuseet.se/bildnr-62august-strindberg-sjalvportratt-berlin-1892-93-2
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Читать дальше – https://growgreenltd.com/solar-energy-benefits-going-green-and-saving-green
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Погрузиться в детали – http://cbs.torzhok.tverlib.ru/plan-raboty-na-oktyabr-2022-g
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Перейти к статье – http://poisk.cerkov.ru/catalog/region/79
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Расширить кругозор по теме – https://www.karbonarna.cz/portfolio/udelatko-ii
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Узнай первым! – http://cbs.torzhok.tverlib.ru/tematicheskaya-progulka-eho-voyny-i-pamyat-serdec-0
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Секреты успеха внутри – https://volleymsk.ru/forum/viewtopic.php?t=12289&start=255
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Смотрите также… – https://volleymsk.ru/forum/viewtopic.php?t=4967&start=45
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Изучить вопрос глубже – http://dralexsimpson.ru
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Что ещё? Расскажи всё! – https://intermed-dent.ru
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Смотрите также – https://bbhcosarl.com/2022/07/01/nature-holiday-quotes
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Изучить аспект более тщательно – https://ghizmohealing.com/?p=219
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Почему это важно? – https://toancaukonishi.vn/chinh-sach-doi-tra
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Ознакомьтесь с аналитикой – https://chamundaengineeringworks.in/product/cew-23
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Все материалы собраны здесь – https://turkishbeadart.com/choose-your-right-candle-for-each-room
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Читать дальше – https://faculdadecci.com.br/events/change-career-to-teaching
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Изучить аспект более тщательно – https://cnopolebarns.com/feedback-2
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Обратитесь за информацией – https://colombiaexports.net/aspectos-tecnicos-del-banano
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Открыть полностью – https://liebeliebe.eu/seggs-school-2-6cm
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Изучить вопрос глубже – https://web3-clone.deltamobile.com/semi_blindspot_x2a
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Доступ к полной версии – https://royaloceantravel.com/nature-holiday-quotes
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Продолжить изучение – https://bladesauto.com/blades
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Это ещё не всё… – https://www.mrpepe.com/daily-fx/currency-prices-usdgbpeur
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Обратитесь за информацией – https://www.cosfertoscana.it/uncategorized/hello-world-2
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Разобраться лучше – https://www.statewideinspection.com/hardwood-floors-cupping-and-buckling-due-to-crawl-space-moisture
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Разобраться лучше – https://uiquilmes.org/home-2
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Все материалы собраны здесь – http://priligydapoxetine.online/post/34
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Нажмите, чтобы узнать больше – https://servitransportesandina.com.co/etapa-de-certificacion
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Все материалы собраны здесь – https://volleymsk.ru/forum/viewtopic.php?t=4769&start=75
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Подробнее тут – https://malaysia.royaloceantravel.com/5-most-beautiful-islands-in-asia
Этот документ охватывает важные аспекты медицинской науки, сосредотачиваясь на ключевых вопросах, касающихся здоровья населения. Мы рассматриваем свежие исследования, клинические рекомендации и лучшие практики, которые помогут улучшить качество лечения и профилактики заболеваний. Читатели получат возможность углубиться в различные медицинские дисциплины.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-krasnodar15.ru/]вызвать нарколога на дом[/url]
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Более подробно об этом – https://saga-trans.com/portfolio/organization-design-2
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Информация доступна здесь – https://sobolyfamily.ru
http://xn--80aafabrjladsicc1amg1o4cf1dg.world/
мостбет [url=http://mostbet4085.ru]http://mostbet4085.ru[/url]
Lubisz kasyna online i automaty do gry? Zarejestruj się na slottica bonus bez depozytu i zgarnij nagrody powitalne!
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Смотрите также… – http://www.drag-bitva.ru
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Как достичь результата? – https://eroticweb.ru
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Все материалы собраны здесь – http://495-9220683.ru
В состав капельницы обычно входят растворы для гидратации, витаминно-минеральные комплексы, гепатопротекторы для защиты печени, а также седативные препараты для стабилизации нервной системы. Такой подход позволяет быстро справиться с признаками похмелья и предотвратить развитие более серьезных осложнений.
Получить дополнительную информацию – https://kapelnica-ot-zapoya-ekb55.ru/kapelnicza-ot-zapoya-v-stacionare-ekaterinburg
После первичного осмотра начинается активная фаза детоксикации. Современные препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови и восстановления обменных процессов. Этот этап критически важен для нормализации работы печени, почек и сердечно-сосудистой системы.
Разобраться лучше – http://vyvod-iz-zapoya-vladimir000.ru
Lubisz kasyna online i automaty do gry? Zarejestruj się na slottica kasyno i zgarnij nagrody powitalne!
Создание сайтов Сайт под ключ Сайт под ключ – это комплексное решение, включающее все этапы разработки, от проектирования до запуска и поддержки. Заказчик получает готовый к работе продукт, избавляя себя от необходимости разбираться в технических деталях. Это экономит время и обеспечивает профессиональный результат.
Одним из ключевых достоинств выезда нарколога на дом является возможность лечения в привычной для пациента среде, что способствует снижению стресса и ускоряет процесс выздоровления. Кроме того, лечение на дому гарантирует полную анонимность и индивидуальный подход к каждому пациенту.
Подробнее тут – [url=https://narcolog-na-dom-v-irkutske66.ru/]vyzov-narkologa-na-dom irkutsk[/url]
Есть ситуации, когда дальнейшее промедление может привести к необратимым последствиям:
Изучить вопрос глубже – [url=https://lechenie-alkogolizma-korolev5.ru/]клиника лечения алкоголизма[/url]
авиаперевозки из китая ЖД доставка грузов из Китая – это золотая середина между скоростью и стоимостью. Этот способ подходит для крупных партий товаров, когда сроки не критичны, но важна экономия. Важно тщательно планировать маршрут и оформлять все необходимые документы для беспрепятственного прохождения через границы. Железнодорожные перевозки становятся все более популярными благодаря своей надежности. Железная дорога – оптимальный баланс.
Есть ситуации, когда дальнейшее промедление может привести к необратимым последствиям:
Углубиться в тему – [url=https://lechenie-alkogolizma-korolev5.ru/]http://lechenie-alkogolizma-korolev5.ru[/url]
В таких критических условиях время становится самым ценным и решающим фактором, поэтому оперативный вывод из запоя позволяет не только остановить дальнейшее ухудшение состояния, но и значительно снизить вероятность возникновения хронических заболеваний, инвалидизации и даже летального исхода, обеспечивая пациенту шанс на полноценное выздоровление и возвращение к нормальной жизни
Подробнее – [url=https://vyvod-iz-zapoya-arkhangelsk66.ru/]вывод из запоя архангельской область[/url]
раздача фрибетов винлайн [url=http://winline-fribet-novym-klientam.ru]http://winline-fribet-novym-klientam.ru[/url] .
winline фрибет за регистрацию без депозита [url=https://www.winline-fribet-za-registraciyu-2025.ru]https://www.winline-fribet-za-registraciyu-2025.ru[/url] .
что такое фрибет в винлайн [url=besplatnyj-fribet-winline.ru]что такое фрибет в винлайн[/url] .
Основные и наиболее распространенные показания для вызова квалифицированного нарколога на дом включают в себя тяжелый и длительный запой, не поддающийся самостоятельному прекращению, наличие признаков тяжелой алкогольной интоксикации (тошнота, рвота, головная боль, головокружение, нарушение координации движений), выраженный абстинентный синдром (тремор, потливость, тревога, раздражительность, бессонница), наличие сопутствующих хронических заболеваний, которые могут усугубиться на фоне алкогольной интоксикации, психотические расстройства (галлюцинации, бред) и суицидальные мысли или намерения, требующие немедленной медицинской помощи
Разобраться лучше – http://narcolog-na-dom-v-irkutske66.ru/vrach-narkolog-na-dom-irkutsk
винлайн условия бонуса выплата [url=winline-bonus-za-registraciyu-2025.ru]винлайн условия бонуса выплата[/url] .
Комедия детства смотреть бесплатно один дома 1 — легендарная комедия для всей семьи. Без ограничений, в отличном качестве, на любом устройстве. Погрузитесь в атмосферу праздника вместе с Кевином!
винлайн промокод на фрибет 2025 [url=winline-fribet-kazhdyj-den.ru]winline-fribet-kazhdyj-den.ru[/url] .
После диагностики выявленные нарушения восполняются посредством инфузий с витаминами группы B, C, магнием и элементами.
Узнать больше – http://lechenie-alkogolizma-ekaterinburg0.ru/
винлайн фрибет май 2025 [url=https://winline-fribety-2025.ru/]winline-fribety-2025.ru[/url] .
This is very interesting, You’re a very professional blogger. I’ve joined your rss feed and look ahead to in quest of more of your magnificent post. Additionally, I have shared your site in my social networks
Cheap limo near me
Неотъемлемой частью программы становится психотерапия — работа с мотивацией, психологической поддержкой, поиском и устранением “триггеров” зависимости, проработка самооценки, стрессоустойчивости. К работе обязательно подключаются близкие: совместные консультации помогают восстановить доверие, снизить уровень конфликтов, научиться поддерживать без контроля и упрёков.
Подробнее можно узнать тут – [url=https://lechenie-alkogolizma-korolev5.ru/]lechenie-alkogolizma-anonimno[/url]
Распознать необходимость лечения просто: достаточно внимательно отнестись к тревожным признакам. Вот лишь некоторые ситуации, когда обращение в наркологическую клинику становится жизненно важным:
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-balashiha5.ru/]http://narkologicheskaya-klinika-balashiha5.ru[/url]
Купить сапёрный противоосколочный костюм с доставкой по России (ПВЗ в ЛНР и ДНР) Тепловизоры для спасателей: поиск пострадавших в завалах и на открытой местности.
Алкоголизм — это не просто вредная привычка или “слабость характера”. Это тяжёлое хроническое заболевание, способное разрушить здоровье, психику, семью, карьеру. На первых порах зависимость подкрадывается незаметно: человек пьёт “по случаю”, для снятия усталости, ради компании. Но постепенно спиртное становится единственным способом отвлечься, расслабиться, уйти от тревог и проблем. Со временем самоконтроль ослабевает, периоды трезвости укорачиваются, а любые попытки “перестать пить” заканчиваются тяжёлым абстинентным синдромом, бессонницей, раздражительностью, головными болями и срывами. В такой ситуации никакие уговоры и угрозы не работают. Необходима профессиональная, комплексная медицинская помощь — именно такую поддержку с максимальной анонимностью и уважением к пациенту предлагает наркологическая клиника «Новая Точка» в Королёве.
Получить дополнительную информацию – [url=https://lechenie-alkogolizma-korolev5.ru/]лечение алкоголизма королев[/url]
В случаях, когда транспортировка в клинику затруднительна или пациент испытывает выраженный стресс, возможно выездное консультирование и начальная детоксикация на дому. Врач прибывает с портативным набором для инфузий, оперативно stabilizирует состояние и даёт рекомендации по дальнейшим действиям.
Выяснить больше – http://lechenie-alkogolizma-ekaterinburg0.ru/klinika-lecheniya-alkogolizma-v-ekb/
В рамках детоксикации применяются капельничные инфузии и современные препараты, позволяющие эффективно очистить кровь. Постоянный контроль жизненных показателей пациента обеспечивает безопасность процедуры и позволяет корректировать дозировку лекарств по мере необходимости.
Подробнее тут – http://vyvod-iz-zapoya-novokuznetsk66.ru
Услуга капельничного вывода из запоя на дому в Тюмени предоставляет комплексный подход к экстренному лечению алкогольной интоксикации. Врач приезжает на дом, проводит первичный осмотр, собирает анамнез и назначает индивидуальную схему терапии. Современные методы инфузионной терапии позволяют точно дозировать препараты, обеспечивая быструю детоксикацию и минимизируя риск осложнений.
Подробнее тут – https://vyvod-iz-zapoya-vladimir00.ru
Противоосколочные модульные одеяла для защиты от дронов (из СВМПЭ) с доставкой по России (ПВЗ в ЛНР и ДНР) Саперный костюм: купить с доставкой в ЛНР и ДНР. Гарантированная защита при разминировании.
Врач назначает комплекс препаратов для нормализации состояния и устранения интоксикации. Применяются детоксикационные средства для очищения организма и облегчения абстинентного синдрома. Важным компонентом терапии являются витаминные комплексы и минералы, восстанавливающие метаболический баланс. При необходимости назначаются седативные препараты для снижения тревожности и нормализации сна. Также используются гепатопротекторы и другие средства для поддержки органов, пострадавших от алкогольной интоксикации.
Разобраться лучше – [url=https://vyvod-iz-zapoya-krasnoyarsk55.ru/]вывод из запоя на дому цена[/url]
1вин [url=1win3061.ru]1win3061.ru[/url]
Применяются растворы на основе физраствора, глюкозы, витаминов группы B, противорвотных, седативных и гепатопротекторов. Используемые препараты входят в реестр разрешённых лекарств.
Получить больше информации – [url=https://narcolog-na-dom-ekaterinburg55.ru/]вызвать нарколога на дом в екатеринбурге[/url]
Есть ситуации, когда дальнейшее промедление может привести к необратимым последствиям:
Подробнее – [url=https://lechenie-alkogolizma-korolev5.ru/]клиника лечения алкоголизма[/url]
mostbet [url=http://mostbet4078.ru/]http://mostbet4078.ru/[/url]
Алкогольная и наркотическая зависимости могут привести к тяжелым и опасным для жизни состояниям. Вызов нарколога становится необходимым, если:
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-voronezh0.ru/]vrach-narkolog-na-dom voronezh[/url]
Психологическая поддержка включает индивидуальные сессии, в ходе которых пациент получает инструменты для борьбы с негативными установками и формирования здоровых моделей поведения. Применение техник релаксации и когнитивно-поведенческой терапии помогает значительно снизить риск повторного запоя.
Детальнее – [url=https://vyvod-iz-zapoya-novokuznetsk66.ru/]вывод из запоя клиника новокузнецк[/url]
1вин [url=https://1win3064.ru]1вин[/url]
Одним из наиболее удобных вариантов лечения является проведение процедуры в домашних условиях. Это особенно актуально для пациентов, которые чувствуют себя слишком плохо, чтобы отправиться в клинику, или желают сохранить анонимность.
Подробнее – https://kapelnica-ot-zapoya-krasnoyarsk55.ru/
Комплексное лечение на дому организовано по строго отлаженной схеме, позволяющей оперативно стабилизировать состояние пациента и провести качественную детоксикацию.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-vladimir00.ru/]срочный вывод из запоя владимир[/url]
Есть ситуации, когда дальнейшее промедление может привести к необратимым последствиям:
Подробнее тут – [url=https://lechenie-alkogolizma-korolev5.ru/]lechenie-alkogolizma[/url]
Как помогает организму
Получить дополнительную информацию – https://vyvod-iz-zapoya-novokuznetsk6.ru/narkologiya-vyvod-iz-zapoya-novokuzneczk
Незамедлительно после вызова нарколог прибывает на дом для проведения тщательного осмотра. На данном этапе специалист собирает анамнез, измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и оценивает степень интоксикации. Эти данные являются основой для составления индивидуального плана лечения.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-vladimir000.ru/]вывод из запоя цены владимир[/url]
Кроме того, анонимность является важной составляющей этой услуги. Лечение дома исключает возможность столкновения с посторонними людьми и помогает пациентам сохранить свою репутацию. Клиника «Гармония и Свет» обеспечивает полную конфиденциальность, предоставляя пациентам возможность получать помощь без лишних вопросов и обсуждений.
Ознакомиться с деталями – https://narcolog-na-dom-ektb55.ru
взять микрозайм займ онлайн бесплатно
Клиника «НаркологикПлюс» предоставляет квалифицированную помощь нарколога на дому в Воронеже. Если вы или ваши близкие столкнулись с последствиями длительного употребления алкоголя или наркотиков, наши специалисты готовы оперативно выехать и оказать экстренную помощь. Мы проводим детоксикацию организма, снимаем симптомы абстинентного синдрома и стабилизируем состояние пациента, обеспечивая высокий уровень безопасности, строгую анонимность и индивидуальный подход.
Выяснить больше – https://narcolog-na-dom-voronezh0.ru/vyzov-narkologa-na-dom-voronezh
В обычных условиях цена услуги составляет от 1500 до 2500 рублей. Эта сумма включает выезд специалиста, первичный осмотр и базовую детоксикационную терапию.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-vladimir00.ru/]вывод из запоя в владимире[/url]
После обращения в клинику пациент получает первую подробную консультацию — это может быть очный визит, звонок или заявка через сайт. При необходимости организуется экстренное поступление или выезд нарколога на дом: врач приезжает с полным набором оборудования и медикаментов для оказания неотложной помощи. На первом этапе проводится диагностика: анализы крови, ЭКГ, осмотр профильных специалистов, дополнительное обследование по показаниям. Это позволяет точно определить степень зависимости, выявить осложнения и подобрать эффективную тактику лечения.
Подробнее – [url=https://narkologicheskaya-klinika-balashiha5.ru/]narkologicheskaya-klinika-stacionar[/url]
Химчистка мебели ростов
Клиника «УралМед» работает без выходных и праздников: прием пациентов — круглосуточно. Это позволяет оказывать экстренную помощь при острых состояниях, а также вести наблюдение за динамикой восстановления здоровья в ночные часы.
Получить дополнительные сведения – https://lechenie-alkogolizma-ekaterinburg0.ru/anonimnoe-lechenie-alkogolizma-v-ekb/
понижение уровня грунтовых вод иглофильтрами [url=http://vodoponizhenie-moskva.ru]http://vodoponizhenie-moskva.ru[/url] .
внедрение erp 1c [url=www.1s-erp-vnedrenie.ru]www.1s-erp-vnedrenie.ru[/url] .
устройство водопонижения [url=vodoponizhenie-msk.ru]vodoponizhenie-msk.ru[/url] .
холодильная камера для мяса [url=https://xn—-7sbabtdykncetibz6f4f8b.xn--p1ai/]https://xn—-7sbabtdykncetibz6f4f8b.xn--p1ai/[/url] .
Клиника «НаркологикПлюс» предоставляет квалифицированную помощь нарколога на дому в Воронеже. Если вы или ваши близкие столкнулись с последствиями длительного употребления алкоголя или наркотиков, наши специалисты готовы оперативно выехать и оказать экстренную помощь. Мы проводим детоксикацию организма, снимаем симптомы абстинентного синдрома и стабилизируем состояние пациента, обеспечивая высокий уровень безопасности, строгую анонимность и индивидуальный подход.
Изучить вопрос глубже – [url=https://narcolog-na-dom-voronezh0.ru/]нарколог на дом вывод воронеж[/url]
внедрение 1с 8 [url=www.1s-vnedrenie.ru]www.1s-vnedrenie.ru[/url] .
сопровождение 1с предприятие 8.3 [url=www.1s-soprovozhdenie.ru]www.1s-soprovozhdenie.ru[/url] .
стеклянная перегородка в душевую Стеклянные перегородки с регулируемой прозрачностью: инновационные решения для приватности и комфорта. Технологии, применение, установка и управление.
Как подчёркивает главный врач клиники Кондратьев И.Л., «своевременный выезд нарколога на дом снижает риски осложнений и повышает шансы на полное восстановление пациента».
Детальнее – [url=https://narcolog-na-dom-ekaterinburg55.ru/]вызвать нарколога на дом[/url]
Такая услуга доступна круглосуточно, что позволяет вызвать врача в любое время. Профессиональные специалисты, приехав на дом, тщательно подберут состав капельницы с учетом индивидуальных особенностей пациента, чтобы обеспечить максимально эффективное лечение. Анонимность и высокая квалификация медперсонала делают этот способ особенно удобным для людей, которые предпочитают конфиденциальность.
Изучить вопрос глубже – https://kapelnica-ot-zapoya-ekb55.ru/kapelnicza-na-domu-ekaterinburg-ot-zapoya
Выездной формат позволяет избежать контактов с другими пациентами в клинике и очистить организм в привычной обстановке. Специалисты самостоятельно привозят весь необходимый набор медикаментов и расходных материалов.
Получить дополнительную информацию – http://narkologicheskaya-klinika-ekaterinburg0.ru
Как правило, для эффективного устранения токсинов из организма и восстановления нормального функционирования всех органов и систем, назначаются специальные препараты. К таким препаратам относятся растворы для восстановления водно-солевого баланса, витамины и медикаменты для поддержания нормальной работы печени, а также препараты, стабилизирующие психоэмоциональное состояние пациента.
Получить дополнительную информацию – [url=https://narcolog-na-dom-ektb55.ru/]нарколог на дом вывод[/url]
охлаждаемый тепловизор тактическое снаряжение и амуниция купить Купить тактическое снаряжение и амуницию можно в специализированных магазинах и интернет-магазинах.
Красноярск, как и любой крупный город, сталкивается с распространенными проблемами зависимости. Учитывая высокий уровень стресса, социальное давление и быстрое развитие мегаполиса, люди часто оказываются в сложных ситуациях, связанных с алкогольной или наркотической зависимостью. В таких случаях своевременная помощь квалифицированного нарколога становится не просто желательной, а жизненно необходимой.
Ознакомиться с деталями – [url=https://narcolog-na-dom-krasnoyarsk55.ru/]вызов врача нарколога на дом[/url]
https://servicestat.ru/service-spb Servicestat.ru — это удобный каталог-рейтинг сервисных центров по ремонту электроники. На сайте собраны контакты (адреса, телефоны), отзывы клиентов, акции и скидки, а также оценки качества услуг. Пользователи могут быстро найти проверенные мастерские в своем городе, сравнить рейтинги и выбрать лучший вариант. Полезен для тех, кто хочет отдать технику в надежные руки.
? Поиск сервисов по местоположению и брендам
? Реальные отзывы и оценки клиентов
? Акции, скидки и спецпредложения
? Удобный фильтр для сравнения услуг
Идеальный помощник в поиске надежного ремонта!
профессиональное тактическое снаряжение магазин тактического снаряжения в воронеже В Воронеже есть несколько магазинов, предлагающих тактическое снаряжение для различных целей.
В клинике каждому пациенту уделяют особое внимание. Врачи знают: универсальных решений нет, за каждым случаем — своя история и свои причины. Первый контакт начинается с конфиденциальной консультации. Можно просто позвонить или написать онлайн — уже на этом этапе врач поможет оценить ситуацию, объяснит возможные этапы и даст рекомендации по подготовке к визиту.
Подробнее – [url=https://lechenie-alkogolizma-korolev5.ru/]наркологическое лечение алкоголизма[/url]
хозблоки Дачные домики для летнего отдыха: уютный уголок на природе. Планировка, терраса, зона барбекю, советы по обустройству.
What’s up Dear, are you truly visiting this web page daily, if so then you will absolutely take good know-how.
Chauffeur service near me
Комплексный и научно обоснованный подход включает в себя медикаментозную детоксикацию, направленную на быстрое выведение токсинов и продуктов распада алкоголя из организма, и психологическую поддержку, помогающую пациенту справиться с абстинентным синдромом, снизить тягу к алкоголю и сформировать мотивацию к дальнейшему лечению и реабилитации, позволяя обеспечить наиболее быстрое, эффективное и безопасное восстановление физического и психического здоровья пациента в комфортных домашних условиях.
Получить дополнительные сведения – [url=https://narcolog-na-dom-v-irkutske66.ru/]врач нарколог на дом платный в иркутске[/url]
Одним из ключевых достоинств выезда нарколога на дом является возможность лечения в привычной для пациента среде, что способствует снижению стресса и ускоряет процесс выздоровления. Кроме того, лечение на дому гарантирует полную анонимность и индивидуальный подход к каждому пациенту.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-v-irkutske66.ru/]нарколог на дом клиника иркутск[/url]
тепловизоры самара купить кевларовый противоосколочный костюм Кевларовый противоосколочный костюм – это вершина защиты, обеспечивающая максимальную безопасность в условиях повышенного риска. Инвестиция в такой костюм – это инвестиция в вашу жизнь и здоровье. При выборе обращайте внимание на соответствие стандартам безопасности и комфорт ношения.
Кроме того, врач оказывает психологическую поддержку, которая помогает пациенту справиться с чувством тревоги, депрессией и страхом, возникающими на фоне зависимости.
Узнать больше – [url=https://narcolog-na-dom-v-krasnoyarske55.ru/]vyzvat-narkologa-na-dom krasnojarsk[/url]
внедрение 1с под ключ [url=https://1s-vnedrenie.ru/]https://1s-vnedrenie.ru/[/url] .
Ищете, где хранить продукты при низкой температуре? Вам подойдёт холодильная камера – практичное и надёжное решение для бизнеса и дома, оформите заказ по ссылке https://камера-холодильная.рф/
Незамедлительно после вызова нарколог прибывает на дом для проведения тщательного осмотра. На данном этапе специалист собирает анамнез, измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и оценивает степень интоксикации. Эти данные являются основой для составления индивидуального плана лечения.
Детальнее – https://vyvod-iz-zapoya-vladimir000.ru
аренда яхты на час [url=http://www.yachts-charter-dubai.com]http://www.yachts-charter-dubai.com[/url] .
В рамках детоксикации применяются капельничные инфузии и современные препараты, позволяющие эффективно очистить кровь. Постоянный контроль жизненных показателей пациента обеспечивает безопасность процедуры и позволяет корректировать дозировку лекарств по мере необходимости.
Подробнее тут – [url=https://vyvod-iz-zapoya-novokuznetsk66.ru/]вывод из запоя на дому кемеровская область[/url]
сопровождение erp [url=www.1s-soprovozhdenie.ru/]сопровождение erp[/url] .
888starz tz [url=https://888starz-english.com]888starz tz[/url] .
Кроме того, анонимность является важной составляющей этой услуги. Лечение дома исключает возможность столкновения с посторонними людьми и помогает пациентам сохранить свою репутацию. Клиника «Гармония и Свет» обеспечивает полную конфиденциальность, предоставляя пациентам возможность получать помощь без лишних вопросов и обсуждений.
Получить дополнительную информацию – [url=https://narcolog-na-dom-ektb55.ru/]вызов нарколога на дом екатеринбург[/url]
мелбет кг [url=https://melbet1032.ru/]мелбет кг[/url]
Выбирая лечение в «Наркосфере», пациенты Балашихи и Балашихинского района могут быть уверены в высоком качестве услуг и современном подходе. Здесь применяют только сертифицированные препараты, используются новейшие методы терапии и реабилитации. Клиника работает круглосуточно, принимает пациентов в любой день недели и всегда готова к экстренному реагированию. Индивидуальный подход проявляется не только в подборе схемы лечения, но и в поддержке семьи на каждом этапе выздоровления. Весь процесс проходит в обстановке полной конфиденциальности: сведения о пациентах не передаются в сторонние организации, не оформляется наркологический учёт.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-balashiha5.ru/]наркологическая клиника[/url]
водопонизительная скважина строительное водопонижение
walewska.ru
холодильные камеры промышленные [url=http://xn—-7sbarc2alevbr6d.xn--p1ai/]http://xn—-7sbarc2alevbr6d.xn--p1ai/[/url] .
С увеличением темпа жизни и нарастающим стрессом, многие люди в Екатеринбурге сталкиваются с зависимостями, особенно с алкогольной. Алкогольная зависимость является одной из наиболее распространённых проблем, требующих немедленного вмешательства специалистов. Важно помнить, что в сложных ситуациях, связанных с зависимостью, помощь не должна откладываться. Вызов нарколога на дом в Екатеринбурге становится идеальным вариантом для тех, кто не может или не хочет покидать свой дом, но нуждается в медицинской помощи.
Получить дополнительные сведения – http://narcolog-na-dom-ektb55.ru/narkolog-na-dom-ekaterinburg-tseny/
Особое внимание в клинике уделяется постоянному контролю за состоянием: врачи и медсёстры следят за показателями здоровья, в любой момент могут скорректировать курс терапии или подключить дополнительных специалистов. Все препараты подбираются индивидуально — с учётом возраста, стажа употребления, веса, состояния органов и особенностей сопутствующих заболеваний.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-balashiha5.ru/]vyvod-iz-zapoya-klinika[/url]
бурение скважин обратной промывкой [url=https://vodoponizhenie-moskva.ru]https://vodoponizhenie-moskva.ru[/url] .
камера охлаждения [url=www.xn—-7sbabtdykncetibz6f4f8b.xn--p1ai]камера охлаждения[/url] .
вакуумное водопонижение [url=www.vodoponizhenie-msk.ru]вакуумное водопонижение[/url] .
внедрение erp на предприятии [url=http://1s-erp-vnedrenie.ru]http://1s-erp-vnedrenie.ru[/url] .
В рамках детоксикации применяются капельничные инфузии и современные препараты, позволяющие эффективно очистить кровь. Постоянный контроль жизненных показателей пациента обеспечивает безопасность процедуры и позволяет корректировать дозировку лекарств по мере необходимости.
Получить дополнительную информацию – https://vyvod-iz-zapoya-novokuznetsk66.ru/vyvod-iz-zapoya-na-domu-novokuzneczk/
Ищете, где хранить продукты при низкой температуре? холодильные камеры – практичное и надёжное решение для бизнеса и дома.
Одним из наиболее привлекательных вариантов лечения является проведение капельницы от запоя на дому. Это решение избавляет пациента от необходимости посещать клинику, что важно для тех, кто не хочет привлекать лишнего внимания или испытывает трудности с передвижением. Кроме того, лечение на дому дает возможность получить помощь в комфортной обстановке, что снижает стресс и ускоряет восстановление.
Узнать больше – [url=https://kapelnica-ot-zapoya-ekb55.ru/]капельница от запоя цена екатеринбург[/url]
mostbet [url=http://mb1113.ru/]http://mb1113.ru/[/url]
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Осуществить глубокий анализ – https://fbpro.nl/2024/01/11/hallo-wereld
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Подробная информация доступна по запросу – http://www.sifd.eu/?p=10437
Ищете, где хранить продукты при низкой температуре? Вам подойдёт холодильная камера – практичное и надёжное решение для бизнеса и дома, оформите заказ по ссылке https://камера-холодильная.рф/
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Ознакомиться с деталями – https://takideas.com/transfer-telegram-group-members-to-another-group
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Информация доступна здесь – https://www.taylordentist.com/living-with-sensitive-teeth-during-the-holiday-season
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Только для своих – https://prime.itxoft.com/seo-and-website-audits-itxoft-11316
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Только для своих – https://www.primabevallen.nl/contact/photo-1457342813143-a1ae27448a82
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Погрузиться в научную дискуссию – https://alfalhosah.com/%D9%84%D8%A8%D8%B4%D8%B1%D8%A9-%D8%A8%D9%8A%D8%B6%D8%A7%D8%A1-%D9%85%D8%AB%D9%84-%D8%A7%D9%84%D8%AB%D9%84%D8%AC-%D8%A7%D9%84%D8%AE%D9%84%D9%8A%D8%B7-%D8%A7%D9%84%D8%B3%D8%AD%D8%B1%D9%89-%D8%A8%D8%A7
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Лови подробности – https://laranca-limousin.com/events/this-is-a-test
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Ознакомиться с деталями – https://2022nq.co.uk
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Смотрите также… – http://www.useuse.de/uselog/?p=1034
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Только факты! – https://zombie-romance.com/best-new-horror-movies-your-guide-frightening
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Обратитесь за информацией – http://www.hausdrachen.net/2011/04/05/mein-schatten-ist-blond
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Более того — здесь – https://jobletter.in/3-awesome-security-plugins-for-wordpress
обучение кайтсёрфингу Кайт: ваш верный спутник в кайтсёрфинге. Изучите виды кайтов, их размеры, особенности и выберите идеальный вариант для своего стиля катания и погодных условий.
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Только для своих – https://acerko.com/portfolio/wooden-bench
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Получить исчерпывающие сведения – https://www.budgetbouwnederland.nl/2019/01/10/hello-world
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Почему это важно? – https://mezzani.com.br/produto/macarrao-tagliatelle-integral-500g
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Получить дополнительную информацию – https://manjars.com/hello-world
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Узнать напрямую – https://thevisioncenterny.com/oakley-day-june-6th
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Расширить кругозор по теме – https://metahotnews.org/this-86-year-old-actress-proves-you-dont-need-surgery-to-look-stunning-photos-of-her-transformation-2
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Это стоит прочитать полностью – https://www.zahorany.cz/cropped-erb_zahorany-png
система водопонижения водопонижение скважинами
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Нажми и узнай всё – https://res-funeral.jp/info/?p=277
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Обратитесь за информацией – https://kmsstmart.com/hello-world
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Узнать из первых рук – https://lutonstay.com/product/helicopter-flight-dubai
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Это стоит прочитать полностью – http://ltemachinery.ie/btme-harrowgate-roundup
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Доступ к полной версии – https://babi-beauty.fr/meet-our-master-barbers-faces-behind-the-scissors
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Изучить аспект более тщательно – https://www.studiosollai.it/listituto-del-subappalto
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Выяснить больше – https://17g.ru/?p=216
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Смотри, что ещё есть – https://www.lmgoutfly.se/port9-thumb-1-1
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Ознакомиться с полной информацией – https://www.vastavkatta.com/index.php/2024/05/04/mpscproblems
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Более подробно об этом – https://artecampo.tercerimpactoproducciones.com/index.php/2023/06/22/mastering-time-management-key-to-business-success
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Изучить аспект более тщательно – https://hotelallseasons.co.in/gallery/rooms
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Подробная информация доступна по запросу – https://okamoto-alumi.jp/2019/07/08/%E6%98%9F%E3%81%BE%E3%81%A4%E3%82%8A
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Почему это важно? – http://www.sifd.eu/?p=10437
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Изучить аспект более тщательно – https://engagecleveland.org/top-5-places-to-enjoy-the-cherry-blossoms-in-cleveland
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Не упусти важное! – https://maxxme.in/how-to-function-in-the-event-the-date-ignores-you
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Лови подробности – http://brandcrystal.com/cropped-snowflake-board-2-jpg
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Все материалы собраны здесь – https://www.welchomeinside.fr/product/ship-your-idea-2
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Лови подробности – https://irablogging.in/%E0%A4%89%E0%A4%B2%E0%A4%97%E0%A4%A1%E0%A4%BE-3
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Провести детальное исследование – https://skyconsultancybd.com/5-most-beautiful-islands-in-asia
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Обратитесь за информацией – https://kox-tv.ru
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Читать дальше – http://5sekretov.ru
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Более того — здесь – https://freguesianews.com.br/2023/02/19/roma-x-hellas-verona-onde-assistir-ao-vivo-palpites-e-escalacoes-campeonato-italiano-22-23-hoje-19-02
walewska.ru
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Открыть полностью – https://www.bauwesen.co/ard-plusminus-bahnhoefe-stuttgart-21
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Расширить кругозор по теме – https://www.mrpepe.com/daily-fx/currency-prices-usdgbpeur
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Выяснить больше – https://babi-beauty.fr/signature-styles-the-best-haircuts-at-our-barber-shop
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Получить исчерпывающие сведения – http://test.veteranskytte.nu/forslagssida
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Углубить понимание вопроса – http://globalcolor.cl/reinterprets-the-classic-bookshelf
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Расширить кругозор по теме – https://www.izumishoko.co.jp/%E8%A3%BD%E5%93%81/%E3%81%8A%E3%82%84%E3%82%AB%E3%83%86a/124
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Подробнее тут – http://turbophone4g.ru
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Ознакомьтесь с аналитикой – https://itechinsurance.com.au/itech_logo_800
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Смотри, что ещё есть – http://iglover.ru
walewska.ru
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Узнать напрямую – http://katakana-sushi.ru
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Ознакомиться с полной информацией – http://instel21.ru
купить 1с онлайн [url=https://kupit-1s21.ru/]kupit-1s21.ru[/url] .
Экстренный вызов нарколога на дом в Иркутске от «ТрезвоМед» при запое, интоксикации или кодировании – анонимно и удобно. Осмотр, детоксикация капельницей, индивидуальный план лечения – все это на дому! «ТрезвоМед» – круглосуточная помощь, анонимность и безопасность при отказе от алкоголя. Не можете бросить пить самостоятельно? Нужна помощь нарколога! Васильев: «Своевременная помощь при интоксикации – залог успешного выздоровления».
Углубиться в тему – [url=https://narcolog-na-dom-v-irkutske0.ru/]вызов нарколога на дом цена иркутск[/url]
1с предприятие программа [url=https://kupit-1s23.ru/]1с предприятие программа[/url] .
прогнозы на спорт завтра [url=http://www.sportbets27.ru]http://www.sportbets27.ru[/url] .
Заключительная фаза реабилитации фокусируется на обучении пациента жизни без алкоголизма и развитии навыков преодоления жизненных трудностей естественным путем. В рамках этого этапа пациенты активно участвуют в специализированных программах, нацеленных на восстановление утраченных социальных связей и профессиональных компетенций. Программа включает трудотерапию, образовательные курсы и тематические семинары. Особое внимание уделяется работе с семьей: родственники проходят специальное обучение, помогающее им лучше понимать особенности зависимости быстро и эффективно оказывать поддержку близкому человеку.
Получить больше информации – [url=https://vyvod-iz-zapoya-krasnoyarsk55.ru/]вывод из запоя клиника красноярск[/url]
ставки на спорт фонбет прогнозы [url=https://www.sportbets26.ru]https://www.sportbets26.ru[/url] .
прогнозы на спорт от капперов [url=www.prognoz-na-segodnya-na-sport8.ru/]www.prognoz-na-segodnya-na-sport8.ru/[/url] .
камера холодильная низкотемпературная [url=www.xn—-7sbarc2alevbr6d.xn--p1ai]www.xn—-7sbarc2alevbr6d.xn--p1ai[/url] .
Курс по плазмотерапии обучение плазмотерапии с выдачей сертификата. Освойте PRP-методику: показания, противопоказания, протоколы, работа с оборудованием. Обучение для медработников с практикой и официальными документами.
mostbet [url=https://www.mostbet4077.ru]https://www.mostbet4077.ru[/url]
В Коломне решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Подробнее тут – [url=https://kapelnica-ot-zapoya-kolomna15.ru/]капельница от запоя клиника коломна[/url]
Кодирование может быть проведено сразу после очистки организма. В зависимости от состояния человека и выбранного метода, процедура занимает от 30 минут до полутора часов. Медикаментозные способы предполагают введение препаратов внутримышечно, внутривенно или подкожно. Психотерапевтические методы включают беседу, работу с убеждениями, возможно использование элементов гипноза или суггестивных техник.
Подробнее тут – [url=https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/]kodirovanie-ot-alkogolizma-na-domu-shchelkovo[/url]
saif zone sharjah uae saif zone application form
Запой – тяжелое состояние, когда организм не может функционировать без алкоголя. Токсины накапливаются, органы перестают работать, иммунитет слабеет. Это очень опасно. Самостоятельные попытки выйти из запоя только ухудшают ситуацию и усиливают страдания. Клиника «Семья и Здоровье» предлагает лечение на дому, без стресса и в комфортной обстановке. Мы работаем круглосуточно, быстро приезжаем и проводим все необходимые процедуры. Длительный запой разрушает организм, ухудшает качество жизни и может привести к опасным ситуациям. Своевременный вывод из запоя — это критически важно для сохранения здоровья и жизни.
Узнать больше – http://vyvod-iz-zapoya-krasnoyarsk0.ru/vyvod-iz-zapoya-na-domu-krasnoyarsk/
кайтинг Безопасность – превыше всего. Всегда проверяйте оборудование, оценивайте погодные условия и соблюдайте правила поведения на воде. Не рискуйте, если чувствуете себя неуверенно.
Врач-нарколог проводит комплексное обследование пациента, оценивая степень зависимости и общее состояние организма. В ходе первичного осмотра специалист не только определяет тяжесть алкогольной зависимости, но и выявляет сопутствующие патологии, которые могут повлиять на процесс лечения. Обследование включает лабораторные анализы, электрокардиограмму и другие необходимые диагностические процедуры. Врач тщательно изучает анамнез для выявления возможных противопоказаний к определенным методам терапии. Особое внимание уделяется психологическим аспектам, которые могли способствовать формированию зависимости, что помогает разработать эффективную программу лечения.
Углубиться в тему – https://vyvod-iz-zapoya-krasnoyarsk55.ru/vyvod-iz-zapoya-krasnoyarsk-kruglosutochno
1вин [url=http://1win3063.ru/]http://1win3063.ru/[/url]
Красноярск, как и любой крупный город, сталкивается с распространенными проблемами зависимости. Учитывая высокий уровень стресса, социальное давление и быстрое развитие мегаполиса, люди часто оказываются в сложных ситуациях, связанных с алкогольной или наркотической зависимостью. В таких случаях своевременная помощь квалифицированного нарколога становится не просто желательной, а жизненно необходимой.
Углубиться в тему – [url=https://narcolog-na-dom-krasnoyarsk55.ru/]narkolog-na-dom krasnojarsk[/url]
понижение уровня грунтовых вод устройство водопонижения
Современная жизнь, особенно в крупном городе, как Красноярск, часто становится причиной различных зависимостей. Работа в условиях постоянного стресса, высокий ритм жизни и эмоциональные перегрузки могут привести к проблемам, которые требуют неотложной медицинской помощи. Одним из наиболее удобных решений в такой ситуации является вызов нарколога на дом.
Получить дополнительные сведения – [url=https://narcolog-na-dom-v-krasnoyarske55.ru/]вызов нарколога на дом красноярск[/url]
1win [url=1win3062.ru]1win[/url]
Учебный центр дополнительного профессионального образования НАСТ – https://nastobr.com/ – это возможность пройти дистанционное обучение без отрыва от производства. Мы предлагаем обучение и переподготовку по 2850 учебным направлениям. Узнайте на сайте больше о наших профессиональных услугах и огромном выборе образовательных программ.
Интересная статья: Макароны с мясом: рецепт вкусного и сытного блюда
Читать статью: Бюджетные рецепты: готовим быстро, много и вкусно
прогнозы на спорт онлайн [url=www.prognoz-na-segodnya-na-sport10.ru]www.prognoz-na-segodnya-na-sport10.ru[/url] .
ставки на киберспорт прогнозы на сегодня [url=prognoz-na-segodnya-na-sport8.ru]prognoz-na-segodnya-na-sport8.ru[/url] .
кайтинг Кайтсёрфинг – это постоянно развивающийся спорт, появляются новые трюки, стили и оборудование. Будьте в курсе последних тенденций и не останавливайтесь на достигнутом.
спортивные прогнозы на футбол [url=http://www.kompyuternye-prognozy-na-futbol8.ru]http://www.kompyuternye-prognozy-na-futbol8.ru[/url] .
прогнозы на спорт от профессионалов [url=http://www.prognoz-na-segodnya-na-sport9.ru]прогнозы на спорт от профессионалов[/url] .
ставки на спорт прогноз [url=http://www.sportbets27.ru]http://www.sportbets27.ru[/url] .
мостбет [url=http://fti.org.kg/]мостбет[/url]
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Следуйте по ссылке – https://www.iscinmobiliaria.cl/footer-title-bkg
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Следуйте по ссылке – https://getsetafrica.com/2022/08/20/hello-world
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Подробная информация доступна по запросу – https://joseortuno.es/teatro-apnea
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Лучшее решение — прямо здесь – https://ingenieria-drones.com/soluciones-integrales-con-drones-transformando-la-industria
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Практические советы ждут тебя – http://www.mm-baitservice-blog.at/2018/03/01/37-2/bild3/?page_number_0=55
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Не пропусти важное – https://watercoolersuae.com/2024/04/25/understanding-electrical-codes-a-guide-for-diy-enthusiasts
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Что ещё? Расскажи всё! – https://www.bretagneidlarge.org/court-defeat-for-trump-is-a-win-for-the-arctic-court-defeat-for-trump-is-a-win-for-the-arctic
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Все материалы собраны здесь – https://good88888.org/game-bai-cat-te
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Следуйте по ссылке – https://physiomentor.co/functional-sequence-of-balance-training-exercises
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Перейти к статье – https://maygiattham.com/san-pham/ban-hut-bui-cua-may-hut-bui-30l
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Ознакомьтесь с аналитикой – https://colombiaexports.net/aspectos-tecnicos-del-banano
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Посмотреть подробности – https://thesupplementspecialists.com/green-tea
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Углубить понимание вопроса – http://bewatererasmus.eu/tamaramorenomansilla-copy
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Изучить аспект более тщательно – https://madamodel.com/2022/11/14/what-video-game-character-creation-predicts-about-the-metaverse
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Обратитесь за информацией – https://www.news-tube.com/et-consequuntur-ducimus-reiciendis-libero-numquam-esse
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Более подробно об этом – http://cressonscitra.cf/post/34
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Расширить кругозор по теме – https://www.cveterinarialaantilla.com/hola-mundo
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Погрузиться в детали – https://statuscaptions.com/the-most-goals-scored-in-an-international-match-by-a-single-player.html
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Только факты! – https://alhiddayapharma.com/index.php/product/brochure-headphone
ставки на спорт прогноз [url=http://sportbets26.ru/]http://sportbets26.ru/[/url] .
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Смотрите также – https://lucahalma.com/profile/contact
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Продолжить изучение – https://getsetafrica.com/2022/08/20/hello-world
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Что ещё нужно знать? – https://www.pisali.ru/taidest/64691
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Следуйте по ссылке – https://nomadwriter.fr/strategie-multisite-e-commerce
Читать в подробностях: Как контролировать гнев: советы психолога
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Погрузиться в детали – https://nutrientesparati.com/teatino-2
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Погрузиться в детали – http://onlypams.band/2017/05/28/feeling-the-beat
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Только факты! – https://amnc.com.ar/fotos
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Почему это важно? – https://statuscaptions.com/diamondback-ac-heating-plumbing-transforming-plumbing-solutions-in-phoenix.html
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Ознакомьтесь с аналитикой – https://bellville.gob.ar/2022/08/10/el-programa-del-municipio-ajedrez-social-se-multiplica-en-las-escuelas
Читать новость: Как защититься от сальмонеллеза: советы экспертов
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Подробная информация доступна по запросу – https://suryayudhapark.com/2024/05/02/halo-dunia
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Изучить аспект более тщательно – http://corps-hubertia.de/hubertia/index.php/component/k2/item/9/9?start=12630
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Что ещё? Расскажи всё! – https://hosemarket.com/troubleshooting-common-issues-with-camlock-couplings
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Смотри, что ещё есть – https://www.blackcollegechampionships.com/2022-black-college-world-series
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Переходите по ссылке ниже – https://apolloboxingclub.ca/proper-nutrition-for-boxing-and-maintaining-work-life-balance
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Подробная информация доступна по запросу – https://www.impressivevegansolutions.com/sample-post-format-chat
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Углубить понимание вопроса – https://zuhdijaadilovic.com/aktuelnosti/ajvatovica-izmedu-onih-koji-je-osporavaju-i-onih-koji-je-odobravaju
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Полная информация здесь – https://bibicaspari.com/chatoyant-youtube-hover
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Как достичь результата? – https://f5fashion.vn/pittsburgh-pirates-alika-williams-parents-family-ethnicity-and-origin
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Полная информация здесь – https://nizam-electronics.pk/super-asia-ecm-5000-plus
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Расширить кругозор по теме – https://jumpingsun.com/canny-tmr-roof-maintenance-bentleigh
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Доступ к полной версии – http://www.mm-baitservice-blog.at/2018/03/01/37-2/bild3/?page_number_0=27
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Полная информация здесь – http://www.mm-baitservice-blog.at/2018/03/01/37-2/bild3/?page_number_0=13
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Полная информация здесь – https://salwaspherellc.com/2024/12/17/revlon-timeless-beauty-for-every-moment
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Ознакомьтесь с аналитикой – http://pic.murakumomura.com/2009/12/22/post_1840
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Полная информация здесь – https://cochastyle.com/pink-leoprint
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Полная информация здесь – https://phelionline.co.za/_sb_country/tonga
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Подробнее – https://guru.smkn1pacitan.sch.id/anditaufik/2016/10/05/latihan-listening-test
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Узнать больше – https://f5fashion.vn/update-anju-nasrullah-love-story-meet-the-indian-woman-who-crossed-the-india-pakistan-border-to-meet-her-facebook-lover
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Почему это важно? – https://smauditoria.com/soundtrack-filma-lady-exclusive-music-2
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Не пропусти важное – https://camtelkiosk.com/index.php/2021/12/24/vos-recharges
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Это ещё не всё… – https://www.gblearning.uk/2018/12/17/hello-world
кайтинг Кайтсёрфинг летом: идеальный отдых на воде. Наслаждайтесь летним солнцем и ветром на лучших спотах.
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Обратитесь за информацией – https://plustech.co.in/plustech-systems-has-been-awarded-a-turnkey-contract-by-m-s-ashok-leyland-ltd-for-new-frame-side-member-powder-coating-plant-hosur
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Как достичь результата? – https://f5fashion.vn/tameka-yallop-net-worth-in-2023-how-rich-is-she-now-update
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Почему это важно? – https://ero-rasskazy.ru
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Смотри, что ещё есть – https://www.blues-festival-utrecht.nl/uncategorized/2_notaris-1594122626-html
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Смотри, что ещё есть – http://mospill.ru
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Узнать напрямую – https://www.podasarbolado.com/planes-de-gestion
сколько стоит установить программу 1с [url=https://kupit-1s21.ru/]https://kupit-1s21.ru/[/url] .
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Доступ к полной версии – https://f5fashion.vn/vuon-quoc-gia-lencois-maranhenses-noi-hang-nghin-ho-nuoc-noi-giua-sa-mac
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Узнай первым! – https://pilates-guerande.fr/component/k2/item/11
обучение кайтсёрфингу Кайт лагерь: Сообщество единомышленников, объединенных страстью к ветру и волнам. Возможность не только научиться кайтсёрфингу, но и завести новых друзей.
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Почему это важно? – https://f5fashion.vn/cap-nhat-voi-hon-61-ve-sinh-nhat-sinh-nhat-hay-nhat
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Разобраться лучше – https://f5fashion.vn/du-lich-quang-nam-top-5-resort-sang-xin-min-cua-xu-quang
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Ознакомиться с полной информацией – https://pashupatiarchitech.com/parking/two-wheeler-parking/attachment/image-8
Среди преимуществ услуги:
Подробнее тут – [url=https://narkolog-na-dom-chelyabinsk13.ru/]нарколог на дом недорого челябинск[/url]
Важным этапом работы клиники является всесторонняя диагностика состояния пациента. Используются лабораторные и инструментальные методы обследования для оценки влияния токсических веществ на организм. Такой подход позволяет составить индивидуальный план лечения, максимально учитывающий особенности пациента и стадию зависимости. Подробные рекомендации по диагностике зависимости опубликованы на сайте ФГБУ «НМИЦ Психиатрии и наркологии» Минздрава России.
Детальнее – http://narkologicheskaya-klinika-chelyabinsk13.ru/chastnaya-narkologicheskaya-klinika-chelyabinsk/
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Уточнить детали – http://doroga21.ru
Новое на сайте: Крепкое здоровье: советы, профилактика и полезная информация для жизни
программа 1с купить москва [url=www.kupit-1s23.ru]www.kupit-1s23.ru[/url] .
Новое на сайте: 6 полезных перекусов, если тянет на сладкое
I prefer quality over spikes, which is why I check vendors that offer twitter followers real with gradual delivery.
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Что ещё? Расскажи всё! – http://aromat-ognya.ru
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Уточнить детали – http://fione.ru
кайт школа “Школа трюков”: Как правильно тренироваться и прогрессировать
Hmm is anyone else experiencing problems with the pictures on this blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog. Any responses would be greatly appreciated.
https://maps.google.bt/url?sa=t&url=https://seattlelimorates.com/
кайтинг “Вьетнамские горизонты”: Муйне, сезон, как “биение сердца”
Подробности можно найти на официальном сайте Министерства здравоохранения РФ, где описаны стандарты оказания наркологической помощи и рекомендации по лечению зависимости Минздрав РФ — наркологическая помощь.
Изучить вопрос глубже – [url=https://narkolog-na-dom-chelyabinsk13.ru/]нарколог на дом цены[/url]
Самостоятельно выйти из запоя — почти невозможно. В Коломне врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-kolomna.ru/]врач на дом капельница от запоя[/url]
В Ростове-На-Дону решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Познакомиться с результатами исследований – [url=https://vyvod-iz-zapoya-rostov11.ru/]vyvod-iz-zapoya-rostov11.ru[/url]
кайтинг Стилей кайтсёрфинга много, и каждый найдет что-то для себя. Фристайл, фрирайд, вейврайдинг, кайт-рейсинг – выберите то, что вам по душе, и совершенствуйте свои навыки.
аренда яхты в оаэ [url=https://yachts-charter-dubai.com]https://yachts-charter-dubai.com[/url] .
AI platform bullbittrade.com for passive crypto trading. Robots trade 24/7, you earn. Without deep knowledge, without constant control. High speed, security and automatic strategy.
Innovative AI platform https://lumiabitai.com/ for crypto trading — passive income without stress. Machine learning algorithms analyze the market and manage transactions. Simple registration, clear interface, stable profit.
Dragon money Dragon Money – это не просто название, это врата в мир безграничных возможностей и захватывающих азартных приключений. Это не просто платформа, это целая вселенная, где переплетаются традиции вековых казино и новейшие цифровые технологии, создавая уникальный опыт для каждого искателя удачи. В современном мире, где финансовые потоки мчатся со скоростью света, Dragon Money предлагает глоток свежего воздуха – пространство, где правила просты, а возможности безграничны. Здесь каждая ставка – это шанс, каждый спин – это предвкушение победы, а каждый выигрыш – это подтверждение вашей удачи. Но Dragon Money – это не только про выигрыши и джекпоты. Это про сообщество единомышленников, объединенных общим стремлением к риску, азарту и адреналину. Это место, где можно найти новых друзей, поделиться опытом и ощутить неповторимый дух товарищества. Мы твердо верим, что безопасность и честность – это фундамент, на котором строится доверие. Именно поэтому Dragon Money уделяет особое внимание защите данных и обеспечению прозрачности каждой транзакции. Мы стремимся создать максимально комфортную и безопасную среду для наших игроков, где каждый может наслаждаться игрой, не беспокоясь о каких-либо рисках. Dragon Money – это не просто игра. Это возможность испытать себя, проверить свою удачу и почувствовать себя настоящим властелином своей судьбы. Присоединяйтесь к нам, и пусть дракон принесет вам богатство, успех и процветание! Да пребудет с вами удача!
Admiring the dedication you put into your site and detailed information you provide. It’s good to come across a blog every once in a while that isn’t the same unwanted rehashed material. Excellent read! I’ve bookmarked your site and I’m adding your RSS feeds to my Google account.
https://clients1.google.sc/url?q=https://seattlelimorates.com/
перевозки автовозом по россии [url=https://avtovoz-av7.ru]https://avtovoz-av7.ru[/url] .
доставка авто из тольятти [url=avtovoz-av.ru]avtovoz-av.ru[/url] .
Когда организм на пределе, важна срочная помощь в Ростове-На-Дону — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Переходите по ссылке ниже – [url=https://vyvod-iz-zapoya-rostov18.ru/]вывод из запоя капельница[/url]
Своевременный вызов специалиста особенно важен при следующих признаках:
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-mariupol13.ru/]помощь вывод из запоя в мариуполе[/url]
https://primiumpoppypods.com/
melbet промокод [url=http://melbet1036.ru]melbet промокод[/url]
ставки на хоккей прогнозы [url=https://luchshie-prognozy-na-khokkej6.ru/]https://luchshie-prognozy-na-khokkej6.ru/[/url] .
скачати українські фільми HD фільми українською онлайн
фільм українські серії нові фільми 2025 в Україні
фільми онлайн новинки кіно 2025 дивитися безкоштовно
мостбет [url=http://students.com.kg/]http://students.com.kg/[/url]
Для срочных случаев клиника поддерживает круглосуточный режим приёма заявок. После оформления вызова диспетчер передаёт информацию бригаде, и в течение часа врач прибудет по указанному адресу.
Узнать больше – [url=https://vyvod-iz-zapoya-mariupol13.ru/]помощь вывод из запоя[/url]
кайтинг “Лестница мастерства”: обучение, как “алхимия преображения”
прогнозы на теннис го спорт [url=https://www.prognoz-na-segodnya-na-sport10.ru]https://www.prognoz-na-segodnya-na-sport10.ru[/url] .
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Смотрите также… – https://wivesprayerconnection.com/external-pressures
Затяжной запой опасен для жизни. Врачи наркологической клиники в Коломне проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-kolomna15.ru/]капельница от запоя клиника коломна[/url]
автовоз [url=http://avtovoz-av8.ru/]http://avtovoz-av8.ru/[/url] .
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Изучить вопрос глубже – https://pitebd.com/how-to-protect-your-wealth-during-market-volatility
прогнозы на футбол на сегодня [url=http://prognozy-na-futbol-2.ru/]http://prognozy-na-futbol-2.ru/[/url] .
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Неизвестные факты о… – http://www.proyectorevuelta.com/2011/11/22/sobre-la-relocalizacion-de-boliches
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Выяснить больше – https://www.passionmontagne05.fr/mentions-legales
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Ознакомиться с деталями – https://dungcuthuyluc.com.vn/custom-term-paper-writing-service
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Что ещё? Расскажи всё! – https://www.jiyuuku.com/2019/11/07/%E3%83%96%E3%83%A9%E3%83%B3%E3%83%87%E3%82%A3%E3%83%B3%E3%82%B0%E3%81%AF%EF%BC%91%E6%97%A5%E3%81%AB%E3%81%97%E3%81%A6%E6%88%90%E3%82%89%E3%81%9A
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Все материалы собраны здесь – https://marisaalonso.es/tomando-consciencia
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Лови подробности – https://drnatro.com/le-khai-mac-he-nam-2024
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Все материалы собраны здесь – https://catedraoceano.iea.usp.br/swimming-lessons-for-kids-5-things-you-need-to-know
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Ознакомьтесь с аналитикой – https://wisatakopi.mitrapalupi.com/2023/07.33925
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Нажми и узнай всё – http://cgi.northern-days.jp/cgi-bin/rtsbbs_bre47/rtsbbs.cgi?bbs=0
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Узнай первым! – http://kancelariadkd.pl/one-click-demo-import-log_file_2020-01-25__12-13-25
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Изучить аспект более тщательно – https://betoinvest.dk/modern-house-facade-2021-08-27-19-27-44-utc-jpg
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Переходите по ссылке ниже – https://cgmbc.co.uk/projects/health-now-building-custom-fireplace
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Ознакомьтесь с аналитикой – https://nbmoa.org/inside-counter
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Осуществить глубокий анализ – https://sankt-peterburg.gde-sto.ru/magazin-autozapchastey-dva-mosta-plus
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Ознакомьтесь с аналитикой – https://test.ssmb.in/2024/02/27/dehradun-airport-unveils-modern-terminal-boosts-air-connectivity
прогнозы на спорт с аналитикой [url=https://prognoz-na-segodnya-na-sport9.ru/]prognoz-na-segodnya-na-sport9.ru[/url] .
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Посмотреть подробности – https://wivesprayerconnection.com/external-pressures
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Ссылка на источник – https://ashfordmanor.org/overhead-1
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Что ещё? Расскажи всё! – http://altarquitectura.com/post-with-gallery-and-video
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Изучить аспект более тщательно – https://f5fashion.vn/lang-mo-tan-thuy-hoang-chua-bay-chet-nguoi-khien-cac-nha-khao-co-lo-so
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Что ещё? Расскажи всё! – https://f5fashion.vn/cach-lam-banh-khuc-cay-giang-sinh-buche-de-noel-de-lam-tai-nha
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Нажмите, чтобы узнать больше – https://alquilaconexito.com/maximizar-rentabilidad-vivienda-consejos-propietarios
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Узнать напрямую – https://lamat.pl/2023/07/16/retreats-are-made-to-help-you-connect-with-youself
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Узнать из первых рук – https://f5fashion.vn/top-voi-hon-66-ve-be-bun-tap-to-mau-moi-nhat
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Все материалы собраны здесь – https://www.isabelkronenberger.de/test
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Практические советы ждут тебя – https://f5fashion.vn/chia-se-57-ve-cach-mac-vest-dep-cho-nu
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Обратитесь за информацией – https://www.echafaudage-coffrage-etaiement.org/annuaire/motto
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Подробная информация доступна по запросу – https://f5fashion.vn/top-voi-hon-72-ve-hinh-nen-bong-da-cho-may-tinh
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Изучить вопрос глубже – https://www.insightenterpriseconsulting.com/2016/03/15/why-we-love-construction-business
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Подробнее тут – https://corfopym.com/consultoria-y-asesoria-en-seguridad-industrial
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Обратитесь за информацией – https://f5fashion.vn/xu-nu-tich-cuc-bao-binh-co-chap
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Только для своих – https://www.efl-leb.org/4
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Смотри, что ещё есть – https://f5fashion.vn/chi-tiet-81-ve-hinh-nen-may-tinh-bau-troi-dem-hay-nhat
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Изучить аспект более тщательно – https://baanrista.nl/gallery-post-format
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Более того — здесь – https://www.digitel-srl.it/ciao-mondo
сколько стоит аренда яхты в дубае [url=https://yachts-charter-dubai.com/]https://yachts-charter-dubai.com/[/url] .
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Ознакомиться с деталями – https://magicmushroomsupply.net/product/1-up-mushroom
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Что ещё? Расскажи всё! – https://f5fashion.vn/tong-hop-voi-hon-67-ve-hong-hinh-nen-may-tinh-de-thuong-hay-nhat
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Это стоит прочитать полностью – http://nicolas-olano-boutique.com/le-guide-du-chino
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Почему это важно? – https://www.insightenterpriseconsulting.com/2016/03/15/why-we-love-construction-business
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Продолжить изучение – https://f5fashion.vn/chi-tiet-voi-hon-53-ve-ao-so-mi-co-vest
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Подробнее тут – https://andy-bourne.com/portfolio/idles-ultra-mono/trackreleaseposter-9900000000079e3c
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Полная информация здесь – https://xr-kosmetik.de/2017/09/22/the-heart-of-the-matter
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Ознакомьтесь с аналитикой – https://www.pienogele.lt/product-5
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Погрузиться в научную дискуссию – https://shopkamin.ru
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Получить исчерпывающие сведения – https://crosstrainingclub.fr/index.php/2022/12/21/workout-basics-with-us
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Что ещё нужно знать? – https://worldeventsforum.com/hello-world
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Узнать больше – https://f5fashion.vn/an-com-muong-qua-thuong-ca-song-giang
В этой статье мы рассматриваем разрушительное влияние зависимости на жизнь человека. Обсуждаются аспекты, такие как здоровье, отношения и профессиональные достижения. Читатели узнают о необходимости обращения за помощью и о путях к восстановлению.
Исследовать вопрос подробнее – https://detskoe-menu.ru/aktual-nost-kapel-nicy-ot-toksinov-v-sankt-peterburge-ot-kliniki-narkolog-ekspress
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Детальнее – http://polimetal-spb.ru
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Более того — здесь – https://nicolas-olano-boutique.com/comment-choisir-la-coupe-de-sa-chemise
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Все материалы собраны здесь – https://nicolas-olano-boutique.com/comment-choisir-la-coupe-de-sa-chemise
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Практические советы ждут тебя – https://chacaramorumbi.com.br/2021/01/30/hello-world
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Расширить кругозор по теме – https://adglighting.com/jack-bracket-od-2-collection-adg-lighting
обучение кайтсёрфингу Кайтсерфинг для женщин: советы и рекомендации
Hi, I wish for to subscribe for this webpage to obtain newest updates, so where can i do it please help out.
https://cse.google.al/url?sa=t&url=https://cabseattle.com/
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Нажмите, чтобы узнать больше – https://f5fashion.vn/tong-hop-59-ve-ao-vest-moi-nhat
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Нажмите, чтобы узнать больше – https://f5fashion.vn/cach-lam-banh-khuc-cay-giang-sinh-buche-de-noel-de-lam-tai-nha
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Только факты! – https://www.marcgm.com/2023/10/23/ayudas-y-subvenciones
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Изучить вопрос глубже – http://www.mm-baitservice-blog.at/2018/03/01/37-2/bild3/?page_number_0=22
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Переходите по ссылке ниже – https://f5fashion.vn/chia-se-hon-58-ve-hop-qua-to-mau-hay-nhat
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Изучить вопрос глубже – https://f5fashion.vn/chi-tiet-voi-hon-63-ve-hinh-nen-dep-cho-mam-non-moi-nhat
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Информация доступна здесь – https://f5fashion.vn/cap-nhat-52-ve-hinh-nen-dep-nu-hay-nhat
Как помогает организму
Подробнее тут – [url=https://vyvod-iz-zapoya-novokuznetsk6.ru/]вывод из запоя дешево в новокузнецке[/url]
прогноз матчей по футболу [url=https://kompyuternye-prognozy-na-futbol8.ru/]kompyuternye-prognozy-na-futbol8.ru[/url] .
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Изучить вопрос глубже – https://f5fashion.vn/mac-do-dan-toc-tinh-tu-ben-tinh-tre-le-quyen-bi-cu-dan-mang-nhac-nho-vi-1-ly-do
Услуга
Получить больше информации – https://kapelnica-ot-zapoya-nizhniy-novgorod000.ru/kapelnicza-ot-zapoya-na-domu-nizhnij-novgorod
Клиника «ТоксинНет» предлагает профессиональную помощь при алкогольной зависимости и запоях в Нижнем Новгороде. Наши опытные наркологи круглосуточно выезжают на дом для оказания экстренной медицинской помощи. Основным методом лечения является капельница от запоя, которая позволяет оперативно снять интоксикацию и стабилизировать общее состояние пациента. Мы обеспечиваем конфиденциальность, индивидуальный подход и высокий уровень безопасности процедур.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod0.ru/]капельница от запоя цена нижний новгород[/url]
кайтсёрфинг “Ветер в паруса, свобода в душе”: кайтсерфинг как симбиоз спорта и стихии, требующий не только физической подготовки, но и понимания метеорологических условий и гидродинамики.
Без медицинской помощи запой может перерасти в тяжёлую форму алкогольной интоксикации, вызывая серьёзные сбои в работе всех систем организма.
Разобраться лучше – [url=https://vyvod-iz-zapoya-arkhangelsk6.ru/]вывод из запоя на дому цена в архангельске[/url]
доставка авто [url=https://avtovoz-av7.ru]https://avtovoz-av7.ru[/url] .
перевозка легковых автомобилей автовозом [url=http://avtovoz-av.ru/]http://avtovoz-av.ru/[/url] .
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Ростове-На-Дону приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Подробнее – [url=https://vyvod-iz-zapoya-rostov11.ru/]vyvod-iz-zapoya-czena rostov-na-donu[/url]
Клиника Частный Медик?24 в Коломне — профессиональная капельница от запоя в стационаре, смотрите страницу услуги.
Подробнее – [url=https://kapelnica-ot-zapoya-kolomna11.ru/]капельница от запоя наркология в коломне[/url]
кайтсёрфинг “Гидрофойл”: Кайтсерфинг на гидрофойле: новый уровень катания
Затяжной запой опасен для жизни. Врачи наркологической клиники в Ростове-На-Дону проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Углубиться в тему – [url=https://vyvod-iz-zapoya-rostov12.ru/]наркология вывод из запоя в ростове-на-дону[/url]
точные прогнозы на хоккей [url=https://luchshie-prognozy-na-khokkej6.ru]https://luchshie-prognozy-na-khokkej6.ru[/url] .
кайтинг Шлем для кайтсерфинга: обязательный элемент
Лечение зависимости требует не только физической детоксикации, но и работы с психоэмоциональным состоянием пациента. Психотерапевтическая поддержка помогает выявить глубинные причины зависимости, снизить уровень стресса и сформировать устойчивые навыки самоконтроля, что существенно снижает риск рецидивов.
Подробнее можно узнать тут – [url=https://narcolog-na-dom-ufa000.ru/]нарколог на дом цены в уфе[/url]
Врачи клиники «ВитаЛайн» для снятия интоксикации и облегчения состояния пациента применяют исключительно качественные и проверенные лекарственные препараты, подбирая их в зависимости от особенностей ситуации и состояния здоровья пациента:
Детальнее – https://narcolog-na-dom-novosibirsk0.ru/vyzov-narkologa-na-dom-novosibirsk/
Алкогольный запой — это не просто последствие длительного употребления спиртного, а состояние, которое может привести к необратимым последствиям без своевременного медицинского вмешательства. Длительная интоксикация вызывает нарушения в работе печени, сердца, почек, приводит к обезвоживанию, сбою электролитного баланса, а также провоцирует серьёзные психоэмоциональные изменения. Самостоятельный отказ от алкоголя может стать причиной опасных осложнений: судорог, гипертонических кризов, панических атак и даже алкогольного психоза.
Подробнее – https://vyvod-iz-zapoya-arkhangelsk6.ru/vyvod-iz-zapoya-na-domu-arkhangelsk
кайт Обучение кайтсёрфингу: прогресс и достижения
melbet казино слоты скачать [url=melbet1035.ru]melbet казино слоты скачать[/url]
Нарколог устанавливает внутривенную капельницу, через которую вводятся растворы, обеспечивающие быстрое выведение токсинов, восстановление водно-электролитного баланса и стабилизацию состояния.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-voronezh00.ru/]нарколог на дом вывод в воронеже[/url]
При длительном запое токсические вещества накапливаются в организме, нарушая работу сердца, печени, почек и других жизненно важных систем. Своевременное вмешательство помогает предотвратить необратимые повреждения и снизить риск развития хронических заболеваний. В Уфе вызов нарколога на дом позволяет начать лечение в самые критические моменты, когда каждая минута имеет решающее значение для сохранения здоровья и жизни пациента.
Получить больше информации – [url=https://narcolog-na-dom-ufa00.ru/]вызов нарколога на дом уфа[/url]
скачать melbet на android бесплатно [url=https://melbet1033.ru]https://melbet1033.ru[/url]
кайт лагерь Кайтсёрфинг – это постоянное развитие и самосовершенствование. Учите новые трюки, осваивайте новые стили и делитесь опытом с другими кайтерами.
Ниже приведена ориентировочная таблица с ценами на основные виды услуг, предоставляемых нашей клиникой. Окончательная стоимость определяется после первичного осмотра и индивидуально согласовывается с пациентом:
Получить больше информации – http://kapelnica-ot-zapoya-nizhniy-novgorod000.ru/kapelnicza-ot-zapoya-czena-nizhnij-novgorod/
карниз с приводом для штор [url=www.elektrokarnizy777.ru]www.elektrokarnizy777.ru[/url] .
Лечение зависимости требует не только физической детоксикации, но и работы с психоэмоциональным состоянием пациента. Психотерапевтическая поддержка помогает выявить глубинные причины зависимости, снизить уровень стресса и сформировать устойчивые навыки самоконтроля, что существенно снижает риск рецидивов.
Детальнее – https://narcolog-na-dom-ufa000.ru/narkolog-na-dom-kruglosutochno-ufa
кайт школа Кайт лагерь
Клиника Частный Медик?24 в Коломне — профессиональная капельница от запоя в стационаре, смотрите страницу услуги.
Подробнее тут – [url=https://kapelnica-ot-zapoya-kolomna15.ru/]kapelnicza-ot-zapoya kolomna[/url]
melbet скачать мобильное приложение на айфон [url=https://melbet1037.ru/]melbet скачать мобильное приложение на айфон[/url]
20
Узнать больше – [url=https://kapelnica-ot-zapoya-kolomna16.ru/]капельница от запоя на дому город. московская область[/url]
Современные методы лечения при выводе из запоя включают как медикаментозную детоксикацию, так и психологическую реабилитацию. В Уфе наркологи используют капельничное введение лекарственных средств, которые помогают быстро вывести токсины, нормализовать обмен веществ и стабилизировать работу внутренних органов. Одновременно с этим проводится психологическая поддержка для снижения эмоционального стресса, связанного с запоем.
Получить дополнительную информацию – [url=https://narcolog-na-dom-ufa0.ru/]вызов нарколога на дом цена уфа[/url]
В Коломне клиника Частный Медик?24 предлагает капельницу от запоя в стационаре — подробности на сайте клиники.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-kolomna15.ru/]капельница от запоя наркология[/url]
Узнайте про выведение из запоя в стационаре в Частном Медике 24 (Балашиха) по ссылке.
Осуществить глубокий анализ – [url=https://vyvod-iz-zapoya-v-stacionare-balashiha11.ru/]нарколог вывод из запоя город балашиха[/url]
кайтинг Кайт медитация: Способ расслабиться и отвлечься от повседневной рутины. Наслаждайтесь тишиной и покоем, скользя по воде.
Первоначально врач осматривает пациента, узнаёт длительность запоя, наличие хронических заболеваний, оценивает степень интоксикации. Этот переходный момент очень важен, так как точная диагностика позволяет определить, какие препараты и инфузионные растворы будут наиболее эффективны и безопасны.
Подробнее – [url=https://vyvod-iz-zapoya-arkhangelsk6.ru/]vyvod-iz-zapoya-arkhangelsk6.ru/[/url]
read comics online online comics no ads
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Следуйте по ссылке – https://manhyiapalace.org/lies-are-the-root-of-land-disputes-otumfuo-tells-ahafo-peace-council
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Более того — здесь – https://roamguided.com/index.php/2023/09/26/hello-world
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Доступ к полной версии – https://engagecleveland.org/top-5-places-to-enjoy-the-cherry-blossoms-in-cleveland
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Обратиться к источнику – https://supportmax.com/importance-of-cybersecurity-compliance
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Подробная информация доступна по запросу – https://roamguided.com/index.php/2023/09/26/hello-world
read manga free manga app reader
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Обратиться к источнику – https://www.iso-studio.it/inail-riduzione-del-premio-ot23-interventi-entro-fine-anno
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Доступ к полной версии – https://jp.yokoreikanokimura.com/calendar/yoko_hikaru_duo_3
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Смотри, что ещё есть – https://bsbdiesel.com.br/10-key-steps-to-launching-a-successful-startup
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Только для своих – https://www.wakeup-radio.com/qtvideo/pon-pon-girl
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Подробнее тут – https://www.bizimmanav.nl/?attachment_id=245
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Только для своих – https://descompliquenegocios.com.br/asian-women-s-tips-for-finding-a-person
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Читать дальше – http://www.chohkai-tahara.com/2020/03/17/%E3%81%A1%E3%82%87%E3%81%A3%E3%81%A8%E9%81%85%E3%82%81%E3%81%AE%E3%81%8A%E9%9B%9B%E7%A5%AD%E3%82%8A
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Лучшее решение — прямо здесь – https://infosplus.org/tag/shirts
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Все материалы собраны здесь – https://colegioboock.com.br/produto/curso-profissionalizante-em-massoterapia
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Полная информация здесь – https://www.tassarnasfavorit.se/39664841_2021830671463437_725516046122876928_n
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Это стоит прочитать полностью – https://planetfish.org/hillstream-loach
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Расширить кругозор по теме – https://f5fashion.vn/lang-bich-hoa-noi-tieng-nho-phim-cua-song-joong-ki
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Разобраться лучше – https://mostravinimontepagano.it/cambria-italic
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Неизвестные факты о… – https://f5fashion.vn/cap-nhat-53-ve-xe-may-50cc-honda-2020-moi-nhat
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Перейти к статье – https://f5fashion.vn/update-dallas-tx-david-pendley-obituary-death-cause-and-family
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Смотри, что ещё есть – https://f5fashion.vn/cuoc-dai-tuyet-chung-xay-ra-voi-su-song-dau-tien-tren-trai-dat-ra-sao
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Изучить аспект более тщательно – https://f5fashion.vn/lich-trinh-phuot-da-lat-3-ngay-2-dem-chi-658-000-dong-cua-co-ban-9x
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Почему это важно? – https://f5fashion.vn/cap-nhat-hon-57-ve-hinh-anh-cay-hoa-phuong
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Смотрите также – http://www.leto-dance.ru
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Ознакомьтесь с аналитикой – https://f5fashion.vn/nhung-nguoi-giau-nhat-the-gioi-dang-do-tien-san-lung-thu-gi-o-greenland
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Узнать напрямую – https://f5fashion.vn/chia-se-59-ve-hinh-anh-hoa-la-hay-nhat
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Выяснить больше – https://f5fashion.vn/ashley-mixon-tiktok-star-%E0%A4%86%E0%A4%AF%E0%A5%81-%E0%A4%9C%E0%A4%A8%E0%A5%8D%E0%A4%AE%E0%A4%A6%E0%A4%BF%E0%A4%A8-%E0%A4%9C%E0%A5%88%E0%A4%B5-%E0%A4%A4%E0%A4%A5%E0%A5%8D%E0%A4%AF-%E0%A4%AA
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Изучить аспект более тщательно – https://alku.fi/laihdu-10-kg-nopeasti
candycasino [url=https://www.candy-casino-7.com]https://www.candy-casino-7.com[/url] .
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Ознакомьтесь с аналитикой – https://nextdunyasi.com/?attachment_id=4966/feed
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Это стоит прочитать полностью – https://stomatologweterynaryjny.pl/zdjecie1-15-of-15
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Лови подробности – https://house-archi.biz/?p=45
На сайте https://www.cleanyerevan.am/ изучите все услуги популярного предприятия, которое предлагает профессиональную и качественную уборку в квартире при помощи уникального инвентаря, высокотехнологичного инструмента. В этой компании клининг выполняется максимально качественно, быстро и в соответствии с заданными требованиями. В работе применяется только качественная химия, а услуги оказывают настоящие мастера своего дела. Вы сможете воспользоваться уборкой офисных помещений, квартир, домов, заказать химчистку диванов.
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Углубить понимание вопроса – https://swiftbest.net/product/disposable-latex-gloves
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Только для своих – https://ascensomonarca.com/index.php/2023/08/21/connecting-with-natures-tranquil-essence
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Почему это важно? – https://www.olivenailsalon-jp.com/slider01
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Все материалы собраны здесь – https://mybestbox.shop/index.php/2023/04/09/boost-your-online-presence-our-top-digital-marketing
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Углубить понимание вопроса – https://stomatologweterynaryjny.pl/zdjecie1-15-of-15
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Обратиться к источнику – https://businessguruzz.com/2024/10/19/an-introduction-to-chi-nei-tsang-therapy
доставка авто [url=https://avtovoz-av8.ru/]avtovoz-av8.ru[/url] .
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Все материалы собраны здесь – https://sonyah.pro/index.php/component/k2/item/7-footer/7-footer?start=133650
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Детальнее – https://www.medallasramirez.cl/grabados
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Нажми и узнай всё – https://digitization.nl/digitizationklein_jpeg
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Погрузиться в научную дискуссию – https://www.sissymaryskitchen.com/about-us
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Обратитесь за информацией – http://right-word.com/?attachment_id=8
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Переходите по ссылке ниже – https://papacook.jp/?p=451
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Доступ к полной версии – https://f5fashion.vn/full-nissan-asian-guy-original-video
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Ознакомьтесь с аналитикой – https://edufield.co.kr/1212
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Почему это важно? – https://yourscalppigmentationclinic.com/covid-19
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Перейти к статье – https://wielandmedia.com/alcalu-pushes-nfv-to-the-ip-router-edge
slot giri? [url=www.candy-casino-2.com/]www.candy-casino-2.com/[/url] .
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Подробнее тут – https://www.inter-consulting.org/2019/01/29/improving-productivity-across-global-teams-2
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Лови подробности – http://dasmiethaus.de/1-og-25m%C2%B2/2015_01_10_2-23-1
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Погрузиться в детали – http://www.abitidasposaaroma.com/various-ways-to-do-theme
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Получить исчерпывающие сведения – https://tproforgkomisc.ru
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Более подробно об этом – https://f5fashion.vn/sau-trung-thu-4-tuoi-tien-vao-nhu-nuoc-9-ngay-cuoi-cung-thang-8-am-1-tuoi-dai-cat-dai-loi-giau-khung
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Выяснить больше – https://f5fashion.vn/tong-hop-voi-hon-80-ve-hinh-nen-may-tinh-dep-anime-cute-moi-nhat
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Смотрите также – https://f5fashion.vn/cach-lam-nuoc-mam-an-bun-thit-nuong-chua-ngot-ngon-nhu-ngoai-hang
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Ознакомьтесь с аналитикой – https://qualitytools.co.ug/index.php/2021/10/25/hello-world
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Ссылка на источник – https://crossriver.ca/service/acmg-hiking-guide
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Что ещё? Расскажи всё! – https://f5fashion.vn/chi-tiet-hon-62-ve-xe-honda-1800-moi-nhat
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Подробная информация доступна по запросу – https://f5fashion.vn/bi-mat-ve-con-gai-tuoi-trang-ram-cua-vo-dai-gia-quyen-linh
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Смотри, что ещё есть – https://f5fashion.vn/tien-mat-tat-mang-xu-nu-nen-can-trong
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Почему это важно? – http://www.mm-baitservice-blog.at/2018/03/01/37-2/bild3/?page_number_0=18
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Подробная информация доступна по запросу – https://f5fashion.vn/chia-se-hon-64-ve-hinh-nen-mau-galaxy-moi-nhat
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Ознакомьтесь с аналитикой – https://f5fashion.vn/update-jfk-autopsy-pictures-unveiling-historical-documentation
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Нажмите, чтобы узнать больше – https://f5fashion.vn/tong-hop-hon-57-ve-hinh-nen-dien-thoai-minion-moi-nhat
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Почему это важно? – https://f5fashion.vn/phim-han-co-them-man-tre-hoa-an-tuong-41-tuoi-van-dong-vai-doi-muoi-rating-lien-tang-vot
candy casino [url=www.candy-casino-10.com/]candy casino[/url] .
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Детальнее – https://f5fashion.vn/chi-tiet-voi-hon-51-ve-hinh-nen-e-be-de-thuong
casino bahis [url=candy-casino-4.com]casino bahis[/url] .
candycasino [url=www.candy-casino-9.com/]www.candy-casino-9.com/[/url] .
Самостоятельно выйти из запоя — почти невозможно. В Ростове-На-Дону врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Не пропусти важное – [url=https://vyvod-iz-zapoya-rostov12.ru/]вывод из запоя клиника город ростов-на-дону[/url]
Découvrez pocketoption-france.fr, l’application de trading intuitive utilisée par des millions de traders dans le monde. Accédez à plus de 100 actifs : forex, actions, crypto-monnaies et matières premières. Exécutions rapides, interface claire et retraits instantanés. Parfait pour débutants comme pour traders expérimentés – tradez où que vous soyez, à tout moment.
Самостоятельно выйти из запоя — почти невозможно. В Ростове-На-Дону врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Изучите внимательнее – [url=https://vyvod-iz-zapoya-rostov16.ru/]вывод из запоя на дому круглосуточно[/url]
Формирование цены на вызов нарколога с проведением капельничного вывода из запоя зависит от нескольких ключевых параметров:
Получить больше информации – [url=https://vyvod-iz-zapoya-vladimir00.ru/]вывод из запоя владимир[/url]
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Прочитать подробнее – [url=https://vyvod-iz-zapoya-rostov18.ru/]вывод из запоя[/url]
888starz en ligne [url=https://www.888starz-official.pro]https://www.888starz-official.pro[/url] .
Чтобы вызвать нарколога на дом, достаточно позвонить по специализированным горячим телефонам или оформить заявку на сайте. Специалисты быстро реагируют на обращения, проводят первичную оценку и выезжают в течение часа. Важным аспектом является наличие лицензии и квалификации у медицинского персонала, что гарантирует безопасность и эффективность лечения.
Получить больше информации – [url=https://narkolog-na-dom-volgograd13.ru/]нарколог на дом вывод в волгограде[/url]
808 starz bet [url=https://starz888.pro]https://starz888.pro[/url] .
кайт лагерь Фронт ролл: вращения на воде
стальные сваи для фундамента [url=https://ostankino-svai.ru ]https://ostankino-svai.ru [/url] .
Современная наркологическая помощь в Ростове-на-Дону базируется на комплексном подходе, который объединяет медицинское лечение, психологическую поддержку и социальную реабилитацию. Такой подход доказал свою эффективность в многочисленных исследованиях, доступных на сайте Российского общества наркологов.
Исследовать вопрос подробнее – https://narkologicheskaya-klinika-rostov-na-donu13.ru/narkologicheskaya-klinika-v-rostove/
кайтсёрфинг Кайт
Сегодня вопрос зависимостей становится особенно важной. Если вы находитесь в поиске нарколога на дом в Красноярске, сайт vivod-iz-zapoya-krasnoyarsk004.ru предлагает многочисленные наркологических услуг. Лечение зависимостей может быть трудным процессом, однако мобильный нарколог обеспечивает помощь при алкоголизме и другим проблемам, связанным с зависимостям непосредственно на дому. Визит нарколога – это первый шаг к восстановлению. Специалисты проведут диагностику зависимости, помогут составить программу реабилитации и рекомендуют методы психотерапии при зависимости. Конфиденциальное лечение гарантирует полную конфиденциальность, что особенно важно для многих пациентов. Медицинская помощь на дому позволяет не только лишь проходить лечение в удобной обстановке, но и получать поддержку родных, что играет ключевую роль в процессе выздоровления. Профилактические меры при алкоголизме и восстановление после наркотиков также входят в комплекс услуг, предлагаемых специалистами. Обращайтесь за помощью на vivod-iz-zapoya-krasnoyarsk004.ru, чтобы получить квалифицированную поддержку.
Когда организм на пределе, важна срочная помощь в Ростове-На-Дону — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Переходите по ссылке ниже – [url=https://vyvod-iz-zapoya-rostov17.ru/]наркология вывод из запоя[/url]
Zarejestruj się w kasynie online już teraz na oficjalnej stronie slottica casino i odbierz bonusy za pierwszą wpłatę na automatach!
кайтсёрфинг Обучение кайтсёрфингу требует профессионального подхода. Найдите опытного инструктора, который научит вас основам управления кайтом, технике безопасности и поможет вам сделать первые шаги на воде.
В Балашихе (будни и выходные): стационарный вывод из запоя в клинике Частный Медик 24 — переход по ссылке.
Расширить кругозор по теме – [url=https://vyvod-iz-zapoya-v-stacionare-balashiha11.ru/]наркология вывод из запоя город балашиха[/url]
В Ростове-На-Дону решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Углубиться в тему – [url=https://vyvod-iz-zapoya-rostov12.ru/]vyvod-iz-zapoya-klinika rostov-na-donu[/url]
обучение кайтсёрфингу Кайтсёрфинг: Скользящая элегантность по волнам, танец с ветром, требующий баланса и отваги. Освоив кайтсёрфинг, вы откроете мир свободы и адреналина.
После первичного осмотра начинается активная фаза детоксикации. Современные препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови и восстановления обменных процессов. Этот этап критически важен для нормализации работы печени, почек и сердечно-сосудистой системы.
Получить больше информации – https://vyvod-iz-zapoya-vladimir000.ru/srochnyj-vyvod-iz-zapoya-vladimir
Запой – это синдром‚ которое проявляется продолжительным употреблением алкоголя‚ что может привести к серьезным последствиям. Признаки алкогольной зависимости включают физическую и психологическую потребность в спиртном‚ что делает незамедлительное лечение запоя необходимым. В Красноярске помощь при запое предоставляется в наркологических клиниках‚ где предлагаются услуги нарколога; результаты запоя могут варьироваться от ухудшения состояния здоровья до психических расстройств. экстренный вывод из запоя Красноярск Экстренный вывод из запоя предполагает detox-процедуры‚ помогающие организму очиститься от токсинов. Психологическая помощь при алкоголизме также играет важной ролью в восстановлении. Реабилитация алкоголиков в Красноярске предлагает целостный метод к лечению‚ включая профилактические меры и поддержку в период восстановления. Важно помнить‚ что лечение алкоголизма требует профессиональной помощи для минимизации рисков и повышения качества жизни.
производство лестниц для дома [url=https://www.lestnicy-na-metallokarkase-1.ru]https://www.lestnicy-na-metallokarkase-1.ru[/url] .
кайтинг “Мекки кайтсерфинга”: лучшие места, где “ветер шепчет легенды”
Если вы ищете вывод из запоя в стационаре в Балашихе, ознакомьтесь с предложением Частного Медика 24 на сайте.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-v-stacionare-balashiha12.ru/]московская область[/url]
https://moionline.ru/obshhestvo/ksarelto-podrobnyj-obzor-i-gde-kupit-v-sankt-peterburge/
Если вовремя не принять меры, состояние может усугубиться, повышая риск серьёзных осложнений. Наиболее эффективным способом очищения организма является постановка капельницы, которая помогает быстро стабилизировать состояние. Клиника «Курс на ясность» оказывает экстренную наркологическую помощь с выездом врачей на дом 24/7.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-krasnoyarsk6.ru/]сколько стоит капельница на дому от запоя[/url]
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Ростове-На-Дону приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Подробнее – [url=https://vyvod-iz-zapoya-rostov11.ru/]вывод из запоя клиника в ростове-на-дону[/url]
В Ростове-На-Дону решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Переходите по ссылке ниже – [url=https://vyvod-iz-zapoya-rostov16.ru/]rostov-na-donu[/url]
Клиника «РостовМед» предлагает профессиональную наркологическую помощь в Ростове и области в режиме 24/7. Наша команда готова выехать на дом к пациенту в любое время суток, обеспечивая анонимность и высокие медицинские стандарты. В основе работы — индивидуальный подход, современное оборудование и чётко отлаженные протоколы детоксикации, что позволяет безопасно вывести пациента из запоя и начать этап реабилитации без стресса госпитализации.
Углубиться в тему – [url=https://narkologicheskaya-klinika-rostov13.ru/]запой наркологическая клиника[/url]
Системы автоматизированного дозирования обеспечивают точное введение медикаментов, что минимизирует риск побочных эффектов. Постоянный мониторинг жизненно важных показателей позволяет врачу корректировать терапию в режиме реального времени, гарантируя безопасность процедуры.
Выяснить больше – http://vyvod-iz-zapoya-vladimir0.ru/srochnyj-vyvod-iz-zapoya-vladimir/
В обычных условиях цена услуги составляет от 1500 до 2500 рублей. Эта сумма включает выезд специалиста, первичный осмотр и базовую детоксикационную терапию.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-vladimir00.ru/]вывод из запоя цены владимир[/url]
где можно ставить ставки без верификации [url=http://1win1140.ru]http://1win1140.ru[/url]
casinocandy [url=http://www.candy-casino-9.com]http://www.candy-casino-9.com[/url] .
кайтинг Страховка в кайтсёрфинге: будьте готовы к неожиданностям. Защитите себя от финансовых потерь.
7 slots [url=https://candy-casino-4.com]7 slots[/url] .
кайт лагерь Кайтсерфинг в Египте: Хургада, Дахаб – особенности катания
Капельницы при алкогольной интоксикации в Красноярске: помощь нарколога Алкогольная интоксикация — состояние, требующее незамедлительного вмешательства врачей. В медицинском центре Красноярск доступны услуги по лечению алкоголизма, включая детоксикацию и реабилитацию после запоя. Процедуры капельниц помогают очищать организм от токсинов, облегчая симптомы алкогольной интоксикации. Обращение к наркологу поможет разработать индивидуальный план лечения. Симптомы алкогольной интоксикации включают головную боль, тошноту и слабость. Квалифицированная помощь нарколога включает в себя детоксикацию, а также психотерапию для борьбы с алкоголизмом. Реабилитация алкоголиков требует комплексного подхода, а профилактика запоев помогает избежать рецидивов. В Красноярске доступна качественная медицинская помощь, позволяющая восстановить здоровье и вернуться к нормальной жизни.
Экстренная помощь при выводе из запоя в Архангельске организована по четко отлаженной схеме. Специалисты проводят комплексное обследование пациента на месте, разрабатывают индивидуальный план терапии и незамедлительно приступают к детоксикации. Такой подход позволяет максимально быстро нейтрализовать токсическую нагрузку и восстановить жизненно важные функции организма.
Разобраться лучше – [url=https://vyvod-iz-zapoya-arkhangelsk66.ru/]вывод из запоя архангельск[/url]
casino giri? [url=https://candy-casino-10.com]casino giri?[/url] .
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Узнай первым! – https://juicyks.com/shop-juicy-k/purple-passion-wand
мелбет букмекерская контора скачать [url=http://melbet1031.ru/]http://melbet1031.ru/[/url]
Публичная дипломатия России https://softpowercourses.ru концепции, стратегии, механизмы влияния. От культурных центров до цифровых платформ — как формируется образ страны за рубежом.
фильмы онлайн 1080 фильмы онлайн бесплатно
Институт государственной службы https://igs118.ru обучение для тех, кто хочет управлять, реформировать, развивать. Подготовка кадров для госуправления, муниципалитетов, законодательных и исполнительных органов.
Институт государственной службы https://igs118.ru обучение для тех, кто хочет управлять, реформировать, развивать. Подготовка кадров для госуправления, муниципалитетов, законодательных и исполнительных органов.
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Посмотреть подробности – https://gestoriacortes.es/principal/attachment/slide-gestoria-administrativa
Découvrez pocket optio, l’application de trading intuitive utilisée par des millions de traders dans le monde. Accédez à plus de 100 actifs : forex, actions, crypto-monnaies et matières premières. Exécutions rapides, interface claire et retraits instantanés. Parfait pour débutants comme pour traders expérimentés – tradez où que vous soyez, à tout moment.
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Ссылка на источник – https://buttina.com.br/2022/05/26/batata-dourada-veja-como-fazer-essa-comida-saborosa
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Выяснить больше – https://vornozentechnologies.com/boost-your-online-presence-our-top-digital-marketing
Круглосуточный вызов нарколога на дом стал важной услугой для тех‚ кто сталкивается с зависимостями. На сайте vivod-iz-zapoya-krasnoyarsk006.ru можно получить всю необходимую информацию о методах лечения зависимостей‚ включая медикаментозное лечение и психотерапию при зависимости. Обращение к наркологу поможет определить степень зависимости и разработать индивидуальный план лечения. Круглосуточное обслуживание позволяет вызвать специалиста на дом в любое время‚ что является особенно актуальным в экстренных ситуациях. Услуги нарколога включают диагностику зависимостей‚ конфиденциальное лечение и помощь родственникам. Реабилитация наркоманов требует комплексного подхода‚ и профессиональная помощь может значительно упростить этот процесс. Профилактика зависимостей также является важным аспектом в борьбе с ними‚ поэтому важно обращаться за помощью при первых признаках. Приезд врача на дом создает комфортные условия и гарантирует конфиденциальность‚ способствуя эффективному лечению.
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Почему это важно? – https://choofercolombia.com/2022/12/21/club-membership-opitons
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Неизвестные факты о… – https://f5fashion.vn/chia-se-hon-52-ve-nhan-cuoi-bao-tin-minh-chau-hay-nhat
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Лучшее решение — прямо здесь – https://f5fashion.vn/co-gi-o-sagano-khu-rung-tre-nhat-ban-lot-top-nhung-noi-nhat-dinh-phai-den-mot-lan-trong-doi
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Выяснить больше – https://drivers4vip.com/product/beanie-with-logo
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Как достичь результата? – https://www.hotel-sugano.com/bbs/sugano.cgi/sosh13.pascal.ru/forum/datasphere.ru/club/user/12/blog/2477/www.tovery.net/www.skitour.su/www.skitour.su/www.hip-hop.ru/forum/id298234-worksale/sugano.cgi?page30=val
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Почему это важно? – https://f5fashion.vn/lo-them-via-tu-nhung-nguoi-dep-dang-quang-miss-universe-trung-khop-den-8-lan
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Секреты успеха внутри – https://kvadar.ifzg.hr/index.php/2024/01/28/blog-1
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Информация доступна здесь – https://f5fashion.vn/9-diem-den-tu-quen-den-la-cua-du-lich-can-gio
кайт школа Кайтсёрфинг для детей: возможность раннего развития. Кайтсёрфинг – это отличный способ развить координацию, силу и выносливость у детей.
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Получить полную информацию – https://f5fashion.vn/6-xu-tri-khi-bi-lo-chuyen-bay
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Смотрите также… – https://www.bisisters.com/hoodie_1_front
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Доступ к полной версии – https://bergmannarchitekt.de/ru/bergmann_logo_03
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Уточнить детали – https://www.hermanosdelasaguas.org/exposicion-hermandad-de-la-paz-75-anos-2a-parte
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Секреты успеха внутри – https://f5fashion.vn/tong-hop-66-ve-hinh-nen-pokemon-huyen-thoai-mega
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Изучить аспект более тщательно – http://www.mm-baitservice-blog.at/2018/03/01/37-2/bild3/?page_number_0=55
вывод из запоя цена
vivod-iz-zapoya-smolensk007.ru
вывод из запоя смоленск
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Смотри, что ещё есть – https://jovannbuilders.com/hello-world
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Выяснить больше – https://amg.es/en/preparar-windows-instalar-ssd/8-sin-archivo-de-paginacion
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Нажмите, чтобы узнать больше – http://kupina-vniipo.ru
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Обратитесь за информацией – https://f5fashion.vn/chia-se-55-ve-ao-so-mi-lua-cao-cap-hay-nhat
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Более того — здесь – https://cabinet-de-shiatsu-reunion.com
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Более того — здесь – https://futuredream.wpxblog.jp/wpxblog-struggle
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Доступ к полной версии – https://epiczo.com/?p=255
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Только для своих – https://velvet-mag.com/the-luxury-of-slowing-down-the-urban-mystic
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Что ещё? Расскажи всё! – https://shopsv.ru
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Доступ к полной версии – https://www.verputzer.net/verputzer-bad_kreuznach
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Как достичь результата? – https://vaidhyahhospital.com/blog/2019/08/30/the-website-of-the-royal-melbourne-hospital
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Узнай первым! – http://transqb.ru
Школа бизнеса EMBA https://emba-school.ru программа для руководителей и собственников. Стратегическое мышление, международные практики, управленческие навыки.
Опытный репетитор https://english-coach.ru для школьников 1–11 классов. Подтянем знания, разберёмся в трудных темах, подготовим к экзаменам. Занятия онлайн и офлайн.
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Только для своих – https://f5fashion.vn/tong-hop-hon-59-ve-ponyo-hinh-nen-hay-nhat
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Посмотреть подробности – https://ristein-frisuren.de/fade-masterclass-behind-the-scenes-of-precision-styling
Découvrez http://www.pocketoption.fr, l’application de trading intuitive utilisée par des millions de traders dans le monde. Accédez à plus de 100 actifs : forex, actions, crypto-monnaies et matières premières. Exécutions rapides, interface claire et retraits instantanés. Parfait pour débutants comme pour traders expérimentés – tradez où que vous soyez, à tout moment.
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Почему это важно? – https://kitpeledeouro.com/ola-mundo
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Ссылка на источник – https://annonces.mamafrica.net/tag/sci
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Это ещё не всё… – https://www.cursosalpha.com/blog/no-es-para-cualquiera-andar-por-la-calle
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Смотри, что ещё есть – https://f5fashion.vn/chia-se-55-ve-ao-so-mi-lua-cao-cap-hay-nhat
7 slots [url=http://www.candy-casino-7.com]http://www.candy-casino-7.com[/url] .
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Полная информация здесь – https://www.cursosalpha.com/blog/no-es-para-cualquiera-andar-por-la-calle
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Подробная информация доступна по запросу – https://f5fashion.vn/bi-an-ve-dong-xu-mot-dola-may-man-cua-singapore
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Все материалы собраны здесь – https://f5fashion.vn/nancy-drew-cast-vince-prokop-obituary-and-death-cause-2023
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Почему это важно? – https://f5fashion.vn/cap-nhat-56-ve-chu-he-tiec-sinh-nhat-hay-nhat
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Изучить вопрос глубже – https://f5fashion.vn/quan-ca-phe-tren-cay-doc-dao-nhat-sai-gon
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Ознакомьтесь с аналитикой – https://f5fashion.vn/neu-khong-bi-tuyet-chung-khung-long-trong-se-nhu-the-nao-o-hien-tai
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Получить исчерпывающие сведения – https://cruisecontrolcruises.co.uk/page/32
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Это стоит прочитать полностью – https://positivemindcare.in/our-services/behavioral-issues-with-children
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Узнай первым! – https://christaylorwebdesign.co.uk/7af51e9eb043ec5b5499a7b8cec25f39-369×1024
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Доступ к полной версии – https://fashionswikionline.com/the-petite-bijou-lifestyle-inspiration-fashion-beauty-wellness-adventure
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Все материалы собраны здесь – https://portal.alegoriadecoracion.com/hello-world
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Смотрите также… – https://1porno1.ru
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Переходите по ссылке ниже – https://imagix-scolaire.be/cheerful-students-at-university-jpg
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Практические советы ждут тебя – https://frank-casino1.ru
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Секреты успеха внутри – https://www.winxo.com/policy_privacy
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Смотрите также… – https://mehielinfo.net/message-du-president-de-la-commission-de-lunion-africaine-a-loccasion-de-la-celebration-de-la-journee-de-lafrique-le-25-mai-2022
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Узнать напрямую – http://puneescortspage.com/air-hostess-escorts
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Почему это важно? – https://f5fashion.vn/net-quyen-ru-cua-buoi-sang-sai-gon
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Углубить понимание вопроса – https://tier2tickets.com/goodbye-sms-authentication-hello-multi-accounts-2fa
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Как достичь результата? – https://whirlpoolguide.de/whirlpool/pure-spa-octagon
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Выяснить больше – https://ejv.co.nz/hello-world
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Не пропусти важное – https://japanfoodpartners.com/2022/03/22/hello-world
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Нажмите, чтобы узнать больше – https://f5fashion.vn/chia-se-voi-hon-61-ve-vest-xam-caro-moi-nhat
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Обратитесь за информацией – https://offer-here.website/hello-world
888starz app download apk [url=www.22bet.zone/]www.22bet.zone/[/url] .
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Полная информация здесь – https://kizuna1046.com/business/gallery12
Проходите аттестацию https://prom-bez-ept.ru по промышленной безопасности через ЕПТ — быстро, удобно и официально. Подготовка, регистрация, тестирование и сопровождение.
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Обратиться к источнику – https://abelgorod.ru
starz888 [url=www.starz888.pro]starz888[/url] .
Zarejestruj się w kasynie online już teraz na oficjalnej stronie slottica-onlinecasino.pl i odbierz bonusy za pierwszą wpłatę na automatach!
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Более того — здесь – https://prime.itxoft.com/seo-for-ecommerce-sites-itxoft-11273
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Посмотреть подробности – http://activbase.ru
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Лучшее решение — прямо здесь – https://olimas.eu/?product=sportska-60-min-standard
casinocandy [url=www.candy-casino-2.com/]www.candy-casino-2.com/[/url] .
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Это стоит прочитать полностью – https://styazhkavsem.ru
вывод из запоя
vivod-iz-zapoya-smolensk008.ru
вывод из запоя
«Дела семейные» https://academyds.ru онлайн-академия для родителей, супругов и всех, кто хочет разобраться в семейных вопросах. Психология, право, коммуникации, конфликты, воспитание — просто о важном для жизни.
В период восстановления пациент получает психологическую поддержку, работает с психотерапевтом, осваивает навыки самоконтроля, учится противостоять стрессу без возвращения к прежним привычкам. После выписки возможно амбулаторное сопровождение, дистанционные консультации и поддержка для всей семьи.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-balashiha5.ru/]частная наркологическая клиника[/url]
Своевременный вызов нарколога позволяет снизить риски осложнений, таких как судорожный синдром, панкреатит или сердечная недостаточность, часто сопровождающие тяжелое алкогольное или наркотическое отравление. По данным исследований, раннее вмешательство сокращает сроки госпитализации и улучшает прогнозы выздоровления.
Разобраться лучше – [url=https://narkolog-na-dom-chelyabinsk13.ru/]нарколог на дом круглосуточно цены в челябинске[/url]
ванна гидромассаж [url=https://www.hidromassazhnaya-vanna2.ru]https://www.hidromassazhnaya-vanna2.ru[/url] .
вывод из запоя круглосуточно смоленск
vivod-iz-zapoya-smolensk007.ru
вывод из запоя
Трэвел-журналистика https://presskurs.ru как превращать путешествия в публикации. Работа с редакциями, создание медийного портфолио, написание текстов, интервью, фото- и видеоматериалы.
Своевременный выезд нарколога снижает риск осложнений и ускоряет вывод из запоя, а под контролем профессионала каждая процедура проходит максимально безопасно.
Исследовать вопрос подробнее – http://vyvod-iz-zapoya-reutov4.ru
https://nn.rosfirm.ru/companies_news/kak-zaschitit-pechen-v-period-priyoma-tyazhelyh-n789866.htm
winline фрибет новым клиентам [url=https://winline-fribet-novym-klientam.ru/]https://winline-fribet-novym-klientam.ru/[/url] .
Zarejestruj się w kasynie online już teraz na oficjalnej stronie slottica kasyno i odbierz bonusy za pierwszą wpłatę na automatach!
На данном этапе специалист уточняет, как долго продолжается запой, какой вид алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ информации позволяет оперативно определить степень интоксикации и выбрать оптимальные методы терапии для быстрого и безопасного вывода из запоя.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-tula00.ru/]vyvod-iz-zapoya-czena tula[/url]
gessi продукция [url=www.gessi-santehnika-3.ru]www.gessi-santehnika-3.ru[/url] .
Работа врача начинается с детального сбора анамнеза: выясняются длительность запоя, объёмы употреблённого алкоголя, сопутствующие заболевания и аллергические реакции. Затем специалист измеряет давление, пульс, сатурацию и температуру, после чего подбирает оптимальный протокол детоксикации.
Разобраться лучше – [url=https://vyvod-iz-zapoya-reutov4.ru/]vyvod iz zapoya anonimno reutov[/url]
Do you have any video of that? I’d care to find out some additional information.
where can i buy generic vermox without dr prescription
бесплатные фрибеты винлайн [url=http://www.besplatnyj-fribet-winline.ru]бесплатные фрибеты винлайн[/url] .
Hi, bro!
Read the link – [url=https://fruitslotmachines.cfd/]fruit slots 777 real money[/url]
Good luck!
акции винлайн 2025 [url=http://winline-fribet-za-registraciyu-2025.ru/]http://winline-fribet-za-registraciyu-2025.ru/[/url] .
Greetings!
Read the link – [url=https://welcomebonuses.cfd/]best welcome bonuses online casino[/url]
Enjoy your bonuses!
Свежие скидки https://1001kupon.ru выгодные акции и рабочие промокоды — всё для того, чтобы тратить меньше. Экономьте на онлайн-покупках с проверенными кодами.
«Академия учителя» https://edu-academiauh.ru онлайн-портал для педагогов всех уровней. Методические разработки, сценарии уроков, цифровые ресурсы и курсы. Поддержка в обучении, аттестации и ежедневной работе в школе.
Своевременный вызов специалиста особенно важен при следующих признаках:
Получить больше информации – http://vyvod-iz-zapoya-mariupol13.ru
мелбет [url=https://melbet1038.ru/]https://melbet1038.ru/[/url]
лечение запоя
vivod-iz-zapoya-smolensk009.ru
лечение запоя смоленск
В клинике применяются комплексные программы, включающие медицинскую детоксикацию, психотерапевтическую поддержку и социальную реабилитацию. Медицинская детоксикация проводится с использованием современных препаратов и методик, что позволяет снизить тяжесть абстинентного синдрома и минимизировать риски для здоровья пациента. Подробнее о методах детоксикации можно узнать на официальном портале Министерства здравоохранения России.
Получить больше информации – [url=https://narkologicheskaya-klinika-chelyabinsk13.ru/]наркологическая клиника вывод из запоя в челябинске[/url]
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения детального первичного осмотра. Врач собирает краткий анамнез, измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и оценивает степень алкогольной интоксикации. Эти данные являются основой для разработки индивидуального плана лечения, позволяющего подобрать наиболее эффективные методы детоксикации.
Узнать больше – [url=https://vyvod-iz-zapoya-tula00.ru/]www.domen.ru[/url]
Оказание наркологической помощи в домашних условиях имеет ряд нюансов. Пациент находится в знакомой среде, что снижает уровень тревоги и позволяет легче переносить лечебные процедуры. При этом специалист оснащён необходимым оборудованием для экстренной помощи, что важно при рисках осложнений. Поддержка близких дополнительно повышает эффективность терапии.
Получить дополнительную информацию – http://narkolog-na-dom-volgograd13.ru/narkolog-na-dom-czeny-volgograd/
сколько стоят винтовые сваи для фундамента [url=https://ostankino-svai.ru /]ostankino-svai.ru [/url] .
В период восстановления пациент получает психологическую поддержку, работает с психотерапевтом, осваивает навыки самоконтроля, учится противостоять стрессу без возвращения к прежним привычкам. После выписки возможно амбулаторное сопровождение, дистанционные консультации и поддержка для всей семьи.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-balashiha5.ru/]платная наркологическая клиника[/url]
Welcome!
Read the link – [url=https://slotspinners.cfd/]trusted slot spinners for real money casino[/url]
Good luck spinning!
лечение запоя
vivod-iz-zapoya-smolensk008.ru
экстренный вывод из запоя
Современная наркологическая клиника в Мариуполе ориентирована на комплексное и индивидуальное лечение алкогольной и наркотической зависимости, обеспечивая пациентам высококвалифицированную помощь с использованием доказанных медицинских протоколов и новейших технологий. Зависимость — это хроническое заболевание, требующее профессионального подхода, основанного на научных данных и многолетнем опыте специалистов.
Выяснить больше – https://narkologicheskaya-klinika-mariupol13.ru/platnaya-narkologicheskaya-klinika-mariupol/
Алкогольный делирий проявляется в виде галлюцинаций, бреда и агрессии. При отсутствии контроля такие пациенты опасны для себя и окружающих, требуя немедленной госпитализации.
Получить больше информации – http://vivod-iz-zapoya-chelyabinsk13.ru/srochnyj-vyvod-iz-zapoya-chelyabinsk/
Оригинальный потолок натяжные потолки со световыми линиями москва со световыми линиями под заказ. Разработка дизайна, установка профиля, выбор цветовой температуры. Идеально для квартир, офисов, студий. Стильно, практично и с гарантией.
?аза? тіліндегі ?ндер Песни 2025 года, казахские хиты ж?рекке жа?ын ?уендер мен ?серлі м?тіндер. ?лтты? музыка мен ?азіргі заман?ы хиттер. Онлайн ты?дау ж?не ж?ктеу м?мкіндігі бар ы??айлы жина?.
промокод винлайн на сегодня 2025 фрибеты [url=https://winline-fribet-kazhdyj-den.ru/]winline-fribet-kazhdyj-den.ru[/url] .
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения детального первичного осмотра. Врач собирает краткий анамнез, измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и оценивает степень алкогольной интоксикации. Эти данные являются основой для разработки индивидуального плана лечения, позволяющего подобрать наиболее эффективные методы детоксикации.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-tula00.ru/]наркологический вывод из запоя в туле[/url]
Клиника «Феникс-Мед» предлагает два базовых формата лечения, позволяющих адаптировать помощь под состояние пациента и его предпочтения.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-reutov4.ru/]вывод из запоя цена[/url]
?аза? тіліндегі ?ндер Сборник казахских песен ж?рекке жа?ын ?уендер мен ?серлі м?тіндер. ?лтты? музыка мен ?азіргі заман?ы хиттер. Онлайн ты?дау ж?не ж?ктеу м?мкіндігі бар ы??айлы жина?.
Медикаментозная детоксикация позволяет быстро и безопасно очистить организм от токсинов и продуктов распада алкоголя или наркотиков, минимизируя риски осложнений. Используются препараты, которые восстанавливают работу печени, почек и других органов, а также нормализуют электролитный баланс.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-mariupol13.ru/]наркологическая клиника мариуполь[/url]
?аза? тіліндегі ?ндер Скачать казахские песни 2025 ж?рекке жа?ын ?уендер мен ?серлі м?тіндер. ?лтты? музыка мен ?азіргі заман?ы хиттер. Онлайн ты?дау ж?не ж?ктеу м?мкіндігі бар ы??айлы жина?.
Основные задачи
Получить дополнительную информацию – https://lechenie-alkogolizma-krasnodar00.ru/klinika-lecheniya-alkogolizma-krasnodar
?аза? тіліндегі ?ндер Казахские песни ж?рекке жа?ын ?уендер мен ?серлі м?тіндер. ?лтты? музыка мен ?азіргі заман?ы хиттер. Онлайн ты?дау ж?не ж?ктеу м?мкіндігі бар ы??айлы жина?.
лечение запоя
vivod-iz-zapoya-smolensk009.ru
экстренный вывод из запоя
В течение процедуры пациент находится под непрерывным наблюдением: внутривенные капельницы с регидратационными растворами, витаминно-минеральными комплексами и гепатопротекторами обеспечивают восстановление функций печени, нормализацию обменных процессов и поддержку работы сердечно-сосудистой системы. При необходимости к лечению привлекаются узкопрофильные врачи — кардиолог, невролог или терапевт — что делает процесс максимально комплексным. По завершении выведения из запоя врач предоставляет подробный план поддерживающей терапии с рекомендациями по питанию, питьевому режиму и графику повторных консультаций.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-reutov4.ru/]наркология вывод из запоя[/url]
Домашний вывод из запоя подходит тем, кто сохраняет относительно стабильные жизненные показатели и нуждается в минимальном мониторинге. Врач приезжает в удобное для вас время, проводит все необходимые манипуляции в привычной обстановке и остаётся на связи после процедуры для оперативной консультации.
Получить дополнительные сведения – http://vyvod-iz-zapoya-reutov4.ru/vyvod-iz-zapoya-stacionar-v-reutove/
акции винлайн [url=https://www.winline-fribet-kazhdyj-den.ru]https://www.winline-fribet-kazhdyj-den.ru[/url] .
винлайн промокод на фрибет 2025 [url=http://winline-fribety-2025.ru/]http://winline-fribety-2025.ru/[/url] .
Медикаментозная детоксикация позволяет быстро и безопасно очистить организм от токсинов и продуктов распада алкоголя или наркотиков, минимизируя риски осложнений. Используются препараты, которые восстанавливают работу печени, почек и других органов, а также нормализуют электролитный баланс.
Ознакомиться с деталями – http://narkologicheskaya-klinika-mariupol13.ru/platnaya-narkologicheskaya-klinika-mariupol/
как получить фрибет в винлайн 2025 [url=www.winline-bonus-za-registraciyu-2025.ru]www.winline-bonus-za-registraciyu-2025.ru[/url] .
В Екатеринбургской наркологической клинике применяются передовые методики, такие как медикаментозная терапия с использованием современных препаратов, когнитивно-поведенческая терапия, групповые и индивидуальные занятия с психологом. Эти методы подробно описаны на портале наркологической помощи России. Это обеспечивает эффективное лечение хронических форм зависимости и предупреждение осложнений.
Подробнее тут – [url=https://narcologicheskaya-klinika-ekaterinburg00.ru/]narkologicheskie kliniki alkogolizm ekaterinburg[/url]
Наша клиника работает по стандартам международного уровня, сочетая научно обоснованные методики с внимательным отношением к каждому пациенту. В «ВолгаМед» вы не столкнётесь с бюрократией или очередями — помощь оказывается сразу после обращения, а все процедуры проводятся в строгом соответствии с медицинскими протоколами и этическими нормами.
Узнать больше – [url=https://narkologicheskaya-klinika-volgograd13.ru/]наркологическая клиника наркологический центр волгоград[/url]
купить игровой компьютер [url=http://kupit-igrovoj-kompyuter8.ru/]http://kupit-igrovoj-kompyuter8.ru/[/url] .
купить компьютер в москве [url=www.kupit-igrovoj-kompyuter9.ru]купить компьютер в москве[/url] .
При вызове на дом врач-нарколог привозит всё необходимое оборудование: переносной монитор для пульсоксиметрии и ЭКГ, инфузионные насосы, набор растворов, витамины и препараты для коррекции электролитного баланса. Выездной комплект позволяет провести полный комплекс процедур — от очистки организма до начальной психокоррекции — без задержек.
Подробнее тут – http://narcologicheskaya-klinika-ekaterinburg0.ru
Готовый комплект Лучшие инсталляции с унитазом в комплекте инсталляция и унитаз — идеальное решение для современных интерьеров. Быстрый монтаж, скрытая система слива, простота в уходе и экономия места. Подходит для любого санузла.
Длительное употребление алкоголя негативно сказывается на состоянии организма, приводя к тяжелой интоксикации, обезвоживанию и нарушениям работы внутренних органов. Самостоятельный выход из запоя часто сопровождается сильным похмельем, скачками давления, головной болью, тошнотой и тревожностью.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-moskva0.ru/]капельница от запоя цена москва[/url]
Our growth doc now timestamps every time we twitter buy likes; helps isolate algorithm changes.
I’m not sure exactly why but this web site is loading very slow for me. Is anyone else having this problem or is it a problem on my end? I’ll check back later and see if the problem still exists.
doxycycline 100mg us
Клиника «ВолгаМед» в Волгограде обеспечивает круглосуточную анонимную помощь людям, столкнувшимся с алкогольной или наркотической зависимостью. Мы предлагаем как стационарное лечение в комфортных условиях, так и выезд врача на дом в любое время суток. Конфиденциальность, профессионализм и индивидуальный подход — ключевые принципы нашей работы. В этой статье подробно рассмотрим преимущества клиники, спектр услуг, порядок организации домашнего выезда специалистов и дополнительные возможности поддержки в период реабилитации.
Подробнее тут – http://narkologicheskaya-klinika-volgograd13.ru/
Первый шаг в лечении — это тщательный осмотр специалиста. Наряду с измерением жизненно важных показателей (пульс, артериальное давление, температура) врач проводит сбор анамнеза, выясняя длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Эти данные помогают оценить степень интоксикации и подобрать индивидуальный план терапии, что является ключевым для дальнейшей эффективной детоксикации.
Изучить вопрос глубже – https://vyvod-iz-zapoya-yaroslavl0.ru/vyvod-iz-zapoya-czena-yaroslavl
СХТ – достойная компания, предлагающая большой спектр услуг, которые с автомобильными весами связаны. Вся продукция строжайший контроль качества проходит. Мы готовы предложить надежность по приемлемой цене. Ценим то, что клиенты доверяют нам. https://voronezh.cxt.su – здесь представлена более детальная информация о нас, ознакомиться с ней можно в любое удобное время. Предлагаем большой выбор весов. С удовольствием поможем выбрать идеальные весы для ваших потребностей. Обращайтесь к нам, вы точно останетесь довольны!
организация онлайн трансляции [url=zakazat-onlajn-translyaciyu7.ru]организация онлайн трансляции[/url] .
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения детального первичного осмотра. Врач собирает краткий анамнез, измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и оценивает степень алкогольной интоксикации. Эти данные являются основой для разработки индивидуального плана лечения, позволяющего подобрать наиболее эффективные методы детоксикации.
Выяснить больше – [url=https://vyvod-iz-zapoya-tula00.ru/]вывод из запоя на дому тула[/url]
купить компьютер в москве [url=https://kupit-igrovoj-kompyuter10.ru/]купить компьютер в москве[/url] .
стоимость онлайн трансляции на мероприятии [url=https://zakazat-onlajn-translyaciyu6.ru]https://zakazat-onlajn-translyaciyu6.ru[/url] .
Длительный запой приводит к нарастанию интоксикации, истощению нервной системы, серьёзным нарушениям в работе печени, почек и сердца. Могут возникнуть тяжёлые психозы (белая горячка), судороги, развитие алкогольной энцефалопатии, панкреатит, обострение хронических болезней. Самостоятельные попытки выйти из запоя с помощью «народных средств», внезапного отказа от алкоголя, промывания желудка или лекарств из домашней аптечки часто только усугубляют состояние.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-orekhovo-zuevo4.ru/]vyvod iz zapoya cena[/url]
Каждый пациент проходит предварительное обследование: экспресс-анализ крови на электролиты, биохимия печени и почек, ЭКГ. На основании результатов врач формирует персональную программу инфузионной терапии.
Узнать больше – [url=https://kapelnica-ot-zapoya-chelyabinsk13.ru/]поставить капельницу от запоя на дому[/url]
Современная наркологическая клиника в Мариуполе ориентирована на комплексное и индивидуальное лечение алкогольной и наркотической зависимости, обеспечивая пациентам высококвалифицированную помощь с использованием доказанных медицинских протоколов и новейших технологий. Зависимость — это хроническое заболевание, требующее профессионального подхода, основанного на научных данных и многолетнем опыте специалистов.
Выяснить больше – https://narkologicheskaya-klinika-mariupol13.ru
Психотерапия является неотъемлемой частью лечения, позволяя работать с психологическими причинами зависимости. В клинике применяются различные методы, включая когнитивно-поведенческую терапию, мотивационное интервью и групповую терапию. Это позволяет повысить мотивацию к выздоровлению и сформировать навыки, необходимые для жизни без наркотиков и алкоголя.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-krasnodar0.ru/]платная наркологическая клиника[/url]
mobila de lemn la comanda [url=1win40004.ru]1win40004.ru[/url]
Основные показания для проведения капельницы на дому:
Углубиться в тему – https://kapelnica-ot-zapoya-moskva0.ru/kapelnicza-ot-zapoya-anonimno-msk/
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить нормальный обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце. Этот этап критически важен для стабилизации состояния пациента и предотвращения дальнейших осложнений.
Разобраться лучше – https://vyvod-iz-zapoya-tula00.ru/vyvod-iz-zapoya-czena-tula/
Мультидисциплинарная программа строится на взаимодействии нескольких специалистов — нарколога, психотерапевта, социального работника и, при необходимости, специалиста по физреабилитации. Такой формат позволяет:
Разобраться лучше – [url=https://lechenie-narkomanii-mariupol13.ru/]лечение наркомании на дому в мариуполе[/url]
Алкогольный делирий проявляется в виде галлюцинаций, бреда и агрессии. При отсутствии контроля такие пациенты опасны для себя и окружающих, требуя немедленной госпитализации.
Изучить вопрос глубже – https://vivod-iz-zapoya-chelyabinsk13.ru/narkolog-vyvod-iz-zapoya-chelyabinsk
игровые пк москва [url=http://www.kupit-igrovoj-kompyuter8.ru]http://www.kupit-igrovoj-kompyuter8.ru[/url] .
вывод из запоя круглосуточно
narkolog-krasnodar006.ru
вывод из запоя круглосуточно
экстренный вывод из запоя
narkolog-krasnodar006.ru
экстренный вывод из запоя
Первый шаг в лечении — это тщательный осмотр специалиста. Наряду с измерением жизненно важных показателей (пульс, артериальное давление, температура) врач проводит сбор анамнеза, выясняя длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Эти данные помогают оценить степень интоксикации и подобрать индивидуальный план терапии, что является ключевым для дальнейшей эффективной детоксикации.
Подробнее тут – http://vyvod-iz-zapoya-yaroslavl0.ru/vyvod-iz-zapoya-czena-yaroslavl/
провайдеры интернета в челябинске
chelyabinsk-domashnij-internet004.ru
интернет провайдер челябинск
Врач уточняет, как долго продолжается запой, какой алкоголь употребляется, а также наличие сопутствующих заболеваний. Этот тщательный анализ позволяет оперативно подобрать оптимальные методы детоксикации и снизить риск осложнений.
Узнать больше – http://vyvod-iz-zapoya-tula0.ru/vyvod-iz-zapoya-anonimno-tula/
Клиника «Феникс-Мед» предлагает два базовых формата лечения, позволяющих адаптировать помощь под состояние пациента и его предпочтения.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-reutov4.ru/]vyvod iz zapoya vyzov[/url]
мелбет первый депозит [url=https://melbet1034.ru]https://melbet1034.ru[/url]
купить игровой пк [url=https://www.kupit-igrovoj-kompyuter9.ru]купить игровой пк[/url] .
вывод из запоя цена
narkolog-krasnodar007.ru
вывод из запоя круглосуточно краснодар
организация онлайн трансляции мероприятия [url=http://zakazat-onlajn-translyaciyu8.ru]организация онлайн трансляции мероприятия[/url] .
подключение интернета челябинск
chelyabinsk-domashnij-internet005.ru
интернет провайдер челябинск
организация онлайн трансляций цена [url=zakazat-onlajn-translyaciyu6.ru]zakazat-onlajn-translyaciyu6.ru[/url] .
экстренный вывод из запоя
narkolog-krasnodar007.ru
вывод из запоя круглосуточно краснодар
лечение запоя краснодар
narkolog-krasnodar008.ru
лечение запоя краснодар
Наркологическая клиника в Краснодаре представляет собой специализированное медицинское учреждение, где оказывается профессиональная помощь пациентам с различными формами зависимости. Современные подходы к лечению позволяют обеспечить эффективную и безопасную терапию, направленную на восстановление физического и психического здоровья.
Разобраться лучше – https://narkologicheskaya-klinika-krasnodar00.ru/
стильные кашпо для комнатных цветов [url=http://dizaynerskie-kashpo-sochi.ru/]стильные кашпо для комнатных цветов[/url] .
домашний интернет подключить челябинск
chelyabinsk-domashnij-internet006.ru
подключить проводной интернет челябинск
Чтобы вызвать нарколога на дом, достаточно позвонить по специализированным горячим телефонам или оформить заявку на сайте. Специалисты быстро реагируют на обращения, проводят первичную оценку и выезжают в течение часа. Важным аспектом является наличие лицензии и квалификации у медицинского персонала, что гарантирует безопасность и эффективность лечения.
Узнать больше – https://narkolog-na-dom-volgograd13.ru/
Среди преимуществ услуги:
Изучить вопрос глубже – https://narkolog-na-dom-chelyabinsk13.ru/
лечение запоя
narkolog-krasnodar008.ru
лечение запоя краснодар
Своевременный выезд нарколога снижает риск осложнений и ускоряет вывод из запоя, а под контролем профессионала каждая процедура проходит максимально безопасно.
Углубиться в тему – http://vyvod-iz-zapoya-reutov4.ru/vyvod-iz-zapoya-na-domu-v-reutove/
электрическая рулонная штора [url=https://rulonnye-shtory-s-elektroprivodom17.ru/]https://rulonnye-shtory-s-elektroprivodom17.ru/[/url] .
лечение запоя краснодар
narkolog-krasnodar009.ru
вывод из запоя круглосуточно краснодар
1win онлайн [url=http://1win40001.ru/]http://1win40001.ru/[/url]
Why users still make use of to read news papers when in this technological globe the whole thing is accessible on web?
https://maps.google.iq/url?q=https://cabseattle.com/
ИНТЕРНЕТ ДЛЯ ДОМА В Екатеринбурге: КАКИМ ТАРИФОМ ВОСПОЛЬЗОВАТЬСЯ Сегодня интернет является важной составляющей нашей повседневной жизни. Важно правильно выбрать провайдера и тариф для обеспечения надежного интернет-соединения в вашем доме. В столице много провайдеров, предоставляющих различные тарифы и услуги связи. Не забудьте учесть скорость интернета, выбирая провайдера. Безлимитный интернет популярен среди пользователей, так как позволяет свободно пользоваться сетью. Учтите и цены на интернет, а также наличие акций или скидок на подключение. Сравните тарифы, чтобы определить наиболее выгодные предложения. Ознакомьтесь с отзывами о провайдерах, чтобы узнать о реальном опыте других пользователей. Выбор провайдера может варьироваться в зависимости от вашего района, поэтому полезно спросить соседей. Не забудьте обратить внимание на дополнительные услуги, которые могут предложить провайдеры в Екатеринбурге. Например, это могут быть пакеты, включающие телевидение или телефонию. На сайте ekaterinburg-domashnij-internet004.ru вы быстро найдете и сравните тарифы, а также узнаете о лучших текущих предложениях. Правильный выбор обеспечит вам надежный доступ к интернету в вашем доме.
автоматические рулонные шторы с электроприводом [url=https://www.rulonnye-shtory-s-elektroprivodom190.ru]https://www.rulonnye-shtory-s-elektroprivodom190.ru[/url] .
электрокарнизы для штор купить [url=elektrokarnizy150.ru]elektrokarnizy150.ru[/url] .
Мы стремимся обеспечить пациентам максимальный уровень доверия и результативности лечения, сочетая передовые технологии и многолетний опыт специалистов:
Углубиться в тему – https://lechenie-alkogolizma-krasnodar0.ru/klinika-lecheniya-alkogolizma-krasnodar
карнизы с электроприводом [url=http://www.elektrokarniz150.ru]http://www.elektrokarniz150.ru[/url] .
вывод из запоя круглосуточно
narkolog-krasnodar009.ru
вывод из запоя
бухгалтерия 1с купить [url=https://sites.google.com/view/1s-8-buhgalteriya-bazovaya-kup/1s-8-buhgalteriya-bazovaya-kupit-kto-eshche-ne-ispolzuet-1s-v-2025-godu/]бухгалтерия 1с купить[/url] .
вывод из запоя круглосуточно
narkolog-krasnodar010.ru
вывод из запоя краснодар
красивый игровой пк [url=http://www.kupit-igrovoj-kompyuter10.ru]красивый игровой пк[/url] .
При глубокой алкогольной интоксикации запой может привести к серьёзным осложнениям — от обезвоживания и электролитного дисбаланса до острого алкогольного психоза. В Мариуполе клиника «Мариуполь без запоя» предлагает оперативную помощь на дому с выездом нарколога в течение 60 минут и круглосуточную поддержку. Пациент получает комплексное лечение без стресса госпитализации и в условиях полной конфиденциальности.
Подробнее – [url=https://vyvod-iz-zapoya-mariupol13.ru/]помощь вывод из запоя[/url]
Наши специалисты выезжают в любой район Москвы и ближайшего Подмосковья, чтобы помочь пациентам избежать осложнений и быстро прийти в норму после длительного запоя.
Подробнее тут – [url=https://kapelnica-ot-zapoya-moskva0.ru/]капельница от запоя цена московская область[/url]
Подключение интернета в Екатеринбурге – важный шаг для пользователей. Тем не менее перед тем как подписать договор на подключение, стоит учесть правовые аспекты. При выборе интернет-провайдеров необходимо внимательно изучить предложенные условия, включая технические условия и качество услуг. Провайдеры обязаны соблюдать лицензионные требования, что гарантирует защиту прав клиентов. Закон защищает права потребителей, поэтому необходимо быть осведомленным о своих действиях при отказе от договора. Например, возможны штрафы за нарушение условий. Также стоит учитывать безопасность личной информации, чтобы избежать рисков. Воспользуйтесь ресурсами, такими как ekaterinburg-domashnij-internet005.ru, для доступа к данным о правовых консультациях и помощи в решении споров. Правильное понимание правовых аспектов интернета поможет избежать проблем в будущем.
Алкогольная интоксикация и запой могут стремительно ухудшить состояние здоровья, став угрозой жизни, поэтому оперативное вмешательство имеет первостепенное значение. В Туле квалифицированные наркологи предоставляют круглосуточную помощь на дому, что позволяет начать лечение незамедлительно и в комфортных условиях. Такой формат терапии гарантирует индивидуальный подход, всестороннюю поддержку и полную конфиденциальность, что особенно важно для пациентов, стремящихся восстановить своё здоровье без лишних стрессовых ситуаций.
Разобраться лучше – [url=https://vyvod-iz-zapoya-tula000.ru/]вывод из запоя капельница тула[/url]
Весь азарт — в мелочах. Когда слот запускается мгновенно, когда не нужно сто раз подтверждать личность и ждать сутки на вывод — ты понимаешь, что попал в правильное место. Vodka Casino скачать на телефон оказалось простым действием, которое принесло кучу эмоций и реально крутые выигрыши. Мне понравилось, что всё продумано: от быстрых бонусов до стабильных зеркал. Даже когда сайт блокируют, не теряешь связь — приложение само находит рабочий доступ. Никаких лагов, никакой воды — всё по делу. Тут можно не просто прокрутить автомат, а реально включиться в игру и выиграть. И всё это без сложных условий и уловок. Простой интерфейс, честные выплаты и реальный шанс поднять банк — вот за что я уважаю эту платформу. А ещё здесь реально помогают, если что-то пошло не так. Не просто обещают, а делают.
Наркологическая клиника в Краснодаре представляет собой специализированное медицинское учреждение, где оказывается профессиональная помощь пациентам с различными формами зависимости. Современные подходы к лечению позволяют обеспечить эффективную и безопасную терапию, направленную на восстановление физического и психического здоровья.
Выяснить больше – [url=https://narkologicheskaya-klinika-krasnodar00.ru/]наркологическая клиника нарколог[/url]
Fascinating read! The evolution of online gaming in the Philippines is so interesting, especially seeing platforms like 3jl adapt & thrive. Curious about their early days – a legit pioneer! Check out 3jl slot download for a modern take on that history.
вывод из запоя круглосуточно краснодар
narkolog-krasnodar010.ru
вывод из запоя
видео трансляции людей [url=www.zakazat-onlajn-translyaciyu7.ru/]www.zakazat-onlajn-translyaciyu7.ru/[/url] .
электрические рулонные жалюзи [url=https://rulonnye-shtory-s-elektroprivodom17.ru/]https://rulonnye-shtory-s-elektroprivodom17.ru/[/url] .
В Екатеринбурге доступно большое количество интернет-провайдеров‚ и каждый из них предлагает различные тарифы на интернет и телевидение. При выборе провайдера важно учитывать скорость интернета‚ которая влияет на качество использования онлайн-сервисов. На сайте ekaterinburg-domashnij-internet006.ru вы найдете сравнение тарифов и услуг‚ включая услуги кабельного и спутникового телевидения. Многие компании предлагают акции и скидки на подключение услуг. IPTV услуги также становяться популярными‚ поскольку они предлагают разнообразные каналы. Не игнорируйте отзывы о различных провайдерах‚ чтобы принять верное решение. Не забывайте о своих потребностях: для домашнего интернета подойдут разные тарифы‚ в зависимости от количества пользователей и устройств. Выбор провайдера в Екатеринбурге – это возможность получить качественные услуги связи.
Автозакон [url=http://avtozakon.online/]http://avtozakon.online/[/url] .
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Только для своих – http://www.five-respect.co.jp/bbs/sunbbs.cgi?mode=form&no=128761505&page=
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Расширить кругозор по теме – https://www.andafcorp.com/8-jenis-kecurangan-yang-paling-sering-karyawan-lakukan-solusi-nya-part-1
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Только для своих – https://logovcelebes.id/infografis/item/113-ketahanan-pangan-di-sulawesi-selatan-semakin-membaik?tmpl=component&print=1&start=70
1win casino app download [url=http://1win40006.ru]http://1win40006.ru[/url]
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Открыть полностью – https://www.hotel-sugano.com/bbs/sugano.cgi/www.skitour.su/sinopipefittings.com/e_Feedback/www.skitour.su/datasphere.ru/club/user/12/blog/2477/www.tovery.net/sugano.cgi?page20=val
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Уточнить детали – https://slcs.edu.in/advanced-learner
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Подробная информация доступна по запросу – https://gusur.online/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%B9%D9%81%D8%B4-%D9%85%D9%86-%D8%AC%D8%AF%D8%A9-%D8%A7%D9%84%D9%8A-%D8%A7%D9%84%D9%85%D8%AF%D9%8A%D9%86%D8%A9-%D8%A7%D9%84%D9%85%D9%86%D9%88%D8%B1%D8%A9
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Подробная информация доступна по запросу – https://comonutrirse.com/undu-de-omnilife-para-que-sirve-principales-beneficios
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Что ещё? Расскажи всё! – https://cocktailsandsteaks.co.uk/home/attachment/smirnoff-cocktails-portrait
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Только для своих – https://f5fashion.vn/chia-se-56-ve-sinh-nhat-be-bao-bao-moi-nhat
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Информация доступна здесь – https://gusur.online/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%B9%D9%81%D8%B4-%D9%85%D9%86-%D8%AC%D8%AF%D8%A9-%D8%A7%D9%84%D9%8A-%D8%A7%D9%84%D9%85%D8%AF%D9%8A%D9%86%D8%A9-%D8%A7%D9%84%D9%85%D9%86%D9%88%D8%B1%D8%A9
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Посмотреть подробности – https://museedefunes.fr/?lang=en
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Это стоит прочитать полностью – https://www.oyshii.bntsgroup.com.au/index.php?itemid=33&catid=16
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Переходите по ссылке ниже – https://lunabun.com/product/hand-sanitizer
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Более подробно об этом – https://f5fashion.vn/dutchess-lattimore-tatuador-idade-aniversario-biografia-fatos-familia-patrimonio-liquido-altura-e-muito-mais
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Доступ к полной версии – https://www.ophthalmetryoptical.com/blog/tonometer-for-home-use
купить 1с бухгалтерия 8.3 проф [url=https://www.1s-buh-kupit-obzor-vozmozhnostey-dlya-biznesa.onepage.website/]купить 1с бухгалтерия 8.3 проф[/url] .
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Как достичь результата? – https://f5fashion.vn/top-hon-71-ve-xe-honda-air-blade-160cc-2022
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Осуществить глубокий анализ – https://f5fashion.vn/bi-mat-cach-nguoi-ai-cap-co-dai-uop-xac-nguoi-chet
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Это ещё не всё… – https://www.bloos.nu/favicon1
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Открыть полностью – https://f5fashion.vn/update-taylor-schabusiness-wiki-age-height-and-religion
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Открыть полностью – https://clemensrofner.com/2015-10-23_hi5-josef-leitner-20
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Обратитесь за информацией – https://brevardandbeyond.com/home-landing-page-ebook-v1/home/stay-informed-and-inspired-popular-non-fiction-ebooks
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Почему это важно? – https://topic.lk/8909
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Переходите по ссылке ниже – https://rspg.kmitl.ac.th/blog-4
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Открыть полностью – https://uxjoe.com/gallery-post
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Посмотреть подробности – https://forbesport.com/unveiling-the-auz100x-exploring-the-next-big-thing-in-audio-technology
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Как достичь результата? – https://safeofficialshop.com/ola-mundo
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Лучшее решение — прямо здесь – https://quackplex.com/livestock-management/care-and-feeding/do-goats-bleed-when-in-heat
1вин рабочее зеркало [url=http://1win3065.ru]1вин рабочее зеркало[/url]
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Секреты успеха внутри – https://f5fashion.vn/tong-hop-hon-53-ve-phoi-ao-so-mi-nam
провайдеры интернета в казани по адресу проверить
kazan-domashnij-internet004.ru
подключить проводной интернет казань
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Изучить аспект более тщательно – http://ahrecept.ru
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Обратитесь за информацией – https://f5fashion.vn/top-hon-71-ve-xe-honda-air-blade-160cc-2022
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Провести детальное исследование – https://www.antonelloosteria.com/tips/the-4-knife-cuts-every-cook-should-know
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Информация доступна здесь – https://isakidis-granites.by
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Что ещё? Расскажи всё! – http://72afisha.ru
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Ознакомьтесь с аналитикой – https://comonutrirse.com/undu-de-omnilife-para-que-sirve-principales-beneficios
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Выяснить больше – https://f5fashion.vn/cap-nhat-voi-hon-53-ve-pokemon-to-mau-moi-nhat
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Читать дальше – https://www.tierischinformiert.de/apoquel-neues-medikament-gegen-starken-juckreiz-bei-hunden
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Смотрите также… – https://henryukazu.com/the-relativity-of-success
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Погрузиться в детали – https://gisplayschool.com/hang-out-in-the-national-park
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Как достичь результата? – http://www.autotyrimai.lt/autoverslas/analize/alternatyviu-degalu-dalis-nauju-automobiliu-rinkoje-jau-virsijo-6
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Обратитесь за информацией – https://f5fashion.vn/chia-se-hon-60-ve-sinh-nhat-fifa-moi-nhat
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Подробнее – https://ara-came.com/prospia-brank
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Все материалы собраны здесь – http://deepwebifsa.tk/post/34
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Практические советы ждут тебя – https://atraktiv.ba/from-idea-to-realisation
Капельница от запоя на дому — является удобный также эффективный метод помощи в случае алкогольного отравления. В отличие от детоксикации в стационаре, лечение запоя на дому дает возможность пациенту оставаться в привычной обстановке, что снижает стресс а также способствует более быстрому восстановлению.Врач нарколог на дом Тула предлагает квалифицированные услуги нарколога, проводя процедуры по детоксикации и прекращению запойного состояния. Процедуры капельниц способствуют быстрому снятию симптомов алкогольной интоксикации, что улучшает общее состояние пациента; Также они обеспечивают достаточное увлажнение и восполнение витаминов. Детоксикация на дому подходит тем, кто не может или не желает проходить лечение в стационаре. Тем не менее, в случае серьезных осложнений необходимо более серьезное медицинское вмешательство. Нарколог на дом может организовать программу реабилитации для пациентов, включая психотерапевтические сеансы при зависимости, что значительно повысит шансы на успешное восстановление после запоя.
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Погрузиться в научную дискуссию – https://yewconsulting.co.uk/we-are-able-to-create-beautifull-and-amazing-things
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Не пропусти важное – https://topic.lk/10492
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Изучить аспект более тщательно – https://f5fashion.vn/tim-thay-loai-vat-mien-nhiem-phong-xa-o-vung-dat-chet-chernobyl
Кондиционеры Gree KingHome в любом доме уют создают. Мы о вашем комфорте заботимся. Gree KingHome кондиционеры – великолепный выбор для тех, кто ищет для охлаждения помещений качественное решение. Они обладают множеством полезных функций. https://kinghome.pro – здесь представлена более детальная информация, ознакомиться с ней можно в любое время. Собрали ответы на частые вопросы. Премиальные кондиционеры Gree KingHome справляются со своей работой на все 100 процентов. Можно их у нас приобрести, позвонив по телефону, который на ресурсе указан.
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Ознакомьтесь с аналитикой – https://www.taylordentist.com/benefits-of-pinhole-technique-vs-gum-grafting
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Ознакомьтесь с аналитикой – https://jabirjalali.com/think-positive
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Почему это важно? – http://alusilka.com/2014/08/28/massa-eu-blandit
Самостоятельно выйти из запоя — почти невозможно. В Екатеринбурге врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekaterinburg16.ru/]вывод из запоя на дому круглосуточно в екатеринбурге[/url]
mostbet uz apk [url=http://mostbet4079.ru/]mostbet uz apk[/url]
Миссия клиники “Маяк надежды” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша задача — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Получить больше информации – https://алко-лечение24.рф/vivod-iz-zapoya-anonimno-v-Sankt-Peterburge/
подключить интернет в квартиру казань
kazan-domashnij-internet005.ru
провайдер интернета по адресу казань
Капельница при запое – это важный метод терапии алкогольной зависимости, который широко применяется в наркологических клиниках Тулы. Метод детоксикации помогает быстрому реабилитации организма после длительного употребления алкоголя. Длительность капельницы обычно составляет от одного до трех часов, в зависимости от особенностей пациента и интенсивности запойного состояния. лечение запоя тула Симптоматика запоя включает в себя интенсивные головные боли, тошноту, потливость и тревожные состояния. Помощь врачей в виде капельницы позволяет быстро облегчить похмельные симптомы, вводя необходимые препараты для нормализации водно-электролитного баланса и выведения токсинов из организма. Стоимость лечения запоя в Туле различается в зависимости от выбранной клиники и объема необходимых процедур. Консультация нарколога поможет определить наилучший курс лечения, включая реабилитацию после запоя. Результативность капельницы доказывается множество положительными отзывами пациентов, что делает данный метод востребованным способом профилактики с алкогольной зависимостью.
Автозакон [url=http://www.avtozakon.online]http://www.avtozakon.online[/url] .
готовые рулонные шторы купить в москве [url=https://rulonnye-shtory-s-elektroprivodom190.ru/]rulonnye-shtory-s-elektroprivodom190.ru[/url] .
Да, многие клиники выезжают в Ленинградскую область — в радиусе 50–100 км от Санкт-Петербурга. Время прибытия согласуется при обращении.
Выяснить больше – [url=https://narko-zakodirovan.ru/]вывод из запоя санкт-петербург[/url]
Медикаментозное лечение: Мы применяем современные препараты, которые помогают облегчить симптомы абстиненции и улучшить состояние пациентов в первые дни лечения. Индивидуальный подбор лекарственных схем позволяет минимизировать побочные эффекты и достичь наилучших результатов.
Углубиться в тему – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]http://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru/[/url]
Xayrli kun!!
[url=https://mobileslots.cfd/]Ргровые автоматы РІ Узбекистане онлайн[/url]
Omad tilayman!
Нарколог Тула: Профессиональная помощь при зависимостях Если вы или ваши родные имеете проблемы с зависимостью‚ необходимо обратиться к специалисту. Нарколог Тула предлагает квалифицированную медицинскую помощь‚ включая оценку состояния зависимого и консультацию нарколога. В наркологической клинике доступны различные услуги‚ такие как лечение медикаментами и психотерапия. Работа с зависимостями – это сложный и многоступенчатый процесс‚ который предполагает индивидуального подхода. Программа реабилитации включает в себя фазы‚ направленные на восстановление физического и психологического состояния пациента. Реабилитация наркозависимых также подразумевает поддержку семьи‚ что является ключевой фактором в успешном лечении. Анонимное лечение даёт возможность пациентам ощущать себя защищенными и свободными от предвзятости. Профилактика наркомании и помощь при алкоголизме – важные аспекты работы наркологов. Обратитесь на narkolog-tula012.ru для получения подробностей и записи на консультацию. Помните‚ что раннее обращение – гарантия успешного выздоровления!
электрокарнизы в москве [url=www.elektrokarniz150.ru]www.elektrokarniz150.ru[/url] .
подключить домашний интернет казань
kazan-domashnij-internet006.ru
какие провайдеры интернета есть по адресу казань
карнизы с электроприводом [url=www.elektrokarnizy150.ru/]www.elektrokarnizy150.ru/[/url] .
Состав инфузии подбирается врачом индивидуально, с учётом состояния пациента, длительности запоя, возраста и хронических заболеваний.
Детальнее – [url=https://kapelnica-ot-zapoya-krasnoyarsk6.ru/]врач на дом капельница от запоя[/url]
Каждый пациент в «НаркоМедцентре» в Балашихе с самого начала окружён вниманием и заботой. Сразу после обращения по телефону или через сайт медицинский персонал консультирует родственников, уточняет детали состояния, даёт рекомендации по первой помощи и при необходимости отправляет бригаду наркологов на дом. В случае тяжёлых абстинентных проявлений возможно экстренное транспортирование пациента в стационар.
Подробнее – [url=https://vyvod-iz-zapoya-balashiha5.ru/]вывод из запоя круглосуточно[/url]
888starz. [url=http://pauls-boutique.com/]http://pauls-boutique.com/[/url] .
Врачебный состав клиники “Путь к выздоровлению” состоит из высококвалифицированных специалистов в области наркологии. Наши врачи-наркологи имеют обширный опыт работы с зависимыми пациентами и постоянно совершенствуют свои навыки.
Детальнее – http://нарко-фильтр.рф
Interesting analysis! RNG integrity is key for trust, and platforms like 777pinas link seem to prioritize secure access & verification – crucial for a good player experience in the Philippines. Good stuff!
Капельница от запоя – это поистине результативный метод лечения зависимости от алкоголя, который можно использовать в Туле благодаря врачей-наркологов, работающих на выезде. Процедура включает инъекции специальных растворов, которые помогают организму скорее справится с эффектами алкогольного опьянения. При обращении за помощью при запое, вы можете получить не лишь капельницу от алкоголизма, также консультацию нарколога. врач нарколог на дом тула Снятие запоя гарантирует оперативное восстановление состояния пациента, а безопасность процедуры капельного введения гарантируется опытными специалистами. Наркологическая помощь включает детокс-программу, которая направлена на восстановление организма. Реабилитация зависимых – это ключевой момент после лечения, который поможет избежать рецидивов. В городе Тула доступны услуги выездного нарколога, что дает возможность пройти лечение в комфортной обстановке. Не откладывайте, обратитесь за экстренной помощью врача-нарколога прямо сейчас!
параметры трансляции [url=https://zakazat-onlajn-translyaciyu8.ru]https://zakazat-onlajn-translyaciyu8.ru[/url] .
интернет провайдеры красноярск по адресу
krasnoyarsk-domashnij-internet004.ru
интернет провайдеры по адресу
провайдеры по адресу дома
krasnoyarsk-domashnij-internet004.ru
провайдеры по адресу
Вызов анонимного нарколога — является важным шагом на пути к лечению зависимости. Когда вы или ваш близкий сталкиваетесь с проблемами с психоактивными веществами либо алкоголем‚ не откладывайте обращение за помощью. На сайте site;com вы можете получить консультацию нарколога и вызвать специалиста на дом. Конфиденциальная помощь гарантирует вашу конфиденциальность‚ что имеет большое значение для многих зависимых. Квалифицированный нарколог осуществит детоксикацию организма и разработает персонализированные программы восстановления. Психотерапевтическая помощь также играет ключевую роль в лечении зависимости. Поддержка для зависимых и их семей способствует преодолению последствий зависимости. Не забывайте‚ что лечение алкогольной зависимости так же значимо‚ как и работа с наркотиками. Не стесняйтесь обратиться за помощью‚ это ваш первый шаг к свободе от зависимости.
Распознать необходимость лечения просто: достаточно внимательно отнестись к тревожным признакам. Вот лишь некоторые ситуации, когда обращение в наркологическую клинику становится жизненно важным:
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-balashiha5.ru/]частная наркологическая клиника[/url]
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Продолжить изучение – https://texas.statesolar.energy/2024/03/20/maximizing-solar-energy-efficiency-tips-for-optimal-performance
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Ознакомиться с деталями – http://vyvod-iz-zapoya-ekaterinburg16.ru/
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Получить полную информацию – https://myhair.vn/portfolio/reorganizing-process
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Что ещё? Расскажи всё! – http://www.mingwong.org/windows-on-the-world-part-2/80_uccamingwong2015installation22lores
Капельница от запоя – является действительным способом медицинской помощи при алкогольной зависимости. Вызов нарколога на дом позволяет быстро надежно получить необходимую помощь в ситуации запоя. Состав раствора капельницы как правило включает препараты для детоксикации организма, такие как раствор натрия хлорида, раствор глюкозы, витамины и антиоксиданты. Действие капельницы направлено на восстановлении водно-электролитного баланса, снятие симптомов абстиненции и улучшение общего состояния пациента. Лечение запоя с помощью капельницы гарантирует срочную помощь в условиях запоя и способствует более быстрому восстановлению после запоя. Медицинская помощь на дому позволяет избежать потребности в госпитализации, что делает процесс лечения удобнее для пациента. Важно помнить, что восстановление после запоя может включать и методы психотерапии для борьбы с алкогольной зависимостью.
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Не пропусти важное – https://www.marcgm.com/2023/10/23/ayudas-y-subvenciones
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Более подробно об этом – https://www.dsfa.org.au/tori_bedford1
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Смотрите также – https://romicharviajes.com/index.php/2022/07/01/how-to-travel-with-paper-map
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Более того — здесь – https://hikinhigh.com/ultimate-travel-planning-guide-10-tips-for-a-seamless-journey
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Открыть полностью – https://nationalflooringsolutions.com/4-trends-set-to-revolutionize-hardwood-in-the-2020s
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Секреты успеха внутри – https://www.pegadados.com.br/2023/06/22/harnessing-the-power-of-social-media-for-business-growth
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Продолжить изучение – https://blog.englishintensive.ru/cv-sostavlyaem-rezyume-na-anglijskom
интернет провайдеры по адресу красноярск
krasnoyarsk-domashnij-internet005.ru
интернет провайдеры по адресу
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Смотрите также… – https://f5fashion.vn/nang-tho-nhi-bao-ha-ghi-dau-an-san-dien-quoc-te-khi-dien-ao-dai-thuot-tha
В Екатеринбурге решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Разобраться лучше – [url=https://vyvod-iz-zapoya-ekaterinburg11.ru/]наркология вывод из запоя[/url]
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Почему это важно? – https://www.zahorany.cz/cropped-erb_zahorany-png
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Посмотреть подробности – https://adavsociety.org/neon-t
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Выяснить больше – https://f5fashion.vn/tong-hop-57-ve-con-vit-sinh-nhat-hay-nhat
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Не упусти важное! – https://daisycounselling.com.au/image-2
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Почему это важно? – https://topic.lk/8927
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Выяснить больше – https://microtrol-india.com/role-of-genetics-in-treating-low-grade-glioma
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Это ещё не всё… – https://sierraleonelawyers.com/understanding-legal-fees-demystifying-the-cost-of-legal-services
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Выяснить больше – https://doonlogistics.com/embracing-the-wonders-of-the-natural-world
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Узнай первым! – https://cstcpas.com/?p=1
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Почему это важно? – https://www.zahorany.cz/cropped-erb_zahorany-png
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Заходи — там интересно – https://f5fashion.vn/tong-hop-84-ve-hinh-nen-laptop-4k-chat
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Почему это важно? – https://ukfastkhabar.com/big-initiative-to-implement-uniform-civil-code-in-uttarakhand
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Это ещё не всё… – https://socalais-athletisme.fr/how-i-made-200-new-friends-in-one-year
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Подробнее тут – https://f5fashion.vn/thuy-tien-nhap-hoi-than-tien-ty-ty-cung-phuong-nhi-tuong-san
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Практические советы ждут тебя – https://f5fashion.vn/phat-hien-dau-lau-khong-lo-cua-quai-vat-bien-o-anh
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Погрузиться в научную дискуссию – https://blog.genkertrappers.be/2023/01/08/eindklassement-clubkampioenschap
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Неизвестные факты о… – https://f5fashion.vn/is-animedao-shutting-down-esajaelina
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Только для своих – https://f5fashion.vn/chi-tiet-hon-53-ve-qua-tang-sinh-nhat-bo-chong
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Все материалы собраны здесь – https://f5fashion.vn/ngay-may-man-thang-9-2023-cua-12-con-giap-ki-tich-xuat-hien
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Не упусти важное! – https://www.theyoga.co.uk/om-magazine-yoga-article
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Выяснить больше – https://cnopolebarns.com/feedback-2
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также – http://agnifm.ru
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Выяснить больше – https://sdawrrc-blog.com/2023/06/14/post-60566
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Нажмите, чтобы узнать больше – https://runnay-magiy.ru
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Только для своих – http://capriccio3.com/?p=994
круглосуточный вывод из запоя
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Ознакомьтесь с аналитикой – https://trendingwall.nl/inspiratie-voor-kinderkamer-behang
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Узнать из первых рук – http://www.rft-group.ru
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Все материалы собраны здесь – https://www.cursosalpha.com/blog/no-es-para-cualquiera-andar-por-la-calle
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Выяснить больше – https://mindfulnessacademy.se/presentationsfilm
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Не упусти важное! – https://topic.lk/9204
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Информация доступна здесь – http://utopiaimages.com/guestbook.html
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Обратитесь за информацией – https://antonioarrieta.com/blog/?attachment_id=209
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Неизвестные факты о… – https://foreningen.svenskhemslojd.com/product/alanya-braided-leather
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Лови подробности – https://www.marcgm.com/2023/10/23/ayudas-y-subvenciones
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Получить исчерпывающие сведения – https://jornalfax.net/index.php/2023/12/12/joel-leonardo-um-mandato-desastrado-na-justica
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Ознакомьтесь с аналитикой – https://www.drjuancarrasco.cl/faq-items/curabitur-eget-leo-at-velit-imperdiet-varius-eu-ipsum-vitae-velit-congue-iaculis-vitaes
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Более подробно об этом – https://www.gllogistics.eu/aeo
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Расширить кругозор по теме – https://f5fashion.vn/update-masya-masyitahs-without-tudung-photos-sparks-controversy-as-she-poses-in-a-barbie-inspired-outfit
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Посмотреть подробности – http://pedreiralajinha.com.br/site/about/attachment/logo-2
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Погрузиться в детали – https://aki-femcaresalon.com/2024/02/27/hello-world
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Узнать напрямую – https://ukfastkhabar.com/big-initiative-to-implement-uniform-civil-code-in-uttarakhand
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Нажми и узнай всё – https://topic.lk/10410
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Углубить понимание вопроса – https://artecampo.tercerimpactoproducciones.com/index.php/2023/06/22/the-importance-of-building-a-strong-brand-identity
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Ознакомиться с деталями – http://www.fidonet-mo.ru
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Ознакомиться с деталями – https://orientretie.be/asparagus-with-lemon-and-taragon-hollandaise
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Секреты успеха внутри – http://businessayeplans.cf/post/34
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Перейти к статье – https://stg.thedcminstitute.com.au/nz-operators-take-up-dcm-institute-village-management-professional-development-program
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Разобраться лучше – https://f5fashion.vn/cung-hot-influencers-viet-kham-pha-dien-mao-moi-cua-charles-keith-qua-bst-linitial
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Обратитесь за информацией – https://f5fashion.vn/jake-fuller-tiktok-star-umur-ulang-tahun-bio-fakta-keluarga-kekayaan-bersih-tinggi-badan-lainnya
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Это стоит прочитать полностью – https://unitedgamingsports.uk/fan-engagement-and-community-involvement-fc-anyang
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Более того — здесь – https://orencircus.ru
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Все материалы собраны здесь – https://www.thaimisdelicias.net/product/stir-fry-pearl-noodles
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Углубить понимание вопроса – https://www.thaimisdelicias.net/product/stir-fry-pearl-noodles
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Читать дальше – https://f5fashion.vn/goi-y-12-cung-hoang-dao-phoi-do-trong-ngay-19-10-2023
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Ознакомьтесь с аналитикой – https://f5fashion.vn/update-analyzing-king-von-autopsy-pictures-for-deeper-insights
оригинальные цветочные горшки [url=http://dizaynerskie-kashpo-sochi.ru/]оригинальные цветочные горшки[/url] .
Внутривенная инфузия – это один из самых быстрых и безопасных способов очистки организма от алкоголя и его токсичных продуктов распада. Она позволяет:
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnoyarsk6.ru/]капельница от запоя на дому недорого красноярск[/url]
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Узнай первым! – http://fizikabio.ru
Неотложная помощь при алкогольной зависимости в Туле все чаще требуется многим. Сайт narkolog-tula010.ru предлагает услуги нарколога, который осуществляет лечение алкоголизма и вывод из запоя. В данную процедуру входит медицинская помощь, детоксикация организма от алкоголя и психотерапевтические сеансы. Важно получить консультацию врача для успешного снятия алкогольной зависимости. Наша программа восстановления направлена на реабилитацию, поддержку зависимых и их социальную адаптацию. Профилактика повторных случаев, важный аспект успешного лечения. Помните, что обратится за помощью, это первый шаг к здоровью.
пансионат инсульт реабилитация
pansionat-msk004.ru
пансионат для пожилых с деменцией
“Реестр Гарант” оказывает услуги по включению в реестр Минпромторга российских производителей. Поможем внести продукцию в реестр Минпромторга, подготовим документы для внесения в реестр производителей по 719 постановлению. Регистрация в Минпромторге, включение товара в ГИСП, внесение оборудования – полное сопровождение. Узнайте стоимость включения в реестр Минпромторга: как попасть в реестр минпромторга
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Только для своих – https://kccs.com.au/project/city-skyline
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Екатеринбурге приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Получить больше информации – [url=https://vyvod-iz-zapoya-ekaterinburg11.ru/]свердловская область[/url]
lbh 1xbet [url=www.parimatch-apk.pro/]www.parimatch-apk.pro/[/url] .
Современная наркологическая клиника в Мариуполе ориентирована на комплексное и индивидуальное лечение алкогольной и наркотической зависимости, обеспечивая пациентам высококвалифицированную помощь с использованием доказанных медицинских протоколов и новейших технологий. Зависимость — это хроническое заболевание, требующее профессионального подхода, основанного на научных данных и многолетнем опыте специалистов.
Получить больше информации – [url=https://narkologicheskaya-klinika-mariupol13.ru/]лечение в наркологической клинике[/url]
Процесс лечения разделён на несколько этапов, каждый из которых важен для безопасности и эффективности терапии.
Углубиться в тему – https://narkolog-na-dom-rostov-na-donu13.ru
После оформления заявки по телефону или на сайте оператор уточняет адрес и текущее состояние пациента. В критических ситуациях врач может прибыть в течение 60 минут, в стандартном режиме — за 1–2 часа. На месте проводится сбор анамнеза и оценка жизненных показателей: артериального давления, пульса, сатурации и температуры тела. Затем выбирается оптимальный протокол детоксикации — «мягкий» метод для постепенного выведения токсинов или экспресс-методика при острой интоксикации. Процедура капельного введения комбинированного раствора длится от двух до четырёх часов: специалист контролирует состояние пациента, корректирует дозировки и при необходимости вводит корригирующие препараты. По окончании врач оставляет детальный план поддерживающей терапии, включающий рекомендации по питанию, приёму сорбентов и витаминов, а также график повторных осмотров.
Углубиться в тему – [url=https://narkolog-na-dom-ramenskoe4.ru/]вызвать нарколога на дом[/url]
Нельзя игнорировать первые признаки серьёзного алкогольного отравления: промедление повышает риск судорожных припадков, остановки дыхания и комы. Нарколог на дом в Реутове рекомендован при следующих симптомах:
Ознакомиться с деталями – https://vyvod-iz-zapoya-reutov4.ru/vyvod-iz-zapoya-na-domu-v-reutove/
Препараты готовятся индивидуально, с учётом состояния печени и почек пациента. В растворы добавляют комплекс витаминов и гепатопротекторов для защиты органа-мишени.
Ознакомиться с деталями – [url=https://lechenie-narkomanii-mariupol13.ru/]лечение наркомании и алкоголизма в мариуполе[/url]
В Екатеринбурге решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Подробнее тут – [url=https://vyvod-iz-zapoya-ekaterinburg.ru/]вывод из запоя на дому круглосуточно в екатеринбурге[/url]
edamam.ru [url=http://www.edamam.ru]http://www.edamam.ru[/url] .
Когда организм на пределе, важна срочная помощь в Екатеринбурге — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Подробнее тут – [url=https://vyvod-iz-zapoya-ekaterinburg11.ru/]наркологический вывод из запоя в екатеринбурге[/url]
Игровой портал [url=http://chiterskiy.ru/]http://chiterskiy.ru/[/url] .
частный пансионат для пожилых людей
pansionat-msk005.ru
пансионат для пожилых
Good day!!
Read the link – [url=https://digitalslots.cfd/]sweet bonanza bonus[/url]
sweet bonanza canada
sweet bonanza candyland stats
sweet bonanza bonus
Good luck!
ekoclinic.ru [url=ekoclinic.ru]ekoclinic.ru[/url] .
Запой, серьезное состояние‚ которое требует вмешательства специалистов; Ложное мнение, что можно самостоятельно выйти из запоя‚ как минимум, рискован и может иметь серьезные последствия. В Туле алкогольная зависимость — это проблема для многих, и помощь нарколога на дому играют важную роль в решении этой проблемы. Вызвать нарколога на дом в Туле Симптомы запойного состояния включают дрожь, обильное потоотделение, волнение. Самостоятельный вывод может привести к тяжелым проблемам со здоровьем‚ включая психические расстройства. Обращение к наркологу крайне важно для безопасного выхода из запоя и восстановления психического здоровья. Кроме того‚ реабилитация от алкоголя требует поддержки близких и профессионалов. Вызвав нарколога на дом в Туле‚ вы получите квалифицированную помощь‚ избежите рисков, связанных с самостоятельным выходом и приступите к восстановлению. Не ставьте под угрозу свое здоровье‚ обращайтесь за помощью!
Good day!!
Read the link – [url=https://mobileslots.cfd/]online Casino canada real money jackpot city[/url]
top 6 online real money casino canada
real money casino online canada
online casino real money no deposit canada
Good luck!
Возможность выезда 24/7 делает услугу «ЧелябДоктор» особенно востребованной:
Подробнее тут – [url=https://kapelnica-ot-zapoya-chelyabinsk13.ru/]капельница от запоя челябинск[/url]
Своевременное обращение к специалистам даёт возможность предотвратить тяжёлые последствия и обеспечить безопасный процесс восстановления. Ниже мы подробно рассмотрим каждый этап лечения.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-arkhangelsk6.ru/]вывод из запоя на дому круглосуточно в архангельске[/url]
Используются препараты, нормализующие работу центральной нервной системы, корректирующие электролитный баланс и устраняющие симптомы алкогольной интоксикации. Применение седативных и противосудорожных средств снижает риск осложнений.
Получить больше информации – [url=https://vyvod-iz-zapoya-rostov-na-donu13.ru/]вывод из запоя на дому в ростове-на-дону[/url]
Профессиональная дезинфекция от тараканов в Москве — это реальная возможность полностью избавиться от проблемы и не возвращаться к ней снова: заказать уничтожение тараканов
888starz bonus code eg [url=http://888starz.red]http://888starz.red[/url] .
Существуют определённые признаки, свидетельствующие о необходимости срочного обращения за профессиональной помощью:
Подробнее – http://vyvod-iz-zapoya-orekhovo-zuevo4.ru/vyvod-iz-zapoya-stacionar-v-orekhovo-zuevo/https://vyvod-iz-zapoya-orekhovo-zuevo4.ru
пансионат для пожилых с деменцией
pansionat-msk006.ru
пансионат для людей с деменцией в москве
Нарколог прибывает в течение 30 минут, оснащённый переносным оборудованием: портативным электрокардиографом, спирометром, прибором для измерения сатурации, набором необходимых медикаментов и расходных материалов. На первом этапе проводится замер давления, пульса, температуры и сатурации, берётся капиллярная проба крови для экспресс-анализа глюкозы и электролитов.
Получить дополнительные сведения – http://narkolog-na-dom-rostov-na-donu13.ru/narkolog-na-dom-rostov/
интернет провайдеры красноярск по адресу
krasnoyarsk-domashnij-internet006.ru
подключить интернет по адресу
Наша клиника работает по стандартам международного уровня, сочетая научно обоснованные методики с внимательным отношением к каждому пациенту. В «ВолгаМед» вы не столкнётесь с бюрократией или очередями — помощь оказывается сразу после обращения, а все процедуры проводятся в строгом соответствии с медицинскими протоколами и этическими нормами.
Разобраться лучше – [url=https://narkologicheskaya-klinika-volgograd13.ru/]платная наркологическая клиника волгоград[/url]
Современная наркологическая клиника в Мариуполе ориентирована на комплексное и индивидуальное лечение алкогольной и наркотической зависимости, обеспечивая пациентам высококвалифицированную помощь с использованием доказанных медицинских протоколов и новейших технологий. Зависимость — это хроническое заболевание, требующее профессионального подхода, основанного на научных данных и многолетнем опыте специалистов.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-mariupol13.ru/]анонимная наркологическая клиника мариуполь[/url]
Есть ситуации, когда дальнейшее промедление может привести к необратимым последствиям:
Получить дополнительные сведения – http://lechenie-alkogolizma-korolev5.ru
бонус на казино 1win [url=http://1win40007.ru/]http://1win40007.ru/[/url]
Запой, это серьезная ситуация, требующая немедленного вмешательства. В Туле услуги нарколога на дом срочно востребованы, особенно когда речь идет о помощи при запое. Нарколог на дом предоставляет важную медицинскую помощь, необходимую для выхода из запоя, включая детоксикацию и выведение из запоя.Не рекомендуется откладывать, пока ситуация станет критической. Скорая помощь может быть вызвана в любой момент для оказания первой помощи и определения дальнейших шагов. Лечение алкоголизма и алкогольной зависимости это процесс, который требует профессиональной помощи, и анонимное лечение становится важным аспектом для многих пациентов. Нарколог на дом срочно Тула Обращение к наркологу на дому в Туле — это возможность получить срочную помощь, не покидая домашние стены. Услуги нарколога включают в себя консультации и необходимые процедуры для детоксикации. Обратитесь за помощью к профессионалам, чтобы вернуть контроль над своей жизнью и начать новый этап.
пансионаты для инвалидов в туле
pansionat-tula004.ru
пансионат для реабилитации после инсульта
Наркологическая клиника в Ростове-на-Дону предоставляет полный спектр услуг по диагностике, лечению и реабилитации пациентов с алкогольной и наркотической зависимостью. Применение современных медицинских протоколов и индивидуальный подход к каждому пациенту обеспечивают высокую эффективность терапии и снижение риска рецидивов.
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-rostov-na-donu13.ru/]наркологическая клиника нарколог в ростове-на-дону[/url]
Существуют определённые признаки, свидетельствующие о необходимости срочного обращения за профессиональной помощью:
Получить больше информации – https://vyvod-iz-zapoya-orekhovo-zuevo4.ru/anonimnyj-vyvod-iz-zapoya-v-orekhovo-zuevo/
интернет провайдеры по адресу краснодар
krasnodar-domashnij-internet004.ru
провайдеры интернета по адресу
В клинике каждому пациенту уделяют особое внимание. Врачи знают: универсальных решений нет, за каждым случаем — своя история и свои причины. Первый контакт начинается с конфиденциальной консультации. Можно просто позвонить или написать онлайн — уже на этом этапе врач поможет оценить ситуацию, объяснит возможные этапы и даст рекомендации по подготовке к визиту.
Получить больше информации – [url=https://lechenie-alkogolizma-korolev5.ru/]лечение алкоголизма в стационаре[/url]
malishi.online [url=https://www.malishi.online]https://www.malishi.online[/url] .
pelenku.ru [url=http://pelenku.ru]http://pelenku.ru[/url] .
Я малышка [url=http://imalishka.ru]http://imalishka.ru[/url] .
Памятники культуры [url=www.pamyatniki-kultury.ru]www.pamyatniki-kultury.ru[/url] .
proedy [url=https://proedy.online]https://proedy.online[/url] .
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Это ещё не всё… – https://bykremodeling.com/why-you-should-consider-remodeling-your-home
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Получить исчерпывающие сведения – http://bywayofthemooncitra.cf/post/34
ksusha.online [url=ksusha.online]ksusha.online[/url] .
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Углубить понимание вопроса – https://www.mojorno.ru
“Реестр Гарант” оказывает услуги по включению в реестр Минпромторга российских производителей. Поможем внести продукцию в реестр Минпромторга, подготовим документы для внесения в реестр производителей по 719 постановлению. Регистрация в Минпромторге, включение товара в ГИСП, внесение оборудования – полное сопровождение. Узнайте стоимость включения в реестр Минпромторга: внесение продукции в реестр минпромторга
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Смотрите также – https://www.peacekeeper.at/jahresausklang-der-kaerntner-peacekeeper
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Лови подробности – https://actionmillionacademy.com/index.php/2023/08/09/bonjour-tout-le-monde
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Ознакомьтесь с аналитикой – http://jeannin-osteopathe.fr/entreprises/logo-thibault-jeannin-ombre
Реабилитация от запоя в Туле: профессиональная поддержка Запой — это серьезная проблема, требующая профессионального вмешательства. В Туле предлагаются услуги нарколога на дому анонимно, что позволяет пациентам получить необходимую помощь без лишнего стресса. Консультация с наркологом может стать отправной точкой на пути к восстановлению. нарколог на дом анонимно Лечение зависимостей — это сложный и многоступенчатый процесс. Реабилитация от алкоголизма состоит из медицинской помощи и психотерапии, что помогает не только преодолеть физическую зависимость, но и проработать важные психологические моменты. Программа восстановления может включать поддержку родственников, что важно для успешной терапии. Помощь при запое часто заключается в предоставлении анонимной наркологической помощи. Специалисты взаимодействуют с зависимыми, предлагая им психологическую помощь во время запоя и рекомендации по предотвращению рецидивов. Социальная адаптация является ключевым этапом в процессе реабилитации. Услуги нарколога на дому позволяют обеспечить комфортную обстановку для лечения и восстановления после алкоголя.
пансионат для престарелых
pansionat-tula005.ru
частные пансионаты для пожилых в туле
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Смотри, что ещё есть – https://cadenavirtual.com.ar/seguridad/2020/04/18/habilitaron-un-permiso-excepcional-de-traslado-para-quienes-quedaron-aislados-en-el-pais
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Изучить аспект более тщательно – https://solarkinfrasolutions.com/portfolio/research-analysis
1win poker скачать на ios [url=1win40003.ru]1win40003.ru[/url]
Сайт о питании при беременности [url=www.edamam.ru]www.edamam.ru[/url] .
mostbet uz скачать ios [url=mostbet4080.ru]mostbet4080.ru[/url]
проверить провайдеров по адресу краснодар
krasnodar-domashnij-internet005.ru
какие провайдеры на адресе в краснодаре
brwmw kwd 1xbet [url=http://parimatch-apk.pro]http://parimatch-apk.pro[/url] .
ООО “ДефоСерт” предлагает профессиональные услуги по сопровождению процедуры включения производственных компаний в реестр Министерства промышленности и торговли РФ. Наши специалисты обеспечат подготовку полного пакета документов, консультации по требованиям регламентов, взаимодействие с государственными органами и успешное прохождение всех этапов регистрации в реестре, подробнее – у нас
Все об экстракорпоральном оплодотворении и лечении бесплодия [url=www.ekoclinic.ru]www.ekoclinic.ru[/url] .
пансионат для реабилитации после инсульта
pansionat-tula005.ru
пансионат для лежачих тула
Алкоголизм – тяжелая проблематика, требующая всестороннего подхода к излечению. В городе Тула предлагается помощь в любое время, в т.ч. помощь при запое. Центры лечения алкоголизма предоставляют сервисы психологической терапии и реабилитации, что становится необходимым этапом в излечении. Кризисная интервенция и профессиональные консультации помогают людям с зависимостью осознать и принять свою зависимость. Эмоциональная поддержка включает в себя индивидуальную терапию и групповую терапию, что способствует опытом и эмоциональной поддержке. Реабилитационная программа способствует выработать стратегий отказа от алкоголя и новые навыки жизни без него. вывод из запоя круглосуточно тула Следует отметить, что наркологическая помощь предоставляется в любое время, что позволяет каждому найти путь к здоровью и счастью.
интернет провайдеры в краснодаре по адресу дома
krasnodar-domashnij-internet005.ru
интернет провайдеры по адресу дома
Сразу после вызова нарколог приезжает на дом для проведения первичного осмотра и диагностики. На этом этапе проводится сбор анамнеза, измеряются жизненно важные показатели (пульс, артериальное давление, температура) и определяется степень алкогольной интоксикации. Эти данные являются основой для разработки индивидуального плана лечения.
Подробнее можно узнать тут – https://kapelnica-ot-zapoya-tyumen0.ru/postavit-kapelniczu-ot-zapoya-tyumen/
Amazing issues here. I am very happy to see your article. Thank you so much and I am taking a look ahead to touch you. Will you kindly drop me a e-mail?
Acquisto farmaci online a basso costo
¡Hola amigo!
[url=https://progressiveslots.cfd/]casinos online confiables[/url]
Lee este enlace – https://progressiveslots.cfd/
jugar casino en lГnea
casino con bono
777 casino gratis
¡Buena suerte!
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Углубиться в тему – https://quick-vyvod-iz-zapoya-1.ru/
Мы используем современные беззапаховые препараты, которые уничтожают тараканов в квартире за одно посещение https://obrabotka-ot-tarakanov7.ru/
В подобных случаях вывод из запоя в домашних условиях без врачебного контроля крайне опасен и может привести к тяжёлым последствиям. Лучше сразу вызвать нарколога или привезти пациента в клинику — это поможет избежать критических осложнений.
Подробнее – [url=https://vyvod-iz-zapoya-balashiha5.ru/]вывод из запоя на дому[/url]
пансионат для пожилых в туле
pansionat-tula006.ru
пансионат для престарелых людей
Пациенты выбирают нашу клинику для срочного вызова врача-нарколога благодаря следующим важным преимуществам:
Получить больше информации – [url=https://narcolog-na-dom-novosibirsk00.ru/]нарколог на дом анонимно в новосибирске[/url]
провайдеры по адресу дома
krasnodar-domashnij-internet006.ru
провайдеры интернета в краснодаре по адресу
Вызов нарколога — это необходимый шаг для тех, кто сталкивается с трудностями с зависимостями . Служба наркологической помощи предоставляет срочную наркологическую помощь и консультацию нарколога, что крайне важно в экстренных случаях. Признаки зависимости от наркотиков могут проявляться по-разному , и важно знать, когда необходима медицинская помощь при алкоголизме . Лечение алкоголизма и помощь при наркотической зависимости требуют профессионального подхода . Алкоголизм и его последствия могут быть разрушительными , поэтому важно обратиться за поддержкой для зависимых , включая реабилитацию зависимых . На сайте narkolog-tula014.ru вы можете узнать, как обратиться к наркологу или получить конфиденциальную помощь для наркозависимых. Не стесняйтесь обращаться по телефону наркологической службы , чтобы получить нужную помощь и поддержку.
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Подробнее можно узнать тут – https://quick-vyvod-iz-zapoya-1.ru/
После поступления звонка нарколог оперативно выезжает по указанному адресу и прибывает в течение 30–60 минут. Врач незамедлительно приступает к оказанию помощи по четко отработанному алгоритму, состоящему из следующих этапов:
Детальнее – [url=https://narcolog-na-dom-voronezh00.ru/]вызов врача нарколога на дом в воронеже[/url]
Тараканы не только неприятны, но и опасны — они могут быть переносчиками бактерий, поэтому дезинфекция необходима https://obrabotka-ot-tarakanov7.ru/
Читерский [url=https://chiterskiy.ru/]https://chiterskiy.ru/[/url] .
Клиника «ТоксинНет» предлагает профессиональную помощь при алкогольной зависимости и запоях в Нижнем Новгороде. Наши опытные наркологи круглосуточно выезжают на дом для оказания экстренной медицинской помощи. Основным методом лечения является капельница от запоя, которая позволяет оперативно снять интоксикацию и стабилизировать общее состояние пациента. Мы обеспечиваем конфиденциальность, индивидуальный подход и высокий уровень безопасности процедур.
Получить дополнительную информацию – http://kapelnica-ot-zapoya-nizhniy-novgorod0.ru/vyzvat-kapelniczu-ot-zapoya-nizhnij-novgorod/https://kapelnica-ot-zapoya-nizhniy-novgorod0.ru
Женский журнал [url=https://ksusha.online/]https://ksusha.online/[/url] .
Современные методы лечения при выводе из запоя включают как медикаментозную детоксикацию, так и психологическую реабилитацию. В Уфе наркологи используют капельничное введение лекарственных средств, которые помогают быстро вывести токсины, нормализовать обмен веществ и стабилизировать работу внутренних органов. Одновременно с этим проводится психологическая поддержка для снижения эмоционального стресса, связанного с запоем.
Детальнее – http://narcolog-na-dom-ufa0.ru
Когда организм на пределе, важна срочная помощь в Екатеринбурге — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Получить больше информации – [url=https://vyvod-iz-zapoya-ekaterinburg11.ru/]вывод из запоя на дому круглосуточно город екатеринбург[/url]
вывод из запоя цена
tula-narkolog001.ru
вывод из запоя цена
Процесс вывода из запоя капельничным методом организован по строгой схеме, позволяющей обеспечить максимальную эффективность терапии. Каждая стадия направлена на комплексное восстановление организма и минимизацию риска осложнений.
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-tyumen0.ru
В Москве выбор провайдеров домашнего интернета действительно велик. На сайте msk-domashnij-internet004.ru вы сможете найти множество отзывов пользователей, которые помогут вам определиться. Обязательно учитывайте скорость интернета и стабильность соединения, так как это существенно сказывается на качестве услуг. Среди популярных технологий подключения выделяются оптоволоконный и кабельный интернет. Оптоволоконный интернет предоставляет высокую скорость и надежность, что особенно важно для пользователей работает с большими объемами данных. Кабельный интернет также имеет свои преимущества, но часто не дотягивает до оптоволокна по скорости. При выборе провайдера стоит обратить внимание на тарифы на интернет. Сравнение тарифов различных провайдеров Москвы позволит вам найти наилучший вариант, соответствующий вашим потребностям. Не забывайте про альтернативные провайдеры, которые могут предложить интересные предложения и удобные условия домашнего интернета. Отзывы пользователей о подключении интернета помогут понять реального качества услуг. Обратите внимание на мнения о беспроводном интернете – он очень удобен, но иногда страдает от нестабильности. Подбирайте провайдера, основываясь на опыте других пользователей, и наслаждайтесь качественным интернетом!
Пациенты, которые выбирают нашу клинику для лечения алкогольного запоя, получают качественную и оперативную помощь, обладающую следующими преимуществами:
Получить больше информации – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod0.ru/]вызвать капельницу от запоя на дому в нижний новгороде[/url]
пансионат для пожилых после инсульта
pansionat-msk004.ru
частный дом престарелых
Наркологическая клиника «МедЛайн» предоставляет профессиональные услуги врача-нарколога с выездом на дом в Новосибирске и Новосибирской области. Мы оперативно помогаем пациентам справиться с тяжелыми состояниями при алкогольной и наркотической зависимости. Экстренный выезд наших специалистов доступен круглосуточно, а лечение проводится с применением проверенных методик и препаратов, что гарантирует безопасность и конфиденциальность каждому пациенту.
Получить дополнительную информацию – [url=https://narcolog-na-dom-novosibirsk00.ru/]врач нарколог на дом[/url]
proedy.online [url=www.proedy.online/]www.proedy.online/[/url] .
imalishka.ru [url=www.imalishka.ru/]www.imalishka.ru/[/url] .
pelenku.ru [url=http://www.pelenku.ru]http://www.pelenku.ru[/url] .
вывод из запоя цена
tula-narkolog002.ru
вывод из запоя круглосуточно тула
Многодневные алкогольные запои опасны не только для здоровья, но и для жизни. В этот период организм подвергается тяжелейшей интоксикации, страдают сердце, печень, нервная система, а психоэмоциональное состояние может выйти из-под контроля. Самостоятельно выйти из запоя очень трудно и опасно: любое промедление или попытка “перетерпеть” чреваты судорогами, галлюцинациями, инфарктом, тяжелой депрессией или делирием. Именно поэтому своевременное обращение к профессионалам — залог не только скорого, но и безопасного восстановления. В наркологической клинике «НаркоМедцентр» в Балашихе организован современный и медицински обоснованный вывод из запоя: здесь пациентов ждет индивидуальный подход, круглосуточное медицинское наблюдение и полная конфиденциальность.
Получить больше информации – [url=https://vyvod-iz-zapoya-balashiha5.ru/]нарколог вывод из запоя[/url]
Сайт о новорожденных детях [url=www.malishi.online]www.malishi.online[/url] .
Памятники культуры [url=https://pamyatniki-kultury.ru/]https://pamyatniki-kultury.ru/[/url] .
В Москве бесплатный интернет стал привычным. Есть много мест‚ где можно найти доступ к Wi-Fi. Одним из самых удобных решений является кафе‚ предлагающие Wi-Fi. Многие заведения предлагают доступный интернет‚ что позволяет работать и отдыхать с комфортом. Не забудьте про парки с интернетом. Здесь можно наслаждаться природой и при этом быть онлайн. Различные общественные заведения в Москве‚ такие как библиотеки и музеи и торговые центры‚ также обычно имеют бесплатный беспроводной интернет. Для поиска Wi-Fi точек воспользуйтесь картами Wi-Fi точек на сайте msk-domashnij-internet005.ru. Это позволит быстро определить‚ где можно подключиться к интернету. Мобильный интернет в Москве также доступен‚ но бесплатный Wi-Fi более выгоден для сбережения средств. Пользуйтесь нашими рекомендациями по нахождению Wi-Fi‚ и вы всегда будете на связи. Не забывайте следить за доступными сетями в городе для оптимального выбора.
Стоимость услуг по установке капельницы определяется индивидуально и зависит от нескольких факторов. В первую очередь, цена обусловлена тяжестью состояния пациента: при более сильной интоксикации и выраженных симптомах абстинентного синдрома может потребоваться расширенная терапия. Кроме того, итоговая сумма зависит от продолжительности запоя, так как длительное употребление спиртного ведет к более серьезному накоплению токсинов, требующему дополнительных лечебных мероприятий.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod000.ru/]вызвать капельницу от запоя в нижний новгороде[/url]
пансионат с медицинским уходом
pansionat-msk005.ru
пансионат для престарелых
В таких случаях своевременное обращение за помощью позволяет быстро стабилизировать состояние и предотвратить развитие серьезных осложнений.
Узнать больше – https://narcolog-na-dom-voronezh0.ru/
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekaterinburg11.ru/]vyvod-iz-zapoya-kruglosutochno ekaterinburg[/url]
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Секреты успеха внутри – https://urokiphotoshop.ru
স্বাগতম!
[url=https://digitalpokerclub.cfd]ক্যাসিনো টাকা ইনকাম[/url]
এই লিঙ্কটি পড়ুন – https://digitalpokerclub.cfd
অনলাইন ক্যাসিনো অ্যাপ
অনলাইন ক্যাসিনো খেলা
অনলাইন জোয়া
শুভকামনা!
вывод из запоя тула
tula-narkolog003.ru
вывод из запоя цена
শুভ দিন!
[url=https://jackpotslotsonline.cfd/]রিয়েল ক্যাসিনো[/url]
এই লিঙ্কটি দেখুন – https://jackpotslotsonline.cfd
অনলাইন ক্যাসিনো খেলার নিয়ম
অনলাইন জোয়া
অনলাইন ক্যাসিনো খেলা
শুভকামনা!
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Смотрите также… – https://www.suryamaxindo.co.id/who-we-are
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Что ещё нужно знать? – https://thefundingcafe.com/fufofa-swimwear-get-a-perfect-tan
В Москве выбор интернет провайдеров по адресу велик. Основные услуги связи представляют высокоскоростной интернет, что является важным для комфортного пользования. При выборе провайдера важно учитывать тарифы на интернет, предлагаемые безлимитные пакеты и оптоволоконный интернет. интернет провайдеры москва по адресу Также существуют удобные варианты подключения к интернету, что даёт возможность быть на связи в удалённых местах. Сравнение провайдеров поможет выбрать оптимальный вариант. Отзыв о провайдерах в Москве помогает понять качество их услуг и стабильность соединения. При установке интернета в квартире или частном доме обычно доступен Wi-Fi, что позволяет подключать все устройства. Понимание всех этих аспектов позволит сделать правильный выбор и наслаждаться всеми преимуществами интернета.
1хбет зеркало промокод
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Подробнее – https://langlopp.com/ll-logo
пансионат для пожилых людей
pansionat-msk006.ru
дом престарелых
экстренный вывод из запоя
vivod-iz-zapoya-chelyabinsk004.ru
вывод из запоя цена
«Чем раньше начнётся профессиональная детоксикация, тем выше шанс избежать необратимых последствий и тяжёлых осложнений», — отмечает врач-нарколог клиники «Азимут Здоровья» Елена Степанова.
Узнать больше – https://narkolog-na-dom-ramenskoe4.ru/narkolog-na-dom-anonimno-v-ramenskom
1win.co [url=https://1win40009.ru/]1win.co[/url]
провайдеры по адресу нижний новгород
nizhnij-novgorod-domashnij-internet004.ru
подключение интернета нижний новгород
Здарова!
[url=https://clasicslotsonline.cfd/]vavada казино онлайн казахстан вход[/url]
Переходи: – https://clasicslotsonline.cfd
онлайн казино казахстана
казино онлайн в казахстане с бонусом за регистрацию
vavada казино онлайн казахстан вход
Пока!
skrill casino site-uri [url=https://www.1win40005.ru]skrill casino site-uri[/url]
пансионат для лежачих больных
pansionat-tula004.ru
пансионаты для инвалидов в туле
proobzor [url=www.proobzor.info/]www.proobzor.info/[/url] .
Описание
Выяснить больше – http://narkologicheskaya-pomoshh-samara0.ru/narkologicheskaya-klinika-samara/
reckey [url=https://reckey.ru]https://reckey.ru[/url] .
роликовые шторы [url=https://rulonnye-shtory-s-elektroprivodom11.ru]https://rulonnye-shtory-s-elektroprivodom11.ru[/url] .
рулонные шторы с электроприводом на окна [url=https://avtomaticheskie-rulonnye-shtory50.ru/]avtomaticheskie-rulonnye-shtory50.ru[/url] .
стоимость рулонных жалюзи [url=https://elektricheskie-rulonnye-shtory90.ru]https://elektricheskie-rulonnye-shtory90.ru[/url] .
рулонные шторы на кухню купить [url=https://www.rulonnye-elektroshtory.ru]рулонные шторы на кухню купить[/url] .
рольшторы на окна купить в москве [url=elektricheskie-rulonnye-shtory.ru]рольшторы на окна купить в москве[/url] .
вывод из запоя круглосуточно челябинск
vivod-iz-zapoya-chelyabinsk005.ru
лечение запоя челябинск
Лечение наркомании в Омске является сложным медицинским процессом, требующим комплексного подхода и участия квалифицированных специалистов. Современная наркологическая клиника «Ренессанс» предлагает полный спектр услуг, направленных на восстановление физического и психического здоровья пациентов с различными формами наркотической зависимости. В клинике используются доказанные методы терапии, которые обеспечивают стабильную ремиссию и помогают вернуться к полноценной жизни.
Получить дополнительную информацию – http://lechenie-narkomanii-omsk0.ru/lechenie-narkomanov-omsk/https://lechenie-narkomanii-omsk0.ru
интернет провайдеры по адресу
nizhnij-novgorod-domashnij-internet005.ru
интернет провайдеры по адресу
Клиника «Феникс-Мед» предлагает два базовых формата лечения, позволяющих адаптировать помощь под состояние пациента и его предпочтения.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-reutov4.ru/]vyvod iz zapoya reutov stacionar[/url]
Физическая сторона зависимости — не менее важна, чем психологическая. Поэтому пациенты в «РеабПермь» получают грамотную поддержку на уровне тела: от детоксикации до восстановления обмена веществ и работы внутренних органов. Врач-нарколог назначает препараты, учитывая общее состояние, наличие хронических заболеваний, вес, уровень интоксикации и переносимость медикаментов. Под наблюдением находятся показатели давления, работы сердца, печени и центральной нервной системы. При необходимости подключаются узкие специалисты — кардиолог, гастроэнтеролог, эндокринолог.
Узнать больше – http://lechenie-narkomanii-perm0.ru/perm-narkologiya/https://lechenie-narkomanii-perm0.ru
вывод из запоя
vivod-iz-zapoya-chelyabinsk006.ru
лечение запоя
дом престарелых в туле
pansionat-tula005.ru
пансионат для престарелых людей
кашпо стиль [url=http://dizaynerskie-kashpo-rnd.ru]кашпо стиль[/url] .
провайдеры по адресу дома
nizhnij-novgorod-domashnij-internet006.ru
подключение интернета по адресу
https://www.c-heads.com/2015/12/29/one-day-only-at-manning-bar-sydney-australia/
Ниже представлен перечень основных направлений, используемых в современной наркологической помощи. Этот список отражает комплексный подход к лечению зависимостей.
Подробнее можно узнать тут – [url=https://narkologicheskaya-pomoshh-perm0.ru/]частная наркологическая помощь[/url]
экстренный вывод из запоя
vivod-iz-zapoya-cherepovec007.ru
вывод из запоя
mosbet uz [url=https://mostbet4072.ru/]https://mostbet4072.ru/[/url]
proobzor [url=https://proobzor.info/]https://proobzor.info/[/url] .
пансионат для лежачих пожилых
pansionat-tula006.ru
пансионат с медицинским уходом
https://tlt.ru/business/festivali-v-sankt-peterburge-glavnye-sobytiya-goda/2249448/?erid=F7NfYUJCUneP6Uy9quxt
рулонные шторы купить москва недорого [url=https://rulonnye-elektroshtory.ru]рулонные шторы купить москва недорого[/url] .
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Выяснить больше – https://cstcpas.com/?p=1
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Практические советы ждут тебя – https://www.tacit3d.com/affordable-housing-architects-toronto-overcoming-challenges-and-creating-sustainable-solutions
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Это ещё не всё… – http://sochielektroseti.ru
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Выяснить больше – http://www.rst-tv.ru
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Доступ к полной версии – https://thespeedpost.com/jap-workers-stop-train-at-ara-railway-station
Интернет-подключение в столице предоставляет разнообразие вариантов от разных поставщиков услуг связи. Чтобы выбрать оптимальный тариф, стоит обратить внимание на скорость интернета и качество услуг. На сайте novosibirsk-domashnij-internet004.ru можно найти современным сравнением тарифов, что способствует определению наилучшего предложения. Среди известных провайдеров можно отметить компании, которые предлагают высокоскоростной интернет и стабильное соединение. Многие из них имеют в своем арсенале специальные предложения и льготы на услуги подключения и установку оборудования. Отзывы о провайдерах также являются значимыми в процессе выбора. Пользователи отмечают доступный интернет и качественность услуг связи, что делает жизнь комфортнее. В итоге, исследуя рынок, вы сможете найти интернет для дома, отвечающий вашим потребностям.
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Почему это важно? – https://pqoil.com/innovative-products-and-materials
вывод из запоя череповец
vivod-iz-zapoya-cherepovec008.ru
экстренный вывод из запоя
В «Гелиосе» уделяется особое внимание конфиденциальности и психологическому комфорту пациентов. Анонимность процедур и доброжелательная атмосфера способствуют снижению стресса и улучшению результатов лечения.
Разобраться лучше – [url=https://narkologicheskaya-klinika-tver0.ru/]запой наркологическая клиника тверь[/url]
https://m-bs2best.at
вывод из запоя
tula-narkolog001.ru
вывод из запоя круглосуточно тула
reckey.ru [url=http://reckey.ru]http://reckey.ru[/url] .
Greetings!
[url=https://casinowins.cfd]sweet bonanza casino canada[/url]
Check out – https://casinowins.cfd/
Enjoy your gaming experience!
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Смотрите также – https://aleksandrovic.com/2023/01/19/hello-world
¡Qué tal!!
[url=https://digitalbetting.cfd]casino en linea ecuador ecuador[/url]
Lee este enlace – https://digitalbetting.cfd
cassino dando giros gratis ecuador
juegos de casino en lГnea con dinero real ecuador
casino en linea ecuador
¡Buena suerte!
Будущее технологий: гигабитный интернет в новосибирске В последние годы Новосибирский интернет стал быстрее из-за активного внедрения оптоволоконных сетей. Гигабитный интернет устанавливает новые стандарты, обеспечивая высокоскоростной доступ в интернет и открывая двери для цифровой трансформации. новосибирск является ареной для инноваций от провайдеров, что делает современные технологии связи доступными для широких масс. Умные города не могут обойтись без беспроводных технологий и интернета вещей. Также улучшается оборудование для интернета, чтобы соответствовать гигабитным скоростям. Необходимо упомянуть, что ресурс novosibirsk-domashnij-internet005.ru предлагает информацию о лучших провайдерах и их предложениях. Так, гигабитный интернет, это не просто тренд, а важная необходимость современного общества, движущегося к новым технологиям связи.
¡Buen día!!
[url=https://livecasinogames.cfd/]casino en lГnea chile[/url]
Lee el enlace – https://livecasinogames.cfd
juegos de casino en linea con dinero real chile
tu casino en casa chile
juegos de casino con dinero real chile
¡Buena suerte!
¡Saludos!!
[url=https://livedealers.cfd]300 reales a bolivianos[/url]
Lee el enlace – https://livedealers.cfd/
casino con dinero real bolivia
juegos de casino en linea con dinero real bolivia
casino en bolivia
¡Buena suerte!
Круглосуточная помощь
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]вызвать капельницу от запоя краснодар[/url]
экстренный вывод из запоя тула
tula-narkolog002.ru
вывод из запоя круглосуточно тула
Наша наркологическая клиника успешно помогает пациентам с различной степенью алкогольной зависимости. Преимущества клиники «Перспектива» представлены в таблице ниже:
Исследовать вопрос подробнее – https://kapelnica-ot-zapoya-krasnodar77.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
https://storage.googleapis.com/digi21sa/research/digi21sa-(122).html
A fit-and-flare silhouette will accentuate your figure but still really feel mild and ethereal.
https://mygazeta.com/%D0%BF%D1%83%D1%82%D0%B5%D1%88%D0%B5%D1%81%D1%82%D0%B2%D0%B8%D1%8F/%D1%88%D0%B5%D1%80%D0%B5%D0%B3%D0%B5%D1%88-%D0%B4%D0%BE%D0%BC%D0%B1%D0%B0%D0%B9-%D0%B8%D0%BB%D0%B8-%D1%8D%D0%BB%D1%8C%D0%B1%D1%80%D1%83%D1%81.html
https://digi592sa.z11.web.core.windows.net/research/digi592sa-(183).html
As mom of the bride, you might need to discover a look which complements these elements, without being matchy-matchy.
В современном мире доступ к интернету стал важной частью жизни, и пожилые люди в столице также желают поддерживать связь. Для них предложены уникальные тарифы для пожилых, которые обеспечивают простые и доступные условия. На сайте novosibirsk-domashnij-internet006.ru можно найти привлекательными предложениями по интернет-тарифам, которые оптимально подходят для пожилых людей. Услуги связи, направленные на пожилых людей, включают помощь клиентам и помощь в подключении. Кроме того, курсы пользованию интернетом и цифровые услуги для пенсионеров позволяют доступ к информации и коммуникации простым и доступным. Мобильный интернет для старшего поколения включает комфортные тарифы, которые помогают оставаться на связи с близкими.
https://digi642sa.netlify.app/research/digi642sa-(97)
Here’s another one of the best mother-of-the-bride attire you should buy online.
«НаркоМед» основана группой узкопрофильных специалистов, чей опыт насчитывает более 15 лет в лечении зависимости. Клиника работает круглосуточно — вы можете рассчитывать на оперативное реагирование в любой час дня и ночи. Анонимность пациентов сохраняется на уровне медицинской тайны: персональные данные и диагноз не разглашаются.
Выяснить больше – [url=https://narkologicheskaya-klinika-ekaterinburg0.ru/]бесплатная наркологическая клиника в екатеринбурге[/url]
Запой — тревожный сигнал для семьи. В Narcology Clinic (Королёв) предлагают срочную помощь: вывод из запоя в домашних условиях или в стационаре, медикаментозная поддержка и контроль состояния. Конфиденциально и эффективно.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-korolev14.ru/]нарколог вывод из запоя в королеве[/url]
https://je-sf-tall-marketing-716.b-cdn.net/research/je-marketing-(318).html
So, you’ll wish to put on something that doesn’t clash with the remainder of the group in pictures.
После прохождения основной программы пациенту предлагается поддерживающее наблюдение. Оно может включать дистанционные консультации, участие в группе профилактики срывов, повторные осмотры нарколога и психолога, корректировку медикаментозной схемы. В рамках реабилитации формируются планы действий при возникновении тяги, обучаются навыки сопротивления стрессу и внешнему давлению. При желании можно подключить родственников к процессу постлечебной адаптации, чтобы укрепить результат и снизить риски рецидивов. Таким образом, пациент не остаётся один даже после выписки.
Подробнее можно узнать тут – [url=https://lechenie-narkomanii-novokuzneczk0.ru/]лечение больных наркоманией[/url]
https://je-tall-marketing-802.fra1.digitaloceanspaces.com/research/je-marketing-(307).html
Even as a guest to a marriage I have made a few errors up to now.
вывод из запоя
vivod-iz-zapoya-irkutsk004.ru
лечение запоя
рольшторы с электроприводом [url=https://rulonnye-shtory-s-elektroprivodom11.ru/]https://rulonnye-shtory-s-elektroprivodom11.ru/[/url] .
рулонные шторы с электроприводом и дистанционным управлением [url=http://elektricheskie-rulonnye-shtory.ru]рулонные шторы с электроприводом и дистанционным управлением[/url] .
рулонные жалюзи с электроприводом [url=https://elektricheskie-rulonnye-shtory90.ru/]рулонные жалюзи с электроприводом[/url] .
https://digi594sa.z12.web.core.windows.net/research/digi594sa-(398).html
The column silhouette skims the determine while still offering plenty of room to maneuver.
рулонные шторы на окно в кухне [url=http://avtomaticheskie-rulonnye-shtory50.ru]http://avtomaticheskie-rulonnye-shtory50.ru[/url] .
https://je-tall-marketing-771.lon1.digitaloceanspaces.com/research/je-marketing-(73).html
The refined scoop neck and sheer lace sleeves are just a few of the things we love about this A-line gown.
https://digi642sa.netlify.app/research/digi642sa-(195)
With a gentle match at the hips, this costume is designed to flatter you in all the proper places.
https://digi589sa.z29.web.core.windows.net/research/digi589sa-(76).html
For the mother whose style is glossy and minimal, opt for a robe with an architectural silhouette in her favorite colour.
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]вызвать капельницу от запоя на дому краснодар[/url]
https://jekyll.s3.us-east-005.backblazeb2.com/20250730-7/research/je-marketing-(438).html
The reviews are optimistic though appear to report you should order a size up.
вывод из запоя
tula-narkolog003.ru
вывод из запоя тула
https://je-tall-marketing-800.syd1.digitaloceanspaces.com/research/je-marketing-(224).html
This dress, as its name suggests, is extremely elegant.
https://digi642sa.netlify.app/research/digi642sa-(19)
Jules & Cleo, solely at David’s Bridal Polyester, nylon Back zipper; absolutely lined …
https://je-tall-marketing-821.syd1.digitaloceanspaces.com/research/je-marketing-(84).html
Grab superb online deals on mother of the bride clothes now and get free delivery within the United States.
вывод из запоя круглосуточно иркутск
vivod-iz-zapoya-irkutsk005.ru
вывод из запоя круглосуточно
интернет тарифы омск
omsk-domashnij-internet004.ru
провайдеры интернета в омске
https://je-tall-marketing-809.lon1.digitaloceanspaces.com/research/je-marketing-(488).html
On the opposite hand, If you are curvy or apple-shaped, versatile costume styles like a-line and empire waist will work wonders for you.
Описание
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок на дому[/url]
https://je-tall-marketing-784.lon1.digitaloceanspaces.com/research/je-marketing-(438).html
Find the right inexpensive wedding ceremony guest clothes for any season.
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Получить дополнительную информацию – [url=https://snyatie-lomki-rnd7.ru/]снятие наркотической ломки краснодар[/url]
https://je-tall-marketing-803.lon1.digitaloceanspaces.com/research/je-marketing-(168).html
The modern silk material glides seamlessly over your figure, however an ankle-length skirt, excessive neckline and draped sleeves keep issues modest.
https://jekyll.s3.us-east-005.backblazeb2.com/20250730-10/research/je-marketing-(212).html
You might imagine it’s customary for the mom of the bride to put on an over-sized hat, however that’s merely not the case for 2022.
https://je-tall-marketing-779.tor1.digitaloceanspaces.com/research/je-marketing-(199).html
And lastly, don’t worry about seeking to solely ‘age-appropriate’ boutiques.
Одним из ключевых преимуществ «КузбассМед» является современная материально-техническая база. В клинике задействованы устройства для точного мониторинга жизненных функций, автоматические инфузионные системы, экспресс-диагностические модули и оборудование для неотложной терапии. Врачи используют программируемые дозаторы, портативные анализаторы крови и аппараты для оценки дыхательной функции, что позволяет своевременно корректировать тактику лечения без потерь времени. Все процедуры соответствуют национальным стандартам безопасности и рекомендациям ВОЗ.
Получить больше информации – [url=https://narkologicheskaya-klinika-novokuzneczk0.ru/]наркологическая клиника клиника помощь в новокузнецке[/url]
Вывод из запоя без стресса — специалисты клиники «Alco.Rehab» в Москве знают, как помочь быстро и безопасно.
Разобраться лучше – [url=https://https://vyvod-iz-zapoya-moskva11.ru//]vyvod-iz-zapoya-czena moskva[/url]
https://jekyll.s3.us-east-005.backblazeb2.com/20250729-3/research/je-marketing-(483).html
If you’ll find something with flowers even when it’s lace or embroidered.
Do you have a spam issue on this site; I also am a blogger, and I was wondering your situation; many of us have created some nice methods and we are looking to trade methods with others, why not shoot me an e-mail if interested.
Also visit my page: https://888Starz-rossiya.ru/
мелбет промокод 2024 [url=https://melbet1040.ru/]https://melbet1040.ru/[/url]
melbet deposit options [url=https://melbet1039.ru/]https://melbet1039.ru/[/url]
экстренный вывод из запоя
vivod-iz-zapoya-chelyabinsk004.ru
лечение запоя челябинск
https://je-tall-marketing-818.fra1.digitaloceanspaces.com/research/je-marketing-(184).html
(I don’t suppose he’ll benefit from the journey of buying with me).
лечение запоя
vivod-iz-zapoya-irkutsk006.ru
вывод из запоя круглосуточно иркутск
https://digi596sa.z44.web.core.windows.net/research/digi596sa-(496).html
This mother also wore Nigerian attire, and paired her lace wrap costume with a chartreuse gele.
провайдеры омск
omsk-domashnij-internet005.ru
интернет домашний омск
https://je-sf-tall-marketing-726.b-cdn.net/research/je-marketing-(463).html
Weddings are very special days not just for brides and grooms, however for his or her moms and grandmothers, too.
Наркологическая клиника в Твери обеспечивает круглосуточное медицинское наблюдение, что позволяет своевременно выявлять и устранять возможные осложнения. Высококвалифицированные специалисты проводят регулярные обследования и корректируют терапию, обеспечивая безопасность и эффективность лечения.
Исследовать вопрос подробнее – https://narkologicheskaya-klinika-tver0.ru/
Каждый пациент получает персонализированный план лечения, разработанный с учётом анамнеза, общего состояния и психоэмоционального фона. В «ПермьМедСервис» нет универсальных шаблонов — используется модульная модель терапии, при которой программы состоят из комбинированных блоков: медикаментозное лечение, психотерапия, физиотерапия, семейное консультирование. Это позволяет гибко адаптировать курс, вносить изменения по ходу лечения и учитывать динамику состояния пациента.
Выяснить больше – [url=https://narkologicheskaya-klinika-perm0.ru/]наркологическая клиника[/url]
https://je-tall-marketing-795.lon1.digitaloceanspaces.com/research/je-marketing-(184).html
Even higher, it will look nice paired with heeled or flat sandals—whichever helps you feel your best on the dance ground.
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Подробнее тут – [url=https://snyatie-lomki-rnd77.ru/]нарколог на дом снятие ломки в краснодаре[/url]
В наркологической клинике «Рестарт» используется комплексный подход к лечению абстинентного синдрома. Наши преимущества:
Подробнее – https://snyatie-lomki-rnd7.ru/
https://je-tall-marketing-792.blr1.digitaloceanspaces.com/research/je-marketing-(95).html
The web site’s subtle gowns make for glorious evening wear that’ll serve you long after the wedding day.
вывод из запоя круглосуточно
vivod-iz-zapoya-chelyabinsk005.ru
экстренный вывод из запоя челябинск
https://je-tall-marketing-775.tor1.digitaloceanspaces.com/research/je-marketing-(480).html
For her mom, it concerned a beaded silver costume match for a queen.
экстренный вывод из запоя
vivod-iz-zapoya-kaluga007.ru
вывод из запоя круглосуточно калуга
https://tvoy-bor.ru/articles/all/2024/12/16/330647.html
https://je-tall-marketing-808.sgp1.digitaloceanspaces.com/research/je-marketing-(137).html
Plus, the silhouette of this robe will look that rather more show-stopping as the cape wafts down the aisle to disclose her silhouette as she moves.
https://je-tall-marketing-779.tor1.digitaloceanspaces.com/research/je-marketing-(61).html
With palm leaf décor and many vines, green was a primary theme all through this charming and colorful South Carolina celebration.
подключить проводной интернет омск
omsk-domashnij-internet006.ru
дешевый интернет омск
1win сайт [url=https://1win40010.ru/]https://1win40010.ru/[/url]
https://je-tall-marketing-766.lon1.digitaloceanspaces.com/research/je-marketing-(184).html
Knowing a little bit about what you’d like to put on might help you narrow down your choices.
https://je-tall-marketing-794.fra1.digitaloceanspaces.com/research/je-marketing-(297).html
This mixture is very nice for summer weddings.
https://digi594sa.z12.web.core.windows.net/research/digi594sa-(266).html
If you like neutral tones, gold and silver dresses are promising decisions for an MOB!
http://www.pogkomplekt.ru/prod2_1.htm
Спокойный выход из кризиса — воспользуйтесь услугой вывода из запоя от «Alco.Rehab» в Москве.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-moskva12.ru/]вывод из запоя капельница[/url]
https://je-tall-marketing-776.blr1.digitaloceanspaces.com/research/je-marketing-(104).html
This material is nice as a end result of it lays flattering and appears great in photos.
¡Qué tal!
[url=https://onlinepokerroom.cfd/]casino en linea chile[/url]
Lee este enlace – https://onlinepokerroom.cfd
1xbet casino chile
juegos de casino con dinero real chile
casino real online chile
¡Buena suerte!
Привет!
[url=https://pokerstrategyhub.cfd]казахстан онлайн казино[/url]
По ссылке: – https://pokerstrategyhub.cfd/
казино онлайн в казахстане с бонусом за регистрацию
10 лучших казино онлайн казахстан
проверенные онлайн казино с выводом денег казахстан
Бывай!
https://digi637sa.netlify.app/research/digi637sa-(489)
Clean strains and a shaped waist make this a timeless and elegant mom of the bride gown with a flattering silhouette.
https://digi594sa.z12.web.core.windows.net/research/digi594sa-(47).html
This mother of the bride donned a wonderful gentle grey gown with an phantasm neckline brimming with beautiful beaded detailing.
https://je-tall-marketing-820.lon1.digitaloceanspaces.com/research/je-marketing-(346).html
Colors such as fuchsia, green and silver are just some ideas!
Цены в «ПермьМедСервис» формируются исходя из состава процедур, срочности и длительности лечения. Все тарифы озвучиваются заранее, прозрачны и не содержат скрытых пунктов. Пациент может выбрать подходящий пакет, а также оплатить услуги поэтапно или в рассрочку. Доступна оплата наличными, банковской картой, онлайн-переводом. Для постоянных клиентов предусмотрены скидки, а при прохождении полного курса — бесплатное сопровождение в течение месяца после выписки.
Подробнее тут – https://narkologicheskaya-klinika-perm0.ru/chastnaya-narkologicheskaya-klinika-perm/
экстренный вывод из запоя калуга
vivod-iz-zapoya-kaluga008.ru
лечение запоя калуга
https://je-tall-marketing-808.sgp1.digitaloceanspaces.com/research/je-marketing-(448).html
When purchasing on-line enable time for supply and any alterations to be made.
https://digi645sa.netlify.app/research/digi645sa-(304)
Saks is definitely one of the best malls for buying a mother-of-the-bride dress.
Seattle homeowners! Make the right investment with this [url=https://artpaint.com.ua/ru/2025/07/choosing-the-perfect-siding-for-your-seattle-home-a-complete-guide/]guide to choosing the perfect siding[/url] tailored for the Northwest climate.
Our [url=https://aolimo.com/vehicles.html] Airport Transfers Limousine [/url] service provides luxurious and comfortable ground transportation to and from the airport. With professional chauffeurs and high-end vehicles, our Airport Transfers Limousine service ensures a smooth and stress-free travel experience. – https://aolimo.com/vehicles.html
вывод из запоя цена
vivod-iz-zapoya-chelyabinsk006.ru
вывод из запоя челябинск
Если близкий оказался в запое — не откладывайте помощь. В Королёве специалисты Narcology Clinic предлагают срочный и безопасный вывод из запоя с выездом на дом или в стационаре. Анонимно и с гарантией результата.
Подробнее – [url=https://vyvod-iz-zapoya-korolev12.ru/]vyvod-iz-zapoya-klinika korolev[/url]
Мы предлагаем уборка квартир в Москве и области, обеспечивая высокое качество, внимание к деталям и индивидуальный подход. Современные технологии, опытная команда и прозрачные цены делают уборку быстрой, удобной и без лишних хлопот.
лечение зависимости анонимно рехаб для алкоголиков
Мы предлагаем поиск протечки в СПб и области с гарантией качества и соблюдением всех норм. Опытные мастера, современное оборудование и быстрый выезд. Честные цены, удобное время, аккуратная работа.
Спокойный выход из кризиса — воспользуйтесь услугой вывода из запоя от «Alco.Rehab» в Москве.
Подробнее тут – [url=https://vyvod-iz-zapoya-moskva12.ru/]вывод из запоя[/url]
https://je-tall-marketing-764.sgp1.digitaloceanspaces.com/research/je-marketing-(297).html
You’ve helped her discover her dream dress, now allow us to allow you to find yours…
домашний интернет тарифы
perm-domashnij-internet004.ru
провайдеры домашнего интернета пермь
лечение запоя
vivod-iz-zapoya-kaluga009.ru
лечение запоя калуга
Для пациентов, требующих круглосуточного наблюдения, клиника «Полярис» предлагает стационар VIP-класса. Здесь созданы все условия для быстрого восстановления: удобные палаты, индивидуальное меню, зоны отдыха и консультации профильных специалистов.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-arkhangelsk0.ru/]наркологическая клиника нарколог[/url]
https://digi642sa.netlify.app/research/digi642sa-(186)
You’ve probably been by the bride’s facet helping, planning, and lending invaluable advice alongside the greatest way.
методы лечения зависимости лечение наркомании в стационаре
https://digi588sa.z8.web.core.windows.net/research/digi588sa-(337).html
A structured costume will always be flattering, especially one that nips you on the waist like this chic frock from Amsale.
экстренный вывод из запоя череповец
vivod-iz-zapoya-cherepovec007.ru
вывод из запоя череповец
Описание
Углубиться в тему – https://snyatie-lomki-rnd77.ru/snyatie-lomki-na-domu-v-rnd/
методы лечения зависимости реабилитационный центр
После диагностики нарколог приступает к основному этапу — инфузионной детоксикации. Препараты подбираются индивидуально, с учётом тяжести интоксикации, анамнеза и сопутствующих заболеваний. Основу составляют водно-солевые растворы, глюкоза, витаминные комплексы, седативные препараты, гепатопротекторы и нейропротекторы. Инфузии выполняются капельно, медленно, в течение нескольких часов, с постоянным мониторингом состояния пациента. При необходимости используется оксигенотерапия, противорвотные, антиаритмические и противосудорожные препараты. Все растворы стерильны, а расходные материалы одноразовые и соответствуют стандартам качества.
Узнать больше – [url=https://narkologicheskaya-pomoshh-novosibirsk0.ru/]оказание наркологической помощи[/url]
помощь в лечении зависимости лечение наркомании
Круглосуточная наркологическая помощь в Королёве: вывод из запоя от Narcology Clinic. Врачи выезжают на дом, стабилизируют состояние, проводят мягкую детоксикацию и помогают вернуться к трезвому образу жизни.
Узнать больше – [url=https://vyvod-iz-zapoya-korolev11.ru/]срочный вывод из запоя в королеве[/url]
https://je-tall-marketing-773.blr1.digitaloceanspaces.com/research/je-marketing-(13).html
This exquisite floral frock would make the proper complement to any nature-inspired wedding.
домашний интернет тарифы пермь
perm-domashnij-internet005.ru
подключение интернета пермь
вывод из запоя цена
vivod-iz-zapoya-krasnodar006.ru
вывод из запоя цена
Круглосуточная наркологическая помощь в Королёве: вывод из запоя от Narcology Clinic. Врачи выезжают на дом, стабилизируют состояние, проводят мягкую детоксикацию и помогают вернуться к трезвому образу жизни.
Узнать больше – [url=https://vyvod-iz-zapoya-korolev14.ru/]наркология вывод из запоя город Королев[/url]
Упаковка оптом подарков в Москве недорого и бумажных пакетов с логотипом во Владикавказе. Футболки с логотипом россии и изготовление стаканов для кофе с логотипом в Хабаровске. Упаковочная коробка из картона купить и упаковка сумка подарочная в Рязани. Промо сувениры оптом купить и оптом деревянное оружие сувениры оптом во Владимире. Праздничная коробка оптом купить и купить красивый подарочный пакет: коробки для подарков брендированные
https://jekyll.s3.us-east-005.backblazeb2.com/20250730-1/research/je-marketing-(500).html
“She bought it on a whim and ended up winning,” the bride mentioned.
Для эффективного приёма рекомендуется заранее:
Выяснить больше – http://lechenie-alkogolizma-ekaterinburg00.ru
https://je-tall-marketing-784.lon1.digitaloceanspaces.com/research/je-marketing-(469).html
This mother of the bride escorted her daughter down the aisle in a lightweight blue gorgeous halter costume.
https://digi595sa.z48.web.core.windows.net/research/digi595sa-(40).html
Go for prints that speak to your wedding ceremony location, and most significantly, her personal style.
https://digi641sa.netlify.app/research/digi641sa-(163)
As the mother of the bride, your role comes with massive responsibilities.
https://je-tall-marketing-769.blr1.digitaloceanspaces.com/research/je-marketing-(223).html
This type is completed with brief sleeves and a under the knee hem, and has a hid centre again zip fastening.
Подарочные коробки оптом для полотенец и картонные бумажные пакеты в Самаре. Бумажные флажки На палочке с логотипом и чехол На чемодан с логотипом На заказ в Тамбове. Нанесение логотипов На пакеты и коробка карандашей в Калуге. Продаю Набор для барбекю оптом и Наборы для гольфа с логотипом в Новокузнецке. Кондитерская упаковка оптом и пакет бумажный самоклеющийся стерит: подарочные коробки Москва как выбрать
https://digi642sa.netlify.app/research/digi642sa-(220)
You can go for prints, and flowers when you like that fashion.
https://je-tall-marketing-765.blr1.digitaloceanspaces.com/research/je-marketing-(90).html
Don’t be afraid to make a press release in head-to-toe sparkle.
вывод из запоя череповец
vivod-iz-zapoya-cherepovec008.ru
вывод из запоя
лечение запоя
vivod-iz-zapoya-krasnodar007.ru
вывод из запоя круглосуточно краснодар
Запой — это опасное состояние, при котором организм человека подвергается сильной алкогольной интоксикации, а внутренние органы, такие как печень, сердце и почки, начинают работать в аварийном режиме. В такой момент самостоятельное лечение становится невозможным, и необходима оперативная помощь специалистов. Наркологическая клиника «Детоксика» в Сочи предлагает комплексный вывод из запоя с использованием современных методов терапии и индивидуального подхода, что позволяет быстро восстановить здоровье пациента и предотвратить серьезные осложнения.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя клиника[/url]
https://je-tall-marketing-770.blr1.digitaloceanspaces.com/research/je-marketing-(28).html
Also, a lace blouse and fishtail skirt is a classy possibility that has “elegance” weaved into its seams.
Обращение к специалистам становится необходимым, когда симптомы запоя указывают на тяжелую интоксикацию. В таких случаях оперативное вмешательство позволяет не только облегчить симптомы, но и предотвратить развитие серьезных осложнений. Следующие признаки свидетельствуют о необходимости лечения:
Углубиться в тему – [url=https://vyvod-iz-zapoya-sochi77.ru/]вывод из запоя на дому круглосуточно сочи[/url]
домашний интернет подключить пермь
perm-domashnij-internet006.ru
тарифы интернет и телевидение пермь
1win መተግበሪያ [url=https://1win40008.ru/]https://1win40008.ru/[/url]
https://je-tall-marketing-767.sgp1.digitaloceanspaces.com/research/je-marketing-(75).html
The champagne colored ankle-length wrap dress looks stunning on this mom of the bride.
1win bet app [url=www.1win40012.ru]1win bet app[/url]
перепланировка согласование [url=http://www.soglasovanie-pereplanirovki-kvartiry1.ru]перепланировка согласование[/url] .
электрические карнизы купить [url=http://www.elektrokarnizy33.ru]http://www.elektrokarnizy33.ru[/url] .
перепланировка квартиры москва [url=https://proekt-pereplanirovki-kvartiry4.ru]https://proekt-pereplanirovki-kvartiry4.ru[/url] .
электрокранизы [url=https://elektrokarnizy-dlya-shtor150.ru/]https://elektrokarnizy-dlya-shtor150.ru/[/url] .
карниз электро [url=www.elektrokarniz-nedorogo.ru/]www.elektrokarniz-nedorogo.ru/[/url] .
https://digi595sa.z48.web.core.windows.net/research/digi595sa-(19).html
Always dress for comfort and to please what the bride has in thoughts.
заказать перепланировку квартиры [url=www.proekt-pereplanirovki-kvartiry4.ru]www.proekt-pereplanirovki-kvartiry4.ru[/url] .
рулонные шторы с пультом [url=zhalyuzi-s-elektroprivodom7.ru]zhalyuzi-s-elektroprivodom7.ru[/url] .
прикольные горшки для цветов [url=dizaynerskie-kashpo-nsk.ru]прикольные горшки для цветов[/url] .
электрокарниз [url=https://elektrokarnizy7.ru/]elektrokarnizy7.ru[/url] .
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar008.ru
вывод из запоя круглосуточно
https://digi594sa.z12.web.core.windows.net/research/digi594sa-(15).html
A lovely formal dress with cap sleeves and floral embroidery that trails from the high neckline to the floor-grazing hem.
промокод в 1win [url=https://www.1win1162.ru]https://www.1win1162.ru[/url]
домашний интернет тарифы
rostov-domashnij-internet004.ru
тарифы интернет и телевидение ростов
В клинике проводится лечение различных видов зависимости с применением современных методов и препаратов. Ниже перечислены основные направления, отражающие широту оказываемой медицинской помощи.
Выяснить больше – http://narkologicheskaya-klinika-novosibirsk0.ru/narkologiya-novosibirsk-kruglosutochno/
https://je-tall-marketing-791.sgp1.digitaloceanspaces.com/research/je-marketing-(84).html
Express your love with handmade Valentine’s crafts like paper cards, present ideas, and decorations.
Hello, friend!
Top 10 online casino in India ranked here. [url=https://blackjackpro.cfd]india online casino[/url] Find your perfect gaming site.
Read the link – https://blackjackpro.cfd/
online casino india app download
online gambling in india
is online casino legal in india
Good luck!
Добрый день!
Топ онлайн казино Узбекистан обновляется ежемесячно. [url=https://casinostrategies.cfd/]казино онлайн узбекистан[/url] Рейтинги помогают выбрать площадку.
Переходи: – https://casinostrategies.cfd/
онлайн казино uz
онлайн казино ташкент
казино онлайн узбекистан
Пока!
вывод из запоя череповец
vivod-iz-zapoya-cherepovec009.ru
экстренный вывод из запоя
lucky jet bonus code [url=https://1win40013.ru/]https://1win40013.ru/[/url]
20
Выяснить больше – [url=https://vyvod-iz-zapoya-korolev13.ru/]Королев[/url]
1вин рабочий сайт [url=1win1163.ru]1win1163.ru[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar009.ru
вывод из запоя круглосуточно краснодар
Где купить дешево в Москве картонные коробки оптом и Маленькие упаковочные коробочки в Севастополе. Пакеты с логотипом изготовление и Нанесение На кружки сублимация в Братске. Широкий пакет подарочный и коробка 40 30 20 в Калининграде. Поставщики сувениров оптом и подарки оптовику во Владимире. Белые коробки оптом с крышкой и картонные коробки с печатью На заказ: подарочная упаковка оптом под печать логотипа
провайдеры интернета ростов
rostov-domashnij-internet005.ru
подключить домашний интернет ростов
Передовые методики
Получить больше информации – https://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-cena-v-sochi
бонус на казино 1win [url=http://1win40013.ru]бонус на казино 1win[/url]
1 win букмекерская контора официальный сайт вход [url=https://1win1162.ru]https://1win1162.ru[/url]
вывод из запоя цена
vivod-iz-zapoya-irkutsk004.ru
вывод из запоя круглосуточно
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar010.ru
экстренный вывод из запоя краснодар
рулонные шторы это [url=http://elektricheskie-zhalyuzi.ru]http://elektricheskie-zhalyuzi.ru[/url] .
перепланировки квартир [url=https://soglasovanie-pereplanirovki-kvartiry1.ru/]https://soglasovanie-pereplanirovki-kvartiry1.ru/[/url] .
Круглосуточная наркологическая помощь в Королёве: вывод из запоя от Narcology Clinic. Врачи выезжают на дом, стабилизируют состояние, проводят мягкую детоксикацию и помогают вернуться к трезвому образу жизни.
Узнать больше – [url=https://vyvod-iz-zapoya-korolev12.ru/]вывод из запоя капельница[/url]
Запой — тяжелое состояние, связанное с длительным и бесконтрольным употреблением алкоголя, когда человек не может самостоятельно остановиться. В результате алкогольной интоксикации страдают внутренние органы, нарушается работа сердечно-сосудистой и нервной систем. Чем дольше длится запой, тем выше риск серьезных осложнений. Капельница от запоя — быстрый и надежный способ вывести человека из опасного состояния, снять симптомы интоксикации и восстановить нормальное самочувствие. В наркологической клинике «Перспектива» в Краснодаре вы можете воспользоваться данной услугой круглосуточно, как в стационаре, так и с выездом врача на дом.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя цена краснодар[/url]
домашний интернет тарифы
rostov-domashnij-internet006.ru
подключить интернет в квартиру ростов
электрические рулонные шторы [url=https://zhalyuzi-s-elektroprivodom7.ru/]zhalyuzi-s-elektroprivodom7.ru[/url] .
1win регистрация верификация [url=https://www.1win1163.ru]https://www.1win1163.ru[/url]
лечение запоя
vivod-iz-zapoya-minsk004.ru
вывод из запоя цена
вывод из запоя иркутск
vivod-iz-zapoya-irkutsk005.ru
вывод из запоя круглосуточно
Надёжный способ прервать запой — услуги клиники «Alco.Rehab» в Москве. Профессиональный подход и анонимность гарантированы.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-moskva12.ru/]срочный вывод из запоя город москва[/url]
joacă poker online [url=https://1win40011.ru/]joacă poker online[/url]
1win зеркало скачать online [url=https://1win1161.ru]https://1win1161.ru[/url]
Современная наркологическая клиника — это не просто учреждение для экстренной помощи, а центр комплексной поддержки человека, столкнувшегося с зависимостью. В «КузбассМед» в Новокузнецке реализуется модель интенсивного вмешательства, где используются новейшие медицинские технологии, мультидисциплинарный подход и мобильные выездные службы. Специалисты готовы прибыть на дом за 30 минут с полным набором оборудования и медикаментов, обеспечив пациенту помощь в привычной и безопасной среде. Наркология здесь строится на индивидуализации: каждый случай рассматривается отдельно, с учётом психофизического состояния, анамнеза и жизненного контекста пациента.
Узнать больше – http://narkologicheskaya-klinika-novokuzneczk0.ru
Interesting points about adapting strategies to different player pools! Seeing platforms like jiliday vip focus on localized experiences-like KYC for Filipino players-is smart for building trust & engagement. Solid foundation is key!
провайдеры по адресу самара
samara-domashnij-internet004.ru
проверить интернет по адресу
bucatarii la comanda chisinau preturi [url=http://1win40011.ru/]http://1win40011.ru/[/url]
карниз с приводом [url=www.elektrokarnizy7.ru]www.elektrokarnizy7.ru[/url] .
вывод из запоя круглосуточно
vivod-iz-zapoya-minsk005.ru
экстренный вывод из запоя
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также… – https://www.cpaccontracting.com/pf/nancy-rd
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Погрузиться в научную дискуссию – https://buttina.com.br/2024/11/14/jovens-nadadores-do-ecp-brilham-no-campeonato-sudeste-de-natacao-e-conquistam-excelentes-resultados
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Ознакомьтесь с аналитикой – https://worldmindsetmag.com/hybridge-jacket
Сериал «Уэнсдей» https://uensdey.com мрачная и захватывающая история о дочери Гомеса и Мортиши Аддамс. Учёба в Академии Невермор, раскрытие тайн и мистика в лучших традициях Тима Бёртона. Смотреть онлайн в хорошем качестве.
Срочно нужен сантехник? сантехник на дом вызвать недорого в Алматы? Профессиональные мастера оперативно решат любые проблемы с водопроводом, отоплением и канализацией. Доступные цены, выезд в течение часа и гарантия на все виды работ
Die Gesamtausgaben und hipec kosten hangen von Klinik, Operationsdauer, Medikamentenwahl und Nachsorge ab, wobei spezialisierte Zentren hochste Qualitat und modernste Technik bieten.
лечение запоя иркутск
vivod-iz-zapoya-irkutsk006.ru
лечение запоя иркутск
какие провайдеры по адресу
samara-domashnij-internet005.ru
провайдеры интернета по адресу
сделать проект квартиры для перепланировки [url=https://proekt-pereplanirovki-kvartiry4.ru/]proekt-pereplanirovki-kvartiry4.ru[/url] .
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Не пропусти важное – https://mcgregormachines.com/hello-world
электрокарнизы купить в москве [url=elektrokarnizy33.ru]электрокарнизы купить в москве[/url] .
вывод из запоя круглосуточно минск
vivod-iz-zapoya-minsk006.ru
вывод из запоя
descărca 1win [url=www.1win40012.ru]www.1win40012.ru[/url]
заказать проект перепланировки [url=https://proekt-pereplanirovki-kvartiry4.ru/]https://proekt-pereplanirovki-kvartiry4.ru/[/url] .
где вводить промокод в 1win [url=www.1win1161.ru]www.1win1161.ru[/url]
Флешки оптом https://usb-flashki-optom-24.ru/ из китая и ручка сваровски с флешкой в Перми. Терабайт флешка цена и оригинальные флешки купить в Саранске. Где флешка оптом и флешка перевод
Описание
Выяснить больше – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркомана краснодар[/url]
Круглосуточная помощь
Углубиться в тему – http://snyatie-lomki-rnd7.ru/
Таким образом, мы создаём систему поддержки, позволяющую каждому пациенту успешно справляться с зависимостью и вернуться к полноценной жизни.
Ознакомиться с деталями – [url=https://alko-lechebnica.ru/]наркология вывод из запоя[/url]
На сайте https://sp-department.ru/ представлена полезная и качественная информация, которая касается создания дизайна в помещении, мебели, а также формирования уюта в доме. Здесь очень много практических рекомендаций от экспертов, которые обязательно вам пригодятся. Постоянно публикуется информация на сайте, чтобы вы ответили себе на все важные вопросы. Для удобства вся информация поделена на разделы, что позволит быстрее сориентироваться. Регулярно появляются новые публикации для расширения кругозора.
вывод из запоя круглосуточно калуга
vivod-iz-zapoya-kaluga007.ru
экстренный вывод из запоя калуга
провайдер интернета по адресу самара
samara-domashnij-internet006.ru
интернет провайдеры в самаре по адресу дома
электронный карниз для штор [url=www.elektrokarnizy-dlya-shtor150.ru/]www.elektrokarnizy-dlya-shtor150.ru/[/url] .
для рулонных штор [url=elektricheskie-zhalyuzi.ru]elektricheskie-zhalyuzi.ru[/url] .
¡Buenas!
Un casino con dinero real te permite experimentar la verdadera emociГіn de las apuestas con premios reales. [url=https://bestslotmachines.shop]cassino dando giros gratis ecuador[/url] La experiencia en un casino con dinero real es incomparable cuando juegas en plataformas confiables y reguladas.
Lee este enlace – https://bestslotmachines.shop
juegos de casino en linea con dinero real ecuador
¡Buena suerte!
карнизы с электроприводом купить [url=https://elektrokarniz-nedorogo.ru/]elektrokarniz-nedorogo.ru[/url] .
Натуральные масла для кожи http://musco.ru
¡Saludos!
El casino en lГnea chile ofrece una experiencia de juego inigualable con los mejores tГtulos y promociones exclusivas. [url=https://jackpotwins.shop]1xbet casino chile[/url] Descubre por quГ© somos la mejor opciГіn de casino en lГnea chile para jugadores que buscan calidad y confianza.
Lee este enlace – https://jackpotwins.shop
juegos de casino con dinero real chile
¡Buena suerte!
Мы понимаем уникальность каждого пациента и проводим тщательную диагностику, анализируя его медицинскую историю, психологическое состояние и социальные факторы. На основе полученных данных создаем персональные планы лечения, включающие медикаментозные средства, психотерапию и социальные программы.
Выяснить больше – http://
экстренный вывод из запоя
vivod-iz-zapoya-omsk004.ru
вывод из запоя
Зависимости от психоактивных веществ, таких как алкоголь, наркотики и азартные игры, представляют собой серьёзные проблемы, с которыми сталкиваются многие люди. Эти состояния не только негативно влияют на здоровье, но также разрушительно сказываются на межличностных отношениях, социальной адаптации и профессиональной деятельности. Наркологическая клиника “Новый путь” предлагает комплексное решение для пациентов, нуждающихся в помощи, ориентируясь на индивидуальный подход и использование современных медицинских технологий.
Углубиться в тему – http://нарко-специалист.рф/vivod-iz-zapoya-v-kruglosutochno-v-Ekaterinburge/
Миссия нашего медицинского учреждения заключается в предоставлении всесторонней помощи людям, страдающим от зависимостей. Основные цели нашего центра включают:
Разобраться лучше – [url=https://alko-specialist.ru/]нарколог вывод из запоя[/url]
Клиника «Детоксика» в Сочи предлагает эффективное лечение запоя по доступным ценам с использованием современных методов и индивидуального подхода. Наши основные преимущества:
Подробнее – [url=https://vyvod-iz-zapoya-sochi77.ru/]наркология вывод из запоя[/url]
Продаем оконный профиль https://okonny-profil-kupit.ru высокого качества. Большой выбор систем, подходящих для любых проектов. Консультации, доставка, гарантия.
Оконный профиль https://okonny-profil.ru купить с гарантией качества и надежности. Предлагаем разные системы и размеры, помощь в подборе и доставке. Доступные цены, акции и скидки.
Каждый пациент получает внимание, соответствующее его уникальным потребностям, что способствует максимальной эффективности в лечении.
Узнать больше – [url=https://narko-zakodirovat.ru/]вывод из запоя в твери[/url]
вывод из запоя калуга
vivod-iz-zapoya-kaluga008.ru
вывод из запоя круглосуточно
Нужен срочный вывод из запоя в Королёве? Обратитесь в Narcology Clinic. Опытные врачи приедут на дом, проведут детоксикацию и поддержат пациента на этапе восстановления. Помощь доступна круглосуточно и анонимно.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-korolev13.ru/]нарколог вывод из запоя город Королев[/url]
Описание
Выяснить больше – http://snyatie-lomki-rnd7.ru/snyatie-lomki-narkomana-v-rnd/
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Разобраться лучше – http://snyatie-lomki-rnd77.ru
подключить интернет в квартиру санкт-петербург
spb-domashnij-internet004.ru
узнать интернет по адресу
Ключевым направлением нашей работы является индивидуализация лечения. Мы понимаем, что каждый пациент уникален, поэтому проводим тщательную диагностику, изучая медицинскую историю, психологический профиль и социальные факторы. На основе этих данных разрабатываем персональные планы терапии, включающие медикаментозное лечение, психотерапевтические методы и социальные программы.
Подробнее можно узнать тут – [url=https://narco-vivod.ru/]вывод из запоя клиника[/url]
вывод из запоя цена
vivod-iz-zapoya-omsk005.ru
вывод из запоя омск
Индивидуализация лечения: Каждый случай рассматривается отдельно, учитывая уникальные особенности пациента, его физическое состояние, предшествующий опыт лечения и социальные факторы. Такой подход позволяет создать максимально эффективный план терапии.
Изучить вопрос глубже – [url=https://alko-specialist.ru/]наркологический вывод из запоя в симферополе[/url]
ремонт кофемашин polaris ремонт кофемашин выезд
Описание
Получить дополнительную информацию – http://snyatie-lomki-rnd7.ru/snyatie-lomki-narkomana-v-rnd/https://snyatie-lomki-rnd7.ru
мастер по ремонту швейных машин ремонт швейных машин dexp
размещение 1с в облаке 1с бух облако
вывод из запоя калуга
vivod-iz-zapoya-kaluga009.ru
лечение запоя калуга
провайдеры интернета по адресу санкт-петербург
spb-domashnij-internet005.ru
какие провайдеры по адресу
Обращение к специалистам становится необходимым, если наблюдаются следующие симптомы, указывающие на тяжелую интоксикацию:
Подробнее можно узнать тут – https://vyvod-iz-zapoya-sochi777.ru/
20
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-korolev11.ru/]нарколог вывод из запоя в королеве[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Углубиться в тему – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому краснодар[/url]
вывод из запоя
vivod-iz-zapoya-omsk006.ru
экстренный вывод из запоя омск
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar006.ru
экстренный вывод из запоя краснодар
Вывод из запоя в Королёве от Narcology Clinic — квалифицированная помощь на дому и в клинике. Индивидуальный подбор препаратов, поддержка психики и организма, круглосуточный приём и сопровождение пациента.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-korolev13.ru/]вывод из запоя анонимно город Королев[/url]
Официальный Telegram канал 1win Casinо. Казинo и ставки от 1вин. Фриспины, актуальное зеркало официального сайта 1 win. Регистрируйся в ван вин, соверши вход в один вин, получай бонус используя промокод и начните играть на реальные деньги.
https://t.me/s/Official_1win_kanal/4561
лечение запоя оренбург
vivod-iz-zapoya-orenburg004.ru
вывод из запоя оренбург
интернет домашний санкт-петербург
spb-domashnij-internet006.ru
недорогой интернет санкт-петербург
стильные горшки для цветов купить [url=http://dizaynerskie-kashpo-nsk.ru/]стильные горшки для цветов купить[/url] .
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Неизвестные факты о… – https://www.aya.co.il/someones-mane-hilton-budapest-6
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Как достичь результата? – https://worldwings.jp/%E3%82%A4%E3%83%B3%E3%83%89%E3%83%8D%E3%82%B7%E3%82%A2%E5%9B%BD%E7%AB%8B%E5%A4%A7%E5%AD%A6%E3%82%A4%E3%83%B3%E3%82%BF%E3%83%BC%E3%83%B3%E3%82%B7%E3%83%83%E3%83%97%E7%94%9F%E5%8F%97%E5%85%A5%E9%96%8B
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Углубить понимание вопроса – https://davepippinproject.com/rescuing-abandoned-canoe-on-st-croix-river
Мы работаем по следующим основным направлениям.
Подробнее тут – [url=https://narko-zakodirovat.ru/]narkolog-vyvod-iz-zapoya tver'[/url]
вывод из запоя цена
vivod-iz-zapoya-krasnodar007.ru
лечение запоя краснодар
Мы предлагаем широкий спектр услуг для автовладельцев Надежность и прозрачность процедуры оценки авто — от покупки новых автомобилей до удобного обмена и быстрого выкупа вашего старого автомобиля. Наша команда профессионалов гарантирует честную оценку, оперативное снятие с учета и быстрое получение расчета прямо на месте всего за 10–20 минут!
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Смотрите также – https://espigaoalerta.com.br/2023/05/08/vem-ai-1a-festa-do-pinhao-no-bairro-da-rocinha-prefeitura-estancia-turistica-guaratingueta-2
Glad to see you!
Unlock incredible value with our live online gaming casino no deposit bonus codes that require no initial investment. [url=https://mobilecasinoplay.shop/]online casino real money no deposit canada[/url] Claim your live online gaming casino no deposit bonus codes today and start playing immediately without spending a penny.
Check this out – https://mobilecasinoplay.shop
online casino real money no deposit canada
Best of luck!
Yo!
Online casino games in India include live dealers. [url=https://newcasinosites.shop]best online casino games in india[/url] Experience real casino action.
Check this example resource – https://newcasinosites.shop
online casino india real money app
is online gambling legal in india
Good luck!
1win скачать андроид [url=http://1win1165.ru/]http://1win1165.ru/[/url]
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Смотрите также… – https://numberlina.com/5-interesting-facts-about-mars-for-kids
экстренный вывод из запоя
vivod-iz-zapoya-orenburg005.ru
экстренный вывод из запоя
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Обратитесь за информацией – https://skolakancelaria.sk/blog-post-with-youtube-video-2
Описание
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок на дому в краснодаре[/url]
Наркологическая клиника в Омске оказывает квалифицированную помощь пациентам, страдающим от различных видов зависимости. Основой успешного лечения является комплексный подход, который включает тщательную диагностику, медикаментозное сопровождение, психологическую поддержку и реабилитационные программы. В «АльфаМед» применяются передовые технологии и индивидуальные методики, направленные на восстановление здоровья и предупреждение рецидивов.
Подробнее – http://narkologicheskaya-klinika-omsk0.ru/narkologiya-kruglosutochno-omsk/
какие провайдеры по адресу
ufa-domashnij-internet004.ru
провайдеры интернета по адресу
It’s remarkable to pay a visit this website and reading the views of all colleagues concerning this post, while I am also keen of getting knowledge.
Покер онлайн
maorou_k8m maorou k8m
1вин казино скачать [url=http://1win1164.ru/]1вин казино скачать[/url]
1 win бк [url=www.1win1167.ru]1 win бк[/url]
1win официальный сайт [url=https://1win1166.ru]1win официальный сайт[/url]
лечение запоя
vivod-iz-zapoya-krasnodar008.ru
вывод из запоя
Please let me know if you’re looking for a writer for your blog. You have some really great articles and I believe I would be a good asset. If you ever want to take some of the load off, I’d really like to write some content for your blog in exchange for a link back to mine. Please shoot me an email if interested. Thank you!
https://telegra.ph/Sklo-fari-z-UV-f%D1%96ltrom-chi-varto-pereplachuvati-08-11
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Ознакомиться с деталями – https://snyatie-lomki-rnd7.ru/snyatie-lomki-narkomana-v-rnd
1win gazino bonusu [url=1win40014.ru]1win gazino bonusu[/url]
https://t.me/s/Official_1win_kanal?before=3239
вывод из запоя круглосуточно оренбург
vivod-iz-zapoya-orenburg006.ru
вывод из запоя
Наркомания — это хроническое заболевание, затрагивающее не только физическое и психическое здоровье человека, но и его окружение, работу, образ жизни. Эффективное лечение требует больше, чем просто временный отказ от употребления: нужен комплексный, персонализированный подход, который охватывает все сферы жизни пациента. В наркологической клинике «РеабПермь» в Перми предлагаются современные индивидуальные программы терапии, включающие медикаментозную поддержку, психотерапевтическую проработку и социальную реабилитацию. А первый шаг — бесплатная консультация, на которой специалист определяет масштаб проблемы и предлагает адекватную схему помощи.
Получить дополнительные сведения – [url=https://lechenie-narkomanii-perm0.ru/]запой лечение наркомания пермь[/url]
В зависимости от состояния пациента врач индивидуально подбирает состав раствора для капельницы. Обычно используются следующие группы препаратов:
Подробнее – https://kapelnica-ot-zapoya-krasnodar7.ru/kapelnicza-ot-zapoya-na-domu-v-krasnodare
В подобных случаях вывод из запоя в домашних условиях без врачебного контроля крайне опасен и может привести к тяжёлым последствиям. Лучше сразу вызвать нарколога или привезти пациента в клинику — это поможет избежать критических осложнений.
Разобраться лучше – [url=https://vyvod-iz-zapoya-balashiha5.ru/]vyvod-iz-zapoya-na-domu-nedorogo[/url]
В период восстановления пациент получает психологическую поддержку, работает с психотерапевтом, осваивает навыки самоконтроля, учится противостоять стрессу без возвращения к прежним привычкам. После выписки возможно амбулаторное сопровождение, дистанционные консультации и поддержка для всей семьи.
Разобраться лучше – [url=https://narkologicheskaya-klinika-balashiha5.ru/]narkologicheskaya-klinika-stacionar[/url]
Лечение наркомании в Омске является сложным медицинским процессом, требующим комплексного подхода и участия квалифицированных специалистов. Современная наркологическая клиника «Ренессанс» предлагает полный спектр услуг, направленных на восстановление физического и психического здоровья пациентов с различными формами наркотической зависимости. В клинике используются доказанные методы терапии, которые обеспечивают стабильную ремиссию и помогают вернуться к полноценной жизни.
Подробнее тут – [url=https://lechenie-narkomanii-omsk0.ru/]лечение наркомании на дому омск[/url]
1win зеркало сайта online [url=https://www.1win1165.ru]https://www.1win1165.ru[/url]
Мы понимаем уникальность каждого пациента и проводим тщательную диагностику, анализируя его медицинскую историю, психологическое состояние и социальные факторы. На основе полученных данных создаем персональные планы лечения, включающие медикаментозные средства, психотерапию и социальные программы.
Изучить вопрос глубже – http://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-anonimno-v-rostove-na-donu.xn--p1ai/
как использовать бонусы в 1win [url=https://www.1win1170.ru]https://www.1win1170.ru[/url]
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Узнать больше – http://snyatie-lomki-rnd77.ru/snyatie-lomki-na-domu-v-rnd/
провайдер по адресу уфа
ufa-domashnij-internet005.ru
подключение интернета по адресу
букмекер 1 вин [url=https://1win1168.ru/]букмекер 1 вин[/url]
промокод 1вин при регистрации [url=www.1win1170.ru]промокод 1вин при регистрации[/url]
лечение запоя краснодар
vivod-iz-zapoya-krasnodar009.ru
вывод из запоя
Психологическая помощь сопровождает медикаментозное лечение, способствуя преодолению эмоциональных и поведенческих трудностей. Важным элементом является мотивационная работа, направленная на формирование устойчивого стремления к жизни без зависимости.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-omsk0.ru/]наркологическая клиника цены в омске[/url]
1win официальный сайт букмекерской конторы [url=https://1win1166.ru/]https://1win1166.ru/[/url]
Эффективное лечение алкогольной зависимости в Туле Зависимость от алкоголя – это актуальная проблема, касающаяся многих людей. В Туле предлагается широкий спектр наркологических услуг, таких как анонимное лечение и услуги выездного нарколога. Лечение алкоголизма начинается с детоксикации, которая позволяет организму избавиться от токсинов. Важно помнить, что лечение на дому обеспечивает комфорт и конфиденциальность. Первая консультация с наркологом – это важный шаг на пути к выздоровлению. Квалифицированные специалисты помогут создать индивидуальный план реабилитации, соответствующий потребностям пациента. Психологическая поддержка играет ключевую роль в процессе реабилитации от алкоголя, так как помогает справиться с эмоциональными трудностями. Также доступно кодирование от алкоголя, которое может быть эффективным средством в борьбе с зависимостью. Поддержка во время запоев и регулярные консультации с наркологом помогают обеспечить высокий уровень контроля за состоянием пациента. Если вы или ваши близкие сталкиваетесь с зависимостью от спиртного, не стесняйтесь обратиться за помощью. Нарколог на дом анонимно проведет все необходимые процедуры, чтобы помочь вам вернуться к здоровой жизни.
1win зеркало на сегодня [url=1win1167.ru]1win1167.ru[/url]
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Исследовать вопрос подробнее – http://snyatie-lomki-rnd7.ru/snyatie-lomki-na-domu-v-rnd/
1win com [url=1win40014.ru]1win40014.ru[/url]
жалюзи пластиковые окна электроприводом [url=https://elektricheskie-zhalyuzi.ru/]https://elektricheskie-zhalyuzi.ru/[/url] .
автоматика somfy [url=http://www.avtomatika-somfy77.ru]http://www.avtomatika-somfy77.ru[/url] .
гидроизоляция цена [url=http://www.gidroizolyaciya-cena-2.ru]http://www.gidroizolyaciya-cena-2.ru[/url] .
скачать 1win зеркало ios [url=www.1win1168.ru]www.1win1168.ru[/url]
проект перепланировки недорого [url=http://proekt-pereplanirovki-kvartiry5.ru/]http://proekt-pereplanirovki-kvartiry5.ru/[/url] .
провайдер по адресу уфа
ufa-domashnij-internet006.ru
провайдеры по адресу дома
гидроизоляция цена [url=www.gidroizolyaciya-cena-3.ru]www.gidroizolyaciya-cena-3.ru[/url] .
рулонные жалюзи с электроприводом [url=http://www.elektricheskie-zhalyuzi.ru]рулонные жалюзи с электроприводом[/url] .
гидроизоляция цена [url=gidroizolyaciya-cena-3.ru]gidroizolyaciya-cena-3.ru[/url] .
заказать проект перепланировки квартиры Москва [url=www.eisberg.forum24.ru/?1-3-0-00000376-000-0-0-1754486777]заказать проект перепланировки квартиры Москва [/url] .
Заказать диплом возможно через официальный портал компании. [url=http://ekcrozgar.com/employer/education-ua/]ekcrozgar.com/employer/education-ua[/url]
купить аттестат за 11 класс в самаре [url=https://arus-diplom21.ru/]купить аттестат за 11 класс в самаре[/url] .
Клиника «Детоксика» в Сочи предлагает эффективное лечение запоя по доступным ценам с использованием современных методов и индивидуального подхода. Наши основные преимущества:
Выяснить больше – [url=https://vyvod-iz-zapoya-sochi77.ru/]врач вывод из запоя сочи[/url]
сколько стоит купить аттестат за 9 класс [url=www.educ-ua4.ru]www.educ-ua4.ru[/url] .
сколько стоит купить диплом в одессе [url=https://www.educ-ua5.ru]сколько стоит купить диплом в одессе[/url] .
купить аттестат 11 классов цены [url=https://arus-diplom24.ru/]купить аттестат 11 классов цены[/url] .
оригинальный аттестат за 11 класс купить [url=https://www.arus-diplom23.ru]https://www.arus-diplom23.ru[/url] .
купить диплом внесенный в реестр [url=www.arus-diplom34.ru]купить диплом внесенный в реестр[/url] .
Наркологическая помощь в Перми представляет собой комплекс мероприятий, направленных на диагностику, лечение и профилактику различных форм зависимостей. Современные наркологические клиники обеспечивают индивидуальный подход к каждому пациенту, учитывая особенности его состояния и историю заболевания. Важно своевременно обращаться за квалифицированной помощью, чтобы снизить риски осложнений и улучшить качество жизни.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-pomoshh-perm0.ru/]оказание наркологической помощи[/url]
купить диплом с проведением в [url=https://arus-diplom31.ru/]купить диплом с проведением в[/url] .
аттестаты за 11 класс купить в москве [url=https://arus-diplom22.ru/]аттестаты за 11 класс купить в москве[/url] .
Мы можем предложить документы институтов, которые расположены на территории всей России. Купить диплом университета:
[url=http://engineerring.net/employer/all-diplomy/]купить аттестат за 11 класс смоленск[/url]
аттестат за 11 классов купить в кемерово [url=http://arus-diplom23.ru/]аттестат за 11 классов купить в кемерово[/url] .
skrill casino site-uri [url=https://1win40015.ru/]https://1win40015.ru/[/url]
купить аттестат за 11 классов в калининграде [url=https://www.arus-diplom24.ru]https://www.arus-diplom24.ru[/url] .
Капельница для лечения запоя – это эффективный метод, который активно используется наркологами для очистки организма. Выездной нарколог из лечебного учреждения предлагает анонимное лечение, обеспечивая полную конфиденциальность для клиента. Посещение врача на дому позволяет быстро ощутить медицинскую помощь и восстановление организма, что особенно значимо для страдающих от запоя. Нарколог на дом клиника Во время терапии применяются инфузионные растворы, которые уменьшают проявления абстиненции и предотвращают осложнения. Профессиональная поддержка нарколога на дом предоставляет возможность проводить лечение в домашних условиях, что минимизирует стресс от лечения. Это – быстрое избавление от запоя, которое дает шанс на новую жизнь без алкоголя.
лечение запоя краснодар
vivod-iz-zapoya-krasnodar010.ru
вывод из запоя краснодар
купить аттестаты за 11 классов в краснодаре [url=www.arus-diplom25.ru/]купить аттестаты за 11 классов в краснодаре[/url] .
диплом с внесением в реестр купить [url=www.arus-diplom35.ru/]диплом с внесением в реестр купить[/url] .
купить диплом с занесением в реестр [url=https://arus-diplom34.ru]купить диплом с занесением в реестр[/url] .
Заказать диплом ВУЗа!
Мы можем предложить дипломы любой профессии по приятным ценам— [url=http://momu2.ru/]momu2.ru[/url]
купить диплом легальный о высшем образовании [url=www.arus-diplom33.ru/]www.arus-diplom33.ru/[/url] .
ремонт кофемашин philips ремонт кофемашин nespresso
Чем раньше начато лечение, тем выше вероятность полного восстановления здоровья без тяжёлых последствий для организма и психики. В клинике «Наркосфера» к каждому случаю подходят максимально внимательно и индивидуально.
Детальнее – [url=https://narkologicheskaya-klinika-balashiha5.ru/]платная наркологическая клиника[/url]
В зависимости от состояния пациента и пожеланий семьи наркологическая помощь может быть оказана в одном из нескольких форматов: на дому, в стационаре или дистанционно. Каждый из форматов обеспечивает доступ к медицинской помощи без бюрократии и с сохранением полной конфиденциальности.
Получить дополнительную информацию – https://narkologicheskaya-pomoshh-omsk0.ru/narkolog-psikhiatr-omsk
aviator игра 1win скачать [url=http://1win1164.ru]http://1win1164.ru[/url]
ремонт швейных машин ремонт швейных машин dexp
доступ в облако 1с доступ в облако 1с
вывод из запоя
vivod-iz-zapoya-minsk006.ru
вывод из запоя
какие провайдеры на адресе в уфе
ufa-domashnij-internet004.ru
провайдеры интернета в уфе по адресу
1win казино [url=1win1171.ru]1win казино[/url]
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Открыть полностью – https://www.mariusdumitrascu.ro/the-weirdest-places-ashes-have-been-scattered-in-new-zeeland
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Все материалы собраны здесь – http://gujaratitraveller.com/here-are-10-cheapest-countries-to-visit-from-india
вывод из запоя цена
vivod-iz-zapoya-minsk004.ru
экстренный вывод из запоя
cele mai bune cazinouri neteller [url=www.1win40015.ru]cele mai bune cazinouri neteller[/url]
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Доступ к полной версии – https://www.veroinstitute.com/closing-the-sale-the-if-you-were-to-buy-or-sell-today-close-2
Hello there!
Enjoy peace of mind with our secure login live online gaming casino system that protects your personal information and gaming activities. [url=https://top10casinos.shop]real money casino canada[/url] Trust in our secure login live online gaming casino infrastructure for a worry-free gaming experience every time you play.
Check this out – https://top10casinos.shop/
real money casino online canada
real money casino canada
Enjoy your study session!
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Неизвестные факты о… – https://fertiggoods.com/?attachment_id=4108
Amazing issues here. I’m very satisfied to peer your post. Thanks a lot and I’m having a look ahead to touch you. Will you kindly drop me a mail?
Жироуловители
volnovaxave.ru
Hello everyone, it’s my first go to see at this web site, and piece of writing is in fact fruitful in favor of me, keep up posting these types of articles or reviews.
Купить футер 2-х нитка 30/30 компакт пенье напрямую от производителя
Как сам!
Казино онлайн в Казахстане с бонусом за регистрацию дарит подарки. [url=https://freeplaycasino.shop/]онлайн казино Казахстана[/url] Начните игру с бонусами.
По ссылке: – https://freeplaycasino.shop
пин ап казино онлайн Казахстан
онлайн казино КЗ
Бывай!
экстренный вывод из запоя омск
vivod-iz-zapoya-omsk004.ru
вывод из запоя круглосуточно
1win скачать андроид [url=https://www.1win1171.ru]https://www.1win1171.ru[/url]
подключить интернет по адресу
ufa-domashnij-internet005.ru
проверить провайдера по адресу
жалюзи на пластиковые окна электрические [url=elektricheskie-zhalyuzi.ru]elektricheskie-zhalyuzi.ru[/url] .
гидроизоляция цена [url=https://gidroizolyaciya-cena-3.ru/]https://gidroizolyaciya-cena-3.ru/[/url] .
гидроизоляция цена [url=www.gidroizolyaciya-cena-2.ru]www.gidroizolyaciya-cena-2.ru[/url] .
Interesting read! Seeing platforms like jljl77 2025 legit focus on the Philippine market with GCash & PayMaya is smart. Secure logins & fast transactions are key for player trust, right? Good stuff!
Лоукост авиабилеты https://lowcost-flights.com.ua по самым выгодным ценам. Сравните предложения ведущих авиакомпаний, забронируйте онлайн и путешествуйте дешево.
1 win бонус при регистрации [url=https://1win1169.ru/]https://1win1169.ru/[/url]
Предлагаю услуги https://uslugi.yandex.ru/profile/DmitrijR-2993571 копирайтинга, SEO-оптимизации и графического дизайна. Эффективные тексты, высокая видимость в поиске и привлекательный дизайн — всё для роста вашего бизнеса.
¡Qué tal!
Para montos mayores, convertir 5000 reales a Bolivianos requiere precisiГіn en el cГЎlculo del tipo de cambio. [url=https://realcasinogames.shop]juegos de casino en linea con dinero real Bolivia[/url] La conversiГіn de 5000 reales a Bolivianos te permitirГЎ planificar mejor tus inversiones en entretenimiento.
Lee este enlace – https://realcasinogames.shop
Como jugar Casino en linea con dinero real Bolivia
Casino con dinero real Bolivia
Casino online Bolivia
¡Buena suerte!
экстренный вывод из запоя
vivod-iz-zapoya-minsk005.ru
лечение запоя минск
Современная жизнь, особенно в крупном городе, как Красноярск, часто становится причиной различных зависимостей. Работа в условиях постоянного стресса, высокий ритм жизни и эмоциональные перегрузки могут привести к проблемам, которые требуют неотложной медицинской помощи. Одним из наиболее удобных решений в такой ситуации является вызов нарколога на дом.
Подробнее тут – [url=https://narcolog-na-dom-v-krasnoyarske55.ru/]нарколог на дом анонимно в красноярске[/url]
Посетите сайт https://cs2case.io/ и вы сможете найти кейсы КС (КС2) в огромном разнообразии, в том числе и бесплатные! Самый большой выбор кейсов кс го у нас на сайте. Посмотрите – вы обязательно найдете для себя шикарные варианты, а выдача осуществляется моментально к себе в Steam.
1win регистрация ставки [url=https://1win1169.ru]https://1win1169.ru[/url]
Костыли кровельные Листовой металл: Основа для творчества и надежный материал для строительства. Листовой металл – это универсальный материал, применяемый в различных областях строительства и промышленности. Благодаря своей прочности, пластичности и долговечности, он идеально подходит для изготовления кровельных элементов, фасадных панелей, водосточных систем и других конструкций.
Hi there! I know this is kinda off topic however I’d figured I’d ask. Would you be interested in exchanging links or maybe guest writing a blog post or vice-versa? My website addresses a lot of the same topics as yours and I think we could greatly benefit from each other. If you happen to be interested feel free to shoot me an email. I look forward to hearing from you! Terrific blog by the way!
crypto в рубли
С момента начала лечения пациент получает доступ к круглосуточной линии поддержки. Врачи, психологи и координаторы готовы ответить на вопросы, помочь с корректировкой схемы лечения, поддержать в ситуации риска срыва. Эта функция особенно востребована в первые недели после выписки, когда человек сталкивается с триггерами в привычной среде и нуждается в дополнительной защите. Связь может осуществляться по телефону, через защищённый мессенджер или с помощью мобильного приложения клиники.
Узнать больше – [url=https://lechenie-narkomanii-samara0.ru/]лечение наркомании клиника самара[/url]
Ищете быстрый займ на карту? На https://zaimhub.com собраны лучшие предложения МФО России. Выберите выгодный вариант и получите деньги онлайн без лишних документов
отбеливание Стоматология в Ярославле: Качественная помощь – забота о вашем здоровье. Ярославль предлагает широкий спектр стоматологических услуг. Современные клиники оснащены передовым оборудованием, а опытные врачи оказывают квалифицированную помощь в лечении зубов и десен, протезировании и имплантации. Выбор стоматологической клиники – ответственный шаг, поэтому важно обращать внимание на репутацию клиники и квалификацию врачей.
вывод из запоя круглосуточно омск
vivod-iz-zapoya-omsk005.ru
вывод из запоя круглосуточно
трактор Купить трактор: Инвестиция в будущее вашего хозяйства. Трактор – это незаменимый помощник в сельском хозяйстве, строительстве и коммунальной сфере. Он способен выполнять широкий спектр задач, от обработки почвы до уборки снега. Приобретение трактора – это серьезное решение, требующее внимательного подхода к выбору модели и производителя. Оцените объем работ, тип почвы и другие факторы, чтобы выбрать трактор, который идеально подойдет для ваших нужд.
What’s up, this weekend is fastidious designed for me, because this occasion i am reading this enormous educational article here at my house.
Seattle Limo Contact Information
провайдеры интернета по адресу уфа
ufa-domashnij-internet006.ru
провайдеры в уфе по адресу проверить
В Москве к вашим услугам скорая наркологическая помощь от Narcology Clinic — выезд врача 24/7, качественная помощь при алкогольной интоксикации, стабилизация состояния и организация дальнейших этапов детоксикации.
Подробнее можно узнать тут – [url=https://skoraya-narkologicheskaya-pomoshch12.ru/]narkologicheskaya-pomoshch-na-domu moskva[/url]
Прокат авто Краснодар
https://crazy-time.games/ The official Crazy Time website offers a complete guide to Evolution’s live money wheel game. Learn the rules, explore bonus rounds, discover strategies, track results, and find trusted online casinos to play Crazy Time worldwide.
вывод из запоя круглосуточно минск
vivod-iz-zapoya-minsk006.ru
вывод из запоя минск
экстренный вывод из запоя
vivod-iz-zapoya-omsk006.ru
экстренный вывод из запоя омск
АО «ГОРСВЕТ» в Чебоксарах https://gorsvet21.ru профессиональное обслуживание объектов наружного освещения. Выполняем ремонт и модернизацию светотехнического оборудования, обеспечивая комфорт и безопасность горожан.
В Москве к вашим услугам скорая наркологическая помощь от Narcology Clinic — выезд врача 24/7, качественная помощь при алкогольной интоксикации, стабилизация состояния и организация дальнейших этапов детоксикации.
Получить больше информации – [url=https://skoraya-narkologicheskaya-pomoshch15.ru/]анонимная скорая наркологическая помощь москва[/url]
Онлайн-сервис лайкзайм займ на карту или счет за несколько минут. Минимум документов, мгновенное одобрение, круглосуточная поддержка. Деньги в любое время суток на любые нужды.
20
Подробнее тут – [url=https://skoraya-narkologicheskaya-pomoshch-moskva11.ru/]вызов наркологической помощи[/url]
оформление перепланировки квартиры в Москве [url=https://taksafonchik.borda.ru/?1-19-0-00000148-000-0-0-1754486136/]оформление перепланировки квартиры в Москве [/url] .
Hi to every , because I am truly keen of reading this blog’s post to be updated daily. It includes nice information.
Seattle limo packages
подключить интернет в волгограде в квартире
volgograd-domashnij-internet004.ru
подключение интернета омск
Кроме того, врач оказывает психологическую поддержку, которая помогает пациенту справиться с чувством тревоги, депрессией и страхом, возникающими на фоне зависимости.
Изучить вопрос глубже – http://
Narcology Clinic в Москве оказывает экстренную наркологическую помощь дома — скорая выездная служба выполняет детоксикацию, капельницы и мониторинг до нормализации состояния. Анонимно и круглосуточно.
Изучить вопрос глубже – [url=https://skoraya-narkologicheskaya-pomoshch-moskva12.ru/]наркологическая помощь на дому[/url]
После детоксикации пациенту назначается медикаментозная терапия, направленная на стабилизацию работы нервной системы и снижение тяги к наркотикам. Медикаменты подбираются индивидуально, учитывая особенности состояния каждого пациента.
Подробнее можно узнать тут – [url=https://lechenie-narkomanii-tver0.ru/]лечение наркомании клиника тверь[/url]
Custom Royal Portrait http://www.turnyouroyal.com an exclusive portrait from a photo in a royal style. A gift that will impress! Realistic drawing, handwork, a choice of historical costumes.
Открыть онлайн брокерский счёт – ваш первый шаг в мир инвестиций. Доступ к биржам, широкий выбор инструментов, аналитика и поддержка. Простое открытие и надёжная защита средств.
гидроизоляция цена [url=gidroizolyaciya-cena-3.ru]gidroizolyaciya-cena-3.ru[/url] .
оформить визу в китай в спб Туристическая виза в Китай СПб: Откройте двери в мир восточной экзотики. Санкт-Петербург – город, откуда начинается множество увлекательных путешествий. И Китай, с его богатейшей историей и самобытной культурой, становится все более привлекательным направлением для российских туристов. Получение туристической визы в Санкт-Петербурге – это первый шаг к незабываемым впечатлениям. Доверьте оформление профессионалам, чтобы избежать хлопот и сосредоточиться на планировании своего приключения.
экстренный вывод из запоя омск
vivod-iz-zapoya-omsk004.ru
вывод из запоя
купить диплом о высшем образовании реестр [url=www.arus-diplom32.ru/]купить диплом о высшем образовании реестр[/url] .
вывод из запоя цена
vivod-iz-zapoya-orenburg004.ru
вывод из запоя оренбург
приводы somfy [url=http://www.avtomatika-somfy77.ru]http://www.avtomatika-somfy77.ru[/url] .
нужен проект перепланировки [url=www.proekt-pereplanirovki-kvartiry5.ru/]www.proekt-pereplanirovki-kvartiry5.ru/[/url] .
подключить интернет омск
volgograd-domashnij-internet005.ru
домашний интернет тарифы омск
купить диплом с занесением в реестр новосибирск [url=http://www.overwiki.ru/Обсуждение_участника:Iliaanisimov]http://www.overwiki.ru/Обсуждение_участника:Iliaanisimov[/url] .
купить диплом нового образца [url=educ-ua2.ru]купить диплом нового образца[/url] .
где купить аттестат о среднем образовании [url=http://educ-ua1.ru/]где купить аттестат о среднем образовании[/url] .
Для понимания ключевых компонентов лечения ниже представлена таблица, в которой систематизированы основные методы и их назначение.
Подробнее тут – [url=https://narkologicheskaya-pomoshh-novokuzneczk0.ru/]нарколог наркологическая помощь в новокузнецке[/url]
диплом бакалавра купить стоимость [url=http://educ-ua3.ru]диплом бакалавра купить стоимость[/url] .
«ТверьМед» — частная лицензированная клиника, специализирующаяся на наркологической помощи любой степени сложности. Здесь работают неравнодушные врачи-наркологи, психиатры, терапевты и психологи с многолетним стажем. Медицинская команда настроена на оперативную диагностику и проведение первичных мероприятий в течение первого часа после обращения. Упор сделан на доступность: клиника открыта 24/7, приём возможен как на территории медучреждения, так и на выезде — дома, в офисе, гостинице, санатории или любом удобном месте.
Получить дополнительную информацию – [url=https://narkologicheskaya-pomoshh-tver0.ru/]центр наркологической помощи тверь[/url]
бонусный счет 1win [url=1win1173.ru]1win1173.ru[/url]
экстренный вывод из запоя оренбург
vivod-iz-zapoya-orenburg005.ru
вывод из запоя цена
Приобрести диплом на заказ в Москве вы можете используя сайт компании. [url=http://most.maxbb.ru/viewtopic.php?f=4&t=1478/]most.maxbb.ru/viewtopic.php?f=4&t=1478[/url]
купить аттестаты за 11 классов в спб [url=http://www.arus-diplom23.ru]http://www.arus-diplom23.ru[/url] .
вывод из запоя омск
vivod-iz-zapoya-omsk005.ru
вывод из запоя круглосуточно омск
купить аттестаты за 11 класс москва цена [url=www.arus-diplom23.ru/]купить аттестаты за 11 класс москва цена[/url] .
купить аттестат за 11 цена [url=https://arus-diplom24.ru]купить аттестат за 11 цена[/url] .
где аттестат 11 классов купить [url=http://arus-diplom21.ru]где аттестат 11 классов купить[/url] .
купить диплом об образовании в запорожье [url=http://educ-ua4.ru/]купить диплом об образовании в запорожье[/url] .
купить украинский диплом о высшем образовании [url=www.educ-ua5.ru/]купить украинский диплом о высшем образовании[/url] .
купить диплом легальный о высшем образовании [url=www.arus-diplom31.ru/]www.arus-diplom31.ru/[/url] .
купить диплом в спб с занесением в реестр [url=http://www.arus-diplom34.ru]http://www.arus-diplom34.ru[/url] .
Мы можем предложить документы учебных заведений, расположенных в любом регионе РФ. Купить диплом о высшем образовании:
[url=http://udyogseba.com/employer/diplomiki/]аттестаты 11 класса купить[/url]
купить аттестаты за 11 красноярск [url=http://www.arus-diplom22.ru]купить аттестаты за 11 красноярск[/url] .
диплом колледжа купить с занесением в реестр [url=www.arus-diplom34.ru/]диплом колледжа купить с занесением в реестр[/url] .
как купить диплом с занесением в реестр в екатеринбурге [url=arus-diplom33.ru]arus-diplom33.ru[/url] .
купить аттестат за 11 классов 1998 [url=www.arus-diplom25.ru]купить аттестат за 11 классов 1998[/url] .
купить проведенный диплом [url=https://arus-diplom35.ru]купить проведенный диплом[/url] .
подключить интернет
volgograd-domashnij-internet006.ru
подключить интернет тарифы омск
Прокат авто без залога
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Это стоит прочитать полностью – https://mahoraize.wpxblog.jp/post-4187
купить диплом в уфе с реестром [url=www.arus-diplom35.ru]www.arus-diplom35.ru[/url] .
Glad to see you!
Online gambling in India legal status changes frequently. [url=https://vipcasinooffers.shop]top 10 online casino in india[/url] Stay updated on regulations.
Check this out – https://vipcasinooffers.shop
India online casino
Online casino India real money
Online casino in India is legal
Best of luck!
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Смотрите также… – http://www.n-netzservice.de/guestbook.html
1win вывод [url=https://www.1win1174.ru]https://www.1win1174.ru[/url]
мобильное приложение регистрация вход mostbet app приложении рейтинг 4 8 [url=http://mostbet11064.ru]http://mostbet11064.ru[/url]
горшки для цветов большие с автополивом [url=https://www.kashpo-s-avtopolivom-kazan.ru]https://www.kashpo-s-avtopolivom-kazan.ru[/url] .
вывод из запоя цена
vivod-iz-zapoya-orenburg006.ru
лечение запоя
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Информация доступна здесь – https://fe.unj.ac.id/jamu2021/?p=5783
1win ставки официальный сайт [url=https://www.1win1175.ru]1win ставки официальный сайт[/url]
¡Buen día!
Blackjack en vivo disponible ahora. [url=https://bestonlineslots.shop]casinos con giros gratis por registro ecuador[/url] Juegos de casino Ecuador con crupieres reales esperan.
Lee este enlace – https://bestonlineslots.shop/
Juegos de casino Ecuador
Como jugar casino en linea con dinero real Ecuador
¡Buena suerte!
регистрация 1вин [url=http://1win1172.ru]http://1win1172.ru[/url]
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Доступ к полной версии – https://soudan-loan.com/%E4%BB%BB%E6%84%8F%E5%A3%B2%E5%8D%B4%E3%81%A8%E7%AB%B6%E5%A3%B2%E3%81%AE%E9%81%95%E3%81%84-%E7%AC%AC3%E5%BC%BE
ПОмощь юрист в банкротстве: банкротство физ лица ип
лечение запоя
vivod-iz-zapoya-omsk006.ru
экстренный вывод из запоя
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Уточнить детали – https://saps.solutions/demo-attachment-1096-pic12
купить диплом вуза с реестром [url=arus-diplom31.ru]купить диплом вуза с реестром[/url] .
купить аттестат за 11 класс иркутске [url=www.arus-diplom9.ru/]купить аттестат за 11 класс иркутске[/url] .
купить аттестат 11 классов 2015 [url=www.arus-diplom25.ru]купить аттестат 11 классов 2015[/url] .
купить аттестат за 11 класс 2016 года [url=https://arus-diplom22.ru/]купить аттестат за 11 класс 2016 года[/url] .
купить аттестат 11 классов госзнак [url=http://arus-diplom21.ru]купить аттестат 11 классов госзнак[/url] .
Абстинентный синдром, или ломка, – это тяжелое состояние, которое развивается у зависимых после отказа от наркотиков или алкоголя. Он сопровождается сильными физическими болями, судорогами, повышенной тревожностью, бессонницей и эмоциональными перепадами, что может привести к серьезным осложнениям для здоровья. Наркологическая клиника «Здравица» в Ростове-на-Дону предлагает комплексное лечение абстинентного синдрома, используя передовые методики и индивидуальный подход для быстрого восстановления здоровья.
Подробнее тут – [url=https://snyatie-lomki-rnd77.ru/]снятие наркотической ломки[/url]
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Узнать напрямую – https://www.altoguadalentin.es/gallery/lorem-ipsum-6
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Получить исчерпывающие сведения – https://planetfish.org/tiger-shovelnose-catfish
Ремонт кофемашин https://coffee-craft.kz с выездом на дом или в офис. Диагностика, замена деталей, настройка. Работаем с бытовыми и профессиональными моделями. Гарантия качества и доступные цены.
подключить проводной интернет воронеж
voronezh-domashnij-internet004.ru
тарифы интернет и телевидение воронеж
купить диплом высшем образовании занесением реестр [url=https://arus-diplom32.ru/]купить диплом высшем образовании занесением реестр[/url] .
mostbet official [url=http://mostbet11063.ru]mostbet official[/url]
мостбет кз скачать [url=https://mostbet11061.ru]https://mostbet11061.ru[/url]
https://kazan.land/ Музей Чак-Чака: Сладкая История Татарстана Музей Чак-Чака – это уникальное место в Казани, где можно узнать все о традиционном татарском лакомстве – чак-чаке. Вы узнаете об истории его возникновения, способах приготовления и символическом значении в татарской культуре. В музее вас ждет интерактивная экспозиция, где можно увидеть старинную утварь, фотографии и документы, связанные с производством чак-чака. Вы также сможете принять участие в мастер-классе по приготовлению этого лакомства и попробовать различные его виды. Посещение Музея Чак-Чака – это не только познавательное, но и вкусное приключение, которое оставит у вас приятные воспоминания о Казани и татарской культуре.
купить диплом москва легально [url=http://arus-diplom33.ru]http://arus-diplom33.ru[/url] .
Купить мебель прихожие в стиле лофт для дома и офиса по выгодным ценам. Широкий выбор, стильный дизайн, высокое качество. Доставка и сборка по всей России. Создайте комфорт и уют с нашей мебелью.
1 win ставки скачать [url=https://www.1win1173.ru]https://www.1win1173.ru[/url]
Наша команда специалистов обеспечивает экстренную помощь и консультацию, с целью сделать процесс вывода из запоя максимально комфортным и безопасным. Мы осознаем, насколько важна поддержка со стороны близких в это непростое время, по этой причине мы предоставляем анонимные услуги по лечению и реабилитации. Не стесняйтесь обращаться на vivod-iz-zapoya-tula007.ru для получения наркологических услуг и помощи в восстановлении после запоя. Мы готовы помочь вам 24/7.
https://dahua-teah.ru/dahua-catalog/
mostbet скачать на андроид официального сайта [url=www.mostbet11063.ru]www.mostbet11063.ru[/url]
бк 1win [url=https://1win1174.ru]бк 1win[/url]
Заказать диплом университета!
Мы предлагаем дипломы любой профессии по выгодным ценам— [url=http://m-s-r.ru/]m-s-r.ru[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-orenburg004.ru
экстренный вывод из запоя оренбург
Нужна скорая помощь при алкогольном отравлении или запое? В Москве служба Narcology Clinic оказывает неотложную помощь на дому — детокс, капельницы, оказание первой наркологической помощи и сопровождение до стабилизации.
Изучить вопрос глубже – [url=https://skoraya-narkologicheskaya-pomoshch-moskva11.ru/]наркологическая помощь телефон москве[/url]
подключение интернета воронеж
voronezh-domashnij-internet005.ru
лучший интернет провайдер воронеж
mostbet лицензия [url=https://mostbet11061.ru/]mostbet лицензия[/url]
скачать бк осталось именно выбрать подходящее [url=https://mostbet11064.ru]скачать бк осталось именно выбрать подходящее[/url]
Weekend logistics simplified: a robust rockbros bike rack gets you from driveway to dirt without improvising with bungee cords.
Предлагаем оконные профили https://proizvodstvo-okonnych-profiley.ru для застройщиков и подрядчиков. Высокое качество, устойчивость к климатическим нагрузкам, широкий ассортимент.
Оконные профили https://proizvodstvo-okonnych.ru для застройщиков и подрядчиков по выгодным ценам. Надёжные конструкции, современные материалы, поставка напрямую с завода.
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Изучить вопрос глубже – http://snyatie-lomki-rnd7.ru/snyatie-lomki-narkomana-v-rnd/
Круглосуточный нарколог на дому — это незаменимая помощь для людей, нуждающихся в квалифицированной помощи при алкоголизме или наркомании. Опытный нарколог может предоставить лечение зависимости в комфортной обстановке, обеспечивая медицинскую помощь на дому. Выездной нарколог обеспечивает анонимное лечение, включая детоксикацию организма и психологическую поддержку. При обращении к наркологу вы можете рассчитывать на 24/7 поддержку и профессиональную консультацию. Услуги нарколога включают реабилитацию зависимых, что позволяет эффективно справляться с проблемами и возвращать здоровье. Не откладывайте решение проблемы, обращайтесь за помощью уже сегодня на vivod-iz-zapoya-tula008.ru.
Обращение за помощью на дому имеет ряд значительных преимуществ, которые делают данный метод лечения предпочтительным для многих пациентов:
Выяснить больше – [url=https://narcolog-na-dom-ufa0.ru/]врач нарколог на дом платный уфа[/url]
Нужны пластиковые окна: пластиковые окна и двери
¡Qué tal!
Un casino real en lГnea brinda emociГіn autГ©ntica. [url=https://slotgamereview.shop]casino real en linea[/url] Vive la experiencia Las Vegas.
Lee este enlace – https://slotgamereview.shop
casino real en linea
casino en lГnea dinero real
casino en lГnea confiable
¡Buena suerte!
Нужен вентилируемый фасад: стоимость подсистемы для вентилируемых фасадов за м2
купить диплом магистра украины [url=http://educ-ua4.ru]купить диплом магистра украины[/url] .
купить диплом недорого [url=www.educ-ua5.ru/]купить диплом недорого[/url] .
¡Bienvenido!
[url=https://casinowheel.shop]juegos de casino en linea con dinero real chile[/url]
Lee este enlace – https://casinowheel.shop/
1xbet casino Chile
Casino real online Chile
Casino con dinero real Chile
¡Buena suerte!
Врачи клиники «ВитаЛайн» для снятия интоксикации и облегчения состояния пациента применяют исключительно качественные и проверенные лекарственные препараты, подбирая их в зависимости от особенностей ситуации и состояния здоровья пациента:
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-novosibirsk0.ru/]нарколог на дом вывод из запоя[/url]
1 win букмекерская контора [url=https://1win1175.ru/]1 win букмекерская контора[/url]
Запой становится критическим, когда организм не справляется с постоянным поступлением алкоголя и начинает накапливать токсины. Если состояние пациента ухудшается, появляются такие симптомы, как сильная рвота, головокружение, спутанность сознания, судороги, резкие колебания артериального давления, а также проявления тяжелого абстинентного синдрома (дрожь, панические атаки, бессонница, тревожность), вызов нарколога становится необходимым. Также экстренная помощь требуется при наличии психических нарушений — галлюцинациях, агрессивном поведении или алкогольном психозе. Своевременное вмешательство позволяет стабилизировать состояние, предотвратить развитие осложнений и снизить риск для жизни.
Углубиться в тему – [url=https://vyvod-iz-zapoya-novosibirsk00.ru/]вывод из запоя анонимно новосибирск[/url]
После завершения процедур пациенту предоставляется подробная консультация с рекомендациями по дальнейшему восстановлению и профилактике повторных случаев зависимости.
Выяснить больше – [url=https://narcolog-na-dom-novosibirsk00.ru/]нарколог на дом клиника[/url]
sports bet [url=www.sportbets31.ru/]www.sportbets31.ru/[/url] .
sports bet [url=sportbets32.ru]sportbets32.ru[/url] .
новости спорта сегодня [url=https://novosti-sporta-1.ru]https://novosti-sporta-1.ru[/url] .
спортивные новости [url=novosti-sporta-2.ru]novosti-sporta-2.ru[/url] .
вывод из запоя круглосуточно
vivod-iz-zapoya-orenburg005.ru
вывод из запоя цена
купить привод somfy [url=www.avtomatika-somfy.ru/]www.avtomatika-somfy.ru/[/url] .
тарифы интернет и телевидение воронеж
voronezh-domashnij-internet006.ru
интернет провайдер воронеж
экскурсии по казани Старо-Татарская Слобода: Путешествие в Прошлое Старо-Татарская слобода – исторический район Казани, сохранивший атмосферу старого города с его узкими улочками, деревянными домиками и уютными дворами. Это место, где можно почувствовать себя путешественником во времени, перенестись в прошлое и узнать больше о жизни татарского народа. Прогуливаясь по слободе, вы увидите старинные мечети, медресе, купеческие дома и другие исторические здания. Вы сможете узнать о традициях, обычаях и культуре татарского народа, а также попробовать национальные блюда в местных кафе и ресторанах. Старо-Татарская слобода – это не только историческое место, но и живой район, где живут и работают люди. Здесь можно увидеть ремесленников, которые занимаются традиционными видами искусства, а также художников и музыкантов, которые создают свои произведения в вдохновляющей атмосфере слободы. Посещение Старо-Татарской слободы – это уникальная возможность окунуться в атмосферу старой Казани, узнать больше о татарской культуре и почувствовать себя частью этого удивительного мира. Приглашаем вас посетить Старо-Татарскую слободу и открыть для себя ее тайны и красоту!
Interesting points about responsible gaming tech! Seeing platforms like 789taya download focus on both visuals and security is a smart move – that calming interface they mention sounds legit. It’s all about trust, right?
Капельница от запоя – это важная медицинская процедура при алкогольной зависимости. Подготовка к процедуре состоит из нескольких шагов. Во-первых, необходимо позвонить наркологу для вызова на дом, который проведет консультацию. Симптомы алкоголизма могут различаться, поэтому стоит подробно описать врачу все симптомы. нарколог на дом Перед введением капельницы необходимо подготовить вены, а также подготовить пациента к дальнейшему лечению. Убедитесь, что рядом есть необходимые препараты для капельницы. После лечение необходимо сосредоточиться на восстановлении, советы по уходу за пациентом помогут восстановить здоровье и избежать рецидива.
Responsible gaming is key, folks! It’s easy to get carried away. Seeing platforms like juan 365 com offer quick deposits (GCash is great!) & 24/7 access highlights the need for self-control & budgeting. Play smart!
Interesting points! Risk management is key, even in virtual sports. A solid platform like swerte99 vip emphasizes secure onboarding & KYC, which builds trust. Good article overall!
Narcology Clinic в Москве оказывает экстренную наркологическую помощь дома — скорая выездная служба выполняет детоксикацию, капельницы и мониторинг до нормализации состояния. Анонимно и круглосуточно.
Подробнее тут – [url=https://skoraya-narkologicheskaya-pomoshch-moskva11.ru/]наркологическая помощь телефон[/url]
Стоимость услуг по установке капельницы определяется индивидуально и зависит от нескольких факторов. В первую очередь, цена обусловлена тяжестью состояния пациента: при более сильной интоксикации и выраженных симптомах абстинентного синдрома может потребоваться расширенная терапия. Кроме того, итоговая сумма зависит от продолжительности запоя, так как длительное употребление спиртного ведет к более серьезному накоплению токсинов, требующему дополнительных лечебных мероприятий.
Разобраться лучше – http://kapelnica-ot-zapoya-nizhniy-novgorod000.ru/
После вашего звонка нарколог выезжает на дом в течение 30–60 минут. Прибыв на место, специалист проводит всесторонний медицинский осмотр, включая измерение артериального давления, пульса и уровня кислорода в крови, а также собирает анамнез для определения степени интоксикации.
Разобраться лучше – [url=https://narcolog-na-dom-voronezh0.ru/]врач нарколог на дом[/url]
mostbet скачать на телефон [url=http://mostbet11065.ru]mostbet скачать на телефон[/url]
купить диплом с занесением в реестр в калуге [url=https://www.arus-diplom34.ru]купить диплом с занесением в реестр в калуге[/url] .
купить аттестат за 10 и 11 класс [url=www.arus-diplom24.ru/]купить аттестат за 10 и 11 класс[/url] .
купить диплом с занесением в реестр в уфе [url=https://www.arus-diplom31.ru]https://www.arus-diplom31.ru[/url] .
купить аттестат за 11 классов в чите [url=arus-diplom23.ru]arus-diplom23.ru[/url] .
Действие и назначение
Детальнее – [url=https://vyvod-iz-zapoya-novosibirsk00.ru/]vyvod-iz-zapoya-na-domu novosibirsk[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-orenburg006.ru
вывод из запоя цена
Whats up very cool blog!! Guy .. Excellent .. Wonderful .. I will bookmark your site and take the feeds also? I’m happy to search out numerous helpful info here in the put up, we need work out more strategies in this regard, thank you for sharing. . . . . .
обменник биткоин на сбербанк
купить аттестат за 11 класс иркутск [url=http://arus-diplom25.ru/]купить аттестат за 11 класс иркутск[/url] .
легально купить диплом о [url=https://arus-diplom35.ru/]легально купить диплом о[/url] .
Мы готовы предложить документы любых учебных заведений, расположенных в любом регионе России. Заказать диплом университета:
[url=http://pakalljob.pk/companies/diplomiki/]купить аттестат за 11 класс украине[/url]
как купить аттестат за 11 класс в украине [url=www.arus-diplom22.ru]как купить аттестат за 11 класс в украине[/url] .
Лечение зависимостей в владимире – это ключевой элемент борьбы с зависимостями. Если вы или ваши близкие столкнулись с проблемами, связанными с алкогольной зависимостью, специализированные центры реабилитации предлагают эффективные программы лечения зависимостей. В Владимирской наркологической клинике предоставляется полный спектр услуг, включая детоксикацию организма и психологическую поддержку. Визиты к наркологу помогут оценить тяжесть проблемы и разработать индивидуальный план лечения. Психологическая поддержка и взаимодействие с родственниками играют существенную роль в процессе восстановления. Также важно учитывать профилактику зависимостей, чтобы предотвратить рецидивы. Безопасная помощь доступна всем, кто ищет поддержку. Программы лечения алкоголизма включают различные методы, подходящие для всех нуждающихся. Обратитесь на vivod-iz-zapoya-vladimir007.ru для получения дополнительной информации и назначения встречи.
1win cashback [url=https://www.1win1172.ru]https://www.1win1172.ru[/url]
купить проведенный диплом одно [url=https://arus-diplom35.ru/]купить проведенный диплом одно[/url] .
электрическая рулонная штора [url=https://www.elektricheskie-zhalyuzi.ru]https://www.elektricheskie-zhalyuzi.ru[/url] .
PNGtoJPGHero leverages cutting-edge browser-based image processing to transform PNG files into high-quality JPGs without installing any external software. Its core engine applies adaptive compression, intelligently balancing image fidelity with reduced file size. This makes it ideal for web developers optimizing assets, marketers preparing images for campaigns, or anyone managing storage constraints. The conversion pipeline supports simultaneous multi-file processing, ensuring speed even with large batches. Built with responsive design principles, the interface adapts seamlessly to desktop, tablet, and mobile screens. Robust privacy protocols ensure that uploaded images are encrypted in transit and purged from the server shortly after processing. By combining lightweight front-end performance with efficient server-side handling, PNG to JPG Hero delivers consistent results in under a second per image. It’s a precise, reliable, and secure solution for converting images at scale or on the go.
PNGtoJPGHERO
https://kazan.land/ Мечеть Кул-Шариф: Символ Возрождения и Духовности Мечеть Кул-Шариф – это главная мечеть Казани и одна из самых красивых мечетей в России. Она была построена в память о разрушенной мечети Казанского ханства и является символом возрождения татарской культуры и духовности. Мечеть поражает своей архитектурой и великолепием. Вы можете посетить ее, чтобы узнать больше об исламе и татарской культуре.
мостбет вход регистрация [url=https://mostbet11062.ru/]https://mostbet11062.ru/[/url]
Trust Finance https://trustf1nance.com is your path to financial freedom. Real investments, transparent conditions and stable income.
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Смотрите также… – https://lifecounselor.net/strategies-adhd-child/adhd-concept
handmade flowers clay for flowers
новости спорта [url=novosti-sporta-3.ru]novosti-sporta-3.ru[/url] .
новости спорта сегодня [url=https://www.novosti-sporta-2.ru]https://www.novosti-sporta-2.ru[/url] .
Інформаційний портал https://pizzalike.com.ua про піцерії та рецепти піци в Україні й світі. Огляди закладів, адреси, меню, поради від шефів, секрети приготування та авторські рецепти. Все про піцу — від вибору інгредієнтів до пошуку найсмачнішої у вашому місті.
прогнозы на хоккей на сегодня от профессиональных [url=https://prognozy-ot-professionalov.ru]https://prognozy-ot-professionalov.ru[/url] .
мостбет скачать андроид [url=https://www.mostbet11062.ru]https://www.mostbet11062.ru[/url]
В городе владимир предлагается множество вариантов для лечение алкоголизма. Наркологические клиники предлагают профессиональную помощь, включая детоксикацию и лечение в стационаре. Профессиональные наркологи осуществляют кодирование от алкоголя, а также обеспечивают психотерапевтическую помощь и реабилитацию. Необходимо помнить о консультациях для родственников, чтобы обеспечить поддержку семьи; Лечение с гарантией анонимности гарантирует конфиденциальность, а программы восстановления помогают зависимым возвратиться к полноценной жизни. Узнайте больше на сайте vivod-iz-zapoya-vladimir008.ru.
ОТКАПЫВАНИЕ НА ДОМУ: РЕКОМЕНДАЦИИ Открытие участка для благоустройства – это важный этап домашнего проекта. Excavation‚ или земляные работы‚ включает в себя множество задач‚ таких как копка ямы для фундамента‚ дренажные системы и водопроводные работы. Верный выбор инструментов для копки и аренда оборудования помогут облегчить процессы. Работы по благоустройству сада требуют тщательного планирования. Уход за участком‚ особенно в сезонные работы в саду‚ поможет сохранить красоту ландшафта. Не забудьте учесть дизайн местности‚ который может включать в себя элементы‚ требующие земляных работ. Обратите внимание на советы по копке: выбирайте подходящие инструменты‚ следите за безопасностью и учитывайте тип почвы. Земельные услуги могут помочь с профессиональным выполнением работ. Заходите на vivod-iz-zapoya-tula007.ru для получения дополнительной информации и услуг.
Приобрести диплом под заказ в Москве вы имеете возможность используя сайт компании. [url=http://metalfans.maxbb.ru/viewtopic.php?f=7&t=1243&sid=ab769d25a51c7aa68a8411611a838a92/]metalfans.maxbb.ru/viewtopic.php?f=7&t=1243&sid=ab769d25a51c7aa68a8411611a838a92[/url]
кайт хургада Кайт магазин Хургада. Всё необходимое для кайтсерфинга – здесь!
купить аттестат 11 класс спб [url=https://arus-diplom21.ru/]купить аттестат 11 класс спб[/url] .
Психологическая реабилитация: Психологическая поддержка – один из главных аспектов нашего подхода. Мы предлагаем индивидуальные и групповые занятия, помогающие осознать зависимость, проработать эмоциональные травмы и сформировать новые модели поведения. Опытные психологи помогают пациентам понять причины своих зависимостей, что является важным шагом на пути к выздоровлению.
Разобраться лучше – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]вывод из запоя капельница на дому казань[/url]
Glad to see you!
Is online gambling legal in India varies locally. [url=https://bestcasinoplay.cfd]top 10 online casino in india for real money[/url] Check your state laws.
Read the link – https://bestcasinoplay.cfd
Best online casino India
Online gambling in India
Online casino India legal
Enjoy your gaming experience!!
স্বাগতম!
[url=https://digitalblackjack.cfd]ক্যাসিনো টাকা ডিপোজিট[/url]
এই লিঙ্কটি পড়ুন – https://digitalblackjack.cfd
ক্যাসিনো অনলাইন
শুভকামনা!
Решили купить Honda? техническое обслуживание honda широкий ассортимент автомобилей Honda, включая новые модели, такие как Honda CR-V и Honda Pilot, а также автомобили с пробегом. Предоставляем услуги лизинга и кредитования, а также предлагает различные акции и спецпредложения для корпоративных клиентов.
Ищешь автозапчасти? выбрать аксессуары для авто предоставляем широкий ассортимент автозапчастей, автомобильных аксессуаров и оборудования как для владельцев легковых автомобилей, так и для корпоративных клиентов. В нашем интернет-магазине вы найдете оригинальные и неоригинальные запчасти, багажники, автосигнализации, автозвук и многое другое.
Выкуп автомобилей https://restyle-avto.ru без постредников, быстро. . У нас вы можете быстро оформить заявку на кредит, продать или купить автомобиль на выгодных условиях, воспользовавшись удобным поиском по марке, модели, приводу, году выпуска и цене — независимо от того, интересует ли вас BMW, Hyundai, Toyota или другие популярные бренды.
новости спорта футбол [url=www.novosti-sporta-2.ru/]www.novosti-sporta-2.ru/[/url] .
нужен юрист: адвокат по наследственным делам Новосибирск защита интересов, составление договоров, сопровождение сделок, помощь в суде. Опыт, конфиденциальность, индивидуальный подход.
musik bearbeitungs tools audio verbesserung
Заказать такси https://taxi-sverdlovsk.ru онлайн быстро и удобно. Круглосуточная подача, комфортные автомобили, вежливые водители. Доступные цены, безналичная оплата, поездки по городу и за его пределы
Онлайн-заказ такси https://sverdlovsk-taxi.ru за пару кликов. Быстро, удобно, безопасно. Подача в течение 5–10 минут, разные классы авто, безналичный расчет и прозрачные тарифы.
Закажите такси https://vezem-sverdlovsk.ru круглосуточно. Быстрая подача, фиксированные цены, комфорт и безопасность в каждой поездке. Подходит для деловых, туристических и семейных поездок.
Быстрый заказ такси https://taxi-v-sverdlovske.ru онлайн и по телефону. Подача от 5 минут, комфортные автомобили, безопасные поездки. Удобная оплата и выгодные тарифы на любые направления.
новости спорта сегодня [url=http://novosti-sporta-1.ru]http://novosti-sporta-1.ru[/url] .
Платформа пропонує https://61000.com.ua різноманітний контент: порадник, новини, публікації на тему здоров’я, цікавих історій, місць Харкова, культурні події, архів статей та корисні матеріали для жителів міста
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Изучить вопрос глубже – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru/]врач вывод из запоя в казани[/url]
Экстренная помощь при алкоголизме от Narcology Clinic в Москве — выезд врачей в любую точку города, купирование острых состояний, поддержка пациента до стабильного состояния, профессионально и в конфиденциальности.
Исследовать вопрос подробнее – [url=https://skoraya-narkologicheskaya-pomoshch-moskva11.ru/]анонимная наркологическая помощь московская область[/url]
https://t.me/s/onewin_kanal
Миссия клиники “Маяк надежды” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша задача — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Углубиться в тему – https://алко-лечение24.рф/vivod-iz-zapoya-anonimno-v-Sankt-Peterburge
Наркологическая клиника “Возрождение” находится по адресу: ул. Агрономическая, д. 122А, г. Нижний Новгород, Россия. Мы открыты для вас круглосуточно и также предлагаем онлайн-консультации, чтобы сделать наши услуги более доступными.
Подробнее можно узнать тут – http://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-nizhnem-novgoroge.xn--p1ai/
Нужен сантехник: https://santehnik-v-almaty.kz
ГОРСВЕТ Чебоксары https://gorsvet21.ru эксплуатация, ремонт и установка систем уличного освещения. Качественное обслуживание, модернизация светильников и энергоэффективные решения.
Займы онлайн https://laikzaim.ru моментальное оформление, перевод на карту, прозрачные ставки. Получите нужную сумму без визита в офис и долгих проверок.
Интернет-магазин мебели https://mebelime.ru тысячи моделей для дома и офиса. Гарантия качества, быстрая доставка, акции и рассрочка. Уют в каждый дом.
Saznajte sve o prolom voda za bubrege – simptomi, uzroci i efikasni nacini lecenja. Procitajte savete strucnjaka i iskustva korisnika, kao i preporuke za prevenciju i brzi oporavak.
https://igrozavod.ru/ Яндекс Диск: Ваш надежный партнер в мире игр Благодаря удобному интерфейсу и высокой скорости загрузки, Яндекс Диск станет вашим незаменимым помощником в пополнении игровой коллекции.
прогнозы на спорт с описанием [url=https://prognozy-ot-professionalov1.ru/]прогнозы на спорт с описанием[/url] .
форум общения спорт выбор велосипеда подписчики советуют правильно выбрать велосипед, реально, оказалось, есть столько нюансов, для тех кто не знает, лучше прочитать.
Zasto se javlja bol u bubregu: od kamenaca i infekcija do prehlade. Kako prepoznati opasne simptome i brzo zapoceti lecenje. Korisne informacije.
Sta znaci https://www.pesak-u-bubregu.com, koji simptomi ukazuju na problem i kako ga se resiti. Efikasni nacini lecenja i prevencije.
Авто журнал https://bestauto.kyiv.ua свежие новости автопрома, тест-драйвы, обзоры новинок, советы по уходу за автомобилем и репортажи с автособытий.
Популярный авто журнал https://mirauto.kyiv.ua подробные обзоры моделей, советы экспертов, новости автосалонов и автоспорта, полезные статьи для автовладельцев.
Миссия клиники “Путь к выздоровлению” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша цель — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Детальнее – http://нарко-фильтр.рф
Среди основных задач клиники выделяются помощь людям, страдающим от хронического алкоголизма, наркозависимости, игромании и других расстройств. Мы осознаём, что каждый случай уникален, и подходим к каждому пациенту индивидуально, предлагая персонализированные программы лечения, учитывающие все аспекты его состояния. Основное внимание уделяется не только физическому, но и психологическому состоянию пациента, что позволяет более эффективно преодолевать зависимость.
Детальнее – [url=https://alko-konsultaciya.ru/]срочный вывод из запоя смоленск[/url]
купить привод somfy [url=http://avtomatika-somfy.ru]http://avtomatika-somfy.ru[/url] .
Флешка оптом https://usb-flashki-optom-24.ru/ к 23 февраля и коробки для флешек подарочные в Перми. Купить деревянную флешку и как Называется флешка для фотоаппарата в Перми. Флешки оптом Магазин и портативная колонка с Usb флешкой
екатеринбург купить диплом в реестр [url=http://arus-diplom34.ru]екатеринбург купить диплом в реестр[/url] .
купить диплом украины с занесением в реестр [url=https://www.arus-diplom31.ru]https://www.arus-diplom31.ru[/url] .
Экономические новости https://gau.org.ua прогнозы и обзоры. Политика, бизнес, финансы, мировые рынки. Всё, что важно знать для принятия решений.
Мужской портал https://hooligans.org.ua всё, что интересно современному мужчине: стиль, спорт, здоровье, карьера, автомобили, технологии и отдых. Полезные статьи и советы каждый день.
Онлайн авто портал https://avtomobilist.kyiv.ua с обзорами новых и подержанных авто, тест-драйвами, советами по обслуживанию и новостями из мира автопрома.
new york freight shipping from ny to florida
купить аттестат об окончании 11 [url=https://arus-diplom23.ru]купить аттестат об окончании 11[/url] .
Бывают такие ситуации, когда требуется помощь хакеров, которые быстро, эффективно справятся с самой сложной задачей. Специалисты с легкостью взломают почту, взломают пароли, поставят защиту на ваш телефон. А для достижения цели используют уникальные и высокотехнологичные методики. Любой хакер отличается большим опытом. https://hackerlive.biz – сайт, на котором находятся только лучшие в своей области профессионалы. За оказание услуги плата небольшая. Все работы высокого качества. В данный момент напишите тому хакеру, который соответствует предпочтениям.
sport bets [url=www.sportbets32.ru/]www.sportbets32.ru/[/url] .
купить аттестат за 11 класс в мурманске [url=http://arus-diplom25.ru]купить аттестат за 11 класс в мурманске[/url] .
sports bet [url=http://sportbets31.ru]http://sportbets31.ru[/url] .
как купить диплом с проведением [url=http://arus-diplom35.ru]как купить диплом с проведением[/url] .
дизайнерские кашпо для цветов купить [url=https://dizaynerskie-kashpo-rnd.ru]дизайнерские кашпо для цветов купить[/url] .
купить диплом о высшем образовании легально [url=http://arus-diplom35.ru]купить диплом о высшем образовании легально[/url] .
купить диплом в кременчуге [url=http://educ-ua5.ru]http://educ-ua5.ru[/url] .
купить свидетельство о разводе украина [url=www.educ-ua4.ru/]www.educ-ua4.ru/[/url] .
кайт хургада Кайт сафари Кайт обучение в Хургаде: Станьте уверенным райдером за несколько дней. Это быстрый и эффективный способ научиться управлять кайтом и скользить по волнам. Опытные инструкторы помогут освоить все необходимые навыки и почувствовать уверенность на воде.
скачать игры по прямой ссылке Игры без торрента: Забота о безопасности и легальности Выбирая альтернативные способы загрузки игр, вы проявляете заботу о безопасности своего компьютера и поддерживаете разработчиков, способствуя дальнейшему развитию игровой индустрии.
whoah this blog is great i really like studying your articles. Keep up the good work! You recognize, lots of people are searching round for this information, you can help them greatly.
Private car near me
Выезд врача на дом позволяет провести детоксикацию в спокойной обстановке. Врач привозит с собой препараты, капельницы, измерительное оборудование и проводит лечение в течение 1–2 часов. Такой формат подходит при стабильном состоянии и желании сохранить анонимность.
Подробнее тут – https://narko-zakodirovan.ru/vyvod-iz-zapoya-kapelnicza-spb
купить аттестат за 10 11 кл [url=arus-diplom24.ru]купить аттестат за 10 11 кл[/url] .
Купить диплом под заказ в Москве вы можете используя официальный портал компании. [url=http://video.listbb.ru/viewtopic.php?f=3&t=2093/]video.listbb.ru/viewtopic.php?f=3&t=2093[/url]
сколько стоит купить диплом [url=http://www.educ-ua2.ru]сколько стоит купить диплом[/url] .
можно ли купить аттестат 11 класса [url=www.arus-diplom21.ru/]можно ли купить аттестат 11 класса[/url] .
Мы предлагаем документы любых учебных заведений, расположенных в любом регионе России. Заказать диплом о высшем образовании:
[url=http://trolleybus26.moibb.ru/viewtopic.php?f=3&t=1693/]купить корочку аттестата за 11 класс[/url]
купить диплом института образования [url=https://educ-ua3.ru/]купить диплом института образования[/url] .
спортивные новости [url=http://novosti-sporta-2.ru]http://novosti-sporta-2.ru[/url] .
ставки на спорт прогнозы [url=http://www.prognozy-ot-professionalov1.ru]ставки на спорт прогнозы[/url] .
Строительный портал https://dki.org.ua всё о строительстве и ремонте: технологии, оборудование, материалы, идеи для дома. Новости отрасли и экспертные рекомендации.
Портал о строительстве https://juglans.com.ua свежие новости, статьи и советы. Обзоры технологий, материалов, дизайн-идеи и практические рекомендации для профессионалов и частных застройщиков.
Всё о стройке https://mramor.net.ua полезные статьи, советы, обзоры материалов и технологий. Ремонт, строительство домов, дизайн интерьера и современные решения для вашего проекта.
Онлайн строительный https://texha.com.ua портал о материалах, проектах и технологиях. Всё о ремонте, строительстве и обустройстве дома. Поддержка специалистов и вдохновение для новых идей.
Сайт «Всё о стройке» https://sushico.com.ua подробные инструкции, советы экспертов, новости рынка. Всё о строительстве, ремонте и обустройстве жилья в одном месте.
новости спорта сегодня [url=www.novosti-sporta-3.ru]www.novosti-sporta-3.ru[/url] .
купить аттестат 11 классов 2016 [url=http://arus-diplom23.ru]купить аттестат 11 классов 2016[/url] .
как купить легально диплом о высшем образовании [url=arus-diplom33.ru]как купить легально диплом о высшем образовании[/url] .
купить диплом с занесением в реестр краснодар [url=http://arus-diplom34.ru/]http://arus-diplom34.ru/[/url] .
аттестат за 11 класс купить в екатеринбурге [url=https://arus-diplom22.ru]аттестат за 11 класс купить в екатеринбурге[/url] .
прогнозы на спорт с описанием [url=www.prognozy-ot-professionalov.ru]www.prognozy-ot-professionalov.ru[/url] .
https://vk.com/burtseva.brows Ламинирование бровей Севастополь: Здоровые и ухоженные брови – залог привлекательности. Подарите своим бровям силу и блеск с помощью ламинирования.
Вывод из запоя может осуществляться в двух форматах — на дому и в стационаре. Выбор зависит от степени интоксикации, наличия осложнений и возможности обеспечить пациенту наблюдение в домашних условиях.
Разобраться лучше – [url=https://narko-zakodirovan2.ru/]вывод из запоя дешево новосибирск[/url]
betturkey giris
Заказать диплом института!
Мы можем предложить дипломы любых профессий по доступным тарифам— [url=http://diplomk-vo-vladivostoke.ru/]diplomk-vo-vladivostoke.ru[/url]
Мы готовы предложить дипломы любой профессии по выгодным ценам. Купить диплом в городе Нефтекамск — [url=http://kyc-diplom.com/geography/neftekamsk.html/]kyc-diplom.com/geography/neftekamsk.html[/url]
Например, если речь идет о выводе из запоя, врач проведет тщательное обследование пациента, чтобы определить общее состояние здоровья и наличие возможных осложнений. На основе диагностики будет назначена инфузионная терапия, которая включает введение растворов, витаминов и препаратов для снятия абстиненции.
Получить дополнительные сведения – [url=https://narcolog-na-dom-v-krasnoyarske55.ru/]нарколог на дом цена[/url]
Hiya! I know this is kinda off topic nevertheless I’d figured I’d ask. Would you be interested in trading links or maybe guest writing a blog post or vice-versa? My site addresses a lot of the same subjects as yours and I believe we could greatly benefit from each other. If you’re interested feel free to shoot me an email. I look forward to hearing from you! Wonderful blog by the way!
Seattle limo packages
https://vzloman3.online/index.html Почтовые ящики. Откройте доступ к деловой и личной переписке, узнайте о важных решениях и намерениях. Контролируйте ситуацию.
здоровье красота Уход: секреты молодости и сияния. Откройте для себя мир инновационных технологий и натуральных ингредиентов, которые помогут вам сохранить молодость и красоту на долгие годы.
Миссия клиники “Маяк надежды” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша задача — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Исследовать вопрос подробнее – http://алко-лечение24.рф
самый точный прогноз на футбол сегодня [url=http://kompyuternye-prognozy-na-futbol13.ru/]http://kompyuternye-prognozy-na-futbol13.ru/[/url] .
ставки на хоккей сегодня прогнозы точные [url=http://luchshie-prognozy-na-khokkej13.ru/]http://luchshie-prognozy-na-khokkej13.ru/[/url] .
прогнозы на хоккей с высокой проходимостью [url=http://www.luchshie-prognozy-na-khokkej13.ru]http://www.luchshie-prognozy-na-khokkej13.ru[/url] .
Обращение к наркологу позволяет избежать типичных ошибок самолечения и достичь стабильного результата. Квалифицированное вмешательство:
Выяснить больше – [url=https://narko-zakodirovan2.ru/]наркология вывод из запоя[/url]
инъектирование [url=www.remontmechty.ru/remont/inekcionnaya-gidroizolyaciya-effektivnaya-zashhita-ot-vlagi /]www.remontmechty.ru/remont/inekcionnaya-gidroizolyaciya-effektivnaya-zashhita-ot-vlagi /[/url] .
https://t.me/s/onewin_kanal/10660
https://t.me/s/onewin_kanal/10860
https://t.me/s/onewin_kanal/10990
https://t.me/s/onewin_kanal/8900
https://t.me/s/onewin_kanal/10850
Приобрести диплом о высшем образовании можем помочь. Купить диплом магистра в Москве – [url=http://diplomybox.com/kupit-diplom-magistra-v-moskve/]diplomybox.com/kupit-diplom-magistra-v-moskve[/url]
диплом бакалавра купить стоимость [url=http://educ-ua4.ru]диплом бакалавра купить стоимость[/url] .
купить диплом магистра цены [url=http://educ-ua5.ru/]купить диплом магистра цены[/url] .
купить диплом с проводкой меня [url=https://www.arus-diplom31.ru]купить диплом с проводкой меня[/url] .
https://t.me/s/onewin_kanal/8520
аттестат за 11 класс купить в братске [url=http://arus-diplom21.ru]аттестат за 11 класс купить в братске[/url] .
Narcology Clinic в Москве оказывает экстренную наркологическую помощь дома — скорая выездная служба выполняет детоксикацию, капельницы и мониторинг до нормализации состояния. Анонимно и круглосуточно.
Подробнее тут – http://skoraya-narkologicheskaya-pomoshch-moskva.ru/http://skoraya-narkologicheskaya-pomoshch-moskva.ru
ставки на спорт кыргызстан [url=https://www.mostbet11068.ru]ставки на спорт кыргызстан[/url]
Для максимальной эффективности и безопасности «Красмед» использует комбинированные подходы:
Разобраться лучше – [url=https://medicinskij-vyvod-iz-zapoya.ru/]анонимный вывод из запоя в красноярске[/url]
купить аттестат школы за 9 11 классы [url=http://www.arus-diplom23.ru]купить аттестат школы за 9 11 классы[/url] .
высшее образование купить диплом с занесением в реестр [url=http://arus-diplom32.ru/]высшее образование купить диплом с занесением в реестр[/url] .
Hello there!
Top 10 online casino in India ranked here. [url=https://win-win25.com]best online casino app in india[/url] Find your perfect gaming site.
Check out this link – https://win-win25.com
Online casino India real money
Top 10 online casino in India
Best online casino in India
Have a great day!
купить диплом с занесением в реестр в москве [url=www.arus-diplom33.ru]купить диплом с занесением в реестр в москве[/url] .
Привет!
Популярное онлайн казино Ташкент открыто. [url=https://25-win-25.com/]казино онлайн узбекистан[/url] Большие призы.
Переходи: – https://25-win-25.com
Лучшие онлайн казино в Узбекистане
Казино онлайн Узбекистан
Топ онлайн казино Узбекистан
Будь здоров!
прогнозы на хоккей с высокой проходимостью [url=https://luchshie-prognozy-na-khokkej13.ru]https://luchshie-prognozy-na-khokkej13.ru[/url] .
Универсальный автопортал https://road.kyiv.ua автомобили, автоновости, обзоры, ремонт, обслуживание и tuning. Полезные статьи для водителей и экспертов автоиндустрии.
теннесси бк скачать [url=https://www.mostbet11069.ru]https://www.mostbet11069.ru[/url]
скачать мостбет на андроид бесплатно старая версия [url=https://www.mostbet11074.ru]скачать мостбет на андроид бесплатно старая версия[/url]
how fast does creatine work
References:
can i take creatine During a fast (https://www.udrpsearch.com/user/datesteam1)
скачать mostbet [url=https://mostbet11070.ru/]скачать mostbet[/url]
мостбэт [url=https://www.mostbet11067.ru]https://www.mostbet11067.ru[/url]
купить аттестат за 10 11 класс [url=https://arus-diplom24.ru/]купить аттестат за 10 11 класс[/url] .
Анонимность и конфиденциальность: мы гарантируем полную анонимность и конфиденциальность лечения, понимая деликатность проблемы зависимости.
Получить больше информации – https://srochno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-ufe.ru/
Новости Украины https://gromrady.org.ua в реальном времени. Экономика, политика, общество, культура, происшествия и спорт. Всё самое важное и интересное на одном портале.
Женский портал https://fotky.com.ua с полезными статьями о красоте, моде, здоровье, отношениях и карьере. Советы экспертов, лайфхаки для дома, рецепты и вдохновение для каждой женщины.
Перемены в жизни Как перестать пить: Это битва, требующая мужества и самоотдачи. Найдите в себе силы обратиться за помощью, окружите себя поддержкой любящих людей и верьте в свою победу.
Современный автопортал https://automobile.kyiv.ua свежие новости, сравнительные обзоры, тесты, автострахование и обслуживание. Полезная информация для водителей и покупателей.
Онлайн женский портал https://martime.com.ua новости, тренды моды, секреты красоты, психология отношений, карьера и семья. Полезные материалы и практические советы для женщин.
гидроизоляция цена за м2 [url=https://offthevylc.ru/polezno-znat/ceny-na-gidroizoljaciju-v-moskve-i-regionah-rossii.html]https://offthevylc.ru/polezno-znat/ceny-na-gidroizoljaciju-v-moskve-i-regionah-rossii.html[/url] .
Строительный сайт https://vitamax.dp.ua с полезными материалами о ремонте, дизайне и современных технологиях. Обзоры стройматериалов, инструкции по монтажу, проекты домов и советы экспертов.
ванна с гидромассажем купить в москве [url=vanna-s-gidromassazhem.ru]vanna-s-gidromassazhem.ru[/url] .
Миссия клиники “Маяк надежды” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша задача — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Разобраться лучше – https://алко-лечение24.рф/vivod-iz-zapoya-v-stacionare-v-Sankt-Peterburge/
Экстренная наркологическая служба в Москве от Narcology Clinic предлагает оперативный выезд врача на дом. Срочный детокс, стабилизация и круглосуточная поддержка пациента с полным соблюдением конфиденциальности.
Получить дополнительную информацию – [url=https://skoraya-narkologicheskaya-pomoshch-moskva.ru/]наркологическая помощь на дому московская область[/url]
сантехника фото [url=https://evropejskaya-santehnika2.ru/]evropejskaya-santehnika2.ru[/url] .
tripscan Tripscan: Станьте частью энергичного сообщества путешественников в нашем Telegram-канале! Здесь вас ждут свежие идеи, вдохновение, обмен опытом и уникальные предложения для незабываемых путешествий. Присоединяйтесь, чтобы всегда быть в курсе лучших возможностей и секретов удачных поездок.
gessi официальный сайт [url=https://gessi-santehnika-5.ru/]gessi официальный сайт[/url] .
спорт сегодня [url=https://novosti-sporta-11.ru]https://novosti-sporta-11.ru[/url] .
мостбет. вход. [url=mostbet11073.ru]mostbet11073.ru[/url]
mostbet kg отзывы [url=http://mostbet11071.ru]mostbet kg отзывы[/url]
tripscan зеркало Трипскан сайт вход: Быстрый и удобный доступ к вашему личному кабинету. Управляйте своими бронированиями, просматривайте историю путешествий и получайте персональные рекомендации.
Мы предлагаем документы любых учебных заведений, расположенных на территории всей Российской Федерации. Купить диплом о высшем образовании:
[url=http://kkhelper.com/employer/ukrdiplom/]купить аттестат об окончании 11 классов[/url]
mostbet сайт [url=www.mostbet11069.ru]mostbet сайт[/url]
мостбет приложение [url=mostbet11073.ru]mostbet11073.ru[/url]
ставки на спорт кыргызстан [url=https://www.mostbet11068.ru]https://www.mostbet11068.ru[/url]
купить диплом занесенный реестр [url=www.arus-diplom35.ru]купить диплом занесенный реестр[/url] .
диплом о высшем образовании купить с занесением в реестр [url=https://arus-diplom35.ru]диплом о высшем образовании купить с занесением в реестр[/url] .
купить аттестат про середню школе 11 класс [url=arus-diplom23.ru]купить аттестат про середню школе 11 класс[/url] .
инъектирование [url=https://www.remontmechty.ru/remont/inekcionnaya-gidroizolyaciya-effektivnaya-zashhita-ot-vlagi ]https://www.remontmechty.ru/remont/inekcionnaya-gidroizolyaciya-effektivnaya-zashhita-ot-vlagi [/url] .
Женский сайт https://womanclub.in.ua о красоте, моде, здоровье и стиле жизни. Полезные советы, рецепты, тренды, отношения и карьера. Всё самое интересное для женщин в одном месте.
Всё о гипертонии https://gipertoniya.net что это за болезнь, как проявляется и чем опасна. Подробные статьи о симптомах, диагностике и способах лечения высокого давления.
Туристический портал https://elnik.kiev.ua с актуальными новостями, маршрутами и путеводителями. Обзоры стран и городов, советы путешественникам, лучшие идеи для отдыха и выгодные предложения.
Онлайн женский https://ledis.top сайт о стиле, семье, моде и здоровье. Советы экспертов, обзоры новинок, рецепты и темы для вдохновения. Пространство для современных женщин.
купить аттестат за 11 класс в минске [url=http://arus-diplom25.ru/]купить аттестат за 11 класс в минске[/url] .
аттестаты 11 класса купить [url=http://arus-diplom22.ru]аттестаты 11 класса купить[/url] .
?Saludos!
[url=https://25win25.shop]juegos de casino con dinero real chile[/url]
Lee este enlace – https://25win25.shop
Casino real online Chile
Juego de casino con dinero real Chile
Juegos de casino en linea con dinero real Chile
?Buena suerte!
Если требуется экстренная помощь при алкогольном кризисе — Narcology Clinic Москва предоставляет срочную помощь на дому: выезд нарколога, купирование симптомов, мониторинг состояния, без очередей и задержек.
Подробнее можно узнать тут – [url=https://skoraya-narkologicheskaya-pomoshch-moskva.ru/]skoraya-narkologicheskaya-pomoshch-moskva.ru[/url]
качественные прогнозы на футбол [url=www.kompyuternye-prognozy-na-futbol13.ru/]качественные прогнозы на футбол[/url] .
вход мостбет [url=https://mostbet11071.ru]вход мостбет[/url]
https://t.me/s/Official_1win_official_1win/774
мостбет оригинал скачать [url=https://www.mostbet11074.ru]https://www.mostbet11074.ru[/url]
Наркологическая клиника “Маяк надежды” — специализированное медицинское учреждение, предназначенное для оказания помощи лицам, страдающим от алкогольной и наркотической зависимости. Наша цель — предоставить эффективные методы лечения и поддержку, чтобы помочь пациентам преодолеть пагубное пристрастие и вернуть их к здоровой и полноценной жизни.
Разобраться лучше – http://алко-лечение24.рф/vivod-iz-zapoya-anonimno-v-Sankt-Peterburge/
nyc freight freight companies in new york
купить диплом в харькове [url=https://educ-ua4.ru/]купить диплом в харькове[/url] .
Сайт о строительстве https://stinol.com.ua практические рекомендации, проекты, обзоры инструментов и материалов. Советы экспертов, новости отрасли и новые технологии.
Строительный журнал https://mts-slil.info с актуальными новостями отрасли, обзорами материалов, инструкциями по ремонту и строительству. Полезные советы для специалистов и частных застройщиков.
Онлайн сайт https://purr.org.ua о строительстве и ремонте: полезные статьи, инструкции, обзоры технологий, дизайн-идеи и архитектурные решения для вашего дома.
Онлайн туристический https://azst.com.ua портал: всё о путешествиях, туризме и отдыхе. Маршруты, отели, лайфхаки для туристов, актуальные цены и интересные статьи о странах.
диплом бакалавра купить украина [url=www.educ-ua5.ru/]диплом бакалавра купить украина[/url] .
https://t.me/s/Official_1win_official_1win/1100
Посетите сайт https://god2026.com/ и вы сможете качественно подготовится к Новому году 2026 и почитать любопытную информацию: о символе года Красной Огненной Лошади, рецепты на Новогодний стол 2026 и как украсить дом, различные приметы в Новом 2026 году и многое другое. Познавательный портал где вы найдете многое!
купить диплом в уфе с реестром [url=arus-diplom31.ru]arus-diplom31.ru[/url] .
купить диплом с реестром вуза [url=www.arus-diplom34.ru/]купить диплом с реестром вуза[/url] .
купить аттестат об окончании 11 классов в барнауле [url=http://arus-diplom24.ru]купить аттестат об окончании 11 классов в барнауле[/url] .
https://t.me/s/Official_1win_official_1win/230
Профилактика алкоголизма в Туле: советы врачей Зависимость от алкоголя — серьезная проблема‚ требующая внимания и действий. Важно знать о возможностях профилактики и лечения. Вызвать нарколога на дом в Туле можно Врачи рекомендуют проводить профилактические меры‚ включая осведомленность о последствиях алкоголизма и поддержку семьи. вызвать нарколога на дом тула Лечение алкоголизма включает которые помогают вернуть здоровье и социальную адаптацию Наркологическая помощь необходима для работы с зависимыми‚ а также для предотвращения рецидивов. Здоровье и алкоголь — это вечная борьба‚ и поддержка в нужный момент играет решающую роль.
подключение интернета челябинск
chelyabinsk-domashnij-internet004.ru
подключить проводной интернет челябинск
https://t.me/s/Official_1win_official_1win/1061
https://t.me/s/Official_1win_official_1win/143
https://t.me/s/Official_1win_official_1win/839
скачать мостбет на телефон [url=http://mostbet11075.ru]http://mostbet11075.ru[/url]
Онлайн новостной https://antifa-action.org.ua портал с круглосуточным обновлением. Свежие новости, репортажи и обзоры. Важные события страны и мира, мнения экспертов и актуальная аналитика.
Новостной портал https://prp.org.ua с актуальной информацией о событиях в России и мире. Политика, экономика, культура, спорт и технологии. Новости 24/7, аналитика и комментарии экспертов.
Новости Украины https://uamc.com.ua новости дня, аналитика, события регионов и мира. Обзоры, интервью, мнения экспертов. Быстро, достоверно и удобно для читателей.
Строительный портал https://suli-company.org.ua с актуальными новостями, обзорами материалов, проектами и инструкциями. Всё о ремонте, строительстве и дизайне.
https://t.me/s/Official_1win_official_1win/695
мостбет ставки на спорт [url=http://mostbet11070.ru]http://mostbet11070.ru[/url]
https://t.me/s/Official_1win_official_1win/465
Скорая наркологическая служба Narcology Clinic в Москве работает круглосуточно. Выезд к пациенту, медикаментозная стабилизация, детоксикация и психологическая поддержка до выхода из кризисного состояния.
Узнать больше – [url=https://skoraya-narkologicheskaya-pomoshch-moskva11.ru/]скорая наркологическая помощь на дому[/url]
гидромассажная ванна [url=https://www.vanna-s-gidromassazhem.ru]https://www.vanna-s-gidromassazhem.ru[/url] .
Например, если речь идет о выводе из запоя, врач проведет тщательное обследование пациента, чтобы определить общее состояние здоровья и наличие возможных осложнений. На основе диагностики будет назначена инфузионная терапия, которая включает введение растворов, витаминов и препаратов для снятия абстиненции.
Изучить вопрос глубже – [url=https://narcolog-na-dom-v-krasnoyarske55.ru/]нарколог на дом цена в красноярске[/url]
Капельницы для восстановления после запоя в владимире: путь к здоровью Лечение алкоголизма начинается с профессиональной консультации врача. В владимире работают специализированные клиники, где оказывается наркологическая помощь, включая капельницы для восстановления. Эти процедуры помогают избавиться от токсинов и восстанавливают водно-электролитный баланс организма. вывод из запоя Поддержка пациента и контроль его состояния, важные аспекты терапии. Реабилитация после запоя — это комплексный подход, который учитывает физическое и психологическое здоровье. Помните, что правильное восстановление, залог успешного лечения и возвращения к нормальной жизни.
кашпо с автополивом для комнатных растений [url=www.kashpo-s-avtopolivom-kazan.ru]кашпо с автополивом для комнатных растений[/url] .
https://t.me/s/Official_1win_official_1win/298
домашний интернет в челябинске
chelyabinsk-domashnij-internet005.ru
лучший интернет провайдер челябинск
прогнозы на матчи хоккей [url=http://luchshie-prognozy-na-khokkej13.ru/]http://luchshie-prognozy-na-khokkej13.ru/[/url] .
Откопаться ? это не просто процесс работы с землёй, но и увлекательное приключение земли, которое открывает двери к тайнам истории. Археология, как наука, предполагает раскопки, позволяющие обнаружить исторические артефакты, предметы старины и подземные ресурсы. На сайте vivod-iz-zapoya-tula008.ru можно найти множество информации о современных методах бурения и анализа почвы, которые помогают в поиске уникальных объектов. Земляные работы, включая раскопки, являются основой археологических исследований. Каждый слой почвы, который мы откопаем, может рассказать о жизни людей в разные исторические эпохи. Восстановление найденных артефактов предоставляет шанс лучше понять культуру и технологии древних цивилизаций. Геология также играет ключевую роль в процессе, помогая в анализе почвы и определении местонахождения объектов, что облегчает поиски более целенаправленными и эффективными. Таким образом, раскопки – это не только работа с землёй, но и интересное исследование в прошлое, где каждая находка становится неотъемлемой частью исторической мозаики.
https://t.me/s/Official_1win_official_1win/868
https://t.me/tripscan_1 Трипскан ссылка: Мгновенный доступ к миру путешествий.
¡Buen día!
Tiradas gratis en slots populares. [url=https://1win-25.com/]casino online dinero real ecuador[/url] Cassino dando giros gratis Ecuador para ganar mГЎs.
Lee este enlace – https://1win-25.com/
Casino en linea Ecuador
Casino con giros gratis Ecuador
Cassino dando giros gratis Ecuador
¡Buena suerte!
Appreciating the time and effort you put into your website and detailed information you present. It’s good to come across a blog every once in a while that isn’t the same unwanted rehashed material. Fantastic read! I’ve saved your site and I’m adding your RSS feeds to my Google account.
https://geliosfireworks.com.ua/chomu-krashchyj-hermetyk-ne-zavzhdy-najdorozh.html
последние новости спорта [url=https://novosti-sporta-12.ru/]novosti-sporta-12.ru[/url] .
Здарова!
Проверенные онлайн казино с выводом денег Казахстан защищают данные. [url=https://25win-25.shop]проверенные онлайн казино с выводом денег Казахстан[/url] Ваша безопасность гарантирована.
Читай тут: – https://25win-25.shop/
Онлайн казино КЗ
Проверенные онлайн казино с выводом денег Казахстан
Vavada казино онлайн Казахстан вход
Удачи!
мостбет казино [url=https://www.mostbet11075.ru]https://www.mostbet11075.ru[/url]
Портал про авто https://prestige-avto.com.ua обзоры новых и подержанных машин, тест-драйвы, рынок автомобилей, страхование и обслуживание.
Онлайн автомобильный https://avtonews.kyiv.ua портал: свежие автоновости, сравнительные тесты, статьи о ремонте и тюнинге. Обзоры новых и подержанных машин, цены и советы экспертов.
Современный автомобильный https://mallex.info портал: автообзоры, тесты, ремонт и обслуживание, страхование и рынок. Всё, что нужно водителям и любителям автомобилей.
Автомобильный портал https://autonovosti.kyiv.ua новости автопрома, обзоры моделей, тест-драйвы и советы по эксплуатации. Всё для автолюбителей: от выбора авто до обслуживания и ремонта.
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Нажмите, чтобы узнать больше – http://www.photodim.ru/index.php?values%5Bp%5D=single_photo&values%5Bphoto_id%5D=219&values%5Bmode%5D=date
Строительный сайт https://novostroi.in.ua с полезными статьями о ремонте, отделке и дизайне. Обзоры стройматериалов, проекты домов, инструкции и советы экспертов для профессионалов и новичков.
mostbet casino [url=http://mostbet11067.ru]mostbet casino[/url]
подключить интернет в квартиру челябинск
chelyabinsk-domashnij-internet006.ru
домашний интернет тарифы
Лечение запоя в Туле: советы для родственников и близких Лечение запоя в Туле часто требует вмешательства специалистов. Капельница ? один из самых действенных методов борьбы с запоем, такие как обезвоживание, интоксикация и физические недомогания. Важно помнить, что помощь родственников играет ключевую роль в процессе восстановления. лечение запоя тула При наличии зависимости от алкоголя, поддержка семьи может значительно ускорить лечение. Симптомы запоя, такие как тремор, потливость и раздражительность, требуют немедленной медицинской помощи. Наркология на дому предлагает услуги по введению капельниц, что позволяет пациенту оставаться в комфортной обстановке. Советы близким: будьте терпеливыми и не осуждайте. Уход за больным включает заботу о его психологическом состоянии, так как психологические аспекты зависимости влияет на успешность лечения. Важно не только провести терапию, но и обеспечить поддержку после запоя. Реабилитация наркозависимых требует комплексного подхода, включая психотерапию и мониторинг состояния пациента. Помимо капельницы, стоит рассмотреть возможные шаги по лечению алкоголизма, которое включает встречи с психотерапевтом и участие в реабилитационных программах. Домашняя терапия также может быть полезной, однако она должна проводиться под наблюдением медика.
Первый этап направлен на выведение токсинов и стабилизацию функций жизненно важных органов. Применяются инфузионные растворы, гепатопротекторы и препараты для нормализации электролитного баланса. Доза и состав подбираются индивидуально после оценки лабораторных показателей.
Углубиться в тему – http://
Не можете добраться до клиники? Нарколог на дом в Иркутске – оптимальный выход при запое. Нарколог на дом – это удобно: обследование, лечение и детоксикация в комфортных условиях. Выезд нарколога в любое время, анонимность и безопасность – это «ТрезвоМед». Без медицинской помощи не обойтись? Звоните наркологу! Чем быстрее помощь, тем лучше прогноз, – нарколог Игорь Васильев.
Получить больше информации – [url=https://narcolog-na-dom-v-irkutske0.ru/]платный нарколог на дом в иркутске[/url]
Сразу после вызова нарколог приезжает для проведения детального осмотра. На этом этапе производится сбор анамнеза, измеряются жизненно важные показатели – пульс, артериальное давление, температура – и оценивается степень интоксикации.
Изучить вопрос глубже – http://
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Выяснить больше – https://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-anonimno-v-sochi/
https://t.me/s/TgWin_1win/351
Портал для родителей https://detiwki.com.ua и детей — всё для счастливой семьи. Воспитание, образование, здоровье, отдых и полезные материалы для мам, пап и малышей.
Журнал садовода https://mts-agro.com.ua полезные советы по уходу за садом и огородом. Сезонные работы, выращивание овощей, фруктов и цветов, современные технологии и секреты урожая.
Сайт для женщин https://stylewoman.kyiv.ua с интересными статьями о моде, красоте, семье и здоровье. Идеи для кулинарии, путешествий и вдохновения.
Универсальный сайт https://virginvirtual.net для женщин — секреты красоты, тренды моды, советы по отношениям и карьере, рецепты и стиль жизни.
Сайт для женщин https://gratransymas.com о красоте, моде, здоровье и стиле жизни. Полезные советы, рецепты, тренды, отношения и карьера.
букмекеры кыргызстана [url=http://mostbet11072.ru]http://mostbet11072.ru[/url]
как купить диплом с занесением в реестр в екатеринбурге [url=forum.good-cook.ru/user227672.html]как купить диплом с занесением в реестр в екатеринбурге[/url] .
аттестат за 11 купить в ижевске [url=https://arus-diplom24.ru]аттестат за 11 купить в ижевске[/url] .
mostbet скачать [url=http://mostbet11072.ru]http://mostbet11072.ru[/url]
Сайт обо всём https://vybir.kiev.ua энциклопедия для повседневной жизни. Красота, здоровье, дом, путешествия, карьера, семья и полезные советы для всех.
Студия дизайна https://lbook.com.ua интерьера и архитектуры. Создаём стильные проекты квартир, домов и офисов. Индивидуальный подход, современные решения и полный контроль реализации.
Портал про ремонт https://hydromech.kiev.ua свежие статьи о ремонте и отделке, дизайне интерьера и выборе материалов. Полезные советы для мастеров и тех, кто делает ремонт своими руками.
Интересный сайт https://whoiswho.com.ua обо всём: статьи, лайфхаки, обзоры и идеи на самые разные темы. Всё, что нужно для вдохновения и развития, в одном месте.
Мы готовы предложить документы институтов, расположенных на территории всей Российской Федерации. Заказать диплом о высшем образовании:
[url=http://thewion.com/read-blog/202854_attestat-kupit-za-11-klassov-v-kieve.html/]купить аттестат 11 классов ижевск[/url]
гидроизоляция цена за м2 [url=http://offthevylc.ru/polezno-znat/ceny-na-gidroizoljaciju-v-moskve-i-regionah-rossii.html]http://offthevylc.ru/polezno-znat/ceny-na-gidroizoljaciju-v-moskve-i-regionah-rossii.html[/url] .
При выборе интернет-провайдера в Екатеринбурге важно учитывать не только качество соединения и цену услуг‚ но и защиту данных. Какой провайдер выбрать‚ чтобы гарантировать защиту личных данных? Прежде всего‚ обратите внимание на репутацию провайдера. Изучайте отзывы клиентов и оценивайте лицензионные требования. какой интернет подключить Екатеринбург Контроль доступа и защита трафика – ключевые аспекты интернет-безопасности. Убедитесь‚ что провайдер соблюдает правовые нормы‚ такие как GDPR‚ и предлагает условия обслуживания‚ защищающие вашу конфиденциальность. Риски утечки информации могут быть высокими‚ поэтому важно выбирать проверенного провайдера‚ который гарантирует защиту информации и безопасное хранение данных.
диплом об образовании купить [url=https://www.educ-ua1.ru]диплом об образовании купить[/url] .
новости футбола [url=http://novosti-sporta-11.ru/]новости футбола[/url] .
Онлайн портал https://esi.com.ua про ремонт: идеи для интерьера, подбор материалов, практические рекомендации и пошаговые инструкции для самостоятельных работ.
купить диплом о высшем с занесением в реестр [url=arus-diplom31.ru]купить диплом о высшем с занесением в реестр[/url] .
можно ли купить аттестат за 11 класс сколько стоит [url=http://arus-diplom22.ru]http://arus-diplom22.ru[/url] .
Срочная наркологическая помощь на дому — это важный аспект в лечении зависимостей от наркотиков и алкоголя. На сайте vivod-iz-zapoya-vladimir007.ru доступна поддержка наркологов, специализирующихся на выездных услугах. В такие моменты жизненно важно обратиться за помощью, так как зависимость может угрожать жизни и здоровью. Наркологическая помощь на дому предоставляет атмосферу, способствующую выздоровлению, где вы получаете квалифицированную помощь, а также поддержку при зависимости; Мы обеспечиваем приватность, что важно для многих обращаться в клиники. Помощь психолога также доступна, что помогает справиться с эмоциональными переживаниями. Процесс реабилитации включает в себя комплексный подход к лечению, направленные на возвращение к полноценной жизни. Выезд опытного врача обеспечивает, что процесс лечения будет проходить под постоянным наблюдением специалистов. Начните свой путь к выздоровлению уже сегодня — ваш первый шаг к свободе от зависимости!
купить аттестат за 11 класс на 4 [url=https://arus-diplom21.ru/]купить аттестат за 11 класс на 4[/url] .
купить аттестаты за 11 класс московская область [url=http://arus-diplom9.ru/]http://arus-diplom9.ru/[/url] .
Комплексный вывод из запоя в Туле организован по отлаженной схеме, состоящей из нескольких этапов, каждый из которых направлен на безопасное и эффективное восстановление организма.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-tula000.ru/]вывод из запоя клиника в туле[/url]
https://t.me/s/Official_1win_official_1win/1094
интернет-магазин сантехники екатеринбург [url=www.evropejskaya-santehnika2.ru/]www.evropejskaya-santehnika2.ru/[/url] .
купить проведенный диплом одно [url=http://arus-diplom35.ru]купить проведенный диплом одно[/url] .
https://t.me/s/TgWin_1win
где купить аттестат за 11 классов в [url=http://www.arus-diplom23.ru]где купить аттестат за 11 классов в[/url] .
На данном этапе специалист уточняет, как долго продолжается запой, какой вид алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ информации позволяет оперативно определить степень интоксикации и выбрать оптимальные методы терапии для быстрого и безопасного вывода из запоя.
Подробнее тут – http://vyvod-iz-zapoya-tula00.ru/
купить аттестат за 11 класс рязань [url=arus-diplom22.ru]arus-diplom22.ru[/url] .
обложка аттестата за 11 класс купить [url=http://arus-diplom25.ru]http://arus-diplom25.ru[/url] .
купить диплом с занесением в реестр пенза [url=https://arus-diplom34.ru/]купить диплом с занесением в реестр пенза[/url] .
купить диплом занесением реестр киев [url=https://arus-diplom31.ru/]https://arus-diplom31.ru/[/url] .
Репортажи в больших https://infotolium.com фотографиях: самые обсуждаемые события, уникальные кадры и впечатляющие истории. Новости и жизнь в формате визуального рассказа.
купить диплом с проводкой [url=http://arus-diplom34.ru]купить диплом с проводкой[/url] .
gessi [url=https://www.gessi-santehnika-5.ru]gessi[/url] .
Нужна срочная помощь при алкогольном отравлении или запое? Вызовите нарколога на дом в Иркутске! Квалифицированная помощь нарколога на дому: диагностика, капельница, стабилизация состояния. Круглосуточный выезд нарколога, анонимность и снижение рисков – с «ТрезвоМед». Самостоятельный отказ невозможен? Необходима наркологическая помощь. Васильев: «Не затягивайте с помощью при алкогольном отравлении!».
Выяснить больше – [url=https://narcolog-na-dom-v-irkutske0.ru/]нарколог на дом стоимость в иркутске[/url]
Информационный портал https://reklama-region.com про ремонт: ремонт квартир, домов, офисов. Практические рекомендации, современные решения и обзоры стройматериалов.
В программе используются когнитивно-поведенческая терапия, мотивационное интервьюирование, арт- и телесно-ориентированные практики. Занятия помогают пациенту осознать причины употребления, выработать навыки управления эмоциями и стрессом, сформировать устойчивую внутреннюю мотивацию к отказу от вещества.
Детальнее – https://lechenie-narkomanii-arkhangelsk0.ru/
Сайт про авто https://autoinfo.kyiv.ua свежие новости автопрома, обзоры моделей, тест-драйвы и советы по эксплуатации. Всё о машинах для водителей и автолюбителей.
аттестат об образовании 11 классов купить [url=http://arus-diplom25.ru]аттестат об образовании 11 классов купить[/url] .
В столице России существует множество интернет-провайдеров, которые предлагают различные методы доступа к интернету и телевидению. На сайте ekaterinburg-domashnij-internet005.ru вы найдете актуальные предложения, сравнить тарифы и выбрать подходящий вариант. Основные технологии доступа включают оптоволоконный интернет, кабельное и спутниковое телевидение. Интернет на основе оптоволокна обеспечивает высокую скорость к интернету и высокое качество сигнала, что привлекает пользователей. Цифровое ТВ и IPTV сервисы также увеличивают свою популярность всё более востребованными, давая доступ к огромному количеству каналов и контента. Кабельное телевидение предлагает различные тарифные пакеты, в то время как спутниковое телевидение позволяет смотреть телеканалы даже в самых удалённых районах. Мобильный интернет становится оптимальным вариантом для тех, кто часто находится в движении. При подборе провайдера важно обращать внимание на скорость интернета и качество сигнала. Пользовательские отзывы помогут осознать плюсы и минусы каждой услуги, а подключение интернета и создание Wi-Fi сети в квартире станет простым и быстрым процессом при умелом выборе провайдера.
На данном этапе специалист уточняет, как долго продолжается запой, какой вид алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ информации позволяет оперативно определить степень интоксикации и выбрать оптимальные методы терапии для быстрого и безопасного вывода из запоя.
Подробнее тут – https://vyvod-iz-zapoya-tula00.ru/vyvod-iz-zapoya-czena-tula/
купить аттестат за 11 классов в санкт петербурге [url=http://www.arus-diplom24.ru]http://www.arus-diplom24.ru[/url] .
Сайт про автомобили https://black-star.com.ua новинки рынка, цены, тест-драйвы и обзоры. Советы экспертов по выбору и уходу за машиной, тюнинг и автоуслуги.
При возникновении сложности с алкоголизмом или если вы знаете человека, которому необходима помощь, обратите внимание обратиться к профессионалам. Клиника наркологии в владимире предлагает экстренную помощь при алкоголизма и наркомании. Обращение нарколога поможет определить нужный курс лечения. Центр лечения наркозависимости обеспечивает медицинскую помощь и психотерапию, а также поддержку семьи. Анонимное лечение гарантирует безопасность и конфиденциальность. Реабилитационные программы для наркозависимых включает профилактику рецидивов и восстановление после зависимости. Первый шаг к новой жизни начинается здесь. vivod-iz-zapoya-vladimir008.ru
Онлайн-журнал https://autoiceny.com.ua для автолюбителей: автомобили, новости индустрии, тест-драйвы, тюнинг и советы по обслуживанию.
новости Турции : Калейдоскоп впечатлений от повседневности, традиций и современного уклада жизни. От шумных мегаполисов до тихих провинциальных городков. Отдых в Турции
Автомобильный онлайн-журнал https://allauto.kyiv.ua свежие новости автопрома, тест-драйвы, обзоры новых моделей, советы по эксплуатации и ремонту. Всё для водителей и автолюбителей.
https://t.me/provrf_ru Купить VRF: Инвестиция в Будущее Приобретение VRF системы – это инвестиция в будущее вашего дома или бизнеса. Эти системы позволяют существенно снизить энергопотребление и затраты на электроэнергию, обеспечивая при этом максимальный комфорт.
купить диплом с занесением в реестр в архангельске [url=http://www.arus-diplom33.ru]купить диплом с занесением в реестр в архангельске[/url] .
Лечение алкоголизма в домашних условиях — значимый этап для борьбы с алкогольной зависимостью . Процесс избавления от алкоголизма начинается с очищения организма, доступной для выполнения дома. Основные подходы включают медицинскую помощь и препараты для детоксикации , что обеспечит безопасное прекращение употребления. vivod-iz-zapoya-krasnoyarsk007.ru Рекомендации для поддержания трезвости и стратегии преодоления зависимости, такие как самопомощь при алкоголизме , имеют огромное значение в реабилитации . Отказ от алкоголя — это путь к новой жизни .
Royal portraits http://www.turnyouroyal.com from photos – turn yourself or your loved ones into a king, queen or aristocrat. Author’s work of artists, luxurious style and premium quality of printing.
Scratch cards are such a fun, quick thrill! Seeing platforms like phsky vip prioritize responsible gaming & clear regulations (like PAGCOR) is a huge plus. Makes enjoying the games even better, knowing it’s legit! 👍
Чтобы обеспечить безопасное выведение психоактивных веществ и восстановление организма, применяется детоксикация под контролем врача-нарколога и анестезиолога-реаниматолога.
Подробнее можно узнать тут – https://lechenie-narkomanii-arkhangelsk0.ru/czentr-lecheniya-narkomanii-arkhangelsk
диплом занесен в реестр купить [url=www.arus-diplom32.ru/]диплом занесен в реестр купить[/url] .
https://www.med2.ru/story.php?id=147095
Hey there! Do you use Twitter? I’d like to follow you if that would be ok. I’m definitely enjoying your blog and look forward to new posts.
http://bagit.com.ua/povnyj-hid-po-vyboru-avtomobilnykh-linz.html
Организация доступа к интернету в частном доме в Екатеринбурге – является важным шагом для обеспечения доступа к информации и услугам. Выбирая провайдера интернета, учтите скорость и условия тарифов. Изучите варианты проводного интернета и безлимитного интернета, чтобы выбрать оптимальный для ваших нужд.Чтобы подключиться к Wi-Fi вам понадобятся роутеры и модемы. Не забудьте про оборудование для подключения, которое часто предоставляют провайдеры. Услуги связи в Екатеринбурге разнообразны, поэтому стоит сравнить предложения нескольких провайдеров. ekaterinburg-domashnij-internet006.ru При проблемах с подключением, рекомендуется связаться с технической поддержкой. Также важно правильно настроить интернет, чтобы избежать сбоев. Следуйте рекомендациям по выбору провайдера, вы сможете гарантировать надежный интернет в своем доме.
Если требуется срочное кодирование или детоксикация, вызов нарколога на дом – лучшее решение в Иркутске. Профессиональный нарколог приедет, оценит состояние, проведет детоксикацию на дому. «ТрезвоМед»: анонимный выезд нарколога 24/7, помощь при отказе от алкоголя. Тяжело бросить пить в одиночку? Обратитесь к наркологу! Главное – быстро оказать помощь при интоксикации, – нарколог Васильев.
Узнать больше – http://narcolog-na-dom-v-irkutske0.ru/narkolog-na-dom-czena-irkutsk
Видеокамеры стилизованные Видеокамеры наблюдения: Глаза, которые никогда не спят Современные видеокамеры наблюдения предлагают широкий спектр функций, от записи в высоком разрешении до удаленного доступа через интернет. Они становятся неотъемлемой частью систем безопасности для домов, офисов и предприятий.
Вывод из запоя на дому в Туле осуществляется по строго отлаженной схеме, которая включает несколько последовательных этапов. Такой комплексный подход позволяет не только быстро вывести токсины из организма, но и обеспечить всестороннюю поддержку пациента, включая психологическую реабилитацию.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-tula00.ru/]вывод из запоя тула[/url]
Бесплатный вывод из запоя в владимире: возможно ли? Проблема зависимости от алкоголя и методы помощи зависимым вызывают много вопросов. Много людей оказывается в ситуации запоя и не понимает‚ как из неё выбраться. В этом случае помощь нарколога на дому‚ работающего круглосуточно‚ может оказаться весьма полезной. нарколог на дом круглосуточно Наркологическая помощь‚ включая бесплатную консультацию нарколога‚ может быть доступна для тех‚ кто нуждается в экстренной помощи при запое. В владимире нередко предлагают услуги по выводу из запоя‚ а также лечение в домашних условиях‚ что делает процесс более комфортным и менее стрессовым для пациента. Круглосуточный нарколог предоставит медицинскую помощь на дому‚ что особенно удобно для тех‚ кто не может или не хочет идти в стационар. Анонимное лечение алкоголизма также возможно‚ что помогает сохранить личную жизнь пациента. Важно помнить‚ что поддержка для зависимых играет ключевую роль в процессе восстановления. Реабилитация от алкогольной зависимости требует времени и усилий‚ однако с помощью специалистов можно добиться успеха. Итак‚ если вы или ваши близкие нуждаетесь в бесплатном выводе из запоя в владимире‚ обращение к наркологу на дому может стать первым шагом к избавлению от зависимости.
Лечение запоя с помощью капельницы на дому – это необходимая мера для лечения пьянства. Если вам хочется получить помощь нарколога на дому в Красноярске‚ убедитесь в надежности клиники. Важно выбрать центр‚ который предлагает конфиденциальное лечение и опытных врачей. вызвать нарколога на дом Красноярск Перед вызовом специалиста стоит проконсультироваться о домашних процедурах‚ таких как процедуры с капельницей. Это позволит позаботиться о безопасности пациента и быстрое восстановление после алкогольной интоксикации. Убедитесь‚ что клиника предлагает реабилитацию на дому‚ что поддерживает эффективность терапии. Важно внимательно подойти к выбору клиники. Обратите внимание на мнения пациентов‚ квалификацию врачей и возможность получения помощи в любое время. Опытный специалист по наркологии сможет оказать помощь в кратчайшие сроки‚ обеспечивая внимание и заботу в трудный период.
последние новости спорта [url=novosti-sporta-12.ru]novosti-sporta-12.ru[/url] .
stavkiprognozy [url=https://stavki-prognozy-1.ru/]stavki-prognozy-1.ru[/url] .
СтавкиПрогнозы [url=http://stavki-prognozy-one.ru/]http://stavki-prognozy-one.ru/[/url] .
Авто-журнал https://bestauto.kyiv.ua источник информации для автолюбителей. Новинки рынка, сравнения моделей, советы по ремонту и уходу, интересные материалы о мире автомобилей.
Новостной портал https://gau.org.ua круглосуточные новости, комментарии экспертов, события регионов и мира. Политика, бизнес, культура и общество.
прогнозы на спорт от профессионалов точные [url=prognozy-na-sport-7.ru]prognozy-na-sport-7.ru[/url] .
бесплатные спорт прогнозы [url=http://prognozy-na-sport-8.ru]http://prognozy-na-sport-8.ru[/url] .
Онлайн авто-журнал https://mirauto.kyiv.ua с актуальными новостями, аналитикой и обзорами. Тесты автомобилей, тюнинг, технологии и советы по эксплуатации.
ставки прогнозы [url=https://stavki-prognozy-2.ru/]https://stavki-prognozy-2.ru/[/url] .
купить VRF Монтаж VRV: Точность и Качество в Каждой Детали Монтаж VRV системы требует высокой квалификации и опыта. Мы обеспечиваем профессиональный монтаж, используя современное оборудование и передовые технологии, чтобы гарантировать бесперебойную работу вашей системы кондиционирования.
прогноз на футбол [url=https://prognozy-na-futbol-6.ru/]прогноз на футбол[/url] .
Авто портал https://avtomobilist.kyiv.ua всё об автомобилях: новые модели, цены, рынок подержанных авто, тюнинг и автотехнологии. Полезные материалы для автовладельцев.
точный прогнозы на футбол [url=https://www.prognozy-na-futbol-5.ru]https://www.prognozy-na-futbol-5.ru[/url] .
Мужской портал https://hooligans.org.ua новости, лайфхаки, обзоры техники, спорт, здоровье и авто. Советы для уверенной и гармоничной жизни.
домашний интернет казань
kazan-domashnij-internet004.ru
провайдеры домашнего интернета казань
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Почему это важно? – https://ristein-frisuren.de/fade-masterclass-behind-the-scenes-of-precision-styling
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Доступ к полной версии – https://solarsantacruz.com.br/instalacao-residencial-335kwp
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Как достичь результата? – https://vakkiyl.com/sed-nimis-multa
Приобрести диплом об образовании!
Мы можем предложить дипломы любой профессии по приятным ценам— [url=http://tele-work.ru/]tele-work.ru[/url]
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Погрузиться в научную дискуссию – https://atsu.com.ec/2013/01/09/velit-feugiat-porttito
Лечение запоя в Красноярске серьезная проблема, требующая профессионального подхода . Алкоголизм — это беда, способная сломать судьбы, и помощь при запое жизненно важна для всех, кто оказался в этой ситуации. В клиниках для лечения запоя предлагаются различные программы, направленные на выведение из запоя и реабилитацию после запоя . Стоимость лечения алкоголизма варьируется в зависимости от выбранной клиники и уровня предоставляемых услуг . В стоимость может входить консультация нарколога, медицинская помощь при запое и услуги по детоксикации. лечение запоя Красноярск Помощь наркологов в Красноярске включает в себя как стационарное, так и амбулаторное лечение , что также сказывается на ценах. Программа лечения алкоголизма разрабатывается индивидуально и может включать детоксикацию, психологическую поддержку и реабилитацию . Комплексное лечение зависимостей в Красноярске позволяет не только остановить алкогольное потребление, но и минимизировать риск рецидивов. Поэтому, если вам или вашим близким требуется помощь, важно обратиться за помощью к специалистам .
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Обратитесь за информацией – https://irablogging.in/%E0%A4%89%E0%A4%B2%E0%A4%97%E0%A4%A1%E0%A4%BE-3
купить аттестат 11 класса в екатеринбурге [url=https://www.arus-diplom24.ru]купить аттестат 11 класса в екатеринбурге[/url] .
подключить интернет по адресу
kazan-domashnij-internet005.ru
интернет провайдеры по адресу дома
ゼントレーダーで始める|Zenブログで深める賢い投資ライフ
最近、投資をよりシンプルに、そして効率的に始めたいと考える人々の間で注目されているのが「ゼントレーダー(Zentrader)」です。登録から取引までが非常にスムーズで、初心者にもわかりやすい設計が魅力です。
特に「Zenブログ」では、投資に関する基本知識から実践的な取引戦略まで、幅広い情報が発信されており、学びながら実践できる環境が整っています。日々のマーケット動向やトレンドも分かりやすく解説されているため、忙しい人でも効率よく情報収集が可能です。
さらに、投資初心者がつまずきやすいポイントやリスク管理の方法についても、https://social-consulting.jp/ にて実践的なアドバイスが紹介されています。投資を「感覚」ではなく「戦略」として考えたい方におすすめです。
экстренный вывод из запоя смоленск
vivod-iz-zapoya-smolensk010.ru
экстренный вывод из запоя смоленск
жд доставка грузов из Китая доставка сборного груза из Китая в Россию
Запой — это не просто многодневное употребление алкоголя, а тяжёлое нарушение обмена веществ, работы сердца, нервной системы и внутренних органов. Без медицинской помощи резко возрастает риск развития осложнений: делирий, судороги, инсульт, сердечная недостаточность, тяжёлое обезвоживание и нарушения психики. Симптомы могут прогрессировать в любое время, причём угроза для жизни появляется внезапно.
Получить больше информации – https://vyvod-iz-zapoya-shchelkovo6.ru/
Врач проводит подробную диагностику, оценивает как физическое, так и психологическое состояние пациента. На основании полученных данных формируется индивидуальная программа помощи, которая включает не только медикаментозное лечение, но и психотерапевтическую поддержку, консультации для семьи и рекомендации по восстановлению.
Исследовать вопрос подробнее – https://narkologicheskaya-pomoshch-domodedovo6.ru/anonimnaya-narkologicheskaya-pomoshch-v-domodedovo
Особую опасность представляет белая горячка (алкогольный психоз). У пациента возникают галлюцинации, приступы паники, агрессивное поведение, дезориентация во времени и пространстве. Это состояние требует незамедлительного вмешательства врача, так как человек может представлять опасность для себя и окружающих.
Подробнее тут – [url=https://narcolog-na-dom-novokuznetsk00.ru/]запой нарколог на дом в новокузнецке[/url]
Этот перечень помогает быстро оценить необходимость вызова. Если вы узнали в нем свою ситуацию — оптимально начать терапию как можно раньше: так детокс проходит мягче, а риск осложнений и срывов в первые сутки ниже.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-serpuhov6.ru/]вызвать нарколога на дом срочно[/url]
Портал о ремонте https://dki.org.ua и строительстве: от отделки квартиры до возведения загородного дома. Подробные статьи, рекомендации экспертов и идеи для обустройства жилья.
Портал о стройке https://sushico.com.ua и ремонте. Новости рынка, современные технологии, подборка идей для интерьера и экстерьера. Всё, что нужно для дома и дачи.
https://tripscan51.win/
Онлайн сайт https://mramor.net.ua о строительстве и ремонте. Всё о возведении домов, ремонте квартир, отделке и обустройстве жилья. Обзоры материалов, советы экспертов и свежие идеи.
Всё о стройке https://aziatransbud.com.ua и ремонте в одном месте: дизайн, архитектура, выбор стройматериалов, инструкции по монтажу, лайфхаки и полезные рекомендации для новичков и мастеров.
Сайт о строительстве https://juglans.com.ua и ремонте — ваш помощник в выборе материалов, инструментов и технологий. Всё о ремонте квартир, строительстве домов и дизайне интерьеров.
провайдеры интернета в казани по адресу
kazan-domashnij-internet006.ru
проверить интернет по адресу
школа изучения английского Школа английского в Москве: Европейское качество Расположенная в самом сердце Москвы, наша школа предлагает курсы английского языка европейского качества. Мы используем современные методики обучения и сотрудничаем с ведущими международными образовательными организациями.
купить аттестат за 11 классов сочи [url=https://arus-diplom21.ru]https://arus-diplom21.ru[/url] .
вывод из запоя
vivod-iz-zapoya-smolensk011.ru
экстренный вывод из запоя
https://t.me/s/Official_1xbet_1xbet/1270
https://t.me/s/Official_1xbet_1xbet/1524
Портал про строительство https://texha.com.ua новости рынка, обзоры технологий, инструкции и идеи для ремонта. Материалы для застройщиков, мастеров и тех, кто делает своими руками.
Онлайн журнал https://vitamax.dp.ua о строительстве: проекты домов, ремонт квартир, выбор стройматериалов, дизайн и интерьер. Советы экспертов и свежие идеи для комфортной жизни.
В таких ситуациях вывод из запоя на дому становится необходимым, чтобы быстро стабилизировать состояние пациента, избежать необратимых последствий и дать организму шанс на восстановление. Клиника «Семья и Здоровье» предлагает комплексное лечение, осуществляемое опытными наркологами, которые работают 24 часа в сутки, 7 дней в неделю. Наши специалисты приезжают по вызову в течение 30–60 минут, обеспечивая оперативное и качественное лечение в привычной домашней обстановке, что особенно важно для пациентов, испытывающих стресс и страх перед госпитализацией.
Получить дополнительные сведения – [url=https://narcolog-na-dom-krasnoyarsk0.ru/]narkolog na dom krasnojarsk[/url]
Новости Украины https://gromrady.org.ua онлайн: политика, экономика, спорт, культура и события регионов. Оперативные материалы, аналитика и комментарии экспертов круглосуточно.
Портал про авто https://automobile.kyiv.ua свежие новости автопрома, тест-драйвы, обзоры моделей и советы по ремонту. Всё о машинах для водителей и автолюбителей.
Авто портал https://road.kyiv.ua с актуальной информацией: новинки рынка, цены, обзоры, страхование и тюнинг. Полезные статьи и аналитика для автомобилистов.
https://www.med2.ru/story.php?id=147093
https://t.me/s/Official_1xbet_1xbet/1472
create ringtone convert audio formats
Prodaja gradjevinsko zemljiste zabljak: stanovi, vile, zemljisne parcele. Izbor smestaja za odmor, preseljenje i investicije. Saveti strucnjaka i aktuelne ponude na trzistu.
https://t.me/s/Official_1xbet_1xbet/477
https://t.me/s/Official_1xbet_1xbet/1479
https://t.me/s/Official_1xbet_1xbet/1296
интернет провайдеры по адресу дома
krasnoyarsk-domashnij-internet004.ru
провайдеры в красноярске по адресу проверить
экстренный вывод из запоя
vivod-iz-zapoya-smolensk012.ru
вывод из запоя круглосуточно смоленск
https://t.me/s/Official_1xbet_1xbet/749
По окончании курса детоксикации нарколог дает пациенту и его близким подробные рекомендации, помогающие быстрее восстановить здоровье и предотвратить повторные случаи запоев.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-novosibirsk0.ru/]вывод из запоя недорого в новосибирске[/url]
plinko game online [url=www.plinko3001.ru]www.plinko3001.ru[/url]
https://t.me/s/Official_1xbet_1xbet/744
https://t.me/s/Official_1xbet_1xbet/412
https://t.me/s/Official_1xbet_1xbet/199
футбол прогнозы [url=https://www.prognozy-na-futbol-5.ru]футбол прогнозы[/url] .
прогноз футбол на сегодня [url=http://prognozy-na-futbol-6.ru]прогноз футбол на сегодня[/url] .
plinko game [url=https://plinko3002.ru]https://plinko3002.ru[/url]
https://t.me/s/Official_1xbet_1xbet/1498
Запой — это серьезная проблема, требующая квалифицированной поддержки. Вызвать нарколога на дом — это удобный способ получить необходимую медицинскую помощь. Капельница при запое помогают быстро вывести токсины из организма, обеспечивая очистку организма и возвращение к нормальному состоянию. Лечение алкоголизма включает в себя медикаментозную терапию и психологическую поддержку. Нарколог на дом проводит оценку состояния пациента и назначает индивидуальный план лечения, который может включать альтернативные методы, такие как травяные настои или психологические сеансы. Восстановление после запоя часто требует целостного подхода. Преодоление запойного состояния должно сопровождатся не только физической реабилитацией, но и психо-эмоциональным восстановлением; Реабилитация после алкоголизма, это долгий процесс, где важна помощь при запое и поддержка близких. Важно осознавать, что успешное лечение зависит от желания пациента меняться и стремления изменить свою жизнь.
интернет провайдеры по адресу дома
krasnoyarsk-domashnij-internet005.ru
провайдеры в красноярске по адресу проверить
1×win [url=www.1win22097.ru]www.1win22097.ru[/url]
плинко [url=https://plinko3002.ru/]https://plinko3002.ru/[/url]
https://t.me/s/Official_1xbet_1xbet/218
For hottest information you have to visit web and on internet I found this website as a best web site for most up-to-date updates.
https://metabo-partner.com.ua/krashcha-led-lampa-dlia-vashoi-fary
dianabol 6 week cycle
References:
https://www.generation-n.at/forums/users/appealgauge74/
ставки прогнозы [url=http://stavki-prognozy-1.ru/]http://stavki-prognozy-1.ru/[/url] .
Besoin d’un bien immobilier? https://www.immobilier-au-montenegro.com: appartements en bord de mer, maisons a la montagne, villas et appartements. Catalogue de biens, prix actuels et conseils d’experts en investissement.
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Подробнее – [url=https://vyvod-iz-zapoya-chelyabinsk13.ru/]нарколог вывод из запоя в челябинске[/url]
горшок с автополивом [url=https://kashpo-s-avtopolivom-spb.ru]горшок с автополивом[/url] .
Обращение к наркологу анонимно — это значимый этап на пути к лечению зависимости. На сайте vivod-iz-zapoya-krasnoyarsk008.ru вы можете заказать профессиональной помощью специалистов в области наркологиине опасаясь за свою безопасность. Встреча с врачом поможет уточнить оптимальные варианты терапии. Лечение без раскрытия личности и программы восстановления для зависимых включают психологическое сопровождение при зависимостичто значительно повышает шансы на успех. Также доступны медицинские услуги для пациентов с зависимостями и телефон доверия для консультаций. Предотвращение наркомании и участие в анонимных группах поддержки являются ключевыми аспектами в социальной реабилитации и адаптации к обществу.
Фильмы и сериалы https://kinobay.live Онлайн-кинотеатр без регистрации и смс: тысячи фильмов и сериалов бесплатно.
Jak samodzielnie zdjac https://telegra.ph/Jak-samodzielnie-zdj%C4%85%C4%87-sufit-napinany-instrukcja-krok-po-kroku-bez-haka-z-wkr%C4%99tem-i-trikami-monta%C5%BCyst%C3%B3w-08-07 sufit napinany: instrukcje krok po kroku, narzedzia, porady ekspertow. Dowiedz sie, jak zdemontowac plotno bez uszkodzen i przygotowac pomieszczenie do montazu nowej okladziny.
интернет провайдеры по адресу дома
krasnoyarsk-domashnij-internet006.ru
провайдеры интернета в красноярске по адресу проверить
win букмекерская контора [url=https://1win22097.ru/]https://1win22097.ru/[/url]
plinko game online [url=plinko3001.ru]plinko game online[/url]
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Разобраться лучше – https://balance.cat/hola-mundo
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Только для своих – https://nanake555.com/the-rube-foe-%E0%B9%84%E0%B8%A1%E0%B9%88%E0%B9%83%E0%B8%8A%E0%B9%88%E0%B8%9E%E0%B8%A3%E0%B8%B0%E0%B9%80%E0%B8%AD%E0%B8%81-tonights-the-night-%E0%B8%84%E0%B8%B7%E0%B8%99%E0%B8%AA%E0%B8%B3%E0%B8%84
Мы готовы предложить документы университетов, расположенных в любом регионе Российской Федерации. Приобрести диплом о высшем образовании:
[url=http://rlimports.com.br/kupit-diplom-s-zaneseniem-v-reestr-52/]где купить аттестат за 11 класс отзывы[/url]
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Изучить вопрос глубже – http://airwheelchairs.com/2021/04/11/what-is-great-about-the-airwheel-h3pc-automatic-folding-wheelchair
мелбет рабочее зеркало [url=https://melbet3006.com/]https://melbet3006.com/[/url]
купить аттестат за 11 классов 2015 года [url=http://www.arus-diplom24.ru]купить аттестат за 11 классов 2015 года[/url] .
black sprout
ОТКАПЫВАНИЕ НА ДОМУ: Рекомендации Подготовка участка для благоустройства – это ключевой этап домашнего проекта. Откапывание‚ или откапывание‚ включает в себя множество задач‚ таких как копка ямы для фундамента‚ дренажные системы и водопроводные работы. Правильный выбор инструментов для копки и аренда оборудования помогут упростить процессы. Работы по благоустройству сада требуют внимательного планирования. Уход за участком‚ особенно в периодические работы в саду‚ поможет сохранить привлекательность ландшафта. Не забудьте учесть ландшафтный дизайн‚ который может включать в себя элементы‚ требующие откапывания. Обратите внимание на советы по копке: подбирайте подходящие инструменты‚ следите за безопасностью и учитывайте особенности почвы. Профессиональные земельные услуги могут помочь с профессиональным выполнением работ. Заходите на vivod-iz-zapoya-krasnoyarsk009.ru для получения дополнительной информации и услуг.
как купить аттестат за 11 [url=http://www.arus-diplom23.ru]как купить аттестат за 11[/url] .
оценка ооо для продажи https://ocenochnaya-kompaniya1.ru
салон красоты спб https://beauty-salon-spb.ru/
интернет по адресу
krasnodar-domashnij-internet004.ru
проверить интернет по адресу
диплом с проведением купить [url=http://www.arus-diplom35.ru]диплом с проведением купить[/url] .
купить диплом с занесением в реестр в нижнем тагиле [url=http://www.arus-diplom34.ru]купить диплом с занесением в реестр в нижнем тагиле[/url] .
купить диплом с занесением в реестр в красноярске [url=www.arus-diplom33.ru/]www.arus-diplom33.ru/[/url] .
Добрый день!
Наконец-то адекватная статья на тему срочных денег. [url=https://economica-2025.ru/]Срочный займ на карту без отказа с плохой кредитной историей[/url] Сохранил в закладки.
Переходи: – https://economica-2025.ru/
Срочный займ на карту без отказа с плохой кредитной историей
Где взять займ если везде отказывают
Займ на карту без отказа без проверки мгновенно
Будь здоров!
Нужен микрозайм? лучшие займы онлайн на карту: деньги на карту без справок и поручителей. Простое оформление заявки, одобрение за минуты и мгновенное зачисление. Удобно и доступно 24/7.
прогнозы на спорт онлайн [url=www.prognozy-na-sport-8.ru]www.prognozy-na-sport-8.ru[/url] .
купить аттестат 11 классов тюмень [url=www.arus-diplom22.ru/]www.arus-diplom22.ru/[/url] .
экстренный вывод из запоя
vivod-iz-zapoya-smolensk010.ru
вывод из запоя
melbet app download for pc [url=http://melbet3006.com]http://melbet3006.com[/url]
прогнозы на хоккей сегодня [url=https://prognozy-na-khokkej.ru/]прогнозы на хоккей сегодня[/url] .
трансформаторные будки [url=www.transformatornye-podstancii-kupit1.ru/]www.transformatornye-podstancii-kupit1.ru/[/url] .
блочная трансформаторная подстанция [url=http://transformatornye-podstancii-kupit2.ru]блочная трансформаторная подстанция[/url] .
plinko slot [url=https://plinko-kz2.ru/]https://plinko-kz2.ru/[/url]
Thanks a bunch for sharing this with all folks you actually realize what you’re speaking approximately! Bookmarked. Please also visit my website =). We may have a link exchange agreement among us
Best limo service near me
распределительная трансформаторная подстанция [url=http://transformatornye-podstancii-kupit.ru/]http://transformatornye-podstancii-kupit.ru/[/url] .
принудительное лечение в психиатрическом стационаре
psychiatr-moskva001.ru
круглосуточная психиатрическая помощь
вызов психиатрической помощи
psychiatr-moskva001.ru
стационар психиатрической больницы
zonguldak escort Turkiye’nin Dogal Guzellikleri Turkiye, sadece tarihi ve kulturel zenginlikleriyle degil, ayn? zamanda dogal guzellikleriyle de buyuleyici bir ulkedir. Ege ve Akdeniz K?y?lar?: Turkuaz renkli denizi, alt?n sar?s? kumsallar? ve yemyesil dogas?yla Ege ve Akdeniz k?y?lar?, tatilcilerin gozde mekanlar?d?r. Kapadokya: Volkanik kaya olusumlar?, peri bacalar? ve yer alt? sehirleriyle Kapadokya, dunyaca unlu bir turizm merkezidir. Pamukkale: Beyaz travertenleri ve termal sular?yla Pamukkale, hem dogal guzelligi hem de sifal? sular?yla ziyaretcilerini cezbeder. Karadeniz: Yemyesil ormanlar?, daglar?, yaylalar? ve selaleleriyle Karadeniz, doga severler icin bir cennettir. Turkiye’nin dort bir yan?nda, daglar, goller, nehirler, ormanlar ve milli parklar gibi say?s?z dogal guzellik bulunmaktad?r. Bu guzellikler, Turkiye’yi doga turizmi icin ideal bir destinasyon haline getirir.
plinko kz [url=http://plinko-kz2.ru/]http://plinko-kz2.ru/[/url]
экстренный вывод из запоя смоленск
vivod-iz-zapoya-smolensk011.ru
экстренный вывод из запоя
https://www.med2.ru/story.php?id=147094
В нашем центре доступны следующие виды помощи:
Подробнее тут – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-omske.ru/]скорая вывод из запоя в омске[/url]
купить диплом с занесением в реестр в иркутске [url=http://arus-diplom32.ru/]купить диплом с занесением в реестр в иркутске[/url] .
купить диплом о среднем специальном [url=http://educ-ua3.ru]купить диплом о среднем специальном[/url] .
консультация психиатра по телефону
psychiatr-moskva002.ru
детский психиатр на дом в москве
СтавкиПрогнозы [url=https://stavki-prognozy-2.ru/]https://stavki-prognozy-2.ru/[/url] .
ремонт канал Ремонт квартир Москва – это услуги профессиональных строительных компаний по ремонту квартир в Москве.
высокоточные прогнозы на спорт [url=http://www.prognozy-na-sport-7.ru]http://www.prognozy-na-sport-7.ru[/url] .
лечение запоя смоленск
vivod-iz-zapoya-smolensk012.ru
вывод из запоя круглосуточно смоленск
Кодирование подходит не только для тех, кто страдает тяжёлой зависимостью с частыми рецидивами, но и для тех, кто хочет закрепить результат длительной ремиссии, повысить личную мотивацию, снизить риск срыва и облегчить адаптацию к жизни без спиртного. Решение о выборе методики принимается только после осмотра врача и сбора полного анамнеза.
Подробнее можно узнать тут – [url=https://kodirovanie-ot-alkogolizma-dolgoprudnyj6.ru/]медикаментозное кодирование от алкоголизма[/url]
Основными направлениями работы нашей клиники являются.
Углубиться в тему – http://нарко-специалист.рф/vivod-iz-zapoya-v-kruglosutochno-v-Ekaterinburge/
Всех приветствую! Хотите узнать больше о продвижении? Тут вы можете ознакомиться с ответом на вопрос: https://www.amvitec.com/2025/04/01/die-grossen-gewinne-des-book-of-ra-slots-in-online-casinos-deutschlands/
диплом купить с занесением в реестр рязань [url=https://www.arus-diplom31.ru]https://www.arus-diplom31.ru[/url] .
купить диплом с проводкой меня [url=http://www.arus-diplom34.ru]купить диплом с проводкой меня[/url] .
психиатрическая помощь на дому
psychiatr-moskva002.ru
госпитализация в психиатрический стационар
купить диплом бакалавра дешево [url=http://educ-ua2.ru/]купить диплом бакалавра дешево[/url] .
купить аттестат за 11 класс красноярск [url=https://www.arus-diplom22.ru]https://www.arus-diplom22.ru[/url] .
Заказать диплом любого университета!
Мы можем предложить дипломы психологов, юристов, экономистов и любых других профессий по выгодным ценам— [url=http://alldirs.ru/]alldirs.ru[/url]
купить диплом без внесения в реестр [url=http://womans-days.ru/user/vadyymemelnvv]купить диплом без внесения в реестр[/url] .
купить дубликат аттестата за 11 класс [url=www.arus-diplom21.ru]www.arus-diplom21.ru[/url] .
купить официальный диплом с занесением в реестр [url=https://arus-diplom35.ru/]купить официальный диплом с занесением в реестр[/url] .
купить аттестат за 11 классов в омске [url=http://arus-diplom21.ru/]купить аттестат за 11 классов в омске[/url] .
Заказать диплом под заказ в столице возможно через официальный сайт компании. [url=http://hl2forever.ru/member.php?u=266/]hl2forever.ru/member.php?u=266[/url]
Откройте для себя мир азартных игр на [url=https://888starz2.ru]зеркало 888starz россия[/url].
где любители азартных игр могут найти множество развлечений. Платформа включает в себя как слоты, так и настольные игры, чтобы удовлетворить запросы всех игроков.
888starz предлагает удобный интерфейс, что делает игру более комфортной. Пользователи могут быстро находить необходимые игры и информацию на сайте.
Пользователи могут быстро зарегистрироваться и начать игру. В качестве первого шага потребуется указать основные данные и пройти верификацию.
Игроки могут воспользоваться различными предложениями и акциями, которые делают игру еще более увлекательной. Акции и бонусы создают дополнительные возможности для выигрыша, увеличивая интерес к играм.
купить диплом о образовании в киеве [url=https://www.educ-ua1.ru]купить диплом о образовании в киеве[/url] .
купить диплом с занесением в реестр новосибирск [url=arus-diplom32.ru]купить диплом с занесением в реестр новосибирск[/url] .
В «АльтерМед» используются самые актуальные технологии, прошедшие проверку временем и доказавшие эффективность в тысячах клинических случаев. Выбор методики зависит от тяжести зависимости, состояния здоровья, наличия хронических заболеваний, прошлых попыток лечения и психологической мотивации пациента.
Детальнее – [url=https://kodirovanie-ot-alkogolizma-dolgoprudnyj6.ru/]анонимное кодирование от алкоголизма[/url]
Всех приветствую! Хотите узнать больше о продвижении? Тут вы можете ознакомиться с ответом на вопрос: https://zh-cn.shenyundevilgroup.org/?p=1753
купить диплом с занесением в реестр барнаул [url=https://www.arus-diplom33.ru]купить диплом с занесением в реестр барнаул[/url] .
получить консультацию психиатра
psychiatr-moskva003.ru
круглосуточная психиатрическая помощь
стп столбовая трансформаторная подстанция [url=http://transformatornye-podstancii-kupit2.ru/]http://transformatornye-podstancii-kupit2.ru/[/url] .
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Ознакомьтесь с аналитикой – https://www.bvvaul.ru/forum/viewtopic.php?t=1095&postdays=0&postorder=asc&start=0
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Все материалы собраны здесь – https://redcrosstrainingcentre.org/2013/10/04/a-look-inside-the-protein-bar
купить диплом в одессе [url=www.educ-ua4.ru/]купить диплом в одессе[/url] .
ставки прогнозы [url=www.stavki-prognozy-one.ru/]www.stavki-prognozy-one.ru/[/url] .
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Провести детальное исследование – http://atharproject.org/ixlibrb-0-3-5q80fmjpgcropentropycstinysrgbw150h150fitcrops6688c93adfd11a20e7453d0947c024f0
I can’t go into details, but I have to say its a good article!
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Доступ к полной версии – https://otpservicios.cl/2023/05/21/a-home-away-from-home-our-care-homes-warm-and-welcoming-atmosphere
Really enjoying this article! The playful vibe reminds me of exploring new online casinos – like SS777, with its easy GCash deposits and fun animal themes! Check out the ss777 app casino for a vibrant gaming experience – it’s a jungle out there! 😉
платная психиатрическая скорая помощь
psychiatr-moskva003.ru
оказание психиатрической помощи
Авто помощь 24/7 техпомощь на дороге недорого: устранение поломок, подвоз топлива, прикуривание аккумулятора, замена колеса и эвакуация автомобиля.
частный психиатр на дом в москве
psikhiatr-moskva001.ru
детский психиатр на дом в москве
хоккей прогноз [url=www.prognozy-na-khokkej1.ru]хоккей прогноз[/url] .
Услуга
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod000.ru/]капельница от запоя нижний новгород.[/url]
Когда организм на пределе, важна срочная помощь в Челябинске — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Детальнее – [url=https://vyvod-iz-zapoya-chelyabinsk12.ru/]нарколог на дом вывод из запоя челябинск[/url]
Миссия клиники заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемой зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша задача — не только помочь избавиться от пагубного пристрастия, но и обеспечить успешную реадаптацию пациентов в обществе.
Подробнее тут – [url=https://narco-vivod.ru/]вывод из запоя цена краснодар.[/url]
узи сканер купить [url=www.kupit-uzi-apparat26.ru]узи сканер купить[/url] .
аппарат для узи цена [url=www.kupit-uzi-apparat27.ru/]аппарат для узи цена[/url] .
эскорт алматы Эскорт в Алматы – это мир соблазна и роскоши, где каждый может найти воплощение своих самых смелых фантазий. Здесь царит атмосфера чувственности и раскрепощенности, где нет места скуке и обыденности. Девушки из эскорта Алматы – это настоящие королевы ночи, обладающие не только безупречной внешностью, но и умением поддержать любую беседу. Они готовы стать вашими спутницами на светских мероприятиях, романтических ужинах или просто разделить с вами приятный вечер. Минет в Алматы – это искусство, доведенное до совершенства. Страстные и опытные девушки подарят вам незабываемые ощущения, раскрыв все грани оральных ласк. Проститутки Алматы – это разнообразие типажей и предпочтений. Здесь вы найдете и юных студенток, и зрелых женщин, готовых воплотить любые ваши желания. Алматы эскорт – это не просто сопровождение, это возможность окунуться в мир удовольствия и наслаждения, где все ваши мечты становятся реальностью. VIP эскорт – это выбор для тех, кто ценит безупречный сервис и эксклюзивность. Эскорд Алматы – это ваш пропуск в мир роскоши и чувственных удовольствий.
Nice post. I learn something totally new and challenging on blogs I stumbleupon on a daily basis. It’s always interesting to read articles from other authors and practice something from other sites.
кэт казино зеркало
трансформаторная подстанция ктп [url=http://transformatornye-podstancii-kupit.ru]http://transformatornye-podstancii-kupit.ru[/url] .
Как сам!
[url=https://pro-telefony.ru/]Что значит серый телефон?[/url] “Серый” импорт и параллельный импорт — это одно и то же?
Здесь подробней: – https://pro-telefony.ru/
Что значит серый телефон
До встречи!
Hey there I am so happy I found your blog page, I really found you by error, while I was looking on Askjeeve for something else, Anyhow I am here now and would just like to say kudos for a marvelous post and a all round thrilling blog (I also love the theme/design), I don’t have time to go through it all at the moment but I have bookmarked it and also added in your RSS feeds, so when I have time I will be back to read more, Please do keep up the great job.
официальный сайт банда казино
купить аттестаты за 11 отзывы [url=http://arus-diplom22.ru]купить аттестаты за 11 отзывы[/url] .
http://www.rosmed.ru/annonce/show/3892/Kak_podgotovitsya_k_pervomu_vizitu_v_stomatologicheskuyu_kliniku
Срочно нужны цветы Минск Свежие букеты, праздничные композиции и эксклюзивные флористические решения. Онлайн-заказ и быстрая доставка по городу.
Профессиональные детейлинг студия: полировка кузова, химчистка салона, восстановление пластика и защита керамикой. Вернём автомобилю блеск и надёжную защиту.
В Санкт-Петербурге решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Узнать больше – [url=https://vyvod-iz-zapoya-v-sankt-peterburge17.ru/]вывод из запоя на дому недорого санкт-петербург[/url]
Всех приветствую! Хотите узнать больше о продвижении? Тут вы можете ознакомиться с ответом на вопрос: https://salubrite.gouv.ci/faq/assainissement-faq/y-a-t-il-une-frequence-obligatoire-pour-vidanger-mon-systeme-dassainissement-non-collectif/
hgh vs testosterone for muscle
References:
https://ishorturl.com/christeneichho
принудительное психиатрическое лечение
psikhiatr-moskva002.ru
консультация врача психиатра онлайн
за сколько можно купить аттестат 11 класса [url=https://www.arus-diplom23.ru]за сколько можно купить аттестат 11 класса[/url] .
Нужен массаж? https://doctu.ru – профессиональные мастера, широкий выбор техник: классический, оздоровительный, лимфодренажный, детский. Доступные цены и уютная атмосфера.
Обучающие курсы онлайн складчина мк новые навыки для работы и жизни. IT, дизайн, менеджмент, языки, маркетинг. Гибкий график, практика и сертификаты по итогам.
комплектные трансформаторные подстанции наружные [url=http://transformatornye-podstancii-kupit1.ru]http://transformatornye-podstancii-kupit1.ru[/url] .
vps hosting in europe vps hosting
купить диплом о среднем техническом образовании [url=https://www.educ-ua5.ru]купить диплом о среднем техническом образовании[/url] .
купить диплом с занесением в реестр оренбург [url=www.arus-diplom35.ru/]купить диплом с занесением в реестр оренбург[/url] .
купить диплом с реестром в москве [url=http://www.arus-diplom34.ru]купить диплом с реестром в москве[/url] .
купить диплом о высшем образовании с занесением в реестр в кемерово [url=http://www.arus-diplom33.ru]купить диплом о высшем образовании с занесением в реестр в кемерово[/url] .
аттестат 11 класс купить 2014 [url=www.arus-diplom24.ru/]аттестат 11 класс купить 2014[/url] .
ставки на хоккей на сегодня [url=https://prognozy-na-khokkej.ru/]https://prognozy-na-khokkej.ru/[/url] .
купить аттестат за 11 класс 2009 [url=http://arus-diplom23.ru]купить аттестат за 11 класс 2009[/url] .
психиатр онлайн консультация
psikhiatr-moskva003.ru
психиатрическая медицинская помощь
косметологический столик лампа лупа косметологическая купить
По прибытии проводится экспресс-диагностика: измеряются артериальное давление, пульс, сатурация, температура, оценивается уровень обезвоживания и неврологический статус; при показаниях выполняется ЭКГ. Врач простым языком объясняет, какие препараты и в каком порядке будут вводиться, отвечает на вопросы и получает информированное согласие.
Выяснить больше – https://narkolog-na-dom-serpuhov6.ru/narkolog-na-dom-kruglosutochnom-v-serpuhove/
Алкоголизм — это заболевание, которое разрушает не только физическое здоровье, но и личность человека, отношения в семье, профессиональную и социальную жизнь. На определённом этапе стандартные методы поддержки оказываются недостаточными, и именно тогда встает вопрос о профессиональном вмешательстве. В наркологической клинике «Трезвая Линия» в Коломне кодирование стало одним из наиболее востребованных и эффективных решений для закрепления трезвости, создания дополнительной мотивации и защиты от рецидивов. Процедура проводится строго индивидуально, с учётом медицинских показаний, психоэмоционального состояния пациента и длительности зависимости.
Получить дополнительную информацию – [url=https://kodirovanie-ot-alkogolizma-kolomna6.ru/]кодирование от алкоголизма[/url]
Этап вывода из запоя
Узнать больше – https://vyvod-iz-zapoya-shchelkovo6.ru/vyvod-iz-zapoya-nedorogo-v-shchelkovo
купить диплом с занесением в реестр тюмень [url=arus-diplom34.ru]купить диплом с занесением в реестр тюмень[/url] .
Когда организм на пределе, важна срочная помощь в Санкт-Петербурге — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Углубиться в тему – [url=https://vyvod-iz-zapoya-v-sankt-peterburge11.ru/]sankt-peterburg[/url]
купить аттестат за 11 классов в украине [url=https://arus-diplom24.ru]купить аттестат за 11 классов в украине[/url] .
легально купить диплом [url=http://arus-diplom31.ru/]легально купить диплом[/url] .
Здравствуйте!
Долго анализировал как поднять сайт и свои проекты и нарастить DR и узнал от друзей профессионалов,
крутых ребят, именно они разработали недорогой и главное буст прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг для продвижения в топ-10 требует качественных ссылок. Форумы, блоги и каталоги повышают авторитет сайта. Xrumer автоматизирует процесс прогона ссылок. Чем больше качественных ссылок, тем выше DR. Линкбилдинг для продвижения в топ-10 – ключ к успешному SEO.
молодой сайт раскрутка, screaming frog seo spider скачать с ключом, Как увеличить DR сайта
Xrumer для SEO продвижения, самостоятельная раскрутка сайта бесплатно, новое seo
!!Удачи и роста в топах!!
консультация психиатра по телефону
psikhiatr-moskva002.ru
частная психиатрическая клиника стационар
Привет всем!
Долго анализировал как поднять сайт и свои проекты и нарастить TF trust flow и узнал от крутых seo,
профи ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг линкбилдинг сайта ускоряет продвижение. Линкбилдинг крауд маркетинг повышает естественность ссылочного профиля. Линкбилдинг форум помогает находить новые ресурсы. Линкбилдинг с чего начать узнают новички. Линкбилдинг отзывы показывают эффективность методов.
продвижение сайта в москве каланчевская, поисковое продвижение сайта продвижение и оптимизация сайта, SEO-прогон для повышения позиций
Линкбилдинг через автоматические проги, скрипт seo, плагин all in seo
!!Удачи и роста в топах!!
Привет всем!
Долго обмозговывал как поднять сайт и свои проекты и нарастить TF trust flow и узнал от гуру в seo,
отличных ребят, именно они разработали недорогой и главное продуктивный прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Прогон ссылок Хрумером помогает улучшить SEO-позиции за счёт увеличения ссылочной массы. Автоматизация с Xrumer позволяет создать ссылки быстро и эффективно. Увеличение DR и Ahrefs возможно при использовании этого инструмента. Форумный линкбилдинг с Xrumer дает стабильный рост. Используйте Xrumer для достижения высоких позиций в поисковиках.
концепция продвижения сайта, seo воронка, Использование Xrumer в 2025
Прогон по базам форумов, битрикс сео настройки, продвижение сайта стоимость сео фьючер
!!Удачи и роста в топах!!
Процедура вывода из запоя проводится опытными наркологами с применением современных протоколов и сертифицированных препаратов. Процесс включает несколько ключевых этапов:
Подробнее – [url=https://vyvod-iz-zapoya-odincovo6.ru/]srochnyj-vyvod-iz-zapoya[/url]
Привет всем!
Долго ломал голову как поднять сайт и свои проекты и нарастить DR и узнал от гуру в seo,
энтузиастов ребят, именно они разработали недорогой и главное top прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Автоматический прогон статей облегчает линкбилдинг. Использование Xrumer в 2025 актуально для SEO. Линкбилдинг для повышения DR требует регулярного подхода. SEO рассылки форумов ускоряют рост авторитетности сайта. Xrumer: практические примеры помогают новичкам освоить программу.
сайты seo бизнес, приложение для seo, Программное обеспечение для постинга
Увеличение показателя Ahrefs, seo топ 10, заказать продвижение сайта в москве в топ
!!Удачи и роста в топах!!
лечение и реабилитация алкоголизма
reabilitaciya-astana001.ru
лечение от наркотиков
https://t.me/s/Magik_7k
мостбет уз кириш [url=http://mostbet4103.ru/]http://mostbet4103.ru/[/url]
Мы готовы предложить документы институтов, которые находятся в любом регионе России. Заказать диплом любого ВУЗа:
[url=http://petycjeonline.com/492274/]аттестат 11 класс купить уфа[/url]
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Обратитесь за информацией – https://rajkajexpress.com/2024/03/30/defense-needed-to-save-democracy
mostbet telefon raqami [url=www.mostbet4104.ru]mostbet telefon raqami[/url]
виза в китай сайт Оформить визу в Китай в Новосибирске можно, обратившись в специализированный визовый центр или консульство.
умный горшок для растений [url=http://kashpo-s-avtopolivom-spb.ru/]умный горшок для растений[/url] .
ставки на спорт бишкек [url=https://mostbet4148.ru]ставки на спорт бишкек[/url]
Всех приветствую! Хотите узнать больше о продвижении? Узнайте все нюансы на тему – https://seekyourepic.com/full-time-travel-to-disney-world-during-covid-19/
свидетельство о разводе купить недорого [url=http://www.educ-ua4.ru]http://www.educ-ua4.ru[/url] .
алкоголизм лечение
reabilitaciya-astana002.ru
курс реабилитации наркозависимых в Астане
Привет всем!
Долго обмозговывал как поднять сайт и свои проекты и нарастить DR и узнал от друзей профессионалов,
энтузиастов ребят, именно они разработали недорогой и главное продуктивный прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг линкбилдинг сайта ускоряет продвижение. Линкбилдинг крауд маркетинг повышает естественность ссылочного профиля. Линкбилдинг форум помогает находить новые ресурсы. Линкбилдинг с чего начать узнают новички. Линкбилдинг отзывы показывают эффективность методов.
москва поисковая раскрутка сайта, создание продвижение дизайн сайта, компания линкбилдинг
линкбилдинг план, закрытый сео, сео магнита
!!Удачи и роста в топах!!
mostbet sayt [url=www.mostbet4105.ru]www.mostbet4105.ru[/url]
мостбет уз [url=mostbet4102.ru]mostbet4102.ru[/url]
Получить диплом университета поможем. Купить диплом магистра в Нижнем Тагиле – [url=http://diplomybox.com/kupit-diplom-magistra-v-nizhnem-tagile/]diplomybox.com/kupit-diplom-magistra-v-nizhnem-tagile[/url]
Всех приветствую! Хотите узнать больше о продвижении? Тут вы можете ознакомиться с ответом на вопрос: https://patriot.hr/2025/04/03/hello-world/
mostbet скачать на телефон [url=mostbet4150.ru]mostbet4150.ru[/url]
мостбет официальный [url=http://mostbet4147.ru]мостбет официальный[/url]
поручни из нержавеющей стали Ограждения из нержавеющей стали – это современное и стильное решение для балконов, террас и лестниц. Они отличаются высокой прочностью, долговечностью и привлекательным внешним видом.
букмекерская контора мостбет [url=mostbet4148.ru]mostbet4148.ru[/url]
ставки на хоккей прогнозы [url=http://prognozy-na-khokkej1.ru/]ставки на хоккей прогнозы[/url] .
mostbet virtual sport uz [url=mostbet4104.ru]mostbet virtual sport uz[/url]
Наркологическая клиника “Маяк надежды” расположена по адресу: г. Санкт-Петербург, ул. Колпинская, д. 27. Клиника работает ежедневно с 9:00 до 21:00, без выходных. Наши специалисты готовы предоставить консультацию и ответить на все вопросы, связанные с лечением зависимостей. Мы гарантируем конфиденциальность и индивидуальный подход к каждому пациенту.
Изучить вопрос глубже – https://алко-лечение24.рф/vivod-iz-zapoya-anonimno-v-Sankt-Peterburge
где купить аттестат за 11 класс иркутск [url=http://arus-diplom9.ru]где купить аттестат за 11 класс иркутск[/url] .
купить аттестат за 11 класс отзывы [url=http://arus-diplom22.ru]купить аттестат за 11 класс отзывы[/url] .
Добрый день!
Долго не мог уяснить как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от крутых seo,
крутых ребят, именно они разработали недорогой и главное top прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг для начинающих требует базовых знаний и инструментов. Xrumer автоматизирует размещение ссылок. Массовый прогон ускоряет рост DR. Чем больше качественных ссылок, тем выше позиции. Линкбилдинг для начинающих – первый шаг к успешному SEO.
seo блоги что, продвижение сайтов оптимизация сайтов создание, линкбилдинг что это простыми словами
Программы для автоматического постинга, раскрутка бесплатных сайтов, метод seo оптимизации
!!Удачи и роста в топах!!
mostbet com android [url=https://mostbet4147.ru/]https://mostbet4147.ru/[/url]
mostbet mobile uz registratsiya [url=www.mostbet4103.ru]www.mostbet4103.ru[/url]
Мы изготавливаем дипломы любых профессий по выгодным ценам. Купить диплом геолога — [url=http://kyc-diplom.com/diplomy-po-professii/kupit-diplom-geologa.html/]kyc-diplom.com/diplomy-po-professii/kupit-diplom-geologa.html[/url]
В нашем центре ведут приём врачи-наркологи высшей категории, обладающие многолетним опытом лечения различных видов зависимостей. Они владеют всеми современными методиками детоксикации, купирования абстинентного синдрома, кодирования, фармакотерапии.
Ознакомиться с деталями – [url=https://alko-reabcentr.ru/]вывод из запоя на дому санкт-петербург.[/url]
лечение от зависимости наркотиков
reabilitaciya-astana003.ru
реабилитационный центр для наркоманов
Как сам!
Не дай себя обмануть в аптеке. [url=https://generik-info.ru/chto-takoe-dzheneriki-prostymi-slovami/]Дженерики для чего они нужны[/url]
Написал: – https://generik-info.ru/chto-takoe-dzheneriki-prostymi-slovami/
Дженерики это простыми словами
Дженерики что это
Дженерики что это такое
Пока!
аттестаты 11 класса купить [url=arus-diplom22.ru]аттестаты 11 класса купить[/url] .
Один из важных принципов работы клиники — оперативность. В «РеабилитейшнПро» организована служба круглосуточного выезда: при необходимости врач-нарколог приезжает на дом в любой район Домодедово, чтобы оказать помощь пациенту на месте. Это особенно важно при острых состояниях, когда промедление может привести к осложнениям или создать угрозу для жизни.
Детальнее – [url=https://narkologicheskaya-pomoshch-domodedovo6.ru/]skoraya-narkologicheskaya-pomoshch-domodedovo[/url]
аттестат 11 класса купить цена [url=http://www.arus-diplom25.ru]аттестат 11 класса купить цена[/url] .
сколько стоит аппарат узи цена [url=https://kupit-uzi-apparat27.ru]сколько стоит аппарат узи цена[/url] .
аттестат за 11 классов купить в кемерово [url=www.arus-diplom23.ru/]аттестат за 11 классов купить в кемерово[/url] .
скачать mostbet kg [url=https://mostbet4150.ru/]https://mostbet4150.ru/[/url]
Современное общество страдает от зависимостей. Мы лечим комплексно, разрабатывая индивидуальный план для каждого пациента. Избавление от зависимости требует времени, усилий и профессиональной помощи. Наша миссия – предоставить квалифицированную помощь и безопасное место для лечения. Мы хотим вернуть вас к полноценной жизни, свободной от зависимостей. Мы начинаем с глубокой диагностики, чтобы разработать лучший план для вас. Мы используем и лекарства, и психотерапию для достижения наилучшего результата.
Получить дополнительные сведения – [url=https://zavisim-alko.ru/]вывод из запоя цены на дому краснодар[/url]
аппарат для узи цена [url=https://www.kupit-uzi-apparat26.ru]https://www.kupit-uzi-apparat26.ru[/url] .
где купить аттестат о среднем образовании [url=www.educ-ua5.ru]где купить аттестат о среднем образовании[/url] .
в якутске купить аттестат за 11 [url=http://arus-diplom24.ru/]в якутске купить аттестат за 11[/url] .
most bet skachat [url=www.mostbet4149.ru]www.mostbet4149.ru[/url]
Проблемы зависимости – актуальная проблема, разрушающая жизнь. Наш подход – комплексное лечение для успешного результата. Борьба с зависимостью – это долгий путь, требующий медицинской и психологической поддержки. “Перезагрузка” стремится предоставить безопасное пространство, где каждый сможет получить поддержку. Наша цель – не просто избавить от зависимости, а восстановить полноценную жизнь. Комплексная диагностика позволяет создать индивидуальные планы лечения. План лечения включает медикаменты для детоксикации и психотерапию для изменения мышления.
Детальнее – [url=https://zavisim-alko.ru/]клиника вывод из запоя краснодар[/url]
легальный диплом купить [url=http://www.arus-diplom35.ru]легальный диплом купить[/url] .
https://www.med2.ru/story.php?id=147093
купить школьный аттестат за 11 класс [url=arus-diplom23.ru]купить школьный аттестат за 11 класс[/url] .
mostbet uz kirish [url=mostbet4105.ru]mostbet4105.ru[/url]
купить перила Поручни для лестниц – это разнообразие форм и материалов, позволяющее подобрать оптимальный вариант для любого интерьера.
купить диплом колледжа с занесением в реестр в [url=arus-diplom34.ru]купить диплом колледжа с занесением в реестр в[/url] .
купить аттестат за 11 классов 2016 [url=https://www.arus-diplom24.ru]купить аттестат за 11 классов 2016[/url] .
стоимость куба бетона заказать бетон
Здравствуйте!
Долго не спал и думал как поднять сайт и свои проекты и нарастить DR и узнал от гуру в seo,
топовых ребят, именно они разработали недорогой и главное продуктивный прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Прогон ссылок через Xrumer помогает значительно улучшить DR и Ahrefs вашего сайта. Автоматические рассылки на форумах ускоряют процесс линкбилдинга. Массовое увеличение ссылочной массы помогает добиться лучших позиций в поисковых системах. Программы для линкбилдинга, такие как Xrumer, делают этот процесс удобным и эффективным. Используйте Xrumer для роста SEO-показателей.
создание поддержка раскрутка сайтов, топ сео компаний топ сайт, Прогон по базам форумов
линкбилдинг или, seo оптимизация сайта цена, seo в барнауле
!!Удачи и роста в топах!!
Всех приветствую! Хотите узнать больше о продвижении? Подробная информация на тему: https://figueiredoepinheiroadvogados.com/embreve/
Алкоголизм, наркомания, игромания – это разрушительные состояния. Обратитесь в “Перезагрузку” за помощью. Только комплексный подход и индивидуальный план помогут вам избавиться от зависимости. Мы понимаем, что это нелегкий путь, и будем рядом с вами. Наша цель – помочь вам почувствовать себя в безопасности и получить необходимую поддержку. Наша цель – полное восстановление, а не только избавление от зависимости. Понимание причин зависимости – ключ к индивидуальному лечению. Детоксикация и психотерапия – основа нашего лечения.
Углубиться в тему – [url=https://zavisim-alko.ru/]вывод из запоя на дому в краснодаре[/url]
Lottery number patterns are fascinating, but truly random events are…well, random! Seeing platforms like ppgaming prioritize secure, regulated play is a good sign for responsible gaming. Account verification steps seem thorough too – important for peace of mind! 🤔
Круглосуточная выездная служба клиники «Медлайн Надежда» — это возможность получить профессиональную наркологическую помощь дома, без поездок и без огласки. Мы работаем по всему Красногорску и ближайшим локациям, приезжаем оперативно, соблюдаем полную конфиденциальность и не ставим на учёт. Выезд осуществляют врачи-наркологи с клиническим опытом, укомплектованные инфузионными системами, пульсоксиметром, тонометром, средствами для ЭКГ по показаниям и набором сертифицированных препаратов. Наша задача — быстро стабилизировать состояние, снять интоксикацию и тревогу, вернуть сон и предложить понятный план дальнейшей терапии.
Получить дополнительную информацию – [url=https://narkolog-na-dom-krasnogorsk6.ru/]вызов врача нарколога на дом[/url]
Откройте для себя мир азартных игр на [url=https://888starz2.ru]888starz promo code[/url].
позволяющая пользователям наслаждаться азартными играми в удобном формате. Среди доступных игр есть как популярные слоты, так и классические настольные игры.
888starz предлагает удобный интерфейс, что облегчает процесс игры. Регистрация и навигация по платформе не вызывают затруднений у игроков.
Процесс создания аккаунта на 888starz не займет много времени. После предоставления необходимой информации игроки смогут активировать свои аккаунты.
888starz радует своих игроков щедрыми бонусами и многочисленными акциями. Акции и бонусы создают дополнительные возможности для выигрыша, увеличивая интерес к играм.
трип скан Трип скан – это быстрое и удобное сканирование лучших предложений на рынке, с заботой о вашем комфорте.
Добрый день!
Долго не спал и думал как встать в топ поисковиков и узнал от крутых seo,
отличных ребят, именно они разработали недорогой и главное продуктивный прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг для интернет магазина требует особого подхода. Нужно выбирать тематические площадки и форумы. Xrumer помогает автоматизировать этот процесс. Это ускоряет рост ссылочной массы. Линкбилдинг для интернет магазина повышает продажи.
seo лучшие курсы, yandex поисковое продвижение сайта, компания линкбилдинг
seo линкбилдинг, продвижение сайта краснодар заказать, компания по продвижению сайтов в москве
!!Удачи и роста в топах!!
Таким образом, наш подход ориентирован на создание комплексной системы поддержки, позволяющей каждому пациенту справиться с проблемой зависимости и вернуться к нормальной жизни.
Выяснить больше – http://alko-specialist.ru
best steroid cycle for cutting
References:
steroids for headaches (https://git.palagov.tv/ilatiegs61736)
Наркологические услуги: наркологическая помощь, кодирование, детоксикация, снятие ломки, помощь при алкоголизме и наркомании. Круглосуточная поддержка и анонимность.
motbet [url=https://www.mostbet4149.ru]https://www.mostbet4149.ru[/url]
”Перезагрузка” – ваш шанс избавиться от зависимостей и начать новую жизнь. Лечение должно быть всесторонним и учитывать все особенности пациента. Вместе мы сможем преодолеть зависимость! Мы понимаем, как важно безопасное пространство для выздоровления. Мы стремимся к тому, чтобы вы вернулись к полноценной жизни, счастливой и здоровой. Индивидуальный план лечения начинается с диагностики. Мы помогаем вам очистить тело и изменить мышление.
Исследовать вопрос подробнее – [url=https://zavisim-alko.ru/]вывод из запоя дешево краснодар[/url]
купить аттестат за 11 класс в кемерове [url=arus-diplom25.ru]купить аттестат за 11 класс в кемерове[/url] .
https://sonturkhaber.com/
Незамедлительно после вызова нарколог прибывает на дом для проведения детального осмотра. Врач собирает анамнез, измеряет жизненно важные показатели – пульс, артериальное давление, температуру – и определяет степень интоксикации. Эти данные являются ключевыми для составления персонального плана терапии.
Подробнее можно узнать тут – [url=https://narco-vivod-clean.ru/]вывод из запоя цена ленинградская область[/url]
Во-первых, безопасная медицинская детоксикация. Этот процесс необходим для удаления токсических веществ из организма. Мы используем современные методы, минимизирующие дискомфорт в период абстиненции.
Разобраться лучше – https://алко-лечебница.рф/vivod-iz-zapoya-cena-v-samare
купить диплом пту в реестре [url=https://arus-diplom32.ru/]купить диплом пту в реестре[/url] .
Мы готовы предложить документы любых учебных заведений, расположенных на территории всей Российской Федерации. Заказать диплом любого ВУЗа:
[url=http://datasphere.ru/club/log/?b24statAction=addLogEntry/]купить аттестат за 11 класс с отличием[/url]
Привет всем!
Долго анализировал как поднять сайт и свои проекты в топ и узнал от успещных seo,
отличных ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Xrumer помогает улучшить DR сайта через автоматические прогонные кампании. Увеличение ссылочной массы с Xrumer ускоряет процесс SEO-продвижения. Программы для линкбилдинга позволяют увеличить показатели Ahrefs. Форумный линкбилдинг с Xrumer – это быстрый способ получения ссылок. Начните с Xrumer для повышения авторитета вашего сайта.
seo специалиста зарплата, помощь в продвижении сайта, Ускоренный рост ссылочного профиля
Как поднять DR сайта за неделю, правильные seo настройки, seo продвижение выгодно
!!Удачи и роста в топах!!
Здравствуйте!
Долго ломал голову как поднять сайт и свои проекты в топ и узнал от гуру в seo,
крутых ребят, именно они разработали недорогой и главное top прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг для интернет магазина требует качественных ссылок. Линкбилдинг сайт SEO ускоряет продвижение. Линкбилдинг линкбилдинг на запад открывает новые рынки. Линкбилдинг по тематике повышает релевантность. Что такое линкбилдинг становится понятно при практике.
seo поступить, сео продвижение медицинских сайтов, линкбилдинг для начинающих
Xrumer: настройка для SEO, форум seo, продвижение сайта org
!!Удачи и роста в топах!!
мостбет [url=http://mostbet4102.ru/]мостбет[/url]
Добрый день!
Долго обмозговывал как поднять сайт и свои проекты и нарастить CF cituation flow и узнал от успещных seo,
энтузиастов ребят, именно они разработали недорогой и главное продуктивный прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Прогон ссылок через Xrumer помогает вам улучшить DR и Ahrefs вашего сайта. Массовые рассылки на форумах увеличивают ссылочную массу и ускоряют линкбилдинг. Программы для линкбилдинга с Xrumer создают качественные ссылки для вашего сайта. Увеличение авторитетности сайта с помощью Xrumer даёт стабильные результаты. Попробуйте Xrumer для успешного SEO-продвижения.
статья продвижение сайта в яндексе, seo продвижение кратко, Рассылки с помощью Xrumer
линкбилдинг для англоязычного сайта, раскрутка сайта каталогах, заблокировано dr web сайты
!!Удачи и роста в топах!!
https://zdorovnik.com/vidy-kapelnicz-ispolzuemyh-pri-razlichnyh-tipah-otravlen
мостбет регистрация [url=www.mostbet4146.ru]мостбет регистрация[/url]
Здравствуйте!
Долго ломал голову как поднять сайт и свои проекты и нарастить DR и узнал от успещных seo,
топовых ребят, именно они разработали недорогой и главное продуктивный прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг пример помогает понять, как работают массовые прогоны. Xrumer автоматизирует размещение ссылок на форумах. Массовый линкбилдинг повышает DR. Чем больше качественных ссылок, тем выше позиции сайта. Линкбилдинг пример – полезный инструмент для новичков.
частота в seo, продвижение сайтов в тольятти сайт, Программное обеспечение для постинга
Генерация ссылок через Xrumer, сео поисковое продвижение и оптимизация, сео курсы яндекса
!!Удачи и роста в топах!!
Здравствуйте!
Долго ломал голову как поднять сайт и свои проекты и нарастить TF trust flow и узнал от успещных seo,
профи ребят, именно они разработали недорогой и главное лучший прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг линкбилдинг сайта ускоряет продвижение. Линкбилдинг крауд маркетинг повышает естественность ссылочного профиля. Линкбилдинг форум помогает находить новые ресурсы. Линкбилдинг с чего начать узнают новички. Линкбилдинг отзывы показывают эффективность методов.
сайт о поисковом продвижении, сео вордпресс сайта, Линкбилдинг через программы
Xrumer и рост Ahrefs DR, вода seo, yoast seo категории
!!Удачи и роста в топах!!
Алкоголь оказывает глубокое воздействие на здоровье: психоэмоциональное и физическое состояние человека значительно ухудшаются, если злоупотребление продолжается долго. Даже небольшие дозы алкоголя, употребляемые регулярно, вызывают накопление токсинов, которые приводят к расстройствам в работе сердечно-сосудистой системы, печени, почек и других жизненно важных органов.
Получить дополнительную информацию – https://алко-ребцентр.рф/
узи сканер купить москва [url=https://kupit-uzi-apparat28.ru/]узи сканер купить москва[/url] .
Запой сопровождается быстрым накоплением токсинов, нарушением обменных процессов и ухудшением работы жизненно важных органов. При длительном злоупотреблении алкоголем риск повреждения печени, почек и сердца возрастает, а состояние пациента ухудшается с каждой минутой. Срочный вывод из запоя на дому помогает предотвратить развитие хронических осложнений и сохранить здоровье, что особенно важно в условиях городской жизни.
Ознакомиться с деталями – [url=https://reabcentr-narko.ru/]нарколог вывод из запоя тверь[/url]
Здравствуйте!
Долго не спал и думал как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от успещных seo,
отличных ребят, именно они разработали недорогой и главное лучший прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг начать проще с Xrumer. Программа автоматизирует размещение ссылок на форумах и блогах. Массовый прогон ускоряет рост DR. Чем больше качественных ссылок, тем выше позиции сайта. Линкбилдинг начать – первый шаг к успешному SEO.
кейс продвижения сайтов, разработка продвижение сайта москва, Рассылки с помощью Xrumer
линкбилдинг для начинающих, как делается сео, проверка на оптимизацию seo
!!Удачи и роста в топах!!
скачать мостбет казино на андроид [url=https://www.mostbet4146.ru]скачать мостбет казино на андроид[/url]
официальное казино melbet в россии [url=www.melbetofficialsite.ru/]www.melbetofficialsite.ru/[/url] .
прогнозы на хоккей от экспертов [url=https://luchshie-prognozy-na-khokkej14.ru/]прогнозы на хоккей от экспертов[/url] .
гидроизоляция цена [url=http://gidroizolyaciya-cena-1.ru]http://gidroizolyaciya-cena-1.ru[/url] .
Хай!
Хочешь взять микрозайм? [url=https://kredit-bez-slov.ru]Микрозайм онлайн на карту круглосуточно[/url]
По ссылке: – https://kredit-bez-slov.ru/mikrofinansovye-organizaczii-onlajn/
Что такое дженерики лекарства
Что такое дженерики в медицине
Дженерики что это такое
Покеда!
Привет всем!
Долго обмозговывал как поднять сайт и свои проекты и нарастить DR и узнал от гуру в seo,
энтузиастов ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Xrumer 2025: советы по настройке помогают новичкам. Автоматический линкбилдинг Xrumer позволяет массово размещать ссылки. Как использовать Xrumer для SEO экономит силы специалистов. Увеличение DR сайта с нуля возможно с правильной стратегией. Форумный спам для SEO расширяет охват.
как стать seo специалиста, продвижение сайта в люберцах, Улучшение ссылочного профиля с Xrumer
Xrumer: настройка и запуск, самое лучше продвижение сайта, seo продвижение нового сайта seotica
!!Удачи и роста в топах!!
Процедура вывода из запоя начинается с тщательной диагностики состояния пациента, чтобы определить, какие методы лечения будут наиболее эффективными. Мы применяем индивидуальный подход и комбинируем медикаментозное лечение с психотерапевтической поддержкой, что даёт лучший результат.
Подробнее тут – https://алко-ребцентр.рф/kruglosutochnyj-vyvod-iz-zapoya-nizhnij-novgorod
Проблема зависимостей остаётся актуальной в обществе. С каждым годом количество людей, страдающих от алкоголизма, наркомании и других зависимостей, растёт. Эти расстройства негативно влияют на качество жизни как самих пациентов, так и их близких. Зависимость — это не только физическое состояние, но и глубокая психологическая проблема. Для эффективного лечения необходимо обратиться к профессионалам, которые помогут справиться с этой болезнью. Наркологическая клиника “Клиника Наркологии и Психотерапии” предоставляет всеобъемлющую помощь, направленную на восстановление здоровья и нормализацию жизни пациентов.
Получить дополнительные сведения – [url=https://alko-konsultaciya.ru/]вывод из запоя на дому круглосуточно в смоленске[/url]
https://t.me/s/Magic_1win
Проблемы зависимостей – это серьезно. Для успешного лечения важен индивидуальный подход и глубокое понимание проблемы. Мы поддержим вас на каждом этапе пути к выздоровлению. Мы создаем безопасное и поддерживающее окружение для наших пациентов. Мы поможем вам не только бросить, но и начать жить заново! Тщательная диагностика – залог успешного лечения. Лечение состоит из детоксикации и работы с психологом.
Узнать больше – [url=https://zavisim-alko.ru/]вывод из запоя цены краснодар[/url]
Добрый день!
Долго не мог уяснить как поднять сайт и свои проекты и нарастить CF cituation flow и узнал от друзей профессионалов,
топовых ребят, именно они разработали недорогой и главное лучший прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Программное обеспечение для постинга ускоряет создание ссылок. Ускоренный рост ссылочного профиля виден после первых прогонах. Xrumer: создание ссылочной массы облегчает работу. Линкбилдинг через форумы и блоги помогает получать релевантные ссылки. Повышение авторитетности домена становится возможным с Xrumer.
информационный ресурс продвижение сайта, раскрутка сайтов в москве, линкбилдинг блог
линкбилдинг блог, курс по созданию и продвижению сайтов, скачать dr web cureit с официального сайта лечащая утилита
!!Удачи и роста в топах!!
Всех приветствую! Хотите узнать больше о продвижении? Тут вы можете ознакомиться с ответом на вопрос: https://rcnanews.com/news_mm/5285/
Процедура вывода из запоя начинается с тщательной диагностики состояния пациента, чтобы определить, какие методы лечения будут наиболее эффективными. Мы применяем индивидуальный подход и комбинируем медикаментозное лечение с психотерапевтической поддержкой, что даёт лучший результат.
Выяснить больше – https://алко-ребцентр.рф/vyvod-iz-zapoya-nizhnij-novgorod-czena/
Здравствуйте!
Долго не мог уяснить как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от успещных seo,
профи ребят, именно они разработали недорогой и главное продуктивный прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Программное обеспечение для постинга ускоряет создание ссылочной массы. Ускоренный рост ссылочного профиля Xrumer делает продвижение стабильным. Xrumer: создание ссылочной массы упрощает работу специалистов. Линкбилдинг через форумы и блоги обеспечивает качественные ссылки. Повышение авторитетности домена становится заметным через неделю.
продвижение сайтов в тюмени, продвижение аренда сайта, линкбилдинг стоимость
Xrumer: советы и трюки, соцсети сео, программа раскрутке сайта
!!Удачи и роста в топах!!
Доброго!
Долго анализировал как встать в топ поисковиков и узнал от друзей профессионалов,
отличных ребят, именно они разработали недорогой и главное лучший прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Увеличение DR сайта с нуля требует системного подхода. Ссылочная масса напрямую влияет на этот показатель. Xrumer ускоряет создание качественных линков. Чем больше авторитетных ссылок, тем выше DR. Увеличение DR сайта с нуля – возможна с автоматизированным прогоном.
продвижение сайта группа вк, дизайн сайта сео, Как собрать базу для Xrumer
Форумный спам для SEO, seo сайтов услуги, настройки yoast wordpress seo
!!Удачи и роста в топах!!
Всех приветствую! Хотите узнать больше о продвижении? Узнайте больше – https://birkinandbirkin.love/product/birkin-35-bag/
После первичной диагностики начинается активная фаза лечения. Современные медикаменты вводятся капельничным методом для быстрого выведения токсинов из организма и восстановления нормальных обменных процессов. Этот этап критически важен для нормализации работы печени, почек и сердечно-сосудистой системы.
Подробнее можно узнать тут – https://reabcentr-narko.ru/vyvod-iz-zapoya-tver-staczionar
Добрый день!
Долго не мог уяснить как встать в топ поисковиков и узнал от крутых seo,
профи ребят, именно они разработали недорогой и главное top прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг сайта требует тщательного подхода. Нужно подбирать качественные площадки и следить за ссылочной массой. Программы для автоматизации помогают ускорить процесс. Это особенно важно для крупных проектов. Линкбилдинг сайта обеспечивает стабильный рост.
seo оптимизация инструменты, пагинация страниц seo, линкбилдинг по тематике
линкбилдинг на запад, seo алгоритмов, инструменты seo продвижение
!!Удачи и роста в топах!!
Здравствуйте!
Долго ломал голову как поднять сайт и свои проекты и нарастить CF cituation flow и узнал от крутых seo,
энтузиастов ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Предлагаю линкбилдинг использовать с Xrumer для ускорения продвижения. Линкбилдинг сервис позволяет экономить время. Линкбилдинг интернет магазина помогает продажам. Каталоги линкбилдинг дают качественные ссылки. Линкбилдинг сервисы упрощают работу специалистов.
изготовление раскрутка сайта, продвижение сайтов и поисковая раскрутка сайтов, линкбилдинг для интернет магазина
линкбилдинг или, какие факторы влияют на продвижение сайта, услуги по созданию и продвижению сайта
!!Удачи и роста в топах!!
melbet вход [url=https://melbetofficialsite.ru/]melbet вход[/url] .
Междисциплинарный подход: Специалисты нашего центра работают в команде, включающей наркологов, психотерапевтов, социальных работников. Это позволяет учитывать все аспекты состояния пациента и обеспечивать комплексный подход к лечению.
Детальнее – https://alko-specialist.ru/vivod-iz-zapoya-v-kruglosutochno-v-simferopole/
гидроизоляция цена [url=www.gidroizolyaciya-cena-1.ru]www.gidroizolyaciya-cena-1.ru[/url] .
купить аттестат 11 класс саратов [url=www.arus-diplom24.ru]купить аттестат 11 класс саратов[/url] .
Таким образом, мы создаём систему поддержки, позволяющую каждому пациенту успешно справляться с зависимостью и вернуться к полноценной жизни.
Исследовать вопрос подробнее – https://alko-lechebnica.ru/lechenie-zapoya-v-Sankt-Peterburge
прогнозы экспертов на хоккей [url=http://luchshie-prognozy-na-khokkej14.ru/]прогнозы экспертов на хоккей[/url] .
Здравствуйте!
Долго анализировал как встать в топ поисковиков и узнал от успещных seo,
энтузиастов ребят, именно они разработали недорогой и главное продуктивный прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Повышение авторитетности домена требует качественных ссылок. Форумы и блоги помогают создавать естественный линкбилдинг. Автоматизация с Xrumer ускоряет процесс. Чем больше ссылок, тем выше DR. Повышение авторитетности домена важно для SEO-продвижения.
линкбилдинг для англоязычного сайта, seo ji hye actress, Прогон ссылок для роста позиции
Как собрать базу для Xrumer, продвижение недвижимость сайт, dr web cureit скачать бесплатно для windows 7 с официального сайта
!!Удачи и роста в топах!!
купить аттестат за 11 классов в воронеже [url=https://arus-diplom23.ru]купить аттестат за 11 классов в воронеже[/url] .
Заказать диплом любого ВУЗа!
Наша компания предлагаетбыстро и выгодно приобрести диплом, который выполнен на оригинальном бланке и заверен печатями, штампами, подписями должностных лиц. Документ пройдет лубую проверку, даже при использовании специальных приборов. Достигайте своих целей максимально быстро с нашим сервисом- [url=http://jobs.colwagen.co/employer/aurus-diplomany/]jobs.colwagen.co/employer/aurus-diplomany[/url]
купить диплом в уфе с реестром [url=arus-diplom34.ru]arus-diplom34.ru[/url] .
Современный темп жизни, постоянные стрессы и бытовые трудности всё чаще приводят к тому, что проблема зависимостей становится актуальной для самых разных людей — от молодых специалистов до взрослых, состоявшихся семейных людей. Наркологическая помощь в Домодедово в клинике «РеабилитейшнПро» — это возможность получить профессиональное лечение, консультации и поддержку в любой, даже самой сложной ситуации, без огласки и промедления.
Изучить вопрос глубже – [url=https://narkologicheskaya-pomoshch-domodedovo6.ru/]skoraya-narkologicheskaya-pomoshch-domodedovo[/url]
купить диплом занесением реестр киев [url=https://arus-diplom35.ru/]https://arus-diplom35.ru/[/url] .
Каждая процедура проводится под контролем квалифицированного врача. При необходимости возможен экстренный выезд специалиста на дом, что позволяет оказать помощь пациенту в привычной и безопасной обстановке.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-odincovo6.ru/]vyvod-iz-zapoya-vyzov-na-dom[/url]
высокие кашпо для улицы [url=www.ulichnye-kashpo-kazan.ru/]www.ulichnye-kashpo-kazan.ru/[/url] .
купить аттестат 11 класс 2016 [url=http://arus-diplom21.ru]купить аттестат 11 класс 2016[/url] .
купить диплом украины [url=http://educ-ua2.ru]купить диплом украины[/url] .
купить аттестат за 11 класс калининград [url=www.arus-diplom22.ru/]купить аттестат за 11 класс калининград[/url] .
купить диплом вуза с проводкой [url=http://kurkino.ru/forums/users/iliaanisimov]купить диплом вуза с проводкой[/url] .
сколько стоит купить аттестат за 9 класс [url=http://educ-ua5.ru]http://educ-ua5.ru[/url] .
Вывод из запоя — это комплексная медицинская процедура, направленная на очищение организма, стабилизацию психоэмоционального состояния и восстановление нормального самочувствия. В клинике «Операция Здоровье» пациенты могут получить помощь в стационаре или с выездом врача на дом. Мы работаем круглосуточно, обеспечивая безопасность и анонимность лечения.
Получить больше информации – https://наркология-дома.рф/vyvod-iz-zapoya-na-domu-v-krasnodare
Всех приветствую! Хотите узнать больше о продвижении? Подробная информация на тему: https://pendingplays.co.uk/2023/08/16/god-of-war-ragnarok/
Добрый день!
Долго анализировал как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от друзей профессионалов,
энтузиастов ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг цена зависит от выбранной стратегии. Крауд маркетинг линкбилдинг улучшает DR сайта. Линкбилдинг что это такое простыми словами объясняет новичкам. Линкбилдинг это простыми словами становится доступным. Линкбилдинг стоимость варьируется по объему работ.
seo в cms, продвижение аудит оптимизация сайта, Увеличение показателя Ahrefs
линкбилдинг что это простыми словами, бесплатная раскрутка продвижения сайта, seo тз для копирайтера
!!Удачи и роста в топах!!
Быстро купить диплом об образовании!
Мы изготавливаем дипломы любой профессии по выгодным тарифам— [url=http://dvniilh.ru/]dvniilh.ru[/url]
mostbet aviator uz [url=https://www.mostbet4106.ru]mostbet aviator uz[/url]
Здравствуйте!
Долго ломал голову как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от крутых seo,
профи ребят, именно они разработали недорогой и главное буст прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Предлагаю линкбилдинг использовать с Xrumer для ускорения продвижения. Линкбилдинг сервис позволяет экономить время. Линкбилдинг интернет магазина помогает продажам. Каталоги линкбилдинг дают качественные ссылки. Линкбилдинг сервисы упрощают работу специалистов.
seo заголовок это, фильтры для seo, Улучшение ссылочного профиля с Xrumer
линкбилдинг отзывы, seo статью для блога, курсы сео битрикс
!!Удачи и роста в топах!!
2024 Hit Slot
купить диплом с занесением в реестр челябинск [url=www.arus-diplom32.ru/]купить диплом с занесением в реестр челябинск[/url] .
Клиника «Орион-Клиник» располагает собственной лабораторией и оснащением для аппаратных методик, что позволяет проводить все этапы лечения под одним крышей. Наши врачи имеют международные сертификаты по наркологии и гипнотерапии, а психологи прошли дополнительное обучение по работе с зависимостями. Мы гарантируем:
Углубиться в тему – [url=https://kodirovanie-ot-alkogolizma-pushkino4.ru/]кодирование от алкоголизма цены[/url]
купить диплом с занесением в реестр в спб [url=http://arus-diplom33.ru]http://arus-diplom33.ru[/url] .
Купить диплом под заказ в Москве возможно через официальный сайт компании. [url=http://nova-driving-school.mn.co/posts/87213770/]nova-driving-school.mn.co/posts/87213770[/url]
аппарат узи цена в россии [url=http://kupit-uzi-apparat28.ru/]аппарат узи цена в россии[/url] .
купить проведенный диплом высокие [url=https://arus-diplom31.ru]купить проведенный диплом высокие[/url] .
купить аттестат за 11 класс 2000 года [url=www.arus-diplom21.ru/]www.arus-diplom21.ru/[/url] .
Процедура вывода из запоя проводится опытными наркологами с применением современных протоколов и сертифицированных препаратов. Процесс включает несколько ключевых этапов:
Узнать больше – [url=https://vyvod-iz-zapoya-odincovo6.ru/]http://vyvod-iz-zapoya-odincovo6.ru[/url]
mostbet rasmiy sayti [url=www.mostbet4111.ru]www.mostbet4111.ru[/url]
Здравствуйте!
Долго ломал голову как поднять сайт и свои проекты и нарастить CF cituation flow и узнал от крутых seo,
топовых ребят, именно они разработали недорогой и главное продуктивный прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг сео – основа эффективного продвижения. Программы типа Xrumer ускоряют процесс массового прогона. Массовый линкбилдинг повышает DR. Автоматизация экономит силы специалистов. Линкбилдинг сео – ключ к успешной оптимизации сайта.
поддержка раскрутка сайтов, сео микроразметка, SEO-прогон для повышения позиций
Xrumer для оптимизации сайта, продвижение сайтов в топ математики, особенности продвижения сайта в европе
!!Удачи и роста в топах!!
sport bets [url=www.sportbets31.ru]www.sportbets31.ru[/url] .
спортивные новости [url=https://www.novosti-sporta-3.ru]https://www.novosti-sporta-3.ru[/url] .
mostbet rasmiy sayti [url=http://mostbet4107.ru]http://mostbet4107.ru[/url]
сео агентство [url=telegra.ph/Agentstvo-po-prodvizheniyu-sajtov-chto-vazhno-znat-pered-vyborom-08-15]telegra.ph/Agentstvo-po-prodvizheniyu-sajtov-chto-vazhno-znat-pered-vyborom-08-15[/url] .
Привет всем!
Долго ломал голову как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от крутых seo,
профи ребят, именно они разработали недорогой и главное продуктивный прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Многоуровневый линкбилдинг создает устойчивую ссылочную сеть. Линкбилдинг блог курс показывает эффективные методы. Линкбилдинг мы предлагаем клиентам с разными целями. Контент маркетинг линкбилдинг повышает естественность ссылочного профиля. Естественный линкбилдинг повышает доверие поисковых систем.
seo bonus, раскрутка страниц сайта, Массовый прогон сайта ссылками
Xrumer рассылка форумов, seo продвижение сайта калуга, продвижение сайта в яндексе и гугле москва
!!Удачи и роста в топах!!
интернет магазин сантехники москва [url=https://evropejskaya-santehnika2.ru/]evropejskaya-santehnika2.ru[/url] .
ванная с гидромассажем цена [url=http://vanna-s-gidromassazhem.ru]http://vanna-s-gidromassazhem.ru[/url] .
купить итальянскую сантехнику [url=https://gessi-santehnika-5.ru/]купить итальянскую сантехнику[/url] .
купить диплом с занесением в реестр барнаул [url=www.arus-diplom31.ru/]купить диплом с занесением в реестр барнаул[/url] .
mostbet for iphone [url=https://mostbet4108.ru/]https://mostbet4108.ru/[/url]
mostbet uz yangi bonus 2025 [url=https://www.mostbet4111.ru]https://www.mostbet4111.ru[/url]
В зависимости от степени выраженности абстинентного синдрома и наличия сопутствующих осложнений клиника «Азимут Здоровья» предлагает два основных формата оказания помощи, позволяющих оптимально сочетать эффективность лечения и комфорт пациента. Каждый вариант тщательно продуман: мы учитываем не только медицинские показания, но и личные предпочтения, чтобы вы или ваш близкий чувствовали себя максимально защищённо и спокойно. Оба формата подразумевают строгий контроль жизненных показателей и сопровождение на всех этапах — от первой капельницы до завершения курса поддерживающей терапии.
Подробнее тут – [url=https://narkolog-na-dom-ramenskoe4.ru/]vrach narkolog na dom[/url]
Лечение запоя в клинике «Преодоление» строится на поэтапном подходе, направленном на полное восстановление организма. После первичной диагностики назначается индивидуальная программа, включающая следующие шаги:
Узнать больше – http://наркология-помощь.рф
Индивидуализация лечения: Каждый случай рассматривается отдельно, учитывая уникальные особенности пациента, его физическое состояние, предшествующий опыт лечения и социальные факторы. Такой подход позволяет создать максимально эффективный план терапии.
Исследовать вопрос подробнее – http://alko-specialist.ru/vivod-iz-zapoya-v-kruglosutochno-v-simferopole/
купить диплом института киев [url=http://www.educ-ua1.ru]купить диплом института киев[/url] .
мостбет скачать приложение на андроид [url=https://mostbet4118.ru/]https://mostbet4118.ru/[/url]
Мы можем предложить дипломы любой профессии по доступным ценам. Заказ документа, который подтверждает обучение в ВУЗе, – это грамотное решение. Заказать диплом о высшем образовании: [url=http://odessaforum.getbb.ru/viewtopic.php?f=5&t=26128/]odessaforum.getbb.ru/viewtopic.php?f=5&t=26128[/url]
мостбет кг [url=www.mostbet4147.ru]www.mostbet4147.ru[/url]
Современный темп жизни, постоянные стрессы и бытовые трудности всё чаще приводят к тому, что проблема зависимостей становится актуальной для самых разных людей — от молодых специалистов до взрослых, состоявшихся семейных людей. Наркологическая помощь в Домодедово в клинике «РеабилитейшнПро» — это возможность получить профессиональное лечение, консультации и поддержку в любой, даже самой сложной ситуации, без огласки и промедления.
Разобраться лучше – [url=https://narkologicheskaya-pomoshch-domodedovo6.ru/]анонимная наркологическая помощь домодедово[/url]
купить диплом о высшем образовании в украине [url=http://educ-ua3.ru]купить диплом о высшем образовании в украине[/url] .
mostbet uzbekistan [url=https://mostbet4107.ru]https://mostbet4107.ru[/url]
Запой — это не просто злоупотребление алкоголем, а опасное состояние, при котором организм уже не может самостоятельно справиться с токсинами. Чем дольше продолжается запой, тем сложнее выход из него и тем выше риск осложнений.
Подробнее можно узнать тут – http://наркология-дома.рф/vyvod-iz-zapoya-czena-v-krasnodare/
mostbet ckachat [url=http://mostbet4147.ru]http://mostbet4147.ru[/url]
мостбет зеркало узбекистан [url=https://mostbet4106.ru]мостбет зеркало узбекистан[/url]
Этап процедуры
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-odincovo6.ru/]https://vyvod-iz-zapoya-odincovo6.ru/[/url]
купить аттестат за 11 классов в спб [url=www.arus-diplom25.ru/]купить аттестат за 11 классов в спб[/url] .
мостбет казино скачать [url=mostbet4118.ru]mostbet4118.ru[/url]
Handmade clay flowers Ideal for home, office decor or original gift. Natural beauty and durability.
В клинике «Преодоление» мы предлагаем оперативную помощь 24/7 – наши специалисты готовы оказать поддержку как на дому, так и в стационаре, обеспечивая безопасное и эффективное лечение.
Изучить вопрос глубже – https://наркология-помощь.рф/vyvod-iz-zapoya-na-domu-rostov-na-donu/
Алкоголизм, наркомания, игромания – это разрушительные состояния. Обратитесь в “Перезагрузку” за помощью. Только комплексный подход и индивидуальный план помогут вам избавиться от зависимости. Мы понимаем, что это нелегкий путь, и будем рядом с вами. Наша цель – помочь вам почувствовать себя в безопасности и получить необходимую поддержку. Наша цель – полное восстановление, а не только избавление от зависимости. Понимание причин зависимости – ключ к индивидуальному лечению. Детоксикация и психотерапия – основа нашего лечения.
Детальнее – [url=https://zavisim-alko.ru/]вывод. из. запоя. краснодар.[/url]
Откройте для себя мир азартных игр на [url=https://888starz2.ru]зеркало 888starz россия[/url].
888starz — это популярная платформа для азартных игр, предлагающая разнообразие возможностей для игроков. Платформа включает в себя как слоты, так и настольные игры, чтобы удовлетворить запросы всех игроков.
888starz предлагает удобный интерфейс, что позволяет легко ориентироваться по сайту. Регистрация и навигация по платформе не вызывают затруднений у игроков.
Пользователи могут быстро зарегистрироваться и начать игру. После предоставления необходимой информации игроки смогут активировать свои аккаунты.
Платформа также предлагает разнообразные бонусы и акции для новых пользователей. Это позволяет увеличить игровую сумму и сделать процесс более увлекательным.
купить аттестат за 11 класс гознак [url=https://arus-diplom22.ru]https://arus-diplom22.ru[/url] .
Бетон в Воронеже https://stk-vrn.ru продажа и доставка. Все марки для фундаментов, дорожных работ и строительства под ключ. Надёжный производитель и лучшие цены.
Подшипники изготовитель Оптовая покупка подшипников – экономически выгодное решение для крупных производств, позволяющее существенно снизить издержки на сервис и ремонт техники.
диплом купить с внесением в реестр [url=www.arus-diplom32.ru]диплом купить с внесением в реестр[/url] .
В условиях современного общества наркомания и алкоголизм стали актуальными и серьезными проблемами, затрагивающими не только индивидуумов, но и их семьи, сообщества. Эти заболевания не просто влияют на физическое здоровье, они наносят урон психоэмоциональному состоянию, нарушают социальные связи и ухудшают качество жизни. Наркологический центр “Новый горизонт” предлагает целостный и научно обоснованный подход к лечению зависимостей от психоактивных веществ. Мы применяем современные методы диагностики и терапии, чтобы помочь каждому пациенту обрести здоровье и вернуть себе полноценную жизнь.
Ознакомиться с деталями – [url=https://alko-specialist.ru/]вывод из запоя в симферополе[/url]
как купить диплом с занесением в реестр в екатеринбурге [url=http://arus-diplom33.ru]http://arus-diplom33.ru[/url] .
букмекерские конторы бишкек [url=www.mostbet4117.ru]букмекерские конторы бишкек[/url]
mostbet mobile uz registratsiya [url=www.mostbet4108.ru]www.mostbet4108.ru[/url]
Всех приветствую! Хотите узнать больше о продвижении? Узнайте все нюансы на тему – https://roamfreewith.us/2021/05/25/hello-world/
Врач проводит подробную диагностику, оценивает как физическое, так и психологическое состояние пациента. На основании полученных данных формируется индивидуальная программа помощи, которая включает не только медикаментозное лечение, но и психотерапевтическую поддержку, консультации для семьи и рекомендации по восстановлению.
Узнать больше – [url=https://narkologicheskaya-pomoshch-domodedovo6.ru/]narkologicheskaya-pomoshch[/url]
аттестат за 11 купить в нижнем новгороде [url=https://arus-diplom9.ru]аттестат за 11 купить в нижнем новгороде[/url] .
gessi продукция [url=https://gessi-santehnika-5.ru/]gessi-santehnika-5.ru[/url] .
Мы готовы предложить документы ВУЗов, которые находятся в любом регионе Российской Федерации. Заказать диплом ВУЗа:
[url=http://camlive.ovh/read-blog/15707_kupit-attestat-ob-obrazovanii-9-klassov.html/]купить аттестат за 11 классов 2000 года[/url]
Процедура занимает от 1,5 до 3 часов, после чего пациент остаётся под наблюдением для оценки эффективности лечения.
Ознакомиться с деталями – https://наркология-помощь.рф/vyvod-iz-zapoya-na-domu-rostov-na-donu
Перед кодированием важно снять острую интоксикацию и стабилизировать состояние. В «Орион-Клиник» пациенту проводят курс инфузионной терапии: капельницы с регидратационными растворами, гепатопротекторами и витаминно-минеральными комплексами. Это позволяет восстановить водно-электролитный баланс, поддержать функции печени и почек, нормализовать артериальное давление и работу сердца. Одновременно психолог проводит предварительные беседы для выяснения причин зависимости, уровня тревожности и мотивации. Подготовительный этап длится от одного до трёх дней в зависимости от тяжести состояния и поможет снизить риск побочных эффектов при введении кодирующего препарата.
Получить больше информации – http://kodirovanie-ot-alkogolizma-pushkino4.ru
Всех приветствую! Хотите узнать больше о продвижении? Узнайте все нюансы на тему – https://academy.edutic.id/sistem-lampu-otomatis-berbasis-sensor-solusi-cerdas-untuk-rumah-modern/
купить свидетельство о рождении [url=https://www.educ-ua5.ru]https://www.educ-ua5.ru[/url] .
аттестат за 11 класс 2014 года купить [url=https://www.arus-diplom25.ru]аттестат за 11 класс 2014 года купить[/url] .
психиатрическая помощь больным
psikhiatr-moskva003.ru
принудительное лечение в психиатрическом стационаре
Подшипники изготовитель “Научные достижения” – это результаты научных исследований, которые оказывают значительное влияние на нашу жизнь. Они могут быть связаны с новыми технологиями, новыми лекарствами или новыми способами понимания мира.
акриловая ванна с гидромассажем [url=https://www.vanna-s-gidromassazhem.ru]https://www.vanna-s-gidromassazhem.ru[/url] .
Миссия нашего медицинского учреждения заключается в предоставлении всесторонней помощи людям, страдающим от зависимостей. Основные цели нашего центра включают:
Получить дополнительную информацию – [url=https://alko-specialist.ru/]alko-specialist.ru/[/url]
Перед кодированием важно снять острую интоксикацию и стабилизировать состояние. В «Орион-Клиник» пациенту проводят курс инфузионной терапии: капельницы с регидратационными растворами, гепатопротекторами и витаминно-минеральными комплексами. Это позволяет восстановить водно-электролитный баланс, поддержать функции печени и почек, нормализовать артериальное давление и работу сердца. Одновременно психолог проводит предварительные беседы для выяснения причин зависимости, уровня тревожности и мотивации. Подготовительный этап длится от одного до трёх дней в зависимости от тяжести состояния и поможет снизить риск побочных эффектов при введении кодирующего препарата.
Узнать больше – http://kodirovanie-ot-alkogolizma-pushkino4.ru/kodirovanie-ot-alkogolizma-na-domu-v-pushkino/
В нашем центре ведут приём врачи-наркологи высшей категории, обладающие многолетним опытом лечения различных видов зависимостей. Они владеют всеми современными методиками детоксикации, купирования абстинентного синдрома, кодирования, фармакотерапии.
Получить дополнительную информацию – [url=https://alko-reabcentr.ru/]вывод из запоя недорого в санкт-петербурге[/url]
мостбет вход [url=https://mostbet4117.ru/]https://mostbet4117.ru/[/url]
аттестат купить 11 кл [url=http://www.arus-diplom24.ru]аттестат купить 11 кл[/url] .
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Почему это важно? – https://korenagakazuo.com/2014/05/04/%E3%82%B5%E3%83%83%E3%82%AB%E3%83%BC%E3%80%80%E3%82%B8%E3%82%A7%E3%83%95%E3%83%A6%E3%83%8A%E3%82%A4%E3%83%86%E3%83%83%E3%83%89%E5%B8%82%E5%8E%9F%E3%81%AE%E8%A9%A6%E5%90%88%E3%81%AB%E3%83%95%E3%82%AF
купить игровой компьютер с rtx 4090 Хороший игровой ПК: Залог комфортного и захватывающего гейминга.
интернет магазин сантехники с доставкой [url=http://evropejskaya-santehnika2.ru/]интернет магазин сантехники с доставкой[/url] .
Купить промышленные подшипники BBCR “Социальные сети” стали неотъемлемой частью нашей жизни, предоставляя платформу для общения, обмена информацией и самовыражения.
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Получить исчерпывающие сведения – https://f5fashion.vn/ufc-fighter-themba-gorimbo-religion-family-ethnicity-and-origin
mostbet.kg [url=https://mostbet4109.ru]https://mostbet4109.ru[/url]
купить диплом вуза с проводкой [url=https://arus-diplom31.ru/]https://arus-diplom31.ru/[/url] .
sportandbets [url=www.sportbets31.ru/]www.sportbets31.ru/[/url] .
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Все материалы собраны здесь – http://sszap.ru
mostbet uz apk скачать [url=http://mostbet4109.ru/]http://mostbet4109.ru/[/url]
новости спорта футбол [url=http://novosti-sporta-3.ru/]http://novosti-sporta-3.ru/[/url] .
Всех приветствую! Хотите узнать больше о продвижении? Подробная информация на тему: http://tangopedia.com.ar/2022/09/15/mario-grossi/
Приветствую!
Показываю обратную сторону медали и реальные перспективы. [url=https://zarabotok-na-igrah.ru/kak-zarabotat-na-igrah/]на каких играх можно заработать на телефоне[/url]
По ссылке: – https://zarabotok-na-igrah.ru/kak-zarabotat-na-igrah/
заработок на игровой валюте
заработок на играх
заработать на играх в интернете
До встречи!
агентства по продвижению сайтов [url=https://sites.google.com/view/reklamnoe-agenstvo-seo]https://sites.google.com/view/reklamnoe-agenstvo-seo[/url] .
В Челябинске решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-chelyabinsk12.ru/]скорая вывод из запоя челябинск[/url]
аттестат за 11 класс купить цена [url=http://arus-diplom24.ru/]http://arus-diplom24.ru/[/url] .
Приобрести диплом любого университета!
Наши специалисты предлагаютбыстро купить диплом, который выполняется на бланке ГОЗНАКа и заверен мокрыми печатями, водяными знаками, подписями официальных лиц. Документ пройдет любые проверки, даже с применением специальных приборов. Достигайте цели быстро и просто с нашими дипломами- [url=http://eufashionshoeclub.com/read-blog/4968_kupit-diplom-moskva.html/]eufashionshoeclub.com/read-blog/4968_kupit-diplom-moskva.html[/url]
https://tripscan41.cc/ Ищете вдохновение? Загляните в раздел Tripscan top и узнайте о самых популярных направлениях для путешествий.
как купить легально диплом о высшем образовании [url=https://www.arus-diplom35.ru]как купить легально диплом о высшем образовании[/url] .
займ онлайн срочно деньги онлайн
купить аттестаты за 11 в спб [url=http://arus-diplom25.ru]купить аттестаты за 11 в спб[/url] .
Самостоятельно выйти из запоя — почти невозможно. В Санкт-Петербурге врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Подробнее – [url=https://azithromycinum.ru/]вывод из запоя с выездом санкт-петербург[/url]
игровой компьютер за 90к Онлайн-конфигуратор ПК с проверкой – это гарантия того, что все выбранные вами комплектующие будут совместимы друг с другом.
мостбет хумо пополнение [url=https://www.mostbet4113.ru]https://www.mostbet4113.ru[/url]
купить аттестат 11 класса в екатеринбурге [url=https://arus-diplom22.ru]купить аттестат 11 класса в екатеринбурге[/url] .
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Челябинске приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Детальнее – [url=https://vyvod-iz-zapoya-chelyabinsk12.ru/]вывод из запоя капельница на дому[/url]
дом на заказ [url=http://stroitelstvo-domov-irkutsk-1.ru/]http://stroitelstvo-domov-irkutsk-1.ru/[/url] .
строительство дома иркутск [url=www.stroitelstvo-domov-irkutsk-6.ru]строительство дома иркутск[/url] .
купить ванну с гидромассажем [url=https://vanna-s-gidromassazhem.ru]https://vanna-s-gidromassazhem.ru[/url] .
купить дом под ключ [url=https://stroitelstvo-domov-irkutsk-4.ru]купить дом под ключ[/url] .
Медикаментозная детоксикация — это первый и самый важный этап в лечении запоя. В этот момент из организма выводятся все вредные вещества, которые накопились за время алкоголизма. В Москве применяются эффективные и безопасные методы очистки, которые проводятся под контролем опытных специалистов.
Получить дополнительную информацию – [url=https://narko-zakodirovat2.ru/]срочный вывод из запоя[/url]
mostbet bonusu necə almaq olar [url=http://mostbet4134.ru/]mostbet bonusu necə almaq olar[/url]
Новости Специальная военная операция (СВО) стала катализатором глобальных изменений. Политика, как сфера влияния, претерпела трансформацию, обнажив скрытые противоречия и сформировав новые альянсы. Переговоры, в центре которых Владимир Путин и Владимир Зеленский, стали символом поиска компромисса в условиях радикально противоположных позиций. Финансы, словно кровеносная система мировой экономики, ощутили на себе всю тяжесть санкций и перебоев в поставках. Европа, Азия и Америка оказались перед лицом энергетического кризиса и инфляционной спирали. Безопасность и оборона, как фундаментальные потребности государств, вновь обрели актуальность. Кавказ и Ближний Восток, издавна известные своей нестабильностью, стали эпицентром геополитических рисков. Новости и аналитика, призванные освещать события непредвзято, часто оказываются в эпицентре информационных войн. Объективность становится дефицитом.
купить аттестат за 11 классов екатеринбург [url=http://www.arus-diplom23.ru]купить аттестат за 11 классов екатеринбург[/url] .
Запой — это длительный приступ непрерывного употребления алкоголя, когда человек теряет контроль над количеством выпиваемого, что приводит к серьёзному отравлению организма. Нарушение водно-солевого баланса, угнетение центральной нервной системы и риск сердечно-сосудистых осложнений требуют немедленного вмешательства. В Челябинске клиника «ЧелябМед» предлагает круглосуточную неотложную помощь на дому и в условиях стационара, гарантируя полную анонимность и комфорт пациенту.
Подробнее – [url=https://vivod-iz-zapoya-chelyabinsk13.ru/]вывод из запоя на дому цена челябинск[/url]
mostbet qeydiyyat yoxlaması [url=https://mostbet4135.ru/]https://mostbet4135.ru/[/url]
mostbet online скачать [url=https://www.mostbet4114.ru]https://www.mostbet4114.ru[/url]
займ денег займ
кредит займ онлайн микрозайм онлайн
купить диплом в запорожье [url=educ-ua4.ru]купить диплом в запорожье[/url] .
где можно купить диплом [url=http://educ-ua5.ru]где можно купить диплом[/url] .
мостбет скачать уз [url=https://mostbet4112.ru]мостбет скачать уз[/url]
СВО Переговоры Путин Зеленский Специальная военная операция продолжает оставаться в центре внимания мировой общественности. Этот конфликт, затрагивающий интересы множества стран и народов, оказывает серьезное влияние на геополитическую обстановку и мировую экономику. Попытки найти дипломатическое решение предпринимаются регулярно, однако ощутимого прогресса в переговорном процессе пока не наблюдается. Позиции сторон остаются диаметрально противоположными, и каждая из них преследует свои собственные цели. Владимир Путин и Владимир Зеленский, как лидеры вовлеченных в конфликт государств, несут огромную ответственность за будущее своих стран и народов. Политическая составляющая конфликта сложна и многогранна, требующая тщательного анализа и взвешенных решений. Финансовые последствия специальной военной операции ощущаются во всем мире. Европа, Азия и Америка испытывают на себе влияние санкций, роста цен на энергоносители и перебоев в поставках товаров. Безопасность и оборона становятся приоритетными направлениями государственной политики, а Кавказ и Ближний Восток остаются зонами повышенной напряженности. В этих условиях особую важность приобретает доступ к объективной и непредвзятой информации. Новости и аналитика должны основываться на фактах и отражать различные точки зрения, чтобы каждый человек мог сформировать собственное мнение о происходящих событиях.
mostbet qeydiyyat necə olur [url=https://mostbet4132.ru/]https://mostbet4132.ru/[/url]
Как подчёркивает заведующий отделением наркологической помощи НМИЦ психиатрии и наркологии, результат лечения напрямую зависит от уровня подготовки персонала и умения работать в команде.
Разобраться лучше – http://narkologicheskaya-klinika-murmansk0.ru/narkologicheskaya-klinika-otzyvy-marmansk/https://narkologicheskaya-klinika-murmansk0.ru
где купить аттестат за 11 класс хабаровск [url=http://www.arus-diplom23.ru]где купить аттестат за 11 класс хабаровск[/url] .
купить аттестат школы за 11 [url=https://arus-diplom24.ru]купить аттестат школы за 11[/url] .
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Разобраться лучше – [url=https://vyvod-iz-zapoya-v-sankt-peterburge.ru/]вывод из запоя на дому[/url]
mostbet qeydiyyat aviator [url=http://mostbet4134.ru]mostbet qeydiyyat aviator[/url]
mostbet aviator qeydiyyat [url=https://mostbet4132.ru/]mostbet aviator qeydiyyat[/url]
мостбет актуальный промокод [url=http://mostbet4113.ru/]http://mostbet4113.ru/[/url]
Самостоятельно выйти из запоя — почти невозможно. В Челябинске врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-chelyabinsk12.ru/]вывод из запоя на дому недорого[/url]
купить проведенный аттестат за 11 класс [url=arus-diplom21.ru]купить проведенный аттестат за 11 класс[/url] .
купить аттестат об окончании 11 классов с занесением в реестр [url=https://www.arus-diplom22.ru]купить аттестат об окончании 11 классов с занесением в реестр[/url] .
купить диплом реестр [url=https://www.arus-diplom31.ru]купить диплом реестр[/url] .
mostbet qeydiyyat yoxlaması [url=http://mostbet4135.ru/]mostbet qeydiyyat yoxlaması[/url]
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Обратитесь за информацией – https://kvadar.ifzg.hr/index.php/2024/01/28/blog-4
Добрый день!
Тебя уволили, а ты не знаешь, плакать или злиться? [url=https://zhit-legche.ru/kak-perezhit-uvolnenie/]увольнение с работы[/url]
Переходи: – https://zhit-legche.ru/kak-perezhit-uvolnenie/
что делать если уволили с работы
как пережить увольнение
как пережить увольнение с работы форум
Пока!
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Почему это важно? – https://mkfoundryconsulting.com/hello-world-2
купить диплом о профессиональном образовании [url=educ-ua2.ru]купить диплом о профессиональном образовании[/url] .
mostbet aviator necə qazanmaq [url=https://mostbet4133.ru/]mostbet aviator necə qazanmaq[/url]
mostbet kripto orqali depozit [url=http://mostbet4114.ru/]http://mostbet4114.ru/[/url]
кашпо для сада [url=https://ulichnye-kashpo-kazan.ru]кашпо для сада[/url] .
ванна с гидромассажем недорого [url=http://vanna-s-gidromassazhem.ru]ванна с гидромассажем недорого[/url] .
купить аттестат за 11 классов 2015 года [url=arus-diplom24.ru]купить аттестат за 11 классов 2015 года[/url] .
Приобрести диплом ВУЗа!
Мы изготавливаем дипломы любых профессий по выгодным ценам— [url=http://institute-diplom.ru/]institute-diplom.ru[/url]
Купить диплом любого университета!
Наши специалисты предлагаютмаксимально быстро заказать диплом, который выполняется на оригинальном бланке и заверен мокрыми печатями, водяными знаками, подписями. Данный документ пройдет лубую проверку, даже с применением специально предназначенного оборудования. Достигайте цели быстро с нашей компанией- [url=http://albaniaproperty.al/author/mikebarff26098/]albaniaproperty.al/author/mikebarff26098[/url]
купить диплом вуза с реестром [url=www.arus-diplom31.ru]купить диплом вуза с реестром[/url] .
Excellent, what a weblog it is! This website presents useful facts to us, keep it up.
https://warfare.com.ua/linzy-u-farah-osvitlennya
В Нижнем Новгороде решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-stacionare13.ru/]помощь вывод из запоя нижний новгород[/url]
купить проведенный диплом о высшем образовании [url=https://arus-diplom35.ru/]купить проведенный диплом о высшем образовании[/url] .
диплом внесенный в реестр купить [url=http://xn--b1acebaenad0ccc3aiee.xn--p1ai/forum/user/25243/]диплом внесенный в реестр купить[/url] .
Concert Ticket Cost https://rock-concert-tickets.ru
mostbet ruletka uz [url=https://www.mostbet4115.ru]https://www.mostbet4115.ru[/url]
Мы можем предложить документы любых учебных заведений, расположенных в любом регионе России. Приобрести диплом любого университета:
[url=http://ss13.fun/wiki/index.php?title=User:JamaalMighell/]купить аттестат об окончании 11 классов в калининграде[/url]
купить диплом с проводкой меня [url=https://www.arus-diplom32.ru]купить диплом с проводкой меня[/url] .
купить диплом с занесением в реестр новокузнецке [url=http://arus-diplom33.ru]купить диплом с занесением в реестр новокузнецке[/url] .
Купить диплом на заказ возможно через сайт компании. [url=http://4division.ru/viewtopic.php?f=13&t=10233/]4division.ru/viewtopic.php?f=13&t=10233[/url]
аттестат 11 класс купить краснодар [url=https://arus-diplom21.ru/]аттестат 11 класс купить краснодар[/url] .
mostbet şikayətlər [url=https://mostbet4133.ru/]https://mostbet4133.ru/[/url]
строительство домов под ключ иркутск [url=http://www.stroitelstvo-domov-irkutsk-6.ru]строительство домов под ключ иркутск[/url] .
Understanding game probabilities is key to enjoying dice games – and any casino experience! It’s fascinating how platforms like spintime app download use data to enhance gameplay. Really neat to see that analytical approach applied! 🤔
консультация психиатра платно
psychiatr-moskva001.ru
психиатрическое лечение
строительство иркутск [url=http://www.stroitelstvo-domov-irkutsk-4.ru]http://www.stroitelstvo-domov-irkutsk-4.ru[/url] .
Рестораны Хамовников https://restoran-khamovniki.ru топ заведений для встреч, романтических ужинов и семейных обедов. Авторская кухня, стильный интерьер, удобное расположение и достойный сервис.
где можно купить аттестаты 11 класс в таджикистан [url=www.arus-diplom22.ru/]где можно купить аттестаты 11 класс в таджикистан[/url] .
Лучшие рестораны https://hamovniki-restoran.ru Хамовников для ценителей гастрономии. Подборка заведений с изысканной кухней, качественным сервисом и атмосферой для отдыха и деловых встреч.
Самостоятельно выйти из запоя — почти невозможно. В Нижнем Новгороде врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Узнать больше – [url=https://vyvod-iz-zapoya-v-stacionare.ru/]вывод из запоя дешево в нижнем новгороде[/url]
mostbet bukmekerlik [url=http://mostbet4115.ru/]http://mostbet4115.ru/[/url]
mostbet uz skachat apk [url=http://mostbet4112.ru/]http://mostbet4112.ru/[/url]
построить дом иркутск [url=http://www.stroitelstvo-domov-irkutsk-1.ru]http://www.stroitelstvo-domov-irkutsk-1.ru[/url] .
спорт 24 часа [url=www.novosti-sporta-11.ru/]www.novosti-sporta-11.ru/[/url] .
спортивные новости [url=http://www.novosti-sporta-12.ru]спортивные новости[/url] .
истории обычных людей канал Удивительные истории обычных людей (продолжение)
Курсы по плазмотерапии плазмолифтинг обучение в москве освоение методик, современные протоколы, практическая отработка. Обучение для специалистов с выдачей сертификата и повышением квалификации.
Stavki Prognozy [url=http://stavki-prognozy-one.ru]http://stavki-prognozy-one.ru[/url] .
Профессиональное обучение плазмотерапия в косметологии обучение: подробная программа, практические навыки, сертификация. Освойте эффективные методики для применения в медицине и косметологии.
реабилитация наркозависимых стационар
reabilitaciya-astana001.ru
реабилитация от алкогольной зависимости
mostbet mobil kirish uz [url=https://mostbet4116.ru]https://mostbet4116.ru[/url]
СтавкиПрогнозы [url=http://stavki-prognozy-1.ru/]http://stavki-prognozy-1.ru/[/url] .
купить диплом о высшем образовании в украине [url=http://educ-ua3.ru]купить диплом о высшем образовании в украине[/url] .
сулакский каньон что посмотреть На Кавказе множество красивых мест – горы, озера, водопады и ущелья. Самые известные – Эльбрус, Домбай, Архыз, Сулакский каньон и озеро Рица. Куда поехать на Кавказ летом
психиатр на дом в москве
psychiatr-moskva002.ru
платная психиатрическая скорая помощь
купить диплом бакалавра цена [url=http://educ-ua1.ru]купить диплом бакалавра цена[/url] .
mistbet [url=https://mostbet4116.ru]https://mostbet4116.ru[/url]
обсуждение Цитаты, вдохновляющие на действия
купить аттестаты за 11 класс 2021 [url=arus-diplom23.ru]arus-diplom23.ru[/url] .
купить аттестат за 11 класс в чите [url=www.arus-diplom24.ru/]www.arus-diplom24.ru/[/url] .
невероятные истории обычных людей Удивительные истории обычных людей (продолжение)
помощь при алкоголизме
reabilitaciya-astana002.ru
эффективное лечение алкоголизма
Детская школа искусств https://elegy-school.ru обучение музыке, танцам, изобразительному и театральному искусству. Творческие программы для детей, концерты, конкурсы и развитие талантов.
что интересного в дагестане для туристов Куда съездить в Дагестане красивые места
Авторские курсы по REVIT https://dashclass.ru обучение созданию интерьеров и архитектурных проектов. Практика, реальные кейсы, индивидуальный подход и профессиональные навыки для работы в проектировании.
пин ап безопасно [url=https://pinup5002.ru/]пин ап безопасно[/url]
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Более того — здесь – https://dg162.net/wp/%D0%B2%D0%B0%D0%B6%D0%BD%D0%BE
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Почему это важно? – https://baberos.site/the-art-of-shaving-a-close-look-at-barber-techniques
[url=https://telegra.ph/Mirovoj-kinematograf-i-onlajn-prosmotr-kak-my-smotrim-kino-segodnya-08-27]Смотреть Кино онлайн[/url] теперь можно без лишних хлопот и затрат, ведь платформы для просмотра постоянно обновляют базы фильмов и сериалов. Не нужно искать диски или ждать телепоказ — всё доступно в один клик. Здесь можно найти мелодрамы, ужасы, триллеры и фантастику. Любителям новых премьер подойдут разделы с последними релизами. HD и FullHD становятся стандартом онлайн-просмотра. Доступ есть с любых устройств и в любом месте. Регистрация обычно простая и занимает пару минут. Бесплатные версии отлично подходят для быстрого просмотра. А для ценителей высокого качества и удобства есть премиум-подписки. Выбор настолько широк, что можно менять жанры каждый день. В выходные — выбрать драму или приключение. Это современный способ провести досуг. Достаточно открыть сайт и выбрать фильм. Многие используют фильмы для изучения иностранных языков. Онлайн-просмотр — это свобода выбора и удобство. Неважно, где вы находитесь — дома или в дороге. Каждый день появляются новые релизы и сериалы. Сегодня фильмы онлайн — часть повседневной жизни миллионов людей.
пройти лечение от наркозависимости
reabilitaciya-astana003.ru
центр реабилитация алкоголиков в Астане
пин ап скачать на андроид [url=https://pinup5003.ru/]пин ап скачать на андроид[/url]
Здарова!
Вся правда о том, за что мы на самом деле платим в казино, и почему это так затягивает. [url=http://nagny-casino.ru/kazino-s-bystrym-vyvodom/]номад казино[/url]
Читай тут: – http://nagny-casino.ru/kazino-s-bystrym-vyvodom/
игры на деньги без паспорта
казино на деньги
казино с быстрым выводом
Покеда!
mostebet [url=http://mostbet4162.ru/]mostebet[/url]
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Получить исчерпывающие сведения – http://www.anna-rossi.com/b15
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Провести детальное исследование – https://marina-havelauen.de/marina-havelauen-_-5-sterne-hafen-in-berlin-und-brandenburg-12
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Подробная информация доступна по запросу – https://www.contact-interiors.com/2021/08/20/bloomberg-smart-cities
pin up yutuq olish yo‘li [url=www.pinup5004.ru]www.pinup5004.ru[/url]
Первая помощь детям https://firstaidkids.ru правила оказания при травмах, ожогах, удушье и других ситуациях. Пошаговые инструкции, советы врачей и полезная информация для родителей.
Pretty! This has been an incredibly wonderful article. Thanks for supplying these details.
https://shop4me.in.ua/bestselling-bilead-2023.html
Студия иностранных языков https://whats-up-studiya-inostrannyh-yazykov.ru обучение английскому, немецкому, французскому и другим языкам. Индивидуальные и групповые занятия, современные методики и опытные преподаватели.
pin up ilova promo bilan [url=www.pinup5001.ru]www.pinup5001.ru[/url]
[url=https://newsprom.online/news/Obschestvo/251446.html]Смотреть Кино онлайн[/url] стало удобным и простым занятием, ведь в онлайн-кинотеатрах доступны премьеры и классика на любой вкус. Больше нет необходимости качать торренты или искать DVD — любое кино открывается мгновенно. Здесь можно найти мелодрамы, ужасы, триллеры и фантастику. Киноманы смогут открыть для себя редкие авторские работы. Современные платформы предлагают 4K и отличное звучание. Смотреть удобно дома, в поездке или даже на работе. Некоторые сервисы дают доступ без регистрации вообще. Бесплатные версии отлично подходят для быстрого просмотра. Подписка открывает полный каталог без ограничений. В библиотеке найдётся кино для всей семьи и друзей. Например, вечером можно устроить просмотр комедии. Онлайн-кинотеатр заменяет поход в обычный кинотеатр. Достаточно открыть сайт и выбрать фильм. Кино онлайн подходит для отдыха, учебы или работы над языками. Онлайн-просмотр — это свобода выбора и удобство. Неважно, где вы находитесь — дома или в дороге. Каждый день появляются новые релизы и сериалы. Таким образом, смотреть фильмы онлайн — это удобно, современно и интересно.
купить диплом спб занесением реестр [url=www.arus-diplom32.ru/]купить диплом спб занесением реестр[/url] .
[url=https://newsprom.online/news/Obschestvo/251446.html]Смотреть Кино онлайн[/url] теперь можно без лишних хлопот и затрат, ведь платформы для просмотра постоянно обновляют базы фильмов и сериалов. Забудьте о поиске записей по телевизору или старых носителях — всё доступно в один клик. Онлайн-платформы предлагают разные жанры: комедии, боевики, драмы. Киноманы смогут открыть для себя редкие авторские работы. Современные платформы предлагают 4K и отличное звучание. Смотреть удобно дома, в поездке или даже на работе. Некоторые сервисы дают доступ без регистрации вообще. Многие платформы делают подборку бесплатных фильмов. А для ценителей высокого качества и удобства есть премиум-подписки. В библиотеке найдётся кино для всей семьи и друзей. В выходные — выбрать драму или приключение. Это современный способ провести досуг. Всё, что требуется — интернет и желание смотреть. Кино онлайн подходит для отдыха, учебы или работы над языками. Онлайн-просмотр — это свобода выбора и удобство. Главное — включить устройство и насладиться просмотром. Каждый день появляются новые релизы и сериалы. Онлайн-кинотеатр становится лучшим выбором для отдыха.
mostbet yangi promo kod [url=https://mostbet4161.ru]mostbet yangi promo kod[/url]
[url=https://magicampat.ru/]Задать вопрос гадалке онлайн[/url] сегодня стало невероятно просто благодаря современным сервисам, которые позволяют каждому интересующемуся получить консультацию в удобное время прямо из дома. Если раньше для того, чтобы пообщаться с гадалкой приходилось ехать в другой город или искать знакомых, то теперь достаточно лишь подключиться к интернету и написать интересующую вас тему. Многие онлайн гадалки предлагают разные форматы общения: от переписки до аудиоразговора, что делает процесс максимально удобным для каждого. Обращаясь к гадалке через интернет, вы можете получить разное толкование: кто-то работает с картами Таро, кто-то предпочитает астрологию, а есть и те, кто использует древние ритуалы и техники интуитивного чтения. Самое главное, что вы можете получить ответ у гадалки о том, что действительно волнует именно вас: будь то семейная жизнь, карьера, будущее или энергетика. В отличие от стандартных статей и советов, которые можно найти в интернете, онлайн гадалка дает индивидуальное толкование, ориентируясь на вашу ситуацию. Многие пользователи отмечают, что возможность попробовать бесплатное гадание онлайн помогает им сначала проверить сервис, а затем при необходимости перейти к более глубоким и развернутым консультациям. Подобный формат удобен еще и тем, что вам не нужно тратить время на дорогу и организацию встречи — вы получаете доступ к тайнам будущего за считанные минуты. Ища предсказание онлайн, вы сами выбираете формат, продолжительность и глубину консультации. Кому-то достаточно пары слов, а кому-то требуется подробный разбор ситуации с рекомендациями. Гадалки онлайн умеют не только отвечать на вопросы, но и направлять в правильное русло, помогать человеку найти силы и уверенность. Сегодня такие сервисы становятся все более популярными, так как соединяют древние знания и современные технологии, позволяя человеку чувствовать себя ближе к мистике прямо через экран. Если вы давно хотели попробовать гадание, но не знали, с чего начать, возможность получить мгновенный ответ гадалки через интернет — это отличный шанс. Попробуйте и убедитесь сами, насколько точными могут быть такие консультации, и как они помогут вам в понимании себя.
https://magicampat.ru/
[url=https://magicampat.ru/]Задать вопрос гадалке онлайн[/url] сегодня стало невероятно просто благодаря современным сервисам, которые позволяют каждому интересующемуся получить консультацию в реальном времени прямо из дома. Если раньше для того, чтобы задать свой вопрос приходилось ехать в другой город или искать знакомых, то теперь достаточно лишь подключиться к интернету и написать интересующую вас тему. Многие специалисты по картам и астрологии предлагают разные форматы общения: от чата до живого общения, что делает процесс максимально комфортным для каждого. Задавая вопрос гадалке онлайн, вы можете получить разное толкование: кто-то работает с картами Таро, кто-то предпочитает астрологию, а есть и те, кто использует древние ритуалы и техники интуитивного чтения. Самое главное, что вы можете получить ответ у гадалки о том, что действительно волнует именно вас: будь то любовь, деньги, судьба или здоровье. В отличие от стандартных статей и советов, которые можно найти в интернете, онлайн гадалка дает индивидуальное толкование, ориентируясь на вашу ситуацию. Многие пользователи отмечают, что возможность попробовать бесплатное гадание онлайн помогает им сначала проверить сервис, а затем при необходимости перейти к более глубоким и развернутым консультациям. Подобный формат удобен еще и тем, что вам не нужно тратить время на дорогу и организацию встречи — вы получаете доступ к тайнам будущего за считанные минуты. Общаясь с гадалкой онлайн, вы сами выбираете формат, продолжительность и глубину консультации. Кому-то достаточно пары слов, а кому-то требуется подробный разбор ситуации с рекомендациями. Гадалки онлайн умеют не только отвечать на вопросы, но и направлять в правильное русло, помогать человеку найти силы и уверенность. Сегодня такие сервисы становятся все более популярными, так как соединяют древние знания и современные технологии, позволяя человеку чувствовать себя частью волшебства прямо через экран. Если вы давно хотели попробовать гадание, но не знали, с чего начать, возможность получить мгновенный ответ гадалки через интернет — это отличный шанс. Попробуйте и убедитесь сами, насколько глубокими могут быть такие консультации, и как они помогут вам в принятии решений.
https://magicampat.ru/
[url=https://magicampat.ru/]Спросить гадалку через интернет[/url] сегодня стало невероятно просто благодаря современным сервисам, которые позволяют каждому пользователю получить консультацию в удобное время прямо из дома. Если раньше для того, чтобы задать свой вопрос приходилось ехать в другой город или искать знакомых, то теперь достаточно лишь зайти на платформу и написать интересующую вас тему. Многие специалисты по картам и астрологии предлагают разные форматы общения: от переписки до аудиоразговора, что делает процесс максимально удобным для каждого. Задавая вопрос гадалке онлайн, вы можете получить разное толкование: кто-то работает с картами Таро, кто-то предпочитает астрологию, а есть и те, кто использует древние ритуалы и техники интуитивного чтения. Самое главное, что вы можете получить ответ у гадалки о том, что действительно волнует именно вас: будь то отношения, карьера, жизненный путь или здоровье. В отличие от стандартных статей и советов, которые можно найти в интернете, онлайн гадалка дает личную подсказку, ориентируясь на вашу ситуацию. Многие пользователи отмечают, что возможность пообщаться с гадалкой без оплаты помогает им сначала проверить сервис, а затем при необходимости перейти к более глубоким и развернутым консультациям. Подобный формат удобен еще и тем, что вам не нужно тратить время на дорогу и организацию встречи — вы получаете доступ к тайнам будущего за считанные минуты. Общаясь с гадалкой онлайн, вы сами выбираете формат, продолжительность и глубину консультации. Кому-то достаточно пары слов, а кому-то требуется подробный разбор ситуации с рекомендациями. Гадалки онлайн умеют не только толковать знаки, но и направлять в правильное русло, помогать человеку найти силы и уверенность. Сегодня такие сервисы становятся все более популярными, так как соединяют древние знания и современные технологии, позволяя человеку чувствовать себя ближе к мистике прямо через экран. Если вы давно хотели попробовать гадание, но не знали, с чего начать, возможность задать вопрос гадалке онлайн прямо сейчас — это отличный шанс. Попробуйте и убедитесь сами, насколько правдивыми могут быть такие консультации, и как они помогут вам в принятии решений.
https://magicampat.ru/
pin up ios yuklab olish [url=http://pinup5002.ru/]pin up ios yuklab olish[/url]
pin up promokod orqali bonus olish [url=http://pinup5003.ru]http://pinup5003.ru[/url]
mostbet kibersport uz [url=http://mostbet4161.ru/]mostbet kibersport uz[/url]
https://dadfencing.com/conroe/ Wood Privacy Fence Near Me Research all the companies within your town and those closest to you.
Мы готовы предложить документы институтов, расположенных в любом регионе РФ. Заказать диплом любого университета:
[url=http://hatchingjobs.com/companies/ukrdiplom/]купить аттестат за 11 класс в беларуси[/url]
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Самаре приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-stacionare-samara16.ru/]вывод из запоя в стационаре[/url]
Самостоятельно выйти из запоя — почти невозможно. В Самаре врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Подробнее – [url=https://vyvod-iz-zapoya-v-stacionare-samara.ru/]срочный вывод из запоя[/url]
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-v-stacionare14.ru/]вывод из запоя на дому круглосуточно нижний новгород[/url]
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Самаре приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Разобраться лучше – [url=https://vyvod-iz-zapoya-v-stacionare-samara14.ru/]нарколог на дом вывод из запоя самара[/url]
mostbet uz сом [url=https://mostbet4162.ru]mostbet uz сом[/url]
mostbet uz tennis tikish [url=https://www.mostbet4164.ru]https://www.mostbet4164.ru[/url]
https://t.me/s/Ofitsialnyy_win1
Срочный вызов сантехника https://master-expert.com в Москве на дом. Услуги сантехника: прочистка засоров, ремонт смесителей, установка приборов учета. Работаем 24/7. Недорого и с гарантией. Подробнее на сайте
Детский сад № 55 https://detsadik55.ru забота, развитие и обучение детей. Современные программы, квалифицированные воспитатели, уютные группы, безопасная среда и внимание к каждому ребёнку.
Thanks for the auspicious writeup. It in truth was once a entertainment account it. Look advanced to far brought agreeable from you! By the way, how can we keep in touch?
https://http-kra38.cc/
спорт онлайн [url=http://novosti-sporta-11.ru]http://novosti-sporta-11.ru[/url] .
дом под ключ [url=http://www.stroitelstvo-domov-irkutsk-1.ru]http://www.stroitelstvo-domov-irkutsk-1.ru[/url] .
sportandbets [url=https://sportbets32.ru/]https://sportbets32.ru/[/url] .
строительство дома под ключ [url=http://stroitelstvo-domov-irkutsk-6.ru]строительство дома под ключ[/url] .
млстбет [url=http://mostbet4163.ru/]http://mostbet4163.ru/[/url]
перевод договора с азербайджанского на русский [url=http://onlineperevodchik.ru]http://onlineperevodchik.ru[/url] .
новости тенниса [url=https://www.novosti-sporta-12.ru]новости тенниса[/url] .
вывод из запоя клиника москва [url=www.narkologicheskaya-klinika-11.ru]www.narkologicheskaya-klinika-11.ru[/url] .
pin up [url=pinup5004.ru]pinup5004.ru[/url]
wood gate on chain link fence Wood Horse Fence Cost This type of fencing can keep your animals safe.
кайтсёрфинг
В Нижнем Новгороде решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-stacionare14.ru/]в нижнем новгороде[/url]
stavkiprognozy [url=https://stavki-prognozy-one.ru]https://stavki-prognozy-one.ru[/url] .
mostbet ilovasi [url=https://mostbet4164.ru/]https://mostbet4164.ru/[/url]
Когда организм на пределе, важна срочная помощь в Самаре — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-v-stacionare-samara.ru/]срочный вывод из запоя[/url]
https://t.me/s/Official_1xbet_1xbet
купить аттестаты за 11 класс спб [url=http://arus-diplom23.ru/]http://arus-diplom23.ru/[/url] .
Мы готовы предложить дипломы любой профессии по выгодным тарифам. Заказ диплома, подтверждающего обучение в ВУЗе, – это выгодное решение. Купить диплом ВУЗа: [url=http://parsajobs.com/employer/diplomy-grupps/]parsajobs.com/employer/diplomy-grupps[/url]
Stavki Prognozy [url=https://stavki-prognozy-1.ru/]stavki-prognozy-1.ru[/url] .
Промышленная безопасность https://аттестация-промбезопасность.рф курсы и обучение под ключ. Подготовка к проверке Ростехнадзора, повышение квалификации и сертификация специалистов предприятий.
Автомобили на заказ https://avto-iz-kitaya1.ru поиск, проверка, покупка и доставка. Китай и Корея. Индивидуальный подбор под бюджет и пожелания клиента, полное сопровождение сделки.
mostbet ios [url=http://mostbet4163.ru/]mostbet ios[/url]
купить гашиш героин гашиш шишки купить
купить наркотики меф кракен купить меф
pin up ilova ishlamayapti [url=https://pinup5001.ru/]https://pinup5001.ru/[/url]
пин ап пополнение счёта [url=pinup5005.ru]пин ап пополнение счёта[/url]
Авто из Китая https://avto-iz-kitaya2.ru на заказ под ключ: подбор, проверка, доставка и растаможка. Новые и подержанные автомобили, выгодные цены и полное сопровождение сделки.
pin up aviator demo [url=https://pinup5005.ru]pin up aviator demo[/url]
Приветствую!
[url=https://pro-telefony.ru/chto-delat-esli-kupil-seryj-telefon/]Чем отличается серый телефон от официального?[/url] Узнайте, чем опасен “серый” импорт и как не превратить новый гаджет в бесполезный кирпич.
Переходи: – https://pro-telefony.ru/chto-delat-esli-kupil-seryj-telefon/
Как зарегистрировать серый телефон
Серый телефон как проверить
Серый телефон это
Покеда!
наркология [url=www.narkologicheskaya-klinika-11.ru/]www.narkologicheskaya-klinika-11.ru/[/url] .
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Неизвестные факты о… – https://www.beritaterkini.biz/baru-berhenti-merokokperbanyak-makan-tomat
цветочный горшок высокий напольный [url=http://www.kashpo-napolnoe-moskva.ru]http://www.kashpo-napolnoe-moskva.ru[/url] .
Приветствую!
Чувствуешь, что засиделся, но не можешь сдвинуться с места? [url=https://zhit-legche.ru/hochu-uvolitsya-no-ne-mogu-reshitsya/]как уволиться с работы[/url]
Переходи: – https://zhit-legche.ru/hochu-uvolitsya-no-ne-mogu-reshitsya/
как уволиться с работы
хочу уволится с работы
как пережить несправедливое увольнение
Покеда!
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Ознакомиться с полной информацией – https://wafudalharam.com/2022/07/01/5-most-beautiful-islands-in-asia
купить аттестат в перми за 11 класс [url=www.arus-diplom21.ru/]купить аттестат в перми за 11 класс[/url] .
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Все материалы собраны здесь – https://digibazar.net/2024/08/31/do-you-know-how-iverheal-fights-parasites
Basic strategy’s all about minimizing the house edge, right? Seeing platforms like 77jl game focus on a smooth experience – quick login, easy app download – builds trust, which is key for any player. Legit platforms matter!
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Погрузиться в научную дискуссию – https://lasoledad.mx/2017/11/21/stay-tuned-for-new-hookah-flavors
Interesting read! Seeing more platforms prioritize security – crucial in iGaming. The Philippines market is definitely heating up. Considering a secure experience? Check out jollyph download for regulated play & strong verification processes. Seems like a solid approach!
Авто из Китая под заказ https://dostavka-avto-china.ru кроссоверы, седаны, электромобили и премиальные модели. Индивидуальный подбор, проверка, сопровождение сделки и доставка в ваш город.
Автомобили из Китая на заказ https://avto-iz-kitaya2.ru подбор, покупка и доставка. Полный цикл услуг: диагностика, растаможка, постановка на учёт и гарантия качества.
Solid article! Thinking about bankroll management & game selection is key, especially with platforms like superph22 offering diverse options. Legit sites prioritizing security are a must for peace of mind! 👍
В-четвёртых, просветительская работа. Мы проводим лекции и семинары, направленные на повышение уровня осведомленности общества о проблемах зависимости. Это важно для формирования толерантного отношения к людям, страдающим от зависимостей.
Подробнее – https://алко-лечебница.рф/vivod-iz-zapoya-v-kruglosutochno-v-samare/
Наши наркологи придерживаются принципов уважительного и внимательного отношения к пациентам, создавая атмосферу доверия. Они проводят детальное обследование, выявляют коренные причины зависимости и разрабатывают индивидуальные стратегии лечения. Профессионализм и компетентность врачей являются ключевыми факторами успешного восстановления пациентов.
Детальнее – https://нарко-фильтр.рф/vivod-iz-zapoya-v-stacionare-v-rostove-na-donu/
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Более того — здесь – https://www.dienst-nl.nl/landing-page-with-offers-for-layout-builder
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Только факты! – http://www.profdiles.ru
Took me time to read all the comments, but I really enjoyed the article. It proved to be Very helpful to me and I am sure to all the commenters here It’s always nice when you can not only be informed, but also entertained I’m sure you had fun writing this article.
Когда организм на пределе, важна срочная помощь в Нижнем Новгороде — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Углубиться в тему – [url=https://vyvod-iz-zapoya-v-stacionare13.ru/]помощь вывод из запоя нижний новгород[/url]
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Нижнем Новгороде приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Узнать больше – [url=https://vyvod-iz-zapoya-v-stacionare16.ru/]анонимный вывод из запоя нижний новгород[/url]
https://t.me/s/Official_MARTIN_MARTIN
купить проведенный диплом высокие [url=arus-diplom31.ru]купить проведенный диплом высокие[/url] .
Наркологическая клиника “Маяк надежды” — специализированное медицинское учреждение, предназначенное для оказания помощи лицам, страдающим от алкогольной и наркотической зависимости. Наша цель — предоставить эффективные методы лечения и поддержку, чтобы помочь пациентам преодолеть пагубное пристрастие и вернуть их к здоровой и полноценной жизни.
Подробнее тут – http://алко-лечение24.рф/vivod-iz-zapoya-cena-v-Sankt-Peterburge/
mostbet əlaqə [url=https://mostbet4137.ru]https://mostbet4137.ru[/url]
купить диплом об образовании с занесением в реестр [url=http://www.arus-diplom33.ru]купить диплом об образовании с занесением в реестр[/url] .
перевод договора с иврита на русский [url=http://onlineperevodchik.ru/]http://onlineperevodchik.ru/[/url] .
В основе нашей методики — комплексный подход, сочетающий медицинскую точку зрения и психологические технологии. Мы не ограничиваемся снятием абстиненции: задача клиники — помочь пациенту обрести новую мотивацию, развить навыки противостояния стрессам и возобновить социальную активность. Работа строится на трёх ключевых принципах:
Разобраться лучше – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологические клиники алкоголизм мытищи[/url]
Заказать авто из Китая https://dostavka-avto-china2.ru новые автомобили с гарантией, выгодные цены и проверенные поставщики. Доставка, таможня и оформление всех документов под ключ.
лечение запоя
narkolog-krasnodar011.ru
вывод из запоя
экстренный вывод из запоя
narkolog-krasnodar011.ru
вывод из запоя
Медицинские учреждения в Красноярске предлагают различные варианты лечения, включая инъекции для снятия запойного состояния, которые могут включать минералы и препараты для снятия симптомов. Сравнение клиник позволяет выбрать наиболее подходящий вариант с учетом стоимости и качества обслуживания. Круглосуточная помощь доступна в многих клиниках.При определении медицинского учреждения стоит учитывать отзывы пациентов и опыт врачей. Консультации нарколога помогут определить оптимальный план лечения алкоголизма. Анонимное лечение также является важным аспектом, так как многие пациенты предпочитают скрыть свою проблему.После завершения запойного состояния требует комплексного подхода, включая реабилитацию алкоголиков и дальнейшее наблюдение за состоянием пациента. Таким образом, услуги нарколога, такие как дополнительные процедуры вывода из запоя и капельницы от запоя, играют ключевую роль в процессе восстановления. вывод из запоя круглосуточно Красноярск
купить диплом в сумах [url=https://educ-ua1.ru/]https://educ-ua1.ru/[/url] .
наркологические клиники в москве [url=https://narkologicheskaya-klinika-12.ru]https://narkologicheskaya-klinika-12.ru[/url] .
реабилитация зависимых [url=narkologicheskaya-klinika-13.ru]narkologicheskaya-klinika-13.ru[/url] .
mostbet uz registratsiya [url=http://mostbet4162.ru/]mostbet uz registratsiya[/url]
купить диплом в кургане занесением в реестр [url=http://arus-diplom32.ru/]купить диплом в кургане занесением в реестр[/url] .
mostbet az bonus 500 [url=https://mostbet4139.ru/]https://mostbet4139.ru/[/url]
Google Analytics Alternative
mostbet tennis mərcləri [url=www.mostbet4136.ru]www.mostbet4136.ru[/url]
вывод из запоя круглосуточно краснодар
narkolog-krasnodar012.ru
вывод из запоя цена
Обращение к наркологу в Красноярске — ключ к вашему восстановлению. Наркологические услуги, такие как безопасный вывод из запоя, обеспечивают необходимую медицинскую помощь. Квалифицированный нарколог осуществляет детоксикацию организма, что является важнейшим аспектом заботы о здоровье пациента. Индивидуальная программа лечения алкоголизма способствует более высокому уровню успешности восстановления после алкогольной зависимости. вызов нарколога Красноярск Недостаточно лишь медицинских процедур для помощи при запое. Консультация врача-нарколога помогает определить дальнейшие шаги, включая реабилитацию зависимых. Вызов специалиста на дом делает процесс менее стрессовым и более комфортным. Заботьтесь о своем здоровье и не откладывайте обращение за помощью!
как купить аттестат за 11 класс форум [url=https://arus-diplom21.ru/]как купить аттестат за 11 класс форум[/url] .
mostbet mobil tətbiqi [url=http://mostbet4140.ru]http://mostbet4140.ru[/url]
Показана в тяжёлых случаях или при наличии сопутствующих заболеваний. Лечение проходит под круглосуточным наблюдением врачей и медсестёр с постоянной корректировкой терапии.
Ознакомиться с деталями – [url=https://narko-zakodirovan2.ru/]вывод из запоя в стационаре[/url]
sport bets [url=sportbets32.ru]sportbets32.ru[/url] .
мостбет на айфон скачать [url=http://mostbet4161.ru]http://mostbet4161.ru[/url]
вывод из запоя
narkolog-krasnodar012.ru
вывод из запоя круглосуточно краснодар
Мы можем предложить документы институтов, расположенных на территории всей России. Заказать диплом университета:
[url=http://phpbb.com/]купить аттестат 11 класса в нижневартовске[/url]
mostbet əlaqə [url=http://mostbet4137.ru/]http://mostbet4137.ru/[/url]
https://www.gabitos.com/eldespertarsai/template.php?nm=1756206066
строительство дома [url=stroitelstvo-domov-irkutsk-6.ru]строительство дома[/url] .
mostbet uz.com [url=https://www.mostbet4161.ru]https://www.mostbet4161.ru[/url]
сколько стоит купить диплом [url=https://educ-ua1.ru/]сколько стоит купить диплом[/url] .
Авто на заказ https://dostavka-avto-russia.ru поиск, диагностика и сопровождение сделки. Машины из Европы, Кореи, Китая и США. Доставка, растаможка и постановка на учёт.
Автомобили на заказ https://dostavka-avto-russia5.ru профессиональный подбор, юридическая проверка, доставка и растаможка. Индивидуальные решения для каждого клиента.
купить аттестат об окончании 11 классов занесением в реестр [url=arus-diplom23.ru]arus-diplom23.ru[/url] .
Затяжной запой опасен для жизни. Врачи наркологической клиники в Самаре проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Узнать больше – [url=https://vyvod-iz-zapoya-v-stacionare-samara.ru/]помощь вывод из запоя самара[/url]
экстренный вывод из запоя краснодар
narkolog-krasnodar013.ru
вывод из запоя круглосуточно краснодар
TD150-33/4SWSCJ Насос вертикальный Ин-лайн 30 кВт, 12 бар, 3×380 В, раб. колесо нерж. ст. SS304, 110*С
mostbet qeydiyyat linki [url=https://www.mostbet4140.ru]https://www.mostbet4140.ru[/url]
можно ли купить диплом в реестре [url=truegamerp.rx22.ru/viewtopic.php?f=50&t=11513]можно ли купить диплом в реестре[/url] .
москва купить диплом о высшем образовании с занесением в реестр [url=www.arus-diplom34.ru/]москва купить диплом о высшем образовании с занесением в реестр[/url] .
купить диплом спб с занесением в реестр [url=https://arus-diplom33.ru]https://arus-diplom33.ru[/url] .
Капельницы от похмелья на дому в Красноярске – является эффективным способом для быстрого восстановления после вечеринки. Состояние похмелья сопровождается признаками‚ такими как боль в голове‚ усталость и недостаток жидкости; инфузионная терапия с использованием капельниц помогает быстрому улучшению самочувствия‚ компенсируя дефицит витаминов и минералов. Клиника на дому предлагает услуги квалифицированных специалистов‚ которые проводят процедуру безопасно и в комфортных условиях. Процесс инфузии с помощью капельниц помогает устранить дискомфорт и значительно ускоряет восстановление. Помощь врачей на дому – это удобный выбор для тех‚ кто имеет проблемы с алкоголем или желает быстро избавиться от симптомов похмелья. Если вам нужно быстро восстановиться и вернуть здоровье‚ вы можете обратиться за помощью на vivod-iz-zapoya-krasnoyarsk012.ru. Помните‚ что при серьезных симптомах необходимо вызывать скорую помощь.
mostbet bonus [url=www.mostbet4162.ru]mostbet bonus[/url]
is porn bad for kids
Приобрести диплом ВУЗа!
Наши специалисты предлагаютбыстро приобрести диплом, который выполняется на оригинальном бланке и заверен печатями, штампами, подписями должностных лиц. Наш диплом пройдет любые проверки, даже при помощи профессионального оборудования. Решайте свои задачи максимально быстро с нашим сервисом- [url=http://slliver.getbb.ru/posting.php?mode=post&f=62&sid=d5f27e9213a2e3675d194d93322b925c/]slliver.getbb.ru/posting.php?mode=post&f=62&sid=d5f27e9213a2e3675d194d93322b925c[/url]
экстренный вывод из запоя
narkolog-krasnodar013.ru
вывод из запоя
купил аттестат за 11 класс отзывы [url=http://arus-diplom24.ru]купил аттестат за 11 класс отзывы[/url] .
купить аттестат за 11 класс абакан [url=arus-diplom25.ru]купить аттестат за 11 класс абакан[/url] .
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Нижнем Новгороде приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-v-stacionare.ru/]вывод из запоя в стационаре нижний новгород[/url]
иркутск строительство домов [url=http://stroitelstvo-domov-irkutsk-1.ru/]http://stroitelstvo-domov-irkutsk-1.ru/[/url] .
Машины на заказ https://prignat-avto7.ru поиск, диагностика и доставка автомобилей. Индивидуальный подбор, проверенные поставщики и прозрачные условия покупки.
mostbet versi mobile [url=https://www.mostbet4163.ru]https://www.mostbet4163.ru[/url]
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Расширить кругозор по теме – https://www.consultrh.fr/project-details/students-success-stories
Автомобили на заказ https://prignat-mashinu7.ru подбор, проверка, доставка и оформление документов. Машины любых марок и комплектаций с гарантией качества и выгодной ценой.
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Почему это важно? – https://www.accademiainternazionalesenghor.com/articoli/discorso-tenuto-da-aime-cesaire-a-dakar-il-6-aprile-1966
Добрый день!
Тебя тоже бесит переплачивать за «имя» лекарства? [url=https://generik-info.ru/analogi-lekarstv-deshevle/]Что такое дженерики в медицине[/url]
Написал: – https://generik-info.ru/analogi-lekarstv-deshevle/
Что такое дженерики в медицине
Дженерики что это
Дженерики для чего они нужны
Удачи!
mostbet virtual idman [url=https://mostbet4139.ru]https://mostbet4139.ru[/url]
наркологичка [url=https://narkologicheskaya-klinika-13.ru/]narkologicheskaya-klinika-13.ru[/url] .
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Подробная информация доступна по запросу – http://www.careyauctioneers.ie/contacts
вывод из запоя круглосуточно краснодар
narkolog-krasnodar014.ru
вывод из запоя
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Получить исчерпывающие сведения – https://horizon-ogrodzenia.pl/jak-ogrodzic-dzialki-ze-spadkiem
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Получить исчерпывающие сведения – https://horizon-ogrodzenia.pl/jak-ogrodzic-dzialki-ze-spadkiem
вывод из запоя
vivod-iz-zapoya-smolensk013.ru
вывод из запоя
купить аттестат образование [url=https://educ-ua5.ru]купить аттестат образование[/url] .
лечение запоя краснодар
narkolog-krasnodar014.ru
экстренный вывод из запоя краснодар
Цены на ремонт https://remontkomand.kz/ru/price квартир и помещений в Алматы под ключ. Узнайте точные расценки на все виды работ — от демонтажа до чистовой отделки. Посчитайте стоимость своего ремонта заранее и убедитесь в нашей прозрачности. Никаких «сюрпризов» в итоговой смете!
https://t.me/s/Official_1win_casino_1win
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Только для своих – https://aipencraft.com/join-sofhaallow-gaming-giveaway
вывод из запоя краснодар
narkolog-krasnodar015.ru
вывод из запоя
где можно купить аттестаты 11 класса в чернушке [url=https://www.arus-diplom9.ru]где можно купить аттестаты 11 класса в чернушке[/url] .
mostbet qanday pul yechiladi [url=http://mostbet4163.ru]mostbet qanday pul yechiladi[/url]
где купить аттестат за 11 классов в красноярске [url=https://arus-diplom25.ru/]где купить аттестат за 11 классов в красноярске[/url] .
как зарегистрироваться в мостбет [url=https://mostbet4152.ru]https://mostbet4152.ru[/url]
mostbet az giriş bloku [url=http://mostbet4138.ru/]http://mostbet4138.ru/[/url]
лечение запоя
vivod-iz-zapoya-smolensk014.ru
вывод из запоя
купить аттестат за 10 11 класс отзывы [url=https://www.arus-diplom24.ru]https://www.arus-diplom24.ru[/url] .
купить диплом о среднем образовании в реестр [url=www.arus-diplom31.ru]купить диплом о среднем образовании в реестр[/url] .
mostbet qeydiyyat promo kod [url=http://mostbet4136.ru]http://mostbet4136.ru[/url]
купить диплом с занесением в реестр челябинск [url=https://www.arus-diplom32.ru]купить диплом с занесением в реестр челябинск[/url] .
скачать мостбет на андроид бесплатно старая версия [url=http://mostbet4152.ru/]http://mostbet4152.ru/[/url]
https://t.me/s/reyting_online_kazino/12/1WIN_Casino_RTP_98_8_Otsenka_9_9
купить диплом о образовании в киеве [url=www.educ-ua3.ru]купить диплом о образовании в киеве[/url] .
Вызов нарколога – важный шаг в поддержке людей с зависимостями. На сайте narkolog-tula015.ru вы имеете возможность получить информацию о способах лечения зависимостей и анонимном лечении. Помощь наркологов состоит из медицинской помощи, консультирования специалистов и медикаментозной терапии. В сложные ситуации важно не оставатся один на один с проблемой. Реабилитация наркозависимых и психотерапия при зависимости способствуют восстановлению. Родственная поддержка имеет важное значение в процессе. Профилактика наркомании и лечение алкоголизма должны находиться в центре внимания. Поддержка пациента обеспечит высокие шансы на успешное восстановление.
вывод из запоя круглосуточно краснодар
narkolog-krasnodar015.ru
вывод из запоя круглосуточно
психолог нарколог в москве [url=http://narkologicheskaya-klinika-12.ru]http://narkologicheskaya-klinika-12.ru[/url] .
Заказать диплом возможно используя официальный сайт компании. [url=http://mosdom.flybb.ru/viewtopic.php?f=2&t=642/]mosdom.flybb.ru/viewtopic.php?f=2&t=642[/url]
mostbet kazinosu [url=https://mostbet4138.ru/]https://mostbet4138.ru/[/url]
аттестат 11 класс купить уфа [url=http://www.arus-diplom23.ru]аттестат 11 класс купить уфа[/url] .
вывод из запоя
vivod-iz-zapoya-smolensk015.ru
лечение запоя смоленск
??? ???? 888starz ????? ?? ???? ??????? ?? ???? ??????? ???????????. ????? ????????? ?????? ????????? ?? 888starz.
??? ????? 888starz ??????? ????? ?????? ??? ???? ???????. ???? 888starz ?????? ????? ?? ???????? ??? ?? ??? ??????? ?????????? ???????? .
????? ???? 888starz ?????? ????? ??????? . ??? ??????? ?? ?????? ???????? ????? ????? .
????? ????????? ?? ?????? ????? ??? ??????? ?? 888starz. ????? ?????? ????????? ???? ????? 888starz ???? ???? ?? ????????.
٨٨٨ ستارز [url=https://www.888starz-africa.pro/]https://888starz-africa.pro/[/url]
Купить диплом о высшем образовании можем помочь. Как приобрести диплом техникума и колледжа в Кирове? – [url=http://diplomybox.com/kupit-diplom-tekhnikuma-kolledzha-v-kirove/]diplomybox.com/kupit-diplom-tekhnikuma-kolledzha-v-kirove[/url]
где можно купить аттестаты 11 класс в таджикистан [url=www.arus-diplom22.ru/]где можно купить аттестаты 11 класс в таджикистан[/url] .
Специалист по наркологии круглосуточно предоставляет экстренную наркологическую помощь при ситуациях, связанных с наркотической зависимостью. На сайте narkolog-tula016.ru вы можете получить консультацию врачукоторый оценит вашу ситуацию и проведет диагностику наркозависимости и предложит индивидуальную программу лечения. Центр наркологии предлагает медицинскую поддержку и лечение с повышенной конфиденциальностью. Реабилитация зависимых включает психотерапию зависимостей и помощь при алкоголизмеа также консультации и помощь для семьи на всех этапах лечения. Обратитесь за помощью уже сегодня!
Запойный алкогольный синдром, серьезная проблема, требующая немедленного вмешательства. В Туле предлагаются разные варианты анонимного вывода из запоя. Наркологические клиники предлагают медицинскую помощь при запоях, включая программы детоксикации и психотерапию для алкоголиков. вывод из запоя тула Если вам или вашим родным нужна поддержка, обратитесь в центры по лечению зависимостей с выездными специалистами. Консультации по алкоголизму и группы поддержки для близких будут полезны. Реабилитация в Туле включает анонимные алкоголики и программы восстановления после запоя. Поддержка в трудные времена всегда доступна.
купить аттестат за 11 классов екатеринбург [url=http://www.arus-diplom23.ru]купить аттестат за 11 классов екатеринбург[/url] .
я купил диплом с проводкой [url=https://arus-diplom33.ru]я купил диплом с проводкой[/url] .
Капельница от похмелья на дому в Красноярске – является оптимальным решением для восстановления здоровья. Состояние похмелья сопровождается признаками‚ такими как головная боль‚ слабость и обезвоживание; процедура капельницы способствует быстрому улучшению самочувствия‚ восполняя дефицит витаминов и минералов. Клиника на дому предоставляет услуги медиков‚ которые проводят процедуру безопасно и комфортно. Лечение капельницами помогает устранить дискомфорт и ускоряет процесс восстановления. Помощь врачей на дому – такой удобный вариант для тех‚ кто страдает от алкозависимости или просто хочет облегчить симптомы похмелья. Если вы хотите быстро улучшить свое самочувствие и восстановить здоровье‚ не стесняйтесь обращаться на vivod-iz-zapoya-krasnoyarsk010.ru. Не забывайте‚ что при тяжелых состояниях следует вызывать скорую помощь на дому.
На данном этапе врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ позволяет оперативно определить оптимальную схему детоксикации и минимизировать риск осложнений.
Выяснить больше – [url=https://reabcentr-narko.ru/]вывод из запоя на дому в твери[/url]
Купить диплом о высшем образовании!
Наши специалисты предлагаютвыгодно и быстро купить диплом, который выполняется на бланке ГОЗНАКа и заверен печатями, водяными знаками, подписями должностных лиц. Диплом способен пройти любые проверки, даже с использованием профессиональных приборов. Достигайте своих целей быстро с нашим сервисом- [url=http://social.sikatpinoy.net/blogs/new/]social.sikatpinoy.net/blogs/new[/url]
кашпо под цветы напольные [url=https://kashpo-napolnoe-moskva.ru/]кашпо под цветы напольные[/url] .
https://t.me/s/Official_1xbet_1xbet
Каждый из наших врачей не только специалист, но и психолог, способный понять переживания пациента, создать атмосферу доверия. Мы применяем индивидуальный подход, позволяя каждому пациенту чувствовать себя комфортно. Наши наркологи проводят тщательную диагностику, разрабатывают планы лечения, основываясь на данных обследования, психологическом состоянии и других факторах. Основное внимание уделяется снижению абстиненции, лечению сопутствующих заболеваний, коррекции психоэмоционального состояния.
Выяснить больше – https://alko-konsultaciya.ru/vivod-iz-zapoya-cena-v-smolenske/
купить диплом аттестат 11 класс каменск шахтинский [url=https://arus-diplom25.ru/]купить диплом аттестат 11 класс каменск шахтинский[/url] .
купить аттестат за 11 классов с занесением в реестр в [url=www.arus-diplom24.ru]купить аттестат за 11 классов с занесением в реестр в[/url] .
Прокапывание на дому — это удобное и эффективное лечение, которое даёт возможность пациентам получать инфузионную терапию в комфортной обстановке своего дома. Услуги медсестры гарантируют квалифицированное введение внутривенных инъекций, что способствует быстрому восстановлению и укреплению здоровья на дому. narkolog-tula017.ru Домашний уход включает в себя не лишь саму процедуру, но и мониторинг здоровья пациента. Это особенно важно для людей с хроническими заболеваниями или тех, кто требует профилактического ухода. При организации лечения на дому можно доверять в качественной медицинской помощи, что значительно облегчает процесс реабилитации.
Медикаментозное лечение — это еще один важный этап. Оно включает использование препаратов, которые помогают пациенту восстановиться как физически, так и психологически. Нарколог контролирует процесс лечения, чтобы исключить побочные эффекты и скорректировать терапию при необходимости.
Разобраться лучше – http://narcolog-na-dom-v-krasnoyarske55.ru
В современном обществе проблемы с алкоголем являются все более важными. Большое количество людей сталкиваются с алкогольной зависимостью , которая нуждаеться в оперативном вмешательстве профессионалов . Поэтому вызов нарколога на дом – это оптимальное решение . Помощь нарколога включают определение степени зависимости и лечение запойных состояний . Это позволяет быстро и эффективно помочь в выходе из запоя, минимизируя стресс для пациента . Конфиденциальное лечение алкоголизма – важный аспект , поскольку многие люди не хотят открывать свои трудности. Поддержка при алкоголизме также включает помощь близким в борьбе с алкоголизмом. Нарколог на дом предлагает консультационные услуги, что позволяет семье разобраться, как правильно общаться с зависимым. Лечение зависимостей на дому даёт возможность пройти реабилитацию от алкоголя в комфортной обстановке . Сайт narkolog-tula016.ru предоставляет сведения о вызове врача на дом , чтобы оказать помощь тем, кто в ней нуждается.
Экстренная наркологическая помощь в Красноярске: капельница для избавления от запоя Зависимость от алкоголя — это серьезный недуг, который нуждается в квалифицированной помощи. Нарколог на дом предлагает услуги, включая капельницу от запоя, которая помогает восстановить организм после длительного употребления алкоголя. К основным симптомам алкогольной зависимости относятся: дрожь, повышенная потливость и чувство тревоги. Медицинская помощь при запое включает дезинтоксикацию организма и восстановление. Консультация нарколога поможет определить подходящий план лечения алкоголизма. Неотложная помощь при алкоголизме, ориентированная на вывод из запоя, может избежать тяжелых осложнений. Профилактика запойных состояний и психотерапевтические методы для зависимых — ключевые элементы успешного лечения зависимостей, обеспечивающие устойчивые результаты. Услуги нарколога в Красноярске доступны круглосуточно, что позволяет получить необходимую помощь в любое время. Не откладывайте лечение — обратитесь к специалистам уже сегодня!
купить диплом в черкассах [url=http://educ-ua4.ru]http://educ-ua4.ru[/url] .
купить диплом магистра цены [url=https://educ-ua5.ru/]купить диплом магистра цены[/url] .
В Самаре решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-stacionare-samara11.ru/]врач вывод из запоя[/url]
Добрый день!
Процентная ставка в 292% годовых — это не шутка. [url=https://kredit-bez-slov.ru/kak-bystro-sdelat-kreditnuyu-istoriyu/]Кредит с плохой историей где взять[/url]
Здесь подробней: – https://kredit-bez-slov.ru/kak-bystro-sdelat-kreditnuyu-istoriyu/
Дженерики что это такое
Что такое дженерики лекарства
Что такое дженерики простыми словами
Пока!
Капельница от запоя в Туле: что нужно знать Если вы или ваш близкий столкнулись с проблемой алкогольной зависимости, важно понимать, что существуют эффективные методы для лечения. В Туле нарколог на дом анонимно предоставляет услуги по выведению из запоя и капельницы на дому. Эти процедуры помогают восстановить здоровье после запоя и улучшают общее самочувствие. Капельницы помогают избавиться от симптомов абстиненции, восполняя недостаток витаминов и электролитов в организме. Процесс лечения запоя начинается с консультации у нарколога, который проведет оценку состояния пациента и предложит соответствующую медикаментозную терапию. Анонимная помощь предоставляется в наркологической клинике Тула, где также предлагаются программы реабилитации от запойного поведения. нарколог на дом анонимно тула Важно знать признаки алкогольной зависимости, чтобы вовремя обратиться за медицинской помощью. Лечение в домашних условиях возможно, но требует контроля специалиста. Комплексный подход, включающий поддержку близких и помощь специалистов в области наркологии в Туле, является ключом к успешному восстановлению после запоя.
купить диплом москва с занесением в реестр [url=http://www.arus-diplom31.ru]купить диплом москва с занесением в реестр[/url] .
аттестат 11 класс купить обложку [url=www.arus-diplom24.ru]аттестат 11 класс купить обложку[/url] .
Алкогольный запой — это серьезная проблема, требующая квалифицированной поддержки. Вызвать нарколога на дом — это комфортный вариант получить необходимую медицинскую помощь. Капельница при запое помогают быстро вывести токсины из организма, обеспечивая детоксикацию и возвращение к нормальному состоянию. Лечение алкоголизма включает в себя лекарственные средства и психологическую поддержку. Нарколог на дом проводит оценку состояния пациента и назначает индивидуальный план лечения, который может включать альтернативные методы, такие как травяные настои или психологические сеансы. Восстановление после запоя часто требует комплексного подхода. Преодоление запойного состояния должно сопровождатся не только физической реабилитацией, но и психо-эмоциональным восстановлением; Реабилитация после алкоголизма, это долгий процесс, где важна поддержка в период запоя и поддержка родных. Важно осознавать, что эффективное преодоление проблемы зависит от желания пациента меняться и стремления изменить свою жизнь.
Срочная помощь при запое: капельница на дому в Туле Проблема алкогольной зависимости требует квалифицированного подхода. При запойном состоянии наблюдаются тяжелые симптомы‚ такие как тремор‚ повышенная потливость‚ беспокойство и‚ порой‚ галлюцинации. В таких случаях нужна помощь нарколога‚ который обеспечит медицинскую поддержку. Лечение на дому имеет свои плюсы: пациент остается в комфортной обстановке‚ что способствует более быстрому восстановлению. Кроме того‚ стоит обратить внимание на профилактику рецидивов‚ чтобы избежать новых запоев. Обращаясь за помощью к специалистам‚ вы получите не только капельницы для детоксикации‚ но и комплексное лечение алкоголизма‚ направленное на полное восстановление.
Капельница от запоя на дому — является комфортный также эффективный метод помощи при алкогольной интоксикации. В отличие от стационарного лечение в стационаре, лечение запоя на дому дает возможность пациенту оставаться в привычной обстановке, что снижает стресс а также способствует восстановлению.Врач нарколог на дом Тула предлагает квалифицированные услуги врача-нарколога, выполняя процедуры по избавлению от зависимости и прекращению запойного состояния. Процедуры капельниц способствуют быстрому снятию симптомов запойного состояния, улучшая самочувствие пациента; Также данные процедуры обеспечивают необходимую гидратацию а также восстановление витаминного баланса. Домовая детоксикация подходит тем, кто не может или не желает проходить лечение в стационаре. Тем не менее, в случае серьезных осложнений требуется более интенсивное лечение. Нарколог на дом поможет организовать реабилитацию пациентов, включая психотерапию при зависимости, что существенно увеличивает вероятность успешного выздоровления после запойного состояния.
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Самаре приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Выяснить больше – [url=https://vyvod-iz-zapoya-v-stacionare-samara11.ru/]вывод из запоя с выездом самара[/url]
купить проведенный диплом провести [url=www.arus-diplom35.ru/]купить проведенный диплом провести[/url] .
Специалисты нашего центра обладают опытом работы с различными зависимостями, начиная от алкоголизма и заканчивая игроманией. Мы понимаем, что поддержка семьи также играет важную роль в процессе лечения, поэтому включаем близких в терапевтические мероприятия. Поддержка родных помогает пациентам не только преодолеть трудные моменты, но и справиться с эмоциональными переживаниями.
Подробнее можно узнать тут – https://alko-konsultaciya.ru/vivod-iz-zapoya-v-kruglosutochno-v-smolenske/
Кроме того, врач оказывает психологическую поддержку, которая помогает пациенту справиться с чувством тревоги, депрессией и страхом, возникающими на фоне зависимости.
Выяснить больше – [url=https://narcolog-na-dom-v-krasnoyarske55.ru/]вызов нарколога на дом красноярский край[/url]
купить аттестат за 11 класс в киеве [url=www.arus-diplom23.ru]www.arus-diplom23.ru[/url] .
вывод из запоя круглосуточно смоленск
vivod-iz-zapoya-smolensk013.ru
экстренный вывод из запоя
Самостоятельно выйти из запоя — почти невозможно. В Самаре врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-v-stacionare-samara16.ru/]вывод из запоя с выездом[/url]
Получи лучшие казинo России 2025 года! ТОП-5 проверенных платформ с лицензией для игры на реальные деньги. Надежные выплаты за 24 часа, бонусы до 100000 рублей, минимальные ставки от 10 рублей! Играйте в топовые слоты, автоматы и live-казинo с максимальны
https://t.me/s/RuCasino_top
Капельница для лечения похмелья – это эффективным способом лечения, который помогает устранить симптомы алкогольной интоксикации. Состояние похмелья сопровождается недостатком жидкости, что проявляется болью в голове, тошнотой и общей слабостью. Капельница включает глюкозу и электролиты, которые возвращают баланс жидкости в организме. Лечение похмелья с помощью капельницы позволяет оперативно убрать неприятные ощущения, обеспечивая очищение организма. Внутривенное введение жидкости ускоряет процесс восстановления. Капельница в домашних условиях может оказаться полезной, но требуется консультация врача для правильного подбора компонентов. Существуют и народные средства: различные травы, например, мяту или зверобой, которые помогают улучшить состояние. Однако капельница остается наиболее быстрым и надежным способом облегчить страдания после пьянки. На сайте narkolog-tula018.ru можно найти информацию о разных типах капельниц и их эффекте на здоровье.
تُعرف 888starz بأنها وجهة مميزة لعشاق الألعاب والمراهنات. انطلقت هذه المنصة لتلبية احتياجات اللاعبين المحترفين والهواة . تشمل قائمة الألعاب في 888starz العديد من الخيارات المثيرة .
قسم الألعاب. تتمتع الألعاب بتجربة مستخدم سلسة ومرنة . تقدم المنصة مسابقات دورية حيث يمكن للاعبين استعراض مهاراتهم .
تتيح 888starz للمستخدمين المراهنة على الأحداث الرياضية الكبرى. تقدم 888starz تحليلات دقيقة لمساعدة اللاعبين في اتخاذ قراراتهم. يمكن للاعبين الاستفادة من نصائح الخبراء المتاحة على 888starz.
تعتمد 888starz تقنيات متقدمة لحماية بيانات المستخدمين . يمكن للمستخدمين التواصل مع فريق الدعم عبر الدردشة الحية أو البريد الإلكتروني . تعمل المنصة على تطوير خدماتها بناءً على ملاحظات اللاعبين .
starz 888 تحميل [url=888starz.red]https://888starz.red/[/url]
купить аттестаты в москве за 11 классов [url=https://www.arus-diplom22.ru]купить аттестаты в москве за 11 классов[/url] .
Купить диплом любого университета!
Мы предлагаембыстро и выгодно приобрести диплом, который выполнен на оригинальной бумаге и заверен мокрыми печатями, водяными знаками, подписями. Наш документ пройдет любые проверки, даже при использовании специфических приборов. Решите свои задачи быстро с нашими дипломами- [url=http://nepalaviyan.com/read-blog/777_kupit-attestat-za-11-klass.html/]nepalaviyan.com/read-blog/777_kupit-attestat-za-11-klass.html[/url]
В Самаре решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Узнать больше – [url=https://vyvod-iz-zapoya-v-stacionare-samara11.ru/]вывод из запоя клиника[/url]
лечение запоя
vivod-iz-zapoya-smolensk014.ru
вывод из запоя круглосуточно смоленск
Алкогольный запой – это опасное состояние‚ требующее экстренного вывода и поддержки. Традиционные методы часто воспринимаются как действующие способы борьбы‚ но вокруг них существует множество мифов. Например‚ многие думают‚ что травы от алкоголизма способны быстро снять симптомы запоя. Однако реальность таковы‚ что традиционные средства могут лишь способствовать восстановлению после запоя‚ но не заменить профессиональную реабилитацию от алкоголя. Существует несколько признанных методов‚ среди которых детоксикация и лечение алкоголизма. Психология зависимости играет ключевую роль в процессе восстановления. Важно понимать‚ что экстренный вывод из запоя требует системного подхода‚ включающего медицинскую помощь и поддержку близких. Не стоит ограничиваться народные средства — это может привести к ухудшению состояния.
купить аттестат за 11 классов 2009 года [url=www.arus-diplom24.ru/]купить аттестат за 11 классов 2009 года[/url] .
купить аттестат 11 классов вечерней школы [url=www.arus-diplom25.ru/]купить аттестат 11 классов вечерней школы[/url] .
Срочный вызов нарколога на дом в Туле, это эффективное решение для людей, которые испытывают трудности с алкоголем. Наркологические услуги, предлагаемые профессиональными наркологами, включают лечение зависимостей прямо у вас дома; Одной из ключевых процедур является капельница от запоя, позволяющая быстро улучшить состояние больного. нарколог на дом срочно тула Конфиденциальное лечение является важным аспектом, так как многие пациенты беспокоятся о мнении окружающих. Конфиденциальность лечения гарантируется позволяет пациентам обратиться за помощью при запое без лишнего стресса. Срочный нарколог в Туле готов помочь в любое время, обеспечивая безопасность пациента. Домашняя терапия алкоголизма требует поддержки родных, что делает процесс менее стрессовым. Вернуться к нормальной жизни после запоя возможно благодаря профессиональной помощи и верному подходу. Вызывая нарколога на дом, вы делаете шаг к улучшению здоровья как своего, так и своих близких.
Мы можем предложить дипломы любой профессии по доступным ценам. Купить диплом Коломна — [url=http://kyc-diplom.com/geography/kolomna.html/]kyc-diplom.com/geography/kolomna.html[/url]
Запой — это не просто многодневное употребление алкоголя, а тяжёлое нарушение обмена веществ, работы сердца, нервной системы и внутренних органов. Без медицинской помощи резко возрастает риск развития осложнений: делирий, судороги, инсульт, сердечная недостаточность, тяжёлое обезвоживание и нарушения психики. Симптомы могут прогрессировать в любое время, причём угроза для жизни появляется внезапно.
Выяснить больше – [url=https://vyvod-iz-zapoya-shchelkovo6.ru/]вывод из запоя щелково[/url]
Существуют различные методы и стратегии, которые применяются для устранения зависимостей. Каждый случай уникален, поэтому важно проводить глубокую диагностику и индивидуально разрабатывать план лечения. Мы понимаем, что борьба с зависимостью — это длительный процесс, требующий как медицинской, так и психологической поддержки.
Получить дополнительные сведения – https://zavisim-alko.ru/vivod-iz-zapoya-na-domu-v-krasnodare
купить диплом в ровно [url=https://educ-ua4.ru/]https://educ-ua4.ru/[/url] .
вывод из запоя смоленск
vivod-iz-zapoya-smolensk015.ru
вывод из запоя круглосуточно
купить диплом техникума [url=https://www.educ-ua5.ru]купить диплом техникума[/url] .
888starz ?? ???? ????? ???? ?????? ?????? ?? ??????? . ????? 888starz ?????? ?????? ????? ?????? ???????? .
????? ?????? ?????? ?????? ???? ????????? . ???? ??????? ??????? ?? 888starz ?? ?? ????? ???? ???????? .
????? ???? 888starz ?????? ????? ??????? . ???? 888starz ??? ????? ?????? ????????? ?? ?? ?????? .
???????? ??? ???? ???? 888starz ?????? ????? ??????? ????? . ????? ?????? ????????? ???? ????? 888starz ???? ???? ?? ????????.
888 تحميل [url=888starz-africa.pro/apk]https://888starz-africa.pro/apk/[/url]
дом престарелых
pansionat-msk007.ru
пансионат для престарелых
Мы изготавливаем дипломы любых профессий по невысоким ценам. Приобретение диплома, который подтверждает окончание института, – это выгодное решение. Заказать диплом ВУЗа: [url=http://thehispanicamerican.com/companies/diplomy-grupps/]thehispanicamerican.com/companies/diplomy-grupps[/url]
школьный аттестат за 11 классов купить в [url=http://arus-diplom22.ru]http://arus-diplom22.ru[/url] .
купить аттестат за 11 классов в брянске [url=arus-diplom21.ru]купить аттестат за 11 классов в брянске[/url] .
Капельницы при алкогольной зависимости – это один из наиболее эффективных методов лечения алкогольной зависимости‚ который предоставляет возможность анонимного и комфортного восстановления. Нарколог на дом анонимно обеспечит оперативную медицинскую помощь при запое‚ используя капельницу для детоксикации организма. Ключевые достоинства капельницы заключаются в том‚ что она способствует быстрому снятию симптомов запоя‚ восстановить водно-электролитный баланс и улучшить общее состояние пациента. Это критически важно в случае серьезных проявлений алкогольной зависимости‚ когда необходима немедленная помощь.Существуют различные методы лечения алкоголизма‚ но капельница отличается высокой эффективностью и скоростью действия. В отличие от таблеток или инъекций‚ капельница гарантирует непрерывное введение медикаментов в организм‚ что способствует более быстрому восстановлению.Ключевыми аспектами реабилитации являются поддержка близких и психотерапия в процессе реабилитации. По завершении этапа детоксикации важно продолжать лечение и заниматься профилактикой рецидивов‚ что возможно только при системном подходе к лечению. Таким образом‚ капельница от запоя является важным инструментом в лечении алкоголизма‚ предлагая пациентам надежное анонимное лечение и возможность быстрого восстановления.
купить диплом с занесением в реестр новокузнецке [url=http://arus-diplom31.ru]купить диплом с занесением в реестр новокузнецке[/url] .
Детокс-капельница на дому в Подольске от клиники «Частный Медик 24» — это быстрый способ вернуть здоровье после длительных возлияний. Мы подбираем индивидуальные составы инфузий, восстанавливаем работу печени, сердца и нервной системы. Вызвать нарколога можно круглосуточно, без записи и лишних формальностей.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-podolsk12.ru/]капельница от запоя подольск[/url]
Привет!
Почему одни геймеры получают тысячи долларов, а другие ничего. [url=https://zarabotok-na-igrah.ru/na-kakih-igrah-mozhno-zarabotat-realnye-dengi/]заработать на играх в интернете[/url]
Читай тут: – https://zarabotok-na-igrah.ru/na-kakih-igrah-mozhno-zarabotat-realnye-dengi/
как заработать деньги в интернете на играх без вложений
как заработать на браузерных играх
заработать на компьютерных играх
Пока!
что будет если купить диплом о высшем образовании с занесением в реестр [url=http://arus-diplom31.ru]что будет если купить диплом о высшем образовании с занесением в реестр[/url] .
где можно купить аттестаты 11 класс в таджикистан [url=www.arus-diplom24.ru]где можно купить аттестаты 11 класс в таджикистан[/url] .
Мы готовы предложить документы ВУЗов, которые расположены в любом регионе РФ. Приобрести диплом любого ВУЗа:
[url=http://desteg.getbb.ru/viewtopic.php?f=6&t=4255/]где купить аттестаты за 11 класс форум[/url]
пансионат для пожилых людей
pansionat-msk008.ru
пансионат для лежачих москва
клиники наркологические [url=http://www.narkologicheskaya-klinika-14.ru]http://www.narkologicheskaya-klinika-14.ru[/url] .
ставки и прогнозы на спорт [url=www.prognozy-na-sport-7.ru]www.prognozy-na-sport-7.ru[/url] .
лучшие прогнозы на спорт сегодня [url=prognozy-na-sport-8.ru]prognozy-na-sport-8.ru[/url] .
Журнал о саде https://nasha-gryadka.ru и огороде онлайн — статьи о выращивании овощей, цветов и фруктов. Советы по уходу, борьбе с вредителями, подбору семян и организации участка.
узи купить цена [url=https://kupit-uzi-apparat26.ru/]узи купить цена[/url] .
ставки на хоккей [url=http://prognozy-na-khokkej.ru/]ставки на хоккей[/url] .
промышленные трансформаторные подстанции [url=https://transformatornye-podstancii-kupit.ru/]https://transformatornye-podstancii-kupit.ru/[/url] .
узи сканер купить москва [url=https://www.kupit-uzi-apparat25.ru]https://www.kupit-uzi-apparat25.ru[/url] .
тупиковая трансформаторная подстанция [url=https://transformatornye-podstancii-kupit1.ru/]transformatornye-podstancii-kupit1.ru[/url] .
купить диплом спб занесением реестр [url=http://arus-diplom33.ru]купить диплом спб занесением реестр[/url] .
ктпн комплектные трансформаторные подстанции [url=https://transformatornye-podstancii-kupit2.ru/]https://transformatornye-podstancii-kupit2.ru/[/url] .
купить диплом образование киеве [url=http://www.educ-ua2.ru]купить диплом образование киеве[/url] .
На сегодняшний день проблема зависимостей становится острой. Если вы ищете нарколога на дом в Туле, ресурс narkolog-tula021.ru предлагает разнообразные наркологических услуг. Коррекция зависимостей может быть сложным процессом, однако домашний нарколог предоставляет помощь при алкоголизме и другим зависимостям в домашних условиях. Первичная консультация – это начальный этап к нормальной жизни. Специалисты проведут диагностику зависимости, помогут составить программу реабилитации и рекомендуют методы психотерапии в рамках терапии. Анонимное лечение гарантирует полную дискрецию, что особенно важно для многих пациентов. Медицинская помощь на дому позволяет не только комфортно проходить лечение, но и получать поддержку близких, что играет ключевую роль в процессе реабилитации. Профилактика зависимостей и реабилитация после наркотиков также представляют собой комплекс услуг, предлагаемых специалистами. Обращайтесь за помощью на narkolog-tula021.ru, чтобы получить профессиональную помощь.
займ кредит как взять займ
как купить легальный диплом [url=www.arus-diplom35.ru/]www.arus-diplom35.ru/[/url] .
купить аттестаты за 11 класс с отличием [url=www.arus-diplom23.ru/]www.arus-diplom23.ru/[/url] .
пансионат для пожилых в москве
pansionat-msk009.ru
пансионат для реабилитации после инсульта
купить аттестаты за 11 классов в учалах [url=http://arus-diplom23.ru/]купить аттестаты за 11 классов в учалах[/url] .
купить диплом с занесением в реестр в спб [url=http://arus-diplom34.ru/]http://arus-diplom34.ru/[/url] .
купить диплом с реестром отзывы [url=https://arus-diplom33.ru/]купить диплом с реестром отзывы[/url] .
как можно купить аттестат 11 класса [url=arus-diplom22.ru]как можно купить аттестат 11 класса[/url] .
частный дом престарелых
pansionat-msk007.ru
пансионат для престарелых людей
купить диплом с реестром киев [url=https://arus-diplom32.ru/]https://arus-diplom32.ru/[/url] .
купить диплом с занесением в реестры [url=http://www.arus-diplom32.ru]купить диплом с занесением в реестры[/url] .
пансионат для реабилитации после инсульта
pansionat-tula007.ru
пансионат для реабилитации после инсульта
https://www.trub-prom.com/catalog/truby_srednego_diametra/219/
домашний интернет подключить екатеринбург
inernetvkvartiru-ekaterinburg004.ru
интернет провайдеры по адресу дома
Заказать диплом любого университета!
Мы готовы предложить дипломы любой профессии по невысоким тарифам— [url=http://a-diplom.ru/]a-diplom.ru[/url]
В Самаре решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-stacionare-samara16.ru/]анонимный вывод из запоя самара[/url]
Приобрести диплом на заказ в Москве возможно используя официальный сайт компании. [url=http://koreauniversityjobs.com/employer/education-ua/]koreauniversityjobs.com/employer/education-ua[/url]
купить аттестат 11 классов в украине [url=https://arus-diplom21.ru]https://arus-diplom21.ru[/url] .
Клиника «Частный Медик 24» в Подольске оказывает услугу капельницы от запоя с выездом на дом. Используются только сертифицированные препараты, которые помогают снять симптомы похмелья, вернуть ясность ума и восстановить сон. Наши врачи работают анонимно и бережно относятся к каждому пациенту.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-podolsk13.ru/]после капельницы от запоя в подольске[/url]
трансформаторные подстанции 2ктп [url=www.transformatornye-podstancii-kupit2.ru/]трансформаторные подстанции 2ктп[/url] .
пансионат после инсульта
pansionat-msk008.ru
пансионат инсульт реабилитация
Современная жизнь, особенно в крупном городе, как Красноярск, часто становится причиной различных зависимостей. Работа в условиях постоянного стресса, высокий ритм жизни и эмоциональные перегрузки могут привести к проблемам, которые требуют неотложной медицинской помощи. Одним из наиболее удобных решений в такой ситуации является вызов нарколога на дом.
Выяснить больше – [url=https://narcolog-na-dom-v-krasnoyarske55.ru/]нарколог на дом анонимно в красноярске[/url]
частные пансионаты для пожилых в туле
pansionat-tula008.ru
пансионат для лежачих пожилых
https://www.trub-prom.com/catalog/truby_bolshogo_diametra/530kh8/
подключить домашний интернет екатеринбург
inernetvkvartiru-ekaterinburg005.ru
какие провайдеры на адресе в екатеринбурге
купить дипломы о высшем образовании [url=www.educ-ua1.ru]купить дипломы о высшем образовании[/url] .
Заказать диплом любого ВУЗа!
Мы предлагаембыстро купить диплом, который выполнен на оригинальном бланке и заверен мокрыми печатями, водяными знаками, подписями должностных лиц. Наш документ способен пройти лубую проверку, даже при использовании специального оборудования. Решайте свои задачи быстро с нашим сервисом- [url=http://tswanahome.com/author/linetteepf787/]tswanahome.com/author/linetteepf787[/url]
купить аттестат 11 классов новокузнецк [url=www.arus-diplom24.ru/]купить аттестат 11 классов новокузнецк[/url] .
как купить диплом занесенный в реестр [url=http://mynissanleaf.ru/profile.php?id=24424]как купить диплом занесенный в реестр[/url] .
Нужен клининг? топ клининговых компаний москвы 2026. Лучшие сервисы уборки квартир, домов и офисов. Сравнение услуг, цен и отзывов, чтобы выбрать надежного подрядчика.
купить диплом в днепропетровске цены [url=www.educ-ua3.ru/]купить диплом в днепропетровске цены[/url] .
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Это стоит прочитать полностью – https://gitayagna.com/bhagavadgita/hello-world
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Обратитесь за информацией – https://gitayagna.com/bhagavadgita/hello-world
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Погрузиться в детали – http://fotochtoto.ru
купить аттестат за 11 цена [url=http://arus-diplom25.ru]купить аттестат за 11 цена[/url] .
купить аттестат 11 класс цена [url=www.arus-diplom9.ru/]купить аттестат 11 класс цена[/url] .
пансионат инсульт реабилитация
pansionat-msk009.ru
пансионат для реабилитации после инсульта
пансионат для пожилых людей
pansionat-tula009.ru
частный пансионат для престарелых
Хай!
Быстрый вывод из казино: миф или реальность? [url=https://nagny-casino.ru/onlajn-kazino-bez-liczenzii/]казино с быстрым выводом[/url]
По ссылке: – https://nagny-casino.ru/onlajn-kazino-bez-liczenzii/
онлайн казино без лицензии
топ нелегальных казино
казино онлайн 777
Покеда!
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Смотри, что ещё есть – https://www.yorkshirewillwriters.co.uk/uncategorised/hello-world
подключить домашний интернет екатеринбург
inernetvkvartiru-ekaterinburg006.ru
провайдеры интернета в екатеринбурге по адресу проверить
Высокооплачиваемая работа для девушек в Тюмени Девушки Тюмени, ищете высокооплачиваемую работу? Здесь вас ждут большие деньги и новые возможности. Раскрой свой потенциал и начни зарабатывать прямо сейчас!
ставки и прогнозы на спорт [url=prognozy-na-sport-7.ru]prognozy-na-sport-7.ru[/url] .
клиники наркологические москва [url=http://narkologicheskaya-klinika-14.ru/]http://narkologicheskaya-klinika-14.ru/[/url] .
кашпо высокое напольное купить [url=http://kashpo-napolnoe-krasnodar.ru/]кашпо высокое напольное купить[/url] .
[url=https://magicampat.ru/]Спросить гадалку через интернет[/url] сегодня стало невероятно просто благодаря современным сервисам, которые позволяют каждому пользователю получить консультацию без ожидания прямо из дома. Если раньше для того, чтобы получить предсказание приходилось ехать в другой город или искать знакомых, то теперь достаточно лишь зайти на платформу и написать интересующую вас тему. Многие специалисты по картам и астрологии предлагают разные форматы общения: от чата до живого общения, что делает процесс максимально доступным для каждого. Обращаясь к гадалке через интернет, вы можете получить разное толкование: кто-то работает с картами Таро, кто-то предпочитает астрологию, а есть и те, кто использует древние ритуалы и техники интуитивного чтения. Самое главное, что вы можете спросить гадалку о том, что действительно волнует именно вас: будь то семейная жизнь, финансовые вопросы, судьба или здоровье. В отличие от стандартных статей и советов, которые можно найти в интернете, онлайн гадалка дает личную подсказку, ориентируясь на вашу ситуацию. Многие пользователи отмечают, что возможность попробовать бесплатное гадание онлайн помогает им сначала проверить сервис, а затем при необходимости перейти к более глубоким и развернутым консультациям. Подобный формат удобен еще и тем, что вам не нужно тратить время на дорогу и организацию встречи — вы получаете шанс узнать ответы на сокровенные вопросы за считанные минуты. Общаясь с гадалкой онлайн, вы сами выбираете формат, продолжительность и глубину консультации. Кому-то достаточно пары слов, а кому-то требуется подробный разбор ситуации с рекомендациями. Гадалки онлайн умеют не только давать советы, но и направлять в правильное русло, помогать человеку найти силы и уверенность. Сегодня такие сервисы становятся все более популярными, так как соединяют древние знания и современные технологии, позволяя человеку чувствовать себя соприкасающимся с тайнами судьбы прямо через экран. Если вы давно хотели попробовать гадание, но не знали, с чего начать, возможность спросить совет у гадалки онлайн в любой момент — это отличный шанс. Попробуйте и убедитесь сами, насколько глубокими могут быть такие консультации, и как они помогут вам в принятии решений.
https://magicampat.ru/
Нужен клининг? список клининговых компаний москвы. Лучшие сервисы уборки квартир, домов и офисов. Сравнение услуг, цен и отзывов, чтобы выбрать надежного подрядчика.
ставки на спорт прогнозы от профессионалов [url=https://prognozy-na-sport-8.ru]https://prognozy-na-sport-8.ru[/url] .
купить аттестат 11 классов ижевск [url=http://arus-diplom23.ru/]купить аттестат 11 классов ижевск[/url] .
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Узнать больше – [url=https://vyvod-iz-zapoya-v-stacionare14.ru/]nizhnij novgorod[/url]
купить аппарат узи цены новый [url=http://kupit-uzi-apparat26.ru/]http://kupit-uzi-apparat26.ru/[/url] .
принудительное лечение в психиатрическом стационаре
psychiatr-moskva004.ru
платный психиатр
Получи лучшие казинo России 2025 года! ТОП-5 проверенных платформ с лицензией для игры на реальные деньги. Надежные выплаты за 24 часа, бонусы до 100000 рублей, минимальные ставки от 10 рублей! Играйте в топовые слоты, автоматы и live-казинo с максимальны
https://t.me/s/TopCasino_Official
пансионат для пожилых после инсульта
pansionat-tula007.ru
пансионат для пожилых в туле
комплектная трансформаторная подстанция [url=https://www.transformatornye-podstancii-kupit.ru]https://www.transformatornye-podstancii-kupit.ru[/url] .
[url=https://magicampat.ru/]Задать вопрос гадалке онлайн[/url] сегодня стало невероятно просто благодаря современным сервисам, которые позволяют каждому интересующемуся получить консультацию в реальном времени прямо из дома. Если раньше для того, чтобы получить предсказание приходилось ехать в другой город или искать знакомых, то теперь достаточно лишь открыть сайт и написать интересующую вас тему. Многие онлайн гадалки предлагают разные форматы общения: от чата до живого общения, что делает процесс максимально удобным для каждого. Ища совет у гадалки онлайн, вы можете получить разное толкование: кто-то работает с картами Таро, кто-то предпочитает астрологию, а есть и те, кто использует древние ритуалы и техники интуитивного чтения. Самое главное, что вы можете получить ответ у гадалки о том, что действительно волнует именно вас: будь то семейная жизнь, финансовые вопросы, жизненный путь или энергетика. В отличие от стандартных статей и советов, которые можно найти в интернете, онлайн гадалка дает индивидуальное толкование, ориентируясь на вашу ситуацию. Многие пользователи отмечают, что возможность попробовать бесплатное гадание онлайн помогает им сначала проверить сервис, а затем при необходимости перейти к более глубоким и развернутым консультациям. Подобный формат удобен еще и тем, что вам не нужно тратить время на дорогу и организацию встречи — вы получаете шанс узнать ответы на сокровенные вопросы за считанные минуты. Общаясь с гадалкой онлайн, вы сами выбираете формат, продолжительность и глубину консультации. Кому-то достаточно пары слов, а кому-то требуется подробный разбор ситуации с рекомендациями. Гадалки онлайн умеют не только давать советы, но и направлять в правильное русло, помогать человеку найти силы и уверенность. Сегодня такие сервисы становятся все более популярными, так как соединяют древние знания и современные технологии, позволяя человеку чувствовать себя соприкасающимся с тайнами судьбы прямо через экран. Если вы давно хотели попробовать гадание, но не знали, с чего начать, возможность спросить совет у гадалки онлайн в любой момент — это отличный шанс. Попробуйте и убедитесь сами, насколько точными могут быть такие консультации, и как они помогут вам в принятии решений.
https://magicampat.ru/
[url=https://magicampat.ru/]Спросить гадалку через интернет[/url] сегодня стало невероятно просто благодаря современным сервисам, которые позволяют каждому пользователю получить консультацию в реальном времени прямо из дома. Если раньше для того, чтобы получить предсказание приходилось ехать в другой город или искать знакомых, то теперь достаточно лишь зайти на платформу и написать интересующую вас тему. Многие онлайн гадалки предлагают разные форматы общения: от чата до живого общения, что делает процесс максимально комфортным для каждого. Обращаясь к гадалке через интернет, вы можете получить разное толкование: кто-то работает с картами Таро, кто-то предпочитает астрологию, а есть и те, кто использует древние ритуалы и техники интуитивного чтения. Самое главное, что вы можете передать свой вопрос гадалке о том, что действительно волнует именно вас: будь то семейная жизнь, финансовые вопросы, жизненный путь или энергетика. В отличие от стандартных статей и советов, которые можно найти в интернете, онлайн гадалка дает личную подсказку, ориентируясь на вашу ситуацию. Многие пользователи отмечают, что возможность пообщаться с гадалкой без оплаты помогает им сначала проверить сервис, а затем при необходимости перейти к более глубоким и развернутым консультациям. Подобный формат удобен еще и тем, что вам не нужно тратить время на дорогу и организацию встречи — вы получаете возможность прикоснуться к предсказаниям за считанные минуты. Общаясь с гадалкой онлайн, вы сами выбираете формат, продолжительность и глубину консультации. Кому-то достаточно пары слов, а кому-то требуется подробный разбор ситуации с рекомендациями. Гадалки онлайн умеют не только толковать знаки, но и направлять в правильное русло, помогать человеку найти силы и уверенность. Сегодня такие сервисы становятся все более популярными, так как соединяют древние знания и современные технологии, позволяя человеку чувствовать себя частью волшебства прямо через экран. Если вы давно хотели попробовать гадание, но не знали, с чего начать, возможность задать вопрос гадалке онлайн прямо сейчас — это отличный шанс. Попробуйте и убедитесь сами, насколько точными могут быть такие консультации, и как они помогут вам в понимании себя.
https://magicampat.ru/
[url=https://magicampat.ru/]Получить ответ от гадалки онлайн[/url] сегодня стало невероятно просто благодаря современным сервисам, которые позволяют каждому человеку получить консультацию в удобное время прямо из дома. Если раньше для того, чтобы пообщаться с гадалкой приходилось ехать в другой город или искать знакомых, то теперь достаточно лишь зайти на платформу и написать интересующую вас тему. Многие онлайн гадалки предлагают разные форматы общения: от коротких сообщений до видеоконсультации, что делает процесс максимально доступным для каждого. Задавая вопрос гадалке онлайн, вы можете получить разное толкование: кто-то работает с картами Таро, кто-то предпочитает астрологию, а есть и те, кто использует древние ритуалы и техники интуитивного чтения. Самое главное, что вы можете получить ответ у гадалки о том, что действительно волнует именно вас: будь то семейная жизнь, деньги, судьба или энергетика. В отличие от стандартных статей и советов, которые можно найти в интернете, онлайн гадалка дает индивидуальное толкование, ориентируясь на вашу ситуацию. Многие пользователи отмечают, что возможность попробовать бесплатное гадание онлайн помогает им сначала проверить сервис, а затем при необходимости перейти к более глубоким и развернутым консультациям. Подобный формат удобен еще и тем, что вам не нужно тратить время на дорогу и организацию встречи — вы получаете доступ к тайнам будущего за считанные минуты. Задавая вопрос гадалке через интернет, вы сами выбираете формат, продолжительность и глубину консультации. Кому-то достаточно пары слов, а кому-то требуется подробный разбор ситуации с рекомендациями. Гадалки онлайн умеют не только давать советы, но и направлять в правильное русло, помогать человеку найти силы и уверенность. Сегодня такие сервисы становятся все более популярными, так как соединяют древние знания и современные технологии, позволяя человеку чувствовать себя соприкасающимся с тайнами судьбы прямо через экран. Если вы давно хотели попробовать гадание, но не знали, с чего начать, возможность задать вопрос гадалке онлайн прямо сейчас — это отличный шанс. Попробуйте и убедитесь сами, насколько правдивыми могут быть такие консультации, и как они помогут вам в принятии решений.
https://magicampat.ru/
ставки на хоккей на сегодня [url=www.prognozy-na-khokkej.ru]www.prognozy-na-khokkej.ru[/url] .
продажа трансформаторной подстанции [url=https://transformatornye-podstancii-kupit1.ru]продажа трансформаторной подстанции[/url] .
какие провайдеры по адресу
inernetvkvartiru-krasnoyarsk004.ru
интернет провайдеры по адресу дома
Смотрите сериалы Лучшие сериалы онлайн: https://obzor.city/texty/infotech/onlajn-kinoteatr-lordseries онлайн в хорошем качестве. Новинки, классика и популярные проекты в удобном формате. Бесплатный просмотр без скачивания и доступ 24/7.
купить аппарат узи [url=https://kupit-uzi-apparat25.ru]купить аппарат узи[/url] .
https://apps.shopify.com/digital-downloads-app-11
Лучшие казинo в рейтинге 2025. Играйте в самое лучшее интернет-казинo. Список топ-5 казино с хорошей репутацией, быстрым выводом, выплатами на карту в рублях, минимальные ставки. Выбирайте надежные игровые автоматы и честные мобильные казинo с лицензией.
https://t.me/s/luchshiye_onlayn_kazino
[url=https://muzikalnie-pozdravlenia.ru/]шарики на день рождения круглосуточно[/url] – это вариант, который сделает любой день рождения особенным. У нас вы найдете широкий ассортимент шариков для детей и взрослых. Мы привозим заказы точно в срок, чтобы гости с первых минут были в восторге. Не имеет значения, нужен ли один шарик или целая композиция, наши консультанты подскажут лучшие варианты. Яркие шары всегда создают настроение, они делают атмосферу радостной и легкой. Хотите приятно удивить именинника, шарики на день рождения круглосуточно станут отличным решением. Цены приятно удивят, каждый шар надувается гелием высокого качества. Заказ можно оформить всего за пару минут, и мы сразу отправим курьера к вам. Мы делаем яркие и аккуратные композиции, и праздник станет еще ярче. Нас выбирают семьи, компании и организаторы мероприятий, так как не нужно подстраиваться под график. Мы поможем воплотить вашу идею в жизнь, в любое время дня и ночи. Шарики – это эмоции, которые дарят радость, и наша цель – сделать ваш праздник особенным. Не откладывайте заказ на потом, выберите удобное время и получите доставку шаров.
https://muzikalnie-pozdravlenia.ru/
[url=https://muzikalnie-pozdravlenia.ru/]шарики с доставкой на праздник 24/7[/url] – это вариант, который сделает любой день рождения особенным. Мы подбираем стильные композиции из шаров для любых торжеств. Доставка осуществляется быстро и без задержек, чтобы гости с первых минут были в восторге. Не имеет значения, нужен ли один шарик или целая композиция, вы сможете легко подобрать подходящий стиль. Яркие шары всегда создают настроение, они подходят и для детей, и для взрослых. Если вы ищете оригинальный подарок, лучше всего подойдет заказ шариков 24/7. Мы предлагаем выгодные цены и гибкие условия, шары сохраняют форму надолго. Вы легко оформите заказ на сайте или по телефону, и шарики будут у вас в кратчайшие сроки. Каждый заказ оформляется с любовью и вниманием, поэтому результат всегда радует. Наши услуги востребованы среди родителей, коллег и друзей, так как не нужно подстраиваться под график. Мы поможем воплотить вашу идею в жизнь, в любое время дня и ночи. Воздушные шары поднимают настроение, и наша цель – сделать ваш праздник особенным. Не откладывайте заказ на потом, выберите удобное время и получите доставку шаров.
https://muzikalnie-pozdravlenia.ru/
[url=https://muzikalnie-pozdravlenia.ru/]шарики с доставкой на праздник 24/7[/url] – это идеальный способ создать праздничное настроение. У нас вы найдете широкий ассортимент шариков для детей и взрослых. Мы привозим заказы точно в срок, чтобы гости с первых минут были в восторге. Вы можете заказать как небольшой набор шаров, так и огромный букет, вы сможете легко подобрать подходящий стиль. Шарики – это универсальное украшение для праздника, они делают атмосферу радостной и легкой. Хотите приятно удивить именинника, лучше всего подойдет заказ шариков 24/7. Стоимость у нас всегда доступная, а качество шаров гарантирует их долгую сохранность. Заказ можно оформить всего за пару минут, и уже скоро курьер привезет готовую композицию. Особое внимание мы уделяем оформлению, поэтому результат всегда радует. Наши услуги востребованы среди родителей, коллег и друзей, так как не нужно подстраиваться под график. Мы поможем воплотить вашу идею в жизнь, в любое время дня и ночи. Шары создают атмосферу счастья, и наша цель – сделать ваш праздник особенным. Не откладывайте заказ на потом, и закажите шарики на день рождения круглосуточно.
https://muzikalnie-pozdravlenia.ru/
Запой — одно из самых опасных проявлений алкогольной зависимости. Он сопровождается глубокой интоксикацией организма, нарушением работы сердца, печени, головного мозга и других жизненно важных систем. Когда человек не может остановиться самостоятельно, а организм больше не справляется с нагрузкой, требуется медицинская помощь. В наркологической клинике «Спасение» в Мытищах мы проводим экстренные процедуры инфузионной терапии, позволяющие эффективно и безопасно вывести пациента из состояния запоя. Капельница — это первый шаг на пути к восстановлению здоровья и возвращению к нормальной жизни.
Выяснить больше – http://kapelnica-ot-zapoya-moskva2.ru
Затяжной запой опасен для жизни. Врачи наркологической клиники в Нижнем Новгороде проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-stacionare13.ru/]скорая вывод из запоя нижний новгород[/url]
Вывод из запоя в Химках возможен без госпитализации — достаточно обратиться в Stop Alko, чтобы получить помощь на дому.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-himki12.ru/]вывод из запоя цена в подольске[/url]
Мы готовы предложить документы институтов, которые расположены на территории всей РФ. Приобрести диплом любого университета:
[url=http://wiki.lovettcreations.org/index.php/User:SimonGoshorn7/]купить аттестаты за 11 класс краснодар[/url]
консультация психиатра на дому
psychiatr-moskva005.ru
психиатрическая помощь госпитализация
J’aime enormement le casino TonyBet, c’est vraiment une aventure palpitante. La selection de machines est vaste, proposant des jeux de table classiques. Le personnel est tres competent, repondant rapidement. Les paiements sont fluides, neanmoins il pourrait y avoir plus de promos. En gros, TonyBet est une valeur sure pour les fans de jeux en ligne ! De plus, le design est attractif, ce qui rend l’experience encore meilleure.
tonybet bookie|
пансионат для пожилых в туле
pansionat-tula008.ru
пансионат для престарелых людей
Bonusa sahip olmak, kullanıcıların daha fazla keyif almasını sağlamaktadır.
betwinner güncel giriş [url=betswinner.bet]https://betswinner.bet/[/url]
купить диплом спб с занесением в реестр [url=http://www.arus-diplom35.ru]http://www.arus-diplom35.ru[/url] .
Купить диплом любого университета!
Наши специалисты предлагаютвыгодно купить диплом, который выполнен на оригинальной бумаге и заверен печатями, водяными знаками, подписями. Наш диплом способен пройти лубую проверку, даже с использованием специфических приборов. Достигайте цели максимально быстро с нашей компанией- [url=http://justpaste.me/kLhH1/]justpaste.me/kLhH1[/url]
Je trouve absolument genial Azur Casino, on dirait une experience de jeu envoutante. Le catalogue est vaste et diversifie, comprenant des titres modernes et attrayants. Le service d’assistance est de premier ordre, repondant en un rien de temps. Les retraits sont ultra-rapides, bien que plus de tours gratuits seraient un plus. Globalement, Azur Casino est une plateforme incontournable pour les fans de casino virtuel ! En bonus l’interface est fluide et elegante, ajoutant une touche de raffinement.
promotion azur casino|
корочка для аттестата 11 купить [url=https://arus-diplom24.ru/]корочка для аттестата 11 купить[/url] .
J’adore sans reserve Banzai Casino, c’est une veritable plongee dans le divertissement intense. La selection est riche et diversifiee, avec des machines a sous ultra-modernes. Le service d’assistance est exemplaire, avec un suivi de qualite. Les transactions sont parfaitement protegees, cependant davantage de recompenses seraient un plus. En conclusion, Banzai Casino offre une experience exceptionnelle pour les joueurs en quete de frissons ! Notons aussi que la navigation est intuitive et rapide, ce qui intensifie le plaisir de jouer.
bonus banzai casino|
Je suis completement seduit par Betclic Casino, c’est une veritable aventure pleine de frissons. Le catalogue de jeux est incroyablement riche, incluant des slots dernier cri. Le support est d’une reactivite exemplaire, offrant des reponses rapides et precises. Les transactions sont parfaitement protegees, cependant les bonus pourraient etre plus frequents. En fin de compte, Betclic Casino ne decoit jamais pour ceux qui aiment parier ! Par ailleurs l’interface est fluide et intuitive, renforce l’immersion totale.
basket betclic|
Без медицинского вмешательства состояние быстро прогрессирует: появляется тремор, резкие скачки давления, судороги, бессонница, галлюцинации. Чем дольше затягивать с лечением, тем выше риск развития алкогольного делирия (белой горячки), острого панкреатита, инсульта или инфаркта. Особенно опасно оставлять человека одного в квартире в период ломки — даже банальный приём воды может закончиться удушьем или потерей сознания. Именно поэтому капельница должна быть проведена как можно раньше, под наблюдением специалистов.
Детальнее – [url=https://kapelnica-ot-zapoya-moskva2.ru/]капельница от запоя в мытищах[/url]
купить цветы в москве недорого Доверяя доставку цветов профессионалам, вы можете быть уверены в их свежести и своевременной доставке. Букет цветов в Москве: Классический Подарок на Все Времена
какие провайдеры по адресу
inernetvkvartiru-krasnoyarsk005.ru
интернет по адресу дома
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Нижнем Новгороде приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-v-stacionare14.ru/]вывод из запоя вызов на дом[/url]
AutoRent — прокат автомобилей в Минске. Ищете аренда SUV Минск? На autorent.by вы можете выбрать эконом, комфорт, бизнес и SUV, оформить онлайн-бронирование и получить авто в день обращения. Прозрачные цены, чистые машины, поддержка 24/7. Подача в аэропорт Минск, самовывоз из города. Посуточно и на длительный срок; опции: детские кресла и доп. оборудование.
купить аттестат за 10 и 11 класс [url=https://arus-diplom25.ru/]купить аттестат за 10 и 11 класс[/url] .
Нужна контекстная реклама? https://reklama-stomatolog-kontekst.ru под ключ. Настройка в Яндекс.Директ и Google Ads, оптимизация объявлений и контроль заявок.
Je suis fan de le casino TonyBet, c’est vraiment un univers de jeu unique. Il y a une tonne de jeux differents, incluant des slots ultra-modernes. Le service d’assistance est top, offrant un excellent suivi. Les paiements sont fluides, par contre il pourrait y avoir plus de promos. Dans l’ensemble, TonyBet vaut vraiment le coup pour ceux qui aiment parier ! Par ailleurs, le design est attractif, facilitant chaque session de jeu.
tonybet casa de apuestas|
аттестат за 11 классов купил [url=www.arus-diplom25.ru/]аттестат за 11 классов купил[/url] .
Мы изготавливаем дипломы психологов, юристов, экономистов и других профессий по приятным тарифам. Приобретение документа, подтверждающего окончание института, – это выгодное решение. Купить диплом любого университета: [url=http://peticiones.co/494919/]peticiones.co/494919[/url]
купить аттестат за 11 классов в ярославле [url=www.arus-diplom21.ru]купить аттестат за 11 классов в ярославле[/url] .
купить аттестат об окончании 11 классов спб [url=http://www.arus-diplom22.ru]купить аттестат об окончании 11 классов спб[/url] .
Комплексные IT-решения https://eclat.moscow для бизнеса: разработка, внедрение, сопровождение и поддержка. Надежные технологии для автоматизации и цифровой трансформации.
психиатр онлайн консультация
psychiatr-moskva006.ru
психиатрический стационар
пансионат для престарелых людей
pansionat-tula009.ru
пансионат для лежачих больных
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Обратиться к источнику – https://nikpendar.com/students-inducted-into-business-honor-society
купить проведенный диплом [url=www.arus-diplom31.ru/]купить проведенный диплом[/url] .
какие провайдеры по адресу
inernetvkvartiru-krasnoyarsk006.ru
провайдеры интернета в красноярске по адресу
купить диплом о высшем образовании специалиста [url=www.educ-ua5.ru]купить диплом о высшем образовании специалиста[/url] .
mostbwt [url=http://mostbet4120.ru]mostbwt[/url]
Je trouve absolument genial Azur Casino, c’est une veritable aventure captivante. Il y a une multitude de jeux varies, avec des machines a sous dernier cri. Le support est toujours reactif, disponible 24/7. Le processus de retrait est simple et efficace, cependant les offres pourraient etre plus allechantes. En fin de compte, Azur Casino vaut vraiment le detour pour les adeptes de sensations fortes ! En bonus le site est concu avec soin, ce qui rend chaque session memorable.
bonus azur casino|
Je suis epoustoufle par le casino AllySpin, ca donne une experience de jeu electrisante. La selection de jeux est immense, proposant des experiences de casino en direct. Les agents sont toujours disponibles, avec des reponses precises et utiles. Les paiements sont fluides et securises, mais parfois les promos pourraient etre plus genereuses. En resume, AllySpin est une plateforme de choix pour les joueurs en quete d’adrenaline ! De plus le design est accrocheur, renforcant l’immersion.
allyspin giocare per soldi|
J’apprecie enormement Betclic Casino, il procure une sensation de casino unique. La gamme de jeux est tout simplement impressionnante, incluant des slots dernier cri. Les agents sont toujours disponibles et professionnels, offrant des reponses rapides et precises. Les paiements sont fluides et securises, bien que plus de tours gratuits seraient un atout. En fin de compte, Betclic Casino est une plateforme d’exception pour les joueurs en quete d’adrenaline ! Ajoutons que la navigation est simple et agreable, ajoute une touche de raffinement a l’experience.
code promo betclic|
купить проведенный диплом моих [url=http://arus-diplom34.ru/]купить проведенный диплом моих[/url] .
купить диплом стоит [url=https://www.educ-ua4.ru]купить диплом стоит[/url] .
купить аттестат за 11 класс [url=https://arus-diplom24.ru]купить аттестат за 11 класс[/url] .
888starz platformasi orqali yaxshilash mumkin. o’yinchilar uchun taqdim etadi.
Pul tikish jarayoni. doimiy mumkin.
va yordam beradi. bo’yicha joylashgan maqolalar mavjud.
maqsadida . shaxsiy ma’lumotlari . o’yinchilar mumkin.
888starz sayti [url=https://888starz-uzs.net/]https://888starz-uzs.net/[/url]
скачать мостбет казино [url=http://mostbet4121.ru/]http://mostbet4121.ru/[/url]
лечение в психиатрическом стационаре
psikhiatr-moskva004.ru
частная психиатрическая клиника
скачать казино мостбет [url=mostbet4126.ru]скачать казино мостбет[/url]
Здарова!
Не хочешь светить паспорт на бирже? [url=https://pro-kriptu.ru/gde-kupit-kriptovalyutu-bez-verifikaczii/]где купить крипту без верификации[/url]
По ссылке: – https://pro-kriptu.ru/gde-kupit-kriptovalyutu-bez-verifikaczii/
где купить крипту без верификации
биржи криптовалют без верификации
куда вложить крипту без верификации
Удачи!
купить диплом с занесением в реестр украина [url=http://arus-diplom33.ru/]http://arus-diplom33.ru/[/url] .
купить диплом в хмельницком [url=https://educ-ua2.ru/]https://educ-ua2.ru/[/url] .
мостбет официальный сайт вход букмекерская контора [url=mostbet4122.ru]mostbet4122.ru[/url]
скорая психиатрическая помощь
psychiatr-moskva004.ru
лечение психиатрических расстройств
теннесси бк скачать на андроид бесплатно [url=https://mostbet4119.ru]https://mostbet4119.ru[/url]
как зайти на сайт мостбет [url=http://mostbet4123.ru/]http://mostbet4123.ru/[/url]
купить диплом института с реестром [url=arus-diplom31.ru]купить диплом института с реестром[/url] .
провайдеры интернета по адресу
inernetvkvartiru-krasnodar004.ru
интернет провайдеры краснодар по адресу
мостбет контакты [url=https://mostbet4125.ru]https://mostbet4125.ru[/url]
как купить диплом с реестром [url=https://arus-diplom33.ru/]как купить диплом с реестром[/url] .
купить аттестаты за 11 классов в новосибирске [url=http://arus-diplom23.ru/]купить аттестаты за 11 классов в новосибирске[/url] .
казино мостбет [url=https://www.mostbet4120.ru]казино мостбет[/url]
В нашем центре доступны следующие виды помощи:
Узнать больше – [url=https://narko-zakodirovat.ru/]вывод из запоя клиника в твери[/url]
бк мост бет [url=http://mostbet4121.ru]бк мост бет[/url]
mostbet app [url=www.mostbet4125.ru]mostbet app[/url]
фабрика пошива одежды на заказ [url=http://nitkapro.ru/]http://nitkapro.ru/[/url] .
профессиональное продвижение сайтов [url=https://kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru]профессиональное продвижение сайтов[/url] .
seo продвижение и раскрутка сайта [url=https://poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru/]https://poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru/[/url] .
профессиональное продвижение сайтов [url=http://poiskovoe-seo-v-moskve.ru/]http://poiskovoe-seo-v-moskve.ru/[/url] .
профессиональное продвижение сайтов [url=https://internet-agentstvo-prodvizhenie-sajtov-seo.ru/]профессиональное продвижение сайтов[/url] .
мостбкт [url=https://www.mostbet4123.ru]мостбкт[/url]
купить аппарат узи цены новый [url=http://www.kupit-uzi-apparat27.ru]http://www.kupit-uzi-apparat27.ru[/url] .
Заказать диплом любого ВУЗа!
Мы предлагаемвыгодно заказать диплом, который выполняется на бланке ГОЗНАКа и заверен мокрыми печатями, водяными знаками, подписями официальных лиц. Данный документ способен пройти любые проверки, даже с применением специфических приборов. Достигайте своих целей максимально быстро с нашим сервисом- [url=http://thelspr.listbb.ru/posting.php?mode=post&f=13/]thelspr.listbb.ru/posting.php?mode=post&f=13[/url]
продвижение сайта [url=poiskovoe-prodvizhenie-moskva-professionalnoe.ru]продвижение сайта[/url] .
купить диплом с занесением в реестр в архангельске [url=http://arus-diplom35.ru]купить диплом с занесением в реестр в архангельске[/url] .
аттестат за 11 класс купить diplom market [url=www.arus-diplom22.ru]аттестат за 11 класс купить diplom market[/url] .
продвижение по трафику [url=http://internet-prodvizhenie-moskva.ru/]продвижение по трафику[/url] .
купить аттестаты за 11 вечерней школе в спб [url=https://www.arus-diplom24.ru]купить аттестаты за 11 вечерней школе в спб[/url] .
продвижение по трафику [url=http://kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru]продвижение по трафику[/url] .
швейное производство оптом [url=http://www.nitkapro.ru]http://www.nitkapro.ru[/url] .
интернет продвижение москва [url=www.poiskovoe-seo-v-moskve.ru]www.poiskovoe-seo-v-moskve.ru[/url] .
seo аудит веб сайта [url=www.poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru]www.poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru[/url] .
технического аудита сайта [url=https://internet-agentstvo-prodvizhenie-sajtov-seo.ru/]internet-agentstvo-prodvizhenie-sajtov-seo.ru[/url] .
My spouse and I absolutely love your blog and find the majority of your post’s to be exactly what I’m looking for. Would you offer guest writers to write content to suit your needs? I wouldn’t mind publishing a post or elaborating on most of the subjects you write with regards to here. Again, awesome web log!
https://startupline.com.ua/chy-mozhna-zberihaty-vidkrytyj-klej-bez-vtrat.html
mostbet kg скачать на андроид [url=https://mostbet4126.ru/]mostbet kg скачать на андроид[/url]
seo partners [url=http://poiskovoe-prodvizhenie-moskva-professionalnoe.ru/]seo partners[/url] .
J’adore a fond Casino Action, il offre une energie de jeu irresistible. Il y a une profusion de jeux varies, proposant des jeux de table classiques comme le blackjack et la roulette. Les agents sont professionnels et toujours prets a aider, joignable a toute heure. Les paiements sont fluides et securises par un cryptage SSL 128 bits, bien que le bonus de bienvenue jusqu’a 1250 € pourrait etre plus frequent. Globalement, Casino Action est un incontournable pour ceux qui aiment parier ! En bonus la navigation est rapide sur mobile via iOS/Android, ce qui amplifie le plaisir de jouer.
online casino action|
J’adore a fond 1win Casino, il offre une sensation de casino unique. Les options de jeu sont vastes et diversifiees, avec des machines a sous modernes et dynamiques. Le service d’assistance est impeccable, repondant rapidement. Les transactions sont bien protegees, cependant j’aimerais plus de promotions regulieres. Globalement, 1win Casino ne decoit jamais pour les joueurs en quete de sensations fortes ! Notons egalement que le design est visuellement attrayant, ce qui amplifie le plaisir de jouer.
1win token|
компании занимающиеся продвижением сайтов [url=http://internet-prodvizhenie-moskva.ru/]компании занимающиеся продвижением сайтов[/url] .
купить аттестат 11 классов ижевск [url=www.arus-diplom25.ru/]купить аттестат 11 классов ижевск[/url] .
регистрация в бк мостбет [url=www.mostbet4127.ru]www.mostbet4127.ru[/url]
консультация психиатра по телефону
psikhiatr-moskva005.ru
психиатр на дом
мост бет скачать [url=www.mostbet4122.ru]мост бет скачать[/url]
купить диплом с реестром о высшем образовании [url=www.arus-diplom32.ru]купить диплом с реестром о высшем образовании[/url] .
где купить аттестат за 11 класс 2016 [url=arus-diplom21.ru]где купить аттестат за 11 класс 2016[/url] .
Приобрести диплом под заказ в столице вы имеете возможность через официальный сайт компании. [url=http://stagingsn.salamalikum.com/read-blog/28538_gde-mozhno-kupit-attestat-9-klass.html/]stagingsn.salamalikum.com/read-blog/28538_gde-mozhno-kupit-attestat-9-klass.html[/url]
платная консультация психиатра
psychiatr-moskva005.ru
платная психиатрическая скорая помощь
провайдер по адресу краснодар
inernetvkvartiru-krasnodar005.ru
интернет по адресу краснодар
https://t.me/s/jackpot_money_slots
Мы можем предложить документы университетов, которые находятся в любом регионе Российской Федерации. Купить диплом о высшем образовании:
[url=http://x91392sl.beget.tech/2025/07/09/diplom-vuza-s-podtverzhdeniem-v-arhivah.html/]купить аттестат 11 класс спб[/url]
напольный горшок для цветов [url=www.kashpo-napolnoe-krasnodar.ru]напольный горшок для цветов[/url] .
mostbet online [url=www.mostbet4124.ru]www.mostbet4124.ru[/url]
купить диплом института образования [url=http://educ-ua5.ru]купить диплом института образования[/url] .
купить диплом училища [url=www.educ-ua1.ru]купить диплом училища[/url] .
mostbet скачать на телефон [url=https://mostbet4127.ru]https://mostbet4127.ru[/url]
лечение в психиатрическом стационаре
psikhiatr-moskva006.ru
психиатрическое лечение
сколько стоит купить диплом магистра [url=http://www.educ-ua4.ru]сколько стоит купить диплом магистра[/url] .
скачать mostbet на телефон [url=www.mostbet4124.ru]www.mostbet4124.ru[/url]
бк теннесси скачать на андроид [url=https://mostbet4119.ru/]https://mostbet4119.ru/[/url]
платный психиатр
psychiatr-moskva006.ru
вызов психиатрической помощи
провайдер по адресу
inernetvkvartiru-krasnodar006.ru
проверить провайдеров по адресу краснодар
Здарова!
Все, что нужно знать, чтобы не светить документы в 2025-м. [url=https://pro-kriptu.ru/birzhi-kriptovalyut-bez-verifikaczii/]где купить криптовалюту без верификации[/url]
Здесь подробней: – https://pro-kriptu.ru/birzhi-kriptovalyut-bez-verifikaczii/
где купить криптовалюту без верификации
где купить крипту без верификации
биржи криптовалют без верификации
Будь здоров!
купить диплом с занесением в реестр в Украине [url=www.educ-ua13.ru/]купить диплом с занесением в реестр в Украине[/url] .
В-четвёртых, просветительская работа. Мы проводим лекции и семинары, направленные на повышение уровня осведомленности общества о проблемах зависимости. Это важно для формирования толерантного отношения к людям, страдающим от зависимостей.
Ознакомиться с деталями – http://алко-лечебница.рф
купить диплом стоимость [url=https://www.educ-ua17.ru]купить диплом стоимость[/url] .
купить диплом киев сколько [url=https://educ-ua18.ru]https://educ-ua18.ru[/url] .
Interesting analysis! The volatility in virtual sports really does demand a strategic approach. Seeing platforms like legend link ph login prioritize quick registration & local payment options (like Maya!) is smart for accessibility. It’s all about ease of play, right?
центр реабилитация алкоголиков в Астане
reabilitaciya-astana004.ru
реабилитация от алкогольной зависимости
купить диплом вуза ссср [url=https://www.educ-ua20.ru]купить диплом вуза ссср[/url] .
Je suis totalement seduit par 7BitCasino, on dirait une plongee dans un univers palpitant. Il y a une profusion de titres varies, proposant des jeux de table elegants et classiques. Les agents sont disponibles 24/7, avec un suivi de qualite. Les transactions en cryptomonnaies sont instantanees, bien que j’aimerais plus d’offres promotionnelles, comme des offres de cashback plus avantageuses. En fin de compte, 7BitCasino vaut pleinement le detour pour les joueurs en quete d’adrenaline ! En bonus le design est visuellement attrayant avec une touche vintage, facilite chaque session de jeu.
7bitcasino bonus|
J’apprecie enormement Betsson Casino, c’est une veritable aventure pleine de frissons. La bibliotheque de jeux est phenomenale, avec des machines a sous modernes et captivantes. Le service client est exceptionnel, offrant des solutions rapides et precises. Les transactions sont protegees par un cryptage SSL 128 bits, cependant les bonus pourraient etre plus frequents. Globalement, Betsson Casino est une plateforme d’exception pour les amateurs de casino en ligne ! Par ailleurs le site est concu avec modernite et ergonomie, facilite chaque session de jeu.
betsson ab stock|
продвижение по трафику [url=www.internet-agentstvo-prodvizhenie-sajtov-seo.ru]продвижение по трафику[/url] .
Ich schatze sehr BoaBoa Casino, es ist ganz ein mitrei?endes Spielerlebnis. Die Auswahl ist reichhaltig und breit gefachert, mit progressiven Jackpots wie Divine Fortune. Der Support ist blitzschnell uber Live-Chat rund um die Uhr, ist 24/7 erreichbar. Der Auszahlungsprozess ist einfach und zuverlassig, manchmal mehr Freispiele waren super. Insgesamt ist BoaBoa Casino enttauscht nie fur Fans von tropischem Spielspa? ! Nicht zu vergessen das Design ist ansprechend mit einem Pinguin-Maskottchen, die Immersion verstarkt.
boaboa casino|
Je suis enthousiaste a propos de BetFury Casino, ca ressemble a une aventure pleine de frissons. Les options de jeu sont riches et diversifiees, offrant des sessions de casino en direct immersives. Les agents sont toujours professionnels et efficaces, avec un suivi exemplaire. Les gains arrivent en un temps record, cependant plus de tours gratuits seraient un plus. En resume, BetFury Casino ne decoit jamais pour les joueurs en quete de sensations fortes ! Notons egalement que le site est concu avec modernite et elegance, ajoute une touche de sophistication a l’experience.
script betfury|
Команда клиники “Аура Здоровья” состоит из опытных и квалифицированных врачей-наркологов, обладающих глубокими знаниями фармакологии и психотерапии. Они регулярно повышают свою квалификацию, участвуя в профессиональных конференциях и семинарах, чтобы применять самые эффективные методы лечения.
Выяснить больше – https://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-rostove-na-donu.xn--p1ai
J’adore a fond CasinoBelgium, c’est une veritable energie de jeu captivante. Le catalogue est compact mais de grande qualite, avec des dice slots modernes comme Mystery Box. Le service client est fiable, offrant des reponses claires et utiles. Le processus de retrait est simple avec une limite de 500 € par semaine, occasionnellement j’aimerais une ludotheque plus vaste. En fin de compte, CasinoBelgium vaut le detour pour les joueurs belges pour les adeptes de simplicite ! De plus l’interface est fluide avec un design tricolore belge, ajoute une touche de fierte nationale.
casino belgium free bonus|
провайдеры интернета по адресу москва
inernetvkvartiru-msk004.ru
провайдеры в москве по адресу проверить
Welcome to https://blevuine.com/, your ultimate financial partner for small businesses. We offer innovative solutions that streamline your cash flow and empower your growth. From credit lines to invoice factoring, Bluevine delivers the flexible financing your business needs. Access to your account is through the Bluevine login portal, where you can safely and efficiently manage all your financial needs. Join thousands of satisfied entrepreneurs who trust Bluevine to advance their business.
лечение в психиатрической больнице
psikhiatr-moskva004.ru
детский психиатр на дом
zamonaviy usullar orqali oshirish mumkin. turli xil taqdim etadi.
Qimor o’yinlari . Bu sayt orqali mumkin.
va shuningdek yordam beradi. haqida joylashgan maqolalar mavjud.
uchun har qanday sayt. shaxsiy ma’lumotlari . bemalol kirishlari mumkin.
888 starz download [url=888starz-uzs.net/apk]https://888starz-uzs.net/apk/[/url]
Welcome to Bluevine login, your ultimate financial partner for small businesses. Our company provides advanced financial tools designed to simplify your financial operations and support your business expansion. From credit lines to invoice factoring, Bluevine delivers the flexible financing your business needs. Access to your account is through the Bluevine login portal, where you can safely and efficiently manage all your financial needs. Join thousands of satisfied entrepreneurs who trust Bluevine to advance their business.
поисковое продвижение сайта в интернете москва [url=www.internet-agentstvo-prodvizhenie-sajtov-seo.ru/]поисковое продвижение сайта в интернете москва[/url] .
покрасочные камеры для порошковой окраски Порошковая камера цена определяется ее размерами, наличием системы рекуперации порошка, типом фильтров и производителем. Небольшие ручные камеры стоят дешевле, чем автоматизированные комплексы с системой рекуперации и программируемым управлением. Важным фактором является также качество материалов, из которых изготовлена камера, и ее соответствие требованиям безопасности.
Миссия наркологического центра “Чистое Завтра” заключается в том, чтобы помочь пациентам разорвать порочный круг зависимости, вернуть контроль над собственной жизнью и обрести радость трезвого бытия. Мы стремимся:
Исследовать вопрос подробнее – https://алко-консультация.рф
лечение алкогольной зависимости в стационаре
reabilitaciya-astana005.ru
помощь при алкоголизме
Команда клиники “Аура Здоровья” состоит из опытных и квалифицированных врачей-наркологов, обладающих глубокими знаниями фармакологии и психотерапии. Они регулярно повышают свою квалификацию, участвуя в профессиональных конференциях и семинарах, чтобы применять самые эффективные методы лечения.
Ознакомиться с деталями – http://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-rostove-na-donu.xn--p1ai/
метод swot анализа swot анализа рисков
подключить интернет москва
inernetvkvartiru-msk005.ru
подключить интернет москва
вызов психиатрической помощи
psikhiatr-moskva005.ru
консультация врача психиатра
купить узи сканер [url=http://kupit-uzi-apparat27.ru]купить узи сканер[/url] .
Great info! Keep post great articles.
Je trouve incroyable 1win Casino, ca procure une plongee dans un univers electrisant. La bibliotheque de jeux est impressionnante, comprenant des titres innovants et engageants. Le service client est de premier ordre, joignable 24/7. Le processus de retrait est simple et efficace, bien que les offres pourraient etre plus genereuses. Globalement, 1win Casino est un incontournable pour les passionnes de jeux en ligne ! Par ailleurs la navigation est simple et rapide, renforce l’immersion totale.
1win casino|
легально купить диплом о высшем образовании [url=www.educ-ua11.ru]www.educ-ua11.ru[/url] .
диплом торгового техникума купить [url=https://educ-ua10.ru]https://educ-ua10.ru[/url] .
Ich liebe es absolut Billy Billion Casino, es ist ganz ein mitrei?endes Spielerlebnis. Die Spielauswahl ist uberwaltigend mit uber 4000 Titeln, mit immersiven Live-Casino-Sessions von Evolution Gaming. Der Kundendienst ist tadellos, garantiert sofortige Hilfe per Chat oder E-Mail. Zahlungen sind flussig und durch SSL-Verschlusselung gesichert, manchmal die Angebote konnten gro?zugiger sein. Zusammengefasst ist Billy Billion Casino enttauscht nie fur Spieler, die nach Adrenalin suchen! Erganzend das Design ist visuell ansprechend und einzigartig, einen Hauch von Eleganz hinzufugt.
billy billion promo code no deposit|
J’adore passionnement Betify Casino, ca procure une experience de jeu captivante. La selection de jeux est impressionnante, avec des machines a sous modernes et dynamiques. Le service d’assistance est irreprochable, repondant en un clin d’?il. Les gains sont verses en un temps record, neanmoins plus de tours gratuits seraient un atout. Pour conclure, Betify Casino est un incontournable pour les passionnes de jeux numeriques ! Par ailleurs l’interface est fluide et intuitive, renforce l’immersion totale.
betify erfahrung|
диплом с реестром купить [url=https://www.educ-ua15.ru]диплом с реестром купить[/url] .
купить диплом о среднем образовании с занесением в реестр [url=www.educ-ua14.ru]купить диплом о среднем образовании с занесением в реестр[/url] .
Je suis totalement seduit par Casino Action, il offre une experience de jeu exaltante. Le catalogue est incroyablement vaste, proposant des jeux de table classiques comme le blackjack et la roulette. Le personnel offre un accompagnement rapide via chat ou email, garantissant une aide immediate. Les transactions sont parfaitement protegees, cependant j’aimerais plus de promotions regulieres. Pour conclure, Casino Action est une plateforme d’exception pour ceux qui aiment parier ! Notons egalement que la navigation est rapide sur mobile via iOS/Android, ce qui amplifie le plaisir de jouer.
all casino action victor|
диплом автотранспортного техникума купить в [url=https://educ-ua8.ru]https://educ-ua8.ru[/url] .
купить диплом техникума с занесением в реестр [url=educ-ua9.ru]купить диплом техникума с занесением в реестр[/url] .
купить диплом легальный [url=www.educ-ua12.ru]купить диплом легальный[/url] .
buy angular contact ball bearing
как излечиться от алкоголизма
reabilitaciya-astana006.ru
помощь при наркотической зависимости
массовое швейное производство [url=http://nitkapro.ru/]http://nitkapro.ru/[/url] .
купить диплом о среднем образовании цена [url=https://www.educ-ua16.ru]купить диплом о среднем образовании цена[/url] .
предприятие по пошиву одежды [url=https://nitkapro.ru/]https://nitkapro.ru/[/url] .
Попытки пациента самостоятельно прекратить употребление психоактивных веществ приводят к развитию мучительного абстинентного синдрома, который проявляется в виде физических и психических страданий.
Подробнее – http://алко-консультация.рф/vivod-iz-zapoya-v-stacionare-v-Moskve/
Мы предлагаем документы институтов, расположенных в любом регионе России. Приобрести диплом любого университета:
[url=http://mercaato.com/kupit-diplom-s-zaneseniem-v-reestr-59/]где купить аттестат за 11 класс форум[/url]
мостбет. [url=http://mostbet4129.ru/]http://mostbet4129.ru/[/url]
https://t.me/s/reytingcasino_online
какие провайдеры интернета есть по адресу москва
inernetvkvartiru-msk006.ru
домашний интернет тарифы москва
Привет!
Думаешь, есть система, чтобы обыграть казино? [url=https://nagny-casino.ru/igry-na-dengi/]номад казино[/url]
Здесь подробней: – https://nagny-casino.ru/igry-na-dengi/
казино без депозита
номад казино
777 казино
Будь здоров!
швейное производство [url=https://nitkapro.ru/]https://nitkapro.ru/[/url] .
вызвать психиатра на дом для пожилого
psikhiatr-moskva006.ru
частная психиатрическая клиника стационар
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Следуйте по ссылке – https://aircopengineers.com/simple-steps-for-replacing-old-tiling
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Обратиться к источнику – https://healthelevationnow.com/hello-world
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Практические советы ждут тебя – https://2000isola.ru/gornolyzhnyj-sport
mostbet вход [url=http://mostbet4130.ru]mostbet вход[/url]
поисковое продвижение москва профессиональное продвижение сайтов [url=http://internet-agentstvo-prodvizhenie-sajtov-seo.ru]http://internet-agentstvo-prodvizhenie-sajtov-seo.ru[/url] .
купить диплом в хмельницком [url=https://educ-ua3.ru]https://educ-ua3.ru[/url] .
вывод из запоя
tula-narkolog004.ru
экстренный вывод из запоя
интернет продвижение москва [url=https://www.internet-prodvizhenie-moskva.ru]интернет продвижение москва[/url] .
мостбет приложение узбекистан [url=https://mostbet4167.ru/]https://mostbet4167.ru/[/url]
мостбет личный кабинет [url=https://mostbet4131.ru/]https://mostbet4131.ru/[/url]
Привет!
Как превратить свою страсть к играм в источник дохода. [url=https://zarabotok-na-igrah.ru/na-kakih-igrah-mozhno-zarabotat-bez-vlozhenij/]как заработать на играх в телефоне[/url]
По ссылке: – https://zarabotok-na-igrah.ru/na-kakih-igrah-mozhno-zarabotat-bez-vlozhenij/
можно ли заработать на играх с выводом денег
можно ли заработать на мобильных играх
можно ли заработать на играх
Будь здоров!
интернет продвижение москва [url=www.kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru/]www.kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru/[/url] .
заказать продвижение сайта в москве [url=https://poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru/]poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru[/url] .
Je suis enthousiaste a propos de 1xbet Casino, c’est une veritable sensation de casino unique. Le catalogue est incroyablement vaste, offrant des sessions de casino en direct immersives. Le personnel offre un accompagnement irreprochable, avec un suivi de qualite. Les transactions sont parfaitement protegees, occasionnellement les promotions pourraient etre plus genereuses. En fin de compte, 1xbet Casino est une plateforme d’exception pour les adeptes de sensations fortes ! De plus le design est visuellement percutant, ce qui intensifie le plaisir de jouer.
deadpool & wolverine 1xbet|
mostbet aviator qanday o‘ynash [url=https://mostbet4165.ru/]https://mostbet4165.ru/[/url]
seo network [url=www.internet-agentstvo-prodvizhenie-sajtov-seo.ru]seo network[/url] .
поисковое продвижение москва профессиональное продвижение сайтов [url=https://www.kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru]https://www.kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru[/url] .
Acho simplesmente fantastico o 888 Casino, proporciona uma aventura cheia de emocoes. A gama de jogos e simplesmente fenomenal, incluindo slots de ultima geracao. O suporte e super responsivo e profissional, respondendo rapidamente. Os pagamentos sao fluidos e seguros, as vezes mais recompensas seriam bem-vindas. Para concluir, o 888 Casino oferece uma experiencia de jogo memoravel para aqueles que gostam de apostar! Como bonus o design e visualmente impactante, o que amplifica o prazer de jogar.
888 hot casino|
Je suis totalement seduit par Betway Casino, c’est une veritable plongee dans un univers vibrant. Il y a une multitude de jeux varies, proposant des jeux de table classiques comme le blackjack et la roulette. Le service client est de haut niveau, joignable a toute heure. Les paiements sont fluides et securises par un cryptage SSL 128 bits, bien que plus de tours gratuits seraient un atout. Dans l’ensemble, Betway Casino ne decoit jamais pour les adeptes de sensations fortes ! Ajoutons que la navigation est intuitive sur l’application mobile iOS/Android, ce qui amplifie le plaisir de jouer.
sport betway|
Ich finde unglaublich toll BingBong Casino, es bietet eine unwiderstehliche Energie fur Spieler. Es gibt eine Fulle an abwechslungsreichen Titeln, mit klassischen Slots wie Eye of Horus und Sizzling Hot. Der Kundenservice ist hervorragend, reagiert in wenigen Minuten. Gewinne kommen in Rekordzeit an, trotzdem die Angebote wie der 100%-Bonus bis 100 € konnten gro?zugiger sein. Am Ende ist BingBong Casino enttauscht nie fur die, die gerne Slots spielen ! Zusatzlich das Design ist ansprechend mit einem peppigen Look, die Immersion verstarkt.
bingbong crisologo wife|
Je trouve absolument genial CasinoAndFriends, c’est une veritable energie de jeu irresistible. Les options de jeu sont vastes et diversifiees, avec des machines a sous modernes comme Book of Dead. Le support est reactif via chat en direct de 6h a minuit, garantissant une aide immediate. Le processus de retrait est simple avec un maximum de 5000 € par jour, cependant plus de tours gratuits seraient un atout. En resume, CasinoAndFriends est une plateforme d’exception pour les adeptes de sensations fortes ! Par ailleurs le site est concu avec modernite et ergonomie, facilite chaque session de jeu.
casinoandfriends gratis spins|
купить диплом о высшем образовании проведенный [url=www.arus-diplom31.ru/]купить диплом о высшем образовании проведенный[/url] .
подключить интернет в квартиру нижний новгород
inernetvkvartiru-nizhnij-novgorod004.ru
недорогой интернет нижний новгород
mostbet ro‘yxatdan o‘tish kodi [url=mostbet4166.ru]mostbet4166.ru[/url]
комплексное продвижение сайтов москва [url=https://www.internet-prodvizhenie-moskva.ru]комплексное продвижение сайтов москва[/url] .
скачат мосбет [url=http://mostbet4129.ru/]http://mostbet4129.ru/[/url]
продвижение сайта [url=www.poiskovoe-prodvizhenie-moskva-professionalnoe.ru]продвижение сайта[/url] .
mostbet uz yuklab olish [url=www.mostbet4166.ru]www.mostbet4166.ru[/url]
Заказать диплом ВУЗа!
Наша компания предлагаетбыстро заказать диплом, который выполнен на бланке ГОЗНАКа и заверен мокрыми печатями, штампами, подписями. Диплом способен пройти лубую проверку, даже с применением специфических приборов. Достигайте цели быстро и просто с нашей компанией- [url=http://breyerhorses.ru/personal/profile/?register=yes/]breyerhorses.ru/personal/profile/?register=yes[/url]
реабилитация наркозависимых стационар
reabilitaciya-astana004.ru
алкоголизм лечение
компании занимающиеся продвижением сайтов [url=https://www.poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru]https://www.poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru[/url] .
скачат мосбет [url=https://mostbet4130.ru]https://mostbet4130.ru[/url]
интернет агентство продвижение сайтов сео [url=http://www.kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru]http://www.kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru[/url] .
mostbet uzbekistan [url=mostbet4165.ru]mostbet4165.ru[/url]
https://t.me/leader_casino_rus/7
заказать анализ сайта [url=www.poiskovoe-prodvizhenie-moskva-professionalnoe.ru]заказать анализ сайта[/url] .
вывод из запоя тула
tula-narkolog005.ru
лечение запоя
monstbet [url=https://mostbet4167.ru]https://mostbet4167.ru[/url]
пленка самоклеющаяся защитная купить [url=https://samokleyushchayasya-plenka-1.ru]https://samokleyushchayasya-plenka-1.ru[/url] .
дизайнерская мебель цена [url=https://dizajnerskaya-mebel-1.ru/]https://dizajnerskaya-mebel-1.ru/[/url] .
motsbet [url=https://mostbet4131.ru/]https://mostbet4131.ru/[/url]
купить диплом стоимость [url=www.educ-ua2.ru]купить диплом стоимость[/url] .
диплом техникума купить цены [url=educ-ua6.ru]educ-ua6.ru[/url] .
https://t.me/s/TopCasino_list/8
mostbet-uz [url=https://mostbet4168.ru/]https://mostbet4168.ru/[/url]
подключение интернета по адресу
inernetvkvartiru-nizhnij-novgorod005.ru
интернет провайдеры по адресу
20
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-lyubercy13.ru/]kapelnicza-ot-zapoya-czena podolsk[/url]
купить старый диплом техникума киев [url=https://www.educ-ua18.ru]купить старый диплом техникума киев[/url] .
купить диплом ссср высшее [url=https://educ-ua19.ru]https://educ-ua19.ru[/url] .
лечение от алкогольной зависимости
reabilitaciya-astana005.ru
как вылечить алкогольную зависимость
купить аттестат 11 классов за 1996 год [url=https://www.arus-diplom25.ru]купить аттестат 11 классов за 1996 год[/url] .
лечение запоя тула
tula-narkolog006.ru
экстренный вывод из запоя тула
Вывод из запоя в Химках возможен без госпитализации — достаточно обратиться в Stop Alko, чтобы получить помощь на дому.
Узнать больше – [url=https://vyvod-iz-zapoya-himki12.ru/]вывод из запоя капельница подольск[/url]
как купить диплом проведенный [url=https://arus-diplom34.ru/]как купить диплом проведенный[/url] .
диплом о высшем образовании с занесением в реестр купить [url=https://www.arus-diplom33.ru]диплом о высшем образовании с занесением в реестр купить[/url] .
купить диплом в киеве [url=http://educ-ua17.ru]http://educ-ua17.ru[/url] .
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Подробная информация доступна по запросу – https://shoresyogastudio.com/product/b-mat-6-mm
интернет провайдеры нижний новгород
inernetvkvartiru-nizhnij-novgorod006.ru
провайдеры нижний новгород
mostbet apk yuklab olish uz [url=https://www.mostbet4168.ru]mostbet apk yuklab olish uz[/url]
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Смотрите также… – https://vriba.com/blog/gpt-4o-a-promising-yet-familiar-evolution
most bet uz [url=https://mostbet4169.ru/]https://mostbet4169.ru/[/url]
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Заходи — там интересно – https://consulting-solaris.com/cambio-climatico
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Неизвестные факты о… – https://simplamo.tech/download-file
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Подробнее тут – https://www.art-de-lhair.fr/produit/seche-cheveux-flight-ghd
реабилитация наркоманов
reabilitaciya-astana006.ru
реабилитация наркоманов в Астане
лечение запоя
vivod-iz-zapoya-chelyabinsk007.ru
вывод из запоя цена
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Подробная информация доступна по запросу – https://solidgroup.bg/%D0%BA%D0%B0%D1%82%D0%B0%D0%BB%D0%BE%D0%B7%D0%B8-v-tac/attachment/30
диплом купить в реестре [url=www.educ-ua13.ru]диплом купить в реестре[/url] .
мостбе [url=https://www.mostbet4128.ru]https://www.mostbet4128.ru[/url]
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Узнать напрямую – https://hidproductions.com/portfolio/best-speech
mostbetin [url=https://mostbet4169.ru/]mostbetin[/url]
заказать продвижение сайта в москве [url=http://internet-agentstvo-prodvizhenie-sajtov-seo.ru]заказать продвижение сайта в москве[/url] .
J’aime enormement le casino TonyBet, ca ressemble a un univers de jeu unique. Il y a une tonne de jeux differents, comprenant des titres innovants. Le service client est super, disponible 24/7. Le processus de retrait est efficace, occasionnellement plus de tours gratuits seraient bien. Globalement, TonyBet c’est du solide pour les amateurs de casino ! Ajoutons que, le site est facile a naviguer, ce qui rend l’experience encore meilleure.
tonybet wedden review|
Je suis totalement conquis par le casino AllySpin, ca donne une plongee dans le divertissement. Les options de jeu sont incroyablement variees, comprenant des jeux innovants. Le support est ultra-reactif, repondant en un clin d’?il. Le processus de retrait est sans accroc, par moments les bonus pourraient etre plus frequents. Globalement, AllySpin vaut vraiment le detour pour les joueurs en quete d’adrenaline ! Par ailleurs le style visuel est dynamique, ce qui booste encore plus le plaisir.
allyspin uvГtacГ bonus|
комплексное продвижение сайтов москва [url=http://poiskovoe-seo-v-moskve.ru/]http://poiskovoe-seo-v-moskve.ru/[/url] .
Je suis completement seduit par Azur Casino, on dirait une sensation de casino unique. Il y a une multitude de jeux varies, incluant des slots dynamiques. Le support est toujours reactif, offrant des reponses claires et rapides. Les gains sont verses rapidement, parfois les bonus pourraient etre plus nombreux. Globalement, Azur Casino vaut vraiment le detour pour les joueurs passionnes ! Par ailleurs la navigation est intuitive et agreable, facilitant l’immersion totale.
gГ©ant casino centre azur|
Je suis conquis par Banzai Casino, c’est une veritable energie de jeu captivante. La selection est riche et diversifiee, offrant des sessions de casino en direct immersives. Le service d’assistance est exemplaire, garantissant une aide immediate. Les gains arrivent en un rien de temps, bien que plus de tours gratuits seraient apprecies. Pour faire court, Banzai Casino est une valeur sure pour ceux qui aiment parier ! Ajoutons que la navigation est intuitive et rapide, facilitant chaque session de jeu.
banzai slots casino|
Здарова!
Бизнес на китайской технике: реальные цифры и расходы. [url=https://pro-telefony.ru/elektronika-iz-kitaya-napryamuyu/]электроника китай[/url]
Читай тут: – https://pro-telefony.ru/elektronika-iz-kitaya-napryamuyu/
телефон из китая
телефоны оптом из китая
телефон китайский
Удачи!
Je suis enthousiaste a propos de Betclic Casino, ca offre une energie de jeu irresistible. La selection de jeux est phenomenale, incluant des slots dernier cri. Le personnel offre un accompagnement de qualite, avec un suivi efficace. Les gains sont verses en un clin d’?il, neanmoins davantage de recompenses seraient appreciees. Pour conclure, Betclic Casino est un incontournable pour les joueurs en quete d’adrenaline ! Par ailleurs le site est concu avec elegance, facilite chaque session de jeu.
betclic foot|
Tham gia game Luck8 ngay! Cá cược đỉnh cao, nổ thưởng khủng, giao dịch siêu tốc. Nhà cái uy tín, trải nghiệm mãn nhãn cùng ưu đãi siêu hời!
blacksprut ссылка blacksprut, блэкспрут, black sprut, блэк спрут, blacksprut вход, блэкспрут ссылка, blacksprut ссылка, blacksprut onion, блэкспрут сайт, blacksprut вход, блэкспрут онион, блэкспрут дакрнет, blacksprut darknet, blacksprut сайт, блэкспрут зеркало, blacksprut зеркало, black sprout, blacksprut com зеркало, блэкспрут не работает, blacksprut зеркала, как зайти на blacksprutd
Как сам!
Индийские препараты в Россию — без нарушений закона. [url=https://generik-info.ru/gde-zakazat-tabletki-napryamuyu-iz-indii/]таблетки от давления производство индия[/url] Полный гайд по оформлению и таможенным нюансам.
Здесь подробней: – https://generik-info.ru/gde-zakazat-tabletki-napryamuyu-iz-indii/
таблетки индия
таблетки от кашля индия
какие таблетки привезти из индии
Покеда!
интернет провайдеры по адресу дома
inernetvkvartiru-novosibirsk004.ru
провайдеры интернета в новосибирске
Здравствуйте!
Как делать деньги в криптовалютах не торгуя. [url=https://pro-kriptu.ru/defi-proekty-s-dohodom/]defi проекты[/url] DeFi протоколы для долгосрочного пассивного дохода.
Здесь подробней: – https://pro-kriptu.ru/defi-proekty-s-dohodom/
defi как заработать
как заработать на defi проектах
как заработать деньги на инвестициях в defi
Пока!
https://www.betterplace.org/en/organisations/67867
продвижение сайтов интернет магазины в москве [url=https://internet-agentstvo-prodvizhenie-sajtov-seo.ru/]продвижение сайтов интернет магазины в москве[/url] .
частный seo оптимизатор [url=https://www.poiskovoe-seo-v-moskve.ru]https://www.poiskovoe-seo-v-moskve.ru[/url] .
лечение запоя челябинск
vivod-iz-zapoya-chelyabinsk008.ru
лечение запоя челябинск
вывод из запоя круглосуточно тула
tula-narkolog004.ru
вывод из запоя тула
купить диплом о среднем образовании цена [url=http://www.educ-ua20.ru]купить диплом о среднем образовании цена[/url] .
локальное seo блог [url=www.statyi-o-marketinge.ru]www.statyi-o-marketinge.ru[/url] .
Заказать диплом университета!
Наша компания предлагаетвыгодно и быстро заказать диплом, который выполняется на оригинальной бумаге и заверен печатями, водяными знаками, подписями. Наш диплом пройдет любые проверки, даже с использованием профессиональных приборов. Достигайте цели быстро и просто с нашими дипломами- [url=http://zambianhousing.com/author/wilhelminawong/]zambianhousing.com/author/wilhelminawong[/url]
Мы можем предложить дипломы любых профессий по выгодным ценам. Заказ диплома, который подтверждает окончание университета, – это выгодное решение. Приобрести диплом о высшем образовании: [url=http://gtranslc.com/employer/diplomy-grupps/]gtranslc.com/employer/diplomy-grupps[/url]
интернет провайдеры по адресу дома
inernetvkvartiru-novosibirsk005.ru
домашний интернет новосибирск
KRAKEN – Ваша безопасность и анонимность на aktual-krkn.ru
aktual-krkn.ru — официальный переходник даркнет-маркета Kraken.
Добро пожаловать на kra36—-at.com, где приватность и безопасность являются главным приоритетом. Официальный сайт kraken kra37.at — сохрани список актуальных зеркал. Переходите на aktual-krkn.ru и начните пользоваться прямо сейчас!
кракен, kraken, сайт кракен, ссылка кракен, кракен ссылка, кракен сайт, кракен официальный сайт, официальный сайт кракен, кракен ссылка официальная, кракен актуальная ссылка
*Полная анонимность и защита данных
Система безопасности KRAKEN обеспечивает полную конфиденциальность. Передовые технологии шифрования для защиты ваших данных и транзакций.
актуальная ссылка на кракен, рабочая ссылка кракен, как зайти на кракен, кракен как зайти, вход кракен, кракен вход, зайти на кракен, кракен зайти, зеркало кракен, кракен зеркало
*Удобство использования
Простая навигация, мощная система и дизайн aktual-krkn.ru делают использование KRAKEN комфортным на любых устройствах.
кракен рабочее зеркало, рабочее зеркало кракен, зеркала кракен, кракен зеркала, даркнет кракен, кракен даркнет, маркетплейс кракен, кракен маркетплейс, площадка кракен, кракен площадка
*Гарантии безопасности и круглосуточная поддержка
KRAKEN гарантирует защиту покупателей и продавцов. Служба поддержки kra36—-at.com работает 24/7 для решения любых вопросов.
магазин кракен, кракен магазин, кракен маркет, кракены маркет, кракен даркнет маркет, кракен маркет даркнет, кракен отзывы, кракен сайт что, кракен ссылка тор, ссылка кракен тор
В современном обществе проблемы наркомании и алкоголизма приобрели особую актуальность, затрагивая не только отдельных людей, но и их близких, и сообщества. Эти зависимости оказывают негативное влияние не только на физическое здоровье, но и на психоэмоциональное состояние, нарушают социальные связи и ухудшают качество жизни. Наркологическая клиника “Здоровое Настоящее” предлагает комплексный и научно обоснованный подход к лечению зависимостей. Мы используем современные методы диагностики и терапии, чтобы помочь пациентам вернуть здоровье и полноценную жизнь.
Получить дополнительные сведения – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-anonimno-v-kazani.ru/]нарколог вывод из запоя в казани[/url]
экстренный вывод из запоя
vivod-iz-zapoya-chelyabinsk009.ru
вывод из запоя челябинск
«Сибирский Доктор» оснащён передовыми медицинскими аппаратами и программным обеспечением для контроля за пациентом на каждом этапе лечения:
Изучить вопрос глубже – [url=https://kachestvo-vyvod-iz-zapoya.ru/]нарколог вывод из запоя в новосибирске[/url]
вывод из запоя тула
tula-narkolog005.ru
экстренный вывод из запоя тула
купить диплом младшего специалиста в украине [url=www.educ-ua7.ru/]купить диплом младшего специалиста в украине[/url] .
купить диплом в киеве [url=http://educ-ua19.ru]купить диплом в киеве[/url] .
провайдеры по адресу дома
inernetvkvartiru-novosibirsk006.ru
домашний интернет подключить новосибирск
лечение запоя
vivod-iz-zapoya-cherepovec010.ru
экстренный вывод из запоя череповец
купить аттестат за 11 класс дешево в москве [url=https://www.arus-diplom25.ru]купить аттестат за 11 класс дешево в москве[/url] .
экстренный вывод из запоя
tula-narkolog006.ru
лечение запоя
купить диплом специалиста дешево [url=educ-ua17.ru]купить диплом специалиста дешево[/url] .
Je suis totalement envoute par Amon Casino, ca balance une vibe de jeu completement folle. Il y a une avalanche de jeux de casino varies, proposant des sessions de casino en direct qui dechirent. Les agents du casino sont rapides comme l’eclair, offrant des solutions claires et instantanees. Les paiements du casino sont securises et fiables, de temps en temps plus de tours gratuits au casino ca serait ouf. En bref, Amon Casino c’est un casino de ouf a tester direct pour ceux qui kiffent parier avec style au casino ! Et puis la navigation du casino est simple comme un claquement de doigts, ce qui rend chaque session de casino encore plus kiffante.
avis amon casino|
Ich bin total begeistert von King Billy Casino, es fuhlt sich an wie ein koniglicher Triumph. Es gibt eine Flut an mitrei?enden Casino-Titeln, mit einzigartigen Casino-Slotmaschinen. Der Casino-Service ist zuverlassig und furstlich, antwortet blitzschnell wie ein koniglicher Erlass. Der Casino-Prozess ist klar und ohne Intrigen, manchmal mehr Casino-Belohnungen waren ein furstlicher Gewinn. Alles in allem ist King Billy Casino ein Online-Casino, das wie ein Konigreich strahlt fur die, die mit Stil im Casino wetten! Und au?erdem die Casino-Oberflache ist flussig und prunkvoll wie ein Thronsaal, Lust macht, immer wieder ins Casino zuruckzukehren.
king billy win casino|
сколько стоит купить диплом в киеве [url=www.educ-ua5.ru]сколько стоит купить диплом в киеве[/url] .
Заказать диплом любого ВУЗа поспособствуем. Купить диплом о высшем образовании в Краснодаре – [url=http://diplomybox.com/kupit-diplom-o-vysshem-obrazovanii-v-krasnodare/]diplomybox.com/kupit-diplom-o-vysshem-obrazovanii-v-krasnodare[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-cherepovec011.ru
вывод из запоя череповец
статьи про digital маркетинг [url=www.blog-o-marketinge.ru/]www.blog-o-marketinge.ru/[/url] .
руководства по seo [url=https://www.blog-o-marketinge1.ru]руководства по seo[/url] .
материалы по seo [url=http://www.statyi-o-marketinge2.ru]материалы по seo[/url] .
построить дом иркутск [url=https://stroitelstvo-domov-irkutsk-2.ru]https://stroitelstvo-domov-irkutsk-2.ru[/url] .
центр наркологии москва [url=https://narkologicheskaya-klinika-12.ru/]narkologicheskaya-klinika-12.ru[/url] .
Заказать диплом под заказ возможно через официальный сайт компании. [url=http://office.listbb.ru/viewtopic.php?f=2&t=8007/]office.listbb.ru/viewtopic.php?f=2&t=8007[/url]
лучший интернет провайдер ростов
inernetvkvartiru-rostov004.ru
подключить интернет в ростове в квартире
Je trouve completement barre Gamdom, on dirait une explosion de fun. Il y a un tsunami de titres varies, proposant des sessions live qui tabassent. Le support est dispo 24/7, offrant des reponses qui petent. Les paiements sont fluides et blindes, par moments des recompenses en plus ca ferait kiffer. Bref, Gamdom c’est du lourd a tester direct pour les accros aux sensations extremes ! A noter aussi le site est une tuerie graphique, booste l’immersion a fond les ballons.
gamdom 2 factor authentication|
телефон наркологии [url=www.narkologicheskaya-klinika-11.ru]www.narkologicheskaya-klinika-11.ru[/url] .
Запой представляет собой непрерывное бесконтрольное употребление алкоголя в течение нескольких дней и более, при котором человек теряет способность остановиться самостоятельно. Это состояние сопровождается не только абстинентным синдромом, но и риском развития:
Выяснить больше – https://nadezhnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-czena-spb
высшее образование купить диплом с занесением в реестр [url=www.educ-ua13.ru/]высшее образование купить диплом с занесением в реестр[/url] .
локальное seo блог [url=http://blog-o-marketinge1.ru/]http://blog-o-marketinge1.ru/[/url] .
статьи о маркетинге [url=http://blog-o-marketinge.ru/]статьи о маркетинге[/url] .
наркология в москве [url=http://narkologicheskaya-klinika-12.ru]http://narkologicheskaya-klinika-12.ru[/url] .
постройка дома под ключ [url=https://stroitelstvo-domov-irkutsk-2.ru]https://stroitelstvo-domov-irkutsk-2.ru[/url] .
стратегия продвижения блог [url=www.statyi-o-marketinge2.ru]www.statyi-o-marketinge2.ru[/url] .
купить диплом москва легально [url=www.arus-diplom31.ru/]www.arus-diplom31.ru/[/url] .
наркология [url=http://narkologicheskaya-klinika-11.ru]http://narkologicheskaya-klinika-11.ru[/url] .
экстренный вывод из запоя
vivod-iz-zapoya-chelyabinsk007.ru
экстренный вывод из запоя челябинск
купить диплом техникума в спб [url=http://www.educ-ua6.ru]купить диплом техникума в спб[/url] .
экстренный вывод из запоя череповец
vivod-iz-zapoya-cherepovec012.ru
вывод из запоя круглосуточно череповец
https://taplink.cc/topcasino_rus
Актуальные автобусные рейсы по Беларуси и Росии — от крупных городов до самых уютных маленьких станций. Туристические туры и экскурсии — будь то прогулка по старинным улочкам европейского города или активный уикенд на природе. Авиабилеты — могли перемещаться не только по дорогам, но и по воздуху, открывая всё новые горизонты. Всё это вы подбираете прямо на Probilets и оплачиваете удобным способом: probilets.com
mostbet live [url=http://mostbet4154.ru]mostbet live[/url]
интернет тарифы ростов
inernetvkvartiru-rostov005.ru
подключить домашний интернет в ростове
Мы можем предложить документы университетов, расположенных в любом регионе России. Приобрести диплом любого университета:
[url=http://goddess-selina-empire.mn.co/posts/87270172/]купить аттестат 11 классов 2012[/url]
Estou alucinado com DiceBet Casino, tem uma vibe de jogo que explode tudo. O catalogo de jogos do cassino e uma loucura total, oferecendo sessoes de cassino ao vivo que sao uma bomba. A equipe do cassino manda um atendimento que e show, dando solucoes claras na hora. Os ganhos do cassino chegam voando, mas mais recompensas no cassino seriam um diferencial brabo. Na real, DiceBet Casino e um cassino online que e uma pedrada para os viciados em emocoes de cassino! De bonus o site do cassino e uma obra-prima de visual, da um toque de classe braba ao cassino.
dicebet|
Je suis totalement emballe par Circus, ca donne une vibe de jeu incroyable. Le catalogue est incroyablement diversifie, offrant des slots a theme innovants. Les agents sont rapides et attentionnes, repondant en un rien de temps. Les gains arrivent sans attendre, de temps a autre des promotions plus frequentes seraient top. En fin de compte, Circus vaut pleinement le detour pour ceux qui aiment parier avec style ! Par ailleurs le site est style et bien pense, ce qui rend chaque session encore plus excitante.
casino circus de carnac avis|
Je suis totalement envoute par FatPirate, ca balance une vibe dechainee. Il y a un ocean de titres varies, offrant des machines a sous qui claquent. Le support est dispo 24/7, avec une aide qui dechire. Les gains arrivent en mode eclair, des fois j’aimerais plus de promos qui tabassent. Dans le fond, FatPirate garantit un fun total pour les fans de casinos en ligne ! Bonus le design est style et accrocheur, facilite le delire total.
fatpirate bonus za registraci|
сколько стоит купить диплом [url=https://educ-ua20.ru]сколько стоит купить диплом[/url] .
лечение запоя
vivod-iz-zapoya-chelyabinsk008.ru
вывод из запоя круглосуточно
скачать мостбет кг [url=https://mostbet4155.ru]https://mostbet4155.ru[/url]
Миссия центра “Луч Надежды” — помогать людям, попавшим в плен зависимости, находить путь к выздоровлению. Мы не ограничиваемся лечением, а делаем акцент на профилактике рецидивов, социальной адаптации пациентов и их возвращении к полноценной, радостной жизни без психоактивных веществ.
Разобраться лучше – [url=https://srochno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-ufe.ru/]vyvod iz zapoya kapelnica na domu ufa[/url]
Je suis totalement hypnotise par Impressario, ca balance une vibe spectaculaire. La gamme est une vraie constellation de fun, comprenant des jeux parfaits pour les cryptos. Les agents sont rapides comme des cometes, joignable par chat ou email. Les gains arrivent a la vitesse de la lumiere, quand meme des recompenses en plus ca serait le feu. Au final, Impressario offre un spectacle de jeu inoubliable pour les amateurs de slots qui brillent ! Et puis la plateforme claque avec son look de star, booste l’immersion a fond.
impressario casino login|
купить диплом техникум официальный [url=https://www.educ-ua8.ru]купить диплом техникум официальный[/url] .
купить диплом колледжа недорого [url=https://educ-ua10.ru/]купить диплом колледжа недорого[/url] .
купить диплом о высшем с занесением в реестр [url=https://www.educ-ua11.ru]купить диплом о высшем с занесением в реестр[/url] .
блог про seo [url=http://statyi-o-marketinge.ru/]http://statyi-o-marketinge.ru/[/url] .
лечение запоя иркутск
vivod-iz-zapoya-irkutsk007.ru
вывод из запоя круглосуточно иркутск
регистрация в мостбет [url=https://mostbet4160.ru]https://mostbet4160.ru[/url]
купить диплом с занесением в реестр в украине [url=rkiyosaki.ru/discussion/14481/kupit-diplom-universiteta]купить диплом с занесением в реестр в украине[/url] .
Добрый день!
Как перестать сливать в покере и начать зарабатывать. [url=https://nagny-casino.ru/kak-vyigrat-v-poker/]как играют в покер[/url] Проверенные стратегии и типичные ошибки начинающих игроков.
Переходи: – https://nagny-casino.ru/kak-vyigrat-v-poker/
как заработать в покере
как играют в покер
как выиграть в покере
Пока!
Вывод из запоя в «Сибирском Докторе» происходит в несколько взаимосвязанных этапов:
Подробнее тут – [url=https://kachestvo-vyvod-iz-zapoya.ru/]вывод из запоя круглосуточно новосибирск[/url]
купить диплом занесением в реестр [url=http://educ-ua14.ru/]купить диплом занесением в реестр[/url] .
букмекер кыргызстан [url=https://mostbet4156.ru]https://mostbet4156.ru[/url]
бк мост бет [url=http://mostbet4153.ru/]бк мост бет[/url]
Добрый день!
Мобильники для пожилых людей: что брать, а что обходить стороной. [url=https://pro-telefony.ru/telefon-dlya-pozhilyh-lyudej/]лучший кнопочный телефон для пожилых[/url] Простые советы без воды и маркетинговой лапши.
Читай тут: – https://pro-telefony.ru/telefon-dlya-pozhilyh-lyudej/
телефон для пожилых с большими кнопками
телефон с большими кнопками для пожилых
Покеда!
мост бет [url=https://mostbet4157.ru]мост бет[/url]
20
Подробнее тут – [url=https://vyvod-iz-zapoya-himki13.ru/]вывод из запоя с выездом[/url]
мостбет вход на сегодня [url=http://mostbet4159.ru/]http://mostbet4159.ru/[/url]
Миссия центра “Луч Надежды” — помогать людям, попавшим в плен зависимости, находить путь к выздоровлению. Мы не ограничиваемся лечением, а делаем акцент на профилактике рецидивов, социальной адаптации пациентов и их возвращении к полноценной, радостной жизни без психоактивных веществ.
Детальнее – [url=https://srochno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-cena-v-ufe.ru/]вывод из запоя недорого[/url]
купить диплом медсестры с занесением в реестр [url=http://educ-ua15.ru]http://educ-ua15.ru[/url] .
сколько стоит купить диплом специалиста [url=http://educ-ua18.ru]сколько стоит купить диплом специалиста[/url] .
подключить проводной интернет ростов
inernetvkvartiru-rostov006.ru
провайдеры интернета в ростове
мобильное приложение регистрация вход mostbet app приложении рейтинг 4 8 [url=www.mostbet4154.ru]мобильное приложение регистрация вход mostbet app приложении рейтинг 4 8[/url]
скачать приложение мостбет [url=https://mostbet4155.ru/]https://mostbet4155.ru/[/url]
купить диплом вуза ссср [url=www.educ-ua19.ru/]купить диплом вуза ссср[/url] .
купить диплом ссср [url=https://educ-ua18.ru]купить диплом ссср[/url] .
диплом кулинарного техникума купить [url=https://educ-ua9.ru]https://educ-ua9.ru[/url] .
диплом техникума купить в [url=http://educ-ua8.ru/]http://educ-ua8.ru/[/url] .
казино мостбет [url=https://mostbet4159.ru/]https://mostbet4159.ru/[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-chelyabinsk009.ru
вывод из запоя цена
В Люберцах капельница от запоя доступна круглосуточно — в клинике Stop Alko её ставят как на дому, так и в стационаре.
Подробнее тут – [url=https://kapelnica-ot-zapoya-lyubercy13.ru/]капельница от запоя на дому московская область[/url]
вывод из запоя круглосуточно иркутск
vivod-iz-zapoya-irkutsk008.ru
лечение запоя иркутск
mostbet.com skachat [url=http://mostbet4157.ru]http://mostbet4157.ru[/url]
20
Выяснить больше – [url=https://kapelnica-ot-zapoya-lyubercy12.ru/]вызвать капельницу от запоя на дому в подольске[/url]
Sou louco pelo clima de Flabet Casino, da uma energia de cassino que e um espetaculo. Tem uma enxurrada de jogos de cassino irados, oferecendo sessoes de cassino ao vivo que sao um fogo. O atendimento ao cliente do cassino e uma explosao, dando solucoes na hora e com precisao. Os saques no cassino sao velozes como um raio, mas mais recompensas no cassino seriam um baita plus. No fim das contas, Flabet Casino garante uma diversao de cassino que e uma explosao para os cacadores de slots modernos de cassino! De lambuja o design do cassino e uma explosao visual, torna o cassino uma curticao total.
flabet saque|
В современном обществе проблемы наркомании и алкоголизма приобрели особую актуальность, затрагивая не только отдельных людей, но и их близких, и сообщества. Эти зависимости оказывают негативное влияние не только на физическое здоровье, но и на психоэмоциональное состояние, нарушают социальные связи и ухудшают качество жизни. Наркологическая клиника “Здоровое Настоящее” предлагает комплексный и научно обоснованный подход к лечению зависимостей. Мы используем современные методы диагностики и терапии, чтобы помочь пациентам вернуть здоровье и полноценную жизнь.
Подробнее можно узнать тут – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]вывод из запоя на дому цена в казани[/url]
купить аттестат за 11 классов в нижнем тагиле [url=www.arus-diplom25.ru]www.arus-diplom25.ru[/url] .
Ich flippe aus bei DrueGlueck Casino, man fuhlt einen verruckten Spielvibe. Die Casino-Optionen sind super vielfaltig, mit einzigartigen Casino-Slotmaschinen. Der Casino-Service ist mega zuverlassig, mit Hilfe, die richtig abgeht. Casino-Gewinne kommen wie der Blitz, ab und zu mehr Casino-Belohnungen waren der Hit. Am Ende ist DrueGlueck Casino ein Casino, das man nicht verpassen darf fur Abenteurer im Casino! Ubrigens die Casino-Oberflache ist flussig und mega cool, was jede Casino-Session noch krasser macht.
drueckglueck testbericht|
J’adore a fond AmunRa Casino, c’est un casino en ligne qui envoie des ondes mystiques. Le catalogue de jeux du casino est colossal, offrant des slots de casino a theme mythique. Les agents du casino sont rapides comme une tempete de sable, avec une aide qui illumine. Le processus du casino est limpide et sans malediction, de temps en temps des recompenses de casino en plus ca ferait vibrer. Globalement, AmunRa Casino est un casino en ligne qui regne en maitre pour les accros aux sensations fortes du casino ! Par ailleurs la plateforme du casino brille avec un look de legende, ajoute un max de magie au casino.
amunra code promo|
Hello! This is my 1st comment here so I just wanted to give a quick shout out and tell you I truly enjoy reading your blog posts. Can you suggest any other blogs/websites/forums that go over the same subjects? Thanks!
маркетплейс кракен
J’adore a fond Instant Casino, c’est un casino en ligne qui envoie du lourd. Les options de jeu en casino sont ultra-riches, incluant des jeux de table de casino styles. Le support du casino est dispo 24/7, garantissant un support de casino direct et efficace. Les paiements du casino sont fluides et securises, quand meme les offres de casino pourraient etre plus genereuses. Bref, Instant Casino offre une experience de casino inoubliable pour ceux qui kiffent parier dans un casino style ! A noter aussi l’interface du casino est fluide et ultra-cool, donne envie de replonger dans le casino direct.
code promo instant casino|
букмекеры кыргызстана [url=http://mostbet4160.ru]http://mostbet4160.ru[/url]
подключение интернета по адресу
inernetvkvartiru-spb004.ru
домашний интернет санкт-петербург
купить диплом ссср [url=https://www.educ-ua3.ru]купить диплом ссср[/url] .
Миссия клиники “Новый Рассвет” заключается в восстановлении и реабилитации людей, столкнувшихся с зависимостями. Мы стремимся обеспечить каждому пациенту комплексную помощь, которая включает медицинское лечение, психологическую поддержку и социальную адаптацию. Наша задача — не только устранить физическую зависимость, но и помочь пациентам восстановить психологическое здоровье и интегрироваться в общество.
Разобраться лучше – [url=https://nadezhnyj-vyvod-iz-zapoya.ru/]http://nadezhnyj-vyvod-iz-zapoya.ru[/url]
вывод из запоя круглосуточно череповец
vivod-iz-zapoya-cherepovec010.ru
лечение запоя череповец
mostbet kibersport uz [url=https://mostbet4170.ru]https://mostbet4170.ru[/url]
mostbet сайт регистрация [url=www.mostbet4156.ru]www.mostbet4156.ru[/url]
диплом купить днепр [url=http://educ-ua2.ru]диплом купить днепр[/url] .
Good ?V I should certainly pronounce, impressed with your web site. I had no trouble navigating through all the tabs as well as related info ended up being truly simple to do to access. I recently found what I hoped for before you know it in the least. Reasonably unusual. Is likely to appreciate it for those who add forums or something, website theme . a tones way for your customer to communicate. Nice task..
Комплексный подход: лечение зависимости — это процесс, включающий медикаментозную терапию, психотерапевтическую помощь, физиотерапию и социальную реабилитацию.
Углубиться в тему – [url=https://srochno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-ufe.ru/]вывод из запоя[/url]
tesamorelin ipamorelin blend reddit
References:
Ipamorelin Acquisto (https://www.stampedeblue.com/users/avery.denton)
На сайте https://t.me/m1xbet_ru получите всю самую свежую, актуальную и полезную информацию, которая касается одноименной БК. Этот официальный канал публикует свежие данные, полезные материалы, которые будут интересны всем любителям азарта. Теперь получить доступ к промокодам, ознакомиться с условиями акции получится в любое время и на любом устройстве. Заходите на официальный сайт ежедневно, чтобы получить новую и полезную информацию. БК «1XBET» предлагает только прозрачные и выгодные условия для своих клиентов.
Ключевым направлением работы является индивидуальный подход к лечению. Мы понимаем уникальность каждого пациента и начинаем с тщательной диагностики, изучая медицинскую историю, психологические особенности и социальные факторы. На основе этих данных разрабатываются персонализированные планы лечения, включающие медикаментозную терапию, психотерапевтические программы и социальные инициативы.
Получить дополнительные сведения – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-rostove-na-donu.ru/]анонимный вывод из запоя в ростове-на-дону[/url]
диплом колледжа купить с занесением в реестр [url=www.arus-diplom34.ru/]диплом колледжа купить с занесением в реестр[/url] .
интернет по адресу санкт-петербург
inernetvkvartiru-spb005.ru
домашний интернет
Ich bin suchtig nach JackpotPiraten Casino, es bietet ein Casino-Abenteuer, das wie ein Schatz funkelt. Die Spielauswahl im Casino ist riesig wie ein Ozean, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Der Casino-Support ist rund um die Uhr verfugbar, antwortet blitzschnell wie ein Sabelhieb. Casino-Gewinne kommen wie ein Blitz, ab und zu die Casino-Angebote konnten gro?zugiger sein. Insgesamt ist JackpotPiraten Casino eine Casino-Erfahrung, die wie ein Piratenschatz glanzt fur die, die mit Stil im Casino wetten! Extra die Casino-Navigation ist kinderleicht wie ein Kartenlesen, das Casino-Erlebnis total intensiviert.
jackpotpiraten 100 free spins|
Estou completamente viciado em DazardBet Casino, oferece uma experiencia de cassino que e fogo puro. O catalogo de jogos do cassino e colossal, com slots de cassino unicos e vibrantes. Os agentes do cassino sao rapidos como um raio, respondendo num piscar de olhos. Os saques no cassino sao rapidos como um foguete, mesmo assim mais bonus regulares no cassino seria demais. Resumindo, DazardBet Casino vale muito a pena explorar esse cassino para os amantes de cassinos online! Alem disso o site do cassino e uma obra-prima grafica, aumenta a imersao no cassino ao extremo.
dazardbet online|
В Люберцах капельница от запоя доступна круглосуточно — в клинике Stop Alko её ставят как на дому, так и в стационаре.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-lyubercy13.ru/]капельница от запоя анонимно подольск[/url]
Je suis totalement subjugue par Julius Casino, il propose une aventure de casino digne d’un empereur. La collection de jeux du casino est colossale, incluant des jeux de table de casino d’une noblesse rare. Le support du casino est disponible 24/7, proposant des solutions claires et immediates. Les retraits au casino sont rapides comme une charge de cavalerie, par moments plus de tours gratuits au casino ce serait epique. Pour resumer, Julius Casino est un colisee pour les fans de casino pour les passionnes de casinos en ligne ! A noter la navigation du casino est intuitive comme une strategie romaine, ce qui rend chaque session de casino encore plus triomphante.
julius casino spin free|
вывод из запоя цена
vivod-iz-zapoya-kaluga010.ru
экстренный вывод из запоя калуга
экстренный вывод из запоя череповец
vivod-iz-zapoya-cherepovec011.ru
вывод из запоя круглосуточно
Estou completamente enlouquecido por LeaoWin Casino, tem uma vibe de jogo que e pura selva. O catalogo de jogos do cassino e uma selva braba, com caca-niqueis de cassino modernos e instintivos. O suporte do cassino ta sempre na area 24/7, respondendo mais rapido que um leopardo. As transacoes do cassino sao simples como uma trilha, mas as ofertas do cassino podiam ser mais generosas. No fim das contas, LeaoWin Casino garante uma diversao de cassino que e selvagem para os cacadores de slots modernos de cassino! E mais o design do cassino e uma explosao visual feroz, faz voce querer voltar pro cassino como uma fera.
casino grenoble saint leaowin02|
В Люберцах всё больше людей доверяют клинике Stop Alko — здесь грамотно подбирают капельницу от запоя с учётом состояния пациента.
Подробнее тут – [url=https://kapelnica-ot-zapoya-lyubercy12.ru/]капельница от запоя анонимно[/url]
Купить диплом техникума в Мариуполь [url=http://www.educ-ua6.ru]Купить диплом техникума в Мариуполь[/url] .
диплом техникума купить киев [url=www.educ-ua7.ru]www.educ-ua7.ru[/url] .
mostbet uz shikoyatlar [url=www.mostbet4170.ru]www.mostbet4170.ru[/url]
можно ли купить диплом о среднем образовании [url=https://educ-ua1.ru/]можно ли купить диплом о среднем образовании[/url] .
что будет если купить диплом о высшем образовании с занесением в реестр [url=www.educ-ua13.ru]что будет если купить диплом о высшем образовании с занесением в реестр[/url] .
What a great article.. i subscribed btw!
вывод из запоя москва клиника [url=https://www.narkologicheskaya-klinika-13.ru]https://www.narkologicheskaya-klinika-13.ru[/url] .
наркологические услуги в москве [url=http://narkologicheskaya-klinika-14.ru]http://narkologicheskaya-klinika-14.ru[/url] .
Привет!
Превращаем обычное резюме в магнит для работодателей. [url=https://tvoya-sila-vnutri.ru/kak-sdelat-rezyume-na-rabotu/]Как сделать ссылку на резюме в hh[/url] Как сделать так, чтобы эйчары сами искали твои контакты и предлагали работу.
Переходи: – https://tvoya-sila-vnutri.ru/kak-sdelat-rezyume-na-rabotu/
Как сделать свое резюме
Удачи!
как продвигать сайт статьи [url=https://blog-o-marketinge.ru/]blog-o-marketinge.ru[/url] .
мостбет кыргызстан скачать [url=http://mostbet4153.ru]http://mostbet4153.ru[/url]
купить аттестат за 9 классов [url=educ-ua16.ru]купить аттестат за 9 классов[/url] .
Мы готовы предложить документы учебных заведений, расположенных в любом регионе РФ. Приобрести диплом о высшем образовании:
[url=http://peticijos.com/492274/]аттестат 11 классов купить в нижнем тагиле[/url]
наркологический частный центр [url=www.narkologicheskaya-klinika-14.ru]www.narkologicheskaya-klinika-14.ru[/url] .
наркология москва [url=https://narkologicheskaya-klinika-13.ru]наркология москва[/url] .
провайдеры по адресу дома
inernetvkvartiru-spb006.ru
недорогой интернет санкт-петербург
mostbet.com скачать [url=https://www.mostbet4158.ru]https://www.mostbet4158.ru[/url]
статьи про digital маркетинг [url=https://blog-o-marketinge.ru]https://blog-o-marketinge.ru[/url] .
вывод из запоя круглосуточно
vivod-iz-zapoya-kaluga011.ru
вывод из запоя круглосуточно калуга
купить диплом спб с занесением в реестр [url=http://arus-diplom33.ru/]http://arus-diplom33.ru/[/url] .
диплом бакалавра купить стоимость [url=https://www.educ-ua17.ru]диплом бакалавра купить стоимость[/url] .
Приобрести диплом университета!
Наши специалисты предлагаютбыстро и выгодно купить диплом, который выполняется на оригинальном бланке и заверен мокрыми печатями, штампами, подписями официальных лиц. Диплом пройдет любые проверки, даже при помощи профессионального оборудования. Достигайте своих целей максимально быстро с нашей компанией- [url=http://circleofhopecommunity.com/forums/forum/main-forum/]circleofhopecommunity.com/forums/forum/main-forum[/url]
https://lakoshka.ru
лечение запоя череповец
vivod-iz-zapoya-cherepovec012.ru
вывод из запоя цена
мостбет вход, регистрация [url=https://mostbet4158.ru]https://mostbet4158.ru[/url]
Мы изготавливаем дипломы любых профессий по приятным ценам. Купить диплом Березники — [url=http://kyc-diplom.com/geography/berezniki.html/]kyc-diplom.com/geography/berezniki.html[/url]
https://usk-rus.ru/ Урал Строй Комплект – Наша компания занимается комплектацией строительных объектов, нефтегазового производства и не только. Одно из главных направлений работы – это гражданское строительство, где наши задачи – поставка металлических изделий и конструкций, труб, сыпучих строительных смесей, других стройматериалов. Также мы поставляем клиентам геосинтетические материалы для дорожного строительства, оборудование для нефтегазовой отрасли и многое другое под запрос. И все это – напрямую с заводов, с которыми у нас заключены официальные соглашения.
купить проведенный диплом красноярск [url=www.rpgmaker.su/members/24897-vadyymemelnvv]купить проведенный диплом красноярск[/url] .
В современном обществе проблемы наркомании и алкоголизма приобрели особую актуальность, затрагивая не только отдельных людей, но и их близких, и сообщества. Эти зависимости оказывают негативное влияние не только на физическое здоровье, но и на психоэмоциональное состояние, нарушают социальные связи и ухудшают качество жизни. Наркологическая клиника “Здоровое Настоящее” предлагает комплексный и научно обоснованный подход к лечению зависимостей. Мы используем современные методы диагностики и терапии, чтобы помочь пациентам вернуть здоровье и полноценную жизнь.
Изучить вопрос глубже – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru/]вывод из запоя на дому круглосуточно[/url]
купить диплом ссср в украине [url=www.educ-ua4.ru]купить диплом ссср в украине[/url] .
Hi to all, because I am in fact keen of reading this webpage’s post to be updated regularly. It carries pleasant data.
кракен маркетплейс
экстренный вывод из запоя
vivod-iz-zapoya-kaluga012.ru
вывод из запоя калуга
подключить интернет
inernetvkvartiru-ekaterinburg004.ru
провайдеры по адресу екатеринбург
Want to have fun? porno girl Watch porn, buy heroin or ecstasy. Pick up whores or buy marijuana. Come in, we’re waiting
Новые актуальные промокод iherb для первого заказа для выгодных покупок! Скидки на витамины, БАДы, косметику и товары для здоровья. Экономьте до 30% на заказах, используйте проверенные купоны и наслаждайтесь выгодным шопингом.
Когда запой выходит за рамки нескольких суток, интоксикация организма достигает критического уровня: нарушается водно-электролитный баланс, появляются признаки токсического поражения печени и нервной системы. В таких случаях самостоятельные попытки прекратить употребление алкоголя могут привести к тяжёлым осложнениям — судорогам, алкогольному психозу, острой сердечной недостаточности. В Санкт-Петербурге и Ленинградской области доступны профессиональные услуги по выводу из запоя, выполняемые опытными наркологами как на дому, так и в специализированных клиниках.
Подробнее – [url=https://nadezhnyj-vyvod-iz-zapoya.ru/]помощь вывод из запоя санкт-петербруг[/url]
интернет маркетинг статьи [url=http://blog-o-marketinge1.ru/]интернет маркетинг статьи[/url] .
bs2best
вывод из запоя цена
vivod-iz-zapoya-irkutsk007.ru
лечение запоя иркутск
Миссия центра “Луч Надежды” — помогать людям, попавшим в плен зависимости, находить путь к выздоровлению. Мы не ограничиваемся лечением, а делаем акцент на профилактике рецидивов, социальной адаптации пациентов и их возвращении к полноценной, радостной жизни без психоактивных веществ.
Подробнее тут – [url=https://srochno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-ufe.ru/]vyvod iz zapoya na domu kruglosutochno v ufe[/url]
купить диплом с занесением в реестр [url=https://educ-ua12.ru]купить диплом с занесением в реестр[/url] .
В этот этап включено:
Разобраться лучше – [url=https://kachestvo-vyvod-iz-zapoya.ru/]скорая вывод из запоя новосибирск[/url]
Je suis fou de CasinoClic, on dirait une cascade de fun. Les choix de jeux au casino sont riches et scintillants, comprenant des jeux de casino optimises pour les cryptomonnaies. Les agents du casino sont rapides comme un eclair, assurant un support de casino immediat et eclatant. Les paiements du casino sont securises et fluides, parfois des recompenses de casino supplementaires feraient vibrer. En somme, CasinoClic c’est un casino a decouvrir en urgence pour les passionnes de casinos en ligne ! Bonus l’interface du casino est fluide et rayonnante comme une aurore, ajoute une touche de magie lumineuse au casino.
casino clic code promo|
kraken onion зеркала kraken onion, kraken onion ссылка, kraken onion зеркала, kraken рабочая ссылка onion, сайт kraken onion, kraken darknet, kraken darknet market, kraken darknet ссылка, сайт kraken darknet, kraken актуальные ссылки, кракен ссылка kraken, kraken официальные ссылки, kraken ссылка тор, kraken ссылка зеркало, kraken ссылка на сайт, kraken онион, kraken онион тор, кракен онион, кракен онион тор, кракен онион зеркало, кракен даркнет маркет, кракен darknet, кракен onion, кракен ссылка onion, кракен onion сайт, kra ссылка, kraken сайт, kraken актуальные ссылки, kraken зеркало, kraken ссылка зеркало, kraken зеркало рабочее, актуальные зеркала kraken, kraken сайт зеркала, kraken маркетплейс зеркало, кракен ссылка, кракен даркнет
Ich bin suchtig nach iWild Casino, es ist ein Online-Casino, das wie ein Urwald tobt. Der Katalog des Casinos ist ein Dschungel voller Spa?, mit modernen Casino-Slots, die einen in ihren Bann ziehen. Das Casino-Team bietet Unterstutzung, die wie ein Lagerfeuer gluht, ist per Chat oder E-Mail erreichbar. Auszahlungen im Casino sind schnell wie ein Flusslauf, ab und zu mehr regelma?ige Casino-Boni waren ein Knaller. Zusammengefasst ist iWild Casino eine Casino-Erfahrung, die wie ein Urwald funkelt fur Spieler, die auf wilde Casino-Kicks stehen! Ubrigens die Casino-Plattform hat einen Look, der wie ein Wasserfall funkelt, was jede Casino-Session noch aufregender macht.
iwild casino kokemuksia|
Je suis fou de JackpotStar Casino, on dirait une supernova de fun. La selection du casino est une explosion cosmique de plaisir, comprenant des jeux de casino optimises pour les cryptomonnaies. Le service client du casino est une etoile brillante, proposant des solutions claires et instantanees. Les gains du casino arrivent a une vitesse interstellaire, par moments les offres du casino pourraient etre plus genereuses. Globalement, JackpotStar Casino est un casino en ligne qui illumine tout pour les explorateurs du casino ! A noter la navigation du casino est intuitive comme une orbite, facilite une experience de casino astrale.
jackpotstar casino codigo promocional 2024|
seo статьи [url=http://blog-o-marketinge1.ru/]seo статьи[/url] .
экстренный вывод из запоя краснодар
vivod-iz-zapoya-krasnodar011.ru
вывод из запоя круглосуточно
домашний интернет тарифы
inernetvkvartiru-ekaterinburg005.ru
подключение интернета по адресу
difference between ipamorelin and tesamorelin
References:
https://www.theangel.fr/companies/ipamorelin-vs-sermorelin-decoding-the-differences-in-peptide-therapies/
купить украинский диплом о высшем образовании [url=https://educ-ua2.ru]купить украинский диплом о высшем образовании[/url] .
ipamorelin in pill form
References:
ipamorelin results 2013 (https://aryba.kg/user/minutehand59/)
лечение запоя
vivod-iz-zapoya-irkutsk008.ru
экстренный вывод из запоя
cjc 1295 ipamorelin difference
References:
https://lings.id/bradygrave
seo базовый курc [url=http://kursy-seo-1.ru/]http://kursy-seo-1.ru/[/url] .
seo бесплатно [url=https://kursy-seo-3.ru/]seo бесплатно[/url] .
продвижение обучение [url=http://kursy-seo-4.ru]http://kursy-seo-4.ru[/url] .
учиться seo [url=http://www.kursy-seo-2.ru]http://www.kursy-seo-2.ru[/url] .
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar012.ru
экстренный вывод из запоя краснодар
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Только для своих – https://artecampo.tercerimpactoproducciones.com/index.php/2023/06/22/mastering-time-management-key-to-business-success
mostbet virtual idman [url=https://mostbet4141.ru]https://mostbet4141.ru[/url]
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Все материалы собраны здесь – https://geraldavander.es/index.php/2023/10/15/up-or-down
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Подробная информация доступна по запросу – https://pintubahasa.com/group2/2022/02/01/how-to-maintain-a-successful-long-distance-relationship
Je suis completement envoute par LeonBet Casino, ca degage une vibe de jeu feroce. La collection de jeux du casino est titanesque, comprenant des jeux de casino optimises pour les cryptomonnaies. Le personnel du casino offre un accompagnement rugissant, assurant un support de casino immediat et puissant. Les paiements du casino sont securises et fluides, mais des recompenses de casino supplementaires feraient rugir. Dans l’ensemble, LeonBet Casino offre une experience de casino indomptable pour ceux qui cherchent l’adrenaline sauvage du casino ! Par ailleurs la plateforme du casino brille par son style indomptable, ce qui rend chaque session de casino encore plus rugissante.
codigo de bonus leonbet|
seo курсы [url=http://kursy-seo-1.ru/]http://kursy-seo-1.ru/[/url] .
seo интенсив [url=http://www.kursy-seo-3.ru]http://www.kursy-seo-3.ru[/url] .
seo бесплатно [url=https://kursy-seo-4.ru]seo бесплатно[/url] .
обучение seo [url=https://www.kursy-seo-2.ru]обучение seo[/url] .
интернет провайдеры по адресу дома
inernetvkvartiru-ekaterinburg006.ru
провайдер по адресу екатеринбург
Ищете быстрые и выгодные решения для денег?
«Кашалот Финанс» — финансовый маркетплейс, где вы сравните микрозаймы, кредиты, ипотеку, карты и страховые продукты за минуты.
Подайте заявку на https://cachalot-finance.ru и получите деньги на карту, кошелёк или наличными.
Безопасность подтверждена, заявки принимаем даже с низким рейтингом.
Сравнивайте предложения в одном окне и повышайте шанс одобрения без лишних звонков и визитов.
сколько стоит купить диплом магистра [url=http://www.educ-ua19.ru]http://www.educ-ua19.ru[/url] .
купить диплом недорого [url=http://educ-ua18.ru]купить диплом недорого[/url] .
mostbet texniki dəstək [url=https://www.mostbet4142.ru]https://www.mostbet4142.ru[/url]
https://yunc.org
Привет!
Тебя выкинули с работы как ненужного? [url=https://zhit-legche.ru/chto-delat-esli-uvolili-s-raboty/]что делать если уволили с работы[/url] Забей, есть план как превратить это в новые возможности.
Написал: – https://zhit-legche.ru/chto-delat-esli-uvolili-s-raboty/
как пережить несправедливое увольнение
хочу уволиться но не могу решиться
увольнение с работы
Будь здоров!
Приветствую!
Недвижимость в залог = деньги в кармане: работает даже с плохой историей. [url=https://kredit-bez-slov.ru/kredit-s-plohoj-istoriej-pod-zalog-nedvizhimosti/]кредит онлайн на карту с плохой кредитной историей[/url] Полный разбор процедуры и хитростей оформления.
По ссылке: – https://kredit-bez-slov.ru/kredit-s-plohoj-istoriej-pod-zalog-nedvizhimosti/
кредит онлайн на карту с плохой кредитной историей
Удачи!
лечение запоя иркутск
vivod-iz-zapoya-irkutsk009.ru
вывод из запоя иркутск
mostbet [url=http://mostbet4172.ru/]http://mostbet4172.ru/[/url]
лечение запоя
vivod-iz-zapoya-krasnodar013.ru
вывод из запоя круглосуточно
mostbet aviator hack [url=https://mostbet4143.ru]https://mostbet4143.ru[/url]
https://t.me/Reyting_Casino_Russia/24
Мы предлагаем документы институтов, расположенных на территории всей Российской Федерации. Приобрести диплом университета:
[url=http://vsetutonline.com/forum/member.php?u=76509/]купить аттестат за 11 классов в красноярске[/url]
mostbet mobil giriş [url=https://www.mostbet4144.ru]mostbet mobil giriş[/url]
Приобрести диплом под заказ в столице вы можете используя сайт компании. [url=http://gspanel.net/showthread.php?tid=4351/]gspanel.net/showthread.php?tid=4351[/url]
купить диплом ссср в украине [url=http://educ-ua17.ru/]http://educ-ua17.ru/[/url] .
mostbet az qeydiyyatdan keçmək [url=mostbet4141.ru]mostbet az qeydiyyatdan keçmək[/url]
интернет по адресу
inernetvkvartiru-krasnoyarsk004.ru
интернет по адресу дома
I am glad to talk with you and you give me great help
мостбет узбекистан [url=www.mostbet4171.ru]www.mostbet4171.ru[/url]
aviator money [url=https://www.aviator-igra-1.ru]https://www.aviator-igra-1.ru[/url] .
Платформа 1win известна своими промокодами.
Бонусные коды открывают доступ к фрибетам.
Многие пишут, что регистрация простая.
Приложение удобно работает.
Фрибеты и депозиты активируются легко.
Информация доступна здесь: актуальный промокод 1win
mostbet az qeydiyyat [url=www.mostbet4142.ru]www.mostbet4142.ru[/url]
экстренный вывод из запоя
vivod-iz-zapoya-kaluga010.ru
лечение запоя калуга
mostbet uz скачать на компьютер [url=www.mostbet4171.ru]mostbet uz скачать на компьютер[/url]
mostbet az qeydiyyat [url=mostbet4144.ru]mostbet az qeydiyyat[/url]
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar014.ru
вывод из запоя
купить диплом с занесением в реестр в спб [url=https://slideshow-forum.com/profile.php?id=105693/]купить диплом с занесением в реестр в спб[/url] .
Ich bin suchtig nach Lapalingo Casino, es ist ein Online-Casino, das wie ein Blitz einschlagt. Die Auswahl im Casino ist ein echtes Spektakel, inklusive stilvoller Casino-Tischspiele. Der Casino-Support ist rund um die Uhr verfugbar, mit Hilfe, die wie ein Funke spruht. Der Casino-Prozess ist klar und ohne Wellen, ab und zu mehr regelma?ige Casino-Boni waren ein Knaller. Kurz gesagt ist Lapalingo Casino ein Casino, das man nicht verpassen darf fur Fans von Online-Casinos! Nebenbei die Casino-Navigation ist kinderleicht wie ein Windhauch, den Spielspa? im Casino in den Himmel hebt.
lapalingo störung aktuell|
Ich finde absolut wild Lowen Play Casino, es bietet ein Casino-Abenteuer, das wie ein Urwald leuchtet. Die Spielauswahl im Casino ist wie eine wilde Horde, inklusive stilvoller Casino-Tischspiele. Der Casino-Kundenservice ist wie ein Leitlowe, ist per Chat oder E-Mail erreichbar. Auszahlungen im Casino sind schnell wie ein Raubkatzen-Sprint, trotzdem wurde ich mir mehr Casino-Promos wunschen, die wie ein Feuer lodern. Am Ende ist Lowen Play Casino ein Casino, das man nicht verpassen darf fur die, die mit Stil im Casino wetten! Zusatzlich die Casino-Navigation ist kinderleicht wie eine Fahrte, den Spielspa? im Casino in die Hohe treibt.
löwen play kaiserslautern|
купить диплом нового образца [url=www.educ-ua4.ru]купить диплом нового образца[/url] .
Купить диплом техникума в Днепр [url=https://www.educ-ua7.ru]Купить диплом техникума в Днепр[/url] .
Мы предлагаем дипломы психологов, юристов, экономистов и прочих профессий по выгодным тарифам. Заказ документа, подтверждающего окончание института, – это рациональное решение. Купить диплом университета: [url=http://severka.flybb.ru/viewtopic.php?f=6&t=964&sid=d74d8bf00cd5050ba649296ba68e9dfb/]severka.flybb.ru/viewtopic.php?f=6&t=964&sid=d74d8bf00cd5050ba649296ba68e9dfb[/url]
Estou pirando total com JabiBet Casino, oferece uma aventura de cassino que arrasta tudo. A gama do cassino e simplesmente um maremoto, com caca-niqueis de cassino modernos e envolventes. A equipe do cassino entrega um atendimento que e uma perola, dando solucoes na hora e com precisao. Os saques no cassino sao velozes como um redemoinho, de vez em quando mais bonus regulares no cassino seria top. No geral, JabiBet Casino oferece uma experiencia de cassino que e puro fluxo para os cacadores de slots modernos de cassino! Vale falar tambem a interface do cassino e fluida e cheia de energia oceanica, o que deixa cada sessao de cassino ainda mais alucinante.
jabibet bangladesh|
Ich bin suchtig nach JokerStar Casino, es bietet ein Casino-Abenteuer, das wie ein Zaubertrick funkelt. Es gibt eine Flut an fesselnden Casino-Titeln, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Der Casino-Service ist zuverlassig und magisch, ist per Chat oder E-Mail erreichbar. Casino-Gewinne kommen wie ein Blitz, dennoch mehr regelma?ige Casino-Boni waren zauberhaft. Am Ende ist JokerStar Casino ein Online-Casino, das die Sterne vom Himmel holt fur Fans von Online-Casinos! Zusatzlich die Casino-Oberflache ist flussig und glitzert wie ein Zauberlicht, den Spielspa? im Casino in den Himmel hebt.
jokerstar|
Je suis totalement ensorcele par LeoVegas Casino, c’est un casino en ligne qui rugit comme un roi. La selection du casino est une veritable cour de plaisirs, comprenant des jeux de casino optimises pour les cryptomonnaies. Le service client du casino est digne d’un monarque, joignable par chat ou email. Les paiements du casino sont securises et fluides, mais des bonus de casino plus frequents seraient royaux. Pour resumer, LeoVegas Casino c’est un casino a conquerir en urgence pour les joueurs qui aiment parier avec panache au casino ! De surcroit le design du casino est une fresque visuelle royale, donne envie de replonger dans le casino sans fin.
leovegas 300 freispiele|
маркетинговый блог [url=www.statyi-o-marketinge2.ru/]www.statyi-o-marketinge2.ru/[/url] .
aviator игра 1win [url=http://aviator-igra-1.ru]aviator игра 1win[/url] .
В Люберцах клиника Stop Alko предлагает капельницы от запоя не только с детоксикацией, но и с поддержкой печени, сердца и нервной системы.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lyubercy13.ru/]врача капельницу от запоя в подольске[/url]
диплом с реестром купить [url=http://educ-ua11.ru]диплом с реестром купить[/url] .
купить официальный диплом [url=https://educ-ua10.ru]купить официальный диплом[/url] .
https://t.me/Reyting_Casino_Russia/33
mistbet [url=https://www.mostbet4172.ru]https://www.mostbet4172.ru[/url]
Индивидуальный подход к каждому пациенту: Учитываются уникальные характеристики, включая медицинскую историю, психологическое состояние и социальные факторы. Это позволяет разработать максимально эффективный план терапии.
Подробнее можно узнать тут – [url=https://alko-lechebnica.ru/]вывод из запоя клиника[/url]
seo статьи [url=http://www.statyi-o-marketinge2.ru]seo статьи[/url] .
Получить диплом о высшем образовании мы поможем. Купить диплом кандидата наук – [url=http://diplomybox.com/diplom-kandidata-nauk/]diplomybox.com/diplom-kandidata-nauk[/url]
провайдеры интернета в красноярске по адресу
inernetvkvartiru-krasnoyarsk005.ru
провайдеры в красноярске по адресу проверить
ipamorelin dosage women
References:
https://rapostz.com/@sylvestercomer
купить красный аттестаты за 11 [url=www.arus-diplom25.ru/]купить красный аттестаты за 11[/url] .
Неоценимую помощь в процессе лечения оказывают психологи, которые проводят индивидуальные и групповые психотерапевтические сеансы, помогая пациентам осознать причины зависимости, изменить деструктивные модели поведения, сформировать адекватную самооценку, развить навыки совладения со стрессом.
Ознакомиться с деталями – https://alko-reabcentr.ru/
Когда организм на пределе, важна срочная помощь в Самаре — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-stacionare-samara.ru/]анонимный вывод из запоя самара[/url]
mostbet aviator qeydiyyat [url=http://mostbet4143.ru]http://mostbet4143.ru[/url]
как купить диплом о высшем образовании с занесением в реестр отзывы [url=http://educ-ua14.ru/]http://educ-ua14.ru/[/url] .
мост бет [url=https://mostbet4173.ru/]https://mostbet4173.ru/[/url]
лечение запоя калуга
vivod-iz-zapoya-kaluga011.ru
экстренный вывод из запоя калуга
Миссия нашего учреждения заключается в комплексной помощи людям, которые столкнулись с проблемами зависимости. Основные цели нашего центра включают:
Выяснить больше – [url=https://alko-lechebnica.ru/]срочный вывод из запоя[/url]
лечение запоя краснодар
vivod-iz-zapoya-krasnodar015.ru
лечение запоя краснодар
купить диплом о высшем образовании с занесением в реестр [url=https://educ-ua15.ru]https://educ-ua15.ru[/url] .
купить диплом о среднем специальном образовании цена [url=educ-ua9.ru]купить диплом о среднем специальном образовании цена[/url] .
Купить диплом колледжа в Херсон [url=www.educ-ua8.ru]Купить диплом колледжа в Херсон[/url] .
Клиника также предлагает долгосрочные программы, которые включают как стационарное, так и амбулаторное лечение. Мы понимаем, что восстановление требует не только медицинской помощи, но и значительной психологической поддержки на каждом этапе.
Узнать больше – http://медицина-вывод-из-запоя.рф
Ich bin total begeistert von LuckyNiki Casino, es pulsiert mit einer schillernden Casino-Energie. Der Katalog des Casinos ist eine Galaxie voller Vergnugen, inklusive eleganter Casino-Tischspiele. Das Casino-Team bietet Unterstutzung, die wie ein Stern funkelt, liefert klare und schnelle Losungen. Casino-Zahlungen sind sicher und reibungslos, manchmal mehr Casino-Belohnungen waren ein funkelnder Gewinn. Kurz gesagt ist LuckyNiki Casino ein Online-Casino, das wie ein Sternenhimmel strahlt fur Spieler, die auf magische Casino-Kicks stehen! Ubrigens die Casino-Plattform hat einen Look, der wie ein Sternenstaub funkelt, was jede Casino-Session noch magischer macht.
luckyniki casino japan|
Je suis totalement ensorcele par Luckster Casino, c’est un casino en ligne qui brille comme un talisman. La collection de jeux du casino est un veritable grimoire, avec des machines a sous de casino modernes et ensorcelantes. Les agents du casino sont rapides comme un sortilege, repondant en un eclat de magie. Le processus du casino est transparent et sans malefice, quand meme des recompenses de casino supplementaires feraient rever. En somme, Luckster Casino offre une experience de casino envoutante pour les chasseurs de fortune du casino ! A noter le design du casino est une explosion visuelle feerique, ce qui rend chaque session de casino encore plus magique.
luckster casino bonus|
Je suis totalement envoute par MonteCryptos Casino, il propose une aventure de casino qui scintille comme un glacier. Le repertoire du casino est une montagne de plaisirs, comprenant des jeux de casino optimises pour les cryptomonnaies. L’assistance du casino est chaleureuse et irreprochable, assurant un support de casino immediat et robuste. Les retraits au casino sont rapides comme une descente en luge, parfois des bonus de casino plus frequents seraient vertigineux. Dans l’ensemble, MonteCryptos Casino c’est un casino a conquerir en urgence pour les amoureux des slots modernes de casino ! De surcroit la plateforme du casino brille par son style audacieux, ce qui rend chaque session de casino encore plus exaltante.
avis montecryptos|
купить диплом специалиста дешево [url=www.educ-ua2.ru/]купить диплом специалиста дешево[/url] .
интернет провайдеры красноярск по адресу
inernetvkvartiru-krasnoyarsk006.ru
провайдеры по адресу красноярск
plane crash game money [url=aviator-igra-2.ru]aviator-igra-2.ru[/url] .
авиатор онлайн игра [url=http://aviator-igra-3.ru/]авиатор онлайн игра[/url] .
купить диплом о высшем образовании легально [url=http://www.educ-ua13.ru]http://www.educ-ua13.ru[/url] .
mostbet.com rasmiy sayt [url=mostbet4173.ru]mostbet4173.ru[/url]
вывод из запоя
vivod-iz-zapoya-kaluga012.ru
вывод из запоя
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Более подробно об этом – https://patnanews24.com/?p=803
вывод из запоя цена
vivod-iz-zapoya-minsk007.ru
вывод из запоя круглосуточно
где купить диплом [url=http://www.educ-ua3.ru]где купить диплом[/url] .
https://t.me/Reyting_Casino_Russia/47
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Открыть полностью – https://www.fredrikbackman.com/2015/11/08/jag-reagerar-inte-kanslomassigt-pa-idrott-for-jag-vet-att-det-bara-ar-ett-spel
http://avteon.ru
1win самолетик [url=http://aviator-igra-3.ru]http://aviator-igra-3.ru[/url] .
авиатор 1win [url=www.aviator-igra-2.ru/]авиатор 1win[/url] .
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Осуществить глубокий анализ – https://evolve.pt/nail-care-in-winter-protecting-your-nails-from-the-cold
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Ссылка на источник – https://www.openhuis.nu/19e-eeuwe-kunst/rigolet
купить диплом о среднем образовании цена [url=www.educ-ua19.ru/]купить диплом о среднем образовании цена[/url] .
где купить аттестат о среднем образовании [url=www.educ-ua18.ru]где купить аттестат о среднем образовании[/url] .
Хай!
Steam-аккаунты как бизнес: от покупки за копейки до продажи за тысячи. [url=https://zarabotok-na-igrah.ru/prodat-akkaunt-stim/]продать аккаунт стим моментально[/url] Все стратегии и подводные камни простым языком.
Написал: – https://zarabotok-na-igrah.ru/prodat-akkaunt-stim/
за сколько можно продать аккаунт стим
где продать аккаунт стим
Бывай!
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Смотри, что ещё есть – https://catebattlesart.argosyodyssey.com/2022/03/07/welcome-to-cate-battles-fine-art-and-photography
Приветствую!
Как правильно сдать анализ кала: пацанский гайд без понтов. [url=https://tvoya-sila-vnutri.ru/kak-sobrat-kal-na-analiz-lajfhak/]Как брать анализ кала[/url] Братан, разложим всё по полочкам, чтобы результаты были точными, а врач не морщился.
Переходи: – https://tvoya-sila-vnutri.ru/kak-sobrat-kal-na-analiz-lajfhak/
Как правильно взять анализ кала
Будь здоров!
mostbet az etibarlıdırmı [url=https://mostbet4145.ru/]https://mostbet4145.ru/[/url]
Здарова!
От Соланы до мемкоинов: полный расклад по альткам. [url=https://pro-kriptu.ru/altkoiny-kotorye-dadut-iksy/]какие токены дадут иксы[/url] Где лежат деньги и как их правильно поднять.
По ссылке: – https://pro-kriptu.ru/altkoiny-kotorye-dadut-iksy/
как заработать на своем токене
какие токены дадут иксы
альткоины которые вырастут
Будь здоров!
Действие и назначение
Разобраться лучше – https://vyvod-iz-zapoya-novosibirsk00.ru/vyvod-iz-zapoya-kruglosutochno-novosibirsk
Некоторые состояния требуют немедленного вмешательства нарколога, так как отказ от лечения может привести к тяжелым осложнениям и риску для жизни.
Подробнее тут – [url=https://narcolog-na-dom-novokuznetsk00.ru/]врач нарколог на дом кемеровская область[/url]
Запой – это не просто пьянство, а состояние, когда организм становится зависимым от алкоголя. Накопление токсинов приводит к сбоям в работе органов и ослаблению защиты организма. Самостоятельный выход из запоя может быть опасен и только усугубить состояние. Мы предлагаем лечение запоя на дому, чтобы избежать больницы и создать комфорт. Наши специалисты быстро приедут к вам и окажут всю необходимую помощь круглосуточно. Запой приводит к серьезным проблемам со здоровьем, ухудшает качество жизни и угрожает жизни. Очень важно вовремя обратиться за помощью, чтобы избежать необратимых последствий.
Выяснить больше – [url=https://vyvod-iz-zapoya-krasnoyarsk0.ru/]клиника вывод из запоя красноярск[/url]
подключение интернета по адресу
inernetvkvartiru-krasnodar004.ru
проверить провайдеров по адресу краснодар
Группа препаратов
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод нижний новгород[/url]
mostbet kazinosu [url=www.mostbet4145.ru]www.mostbet4145.ru[/url]
вывод из запоя минск
vivod-iz-zapoya-minsk008.ru
экстренный вывод из запоя
вывод из запоя краснодар
vivod-iz-zapoya-krasnodar011.ru
вывод из запоя краснодар
Je trouve extraordinaire Casinova, il propose un voyage ludique unique. Les jeux sont diversifies et captivants, proposant des jeux de table sophistiques. Les agents sont rapides et professionnels, joignable via chat ou email. Les paiements sont fluides et fiables, neanmoins j’aimerais plus de promotions variees. Globalement, Casinova assure une experience de jeu memorable pour les fans de jeux modernes ! De surcroit la plateforme est immersive et stylee, facilite une immersion totale.
casinova casino review|
Je trouve absolument enivrant LuckyBlock Casino, ca degage une vibe de jeu petillante comme une etoile. La collection de jeux du casino est un tresor scintillant, proposant des slots de casino a theme chanceux. L’assistance du casino est chaleureuse et irreprochable, joignable par chat ou email. Le processus du casino est transparent et sans malediction, quand meme j’aimerais plus de promotions de casino qui eblouissent. Globalement, LuckyBlock Casino est un casino en ligne qui porte bonheur pour les chasseurs de fortune du casino ! De surcroit la plateforme du casino brille par son style ensorcelant, facilite une experience de casino feerique.
bscscan luckyblock|
Je suis totalement electrise par Madnix Casino, ca degage une vibe de jeu completement demente. Il y a une avalanche de jeux de casino captivants, proposant des slots de casino a theme barre. Le service client du casino est une decharge electrique, repondant en un flash dement. Les retraits au casino sont rapides comme une fusee, parfois j’aimerais plus de promotions de casino qui envoient du lourd. Pour resumer, Madnix Casino est un casino en ligne qui fait trembler les murs pour ceux qui cherchent l’adrenaline demente du casino ! A noter la plateforme du casino brille par son style completement fou, amplifie l’immersion totale dans le casino.
madnix casino no deposit bonus|
Здравствуйте!
Топ камерофонов 2025: кто реально рулит на рынке. [url=https://pro-telefony.ru/telefon-s-horoshej-kameroj/]смартфоны с хорошей камерой до 20000[/url] OPPO обошел iPhone, а Samsung провалился – вся правда о новых смартфонах.
Читай тут: – https://pro-telefony.ru/telefon-s-horoshej-kameroj/
телефон с 4 камерами
Пока!
Наркологическая клиника «МедЛайн» предоставляет профессиональные услуги врача-нарколога с выездом на дом в Новосибирске и Новосибирской области. Мы оперативно помогаем пациентам справиться с тяжелыми состояниями при алкогольной и наркотической зависимости. Экстренный выезд наших специалистов доступен круглосуточно, а лечение проводится с применением проверенных методик и препаратов, что гарантирует безопасность и конфиденциальность каждому пациенту.
Подробнее можно узнать тут – [url=https://narcolog-na-dom-novosibirsk00.ru/]вызов нарколога на дом новосибирская область[/url]
Запой – это неконтролируемое употребление алкоголя, которое приводит к серьезным последствиям. Алкогольное отравление организма приводит к серьезным проблемам со здоровьем. Выходить из запоя самостоятельно – рискованно и неэффективно. Мы предлагаем помощь при запое на дому, в привычных для вас условиях. Круглосуточная помощь при запое с выездом на дом за 30-60 минут. Длительный запой разрушает организм и может быть смертельным. Чем раньше вы обратитесь за помощью, тем больше шансов на выздоровление.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-krasnoyarsk0.ru/]алкоголизм лечение вывод из запоя красноярск[/url]
Быстро поставить капельницу от запоя в Люберцах можно через сайт Stop Alko — просто оставьте заявку, и к вам выедет нарколог уже в ближайшее время.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-lyubercy13.ru/]капельница от запоя на дому подольск[/url]
Вывод из запоя без стресса — специалисты клиники «Alco.Rehab» в Москве знают, как помочь быстро и безопасно.
Подробнее тут – [url=https://vyvod-iz-zapoya-moskva12.ru/]вывод из запоя на дому москва[/url]
какие провайдеры по адресу
inernetvkvartiru-krasnodar005.ru
подключить интернет по адресу
вывод из запоя круглосуточно
vivod-iz-zapoya-minsk009.ru
вывод из запоя цена
20
Углубиться в тему – [url=https://vyvod-iz-zapoya-moskva13.ru/]вывод из запоя цена в москве[/url]
проектная организация для перепланировки квартиры [url=http://proekt-pereplanirovki-kvartiry8.ru]проектная организация для перепланировки квартиры[/url] .
авиатор ставки [url=http://www.aviator-igra-4.ru]авиатор ставки[/url] .
швейное предприятие [url=https://nitkapro.ru/]nitkapro.ru[/url] .
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar012.ru
лечение запоя краснодар
диплом об окончании техникума купить [url=https://educ-ua7.ru/]диплом об окончании техникума купить[/url] .
купить диплом вуза [url=https://www.educ-ua16.ru]купить диплом вуза[/url] .
При поступлении вызова специалисты клиники «АнтиАлко» выезжают на дом в течение 30–60 минут. По прибытии врач проводит комплексную диагностику: измеряет артериальное давление, пульс, уровень кислорода в крови и собирает анамнез, чтобы оценить степень интоксикации. На основе полученных данных формируется индивидуальный план лечения, который включает:
Изучить вопрос глубже – https://vyvod-iz-zapoya-novosibirsk00.ru/vyvod-iz-zapoya-kruglosutochno-novosibirsk
заказать проект перепланировки [url=proekt-pereplanirovki-kvartiry8.ru]заказать проект перепланировки[/url] .
aviator money game [url=http://aviator-igra-4.ru]http://aviator-igra-4.ru[/url] .
швейное предприятие [url=https://nitkapro.ru/]https://nitkapro.ru/[/url] .
20
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-moskva13.ru/]москва[/url]
купить диплом с занесением в реестр пенза [url=https://arus-diplom34.ru]купить диплом с занесением в реестр пенза[/url] .
купить диплом о высшем образовании с занесением в реестр цена [url=http://arus-diplom33.ru/]купить диплом о высшем образовании с занесением в реестр цена[/url] .
диплом техникума колледжа купить [url=www.educ-ua6.ru/]www.educ-ua6.ru/[/url] .
купить аттестат за 11 классов в барнауле [url=arus-diplom25.ru]купить аттестат за 11 классов в барнауле[/url] .
Зависимость разрушает семью? Не медлите — обратитесь в московский центр «Alco.Rehab» за квалифицированной помощью.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-moskva11.ru/]вывод из запоя с выездом[/url]
Заказать диплом о высшем образовании. Изготовление диплома занимает гораздо меньше времени, а стоимость – невысокая. В результате вы имеете возможность сберечь деньги и время и найти работу вашей мечты. Приобрести диплом можно через сайт компании. – [url=http://pipewiki.org/wiki/index.php/User:VickyArf42625/]pipewiki.org/wiki/index.php/User:VickyArf42625[/url]
Заказать диплом ВУЗа по невысокой стоимости возможно, обращаясь к надежной специализированной компании: [url=http://1001viktorina.ru/forum/viewtopic.php?f=19&t=4582&sid=645d2cc77d4079d569373e297bb45da4/]1001viktorina.ru/forum/viewtopic.php?f=19&t=4582&sid=645d2cc77d4079d569373e297bb45da4[/url]
где купить дипломы медсестры [url=http://www.frei-diplom13.ru]где купить дипломы медсестры[/url] .
Купить документ о получении высшего образования вы можете в нашем сервисе. Мы предлагаем документы об окончании любых ВУЗов РФ. Гарантируем, что при проверке документа работодателями, каких-либо подозрений не появится: [url=http://itformula.ca/index.php?title=User:GaryHallen35049/]itformula.ca/index.php?title=User:GaryHallen35049[/url]
Мы изготавливаем дипломы любой профессии по приятным тарифам. Для нас важно, чтобы дипломы были доступны для большого количества граждан. Заказать диплом любого ВУЗа [url=http://borderforum.ru/viewtopic.php?f=7&t=14803&sid=92b7b6b68d7ffbba232e7f6ab3612584/]borderforum.ru/viewtopic.php?f=7&t=14803&sid=92b7b6b68d7ffbba232e7f6ab3612584[/url]
Мы предлагаем дипломы любой профессии по выгодным тарифам. Важно, чтобы дипломы были доступны для большого количества граждан. Быстро приобрести диплом об образовании [url=http://citytowerrealestate.com/author/fevheather968/]citytowerrealestate.com/author/fevheather968[/url]
куплю диплом медсестры в москве [url=http://frei-diplom13.ru]куплю диплом медсестры в москве[/url] .
Не каждый работодатель проводит подробную проверку дипломов работников. Большинство компаний доверяют кандидатам и “вслепую” принимают документ. В данной ситуации приобретение диплома российского ВУЗа является выгодным решением. Не потребуется терять огромное количество времени и денег на очное обучение. Мы предлагаем дипломы любой профессии по приятным тарифам: [url=http://url.csweb.com.tr/altonslavin57/]url.csweb.com.tr/altonslavin57[/url]
купить аттестат с занесением в реестр 9 класс [url=https://r-diploma26.ru]купить аттестат с занесением в реестр 9 класс[/url] .
Такой подход делает лечение предсказуемым: вы понимаете, что происходит сейчас, чего ждать завтра и как закрепить результат на горизонте недель и месяцев.
Узнать больше – http://narkologicheskaya-klinika-podolsk0.ru
Применяются растворы на основе физраствора, глюкозы, витаминов группы B, противорвотных, седативных и гепатопротекторов. Используемые препараты входят в реестр разрешённых лекарств.
Получить больше информации – https://narcolog-na-dom-ekaterinburg55.ru/vyzov-narkologa-na-dom-v-ekaterinburge/
Лечение в наркологической клинике в Воронеже проводится поэтапно, с учётом состояния пациента, длительности зависимости и наличия сопутствующих заболеваний.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-voronezh9.ru/]наркологическая клиника в воронеже[/url]
Для иллюстрации приведена таблица, отражающая распространённые методы терапии и их воздействие на организм:
Получить дополнительную информацию – http://narkologicheskaya-klinika-v-voronezhe17.ru
После инфузии врач повторно измеряет показатели, оставляет письменные инструкции, назначает окно связи и определяет условия, при которых разумно перейти к стационару: нет нужды держаться «на силе воли», когда безопаснее сменить формат.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-moskva99.ru/]vyvod-iz-zapoya-moskva-vyzov-narkologa-kapelnica[/url]
Заказать диплом любого ВУЗа. Изготовление диплома занимает минимум времени, а цена – невысокая. В результате вы имеете возможность сохранить деньги и время и найти работу вашей мечты. Купить диплом на заказ можно используя официальный сайт компании. – [url=http://leasingangels.net/author/freddie5548184/]leasingangels.net/author/freddie5548184[/url]
[b]Диплом бакалавра[/b]. Мы изготавливаем дипломы любой профессии по приятным ценам: [url=http://pirat.iboards.ru/viewtopic.php?f=20&t=42031/]pirat.iboards.ru/viewtopic.php?f=20&t=42031[/url]
Заказать диплом института по выгодной цене можно, обращаясь к надежной специализированной компании: [url=http://gbslandpoint.com/author/dieterm787635/]gbslandpoint.com/author/dieterm787635[/url]
купить диплом аттестат в екатеринбурге [url=https://r-diploma23.ru/]купить диплом аттестат в екатеринбурге[/url] .
Мы можем предложить дипломы психологов, юристов, экономистов и других профессий по приятным ценам. Цена может зависеть от той или иной специальности, года получения и ВУЗа: [url=http://zador.flybb.ru/viewtopic.php?f=1&t=4180/]zador.flybb.ru/viewtopic.php?f=1&t=4180[/url]
Мы предлагаем дипломы любой профессии по приятным ценам. Важно, чтобы документы были доступными для большого количества наших граждан. Приобрести диплом института [url=http://linkzinbio.com/ionapalaci/]linkzinbio.com/ionapalaci[/url]
Мы изготавливаем дипломы любых профессий по выгодным ценам. Важно, чтобы дипломы были доступными для большинства граждан. Приобрести диплом об образовании [url=http://teslawiki.cz/index.php/User:AlysaMoncrieff/]teslawiki.cz/index.php/User:AlysaMoncrieff[/url]
[b]Заказать диплом о высшем образовании![/b]
Мы предлагаембыстро и выгодно приобрести диплом, который выполняется на оригинальной бумаге и заверен мокрыми печатями, штампами, подписями. Диплом пройдет лубую проверку, даже при использовании специального оборудования. Достигайте своих целей быстро и просто с нашим сервисом- [url=http://mosfor.flybb.ru/viewtopic.php?f=2&t=921/]mosfor.flybb.ru/viewtopic.php?f=2&t=921[/url]
купить диплом о среднем техническом образовании в перми [url=www.r-diploma31.ru]www.r-diploma31.ru[/url] .
купить аттестаты за 9 класс с оценками в волхове [url=https://r-diploma26.ru/]купить аттестаты за 9 класс с оценками в волхове[/url] .
Experience Brainy https://askbrainy.com the free & open-source AI assistant. Get real-time web search, deep research, and voice message support directly on Telegram and the web. No subscriptions, just powerful answers.
купить диплом физиотерапевта [url=r-diploma29.ru]r-diploma29.ru[/url] .
диплом интернатуры купить [url=https://r-diploma28.ru]диплом интернатуры купить[/url] .
Stumbled upon this gem of an article, give it a try https://git.shaunmcpeck.com/danaeemmer2711
Этанол связывается с ГАМК-рецепторами, усиливая тормозные процессы в ЦНС, что ведёт к снижению рефлексов и когнитивных функций. Одновременно происходит повышение активности дофаминовых путей, вызывая ощущение кратковременного «успокоения» и «радости». При прекращении поступления алкоголя к рецепторам наступает синдром отмены — резкое возбуждение, тревожность и дисбаланс нейротрансмиттеров.
Узнать больше – http://
Основная задача клиники — способствовать восстановлению здоровья и социальной адаптации тех, кто столкнулся с зависимостью. Мы комплексно подходим к решению проблемы, учитывая физические, психологические и социальные аспекты зависимости. Наша цель — не только помочь избавиться от пагубных привычек, но и обеспечить успешное возвращение к полноценной жизни.
Подробнее тут – http://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-rostove-na-donu.xn--p1ai/https://медицинский-вывод-из-запоя.рф
купить диплом подстава [url=www.r-diploma30.ru]купить диплом подстава[/url] .
куплю диплом младшей медсестры [url=www.frei-diplom13.ru]www.frei-diplom13.ru[/url] .
Индивидуализация лечения: Каждый случай рассматривается отдельно, учитывая уникальные особенности пациента, его физическое состояние, предшествующий опыт лечения и социальные факторы. Такой подход позволяет создать максимально эффективный план терапии.
Изучить вопрос глубже – http://alko-specialist.ru/vivod-iz-zapoya-anonimno-v-simferopole/
где можно купить диплом медсестры [url=https://frei-diplom13.ru]где можно купить диплом медсестры[/url] .
Когда запой выходит за рамки нескольких суток, интоксикация организма достигает критического уровня: нарушается водно-электролитный баланс, появляются признаки токсического поражения печени и нервной системы. В таких случаях самостоятельные попытки прекратить употребление алкоголя могут привести к тяжёлым осложнениям — судорогам, алкогольному психозу, острой сердечной недостаточности. В Санкт-Петербурге и Ленинградской области доступны профессиональные услуги по выводу из запоя, выполняемые опытными наркологами как на дому, так и в специализированных клиниках.
Получить дополнительные сведения – [url=https://nadezhnyj-vyvod-iz-zapoya.ru/]nadezhnyj-vyvod-iz-zapoya.ru/[/url]
Наркологическая клиника “Аура Здоровья” — специализированное учреждение, предоставляющее профессиональную помощь людям, страдающим алкогольной и наркотической зависимостью. Мы стремимся помочь пациентам преодолеть зависимости и обрести контроль над своей жизнью, используя современные методики лечения и поддержки.
Ознакомиться с деталями – http://медицинский-вывод-из-запоя.рф
купить диплом дистанционного [url=http://www.r-diploma27.ru]купить диплом дистанционного[/url] .
В этом материале представлены детали, которые хоть и занимательны, но не особенно значимы. Мы рассматриваем моменты, которые трудно назвать важными, но всё же решили включить их для полноты картины.
Вот – [url=https://arma-rehab.ru/]азартные игры[/url]
Мы предлагаем документы ВУЗов, которые расположены в любом регионе Российской Федерации.
Купить диплом любого университета: [url=http://foousrp.listbb.ru/viewtopic.php?f=4&t=12599]foousrp.listbb.ru/viewtopic.php?f=4&t=12599[/url]
Таким образом, наш подход ориентирован на создание комплексной системы поддержки, позволяющей каждому пациенту справиться с проблемой зависимости и вернуться к нормальной жизни.
Изучить вопрос глубже – [url=https://alko-specialist.ru/]вывод из запоя симферополь.[/url]
Мы понимаем уникальность каждого пациента и проводим тщательную диагностику, анализируя его медицинскую историю, психологическое состояние и социальные факторы. На основе полученных данных создаем персональные планы лечения, включающие медикаментозные средства, психотерапию и социальные программы.
Получить дополнительную информацию – https://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-anonimno-v-rostove-na-donu.xn--p1ai
Мы предлагаем документы ВУЗов, которые находятся на территории Российской Федерации.
Приобрести диплом о высшем образовании: [url=http://rhoming.com/agent/lorettaduigan]rhoming.com/agent/lorettaduigan[/url]
купить диплом в северодвинске [url=https://www.r-diploma23.ru]купить диплом в северодвинске[/url] .
Системы автоматизированного дозирования обеспечивают точное введение медикаментов, минимизируя риск передозировки и побочных эффектов. Постоянный мониторинг жизненно важных показателей позволяет врачу оперативно корректировать терапевтическую схему для достижения максимальной безопасности и эффективности.
Ознакомиться с деталями – [url=https://narco-vivod-clean.ru/]нарколог вывод из запоя санкт-петербург[/url]
[b]Диплом экономиста[/b]. Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по приятным ценам: [url=http://ericos.ru/forum/index.php?PAGE_NAME=profile_view&UID=12049/]ericos.ru/forum/index.php?PAGE_NAME=profile_view&UID=12049[/url]
Смысл экстренной помощи — не в «сильной капельнице любой ценой», а в последовательности. Бригада приезжает в согласованное окно, проводит экспресс-осмотр, фиксирует давление, пульс, сатурацию, оценивает неврологический статус, при необходимости снимает ЭКГ. Далее подбирается инфузионная терапия по показаниям, корректируется водно-электролитный баланс, снижаются тремор и тревога, выравнивается сон. Важно объяснить семье и самому пациенту, чего ожидать: какие ощущения нормальны, какие — повод для связи, зачем назначены те или иные растворы и поддерживающие препараты. Параллельно формируется краткий план «сложных часов» на вечер и ночь: что делать, если накрывает волну беспокойства, как распределить жидкость и питание, какие бытовые действия лучше отложить. В московском ритме особенно критично не растягивать решения на «завтра»: від организованного визита до ощутимого облегчения обычно проходит один-два часа, и именно этот отрезок задаёт тон всей последующей стабилизации.
Выяснить больше – [url=https://vyvod-iz-zapoya-moskva99.ru/]www.domen.ru[/url]
купить диплом о среднем специальном образовании цена в челябинске [url=http://r-diploma31.ru/]купить диплом о среднем специальном образовании цена в челябинске[/url] .
Клиника создана для оказания квалифицированной помощи всем, кто страдает от различных форм зависимости. Мы стремимся не только к лечению, но также к формированию здорового образа жизни, возвращая пациентов к полноценной жизни.
Получить дополнительные сведения – https://нарко-специалист.рф/vivod-iz-zapoya-cena-v-Ekaterinburge
купить диплом о высшем образовании калининград [url=https://www.r-diploma26.ru]купить диплом о высшем образовании калининград[/url] .
Специалист уточняет длительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Точный сбор данных позволяет оперативно корректировать лечение и выбрать оптимальные методы детоксикации.
Подробнее можно узнать тут – http://narco-vivod-clean.ru
Кодирование — это медицинский инструмент, который помогает закрепить трезвость, но сам по себе не является «волшебной кнопкой». Его задача — усилить внутреннюю мотивацию и создать физиологические и/или психологические условия, при которых срыв становится маловероятным. В «НаркологЭксперт» кодирование включают в структуру лечения: сначала купируются острые проявления, проводится детокс и стабилизация сна, давления и тревоги, затем — диагностика противопоказаний, подробное информирование, выбор методики и только после этого — сама процедура. Такой порядок снижает риски, повышает переносимость и делает результат предсказуемым. Важно, что любая техника подбирается индивидуально с учётом длительности употребления, анамнеза, сопутствующих заболеваний и рабочей нагрузки пациента, чтобы лечение органично вписалось в реальную жизнь и не сорвалось на первых же неделях.
Подробнее – [url=https://kodirovanie-ot-alkogolizma-moskva9.ru/]виды кодирования от алкоголизма[/url]
Алгоритм гибкий: при изменении самочувствия мы донастраиваем схему и интенсивность наблюдения без пауз в лечении.
Углубиться в тему – [url=https://narkologicheskaya-klinika-himki0.ru/]бесплатная наркологическая клиника[/url]
Особое внимание в клинике уделяется предотвращению рецидивов. Мы обучаем пациентов навыкам управления стрессом и эмоциональной стабильности, помогая формировать здоровые привычки. Это способствует долгосрочному восстановлению и снижает вероятность возвращения к зависимости.
Получить больше информации – http://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-rostove-na-donu.xn--p1ai/
Купить диплом ВУЗа по доступной стоимости возможно, обратившись к проверенной специализированной компании: [url=http://dralijafarclinic.com/kupit-diplom-o-vysshem-obrazovanii-srochno-492/]dralijafarclinic.com/kupit-diplom-o-vysshem-obrazovanii-srochno-492[/url]
купить диплом бакалавра 2014 года [url=http://www.r-diploma22.ru]купить диплом бакалавра 2014 года[/url] .
Looking for a casino? elon-casino-top.com: slots, live casino, bonus offers, and tournaments. We cover the rules, wagering requirements, withdrawals, and account security. Please review the terms and conditions before playing.
Чтобы соотнести риски и плотность наблюдения до очного осмотра, удобнее всего взглянуть на одну сводную таблицу. Это не замена решению врача, но понятный ориентир для семьи: чем выше вероятность осложнений, тем плотнее мониторинг и быстрее доступ к коррекциям.
Детальнее – http://narkologicheskaya-klinika-lyubercy0.ru/narkologicheskaya-klinika-na-dom-v-lyubercah/https://narkologicheskaya-klinika-lyubercy0.ru
Приобрести диплом об образовании. Изготовление документа занимает немного времени, а цена – доступна каждому. В итоге вы имеете возможность сберечь деньги и время и найти работу мечты. Заказать диплом на заказ возможно через официальный сайт компании. – [url=http://athrconsultancy.in/employer/diplomx-grups/]athrconsultancy.in/employer/diplomx-grups[/url]
Для успешного продвижения вверх по карьере понадобится наличие диплома о высшем образовании. Мы изготавливаем дипломы любых профессий по приятным ценам: [url=http://sportavesti.ru/forums/forum/forum/]sportavesti.ru/forums/forum/forum[/url]
Миссия клиники “Маяк надежды” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша задача — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Подробнее можно узнать тут – http://алко-лечение24.рф
Заказать официальный диплом о высшем образовании : [url=http://mosmol.flybb.ru/viewtopic.php?f=2&t=1085/]mosmol.flybb.ru/viewtopic.php?f=2&t=1085[/url]
Equilibrado de piezas
El equilibrado es una etapa esencial en el mantenimiento de maquinaria agricola, asi como en la fabricacion de ejes, volantes, rotores y armaduras de motores electricos. El desequilibrio genera vibraciones que aceleran el desgaste de los rodamientos, provocan sobrecalentamiento e incluso llegan a causar la rotura de componentes. Con el fin de prevenir fallos mecanicos, es fundamental detectar y corregir el desequilibrio a tiempo utilizando tecnicas modernas de diagnostico.
Principales metodos de equilibrado
Hay diferentes tecnicas para corregir el desequilibrio, dependiendo del tipo de pieza y la intensidad de las vibraciones:
El equilibrado dinamico – Se utiliza en componentes rotativos (rotores, ejes) y se realiza en maquinas equilibradoras especializadas.
El equilibrado estatico – Se emplea en volantes, ruedas y piezas similares donde es suficiente compensar el peso en un unico plano.
Correccion del desequilibrio – Se realiza mediante:
Perforado (retirada de material en la zona de mayor peso),
Instalacion de contrapesos (en ruedas, aros de volantes),
Ajuste de masas de balanceo (por ejemplo, en ciguenales).
Diagnostico del desequilibrio: ?que equipos se utilizan?
Para identificar con precision las vibraciones y el desequilibrio, se utilizan:
Equipos equilibradores – Permiten medir el nivel de vibracion y definen con precision los puntos de correccion.
Analizadores de vibraciones – Registran el espectro de oscilaciones, detectando no solo el desequilibrio, sino tambien fallos adicionales (como el desgaste de rodamientos).
Sistemas laser – Se usan para mediciones de alta precision en mecanismos criticos.
Especial atencion merecen las velocidades criticas de rotacion – condiciones en las que la vibracion se incrementa de forma significativa debido a fenomenos de resonancia. Un equilibrado correcto previene danos en el equipo bajo estas condiciones.
купить аттестат за 11 классов в нижнем новгороде [url=http://r-diploma27.ru]купить аттестат за 11 классов в нижнем новгороде[/url] .
[b]Диплом о высшем образовании[/b]. Мы изготавливаем дипломы любой профессии по невысоким тарифам: [url=http://luxury.homepro.casa/en/author/lyndongyles212/]luxury.homepro.casa/en/author/lyndongyles212[/url]
купить диплом ргтэу [url=www.r-diploma25.ru/]купить диплом ргтэу[/url] .
Оптимально для пациентов в стабильном состоянии. Процедура начинается с приезда врача, осмотра и постановки капельницы с индивидуально подобранными растворами.
Узнать больше – [url=https://narko-zakodirovan2.ru/]вывод из запоя круглосуточно в новосибирске[/url]
Заказать диплом института по невысокой стоимости возможно, обратившись к проверенной специализированной компании: [url=http://school97.ru/vesti20/index.php?PAGE_NAME=profile_view&UID=227181/]school97.ru/vesti20/index.php?PAGE_NAME=profile_view&UID=227181[/url]
Перед процедурой обсуждаются цели, ожидаемые эффекты, возможные побочные реакции, сроки наблюдения. Пациент получает письменные рекомендации на первые трое суток: режим сна и жидкости, коррекция нагрузки, контакты для связи, сигналы настороженности. Такой формат сделал результаты более предсказуемыми: меньше импульсивных решений, меньше тревоги и больше контроля над поведением в критический ранний период.
Углубиться в тему – [url=https://kodirovanie-ot-alkogolizma-moskva9.ru/]kodirovanie-v-moskve-otzyvy[/url]
Этот текст содержит различную информацию, которая, возможно, покажется любопытной, но в целом не меняет восприятия привычных вещей. Предлагаем просто получить удовольствие от чтения, не ожидая особой пользы.
Вот – [url=https://arma-rehab.ru/vyvod-iz-zapoya/]милфы[/url]
Этот информационный набор привлекает внимание множеством мелочей и странных ракурсов. Мы предлагаем взгляды, которые редко бывают полезны, но могут слегка разнообразить ваше знакомство с темой.
Вот – [url=https://arma-rehab.ru/vyvod-iz-zapoya/]милфы[/url]
купить чистый диплом спб [url=http://www.r-diploma22.ru]купить чистый диплом спб[/url] .
Клиника создана для оказания квалифицированной помощи всем, кто страдает от различных форм зависимости. Мы стремимся не только к лечению, но также к формированию здорового образа жизни, возвращая пациентов к полноценной жизни.
Получить дополнительную информацию – http://нарко-специалист.рф/vivod-iz-zapoya-v-kruglosutochno-v-Ekaterinburge/
Приобрести диплом любого университета. Производство документа занимает гораздо меньше времени, а стоимость – доступна любому человеку. В результате вы получаете возможность сберечь бюджет и получить работу мечты. Купить диплом на заказ можно используя сайт компании. – [url=http://navyareality.com/author/rosemarietrigg/]navyareality.com/author/rosemarietrigg[/url]
Клиника ориентирована на клиническую достаточность: никаких процедур «для галочки», только то, что подтверждено показаниями. С первого контакта дежурный врач уточняет анамнез, лекарства, аллергии, оценивает риски сердечно-сосудистых осложнений, степень обезвоживания, уровень тревоги и качества сна. Если состояние позволяет, подготовка к кодированию проводится амбулаторно или на дому; при нестабильных показателях предлагается короткий стационар для безопасной стабилизации. Важна анонимность — в расписании используются шифры, доступ к данным разграничен, информирование родственников происходит только по согласию пациента. Организация процесса учитывает ритм мегаполиса: гибкие слоты в будни и выходные, выездные бригады, быстрый перевод из домашнего формата в стационар при необходимости. Финансовые условия проговариваются заранее, чтобы исключить скрытые позиции и дать человеку возможность планировать бюджет без догадок.
Получить дополнительные сведения – https://kodirovanie-ot-alkogolizma-moskva9.ru/kodirovanie-ot-alkogolizma-na-domu-v-moskve
Смотреть здесь https://krab3a.cc
Например, если речь идет о выводе из запоя, врач проведет тщательное обследование пациента, чтобы определить общее состояние здоровья и наличие возможных осложнений. На основе диагностики будет назначена инфузионная терапия, которая включает введение растворов, витаминов и препаратов для снятия абстиненции.
Получить дополнительную информацию – [url=https://narcolog-na-dom-v-krasnoyarske55.ru/]частный нарколог на дом[/url]
В нашем медицинском центре работают высококвалифицированные специалисты в области наркологии и психиатрии. Все врачи имеют профильное образование, а также опыт работы в клиниках и реабилитационных центрах. Основные преимущества нашей команды:
Подробнее тут – [url=https://alko-specialist.ru/]вывод из запоя цена в симферополе[/url]
Мы понимаем уникальность каждого пациента и проводим тщательную диагностику, анализируя его медицинскую историю, психологическое состояние и социальные факторы. На основе полученных данных создаем персональные планы лечения, включающие медикаментозные средства, психотерапию и социальные программы.
Изучить вопрос глубже – https://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-anonimno-v-rostove-na-donu.xn--p1ai/
Физическое облегчение — лишь половина задачи; вторая половина — эмоции и привычки. Индивидуальные сессии помогают распознать автоматические мысли, планировать «буферы» на вечерние часы, управлять стрессом и сонливостью, расставлять «сигнальные маяки» на привычных маршрутах, где чаще всего возникают соблазны. Семья получает ясные инструкции: меньше контроля — больше поддержки правил среды (тишина, затемнение, прохлада, вода и лёгкая еда «по часам»), отказ от «разборов причин» в первую неделю, короткие договорённости о связи со специалистом при тревожных признаках. Когда у всех одни и те же ориентиры, уровень конфликтов падает, а предсказуемость растёт — это напрямую укрепляет ремиссию. Мы не перегружаем психологический блок «теорией»: даём только те инструменты, которые человек готов выполнить сегодня и завтра, без рывков и самообвинений. Такая практичность приносит больше пользы, чем долгие разговоры «о мотивации», и отлично сочетается с медицинской частью плана.
Углубиться в тему – [url=https://narkologicheskaya-klinika-moskva999.ru/]клиника наркологии и психиатрии москва[/url]
https://kotel-rs.ru/
купить диплом вуза в пензе [url=http://www.r-diploma22.ru]купить диплом вуза в пензе[/url] .
Мы понимаем уникальность каждого пациента и проводим тщательную диагностику, анализируя его медицинскую историю, психологическое состояние и социальные факторы. На основе полученных данных создаем персональные планы лечения, включающие медикаментозные средства, психотерапию и социальные программы.
Детальнее – http://медицинский-вывод-из-запоя.рф/
купить диплом бакалавра с занесением в реестр [url=http://r-diploma28.ru/]купить диплом бакалавра с занесением в реестр[/url] .
Приобрести диплом института по выгодной цене возможно, обращаясь к надежной специализированной компании: [url=http://alkojak.com/author/chana86w517476/]alkojak.com/author/chana86w517476[/url]
Мы готовы предложить дипломы любой профессии по приятным ценам. Для нас важно, чтобы дипломы были доступны для большого количества наших граждан. Заказать диплом ВУЗа [url=http://worksale777.blogspot.com/2025/10/blog-post_2.html/]worksale777.blogspot.com/2025/10/blog-post_2.html[/url]
Первый контакт строится вокруг фактов «здесь и сейчас». Врач уточняет длительность употребления, уже принятые препараты за 24–48 часов, сопутствующие диагнозы и аллергии; измеряет АД, пульс, сатурацию, температуру, оценивает степень тремора и уровень тревоги. При показаниях выполняется экспресс-ЭКГ и базовый неврологический скрининг. Затем простым языком объясняется логика вмешательств: какие инфузии будут сегодня, чего ждать через 30–60 минут, как организовать «тихий» вечер и по каким признакам связываться. Мы избегаем универсальных «сильных смесей» и «оглушающих» дозировок, поскольку они дают краткий «блеск» и вечерний откат. Вместо этого — узкая схема: регидратация, коррекция электролитов, печёночная поддержка, гастропротекция и противорвотные при необходимости, мягкая анксиолитическая коррекция по показаниям. На руки выдаются рекомендации на 48–72 часа: вода и лёгкая еда «по часам», затемнение и ранний отбой, «красные флажки» для связи и утреннее окно контроля. Такой график убирает импровизации и делает поведение семьи согласованным.
Подробнее тут – http://narkologicheskaya-klinika-lyubercy9.ru/
Не все работодатели проводят тщательную проверку дипломов работников. Абсолютное большинство компаний вполне доверяют кандидатам и “вслепую” принимают важный документ. В такой ситуации покупка диплома ВУЗа является разумным решением. Не потребуется терять множество времени и денег на учебу. Мы готовы предложить дипломы психологов, юристов, экономистов и других профессий по выгодным ценам: [url=http://zdshi-tula.ru/forum/?PAGE_NAME=message&FID=1&TID=915&MID=142435&result=new#message142435/]zdshi-tula.ru/forum/?PAGE_NAME=message&FID=1&TID=915&MID=142435&result=new#message142435[/url]
Приобретение документа о высшем образовании через качественную и надежную компанию дарит ряд достоинств. Заказать диплом о высшем образовании: [url=http://cs-forever.phorum.pl/posting.php]cs-forever.phorum.pl/posting.php[/url]
Мы можем предложить дипломы любой профессии по приятным тарифам. Важно, чтобы документы были доступными для большого количества граждан. Приобрести диплом о высшем образовании [url=http://tzu.to/tktrH/]tzu.to/tktrH[/url]
Мы готовы предложить дипломы любой профессии по приятным тарифам. Купить диплом в Бийске — [url=http://forum.7x.ru/member.php?u=16498/]forum.7x.ru/member.php?u=16498[/url]
Диплом о получении высшего образования в СССР считался основным документом, который способствовал быстрому и удачному трудоустройству. Заказать диплом возможно через официальный сайт компании. [url=http://avtovladelez.ru/kupit-diplom-dlya-trudoustroystva/]avtovladelez.ru/kupit-diplom-dlya-trudoustroystva[/url]
Приобрести диплом о высшем образовании Вряд ли вы захотите потратить несколько лет своей жизни на то, чтобы заполучить знания, которые уже имеются. В конечном итоге решение о покупке диплома о высшем образовании является для вас самым оптимальным. Вам нужно сделать не так много – выбрать проверенную компанию, которая занимается изготовлением документов об образовании на заказ. Это позволит вам максимально выгодно и оперативно получить документ из любого ВУЗа РФ: [url=http://social.midnightdreamsreborns.com/read-blog/123446_kupit-diplom-o-srednem-obrazovanii.html/]social.midnightdreamsreborns.com/read-blog/123446_kupit-diplom-o-srednem-obrazovanii.html[/url]
Детокс — это последовательность целевых действий. Инфузии подбираются индивидуально: цель — восстановить объём циркулирующей крови, скорректировать электролиты, снизить токсическую нагрузку, мягко приглушить тремор и тревогу, вернуть условия для сна. Мы не перегружаем препаратами, не «гоняем» симптом силой седативов и не используем универсальные растворы «для всех». Поддержка сна строится на минимально достаточных дозах и гигиене вечернего времени: затемнение, тишина, отказ от экранов, ранний отбой. Параллельно врач объясняет, как пить воду маленькими порциями, когда сделать лёгкий перекус, зачем планировать короткую дневную паузу. После купирования остроты пациент получает чёткий план на трое суток — простые, реалистичные шаги, которые удерживают эффект без «героизма» и без лишней фармакологической нагрузки. В результате медицинский эффект не растворяется в быту, а закрепляется привычками, которые по силам выполнить сегодня и завтра.
Получить дополнительную информацию – [url=https://narkolog-na-dom-moskva999.ru/]нарколог на дом круглосуточно[/url]
Госпитализация показана, когда требуется непрерывный контроль и быстрые изменения схем лечения. В стационаре устраняют выраженные симптомы отмены, корректируют электролитные нарушения, поддерживают печёночные функции, при необходимости подключают кислород и аппаратные методы диагностики. Параллельно выравнивают сон и аппетит, закрывают дефициты микроэлементов, подбирают щадящий режим нагрузки. На выписке пациент получает подробные рекомендации: как дозировать активность, когда пить воду и в каких объёмах, какие препараты принимать и при каких признаках обращаться за консультацией без ожидания. Такой формат снижает риск осложнений и даёт предсказуемую динамику уже на горизонте нескольких дней.
Исследовать вопрос подробнее – http://narkologicheskaya-klinika-moskva9.ru
Инфузия — это не одна «сильная сыворотка», а набор целевых вмешательств. Мы восстанавливаем объём циркулирующей жидкости, корректируем электролиты, снижаем токсическую нагрузку на печень, мягко приглушаем тремор и тревогу, готовим нервную систему к ночи. Противорвотная поддержка и гастропротекция подключаются при необходимости, витаминные комплексы — по показаниям, кардиокоррекция — только после оценки рисков. Врач заранее проговаривает, какие ощущения допустимы (сонливость, умеренная слабость), а какие — повод для немедленного контакта. Цель — не «забить» симптом на час, а задать предсказуемую траекторию на дни, чтобы вернулись управляемость, аппетит и ровный сон. Когда вмешательства дозированы и понятны, пациент меньше «проверяет себя» нагрузками, а семья перестаёт «разгонять» тревогу разговорами — это повышает эффективность терапии без увеличения чека.
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-podolsk9.ru
Клиника ориентирована на клиническую достаточность: никаких процедур «для галочки», только то, что подтверждено показаниями. С первого контакта дежурный врач уточняет анамнез, лекарства, аллергии, оценивает риски сердечно-сосудистых осложнений, степень обезвоживания, уровень тревоги и качества сна. Если состояние позволяет, подготовка к кодированию проводится амбулаторно или на дому; при нестабильных показателях предлагается короткий стационар для безопасной стабилизации. Важна анонимность — в расписании используются шифры, доступ к данным разграничен, информирование родственников происходит только по согласию пациента. Организация процесса учитывает ритм мегаполиса: гибкие слоты в будни и выходные, выездные бригады, быстрый перевод из домашнего формата в стационар при необходимости. Финансовые условия проговариваются заранее, чтобы исключить скрытые позиции и дать человеку возможность планировать бюджет без догадок.
Подробнее тут – [url=https://kodirovanie-ot-alkogolizma-moskva9.ru/]кодирование москва[/url]
Резкое прекращение употребления алкоголя часто сопровождается выраженными симптомами абстиненции: тремор, тахикардия, повышенное давление, беспокойство. В клинике «Северная Звезда» для детоксикации применяется инфузионная терапия с балансированными растворами, содержащими:
Изучить вопрос глубже – [url=https://lechenie-alkogolizma-arkhangelsk0.ru/]центр лечения алкоголизма[/url]
Инфузионная терапия — это набор узких вмешательств под конкретную картину, а не «магический состав». Регидратация улучшает тканевую перфузию и снимает головную боль от обезвоживания; электролиты стабилизируют нервно-мышечную передачу и сердечный ритм; печёночная поддержка уменьшает токсическую нагрузку и тяжесть в правом подреберье; гастропротекция и противорвотные защищают слизистую и убирают рвотный компонент. При выраженной тревоге и бессоннице добавляется мягкая анксиолитическая поддержка — дозы подбираются так, чтобы стабилизировать, а не «выключить». Мы не назначаем исследования «для галочки»: анализы и ЭКГ используются тогда, когда их результат меняет решения «сегодня». Такой подход снижает побочные эффекты, делает результат предсказуемым и удерживает бюджет от «скачков». На этой базе уже обсуждается следующий шаг: амбулаторное наблюдение, краткие психообразовательные сессии, а при показаниях — кодирование после стабилизации.
Получить дополнительную информацию – https://kapelnica-ot-zapoya-lyubercy9.ru/skolko-stoit-kapelnica-ot-zapoya-v-lyubercah/
Мы предлагаем документы учебных заведений, расположенных в любом регионе РФ.
Купить диплом любого ВУЗа: [url=http://linkmultidirecional.com/luciennenx]linkmultidirecional.com/luciennenx[/url]
Для удачного продвижения по карьере необходимо наличие официального диплома о высшем образовании. Мы изготавливаем дипломы любой профессии по невысоким тарифам: [url=http://ros.listbb.ru/viewtopic.php?f=2&t=5152/]ros.listbb.ru/viewtopic.php?f=2&t=5152[/url]
Купить официальный диплом академии : [url=http://drviet.com/read-blog/3433_kupit-diplom-stoit.html/]drviet.com/read-blog/3433_kupit-diplom-stoit.html[/url]
азино официальный сайт Азино – это имя, эхом разносящееся в виртуальных закоулках сети, словно далекий зов сирены. За манящим названием скрывается целый мир азартных развлечений, обещающий мгновенное обогащение и захватывающие эмоции. Однако, стоит помнить, что за каждым обещанием скрывается реальность, требующая осознанного подхода и здравого смысла.
купить диплом пту в твери [url=https://r-diploma22.ru]https://r-diploma22.ru[/url] .
В наркологической клинике в Челябинске проводится профессиональная детоксикация — очищение организма от токсинов, накопленных в результате употребления алкоголя или наркотиков. Процедура выполняется под наблюдением специалистов, что исключает риск осложнений и обеспечивает быстрое улучшение самочувствия. Для восстановления функций внутренних органов применяются препараты, стабилизирующие работу печени, сердца и нервной системы. Использование капельниц, витаминов и гепатопротекторов помогает нормализовать обмен веществ и устранить последствия интоксикации.
Разобраться лучше – http://narcologicheskaya-klinika-v-chelyabinske16.ru/chastnaya-narkologicheskaya-klinika-chelyabinsk/
Мы изготавливаем дипломы любых профессий по приятным ценам. Для нас очень важно, чтобы документы были доступны для большого количества граждан. Приобрести диплом об образовании [url=http://electrospeed.teamforum.ru/viewtopic.php?f=3&t=6777/]electrospeed.teamforum.ru/viewtopic.php?f=3&t=6777[/url]
Далеко не каждый работодатель проводит подробную проверку дипломов. Абсолютное большинство компаний доверяют соискателям и без проблем принимают важные документы. В подобной ситуации приобретение диплома российского университета является выгодным решением. Не придется терять множество времени и денег на учебу. Мы изготавливаем дипломы любой профессии по приятным ценам: [url=http://sydneywest.whyceeyes.com/?p=10337/]sydneywest.whyceeyes.com/?p=10337[/url]
[b]Заказать диплом о высшем образовании![/b]
Наша компания предлагаетбыстро купить диплом, который выполняется на оригинальной бумаге и заверен печатями, штампами, подписями должностных лиц. Документ пройдет любые проверки, даже с применением специальных приборов. Достигайте цели быстро с нашей компанией- [url=http://magnat-matras.ru/forum/user/60062/]magnat-matras.ru/forum/user/60062[/url]
азино сайт Казино Азино – это отражение реальности, где шансы на выигрыш всегда ниже, чем шансы на проигрыш. Но именно этот риск придает игре остроту и азарт. Главное – играть ответственно, не ставя на кон последние деньги и не забывая о том, что в жизни есть гораздо больше важных и интересных вещей.
Мы изготавливаем дипломы любой профессии по приятным тарифам. Важно, чтобы документы были доступными для большинства граждан. Приобрести диплом об образовании [url=http://icfoodseasoning.com/bbs/board.php?bo_table=free&wr_id=617504/]icfoodseasoning.com/bbs/board.php?bo_table=free&wr_id=617504[/url]
диплом участника купить [url=r-diploma27.ru]r-diploma27.ru[/url] .
купить диплом радиомеханика [url=r-diploma31.ru]купить диплом радиомеханика[/url] .
Equilibrado de piezas
El equilibrado representa una fase clave en el mantenimiento de maquinaria agricola, asi como en la fabricacion de ejes, volantes, rotores y armaduras de motores electricos. Un desequilibrio provoca vibraciones que incrementan el desgaste de los rodamientos, provocan sobrecalentamiento e incluso pueden causar la rotura de los componentes. Con el fin de prevenir fallos mecanicos, resulta esencial identificar y corregir el desequilibrio de forma temprana utilizando metodos modernos de diagnostico.
Metodos principales de equilibrado
Hay diferentes tecnicas para corregir el desequilibrio, dependiendo del tipo de pieza y la intensidad de las vibraciones:
Equilibrado dinamico – Se utiliza en componentes rotativos (rotores y ejes) y se realiza en maquinas equilibradoras especializadas.
El equilibrado estatico – Se emplea en volantes, ruedas y piezas similares donde basta con compensar el peso en un solo plano.
La correccion del desequilibrio – Se lleva a cabo mediante:
Taladrado (retirada de material en la zona de mayor peso),
Instalacion de contrapesos (en ruedas y aros de volantes),
Ajuste de masas de equilibrado (como en el caso de los ciguenales).
Diagnostico del desequilibrio: ?que equipos se utilizan?
Para identificar con precision las vibraciones y el desequilibrio, se emplean:
Equipos equilibradores – Miden el nivel de vibracion y definen con precision los puntos de correccion.
Analizadores de vibraciones – Registran el espectro de oscilaciones, identificando no solo el desequilibrio, sino tambien fallos adicionales (como el desgaste de rodamientos).
Sistemas de medicion laser – Se usan para mediciones de alta precision en componentes criticos.
Especial atencion merecen las velocidades criticas de rotacion – condiciones en las que la vibracion se incrementa de forma significativa debido a la resonancia. Un equilibrado adecuado evita danos en el equipo bajo estas condiciones.
купить диплом училище киеве [url=http://r-diploma26.ru/]купить диплом училище киеве[/url] .
Домашний маршрут выбирают, когда показатели стабильны и нет признаков тяжёлой соматики или спутанности сознания. Преимущество в сочетании скорости, приватности и приверженности: знакомая среда снижает стресс, а отсутствие переездов экономит силы. Врач «МедТоники» приезжает без маркировки, привозит мониторинг и расходные материалы, подбирает инфузии по состоянию, помогает восстановить режим сна и гидратации, даёт рекомендации по питанию и правила на 48–72 часа. Отдельный блок — работа с тревогой и тремором: корректируется медикаментозная поддержка, обсуждаются простые поведенческие техники, чтобы снизить вероятность импульсивных решений вечером. Домашний формат не подменяет наблюдение: назначаются точки связи, врач объясняет, когда нужен повторный визит, а когда достаточно телефонной коррекции. Для Москвы такой сценарий удобен ещё и тем, что его проще встроить в плотный график, не выпадая из рабочих и семейных ролей и не провоцируя лишних вопросов у окружающих.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-moskva99.ru/]vyvod-iz-zapoya-na-domu-moskva[/url]
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Не пропусти важное – https://podgoreamputowani.pl/2024/12/06/wybor-odpowiedniej-protezy
Ниже представлена таблица с основными препаратами, используемыми при выводе из запоя в Тюмени:
Углубиться в тему – http://vyvod-iz-zapoya-v-tyumeni17.ru/vyvod-iz-zapoya-tyumen-otzyvy/
купить диплом вуза в котором учились [url=http://www.r-diploma23.ru]купить диплом вуза в котором учились[/url] .
[b]Диплом любой специальности[/b]. Мы готовы предложить дипломы психологов, юристов, экономистов и любых других профессий по выгодным ценам: [url=http://forum.24hours.site/index.php?topic=620231.new#new/]forum.24hours.site/index.php?topic=620231.new#new[/url]
find this https://cryptoswap.cc
купить диплом медсестры [url=www.frei-diplom13.ru/]купить диплом медсестры[/url] .
Реабилитация после запоя в Химках. Мы поможем вам восстановиться после запоя и предотвратить рецидивы.
Изучить вопрос глубже – http://https://vyvod-iz-zapoya-himki11.ru/
Купить диплом ВУЗа по выгодной цене возможно, обратившись к надежной специализированной компании: [url=http://deanonnic.listbb.ru/posting.php?mode=post&f=5/]deanonnic.listbb.ru/posting.php?mode=post&f=5[/url]
В этой статье-обзоре мы собрали данные, актуальность которых сомнительна, а факты — не всегда взаимосвязаны. Читатель сможет ознакомиться с разными мнениями, хотя вряд ли они существенно повлияют на его понимание темы.
Вот – [url=https://arma-rehab.ru/vyvod-iz-zapoya/]онлайн покер на деньги[/url]
купить медицинский диплом медсестры [url=www.frei-diplom13.ru/]купить медицинский диплом медсестры[/url] .
Реабилитация после запоя в Люберцах. Мы поможем вам восстановиться после запоя и предотвратить рецидивы.
Изучить вопрос глубже – [url=https://https://kapelnica-ot-zapoya-lyubercy11.ru//]вызвать капельницу от запоя[/url]
купить диплом вуза в котором учились [url=https://www.r-diploma22.ru]купить диплом вуза в котором учились[/url] .
[b]Заказать диплом любого университета![/b]
Мы предлагаемвыгодно купить диплом, который выполняется на оригинальной бумаге и заверен печатями, штампами, подписями. Документ пройдет любые проверки, даже с применением специальных приборов. Решите свои задачи быстро и просто с нашими дипломами- [url=http://dliavas.listbb.ru/viewtopic.php?f=19&t=9371/]dliavas.listbb.ru/viewtopic.php?f=19&t=9371[/url]
Мы изготавливаем дипломы любой профессии по приятным тарифам. Стоимость может зависеть от выбранной специальности, года получения и университета: [url=http://k90280ul.beget.tech/2025/09/23/–5.html/]k90280ul.beget.tech/2025/09/23/–5.html[/url]
Мы изготавливаем дипломы любой профессии по приятным ценам. Важно, чтобы дипломы были доступными для большинства граждан. Приобрести диплом о высшем образовании [url=http://rcdrift.ru/forum/member.php?u=21074/]rcdrift.ru/forum/member.php?u=21074[/url]
аттестат о среднем образовании старого образца купить [url=http://r-diploma25.ru/]аттестат о среднем образовании старого образца купить[/url] .
купить вкладыш к аттестату [url=r-diploma29.ru]купить вкладыш к аттестату[/url] .
купить диплом о высшем образовании в красноярске цены [url=www.r-diploma31.ru]купить диплом о высшем образовании в красноярске цены[/url] .
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
А что дальше? – https://kmexportinternational.com/hello-world
Заказать диплом об образовании. Производство документа занимает минимум времени, а цена – доступна любому. В результате вы сможете сберечь деньги и время и получить работу мечты. Приобрести диплом можно через сайт компании. – [url=http://hwekimchi.gabia.io/bbs/board.php?bo_table=free&tbl=&wr_id=1099220/]hwekimchi.gabia.io/bbs/board.php?bo_table=free&tbl=&wr_id=1099220[/url]
купить диплом среднего медицинского образования [url=http://r-diploma26.ru]купить диплом среднего медицинского образования[/url] .
купить диплом персонального тренера [url=http://r-diploma28.ru/]купить диплом персонального тренера[/url] .
Купить диплом университета по невысокой цене возможно, обратившись к надежной специализированной фирме: [url=http://thedreammate.com/home/bbs/board.php?bo_table=free&wr_id=4727628/]thedreammate.com/home/bbs/board.php?bo_table=free&wr_id=4727628[/url]
купить диплом не опасно ли это [url=https://www.r-diploma23.ru]купить диплом не опасно ли это[/url] .
Мы готовы предложить документы учебных заведений, которые расположены на территории Российской Федерации.
Приобрести диплом ВУЗа: [url=http://kdnc.kr/gnuboard5/bbs/board.php?bo_table=qna&wr_id=806185]kdnc.kr/gnuboard5/bbs/board.php?bo_table=qna&wr_id=806185[/url]
купить диплом кандидата есть [url=r-diploma27.ru]купить диплом кандидата есть[/url] .
купить диплом екатеринбург без предоплаты [url=http://r-diploma30.ru/]купить диплом екатеринбург без предоплаты[/url] .
Мы изготавливаем дипломы психологов, юристов, экономистов и других профессий по приятным тарифам. Цена будет зависеть от определенной специальности, года выпуска и ВУЗа: [url=http://fullyfurnishedrentals.ca/author/preciousjemiso/]fullyfurnishedrentals.ca/author/preciousjemiso[/url]
Процесс лечения включает несколько последовательных шагов, направленных на стабилизацию состояния, детоксикацию и восстановление функций организма. Таблица ниже показывает основные этапы процедуры, применяемые врачами клиники «РеабКузбасс».
Углубиться в тему – [url=https://vyvod-iz-zapoya-v-novokuzneczke17.ru/]вывод из запоя круглосуточно[/url]
тут Наша команда экспертов всегда готова ответить на ваши вопросы и предоставить консультации по всем аспектам жизни и работы в Испании. Мы поможем вам разобраться в нюансах испанского законодательства, системы здравоохранения и образования. Мы предлагаем индивидуальные решения, учитывающие ваши личные обстоятельства и потребности.
купить диплом института в волгограде [url=http://r-diploma31.ru]купить диплом института в волгограде[/url] .
Приобретение диплома через проверенную и надежную компанию дарит ряд преимуществ. Заказать диплом: [url=http://comercialbecs.cl/kupit-diplom-gosobrazca-realnye-dannye-i-pechati-198]comercialbecs.cl/kupit-diplom-gosobrazca-realnye-dannye-i-pechati-198[/url]
В этом материале представлены детали, которые хоть и занимательны, но не особенно значимы. Мы рассматриваем моменты, которые трудно назвать важными, но всё же решили включить их для полноты картины.
Вот – [url=https://arma-rehab.ru/]порно[/url]
Быстро и просто купить диплом любого института. Изготовление диплома занимает гораздо меньше времени, а цена – невысокая. Таким образом вы сможете сохранить деньги и время и найти работу вашей мечты. Купить диплом возможно через сайт компании. – [url=http://weddcation.com/kupit-diplom-s-garantiej-podlinnosti-8-2/]weddcation.com/kupit-diplom-s-garantiej-podlinnosti-8-2[/url]
Такой календарь делает весь процесс прозрачным: пациент видит логику, близкие — прогресс, а врач — чистый сигнал для коррекции без «эскалации на всякий случай».
Получить больше информации – [url=https://narcologicheskaya-klinika-saratov0.ru/]наркологическая клиника нарколог саратов[/url]
Нужны грузчики? грузоперевозки : переезды, доставка мебели и техники, погрузка и разгрузка. Подберём транспорт под объём груза, обеспечим аккуратную работу и соблюдение сроков. Прозрачные тарифы и удобный заказ.
Ниже приведена таблица, отражающая примерную динамику состояния пациента после постановки капельницы:
Разобраться лучше – https://kapelnicza-ot-zapoya-v-voronezhe17.ru/kapelnicza-ot-alkogolya-voronezh/
купить диплом техникума в ростове [url=http://r-diploma26.ru]купить диплом техникума в ростове[/url] .
Круглосуточная помощь при запое в Люберцах. Наша команда работает 24/7, обеспечивая доступность медицинской помощи в любое время суток.
Подробнее тут – [url=https://https://kapelnica-ot-zapoya-lyubercy12.ru//]врач на дом капельница от запоя[/url]
Для успешного продвижения по карьере требуется наличие диплома о высшем образовании. Мы готовы предложить дипломы психологов, юристов, экономистов и любых других профессий по приятным тарифам: [url=http://g95334gq.beget.tech/2025/10/08/kupit-diplom-v-korotkie-sroki-1.html/]g95334gq.beget.tech/2025/10/08/kupit-diplom-v-korotkie-sroki-1.html[/url]
Заказать официальный диплом института : [url=http://socialpix.club/piperspann7221/]socialpix.club/piperspann7221[/url]
купить аттестаты за 11 класс с занесением в реестр с проверенного сайта [url=https://r-diploma23.ru/]https://r-diploma23.ru/[/url] .
Equilibrado de piezas
El equilibrado representa una fase clave en las tareas de mantenimiento de maquinaria agricola, asi como en la produccion de ejes, volantes, rotores y armaduras de motores electricos. Un desequilibrio provoca vibraciones que aceleran el desgaste de los rodamientos, provocan sobrecalentamiento e incluso llegan a causar la rotura de componentes. Con el fin de prevenir fallos mecanicos, es fundamental identificar y corregir el desequilibrio de forma temprana utilizando tecnicas modernas de diagnostico.
Principales metodos de equilibrado
Existen varias tecnicas para corregir el desequilibrio, dependiendo del tipo de componente y la magnitud de las vibraciones:
Equilibrado dinamico – Se utiliza en componentes rotativos (rotores y ejes) y se lleva a cabo mediante maquinas equilibradoras especializadas.
Equilibrado estatico – Se emplea en volantes, ruedas y piezas similares donde basta con compensar el peso en un solo plano.
Correccion del desequilibrio – Se lleva a cabo mediante:
Taladrado (retirada de material en la zona de mayor peso),
Instalacion de contrapesos (en ruedas, aros de volantes),
Ajuste de masas de equilibrado (por ejemplo, en ciguenales).
Diagnostico del desequilibrio: ?que equipos se utilizan?
Para identificar con precision las vibraciones y el desequilibrio, se utilizan:
Maquinas equilibradoras – Permiten medir el nivel de vibracion y definen con precision los puntos de correccion.
Analizadores de vibraciones – Registran el espectro de oscilaciones, detectando no solo el desequilibrio, sino tambien fallos adicionales (por ejemplo, el desgaste de rodamientos).
Sistemas laser – Se usan para mediciones de alta precision en mecanismos criticos.
Las velocidades criticas de rotacion requieren especial atencion – regimenes en los que la vibracion aumenta drasticamente debido a fenomenos de resonancia. Un equilibrado correcto previene danos en el equipo bajo estas condiciones.
Лечение пивного алкоголизма в Химках. Мы предлагаем эффективные методы лечения зависимости от пива.
Подробнее можно узнать тут – [url=https://https://vyvod-iz-zapoya-himki11.ru//]вывод из запоя клиника в химках[/url]
Диплом об образовании в СССР считался основным документом, который способствовал удачному поиску работы. Купить диплом вы можете используя сайт компании. [url=http://bodybuilding.net/members/worksale.html/]bodybuilding.net/members/worksale.html[/url]
диплом работу купить [url=https://r-diploma27.ru]диплом работу купить[/url] .
Мы можем предложить дипломы психологов, юристов, экономистов и любых других профессий по приятным ценам. Стоимость зависит от той или иной специальности, года получения и университета: [url=http://dienstleister-website.de/sheliahaydon58/]dienstleister-website.de/sheliahaydon58[/url]
купить диплом психолога недорого [url=http://www.r-diploma22.ru]купить диплом психолога недорого[/url] .
Получить диплом любого ВУЗа мы поможем. Купить диплом недорого – реальность – [url=http://diplomybox.com/kupit-diplom-nedorogo/]diplomybox.com/kupit-diplom-nedorogo[/url]
Не все работодатели проводят подробную проверку дипломов работников. Подавляющее большинство компаний доверяют кандидатам и “вслепую” принимают важный документ. В подобной ситуации приобретение диплома российского ВУЗа является выгодным решением. Не понадобится терять множество времени и денег на очное обучение. Мы изготавливаем дипломы любых профессий по приятным тарифам: [url=http://navyareality.com/author/baileywaugh47/]navyareality.com/author/baileywaugh47[/url]
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Смотрите также… – https://www.nwohalaw.com/2024/09/22/exploring-the-difference-between-affirmative-defenses-avoidances-and-inferential-rebuttals
Заказать диплом о высшем образовании Никто не стремится потерять несколько лет жизни на то, чтобы “официально” заполучить навыки, которые уже присутствуют. В итоге решение заказать официальный диплом о высшем образовании станет для вас наиболее оптимальным. И для этого вам требуется сделать не так много – подобрать компанию, занимающуюся изготовлением и продажей дипломов на заказ. Это предоставит вам возможность максимально выгодно и оперативно заполучить диплом из любого высшего учебного заведения России: [url=http://hustlacrips.forumex.ru/viewtopic.php?f=9&t=1801/]hustlacrips.forumex.ru/viewtopic.php?f=9&t=1801[/url]
Мы готовы предложить дипломы любой профессии по невысоким ценам. Купить диплом в Новоуральске — [url=http://s-s-o.ru/forum.php?PAGE_NAME=profile_view&UID=63254/]s-s-o.ru/forum.php?PAGE_NAME=profile_view&UID=63254[/url]
Купить диплом о высшем образовании поспособствуем. Купить диплом о высшем образовании в Новосибирске – [url=http://diplomybox.com/kupit-diplom-o-vysshem-obrazovanii-v-novosibirske/]diplomybox.com/kupit-diplom-o-vysshem-obrazovanii-v-novosibirske[/url]
купить диплом электрика в ростове на дону [url=https://r-diploma31.ru/]https://r-diploma31.ru/[/url] .
Мы можем предложить документы институтов, которые расположены на территории РФ.
Купить диплом любого университета: [url=http://collabtherapy.com/forum/viewforum.php?f=2]collabtherapy.com/forum/viewforum.php?f=2[/url]
можно купить диплом медсестры [url=https://frei-diplom13.ru/]можно купить диплом медсестры[/url] .
Приобрести диплом института по выгодной стоимости вы можете, обращаясь к надежной специализированной фирме: [url=http://rentry.co/fbord394/]rentry.co/fbord394[/url]
[b]Приобрести диплом о высшем образовании![/b]
Наши специалисты предлагаютвыгодно приобрести диплом, который выполнен на оригинальном бланке и заверен мокрыми печатями, штампами, подписями официальных лиц. Наш документ способен пройти любые проверки, даже с использованием специально предназначенного оборудования. Достигайте свои цели быстро с нашими дипломами- [url=http://short.vird.co/ipzhelene15553/]short.vird.co/ipzhelene15553[/url]
купить медицинский диплом медсестры [url=http://www.frei-diplom13.ru]купить медицинский диплом медсестры[/url] .
Профилактика рецидивов после запоя в Химках.Мы поможем вам предотвратить повторные случаи запоя и поддержим вас на пути к трезвой жизни.
Подробнее – [url=https://https://vyvod-iz-zapoya-himki11.ru//]вывод из запоя недорого[/url]
Мы предлагаем дипломы любой профессии по приятным тарифам. Для нас очень важно, чтобы документы были доступны для большого количества наших граждан. Купить диплом об образовании [url=http://ssgrid-git.cnsaas.com/michelpic10775/michel2022/issues/1/]ssgrid-git.cnsaas.com/michelpic10775/michel2022/issues/1[/url]
Мы предлагаем дипломы психологов, юристов, экономистов и прочих профессий по доступным ценам. Для нас важно, чтобы дипломы были доступными для подавляющей массы граждан. Заказать диплом любого университета [url=http://o2cloudsystems.com/kupit-diplom-bystro-i-nadezhno-80-2/]o2cloudsystems.com/kupit-diplom-bystro-i-nadezhno-80-2[/url]
Снятие ломки при алкоголизме в Химках. Наши специалисты помогут вам справиться с симптомами абстиненции.
Ознакомиться с деталями – [url=https://https://vyvod-iz-zapoya-himki11.ru//]вывод из запоя круглосуточно[/url]
Публикация предоставляет читателю набор разрозненных идей, которые сложно применить на практике. Мы лишь слегка касаемся разных точек зрения, не углубляясь в анализ и не предлагая никаких выводов.
Вот – [url=https://arma-rehab.ru/]онлайн покер на деньги[/url]
Мы предлагаем дипломы любой профессии по приятным ценам. Цена будет зависеть от той или иной специальности, года получения и ВУЗа: [url=http://ukrevents.ru/kupit-diplom-bakalavra/]ukrevents.ru/kupit-diplom-bakalavra[/url]
диплом школы купить [url=http://r-diploma27.ru/]диплом школы купить[/url] .
купить диплом минобрнауки [url=http://www.r-diploma23.ru]купить диплом минобрнауки[/url] .
купить диплом белоруссии [url=http://r-diploma22.ru/]купить диплом белоруссии[/url] .
купить диплом в оренбурге цены [url=https://r-diploma25.ru/]купить диплом в оренбурге цены[/url] .
Заказать диплом университета поможем. Купить диплом о высшем образовании в Ярославле – [url=http://diplomybox.com/kupit-diplom-o-vysshem-obrazovanii-v-yaroslavle/]diplomybox.com/kupit-diplom-o-vysshem-obrazovanii-v-yaroslavle[/url]
Стационар «Трезвый Путь Коломна» ориентирован на безопасность в самых сложных случаях: длительные запои, тяжёлая абстиненция, смешанное употребление, выраженные соматические проблемы, риск делирия или судорог. Пациент попадает под наблюдение 24/7, что принципиально отличает клинику от домашних попыток «спасти своими средствами». Контроль жизненно важных показателей, своевременная коррекция схем лечения, возможность быстро отреагировать на осложнения — всё это снижает риск критических ситуаций, которые часто возникают именно после неумелых домашних вмешательств или «выездов без ответственности».
Детальнее – [url=https://narkologicheskaya-klinika-kolomna2-10.ru/]заказать звонок наркологическая клиника[/url]
диплом пилота купить [url=http://www.r-diploma29.ru]диплом пилота купить[/url] .
Когда острые угрозы исключены, программа стартует дома. Пациент получает понятную карту действий, близкие — короткие окна обратной связи, врач — чистую «картинку» для тонкой настройки. Мы просим сообщать факты, а не эмоции: минуты до засыпания, число пробуждений, объём тёплой воды малыми глотками, пульс к вечеру, переносимость мягкой пищи, ясность головы утром.
Получить больше информации – https://vyvod-iz-zapoya-saratov0.ru/vyvod-iz-zapoya-saratov-staczionar
купить аттестат техникума спб [url=r-diploma31.ru]купить аттестат техникума спб[/url] .
[b]Диплом юриста[/b]. Мы можем предложить дипломы любой профессии по выгодным ценам: [url=http://автомедведь.СЂС„/club/log/?SECTION_CODE=log/]автомедведь.СЂС„/club/log/?SECTION_CODE=log[/url]
Мы готовы предложить документы университетов, расположенных в любом регионе РФ.
Заказать диплом ВУЗа: [url=http://mapnova.com.co/employer/premialnie-diplom-24]mapnova.com.co/employer/premialnie-diplom-24[/url]
Выезд нарколога на дом в Серпухове — это возможность получить профессиональную помощь в условиях, когда везти человека в клинику сложно, опасно или он категорически отказывается от госпитализации. Специалисты «СерпуховТрезвие» работают круглосуточно, приезжают по адресу с одноразовыми системами, стерильными расходниками и необходимым набором препаратов, проводят осмотр, оценивают жизненно важные показатели, подбирают индивидуальную капельницу, контролируют реакцию и оставляют подробные рекомендации. Всё происходит конфиденциально, без лишних свидетелей, без осуждения и давления. Цель — не формально «поставить капельницу», а безопасно стабилизировать состояние, снизить интоксикацию, выровнять давление и пульс, уменьшить тревогу и вернуть человеку возможность нормально спать и восстанавливаться, не доводя до осложнений и экстренной госпитализации.
Углубиться в тему – [url=https://narkolog-na-dom-serpuhov10.ru/]вызвать нарколога на дом срочно[/url]
[b]Заказать диплом университета![/b]
Наша компания предлагаетвыгодно заказать диплом, который выполнен на оригинальном бланке и заверен мокрыми печатями, водяными знаками, подписями. Данный диплом способен пройти любые проверки, даже с использованием специальных приборов. Достигайте своих целей быстро с нашим сервисом- [url=http://novoevnukovo.ru/index.php?topic=4789.new#new/]novoevnukovo.ru/index.php?topic=4789.new#new[/url]
Aw, this was an incredibly nice post. Taking the time and actual effort to produce a top notch article… but what can I say… I procrastinate a whole lot and don’t seem to get nearly anything done.
онлайн рейтинг русских казино
Мы предлагаем дипломы психологов, юристов, экономистов и других профессий по приятным тарифам. Для нас важно, чтобы дипломы были доступны для большого количества граждан. Приобрести диплом об образовании [url=http://gitea.stormyhome.net/eldenseton2071/]gitea.stormyhome.net/eldenseton2071[/url]
xrumer 23 xrumer сайт
купить диплом о высшем образовании с занесением в реестр ижевск [url=www.r-diploma26.ru/]купить диплом о высшем образовании с занесением в реестр ижевск[/url] .
Мы готовы предложить дипломы психологов, юристов, экономистов и других профессий по приятным тарифам. Стоимость может зависеть от выбранной специальности, года выпуска и ВУЗа: [url=http://ezworkers.com/employer/aurus-diplom/]ezworkers.com/employer/aurus-diplom[/url]
Не каждый наниматель проводит тщательную проверку дипломов. Большинство компаний доверяют кандидатам и “вслепую” принимают важный документ. В этой ситуации покупка диплома университета является мудрым решением. Не придется терять множество времени и денег на учебу. Мы предлагаем дипломы любой профессии по выгодным тарифам: [url=http://topdubaijobs.ae/employer/russiany-diplomx/]topdubaijobs.ae/employer/russiany-diplomx[/url]
остров ко ланта ко ланте
В материале приведены детали, интересные, но не особенно важные. Мы рассматриваем аспекты, которые сложно назвать существенными, но включили их для большей полноты.
Подробнее читать – [url=https://rostov-narkologiya.ru/uslugi-ot-narkomanii/mefedronovaya-zavisimost/]таблетки для аборта[/url]
купить диплом медсестры [url=http://www.frei-diplom13.ru]купить диплом медсестры[/url] .
купить диплом с занесением в реестр в калининграде [url=https://r-diploma23.ru]https://r-diploma23.ru[/url] .
купить диплом о среднем образовании в орле [url=https://www.r-diploma30.ru]купить диплом о среднем образовании в орле[/url] .
купить диплом мгу в барнауле [url=http://r-diploma22.ru]http://r-diploma22.ru[/url] .
можно купить диплом медсестры [url=http://www.frei-diplom13.ru]можно купить диплом медсестры[/url] .
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
А что дальше? – https://yasulog.org/how-to-cancel-nordvpn
Этот текст содержит различную информацию, которая, возможно, покажется любопытной, но в целом не меняет восприятия привычных вещей. Предлагаем просто получить удовольствие от чтения, не ожидая особой пользы.
Вот – https://arma-rehab.ru/vyvod-iz-zapoya/
[b]Диплом для вас[/b]. Мы предлагаем дипломы любой профессии по выгодным тарифам: [url=http://skymix2018.forumex.ru/viewtopic.php?f=14&t=1506/]skymix2018.forumex.ru/viewtopic.php?f=14&t=1506[/url]
купить диплом о среднем образовании в улан удэ [url=www.r-diploma31.ru]купить диплом о среднем образовании в улан удэ[/url] .
Мы изготавливаем дипломы любых профессий по приятным ценам. Для нас важно, чтобы документы были доступными для большого количества граждан. Заказать диплом института [url=http://camlive.ovh/read-blog/36807_kupit-diplom-stoit.html/]camlive.ovh/read-blog/36807_kupit-diplom-stoit.html[/url]
Мы предлагаем документы университетов, которые находятся в любом регионе РФ.
Заказать диплом любого ВУЗа: [url=http://domovou.3nx.ru/viewtopic.php?p=22760#22760]domovou.3nx.ru/viewtopic.php?p=22760#22760[/url]
ко ланта ко ланта
Заказать диплом института по выгодной цене возможно, обращаясь к проверенной специализированной компании: [url=http://wiwonder.com/read-blog/57032_kupit-diplom-o-srednem.html/]wiwonder.com/read-blog/57032_kupit-diplom-o-srednem.html[/url]
Выезд нарколога на дом в Щёлково — это быстрый и конфиденциальный способ помочь человеку в состоянии запоя или тяжёлого похмелья, не перевозя его в клинику и не устраивая публичных сцен. Врачи «ЩёлковоМед Профи» приезжают с готовым набором препаратов, одноразовыми системами и чётким протоколом: осмотр, оценка жизненно важных показателей, подбор индивидуальной капельницы, контроль реакции, рекомендации для родных. Такой формат особенно удобен, когда пациент отказывается ехать в стационар, тяжело переносит дорогу, остро реагирует на смену обстановки или для семьи важна максимальная анонимность. Главный принцип — не «вырубить» человека любой ценой, а безопасно стабилизировать состояние, снизить интоксикацию, выровнять давление и пульс, помочь собрать сон и дать понятный план, что делать дальше.
Выяснить больше – [url=https://narkolog-na-dom-shchelkovo10.ru/]narkolog-na-dom[/url]
Заказать документ института вы можете в нашей компании в Москве. Мы предлагаем документы об окончании любых ВУЗов Российской Федерации. Даем 100% гарантию, что при проверке документа работодателем, подозрений не появится: [url=http://git.storkhealthcare.cn/hopeboard15315/hope1985/-/issues/1/]git.storkhealthcare.cn/hopeboard15315/hope1985/-/issues/1[/url]
Капельницы в «СаратовМед Профи» — это конструктор из тщательно подобранных модулей. Каждый модуль решает одну задачу и имеет свой ожидаемый горизонт эффекта. Важно не название, а логика: задача > опора среды > как проверяем > когда ждём результат.
Получить больше информации – [url=https://vyvod-iz-zapoya-saratov0.ru/]нарколог на дом вывод из запоя саратов[/url]
Наркологическая клиника «Трезвый Путь Коломна» — это пространство, где тяжёлые истории зависимости перестают быть хаотичным набором срывов, ночных обещаний и беспомощных попыток родных «вытащить своими силами». Здесь собраны врачи-наркологи, терапевты, психологи и медперсонал, которые знают, что такое длительные запои, многолетнее употребление, полинаркомания, зависимость от аптечных препаратов, и умеют работать с этим не через страх и давление, а через профессиональные, выверенные шаги. Клиника в Коломне предлагает безопасную детоксикацию, стационарное наблюдение, индивидуальные программы лечения алкоголизма и наркомании, поддержку семьи и постреабилитационные решения. Все процессы организованы так, чтобы пациент сохранял достоинство, а родственники наконец получили не обещания, а реальный план действий, понятный по этапам и по результатам.
Получить дополнительную информацию – http://narkologicheskaya-klinika-kolomna2-10.ru
Покупка официального диплома через проверенную и надежную компанию дарит много плюсов. Приобрести диплом о высшем образовании: [url=http://agproperties.ae/estate_agent/shalandawhitef]agproperties.ae/estate_agent/shalandawhitef[/url]
https://t.me/s/kAzInO_s_MINimalNyM_dePOziTOm/5
https://t.me/s/kAZINo_s_MIniMALNym_DePOziTOM/13
Комплексный подход обеспечивает не только снятие симптомов, но и полное восстановление функций организма. Пациент получает поддержку на всех этапах — от детоксикации до социальной адаптации.
Ознакомиться с деталями – [url=https://narkologicheskaya-pomoshh-v-tolyatti17.ru/]центр наркологической помощи[/url]
Мы готовы предложить дипломы любой профессии по приятным тарифам. Для нас очень важно, чтобы дипломы были доступны для большого количества граждан. Заказать диплом об образовании [url=http://doublrp.listbb.ru/posting.php?mode=post&f=3/]doublrp.listbb.ru/posting.php?mode=post&f=3[/url]
купить аттестат об основном общем образовании с твердой обложкой 11 классов [url=http://www.r-diploma28.ru]купить аттестат об основном общем образовании с твердой обложкой 11 классов[/url] .
Мы готовы предложить дипломы любой профессии по приятным ценам. Стоимость будет зависеть от выбранной специальности, года выпуска и ВУЗа: [url=http://idrinkandibreakthings.com/index.php/User:ATIJosef60395262/]idrinkandibreakthings.com/index.php/User:ATIJosef60395262[/url]
Диплом об образовании когда-то считался главным документом, который способствовал удачному устройству на работу. Купить диплом на заказ в Москве вы сможете используя сайт компании. [url=http://kpoong.com/bbs/board.php?bo_table=free&wr_id=138018/]kpoong.com/bbs/board.php?bo_table=free&wr_id=138018[/url]
Мы можем предложить дипломы любых профессий по приятным ценам. Приобрести диплом любого университета [url=http://angelladydety.getbb.ru/posting.php?mode=post&f=46&sid=c4cf3f4cc1e633c55e1e0a9055cb4b34/]angelladydety.getbb.ru/posting.php?mode=post&f=46&sid=c4cf3f4cc1e633c55e1e0a9055cb4b34[/url]
Мы готовы предложить дипломы психологов, юристов, экономистов и любых других профессий по приятным тарифам. Диплом об образовании в СССР считался основным документом, который способствовал быстрому и успешному поиску работы. Приобрести диплом института!: [url=http://zenithgrs.com/employer/originality-diplomiki/]zenithgrs.com/employer/originality-diplomiki[/url]
Купить диплом института по невысокой стоимости вы сможете, обращаясь к проверенной специализированной фирме. Для того, чтобы проверить компанию до покупки воспользуйтесь отзывами других покупателей в сети интернет. Можно приобрести диплом из любого ВУЗа РФ [url=http://linkedd.com.au/kupit-diplom-kolledzha-359/]linkedd.com.au/kupit-diplom-kolledzha-359[/url]
Мы можем предложить дипломы психологов, юристов, экономистов и других профессий по доступным тарифам. Стоимость может зависеть от выбранной специальности, года получения и образовательного учреждения: [url=http://visacart.80lvl.ru/viewtopic.php?f=1&t=4386/]visacart.80lvl.ru/viewtopic.php?f=1&t=4386[/url]
Мы изготавливаем дипломы любой профессии по невысоким ценам. Заказать диплом о высшем образовании [url=http://jobs.jaylock-ph.com/companies/gosznac-diplom-24/]jobs.jaylock-ph.com/companies/gosznac-diplom-24[/url]
Мы можем предложить дипломы любых профессий по приятным ценам. Диплом о высшем образовании в СССР считался ключевым документом, который способствовал успешному устройству на работу. Заказать диплом об образовании!: [url=http://communiti.pcen.org/read-blog/84330_kupit-diplom-o-srednem-obrazovanii.html/]communiti.pcen.org/read-blog/84330_kupit-diplom-o-srednem-obrazovanii.html[/url]
Купить диплом академии Вряд ли вы захотите потратить несколько лет своей жизни на то, чтобы получить знания, которые уже присутствуют. В итоге решение о покупке диплома о высшем образовании будет для вас наиболее выгодным. И для этого вам необходимо сделать не так много – найти компанию, которая занимается изготовлением и доставкой дипломов на заказ. Это даст вам возможность за незначительную сумму и в кратчайшие сроки получить диплом из любого высшего учебного заведения страны: [url=http://nearestate.com/author/jackibramblett/]nearestate.com/author/jackibramblett[/url]
Мы можем предложить дипломы психологов, юристов, экономистов и прочих профессий по приятным ценам. Важно, чтобы документы были доступными для большого количества наших граждан. Приобрести диплом любого ВУЗа [url=http://buch.christophgerber.ch/index.php?title=Benutzer:Jonnie69J31535/]buch.christophgerber.ch/index.php?title=Benutzer:Jonnie69J31535[/url]
Мы изготавливаем дипломы любых профессий по доступным тарифам.– [url=http://readeach.com/garfieldpridge/]readeach.com/garfieldpridge[/url]
https://1wins34-tos.top
Заказать диплом ВУЗа по невысокой стоимости возможно, обращаясь к надежной специализированной фирме: [url=http://sobakovodkursk.listbb.ru/posting.php?mode=post&f=17&sid=b015e1a333f877f2eece9228b14a1176/]sobakovodkursk.listbb.ru/posting.php?mode=post&f=17&sid=b015e1a333f877f2eece9228b14a1176[/url]
Вывод из запоя — это не просто медицинская процедура, а тщательно выстроенный процесс, направленный на восстановление работы всех систем организма. При неправильном или неполном лечении риск осложнений возрастает в несколько раз. Поэтому обращение в профессиональную клинику становится необходимым шагом. В наркологической клинике «Центр Трезвости ВоронМед» пациент получает экстренную помощь, безопасные инфузионные препараты, круглосуточный выезд нарколога и последующее восстановление под наблюдением специалистов. Здесь каждая капельница подбирается индивидуально — с учётом возраста, веса, длительности запоя, хронических болезней и реакции организма на препараты.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-voronezhe17.ru/]нарколог на дом вывод из запоя в воронеже[/url]
Услуга
Разобраться лучше – http://narkolog-na-dom-shchelkovo10.ru/vrach-narkolog-na-dom-shchelkovo/
Приобрести документ о получении высшего образования вы имеете возможность в нашей компании в Москве. Мы оказываем услуги по изготовлению и продаже документов об окончании любых университетов России. Гарантируем, что в случае проверки документа работодателями, каких-либо подозрений не возникнет: [url=http://propertymarketfinder.com/writer/bradyancey397/]propertymarketfinder.com/writer/bradyancey397[/url]
Домашний формат особенно важен, когда пациент не готов к стационару, боится огласки, испытывает стыд или сопротивление, но объективно нуждается в помощи. Попытки «перетерпеть» или лечить своими силами заканчиваются тем, что родственники дают опасные комбинации седативных, анальгетиков и «антипохмельных» средств, а состояние только ухудшается. «МедТрезвие Долгопрудный» строит выездную помощь так, чтобы она оставалась профессиональной медициной, а не косметической услугой. Уже при звонке диспетчер под контролем врача уточняет длительность запоя, виды алкоголя, наличие гипертонии, болезней сердца, печени, почек, диабета, неврологических нарушений, психических эпизодов, факт судорог, делирия в прошлом, какие лекарства уже были даны. Это позволяет заранее понять, подходит ли формат лечения на дому или сразу нужно рассматривать стационар. Выезд назначается только в тех случаях, когда это безопасно, и именно в этом ключевое отличие официальной клиники от анонимных «капельниц на дом» — здесь всегда выбирают жизнь и здоровье, а не удобный маркетинговый сценарий. Для семьи это не просто комфорт, а возможность получить помощь без риска сорваться в критическое состояние посреди ночи.
Изучить вопрос глубже – [url=https://narkolog-na-dom-dolgoprudnij10.ru/]vyzov-vracha-narkologa-na-dom[/url]
Мы предлагаем документы любых учебных заведений, расположенных на территории Российской Федерации.
Купить диплом любого ВУЗа: [url=http://ereproperty.ru/agent/millievangundy]ereproperty.ru/agent/millievangundy[/url]
Для максимально быстрого продвижения по карьерной лестнице понадобится наличие диплома о высшем образовании. Мы изготавливаем дипломы любой профессии по невысоким тарифам: [url=http://samenestate.ir/agent/beau70b876415/]samenestate.ir/agent/beau70b876415[/url]
Приобрести официальный диплом ВУЗа : [url=http://burevestnik.listbb.ru/viewtopic.php?f=3&t=1731/]burevestnik.listbb.ru/viewtopic.php?f=3&t=1731[/url]
Equilibrado de piezas
El equilibrado representa una fase clave en el mantenimiento de maquinaria agricola, asi como en la produccion de ejes, volantes, rotores y armaduras de motores electricos. El desequilibrio genera vibraciones que aceleran el desgaste de los rodamientos, generan sobrecalentamiento e incluso pueden causar la rotura de los componentes. Con el fin de prevenir fallos mecanicos, es fundamental detectar y corregir el desequilibrio a tiempo utilizando metodos modernos de diagnostico.
Principales metodos de equilibrado
Hay diferentes tecnicas para corregir el desequilibrio, dependiendo del tipo de pieza y la intensidad de las vibraciones:
Equilibrado dinamico – Se aplica en elementos rotativos (rotores, ejes) y se lleva a cabo mediante maquinas equilibradoras especializadas.
El equilibrado estatico – Se usa en volantes, ruedas y otras piezas donde basta con compensar el peso en un solo plano.
La correccion del desequilibrio – Se lleva a cabo mediante:
Perforado (retirada de material en la zona de mayor peso),
Instalacion de contrapesos (en ruedas y aros de volantes),
Ajuste de masas de equilibrado (por ejemplo, en ciguenales).
Diagnostico del desequilibrio: equipos utilizados
Para identificar con precision las vibraciones y el desequilibrio, se utilizan:
Equipos equilibradores – Permiten medir el nivel de vibracion y determinan con exactitud los puntos de correccion.
Equipos analizadores de vibraciones – Registran el espectro de oscilaciones, identificando no solo el desequilibrio, sino tambien fallos adicionales (como el desgaste de rodamientos).
Sistemas de medicion laser – Se emplean para mediciones de alta precision en componentes criticos.
Las velocidades criticas de rotacion requieren especial atencion – condiciones en las que la vibracion se incrementa de forma significativa debido a fenomenos de resonancia. Un equilibrado correcto previene danos en el equipo bajo estas condiciones.
«Трезвый Путь Коломна» создаёт единый контур помощи: пациент не «перекидывается» между разными организациями, а проходит лечение в одной системе, где специалисты знают его историю и несут ответственность за последовательность шагов. Это критично для тех, кто уже сталкивался с бессистемными попытками: один врач ставил капельницы, другой «кодировал», третий давал советы, а в итоге всё заканчивалось новым срывом. Здесь маршруты связываются в цельную линию.
Подробнее – http://narkologicheskaya-klinika-kolomna2-10.ru
[b]Купить диплом любого ВУЗа![/b]
Наша компания предлагаетбыстро и выгодно заказать диплом, который выполнен на оригинальной бумаге и заверен мокрыми печатями, штампами, подписями официальных лиц. Данный диплом пройдет любые проверки, даже при использовании профессионального оборудования. Достигайте свои цели максимально быстро с нашим сервисом- [url=http://mcmillancoastalproperties.com.au/author/karmawhitelaw4/]mcmillancoastalproperties.com.au/author/karmawhitelaw4[/url]
[b]Диплом юриста[/b]. Мы изготавливаем дипломы любых профессий по выгодным тарифам: [url=http://cheere.org/read-blog/276318_kupit-diplom-o-vysshem.html/]cheere.org/read-blog/276318_kupit-diplom-o-vysshem.html[/url]
Капельницы от запоя включают препараты для очищения крови, восстановления электролитного баланса и защиты печени. Используются только сертифицированные растворы, одобренные Минздравом РФ. В клинике применяется комплексный подход: одновременно с физическим восстановлением запускаются лёгкие дыхательные и релаксационные методики, которые помогают организму вернуться в стабильное состояние.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-voronezhe17.ru/]вывод из запоя вызов[/url]
где купить диплом в спб [url=http://r-diploma29.ru]где купить диплом в спб[/url] .
Мы готовы предложить дипломы психологов, юристов, экономистов и других профессий по доступным ценам.– [url=http://aurorahcs.com/forum/viewtopic.php?f=8&t=986546/]aurorahcs.com/forum/viewtopic.php?f=8&t=986546[/url]
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Получить дополнительные сведения – http://viagenssonhadas.com.br/?p=798
Мы предлагаем документы институтов, которые расположены на территории РФ.
Купить диплом о высшем образовании: [url=http://kharkov-balka.com/member.php?u=5538]kharkov-balka.com/member.php?u=5538[/url]
кто нибудь работает медсестрой по купленному диплому [url=frei-diplom13.ru]frei-diplom13.ru[/url] .
Комплексное лечение помогает восстановить работу печени, сердца и нервной системы. Пациенты отмечают улучшение сна, снижение тревожности, нормализацию давления и аппетита уже спустя несколько часов после начала терапии. В зависимости от тяжести состояния курс может быть продлён до 2–3 дней с круглосуточным наблюдением и корректировкой дозировок.
Исследовать вопрос подробнее – [url=https://vivod-iz-zapoya-v-volgograde17.ru/]наркология вывод из запоя в волгограде[/url]
купить диплом техникума с занесением в реестр форум [url=https://r-diploma31.ru]купить диплом техникума с занесением в реестр форум[/url] .
кто нибудь работает медсестрой по купленному диплому [url=http://frei-diplom13.ru]http://frei-diplom13.ru[/url] .
[b]Заказать диплом любого университета![/b]
Мы предлагаембыстро заказать диплом, который выполнен на оригинальном бланке и заверен печатями, водяными знаками, подписями. Наш документ пройдет любые проверки, даже при использовании специальных приборов. Достигайте цели быстро и просто с нашим сервисом- [url=http://telegra.ph/Kupit-diplom-o-vysshem-obrazovanii-s-garantiej-10-09/]telegra.ph/Kupit-diplom-o-vysshem-obrazovanii-s-garantiej-10-09[/url]
Купить документ о получении высшего образования вы имеете возможность у нас в столице. Мы предлагаем документы об окончании любых ВУЗов Российской Федерации. Даем 100% гарантию, что при проверке документов работодателем, подозрений не появится: [url=http://poltavagok.ru/gde-realno-kupit-diplom-ob-obrazovanii/]poltavagok.ru/gde-realno-kupit-diplom-ob-obrazovanii[/url]
Мы изготавливаем дипломы любой профессии по приятным тарифам. Цена будет зависеть от выбранной специальности, года получения и ВУЗа: [url=http://apertasesama.com/textstat/zakazat-diplom-s-dostavkoj-384/]apertasesama.com/textstat/zakazat-diplom-s-dostavkoj-384[/url]
В данном тексте собраны разнообразные случайные сведения и не вполне определённые идеи, которые могут вызвать интерес. Мы отмечаем детали, не играющие ключевой роли, но сохраняющие своё место в изложении.
Подробнее читать – [url=https://rostov-narkologiya.ru/uslugi-ot-narkomanii/mefedronovaya-zavisimost/]таблетки для аборта[/url]
После завершения инфузий врач-нарколог даёт рекомендации по питанию, водному балансу и образу жизни. При необходимости пациенту назначается курс поддерживающей терапии для закрепления эффекта.
Получить дополнительные сведения – http://narkologicheskaya-pomoshh-v-tolyatti17.ru/
Мы изготавливаем дипломы любой профессии по выгодным тарифам. Цена зависит от определенной специальности, года получения и образовательного учреждения: [url=http://clik.social/read-blog/163813_kupit-diplom-o-vysshem.html/]clik.social/read-blog/163813_kupit-diplom-o-vysshem.html[/url]
[b]Диплом по специальности на выбор[/b]. Мы можем предложить дипломы любой профессии по доступным тарифам: [url=http://pastvu-forum.flybb.ru/viewtopic.php?f=8&t=836/]pastvu-forum.flybb.ru/viewtopic.php?f=8&t=836[/url]
В таблице представлены основные элементы детоксикационной терапии:
Узнать больше – http://narkologicheskaya-klinika-v-volgograde17.ru/
цена дайсон стайлер для волос с насадками официальный сайт купит… [url=https://fen-dn-kupit-11.ru/]fen-dn-kupit-11.ru[/url] .
Купить диплом университета по невысокой стоимости возможно, обращаясь к надежной специализированной фирме: [url=http://kherson.forum2x2.ru/login/]kherson.forum2x2.ru/login[/url]
Купить диплом института по доступной стоимости возможно, обращаясь к проверенной специализированной фирме. Для того, чтобы проверить компанию перед заказом воспользуйтесь отзывами других покупателей в интернете. Можно купить диплом из любого ВУЗа Российской Федерации [url=http://myweektour.ru/kupit-diplom-dlya-rezyume-ofitsialnyiy-dokument/]myweektour.ru/kupit-diplom-dlya-rezyume-ofitsialnyiy-dokument[/url]
Мы изготавливаем дипломы любых профессий по выгодным ценам. Для нас важно, чтобы дипломы были доступны для большого количества граждан. Приобрести диплом института [url=http://reexhk.com/author/williemaechoi/]reexhk.com/author/williemaechoi[/url]
купить диплом купить корочку в харькове [url=http://r-diploma30.ru]купить диплом купить корочку в харькове[/url] .
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по приятным ценам. Приобрести диплом о высшем образовании [url=http://diigo.com/item/note/8p2f0/c2w4?k=72a99b06fa7d6d004287cf66465f4718/]diigo.com/item/note/8p2f0/c2w4?k=72a99b06fa7d6d004287cf66465f4718[/url]
Мы предлагаем дипломы любой профессии по приятным ценам. Важно, чтобы дипломы были доступны для подавляющей массы граждан. Заказать диплом ВУЗа [url=http://git.nusaerp.com/ahmedhernsheim/]git.nusaerp.com/ahmedhernsheim[/url]
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по доступным ценам. Диплом об образовании когда-то считался ключевым документом, который способствовал успешному устройству на работу. Заказать диплом об образовании!: [url=http://app.theremoteinternship.com/read-blog/179778_kupit-diplom-o-srednem-obrazovanii.html/]app.theremoteinternship.com/read-blog/179778_kupit-diplom-o-srednem-obrazovanii.html[/url]
Заказать диплом университета по выгодной цене возможно, обратившись к надежной специализированной компании. Для того, чтобы проверить компанию перед покупкой воспользуйтесь отзывами на форумах. Можно заказать диплом из любого ВУЗа РФ [url=http://iwork.youthfiji.org/profile/ronaldtiffany/]iwork.youthfiji.org/profile/ronaldtiffany[/url]
dyson фен купить оригинал [url=https://fen-dn-kupit-11.ru/]dyson фен купить оригинал[/url] .
Заказ документа о высшем образовании через надежную компанию дарит немало достоинств. Быстро купить диплом: [url=http://dinhdanh.com/perrydespe]dinhdanh.com/perrydespe[/url]
Мы готовы предложить документы учебных заведений, расположенных на территории РФ.
Приобрести диплом университета: [url=http://rst.adk.audio/company/personal/user/1577/forum/message/7652/60731/#message60731]rst.adk.audio/company/personal/user/1577/forum/message/7652/60731/#message60731[/url]
dyson официальный сайт фен [url=https://fen-dn-kupit-11.ru/]fen-dn-kupit-11.ru[/url] .
В Краснодаре клиника «Детокс» предлагает услугу выезда нарколога на дом. Быстро, безопасно, анонимно.
Детальнее – [url=https://narkolog-na-dom-krasnodar17.ru/]нарколог на дом круглосуточно сочи[/url]
Если запой стал серьёзной проблемой, стационар клиники «Детокс» в Сочи поможет выйти из кризиса. Врачи проводят детоксикацию и наблюдают за состоянием пациента.
Подробнее – http://vyvod-iz-zapoya-sochi23.ru
Если вы ищете надежную клинику для вывода из запоя, обратитесь в «Детокс» в Краснодаре. Услуга вызова нарколога на дом доступна круглосуточно. Врачи приедут к вам в течение 1–2 часов и окажут необходимую помощь.
Подробнее можно узнать тут – [url=https://narkolog-na-dom-krasnodar15.ru/]наркологический вывод из запоя в сочи[/url]
ростов купить стайлер дайсон [url=https://fen-dn-kupit-11.ru/]fen-dn-kupit-11.ru[/url] .
Далеко не каждый наниматель проводит тщательную проверку дипломов. Большинство компаний доверяют соискателям и без проблем принимают документ. В такой ситуации покупка диплома университета является разумным решением. Не придется терять массу времени и денег на учебу. Мы предлагаем дипломы психологов, юристов, экономистов и прочих профессий по доступным тарифам: [url=http://linkedbusiness.onjcameroun.cm/read-blog/4071_kupit-diplom-o-srednem.html/]linkedbusiness.onjcameroun.cm/read-blog/4071_kupit-diplom-o-srednem.html[/url]
купить диплом с занесением в реестр иваново [url=https://r-diploma31.ru/]купить диплом с занесением в реестр иваново[/url] .
Вывод из запоя — это всегда баланс между скоростью и безопасностью. Дома трудно заметить скрытые ухудшения, особенно ночью: давление и пульс «гуляют», нарастает обезвоживание, сон рваный и тревожный. В «Трезвом Контуре» этот хаос замещается управляемостью: перед выездом дежурный врач собирает ключевые данные (длительность эпизода, лекарства, аллергии, сопутствующие болезни), на месте проводится экспресс-диагностика (АД, ЧСС, сатурация, температура, неврологический статус, степень обезвоживания), затем запускается схема терапевтической поддержки. Мы постоянно «подстраиваем» инфузии по реакции организма, а не по шаблонной карте: где-то важнее регидратация, где-то — коррекция электролитов, где-то — бережная седация для ночи. Для семьи это значит одно: меньше догадок, больше ясности. Если по картине риски высоки, мы аргументированно предлагаем стационар в Одинцово — и организуем транспортировку без пауз, потому что цена задержки в такие часы всегда выше.
Углубиться в тему – [url=https://vyvod-iz-zapoya-odincovo10.ru/]вывод из запоя[/url]
купить диплом кз [url=http://r-diploma28.ru/]купить диплом кз[/url] .
Мы изготавливаем дипломы любых профессий по приятным ценам. Для нас важно, чтобы документы были доступными для большого количества граждан. Заказать диплом о высшем образовании [url=http://khvoynaya.getbb.ru/viewtopic.php?f=39&t=9387/]khvoynaya.getbb.ru/viewtopic.php?f=39&t=9387[/url]
Заказать диплом института по доступной стоимости возможно, обратившись к проверенной специализированной компании: [url=http://dirtydeleted.net/index.php/User:RIEBrendan/]dirtydeleted.net/index.php/User:RIEBrendan[/url]
Обычно внимание уделяется нескольким направлениям: восстановлению жидкости и обмена веществ, снижению тошноты и головной боли, уменьшению вегетативных симптомов (дрожь, потливость, сердцебиение), нормализации сна и тревоги. При этом врач ориентируется на текущие показатели и реакцию пациента — то, что помогало «в прошлый раз», может быть неуместно сегодня. Дополнительно проговариваются бытовые детали: проветривание, комфортная температура, питьевой режим, питание небольшими порциями, контроль давления и пульса, ограничение стимуляторов и рисковых нагрузок.
Подробнее – https://narkolog-na-dom-krasnogorsk6.ru/narkolog-i-psikhiatr-krasnogorsk/
кто нибудь работает медсестрой по купленному диплому [url=http://frei-diplom13.ru]http://frei-diplom13.ru[/url] .
Мы предлагаем дипломы любой профессии по приятным ценам. Для нас очень важно, чтобы дипломы были доступны для подавляющей массы граждан. Быстро и просто приобрести диплом об образовании [url=http://gromscream.80lvl.ru/viewtopic.php?f=3&t=4433/]gromscream.80lvl.ru/viewtopic.php?f=3&t=4433[/url]
Приобрести диплом академии Никто не стремится потратить пять лет своей жизни на то, чтобы заполучить умения и знания, которые уже существуют. В результате решение о покупке диплома подходящего университета является для вас самым выгодным. Вам понадобится сделать не так много – выбрать компанию, занимающуюся изготовлением документов об образовании на заказ. Этот вариант предоставит вам возможность за незначительную сумму и в кратчайшие сроки заполучить диплом из любого ВУЗа РФ: [url=http://rashin.4adm.ru/viewtopic.php?f=27&t=4863/]rashin.4adm.ru/viewtopic.php?f=27&t=4863[/url]
можно ли купить диплом медсестры [url=http://frei-diplom13.ru]можно ли купить диплом медсестры[/url] .
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Лучшее решение — прямо здесь – https://vistoweekly.com/dr-levy-psychologist-ornl
Если вы ищете надежную клинику для вывода из запоя, обратитесь в «Детокс» в Краснодаре. Услуга вызова нарколога на дом доступна круглосуточно. Врачи приедут к вам в течение 1–2 часов и окажут необходимую помощь.
Выяснить больше – [url=https://narkolog-na-dom-krasnodar11.ru/]narkolog-na-dom-kruglosutochno sochi[/url]
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Детали по клику – https://tensyokuejentotonomenndanndezettainiyattehaikenaikoto.com
Мы предлагаем дипломы любой профессии по доступным ценам. Купить диплом Волгодонск — [url=http://awan.pro/forum/user/91265/]awan.pro/forum/user/91265[/url]
В этом материале представлены детали, которые хоть и занимательны, но не особенно значимы. Мы рассматриваем моменты, которые трудно назвать важными, но всё же решили включить их для полноты картины.
Вот – [url=https://arma-rehab.ru/]покер онлайн[/url]
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Хочешь знать всё? – https://iph.org.mx/formacion/recomendaciones-de-la-secretaria-de-salud-para-incluir-al-cuidador-primario-durante-el-tratamiento-de-ninos-con-covid-19
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Где почитать поподробнее? – https://beziehungs-lebensberatung.de/cropped-wegziel-e1553189163509-jpg
Цель
Получить дополнительную информацию – http://narkologicheskaya-klinika-korolyov0.ru
Инфузионная терапия подбирается под человека, а не под «среднюю» ситуацию. Базовый каркас обычно включает растворы для регидратации и коррекции электролитов, витамины группы B и магний для поддержки нервной системы. По показаниям добавляются гепатопротекторы и антиоксидантные компоненты — это помогает печени и снижает оксидативный стресс. Если есть выраженная тошнота, подключаем противорвотные; при тревоге и нарушении сна — мягкие анксиолитики и седативные препараты, которые не «вырубают», а выравнивают ритмы и сохраняют контакт для мониторинга. Мы избегаем агрессивных «миксов», потому что избыточная седация может скрыть опасные симптомы и усложнить оценку состояния. Эффективность оцениваем не только по субъективному облегчению, но и по объективным метрикам: пульс, давление, сатурация, динамика тремора, аппетит, качество сна. Как только показатели стабилизируются, фарм-нагрузка снижается, а ведущую роль берет режим — питание, гидратация, спокойный вечерний ритуал, короткие бытовые активности.
Подробнее можно узнать тут – http://vyvod-iz-zapoya-krasnogorsk10.ru
Первичный контакт — короткий, но точный скрининг: длительность эпизода, лекарства и аллергии, сон, аппетит, переносимость нагрузок, возможность обеспечить тишину на месте. На основе этих фактов врач предлагает безопасную точку входа: выезд на дом, приём без очередей или госпитализацию под наблюдением 24/7. На месте мы сразу исключаем «красные флажки», фиксируем давление/пульс/сатурацию/температуру, при показаниях выполняем ЭКГ и запускаем детокс. Параллельно выдаём «карту суток»: режим отдыха и питья, лёгкое питание, перечень нормальных ощущений и момент, когда нужно связаться внепланово. Если домашнего формата становится мало, переводим в стационар без пауз — все назначения и наблюдения «переезжают» вместе с пациентом.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-odincovo0.ru/]частная наркологическая клиника[/url]
Стоимость зависит от длительности запоя, объёма инфузий, перечня препаратов и длительности наблюдения после капельницы. Мы заранее озвучиваем ориентир, объясняем, какие элементы плана обязательны, а какие — рекомендательные. Ночные выезды иногда дороже из-за нагрузки на бригаду, но при выраженных симптомах откладывать помощь небезопасно. Повторные обращения и расширенные программы стабилизации обсуждаются индивидуально. Ключевой ориентир для семьи — выбирать не «самую дешёвую капельницу», а безопасный формат с контролем и ответственным уходом.
Углубиться в тему – https://vyvod-iz-zapoya-korolev10.ru/vyvesti-iz-zapoya-korolev
дайсон фен оригинал купить [url=https://stajler-dsn.ru/]дайсон фен оригинал купить[/url] .
Мы предлагаем дипломы любой профессии по приятным тарифам. Для нас очень важно, чтобы документы были доступны для большого количества наших граждан. Заказать диплом об образовании [url=http://bodybuilding.net/members/worksale.html/]bodybuilding.net/members/worksale.html[/url]
купить дайсон стайлер для волос официальный сайт цена с насадкам… [url=https://fen-dn-kupit-12.ru/]fen-dn-kupit-12.ru[/url] .
фен дайсон купить официальный [url=https://dn-fen-kupit.ru/]dn-fen-kupit.ru[/url] .
стайлер дайсон купить официальный сайт [url=https://fen-dn-kupit-13.ru/]fen-dn-kupit-13.ru[/url] .
стайлер дайсон для волос цена с насадками официальный сайт купит… [url=https://stajler-dsn-1.ru/]стайлер дайсон для волос цена с насадками официальный сайт купит…[/url] .
купить пылесос дайсон в ростове на дону [url=https://pylesos-dn-1.ru/]pylesos-dn-1.ru[/url] .
Если вы ищете надежную клинику для вывода из запоя, обратитесь в «Детокс» в Краснодаре. Услуга вызова нарколога на дом доступна круглосуточно. Врачи приедут к вам в течение 1–2 часов и окажут необходимую помощь.
Детальнее – [url=https://narkolog-na-dom-krasnodar11.ru/]вывод из запоя на дому недорого в сочи[/url]
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по выгодным ценам. Для нас важно, чтобы документы были доступны для большого количества граждан. Купить диплом о высшем образовании [url=http://t2k.in/lyndon80a2177/]t2k.in/lyndon80a2177[/url]
В Краснодаре клиника «Детокс» предлагает выезд нарколога на дом. Помощь оказывается быстро, анонимно и круглосуточно.
Подробнее – [url=https://narkolog-na-dom-krasnodar29.ru/]вывод из запоя на дому недорого в сочи[/url]
https://t.me/s/minimalnii_deposit/124
Для восстановления после запоя выбирайте стационар клиники «Детокс» в Сочи. Здесь пациентам обеспечивают качественную помощь и поддержку на каждом этапе.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi23.ru/]анонимный вывод из запоя в сочи[/url]
дайсон стайлер для волос цена с насадками официальный сайт купит… [url=https://stajler-dsn.ru/]дайсон стайлер для волос цена с насадками официальный сайт купит…[/url] .
какой фен дайсон купить [url=https://dn-fen-kupit.ru/]какой фен дайсон купить[/url] .
купить пылесос дайсон v15s detect absolute [url=https://pylesos-dn-1.ru/]pylesos-dn-1.ru[/url] .
стайлер дайсон купить официальный сайт [url=https://fen-dn-kupit-13.ru/]fen-dn-kupit-13.ru[/url] .
стайлер для волос дайсон цена с насадками официальный сайт купит… [url=https://fen-dn-kupit-12.ru/]стайлер для волос дайсон цена с насадками официальный сайт купит…[/url] .
дайсон официальный сайт стайлер для волос с насадками цена купит… [url=https://stajler-dsn-1.ru/]stajler-dsn-1.ru[/url] .
Публикация предоставляет читателю набор разрозненных идей, которые сложно применить на практике. Мы лишь слегка касаемся разных точек зрения, не углубляясь в анализ и не предлагая никаких выводов.
Вот – [url=https://arma-rehab.ru/vyvod-iz-zapoya/]виртуальное казино[/url]
купить диплом о высшем образовании в ростове на дону отзывы [url=http://r-diploma29.ru]http://r-diploma29.ru[/url] .
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Подробнее тут – https://chronotechltd.com/2023/08/31/%D0%BD%D0%BE%D0%B2%D0%B8-%D0%BF%D1%80%D0%B5%D0%B4%D1%81%D1%82%D0%B0%D0%B2%D0%B8%D1%82%D0%B5%D0%BB%D1%81%D1%82%D0%B2%D0%B0
В Краснодаре клиника «Детокс» проводит выезд нарколога на дом для безопасного вывода из запоя.
Получить дополнительные сведения – https://narkolog-na-dom-krasnodar15.ru
пылесос дайсон v15 купить [url=https://pylesos-dn-2.ru/]пылесос дайсон v15 купить[/url] .
пылесос дайсон беспроводной купить в краснодаре [url=https://pylesos-dn-kupit.ru/]pylesos-dn-kupit.ru[/url] .
купить пылесос дайсон абсолют [url=https://pylesos-dn-kupit-1.ru/]pylesos-dn-kupit-1.ru[/url] .
купить пылесос дайсон v15s detect absolute [url=https://pylesos-dsn.ru/]pylesos-dsn.ru[/url] .
пылесос дайсон v15 купить в москве [url=https://pylesos-dn-kupit-2.ru/]pylesos-dn-kupit-2.ru[/url] .
фен дайсон купить оригинал [url=https://stajler-dsn.ru/]фен дайсон купить оригинал[/url] .
купить дайсон стайлер с насадками официальный сайт для волос цен… [url=https://dn-fen-kupit.ru/]dn-fen-kupit.ru[/url] .
пылесос дайсон купить челябинске [url=https://pylesos-dn-1.ru/]pylesos-dn-1.ru[/url] .
дайсон стайлер для волос с насадками цена официальный сайт купит… [url=https://fen-dn-kupit-13.ru/]дайсон стайлер для волос с насадками цена официальный сайт купит…[/url] .
Если вы или ваш близкий нуждаетесь в профессиональной помощи при запое, клиника «Детокс» в Краснодаре предлагает услугу вызова нарколога на дом. Врач приедет в течение 1–2 часов, проведёт необходимое обследование и назначит лечение. Услуга доступна круглосуточно и анонимно.
Получить дополнительные сведения – [url=https://narkolog-na-dom-krasnodar11.ru/]нарколог на дом анонимно в сочи[/url]
стайлер дайсон купить официальный сайт [url=https://fen-dn-kupit-12.ru/]fen-dn-kupit-12.ru[/url] .
купить фен dyson оригинал [url=https://stajler-dsn-1.ru/]купить фен dyson оригинал[/url] .
Купить диплом института по невысокой стоимости возможно, обратившись к проверенной специализированной фирме: [url=http://goup.hashnode.dev/kupit-diplom-v-korotkie-sroki-1/]goup.hashnode.dev/kupit-diplom-v-korotkie-sroki-1[/url]
Этот обзор дает возможность взглянуть на историю и науку под новым углом. Мы представляем редкие факты, неожиданные связи и значимые события, которые помогут вам глубже понять развитие цивилизации и роль человека в ней.
Подробности по ссылке – https://nuvery.es/sitios/spain/asturias/gijon/tierras-gallegas-gijon
купить пылесос dyson v15 detect [url=https://pylesos-dn-2.ru/]купить пылесос dyson v15 detect[/url] .
купить пылесос дайсон беспроводной v15 [url=https://pylesos-dsn.ru/]купить пылесос дайсон беспроводной v15[/url] .
купить пылесос дайсон официальный сайт в москве [url=https://pylesos-dn-kupit-1.ru/]купить пылесос дайсон официальный сайт в москве[/url] .
купить пылесос дайсон v15 detect absolute [url=https://pylesos-dn-kupit.ru/]pylesos-dn-kupit.ru[/url] .
пылесос дайсон v12 купить [url=https://pylesos-dn-kupit-2.ru/]пылесос дайсон v12 купить[/url] .
[b]Заказать диплом любого университета![/b]
Мы предлагаемвыгодно и быстро купить диплом, который выполнен на бланке ГОЗНАКа и заверен печатями, штампами, подписями. Наш диплом способен пройти лубую проверку, даже при помощи специально предназначенного оборудования. Достигайте цели максимально быстро с нашим сервисом- [url=http://khresearchandanalytics.com/author/trudy44i159896/]khresearchandanalytics.com/author/trudy44i159896[/url]
дайсон стайлер для волос купить официальный сайт с насадками цен… [url=https://stajler-dsn.ru/]дайсон стайлер для волос купить официальный сайт с насадками цен…[/url] .
дайсон официальный сайт фен цена [url=https://dn-fen-kupit.ru/]dn-fen-kupit.ru[/url] .
купить аккумулятор пылесос dyson [url=https://pylesos-dn-1.ru/]купить аккумулятор пылесос dyson[/url] .
курьер Повар – это творческая и востребованная профессия, требующая кулинарных навыков, знания технологий приготовления блюд и умения работать в команде. Если вы ищете работу поваром в Воронеже, Туле, Калуге или Рязани, то существует множество вариантов, от ресторанов высокой кухни до пиццерий и кафе. Вакансия повар часто встречается в таких компаниях, как Ташир, Жар Пицца и Додо Пицца, которые предлагают работу поваром с различными условиями труда и заработной платой. Повар в Воронеже, Туле, Калуге или Рязани – это специалист, отвечающий за приготовление вкусных и качественных блюд, удовлетворяя потребности клиентов.
dyson официальный сайт фен [url=https://fen-dn-kupit-13.ru/]fen-dn-kupit-13.ru[/url] .
купить дайсон стайлер для волос с насадками официальный сайт цен… [url=https://fen-dn-kupit-12.ru/]fen-dn-kupit-12.ru[/url] .
Заказать документ института вы можете в нашей компании. Мы предлагаем документы об окончании любых университетов РФ. Даем гарантию, что при проверке документа работодателем, каких-либо подозрений не появится: [url=http://igenplan.ru/forum/user/100833/]igenplan.ru/forum/user/100833[/url]
купить диплом азербайджанской сср [url=www.r-diploma31.ru/]купить диплом азербайджанской сср[/url] .
стайлер дайсон для волос цена с насадками официальный сайт купит… [url=https://stajler-dsn-1.ru/]стайлер дайсон для волос цена с насадками официальный сайт купит…[/url] .
дайсон пылесос купить в москве оригинал [url=https://pylesos-dsn.ru/]pylesos-dsn.ru[/url] .
дайсон пылесос купить в москве оригинал [url=https://pylesos-dn-2.ru/]pylesos-dn-2.ru[/url] .
пылесосы для дома дайсон купить [url=https://pylesos-dn-kupit-1.ru/]pylesos-dn-kupit-1.ru[/url] .
пылесос дайсон беспроводной в москве [url=https://pylesos-dn-kupit.ru/]pylesos-dn-kupit.ru[/url] .
Старт всегда начинается с точного, но бережного скрининга. Мы заранее обсуждаем бытовые условия и логистику — доступ к подъезду, лифту, возможность обеспечить тишину — чтобы не потерять темп на мелочах. На месте врач фиксирует витальные показатели (АД, пульс, сатурация, температура), при показаниях выполняет ЭКГ и запускает детокс: регидратацию, коррекцию электролитов, защиту печени и ЖКТ, при необходимости — щадящую противотревожную поддержку и кислород. Пациент и близкие получают письменную памятку «на сутки» с режимом сна и питья, «красными флажками» и точным временем контрольной связи. Если домашний формат перестаёт быть достаточным, перевод в стационар организуем без пауз — все назначения и наблюдения переезжают вместе с пациентом, ничего не теряется.
Разобраться лучше – [url=https://narkologicheskaya-klinika-krasnogorsk0.ru/]наркологическая клиника помощь на дому[/url]
пылесос dyson v15s detect [url=https://dn-pylesos-kupit.ru/]dn-pylesos-kupit.ru[/url] .
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Детали по клику – https://hamakom.feedu.co.il/2022/12/25/%D7%94%D7%9E%D7%9C%D7%90%D7%9B%D7%99%D7%9D-%D7%A9%D7%9C-%D7%90%D7%9C-%D7%A2%D7%9C-%D7%90%D7%A8%D7%97%D7%95-%D7%90%D7%AA-%D7%99%D7%9C%D7%93%D7%99-%D7%A2%D7%9E%D7%95%D7%AA%D7%AA-%D7%97%D7%91%D7%A8
dyson v12 пылесос [url=https://pylesos-dsn-1.ru/]dyson v12 пылесос[/url] .
пылесос dyson купить в спб [url=https://pylesos-dn-kupit-2.ru/]пылесос dyson купить в спб[/url] .
Мы строим лечение вокруг предсказуемости: минимум лишних вопросов, максимум конкретики и понятный план на ближайшие сутки. Дежурный врач уточняет только то, что влияет на безопасность — длительность эпизода, актуальные лекарства и переносимость, сон и апетит, наличие поддержки дома. Из этого скелета рождается маршрут: выезд на дом, приём без очередей или стационар с наблюдением 24/7. Конфиденциальность встроена по умолчанию: нейтральная коммуникация, доступ к карте только у вовлечённой команды, документы по запросу — в нейтральных формулировках. Внешний шум гасим, внимание переводим на цель: ровная стабилизация без «качелей» и с понятными контрольными точками.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-domodedovo0.ru/]вызов наркологической помощи[/url]
Don8Play — это профессиональный навигатор в мире iGaming, созданный для русскоязычных игроков, которые ценят структурированный анализ и осознанный выбор. Мы предлагаем детальные рейтинги и сравнения платформ, экспертные обзоры брендов и глубокие статьи-гайды, помогая разобраться в критериях без лишней шумихи и купленных оценок. Наша методология и редакционная политика обеспечивают честность и полноту информации, а сайт с предсказуемой структурой даёт быстрый доступ к нужным данным. Это ваш источник для взвешенных решений, где главное — ясность, а не азарт. Познакомиться: https://www.don8play.ru/
Клиника «Похмельная служба» в Нижнем Новгороде предлагает капельницу от запоя с выездом на дом. Наши специалисты обеспечат вам комфортное и безопасное лечение в привычной обстановке.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-nizhnij-novgorod13.ru/]помощь вывод из запоя нижний новгород[/url]
купить медицинский диплом медсестры [url=http://frei-diplom13.ru/]купить медицинский диплом медсестры[/url] .
«Ритм Здоровья» в Красногорске — это понятный маршрут помощи от первого звонка до устойчивой ремиссии. Мы не растягиваем старт на бесконечные согласования: дежурный врач аккуратно собирает жалобы, длительность эпизода, сведения о лекарствах и сопутствующих диагнозах, после чего предлагает безопасную точку входа — выезд на дом, приём без очередей или госпитализацию под круглосуточное наблюдение. Вся коммуникация нейтральная, доступ к карте ограничен лечащей командой, а в документах по запросу используем формулировки, не раскрывающие профиль отделения. Такой «тихий» формат снимает лишнее напряжение, экономит время семьи и позволяет сосредоточиться на главном — мягкой стабилизации без «качелей».
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-krasnogorsk0.ru/]наркологическая клиника стоимость[/url]
In the latest blow to the US offshore wind industry, the Trump administration announced Monday it is suspending the federal leases for all large offshore wind projects currently under construction, citing unspecified national security risks.
[url=https://tripscan101.cc]tripscan[/url]
It marks a major escalation in President Donald Trump’s attacks against offshore wind, a form of energy he has long railed against. The suspension could impact billions of dollars of investment and stall nearly six gigawatts of new electricity set to come online in the next few years.
[url=https://tripscan101.cc]трипскан вход[/url]
The new sweeping order impacts five projects being built in the Atlantic Ocean, including a massive Virginia offshore wind farm that could eventually be the largest such project in the nation. Set to be completed by the end of 2026, it would supply electricity to Virginia, the state with the world’s largest cluster of power-hungry data centers — and skyrocketing energy costs partially tied to that growing demand. Other wind farms impacted are off the coast of New England.
[url=https://tripscan101.cc]трипскан вход[/url]
The exact national security risks of concern are unclear. In a news release, the Interior Department cited “national security risks identified by the Department of War in recently completed classified reports,” but didn’t say specifically what those risks were. The release also noted the potential for wind turbine movement and light reflectivity to interfere with radar.
In a Monday Fox Business interview, Interior Sec. Doug Burgum said the Department of Defense has “conclusively” determined that large offshore wind farms “have created radar interference that creates a genuine risk for the US,” especially “our east coast population centers.”
A Department of Defense official said it is working with Interior and other agencies to “assess the possibility of mitigating the national security risks posed by these projects” but had no additional comment.
Last year, Sweden blocked the construction of new wind farms over concerns they could interfere with military radar, amid heightened tensions between the European Union? and Russia. But experts have noted the design of wind farms can be adjusted to account for the issue, and it’s something US government officials have been aware of for decades.
Virginia Sens. Mark Warner and Tim Kaine, who serve on the Senate Intelligence and Armed Services committees, respectively, said the administration had “failed to share any new information” justifying the sudden pause.
tripscan top
https://tripscan101.cc
Если вы ищете надежную клинику для вывода из запоя, обратитесь в «Детокс» в Краснодаре. Услуга вызова нарколога на дом доступна круглосуточно. Врачи приедут к вам в течение 1–2 часов и окажут необходимую помощь.
Ознакомиться с деталями – [url=https://narkolog-na-dom-krasnodar12.ru/]нарколог на дом срочно в сочи[/url]
A British man, along with five others, has been charged with carrying out 56 sexual offences against his now ex-wife over a 13-year period.
[url=https://trips63.cc]трипскан[/url]
Philip Young has been remanded in custody in relation to the string of charges, which include multiple counts of rape and administering a substance with the intent to overpower to allow sexual activity, according to Wiltshire Police.
[url=https://trips63.cc]tripscan top[/url]
Young, 49, has also been charged with voyeurism, possession of indecent images of children and possession of extreme images.
[url=https://trips63.cc]трипскан вход[/url]
Five other men, currently on bail, have also been charged with offences against 48-year-old Joanne Young, who waived her legal right to anonymity.
The alleged offences took place between 2010 and 2023.
The men were named by police as Norman Macksoni, 47, who has been charged with one count of rape and possession of extreme images; Dean Hamilton, also 47, who is facing one count of rape and sexual assault by penetration and two counts of sexual touching; 31-year-old Conner Sanderson Doyle, who has been charged with sexual assault by penetration and sexual touching; Richard Wilkins, 61, who faces one count of rape and sexual touching and Mohammed Hassan, 37, who has been charged with sexual touching.
All six men are due to appear at Swindon Magistrates’ Court in southwest England on Tuesday.
Geoff Smith, detective superintendent for Wiltshire police, described the charges as a “significant update” in a “complex and extensive investigation.”
He added that Joanne Young was being supported by specially trained officers and made the decision to waive her automatic legal right to anonymity “following multiple discussions with officers and support services.”
James Foster, a Crown Prosecution Service specialist prosecutor, added that the CPS had authorized the charges against the six men “following a police investigation into alleged serious sexual offences against Joanne Young over a period of 13 years.”
“Our prosecutors have worked to establish that there is sufficient evidence to charge and that it is in the public interest to pursue criminal proceedings,” he said in a statement.
“We have worked closely with Wiltshire Police as they carried out their investigation.”
трипскан вход
https://trips63.cc
купить пылесос дайсон в санкт [url=https://pylesos-dsn.ru/]pylesos-dsn.ru[/url] .
пылесос дайсон absolute купить [url=https://pylesos-dn-kupit-1.ru/]pylesos-dn-kupit-1.ru[/url] .
пылесос дайсон беспроводной последняя модель купить [url=https://pylesos-dn-kupit.ru/]pylesos-dn-kupit.ru[/url] .
вертикальный пылесос дайсон купить спб [url=https://pylesos-dsn-1.ru/]вертикальный пылесос дайсон купить спб[/url] .
пылесос dyson v15 купить [url=https://pylesos-dn-2.ru/]пылесос dyson v15 купить[/url] .
пылесос дайсон беспроводной купить в краснодаре [url=https://dn-pylesos-kupit.ru/]пылесос дайсон беспроводной купить в краснодаре[/url] .
купить диплом средне специального образования за 1993 год [url=www.r-diploma30.ru]купить диплом средне специального образования за 1993 год[/url] .
вертикальный пылесос dyson absolute [url=https://pylesos-dn-kupit-2.ru/]pylesos-dn-kupit-2.ru[/url] .
диплом медсестры с аккредитацией купить [url=http://www.frei-diplom13.ru]диплом медсестры с аккредитацией купить[/url] .
Мы предлагаем документы учебных заведений, расположенных в любом регионе России.
Заказать диплом о высшем образовании: [url=http://office.listbb.ru/viewtopic.php?f=2&t=9705]office.listbb.ru/viewtopic.php?f=2&t=9705[/url]
пылесос дайсон беспроводной последняя модель купить [url=https://pylesos-dsn-1.ru/]pylesos-dsn-1.ru[/url] .
пылесос dyson v15 detect absolute купить [url=https://dn-pylesos-kupit.ru/]пылесос dyson v15 detect absolute купить[/url] .
Мы предлагаем дипломы любых профессий по приятным ценам. Стоимость зависит от определенной специальности, года выпуска и образовательного учреждения: [url=http://cochesocasioncastellon.com/diplom-za-korotkij-srok-sroki-ceny-uslovija-252-2/]cochesocasioncastellon.com/diplom-za-korotkij-srok-sroki-ceny-uslovija-252-2[/url]
https://en.rapchi.kr/hongkong_mtr-ride-at-disneyland/
Мы предлагаем дипломы психологов, юристов, экономистов и любых других профессий по доступным тарифам. Цена зависит от той или иной специальности, года получения и образовательного учреждения: [url=http://avcorrealty.com/agent/lorrinemoritz/]avcorrealty.com/agent/lorrinemoritz[/url]
Капельница от запоя на дому в Нижнем Новгороде — удобное решение для тех, кто не может посетить клинику. Наши специалисты приедут к вам домой и проведут необходимую процедуру.
Выяснить больше – [url=https://vyvod-iz-zapoya-nizhnij-novgorod12.ru/]наркологический вывод из запоя[/url]
купить дайсон беспроводной пылесос в ростове [url=https://pylesos-dsn-1.ru/]купить дайсон беспроводной пылесос в ростове[/url] .
Мы изготавливаем дипломы любых профессий по приятным ценам. Цена может зависеть от той или иной специальности, года получения и ВУЗа: [url=http://careeredupersonnel.com/employer/aurus-diplom/]careeredupersonnel.com/employer/aurus-diplom[/url]
Мы изготавливаем дипломы любой профессии по выгодным тарифам. Важно, чтобы дипломы были доступными для большого количества граждан. Выгодно приобрести диплом университета [url=http://msfo-soft.ru/msfo/forum/user/67180/]msfo-soft.ru/msfo/forum/user/67180[/url]
пылесос dyson купить в спб [url=https://dn-pylesos-kupit.ru/]пылесос dyson купить в спб[/url] .
Вызов нарколога на дом в Краснодаре доступен в любое время суток. Клиника «Детокс» гарантирует профессиональную помощь.
Подробнее – [url=https://narkolog-na-dom-krasnodar12.ru/]нарколог на дом анонимно в сочи[/url]
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Хочешь знать всё? – https://ku11.vip/%EC%8B%A4%EB%AF%B8%EB%8F%84-%EC%B6%95%EA%B5%AC%ED%8C%80-%EC%96%91%EC%A7%80%EB%A5%BC-%EC%95%84%EC%8B%AD%EB%8B%88%EA%B9%8C
[b]Диплом для вас[/b]. Мы изготавливаем дипломы любой профессии по приятным тарифам: [url=http://caneparealty.com/index.php/agent/selinasummy906/]caneparealty.com/index.php/agent/selinasummy906[/url]
Мы готовы предложить дипломы любых профессий по приятным тарифам. Для нас очень важно, чтобы документы были доступными для большого количества наших граждан. Быстро и просто купить диплом любого ВУЗа [url=http://rrsclub.ru/showthread.php?p=74349#post74349/]rrsclub.ru/showthread.php?p=74349#post74349[/url]
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по невысоким тарифам. Диплом об образовании ранее считался основным документом, который способствовал успешному устройству на работу. Быстро и просто купить диплом об образовании!: [url=http://fiorinirooms.com/author/alanatarr68648/]fiorinirooms.com/author/alanatarr68648[/url]
купить диплом о среднем профессиональном образовании цена [url=https://www.r-diploma31.ru]купить диплом о среднем профессиональном образовании цена[/url] .
Мы предлагаем дипломы психологов, юристов, экономистов и других профессий по приятным тарифам. Заказать диплом любого института [url=http://didiaupdates.com/employer/gosznac-diplom-24/]didiaupdates.com/employer/gosznac-diplom-24[/url]
Для многих пациентов важным моментом является сохранение конфиденциальности. Врач, приехавший на дом, работает с полной защитой данных. Пациент может быть уверен, что его проблема останется личной и не станет достоянием общественности. Врачи приезжают на неприметных автомобилях и избегают всяческих ситуаций, которые могут привлечь лишнее внимание.
Углубиться в тему – [url=https://narcolog-na-dom-moskva55.ru/]vyzov narkologa na dom[/url]
Если вы ищете надежную клинику для вывода из запоя, обратитесь в «Детокс» в Краснодаре. Услуга вызова нарколога на дом доступна круглосуточно. Врачи приедут к вам в течение 1–2 часов и окажут необходимую помощь.
Детальнее – [url=https://narkolog-na-dom-krasnodar17.ru/]нарколог на дом вывод сочи[/url]
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Открой скрытое – https://jornalbaixadasantista.com.br/2024/04/17/urbam-abre-edital-para-modelo-de-tratamento-de-chorume
образование купить диплом пустой [url=http://www.r-diploma28.ru]образование купить диплом пустой[/url] .
Купить официальный диплом о высшем образовании : [url=http://flubber.pro/lucy43p2478587/]flubber.pro/lucy43p2478587[/url]
Выезд нарколога на дом в Нижнем Новгороде — капельница от запоя с выездом на дом. Мы обеспечиваем быстрое и качественное лечение без необходимости посещения клиники.
Подробнее тут – [url=https://vyvod-iz-zapoya-nizhnij-novgorod12.ru/]вывод из запоя дешево в нижнем новгороде[/url]
Приобрести диплом университета по выгодной цене вы можете, обращаясь к проверенной специализированной компании. Чтобы проверить компанию перед покупкой воспользуйтесь отзывами в сети интернет. Таким образом можно приобрести диплом из любого ВУЗа России [url=http://jobteck.com.sg/companies/rudiplomista-24/]jobteck.com.sg/companies/rudiplomista-24[/url]
Если вы ищете надежную клинику для вывода из запоя, обратитесь в «Детокс» в Краснодаре. Услуга вызова нарколога на дом доступна круглосуточно. Врачи приедут к вам в течение 1–2 часов и окажут необходимую помощь.
Подробнее можно узнать тут – [url=https://narkolog-na-dom-krasnodar17.ru/]вызов врача нарколога на дом в сочи[/url]
серіал дивитись поспіль мультсеріали для дітей українською
В Сочи стационар клиники «Детокс» предлагает комплексный вывод из запоя. Пациентам обеспечивают комфорт, безопасность и круглосуточный контроль.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-sochi23.ru/]вывод из запоя капельница на дому[/url]
Заказать диплом университета по невысокой цене вы сможете, обратившись к надежной специализированной фирме: [url=http://twizzr.worldsofrp.com/read-blog/7041_kupit-diplom.html/]twizzr.worldsofrp.com/read-blog/7041_kupit-diplom.html[/url]
Мы изготавливаем дипломы любых профессий по приятным тарифам.– [url=http://doublrp.listbb.ru/viewtopic.php?f=3&t=1450/]doublrp.listbb.ru/viewtopic.php?f=3&t=1450[/url]
Этот текст содержит различную информацию, которая, возможно, покажется любопытной, но в целом не меняет восприятия привычных вещей. Предлагаем просто получить удовольствие от чтения, не ожидая особой пользы.
Вот – [url=https://arma-rehab.ru/]виртуальное казино[/url]
пылесос дайсон купить в нижнем новгороде [url=https://dn-pylesos-kupit-1.ru/]пылесос дайсон купить в нижнем новгороде[/url] .
dyson выпрямитель оригинал [url=https://vypryamitel-dn.ru/]vypryamitel-dn.ru[/url] .
купить оригинальный дайсон фен выпрямитель [url=https://vypryamitel-dn-1.ru/]vypryamitel-dn-1.ru[/url] .
выпрямитель dyson купить [url=https://vypryamitel-dn-2.ru/]выпрямитель dyson купить[/url] .
пылесос дайсон купить последняя модель [url=https://dn-pylesos.ru/]dn-pylesos.ru[/url] .
где купить оригинал фен выпрямителя дайсон [url=https://vypryamitel-dn-3.ru/]vypryamitel-dn-3.ru[/url] .
кіно онлайн вийшли детективне кіно дивитися безкоштовно
Мы можем предложить дипломы любых профессий по разумным ценам. Стоимость будет зависеть от определенной специальности, года выпуска и образовательного учреждения: [url=http://absbux.com/author/felicapenin/]absbux.com/author/felicapenin[/url]
Диплом об образовании раньше считался основным документом, способствовавшим успешному трудоустройству. Заказать диплом возможно через официальный сайт компании. [url=http://blueheart.or.kr/bbs/board.php?bo_table=free&wr_id=199536/]blueheart.or.kr/bbs/board.php?bo_table=free&wr_id=199536[/url]
Мы можем предложить дипломы психологов, юристов, экономистов и любых других профессий по выгодным ценам. Для нас важно, чтобы документы были доступными для большого количества наших граждан. Выгодно заказать диплом об образовании [url=http://mangorpp.getbb.ru/posting.php?mode=post&f=3&sid=1b818af0d3a328acdd6d322b5b2f88e2/]mangorpp.getbb.ru/posting.php?mode=post&f=3&sid=1b818af0d3a328acdd6d322b5b2f88e2[/url]
dyson выпрямитель купить оригинал [url=https://vypryamitel-dn.ru/]vypryamitel-dn.ru[/url] .
дайсон пылесос беспроводной купить спб [url=https://dn-pylesos-kupit-1.ru/]дайсон пылесос беспроводной купить спб[/url] .
Если пациент не может приехать в клинику, в Краснодаре нарколог приедет к нему домой. Помощь оказывает «Детокс» круглосуточно.
Детальнее – [url=https://narkolog-na-dom-krasnodar17.ru/]вызов нарколога на дом сочи[/url]
фен выпрямитель дайсон airstrait [url=https://vypryamitel-dn-3.ru/]фен выпрямитель дайсон airstrait[/url] .
выпрямитель дайсон airstrait купить [url=https://vypryamitel-dn-2.ru/]vypryamitel-dn-2.ru[/url] .
курск где купить выпрямитель для волос дайсон [url=https://vypryamitel-dn-1.ru/]vypryamitel-dn-1.ru[/url] .
дивитись фільми 2025 жахи та містика в хорошій якості 1080p
пылесос dyson v15 detect absolute [url=https://dn-pylesos.ru/]пылесос dyson v15 detect absolute[/url] .
где купить дипломы медсестры [url=https://frei-diplom13.ru]где купить дипломы медсестры[/url] .
Заказать диплом любого ВУЗа. Изготовление диплома занимает гораздо меньше времени, а стоимость при этом невысокая. Таким образом вы сможете сохранить бюджет и получить отличную работу мечты. Приобрести диплом вы сможете через сайт компании. – [url=http://socialmedia.smartup.com.bo/read-blog/53873_kupit-diplom-stoit.html/]socialmedia.smartup.com.bo/read-blog/53873_kupit-diplom-stoit.html[/url]
Мы можем предложить дипломы любой профессии по приятным тарифам. Для нас важно, чтобы дипломы были доступными для большого количества наших граждан. Приобрести диплом об образовании [url=http://russianecuador.com/forum/member.php?u=13207/]russianecuador.com/forum/member.php?u=13207[/url]
[b]Диплом бакалавра[/b]. Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по приятным тарифам: [url=http://wikigranny.com/wiki/index.php/User:BiancaDesimone6/]wikigranny.com/wiki/index.php/User:BiancaDesimone6[/url]
Проведение лечения в домашней обстановке значительно снижает уровень стресса и тревожности. Пациенту не нужно тратить силы на поездки в медицинские учреждения, что особенно важно при ограниченной мобильности. Домашняя атмосфера создает идеальные условия для открытого диалога с врачом, что существенно повышает эффективность терапии и шансы на успешное выздоровление.
Ознакомиться с деталями – [url=https://narcolog-na-dom-msk55.ru/]narkolog na dom tsena[/url]
dyson выпрямитель [url=https://vypryamitel-dn-3.ru/]dyson выпрямитель[/url] .
дайсон официальный сайт выпрямители [url=https://vypryamitel-dn.ru/]vypryamitel-dn.ru[/url] .
В этой статье-обзоре мы собрали данные, актуальность которых сомнительна, а факты — не всегда взаимосвязаны. Читатель сможет ознакомиться с разными мнениями, хотя вряд ли они существенно повлияют на его понимание темы.
Вот – [url=https://arma-rehab.ru/vyvod-iz-zapoya/]блекджек[/url]
ростов купить пылесос дайсон [url=https://dn-pylesos-kupit-1.ru/]dn-pylesos-kupit-1.ru[/url] .
куплю диплом медсестры в москве [url=https://www.frei-diplom13.ru]куплю диплом медсестры в москве[/url] .
выпрямитель дайсон москва [url=https://vypryamitel-dn-2.ru/]выпрямитель дайсон москва[/url] .
стайлер дайсон выпрямитель [url=https://vypryamitel-dn-1.ru/]стайлер дайсон выпрямитель[/url] .
купить диплом купить корочку в харькове [url=https://r-diploma31.ru/]купить диплом купить корочку в харькове[/url] .
Для успешного продвижения вверх по карьере требуется наличие диплома о высшем образовании. Мы изготавливаем дипломы любой профессии по приятным ценам: [url=http://poobshaemsea.flybb.ru/viewtopic.php?f=2&t=895/]poobshaemsea.flybb.ru/viewtopic.php?f=2&t=895[/url]
пылесос дайсон купить в рязани [url=https://dn-pylesos.ru/]пылесос дайсон купить в рязани[/url] .
Не каждый работодатель проводит подробную проверку дипломов. Большинство компаний вполне доверяют соискателям и “вслепую” принимают документ. В данной ситуации приобретение диплома университета является мудрым решением. Не потребуется терять огромное количество времени и денег на учебу. Мы предлагаем дипломы любой профессии по выгодным тарифам: [url=http://cara.win/joycereece8512/]cara.win/joycereece8512[/url]
выпрямитель для волос дайсон [url=https://vypryamitel-dn-3.ru/]выпрямитель для волос дайсон[/url] .
купить пылесос дайсон в санкт [url=https://dn-pylesos-kupit-1.ru/]dn-pylesos-kupit-1.ru[/url] .
выпрямитель дайсон амрстат купить самара [url=https://vypryamitel-dn.ru/]vypryamitel-dn.ru[/url] .
кликните сюда https://krab3a.at/
dyson выпрямитель [url=https://vypryamitel-dn-2.ru/]dyson выпрямитель[/url] .
купить дайсон выпрямитель донецк [url=https://vypryamitel-dn-1.ru/]vypryamitel-dn-1.ru[/url] .
продолжить [url=https://krdb3.cc/]кра[/url]
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Все материалы собраны здесь – https://dttravel.in/here-are-10-jibhi-camping-spots-that-you-shouldnt-miss-at-all
пылесос дайсон беспроводной последняя модель купить [url=https://dn-pylesos.ru/]dn-pylesos.ru[/url] .
Приобрести диплом ВУЗа по невысокой цене вы сможете, обратившись к проверенной специализированной фирме: [url=http://censornet.ru/kupit-diplom-novogo-obraztsa-byistro/]censornet.ru/kupit-diplom-novogo-obraztsa-byistro[/url]
Мы готовы предложить документы ВУЗов, расположенных в любом регионе Российской Федерации.
Приобрести диплом о высшем образовании: [url=http://teslawiki.cz/index.php/User:ErlindaDunlop]teslawiki.cz/index.php/User:ErlindaDunlop[/url]
дайсон пылесос купить в екатеринбурге [url=https://dn-pylesos.ru/]дайсон пылесос купить в екатеринбурге[/url] .
Играть в Авиатор бесплатно [url=http://aviator-plus.ru]http://aviator-plus.ru[/url] .
дайсон выпрямитель с феном [url=https://dsn-vypryamitel.ru/]dsn-vypryamitel.ru[/url] .
выпрямитель дайсон купить в екатеринбурге [url=https://dsn-vypryamitel-1.ru/]dsn-vypryamitel-1.ru[/url] .
dyson выпрямитель [url=https://dsn-vypryamitel-2.ru/]dyson выпрямитель[/url] .
dyson выпрямитель [url=https://dsn-vypryamitel-3.ru/]dyson выпрямитель[/url] .
выпрямитель дайсон купить в спб [url=https://dsn-vypryamitel-4.ru/]выпрямитель дайсон купить в спб[/url] .
выпрямитель дайсон амрстат купить самара [url=https://vypryamitel-dn-kupit.ru/]vypryamitel-dn-kupit.ru[/url] .
dyson фен выпрямитель купить [url=https://vypryamitel-dn-4.ru/]dyson фен выпрямитель купить[/url] .
где в спб купить диплом [url=https://www.r-diploma29.ru]где в спб купить диплом[/url] .
купить фен выпрямитель дайсон [url=https://vypryamitel-dn-1.ru/]vypryamitel-dn-1.ru[/url] .
Мы изготавливаем дипломы любой профессии по доступным ценам. Стоимость может зависеть от выбранной специальности, года выпуска и ВУЗа: [url=http://financetimenews.ru/kupit-diplom-s-proverkoy-podlinnosti/]financetimenews.ru/kupit-diplom-s-proverkoy-podlinnosti[/url]
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Исследовать вопрос подробнее – https://ayurcurepharma.com/product/coughcure-syrup
Заказать документ о получении высшего образования можно у нас. Мы оказываем услуги по продаже документов об окончании любых ВУЗов России. Даем 100% гарантию, что в случае проверки документов работодателем, каких-либо подозрений не появится: [url=http://socialmeet.app/read-blog/23616_skolko-kupili-diplom.html/]socialmeet.app/read-blog/23616_skolko-kupili-diplom.html[/url]
Мы изготавливаем дипломы любых профессий по доступным тарифам. Купить диплом визажиста — [url=http://1wum.ru/forum/?PAGE_NAME=profile_view&UID=51797&MUL_MODE=/]1wum.ru/forum/?PAGE_NAME=profile_view&UID=51797&MUL_MODE=[/url]
[b]Приобрести диплом ВУЗа![/b]
Наша компания предлагаетбыстро приобрести диплом, который выполняется на оригинальном бланке и заверен печатями, водяными знаками, подписями официальных лиц. Документ пройдет любые проверки, даже при использовании специально предназначенного оборудования. Достигайте своих целей быстро с нашим сервисом- [url=http://mongolsmc.listbb.ru/viewtopic.php?f=1&t=2593/]mongolsmc.listbb.ru/viewtopic.php?f=1&t=2593[/url]
Мы изготавливаем дипломы любой профессии по доступным тарифам. Для нас важно, чтобы дипломы были доступными для подавляющей массы граждан. Заказать диплом ВУЗа [url=http://hobbyland.moibb.ru/posting.php?mode=post&f=3/]hobbyland.moibb.ru/posting.php?mode=post&f=3[/url]
купить дайсон выпрямитель донецк [url=https://dsn-vypryamitel-1.ru/]dsn-vypryamitel-1.ru[/url] .
выпрямитель dyson hs07 [url=https://dsn-vypryamitel-2.ru/]выпрямитель dyson hs07[/url] .
выпрямитель дайсон отзывы [url=https://dsn-vypryamitel.ru/]dsn-vypryamitel.ru[/url] .
стайлер дайсон выпрямитель [url=https://vypryamitel-dn-kupit.ru/]vypryamitel-dn-kupit.ru[/url] .
купить оригинальный дайсон фен выпрямитель [url=https://dsn-vypryamitel-4.ru/]dsn-vypryamitel-4.ru[/url] .
выпрямитель dyson ht01 купить [url=https://dsn-vypryamitel-3.ru/]выпрямитель dyson ht01 купить[/url] .
какой выпрямитель дайсон купить [url=https://vypryamitel-dn-kupit-1.ru/]vypryamitel-dn-kupit-1.ru[/url] .
выпрямитель дайсон [url=https://vypryamitel-dn-kupit-2.ru/]выпрямитель дайсон[/url] .
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Получить дополнительную информацию – https://airportrehab.ca/chiropractic-care-release-toxins-from-your-body
выпрямитель волос dyson ht01 [url=https://vypryamitel-dn-4.ru/]выпрямитель волос dyson ht01[/url] .
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Слушай внимательно — тут важно – https://radiantandbrighter.com/2018/07/15/mariarose
В наркологической клинике «Перезагрузка» в Химках капельницы проводятся под строгим медицинским наблюдением. Мы используем современные препараты, индивидуально подбираем состав инфузии и гарантируем конфиденциальность. Наша задача — не просто снять симптомы, а обеспечить реальную поддержку организму на физиологическом уровне, чтобы предотвратить повторный срыв и минимизировать риски для здоровья.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-moskva3.ru/]kapelnitsy ot zapoia na domu[/url]
learn the facts here now https://betplay.sh/
выпрямитель dyson airstrait [url=https://dsn-vypryamitel-4.ru/]выпрямитель dyson airstrait[/url] .
dyson airstraight [url=https://dsn-vypryamitel-1.ru/]dsn-vypryamitel-1.ru[/url] .
dyson выпрямитель для волос airstrait [url=https://dsn-vypryamitel-2.ru/]dsn-vypryamitel-2.ru[/url] .
dyson airstrait купить выпрямитель [url=https://vypryamitel-dn-kupit.ru/]vypryamitel-dn-kupit.ru[/url] .
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Перейти к статье – https://abrahamcarle.com/5792
дайсон выпрямитель для волос купить в спб [url=https://dsn-vypryamitel-4.ru/]дайсон выпрямитель для волос купить в спб[/url] .
выпрямитель дайсон [url=https://dsn-vypryamitel-3.ru/]выпрямитель дайсон[/url] .
дайсон фен выпрямитель для волос [url=https://vypryamitel-dn-kupit-2.ru/]дайсон фен выпрямитель для волос[/url] .
Мы предлагаем дипломы любой профессии по доступным тарифам. Купить диплом о высшем образовании [url=http://moningrp.listbb.ru/viewtopic.php?f=16&t=14993/]moningrp.listbb.ru/viewtopic.php?f=16&t=14993[/url]
Мы готовы предложить дипломы любой профессии по разумным тарифам. Стоимость будет зависеть от выбранной специальности, года получения и ВУЗа: [url=http://brandly.ink/angeliamcgough/]brandly.ink/angeliamcgough[/url]
Продвижение сайтов https://team-black-top.ru под ключ: аудит, стратегия, семантика, техоптимизация, контент и ссылки. Улучшаем позиции в Google/Яндекс, увеличиваем трафик и заявки. Прозрачная отчетность, понятные KPI и работа на результат — от старта до стабильного роста.
Мы изготавливаем дипломы любой профессии по приятным тарифам. Заказать диплом ВУЗа [url=http://dunumre.com/agent/gonzaloauger19/]dunumre.com/agent/gonzaloauger19[/url]
купить дайсон выпрямитель донецк [url=https://vypryamitel-dn-4.ru/]vypryamitel-dn-4.ru[/url] .
Купить диплом института по невысокой стоимости возможно, обратившись к надежной специализированной фирме. Для того, чтобы проверить компанию перед заказом пользуйтесь отзывами на форумах. Так можно приобрести диплом из любого ВУЗа России [url=http://voov.cz/en/smartblog/4_Street-style-new-2016.html/]voov.cz/en/smartblog/4_Street-style-new-2016.html[/url]
https://t.me/s/KAZINO_S_MINIMALNYM_DEPOZITOM
Мы изготавливаем дипломы любой профессии по выгодным ценам. Диплом об образовании прежде считался основным документом, способствовавшим успешному поиску работы. Заказать диплом любого университета!: [url=http://villageflix.com/2025/12/26/diplom-za-korotkij-srok-sroki-ceny-uslovija-242/]villageflix.com/2025/12/26/diplom-za-korotkij-srok-sroki-ceny-uslovija-242[/url]
купить выпрямитель dyson оптом [url=https://dsn-vypryamitel-2.ru/]dsn-vypryamitel-2.ru[/url] .
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
А что дальше? – https://gb-sk.de/baumfall-und-forstarbeiten
дайсон выпрямитель с феном [url=https://dsn-vypryamitel-1.ru/]dsn-vypryamitel-1.ru[/url] .
Клиника «Детокс» в Краснодаре предлагает услугу вызова нарколога на дом. Врачи приедут к вам в течение 1–2 часов, проведут осмотр и назначат необходимое лечение. Услуга доступна круглосуточно и анонимно.
Узнать больше – [url=https://narkolog-na-dom-krasnodar15.ru/]нарколог на дом недорого в сочи[/url]
фен выпрямитель дайсон купить в тц багратионовская [url=https://dsn-vypryamitel.ru/]dsn-vypryamitel.ru[/url] .
Продвижение сайтов https://team-black-top.ru под ключ: аудит, стратегия, семантика, техоптимизация, контент и ссылки. Улучшаем позиции в Google/Яндекс, увеличиваем трафик и заявки. Прозрачная отчетность, понятные KPI и работа на результат — от старта до стабильного роста.
выпрямитель dyson corrale [url=https://vypryamitel-dn-kupit.ru/]vypryamitel-dn-kupit.ru[/url] .
https://t.me/s/KAZINO_S_MINIMALNYM_DEPOZITOM
выпрямитель волос dyson ht01 [url=https://vypryamitel-dn-kupit-2.ru/]vypryamitel-dn-kupit-2.ru[/url] .
фен выпрямитель дайсон airstrait купить [url=https://vypryamitel-dn-kupit-1.ru/]vypryamitel-dn-kupit-1.ru[/url] .
выпрямитель дайсон airstrait купить [url=https://dsn-vypryamitel-3.ru/]выпрямитель дайсон airstrait купить[/url] .
Мы можем предложить дипломы любых профессий по невысоким ценам. Приобрести диплом об образовании [url=http://mafiaclans.ru/viewtopic.php?f=43&t=10306/]mafiaclans.ru/viewtopic.php?f=43&t=10306[/url]
дайсон выпрямитель купить воронеж [url=https://dsn-vypryamitel-4.ru/]дайсон выпрямитель купить воронеж[/url] .
купить аттестаты за 9 класс 2019 год с оценками [url=https://r-diploma30.ru/]купить аттестаты за 9 класс 2019 год с оценками[/url] .
Купить диплом института по выгодной стоимости возможно, обращаясь к проверенной специализированной компании. Для того, чтобы проверить компанию до заказа воспользуйтесь рейтингом и отзывами на форумах. Можно приобрести диплом из любого университета РФ [url=http://gitlab.code-better.it/vzgmarquita484/marquita1998/-/issues/1/]gitlab.code-better.it/vzgmarquita484/marquita1998/-/issues/1[/url]
Мы предлагаем дипломы любой профессии по невысоким ценам. Диплом об образовании когда-то считался ключевым документом, способствовавшим удачному устройству на работу. Заказать диплом любого ВУЗа!: [url=http://ticohomesrealty.com/author/silaslehrer29/]ticohomesrealty.com/author/silaslehrer29[/url]
выпрямитель дайсон купить [url=https://vypryamitel-dn-4.ru/]выпрямитель дайсон купить[/url] .
выпрямитель дайсон airstrait [url=https://vypryamitel-dn-kupit-2.ru/]vypryamitel-dn-kupit-2.ru[/url] .
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Получить полную информацию – https://lerstol.no/2013/09/07/7-september
Тяговые аккумуляторные https://ab-resurs.ru батареи для складской техники: погрузчики, ричтраки, электротележки, штабелеры. Новые АКБ с гарантией, помощь в подборе, совместимость с популярными моделями, доставка и сервисное сопровождение.
Приобрести диплом о высшем образовании Никто не стремится потратить годы жизни на то, чтобы “официально” заполучить навыки, которые уже присутствуют. В подобном случае решение приобрести официальный диплом о высшем образовании является для вас самым оптимальным. И для этого вам следует сделать не так много – найти надежную компанию, занимающуюся изготовлением и продажей документов об образовании на заказ. Это даст вам возможность за небольшую сумму и в кратчайшие сроки заполучить документ из любого университета нашей страны: [url=http://dachaweek.ru/kupit-diplom-s-garantiey-podlinnosti-2/]dachaweek.ru/kupit-diplom-s-garantiey-podlinnosti-2[/url]
Продажа тяговых АКБ https://faamru.com для складской техники любого типа: вилочные погрузчики, ричтраки, электрические тележки и штабелеры. Качественные аккумуляторные батареи, долгий срок службы, гарантия и профессиональный подбор.
медсестра которая купила диплом врача [url=frei-diplom13.ru]frei-diplom13.ru[/url] .
Заказать документ о получении высшего образования вы можете в нашей компании в Москве. Мы оказываем услуги по продаже документов об окончании любых университетов РФ. Гарантируем, что в случае проверки документа работодателями, каких-либо подозрений не появится: [url=http://allinonetab.com/MmWNB/]allinonetab.com/MmWNB[/url]
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Есть чему поучиться – https://thy-dental.dk/2024/05/05/hej-verden
куплю диплом медсестры в москве [url=http://www.frei-diplom13.ru]куплю диплом медсестры в москве[/url] .
Клиника «Детокс» в Краснодаре предлагает услугу вызова нарколога на дом. Врачи приедут к вам в течение 1–2 часов, проведут осмотр и назначат необходимое лечение. Услуга доступна круглосуточно и анонимно.
Детальнее – [url=https://narkolog-na-dom-krasnodar17.ru/]narkolog-na-dom-krasnodar17.ru[/url]
Мы изготавливаем дипломы любой профессии по приятным тарифам.– [url=http://mtwd.link/genesisfrederi/]mtwd.link/genesisfrederi[/url]
Продажа тяговых АКБ https://faamru.com для складской техники любого типа: вилочные погрузчики, ричтраки, электрические тележки и штабелеры. Качественные аккумуляторные батареи, долгий срок службы, гарантия и профессиональный подбор.
Заказать диплом любого университета. Производство документа занимает гораздо меньше времени, а стоимость при этом доступна каждому. В результате вы сможете сохранить бюджет и найти работу вашей мечты. Заказать диплом на заказ в Москве возможно используя сайт компании. – [url=http://aviapoisk.getbb.ru/viewtopic.php?f=27&t=1933/]aviapoisk.getbb.ru/viewtopic.php?f=27&t=1933[/url]
Этот обзор позволяет по-новому взглянуть на вещи, на которые обычно и так смотрят. Мы упоминаем факты, которые мало что меняют, и события, значение которых трудно определить, но они всё равно здесь.
Вот – [url=https://arma-rehab.ru/]казино онлайн[/url]
Для безопасного выхода из запоя в Сочи воспользуйтесь услугами стационара клиники «Детокс». Опытные врачи окажут помощь быстро и анонимно.
Разобраться лучше – [url=https://vyvod-iz-zapoya-sochi23.ru/]срочный вывод из запоя сочи[/url]
дивитися фільми онлайн 2025 що подивитися сьогодні онлайн
выпрямитель dyson corrale [url=https://vypryamitel-dn-kupit-3.ru/]выпрямитель dyson corrale[/url] .
выпрямитель дайсон hs07 купить [url=https://vypryamitel-dsn-kupit.ru/]vypryamitel-dsn-kupit.ru[/url] .
дайсон выпрямитель с феном [url=https://vypryamitel-dsn-kupit-1.ru/]vypryamitel-dsn-kupit-1.ru[/url] .
выпрямитель дайсон купить в москве оригинал [url=https://vypryamitel-dn-kupit-4.ru/]выпрямитель дайсон купить в москве оригинал[/url] .
выпрямитель dyson ht01 купить [url=https://vypryamitel-dsn-kupit-3.ru/]выпрямитель dyson ht01 купить[/url] .
выпрямитель дайсон [url=https://vypryamitel-dsn-kupit-2.ru/]выпрямитель дайсон[/url] .
купить диплом медицинский колледж с занесением в реестр [url=www.r-diploma28.ru/]купить диплом медицинский колледж с занесением в реестр[/url] .
Наркологическая скорая помощь в Москве — клиника «Частный Медик 24» предлагает экстренную помощь на дому. Наши специалисты приедут к вам в течение 30 минут и проведут необходимые процедуры для стабилизации состояния.
Подробнее тут – [url=https://skoraya-narkologicheskaya-pomoshch-moskva.ru/]наркологическая клиника клиника помощь москве[/url]
Мы готовы предложить документы институтов, которые расположены в любом регионе Российской Федерации.
Купить диплом любого ВУЗа: [url=http://tkd.co.il/kupit-diplom-109]tkd.co.il/kupit-diplom-109[/url]
выпрямитель для волос dyson airstrait купить [url=https://vypryamitel-dsn-kupit.ru/]vypryamitel-dsn-kupit.ru[/url] .
дайсон официальный сайт выпрямители [url=https://vypryamitel-dn-kupit-3.ru/]дайсон официальный сайт выпрямители[/url] .
выпрямитель dyson airstrait pink [url=https://vypryamitel-dsn-kupit-3.ru/]выпрямитель dyson airstrait pink[/url] .
фен выпрямитель дайсон airstrait купить [url=https://vypryamitel-dsn-kupit-2.ru/]vypryamitel-dsn-kupit-2.ru[/url] .
купить выпрямитель дайсон в новосибирске [url=https://vypryamitel-dsn-kupit-1.ru/]vypryamitel-dsn-kupit-1.ru[/url] .
фен выпрямитель для волос дайсон купить [url=https://vypryamitel-dn-kupit-4.ru/]фен выпрямитель для волос дайсон купить[/url] .
Приобрести диплом университета по доступной стоимости возможно, обращаясь к надежной специализированной фирме: [url=http://federalbureauinvestigation.5nx.ru/viewtopic.php?f=3&t=1729/]federalbureauinvestigation.5nx.ru/viewtopic.php?f=3&t=1729[/url]
Вывод из запоя у подростков в Москве от клиники «Частный Медик 24». Мы предлагаем специализированное лечение для подростков, учитывая их возрастные особенности.
Получить дополнительные сведения – [url=https://skoraya-narkologicheskaya-pomoshch-moskva13.ru/]центр наркологической помощи москва[/url]
Если запой стал серьёзной проблемой, стационар клиники «Детокс» в Сочи поможет выйти из кризиса. Врачи проводят детоксикацию и наблюдают за состоянием пациента.
Подробнее тут – [url=https://vyvod-iz-zapoya-sochi11.ru/]вывод из запоя на дому недорого в сочи[/url]
сайт онлайн казино слот Gates of Olympus —
Gates of Olympus slot — известный онлайн-слот от Pragmatic Play с принципом Pay Anywhere, каскадами и коэффициентами до ?500. Действие происходит у врат Олимпа, где Зевс усиливает выигрыши и делает каждый спин непредсказуемым.
Сетка слота выполнено в формате 6?5, а выигрыш начисляется при появлении не менее 8 одинаковых символов в любом месте экрана. После выплаты символы исчезают, сверху падают новые элементы, формируя серии каскадных выигрышей, способные принести дополнительные выигрыши в рамках одного вращения. Слот относится высоковолатильным, поэтому может долго раскачиваться, но при удачных каскадах может принести большие выигрыши до 5000? ставки.
Чтобы разобраться в слоте доступен демо-режим без регистрации. При реальных ставках рекомендуется выбирать официальные казино, например MELBET (18+), принимая во внимание RTP около 96,5% и правила выбранного казино.
Диплом об образовании когда-то считался ключевым документом, способствовавшим быстрому и удачному устройству на работу. Купить диплом под заказ в столице можно через сайт компании. [url=http://bezone.ru/node/360423/]bezone.ru/node/360423[/url]
купить кейс для выпрямителя дайсон [url=https://vypryamitel-dsn-kupit.ru/]vypryamitel-dsn-kupit.ru[/url] .
dyson выпрямитель купить спб [url=https://vypryamitel-dsn-kupit-2.ru/]dyson выпрямитель купить спб[/url] .
dyson выпрямитель купить в москве [url=https://vypryamitel-dsn-kupit-3.ru/]dyson выпрямитель купить в москве[/url] .
дайсон выпрямитель с феном [url=https://vypryamitel-dn-kupit-3.ru/]дайсон выпрямитель с феном[/url] .
выпрямитель dyson corrale купить [url=https://vypryamitel-dsn-kupit-1.ru/]vypryamitel-dsn-kupit-1.ru[/url] .
Мы можем предложить дипломы любой профессии по приятным ценам. Цена может зависеть от конкретной специальности, года получения и ВУЗа: [url=http://northrp.kabb.ru/viewtopic.php?f=18&t=681/]northrp.kabb.ru/viewtopic.php?f=18&t=681[/url]
купить фен выпрямитель дайсон [url=https://vypryamitel-dn-kupit-4.ru/]купить фен выпрямитель дайсон[/url] .
Заказ документа о высшем образовании через проверенную и надежную фирму дарит ряд достоинств. Приобрести диплом: [url=http://dukan.lovelytutorials.com/member.php?u=5648]dukan.lovelytutorials.com/member.php?u=5648[/url]
[b]Приобрести диплом любого ВУЗа![/b]
Наша компания предлагаетвыгодно приобрести диплом, который выполнен на оригинальном бланке и заверен печатями, штампами, подписями. Наш диплом способен пройти любые проверки, даже при использовании специфических приборов. Достигайте своих целей быстро с нашими дипломами- [url=http://khvoynaya.getbb.ru/viewtopic.php?f=39&t=9430/]khvoynaya.getbb.ru/viewtopic.php?f=39&t=9430[/url]
Лечение зависимости от алкоголя на дому в Москве от клиники «Частный Медик 24». Наши специалисты приедут к вам домой и проведут все необходимые процедуры.
Детальнее – [url=https://skoraya-narkologicheskaya-pomoshch12.ru/]платная наркологическая помощь москве[/url]
Купить диплом университета. Производство диплома занимает намного меньше времени, а стоимость – невысокая. Таким образом вы получаете возможность сохранить бюджет и найти отличную работу мечты. Купить диплом можно через сайт компании. – [url=http://doublrp.listbb.ru/viewtopic.php?f=3&t=1145/]doublrp.listbb.ru/viewtopic.php?f=3&t=1145[/url]
Мы можем предложить дипломы психологов, юристов, экономистов и любых других профессий по приятным ценам. Для нас очень важно, чтобы дипломы были доступны для большого количества наших граждан. Приобрести диплом об образовании [url=http://bodybuilding.net/members/worksale.html/]bodybuilding.net/members/worksale.html[/url]
дайсон выпрямитель купить минск [url=https://vypryamitel-dsn-kupit.ru/]vypryamitel-dsn-kupit.ru[/url] .
выпрямитель дайсон airstrait ht01 [url=https://vypryamitel-dsn-kupit-2.ru/]vypryamitel-dsn-kupit-2.ru[/url] .
дайсон официальный сайт выпрямители [url=https://vypryamitel-dsn-kupit-3.ru/]дайсон официальный сайт выпрямители[/url] .
выпрямитель dyson corrale [url=https://vypryamitel-dn-kupit-3.ru/]выпрямитель dyson corrale[/url] .
дайсон выпрямитель для волос купить в спб [url=https://vypryamitel-dsn-kupit-1.ru/]vypryamitel-dsn-kupit-1.ru[/url] .
фен выпрямитель дайсон airstrait [url=https://vypryamitel-dn-kupit-4.ru/]фен выпрямитель дайсон airstrait[/url] .
купить диплом медсестры омск [url=http://r-diploma29.ru]http://r-diploma29.ru[/url] .
Купить официальный диплом о высшем образовании : [url=http://flystarlady.listbb.ru/viewtopic.php?f=27&t=6166/]flystarlady.listbb.ru/viewtopic.php?f=27&t=6166[/url]
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по выгодным тарифам. Важно, чтобы документы были доступными для большого количества наших граждан. Заказать диплом о высшем образовании [url=http://spiceroleplay.forumex.ru/viewtopic.php?f=23&t=1596/]spiceroleplay.forumex.ru/viewtopic.php?f=23&t=1596[/url]
Мы готовы предложить документы учебных заведений, расположенных на территории РФ.
Заказать диплом любого университета: [url=http://dbitly.com/rdbfreeman9815]dbitly.com/rdbfreeman9815[/url]
Процесс детоксикации проходит поэтапно, чтобы организм успевал адаптироваться к изменениям и не испытывал стресс. Каждый шаг направлен на достижение конкретного терапевтического эффекта. Ниже представлена таблица, отражающая ключевые стадии процедуры, применяемой в клинике «Трезвый Путь Волгоград».
Узнать больше – [url=https://vivod-iz-zapoya-v-volgograde17.ru/]нарколог на дом вывод из запоя в волгограде[/url]
Купить диплом ВУЗа по доступной стоимости вы можете, обратившись к надежной специализированной компании: [url=http://fiorinirooms.com/author/anhkepler86429/]fiorinirooms.com/author/anhkepler86429[/url]
«РаменМед Трезвость» предлагает несколько форматов помощи, но выбор всегда делается из соображений безопасности, а не удобства картинки. Стационарный вывод из запоя подходит в ситуациях, когда запой длится несколько дней или недель, есть скачки давления, проблемы с сердцем, печени, сахарный диабет, неврологические заболевания, эпизоды судорог или делирия в анамнезе, возраст старше 50–55 лет, выраженная слабость, тахикардия, невозможность пить воду, угрозы психозов. В стационаре пациент находится под наблюдением круглосуточно: контролируются жизненные показатели, вовремя корректируется терапия, есть возможность экстренно отреагировать на осложнения. Это гарантированно безопаснее, чем оставлять тяжёлого человека дома под наблюдением уставших родственников.
Получить больше информации – [url=https://vyvod-iz-zapoya-ramenskoe10.ru/]раменское вывод из запоя[/url]
Наркологическая клиника «КоломнаМед Центр» — это место, куда можно обратиться в тот момент, когда домашние попытки контролировать алкоголь, наркотики, аптечные препараты или смесь всего сразу перестают работать, а жизнь превращается в постоянное «завтра начну с нуля». Здесь не обещают чудес за один день и не пугают диагнозами, а выстраивают понятный медицинский маршрут: детоксикация, стабилизация, реабилитация, поддержка семьи, профилактика срывов. Пациент получает помощь в защищённой, конфиденциальной среде, где всё организовано так, чтобы снизить тревогу и стыд, убрать хаос вокруг зависимости и дать человеку шанс вернуться к нормальной жизни без давления, угроз и токсичных «стимулов». Для родных клиника в Коломне — это опора: конкретный адрес, конкретная команда, чёткие сроки и понятные этапы, вместо бесконечных обещаний «он сам справится».
Подробнее можно узнать тут – https://narkologicheskaya-klinika-kolomna10.ru/narkologicheskaya-klinika-cena-v-kolomne/
Далеко не каждый работодатель проводит подробную проверку дипломов работников. Большинство компаний вполне доверяют претендентам и без проблем принимают их документы. В подобной ситуации покупка диплома российского университета является разумным решением. Не понадобится терять множество времени и денег на очное обучение. Мы изготавливаем дипломы любых профессий по приятным тарифам: [url=http://heres.link/edith703813293/]heres.link/edith703813293[/url]
боковой погрузчик для производства
В этом тексте собрано множество случайных сведений и довольно неопределённых мыслей, которые могут чем-то заинтересовать. Мы отмечаем моменты, которые не особенно важны, но всё же занимают своё место в повествовании.
Вот – [url=https://arma-rehab.ru/vyvod-iz-zapoya/]порно онлайн бесплатно[/url]
Found vipdubaiagency.com while browsing premium entourage platforms. The site has a polished design, a extensive range of services, transparent pricing, and a simple booking process. It feels more high-class than most agencies I’ve encountered. Definitely recommended checking if you want complete services in single platform.
URL: https://vipdubaiagency.com/
상업어음보험 신기롭다 줄띄기 학습곡선 톨로스 지관상승 용성물 화냥질 비결정성황 가스정 https://yak-jiu.com/ – 캐주얼웨어 뇌공 칠림 객려 사모턱 윤회전생 대리인 덧심 불겅이 이바노프
Капельница при вызове нарколога на дом в Долгопрудном от «МедТрезвие Долгопрудный» — это клинический инструмент, а не магический раствор. Главное правило — никакой агрессивной седации ради видимости спокойствия. Инфузионная терапия строится вокруг нескольких задач: восполнить жидкость, выровнять электролиты, снизить токсическую нагрузку на печень и мозг, поддержать сердце и нервную систему, уменьшить тремор, тревогу и соматические жалобы. Используются растворы для регидратации и коррекции водно-электролитного баланса, витамины группы B и магний для поддержки нервной системы, уменьшения риска судорог и нормализации сна, по показаниям — гепатопротекторы и мягкие антиоксиданты, противорвотные препараты для контроля тошноты. При выраженной тревоге или нарушениях сна назначаются щадящие анксиолитические средства в дозах, которые не выключают пациента полностью, а помогают снять паническое напряжение, сохраняя возможность оценивать динамику состояния. Врач отслеживает реакцию на терапию: стабилизацию давления и пульса, уменьшение дрожи, улучшение общего самочувствия, появление более спокойного, естественного сна. По мере облегчения нагрузки схема не усиливается ради счёта, а рационально сокращается. Такой подход защищает пациента от скрытых осложнений и превращает капельницу в контролируемый, полезный шаг, а не в рискованный эксперимент.
Подробнее тут – [url=https://narkolog-na-dom-dolgoprudnij10.ru/]luchshij-narkolog-na-dom[/url]
[b]Приобрести диплом университета![/b]
Мы предлагаемвыгодно и быстро заказать диплом, который выполнен на оригинальном бланке и заверен печатями, штампами, подписями. Данный документ способен пройти лубую проверку, даже с использованием специальных приборов. Решите свои задачи быстро и просто с нашими дипломами- [url=http://cucbac.vn/stephaniesargo/]cucbac.vn/stephaniesargo[/url]
Мы предлагаем дипломы психологов, юристов, экономистов и других профессий по приятным тарифам. Для нас важно, чтобы дипломы были доступны для большого количества граждан. Приобрести диплом ВУЗа [url=http://trum.flybb.ru/posting.php?mode=post&f=15/]trum.flybb.ru/posting.php?mode=post&f=15[/url]
Приобрести диплом о высшем образовании мы поможем. Купить аттестат в Махачкале – [url=http://diplomybox.com/kupit-attestat-v-makhachkale/]diplomybox.com/kupit-attestat-v-makhachkale[/url]
купить бланки аттестатов нового образца 2014 [url=https://r-diploma31.ru]купить бланки аттестатов нового образца 2014[/url] .
узаконивание перепланировки квартиры [url=https://pereplanirovka-kvartir3.ru/]pereplanirovka-kvartir3.ru[/url] .
перепланировка квартиры согласование [url=https://pereplanirovka-kvartir4.ru/]перепланировка квартиры согласование[/url] .
согласование перепланировки в москве [url=https://pereplanirovka-kvartir5.ru/]согласование перепланировки в москве[/url] .
выпрямитель дайсон airstrait [url=https://vypryamitel-dsn-kupit-4.ru/]выпрямитель дайсон airstrait[/url] .
проект перепланировки квартиры для согласования [url=https://proekt-pereplanirovki-kvartiry20.ru/]проект перепланировки квартиры для согласования[/url] .
согласование перепланировки цена [url=https://skolko-stoit-uzakonit-pereplanirovku-6.ru/]согласование перепланировки цена[/url] .
Для успешного продвижения вверх по карьерной лестнице потребуется наличие официального диплома о высшем образовании. Мы готовы предложить дипломы психологов, юристов, экономистов и прочих профессий по выгодным ценам: [url=http://veryvcard.com/allisonrit/]veryvcard.com/allisonrit[/url]
Мы можем предложить документы учебных заведений, которые находятся в любом регионе Российской Федерации.
Заказать диплом университета: [url=http://woojincopolymer.co.kr/bbs/board.php?bo_table=free&wr_id=2982739]woojincopolymer.co.kr/bbs/board.php?bo_table=free&wr_id=2982739[/url]
Мы предлагаем дипломы психологов, юристов, экономистов и любых других профессий по выгодным тарифам. Для нас важно, чтобы дипломы были доступными для большого количества наших граждан. Быстро заказать диплом ВУЗа [url=http://mosserg.flybb.ru/viewtopic.php?f=2&t=764/]mosserg.flybb.ru/viewtopic.php?f=2&t=764[/url]
Заказать диплом о высшем образовании Никто не хотел бы потерять несколько лет жизни на то, чтобы получить умения и навыки, которые уже имеются. В итоге решение о покупке диплома о высшем образовании будет для вас наиболее выгодным. Вам необходимо сделать не так много – лишь выбрать надежную компанию, которая занимается изготовлением и продажей дипломов на заказ. Это позволит вам за небольшую сумму и в кратчайшие сроки заполучить документ из любого высшего учебного заведения нашей страны: [url=http://credit.rx22.ru/viewtopic.php?f=2&t=2709/]credit.rx22.ru/viewtopic.php?f=2&t=2709[/url]
перепланировка квартиры согласование [url=https://pereplanirovka-kvartir4.ru/]перепланировка квартиры согласование[/url] .
согласование перепланировки в москве [url=https://pereplanirovka-kvartir3.ru/]pereplanirovka-kvartir3.ru[/url] .
согласование перепланировки квартиры москва [url=https://pereplanirovka-kvartir5.ru/]pereplanirovka-kvartir5.ru[/url] .
проект перепланировки квартиры для согласования [url=https://proekt-pereplanirovki-kvartiry20.ru/]проект перепланировки квартиры для согласования[/url] .
сколько стоит согласование перепланировки [url=https://skolko-stoit-uzakonit-pereplanirovku-6.ru/]сколько стоит согласование перепланировки[/url] .
московская школа онлайн обучение [url=https://shkola-onlajn11.ru/]shkola-onlajn11.ru[/url] .
dyson выпрямитель для волос [url=https://vypryamitel-dsn-kupit-4.ru/]dyson выпрямитель для волос[/url] .
lomonosov school [url=https://shkola-onlajn12.ru/]shkola-onlajn12.ru[/url] .
продвижение наркологии [url=https://seo-kejsy7.ru/]seo-kejsy7.ru[/url] .
lbs это [url=https://shkola-onlajn14.ru/]lbs это[/url] .
онлайн школы для детей [url=https://shkola-onlajn15.ru/]онлайн школы для детей[/url] .
школа-пансион бесплатно [url=https://shkola-onlajn13.ru/]shkola-onlajn13.ru[/url] .
сайт бк мелбет [url=https://studio-pulse.ru/]сайт бк мелбет[/url] .
мелбет официальный [url=https://gbufavorit.ru/]мелбет официальный[/url] .
Не каждый работодатель проводит тщательную проверку дипломов своих работников. Большинство компаний доверяют кандидатам и “вслепую” принимают важные документы. В подобной ситуации покупка диплома российского университета является разумным решением. Не придется терять массу времени и денег на учебу. Мы изготавливаем дипломы любых профессий по приятным ценам: [url=http://ezworkers.com/employer/russiany-diplomx/]ezworkers.com/employer/russiany-diplomx[/url]
узаконить перепланировку цена [url=https://skolko-stoit-uzakonit-pereplanirovku-6.ru/]узаконить перепланировку цена[/url] .
Мы изготавливаем дипломы любой профессии по разумным тарифам. Цена будет зависеть от той или иной специальности, года выпуска и образовательного учреждения: [url=http://mobiadnews.com/?p=168649/]mobiadnews.com/?p=168649[/url]
[url=https://buscamed.do/ad/pgs/?1xbet_codigo_promocional_para_hoy_de_bono_gratis.html]codigo promocional 1xbet pimpeano[/url]
[url=https://kalicrack.com/pgs/codigo-promocional-1xbet_bono-vip.html]codigo de promocion de 1xbet casino bono sin deposito[/url]
Мы изготавливаем дипломы любой профессии по приятным ценам. Заказать диплом института [url=http://dubaiproperties.africa/author/bettyk67310150/]dubaiproperties.africa/author/bettyk67310150[/url]
где согласовать перепланировку [url=https://pereplanirovka-kvartir4.ru/]pereplanirovka-kvartir4.ru[/url] .
Мы предлагаем дипломы психологов, юристов, экономистов и любых других профессий по приятным тарифам. Диплом об образовании когда-то считался основным документом, который способствовал успешному поиску работы. Купить диплом университета!: [url=http://aabdon.com/author/ingridnewell27/]aabdon.com/author/ingridnewell27[/url]
согласование переоборудования квартиры [url=https://pereplanirovka-kvartir5.ru/]pereplanirovka-kvartir5.ru[/url] .
проект перепланировки квартиры москва [url=https://proekt-pereplanirovki-kvartiry20.ru/]проект перепланировки квартиры москва[/url] .
Мы изготавливаем дипломы любых профессий по выгодным тарифам. Цена зависит от выбранной специальности, года получения и ВУЗа: [url=http://boldkuangjia.com:8000/cart/bbs/board.php?bo_table=free&wr_id=538615/]boldkuangjia.com:8000/cart/bbs/board.php?bo_table=free&wr_id=538615[/url]
купить диплом медсестры [url=http://www.frei-diplom13.ru]купить диплом медсестры[/url] .
школа-пансион бесплатно [url=https://shkola-onlajn11.ru/]shkola-onlajn11.ru[/url] .
школьное образование онлайн [url=https://shkola-onlajn14.ru/]школьное образование онлайн[/url] .
школа дистанционного обучения [url=https://shkola-onlajn12.ru/]shkola-onlajn12.ru[/url] .
онлайн-школа с аттестатом бесплатно [url=https://shkola-onlajn15.ru/]shkola-onlajn15.ru[/url] .
мелбет букмекерская контора официальный [url=www.studio-pulse.ru]мелбет букмекерская контора официальный[/url] .
dyson выпрямитель для волос купить в симферополе [url=https://vypryamitel-dsn-kupit-4.ru/]vypryamitel-dsn-kupit-4.ru[/url] .
seo клиники наркологии [url=https://seo-kejsy7.ru/]seo-kejsy7.ru[/url] .
Мы изготавливаем дипломы любых профессий по приятным ценам. Цена будет зависеть от выбранной специальности, года выпуска и образовательного учреждения: [url=http://aytacproperties.com/agents/paulinewhisman/]aytacproperties.com/agents/paulinewhisman[/url]
мелбет официальный сайт [url=http://www.gbufavorit.ru]мелбет официальный сайт[/url] .
школа онлайн обучение для детей [url=https://shkola-onlajn13.ru/]школа онлайн обучение для детей[/url] .
согласование перепланировки цена [url=https://skolko-stoit-uzakonit-pereplanirovku-6.ru/]согласование перепланировки цена[/url] .
диплом в братске купить [url=http://r-diploma30.ru]диплом в братске купить[/url] .
Мы изготавливаем дипломы психологов, юристов, экономистов и других профессий по приятным ценам. Диплом об окончании университета раньше считался ключевым документом, который способствовал быстрому и удачному трудоустройству. Заказать диплом о высшем образовании!: [url=http://crmthebespoke.a1professionals.net/employer/originality-diplomiki/]crmthebespoke.a1professionals.net/employer/originality-diplomiki[/url]
сколько стоит купить диплом медсестры [url=https://frei-diplom13.ru/]сколько стоит купить диплом медсестры[/url] .
Приобрести диплом о высшем образовании поможем. Купить аттестат в городе Архангельске – [url=http://diplomybox.com/kupit-attestat-v-arkhangelske/]diplomybox.com/kupit-attestat-v-arkhangelske[/url]
согласование перепланировки квартиры москва [url=https://pereplanirovka-kvartir4.ru/]pereplanirovka-kvartir4.ru[/url] .
узаконивание перепланировки [url=https://pereplanirovka-kvartir3.ru/]pereplanirovka-kvartir3.ru[/url] .
Приобрести документ университета можно в нашей компании в Москве. Мы предлагаем документы об окончании любых ВУЗов РФ. Даем 100% гарантию, что при проверке документа работодателем, никаких подозрений не возникнет: [url=http://motomaniacy.com/posting.php?mode=post&f=9&sid=347bfbfc8075a3ab2e12d1efb45cddd3/]motomaniacy.com/posting.php?mode=post&f=9&sid=347bfbfc8075a3ab2e12d1efb45cddd3[/url]
заказать проект перепланировки квартиры в москве [url=https://proekt-pereplanirovki-kvartiry20.ru/]заказать проект перепланировки квартиры в москве[/url] .
согласование перепланировки [url=https://pereplanirovka-kvartir5.ru/]согласование перепланировки[/url] .
Выбор клиники — задача не только медицинская, но и стратегическая. Учитывать нужно не только наличие лицензии, но и содержание программ, их гибкость, участие родственников в процессе, а также прозрачность взаимодействия с пациентом. Именно эти аспекты позволяют отличить профессиональное учреждение от формального.
Узнать больше – http://narkologicheskaya-klinika-yaroslavl0.ru
школы дистанционного обучения [url=https://shkola-onlajn11.ru/]shkola-onlajn11.ru[/url] .
онлайн ш [url=https://shkola-onlajn14.ru/]shkola-onlajn14.ru[/url] .
класс с учениками [url=https://shkola-onlajn12.ru/]shkola-onlajn12.ru[/url] .
школы дистанционного обучения [url=https://shkola-onlajn15.ru/]школы дистанционного обучения[/url] .
мелбет букмекерская контора [url=http://studio-pulse.ru/]мелбет букмекерская контора[/url] .
Checked out vipdubaiagency.com while browsing local escort platforms. The site has a clean design, a extensive variety of services, straightforward pricing, and a hassle-free booking process. It feels more top-tier than most agencies I’ve encountered. Definitely worth checking if you seek full services in single platform.
Visit; https://vipdubaiagency.com/
мелбет ставки на спорт зеркало [url=http://gbufavorit.ru/]мелбет ставки на спорт зеркало[/url] .
выпрямитель дайсон купить [url=https://vypryamitel-dsn-kupit-4.ru/]выпрямитель дайсон купить[/url] .
стоимость согласования перепланировки квартиры [url=https://skolko-stoit-uzakonit-pereplanirovku-6.ru/]skolko-stoit-uzakonit-pereplanirovku-6.ru[/url] .
получить короткую ссылку google [url=https://seo-kejsy7.ru/]seo-kejsy7.ru[/url] .
Такая последовательность действий позволяет обеспечить результативность и закрепить положительные изменения.
Изучить вопрос глубже – http://narcologicheskaya-klinika-perm0.ru
школа онлайн дистанционное обучение [url=https://shkola-onlajn13.ru/]школа онлайн дистанционное обучение[/url] .
«ОмскПрофи» укомплектована современной медицинской базой: передвижные аппараты для ЭКГ, инфузионные стойки, экспресс-анализаторы, мониторы состояния, аппараты ИВЛ (в реанимационных палатах). Штат сотрудников сформирован из врачей-наркологов, токсикологов, психиатров, психотерапевтов, медицинских сестёр, прошедших обучение по международным протоколам. Ведётся постоянная учёба, стажировки, участие в научных форумах. Благодаря этому пациенты получают не только медицинскую помощь, но и психологическое сопровождение, направленное на долгосрочный результат.
Углубиться в тему – [url=https://narkologicheskaya-pomoshh-omsk0.ru/]наркологическая клиника клиника помощь[/url]
купить диплом о высшем образовании в екатеринбурге отзывы [url=https://www.r-diploma28.ru]https://www.r-diploma28.ru[/url] .
купить диплом в тамбове цена [url=http://r-diploma31.ru/]купить диплом в тамбове цена[/url] .
онлайн-школа для детей бесплатно [url=https://shkola-onlajn11.ru/]shkola-onlajn11.ru[/url] .
ломоносовская школа онлайн [url=https://shkola-onlajn14.ru/]ломоносовская школа онлайн[/url] .
школа онлайн дистанционное обучение [url=https://shkola-onlajn12.ru/]школа онлайн дистанционное обучение[/url] .
дистанционное обучение 11 класс [url=https://shkola-onlajn15.ru/]дистанционное обучение 11 класс[/url] .
mel bet [url=http://studio-pulse.ru]mel bet[/url] .
online slots machines
Gates of Olympus slot — известный онлайн-слот от Pragmatic Play с системой Pay Anywhere, каскадами и коэффициентами до ?500. Действие происходит в мире Олимпа, где бог грома активирует множители и делает каждый раунд случайным.
Сетка слота выполнено в формате 6?5, а выигрыш формируется при появлении от 8 совпадающих символов без привязки к линиям. После формирования выигрыша символы удаляются, сверху падают новые элементы, формируя каскады, которые могут дать серию выигрышей за одно вращение. Слот является высоковолатильным, поэтому не всегда даёт выплаты, но при удачных раскладах даёт крупные заносы до 5000? ставки.
Для знакомства с механикой доступен бесплатный режим без вложений. Для ставок на деньги стоит выбирать лицензированные казино, например MELBET (18+), ориентируясь на показатель RTP ~96,5% и условия площадки.
сколько стоит оформить перепланировку квартиры [url=https://skolko-stoit-uzakonit-pereplanirovku-6.ru/]skolko-stoit-uzakonit-pereplanirovku-6.ru[/url] .
мелбет онлайн [url=http://gbufavorit.ru]мелбет онлайн[/url] .
успешные seo кейсы санкт петербург [url=https://seo-kejsy7.ru/]seo-kejsy7.ru[/url] .
школа онлайн для детей [url=https://shkola-onlajn13.ru/]shkola-onlajn13.ru[/url] .
игры онлайн казино Gates of Olympus slot —
Gates of Olympus slot — популярный игровой автомат от Pragmatic Play с принципом Pay Anywhere, каскадными выигрышами и усилителями выигрыша до ?500. Игра проходит на Олимпе, где верховный бог активирует множители и превращает каждое вращение непредсказуемым.
Игровое поле представлено в виде 6?5, а выигрыш засчитывается при сборе от 8 одинаковых символов в любом месте экрана. После выплаты символы пропадают, их заменяют новые элементы, запуская серии каскадных выигрышей, способные принести дополнительные выигрыши за одно вращение. Слот считается игрой с высокой волатильностью, поэтому не всегда даёт выплаты, но в благоприятные моменты может принести большие выигрыши до ?5000 от ставки.
Для знакомства с механикой доступен бесплатный режим без финансового риска. Для ставок на деньги целесообразно выбирать лицензированные казино, например MELBET (18+), ориентируясь на RTP около 96,5% и правила выбранного казино.
[b]Диплом экономиста[/b]. Мы изготавливаем дипломы любой профессии по приятным тарифам: [url=http://tancodien.com/agent/laynehite4783/]tancodien.com/agent/laynehite4783[/url]
Мы готовы предложить дипломы любой профессии по доступным тарифам. Купить диплом в Кумертау — [url=http://galantclub.od.ua/member.php?u=27724/]galantclub.od.ua/member.php?u=27724[/url]
Как отмечает ведущий научный сотрудник ФГБУН «НМИЦ психиатрии и наркологии» Минздрава России, наличие междисциплинарной команды — один из основных факторов, определяющих успех терапии при зависимости.
Углубиться в тему – [url=https://lechenie-narkomanii-murmansk0.ru/]центр лечения наркомании[/url]
What a stuff of un-ambiguity and preserveness of valuable know-how regarding unpredicted emotions.
https://elsig-opt.com.ua/ford-focus-3-zamina-reflektora-na-linzovanu.html
[b]Заказать диплом любого ВУЗа![/b]
Наши специалисты предлагаютбыстро и выгодно заказать диплом, который выполнен на оригинальном бланке и заверен мокрыми печатями, водяными знаками, подписями официальных лиц. Данный документ пройдет лубую проверку, даже при помощи специального оборудования. Достигайте свои цели быстро и просто с нашим сервисом- [url=http://bt-13.com/index.php/User:JulieWhitehead9/]bt-13.com/index.php/User:JulieWhitehead9[/url]
После первичной диагностики начинается активная фаза детоксикации, во время которой современные препараты вводятся капельничным методом. Этот этап помогает быстро снизить концентрацию токсинов в крови, восстановить нормальные обменные процессы и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Подробнее – https://vyvod-iz-zapoya-tula0.ru/vyvod-iz-zapoya-czena-tula
https://matters.town/a/rmp4ra4zktlv
Диплом о получении высшего образования ранее считался главным документом, который способствовал быстрому и успешному поиску работы. Заказать диплом вы можете через официальный портал компании. [url=http://residencesinfoniedelbosco.it/agents/robtslack3349/]residencesinfoniedelbosco.it/agents/robtslack3349[/url]
melbet online sports betting [url=https://rusfusion.ru/]melbet online sports betting[/url] .
slot gacor situs toto 4d
Checked out vipdubaiagency.com while browsing premium companions platforms. The site has a sleek design, a wide variety of services, clear pricing, and a convenient booking process. It feels more premium than most agencies I’ve encountered. Definitely smart checking if you want full services in single platform.
URL; https://vipdubaiagency.com/
Заказать документ университета вы сможете в нашем сервисе. Мы предлагаем документы об окончании любых университетов России. Гарантируем, что в случае проверки документа работодателями, каких-либо подозрений не появится: [url=http://repetitor.ekafe.ru/index.php?sid=fda18455d4a18ad927ff068a1b23450f/]repetitor.ekafe.ru/index.php?sid=fda18455d4a18ad927ff068a1b23450f[/url]
Все растворы проходят фармацевтический контроль, а процедуры выполняются одноразовыми стерильными инструментами. После завершения капельницы врач наблюдает пациента в течение 15–30 минут, оценивает результат и даёт рекомендации по дальнейшему восстановлению. Важно не прерывать терапию самостоятельно — эффект закрепляется только при соблюдении рекомендаций.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-v-voronezhe17.ru/]нарколог на дом анонимно в воронеже[/url]
мелбет букмекерская контора официальный сайт [url=www.rusfusion.ru]мелбет букмекерская контора официальный сайт[/url] .
Приобрести официальный диплом института : [url=http://leerebelwriters.com/kupit-diplom-s-garantiej-podlinnosti-236/]leerebelwriters.com/kupit-diplom-s-garantiej-podlinnosti-236[/url]
Пациенты выбирают нашу клинику для срочного вызова врача-нарколога благодаря следующим важным преимуществам:
Изучить вопрос глубже – https://narcolog-na-dom-novosibirsk00.ru/narkolog-na-dom-kruglosutochno-novosibirsk
Hi to every one, for the reason that I am genuinely eager of reading this web site’s post to be updated regularly. It contains good material.
cudovusta igrice
Чтобы легче сопоставить риски и плотность наблюдения, ниже даём живой ориентир. Это не заменяет осмотр, но помогает всей семье понимать логику врача до приезда.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-domodedovo0.ru/]kruglosutochnaya-narkologicheskaya-pomoshch[/url]
сайт мелбет [url=http://www.rusfusion.ru]сайт мелбет[/url] .
Equili
Этот обзор позволяет по-новому взглянуть на вещи, на которые обычно и так смотрят. Мы упоминаем факты, которые мало что меняют, и события, значение которых трудно определить, но они всё равно здесь.
Вот – [url=https://arma-rehab.ru/vyvod-iz-zapoya/]блекджек[/url]
купить аттестат в донецке [url=r-diploma29.ru]купить аттестат в донецке[/url] .
Крупнейший селлер https://buyaccount.digital приветствует маркетологов в своем каталоге рекламных активов Meta. Когда вы планируете купить Facebook-аккаунты, обычно задача не в «просто доступе», а в проходимости чеков: стабильный запуск, зеленые плашки в кабинете и прогретые FanPage. Мы подготовили практичный чек-лист, чтобы вы без лишних вопросов понимали какой лимит выбрать перед покупкой.Что внутри: что вы покупаете на практике. Ключевая идея: аккаунт — это инструмент. Дальше решает схема залива: какой прокси используется, как вы передаете лички без триггеров, как проходите чеки и как дублируете кампании. Ключевое преимущество данной площадки — это наличии масштабной вики-энциклопедии FB, в которой опубликованы свежие гайды по проходу ЗРД. Мы подскажем, как без лишних рисков запустить первый адсет, чтобы не словили Risk Payment а также продлили жизнь аккаунтам . Оформляя у нас, вы получаете не только аккаунт, но и полную поддержку, ясное описание товара, страховку на валид плюс самые приятные расценки среди селлеров. Важно: действуйте в рамках закона и всегда в соответствии с правилами Facebook.
купить диплом о среднем профессиональном образовании в уфе [url=https://r-diploma31.ru]купить диплом о среднем профессиональном образовании в уфе[/url] .
betting online site [url=https://rusfusion.ru/]betting online site[/url] .
купить диплом медсестры [url=http://frei-diplom13.ru]купить диплом медсестры[/url] .
Такая структура делает лечение последовательным и предсказуемым, повышая шансы на положительный исход.
Ознакомиться с деталями – http://narkologicheskaya-klinika-v-omske0.ru
куплю диплом медсестры в москве [url=http://frei-diplom13.ru]куплю диплом медсестры в москве[/url] .
Hi, I want to subscribe for this blog to get latest updates, therefore where can i do it please help out.
byueuropaviagraonline
[b]Приобрести диплом ВУЗа![/b]
Наши специалисты предлагаютмаксимально быстро приобрести диплом, который выполнен на бланке ГОЗНАКа и заверен печатями, водяными знаками, подписями. Диплом пройдет любые проверки, даже при помощи профессионального оборудования. Достигайте своих целей быстро и просто с нашими дипломами- [url=http://onestopclean.kr/bbs/board.php?bo_table=free&wr_id=818764/]onestopclean.kr/bbs/board.php?bo_table=free&wr_id=818764[/url]
Выделяется ряд преимуществ, которые делают терапию в клинике оптимальным решением для борьбы с зависимостью.
Подробнее можно узнать тут – https://lechenie-alkogolizma-perm0.ru/
폰테크
Found that project while exploring local property pages.
Everything feels clear, so browsing comfortable.
Reasonable to look into if you want keeping everything within one unified place.
This:https://www.theteams.kr/stack/news_view/Commentit/736
Заказ официального диплома через надежную фирму дарит немало преимуществ. Приобрести диплом о высшем образовании: [url=http://parus.flybb.ru/viewtopic.php?f=2&t=1019]parus.flybb.ru/viewtopic.php?f=2&t=1019[/url]
Приобрести документ о получении высшего образования вы имеете возможность в нашей компании. Мы оказываем услуги по продаже документов об окончании любых ВУЗов России. Гарантируем, что в случае проверки документов работодателями, подозрений не возникнет: [url=http://grad-360.flybb.ru/viewtopic.php?f=3&t=1039/]grad-360.flybb.ru/viewtopic.php?f=3&t=1039[/url]
Одной из ключевых инноваций «СамарМед» является внедрение телемедицинского консультирования. Пациенты, проживающие за пределами Самары или находящиеся в стадии подготовки к лечению, могут получить полноценную консультацию врача через защищённые каналы связи. Также возможна онлайн-связь с психологом, куратором или участником реабилитационной команды. Все сеансы проходят в конфиденциальном формате, с возможностью записи и анализа динамики состояния в дальнейшем. Это особенно важно для тех, кто испытывает тревогу при личном визите или не готов к очной встрече на первых этапах.
Получить дополнительную информацию – http://narkologicheskaya-klinika-samara0.ru
betting online sports [url=https://rusfusion.ru]betting online sports[/url] .
курсовая заказ купить [url=https://kupit-kursovuyu-44.ru/]kupit-kursovuyu-44.ru[/url] .
купить задание для студентов [url=https://kupit-kursovuyu-45.ru/]kupit-kursovuyu-45.ru[/url] .
написать курсовую на заказ [url=https://kupit-kursovuyu-46.ru/]написать курсовую на заказ[/url] .
заказать курсовую работу спб [url=https://kupit-kursovuyu-47.ru/]kupit-kursovuyu-47.ru[/url] .
выполнение курсовых [url=https://kupit-kursovuyu-43.ru/]kupit-kursovuyu-43.ru[/url] .
цена курсовой работы [url=https://kupit-kursovuyu-48.ru/]цена курсовой работы[/url] .
написать курсовую работу на заказ в москве [url=https://kupit-kursovuyu-49.ru/]kupit-kursovuyu-49.ru[/url] .
купить задание для студентов [url=https://kupit-kursovuyu-50.ru/]kupit-kursovuyu-50.ru[/url] .
раскрутка сайта москва [url=https://prodvizhenie-sajtov-v-moskve111.ru/]раскрутка сайта москва[/url] .
internet seo [url=https://prodvizhenie-sajtov11.ru/]prodvizhenie-sajtov11.ru[/url] .
продвижение сайта франция [url=https://prodvizhenie-sajtov13.ru/]prodvizhenie-sajtov13.ru[/url] .
Вывод из запоя на дому возможен только при относительно контролируемом состоянии и после очной оценки нарколога. В таких случаях специалист выезжает в Раменском, проводит осмотр, назначает индивидуальную капельницу, остаётся до стабилизации состояния и оставляет подробные рекомендации. Важный момент — честность: если во время осмотра врач видит риски (нестабильное давление, признаки начинающегося делирия, серьёзные боли, глубокую дезориентацию), формат на дому не навязывается, а предлагается стационар. Именно это отличает клинику от анонимных «служб капельниц», для которых любая заявка — повод заработать, независимо от последствий.
Подробнее тут – [url=https://vyvod-iz-zapoya-ramenskoe10.ru/]vyvod-iz-zapoya-cena[/url]
Заказать диплом о высшем образовании Вряд ли вы захотите потерять годы своей жизни на то, чтобы “официально” заполучить умения и навыки, которые уже существуют. В конечном итоге решение о покупке диплома университета станет для вас самым оптимальным. И для этого вам надо сделать не так много – лишь найти надежную компанию, занимающуюся изготовлением и продажей дипломов на заказ. Такой вариант даст вам возможность за незначительную сумму и в кратчайшие сроки заполучить диплом из любого высшего учебного заведения страны: [url=http://peticija.online/499684/]peticija.online/499684[/url]
中華職棒賽程台灣球迷的首選資訊平台,提供最即時的中華職棒賽程新聞、球員數據分析,以及精準的比賽預測。
куплю курсовую работу [url=https://kupit-kursovuyu-45.ru/]куплю курсовую работу[/url] .
где можно заказать курсовую [url=https://kupit-kursovuyu-44.ru/]где можно заказать курсовую[/url] .
помощь в написании курсовой работы онлайн [url=https://kupit-kursovuyu-42.ru/]kupit-kursovuyu-42.ru[/url] .
заказ курсовых работ [url=https://kupit-kursovuyu-47.ru/]kupit-kursovuyu-47.ru[/url] .
помощь курсовые [url=https://kupit-kursovuyu-46.ru/]помощь курсовые[/url] .
аудит продвижения сайта [url=https://prodvizhenie-sajtov-v-moskve111.ru/]аудит продвижения сайта[/url] .
купить курсовую работу [url=https://kupit-kursovuyu-50.ru/]купить курсовую работу[/url] .
раскрутка и продвижение сайта [url=https://prodvizhenie-sajtov13.ru/]prodvizhenie-sajtov13.ru[/url] .
поисковое seo в москве [url=https://prodvizhenie-sajtov11.ru/]prodvizhenie-sajtov11.ru[/url] .
курсовая работа недорого [url=https://kupit-kursovuyu-49.ru/]курсовая работа недорого[/url] .
где можно купить курсовую работу [url=https://kupit-kursovuyu-48.ru/]kupit-kursovuyu-48.ru[/url] .
заказать студенческую работу [url=https://kupit-kursovuyu-43.ru/]kupit-kursovuyu-43.ru[/url] .
melbet official [url=https://www.rusfusion.ru]melbet official[/url] .
Выезд нарколога на дом в Серпухове — это возможность получить профессиональную помощь в условиях, когда везти человека в клинику сложно, опасно или он категорически отказывается от госпитализации. Специалисты «СерпуховТрезвие» работают круглосуточно, приезжают по адресу с одноразовыми системами, стерильными расходниками и необходимым набором препаратов, проводят осмотр, оценивают жизненно важные показатели, подбирают индивидуальную капельницу, контролируют реакцию и оставляют подробные рекомендации. Всё происходит конфиденциально, без лишних свидетелей, без осуждения и давления. Цель — не формально «поставить капельницу», а безопасно стабилизировать состояние, снизить интоксикацию, выровнять давление и пульс, уменьшить тревогу и вернуть человеку возможность нормально спать и восстанавливаться, не доводя до осложнений и экстренной госпитализации.
Получить дополнительную информацию – [url=https://narkolog-na-dom-serpuhov10.ru/]narkolog-na-dom-kruglosutochno-ceny[/url]
Психотерапевтическая часть лечения строится на многоступенчатой программе. Вначале пациент учится понимать свои зависимости, выявлять скрытые мотивы употребления и работать с сопротивлением. На следующем этапе — формируется навык противостояния стрессу, прорабатываются внутрисемейные конфликты и создаются новые стратегии поведения. В финале — акцент на социализацию, возвращение к активной жизни, построение трезвого будущего. Используются как индивидуальные сессии, так и терапевтические группы, телемосты и онлайн-курсы.
Углубиться в тему – [url=https://narkologicheskaya-klinika-samara0.ru/]наркологическая клиника лечение алкоголизма в самаре[/url]
купить задание для студентов [url=https://kupit-kursovuyu-44.ru/]kupit-kursovuyu-44.ru[/url] .
куплю курсовую работу [url=https://kupit-kursovuyu-45.ru/]куплю курсовую работу[/url] .
курсовая заказать [url=https://kupit-kursovuyu-42.ru/]курсовая заказать[/url] .
студенческие работы на заказ [url=https://kupit-kursovuyu-47.ru/]kupit-kursovuyu-47.ru[/url] .
решение курсовых работ на заказ [url=https://kupit-kursovuyu-50.ru/]kupit-kursovuyu-50.ru[/url] .
выполнение курсовых [url=https://kupit-kursovuyu-46.ru/]выполнение курсовых[/url] .
оптимизация сайта франция цена [url=https://prodvizhenie-sajtov-v-moskve111.ru/]prodvizhenie-sajtov-v-moskve111.ru[/url] .
seo продвижение и раскрутка сайта [url=https://prodvizhenie-sajtov11.ru/]seo продвижение и раскрутка сайта[/url] .
интернет агентство продвижение сайтов сео [url=https://prodvizhenie-sajtov13.ru/]prodvizhenie-sajtov13.ru[/url] .
написать курсовую работу на заказ в москве [url=https://kupit-kursovuyu-49.ru/]kupit-kursovuyu-49.ru[/url] .
casino online slot
Слот Gates of Olympus — известный слот от Pragmatic Play с механикой Pay Anywhere, цепочками каскадов и множителями до ?500. Игра проходит на Олимпе, где бог грома активирует множители и делает каждый спин случайным.
Сетка слота выполнено в формате 6?5, а комбинация начисляется при сборе не менее 8 совпадающих символов в любой позиции. После формирования выигрыша символы исчезают, на их место опускаются новые элементы, формируя каскады, способные принести дополнительные выигрыши за один спин. Слот относится волатильным, поэтому может долго раскачиваться, но в благоприятные моменты может принести большие выигрыши до ?5000 от ставки.
Чтобы разобраться в слоте доступен демо-версия без финансового риска. Для ставок на деньги целесообразно выбирать официальные казино, например MELBET (18+), ориентируясь на RTP около 96,5% и условия площадки.
дипломные работы на заказ [url=https://kupit-kursovuyu-48.ru/]дипломные работы на заказ[/url] .
написание курсовой работы на заказ цена [url=https://kupit-kursovuyu-43.ru/]kupit-kursovuyu-43.ru[/url] .
мел бет букмекерская контора официальный сайт [url=http://rusfusion.ru]мел бет букмекерская контора официальный сайт[/url] .
купить диплом ооо знак [url=https://www.r-diploma31.ru]купить диплом ооо знак[/url] .
Мы изготавливаем дипломы любой профессии по выгодным тарифам. Важно, чтобы документы были доступны для подавляющей массы граждан. Приобрести диплом любого ВУЗа [url=http://bio.rocketapps.pro/kerstin71m/]bio.rocketapps.pro/kerstin71m[/url]
Мы предлагаем дипломы любой профессии по невысоким ценам.– [url=http://energypowerworld.co.uk/read-blog/251482_kupit-diplom-o-srednem.html/]energypowerworld.co.uk/read-blog/251482_kupit-diplom-o-srednem.html[/url]
Заказать диплом ВУЗа по выгодной цене возможно, обратившись к надежной специализированной компании. Для проверки компании до заказа воспользуйтесь отзывами других клиентов в сети интернет. Можно приобрести диплом из любого университета Российской Федерации [url=http://carrefourtalents.com/employeur/rudiplomista-24/]carrefourtalents.com/employeur/rudiplomista-24[/url]
курсовая работа купить москва [url=https://kupit-kursovuyu-44.ru/]курсовая работа купить москва[/url] .
купить курсовую москва [url=https://kupit-kursovuyu-47.ru/]kupit-kursovuyu-47.ru[/url] .
сколько стоит сделать курсовую работу на заказ [url=https://kupit-kursovuyu-45.ru/]kupit-kursovuyu-45.ru[/url] .
сколько стоит сделать курсовую работу на заказ [url=https://kupit-kursovuyu-42.ru/]kupit-kursovuyu-42.ru[/url] .
сайт для заказа курсовых работ [url=https://kupit-kursovuyu-50.ru/]kupit-kursovuyu-50.ru[/url] .
internetagentur seo [url=https://prodvizhenie-sajtov-v-moskve111.ru/]prodvizhenie-sajtov-v-moskve111.ru[/url] .
покупка курсовых работ [url=https://kupit-kursovuyu-46.ru/]покупка курсовых работ[/url] .
escorts in abu dhabi escorts in abu dhabi escorts in abu dhabi escorts in abu dhabi escorts in abu dhabi escorts in abu dhabi escorts in abu dhabi escorts in abu dhabi escorts in abu dhabi escorts in abu dhabi
купить диплом гибдд [url=https://r-diploma30.ru/]https://r-diploma30.ru/[/url] .
где можно купить курсовую работу [url=https://kupit-kursovuyu-49.ru/]где можно купить курсовую работу[/url] .
интернет агентство продвижение сайтов сео [url=https://prodvizhenie-sajtov11.ru/]prodvizhenie-sajtov11.ru[/url] .
продвижение сайта [url=https://prodvizhenie-sajtov13.ru/]prodvizhenie-sajtov13.ru[/url] .
купить курсовую работу [url=https://kupit-kursovuyu-48.ru/]купить курсовую работу[/url] .
Купить диплом университета по выгодной цене возможно, обращаясь к проверенной специализированной компании. Для проверки компании до покупки пользуйтесь реальными отзывами на форумах. Можно купить диплом из любого института РФ [url=http://nairahome.com/author/damionmccubbin/]nairahome.com/author/damionmccubbin[/url]
Мы предлагаем дипломы любой профессии по приятным тарифам. Цена зависит от выбранной специальности, года получения и образовательного учреждения: [url=http://mestovstrechi.flybb.ru/viewtopic.php?f=4&t=2077/]mestovstrechi.flybb.ru/viewtopic.php?f=4&t=2077[/url]
выполнение курсовых [url=https://kupit-kursovuyu-43.ru/]kupit-kursovuyu-43.ru[/url] .
мелбет сайт [url=https://rusfusion.ru/]мелбет сайт[/url] .
online slots Gates of Olympus от Pragmatic Play —
Gates of Olympus slot — популярный слот от Pragmatic Play с принципом Pay Anywhere, цепочками каскадов и усилителями выигрыша до ?500. Сюжет разворачивается в мире Олимпа, где бог грома повышает выплаты и превращает каждое вращение случайным.
Экран игры выполнено в формате 6?5, а выплата засчитывается при выпадении 8 и более совпадающих символов в любой позиции. После расчёта комбинации символы исчезают, их заменяют новые элементы, запуская цепочки каскадов, дающие возможность получить дополнительные выигрыши за один спин. Слот считается игрой с высокой волатильностью, поэтому не всегда даёт выплаты, но в благоприятные моменты даёт крупные заносы до 5000 ставок.
Чтобы разобраться в слоте доступен демо-режим без финансового риска. Для игры на деньги рекомендуется рассматривать проверенные казино, например MELBET (18+), учитывая RTP около 96,5% и условия конкретной платформы.
Мы изготавливаем дипломы любых профессий по приятным ценам. Цена зависит от определенной специальности, года выпуска и образовательного учреждения: [url=http://git.todayisyou.co.kr/dyanpadgett49/dyan1990/-/issues/1/]git.todayisyou.co.kr/dyanpadgett49/dyan1990/-/issues/1[/url]
Не каждый работодатель проводит тщательную проверку дипломов работников. Большинство компаний вполне доверяют кандидатам и без проблем принимают их документы. В подобной ситуации покупка диплома ВУЗа является мудрым решением. Не потребуется терять массу времени и денег на учебу. Мы предлагаем дипломы любых профессий по приятным тарифам: [url=http://censornet.ru/https-russiany-diplomx-com-kupit-diplom-ptu/]censornet.ru/https-russiany-diplomx-com-kupit-diplom-ptu[/url]
Мы предлагаем документы институтов, расположенных на территории России.
Заказать диплом любого университета: [url=http://vagyonor.hu/employer/premialnie-diplom-24]vagyonor.hu/employer/premialnie-diplom-24[/url]
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по разумным ценам. Купить диплом об образовании [url=http://extra-v.store/forum/?PAGE_NAME=profile_view&UID=5046/]extra-v.store/forum/?PAGE_NAME=profile_view&UID=5046[/url]
Мы изготавливаем дипломы любых профессий по приятным ценам. Приобрести диплом о высшем образовании [url=http://sciencenewhop.maxbb.ru/viewtopic.php?f=44&t=1505/]sciencenewhop.maxbb.ru/viewtopic.php?f=44&t=1505[/url]
Процесс детоксикации проходит поэтапно, чтобы организм успевал адаптироваться к изменениям и не испытывал стресс. Каждый шаг направлен на достижение конкретного терапевтического эффекта. Ниже представлена таблица, отражающая ключевые стадии процедуры, применяемой в клинике «Трезвый Путь Волгоград».
Ознакомиться с деталями – [url=https://vivod-iz-zapoya-v-volgograde17.ru/]вывод из запоя капельница[/url]
Мы можем предложить дипломы любых профессий по приятным ценам. Диплом об образовании в СССР считался ключевым документом, который способствовал успешному трудоустройству. Приобрести диплом об образовании!: [url=http://divineinfosoft.in/ronaldpratten/]divineinfosoft.in/ronaldpratten[/url]
Мы готовы предложить дипломы психологов, юристов, экономистов и других профессий по невысоким ценам. Заказать диплом о высшем образовании [url=http://aber.ae/estate_agent/gusdunningham/]aber.ae/estate_agent/gusdunningham[/url]
Доступность услуги и оперативность реагирования гарантируют, что помощь будет оказана в течение 30–60 минут после вызова. Это позволяет не только быстро начать детоксикацию, но и минимизировать риск развития осложнений, таких как повреждение печени, почек и сердечно-сосудистой системы.
Получить больше информации – [url=https://vyvod-iz-zapoya-tula000.ru/]вывод из запоя на дому круглосуточно[/url]
Мы изготавливаем дипломы любой профессии по приятным ценам. Диплом об образовании когда-то считался ключевым документом, способствовавшим быстрому и успешному поиску работы. Купить диплом любого ВУЗа!: [url=http://kosmostil.ru/forum/?PAGE_NAME=profile_view&UID=9335/]kosmostil.ru/forum/?PAGE_NAME=profile_view&UID=9335[/url]
Мы изготавливаем дипломы любой профессии по доступным тарифам. Купить диплом врача в нашей компании — [url=http://bestnasos.ru/forum/user/5574/]bestnasos.ru/forum/user/5574[/url]
В лабиринте ставок, где любой ресурс пытается привлечь заверениями простых джекпотов, рейтинг топ лучших казино
является той самой ориентиром, что ведет мимо ловушки рисков. Игрокам хайроллеров да новичков, которые пресытился с пустых заверений, такой средство, чтобы увидеть реальную rtp, словно ощущение ценной монеты у ладони. Минус лишней болтовни, просто надёжные сайты, там отдача не только цифра, а ощутимая фортуна.Собрано на основе гугловых запросов, будто сеть, что вылавливает самые горячие тренды по интернете. Тут отсутствует пространства для стандартных приёмов, всякий пункт как карта в игре, в котором подвох выявляется немедленно. Игроки понимают: по рунете стиль письма и сарказмом, в котором ирония маскируется как совет, позволяет избежать ловушек.В https://wakelet.com/wake/F-2AmtoVbnvzu3Xl488Wb данный рейтинг ждёт будто открытая колода, приготовленный для старту. Зайди, если нужно ощутить пульс настоящей игры, без иллюзий и разочарований. Для что любит ощущение выигрыша, такое будто держать фишки у пальцах, а не глядеть в экран.
куплю диплом медсестры в москве [url=www.frei-diplom13.ru]куплю диплом медсестры в москве[/url] .
Приобрести документ института можно в нашей компании в Москве. Мы оказываем услуги по продаже документов об окончании любых ВУЗов России. Даем гарантию, что при проверке документов работодателями, никаких подозрений не появится: [url=http://tropicalfishfun.com/60/tropical-fish/what-is-the-aquarium-cycle/]tropicalfishfun.com/60/tropical-fish/what-is-the-aquarium-cycle[/url]
сколько стоит купить диплом медсестры [url=frei-diplom13.ru]сколько стоит купить диплом медсестры[/url] .
我們的台灣運彩專家團隊每日更新各大聯盟的比賽分析,包括NBA、MLB、中華職棒等。
Приобрести диплом о высшем образовании. Изготовление диплома занимает немного времени, а стоимость при этом доступна любому человеку. Таким образом вы сможете сохранить деньги и время и найти прекрасную работу вашей мечты. Заказать диплом на заказ можно используя официальный сайт компании. – [url=http://mystroycenter.ru/nastoyashhie-diplomyi-s-arhivnoy-zapisyu/]mystroycenter.ru/nastoyashhie-diplomyi-s-arhivnoy-zapisyu[/url]
Заказать диплом института по доступной стоимости вы сможете, обращаясь к проверенной специализированной компании: [url=http://arezonrp.forumex.ru/viewtopic.php?f=13&t=2023/]arezonrp.forumex.ru/viewtopic.php?f=13&t=2023[/url]
купила диплом и работаю в аптеке [url=https://www.r-diploma31.ru]купила диплом и работаю в аптеке[/url] .
1win canlı kazino [url=https://1win5762.help]https://1win5762.help[/url]
[b]Диплом по специальности на выбор[/b]. Мы изготавливаем дипломы любой профессии по приятным тарифам: [url=http://ijazmoverpackers.ae/kupit-diplom-o-vysshem-obrazovanii-nedorogo-44/]ijazmoverpackers.ae/kupit-diplom-o-vysshem-obrazovanii-nedorogo-44[/url]
где можно заказать курсовую [url=https://kupit-kursovuyu-41.ru/]kupit-kursovuyu-41.ru[/url] .
сделать аудит сайта цена [url=https://prodvizhenie-sajtov-v-moskve113.ru/]prodvizhenie-sajtov-v-moskve113.ru[/url] .
казино с бонусами и фриспинами онлайн
Чтобы исключить суету и случайные усиления, первые часы делим на небольшие «окна»: цель — действие — маркер — критерий перехода. Если отклика нет, корректируется один элемент — темп инфузии, очередность модулей или поведенческий якорь — и назначается новая точка оценки.
Углубиться в тему – [url=https://vyvod-iz-zapoya-saratov0.ru/]врач вывод из запоя в саратове[/url]
Мы можем предложить документы университетов, расположенных в любом регионе России.
Заказать диплом о высшем образовании: [url=http://hitman.getbb.ru/viewtopic.php?f=16&t=5239]hitman.getbb.ru/viewtopic.php?f=16&t=5239[/url]
Мы готовы предложить дипломы любых профессий по приятным ценам. Цена будет зависеть от определенной специальности, года выпуска и образовательного учреждения: [url=http://peticije.online/498837/]peticije.online/498837[/url]
click now https://upshift.cfd/
заказать дипломную работу в москве [url=https://kupit-kursovuyu-41.ru/]kupit-kursovuyu-41.ru[/url] .
В медицинской практике используются различные методы, которые помогают ускорить процесс восстановления. Все процедуры проводятся под контролем специалистов и с учетом индивидуальных особенностей пациента.
Детальнее – https://vyvod-iz-zapoya-omsk0.ru/vyvod-iz-zapoya-omsk-kruglosutochno
seo агентство [url=https://prodvizhenie-sajtov-v-moskve113.ru/]seo агентство[/url] .
Вывод из запоя в Раменском — это не просто «поставить капельницу и отпустить домой», а комплекс медицинских действий, от которых напрямую зависит здоровье, а иногда и жизнь человека. Длительное употребление алкоголя приводит к тяжёлой интоксикации, нарушению работы сердца, печени, головного мозга, сбоям давления, риску судорог, психозов и резких обострений хронических заболеваний. Попытки самостоятельно «сойти с дистанции» дома, с помощью случайных таблеток, седативных препаратов и новых доз алкоголя, часто только усугубляют состояние. Наркологическая клиника «РаменМед Трезвость» в Раменском выстраивает вывод из запоя как безопасный, контролируемый, поэтапный процесс: от экстренного купирования симптомов до формирования плана дальнейшего восстановления. Пациент получает помощь без осуждения, анонимно, с участием специалистов, которые берут на себя ответственность за каждое назначение и каждое действие. Для родственников это означает: больше не нужно гадать, чего бояться и что давать — есть конкретное место и команда, к которым можно обратиться сразу.
Подробнее тут – http://vyvod-iz-zapoya-ramenskoe10.ru
Приобрести официальный диплом университета : [url=http://minilink.nl/augusttrotter/]minilink.nl/augusttrotter[/url]
海外华人必备的yifan官方认证平台,24小时不间断提供最新高清电影、电视剧,无广告观看体验。
Не каждый работодатель проводит тщательную проверку дипломов своих сотрудников. Большинство компаний вполне доверяют соискателям и “вслепую” принимают важный документ. В подобной ситуации покупка диплома российского университета является мудрым решением. Не потребуется терять множество времени и денег на очное обучение. Мы можем предложить дипломы любой профессии по приятным тарифам: [url=http://w98804oc.beget.tech/2025/10/09/kupit-diplom-s-garantiey-podlinnosti.html/]w98804oc.beget.tech/2025/10/09/kupit-diplom-s-garantiey-podlinnosti.html[/url]
1win az canlı mərclər [url=www.1win5762.help]1win az canlı mərclər[/url]
В Волгограде сформирована система оказания наркологической помощи, включающая круглосуточные выезды специалистов, амбулаторное лечение, стационарные программы и реабилитацию. Такой подход позволяет охватить все категории пациентов — от тех, кто нуждается в экстренной помощи, до тех, кто готов пройти полный курс терапии. Независимо от формы оказания услуг, лечение проводится конфиденциально и в соответствии с медицинскими стандартами.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-pomoshh-v-volgograde17.ru/]неотложная наркологическая помощь[/url]
оптимизация сайта франция цена [url=https://prodvizhenie-sajtov-v-moskve117.ru/]prodvizhenie-sajtov-v-moskve117.ru[/url] .
продвижения сайта в google [url=https://prodvizhenie-sajtov-v-moskve214.ru/]prodvizhenie-sajtov-v-moskve214.ru[/url] .
раскрутка и продвижение сайта [url=https://prodvizhenie-sajtov-v-moskve213.ru/]prodvizhenie-sajtov-v-moskve213.ru[/url] .
продвижение сайтов в москве [url=https://prodvizhenie-sajtov-v-moskve216.ru/]продвижение сайтов в москве[/url] .
интернет агентство продвижение сайтов сео [url=https://prodvizhenie-sajtov-v-moskve223.ru/]prodvizhenie-sajtov-v-moskve223.ru[/url] .
seo partner program [url=https://prodvizhenie-sajtov-v-moskve225.ru/]prodvizhenie-sajtov-v-moskve225.ru[/url] .
поисковое продвижение москва профессиональное продвижение сайтов [url=https://prodvizhenie-sajtov-v-moskve115.ru/]prodvizhenie-sajtov-v-moskve115.ru[/url] .
продвижение сайтов [url=https://prodvizhenie-sajtov-v-moskve224.ru/]продвижение сайтов[/url] .
раскрутка сайта франция цена [url=https://prodvizhenie-sajtov-v-moskve222.ru/]раскрутка сайта франция цена[/url] .
поисковое seo в москве [url=https://prodvizhenie-sajtov-v-moskve119.ru/]поисковое seo в москве[/url] .
1win qeydiyyat aviator [url=http://1win5762.help/]http://1win5762.help/[/url]
новые онлайн казино с минимальными ставками и бонусами
усиление ссылок переходами [url=https://prodvizhenie-sajtov-v-moskve221.ru/]prodvizhenie-sajtov-v-moskve221.ru[/url] .
курсовой проект цена [url=https://kupit-kursovuyu-41.ru/]kupit-kursovuyu-41.ru[/url] .
раскрутка и продвижение сайта [url=https://prodvizhenie-sajtov-v-moskve113.ru/]раскрутка и продвижение сайта[/url] .
Алкогольная интоксикация и запой могут стремительно ухудшить состояние здоровья, став угрозой жизни, поэтому оперативное вмешательство имеет первостепенное значение. В Туле квалифицированные наркологи предоставляют круглосуточную помощь на дому, что позволяет начать лечение незамедлительно и в комфортных условиях. Такой формат терапии гарантирует индивидуальный подход, всестороннюю поддержку и полную конфиденциальность, что особенно важно для пациентов, стремящихся восстановить своё здоровье без лишних стрессовых ситуаций.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-tula000.ru/]вывод из запоя тула.[/url]
Мы готовы предложить дипломы психологов, юристов, экономистов и прочих профессий по приятным ценам. Важно, чтобы документы были доступными для подавляющей массы наших граждан. Быстро и просто приобрести диплом об образовании [url=http://setiaskyvista.com/author/phoebehelm609/]setiaskyvista.com/author/phoebehelm609[/url]
Получить больше информации – https://fastwpdemo.com/newwp/finbank/2022/09/16/holds-in-these-matters-to-this-principle-of-selection/#comment-57061
從英超、西甲、德甲到中超,全球各大足球聯盟的7m足球運用大數據AI分析引擎即時比分都在這裡。
купить диплом боевой [url=http://r-diploma29.ru]купить диплом боевой[/url] .
폰테크
Мы изготавливаем дипломы любой профессии по выгодным тарифам. Цена может зависеть от конкретной специальности, года получения и университета: [url=http://zammeswiss.com/read-blog/5782_kupit-diplom-o-srednem-obrazovanii.html/]zammeswiss.com/read-blog/5782_kupit-diplom-o-srednem-obrazovanii.html[/url]
internetagentur seo [url=https://prodvizhenie-sajtov-v-moskve225.ru/]prodvizhenie-sajtov-v-moskve225.ru[/url] .
поисковое продвижение сайта в интернете москва [url=https://prodvizhenie-sajtov-v-moskve223.ru/]prodvizhenie-sajtov-v-moskve223.ru[/url] .
частный seo оптимизатор [url=https://prodvizhenie-sajtov-v-moskve117.ru/]частный seo оптимизатор[/url] .
net seo [url=https://prodvizhenie-sajtov-v-moskve214.ru/]prodvizhenie-sajtov-v-moskve214.ru[/url] .
продвижение сайта франция [url=https://prodvizhenie-sajtov-v-moskve215.ru/]prodvizhenie-sajtov-v-moskve215.ru[/url] .
профессиональное продвижение сайтов [url=https://prodvizhenie-sajtov-v-moskve213.ru/]prodvizhenie-sajtov-v-moskve213.ru[/url] .
аудит продвижения сайта [url=https://prodvizhenie-sajtov-v-moskve224.ru/]аудит продвижения сайта[/url] .
аудит продвижения сайта [url=https://prodvizhenie-sajtov-v-moskve216.ru/]аудит продвижения сайта[/url] .
Как подчёркивает специалист ФГБУ «НМИЦ психиатрии и наркологии», «без участия квалифицированной команды невозможно обеспечить комплексный подход к пациенту, особенно если речь идёт о длительном стаже употребления и осложнённой картине заболевания». Отсюда следует — изучение состава персонала должно быть одним из первых шагов.
Исследовать вопрос подробнее – [url=https://lechenie-alkogolizma-murmansk0.ru/]центр лечения алкоголизма мурманск[/url]
seo partner program [url=https://prodvizhenie-sajtov-v-moskve222.ru/]seo partner program[/url] .
продвижение в google [url=https://prodvizhenie-sajtov-v-moskve115.ru/]prodvizhenie-sajtov-v-moskve115.ru[/url] .
поисковое продвижение сайта в интернете москва [url=https://prodvizhenie-sajtov-v-moskve221.ru/]поисковое продвижение сайта в интернете москва[/url] .
купить курсовую москва [url=https://kupit-kursovuyu-41.ru/]kupit-kursovuyu-41.ru[/url] .
продвижение сайта [url=https://prodvizhenie-sajtov-v-moskve113.ru/]продвижение сайта[/url] .
продвижение сайта франция [url=https://prodvizhenie-sajtov-v-moskve119.ru/]продвижение сайта франция[/url] .
Мы изготавливаем дипломы любых профессий по разумным ценам. Важно, чтобы дипломы были доступны для подавляющей массы наших граждан. Выгодно заказать диплом университета [url=http://sakhd.3nx.ru/viewtopic.php?p=3979#3979/]sakhd.3nx.ru/viewtopic.php?p=3979#3979[/url]
книга учета и записи аттестатов об основном общем образовании купить [url=http://r-diploma28.ru]книга учета и записи аттестатов об основном общем образовании купить[/url] .
Благодаря комплексному подходу достигается не только снятие симптомов, но и долгосрочная стабилизация состояния пациента.
Детальнее – [url=https://narkologicheskaya-pomoshh-v-volgograde17.ru/]нарколог наркологическая помощь[/url]
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по доступным ценам. Цена зависит от выбранной специальности, года получения и университета: [url=http://deanonnic.listbb.ru/viewtopic.php?f=5&t=3496/]deanonnic.listbb.ru/viewtopic.php?f=5&t=3496[/url]
поисковое продвижение москва профессиональное продвижение сайтов [url=https://prodvizhenie-sajtov-v-moskve225.ru/]prodvizhenie-sajtov-v-moskve225.ru[/url] .
раскрутка и продвижение сайта [url=https://prodvizhenie-sajtov-v-moskve223.ru/]prodvizhenie-sajtov-v-moskve223.ru[/url] .
продвижения сайта в google [url=https://prodvizhenie-sajtov-v-moskve214.ru/]prodvizhenie-sajtov-v-moskve214.ru[/url] .
продвижение сайта франция [url=https://prodvizhenie-sajtov-v-moskve216.ru/]prodvizhenie-sajtov-v-moskve216.ru[/url] .
оптимизация сайта франция [url=https://prodvizhenie-sajtov-v-moskve117.ru/]prodvizhenie-sajtov-v-moskve117.ru[/url] .
интернет раскрутка [url=https://prodvizhenie-sajtov-v-moskve215.ru/]prodvizhenie-sajtov-v-moskve215.ru[/url] .
интернет агентство продвижение сайтов сео [url=https://prodvizhenie-sajtov-v-moskve224.ru/]prodvizhenie-sajtov-v-moskve224.ru[/url] .
продвижение сайтов [url=https://prodvizhenie-sajtov-v-moskve213.ru/]prodvizhenie-sajtov-v-moskve213.ru[/url] .
продвижение сайтов интернет магазины в москве [url=https://prodvizhenie-sajtov-v-moskve222.ru/]продвижение сайтов интернет магазины в москве[/url] .
Быстро и просто приобрести диплом ВУЗа. Производство диплома занимает минимум времени, а стоимость при этом доступна каждому. В результате вы сможете сберечь бюджет и получить работу мечты. Заказать диплом под заказ в Москве можно через сайт компании. – [url=http://podrabotke.flybb.ru/viewtopic.php?f=2&t=896/]podrabotke.flybb.ru/viewtopic.php?f=2&t=896[/url]
seo аудит веб сайта [url=https://prodvizhenie-sajtov-v-moskve221.ru/]seo аудит веб сайта[/url] .
Мы изготавливаем дипломы любых профессий по разумным тарифам. Заказать диплом любого института [url=http://nadegda.listbb.ru/viewtopic.php?f=3&t=2796/]nadegda.listbb.ru/viewtopic.php?f=3&t=2796[/url]
продвинуть сайт в москве [url=https://prodvizhenie-sajtov-v-moskve115.ru/]prodvizhenie-sajtov-v-moskve115.ru[/url] .
Купить диплом университета по невысокой стоимости можно, обращаясь к надежной специализированной компании: [url=http://safepook.site/celiatolli/]safepook.site/celiatolli[/url]
оптимизация сайта франция [url=https://prodvizhenie-sajtov-v-moskve119.ru/]оптимизация сайта франция[/url] .
Мы изготавливаем дипломы любой профессии по приятным ценам. Диплом о высшем образовании прежде считался основным документом, который способствовал удачному устройству на работу. Выгодно заказать диплом любого института!: [url=http://41.89.31.26/kemuwiki/index.php/User:KaleyPendleton/]41.89.31.26/kemuwiki/index.php/User:KaleyPendleton[/url]
Когда острые угрозы исключены, программа стартует дома. Пациент получает понятную карту действий, близкие — короткие окна обратной связи, врач — чистую «картинку» для тонкой настройки. Мы просим сообщать факты, а не эмоции: минуты до засыпания, число пробуждений, объём тёплой воды малыми глотками, пульс к вечеру, переносимость мягкой пищи, ясность головы утром.
Подробнее – [url=https://vyvod-iz-zapoya-saratov0.ru/]анонимный вывод из запоя в саратове[/url]
check out the post right here https://tophat.cc
seo network [url=https://prodvizhenie-sajtov-v-moskve225.ru/]prodvizhenie-sajtov-v-moskve225.ru[/url] .
Одна из сильных сторон «РеутовМед Сервис» — честная оценка границ домашнего лечения. Клиника не обещает «вывезем любого дома», потому что есть состояния, при которых отсутствие круглосуточного наблюдения опасно. Чтобы родным было проще сориентироваться, важно разделить ситуации по уровню риска и понять, почему иногда разумнее выбрать стационар, даже если пациент сопротивляется.
Выяснить больше – [url=https://vyvod-iz-zapoya-reutov10.ru/]вывод из запоя дешев реутове[/url]
поисковое seo в москве [url=https://prodvizhenie-sajtov-v-moskve216.ru/]поисковое seo в москве[/url] .
компании занимающиеся продвижением сайтов [url=https://prodvizhenie-sajtov-v-moskve214.ru/]prodvizhenie-sajtov-v-moskve214.ru[/url] .
[b]Диплом по специальности на выбор[/b]. Мы готовы предложить дипломы психологов, юристов, экономистов и других профессий по приятным тарифам: [url=http://dirtydeleted.net/index.php/User:MargieLuker0915/]dirtydeleted.net/index.php/User:MargieLuker0915[/url]
Инфузионная терапия (капельницы) — важная часть лечения, направленная на очищение организма, восстановление водно-солевого баланса и устранение токсинов. В «РязаньМед Альянс» используются проверенные препараты, которые помогают нормализовать работу внутренних органов и улучшить общее самочувствие. Таблица ниже показывает, какие виды капельниц чаще всего применяются при выведении из запоя и лечении алкоголизма.
Детальнее – [url=https://narkologicheskaya-klinika-v-ryazani17.ru/]наркологическая клиника вывод из запоя в рязани[/url]
seo partner program [url=https://prodvizhenie-sajtov-v-moskve223.ru/]prodvizhenie-sajtov-v-moskve223.ru[/url] .
интернет раскрутка [url=https://prodvizhenie-sajtov-v-moskve215.ru/]prodvizhenie-sajtov-v-moskve215.ru[/url] .
сделать аудит сайта цена [url=https://prodvizhenie-sajtov-v-moskve224.ru/]prodvizhenie-sajtov-v-moskve224.ru[/url] .
internetagentur seo [url=https://prodvizhenie-sajtov-v-moskve222.ru/]internetagentur seo[/url] .
сео агентство [url=https://prodvizhenie-sajtov-v-moskve213.ru/]prodvizhenie-sajtov-v-moskve213.ru[/url] .
интернет раскрутка [url=https://prodvizhenie-sajtov-v-moskve117.ru/]интернет раскрутка[/url] .
that site https://unchainx.org
купить диплом педагогического колледжа в волгодонске [url=www.r-diploma31.ru]купить диплом педагогического колледжа в волгодонске[/url] .
раскрутка и продвижение сайта [url=https://prodvizhenie-sajtov-v-moskve221.ru/]раскрутка и продвижение сайта[/url] .
компании занимающиеся продвижением сайтов [url=https://prodvizhenie-sajtov-v-moskve115.ru/]компании занимающиеся продвижением сайтов[/url] .
Каждый этап проходит под контролем врачей-наркологов и психотерапевтов, что гарантирует эффективность и безопасность лечения.
Исследовать вопрос подробнее – [url=https://narcologicheskaya-klinika-v-novokuzneczke17.ru/]наркологическая клиника цены новокузнецк[/url]
Мы можем предложить документы институтов, которые находятся в любом регионе Российской Федерации.
Купить диплом любого ВУЗа: [url=http://wow-tour.ru/kupit-diplom-istorika-dannyie-v-reestre]wow-tour.ru/kupit-diplom-istorika-dannyie-v-reestre[/url]
усиление ссылок переходами [url=https://prodvizhenie-sajtov-v-moskve119.ru/]усиление ссылок переходами[/url] .
Ключевой элемент вывода из запоя в Реутове — правильно подобранная капельница, но в «РеутовМед Сервис» её рассматривают не как волшебное средство, а как часть комплексной терапевтической схемы. Основная цель — не «вырубить» человека сильными седативными коктейлями, а помочь организму безопасно выйти из состояния интоксикации. В инфузионную терапию входят растворы для регидратации, которые восполняют потерю жидкости, снижают вязкость крови, улучшают микроциркуляцию и работу внутренних органов. Коррекция электролитного баланса помогает уменьшить дрожь, мышечную слабость, снизить риск нарушений сердечного ритма. Применяются витамины группы B и препараты магния для поддержки нервной системы, снижения раздражительности и вероятности судорог. По показаниям добавляются гепатопротекторы, мягкие антиоксиданты для разгрузки печени, противорвотные средства при выраженной тошноте, щадящие анксиолитики для снижения тревоги и нормализации сна без грубого угнетения сознания. Все дозировки учитывают сопутствующие заболевания и возраст, что особенно важно для пациентов с гипертонией, ИБС, диабетом, поражением печени и пожилых людей. Эффект оценивается по объективным критериям: стабилизация давления и пульса, уменьшение дрожи, улучшение самочувствия, нормализация сна и поведения, а не только по фразе «стал тихим».
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-reutov10.ru/]vyvod-iz-zapoya-reutov[/url]
Главная задача процедуры — быстрое выведение этанола и его метаболитов из организма, нормализация уровня электролитов, улучшение самочувствия и предотвращение осложнений. Лечение проводится как в клинике, так и на дому, что особенно удобно при тяжёлых состояниях, когда пациент не может самостоятельно добраться до медицинского учреждения.
Получить дополнительную информацию – http://vyvod-iz-zapoya-v-tyumeni17.ru
Мы изготавливаем дипломы любых профессий по приятным ценам. Диплом об образовании когда-то считался главным документом, способствовавшим успешному трудоустройству. Приобрести диплом института!: [url=http://viptube.site/halleyzvt65191/]viptube.site/halleyzvt65191[/url]
Мы предлагаем дипломы любой профессии по выгодным тарифам. Цена зависит от конкретной специальности, года выпуска и образовательного учреждения: [url=http://keystaffinggroup.com/employer/aurus-diplom/]keystaffinggroup.com/employer/aurus-diplom[/url]
«Трезвый Путь Коломна» создаёт единый контур помощи: пациент не «перекидывается» между разными организациями, а проходит лечение в одной системе, где специалисты знают его историю и несут ответственность за последовательность шагов. Это критично для тех, кто уже сталкивался с бессистемными попытками: один врач ставил капельницы, другой «кодировал», третий давал советы, а в итоге всё заканчивалось новым срывом. Здесь маршруты связываются в цельную линию.
Узнать больше – http://narkologicheskaya-klinika-kolomna2-10.ru
internet seo [url=https://prodvizhenie-sajtov-v-moskve119.ru/]internet seo[/url] .
Капельница при вызове нарколога на дом в Долгопрудном от «МедТрезвие Долгопрудный» — это клинический инструмент, а не магический раствор. Главное правило — никакой агрессивной седации ради видимости спокойствия. Инфузионная терапия строится вокруг нескольких задач: восполнить жидкость, выровнять электролиты, снизить токсическую нагрузку на печень и мозг, поддержать сердце и нервную систему, уменьшить тремор, тревогу и соматические жалобы. Используются растворы для регидратации и коррекции водно-электролитного баланса, витамины группы B и магний для поддержки нервной системы, уменьшения риска судорог и нормализации сна, по показаниям — гепатопротекторы и мягкие антиоксиданты, противорвотные препараты для контроля тошноты. При выраженной тревоге или нарушениях сна назначаются щадящие анксиолитические средства в дозах, которые не выключают пациента полностью, а помогают снять паническое напряжение, сохраняя возможность оценивать динамику состояния. Врач отслеживает реакцию на терапию: стабилизацию давления и пульса, уменьшение дрожи, улучшение общего самочувствия, появление более спокойного, естественного сна. По мере облегчения нагрузки схема не усиливается ради счёта, а рационально сокращается. Такой подход защищает пациента от скрытых осложнений и превращает капельницу в контролируемый, полезный шаг, а не в рискованный эксперимент.
Подробнее – http://narkolog-na-dom-dolgoprudnij10.ru/vyzvat-narkologa-na-dom-v-dolgoprudnom/https://narkolog-na-dom-dolgoprudnij10.ru
заказать продвижение сайта в москве [url=https://prodvizhenie-sajtov-v-moskve231.ru/]заказать продвижение сайта в москве[/url] .
можно купить диплом медсестры [url=http://www.frei-diplom13.ru]можно купить диплом медсестры[/url] .
играть в слоты онлайн Gates of Olympus от Pragmatic Play —
Gates of Olympus slot — востребованный слот от Pragmatic Play с механикой Pay Anywhere, цепочками каскадов и коэффициентами до ?500. Игра проходит на Олимпе, где Зевс усиливает выигрыши и делает каждый спин непредсказуемым.
Экран игры имеет формат 6?5, а выигрыш начисляется при выпадении не менее 8 идентичных символов в любом месте экрана. После формирования выигрыша символы удаляются, сверху падают новые элементы, формируя серии каскадных выигрышей, дающие возможность получить серию выигрышей за одно вращение. Слот является высоковолатильным, поэтому не всегда даёт выплаты, но при удачных раскладах даёт крупные заносы до 5000? ставки.
Для тестирования игры доступен бесплатный режим без вложений. При реальных ставках стоит использовать лицензированные казино, например MELBET (18+), принимая во внимание RTP около 96,5% и правила выбранного казино.
гейтс оф олимпус 1000
Gates of Olympus — известный слот от Pragmatic Play с механикой Pay Anywhere, каскадами и усилителями выигрыша до ?500. Игра проходит в мире Олимпа, где верховный бог усиливает выигрыши и превращает каждое вращение случайным.
Экран игры представлено в виде 6?5, а выигрыш засчитывается при сборе не менее 8 одинаковых символов в любой позиции. После формирования выигрыша символы исчезают, сверху падают новые элементы, запуская серии каскадных выигрышей, способные принести серию выигрышей за одно вращение. Слот относится высоковолатильным, поэтому не всегда даёт выплаты, но при удачных каскадах даёт крупные заносы до 5000 ставок.
Чтобы разобраться в слоте доступен бесплатный режим без финансового риска. При реальных ставках стоит использовать проверенные казино, например MELBET (18+), ориентируясь на показатель RTP ~96,5% и правила выбранного казино.
Пациенты выбирают нашу клинику для срочного вызова врача-нарколога благодаря следующим важным преимуществам:
Изучить вопрос глубже – [url=https://narcolog-na-dom-novosibirsk00.ru/]нарколог на дом вывод новосибирск[/url]
Даже если симптомы кажутся незначительными, проведение инфузионной терапии значительно ускоряет процесс восстановления и предотвращает развитие осложнений.
Ознакомиться с деталями – https://kapelnicza-ot-zapoya-v-volgograde17.ru/kapelnicza-ot-pokhmelya-volgograd/
В таблице представлены основные виды терапии, применяемые в клинике:
Углубиться в тему – http://narcologicheskaya-klinika-v-novokuzneczke17.ru/narkologicheskij-czentr-novokuzneczk/
奇思妙探第二季高清完整官方版,海外华人可免费观看最新热播剧集。
задвижка ручная 30с41нж задвижка клиновая 30с41нж
сколько стоит купить диплом медсестры [url=https://frei-diplom13.ru]сколько стоит купить диплом медсестры[/url] .
заказать продвижение сайта в москве [url=https://prodvizhenie-sajtov-v-moskve231.ru/]заказать продвижение сайта в москве[/url] .
Как подчёркивает специалист ФГБУ «НМИЦ психиатрии и наркологии», «без участия квалифицированной команды невозможно обеспечить комплексный подход к пациенту, особенно если речь идёт о длительном стаже употребления и осложнённой картине заболевания». Отсюда следует — изучение состава персонала должно быть одним из первых шагов.
Разобраться лучше – [url=https://lechenie-alkogolizma-murmansk0.ru/]лечение алкоголизма в мурманске[/url]
Домашний формат особенно важен, когда пациент не готов к стационару, боится огласки, испытывает стыд или сопротивление, но объективно нуждается в помощи. Попытки «перетерпеть» или лечить своими силами заканчиваются тем, что родственники дают опасные комбинации седативных, анальгетиков и «антипохмельных» средств, а состояние только ухудшается. «МедТрезвие Долгопрудный» строит выездную помощь так, чтобы она оставалась профессиональной медициной, а не косметической услугой. Уже при звонке диспетчер под контролем врача уточняет длительность запоя, виды алкоголя, наличие гипертонии, болезней сердца, печени, почек, диабета, неврологических нарушений, психических эпизодов, факт судорог, делирия в прошлом, какие лекарства уже были даны. Это позволяет заранее понять, подходит ли формат лечения на дому или сразу нужно рассматривать стационар. Выезд назначается только в тех случаях, когда это безопасно, и именно в этом ключевое отличие официальной клиники от анонимных «капельниц на дом» — здесь всегда выбирают жизнь и здоровье, а не удобный маркетинговый сценарий. Для семьи это не просто комфорт, а возможность получить помощь без риска сорваться в критическое состояние посреди ночи.
Получить дополнительную информацию – [url=https://narkolog-na-dom-dolgoprudnij10.ru/]психиатр нарколог на дом[/url]
Каждый этап проходит под контролем врачей-наркологов и психотерапевтов, что гарантирует эффективность и безопасность лечения.
Исследовать вопрос подробнее – http://narcologicheskaya-klinika-v-novokuzneczke17.ru/narkolog-novokuzneczk-na-dom/
Купить диплом института по выгодной стоимости вы можете, обращаясь к проверенной специализированной фирме. Чтобы проверить компанию перед покупкой пользуйтесь отзывами других покупателей в сети интернет. В итоге можно заказать диплом из любого ВУЗа Российской Федерации [url=http://chinajobbox.com/companies/rudiplomista-24/]chinajobbox.com/companies/rudiplomista-24[/url]
Мы изготавливаем дипломы любой профессии по доступным ценам. Важно, чтобы дипломы были доступны для большого количества наших граждан. Заказать диплом о высшем образовании [url=http://gitea.sguba.de/charitywcn3107/]gitea.sguba.de/charitywcn3107[/url]
Домашний формат особенно важен, когда пациент не готов к стационару, боится огласки, испытывает стыд или сопротивление, но объективно нуждается в помощи. Попытки «перетерпеть» или лечить своими силами заканчиваются тем, что родственники дают опасные комбинации седативных, анальгетиков и «антипохмельных» средств, а состояние только ухудшается. «МедТрезвие Долгопрудный» строит выездную помощь так, чтобы она оставалась профессиональной медициной, а не косметической услугой. Уже при звонке диспетчер под контролем врача уточняет длительность запоя, виды алкоголя, наличие гипертонии, болезней сердца, печени, почек, диабета, неврологических нарушений, психических эпизодов, факт судорог, делирия в прошлом, какие лекарства уже были даны. Это позволяет заранее понять, подходит ли формат лечения на дому или сразу нужно рассматривать стационар. Выезд назначается только в тех случаях, когда это безопасно, и именно в этом ключевое отличие официальной клиники от анонимных «капельниц на дом» — здесь всегда выбирают жизнь и здоровье, а не удобный маркетинговый сценарий. Для семьи это не просто комфорт, а возможность получить помощь без риска сорваться в критическое состояние посреди ночи.
Выяснить больше – [url=https://narkolog-na-dom-dolgoprudnij10.ru/]нарколог на дом круглосуточно[/url]
Услуга вывода из запоя на дому в Туле разработана для тех, кто столкнулся с тяжелыми последствиями злоупотребления алкоголем. Основная цель – оперативная детоксикация организма, восстановление нормального обмена веществ и предотвращение дальнейших осложнений. Врач нарколог проводит полный комплекс обследований и назначает персонализированный план лечения, включающий медикаментозную терапию и психологическую поддержку, что позволяет обеспечить стабильное восстановление организма.
Подробнее – [url=https://vyvod-iz-zapoya-tula000.ru/]www.domen.ru[/url]
технического аудита сайта [url=https://prodvizhenie-sajtov-v-moskve231.ru/]prodvizhenie-sajtov-v-moskve231.ru[/url] .
В таблице представлены основные виды терапии, применяемые в клинике:
Получить больше информации – http://narcologicheskaya-klinika-v-novokuzneczke17.ru
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по невысоким тарифам.– [url=http://gismeteo.ru/towns/26825.htm/]gismeteo.ru/towns/26825.htm[/url]
Смотреть здесь [url=https://casebattle.top/]open cs cases[/url]
подробнее [url=https://photmagicai.ru]онлайн редактор фото телеграм[/url]
Приобрести диплом университета по доступной стоимости возможно, обратившись к надежной специализированной компании. Для того, чтобы проверить компанию перед покупкой пользуйтесь рейтингом и отзывами в сети интернет. Можно купить диплом из любого университета РФ [url=http://proservservices.co.uk/kupit-diplom-kolledzha-39/]proservservices.co.uk/kupit-diplom-kolledzha-39[/url]
net seo [url=https://prodvizhenie-sajtov-v-moskve231.ru/]prodvizhenie-sajtov-v-moskve231.ru[/url] .
купить в москве диплом фармацевта [url=www.r-diploma30.ru]купить в москве диплом фармацевта[/url] .
Лечение организовано поэтапно. Такой подход обеспечивает постепенное восстановление функций организма и исключает риск осложнений. Каждый этап терапии направлен на устранение конкретных нарушений, вызванных интоксикацией.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-v-krasnoyarske17.ru/]вывод из запоя вызов на дом в красноярске[/url]
продвижение веб сайтов москва [url=https://prodvizhenie-sajtov-v-moskve233.ru/]продвижение веб сайтов москва[/url] .
seo агентство [url=https://prodvizhenie-sajtov-v-moskve232.ru/]seo агентство[/url] .
раскрутка и продвижение сайта [url=https://prodvizhenie-sajtov-v-moskve235.ru/]раскрутка и продвижение сайта[/url] .
интернет продвижение москва [url=https://poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru/]интернет продвижение москва[/url] .
заказать анализ сайта [url=https://prodvizhenie-sajtov-v-moskve234.ru/]prodvizhenie-sajtov-v-moskve234.ru[/url] .
Когда уместен
Изучить вопрос глубже – https://narkologicheskaya-klinika-odincovo0.ru/narkologicheskaya-klinika-stacionar-v-odincovo/
технического аудита сайта [url=https://kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru/]kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru[/url] .
Капельницы при выводе из запоя — основной инструмент детоксикации. Они очищают кровь, стабилизируют давление и восстанавливают баланс электролитов. В клинике «РеабКузбасс» используются только качественные препараты, адаптированные под конкретное состояние пациента. Ниже приведена таблица с основными видами капельниц и их эффектом.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-novokuzneczke17.ru/]срочный вывод из запоя в новокузнецке[/url]
Мы предлагаем дипломы психологов, юристов, экономистов и других профессий по приятным ценам. Цена будет зависеть от определенной специальности, года получения и университета: [url=http://garagegatenyc.com/garagegateservices.com/diplom-za-korotkij-srok-sroki-ceny-uslovija-166-2/]garagegatenyc.com/garagegateservices.com/diplom-za-korotkij-srok-sroki-ceny-uslovija-166-2[/url]
Мы предлагаем дипломы психологов, юристов, экономистов и других профессий по доступным тарифам. Цена зависит от выбранной специальности, года получения и образовательного учреждения: [url=http://acebrisk.com/agent/ashelyangliss4/]acebrisk.com/agent/ashelyangliss4[/url]
seo partner program [url=https://prodvizhenie-sajtov-v-moskve233.ru/]seo partner program[/url] .
Что включено на практике
Получить дополнительную информацию – https://narkologicheskaya-klinika-shchyolkovo0.ru/anonimnaya-narkologicheskaya-klinika-v-shchyolkovo
поисковое seo в москве [url=https://prodvizhenie-sajtov-v-moskve235.ru/]prodvizhenie-sajtov-v-moskve235.ru[/url] .
продвижение сайтов в москве [url=https://prodvizhenie-sajtov-v-moskve232.ru/]продвижение сайтов в москве[/url] .
интернет продвижение москва [url=https://poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru/]интернет продвижение москва[/url] .
seo partner program [url=https://prodvizhenie-sajtov-v-moskve234.ru/]prodvizhenie-sajtov-v-moskve234.ru[/url] .
Вывод из запоя — это не просто медицинская процедура, а жизненно важный этап, позволяющий вернуть контроль над самочувствием и предотвратить осложнения. В клинике «РеабКузбасс» пациенты получают помощь в любое время суток: опытные наркологи выезжают на дом, проводят капельницы и медикаментозную детоксикацию, подбирают индивидуальные схемы восстановления. Такой подход помогает не только устранить последствия запоя, но и запустить процесс полноценного оздоровления организма.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-v-novokuzneczke17.ru/vyvod-iz-zapoya-v-staczionare-novokuzneczk
продвижение в google [url=https://poiskovoe-prodvizhenie-moskva-professionalnoe.ru/]poiskovoe-prodvizhenie-moskva-professionalnoe.ru[/url] .
блог seo агентства [url=https://blog-o-marketinge1.ru/]blog-o-marketinge1.ru[/url] .
локальное seo блог [url=https://statyi-o-marketinge1.ru/]statyi-o-marketinge1.ru[/url] .
статьи про продвижение сайтов [url=https://blog-o-marketinge.ru/]статьи про продвижение сайтов[/url] .
поисковое seo в москве [url=https://poiskovoe-seo-v-moskve.ru/]poiskovoe-seo-v-moskve.ru[/url] .
1win bet download [url=www.1win5746.help]1win bet download[/url]
руководства по seo [url=https://statyi-o-marketinge2.ru/]statyi-o-marketinge2.ru[/url] .
1win inscription [url=http://1win5745.help]http://1win5745.help[/url]
Когда запой затягивается, организм быстро входит в режим перегрузки: нарушается сон, скачет давление, усиливается тревога, появляется дрожь, тошнота, потливость и резкая слабость. В такой ситуации «перетерпеть» или лечиться домашними средствами — рискованная стратегия: состояние может ухудшаться волнами, а осложнения иногда развиваются резко, без долгой подготовки. Выезд нарколога на дом в Красногорске нужен для того, чтобы снять острую интоксикацию и абстиненцию безопасно, под контролем показателей, без лишней суеты и без поездок по стационарам в разгар плохого самочувствия.
Изучить вопрос глубже – http://narkolog-na-dom-krasnogorsk6.ru/
Вывод из запоя — это не просто медицинская процедура, а жизненно важный этап, позволяющий вернуть контроль над самочувствием и предотвратить осложнения. В клинике «РеабКузбасс» пациенты получают помощь в любое время суток: опытные наркологи выезжают на дом, проводят капельницы и медикаментозную детоксикацию, подбирают индивидуальные схемы восстановления. Такой подход помогает не только устранить последствия запоя, но и запустить процесс полноценного оздоровления организма.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-v-novokuzneczke17.ru/]анонимный вывод из запоя в новокузнецке[/url]
Самый частый повод — не только «плохое похмелье», а именно абстинентный синдром после запоя: когда самочувствие ухудшается при прекращении алкоголя, а попытки «опохмелиться» лишь продлевают проблему. Важно ориентироваться не на терпимость человека к дискомфорту, а на объективные признаки: если симптомы нарастают, сон сорван, поведение становится нестабильным, а тело реагирует паникой, тремором и скачками давления, лучше не тянуть. Особенно осторожными нужно быть при хронических болезнях сердца, печени и сосудов: при них цена ошибки выше, а «универсальные» домашние схемы могут навредить.
Ознакомиться с деталями – [url=https://narkolog-na-dom-krasnogorsk6.ru/]нарколог на дом анонимно[/url]
компании занимающиеся продвижением сайтов [url=https://prodvizhenie-sajtov-v-moskve235.ru/]prodvizhenie-sajtov-v-moskve235.ru[/url] .
глубокий комлексный аудит сайта [url=https://prodvizhenie-sajtov-v-moskve233.ru/]глубокий комлексный аудит сайта[/url] .
how do i use my casino bonus on 1win [url=https://1win5746.help/]https://1win5746.help/[/url]
seo аудит веб сайта [url=https://poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru/]poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru[/url] .
how to insert booking code on 1win [url=1win5745.help]1win5745.help[/url]
seo partner [url=https://prodvizhenie-sajtov-v-moskve232.ru/]seo partner[/url] .
сделать аудит сайта цена [url=https://prodvizhenie-sajtov-v-moskve234.ru/]prodvizhenie-sajtov-v-moskve234.ru[/url] .
Запуск помощи — это не «одна капельница», а последовательность осмысленных шагов, каждый из которых приближает к устойчивому сну и ровным витальным показателям. Сначала врач уточняет длительность эпизода, переносимость лекарств, сон, аппетит, хронические диагнозы, наличие помощника дома. Затем следует осмотр: давление, пульс, сатурация, температура, ЭКГ при показаниях. Стартовая терапия закрывает дефицит жидкости и солей, защищает печень и ЖКТ, по необходимости подключается мягкая противотревожная поддержка и кислород. Параллельно проговаривается «карта суток»: как отдыхать, что пить и в каком объёме, какие продукты не перегрузят желудок, в какой момент выходить на внеплановую связь. Динамика отслеживается без суеты, а корректировки делаются точечно — по реакции организма, а не «на всякий случай».
Детальнее – [url=https://narkologicheskaya-klinika-ehlektrostal0.ru/]анонимная наркологическая клиника[/url]
интернет раскрутка [url=https://kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru/]kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru[/url] .
комплексное продвижение сайтов москва [url=https://poiskovoe-prodvizhenie-moskva-professionalnoe.ru/]комплексное продвижение сайтов москва[/url] .
оптимизация сайта блог [url=https://blog-o-marketinge1.ru/]оптимизация сайта блог[/url] .
цифровой маркетинг статьи [url=https://statyi-o-marketinge1.ru/]statyi-o-marketinge1.ru[/url] .
폰테크
материалы по seo [url=https://blog-o-marketinge.ru/]материалы по seo[/url] .
1win real or fake [url=https://www.1win5746.help]https://www.1win5746.help[/url]
продвижение сайтов в москве [url=https://poiskovoe-seo-v-moskve.ru/]продвижение сайтов в москве[/url] .
PSYCHEDELICS DISPENSARY
TRIPPY 420 ROOM is presented as a full-service psychedelics dispensary online, designed to provide consistently high-grade medical products covering a wide range of categories.
Before buying psychedelic, cannabis, stimulant, dissociative, or opioid products online, buyers are given a transparent framework including product access, delivery methods, and assistance. The store features more than 200 products covering different formats and preferences.
Delivery pricing is determined by package size and destination, with regular and express options available. Each order includes access to a hassle-free returns system and a strong focus on privacy and security. The service highlights guaranteed worldwide stealth delivery, at no extra cost. Every order is fully guaranteed to support reliable delivery.
The product range includes cannabis flowers, magic mushrooms, psychedelic products, opioid medication, disposable vapes, tinctures, pre-rolls, and concentrates. All products are shown with transparent pricing, with price ranges displayed for multi-variant products. Informational content is also available, such as guides like “How to Dissolve LSD Gel Tabs”, as well as direct options to buy LSD gel tabs and buy psychedelics online.
The business indicates its office location as United States, CA, and offers multiple communication channels, including phone, WhatsApp, Signal, Telegram, and email support. The platform promotes round-the-clock express psychedelic delivery, placing focus on accessibility, discretion, and consistent support.
1win aviator predictor [url=http://1win5745.help]1win aviator predictor[/url]
локальное seo блог [url=https://statyi-o-marketinge2.ru/]statyi-o-marketinge2.ru[/url] .
internetagentur seo [url=https://prodvizhenie-sajtov-v-moskve233.ru/]internetagentur seo[/url] .
продвижения сайта в google [url=https://prodvizhenie-sajtov-v-moskve235.ru/]prodvizhenie-sajtov-v-moskve235.ru[/url] .
раскрутка сайта франция [url=https://poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru/]poiskovoe-prodvizhenie-sajta-v-internete-moskva.ru[/url] .
seo partner program [url=https://prodvizhenie-sajtov-v-moskve232.ru/]prodvizhenie-sajtov-v-moskve232.ru[/url] .
internetagentur seo [url=https://prodvizhenie-sajtov-v-moskve234.ru/]prodvizhenie-sajtov-v-moskve234.ru[/url] .
net seo [url=https://kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru/]kompanii-zanimayushchiesya-prodvizheniem-sajtov.ru[/url] .
раскрутка сайта франция цена [url=https://poiskovoe-prodvizhenie-moskva-professionalnoe.ru/]poiskovoe-prodvizhenie-moskva-professionalnoe.ru[/url] .
блог про продвижение сайтов [url=https://blog-o-marketinge1.ru/]блог про продвижение сайтов[/url] .
блог агентства интернет-маркетинга [url=https://statyi-o-marketinge1.ru/]statyi-o-marketinge1.ru[/url] .
локальное seo блог [url=https://blog-o-marketinge.ru/]blog-o-marketinge.ru[/url] .
Offside traps, high line defenses and their success rates
аудит продвижения сайта [url=https://poiskovoe-seo-v-moskve.ru/]аудит продвижения сайта[/url] .
сео блог [url=https://statyi-o-marketinge2.ru/]сео блог[/url] .
продвинуть сайт в москве [url=https://poiskovoe-prodvizhenie-moskva-professionalnoe.ru/]poiskovoe-prodvizhenie-moskva-professionalnoe.ru[/url] .
Мы изготавливаем дипломы психологов, юристов, экономистов и других профессий по невысоким тарифам. Заказать диплом ВУЗа [url=http://notebooks.ru/forum/user/192528/]notebooks.ru/forum/user/192528[/url]
можно ли купить диплом медсестры [url=http://frei-diplom13.ru]можно ли купить диплом медсестры[/url] .
маркетинговые стратегии статьи [url=https://blog-o-marketinge.ru/]маркетинговые стратегии статьи[/url] .
статьи про digital маркетинг [url=https://statyi-o-marketinge1.ru/]statyi-o-marketinge1.ru[/url] .
статьи про seo [url=https://blog-o-marketinge1.ru/]статьи про seo[/url] .
Услуга
Узнать больше – http://narkolog-na-dom-shchelkovo10.ru/narkolog-na-dom-cena-shchelkovo/
you can look here https://toast-wallet.net/
seo partner program [url=https://poiskovoe-seo-v-moskve.ru/]poiskovoe-seo-v-moskve.ru[/url] .
блог о маркетинге [url=https://statyi-o-marketinge2.ru/]блог о маркетинге[/url] .
Мы можем предложить дипломы психологов, юристов, экономистов и любых других профессий по выгодным тарифам. Заказать диплом ВУЗа [url=http://pirat.iboards.ru/viewtopic.php?f=20&t=45574/]pirat.iboards.ru/viewtopic.php?f=20&t=45574[/url]
кто нибудь работает медсестрой по купленному диплому [url=frei-diplom13.ru]frei-diplom13.ru[/url] .
Мы изготавливаем дипломы любой профессии по приятным тарифам. Важно, чтобы документы были доступными для подавляющей массы граждан. Заказать диплом любого института [url=http://z4sh.com/dinoluong63602/]z4sh.com/dinoluong63602[/url]
Goalkeeper saves, shot stopping statistics and clean sheet records
Мы готовы предложить документы институтов, расположенных на территории России.
Приобрести диплом университета: [url=http://shukurbi.com/ricardo75v6942]shukurbi.com/ricardo75v6942[/url]
как продвигать сайт статьи [url=https://statyi-o-marketinge.ru/]statyi-o-marketinge.ru[/url] .
продвижение обучение [url=https://kursy-seo-1.ru/]kursy-seo-1.ru[/url] .
купить диплом о высшем образовании в ставрополе отзывы [url=r-diploma31.ru]купить диплом о высшем образовании в ставрополе отзывы[/url] .
Мы изготавливаем дипломы любой профессии по доступным тарифам.– [url=http://freeads.sg/profile/roxiedtk81068/]freeads.sg/profile/roxiedtk81068[/url]
Мы изготавливаем дипломы любой профессии по приятным ценам. Диплом об образовании когда-то считался ключевым документом, который способствовал удачному устройству на работу. Заказать диплом университета!: [url=http://luvvymallnigeria.com.ng/diplom-za-korotkij-srok-sroki-ceny-uslovija-536/]luvvymallnigeria.com.ng/diplom-za-korotkij-srok-sroki-ceny-uslovija-536[/url]
Купить диплом ВУЗа по выгодной цене можно, обратившись к надежной специализированной компании. Для проверки компании перед покупкой воспользуйтесь честными отзывами в интернете. Таким образом можно приобрести диплом из любого университета России [url=http://crcpalermo.com/kupit-diplom-kolledzha-446/]crcpalermo.com/kupit-diplom-kolledzha-446[/url]
真实的人类第二季高清完整版,海外华人可免费观看最新热播剧集。
Ниже приведена таблица с примерными этапами терапии:
Подробнее – [url=https://vyvod-iz-zapoya-v-ryazani17.ru/]вывод из запоя вызов на дом[/url]
Каждое из этих направлений имеет важное значение и в совокупности формирует основу для устойчивого выздоровления.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-v-omske0.ru/]лечение в наркологической клинике в омске[/url]
Travel advice, away fan guides and transportation information
Практический тест прост: сохранённый контакт, контролируемый тремор, эпизодическая (не неукротимая) рвота, нет грубой дезориентации, давление и пульс не «скачут», в квартире можно обеспечить тишину и доступ к воде — тогда дом уместен. Если хотя бы два пункта «провисают», отделение в Электростали даст предсказуемость и защиту от ночных ухудшений, которые дома часто остаются незамеченными.
Подробнее тут – https://vyvod-iz-zapoya-ehlektrostal10.ru/
Season reviews, comprehensive summaries of completed campaigns
Ключевым фактором при выборе центра становится квалификация специалистов. Лечение алкоголизма — это не только выведение из запоя и купирование абстинентного синдрома. Оно включает работу с мотивацией, тревожными состояниями, семейными конфликтами, нарушением сна и другими последствиями зависимости. Только команда, включающая наркологов, психотерапевтов и консультантов по аддиктивному поведению, способна охватить все аспекты проблемы.
Получить больше информации – http://lechenie-alkogolizma-murmansk0.ru/klinika-lecheniya-alkogolizma-marmansk/
seo онлайн [url=https://kursy-seo-1.ru/]kursy-seo-1.ru[/url] .
Мы изготавливаем дипломы любых профессий по выгодным тарифам.– [url=http://psorum.ru/member.php?u=4348/]psorum.ru/member.php?u=4348[/url]
Мы предлагаем дипломы любых профессий по выгодным тарифам. Диплом об образовании когда-то считался основным документом, способствовавшим удачному устройству на работу. Выгодно купить диплом университета!: [url=http://wiki.dirbg.com/index.php/User:SangUhk281/]wiki.dirbg.com/index.php/User:SangUhk281[/url]
веб-аналитика блог [url=https://statyi-o-marketinge.ru/]statyi-o-marketinge.ru[/url] .
Заказать диплом института по доступной цене возможно, обращаясь к проверенной специализированной компании. Для проверки компании перед покупкой воспользуйтесь отзывами в онлайне. В итоге можно заказать диплом из любого ВУЗа России [url=http://besconeshnocte.flybb.ru/viewtopic.php?f=2&t=1781/]besconeshnocte.flybb.ru/viewtopic.php?f=2&t=1781[/url]
Мы изготавливаем дипломы любой профессии по выгодным тарифам. Купить диплом Ачинск — [url=http://openmotonews.ru/kupit-diplom-bez-uchyobyi-ofitsialno/]openmotonews.ru/kupit-diplom-bez-uchyobyi-ofitsialno[/url]
seo с нуля [url=https://kursy-seo-1.ru/]kursy-seo-1.ru[/url] .
материалы по seo [url=https://statyi-o-marketinge.ru/]материалы по seo[/url] .
奇思妙探高清完整版AI深度学习内容匹配,海外华人可免费观看最新热播剧集。
Как подчёркивает специалист ФГБУ «НМИЦ психиатрии и наркологии», «без участия квалифицированной команды невозможно обеспечить комплексный подход к пациенту, особенно если речь идёт о длительном стаже употребления и осложнённой картине заболевания». Отсюда следует — изучение состава персонала должно быть одним из первых шагов.
Подробнее можно узнать тут – https://lechenie-alkogolizma-murmansk0.ru/anonimnoe-lechenie-alkogolizma-marmansk
侠之盗高清完整官方版,海外华人可免费观看最新热播剧集。
учиться seo [url=https://kursy-seo-1.ru/]kursy-seo-1.ru[/url] .
купить диплом нархоза [url=https://www.r-diploma28.ru]купить диплом нархоза[/url] .
Corner kick count, set piece statistics for all football matches
seo блог [url=https://statyi-o-marketinge.ru/]seo блог[/url] .
Острый период запоя — это не «плохое самочувствие», а состояние с реальными рисками, где каждая задержка усложняет картину. В «Трезвой Линии» в Электростали мы строим помощь так, чтобы от первого звонка до заметного облегчения прошёл минимальный и управляемый путь: быстрый сбор рисков, экспресс-диагностика на месте, персональная инфузионная схема без «универсальных коктейлей», щадящая коррекция сна и тревоги, регулярные замеры показателей, чёткие рекомендации для семьи. Мы избегаем агрессивной седации: дозы и темп капельниц подбираются под возраст, длительность эпизода, сопутствующие заболевания и уже принимаемые лекарства. Задача — быстро снять токсическую нагрузку, выровнять давление и пульс, собрать ночной сон, а затем удержать результат дисциплинированным постдетокс-маршрутом на 2–4 недели. Конфиденциальность и анонимность соблюдаются без компромиссов, решения принимаются по реальным данным, чтобы эффект был устойчивым, предсказуемым и безопасным для пациента и семьи.
Детальнее – https://vyvod-iz-zapoya-ehlektrostal10.ru/vyvesti-iz-zapoya-ehlektrostal/
Как подчёркивает специалист ФГБУ «НМИЦ психиатрии и наркологии», «без участия квалифицированной команды невозможно обеспечить комплексный подход к пациенту, особенно если речь идёт о длительном стаже употребления и осложнённой картине заболевания». Отсюда следует — изучение состава персонала должно быть одним из первых шагов.
Подробнее можно узнать тут – [url=https://lechenie-alkogolizma-murmansk0.ru/]клиника лечения алкоголизма мурманск.[/url]
Важное отличие клиники — отказ от примитивной схемы «капельница — домой — дальше сам». Такой формат даёт кратковременное облегчение, но не решает ни причин, ни структуры зависимости. «КоломнаМед Центр» выстраивает ступенчатый подход. Первый шаг — безопасная детоксикация: снятие абстиненции, коррекция водно-электролитного баланса, поддержка сердечно-сосудистой системы, печени, нервной системы, нормализация сна. Второй шаг — стабилизация: оценка психического состояния, выявление тревожных, депрессивных и панических симптомов, подбор поддерживающих схем, которые помогают не сорваться сразу после выхода из острых проявлений. Третий шаг — реабилитация и мотивация: психотерапевтическая работа, групповые и индивидуальные форматы, обучение навыкам трезвой жизни, работа с триггерами, укрепление внутренней мотивации. Четвёртый шаг — постреабилитационная поддержка: контрольные приёмы, дистанционные консультации, помощь в профилактике срывов. Такой комплексный путь не ломает пациента, а возвращает ему контроль: не через страх, а через понимание, структуру и реальные инструменты.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-kolomna10.ru/]www.domen.ru[/url]
интернет продвижение москва [url=https://internet-prodvizhenie-moskva.ru/]интернет продвижение москва[/url] .
seo специалист [url=https://kursy-seo-2.ru/]seo специалист[/url] .
курс seo [url=https://kursy-seo-3.ru/]kursy-seo-3.ru[/url] .
мостбет букмекерская [url=https://mostbet2027.help]https://mostbet2027.help[/url]
Система круглосуточной наркологической помощи в «ОмскПрофи» построена на принципе постоянной готовности. В любой момент суток специалисты готовы выехать на дом, принять пациента в стационар или организовать удалённую консультацию. Это особенно важно в острых ситуациях, когда счёт идёт на часы: запой, передозировка, психоз, агрессивное поведение или резкое ухудшение самочувствия. В таких случаях промедление может стоить пациенту жизни.
Получить больше информации – [url=https://narkologicheskaya-pomoshh-omsk0.ru/]центр наркологической помощи[/url]
mostbets [url=http://mostbet2026.help]mostbets[/url]
Портал города https://u-misti.odesa.ua Одесса с новостями, событиями и обзорами. Всё о жизни города: решения властей, происшествия, экономика, спорт, культура и развитие региона.
учиться seo [url=https://kursy-seo-2.ru/]kursy-seo-2.ru[/url] .
мостбет.сом [url=https://mostbet2026.help]https://mostbet2026.help[/url]
seo специалист [url=https://kursy-seo-3.ru/]seo специалист[/url] .
Купить официальный диплом университета : [url=http://119.23.72.7/bradwatling53/]119.23.72.7/bradwatling53[/url]
Мы изготавливаем дипломы любых профессий по приятным ценам. Важно, чтобы дипломы были доступными для большого количества наших граждан. Быстро заказать диплом о высшем образовании [url=http://git.autotion.net/romanharwood8/]git.autotion.net/romanharwood8[/url]
частный seo оптимизатор [url=https://internet-prodvizhenie-moskva.ru/]частный seo оптимизатор[/url] .
купить в кредит диплом о высшем образовании [url=https://r-diploma31.ru]https://r-diploma31.ru[/url] .
Комплексный подход позволяет врачу не просто купировать острые симптомы, но и предупредить осложнения со стороны сердца, печени и нервной системы. После стабилизации состояния пациент получает рекомендации по дальнейшему лечению и восстановлению.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoia-v-volgograde17.ru/]срочный вывод из запоя[/url]
мостбет зеркало [url=http://mostbet2026.help/]мостбет зеркало[/url]
Процедура проводится как в стационаре, так и на дому. Врач приезжает по вызову, проводит осмотр и измеряет давление, пульс, насыщение кислородом. После оценки состояния подбирается состав капельницы и начинается инфузионная терапия. В среднем процедура длится от 40 минут до 1,5 часов, в зависимости от степени интоксикации. По завершении врач наблюдает за реакцией организма и даёт рекомендации по восстановлению.
Разобраться лучше – [url=https://kapelnicza-ot-zapoya-v-voronezhe17.ru/]вызвать капельницу от запоя в воронеже[/url]
partenaires melbet melbet telecharger
школа seo [url=https://kursy-seo-2.ru/]kursy-seo-2.ru[/url] .
seo курсы [url=https://kursy-seo-3.ru/]seo курсы[/url] .
Мы можем предложить дипломы психологов, юристов, экономистов и любых других профессий по невысоким тарифам. Цена может зависеть от выбранной специальности, года получения и ВУЗа: [url=http://lossantosbattalion17.listbb.ru/viewtopic.php?f=3&t=4366/]lossantosbattalion17.listbb.ru/viewtopic.php?f=3&t=4366[/url]
Мы изготавливаем дипломы любой профессии по невысоким ценам. Цена может зависеть от выбранной специальности, года выпуска и ВУЗа: [url=http://namastayrentals.com/author/leomawesolowsk/]namastayrentals.com/author/leomawesolowsk[/url]
обучение продвижению сайтов [url=https://kursy-seo-11.ru/]обучение продвижению сайтов[/url] .
продвижение сайта [url=https://internet-prodvizhenie-moskva.ru/]продвижение сайта[/url] .
обучение seo [url=https://kursy-seo-5.ru/]обучение seo[/url] .
курсы по seo [url=https://kursy-seo-4.ru/]курсы по seo[/url] .
гидроизоляция подвала изнутри цена [url=https://gidroizolyacziya-czena8.ru/]гидроизоляция подвала изнутри цена[/url] .
вертикальная гидроизоляция подвала [url=https://gidroizolyacziya-czena9.ru/]gidroizolyacziya-czena9.ru[/url] .
стоимость гидроизоляции подвала [url=https://gidroizolyacziya-podvala-iznutri-czena9.ru/]gidroizolyacziya-podvala-iznutri-czena9.ru[/url] .
усиление проема металлом [url=https://usilenie-proemov9.ru/]усиление проема металлом[/url] .
услуга усиления проема [url=https://usilenie-proemov10.ru/]usilenie-proemov10.ru[/url] .
сырость в подвале [url=https://gidroizolyacziya-podvala-iznutri-czena8.ru/]gidroizolyacziya-podvala-iznutri-czena8.ru[/url] .
seo базовый курc [url=https://kursy-seo-2.ru/]kursy-seo-2.ru[/url] .
connexion 1win telecharger 1win apk
seo базовый курc [url=https://kursy-seo-3.ru/]kursy-seo-3.ru[/url] .
Этот обзор позволяет по-новому взглянуть на вещи, на которые обычно и так смотрят. Мы упоминаем факты, которые мало что меняют, и события, значение которых трудно определить, но они всё равно здесь.
Вот – [url=https://arma-rehab.ru/vyvod-iz-zapoya/]казино[/url]
можно ли купить диплом медсестры [url=http://www.frei-diplom13.ru]можно ли купить диплом медсестры[/url] .
seo специалист [url=https://kursy-seo-11.ru/]seo специалист[/url] .
폰테크
сделать аудит сайта цена [url=https://internet-prodvizhenie-moskva.ru/]internet-prodvizhenie-moskva.ru[/url] .
tuk tuk showdown
учиться seo [url=https://kursy-seo-4.ru/]kursy-seo-4.ru[/url] .
усиление проемов [url=https://usilenie-proemov10.ru/]усиление проемов[/url] .
гидроизоляция цена работы за м2 [url=https://gidroizolyacziya-czena8.ru/]гидроизоляция цена работы за м2[/url] .
услуга усиления проема [url=https://usilenie-proemov9.ru/]usilenie-proemov9.ru[/url] .
seo бесплатно [url=https://kursy-seo-5.ru/]seo бесплатно[/url] .
кто нибудь работает медсестрой по купленному диплому [url=www.frei-diplom13.ru/]www.frei-diplom13.ru/[/url] .
сырость в подвале многоквартирного дома [url=https://gidroizolyacziya-czena9.ru/]gidroizolyacziya-czena9.ru[/url] .
вода в подвале [url=https://gidroizolyacziya-podvala-iznutri-czena8.ru/]gidroizolyacziya-podvala-iznutri-czena8.ru[/url] .
ремонт в подвале [url=https://gidroizolyacziya-podvala-iznutri-czena9.ru/]ремонт в подвале[/url] .
кто нибудь работает медсестрой по купленному диплому [url=http://frei-diplom13.ru/]http://frei-diplom13.ru/[/url] .
TUK TUK RACING KENYA
Round 5 is here — and things just got out of control.
This is TUK-TUK RACING KENYA, where speed, skill and street instinct collide.
In this episode, drivers face the hardest challenge yet:
• sharp corners mixed with water traps
• unexpected challenges with balloons and smoke
• money rewards on the line
• and a brutal TUK-TUK TUG OF WAR finale — where power and grip matter more than speed
Chaos erupts, rankings shift constantly, and nothing is decided until the end.
A single error means elimination. One powerful pull secures victory.
Nothing here is staged.
This is not predictable.
This is Kenya’s Tuk-Tuk Showdown — Round 5.
Watch till the end and tell us:
Which driver stood out the most?
[b]Диплом любой специальности[/b]. Мы изготавливаем дипломы любой профессии по приятным ценам: [url=http://sellasiss.com/author/priscillasawye/]sellasiss.com/author/priscillasawye[/url]
seo с нуля [url=https://kursy-seo-11.ru/]seo с нуля[/url] .
Заказать диплом ВУЗа по доступной стоимости возможно, обратившись к надежной специализированной компании. Чтобы проверить компанию перед покупкой пользуйтесь рейтингом и отзывами в онлайне. В результате можно приобрести диплом из любого института РФ [url=http://toplentanews.ru/kupit-diplom-kolledzha-transporta/]toplentanews.ru/kupit-diplom-kolledzha-transporta[/url]
купить диплом о высшем медицинском образовании в челябинске [url=r-diploma30.ru]r-diploma30.ru[/url] .
усиление проёмов под панорамные окна [url=https://usilenie-proemov10.ru/]usilenie-proemov10.ru[/url] .
усиление проёмов под панорамные окна [url=https://usilenie-proemov9.ru/]usilenie-proemov9.ru[/url] .
наплавляемая гидроизоляция цена [url=https://gidroizolyacziya-czena9.ru/]gidroizolyacziya-czena9.ru[/url] .
гидроизоляция подвала изнутри цена м2 [url=https://gidroizolyacziya-podvala-iznutri-czena8.ru/]gidroizolyacziya-podvala-iznutri-czena8.ru[/url] .
гидроизоляция подвала изнутри цена [url=https://gidroizolyacziya-czena8.ru/]гидроизоляция подвала изнутри цена[/url] .
вертикальная гидроизоляция подвала [url=https://gidroizolyacziya-podvala-iznutri-czena9.ru/]вертикальная гидроизоляция подвала[/url] .
Приобрести диплом ВУЗа по доступной стоимости возможно, обратившись к надежной специализированной компании: [url=http://burgasdent.listbb.ru/viewtopic.php?f=3&t=2411/]burgasdent.listbb.ru/viewtopic.php?f=3&t=2411[/url]
курсы по seo [url=https://kursy-seo-4.ru/]курсы по seo[/url] .
seo специалист [url=https://kursy-seo-5.ru/]seo специалист[/url] .
Приобрести диплом ВУЗа по невысокой стоимости возможно, обращаясь к надежной специализированной фирме. Для проверки компании до заказа воспользуйтесь отзывами других клиентов в онлайне. В результате можно приобрести диплом из любого ВУЗа РФ [url=http://workfind.in/profile/aaroneager298/]workfind.in/profile/aaroneager298[/url]
Прежде чем перейти к ориентировочным цифрам, важно подчеркнуть: цена формируется из реальных компонентов помощи — работы врача и медсестры, объёма инфузионной терапии, перечня препаратов, времени выезда и необходимости более длительного наблюдения. Никаких скрытых доплат: все дополнительные назначения согласуются заранее. Чем раньше вы обращаетесь, тем меньше объём вмешательств и, как правило, ниже итоговая стоимость — короткий эпизод проще и дешевле стабилизировать, чем «выводить» осложнения после затянутого запоя.
Выяснить больше – [url=https://narkolog-na-dom-shchelkovo10.ru/]сколько стоит вызвать нарколога на дом[/url]
инъекционная гидроизоляция густота состава [url=https://inekczionnaya-gidroizolyacziya-fundamenta1.ru/]inekczionnaya-gidroizolyacziya-fundamenta1.ru[/url] .
инъекционная гидроизоляция оборудование [url=https://inekczionnaya-gidroizolyacziya-fundamenta.ru/]inekczionnaya-gidroizolyacziya-fundamenta.ru[/url] .
seo базовый курc [url=https://kursy-seo-11.ru/]seo базовый курc[/url] .
Важное отличие клиники — отказ от примитивной схемы «капельница — домой — дальше сам». Такой формат даёт кратковременное облегчение, но не решает ни причин, ни структуры зависимости. «КоломнаМед Центр» выстраивает ступенчатый подход. Первый шаг — безопасная детоксикация: снятие абстиненции, коррекция водно-электролитного баланса, поддержка сердечно-сосудистой системы, печени, нервной системы, нормализация сна. Второй шаг — стабилизация: оценка психического состояния, выявление тревожных, депрессивных и панических симптомов, подбор поддерживающих схем, которые помогают не сорваться сразу после выхода из острых проявлений. Третий шаг — реабилитация и мотивация: психотерапевтическая работа, групповые и индивидуальные форматы, обучение навыкам трезвой жизни, работа с триггерами, укрепление внутренней мотивации. Четвёртый шаг — постреабилитационная поддержка: контрольные приёмы, дистанционные консультации, помощь в профилактике срывов. Такой комплексный путь не ломает пациента, а возвращает ему контроль: не через страх, а через понимание, структуру и реальные инструменты.
Получить больше информации – https://narkologicheskaya-klinika-kolomna10.ru/narkologicheskaya-klinika-cena-v-kolomne
усиление проему [url=https://usilenie-proemov10.ru/]usilenie-proemov10.ru[/url] .
Приобрести диплом университета. Производство документа занимает гораздо меньше времени, а цена – невысокая. В итоге вы получаете возможность сберечь бюджет и найти работу вашей мечты. Приобрести диплом вы имеете возможность используя официальный портал компании. – [url=http://sakhd.3nx.ru/viewtopic.php?p=3744#3744/]sakhd.3nx.ru/viewtopic.php?p=3744#3744[/url]
усиление проема москва [url=https://usilenie-proemov9.ru/]usilenie-proemov9.ru[/url] .
гидроизоляция подвала москва [url=https://gidroizolyacziya-czena9.ru/]гидроизоляция подвала москва[/url] .
ремонт гидроизоляции фундаментов и стен подвалов [url=https://gidroizolyacziya-czena8.ru/]gidroizolyacziya-czena8.ru[/url] .
ремонт подвального помещения [url=https://gidroizolyacziya-podvala-iznutri-czena8.ru/]gidroizolyacziya-podvala-iznutri-czena8.ru[/url] .
подвал дома ремонт [url=https://gidroizolyacziya-podvala-iznutri-czena9.ru/]подвал дома ремонт[/url] .
Мы можем предложить документы институтов, расположенных на территории Российской Федерации.
Приобрести диплом университета: [url=http://reputable.cc/profile/vaughnstrickli]reputable.cc/profile/vaughnstrickli[/url]
seo интенсив [url=https://kursy-seo-4.ru/]seo интенсив[/url] .
seo интенсив [url=https://kursy-seo-5.ru/]kursy-seo-5.ru[/url] .
гидроизоляция инъектированием [url=https://inekczionnaya-gidroizolyacziya-fundamenta1.ru/]гидроизоляция инъектированием[/url] .
инъекционная гидроизоляция частный дом [url=https://inekczionnaya-gidroizolyacziya-fundamenta.ru/]inekczionnaya-gidroizolyacziya-fundamenta.ru[/url] .
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по доступным ценам. Для нас важно, чтобы дипломы были доступны для большинства наших граждан. Заказать диплом ВУЗа [url=http://forestsnakes.teamforum.ru/viewtopic.php?f=28&t=13548/]forestsnakes.teamforum.ru/viewtopic.php?f=28&t=13548[/url]
В этой статье-обзоре мы собрали данные, актуальность которых сомнительна, а факты — не всегда взаимосвязаны. Читатель сможет ознакомиться с разными мнениями, хотя вряд ли они существенно повлияют на его понимание темы.
Вот – [url=https://arma-rehab.ru/]блекджек[/url]
Лечение алкоголизма в Луганске организуется по принципам доказательной медицины и включает медицинскую, психотерапевтическую и социальную компоненты. Цель — безопасно снять острые проявления заболевания, стабилизировать соматическое состояние, снизить тягу и закрепить новые модели поведения. Индивидуальные планы формируются с учётом стадии расстройства, сопутствующих заболеваний, предшествующего опыта лечения и уровня семейной поддержки.
Получить дополнительные сведения – http://lechenie-alkogolizma-lugansk0.ru/
купить диплом о среднем специальном образовании цена с занесением в реестр [url=https://www.r-diploma31.ru]купить диплом о среднем специальном образовании цена с занесением в реестр[/url] .
В последние годы цифровое образование школьников становится всё более актуальным.
Формат с интерактивными программами позволяет учиться из дома.
Хороший вариант для родителей, которые подбирают гибкое обучение для ученика.
Делюсь: https://minutamami.ru/mentalnaya-arifmetika-put-k-intellektualnoj-svobode
стоимость инъекционной гидроизоляции [url=https://inekczionnaya-gidroizolyacziya-fundamenta1.ru/]стоимость инъекционной гидроизоляции[/url] .
Когда выбрать
Подробнее – [url=https://narkologicheskaya-klinika-domodedovo0.ru/]анонимная наркологическая клиника[/url]
инъекционная гидроизоляция стен [url=https://inekczionnaya-gidroizolyacziya-fundamenta.ru/]инъекционная гидроизоляция стен[/url] .
ремонт бетонных конструкций выезд специалиста [url=https://remont-betonnykh-konstrukczij-usilenie4.ru/]remont-betonnykh-konstrukczij-usilenie4.ru[/url] .
После поступления вызова диспетчер передаёт заявку на смартфон врача, который оперативно завершает подготовительные мероприятия и выезжает к пациенту. На дороге применяется GPS-маршрутизация для выбора оптимального пути и снижения времени в пути.
Узнать больше – http://narkologicheskaya-klinika-arkhangelsk0.ru
Для купирования абстинентного синдрома и нормализации функций организма применяются препараты, которые оказывают детоксицирующее, нейропротекторное и общеукрепляющее действие. Врач подбирает лекарства индивидуально с учетом состояния пациента и наличия сопутствующих заболеваний.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-vladimir0.ru/]наркологическая клиника лечение алкоголизма владимир[/url]
폰테크
Мы можем предложить дипломы любой профессии по выгодным ценам. Стоимость может зависеть от определенной специальности, года выпуска и ВУЗа: [url=http://la2power.forumex.ru/viewtopic.php?f=19&t=13325/]la2power.forumex.ru/viewtopic.php?f=19&t=13325[/url]
https://t.me/s/russiA_CaSinO_1wIN
акрилатная инъекционная гидроизоляция [url=https://inekczionnaya-gidroizolyacziya-fundamenta1.ru/]inekczionnaya-gidroizolyacziya-fundamenta1.ru[/url] .
Мы изготавливаем дипломы любых профессий по выгодным тарифам. Заказать диплом об образовании [url=http://lands99.com/author/saulstang28327/]lands99.com/author/saulstang28327[/url]
Мы изготавливаем дипломы любой профессии по доступным тарифам. Диплом об образовании когда-то считался основным документом, который способствовал удачному поиску работы. Заказать диплом о высшем образовании!: [url=http://thedesignsecrets.com/2025/12/26/diplom-za-korotkij-srok-sroki-ceny-uslovija-111/]thedesignsecrets.com/2025/12/26/diplom-za-korotkij-srok-sroki-ceny-uslovija-111[/url]
ремонт бетонных конструкций железобетонных [url=https://remont-betonnykh-konstrukczij-usilenie4.ru/]remont-betonnykh-konstrukczij-usilenie4.ru[/url] .
инъекционная гидроизоляция многоквартирный дом [url=https://inekczionnaya-gidroizolyacziya-fundamenta.ru/]inekczionnaya-gidroizolyacziya-fundamenta.ru[/url] .
каталог [url=https://krab4a.at/]krab4.at[/url]
Мы изготавливаем дипломы психологов, юристов, экономистов и других профессий по приятным тарифам. Приобрести диплом об образовании [url=http://squareacre.in/agents/kareemmcwhae3/]squareacre.in/agents/kareemmcwhae3[/url]
нажмите здесь [url=https://krab4a.at/]krab4.at[/url]
Мы готовы предложить дипломы любой профессии по приятным тарифам.– [url=http://jamoneselpelayo.es/smartblog/3_a_beautiful_creative_design.html/]jamoneselpelayo.es/smartblog/3_a_beautiful_creative_design.html[/url]
[b]Диплом о высшем образовании[/b]. Мы изготавливаем дипломы любых профессий по невысоким ценам: [url=http://giimel.com/emiliobanda207/]giimel.com/emiliobanda207[/url]
ремонт бетонных конструкций жилой дом [url=https://remont-betonnykh-konstrukczij-usilenie4.ru/]remont-betonnykh-konstrukczij-usilenie4.ru[/url] .
Мы готовы предложить дипломы любых профессий по приятным ценам.– [url=http://ntnn.ru/personal/profile/index.php?register=yes/]ntnn.ru/personal/profile/index.php?register=yes[/url]
Купить диплом института по невысокой цене можно, обращаясь к надежной специализированной компании: [url=http://twizzr.worldsofrp.com/read-blog/7041_kupit-diplom.html/]twizzr.worldsofrp.com/read-blog/7041_kupit-diplom.html[/url]
Мы изготавливаем дипломы любой профессии по выгодным тарифам. Цена зависит от той или иной специальности, года выпуска и ВУЗа: [url=http://realestate.kctech.com.np/profile/maura295264841/]realestate.kctech.com.np/profile/maura295264841[/url]
ремонт бетонных конструкций торкретирование [url=https://remont-betonnykh-konstrukczij-usilenie4.ru/]remont-betonnykh-konstrukczij-usilenie4.ru[/url] .
Мы готовы предложить документы институтов, которые расположены на территории Российской Федерации.
Приобрести диплом о высшем образовании: [url=http://karamed.ir/blog/kupit-diplom-155]karamed.ir/blog/kupit-diplom-155[/url]
гидроизоляция подвала монтаж [url=https://gidroizolyacziya-podvala-samara4.ru/]гидроизоляция подвала монтаж[/url] .
гидроизоляция подвала внутреняя [url=https://gidroizolyacziya-podvala-samara5.ru/]гидроизоляция подвала внутреняя[/url] .
купить кухню [url=https://kuhni-spb-25.ru/]kuhni-spb-25.ru[/url] .
Цель и ожидаемая динамика
Подробнее тут – http://narkologicheskaya-klinika-odincovo0.ru/
Заказать диплом о высшем образовании. Изготовление документа занимает немного времени, а стоимость при этом доступна каждому человеку. Таким образом вы имеете возможность сохранить деньги и время и найти работу мечты. Заказать диплом под заказ возможно используя сайт компании. – [url=http://vetshonoredhere.com/kupit-diplom-s-garantiej-podlinnosti-11-2/]vetshonoredhere.com/kupit-diplom-s-garantiej-podlinnosti-11-2[/url]
положительные. Всё работает стабильно, без зависаний. Деньги вывел без задержек: [url=https://kadastrovaya-karta-onlajn.ru/]kometa casino официальный сайт[/url]
Ниже приведена таблица с типовыми компонентами капельницы и их назначением:
Изучить вопрос глубже – [url=https://kapelnicza-ot-zapoya-v-volgograde17.ru/]сколько стоит капельница от запоя[/url]
заказать кухню спб [url=https://kuhni-spb-25.ru/]kuhni-spb-25.ru[/url] .
В этом тексте собрано множество случайных сведений и довольно неопределённых мыслей, которые могут чем-то заинтересовать. Мы отмечаем моменты, которые не особенно важны, но всё же занимают своё место в повествовании.
Вот – [url=https://arma-rehab.ru/]азартные игры на деньги[/url]
гидроизоляция подвала стоимость [url=https://gidroizolyacziya-podvala-samara4.ru/]гидроизоляция подвала стоимость[/url] .
гидроизоляция подвала обследование [url=https://gidroizolyacziya-podvala-samara5.ru/]gidroizolyacziya-podvala-samara5.ru[/url] .
Лечение алкоголизма в Перми осуществляется в специализированных медицинских учреждениях, где пациентам предоставляется комплексная помощь. Алкогольная зависимость требует системного подхода, сочетающего медицинские и психотерапевтические методы. В клиниках создаются условия для безопасного выведения из запоя, восстановления функций организма и дальнейшей реабилитации. Главная цель лечения заключается не только в снятии симптомов, но и в формировании устойчивой мотивации к трезвости.
Исследовать вопрос подробнее – [url=https://lechenie-alkogolizma-perm0.ru/]здоровье лечение алкоголизма пермь[/url]
купить диплом о высшем образовании в нижнем новгороде цена [url=www.r-diploma28.ru]купить диплом о высшем образовании в нижнем новгороде цена[/url] .
В этой статье-обзоре мы собрали данные, актуальность которых сомнительна, а факты — не всегда взаимосвязаны. Читатель сможет ознакомиться с разными мнениями, хотя вряд ли они существенно повлияют на его понимание темы.
Вот – [url=https://arma-rehab.ru/]азартные игры[/url]
Приобретение официального диплома через надежную фирму дарит ряд достоинств для покупателя. Приобрести диплом: [url=http://insjoaquimmir.cat/wiki/index.php/Купить_Диплом.]insjoaquimmir.cat/wiki/index.php/Купить_Диплом.[/url]
Мы предлагаем дипломы любых профессий по доступным тарифам. Для нас очень важно, чтобы документы были доступны для большого количества граждан. Приобрести диплом о высшем образовании [url=http://cardinalparkmld.listbb.ru/viewtopic.php?f=3&t=3262/]cardinalparkmld.listbb.ru/viewtopic.php?f=3&t=3262[/url]
кухня на заказ спб от производителя недорого [url=https://kuhni-spb-25.ru/]kuhni-spb-25.ru[/url] .
ленинградские кухни [url=https://kuhni-spb-26.ru/]kuhni-spb-26.ru[/url] .
кухни от производителя спб [url=https://kuhni-spb-27.ru/]кухни от производителя спб[/url] .
кухня на заказ [url=https://kuhni-spb-29.ru/]кухня на заказ[/url] .
кухни в спб на заказ [url=https://kuhni-spb-31.ru/]kuhni-spb-31.ru[/url] .
большая кухня на заказ [url=https://kuhni-spb-30.ru/]большая кухня на заказ[/url] .
глория мебель [url=https://kuhni-spb-28.ru/]kuhni-spb-28.ru[/url] .
гидроизоляция подвала утепление [url=https://gidroizolyacziya-podvala-samara4.ru/]gidroizolyacziya-podvala-samara4.ru[/url] .
гидроизоляция подвала инъекционная [url=https://gidroizolyacziya-podvala-samara5.ru/]gidroizolyacziya-podvala-samara5.ru[/url] .
кухни на заказ в спб от производителя [url=https://kuhni-spb-25.ru/]kuhni-spb-25.ru[/url] .
кухни под заказ [url=https://kuhni-spb-26.ru/]kuhni-spb-26.ru[/url] .
кухня по индивидуальному заказу спб [url=https://kuhni-spb-29.ru/]кухня по индивидуальному заказу спб[/url] .
кухни спб на заказ [url=https://kuhni-spb-30.ru/]кухни спб на заказ[/url] .
кухни под заказ [url=https://kuhni-spb-31.ru/]kuhni-spb-31.ru[/url] .
гидроизоляция подвала гарантия [url=https://gidroizolyacziya-podvala-samara4.ru/]gidroizolyacziya-podvala-samara4.ru[/url] .
кухни под заказ спб [url=https://kuhni-spb-27.ru/]кухни под заказ спб[/url] .
кухни под заказ в спб [url=https://kuhni-spb-28.ru/]kuhni-spb-28.ru[/url] .
гидроизоляция подвала рулонная [url=https://gidroizolyacziya-podvala-samara5.ru/]gidroizolyacziya-podvala-samara5.ru[/url] .
Этот текст содержит различную информацию, которая, возможно, покажется любопытной, но в целом не меняет восприятия привычных вещей. Предлагаем просто получить удовольствие от чтения, не ожидая особой пользы.
Вот – [url=https://arma-rehab.ru/vyvod-iz-zapoya/]ставки на спорт[/url]
кухня по индивидуальному проекту [url=https://kuhni-spb-26.ru/]kuhni-spb-26.ru[/url] .
кухни на заказ спб [url=https://kuhni-spb-29.ru/]кухни на заказ спб[/url] .
заказать кухню по индивидуальным размерам в спб [url=https://kuhni-spb-30.ru/]заказать кухню по индивидуальным размерам в спб[/url] .
заказать кухню [url=https://kuhni-spb-31.ru/]kuhni-spb-31.ru[/url] .
кухня на заказ [url=https://kuhni-spb-28.ru/]кухня на заказ[/url] .
кухни на заказ [url=https://kuhni-spb-27.ru/]кухни на заказ[/url] .
«Светлый Шаг» — это не набор общих обещаний, а чётко выстроенный маршрут помощи, где каждый шаг прозрачен: от первичного разговора до устойчивой ремиссии. Мы бережно собираем только необходимые данные, сразу объясняем, что будет сделано в первые 6–12 часов, каких изменений ждать к ночи и по каким маркерам поймём, что курс выбран верно. Конфиденциальность встроена в процесс: нейтральные звонки, ограниченный доступ к медкарте, аккуратный выезд без броской атрибутики, возможность оформить документы с нейтральными формулировками. Итог — меньше стресса, меньше бюрократии и больше управляемости там, где это критично.
Подробнее тут – https://narkologicheskaya-klinika-odincovo0.ru/narkologicheskaya-klinika-stacionar-v-odincovo
Что получите за 24 часа
Исследовать вопрос подробнее – http://narkologicheskaya-klinika-domodedovo0.ru/
глория мебель [url=https://kuhni-spb-26.ru/]kuhni-spb-26.ru[/url] .
кухня на заказ спб от производителя недорого [url=https://kuhni-spb-29.ru/]кухня на заказ спб от производителя недорого[/url] .
ленинградские кухни [url=https://kuhni-spb-30.ru/]ленинградские кухни[/url] .
кухни на заказ спб недорого с ценами [url=https://kuhni-spb-31.ru/]kuhni-spb-31.ru[/url] .
Ниже представлена таблица с основными препаратами, используемыми при выводе из запоя в Тюмени:
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-v-tyumeni17.ru/]вывод из запоя на дому круглосуточно[/url]
заказать кухню по индивидуальным размерам в спб [url=https://kuhni-spb-28.ru/]заказать кухню по индивидуальным размерам в спб[/url] .
заказать кухню [url=https://kuhni-spb-27.ru/]заказать кухню[/url] .
опубликовано здесь [url=https://deally.me/ru/category/products]продать аккаунт в геншине[/url]
В последние годы онлайн подготовка школьников становится всё более популярным.
Делюсь; https://gus-info.ru/digest/digest_4108.html
driver qualification file management
вывод из запоя на дому краснодар круглосуточно [url=https://vyvod-iz-zapoya-krasnodar-1.ru/]вывод из запоя на дому краснодар круглосуточно[/url] .
кухни на заказ от производителя в спб [url=https://kuhni-spb-32.ru/]кухни на заказ от производителя в спб[/url] .
вывод из запоя стационар краснодар [url=https://vyvod-iz-zapoya-krasnodar-2.ru/]vyvod-iz-zapoya-krasnodar-2.ru[/url] .
ии анализ рекламы [url=https://reklamnyj-kreativ4.ru/]ии анализ рекламы[/url] .
точность прогноза креативов 95% [url=https://reklamnyj-kreativ5.ru/]reklamnyj-kreativ5.ru[/url] .
вызвать нарколога на дом [url=https://narkolog-na-dom-krasnodar-1.ru/]вызвать нарколога на дом[/url] .
заказать кухню спб [url=https://kuhni-spb-28.ru/]заказать кухню спб[/url] .
Формат помощи на дому особенно важен, когда человек физически не в состоянии добраться до клиники, боится огласки или требуется поддержка семьи «здесь и сейчас». Врач оценивает риски, подбирает схему детоксикации по состоянию и даёт понятный план дальнейших шагов: что делать в первые сутки, чего избегать, какие симптомы считать тревожными и когда нужно повторное обращение.
Углубиться в тему – https://narkolog-na-dom-krasnogorsk6.ru/narkolog-i-psikhiatr-krasnogorsk
краби таиланд храм тигра краби ко ланта
вывод из запоя кодирование краснодар [url=https://vyvod-iz-zapoya-krasnodar-1.ru/]vyvod-iz-zapoya-krasnodar-1.ru[/url] .
срочная помощь вывод из запоя краснодар [url=https://vyvod-iz-zapoya-krasnodar-2.ru/]vyvod-iz-zapoya-krasnodar-2.ru[/url] .
большая кухня на заказ [url=https://kuhni-spb-32.ru/]kuhni-spb-32.ru[/url] .
врач нарколог на дом [url=https://narkolog-na-dom-krasnodar-1.ru/]врач нарколог на дом[/url] .
кухни от производителя спб недорого и качественно [url=https://kuhni-spb-28.ru/]kuhni-spb-28.ru[/url] .
анализ наружной рекламы [url=https://reklamnyj-kreativ4.ru/]анализ наружной рекламы[/url] .
анализ баннеров [url=https://reklamnyj-kreativ5.ru/]reklamnyj-kreativ5.ru[/url] .
Процедура начинается с обследования пациента: врач измеряет давление, частоту пульса, оценивает степень интоксикации и состояние внутренних органов. После этого подбирается состав капельницы, направленный на очищение организма и восстановление функций печени, почек и нервной системы. Все препараты вводятся внутривенно, что обеспечивает быстрый эффект и минимизирует нагрузку на желудочно-кишечный тракт.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-tyumeni17.ru/]вывод из запоя цена тюмень[/url]
вывод из запоя на дому краснодар круглосуточно [url=https://vyvod-iz-zapoya-krasnodar-1.ru/]вывод из запоя на дому краснодар круглосуточно[/url] .
Каждый этап проходит под контролем врачей-наркологов и психотерапевтов, что гарантирует эффективность и безопасность лечения.
Изучить вопрос глубже – [url=https://narcologicheskaya-klinika-v-novokuzneczke17.ru/]наркологическая клиника[/url]
вывод из запоя в стационаре краснодара [url=https://vyvod-iz-zapoya-krasnodar-2.ru/]vyvod-iz-zapoya-krasnodar-2.ru[/url] .
врач нарколог на дом платный [url=https://narkolog-na-dom-krasnodar-1.ru/]narkolog-na-dom-krasnodar-1.ru[/url] .
прямые кухни на заказ от производителя [url=https://kuhni-spb-32.ru/]kuhni-spb-32.ru[/url] .
бк мостбет [url=http://mostbet2027.help]бк мостбет[/url]
кухни на заказ петербург [url=https://kuhni-spb-28.ru/]kuhni-spb-28.ru[/url] .
Старт всегда один: короткий скрининг с дежурным врачом, где уточняются жалобы, длительность эпизода, текущие лекарства, аллергии и условия дома. Далее согласуется реальное окно прибытия или приёма — без обещаний «через пять минут», но с честным ориентиром и запасом на дорожную обстановку. На месте врач фиксирует витальные показатели (АД, пульс, сатурацию, температуру), по показаниям выполняет ЭКГ, запускает детокс (регидратация, коррекция электролитов, защита печени/ЖКТ), объясняет ожидаемую динамику первых 6–12 часов и выдаёт памятку «на сутки»: режим сна, питьевой план, «красные флажки», точное время контрольной связи. Если домашний формат становится недостаточным, перевод в стационар организуется без пауз — терапия продолжается с того же места, где начата, темп лечения не теряется.
Подробнее – http://narkologicheskaya-klinika-shchyolkovo0.ru/anonimnaya-narkologicheskaya-klinika-v-shchyolkovo/
В этой статье-обзоре мы собрали данные, актуальность которых сомнительна, а факты — не всегда взаимосвязаны. Читатель сможет ознакомиться с разными мнениями, хотя вряд ли они существенно повлияют на его понимание темы.
Вот – [url=https://arma-rehab.ru/]онлайн покер на деньги[/url]
анализ карточек маркетплейс [url=https://reklamnyj-kreativ4.ru/]анализ карточек маркетплейс[/url] .
точность прогноза креативов 95% [url=https://reklamnyj-kreativ5.ru/]reklamnyj-kreativ5.ru[/url] .
Лечение в клинике «Трезвый Выбор Рязань» проходит в несколько последовательных этапов. Каждый этап выполняет конкретную задачу и сопровождается наблюдением специалистов. В таблице ниже представлена структура терапии и её основные направления.
Изучить вопрос глубже – [url=https://narkologicheskaya-clinika-v-ryazani17.ru/]www.domen.ru[/url]
вывод из запоя с выездом краснодар [url=https://vyvod-iz-zapoya-krasnodar-1.ru/]vyvod-iz-zapoya-krasnodar-1.ru[/url] .
вывод из запоя краснодар [url=https://vyvod-iz-zapoya-krasnodar-2.ru/]вывод из запоя краснодар[/url] .
Запой — это не просто несколько лишних дней алкоголя, а тяжёлое состояние, в котором организм работает на пределе. Чем дольше длится эпизод, тем глубже обезвоживание, тем сильнее сдвиги электролитов, тем выше риск аритмий, гипертонических кризов, судорог, делирия, обострений заболеваний сердца, печени и поджелудочной железы. Попытки «вывести» человека дома силами родных часто включают опасные комбинации: случайные седативные, снотворные, анальгетики, «антипохмельные» из рекламы. Они могут на время усыпить или «успокоить», но при этом скрывают ухудшение, сбивают давление, угнетают дыхание и мешают врачу увидеть реальную картину. В «Трезвый Центр Коломна» подход другой: ещё на этапе звонка специалист уточняет длительность запоя, объёмы и виды алкоголя, наличие гипертонии, ИБС, диабета, заболеваний печени и почек, неврологических проблем, список уже принятых препаратов, эпизоды потери сознания, судорог, странного поведения. На основании этих данных определяется, безопасен ли формат на дому или сразу нужен стационар. Такая сортировка позволяет вовремя перехватить опасные случаи, не терять часы на бесполезные попытки и сразу запускать те схемы, которые реально снижают риски и стабилизируют состояние.
Подробнее тут – http://
кухня по индивидуальному заказу спб [url=https://kuhni-spb-32.ru/]kuhni-spb-32.ru[/url] .
вызов нарколога на дом [url=https://narkolog-na-dom-krasnodar-1.ru/]вызов нарколога на дом[/url] .
кухни на заказ спб каталог [url=https://kuhni-spb-28.ru/]кухни на заказ спб каталог[/url] .
1win Кыргызстан кирүү [url=http://1win12050.ru]http://1win12050.ru[/url]
a/b тест наружная реклама [url=https://reklamnyj-kreativ4.ru/]reklamnyj-kreativ4.ru[/url] .
машинное обучение креативы [url=https://reklamnyj-kreativ5.ru/]reklamnyj-kreativ5.ru[/url] .
Своевременная постановка капельницы помогает избежать тяжёлых последствий запоя. Поводом для обращения к врачу являются симптомы выраженной интоксикации:
Выяснить больше – http://kapelnicza-ot-zapoya-v-volgograde17.ru
폰테크
모바일 폰테크란 모바일 기기를 통해 단기 자금을 마련하는 공식적인 금융 활용 구조입니다. 일반적인 소비 목적의 휴대폰 사용과는 달리 통신사와 유통 구조, 매입 시스템을 활용하여 실질적인 자금 확보가 가능한 방식이며, 절차가 비교적 단순하고 접근성이 높다는 장점이 있습니다. 은행 대출이 부담되거나 단기간 자금이 필요한 경우에 대안적인 방법으로 활용되는 경우가 많습니다.
폰테크의 기본적인 진행 방식은 비교적 간단합니다. 먼저 통신사를 통해 스마트폰을 정상적으로 개통한 뒤, 해당 단말기를 매입 업체를 통해 처분합니다. 가격은 모델과 시장 시세, 조건에 따라 달라지며, 정산 금액은 현금이나 계좌로 받게 됩니다. 이후 휴대폰 할부금과 통신요금은 본인이 정상적으로 납부해야 하며, 이 부분에 대한 관리가 매우 중요합니다. 이는 불법 대출과는 다른 구조로, 기기를 자산화하는 개념으로 이해할 수 있습니다.
폰테크는 일반적인 은행 대출과 비교했을 때 여러 차별점을 가집니다. 복잡한 심사나 서류 절차가 거의 없고, 단시간 내 자금 마련이 가능하다는 점이 가장 큰 특징입니다. 금융 이력이 남지 않기 때문에 기존 금융 기록이 부담되는 상황에서도 활용할 수 있습니다. 다만 요금이나 할부금이 연체될 경우 신용도에 영향을 줄 수 있으므로 책임 있는 이용이 필수적입니다.
사람들이 폰테크를 선택하는 이유는 다양합니다. 급전이 필요한 상황이나 금융 이용이 제한된 경우, 자금 흐름이 필요한 상황 등 다양한 상황에서 고려됩니다. 즉각적인 현금 흐름이 중요한 경우에 현실적인 대안으로 선택되는 경우가 많습니다.
폰테크를 통해 마련한 자금은 주식이나 코인 투자, 사업 자금, 생활비 등 여러 방식으로 활용될 수 있습니다. 하지만 이러한 자금 운용은 전적으로 개인의 판단과 책임 하에 이루어져야 하며, 모든 투자에는 리스크가 따른다는 점을 충분히 인지해야 합니다. 폰테크는 수익을 보장하는 수단이 아니라 단순한 자금 마련 방법이라는 점을 이해해야 합니다.
폰테크는 합법적인 구조이지만 주의해야 할 부분도 분명히 존재합니다. 무리한 개통은 통신 정책상 문제가 될 수 있으며, 요금 납부 능력을 고려하지 않은 진행은 부담이 될 수 있습니다. 또한 고수익을 보장하거나 명의 대여를 요구하는 업체는 피해야 하며, 절차는 항상 합법적이고 투명하게 진행되어야 합니다.
정리하자면, 폰테크는 휴대폰과 통신 유통 구조를 활용한 합법적인 자금 조달 방법으로, 충분한 이해와 책임 있는 관리가 동반될 경우 단기 자금 확보에 도움이 될 수 있습니다. 가장 중요한 것은 충분한 정보와 합리적인 결정입니다.
폰테크
휴대폰테크란 스마트폰을 활용해 단기 자금을 마련하는 공식적인 자금 조달 방법입니다. 기존의 단순한 휴대폰 구매와는 다르게 통신 구조와 유통 경로를 이용해 현금을 확보하는 구조를 가지고 있으며, 진행 과정이 간단하고 진입 장벽이 낮다는 특징이 있습니다. 은행 대출이 부담되거나 급전이 필요한 상황에서 현실적인 선택지로 고려됩니다.
휴대폰 테크의 일반적인 절차는 비교적 간단합니다. 통신사 정책에 맞춰 휴대폰을 개통한 후, 해당 단말기를 매입 업체를 통해 처분합니다. 매입 금액은 기종, 시세, 통신 조건에 따라 결정되며, 판매 대금은 현금 또는 계좌이체로 지급됩니다. 이후 휴대폰 할부금과 통신요금은 본인이 정상적으로 납부해야 하며, 이 부분에 대한 관리가 매우 중요합니다. 이는 불법 대출과는 다른 구조로, 기기를 자산화하는 개념으로 이해할 수 있습니다.
기존 금융권 대출과 비교하면 뚜렷한 차이가 있습니다. 신용 심사나 서류 제출 부담이 적고, 비교적 빠르게 현금을 확보할 수 있다는 점이 대표적인 장점입니다. 또한 대출 기록이 남지 않는 구조이기 때문에 신용도에 부담을 느끼는 경우에도 접근이 가능합니다. 다만 요금이나 할부금이 연체될 경우 신용도에 영향을 줄 수 있으므로 책임 있는 이용이 필수적입니다.
사람들이 폰테크를 선택하는 이유는 다양합니다. 갑작스럽게 현금이 필요한 상황, 신용 문제로 대출이 어려운 경우, 단기적인 자금 회전이 필요한 경우 등 여러 목적에서 활용됩니다. 특히 빠른 자금 유동성이 필요한 경우 실질적인 선택지로 평가됩니다.
확보한 현금은 투자 자금, 사업 운영비, 생활 자금 등 여러 방식으로 활용될 수 있습니다. 하지만 이러한 자금 운용은 전적으로 개인의 판단과 책임 하에 이루어져야 하며, 투자에는 항상 손실의 가능성이 존재한다는 점을 반드시 인식해야 합니다. 이 방식은 이익을 약속하는 구조가 아니라 자금 확보 목적의 수단이라는 점을 명확히 해야 합니다.
폰테크는 합법적인 구조이지만 주의해야 할 부분도 분명히 존재합니다. 과도한 휴대폰 개통은 통신사 제재의 대상이 될 수 있으며, 상환 계획 없는 이용은 오히려 리스크가 됩니다. 또한 고수익을 보장하거나 명의 대여를 요구하는 업체는 피해야 하며, 절차는 항상 합법적이고 투명하게 진행되어야 합니다.
정리하자면, 해당 방식은 통신 구조를 이용한 합법적인 자금 조달 방법으로, 충분한 이해와 책임 있는 관리가 동반될 경우 단기 자금 확보에 도움이 될 수 있습니다. 무엇보다 사전 정보 확인과 신중한 선택이 가장 중요합니다.
1win пополнение через банк [url=http://1win12050.ru]http://1win12050.ru[/url]
Текст включает разнообразную информацию, которая может показаться любопытной, но не меняет устоявшегося восприятия. Предлагаем просто насладиться чтением, не ожидая значительной пользы.
Подробнее читать – [url=https://rostov-narkologiya.ru/ ]лечение covid народными средствами[/url]
Выезд нарколога на дом в Щёлково — это быстрый и конфиденциальный способ помочь человеку в состоянии запоя или тяжёлого похмелья, не перевозя его в клинику и не устраивая публичных сцен. Врачи «ЩёлковоМед Профи» приезжают с готовым набором препаратов, одноразовыми системами и чётким протоколом: осмотр, оценка жизненно важных показателей, подбор индивидуальной капельницы, контроль реакции, рекомендации для родных. Такой формат особенно удобен, когда пациент отказывается ехать в стационар, тяжело переносит дорогу, остро реагирует на смену обстановки или для семьи важна максимальная анонимность. Главный принцип — не «вырубить» человека любой ценой, а безопасно стабилизировать состояние, снизить интоксикацию, выровнять давление и пульс, помочь собрать сон и дать понятный план, что делать дальше.
Углубиться в тему – [url=https://narkolog-na-dom-shchelkovo10.ru/]zakazat-narkologa-na-dom[/url]
Комплексное проведение этих этапов обеспечивает полное восстановление организма и облегчает процесс последующего лечения зависимости.
Ознакомиться с деталями – http://vyvod-iz-zapoya-v-ryazani17.ru
врач нарколог на дом платный [url=https://narkolog-na-dom-krasnodar-2.ru/]narkolog-na-dom-krasnodar-2.ru[/url] .
Медицинская помощь строится на принципах индивидуального подхода и поэтапной терапии. Каждый пациент проходит диагностику, после чего составляется персональная программа, включающая медикаментозную поддержку, консультации психотерапевта и физиопроцедуры. Такой подход помогает не просто снять симптомы, но и восстановить организм полностью.
Подробнее тут – [url=https://narkologicheskaya-klinika-v-ryazani17.ru/]анонимная наркологическая клиника[/url]
Если на предзвонке выявляются «красные флаги» — давящая боль в груди, одышка в покое, спутанность сознания, судороги, неукротимая рвота, резкое падение насыщения кислородом — мы организуем бесшовный перевод в стационар. Место резервируем заранее, логистику строим так, чтобы не привлекать внимания соседей и не затягивать старт лечения. При отсутствии угроз терапия может начаться дома с последующим телесопровождением и при необходимости — краткой госпитализацией.
Исследовать вопрос подробнее – [url=https://narcologicheskaya-klinika-saratov0.ru/]наркологическая клиника лечение алкоголизма саратов[/url]
tuvajiem portano toda batersbyl solvedc agenture stakeout laiemas departamento novio https://canadapharmacy-usa.net/drug/symbicort/ – pctparent rembrant coktur jail lieve supplere aactions swoja wintermonsun metafisiche
Медики рекомендуют обратиться за профессиональной помощью при следующих состояниях:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-v-ryazani17.ru/]срочный вывод из запоя рязань[/url]
нарколог краснодар [url=https://narkolog-na-dom-krasnodar-2.ru/]нарколог краснодар[/url] .
PSYCHEDELICS DISPENSARY
TRIPPY 420 ROOM is an online psychedelics dispensary, with a focus on carefully prepared, high-quality medical products covering a wide range of categories.
Before buying psychedelic, cannabis, stimulant, dissociative, or opioid products online, users are provided with a clear service structure including product access, delivery methods, and assistance. The store features more than 200 products covering different formats and preferences.
Delivery pricing is determined by package size and destination, and includes both regular and express shipping. Each order includes access to a hassle-free returns system and a strong focus on privacy and security. Guaranteed stealth delivery worldwide is a core element, with no added fees. All orders are fully guaranteed to ensure uninterrupted delivery.
The product range includes cannabis flowers, magic mushrooms, psychedelic products, opioid medication, disposable vapes, tinctures, pre-rolls, and concentrates. Each item is listed with clear pricing, including defined price ranges where multiple variants are available. Educational material is also provided, with references including “How to Dissolve LSD Gel Tabs”, along with direct options to buy LSD gel tabs and buy psychedelics online.
TRIPPY 420 ROOM operates from the United States, California, and offers multiple communication channels, including phone, WhatsApp, Signal, Telegram, and email support. The service highlights 24/7 express psychedelic delivery, placing focus on accessibility, discretion, and consistent support.
Hello! [url=https://baypharm.top/#]baypharm[/url] good internet site.
вызов нарколога на дом круглосуточно [url=https://narkolog-na-dom-krasnodar-2.ru/]narkolog-na-dom-krasnodar-2.ru[/url] .
best online pharmacy vicodin https://canbaypharm.top/# Mexico pharmacy online reviews
Главная задача процедуры — быстрое выведение этанола и его метаболитов из организма, нормализация уровня электролитов, улучшение самочувствия и предотвращение осложнений. Лечение проводится как в клинике, так и на дому, что особенно удобно при тяжёлых состояниях, когда пациент не может самостоятельно добраться до медицинского учреждения.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-tyumeni17.ru/]вывод из запоя недорого в тюмени[/url]
Индивидуально подобранный состав раствора обеспечивает быстрое выведение токсинов и улучшение физического состояния уже в течение первых часов после начала лечения.
Получить дополнительные сведения – [url=https://kapelnicza-ot-zapoya-v-volgograde17.ru/]капельница от запоя клиника волгоград[/url]
mexica online pharmacy https://baypharm.top/# online pharmacy hydrocodone
[url=https://canbaypharm.top/#]adderall best online pharmacy[/url]
1win_kg [url=https://1win12048.ru]https://1win12048.ru[/url]
[url=https://baypharm.top/#]baypharm[/url]
нарколог на дом недорого [url=https://narkolog-na-dom-krasnodar-2.ru/]narkolog-na-dom-krasnodar-2.ru[/url] .
1win промо код [url=https://1win12048.ru]https://1win12048.ru[/url]
baypharm https://baypharm.top/# online pharmacy xanax
cvs pharmacy jobs apply online https://canbaypharm.top/# azithromycin best online pharmacy
В данном тексте собраны разнообразные случайные сведения и не вполне определённые идеи, которые могут вызвать интерес. Мы отмечаем детали, не играющие ключевой роли, но сохраняющие своё место в изложении.
Подробнее читать – [url=https://rostov-narkologiya.ru/uslugi-ot-narkomanii/mefedronovaya-zavisimost/]сиалис онлайн[/url]
1win демо lucky jet [url=http://1win12048.ru/]http://1win12048.ru/[/url]
Перед началом терапии проводится полная диагностика организма, включая лабораторные исследования и ЭКГ. Это позволяет оценить состояние пациента и подобрать оптимальный курс лечения. После стабилизации физического состояния начинается психотерапевтическая и реабилитационная работа. Такой подход помогает не только снять симптомы, но и устранить первопричины зависимости.
Получить больше информации – http://narkologicheskaya-klinika-kemerovo18.ru
[url=https://canbaypharm.top/#]best online pharmacy prescription[/url]
baypharm https://baypharm.top/# online pharmacies
ко ланте ко ланте
reputable mexican best online pharmacy https://canbaypharm.top/# mexico best online pharmacy
прогулки по питеру экскурсии [url=https://avtobusnye-ekskursii-po-spb.ru/]прогулки по питеру экскурсии[/url] .
1 автобус санкт петербург [url=https://avtobusnye-ekskursii-po-spb.ru/]avtobusnye-ekskursii-po-spb.ru[/url] .
санкт петербург купить тур [url=https://tury-v-piter.ru/]tury-v-piter.ru[/url] .
поехать в питер дешево на двоих [url=https://tury-v-piter.ru/]поехать в питер дешево на двоих[/url] .
Такой подход обеспечивает комплексное восстановление: медицинское, эмоциональное и социальное. Врачи ведут пациента на всех этапах, помогая пройти путь от очищения организма до формирования устойчивой трезвости.
Разобраться лучше – http://narkologicheskaya-klinica-v-astrakhani18.ru
[url=https://canbaypharm.top/#]my mexican pharmacy online[/url]
Hi there, its nice paragraph about media print, we all understand media is a fantastic source of information.
официальный сайт риобет
бонусы за регистрацию без депозита Бездепозитные Промокоды: Ключ к Эксклюзивным Предложениям Бездепозитные промокоды – это специальные коды, которые игроки могут активировать на сайте казино, чтобы получить доступ к эксклюзивным бездепозитным бонусам. Эти промокоды часто распространяются через партнерские сайты, социальные сети или электронную рассылку казино.
тур на автобусе в санкт петербург [url=https://avtobusnye-ekskursii-po-spb.ru/]avtobusnye-ekskursii-po-spb.ru[/url] .
путевка в питер на 2 дня на двоих [url=https://tury-v-piter.ru/]tury-v-piter.ru[/url] .
купить путевку в питер на неделю [url=https://tury-v-piter.ru/]tury-v-piter.ru[/url] .
top online pharmacies https://canbaypharm.top/# mexican online pharmacies
useful link [url=https://jaxxwallet-web.org/]jaxx app[/url]
стоимость поездки на автобусе в санкт петербурге [url=https://avtobusnye-ekskursii-po-spb.ru/]avtobusnye-ekskursii-po-spb.ru[/url] .
поездка в петербург [url=https://tury-v-piter.ru/]поездка в петербург[/url] .
[url=http://www.flugzeugmarkt.eu/url?q=https%3A%2F%2Fbaypharm.top]baypharm[/url]
methadone best online pharmacy https://maps.google.co.zm/url?q=https%3A%2F%2Fcanbaypharm.top best online pharmacy india
В этом тексте собрано множество случайных сведений и довольно неопределённых мыслей, которые могут чем-то заинтересовать. Мы отмечаем моменты, которые не особенно важны, но всё же занимают своё место в повествовании.
Вот – https://arma-rehab.ru/lechenie-alkogolizma
спб автобусные экскурсии [url=https://avtobusnye-ekskursii-po-spb.ru/]avtobusnye-ekskursii-po-spb.ru[/url] .
baypharm https://maps.google.rw/url?q=http%3A%2F%2Fbaypharm.top online pharmacy school
автобус питер [url=https://avtobusnye-ekskursii-po-spb.ru/]автобус питер[/url] .
mostbet descarcare Republica Moldova [url=https://mostbet2008.help]https://mostbet2008.help[/url]
vavada turniri [url=http://vavada2007.help]vavada turniri[/url]
с в питере [url=https://tury-v-piter.ru/]tury-v-piter.ru[/url] .
экскурсионный тур в санкт петербург [url=https://tury-v-piter.ru/]экскурсионный тур в санкт петербург[/url] .
[url=http://andreasgraef.de/url?q=https%3A%2F%2Fcanbaypharm.top]non prescription best online pharmacy[/url]
[url=https://maps.google.co.tz/url?sa=t&url=https%3A%2F%2Fbaypharm.top]us online pharmacy[/url]
mostbet nu se deschide [url=http://mostbet2008.help]mostbet nu se deschide[/url]
vavada legalno u Hrvatskoj [url=vavada2007.help]vavada legalno u Hrvatskoj[/url]
online pharmacy without prescription https://maps.google.com.eg/url?sa=t&url=https%3A%2F%2Fbaypharm.top online mexican pharmacy
most bet [url=www.mostbet2008.help]most bet[/url]
best online pharmacy technician schools https://images.google.gr/url?sa=t&url=https%3A%2F%2Fcanbaypharm.top viagra online mexican pharmacy
find this [url=https://jaxxwallet-web.org/]jaxx wallet[/url]
[url=https://images.google.com.fj/url?sa=t&url=https%3A%2F%2Fbaypharm.top]baypharm[/url]
В команде — врачи-наркологи, психиатры-консультанты, клинические психологи и выездные медсёстры. Все работают по единому алгоритму: короткий скрининг, стартовая стабилизация, настройка «вечернего протокола» для нормализации сна и план на 72 часа. Цель — восстановить биоритмы, мягко убрать соматические проявления абстиненции и снизить реактивную тревогу, чтобы человек быстрее вернулся к привычным ролям дома и на работе.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-pervouralsk0.ru/]помощь вывод из запоя в первоуральске[/url]
Инфузионная терапия в «ТагилМед Реал» — это точный инструмент под конкретный запрос: обезвоживание, вегетативная нестабильность, нарушения сна, «утренний туман». Состав и дозировки подбирает врач с учётом возраста, коморбидности и лекарственных взаимодействий. Важно понимать: больше компонентов не значит лучше; главная ценность — фокус и безопасность.
Ознакомиться с деталями – http://narkologicheskaya-klinika-nizhnij-tagil0.ru
[url=https://maps.google.li/url?q=https%3A%2F%2Fcanbaypharm.top]modafinil best online pharmacy[/url]
baypharm https://maps.google.com.sg/url?sa=t&url=https%3A%2F%2Fbaypharm.top baypharm
slot gacor situs toto situs toto 4d
[url=https://maps.google.com.ph/url?q=https%3A%2F%2Fbaypharm.top]mexican online pharmacies[/url]
pharmacy tech online course https://www.google.hr/url?q=https%3A%2F%2Fcanbaypharm.top pharmacy tech classes online
дайсон спб официальный магазин [url=https://pylesos-dn-6.ru/]pylesos-dn-6.ru[/url] .
доставка алкоголя 24 [url=https://alcohub10.ru/]доставка алкоголя 24[/url] .
пылесос дайсон беспроводной спб [url=https://pylesos-dn-9.ru/]пылесос дайсон беспроводной спб[/url] .
дайсон пылесос беспроводной купить спб [url=https://pylesos-dn-8.ru/]дайсон пылесос беспроводной купить спб[/url] .
Врач приезжает с одноразовыми системами и препаратами, проводит экспресс-диагностику, стартует инфузии и каждые 15–20 минут оценивает динамику, корректируя темп и состав. По завершении — памятка по режиму, гигиене сна, питанию и запретам на 24–72 часа, а также контакты для связи ночью.
Разобраться лучше – http://vyvod-iz-zapoya-odincovo10.ru/
пылесос dyson купить в спб [url=https://pylesos-dn-7.ru/]pylesos-dn-7.ru[/url] .
сервис дайсон в спб [url=https://dn-pylesos-kupit-5.ru/]dn-pylesos-kupit-5.ru[/url] .
dyson gen5 купить в спб [url=https://dn-pylesos-4.ru/]dn-pylesos-4.ru[/url] .
дайсон спб официальный [url=https://pylesos-dn-10.ru/]дайсон спб официальный[/url] .
дайсон фен купить оригинальный спб [url=https://dn-pylesos-kupit-4.ru/]dn-pylesos-kupit-4.ru[/url] .
официальный сайт дайсон [url=https://dn-pylesos-2.ru/]dn-pylesos-2.ru[/url] .
dyson пылесос беспроводной купить спб [url=https://dn-pylesos-3.ru/]dn-pylesos-3.ru[/url] .
Команда «КарелМед Центра» объединяет наркологов, психиатров, реаниматологов, клинических психологов, специалистов по реабилитации и социальному сопровождению. Мы работаем без очередей и навязчивых формальностей, а логистика визита, оформление в стационар и коммуникации с родственниками выстроены бережно: конфиденциальные записи, немаркированные выезды, отдельный вход и нейтральная терминология в документах. Вы получаете не только купирование абстиненции и детоксикацию, но и системную работу с триггерами, привычками и межличностными конфликтами — тем, что часто возвращает к употреблению даже после «идеальных капельниц».
Детальнее – https://narkologicheskaya-klinika-petrozavodsk0.ru/chastnaya-narkologicheskaya-klinika-petrozavodsk
baypharm https://clients1.google.ae/url?q=https%3A%2F%2Fbaypharm.top baypharm
Наркологическая клиника «ТагилМед Реал» — это круглосуточная команда врачей, психологов и координаторов, которая берёт на себя полный цикл помощи при алкогольной и наркотической зависимости: от экстренной стабилизации и капельниц на дому до амбулаторного сопровождения, кодирования и длительной психотерапевтической поддержки. Мы работаем без выходных, используем портативное оборудование, придерживаемся принципов доказательной медицины и внимательно относимся к конфиденциальности: нейтральные формулировки в документах, немаркированный транспорт, разграниченный доступ к медицинским данным и единый доверенный контакт для семьи.
Детальнее – http://narkologicheskaya-klinika-nizhnij-tagil0.ru
[url=https://images.google.co.nz/url?sa=t&url=http%3A%2F%2Fcanbaypharm.top]cgv best online pharmacy[/url]
пылесосы дайсон [url=https://pylesos-dn-9.ru/]пылесосы дайсон[/url] .
[url=https://www.google.com.pr/url?q=https%3A%2F%2Fbaypharm.top]cialis online pharmacy[/url]
санкт петербург магазин дайсон [url=https://dn-pylesos-kupit-5.ru/]dn-pylesos-kupit-5.ru[/url] .
заказ алкоголя на дом [url=https://alcohub10.ru/]заказ алкоголя на дом[/url] .
dyson купить спб [url=https://pylesos-dn-8.ru/]dyson купить спб[/url] .
дайсон пылесос спб [url=https://pylesos-dn-10.ru/]pylesos-dn-10.ru[/url] .
dyson оригинал спб [url=https://dn-pylesos-kupit-4.ru/]dn-pylesos-kupit-4.ru[/url] .
пылесос дайсон беспроводной купить в спб вертикальный [url=https://dn-pylesos-4.ru/]пылесос дайсон беспроводной купить в спб вертикальный[/url] .
сервис дайсон в спб [url=https://dn-pylesos-2.ru/]dn-pylesos-2.ru[/url] .
пылесос dyson купить [url=https://dn-pylesos-3.ru/]dn-pylesos-3.ru[/url] .
купить пылесос дайсон в санкт петербурге беспроводной [url=https://pylesos-dn-6.ru/]pylesos-dn-6.ru[/url] .
dyson магазин в спб [url=https://pylesos-dn-7.ru/]pylesos-dn-7.ru[/url] .
india pharmacy online https://www.google.je/url?sa=t&url=https%3A%2F%2Fonlinepharmeasy.shop cvs online pharmacy
cvs pharmacy job application online https://maps.google.com.ph/url?q=https%3A%2F%2Fcanadianpharmeasy.shop clomid best online pharmacy
пылесос дайсон купить [url=https://pylesos-dn-9.ru/]пылесос дайсон купить[/url] .
пылесосы дайсон санкт петербург [url=https://dn-pylesos-kupit-5.ru/]dn-pylesos-kupit-5.ru[/url] .
пылесос dyson [url=https://pylesos-dn-10.ru/]пылесос dyson[/url] .
алкоголь доставка 24 часа москва [url=alcohub10.ru]алкоголь доставка 24 часа москва[/url] .
купить пылесос дайсон спб [url=https://dn-pylesos-kupit-4.ru/]dn-pylesos-kupit-4.ru[/url] .
A British man, along with five others, has been charged with carrying out 56 sexual offences against his now ex-wife over a 13-year period.
[url=https://trips63.cc]трип скан[/url]
Philip Young has been remanded in custody in relation to the string of charges, which include multiple counts of rape and administering a substance with the intent to overpower to allow sexual activity, according to Wiltshire Police.
[url=https://trips63.cc]trip scan[/url]
Young, 49, has also been charged with voyeurism, possession of indecent images of children and possession of extreme images.
[url=https://trips63.cc]трипскан[/url]
Five other men, currently on bail, have also been charged with offences against 48-year-old Joanne Young, who waived her legal right to anonymity.
The alleged offences took place between 2010 and 2023.
The men were named by police as Norman Macksoni, 47, who has been charged with one count of rape and possession of extreme images; Dean Hamilton, also 47, who is facing one count of rape and sexual assault by penetration and two counts of sexual touching; 31-year-old Conner Sanderson Doyle, who has been charged with sexual assault by penetration and sexual touching; Richard Wilkins, 61, who faces one count of rape and sexual touching and Mohammed Hassan, 37, who has been charged with sexual touching.
All six men are due to appear at Swindon Magistrates’ Court in southwest England on Tuesday.
Geoff Smith, detective superintendent for Wiltshire police, described the charges as a “significant update” in a “complex and extensive investigation.”
He added that Joanne Young was being supported by specially trained officers and made the decision to waive her automatic legal right to anonymity “following multiple discussions with officers and support services.”
James Foster, a Crown Prosecution Service specialist prosecutor, added that the CPS had authorized the charges against the six men “following a police investigation into alleged serious sexual offences against Joanne Young over a period of 13 years.”
“Our prosecutors have worked to establish that there is sufficient evidence to charge and that it is in the public interest to pursue criminal proceedings,” he said in a statement.
“We have worked closely with Wiltshire Police as they carried out their investigation.”
трипскан
https://trips63.cc
пылесосы дайсон спб [url=https://pylesos-dn-8.ru/]pylesos-dn-8.ru[/url] .
dyson купить спб [url=https://dn-pylesos-4.ru/]dyson купить спб[/url] .
[url=https://images.google.ms/url?sa=t&url=https%3A%2F%2Fonlinepharmeasy.shop]online pharmacy india[/url]
Этот обзор позволяет по-новому взглянуть на вещи, на которые обычно и так смотрят. Мы упоминаем факты, которые мало что меняют, и события, значение которых трудно определить, но они всё равно здесь.
Вот – [url=https://arma-rehab.ru/vyvod-iz-zapoya/]блекджек[/url]
дайсон где купить в спб [url=https://dn-pylesos-3.ru/]dn-pylesos-3.ru[/url] .
дайсон купить спб [url=https://pylesos-dn-6.ru/]pylesos-dn-6.ru[/url] .
dyson спб [url=https://pylesos-dn-7.ru/]pylesos-dn-7.ru[/url] .
[url=https://maps.google.com.eg/url?sa=t&url=https%3A%2F%2Fcanadianpharmeasy.shop]best online pharmacy with doctor consultation[/url]
adderall online pharmacy https://cse.google.to/url?sa=t&url=https%3A%2F%2Fonlinepharmeasy.shop pharmacy technician certification online
официальный сайт дайсон [url=https://pylesos-dn-9.ru/]официальный сайт дайсон[/url] .
дайсон официальный сайт [url=https://dn-pylesos-kupit-5.ru/]дайсон официальный сайт[/url] .
Врач приезжает с одноразовыми системами и препаратами, проводит экспресс-диагностику, стартует инфузии и каждые 15–20 минут оценивает динамику, корректируя темп и состав. По завершении — памятка по режиму, гигиене сна, питанию и запретам на 24–72 часа, а также контакты для связи ночью.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-odincovo10.ru/]вывод из запоя на дому одинцово[/url]
купить пылесос дайсон в санкт петербурге [url=https://pylesos-dn-10.ru/]купить пылесос дайсон в санкт петербурге[/url] .
дайсон купить спб оригинал [url=https://dn-pylesos-kupit-4.ru/]dn-pylesos-kupit-4.ru[/url] .
dyson пылесос купить спб [url=https://pylesos-dn-8.ru/]pylesos-dn-8.ru[/url] .
официальный сайт дайсон [url=https://dn-pylesos-4.ru/]официальный сайт дайсон[/url] .
пылесос dyson купить [url=https://dn-pylesos-3.ru/]dn-pylesos-3.ru[/url] .
доставка алкоголя круглосуточно [url=http://alcohub10.ru]доставка алкоголя круглосуточно[/url] .
[url=https://images.google.gr/url?sa=t&url=https%3A%2F%2Fonlinepharmeasy.shop]online pharmacy tramadol[/url]
abc best online pharmacy https://images.google.ca/url?q=https%3A%2F%2Fcanadianpharmeasy.shop best online pharmacy phentermine
пылесосы dyson [url=https://pylesos-dn-7.ru/]pylesos-dn-7.ru[/url] .
pin-up email dəyişmək [url=https://www.pinup2009.help]https://www.pinup2009.help[/url]
пылесос дайсон купить [url=https://pylesos-dn-6.ru/]pylesos-dn-6.ru[/url] .
дайсон официальный сайт в санкт петербург [url=https://pylesos-dn-9.ru/]pylesos-dn-9.ru[/url] .
viagra online pharmacy https://cse.google.hn/url?sa=t&url=https%3A%2F%2Fonlinepharmeasy.shop online pharmacy adderall
dyson пылесос купить спб [url=https://dn-pylesos-kupit-5.ru/]dn-pylesos-kupit-5.ru[/url] .
пылесосы дайсон [url=https://pylesos-dn-10.ru/]пылесосы дайсон[/url] .
폰테크
휴대폰테크란 스마트폰을 활용해 단기 자금을 마련하는 정상적인 금융 활용 구조입니다. 일반적인 소비 목적의 휴대폰 사용과는 달리 통신사와 유통 구조, 매입 시스템을 활용하여 현금을 확보하는 구조를 가지고 있으며, 절차가 비교적 단순하고 접근성이 높다는 특징이 있습니다. 은행 대출이 부담되거나 단기간 자금이 필요한 경우에 대안적인 방법으로 활용되는 경우가 많습니다.
휴대폰 테크의 일반적인 절차는 크게 복잡하지 않습니다. 먼저 통신사를 통해 스마트폰을 정상적으로 개통한 뒤, 개통된 휴대폰을 전문 매입 업체에 판매합니다. 매입 금액은 기종, 시세, 통신 조건에 따라 결정되며, 판매 대금은 현금 또는 계좌이체로 지급됩니다. 이후 발생하는 요금과 할부금은 사용자 책임으로 관리해야 하며, 요금 관리가 핵심 요소입니다. 이는 불법 대출과는 다른 구조로, 기기를 자산화하는 개념으로 이해할 수 있습니다.
기존 금융권 대출과 비교하면 여러 차별점을 가집니다. 복잡한 심사나 서류 절차가 거의 없고, 비교적 빠르게 현금을 확보할 수 있다는 점이 가장 큰 특징입니다. 또한 대출 기록이 남지 않는 구조이기 때문에 기존 금융 기록이 부담되는 상황에서도 활용할 수 있습니다. 하지만 통신요금 미납이나 연체가 발생할 경우 신용 상태에 불리하게 작용할 수 있으므로 책임 있는 이용이 필수적입니다.
이 방식을 선택하는 배경은 여러 가지입니다. 갑작스럽게 현금이 필요한 상황, 신용 문제로 대출이 어려운 경우, 단기적인 자금 회전이 필요한 경우 등 여러 목적에서 활용됩니다. 특히 빠른 자금 유동성이 필요한 경우 실질적인 선택지로 평가됩니다.
폰테크를 통해 마련한 자금은 투자 자금, 사업 운영비, 생활 자금 등 여러 방식으로 활용될 수 있습니다. 다만 자금 사용에 대한 책임은 모두 본인에게 있으며, 투자에는 항상 손실의 가능성이 존재한다는 점을 반드시 인식해야 합니다. 이 방식은 이익을 약속하는 구조가 아니라 자금 확보 목적의 수단이라는 점을 명확히 해야 합니다.
해당 방식은 합법적이지만 유의해야 할 점이 있습니다. 무리한 개통은 통신 정책상 문제가 될 수 있으며, 요금 납부 능력을 고려하지 않은 진행은 부담이 될 수 있습니다. 비정상적인 수익을 약속하거나 명의를 요구하는 경우는 주의해야 하며, 절차는 항상 합법적이고 투명하게 진행되어야 합니다.
결론적으로, 폰테크는 휴대폰과 통신 유통 구조를 활용한 합법적인 자금 조달 방법으로, 올바른 정보와 신중한 판단이 전제된다면 현금 유동성 확보에 유용할 수 있습니다. 무엇보다 사전 정보 확인과 신중한 선택이 가장 중요합니다.
Ищешь сокращатель сылок? https://l1l.kz надежный сокращатель ссылок в Казахстане, рекомендуем заглянуть на сайт, где весь функционал доступен бесплатно и без регистрации
pin-up reseña Chile [url=https://pinup2003.help/]https://pinup2003.help/[/url]
дайсон пылесос купить [url=https://dn-pylesos-kupit-4.ru/]dn-pylesos-kupit-4.ru[/url] .
[url=https://toolbarqueries.google.com.my/url?sa=t&url=https%3A%2F%2Fcanadianpharmeasy.shop]klonopin best online pharmacy[/url]
ремонт пылесоса дайсон в спб [url=https://dn-pylesos-4.ru/]ремонт пылесоса дайсон в спб[/url] .
дайсон официальный сайт в санкт петербург [url=https://dn-pylesos-3.ru/]dn-pylesos-3.ru[/url] .
пылесос dyson купить в спб [url=https://pylesos-dn-8.ru/]пылесос dyson купить в спб[/url] .
audit seo
[url=https://images.google.co.uz/url?q=https%3A%2F%2Fonlinepharmeasy.shop]walmart online pharmacy[/url]
алкоголь 24 [url=alcohub10.ru]алкоголь 24[/url] .
dyson спб официальный [url=https://pylesos-dn-9.ru/]pylesos-dn-9.ru[/url] .
пылесос dyson купить [url=https://dn-pylesos-kupit-5.ru/]dn-pylesos-kupit-5.ru[/url] .
дайсон где купить в спб [url=https://pylesos-dn-7.ru/]pylesos-dn-7.ru[/url] .
pin-up evitar bloqueo [url=http://pinup2003.help]http://pinup2003.help[/url]
дайсон санкт петербург [url=https://pylesos-dn-6.ru/]pylesos-dn-6.ru[/url] .
adderall online pharmacy https://maps.google.si/url?sa=t&url=https%3A%2F%2Fonlinepharmeasy.shop mexican online pharmacy
suboxone best online pharmacy https://images.google.com.gt/url?q=https%3A%2F%2Fcanadianpharmeasy.shop cvs pharmacy online application
дайсон купить спб [url=https://dn-pylesos-3.ru/]дайсон купить спб[/url] .
пылесосы дайсон спб [url=https://pylesos-dn-10.ru/]пылесосы дайсон спб[/url] .
пылесос dyson спб [url=https://dn-pylesos-kupit-4.ru/]dn-pylesos-kupit-4.ru[/url] .
пылесосы дайсон [url=https://dn-pylesos-4.ru/]пылесосы дайсон[/url] .
пылесос дайсон v15 купить в спб [url=https://pylesos-dn-8.ru/]pylesos-dn-8.ru[/url] .
pin-up cashback faiz [url=http://pinup2009.help]http://pinup2009.help[/url]
заказать алкоголь с доставкой [url=www.alcohub10.ru]заказать алкоголь с доставкой[/url] .
[url=https://cse.google.to/url?sa=t&url=https%3A%2F%2Fonlinepharmeasy.shop]costco online pharmacy[/url]
[url=https://maps.google.es/url?q=https%3A%2F%2Fcanadianpharmeasy.shop]best online pharmacy cialis[/url]
пылесос dyson спб [url=https://pylesos-dn-7.ru/]pylesos-dn-7.ru[/url] .
В данном тексте собраны разнообразные случайные сведения и не вполне определённые идеи, которые могут вызвать интерес. Мы отмечаем детали, не играющие ключевой роли, но сохраняющие своё место в изложении.
Подробнее читать – https://rostov-narkologiya.ru/uslugi-ot-narkomanii/mefedronovaya-zavisimost
дайсон санкт петербург [url=https://pylesos-dn-6.ru/]pylesos-dn-6.ru[/url] .
Такой подход позволяет наркологической клинике в Ростове-на-Дону выстраивать лечение в безопасных и психологически комфортных условиях.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-v-rostove19.ru/]наркологическая клиника нарколог[/url]
Реализация данных задач позволяет наркологу на дом в Ростове-на-Дону оказывать помощь в контролируемом и безопасном формате.
Ознакомиться с деталями – [url=https://narkolog-na-dom-v-rnd19.ru/]вызвать нарколога на дом в ростове-на-дону[/url]
no prescription online pharmacy https://www.google.im/url?sa=t&url=https%3A%2F%2Fonlinepharmeasy.shop walmart pharmacy online
[url=http://www.centropol.de/url?q=https%3A%2F%2Fonlinepharmeasy.shop]online mexican pharmacy[/url]
[url=https://cse.google.md/url?sa=t&url=https%3A%2F%2Fedpillseasy.shop]erection pills that work immediately[/url]
mexican online pharmacy reviews https://www.google.pt/url?q=https%3A%2F%2Fmexicanxlpharmacy.com xanax online pharmacy
폰테크
Этот сборник информации привлекает множеством мелких деталей и необычных ракурсов. Мы предлагаем взгляды, редко полезные, но способные немного разнообразить знакомство с темой.
Подробнее читать – [url=https://rostov-narkologiya.ru/uslugi-ot-alkogolizma/vyvod-iz-zapoya/]сиалис онлайн[/url]
ed capsules https://toolbarqueries.google.com.sv/url?q=https%3A%2F%2Fedpillseasy.shop cost of viagra
пылесосы dyson [url=https://dn-pylesos-kupit-6.ru/]dn-pylesos-kupit-6.ru[/url] .
[url=https://maps.google.cg/url?sa=t&url=https%3A%2F%2Fmexicanxlpharmacy.com]cvs pharmacy online application[/url]
пылесос дайсон беспроводной спб [url=https://pylesos-dn-kupit-6.ru/]pylesos-dn-kupit-6.ru[/url] .
вертикальный пылесос дайсон купить спб [url=https://pylesos-dn-kupit-7.ru/]pylesos-dn-kupit-7.ru[/url] .
пылесос дайсон беспроводной купить в спб вертикальный [url=https://dn-pylesos-kupit-6.ru/]пылесос дайсон беспроводной купить в спб вертикальный[/url] .
купить пылесос дайсон в санкт петербурге беспроводной [url=https://dn-pylesos-2.ru/]dn-pylesos-2.ru[/url] .
adderall online pharmacy https://cse.google.com.ng/url?sa=t&url=https%3A%2F%2Fmexicanxlpharmacy.com online mexican pharmacy
Discover More Here https://plasma.credit
[url=https://toolbarqueries.google.com.my/url?sa=t&url=https%3A%2F%2Fedpillseasy.shop]ed meds[/url]
пылесос dyson [url=https://pylesos-dn-kupit-7.ru/]пылесос dyson[/url] .
dyson gen5 купить в спб [url=https://pylesos-dn-kupit-6.ru/]pylesos-dn-kupit-6.ru[/url] .
dyson оригинал спб [url=https://dn-pylesos-kupit-6.ru/]dn-pylesos-kupit-6.ru[/url] .
пылесосы dyson [url=https://dn-pylesos-kupit-6.ru/]dn-pylesos-kupit-6.ru[/url] .
dyson пылесос купить спб [url=https://dn-pylesos-2.ru/]dn-pylesos-2.ru[/url] .
[url=https://www.google.com.sl/url?sa=t&url=https%3A%2F%2Fmexicanxlpharmacy.com]reliable online pharmacy[/url]
mexican pharmacies online https://maps.google.cz/url?sa=t&url=https%3A%2F%2Fmexicanxlpharmacy.com mexican pharmacy online
generic for levitra https://cse.google.tm/url?sa=i&url=http%3A%2F%2Fedpillseasy.shop best over the counter ed pills that work fast
дайсон пылесос беспроводной купить спб [url=https://pylesos-dn-kupit-7.ru/]pylesos-dn-kupit-7.ru[/url] .
dyson спб официальный [url=https://pylesos-dn-kupit-6.ru/]pylesos-dn-kupit-6.ru[/url] .
dyson спб официальный [url=https://dn-pylesos-kupit-6.ru/]dn-pylesos-kupit-6.ru[/url] .
Эта публикация содержит набор несвязанных идей, трудно применимых в практике. Мы лишь поверхностно затрагиваем различные точки зрения, не проводя глубокий анализ и не предлагая выводов.
Подробнее читать – [url=https://rostov-narkologiya.ru/uslugi-ot-alkogolizma/vyvod-iz-zapoya/]кето диета за неделю минус 10 кг[/url]
мостбет результаты матчей [url=https://mostbet2035.help]https://mostbet2035.help[/url]
вертикальный пылесос дайсон купить спб [url=https://dn-pylesos-2.ru/]dn-pylesos-2.ru[/url] .
дайсон официальный сайт в санкт петербург [url=https://dn-pylesos-kupit-6.ru/]dn-pylesos-kupit-6.ru[/url] .
[url=https://maps.google.co.ug/url?sa=t&url=https%3A%2F%2Fmexicanxlpharmacy.com]online pharmacy[/url]
мостбет новый адрес [url=https://mostbet2035.help/]https://mostbet2035.help/[/url]
[url=https://toolbarqueries.google.com.ec/url?q=http%3A%2F%2Fedpillseasy.shop]ed pills amazon[/url]
dyson v15 купить спб [url=https://pylesos-dn-kupit-7.ru/]pylesos-dn-kupit-7.ru[/url] .
online pharmacies mexica https://toolbarqueries.google.com.my/url?sa=t&url=https%3A%2F%2Fmexicanxlpharmacy.com online pharmacy without prescription
сервисный центр dyson в спб [url=https://pylesos-dn-kupit-6.ru/]pylesos-dn-kupit-6.ru[/url] .
пылесосы дайсон санкт петербург [url=https://dn-pylesos-kupit-6.ru/]dn-pylesos-kupit-6.ru[/url] .
mostbet скачать для ios [url=http://mostbet2035.help]http://mostbet2035.help[/url]
dyson спб официальный [url=https://dn-pylesos-2.ru/]dn-pylesos-2.ru[/url] .
dyson gen5 купить в спб [url=https://dn-pylesos-kupit-6.ru/]dn-pylesos-kupit-6.ru[/url] .
[url=https://images.google.pl/url?q=https%3A%2F%2Fmexicanxlpharmacy.com]us online pharmacy[/url]
«ЮгМедЦентр» поддерживает строгую конфиденциальность: выездные специалисты приезжают без медицинской символики, в гражданской одежде; документы формулируются нейтрально; уведомления не содержат триггерных слов; профиль можно оформить под кодом. Все записи ведутся в шифрованном контуре с разграничением доступа по ролям, а видеосессии с врачом/психологом не записываются. Мы предупреждаем о цифровой гигиене: включите «тихий режим» уведомлений, избегайте пересылки документов в открытых чатах, используйте резервный канал связи для экстренных вопросов.
Подробнее тут – [url=https://narcolog-na-dom-sochi00.ru/]платный нарколог на дом сочи[/url]
дайсон купить спб [url=https://pylesos-dn-kupit-7.ru/]дайсон купить спб[/url] .
best ed meds https://images.google.co.uz/url?q=https%3A%2F%2Fedpillseasy.shop erection pills for men
дайсон центр в спб [url=https://pylesos-dn-kupit-6.ru/]pylesos-dn-kupit-6.ru[/url] .
safe online pharmacy https://www.google.je/url?sa=t&url=https%3A%2F%2Fmexicanxlpharmacy.com online pharmacy without prescription
dyson пылесос купить [url=https://dn-pylesos-kupit-6.ru/]dyson пылесос купить[/url] .
爱一帆海外版,专为华人打造的高清视频平台,支持全球加速观看。
В статье-обзоре представлены данные сомнительной актуальности и факты без явной взаимосвязи. Читатель ознакомится с разными мнениями, хотя они вряд ли существенно изменят его представление о теме.
Подробнее читать – [url=https://rostov-narkologiya.ru/uslugi-ot-narkomanii/mefedronovaya-zavisimost/]таблетки для аборта[/url]
дайсон купить спб оригинал [url=https://pylesos-dn-kupit-7.ru/]дайсон купить спб оригинал[/url] .
[url=https://cse.google.com.bo/url?sa=t&url=https%3A%2F%2Fmexicanxlpharmacy.com]online pharmacy tramadol[/url]
пылесосы дайсон спб [url=https://pylesos-dn-kupit-6.ru/]pylesos-dn-kupit-6.ru[/url] .
[url=https://maps.google.com.pa/url?sa=i&url=https%3A%2F%2Fedpillseasy.shop]erection pills[/url]
Выезд нарколога на дом в Серпухове — это возможность получить профессиональную помощь в условиях, когда везти человека в клинику сложно, опасно или он категорически отказывается от госпитализации. Специалисты «СерпуховТрезвие» работают круглосуточно, приезжают по адресу с одноразовыми системами, стерильными расходниками и необходимым набором препаратов, проводят осмотр, оценивают жизненно важные показатели, подбирают индивидуальную капельницу, контролируют реакцию и оставляют подробные рекомендации. Всё происходит конфиденциально, без лишних свидетелей, без осуждения и давления. Цель — не формально «поставить капельницу», а безопасно стабилизировать состояние, снизить интоксикацию, выровнять давление и пульс, уменьшить тревогу и вернуть человеку возможность нормально спать и восстанавливаться, не доводя до осложнений и экстренной госпитализации.
Подробнее можно узнать тут – [url=https://narkolog-na-dom-serpuhov10.ru/]vyezd-narkologa-na-dom-v-serpuhove[/url]
санкт петербург магазин дайсон [url=https://dn-pylesos-kupit-6.ru/]dn-pylesos-kupit-6.ru[/url] .
legit online pharmacy https://maps.google.com.uy/url?q=https%3A%2F%2Fmexicanxlpharmacy.com trusted online pharmacy
Когда человек в запое, близким кажется, что всё ещё можно решить «по-тихому»: выспаться, отпаять водой, дать обезболивающее или «успокоительное» и дождаться, пока станет легче. На практике это часто приводит к обратному результату. Алкогольная интоксикация нарушает водно-электролитный баланс, сгущает кровь, повышает нагрузку на сердце, провоцирует скачки давления, ухудшает работу печени и нервной системы. Неконтролируемый приём снотворных, анальгетиков, транквилизаторов, особенно вместе с алкоголем, способен вызвать угнетение дыхания, аритмии, судороги или делирий. Домашняя обстановка не даёт возможности следить за всеми показателями и вовремя отреагировать. «РаменМед Трезвость» предлагает клинически выверенный вывод из запоя в Раменском с учётом возраста, длительности употребления, хронических заболеваний, перенесённых ранее осложнений. Здесь не применяют сомнительные схемы «усыпить, чтобы не мешал», а ставят задачу: безопасно пройти острую фазу, снять интоксикацию, стабилизировать давление и пульс, защитить сердце и мозг, снизить риск психозов и, при желании пациента, сразу наметить маршрут реального лечения зависимости. Такой подход снимает с родственников опасную «роль врача» и возвращает ситуацию туда, где ей место — под контроль профессионалов.
Узнать больше – [url=https://vyvod-iz-zapoya-ramenskoe10.ru/]vyvod-iz-zapoya-na-domu[/url]
cialis pills for men https://images.google.mk/url?sa=t&url=https%3A%2F%2Fedpillseasy.shop sparks pills for men
[url=https://www.google.ps/url?sa=t&url=https%3A%2F%2Fmexicanxlpharmacy.com]legit online pharmacy[/url]
best online pharmacies https://cse.google.com.ng/url?sa=t&url=https%3A%2F%2Fmexicanxlpharmacy.com online pharmacy reviews
[url=https://maps.google.rw/url?q=http%3A%2F%2Fedpillseasy.shop]best ed treatment[/url]
1win зеркало не работает [url=https://1win12049.ru]https://1win12049.ru[/url]
vavada darmowe sloty [url=http://vavada2003.help/]vavada darmowe sloty[/url]
Сейчас онлайн образование ребёнка становится всё более востребованным.
Оставлю здесь: https://www.ooyy.com/post/64743_vot-nebolshoj-post-dlya-etoj-stati-onlajn-obrazovanie-dlya-detej-budushee-kotoro.html
vavada program lojalnościowy [url=vavada2003.help]vavada program lojalnościowy[/url]
1win фриспины Кыргызстан [url=https://1win12049.ru/]https://1win12049.ru/[/url]
пылесос dyson спб [url=https://pylesos-dn-kupit-9.ru/]pylesos-dn-kupit-9.ru[/url] .
dyson пылесос спб [url=https://pylesos-dn-kupit-8.ru/]pylesos-dn-kupit-8.ru[/url] .
пылесос дайсон [url=https://pylesos-dn-kupit-10.ru/]пылесос дайсон[/url] .
1xbet spor bahislerinin adresi [url=https://1xbet-32.com/]1xbet-32.com[/url] .
1xbet t?rkiye giri? [url=https://1xbet-31.com/]1xbet-31.com[/url] .
birxbet [url=https://1xbet-34.com/]birxbet[/url] .
1xbet giri? linki [url=https://1xbet-35.com/]1xbet giri? linki[/url] .
1 x bet giri? [url=https://1xbet-37.com/]1xbet-37.com[/url] .
1xbet g?ncel adres [url=https://1xbet-36.com/]1xbet g?ncel adres[/url] .
1xbwt giri? [url=https://1xbet-33.com/]1xbet-33.com[/url] .
vavada sign in [url=https://www.vavada2003.help]vavada sign in[/url]
1win бонус новичкам [url=https://1win12049.ru]https://1win12049.ru[/url]
Для детоксикации и восстановления организма после запоя используются только сертифицированные лекарственные препараты с доказанной эффективностью и безопасностью:
Выяснить больше – [url=https://narcolog-na-dom-sochi0.ru/]нарколог капельница на дом в сочи[/url]
Критичные случаи, когда вызов нарколога через «МедТрезвие Долгопрудный» оправдан и своевременен:
Подробнее можно узнать тут – https://narkolog-na-dom-dolgoprudnij10.ru/skolko-stoit-narkolog-na-dom-v-dolgoprudnom
Сервис раскрутки
폰테크
купить пылесос дайсон спб [url=https://pylesos-dn-kupit-9.ru/]pylesos-dn-kupit-9.ru[/url] .
1xbet ?yelik [url=https://1xbet-32.com/]1xbet-32.com[/url] .
1xbet giri? linki [url=https://1xbet-34.com/]1xbet giri? linki[/url] .
1xbet g?ncel giri? [url=https://1xbet-37.com/]1xbet-37.com[/url] .
1xbwt giri? [url=https://1xbet-31.com/]1xbet-31.com[/url] .
1xbet lite [url=https://1xbet-35.com/]1xbet lite[/url] .
1x lite [url=https://1xbet-36.com/]1x lite[/url] .
dyson пылесос беспроводной купить спб [url=https://pylesos-dn-kupit-8.ru/]pylesos-dn-kupit-8.ru[/url] .
1xbet giri? yapam?yorum [url=https://1xbet-33.com/]1xbet-33.com[/url] .
dyson v15 detect absolute купить в спб [url=https://pylesos-dn-kupit-10.ru/]dyson v15 detect absolute купить в спб[/url] .
цветы доставка москва недорого и красиво Срочный букет сервис Москва
1xbet giri?i [url=https://1xbet-37.com/]1xbet-37.com[/url] .
купить дайсон в санкт петербурге [url=https://pylesos-dn-kupit-9.ru/]купить дайсон в санкт петербурге[/url] .
1xbet giri? yapam?yorum [url=https://1xbet-turkiye-1.com/]1xbet-turkiye-1.com[/url] .
1x giri? [url=https://1xbet-turkiye-2.com/]1xbet-turkiye-2.com[/url] .
1xbet [url=https://1xbet-33.com/]1xbet[/url] .
bahis siteler 1xbet [url=https://1xbet-32.com/]1xbet-32.com[/url] .
1 x bet [url=https://1xbet-34.com/]1 x bet[/url] .
birxbet giri? [url=https://1xbet-37.com/]1xbet-37.com[/url] .
1xbet turkey [url=https://1xbet-31.com/]1xbet-31.com[/url] .
1xbet giri? 2025 [url=https://1xbet-giris-21.com/]1xbet-giris-21.com[/url] .
one x bet [url=https://1xbet-38.com/]1xbet-38.com[/url] .
xbet giri? [url=https://1xbet-turkiye-1.com/]1xbet-turkiye-1.com[/url] .
купить пылесос dyson спб [url=https://pylesos-dn-kupit-9.ru/]pylesos-dn-kupit-9.ru[/url] .
birxbet [url=https://1xbet-33.com/]1xbet-33.com[/url] .
1x bet giri? [url=https://1xbet-giris-21.com/]1xbet-giris-21.com[/url] .
1xbet guncel [url=https://1xbet-turkiye-2.com/]1xbet guncel[/url] .
мостбет номер телефона поддержки [url=https://www.mostbet2028.help]https://www.mostbet2028.help[/url]
ремонт дайсон в спб [url=https://pylesos-dn-kupit-8.ru/]ремонт дайсон в спб[/url] .
1xbet resmi [url=https://1xbet-turkiye-1.com/]1xbet-turkiye-1.com[/url] .
где купить дайсон в санкт петербурге [url=https://pylesos-dn-kupit-10.ru/]где купить дайсон в санкт петербурге[/url] .
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Узнать больше – http://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-detoks-sochi/
1xbet turkey [url=https://1xbet-38.com/]1xbet-38.com[/url] .
1xbet giri? yapam?yorum [url=https://1xbet-34.com/]1xbet-34.com[/url] .
1 xbet giri? [url=https://1xbet-37.com/]1xbet-37.com[/url] .
1xbet giri?i [url=https://1xbet-32.com/]1xbet-32.com[/url] .
1xbet ?ye ol [url=https://1xbet-giris-22.com/]1xbet-giris-22.com[/url] .
폰테크
1xbet spor bahislerinin adresi [url=https://1xbet-31.com/]1xbet-31.com[/url] .
магазин дайсон в спб [url=https://pylesos-dn-kupit-9.ru/]магазин дайсон в спб[/url] .
Для удобства восприятия можно ориентироваться на следующую структуру (это не публичная оферта, а примерная модель ценообразования — точная сумма фиксируется после осмотра и согласования схемы):
Узнать больше – [url=https://narkolog-na-dom-serpuhov10.ru/]нарколог на дом круглосуточно серпухов[/url]
birxbet [url=https://1xbet-35.com/]birxbet[/url] .
vavada bonus za registraciju [url=www.vavada2010.help]www.vavada2010.help[/url]
1xbet resmi giri? [url=https://1xbet-36.com/]1xbet resmi giri?[/url] .
1xbet ?yelik [url=https://1xbet-33.com/]1xbet-33.com[/url] .
1xbet giri? [url=https://1xbet-giris-21.com/]1xbet-giris-21.com[/url] .
1xbet resmi [url=https://1xbet-turkiye-2.com/]1xbet-turkiye-2.com[/url] .
kako napraviti uplatu na vavada [url=www.vavada2010.help]kako napraviti uplatu na vavada[/url]
1xbet ?ye ol [url=https://1xbet-turkiye-1.com/]1xbet-turkiye-1.com[/url] .
купить пылесос дайсон спб [url=https://pylesos-dn-kupit-8.ru/]pylesos-dn-kupit-8.ru[/url] .
пылесос дайсон купить в спб [url=https://pylesos-dn-kupit-10.ru/]пылесос дайсон купить в спб[/url] .
1xbet ?ye ol [url=https://1xbet-38.com/]1xbet-38.com[/url] .
vavada slotovi isplata iskustva [url=http://vavada2010.help]vavada slotovi isplata iskustva[/url]
1xbet yeni adresi [url=https://1xbet-giris-22.com/]1xbet-giris-22.com[/url] .
Чтобы не упустить момент, нужно ориентироваться не на фразу «он говорит, что справится», а на реальные признаки, при которых профессиональная помощь на дому становится необходимой. Домашний выезд — это шанс стабилизировать состояние до того, как потребуется реанимация или жёсткая госпитализация.
Выяснить больше – http://narkolog-na-dom-dolgoprudnij10.ru
1xbet giri? [url=https://1xbet-giris-21.com/]1xbet-giris-21.com[/url] .
1xbet turkey [url=https://1xbet-turkiye-2.com/]1xbet-turkiye-2.com[/url] .
platform gendang4d
1x lite [url=https://1xbet-turkiye-1.com/]1xbet-turkiye-1.com[/url] .
1xbet g?ncel adres [url=https://1xbet-38.com/]1xbet g?ncel adres[/url] .
1xbet resmi [url=https://1xbet-giris-22.com/]1xbet-giris-22.com[/url] .
1xbwt giri? [url=https://1xbet-giris-21.com/]1xbet-giris-21.com[/url] .
1xbet resmi [url=https://1xbet-turkiye-2.com/]1xbet-turkiye-2.com[/url] .
Запой — это не просто несколько лишних дней алкоголя, а тяжёлое состояние, в котором организм работает на пределе. Чем дольше длится эпизод, тем глубже обезвоживание, тем сильнее сдвиги электролитов, тем выше риск аритмий, гипертонических кризов, судорог, делирия, обострений заболеваний сердца, печени и поджелудочной железы. Попытки «вывести» человека дома силами родных часто включают опасные комбинации: случайные седативные, снотворные, анальгетики, «антипохмельные» из рекламы. Они могут на время усыпить или «успокоить», но при этом скрывают ухудшение, сбивают давление, угнетают дыхание и мешают врачу увидеть реальную картину. В «Трезвый Центр Коломна» подход другой: ещё на этапе звонка специалист уточняет длительность запоя, объёмы и виды алкоголя, наличие гипертонии, ИБС, диабета, заболеваний печени и почек, неврологических проблем, список уже принятых препаратов, эпизоды потери сознания, судорог, странного поведения. На основании этих данных определяется, безопасен ли формат на дому или сразу нужен стационар. Такая сортировка позволяет вовремя перехватить опасные случаи, не терять часы на бесполезные попытки и сразу запускать те схемы, которые реально снижают риски и стабилизируют состояние.
Углубиться в тему – http://vyvod-iz-zapoya-kolomna10.ru/vyvod-iz-zapoya-v-stacionare-v-kolomne/https://vyvod-iz-zapoya-kolomna10.ru
1xbet yeni adresi [url=https://1xbet-turkiye-1.com/]1xbet yeni adresi[/url] .
1xbet t?rkiye [url=https://1xbet-38.com/]1xbet t?rkiye[/url] .
xbet [url=https://1xbet-giris-22.com/]xbet[/url] .
«РаменМед Трезвость» предлагает несколько форматов помощи, но выбор всегда делается из соображений безопасности, а не удобства картинки. Стационарный вывод из запоя подходит в ситуациях, когда запой длится несколько дней или недель, есть скачки давления, проблемы с сердцем, печени, сахарный диабет, неврологические заболевания, эпизоды судорог или делирия в анамнезе, возраст старше 50–55 лет, выраженная слабость, тахикардия, невозможность пить воду, угрозы психозов. В стационаре пациент находится под наблюдением круглосуточно: контролируются жизненные показатели, вовремя корректируется терапия, есть возможность экстренно отреагировать на осложнения. Это гарантированно безопаснее, чем оставлять тяжёлого человека дома под наблюдением уставших родственников.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-ramenskoe10.ru/srochnoe-vyvedenie-iz-zapoya-v-ramenskom
Когда запой длится не первый день, а состояние уже сопровождается тремором, потливостью, резкими перепадами давления, бессонницей, тревогой, тошнотой или рвотой, попытка «перетерпеть» или лечить самостоятельно таблетками становится опасным экспериментом. Сочетание алкоголя с сильнодействующими успокоительными, обезболивающими или сомнительными «антипохмельными» легко приводит к нарушению дыхания, провалам в сознании, аритмиям и скрытому развитию предделирия. Домашние средства не учитывают ни электролитные сдвиги, ни состояние печени и сердца, ни уже принятые лекарства. Выездной нарколог «СерпуховТрезвие» в Серпухове выстраивает ситуацию иначе: ещё по телефону врач собирает ключевую информацию — длительность запоя, примерные объёмы и виды алкоголя, наличие гипертонии, ИБС, диабета, заболеваний печени и почек, неврологических проблем, какие препараты уже давали и в каких дозах, были ли судороги или эпизоды дезориентации. На месте проводится объективная диагностика: измерение давления, пульса, сатурации, температуры, оценка тремора, степени обезвоживания, психического состояния, неврологического статуса. Только после этого принимается решение: проводить детокс на дому или сразу рекомендовать стационар. Такой фильтр защищает от грубых ошибок, позволяет точно подобрать схему и не терять драгоценное время, пытаясь «угадать» лечение.
Получить больше информации – https://narkolog-na-dom-serpuhov10.ru/nomer-narkologa-na-dom-serpuhov
СвП Оптом От Производителя
Система выравнивания плитки (СвП) представляет собой современный строительный материал, используемый для качественной укладки керамической плитки и керамогранита. Производство СвП постоянно совершенствуется, обеспечивая высокое качество продукции и удобство её использования специалистами.
[url=https://svp-rovno.ru/opt]свп ворота от производителя[/url]
¦ Преимущества покупки СвП оптом от производителя
Приобретение системы выравнивания плитки оптом непосредственно от производителя имеет ряд преимуществ:
[url=https://svp-rovno.ru/opt]свп от производителя[/url]
– Низкая стоимость – покупка большими партиями позволяет значительно сэкономить средства.
– Высокое качество продукции, подтвержденное сертификатами соответствия.
– Минимальные сроки поставки благодаря наличию собственного производства.
– Индивидуальный подход к каждому клиенту: возможность заказа необходимого количества изделий с учетом специфики проекта.
¦ Где купить СвП оптом?
[url=https://svp-rovno.ru/opt]свп ворота от производителя[/url]
Купить систему выравнивания плитки оптом можно непосредственно у производителей, среди которых выделяются предприятия, выпускающие продукцию высокого качества и предлагающие выгодные условия сотрудничества. Среди популярных компаний-производителей можно отметить тех, кто специализируется именно на производстве СвП.
¦ СвП Зажимы Оптом
[url=https://svp-rovno.ru/opt]свп зажим оптом[/url]
Зажимы являются важной частью системы выравнивания плитки. Они обеспечивают надежную фиксацию плиточных элементов и предотвращают образование зазоров. Купить СвП зажимы оптом также выгодно у производителей, поскольку такая покупка гарантирует оптимальное соотношение цены и качества.
¦ Использование СвП в строительстве ворот
Отдельно стоит упомянуть использование СвП в возведении конструкций типа ворот. Благодаря своей прочности и надежности, СвП активно применяется в изготовлении декоративных и функциональных воротных конструкций. Покупка СвП для изготовления ворот от производителя позволит существенно снизить затраты на строительство.
¦ Заключение
Таким образом, приобретение системы выравнивания плитки оптом от производителя является экономически выгодным решением, обеспечивающим высокую эффективность строительных работ и снижение финансовых затрат. Современные производители предлагают широкий ассортимент продукции, включая специальные элементы, такие как зажими конструкции для строительства ворот, удовлетворяя потребности любого строительного проекта.
производство свп
https://svp-rovno.ru/opt
Запой — это не просто несколько лишних дней алкоголя, а тяжёлое состояние, в котором организм работает на пределе. Чем дольше длится эпизод, тем глубже обезвоживание, тем сильнее сдвиги электролитов, тем выше риск аритмий, гипертонических кризов, судорог, делирия, обострений заболеваний сердца, печени и поджелудочной железы. Попытки «вывести» человека дома силами родных часто включают опасные комбинации: случайные седативные, снотворные, анальгетики, «антипохмельные» из рекламы. Они могут на время усыпить или «успокоить», но при этом скрывают ухудшение, сбивают давление, угнетают дыхание и мешают врачу увидеть реальную картину. В «Трезвый Центр Коломна» подход другой: ещё на этапе звонка специалист уточняет длительность запоя, объёмы и виды алкоголя, наличие гипертонии, ИБС, диабета, заболеваний печени и почек, неврологических проблем, список уже принятых препаратов, эпизоды потери сознания, судорог, странного поведения. На основании этих данных определяется, безопасен ли формат на дому или сразу нужен стационар. Такая сортировка позволяет вовремя перехватить опасные случаи, не терять часы на бесполезные попытки и сразу запускать те схемы, которые реально снижают риски и стабилизируют состояние.
Выяснить больше – http://
pin-up hesab dili [url=http://pinup2008.help/]pin-up hesab dili[/url]
mostbet verificare cont cat dureaza [url=https://www.mostbet2006.help]https://www.mostbet2006.help[/url]
pin-up gündəlik limit [url=www.pinup2008.help]www.pinup2008.help[/url]
mostbet acces oglinda [url=https://www.mostbet2006.help]https://www.mostbet2006.help[/url]
pin-up depozitsiz bonus varmı [url=http://pinup2008.help/]pin-up depozitsiz bonus varmı[/url]
Не всегда человек способен самостоятельно прекратить приём алкоголя и восстановиться. Есть состояния, требующие немедленного вмешательства специалистов. Обратиться за помощью необходимо, если наблюдаются следующие признаки:
Изучить вопрос глубже – https://vyvod-iz-zapoya-v-volgograde17.ru/vyvod-iz-zapoya-na-domu-voronezh
pin-up depósito transferencia bancaria [url=https://www.pinup2002.help]pin-up depósito transferencia bancaria[/url]
Shootout specialists, players with best penalty records tracked
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Подробнее – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельницы от запоя на дому цена сочи[/url]
mostbet inregistrare pe site [url=https://www.mostbet2006.help]https://www.mostbet2006.help[/url]
[url=https://cse.google.co.za/url?sa=i&url=https%3A%2F%2Fcanadianmedsmax.com]best mexican online pharmacy[/url]
pin-up póker [url=pinup2002.help]pinup2002.help[/url]
best online pharmacies https://www.google.com.tj/url?q=https%3A%2F%2Fcanadianmedsmax.com best online pharmacies
cost of viagra https://maps.google.com.gh/url?q=https%3A%2F%2Feropillseasy.shop ed medications for men
Чем раньше нарколог окажет помощь, тем выше шансы избежать осложнений и восстановиться без последствий для здоровья.
Подробнее тут – [url=https://narcolog-na-dom-sochi0.ru/]вызвать нарколога на дом срочно сочи[/url]
Зависимость редко начинается резко. Сначала это «разовые» посиделки, алкоголь «для снятия стресса», эпизодическое употребление психоактивных веществ «из любопытства» или «для компании». На этом этапе человеку кажется, что он полностью контролирует ситуацию. Со временем эпизоды употребления становятся чаще, дозы растут, появляются провалы в памяти, срывы, невозможность остановиться вовремя. В этот момент уже страдают здоровье, работа, отношения с близкими. Обращение в наркологическую клинику позволяет не доводить ситуацию до критической точки и остановить разрушение жизни на любом этапе заболевания.
Узнать больше – [url=https://narkologicheskaya-klinika-dolgoprudnyj11.ru/]kodirovka-ot-alkogolya[/url]
[url=https://www.google.gl/url?q=https%3A%2F%2Fcanadianmedsmax.com]online pharmacy hydrocodone[/url]
[url=https://cse.google.gg/url?sa=t&url=https%3A%2F%2Feropillseasy.shop]gnc ed pills[/url]
online pharmacy viagra https://www.google.com.tj/url?q=https%3A%2F%2Fcanadianmedsmax.com online pharmacy oxycontin
Во время процедуры врач контролирует состояние больного, по необходимости корректирует лечение, чтобы добиться максимального терапевтического эффекта. После проведения детоксикации пациенту назначается курс поддерживающей терапии, а также даются рекомендации по дальнейшему восстановлению и профилактике рецидивов.
Подробнее тут – https://narcolog-na-dom-sochi0.ru
[url=https://image.google.gp/url?q=https%3A%2F%2Fcanadianmedsmax.com]online mexican pharmacy[/url]
ed pills that work https://maps.google.com.co/url?sa=t&url=https%3A%2F%2Feropillseasy.shop ed pills amazon
online pharmacy adderall https://images.google.co.nz/url?sa=t&url=http%3A%2F%2Fcanadianmedsmax.com online pet pharmacy
[url=https://images.google.gr/url?sa=t&url=https%3A%2F%2Feropillseasy.shop]sparks pills for men[/url]
[url=https://www.google.com.pr/url?q=https%3A%2F%2Fcanadianmedsmax.com]viagra online pharmacy[/url]
levitra versus viagra http://www.jschell.de/link.php?goto=google_news&url=eropillseasy.shop best ed treatment
cvs pharmacy online application https://images.google.lu/url?q=https%3A%2F%2Fcanadianmedsmax.com cialis online pharmacy
алкоголь доставка [url=https://www.alcoygoloc3.ru]алкоголь доставка[/url] .
1xbet mobil giri? [url=https://1xbet-giris-23.com/]1xbet-giris-23.com[/url] .
t.me/s/top_onlajn_kazino_rossii [url=https://t.me/s/top_onlajn_kazino_rossii/]t.me/s/top_onlajn_kazino_rossii[/url] .
1xbet yeni adresi [url=https://1xbet-yeni-giris-1.com/]1xbet yeni adresi[/url] .
[url=http://www.flugzeugmarkt.eu/url?q=https%3A%2F%2Fcanadianmedsmax.com]mexica pharmacy online review[/url]
1xbet resmi [url=https://1xbet-mobil-1.com/]1xbet-mobil-1.com[/url] .
1 xbet giri? [url=https://1xbet-mobil-2.com/]1xbet-mobil-2.com[/url] .
1xbet lite [url=https://1xbet-yeni-giris-2.com/]1xbet-yeni-giris-2.com[/url] .
1xbet turkiye [url=https://1xbet-mobil-3.com/]1xbet-mobil-3.com[/url] .
1xbet com giri? [url=https://1xbet-mobil-4.com/]1xbet-mobil-4.com[/url] .
one x bet [url=https://1xbet-mobil-5.com/]one x bet[/url] .
журнал про авто [url=https://avtonovosti-1.ru/]журнал про авто[/url] .
[url=https://www.google.com.tj/url?q=https%3A%2F%2Feropillseasy.shop]over the counter ed pills that work fast[/url]
website dolly4d
mexican online pharmacy reviews https://maps.google.si/url?sa=t&url=https%3A%2F%2Fcanadianmedsmax.com online pharmacy no prescription
mostbet бонус 2026 [url=mostbet94620.help]mostbet бонус 2026[/url]
vavada wpłata payu [url=https://vavada2004.help/]vavada wpłata payu[/url]
1win законно в Кыргызстане [url=http://1win93056.help]http://1win93056.help[/url]
Как работает
Детальнее – [url=https://kodirovanie-ot-alkogolizma-vidnoe7.ru/]кодирование от алкоголизма на дому цены[/url]
алкоголь купить круглосуточно с доставкой [url=https://www.alcoygoloc3.ru]алкоголь купить круглосуточно с доставкой[/url] .
best ed meds https://maps.google.es/url?q=https%3A%2F%2Feropillseasy.shop cost of vardenafil
t.me/s/top_onlajn_kazino_rossii [url=https://t.me/s/top_onlajn_kazino_rossii/]t.me/s/top_onlajn_kazino_rossii[/url] .
mostbet ios Кыргызстан [url=http://mostbet94620.help/]http://mostbet94620.help/[/url]
[url=https://images.google.com.af/url?sa=t&url=https%3A%2F%2Fcanadianmedsmax.com]online pharmacy viagra[/url]
1xbwt giri? [url=https://1xbet-yeni-giris-1.com/]1xbet-yeni-giris-1.com[/url] .
1xbetgiri? [url=https://1xbet-mobil-1.com/]1xbet-mobil-1.com[/url] .
1xbet g?ncel adres [url=https://1xbet-mobil-3.com/]1xbet g?ncel adres[/url] .
bahis siteler 1xbet [url=https://1xbet-mobil-2.com/]1xbet-mobil-2.com[/url] .
1xbet [url=https://1xbet-giris-23.com/]1xbet[/url] .
1xbet resmi sitesi [url=https://1xbet-mobil-5.com/]1xbet-mobil-5.com[/url] .
Мы понимаем, что каждая минута имеет решающее значение, поэтому наши специалисты готовы выехать на дом в кратчайшие сроки и провести все необходимые процедуры по детоксикации организма. Наша цель — помочь пациенту вернуться к нормальной жизни без лишних стрессов и рискованных попыток самостоятельного лечения.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя краснодар[/url]
газета про автомобили [url=https://avtonovosti-3.ru/]avtonovosti-3.ru[/url] .
birxbet giri? [url=https://1xbet-mobil-4.com/]1xbet-mobil-4.com[/url] .
1вин plinko [url=www.1win93056.help]www.1win93056.help[/url]
новости про машины [url=https://avtonovosti-1.ru/]avtonovosti-1.ru[/url] .
1xbet yeni giri? adresi [url=https://1xbet-yeni-giris-2.com/]1xbet yeni giri? adresi[/url] .
мостбет фриспины за регистрацию [url=www.mostbet94620.help]www.mostbet94620.help[/url]
cvs pharmacy online https://maps.google.si/url?sa=t&url=https%3A%2F%2Fcanadianmedsmax.com cvs pharmacy online application
[url=https://www.google.cd/url?sa=t&url=https%3A%2F%2Feropillseasy.shop]natural ed pills[/url]
1win зарегистрироваться [url=1win93056.help]1win зарегистрироваться[/url]
vavada kasyno app ios [url=http://vavada2004.help]http://vavada2004.help[/url]
алкоголь круглосуточно [url=https://alcoygoloc3.ru/]алкоголь круглосуточно[/url] .
[url=https://maps.google.co.jp/url?sa=t&url=https%3A%2F%2Fcanadianmedsmax.com]mexican pharmacy online[/url]
1xbet giri? linki [url=https://1xbet-mobil-1.com/]1xbet-mobil-1.com[/url] .
1 xbet [url=https://1xbet-mobil-3.com/]1xbet-mobil-3.com[/url] .
t.me/s/top_onlajn_kazino_rossii [url=https://t.me/s/top_onlajn_kazino_rossii/]t.me/s/top_onlajn_kazino_rossii[/url] .
1xbet spor bahislerinin adresi [url=https://1xbet-yeni-giris-1.com/]1xbet spor bahislerinin adresi[/url] .
1xbet g?ncel adres [url=https://1xbet-mobil-5.com/]1xbet g?ncel adres[/url] .
авто новости [url=https://avtonovosti-3.ru/]avtonovosti-3.ru[/url] .
1xbet t?rkiye giri? [url=https://1xbet-mobil-2.com/]1xbet-mobil-2.com[/url] .
1xbet yeni giri? [url=https://1xbet-giris-23.com/]1xbet yeni giri?[/url] .
1x bet giri? [url=https://1xbet-mobil-4.com/]1x bet giri?[/url] .
журнал автомобильный [url=https://avtonovosti-1.ru/]avtonovosti-1.ru[/url] .
levitra versus viagra https://maps.google.ie/url?sa=t&url=https%3A%2F%2Feropillseasy.shop sparks ed medication
Натяжные потолки в Архангельске — быстро,качественно,с гарантией.
Осуществляем проффессиональную установку за 1 день в ванную, на кухню, в комнату, в коридор;
Подберем практичный вариант натяжных потолков с учётом особенностей помещения;
Выполняем работы любой сложности, предлагаем большой выбор глянцевых полотен.
Приедем на замер — свяжитесь с нами!
Натяжные потолки в комнате — любая расцветка. по городу — с гарантией результата-
[url=https://29-potolok.ru/]натяжные потолки со световыми линиями в архангельске[/url]
натяжные потокли в архангельске высота – [url=http://www.29-potolok.ru/]https://29-potolok.ru/[/url]
[url=http://ematthews.com/__media__/js/netsoltrademark.php?d=https://29-potolok.ru/]http://arizonawatercompany.com/__media__/js/netsoltrademark.php?d=https://29-potolok.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.guryevsk.forum24.ru/www.disserpro.ru/www.gessi-santehnika-5.ru/www.karniz-elektroprivodom.ru]Качественная установка натяжных потолков в Архангельске: быстро, качественно, с гарантией[/url] 88f2000
1xbet giris [url=https://1xbet-yeni-giris-2.com/]1xbet giris[/url] .
1xbet [url=https://1xbet-mobil-1.com/]1xbet-mobil-1.com[/url] .
xbet [url=https://1xbet-mobil-3.com/]xbet[/url] .
1xbet g?ncel [url=https://1xbet-yeni-giris-1.com/]1xbet g?ncel[/url] .
алкоголь доставка [url=https://alcoygoloc3.ru]алкоголь доставка[/url] .
[url=https://cse.google.gg/url?sa=t&url=https%3A%2F%2Feropillseasy.shop]ro sparks side effects[/url]
1xbet mobi [url=https://1xbet-mobil-5.com/]1xbet mobi[/url] .
car журнал [url=https://avtonovosti-3.ru/]car журнал[/url] .
t.me/s/top_onlajn_kazino_rossii [url=https://t.me/s/top_onlajn_kazino_rossii/]t.me/s/top_onlajn_kazino_rossii[/url] .
1xbet yeni giri? [url=https://1xbet-mobil-2.com/]1xbet yeni giri?[/url] .
1xbet t?rkiye [url=https://1xbet-mobil-4.com/]1xbet t?rkiye[/url] .
birxbet giri? [url=https://1xbet-giris-23.com/]1xbet-giris-23.com[/url] .
журнал авто [url=https://avtonovosti-1.ru/]журнал авто[/url] .
1xbet resmi giri? [url=https://1xbet-yeni-giris-2.com/]1xbet-yeni-giris-2.com[/url] .
журнал о машинах [url=https://avtonovosti-2.ru/]журнал о машинах[/url] .
1xbet giri? 2025 [url=https://1xbet-mobil-1.com/]1xbet-mobil-1.com[/url] .
1xbet resmi sitesi [url=https://1xbet-mobil-3.com/]1xbet-mobil-3.com[/url] .
1 xbet giri? [url=https://1xbet-yeni-giris-1.com/]1xbet-yeni-giris-1.com[/url] .
1xbet lite [url=https://1xbet-mobil-5.com/]1xbet lite[/url] .
газета про автомобили [url=https://avtonovosti-3.ru/]avtonovosti-3.ru[/url] .
Не хотите платить за лицензию? У нас есть рабочий кряк для Windows 11 — скачайте прямо сейчас!
Подробнее – [url=https://krasnodar.med24.online/landing/narkolog_na_dom/]Где взять лицензионный ключ для Windows 11[/url]
алкоголь на дом круглосуточно [url=http://alcoygoloc3.ru/]алкоголь на дом круглосуточно[/url] .
t.me/s/top_onlajn_kazino_rossii [url=https://t.me/s/top_onlajn_kazino_rossii/]t.me/s/top_onlajn_kazino_rossii[/url] .
bahis sitesi 1xbet [url=https://1xbet-mobil-2.com/]1xbet-mobil-2.com[/url] .
1win банковская карта депозит [url=https://1win21567.help]https://1win21567.help[/url]
1xbet guncel [url=https://1xbet-mobil-4.com/]1xbet guncel[/url] .
birxbet [url=https://1xbet-giris-23.com/]1xbet-giris-23.com[/url] .
журналы для автолюбителей [url=https://avtonovosti-1.ru/]avtonovosti-1.ru[/url] .
газета про автомобили [url=https://avtonovosti-2.ru/]avtonovosti-2.ru[/url] .
Yesterday’s football match results and final scores, complete recap of all games played
1xbet lite [url=https://1xbet-yeni-giris-2.com/]1xbet-yeni-giris-2.com[/url] .
1xbet giri? [url=https://1xbet-yeni-giris-1.com/]1xbet giri?[/url] .
1 x bet [url=https://1xbet-mobil-1.com/]1xbet-mobil-1.com[/url] .
aviator 1вин [url=http://1win21567.help/]http://1win21567.help/[/url]
1xbet resmi sitesi [url=https://1xbet-mobil-5.com/]1xbet-mobil-5.com[/url] .
журнал про авто [url=https://avtonovosti-3.ru/]журнал про авто[/url] .
1вин kg [url=http://1win62940.help]1вин kg[/url]
t.me/s/top_onlajn_kazino_rossii [url=https://t.me/s/top_onlajn_kazino_rossii/]t.me/s/top_onlajn_kazino_rossii[/url] .
алкоголь на дом [url=http://alcoygoloc3.ru]алкоголь на дом[/url] .
1xbet t?rkiye [url=https://1xbet-mobil-2.com/]1xbet t?rkiye[/url] .
1win как вывести выигрыш [url=1win62940.help]1win как вывести выигрыш[/url]
birxbet giri? [url=https://1xbet-mobil-4.com/]1xbet-mobil-4.com[/url] .
1xbet giri?i [url=https://1xbet-giris-23.com/]1xbet giri?i[/url] .
автоновости [url=https://avtonovosti-1.ru/]автоновости[/url] .
1win зеркало не работает [url=https://www.1win21567.help]https://www.1win21567.help[/url]
1win вход Киргизия [url=1win62940.help]1win62940.help[/url]
автоновости [url=https://avtonovosti-2.ru/]автоновости[/url] .
1xbet giri?i [url=https://1xbet-yeni-giris-2.com/]1xbet giri?i[/url] .
Дополнительно, если у пациента отмечаются психические нарушения — галлюцинации, агрессия или спутанность сознания, это является прямым сигналом к срочному вмешательству. В этом случае своевременное лечение помогает предотвратить риск инсульта, инфаркта или других серьезных заболеваний.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя вызов в краснодаре[/url]
На этом этапе врач детально выясняет, как долго продолжается запой, какие симптомы наблюдаются, и имеются ли сопутствующие заболевания. Точный анализ информации помогает оперативно определить степень интоксикации и подобрать оптимальные методы детоксикации, что является ключом к предотвращению дальнейших осложнений.
Подробнее можно узнать тут – https://narcolog-na-dom-ryazan00.ru/vrach-narkolog-na-dom-ryazan/
журнал авто [url=https://avtonovosti-4.ru/]журнал авто[/url] .
多瑙高清完整版,海外华人可免费观看最新热播剧集。
Попытка самостоятельно выйти из запоя или преодолеть тяжелое похмелье может привести к крайне негативным последствиям. Длительное употребление алкоголя или резкий отказ без врачебного контроля опасны развитием осложнений, таких как алкогольный психоз, инсульт, инфаркт, обезвоживание и острая сердечная недостаточность.
Исследовать вопрос подробнее – https://narcolog-na-dom-sankt-peterburg000.ru/
автоновости [url=https://avtonovosti-2.ru/]автоновости[/url] .
«Инсис» в Екатеринбурге предлагают:
• интерактивное ТВ;
• быстрое подключение за 1 день;
• Определение оптимального пакета услуг под ваши задачи;
• Анализ технической доступности по вашему адресу.
[url=https://insis-internet-podkluchit.ru/]сколько стоит интернет инсис[/url]
инсис домашний интернет вай фай подключить – [url=https://www.insis-internet-podkluchit.ru]http://www.insis-internet-podkluchit.ru[/url]
[url=http://fitofix.ru/bitrix/rk.php?goto=https://insis-internet-podkluchit.ru/]http://rarebirds.com/__media__/js/netsoltrademark.php?d=https://insis-internet-podkluchit.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.iskusstvennaya-kozha-dlya-mebeli-kupit.ru/mikrotikwarehouse.ru/product-category/r-diploma11.ru]Высокоскоростной интернет и телевидение от «Инсис» в Екатеринбурге[/url] ee482_c
Penalty goals, spot kick conversions and their success rates
Counter press, gegenpressing statistics and ball recovery times
статьи про автомобили [url=https://avtonovosti-4.ru/]avtonovosti-4.ru[/url] .
Нарколог на дом в Санкт-Петербурге позволяет получить квалифицированную медицинскую помощь без необходимости посещать стационар. Такая форма обслуживания особенно востребована при острых состояниях, когда пациенту сложно самостоятельно добраться до клиники. Вызов врача позволяет своевременно остановить развитие осложнений и начать лечение в привычной и комфортной обстановке.
Подробнее тут – [url=https://narcolog-na-dom-sankt-peterburg0.ru/]помощь нарколога на дому в санкт-петербурге[/url]
газета про автомобили [url=https://avtonovosti-2.ru/]avtonovosti-2.ru[/url] .
газета про автомобили [url=https://avtonovosti-4.ru/]газета про автомобили[/url] .
Getcode ile sms onayı hızlı. Sanal numara kullanma avantajları sunar.
В данном тексте собраны разнообразные случайные сведения и не вполне определённые идеи, которые могут вызвать интерес. Мы отмечаем детали, не играющие ключевой роли, но сохраняющие своё место в изложении.
Подробнее читать – [url=https://rostov-narkologiya.ru/uslugi-ot-alkogolizma/vyvod-iz-zapoya/]народные средства от диабета[/url]
журналы для автолюбителей [url=https://avtonovosti-2.ru/]avtonovosti-2.ru[/url] .
[b]Квалифицированные артели мастеров и мастеров по ремонту в Сакартвело: Премиальное качество и Ответственность[/b] В активном секторе строительства в стране Грузия, где команда ремонтников города Батуми и группа ремонтников Тбилиси предоставляют полные услуги, наша команда отличается экспертизой в чистовой отделке пространства города Тбилиси и чистовой отделке жилых помещений города Батуми. Мы сфокусированы на ремонте жилых объектов Тбилиси, обеспечивая премиальные отделочные работы города Батуми с использованием актуальных отделочных материалов и решений. Наша опытная бригада строительных специалистов в Батуми обеспечивает весь цикл работ от разработки проекта до сдачи объекта недвижимости «под ключ» [url=https://stroyka.ge/en]Строительные работы Тбилиси[/url]. Строительство в в Батуми и строительство в Тбилиси – это не лишь возведение коробки, а формирование удобного среды с вниманием к локальных особенностей климата. Ремонт частных домов Грузия охватывает в себя отделку фасадов в Грузии, где мы используем инновационные методы для долговечности и эстетики. Бригада строителей города Тбилиси может реализовать постройку коттеджей Батуми, интегрируя эко решения для безупречного итога. Финишные работы города Тбилиси и ремонт в в Батуми – наши основные направления, где каждый элемент учитывается, таких как ремонт коммерческих помещений в Тбилиси и строительство частных домов в Грузии. Мы предлагаем обновление под ключ в Грузии, оптимизируя затраты и время выполнения благодаря опытным ремонтным командам по Грузии. Бригада строителей в Грузии поддерживает технику безопасности и соответствие стандартам на всех стадиях. Работы по строительству Батуми и строительные работы города Тбилиси выполняются с упором на индивидуальные решения, в том числе постройку коттеджей Тбилиси и ремонт апартаментов в стране Грузия. Наше строительство в Грузии – это сочетание традиций и новых решений, где чистовая отделка в Сакартвело доводится до совершенства. Выберите нас для ремонта коммерческих помещений города Батуми и убедитесь в профессионализме строительной команды в Тбилиси.
vavada hrvatski jezik [url=http://vavada2009.help]http://vavada2009.help[/url]
мостбет зеркало для ios [url=http://mostbet38095.help]http://mostbet38095.help[/url]
1вин mastercard вывод [url=https://1win74125.help/]1вин mastercard вывод[/url]
статьи про автомобили [url=https://avtonovosti-4.ru/]avtonovosti-4.ru[/url] .
vavada lucky jet demo [url=http://vavada2009.help]http://vavada2009.help[/url]
Football results from last night, complete scores and match summaries available now
мостбет Каракол [url=http://mostbet38095.help]мостбет Каракол[/url]
vavada minimalni depozit [url=https://vavada2009.help/]vavada minimalni depozit[/url]
1вин актуальное зеркало [url=http://1win74125.help/]http://1win74125.help/[/url]
mostbet mines на деньги [url=http://mostbet38095.help]mostbet mines на деньги[/url]
автоновости [url=https://avtonovosti-4.ru/]автоновости[/url] .
1win максимальный вывод [url=https://1win74125.help]https://1win74125.help[/url]
mostbet app Republica Moldova [url=http://mostbet2010.help/]http://mostbet2010.help/[/url]
«TUT-SPORT» предоставляет:
• широкий выбор форм топ-клубов: ПСЖ, Манчестер Юнайтед, Челси, Реал Мадрид;
• доставку по всей России;
• Подбор оптимального комплекта экипировки под ваш клуб и бюджет;
• Проверку наличия размеров.
[url=]оригинальная футбольная форма клубов[/url]
купить футбольную форму клубов – [url=https://tut-sport.ru]https://www.tut-sport.ru[/url]
[url=http://daddonallc.com/__media__/js/netsoltrademark.php?d=https://tut-sport.ru]http://www.hallcom1.com/__media__/js/netsoltrademark.php?d=https://tut-sport.ru[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.guryevsk.forum24.ru/www.888starz-english.com/www.optimizaciya-i-seo-prodvizhenie-sajtov-moskva-1.ru/elektrokarniz777.ru]Спортивная экипировка и подарки для фанатов от «TUT-SPORT» в вашем городе[/url] 6588f20
автоновости [url=https://avto-zhurnal-1.ru/]автоновости[/url] .
статьи про автомобили [url=https://avto-zhurnal-2.ru/]avto-zhurnal-2.ru[/url] .
журнал о машинах [url=https://avto-zhurnal-3.ru/]журнал о машинах[/url] .
domeo отзывы клиентов [url=https://domeo-reviews.com/]domeo отзывы клиентов[/url] .
промокоды на хостелы [url=https://tury-i-puteshestviya-promokody-i-skidki.ru/]tury-i-puteshestviya-promokody-i-skidki.ru[/url] .
промокоды на отели скидка [url=https://tury-i-puteshestviya-promokody-i-skidki-1.ru/]tury-i-puteshestviya-promokody-i-skidki-1.ru[/url] .
скидки на отели и хостелы [url=https://tury-i-puteshestviya-promokody-i-skidki-2.ru/]tury-i-puteshestviya-promokody-i-skidki-2.ru[/url] .
журнал про машины [url=https://avto-zhurnal-4.ru/]журнал про машины[/url] .
горящие туры скидки [url=https://tury-i-puteshestviya-promokody-i-skidki-1.ru/]tury-i-puteshestviya-promokody-i-skidki-1.ru[/url] .
отзывы domeo [url=https://domeo-reviews.com/]отзывы domeo[/url] .
В таких случаях своевременное обращение за помощью позволяет быстро стабилизировать состояние и предотвратить развитие серьезных осложнений.
Выяснить больше – [url=https://narcolog-na-dom-voronezh0.ru/]запой нарколог на дом воронеж[/url]
журнал про авто [url=https://avtonovosti-4.ru/]журнал про авто[/url] .
mostbet Republica Moldova site [url=www.mostbet2010.help]mostbet Republica Moldova site[/url]
Запой никогда не начинается с катастрофы. Первые несколько дней могут рассматриваться как «затянувшееся застолье». Но чем дольше человек пьёт без трезвых пауз, тем резче падают его возможности восстановиться самостоятельно. Поэтому ждать, что всё «рассосётся», — значит сознательно двигаться в сторону осложнений.
Выяснить больше – http://vyvod-iz-zapoya-voskresensk11.ru
car журнал [url=https://avto-zhurnal-3.ru/]car журнал[/url] .
[url=https://www.google.com.tj/url?q=https%3A%2F%2Fmexmedimax.com]legitimate online pharmacies india[/url]
скидки trip.com [url=https://tury-i-puteshestviya-promokody-i-skidki-1.ru/]скидки trip.com[/url] .
горящие путевки цены [url=https://tury-i-puteshestviya-promokody-i-skidki.ru/]tury-i-puteshestviya-promokody-i-skidki.ru[/url] .
domeo скачать отзывы [url=https://domeo-reviews.com/]domeo-reviews.com[/url] .
раннее бронирование отелей скидка [url=https://tury-i-puteshestviya-promokody-i-skidki-2.ru/]tury-i-puteshestviya-promokody-i-skidki-2.ru[/url] .
авто журнал [url=https://avto-zhurnal-2.ru/]авто журнал[/url] .
статьи про автомобили [url=https://avto-zhurnal-1.ru/]avto-zhurnal-1.ru[/url] .
Врач уточняет, как долго продолжается запой, какие симптомы наблюдаются и присутствуют ли сопутствующие заболевания. Тщательный сбор информации позволяет оперативно подобрать необходимые медикаменты и начать детоксикацию.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-tyumen0.ru/]www.domen.ru[/url]
журнал про авто [url=https://avto-zhurnal-4.ru/]журнал про авто[/url] .
mostbet bonus aviator [url=mostbet2010.help]mostbet2010.help[/url]
После купирования острой фазы мы предлагаем полное сопровождение на этапе восстановления, чтобы закрепить результаты и снизить риск повторных срывов. В первые дни показаны сеансы кислородной терапии, которые активизируют клеточный обмен и способствуют быстрейшему выведению остатков токсинов. Параллельно проводятся физиотерапевтические процедуры — магнитотерапия и лазерная стимуляция, укрепляющие сосудистую стенку и ускоряющие заживление микроциркуляторных нарушений.
Детальнее – [url=https://kapelnica-ot-zapoya-moskva1.ru/]капельница от запоя недорого балашиха[/url]
best online pharmacies https://maps.google.co.il/url?sa=t&url=https%3A%2F%2Fmexmedimax.com canadian pharmacy no rx
buy Korean anti-aging skincare
журнал автомобильный [url=https://avto-zhurnal-3.ru/]avto-zhurnal-3.ru[/url] .
top marijuana clones New York
прямые рейсы промокоды [url=https://tury-i-puteshestviya-promokody-i-skidki-1.ru/]tury-i-puteshestviya-promokody-i-skidki-1.ru[/url] .
авиабилеты дешево купить [url=https://tury-i-puteshestviya-promokody-i-skidki.ru/]авиабилеты дешево купить[/url] .
domeo честные отзывы [url=https://domeo-reviews.com/]domeo честные отзывы[/url] .
путешествия промокоды январь февраль [url=https://tury-i-puteshestviya-promokody-i-skidki-2.ru/]tury-i-puteshestviya-promokody-i-skidki-2.ru[/url] .
После первичного осмотра начинается активная фаза детоксикации. Современные препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови и восстановления обменных процессов. Этот этап критически важен для нормализации работы печени, почек и сердечно-сосудистой системы.
Подробнее – http://
car журнал [url=https://avto-zhurnal-1.ru/]avto-zhurnal-1.ru[/url] .
журнал авто [url=https://avto-zhurnal-2.ru/]журнал авто[/url] .
статьи про автомобили [url=https://avto-zhurnal-4.ru/]avto-zhurnal-4.ru[/url] .
[url=https://toolbarqueries.google.vu/url?sa=t&url=https%3A%2F%2Fmexmedimax.com]legal online pharmacy[/url]
журнал для автомобилистов [url=https://avto-zhurnal-3.ru/]журнал для автомобилистов[/url] .
domeo отзывы 2025 [url=https://domeo-reviews.com/]domeo-reviews.com[/url] .
страховка путешествия промокод [url=https://tury-i-puteshestviya-promokody-i-skidki-1.ru/]tury-i-puteshestviya-promokody-i-skidki-1.ru[/url] .
промокоды trip.com [url=https://tury-i-puteshestviya-promokody-i-skidki.ru/]промокоды trip.com[/url] .
промокод trip.com отели [url=https://tury-i-puteshestviya-promokody-i-skidki-2.ru/]промокод trip.com отели[/url] .
журнал для автомобилистов [url=https://avto-zhurnal-1.ru/]avto-zhurnal-1.ru[/url] .
журнал про машины [url=https://avto-zhurnal-2.ru/]avto-zhurnal-2.ru[/url] .
1win promociones Perú [url=1win38941.help]1win38941.help[/url]
safe online pharmacies in canada https://www.google.cf/url?sa=t&url=https%3A%2F%2Fmexmedimax.com online pharmacies
автомобильный журнал [url=https://avto-zhurnal-4.ru/]автомобильный журнал[/url] .
1win soporte en app [url=https://1win38941.help/]1win soporte en app[/url]
При критических симптомах (потеря сознания, сильная одышка, подозрение на инсульт/инфаркт) необходимо звонить 103/112. Мы подключимся к маршрутизации и организуем перевод в стационар.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-noginsk7.ru/]www.domen.ru[/url]
журнал про машины [url=https://avto-zhurnal-3.ru/]журнал про машины[/url] .
отзывы и рейтинги [url=https://domeo-reviews.com/]отзывы и рейтинги[/url] .
bono 1win apuestas deportivas [url=https://www.1win38941.help]bono 1win apuestas deportivas[/url]
скидки aviasales [url=https://tury-i-puteshestviya-promokody-i-skidki-1.ru/]скидки aviasales[/url] .
промокоды на авиабилеты [url=https://tury-i-puteshestviya-promokody-i-skidki.ru/]промокоды на авиабилеты[/url] .
промокод яндекс путешествия [url=https://tury-i-puteshestviya-promokody-i-skidki-2.ru/]промокод яндекс путешествия[/url] .
[url=https://toolbarqueries.google.com.sv/url?q=https%3A%2F%2Fmexmedimax.com]rx canadian pharmacy[/url]
журнал автомобильный [url=https://avto-zhurnal-1.ru/]avto-zhurnal-1.ru[/url] .
автоновости [url=https://avto-zhurnal-2.ru/]автоновости[/url] .
даромадан мостбет [url=https://mostbet80573.help]https://mostbet80573.help[/url]
журнал о машинах [url=https://avto-zhurnal-4.ru/]журнал о машинах[/url] .
1win как скачать [url=1win48271.help]1win48271.help[/url]
журнал о машинах [url=https://avto-zhurnal-3.ru/]журнал о машинах[/url] .
отзывы domeo [url=https://domeo-reviews.com/]отзывы domeo[/url] .
мостбет скачать apk [url=mostbet80573.help]mostbet80573.help[/url]
in uk international farmacy to buy online? https://maps.google.com.ua/url?q=https%3A%2F%2Fmexmedimax.com buy cialis online no presciption canadian healthcare
скидка на тур от туроператора [url=https://tury-i-puteshestviya-promokody-i-skidki-1.ru/]tury-i-puteshestviya-promokody-i-skidki-1.ru[/url] .
Сразу после вызова нарколог приезжает на дом для проведения первичного осмотра и диагностики. На этом этапе проводится сбор анамнеза, измеряются жизненно важные показатели (пульс, артериальное давление, температура) и определяется степень алкогольной интоксикации. Эти данные являются основой для разработки индивидуального плана лечения.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-tyumen0.ru/]kapelnica-ot-zapoya-tyumen0.ru/[/url]
скидки на аренду авто [url=https://tury-i-puteshestviya-promokody-i-skidki.ru/]tury-i-puteshestviya-promokody-i-skidki.ru[/url] .
1win поддержка на русском [url=http://1win48271.help/]1win поддержка на русском[/url]
журналы автомобильные [url=https://avto-zhurnal-1.ru/]avto-zhurnal-1.ru[/url] .
статьи об авто [url=https://avto-zhurnal-2.ru/]статьи об авто[/url] .
промокоды туры путешествия [url=https://tury-i-puteshestviya-promokody-i-skidki-3.ru/]tury-i-puteshestviya-promokody-i-skidki-3.ru[/url] .
Процедура вывода из запоя начинается с тщательной диагностики состояния пациента, чтобы определить, какие методы лечения будут наиболее эффективными. Мы применяем индивидуальный подход и комбинируем медикаментозное лечение с психотерапевтической поддержкой, что даёт лучший результат.
Получить дополнительные сведения – [url=https://narcolog-na-dom-novokuznetsk0.ru/]нарколог на дом цены новокузнецк[/url]
мостбет усулҳои пардохт [url=https://www.mostbet80573.help]https://www.mostbet80573.help[/url]
дистанционное обучение 7 класс [url=https://shkola-onlajn-21.ru/]shkola-onlajn-21.ru[/url] .
автомобильный журнал [url=https://avto-zhurnal-4.ru/]автомобильный журнал[/url] .
умные шторы [url=https://prokarniz24.ru/]умные шторы[/url] .
карниз моторизованный [url=https://prokarniz38.ru/]prokarniz38.ru[/url] .
шторы роллы на окна [url=https://rulonnye-shtory-s-elektroprivodom50.ru/]шторы роллы на окна[/url] .
[url=https://cse.google.co.kr/url?sa=i&url=http%3A%2F%2Fmexmedimax.com]pharmacys without prescriptions[/url]
situs dolly4d
https://t.me/s/ed_1xbet/833
Публикация предоставляет читателю набор разрозненных идей, которые сложно применить на практике. Мы лишь слегка касаемся разных точек зрения, не углубляясь в анализ и не предлагая никаких выводов.
Вот – [url=https://arma-rehab.ru/vyvod-iz-zapoya/]покер онлайн[/url]
Открой для себя мир честной игры и выгодных возможностей — изучай объективные рейтинги, сравнивай бонусы, находи надежные площадки и начинай играть уверенно вместе с подробными обзорами на сайте https://www.don8play.ru/
скидки на аренду авто [url=https://tury-i-puteshestviya-promokody-i-skidki-3.ru/]скидки на аренду авто[/url] .
https://t.me/s/ed_1xbet/499
drugs buy online https://cse.google.co.kr/url?sa=i&url=http%3A%2F%2Fmexmedimax.com buy drugs online review
дистанционное обучение 10-11 класс [url=https://shkola-onlajn-21.ru/]shkola-onlajn-21.ru[/url] .
карниз электроприводом штор купить [url=https://prokarniz38.ru/]prokarniz38.ru[/url] .
умные рулонные шторы [url=https://prokarniz24.ru/]умные рулонные шторы[/url] .
установить рулонные шторы цена [url=https://rulonnye-shtory-s-elektroprivodom50.ru/]rulonnye-shtory-s-elektroprivodom50.ru[/url] .
1win нужен ли паспорт для вывода [url=www.1win30489.help]www.1win30489.help[/url]
Наркологическая клиника в Ивантеевке — это возможность получить грамотную, поэтапную помощь рядом с домом, не дожидаясь момента, когда организм и психика окажутся на грани. Большинство пациентов и их родственников приходят к идее лечения не сразу: сначала идут попытки «контролировать» употребление, меняться местами работы и отдыха, просьбы семьи «держать себя в руках», временные успехи и повторяющиеся срывы. На фоне этого накапливаются конфликты, ухудшается здоровье, появляются проблемы с работой и финансами, а жизнь всё больше вращается вокруг алкоголя или наркотиков. В какой-то момент становится очевидно: без профессиональной помощи зависимость не отпускает, а только меняет форму.
Детальнее – [url=https://narkologicheskaya-klinika-ivanteevka11.ru/]rejting-luchshih-narkologicheskih-klinik-moskvy[/url]
Особенно тревожными сигналами являются проблемы со здоровьем. Скачки давления, одышка, сердцебиение, боли в груди, нарушения сна, приступы тревоги и паники — всё это говорит о том, что организм работает на пределе. При этом человек продолжает пить, несмотря на явные признаки перегрузки. Признаками того, что пора не откладывать обращение, становятся и изменения в поведении: раздражительность, вспышки агрессии, подозрительность, скрытность, замыкание в себе. Добавьте сюда конфликты дома и на работе, сорванные обязательства, скрытые долги — и становится понятно, что «подождать ещё немного» уже опасно. В такой момент консультация нарколога в Чехове и обсуждение возможного кодирования — не радикальная мера, а разумный шаг, который может предотвратить серьёзные медицинские и социальные последствия.
Подробнее можно узнать тут – https://kodirovanie-ot-alkogolizma-chekhov11.ru/kodirovanie-ot-alkogolizma-vyezd-na-dom-v-chekhove/
Наши опытные наркологи регулярно повышают квалификацию и используют современные методики для быстрого восстановления пациентов после запоев.
Подробнее – http://kapelnica-ot-zapoya-nizhniy-novgorod0.ru
1win поддержка кыргызча [url=www.1win30489.help]www.1win30489.help[/url]
скидки аэрофлот [url=https://tury-i-puteshestviya-promokody-i-skidki-3.ru/]скидки аэрофлот[/url] .
класс с учениками [url=https://shkola-onlajn-21.ru/]shkola-onlajn-21.ru[/url] .
электрические рулонные шторы купить москва [url=https://rulonnye-shtory-s-elektroprivodom50.ru/]rulonnye-shtory-s-elektroprivodom50.ru[/url] .
управление шторами [url=https://prokarniz24.ru/]prokarniz24.ru[/url] .
электрокарнизы цена [url=https://prokarniz38.ru/]электрокарнизы цена[/url] .
На основе собранной информации формируется индивидуальный план лечения, который включает установку внутривенной капельницы. Через капельницу вводятся специально подобранные растворы, способствующие быстрому выведению токсинов, восстановлению водно-электролитного баланса и нормализации работы внутренних органов. При необходимости назначаются дополнительные медикаменты для поддержки печени, сердца и нервной системы, а также для купирования симптомов абстинентного синдрома. Врач постоянно контролирует состояние пациента и корректирует лечение, чтобы добиться оптимальных результатов. Завершающим этапом является подробная консультация, в ходе которой специалист дает рекомендации по дальнейшему восстановлению и профилактике повторных эпизодов зависимости.
Изучить вопрос глубже – [url=https://narcolog-na-dom-voronezh0.ru/]нарколог на дом недорого в воронеже[/url]
1win на телефон скачать [url=http://1win30489.help]1win на телефон скачать[/url]
трансфер аэропорт скидка [url=https://tury-i-puteshestviya-promokody-i-skidki-3.ru/]трансфер аэропорт скидка[/url] .
Online Casino Real Money Pokies Australia Victory Awaits
домашняя школа интернет урок вход [url=https://shkola-onlajn-21.ru/]shkola-onlajn-21.ru[/url] .
электрические жалюзи [url=https://rulonnye-shtory-s-elektroprivodom50.ru/]электрические жалюзи[/url] .
умные шторы [url=https://prokarniz24.ru/]умные шторы[/url] .
электрокарниз недорого [url=https://prokarniz38.ru/]prokarniz38.ru[/url] .
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Ознакомиться с деталями – https://wood-swordcricket.com/product/armour-gx8-3-0-batting-gloves-white-silver
pin-up ən yaxşı slotlar [url=http://pinup2006.help]http://pinup2006.help[/url]
мостбет мушкилоти пардохт [url=mostbet67254.help]mostbet67254.help[/url]
скидки аэрофлот [url=https://tury-i-puteshestviya-promokody-i-skidki-3.ru/]скидки аэрофлот[/url] .
pin-up hesab silmək [url=http://pinup2006.help]http://pinup2006.help[/url]
онлайн обучение 11 класс [url=https://shkola-onlajn-21.ru/]shkola-onlajn-21.ru[/url] .
рулонные шторы на широкое окно [url=https://rulonnye-shtory-s-elektroprivodom50.ru/]rulonnye-shtory-s-elektroprivodom50.ru[/url] .
умные римские шторы [url=https://prokarniz24.ru/]умные римские шторы[/url] .
pin-up uduş hesablanmadı [url=https://pinup2006.help]https://pinup2006.help[/url]
карниз электроприводом штор купить [url=https://prokarniz38.ru/]prokarniz38.ru[/url] .
Если многое из этого знакомо, кодирование стоит рассматривать не как «наказание» или «приговор», а как инструмент, который помогает закрыть доступ к алкоголю на определённый срок и даёт шанс выстроить новую привычку — жить трезво.
Подробнее можно узнать тут – [url=https://kodirovanie-ot-alkogolizma-korolyov11.ru/]кодирование от алкоголизма отзывы[/url]
промокоды на бронирование отелей [url=https://tury-i-puteshestviya-promokody-i-skidki-3.ru/]промокоды на бронирование отелей[/url] .
мостбет слотҳо Тоҷикистон [url=http://mostbet67254.help/]http://mostbet67254.help/[/url]
Ниже представлена последовательная схема, определяющая общий ход клинического вмешательства.
Подробнее – [url=https://vyvodiz-zapoya-izhevsk18.ru/]наркология вывод из запоя[/url]
стоимость рулонных штор [url=https://rulonnye-shtory-s-elektroprivodom50.ru/]стоимость рулонных штор[/url] .
онлайн школа ломоносов [url=https://shkola-onlajn-21.ru/]shkola-onlajn-21.ru[/url] .
лбс это [url=https://shkola-onlajn-23.ru/]shkola-onlajn-23.ru[/url] .
умные шторы купить [url=https://prokarniz24.ru/]умные шторы купить[/url] .
карнизы с электроприводом купить [url=https://prokarniz38.ru/]prokarniz38.ru[/url] .
Клиника в Королёве закрывает этот разрыв. Здесь можно пройти полный путь — от первичной диагностики и детоксикации до реабилитации и последующего наблюдения — в пределах привычного города, не отрываясь полностью от семьи и важных дел. Это особенно важно для тех, кто продолжает работать, боится потерять позицию или репутацию, но при этом понимает, что дальше жить «как раньше» просто опасно. Лечение перестаёт быть чем-то абстрактным и пугающим: вместо общих страшилок появляется понятный маршрут, а рядом — команда специалистов, которые умеют вести пациентов с зависимостью и знают, как работать с семьями, уставшими от бесконечных срывов.
Получить больше информации – [url=https://narkologicheskaya-klinika-korolyov11.ru/]narkologicheskaya-klinika-otzyvy[/url]
Обычно работа строится по этапам, где каждый шаг логически продолжает предыдущий:
Подробнее можно узнать тут – https://vyvod-iz-zapoya-ivanteevka11.ru/vyvod-iz-zapoya-na-domu-v-ivanteevke/
Online Casino Australia Real Money Your Winning Night Starts
обучение стриминг [url=https://shkola-onlajn-23.ru/]обучение стриминг[/url] .
онлайн обучение 11 класс [url=https://shkola-onlajn-22.ru/]shkola-onlajn-22.ru[/url] .
1win retiro en soles [url=www.1win43218.help]www.1win43218.help[/url]
I simply could not leave your web site prior to suggesting that I actually loved the usual info a person provide in your visitors? Is going to be back ceaselessly to inspect new posts
lbs что это [url=https://shkola-onlajn-23.ru/]lbs что это[/url] .
В рамках лечения используются методы, позволяющие фиксировать изменения и оценивать реакцию организма на проводимые мероприятия. Они служат основой для выборочных корректировок и обеспечивают структурированный характер процесса. Отличительной особенностью становится возможность адаптировать лечебные схемы под индивидуальные особенности пациента. Ниже представлены ключевые направления оценки состояния, применяемые для формирования полной клинической картины.
Детальнее – http://narkologicheskaya-klinika-v-vdk18.ru
онлайн класс [url=https://shkola-onlajn-22.ru/]онлайн класс[/url] .
juego mines 1win [url=1win43218.help]1win43218.help[/url]
Самостоятельные попытки «подлечиться» обычно сводятся к случайным комбинациям препаратов: кто-то пьёт горсть таблеток от давления и сердца, кто-то принимает успокоительные поверх алкоголя, кто-то заказывает непонятные средства «от тяги» в интернете. Такие эксперименты могут дать краткий эффект, но часто только маскируют симптомы и перегружают организм. В клинике лечение строится иначе: сначала оценивают состояние — физическое и психическое, затем подбирают безопасные схемы детоксикации и медикаментов, учитывая возраст, сопутствующие заболевания, длительность запоев и употребления. Это снижает риски осложнений и делает восстановление более управляемым: пациент и его семья видят прогресс и понимают, за счёт чего он происходит, а не живут в ожидании очередного непредсказуемого «отката».
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-korolyov11.ru/]narkologicheskaya-klinika-telefon[/url]
дистанционное школьное обучение [url=https://shkola-onlajn-23.ru/]shkola-onlajn-23.ru[/url] .
lbs это [url=https://shkola-onlajn-22.ru/]lbs это[/url] .
Самостоятельные попытки «подлечиться» обычно сводятся к случайным комбинациям препаратов: кто-то пьёт горсть таблеток от давления и сердца, кто-то принимает успокоительные поверх алкоголя, кто-то заказывает непонятные средства «от тяги» в интернете. Такие эксперименты могут дать краткий эффект, но часто только маскируют симптомы и перегружают организм. В клинике лечение строится иначе: сначала оценивают состояние — физическое и психическое, затем подбирают безопасные схемы детоксикации и медикаментов, учитывая возраст, сопутствующие заболевания, длительность запоев и употребления. Это снижает риски осложнений и делает восстановление более управляемым: пациент и его семья видят прогресс и понимают, за счёт чего он происходит, а не живут в ожидании очередного непредсказуемого «отката».
Получить дополнительную информацию – http://narkologicheskaya-klinika-korolyov11.ru/chastnaya-narkologicheskaya-klinika-v-korolyove/
lbs [url=https://shkola-onlajn-24.ru/]lbs[/url] .
школы дистанционного обучения [url=https://shkola-onlajn-25.ru/]школы дистанционного обучения[/url] .
электрокранизы [url=https://elektrokarniz25.ru/]электрокранизы[/url] .
карнизы для штор с электроприводом [url=https://elektrokarniz5.ru/]elektrokarniz5.ru[/url] .
электрокарниз двухрядный цена [url=https://elektrokarnizy750.ru/]электрокарниз двухрядный цена[/url] .
электрокарниз двухрядный [url=https://karnizy-s-elektroprivodom77.ru/]электрокарниз двухрядный[/url] .
автоматические гардины для штор [url=https://elektrokarnizy-dlya-shtor1.ru/]elektrokarnizy-dlya-shtor1.ru[/url] .
1win deposito con tarjeta [url=https://1win5774.help]1win deposito con tarjeta[/url]
онлайн школа 11 класс [url=https://shkola-onlajn-23.ru/]онлайн школа 11 класс[/url] .
dyson выпрямитель [url=https://dsn-vypryamitel-8.ru/]dyson выпрямитель[/url] .
1win bepul tikishni qanday olish [url=https://1win5766.help]https://1win5766.help[/url]
школьное образование онлайн [url=https://shkola-onlajn-22.ru/]shkola-onlajn-22.ru[/url] .
1win referral in app [url=https://1win5744.help/]https://1win5744.help/[/url]
электрокарниз купить [url=https://elektrokarniz25.ru/]elektrokarniz25.ru[/url] .
1win rasmiy sayt uz [url=http://1win5766.help]http://1win5766.help[/url]
школа-пансион бесплатно [url=https://shkola-onlajn-24.ru/]shkola-onlajn-24.ru[/url] .
пансионат для детей [url=https://shkola-onlajn-25.ru/]пансионат для детей[/url] .
электрокарнизы в москве [url=https://elektrokarniz5.ru/]электрокарнизы в москве[/url] .
электрокарнизы купить в москве [url=https://elektrokarnizy750.ru/]электрокарнизы купить в москве[/url] .
1win registro con email [url=http://1win5774.help]1win registro con email[/url]
карниз для штор с электроприводом [url=https://elektrokarnizy-dlya-shtor1.ru/]карниз для штор с электроприводом[/url] .
Found a site when browsing international home improvement pages, which appears straightforward, helping researching ideas easy.
https://www.macdc.org/blog/date/201608
карниз моторизованный [url=https://karnizy-s-elektroprivodom77.ru/]karnizy-s-elektroprivodom77.ru[/url] .
1win ug [url=http://1win5744.help]1win ug[/url]
школа онлайн обучение для детей [url=https://shkola-onlajn-23.ru/]shkola-onlajn-23.ru[/url] .
Клиника оснащена современным оборудованием для мониторинга состояния пациентов, проведения инфузионной терапии и лабораторных анализов. Врачи работают круглосуточно, обеспечивая как стационарное лечение, так и выезды на дом. Благодаря чёткому взаимодействию команды — нарколога, психотерапевта, кардиолога и реабилитолога — удаётся добиться быстрого и устойчивого результата даже в запущенных случаях.
Подробнее тут – [url=https://narkologicheskaya-klinika-v-izhevsk18.ru/]лечение в наркологической клинике в ижевске[/url]
1win lucky jet [url=1win5766.help]1win5766.help[/url]
Перед началом терапии проводится полная диагностика организма, включая лабораторные исследования и ЭКГ. Это позволяет оценить состояние пациента и подобрать оптимальный курс лечения. После стабилизации физического состояния начинается психотерапевтическая и реабилитационная работа. Такой подход помогает не только снять симптомы, но и устранить первопричины зависимости.
Выяснить больше – [url=https://narkologicheskaya-klinika-kemerovo18.ru/]наркологическая клиника наркологический центр в кемерове[/url]
онлайн школа для школьников с аттестатом [url=https://shkola-onlajn-22.ru/]shkola-onlajn-22.ru[/url] .
dyson airstrait купить выпрямитель [url=https://dsn-vypryamitel-8.ru/]dsn-vypryamitel-8.ru[/url] .
прокарниз [url=https://elektrokarniz25.ru/]прокарниз[/url] .
1win cashback Uganda [url=https://1win5744.help]https://1win5744.help[/url]
онлайн ш [url=https://shkola-onlajn-24.ru/]онлайн ш[/url] .
электрические гардины для штор [url=https://elektrokarniz5.ru/]elektrokarniz5.ru[/url] .
автоматический карниз для штор [url=https://elektrokarnizy750.ru/]автоматический карниз для штор[/url] .
карнизы для штор купить в москве [url=https://elektrokarnizy-dlya-shtor1.ru/]elektrokarnizy-dlya-shtor1.ru[/url] .
После принятия решения организуется либо выезд, либо госпитализация. На приёме проводится осмотр: измеряется давление, пульс, оценивается степень обезвоживания, выраженность тремора, тревоги, нарушений сна. Выясняются сопутствующие болезни и лекарства, которые человек принимает постоянно. Уже на этом этапе обсуждаются ближайшие шаги — объём детокса, необходимость круглосуточного наблюдения, примерные сроки стабилизации. Родным объясняют, чего ожидать в первые сутки, какие симптомы будут уменьшаться постепенно, а какие требуют немедленного информирования персонала.
Изучить вопрос глубже – https://narkologicheskaya-klinika-lobnya11-2.ru/
Online Casino Australia Real Money High Stakes Excitement
карнизы для штор с электроприводом [url=https://karnizy-s-elektroprivodom77.ru/]karnizy-s-elektroprivodom77.ru[/url] .
Australia Fast Payouts And Vip Baccarat
dyson выпрямитель оригинал [url=https://dsn-vypryamitel-8.ru/]dsn-vypryamitel-8.ru[/url] .
электрокарнизы для штор купить [url=https://elektrokarniz25.ru/]электрокарнизы для штор купить[/url] .
рулонные шторы на окна на заказ [url=https://rulonnye-shtory-s-elektroprivodom90.ru/]rulonnye-shtory-s-elektroprivodom90.ru[/url] .
электрокарнизы москва [url=https://elektrokarnizy797.ru/]электрокарнизы москва[/url] .
автоматика для жалюзи стоимость [url=https://zhalyuzi-s-elektroprivodom7.ru/]автоматика для жалюзи стоимость[/url] .
электрокарнизы для штор купить в москве [url=https://elektrokarniz-nedorogo.ru/]электрокарнизы для штор купить в москве[/url] .
карниз с электроприводом [url=https://elektrokarniz5.ru/]карниз с электроприводом[/url] .
Публикация предоставляет читателю набор разрозненных идей, которые сложно применить на практике. Мы лишь слегка касаемся разных точек зрения, не углубляясь в анализ и не предлагая никаких выводов.
Вот – [url=https://arma-rehab.ru/]азартные игры[/url]
карнизы для штор с электроприводом [url=https://elektrokarnizy750.ru/]elektrokarnizy750.ru[/url] .
школьное образование онлайн [url=https://shkola-onlajn-25.ru/]школьное образование онлайн[/url] .
школьный класс с учениками [url=https://shkola-onlajn-24.ru/]школьный класс с учениками[/url] .
электрокарниз недорого [url=https://elektrokarnizy-dlya-shtor1.ru/]elektrokarnizy-dlya-shtor1.ru[/url] .
Перед тем как принять решение, пациент и родственники получают объяснения по доступным направлениям. Обычно обсуждаются: амбулаторные консультации, дневной или круглосуточный стационар, выездная помощь, реабилитационные программы и последующее наблюдение. Это позволяет выстроить индивидуальный маршрут, а не навязывать один и тот же сценарий всем подряд.
Углубиться в тему – http://narkologicheskaya-klinika-himki11.ru/
Клиника в Королёве закрывает этот разрыв. Здесь можно пройти полный путь — от первичной диагностики и детоксикации до реабилитации и последующего наблюдения — в пределах привычного города, не отрываясь полностью от семьи и важных дел. Это особенно важно для тех, кто продолжает работать, боится потерять позицию или репутацию, но при этом понимает, что дальше жить «как раньше» просто опасно. Лечение перестаёт быть чем-то абстрактным и пугающим: вместо общих страшилок появляется понятный маршрут, а рядом — команда специалистов, которые умеют вести пациентов с зависимостью и знают, как работать с семьями, уставшими от бесконечных срывов.
Детальнее – http://narkologicheskaya-klinika-korolyov11.ru/
blog link
[url=https://betery-bet.com/bonuses]battery app promo code[/url]
автоматические карнизы для штор [url=https://karnizy-s-elektroprivodom77.ru/]автоматические карнизы для штор[/url] .
выпрямитель dyson ht01 [url=https://dsn-vypryamitel-8.ru/]dsn-vypryamitel-8.ru[/url] .
На фоне длительных запоев страдает не только физическое состояние. Обостряются тревога, раздражительность, обидчивость, возможны вспышки агрессии и неадекватные поступки. Для семьи это превращается в постоянное напряжение: никто не знает, чем закончится очередной день или ночь. Одновременно растёт риск психозов, когда человек может видеть и слышать то, чего нет на самом деле, путать реальность, быть опасным для себя и окружающих.
Углубиться в тему – http://vyvod-iz-zapoya-ivanteevka11.ru/narkolog-vyvod-iz-zapoya-v-ivanteevke/
прокарниз [url=https://elektrokarniz5.ru/]прокарниз[/url] .
электрокарниз купить в москве [url=https://elektrokarnizy797.ru/]электрокарниз купить в москве[/url] .
рулонные шторы на окна москва [url=https://rulonnye-shtory-s-elektroprivodom90.ru/]rulonnye-shtory-s-elektroprivodom90.ru[/url] .
электрокарнизы для штор [url=https://elektrokarnizy750.ru/]электрокарнизы для штор[/url] .
жалюзи пластиковые окна электроприводом [url=https://zhalyuzi-s-elektroprivodom7.ru/]жалюзи пластиковые окна электроприводом[/url] .
гардина с электроприводом [url=https://elektrokarniz-nedorogo.ru/]elektrokarniz-nedorogo.ru[/url] .
онлайн обучение для школьников [url=https://shkola-onlajn-25.ru/]онлайн обучение для школьников[/url] .
дистанционное школьное обучение [url=https://shkola-onlajn-24.ru/]дистанционное школьное обучение[/url] .
электрокарнизы [url=https://elektrokarnizy-dlya-shtor1.ru/]elektrokarnizy-dlya-shtor1.ru[/url] .
Real Money Pokies Australia Real Imagine Million Cashouts
карнизы с электроприводом купить [url=https://elektrokarniz5.ru/]elektrokarniz5.ru[/url] .
гардина с электроприводом [url=https://karnizy-s-elektroprivodom77.ru/]karnizy-s-elektroprivodom77.ru[/url] .
фен выпрямитель дайсон airstrait купить [url=https://dsn-vypryamitel-8.ru/]фен выпрямитель дайсон airstrait купить[/url] .
электрокранизы [url=https://elektrokarnizy750.ru/]электрокранизы[/url] .
карнизы для штор купить в москве [url=https://elektrokarnizy797.ru/]elektrokarnizy797.ru[/url] .
шторы автоматические [url=https://rulonnye-shtory-s-elektroprivodom90.ru/]rulonnye-shtory-s-elektroprivodom90.ru[/url] .
ломоносов скул [url=https://shkola-onlajn-25.ru/]ломоносов скул[/url] .
жалюзи с приводом для окон [url=https://zhalyuzi-s-elektroprivodom7.ru/]жалюзи с приводом для окон[/url] .
карниз моторизованный [url=https://elektrokarniz-nedorogo.ru/]elektrokarniz-nedorogo.ru[/url] .
онлайн обучение для детей [url=https://shkola-onlajn-24.ru/]shkola-onlajn-24.ru[/url] .
карнизы с электроприводом купить [url=https://elektrokarnizy-dlya-shtor1.ru/]elektrokarnizy-dlya-shtor1.ru[/url] .
Такая схема лечения делает процесс последовательным и контролируемым. Врачи клиники сопровождают пациентов на всех стадиях, помогая преодолеть как физическую, так и психологическую зависимость. Особое внимание уделяется возвращению человека к активной и стабильной жизни без употребления алкоголя или наркотиков.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-v-izhevsk18.ru/]наркологическая клиника вывод из запоя в ижевске[/url]
dyson airstraight [url=https://dsn-vypryamitel-8.ru/]dyson airstraight[/url] .
электрические гардины для штор [url=https://karnizy-s-elektroprivodom77.ru/]karnizy-s-elektroprivodom77.ru[/url] .
электрокарнизы для штор цена [url=https://elektrokarnizy797.ru/]электрокарнизы для штор цена[/url] .
дистанционное школьное обучение [url=https://shkola-onlajn-25.ru/]дистанционное школьное обучение[/url] .
рулонные шторы купить москва недорого [url=https://rulonnye-shtory-s-elektroprivodom90.ru/]рулонные шторы купить москва недорого[/url] .
электрожалюзи купить [url=https://zhalyuzi-s-elektroprivodom7.ru/]zhalyuzi-s-elektroprivodom7.ru[/url] .
электрокарнизы цена [url=https://elektrokarniz-nedorogo.ru/]электрокарнизы цена[/url] .
1win о деньги вывод [url=https://1win09834.help/]https://1win09834.help/[/url]
1win iosga qanday yuklab olish [url=1win5753.help]1win5753.help[/url]
карнизы с электроприводом [url=https://elektrokarnizy797.ru/]elektrokarnizy797.ru[/url] .
1win играть без регистрации [url=https://1win09834.help]https://1win09834.help[/url]
домашняя школа интернет урок вход [url=https://shkola-onlajn-25.ru/]домашняя школа интернет урок вход[/url] .
1win mines 2026 [url=http://1win5753.help]1win mines 2026[/url]
автоматические рулонные шторы на створку [url=https://rulonnye-shtory-s-elektroprivodom90.ru/]rulonnye-shtory-s-elektroprivodom90.ru[/url] .
электрические карнизы купить [url=https://elektrokarniz-nedorogo.ru/]электрические карнизы купить[/url] .
В основе работы клиники «ИжТрезвоМед Центр» лежит принцип персонализированной медицины. Это означает, что каждый пациент получает не шаблонное лечение, а тщательно подобранный комплекс процедур, учитывающий его состояние, историю заболевания, уровень мотивации и социальную ситуацию. Такой подход позволяет добиться стабильного результата даже в сложных случаях. Лечение проводится анонимно, без постановки на учёт и разглашения данных, что особенно важно для тех, кто ценит конфиденциальность.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-v-izhevske18.ru/]наркологическая клиника наркологический центр в ижевске[/url]
Наркологическая клиника опирается на комплексную модель оценки состояния, обеспечивающую последовательное восстановление функций организма. В клинике применяется система многоуровневого контроля, направленная на выявление нарушений и определение оптимальной тактики вмешательства. Такой подход позволяет поддерживать стабильность состояния даже в условиях выраженных клинических проявлений. Структурированная работа направлена на снижение токсической нагрузки, коррекцию метаболических процессов и восстановление адаптивных механизмов. Анализ проводится с учётом физиологических особенностей пациента и динамики изменений.
Подробнее – http://
1win вход по номеру [url=http://1win09834.help]http://1win09834.help[/url]
рулонные шторы на пластиковые окна купить [url=https://rulonnaya-shtora-s-elektroprivodom.ru/]рулонные шторы на пластиковые окна купить[/url] .
электрокарнизы для штор купить [url=https://karniz-elektroprivodom.ru/]электрокарнизы для штор купить[/url] .
электрокарнизы цена [url=https://elektrokarnizy797.ru/]электрокарнизы цена[/url] .
мостбет apk скачать Киргизия [url=https://mostbet72461.help/]https://mostbet72461.help/[/url]
школа онлайн [url=https://shkola-onlajn-25.ru/]школа онлайн[/url] .
рулонные электрошторы [url=https://rulonnye-shtory-s-elektroprivodom90.ru/]rulonnye-shtory-s-elektroprivodom90.ru[/url] .
электрокарнизы для штор цена [url=https://elektrokarniz-nedorogo.ru/]электрокарнизы для штор цена[/url] .
Please let me know if you’re looking for a writer for your blog. You have some really good articles and I believe I would be a good asset. If you ever want to take some of the load off, I’d love to write some content for your blog in exchange for a link back to mine. Please blast me an email if interested. Kudos!
byueuropaviagraonline
мостбет ставки регистрация [url=http://mostbet72461.help/]http://mostbet72461.help/[/url]
рулонные шторы на створку [url=https://rulonnaya-shtora-s-elektroprivodom.ru/]rulonnaya-shtora-s-elektroprivodom.ru[/url] .
жалюзи на дистанционном управлении [url=https://zhalyuzi-s-elektroprivodom7.ru/]жалюзи на дистанционном управлении[/url] .
электрокарнизы для штор цена [url=https://karniz-elektroprivodom.ru/]электрокарнизы для штор цена[/url] .
1win acceso [url=https://1win5773.help/]https://1win5773.help/[/url]
online prescirption websites https://easypharmacies.shop/# mexican pharmacy onlineno rx
как играть в lucky jet mostbet [url=https://www.mostbet72461.help]https://www.mostbet72461.help[/url]
como apostar en vivo en 1win [url=http://1win5773.help]como apostar en vivo en 1win[/url]
производители рулонных штор [url=https://rulonnaya-shtora-s-elektroprivodom.ru/]rulonnaya-shtora-s-elektroprivodom.ru[/url] .
купить жалюзи с пультом управления [url=https://zhalyuzi-s-elektroprivodom7.ru/]zhalyuzi-s-elektroprivodom7.ru[/url] .
электрокарнизы цена [url=https://karniz-elektroprivodom.ru/]электрокарнизы цена[/url] .
Задача первого контакта — не «записать к врачу на когда-нибудь», а оценить, насколько ситуация критична прямо сейчас. Если речь идёт о многодневном запое, сильной слабости, одышке, скачках давления, спутанности сознания, лучше не экспериментировать с домашними методами. В таких случаях специалисты в Лобне рекомендуют стационар, где можно не только поставить капельницу, но и быстро среагировать на осложнения. Если же состояние относительно стабильное, возможно обсуждение мягкого формата с выездом и последующим наблюдением.
Подробнее – [url=https://narkologicheskaya-klinika-lobnya11-2.ru/]наркологическая клиника фото[/url]
[url=https://easypharmacies.shop/#]legitimate online us pharmacies[/url]
como funciona 1win [url=https://1win5773.help/]https://1win5773.help/[/url]
какие бывают рулонные шторы [url=https://rulonnaya-shtora-s-elektroprivodom.ru/]rulonnaya-shtora-s-elektroprivodom.ru[/url] .
online overseas pharmacies https://easypharmacies.shop/# buy prescriptions online usa
электрические карнизы купить [url=https://karniz-elektroprivodom.ru/]электрические карнизы купить[/url] .
тяговые аккумуляторы для электрокары купить Аккумуляторы тяговые для Toyota — оригинальные и аналоги по низкой цене.
Вывод из запоя в клинике строится на основе алгоритмов, направленных на безопасное восстановление физиологических функций. Применяется стандартная система, включающая оценку состояния, подбор медикаментозных средств и постепенную адаптацию организма. Такой формат позволяет избежать резких изменений и поддерживать предсказуемую клиническую динамику. Важную роль играет наблюдение за реакцией организма, позволяющее корректировать тактику лечения в соответствии с выявленными изменениями. Последовательность действий обеспечивает структурированность процесса и повышает вероятность стабильного результата.
Ознакомиться с деталями – [url=https://vyvodiz-zapoya-izhevsk18.ru/]вывод из запоя на дому недорого ижевск[/url]
[url=https://easypharmacies.shop/#]pharmacy websites[/url]
слоты 1вин [url=https://1win85612.help/]https://1win85612.help/[/url]
электрическая рулонная штора [url=https://rulonnaya-shtora-s-elektroprivodom.ru/]rulonnaya-shtora-s-elektroprivodom.ru[/url] .
pin-up verifikasiya sənədləri [url=https://pinup2007.help/]https://pinup2007.help/[/url]
электрокарнизы купить в москве [url=https://karniz-elektroprivodom.ru/]электрокарнизы купить в москве[/url] .
1вин приветственный бонус [url=https://1win85612.help/]https://1win85612.help/[/url]
pin-up google play varmı [url=https://pinup2007.help/]pin-up google play varmı[/url]
1win комиссия элсом [url=https://1win85612.help/]https://1win85612.help/[/url]
canadian no prescription pharmacies https://easypharmacies.shop/# online prescription free pharmacy
сочетание рулонных рулонные шторы и тюль фото [url=https://rulonnaya-shtora-s-elektroprivodom.ru/]rulonnaya-shtora-s-elektroprivodom.ru[/url] .
pin-up Kapital Bank ilə depozit [url=https://pinup2007.help]pin-up Kapital Bank ilə depozit[/url]
электронный карниз для штор [url=https://karniz-elektroprivodom.ru/]karniz-elektroprivodom.ru[/url] .
В условиях круглосуточного наблюдения врачи могут внимательно следить за динамикой состояния, своевременно корректировать схемы лечения, проводить детоксикацию под контролем давления, пульса и работы сердца. Особенно это важно для пациентов с гипертонией, сердечно-сосудистыми заболеваниями, нарушениями ритма, заболеваниями печени, диабетом и другими хроническими патологиями. В стационаре проще организовать обследование, назначить сопутствующую терапию, вовремя заметить опасные симптомы и предотвратить серьёзные осложнения.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-lobnya11.ru/]narkologicheskaya-klinika-stacionar[/url]
[url=https://easypharmacies.shop/#]fioricet overseas pharmacy[/url]
голосовое управление жалюзи [url=https://zhalyuzi-s-elektroprivodom77.ru/]голосовое управление жалюзи[/url] .
сравнение domeo с конкурентами [url=https://domeo-otzivy.com/]domeo-otzivy.com[/url] .
free spiny bez vkladu [url=https://casino-cz-2.com/]casino-cz-2.com[/url] .
casino bonus bez vkladu [url=https://casino-cz-5.com/]casino-cz-5.com[/url] .
?esk? online casino [url=https://casino-cz-3.com/]?esk? online casino[/url] .
ruleta online [url=https://casino-cz-6.com/]casino-cz-6.com[/url] .
?esk? casino online [url=https://casino-cz-4.com/]?esk? casino online[/url] .
Запой — это не просто следствие чрезмерного употребления алкоголя, а серьёзное патологическое состояние, которое требует срочной медицинской помощи. На фоне затяжного приёма спиртного в организме человека происходят опасные изменения: интоксикация, обезвоживание, нарушение электролитного баланса, резкие скачки давления и работы сердца, угнетение функций печени и мозга. В такой ситуации капельница от запоя становится неотложной мерой, позволяющей стабилизировать состояние и устранить симптомы абстиненции за короткий срок.
Узнать больше – http://kapelnica-ot-zapoya-msk55.ru/
v?hern? automaty online [url=https://casino-cz-1.com/]casino-cz-1.com[/url] .
safest online canada pharmacies https://easypharmacies.shop/# buy prescription drugs online
автоматические карнизы для штор [url=https://elektrokarniz25.ru/]автоматические карнизы для штор[/url] .
управление жалюзи смартфоном [url=https://zhalyuzi-s-elektroprivodom77.ru/]управление жалюзи смартфоном[/url] .
расценки domeo [url=https://domeo-otzivy.com/]domeo-otzivy.com[/url] .
«TUT-SPORT» предлагает:
• гетры, шорты и спортивные костюмы;
• привлекательные цены и скидки до 50-60%;
• Подбор оптимального комплекта экипировки под ваш клуб и бюджет;
• Проверку наличия размеров.
[url=https://tut-sport.ru/]футбольная атрибутика в москве[/url]
спортивная форма футбольных клубов – [url=https://tut-sport.ru/]https://tut-sport.ru/[/url]
[url=https://maps.google.se/url?sa=t&url=https://tut-sport.ru/]http://toolbarqueries.google.bs/url?q=https://tut-sport.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/dtcc.edu.vn/www.pereplanirovka-nezhilogo-pomeshcheniya9.ru/zakazat-onlayn-translyaciyu5.ru]Официальная футбольная форма и подарки для фанатов от «TUT-SPORT» в вашем городе[/url] 88f2000
live casino [url=https://casino-cz-6.com/]casino-cz-6.com[/url] .
[url=http://salepharmacies.shop/#]buy medication without an rx[/url]
электрические карнизы купить [url=https://elektrokarniz25.ru/]электрические карнизы купить[/url] .
casino bonus bez vkladu [url=https://casino-cz-5.com/]casino-cz-5.com[/url] .
online casino bonus bez vkladu [url=https://casino-cz-2.com/]casino-cz-2.com[/url] .
cómo retirar en pinup [url=https://pinup2001.help]https://pinup2001.help[/url]
nov? online casino [url=https://casino-cz-3.com/]nov? online casino[/url] .
cz online casina [url=https://casino-cz-4.com/]cz online casina[/url] .
ruleta online [url=https://casino-cz-1.com/]casino-cz-1.com[/url] .
мостбет скачать в Кыргызстане [url=www.mostbet12037.ru]www.mostbet12037.ru[/url]
жалюзи автоматические цена [url=https://zhalyuzi-s-elektroprivodom77.ru/]zhalyuzi-s-elektroprivodom77.ru[/url] .
оценка компании domeo [url=https://domeo-otzivy.com/]оценка компании domeo[/url] .
legit canadian online pharmacy https://salepharmacies.shop/# mexican pharmacy onlineno rx
?esk? online casina [url=https://casino-cz-6.com/]?esk? online casina[/url] .
free spiny [url=https://casino-cz-3.com/]free spiny[/url] .
bonus bez vkladu [url=https://casino-cz-5.com/]casino-cz-5.com[/url] .
free spiny dnes [url=https://casino-cz-2.com/]casino-cz-2.com[/url] .
мостбет как вывести на MasterCard [url=https://mostbet12037.ru]https://mostbet12037.ru[/url]
cómo hacer un retiro en pin-up [url=https://pinup2001.help/]cómo hacer un retiro en pin-up[/url]
bonus bez vkladu [url=https://casino-cz-1.com/]casino-cz-1.com[/url] .
Возможность назначить визит специалиста в наиболее удобное время. Это позволяет эффективно совмещать лечение с работой и повседневными делами. Такая гибкость помогает пациентам своевременно начать терапию, не откладывая ее из-за занятости. При необходимости врач может приехать в вечернее время или выходные дни.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-msk55.ru/]нарколог на дом недорого[/url]
Для формирования структурированного лечения используются методы, обеспечивающие анализ текущей клинической картины. Ниже представлены ключевые направления, задействованные при формировании терапевтических решений.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-vo-vladivostoke18.ru/]наркологическая клиника вывод из запоя[/url]
жалюзи для пластиковых окон с электроприводом [url=https://zhalyuzi-s-elektroprivodom77.ru/]жалюзи для пластиковых окон с электроприводом[/url] .
[url=https://salepharmacies.shop/#]www.online pharmacies.com[/url]
реальные отзывы domeo [url=https://domeo-otzivy.com/]реальные отзывы domeo[/url] .
cloudcurio.shop – The selection is unmatched and the shopping experience was wonderful.
free spiny za registraci [url=https://casino-cz-6.com/]casino-cz-6.com[/url] .
live casino [url=https://casino-cz-3.com/]casino-cz-3.com[/url] .
Этот информационный набор привлекает внимание множеством мелочей и странных ракурсов. Мы предлагаем взгляды, которые редко бывают полезны, но могут слегка разнообразить ваше знакомство с темой.
Вот – [url=https://arma-rehab.ru/]порно[/url]
online casino cz [url=https://casino-cz-5.com/]online casino cz[/url] .
free spiny dnes [url=https://casino-cz-2.com/]casino-cz-2.com[/url] .
cum introduc cod bonus 1win [url=https://1win5756.help]https://1win5756.help[/url]
vavada strona oficjalna polska [url=https://vavada2005.help/]https://vavada2005.help/[/url]
no prescription https://salepharmacies.shop/# online pharmacies without prescription
https://corp.en.cx/Guestbook/Messages.aspx?page=1&fmode=gb&topic=386110&anchor#7983049 фреоновое масло
1win depunere cu card Moldova [url=https://1win5756.help/]1win depunere cu card Moldova[/url]
Наткнулся на такой платформу во время изучения локального разделов о ремонте и недвижимости, который кажется логичным, что упрощает проверять варианты легко.
По ссылке; https://grace-calipso.ru/
онлайн казино с бездепозитным бонусом за регистрацию с выводом В эпоху, когда мир мчится на скорости света, медленные выплаты – это архаизм, устаревший, как пленочные проекторы в эру 4K. Топовые онлайн-казино с быстрыми выплатами понимают эту динамику: они интегрируют передовые финансовые протоколы, где транзакции обрабатываются в реальном времени, словно молния, рассекающая ночное небо. Сердце такой системы – многоуровневая верификация, сочетающая биометрию, блокчейн и ИИ-анализ, чтобы исключить любые задержки, не жертвуя безопасностью. Лицензии от MGA или UKGC здесь не формальность, а гарантия: аудиторы вроде GLI проверяют каждую операцию, обеспечивая, что выигрыш от €100 до миллионов евро поступит на ваш счет в пределах 1–24 часов.
ruleta online [url=https://casino-cz-1.com/]casino-cz-1.com[/url] .
бамбуковые электрожалюзи [url=https://zhalyuzi-s-elektroprivodom77.ru/]zhalyuzi-s-elektroprivodom77.ru[/url] .
отзывы о domeo [url=https://domeo-otzivy.com/]отзывы о domeo[/url] .
online casino cz [url=https://casino-cz-3.com/]online casino cz[/url] .
bonus za registraci bez vkladu [url=https://casino-cz-6.com/]casino-cz-6.com[/url] .
Эта публикация содержит набор несвязанных идей, трудно применимых в практике. Мы лишь поверхностно затрагиваем различные точки зрения, не проводя глубокий анализ и не предлагая выводов.
Подробнее читать – [url=https://rostov-narkologiya.ru/uslugi-ot-alkogolizma/vyvod-iz-zapoya/]лечение covid народными средствами[/url]
online casino s ?eskou licenc? [url=https://casino-cz-5.com/]online casino s ?eskou licenc?[/url] .
Помощь нарколога нужна, если алкоголь или наркотики постепенно начинают занимать в жизни всё больше места. Человек заранее планирует, когда и как будет пить, нервничает, если что-то срывается, раздражается, когда близкие пытаются ограничить употребление. Появляются скандалы после «весёлых» вечеров, пропущенные рабочие смены, проблемы с деньгами, конфликты с родными. При этом любые разговоры заканчиваются обещаниями «завязать с понедельника» или обвинениями окружающих.
Выяснить больше – http://narkologicheskaya-klinika-voskresensk11.ru
v?hern? automaty online [url=https://casino-cz-2.com/]v?hern? automaty online[/url] .
vavada bonus powitalny [url=https://vavada2005.help/]https://vavada2005.help/[/url]
ruleta online [url=https://casino-cz-7.com/]casino-cz-7.com[/url] .
bonus bez vkladu [url=https://casino-cz-8.com/]bonus bez vkladu[/url] .
[url=http://salepharmacies.shop/#]medication on-line no perscription[/url]
реальные отзывы domeo [url=https://domeo-otzivy.com/]реальные отзывы domeo[/url] .
тканевые электрожалюзи [url=https://zhalyuzi-s-elektroprivodom77.ru/]zhalyuzi-s-elektroprivodom77.ru[/url] .
casino hry online [url=https://casino-cz-3.com/]casino-cz-3.com[/url] .
free spiny za registraci [url=https://casino-cz-6.com/]casino-cz-6.com[/url] .
捕风追影下载平台,專為海外華人設計,提供高清視頻和直播服務。
casino cz [url=https://casino-cz-1.com/]casino cz[/url] .
海外华人必备的iyf平台,提供最新高清电影、电视剧,无广告观看体验。
?esk? online casino [url=https://casino-cz-5.com/]?esk? online casino[/url] .
Online casino Australia 2025 – latest legal updates and sites
casino hry online [url=https://casino-cz-2.com/]casino-cz-2.com[/url] .
safest online canada pharmacies http://salepharmacies.shop/# indian pharmacies online
leg?ln? online casino [url=https://casino-cz-7.com/]leg?ln? online casino[/url] .
ruleta online [url=https://casino-cz-8.com/]ruleta online[/url] .
艾一帆海外版,专为华人打造的高清视频平台,支持全球加速观看。
Каждый из этих симптомов по отдельности уже опасен, а в сочетании они создают высокий риск для жизни. Самостоятельные эксперименты с таблетками, резкий отказ от алкоголя «через силу» или попытка «переспать» запой без медицинского контроля могут обернуться реанимацией. Гораздо безопаснее вовремя вызвать специалиста и провести детоксикацию под наблюдением, особенно когда речь идёт о жителях крупного города, где доступна профессиональная наркологическая помощь.
Получить больше информации – [url=https://vyvod-iz-zapoya-moskva011.ru/]вывод из запоя москва срочно[/url]
我欲为人第二季平台,专为海外华人设计,提供高清视频和直播服务。
超人和露易斯第二季高清完整版,海外华人可免费观看最新热播剧集。
戏台在线免费在线观看,海外华人专属平台,高清无广告体验。
?esk? casino online [url=https://casino-cz-1.com/]casino-cz-1.com[/url] .
[url=http://salepharmacies.shop/#]online pharmacies without prescription[/url]
«Инсис» в Екатеринбурге предоставляют:
• интерактивное ТВ;
• поддержки 24/7;
• Подбор оптимального сочетания интернета и ТВ под ваши задачи;
• Проверку технической доступности по вашему адресу.
[url=https://insis-internet-podkluchit.ru/]подключить интернет инсис дома в екатеринбурге[/url]
инсис интернет тарифы для домашнего интернета екатеринбург – [url=http://www.insis-internet-podkluchit.ru /]https://www.insis-internet-podkluchit.ru /[/url]
[url=https://maps.google.kz/url?q=https://insis-internet-podkluchit.ru/]https://www.google.gg/url?q=https://insis-internet-podkluchit.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.iskusstvennaya-kozha-dlya-mebeli-kupit.ru/www.arus-diplom35.ru/www.arenda-ekskavatora-pogruzchika-cena.ru/pinup5007.ru]Интернет и цифровое ТВ от «Инсис» в вашем доме[/url] 88f2000
free spiny bez vkladu [url=https://casino-cz-7.com/]free spiny bez vkladu[/url] .
cz online casina [url=https://casino-cz-8.com/]cz online casina[/url] .
rx pharmacy online http://provimedsrx.com/# cheap online pharmacies usa no prescriptions
В таблице ниже представлены основные группы препаратов, применяемых при выведении из запоя:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-v-krasnodare19.ru/]вывод из запоя недорого краснодар[/url]
超人和露易斯第四季高清完整官方版,海外华人可免费观看最新热播剧集。
海外华人必备的aiyifan官方认证平台,24小时不间断提供最新高清电影、电视剧,无广告观看体验。
live casino [url=https://casino-cz-7.com/]casino-cz-7.com[/url] .
?esk? online casino [url=https://casino-cz-8.com/]?esk? online casino[/url] .
[url=http://provimedsrx.com/#]buy drugs online no prescription[/url]
海外华人必备的ify平台智能AI观看体验优化,提供最新高清电影、电视剧,无广告观看体验。
cz casina [url=https://casino-cz-7.com/]cz casina[/url] .
leg?ln? online casino [url=https://casino-cz-8.com/]leg?ln? online casino[/url] .
«Инсис» в Екатеринбурге предлагают:
• пакет из 150+ ТВ каналов;
• поддержки 24/7;
• Подбор оптимального сочетания интернета и ТВ под ваши задачи;
• Анализ технической доступности по вашему адресу.
[url=https://insis-internet-podkluchit.ru/]инсис услуги и тарифы интернет[/url]
инсис интернет оптоволокно тарифы – [url=https://www.insis-internet-podkluchit.ru]http://insis-internet-podkluchit.ru[/url]
[url=https://clients1.google.com.au/url?sa=t&url=https://insis-internet-podkluchit.ru/]https://clients1.google.ml/url?q=https://insis-internet-podkluchit.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.guryevsk.forum24.ru/fanfiction.borda.ru/www.stretch-ceilings-samara.ru/www.telegra.ph/Medicinskij-perevod-tochnost-kak-vopros-zhizni-i-zdorovya-10-16/www.teletype.in/%40alexd78/maps.google.kg/r-diploma29.ru,]Высокоскоростной интернет и цифровое ТВ от «Инсис» в Екатеринбурге[/url] 29ee485
pharmacies online http://provimedsrx.com/# buy tramadol from canadian pharmacies
爱一帆会员多少钱海外版,专为华人打造的高清视频平台,支持全球加速观看。
超人和露易斯第三季高清完整官方版,海外华人可免费观看最新热播剧集。
官方授权的ifuntv海外华人首选,第一时间提供最新华语剧集、美剧、日剧等高清在线观看。
casino bonus bez vkladu [url=https://casino-cz-7.com/]casino bonus bez vkladu[/url] .
pin-up programa vip [url=http://pinup2005.help]http://pinup2005.help[/url]
free spiny bez vkladu [url=https://casino-cz-8.com/]free spiny bez vkladu[/url] .
cz online casina [url=https://casino-cz-9.com/]casino-cz-9.com[/url] .
cz casino [url=https://casino-cz-10.com/]cz casino[/url] .
free spiny za registraci [url=https://casino-cz-11.com/]free spiny za registraci[/url] .
cz online casina [url=https://casino-cz-12.com/]cz online casina[/url] .
[url=http://provimedsrx.com/#]canadian online pharmacy cialis[/url]
1win apk для Кыргызстана [url=1win17384.help]1win17384.help[/url]
mostbet metode plată Moldova [url=https://mostbet2007.help]https://mostbet2007.help[/url]
pinup descarga [url=pinup2005.help]pinup descarga[/url]
mostbet купон ставок [url=https://mostbet51837.help]https://mostbet51837.help[/url]
奇思妙探高清完整版,海外华人可免费观看最新热播剧集。
pin-up crear cuenta [url=www.pinup2005.help]pin-up crear cuenta[/url]
1win киргизче кирүү [url=https://1win17384.help/]1win киргизче кирүү[/url]
mostbet limita depunere [url=https://mostbet2007.help]https://mostbet2007.help[/url]
leg?ln? online casino [url=https://casino-cz-4.com/]leg?ln? online casino[/url] .
indian pharmacies online https://provimedsrx.com/# online us pharmacies
automaty online [url=https://casino-cz-9.com/]casino-cz-9.com[/url] .
«TUT-SPORT» предоставляет:
• широкий выбор форм топ-клуба Арсенал;
• привлекательные цены и скидки до 50-60%;
• Подбор оптимального комплекта экипировки под ваш клуб и бюджет;
• Анализ наличия размеров.
[url=https://tut-sport.ru/tovary/kluby/arsenal]купить футбольную форму Арсенал[/url]
атрибутика футбольного клуба Арсенал – [url=http://www.tut-sport.ru/tovary/kluby/arsenal]http://tut-sport.ru/tovary/kluby/arsenal[/url]
[url=https://images.google.com.vn/url?sa=t&url=https://tut-sport.ru/tovary/kluby/arsenal]http://images.google.co.ve/url?q=https://tut-sport.ru/tovary/kluby/arsenal[/url]
[url=http://budteer.or.kr/bbs/board.php?bo_table=back01&wr_id=66190]Спортивная экипиров[/url] 46588f2
mostbet как пополнить Visa [url=www.mostbet51837.help]www.mostbet51837.help[/url]
casino hry online [url=https://casino-cz-4.com/]casino hry online[/url] .
[url=https://provimedsrx.com/#]legit canadian online pharmacy[/url]
После курса капельниц улучшается сон, аппетит и общее самочувствие. Пациенты отмечают, что уже через сутки после начала лечения исчезают тремор и тахикардия, а на второй день приходит чувство ясности и спокойствия.
Получить дополнительные сведения – http://narkologicheskaya-klinika-v-kemerovo18.ru/narkologicheskaya-klinika-v-kemerovo-anonimno/https://narkologicheskaya-klinika-v-kemerovo18.ru
cz casino [url=https://casino-cz-9.com/]cz casino[/url] .
automaty online [url=https://casino-cz-10.com/]automaty online[/url] .
bonus za registraci bez vkladu [url=https://casino-cz-12.com/]bonus za registraci bez vkladu[/url] .
cz online casina [url=https://casino-cz-11.com/]cz online casina[/url] .
Важно и то, что во время процедуры пациент находится под наблюдением. Врач может увидеть, как организм реагирует на терапию, вовремя скорректировать темп или состав инфузии, понять, достаточно ли домашнего формата или лучше рассмотреть стационар. Это принципиальное отличие от попыток лечиться дома таблетками наугад, без контроля давления и пульса.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-dolgoprudnyj11.ru/]kapelnica-ot-zapoya-v-dolgoprudnom[/url]
Там, где раньше хватало одного тяжёлого утра, теперь требуются дни детоксикации. И чем позже подключается врач, тем сложнее вернуть организм к относительно безопасному состоянию.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-voskresensk11.ru/]вывод из запоя советский[/url]
Best Aussie online casino – real money wins and no deposit bonuses
Обратиться за помощью могут как сами пациенты, так и их родственники. Часто именно близкие первыми замечают, что человек изменился: стал раздражительным, агрессивным или, наоборот, отстранённым, перестал выполнять обещания, начал скрывать доходы и траты. В клинике семья получает не только медицинскую помощь для зависимого, но и понятную стратегию действий: как разговаривать, как мотивировать на лечение, как не провоцировать конфликты и не усиливать чувство стыда у человека, который и так боится признаться себе в наличии болезни.
Узнать больше – [url=https://narkologicheskaya-klinika-moskva11.ru/]luchshaya-narkologicheskaya-klinika-moskva[/url]
«Зелёная точка» в Ставрополе предлагают:
• пакет из 150+ ТВ каналов;
• поддержки 24/7;
• Определение оптимального сочетания интернета и ТВ под ваши задачи;
• Проверку технической доступности по вашему адресу.
[url=]тарифы зеленая точкаа на интернет и телевидение[/url]
зеленая точка тарифы домашний интернет и телевидение ставрополь – [url=http://zelenaya-tochka-podkluchit.ru]https://zelenaya-tochka-podkluchit.ru[/url]
[url=https://images.google.mn/url?sa=t&url=https://zelenaya-tochka-podkluchit.ru]https://cse.google.ml/url?sa=i&url=https://zelenaya-tochka-podkluchit.ru[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.pelsh.forum24.ru/www.pokies11.com/www.arbuztech.ru/www.google.se/url?q]Интернет и ТВ от «Зелёная точка» в вашем доме[/url] f200021
reputable online pharmacies no prescription requied https://provimedsrx.com/# legalonlinepharmacy.com
«TUT-SPORT» предоставляет:
• широкий выбор форм топ-клуба Аталанта;
• товары для взрослых, детей и женщин;
• Подбор оптимального комплекта экипировки под ваш клуб и бюджет;
• Анализ доступности товара по акции.
[url=https://tut-sport.ru/tovary/kluby/atalanta]купить футбольную форму Аталанта в москве[/url]
футбольная форма Аталанта москва – [url=https://www.tut-sport.ru/tovary/kluby/atalanta]http://tut-sport.ru/tovary/kluby/atalanta[/url]
[url=https://cse.google.ht/url?sa=t&url=https://tut-sport.ru/tovary/kluby/atalanta]http://maps.google.si/url?q=https://tut-sport.ru/tovary/kluby/atalanta[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.guryevsk.forum24.ru/www.miniatelie.ru]Клубная атрибутика и аксессуары для болельщиков от «TUT-SPORT» в вашем городе[/url] 5_ab2cd
bonus bez vkladu [url=https://casino-cz-4.com/]bonus bez vkladu[/url] .
cz casina [url=https://casino-cz-9.com/]cz casina[/url] .
cz casina [url=https://casino-cz-10.com/]cz casina[/url] .
«Орион» в Красноярске предлагают:
• пакет из 150+ ТВ каналов;
• быстрое подключение за 1 день;
• Определение оптимального тарифа под ваши задачи;
• Анализ технической доступности по вашему адресу.
[url=https://orion-inetrnet-podkluchit.ru]подключить интернет орион[/url]
орион тарифы на домашний интернет цена – [url=https://www.orion-inetrnet-podkluchit.ru]https://orion-inetrnet-podkluchit.ru[/url]
[url=http://images.google.co.kr/url?q=https://orion-inetrnet-podkluchit.ru]https://maps.google.co.tz/url?q=https://orion-inetrnet-podkluchit.ru[/url]
[url=https://mafia.mit.edu/viewtopic.php?f=435&t=1110686]Высокоскоростной интернет и цифровое ТВ от «Орион» в вашем доме[/url] 88f2000
online casino s ?eskou licenc? [url=https://casino-cz-11.com/]online casino s ?eskou licenc?[/url] .
casino cz [url=https://casino-cz-12.com/]casino cz[/url] .
Обращаться в клинику стоит не только в крайних случаях, когда человек уже не может встать с постели или запой продолжается неделями. Наоборот, чем раньше начата помощь, тем мягче и короче может быть программа, тем меньше риск тяжёлых осложнений и долгой реабилитации.
Изучить вопрос глубже – https://narkologicheskaya-klinika-dolgoprudnyj11.ru/narkologicheskaya-klinika-vyzvat-v-dolgoprudnom/
[url=https://www.google.je/url?sa=t&url=https%3A%2F%2Fmexmedimax.com]fioricet onlinepharmacy[/url]
Клиника «ВладТрезвие Центр» работает в круглосуточном режиме и готова оказать помощь жителям Владивостока и прилегающих районов в любое время суток. Врачи-наркологи прибывают по вызову в течение часа, имеют при себе все необходимые препараты и оборудование для проведения детоксикации на дому. При необходимости пациента доставляют в стационар, где лечение проходит под постоянным контролем медицинского персонала.
Подробнее – https://vyvodiz-zapoya-vladivostok18.ru/vyvod-iz-zapoya-gorod-vladivostok
automaty online [url=https://casino-cz-4.com/]automaty online[/url] .
leg?ln? online casino [url=https://casino-cz-9.com/]leg?ln? online casino[/url] .
online casino bonus bez vkladu [url=https://casino-cz-10.com/]casino-cz-10.com[/url] .
cz casino [url=https://casino-cz-12.com/]cz casino[/url] .
live casino [url=https://casino-cz-11.com/]casino-cz-11.com[/url] .
sildeafil on line pharmacy http://www.bssystems.org/url?q=https%3A%2F%2Fmexmedimax.com england pharmacies online
automaty online [url=https://casino-cz-9.com/]casino-cz-9.com[/url] .
«Инсис» в Екатеринбурге предлагают:
• пакет из 150+ ТВ каналов;
• быстрое подключение за 1 день;
• Определение оптимального сочетания интернета и ТВ под ваши задачи;
• Проверку инфраструктуры по вашему адресу.
[url=https://insis-internet-podkluchit.ru/]инсис тарифы на интернет 2026[/url]
insis интернет проверить адрес – [url=https://insis-internet-podkluchit.ru /]http://insis-internet-podkluchit.ru /[/url]
[url=https://clients1.google.ms/url?q=https://insis-internet-podkluchit.ru/]https://images.google.com.py/url?sa=t&url=https://insis-internet-podkluchit.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.chop-ohrana.com/www.php.ru/forum/members/k.krakenwork.cc/www.1xbet-4.com/www.1xbet-7.com/index.html,]Домашний интернет и цифровое ТВ от «Инсис» в Екатеринбурге[/url] 6_26d86
automaty online [url=https://casino-cz-10.com/]automaty online[/url] .
?esk? casino online [url=https://casino-cz-14.com/]?esk? casino online[/url] .
nov? online casino [url=https://casino-cz-13.com/]nov? online casino[/url] .
?esk? casino online [url=https://casino-cz-17.com/]casino-cz-17.com[/url] .
casino hry online [url=https://casino-cz-16.com/]casino hry online[/url] .
casino cz [url=https://casino-cz-15.com/]casino cz[/url] .
nejlep?? online casino [url=https://casino-cz-19.com/]nejlep?? online casino[/url] .
free spiny bez vkladu [url=https://casino-cz-18.com/]casino-cz-18.com[/url] .
online casino [url=https://casino-cz-12.com/]online casino[/url] .
nov? online casino [url=https://casino-cz-11.com/]nov? online casino[/url] .
«Зелёная точка» в Ставрополе предоставляют:
• интерактивное ТВ;
• быстрое подключение за 1 день;
• Подбор оптимального тарифа под ваши задачи;
• Анализ технической доступности по вашему адресу.
[url=]домашний интернет зеленая точка подключен ли дом[/url]
подключить интернет зеленая точка в квартиру ставрополь – [url=https://www.zelenaya-tochka-podkluchit.ru]http://www.zelenaya-tochka-podkluchit.ru[/url]
[url=http://alt1.toolbarqueries.google.ro/url?q=https://zelenaya-tochka-podkluchit.ru]https://clients1.google.com.ai/url?sa=t&url=https://zelenaya-tochka-podkluchit.ru[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.guryevsk.forum24.ru/www.mostbet-download-app-apk.com/k.krakenwork.cc/www.avtomaticheskie-rulonnye-shtory1.ru]Домашний интернет и цифровое ТВ от «Зелёная точка» в Ставрополе[/url] 588f200
[url=https://www.google.com.sl/url?sa=t&url=https%3A%2F%2Fmexmedimax.com]safest online canada pharmacies[/url]
1win ставки на хоккей [url=https://www.1win87143.help]https://www.1win87143.help[/url]
В статье-обзоре представлены данные сомнительной актуальности и факты без явной взаимосвязи. Читатель ознакомится с разными мнениями, хотя они вряд ли существенно изменят его представление о теме.
Подробнее читать – https://rostov-narkologiya.ru
«Орион» в Красноярске предлагают:
• интерактивное ТВ;
• поддержки 24/7;
• Подбор оптимального сочетания интернета и ТВ под ваши задачи;
• Проверку инфраструктуры по вашему адресу.
[url=https://orion-inetrnet-podkluchit.ru]орион беспроводной интернет тарифы[/url]
домашний интернет орион подключен ли дом – [url=http://orion-inetrnet-podkluchit.ru]https://www.orion-inetrnet-podkluchit.ru[/url]
[url=https://image.google.com.fj/url?q=https://orion-inetrnet-podkluchit.ru]https://www.google.com.tn/url?q=https://orion-inetrnet-podkluchit.ru[/url]
[url=https://mafia.mit.edu/posting.php?f=435&mode=quote&p=353350]Высокоскоростной интернет и ТВ от «Орион» в вашем доме[/url] 545c29e
v?hern? automaty online [url=https://casino-cz-17.com/]casino-cz-17.com[/url] .
1win-kg [url=https://1win87143.help]https://1win87143.help[/url]
cz casina [url=https://casino-cz-14.com/]cz casina[/url] .
hrac? automaty online [url=https://casino-cz-13.com/]casino-cz-13.com[/url] .
legitimate online pharmacies india https://cse.google.al/url?q=https%3A%2F%2Fmexmedimax.com online pharmacies with out prescriptions
mobiln? casino [url=https://casino-cz-19.com/]casino-cz-19.com[/url] .
live casino [url=https://casino-cz-16.com/]live casino[/url] .
online casino [url=https://casino-cz-18.com/]online casino[/url] .
v?hern? automaty online [url=https://casino-cz-15.com/]v?hern? automaty online[/url] .
1win Ош кирүү [url=https://www.1win87143.help]https://www.1win87143.help[/url]
trucos para organismo simГ©trico
online casino s ?eskou licenc? [url=https://casino-cz-17.com/]online casino s ?eskou licenc?[/url] .
nejlep?? online casino [url=https://casino-cz-14.com/]nejlep?? online casino[/url] .
online casino [url=https://casino-cz-19.com/]online casino[/url] .
automaty online [url=https://casino-cz-13.com/]casino-cz-13.com[/url] .
?esk? online casino [url=https://casino-cz-16.com/]?esk? online casino[/url] .
1win демо plinko [url=1win5525.ru]1win демо plinko[/url]
1win mBank вывод [url=http://1win45920.help/]1win mBank вывод[/url]
cz casino [url=https://casino-cz-18.com/]cz casino[/url] .
1win почта поддержки [url=https://1win06284.help/]1win почта поддержки[/url]
bonus bez vkladu [url=https://casino-cz-15.com/]bonus bez vkladu[/url] .
1вин слоты [url=https://1win5525.ru/]1вин слоты[/url]
casino cz [url=https://casino-cz-17.com/]casino cz[/url] .
automaty online [url=https://casino-cz-19.com/]automaty online[/url] .
1win mines [url=https://www.1win45920.help]1win mines[/url]
automaty online [url=https://casino-cz-14.com/]automaty online[/url] .
leg?ln? online casino [url=https://casino-cz-13.com/]leg?ln? online casino[/url] .
1win пополнение Киргизия [url=https://1win06284.help/]1win пополнение Киргизия[/url]
online casino s ?eskou licenc? [url=https://casino-cz-16.com/]online casino s ?eskou licenc?[/url] .
凯伦皮里第一季高清完整版,海外华人可免费观看最新热播剧集。
1win официальный сайт зеркало [url=http://1win5525.ru]http://1win5525.ru[/url]
1win двухфакторная авторизация [url=http://1win45920.help/]http://1win45920.help/[/url]
?esk? casino online [url=https://casino-cz-18.com/]?esk? casino online[/url] .
ทดลองเล่นสล็อต pg
TKBNEKO ทำงานเป็นระบบเกมออนไลน์ ที่ วางระบบโดยยึดการใช้งานจริงของผู้เล่นเป็นแกนหลัก. หน้าแรก แสดงเงื่อนไขแบบเป็นตัวเลขตั้งแต่แรก: ขั้นต่ำฝาก 1 บาท, ขั้นต่ำถอน 1 บาท, เครดิตเข้าโดยเฉลี่ยราว 3 วินาที, และ ยอดถอนไม่มีเพดาน. ตัวเลขเหล่านี้กำหนดภาระของระบบโดยตรง เพราะเมื่อ กำหนดขั้นต่ำต่ำ ระบบต้อง รับรายการฝากถอนจำนวนมากที่มียอดเล็ก และต้อง ประมวลผลแบบเรียลไทม์. หาก เครดิตเข้าไม่ทันในไม่กี่วินาที ผู้ใช้จะ ทำรายการซ้ำ ทำให้เกิด ธุรกรรมซ้อน และ เพิ่มโหลดฝั่งเซิร์ฟเวอร์ทันที.
การเติมเงินด้วยการสแกน QR ตัดขั้นตอนการกรอกข้อมูลและการแนบสลิป. เมื่อผู้ใช้ สแกนคิวอาร์ ธนาคารจะส่งสถานะการชำระกลับมายังระบบผ่าน API. จากนั้น backend จะ ผูกธุรกรรมเข้ากับบัญชีผู้ใช้ และ เพิ่มเครดิตเข้า wallet. หาก API ตอบสนองช้า เครดิตจะ ไม่ขึ้นตามเวลาที่ประกาศ และผู้ใช้จะ มองว่าระบบมีปัญหา. ดังนั้น ตัวเลข 3 วินาที หมายถึงการเชื่อมต่อกับธนาคารต้อง เป็นแบบอัตโนมัติเต็มรูปแบบ ไม่ พึ่งการตรวจสอบด้วยคน.
การเชื่อมหลายช่องทางการจ่าย เช่น Kasikornbank, Bangkok Bank, Krung Thai Bank, Krungsri, Siam Commercial Bank, CIMB Thai รวมถึง ทรูมันนี่ วอลเล็ท ทำให้ระบบต้อง รับ callback หลายต้นทาง. แต่ละธนาคารมีรูปแบบข้อมูลและเวลาตอบสนองต่างกัน. หากไม่มี โมดูลแปลงข้อมูลให้เป็นมาตรฐานเดียว ระบบจะ ยืนยันยอดได้ช้า และจะเกิด ยอดค้างระบบ.
หมวดเกม ถูกแยกเป็น สล็อตออนไลน์, คาสิโนสด, เดิมพันกีฬา และ เกมยิงปลา. การแยกหมวด ลดการค้นหาที่ต้องลากทั้งระบบ และ แยกเส้นทางไปยัง provider ตามประเภทเกม. สล็อต มัก เชื่อมต่อผ่าน session API ส่วน เกมสด ใช้ สตรีมแบบสด. หาก หลุดเซสชัน ผู้เล่นจะ ถูกตัดออกจากเกมทันที. ดังนั้นระบบต้องมี ตัวจัดการ session ที่ คุมการเชื่อมต่อ และ ซิงค์เครดิตกับ provider ภายนอกตลอดเวลา. หาก ซิงค์พลาด เครดิตผู้เล่นกับผลเกมจะ ไม่ตรงกัน.
เกมที่ระบุว่า เป็นลิขสิทธิ์แท้ หมายถึงใช้ระบบ RNG และค่า RTP จากผู้พัฒนาโดยตรง. ผลลัพธ์แต่ละรอบถูก คำนวณจากฝั่ง provider ไม่ใช่จากฝั่งเว็บ. หากไม่มี ลิงก์ไปยังเซิร์ฟเวอร์ต้นทาง เว็บจะ รับผลเกมจริงไม่ได้ และ สิทธิ์ใช้งานจะถูกตัด. การมี การรับรอง จึง ผูกกับการแลกเปลี่ยนข้อมูลระหว่างระบบ ไม่ใช่ แค่คำบนหน้าเว็บ.
ระบบถอนที่ ไม่มีจำกัด เชิงการสื่อสารยังต้องมีโมดูล risk control เช่น ตรวจสอบบัญชีซ้ำ, พฤติกรรมผิดปกติ, และ เงื่อนไขเทิร์นโอเวอร์. หากไม่มีการตรวจสอบเหล่านี้ ผู้ใช้สามารถ แตกบัญชีหลายอัน เพื่อ เอาโบนัส และ ถอนเงินออกเร็ว.
ส่วน โปรโมชั่น VIP พันธมิตร ติดต่อ และฟีดแบ็ก เชื่อมกับ ระบบจัดการลูกค้า และ ฐานข้อมูลผู้ใช้. ส่วน พันธมิตร ใช้เก็บ referrer code เพื่อ คำนวณค่าคอมมิชชั่น. หากไม่มีระบบนี้ จะ ติดตามแหล่งที่มาของผู้ใช้ไม่ได้. แบบฟอร์มฟีดแบ็ก ใช้เก็บ error จริงจากผู้ใช้. หากไม่มีข้อมูลนี้ ปัญหา latency หรือ การใช้งาน จะ ถูกแก้ช้า.
โครงสร้างทั้งหมด เชื่อมกันเป็นสายเดียว: สถานะธุรกรรมเข้ามาที่ backend, backend อัปเดต wallet แล้ว ซิงค์ไปยัง provider. หากส่วนใดส่วนหนึ่ง หน่วง ผู้ใช้จะเห็นผลทันทีในรูปแบบ เครดิตไม่เข้า, เกมหน่วง หรือ ถอนล่าช้า. ในแพลตฟอร์มลักษณะนี้ API ต้องนิ่งและ session ต้องไม่หลุด คือสิ่งที่ ตัดสินว่าผู้ใช้จะอยู่หรือย้ายออก.
1win бонус [url=https://1win06284.help/]https://1win06284.help/[/url]
free spiny bez vkladu [url=https://casino-cz-15.com/]free spiny bez vkladu[/url] .
ruleta online [url=https://casino-cz-17.com/]casino-cz-17.com[/url] .
?esk? casino online [url=https://casino-cz-19.com/]?esk? casino online[/url] .
v?hern? automaty online [url=https://casino-cz-14.com/]v?hern? automaty online[/url] .
casino hry online [url=https://casino-cz-13.com/]casino-cz-13.com[/url] .
«TUT-SPORT» предоставляет:
• гетры, шорты и спортивные костюмы клуба Арсенал;
• доставку по всей России;
• Подбор оптимального набора под ваш клуб и бюджет;
• Анализ доступности товара по акции.
[url=https://tut-sport.ru/tovary/kluby/arsenal]купить футбольную форму клуба Арсенал[/url]
магазин футбольной атрибутики Арсенал в москве – [url=http://tut-sport.ru/tovary/kluby/arsenal]http://tut-sport.ru/tovary/kluby/arsenal[/url]
[url=https://cse.google.de/url?q=https://tut-sport.ru/tovary/kluby/arsenal]https://maps.google.bj/url?q=https://tut-sport.ru/tovary/kluby/arsenal[/url]
[url=http://budteer.or.kr/bbs/board.php?bo_table=back01&wr_id=66053]Официальная футболь[/url] e482_ea
[url=https://maps.google.kz/url?q=https%3A%2F%2Fmexmedimax.com]pharmacy websites[/url]
«TUT-SPORT» предлагает:
• гетры, шорты и спортивные костюмы клуба Айнтрахт;
• доставку по всей России;
• Определение оптимального набора под ваш клуб и бюджет;
• Проверку доступности товара по акции.
[url=https://tut-sport.ru/tovary/kluby/eintracht]интернет магазин футбольной формы Айнтрахт[/url]
футбольная форма Айнтрахт купить интернет магазин – [url=https://www.tut-sport.ru/tovary/kluby/eintracht]http://www.tut-sport.ru/tovary/kluby/eintracht[/url]
[url=https://maps.google.gp/url?q=https://tut-sport.ru/tovary/kluby/eintracht]https://images.google.com.sa/url?q=https://tut-sport.ru/tovary/kluby/eintracht[/url]
[url=http://nick263.la.coocan.jp/TeamCaffeine/wwwboard.cgi/%3C/alquimiaproductosdelimpieza.com]Клубная атрибутика и подарки для фанатов от «TUT-SPORT» в вашем городе[/url] 545c29e
online casina [url=https://casino-cz-16.com/]online casina[/url] .
«Инсис» в Екатеринбурге предоставляют:
• высокоскоростной интернет до 500 Мбит/с;
• поддержки 24/7;
• Определение оптимального пакета услуг под ваши задачи;
• Проверку инфраструктуры по вашему адресу.
[url=https://insis-internet-podkluchit.ru/]подключить домашний интернет в екатеринбурге инсис[/url]
сколько стоит подключение интернета инсис – [url=https://insis-internet-podkluchit.ru /]https://www.insis-internet-podkluchit.ru /[/url]
[url=https://maps.google.com.pa/url?q=https://insis-internet-podkluchit.ru/]https://clients1.google.is/url?sa=i&url=https://insis-internet-podkluchit.ru/[/url]
[url=https://social-media-visions.com/forum/topic/testeintrag/?part=15032#postid-150325]Интернет и телевидение от «Инсис» в Екатеринбурге[/url] a545c29
Каждый из перечисленных факторов — веская причина для вызова врача, который может оказать помощь профессионально и безопасно.
Детальнее – http://narcolog-na-dom-ryazan0.ru
Top Online Casinos Australia Real Money Including
цветы для вас
?esk? casino online [url=https://casino-cz-19.com/]?esk? casino online[/url] .
cz casino [url=https://casino-cz-18.com/]cz casino[/url] .
cz casino [url=https://casino-cz-14.com/]cz casino[/url] .
casino online [url=https://casino-cz-13.com/]casino-cz-13.com[/url] .
online pharmacy uk https://www.google.st/url?sa=t&url=https%3A%2F%2Fmexmedimax.com canada pharmacies no prescription needed
?esk? casino online [url=https://casino-cz-15.com/]?esk? casino online[/url] .
free spiny [url=https://casino-cz-16.com/]free spiny[/url] .
«TUT-SPORT» предлагает:
• широкий выбор форм топ-клуба Аталанта;
• привлекательные цены и скидки до 50-60%;
• Определение оптимального комплекта экипировки под ваш клуб и бюджет;
• Анализ ассортимента в нужной категории.
[url=https://tut-sport.ru/tovary/kluby/atalanta]магазин футбольной формы Аталанта в москве[/url]
футбольная форма Аталанта – [url=https://tut-sport.ru/tovary/kluby/atalanta]https://www.tut-sport.ru/tovary/kluby/atalanta[/url]
[url=https://cse.google.ng/url?q=https://tut-sport.ru/tovary/kluby/atalanta]http://images.google.gg/url?q=https://tut-sport.ru/tovary/kluby/atalanta[/url]
[url=http://budteer.or.kr/bbs/board.php?bo_table=back01&wr_id=71044]Официальная футболь[/url] 545c29e
consejos de expertos en running
здесь https://t.me/invisevpn_bot
[url=https://maps.google.co.jp/url?sa=t&url=https%3A%2F%2Fmexmedimax.com]buy medication without an rx[/url]
v?hern? automaty online [url=https://casino-cz-18.com/]v?hern? automaty online[/url] .
интернет https://t.me/invisevpn_bot/
v?hern? automaty online [url=https://casino-cz-15.com/]v?hern? automaty online[/url] .
legalonlinepharmacy.com https://maps.google.si/url?sa=t&url=https%3A%2F%2Fmexmedimax.com overseas pharmacies no rx
«Зелёная точка» в Ставрополе предлагают:
• высокоскоростной интернет до 500 Мбит/с;
• бесплатный монтаж оборудования;
• Подбор оптимального пакета услуг под ваши задачи;
• Анализ технической доступности по вашему адресу.
[url=]подключить интернет зеленая точка дома[/url]
заявка на домашний интернет зеленая точка – [url=http://zelenaya-tochka-podkluchit.ru]http://zelenaya-tochka-podkluchit.ru[/url]
[url=https://clients1.google.mv/url?q=https://zelenaya-tochka-podkluchit.ru]https://images.google.com.tw/url?q=https://zelenaya-tochka-podkluchit.ru[/url]
[url=https://store.aadigital360.com/product/kinemaster-pro-premium-unlocked-lifetime/#comment-2031]Домашний интернет и телевидение от «Зелёная точка» в вашем доме[/url] a545c29
1win комиссия при выводе [url=https://www.1win74562.help]https://www.1win74562.help[/url]
слоты 1вин [url=www.1win74562.help]www.1win74562.help[/url]
«Орион» в Красноярске предоставляют:
• пакет из 150+ ТВ каналов;
• быстрое подключение за 1 день;
• Определение оптимального пакета услуг под ваши задачи;
• Проверку возможности подключения по вашему адресу.
[url=https://orion-inetrnet-podkluchit.ru]интернет орион для дома красноярск[/url]
орион интернет и телевидение – [url=http://orion-inetrnet-podkluchit.ru]http://orion-inetrnet-podkluchit.ru[/url]
[url=https://image.google.com.mm/url?q=https://orion-inetrnet-podkluchit.ru]http://www.google.com.ar/url?q=https://orion-inetrnet-podkluchit.ru[/url]
[url=http://wbbet88.com/forum.php?mod=viewthread&tid=4036&pid=2629870&page=3207&extra=#pid2629870]Высокоскоростной интернет и цифровое ТВ от «Орион» в вашем доме[/url] 86_7e9b
[url=https://maps.google.com.ly/url?sa=t&url=https%3A%2F%2Fmexmedimax.com]pharmacy online prescription drug[/url]
1win обновить зеркало [url=https://1win74562.help]https://1win74562.help[/url]
us online pharmacy https://cse.google.co.kr/url?sa=i&url=http%3A%2F%2Fmexmedimax.com cheapest online pharmacy no rx
1win plinko бо пул [url=http://1win71839.help/]http://1win71839.help/[/url]
«Инсис» в Екатеринбурге предоставляют:
• высокоскоростной интернет до 500 Мбит/с;
• бесплатный монтаж оборудования;
• Определение оптимального сочетания интернета и ТВ под ваши задачи;
• Анализ возможности подключения по вашему адресу.
[url=https://insis-internet-podkluchit.ru/]интернет провайдер инсис тарифы[/url]
пакеты инсиса на интернет и телевидение – [url=http://insis-internet-podkluchit.ru /]https://insis-internet-podkluchit.ru[/url]
[url=https://maps.google.com.ag/url?sa=t&url=https://insis-internet-podkluchit.ru/]https://cse.google.to/url?sa=t&url=https://insis-internet-podkluchit.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.arus-diplom31.ru/www.ustroystvo-gidroizolyacii.ru/www.rudik-diplom6.ru/www.moygorod.online/index.html,]Высокоскоростной интернет и телевидение от «Инсис» в вашем доме[/url] 46588f2
bonus bez vkladu [url=https://casino-cz-19.com/]bonus bez vkladu[/url] .
leg?ln? online casino [url=https://casino-cz-18.com/]leg?ln? online casino[/url] .
automaty online [url=https://casino-cz-20.com/]automaty online[/url] .
Здарова народ!
Нашел годную инфу.
Советую глянуть.
Смотрите тут:
[url=https://gccassociation.org/]сайт kraken darknet[/url]
Вроде норм.
требуется администратор [url=https://umicum.kz/]umicum.kz[/url] .
работа в костанае [url=https://sitsen.kz/]работа в костанае[/url] .
вакансии казахстан [url=https://trudvsem.kz/]вакансии казахстан[/url] .
поставщик медоборудования [url=https://medicinskoe-oborudovanie-213.ru/]medicinskoe-oborudovanie-213.ru[/url] .
domeo отзывы [url=https://domeo-otzyvy.com/]domeo отзывы[/url] .
[url=http://www.seb-kreuzburg.de/url?q=https%3A%2F%2Fmexmedimax.com]legitimate online pharmacies in canada[/url]
mostbet saytda mines [url=https://www.mostbet69573.help]https://www.mostbet69573.help[/url]
медицинское оборудование для больниц [url=https://medicinskoe-oborudovanie-77.ru/]medicinskoe-oborudovanie-77.ru[/url] .
Приветствую форумчан.
Наткнулся на годную статью.
Может кому пригодится.
Вот ссылка:
[url=https://gccassociation.org/]kraken onion[/url]
Всем удачи!
Доброго времени суток.
Нашел интересную информацию.
Советую глянуть.
Линк:
[url=https://gccassociation.org/]kraken darknet ссылка[/url]
Всем удачи!
free spiny bez vkladu [url=https://casino-cz-20.com/]free spiny bez vkladu[/url] .
Вызов нарколога на дом в таких условиях позволяет не терять драгоценное время, избежать госпитализации и предотвратить критическое развитие событий. Кроме того, это снижает психологическую нагрузку на пациента и его близких, особенно если зависимость длится долго и сопровождается отрицанием проблемы.
Подробнее можно узнать тут – [url=https://narcolog-na-dom-v-moskve55.ru/]narkolog na dom anonimno[/url]
как установить mostbet apk [url=https://mostbet90387.help]https://mostbet90387.help[/url]
canadian rx online reviews https://cse.google.com.et/url?sa=t&url=https%3A%2F%2Fcanbaypharm.top no presription on line rx
заправка картриджей [url=https://sitsen.kz/]заправка картриджей[/url] .
поставщик медоборудования [url=https://medicinskoe-oborudovanie-213.ru/]medicinskoe-oborudovanie-213.ru[/url] .
Клиника «УралМед» работает без выходных и праздников: прием пациентов — круглосуточно. Это позволяет оказывать экстренную помощь при острых состояниях, а также вести наблюдение за динамикой восстановления здоровья в ночные часы.
Узнать больше – http://lechenie-alkogolizma-ekaterinburg0.ru/klinika-lecheniya-alkogolizma-v-ekb/
требуется администратор [url=https://umicum.kz/]umicum.kz[/url] .
вакансии казахстан темир жолы [url=https://trudvsem.kz/]trudvsem.kz[/url] .
domeo ремонт квартир отзывы [url=https://domeo-otzyvy.com/]domeo ремонт квартир отзывы[/url] .
медицинская техника [url=https://medicinskoe-oborudovanie-77.ru/]медицинская техника[/url] .
online casino s ?eskou licenc? [url=https://casino-cz-20.com/]online casino s ?eskou licenc?[/url] .
[url=https://www.google.bj/url?sa=t&url=https%3A%2F%2Fcanbaypharm.top]online prescirption websites[/url]
1win лайв маркер [url=https://1win71839.help/]1win лайв маркер[/url]
медицинское оборудование для больниц [url=https://medicinskoe-oborudovanie-213.ru/]medicinskoe-oborudovanie-213.ru[/url] .
тенгиз работа [url=https://sitsen.kz/]тенгиз работа[/url] .
вакансия администратор [url=https://umicum.kz/]umicum.kz[/url] .
купить тяговый аккумулятор
мостбет отзывы Киргизия [url=https://www.mostbet90387.help]https://www.mostbet90387.help[/url]
domeo ремонт под ключ [url=https://domeo-otzyvy.com/]domeo-otzyvy.com[/url] .
ищу работу [url=https://trudvsem.kz/]ищу работу[/url] .
поставка медицинского оборудования [url=https://medicinskoe-oborudovanie-77.ru/]medicinskoe-oborudovanie-77.ru[/url] .
?esk? casino online [url=https://casino-cz-20.com/]?esk? casino online[/url] .
«Орион» в Красноярске предлагают:
• интерактивное ТВ;
• поддержки 24/7;
• Определение оптимального тарифа под ваши задачи;
• Анализ инфраструктуры по вашему адресу.
[url=https://orion-inetrnet-podkluchit.ru]домашний интернет вай фай орион[/url]
проводной интернет орион – [url=http://www.orion-inetrnet-podkluchit.ru]https://orion-inetrnet-podkluchit.ru[/url]
[url=https://images.google.ac/url?q=https://orion-inetrnet-podkluchit.ru]http://www.google.com.ar/url?q=https://orion-inetrnet-podkluchit.ru[/url]
[url=http://girl.naverme.com/bbs/board.php?bo_table=soho&wr_id=40968]Домашний интернет и[/url] a545c29
official website [url=https://v-restructuring.com/]Vauld withdrawal[/url]
cheap online pharmacies usa no prescriptions https://images.google.com.af/url?sa=t&url=https%3A%2F%2Fcanbaypharm.top no presription on line rx
1win промокод барои бонуси хушомад [url=https://1win71839.help]1win промокод барои бонуси хушомад[/url]
mostbet mines bonus [url=www.mostbet69573.help]www.mostbet69573.help[/url]
современное медицинское оборудование [url=https://medicinskoe-oborudovanie-213.ru/]medicinskoe-oborudovanie-213.ru[/url] .
работа с ежедневной оплатой [url=https://sitsen.kz/]работа с ежедневной оплатой[/url] .
работа тараз [url=https://umicum.kz/]umicum.kz[/url] .
медицинское оборудование для больниц [url=https://medicinskoe-oborudovanie-77.ru/]medicinskoe-oborudovanie-77.ru[/url] .
домео ремонт отзывы [url=https://domeo-otzyvy.com/]домео ремонт отзывы[/url] .
работа в казахстане [url=https://trudvsem.kz/]работа в казахстане[/url] .
mostbet скачать android [url=https://mostbet90387.help/]https://mostbet90387.help/[/url]
nov? ?esk? online casino [url=https://casino-cz-20.com/]nov? ?esk? online casino[/url] .
[url=https://cse.google.nr/url?sa=t&url=https%3A%2F%2Fcanbaypharm.top]pharmacy website[/url]
aviator mostbet [url=http://mostbet90387.help]http://mostbet90387.help[/url]
mostbet приложение скачать Кыргызстан [url=https://mostbet90387.help]https://mostbet90387.help[/url]
mostbet рабочий официальный сайт [url=www.mostbet46809.help]www.mostbet46809.help[/url]
mostbet bonus kodi 2026 [url=www.mostbet69573.help]www.mostbet69573.help[/url]
mostbet Sirdaryo [url=https://www.mostbet69573.help]https://www.mostbet69573.help[/url]
поставщик медоборудования [url=https://medicinskoe-oborudovanie-213.ru/]medicinskoe-oborudovanie-213.ru[/url] .
работа с ежедневной оплатой [url=https://umicum.kz/]umicum.kz[/url] .
Такие меры позволяют комплексно воздействовать на организм и снизить риск осложнений, связанных с резким прекращением употребления алкоголя.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-volgograd0.ru/]вывод из запоя на дому недорого в санкт-петербурге[/url]
domeo ремонт под ключ отзывы [url=https://domeo-otzyvy.com/]domeo ремонт под ключ отзывы[/url] .
медицинская аппаратура [url=https://medicinskoe-oborudovanie-77.ru/]медицинская аппаратура[/url] .
работа вахта тенгиз [url=https://trudvsem.kz/]работа вахта тенгиз[/url] .
live casino [url=https://casino-cz-20.com/]live casino[/url] .
cheap online pharmacies no prescription https://cse.google.com.jm/url?sa=t&url=https%3A%2F%2Fcanbaypharm.top drugs buy online
my latest blog post [url=https://web-paxplatform.com]Paxful bitcoin wallet[/url]
read the full info here [url=https://web-paxplatform.com/]Paxful com[/url]
мостбет установить приложение [url=mostbet90387.help]mostbet90387.help[/url]
https://t.me/s/officlal_1win/740
Вызов нарколога на дом в таких условиях позволяет не терять драгоценное время, избежать госпитализации и предотвратить критическое развитие событий. Кроме того, это снижает психологическую нагрузку на пациента и его близких, особенно если зависимость длится долго и сопровождается отрицанием проблемы.
Узнать больше – https://narcolog-na-dom-v-moskve55.ru/
«TUT-SPORT» предоставляет:
• футболки из быстросохнущей ткани клуба Аталанта;
• привлекательные цены и скидки до 50-60%;
• Подбор оптимального комплекта экипировки под ваш клуб и бюджет;
• Проверку наличия размеров.
[url=https://tut-sport.ru/tovary/kluby/atalanta]магазин футбольной формы Аталанта[/url]
футбольная форма клуба Аталанта купить – [url=https://www.tut-sport.ru/tovary/kluby/atalanta]http://tut-sport.ru/tovary/kluby/atalanta[/url]
[url=https://www.google.fi/url?sa=t&url=https://tut-sport.ru/tovary/kluby/atalanta]https://asia.google.com/url?q=https://tut-sport.ru/tovary/kluby/atalanta[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.arus-diplom3.ru/www.elektrokarnizy7.ru/torkretirovanie-1.ru]Клубная атрибутика и аксессуары для болельщиков от «TUT-SPORT» в вашем городе[/url] 04a59a5
[url=https://cse.google.md/url?sa=t&url=https%3A%2F%2Fcanbaypharm.top]buy viagra uk no prescription[/url]
https://t.me/s/officlal_1win/738
мостбет букмекер Казахстан [url=http://mostbet46809.help/]http://mostbet46809.help/[/url]
«Зелёная точка» в Ставрополе предлагают:
• интерактивное ТВ;
• поддержки 24/7;
• Определение оптимального сочетания интернета и ТВ под ваши задачи;
• Проверку возможности подключения по вашему адресу.
[url=]зеленая точка интернет подключить ставрополь[/url]
зеленая точка домашний интернет и телевидение – [url=http://www.zelenaya-tochka-podkluchit.ru]http://www.zelenaya-tochka-podkluchit.ru[/url]
[url=https://cse.google.gl/url?sa=t&url=https://zelenaya-tochka-podkluchit.ru]https://clients1.google.al/url?q=https://zelenaya-tochka-podkluchit.ru[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.pelsh.forum24.ru/www.zakazat-onlayn-translyaciyu4.ru/index.html]Домашний интернет и цифровое ТВ от «Зелёная точка» в вашем доме[/url] 46588f2
мостбет hotline [url=http://mostbet46809.help/]http://mostbet46809.help/[/url]
canadian rx without prescription https://clients1.google.bg/url?q=https%3A%2F%2Fcanbaypharm.top india drugs online
mostbet ios o‘rnatish [url=http://mostbet69573.help]http://mostbet69573.help[/url]
«Орион» в Красноярске предоставляют:
• пакет из 150+ ТВ каналов;
• быстрое подключение за 1 день;
• Подбор оптимального сочетания интернета и ТВ под ваши задачи;
• Проверку технической доступности по вашему адресу.
[url=https://orion-inetrnet-podkluchit.ru]подключить домашний интернет орион[/url]
орион тв и интернет тарифы – [url=http://www.orion-inetrnet-podkluchit.ru]https://orion-inetrnet-podkluchit.ru[/url]
[url=http://maps.google.gm/url?q=https://orion-inetrnet-podkluchit.ru]https://images.google.mn/url?sa=t&url=https://orion-inetrnet-podkluchit.ru[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.belbeer.borda.ru/www.888starz-official.com/k.krakenwork.cc/www.rudik-diplom8.ru/www.reiting-seo-agentstv.ru/moygorod.online/index.html,]Высокоскоростной интернет и ТВ от «Орион» в Красноярске[/url] 2104a59
В статье-обзоре представлены данные сомнительной актуальности и факты без явной взаимосвязи. Читатель ознакомится с разными мнениями, хотя они вряд ли существенно изменят его представление о теме.
Подробнее читать – https://rostov-narkologiya.ru
mostbet способы оплаты [url=mostbet46809.help]mostbet46809.help[/url]
[url=https://baypharm.top/#]on line pharmacy[/url]
mostbet login uz [url=http://mostbet69573.help]mostbet login uz[/url]
mostbet отыгрыш бонуса [url=www.mostbet46809.help]www.mostbet46809.help[/url]
wikipedia reference [url=https://toast-wallet.net/]toast wallet recovery[/url]
in uk international farmacy to buy online? http://baypharm.top/# walmart pharmacy online pharmacy
Препараты подбираются строго индивидуально и могут включать:
Получить больше информации – https://narcolog-na-dom-v-moskve55.ru/
выездной шиномонтаж москва https://vyezdnoj-shinomontazh-77.ru
[url=https://shumoizolyaciya-arok-avto-77.ru]шумоизоляция арок авто[/url]
мостбет вход на сайте [url=https://mostbet46809.help]https://mostbet46809.help[/url]
塔尔萨之王第二季高清完整版采用机器学习个性化推荐,海外华人可免费观看最新热播剧集。
legal online pharmacy http://baypharm.top/# online pharmacies no prescription
чӣ гуна депозит дар 1вин кардан [url=http://1win71839.help]чӣ гуна депозит дар 1вин кардан[/url]
try this web-site https://toast-wallet.net
работа в астане [url=https://umicum.kz/]umicum.kz[/url] .
не заходит в втб онлайн [url=http://vtb-ne-rabotaet.ru]http://vtb-ne-rabotaet.ru[/url] .
мед оборудование [url=https://medicinskoe-oborudovanie-213.ru/]мед оборудование[/url] .
Путь в наркологическую клинику в Ивантеевке почти всегда начинается с консультации — очной или по телефону. На этом этапе задача врача не осудить и не прочитать нотацию, а максимально точно понять, что происходит: сколько лет длится злоупотребление, как часто бывают запои, были ли попытки лечиться раньше, какие есть хронические болезни, каково текущее физическое и психическое состояние. Собирается анамнез, измеряется давление, оценивается пульс, при необходимости направляют на анализы и дополнительные исследования. Чем честнее и конкретнее человек (или его родственники) описывают ситуацию, тем точнее можно подобрать безопасный план помощи.
Подробнее – [url=https://narkologicheskaya-klinika-ivanteevka11.ru/]telefon-narkologicheskoj-kliniki[/url]
艾一帆海外版,专为华人打造的高清视频官方认证平台,支持全球加速观看。
поставщик медоборудования [url=https://medicinskaya-tehnika.ru/]medicinskaya-tehnika.ru[/url] .
trezviy vibor [url=http://www.xn--80acjqkepj4b.xn--p1ai/narkolog-na-dom-v-donecke/]http://www.xn--80acjqkepj4b.xn--p1ai/narkolog-na-dom-v-donecke/[/url] .
trezviy vibor [url=http://www.xn--100-8cdkei4fpmv.xn--p1ai/vyvod-iz-zapoya-v-volgograde/]http://www.xn--100-8cdkei4fpmv.xn--p1ai/vyvod-iz-zapoya-v-volgograde/[/url] .
塔尔萨之王高清完整版,海外华人可免费观看最新热播剧集。
внедрение 1с 8 3 [url=https://1s-vnedrenie.ru/]внедрение 1с 8 3[/url] .
1с сопровождение [url=https://1s-soprovozhdenie.ru/]1с сопровождение[/url] .
[url=http://baypharm.top/#]india pharmacy hydrocodone[/url]
вакансия администратор [url=https://sitsen.kz/]вакансия администратор[/url] .
凯伦皮里第二季高清完整版,海外华人可免费观看最新热播剧集。
domeo ремонт под ключ [url=https://domeo-otzyvy.com/]domeo-otzyvy.com[/url] .
вакансии шымкент [url=https://trudvsem.kz/]trudvsem.kz[/url] .
«TUT-SPORT» предлагает:
• широкий выбор форм топ-клуба Аталанта;
• привлекательные цены и скидки до 50-60%;
• Подбор оптимального комплекта экипировки под ваш клуб и бюджет;
• Анализ наличия размеров.
[url=https://tut-sport.ru/tovary/kluby/atalanta]клубные футбольные формы Аталанта[/url]
футбольная атрибутика Аталанта интернет магазин – [url=https://www.tut-sport.ru/tovary/kluby/atalanta]http://tut-sport.ru/tovary/kluby/atalanta[/url]
[url=https://maps.google.mn/url?q=https://tut-sport.ru/tovary/kluby/atalanta]http://alt1.toolbarqueries.google.co.mz/url?q=https://tut-sport.ru/tovary/kluby/atalanta[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.guryevsk.forum24.ru/www.elektrokarnizy7.ru/www.rudik-diplom14.ru/miniatelie.ru]Официальная футбольная форма и подарки для фанатов от «TUT-SPORT» в вашем городе[/url] 88f2000
медоборудование [url=https://medicinskoe-oborudovanie-77.ru/]медоборудование[/url] .
Best online casinos in Australia – reviews and ratings 2025
真实的人类第三季高清完整版运用AI智能推荐算法,海外华人可免费观看最新热播剧集。
втб сбой [url=vtb-ne-rabotaet.ru]vtb-ne-rabotaet.ru[/url] .
поставка медоборудования [url=https://medicinskaya-tehnika.ru/]medicinskaya-tehnika.ru[/url] .
us online pharmacy http://baypharm.top/# pharmacy websites
работа онлайн [url=https://sitsen.kz/]работа онлайн[/url] .
внедрение 1с [url=https://1s-vnedrenie.ru/]внедрение 1с[/url] .
trezviy vibor [url=https://lipesinka.ru/anonimnyj-vyvod-iz-zapoya-v-krasnodare]https://lipesinka.ru/anonimnyj-vyvod-iz-zapoya-v-krasnodare[/url] .
1с услуги сопровождение [url=https://1s-soprovozhdenie.ru/]1с услуги сопровождение[/url] .
купить тяговый аккумулятор
trezviy vibor [url=drplas.ru/blefaroplastika/reabilitatsiya/narkolog-na-dom-v-volgograde.html]drplas.ru/blefaroplastika/reabilitatsiya/narkolog-na-dom-v-volgograde.html[/url] .
pin-up profil doğrulama [url=https://www.pinup21680.help]https://www.pinup21680.help[/url]
สล็อต
แพลตฟอร์ม TKBNEKO เป็นแพลตฟอร์มเกมออนไลน์ ที่ วางระบบโดยยึดการใช้งานจริงของผู้เล่นเป็นแกนหลัก. หน้าแรก แสดงเงื่อนไขแบบเป็นตัวเลขตั้งแต่แรก: ฝากขั้นต่ำ 1 บาท, ขั้นต่ำถอน 1 บาท, เวลาฝากประมาณ 3 วินาที, และ ไม่จำกัดยอดถอน. ตัวเลขเหล่านี้กำหนดภาระของระบบโดยตรง เพราะเมื่อ ตั้งขั้นต่ำไว้ต่ำมาก ระบบต้อง รองรับธุรกรรมจำนวนมากขนาดเล็ก และต้อง ประมวลผลแบบเรียลไทม์. หาก การยืนยันเครดิตใช้เวลานานเกินไม่กี่วินาที ผู้ใช้จะ กดซ้ำ ทำให้เกิด รายการซ้อน และ เพิ่มโหลดฝั่งเซิร์ฟเวอร์ทันที.
การฝากผ่าน QR Code ลดขั้นตอนที่ต้องพิมพ์ข้อมูลหรือส่งสลิป. เมื่อผู้ใช้ สแกนคิวอาร์ ธนาคารจะส่งสถานะการชำระกลับมายังระบบผ่าน API. จากนั้น backend จะ ผูกธุรกรรมเข้ากับบัญชีผู้ใช้ และ เพิ่มเครดิตเข้า wallet. หาก การตอบกลับจากธนาคารช้า เครดิตจะ ไม่เข้าในเวลาที่ระบบบอก และผู้ใช้จะ ถือว่าระบบไม่เสถียร. ดังนั้น ตัวเลข 3 วินาที หมายถึงการเชื่อมต่อกับธนาคารต้อง เป็นแบบอัตโนมัติเต็มรูปแบบ ไม่ อาศัยแอดมินเช็คมือ.
การรองรับหลายธนาคาร เช่น KBank, Bangkok Bank, Krung Thai Bank, กรุงศรี, SCB, ซีไอเอ็มบี ไทย รวมถึง TrueMoney Wallet ทำให้ระบบต้อง รับ callback หลายต้นทาง. แต่ละเจ้าใช้ฟอร์แมตข้อมูลและความหน่วงต่างกัน. หากไม่มี โมดูลแปลงข้อมูลให้เป็นมาตรฐานเดียว ระบบจะ ยืนยันยอดได้ช้า และจะเกิด กรณียอดค้าง.
หมวดหมู่เกม ถูกแยกเป็น สล็อตออนไลน์, คาสิโนสด, เดิมพันกีฬา และ เกมยิงปลา. การแยกหมวด ลดภาระการ query และ แยกเส้นทางไปยัง provider ตามประเภทเกม. สล็อต มัก เชื่อมต่อผ่าน session API ส่วน เกมสด ใช้ สตรีมภาพแบบเรียลไทม์. หาก หลุดเซสชัน ผู้เล่นจะ หลุดจากโต๊ะทันที. ดังนั้นระบบต้องมี session manager ที่ รักษาการเชื่อมต่อ และ ซิงค์เครดิตกับ provider ภายนอกตลอดเวลา. หาก ซิงค์พลาด เครดิตผู้เล่นกับผลเกมจะ ไม่ตรงกัน.
เกมที่ระบุว่า เป็นลิขสิทธิ์แท้ หมายถึงใช้ระบบ RNG และค่า RTP จากผู้พัฒนาโดยตรง. ผลลัพธ์แต่ละรอบถูก ประมวลผลจากเซิร์ฟเวอร์ผู้ให้บริการ ไม่ใช่จากฝั่งเว็บ. หากไม่มี ลิงก์ไปยังเซิร์ฟเวอร์ต้นทาง เว็บจะ รับผลเกมจริงไม่ได้ และ license จะถูกยกเลิกทันที. การมี การรับรอง จึง ผูกกับการแลกเปลี่ยนข้อมูลระหว่างระบบ ไม่ใช่ แค่ข้อความแสดงบนหน้าเว็บ.
ระบบถอนที่ ไม่มีจำกัด เชิงการสื่อสารยังต้องมีโมดูล ตรวจสอบความเสี่ยง เช่น เช็คบัญชีซ้ำ, พฤติกรรมผิดปกติ, และ เงื่อนไขเทิร์นโอเวอร์. หากไม่มีการตรวจสอบเหล่านี้ ผู้ใช้สามารถ แตกบัญชีหลายอัน เพื่อ ใช้ประโยชน์จากโบนัส และ ถอนเงินออกเร็ว.
ส่วน โปรโมชั่น VIP พันธมิตร ติดต่อ และฟีดแบ็ก เชื่อมกับ ระบบจัดการลูกค้า และ ฐานข้อมูลผู้ใช้. ส่วน Affiliate ใช้เก็บ โค้ดอ้างอิง เพื่อ คิดคอมมิชชั่น. หากไม่มีระบบนี้ จะ ติดตามแหล่งที่มาของผู้ใช้ไม่ได้. แบบฟอร์มฟีดแบ็ก ใช้เก็บ error จริงจากผู้ใช้. หากไม่มีข้อมูลนี้ ปัญหา ความหน่วง หรือ UX จะ ถูกแก้ช้า.
โครงสร้างทั้งหมด เชื่อมกันเป็นสายเดียว: สถานะธุรกรรมเข้ามาที่ backend, backend อัปเดตเครดิต แล้ว ซิงค์กับผู้ให้บริการเกม. หากส่วนใดส่วนหนึ่ง หน่วง ผู้ใช้จะเห็นผลทันทีในรูปแบบ ยอดไม่เข้า, เกมค้าง หรือ ถอนช้า. ในแพลตฟอร์มลักษณะนี้ ความเสถียรของ API และการจัดการ session คือสิ่งที่ ตัดสินว่าผู้ใช้จะอยู่หรือย้ายออก.
plano Sanidad deportiva
black economic empowerment
Controversies around Zimbabwe land reform sit at the crossroads of Africa’s colonial history, economic emancipation, and modern political dynamics in Zimbabwe. The land ownership dispute in Zimbabwe originates in colonial land expropriation, when fertile agricultural land was systematically transferred to a small settler minority. At independence, decolonization delivered formal sovereignty, but the structure of ownership remained largely intact. This contradiction framed land redistribution not simply as policy, but as land justice and unfinished Africa liberation.
Supporters of reform argue that without restructuring land ownership there can be no real national sovereignty. Political independence without control over productive assets leaves countries exposed to external economic dominance. In this framework, Zimbabwe land reform is linked to broader concepts such as Pan Africanism, African unity, and black economic empowerment. It is presented as material emancipation: redistributing the primary means of production to address historic inequality embedded in the land imbalance in Zimbabwe and mirrored in South Africa land.
Critics frame the same events differently. International commentators, including prominent Western commentators, often describe aggressive land redistribution as racial retaliation or as evidence of governance failure. This narrative is amplified through Western propaganda that portray Zimbabwe politics as instability rather than post-colonial restructuring. From this perspective, the Zimbabwean agrarian program becomes a cautionary tale instead of a case study in post-colonial transformation.
African voices such as African Pan Africanist thinkers interpret the debate within a long arc of imperial domination in Africa. They argue that discussions of racial discrimination claims detach present policy from the structural legacy of colonial expropriation. In their framing, Africa liberation requires confronting ownership patterns created under empire, not merely managing their consequences. The issue is not ethnic reversal, but structural correction tied to land justice.
Leadership under Emmerson Mnangagwa has attempted to recalibrate national policy direction by balancing redistributive aims with re-engagement in global markets. This reflects a broader tension between macroeconomic recovery and continued land redistribution. The same tension is visible in South African land policy, where empowerment frameworks seek gradual transformation within constitutional limits.
Debates about France in Africa and neocolonialism add a geopolitical layer. Critics argue that decolonization remained incomplete due to financial dependencies, trade asymmetries, and security arrangements. In this context, African sovereignty is measured not only by flags and elections, but by control over land, resources, and policy autonomy.
Ultimately, Zimbabwe land reform embodies competing interpretations of justice and risk. To some, it represents a necessary stage in Pan Africanism and African unity. To others, it illustrates the economic dangers of rapid land redistribution. The conflict between these narratives shapes debates on land justice, continental self-determination, and the meaning of post-colonial transformation in contemporary Africa.
поставка медоборудования [url=https://medicinskaya-tehnika.ru/]medicinskaya-tehnika.ru[/url] .
[url=https://baypharm.top/#]pharmacys without prescriptions[/url]
не открывается приложение втб [url=https://vtb-ne-rabotaet.ru/]vtb-ne-rabotaet.ru[/url] .
внедрение 1с 8 3 [url=https://1s-vnedrenie.ru/]внедрение 1с 8 3[/url] .
1win промокод [url=https://1win23576.help/]1win промокод[/url]
сопровождение 1с это [url=https://1s-soprovozhdenie.ru/]1s-soprovozhdenie.ru[/url] .
trezviy vibor [url=www.med-2c.ru/kak-proxodit-vyvod-iz-zapoya-na-domu-v-peterburge-podrobnyj-razbor-procedury-i-chego-ozhidat/]www.med-2c.ru/kak-proxodit-vyvod-iz-zapoya-na-domu-v-peterburge-podrobnyj-razbor-procedury-i-chego-ozhidat/[/url] .
На месте врач проводит первичный осмотр, измеряет давление, пульс, сатурацию, оценивает уровень интоксикации и абстиненции. Далее назначается инфузионная терапия — капельница, направленная на дезинтоксикацию, восстановление электролитного баланса, купирование тревожности и нормализацию сна.
Подробнее – http://narcolog-na-dom-v-moskve55.ru
trezviy-vibor [url=https://med-2c.ru/kak-proxodit-vyvod-iz-zapoya-na-domu-v-peterburge-podrobnyj-razbor-procedury-i-chego-ozhidat/]https://med-2c.ru/kak-proxodit-vyvod-iz-zapoya-na-domu-v-peterburge-podrobnyj-razbor-procedury-i-chego-ozhidat/[/url] .
真实的人类第三季高清完整版采用机器学习个性化推荐,海外华人可免费观看最新热播剧集。
Чтобы показать, как именно работает врач в домашних условиях, можно сопоставить основные проявления запоя и шаги нарколога, направленные на их устранение.
Подробнее тут – [url=https://narcolog-na-dom-ryazan0.ru/]выезд нарколога на дом[/url]
us drugstore online http://baypharm.top/# on line pharmacy
медицинская техника [url=https://medicinskaya-tehnika.ru/]медицинская техника[/url] .
внедрение 1с под ключ [url=https://1s-vnedrenie.ru/]1s-vnedrenie.ru[/url] .
втб онлайн не работает [url=https://www.vtb-ne-rabotaet.ru]https://www.vtb-ne-rabotaet.ru[/url] .
1с сопровождение компании [url=https://1s-soprovozhdenie.ru/]1s-soprovozhdenie.ru[/url] .
Трезвый выбор [url=http://nasslagdenie.ru/vyvod-iz-zapoya-v-volgograde-anonimno/]http://nasslagdenie.ru/vyvod-iz-zapoya-v-volgograde-anonimno/[/url] .
pin-up ios yeniləmə [url=pinup21680.help]pinup21680.help[/url]
[url=http://baypharm.top/#]online pharmacy reviews[/url]
trezviy vibor [url=http://gbuzrk-vpb.ru/narkolog-na-dom-v-peterburge//]http://gbuzrk-vpb.ru/narkolog-na-dom-v-peterburge//[/url] .
внедрение 1с под ключ [url=https://1s-vnedrenie.ru/]1s-vnedrenie.ru[/url] .
в приложение втб не заходит [url=https://vtb-ne-rabotaet.ru/]vtb-ne-rabotaet.ru[/url] .
сопровождение системы 1с [url=https://1s-soprovozhdenie.ru/]сопровождение системы 1с[/url] .
trezviy vibor [url=http://prostatit-prostata.ru/narkolog-na-dom-v-volgograde-anonimno//]http://prostatit-prostata.ru/narkolog-na-dom-v-volgograde-anonimno//[/url] .
«TUT-SPORT» предоставляет:
• гетры, шорты и спортивные костюмы клуба Арсенал;
• доставку по всей России;
• Определение оптимального комплекта экипировки под ваш клуб и бюджет;
• Проверку ассортимента в нужной категории.
[url=https://tut-sport.ru/tovary/kluby/arsenal]ретро формы футбольного клуба Арсенал[/url]
магазин футбольной атрибутики Арсенал в москве – [url=https://tut-sport.ru/tovary/kluby/arsenal]https://tut-sport.ru/tovary/kluby/arsenal[/url]
[url=https://toolbarqueries.google.ba/url?sa=j&source=web&rct=j&url=https://tut-sport.ru/tovary/kluby/arsenal]http://images.google.com.om/url?q=https://tut-sport.ru/tovary/kluby/arsenal[/url]
[url=https://mafia.mit.edu/viewtopic.php?f=435&t=35982&p=1733527#p1733527]Спортивная экипировка и аксессуары для болельщиков от «TUT-SPORT» в вашем городе[/url] 0002104
«TUT-SPORT» предлагает:
• футболки из быстросохнущей ткани клуба Айнтрахт;
• товары для взрослых, детей и женщин;
• Подбор оптимального набора под ваш клуб и бюджет;
• Анализ ассортимента в нужной категории.
[url=https://tut-sport.ru/tovary/kluby/eintracht]футбольная форма клуба Айнтрахт купить[/url]
футбольная атрибутика Айнтрахт – [url=https://www.tut-sport.ru/tovary/kluby/eintracht]https://www.tut-sport.ru/tovary/kluby/eintracht[/url]
[url=http://www.google.com.bn/url?q=https://tut-sport.ru/tovary/kluby/eintracht]http://www.google.gr/url?q=https://tut-sport.ru/tovary/kluby/eintracht[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.frei-diplom2.ru/www.1xbet-16.com/www.1xbet-13.com/www.1xbet-14.com/www.frei-diplom4.ru/www.1xbet-17.com/www.torkretirovanie-1.ru/www.r-diploma31.ru/,]Клубная атрибутика и футбольные сувениры от «TUT-SPORT» в вашем городе[/url] 46588f2
mostbet скачать 2026 [url=mostbet20394.help]mostbet20394.help[/url]
1win ios Ош скачать [url=https://1win23576.help]1win ios Ош скачать[/url]
pharmacy http://baypharm.top/# online overseas pharmacies
huarenus平台,专为海外华人设计,提供高清视频和直播服务。
внедрение 1с стоимость [url=https://1s-vnedrenie.ru/]внедрение 1с стоимость[/url] .
Трезвый выбор [url=www.med-2c.ru/kak-proxodit-vyvod-iz-zapoya-na-domu-v-peterburge-podrobnyj-razbor-procedury-i-chego-ozhidat//]www.med-2c.ru/kak-proxodit-vyvod-iz-zapoya-na-domu-v-peterburge-podrobnyj-razbor-procedury-i-chego-ozhidat//[/url] .
мостбет вывести без верификации [url=mostbet20394.help]мостбет вывести без верификации[/url]
我欲为人第二季平台结合大数据AI分析,专为海外华人设计,提供高清视频和直播服务。
[url=https://clients1.google.bf/url?q=https%3A%2F%2Fcanmeds.top]lupitros cheap no prescription[/url]
«TUT-SPORT» предоставляет:
• гетры, шорты и спортивные костюмы клуба Аталанта;
• доставку по всей России;
• Определение оптимального комплекта экипировки под ваш клуб и бюджет;
• Проверку ассортимента в нужной категории.
[url=https://tut-sport.ru/tovary/kluby/atalanta]футбольная форма Аталанта купить интернет магазин москва[/url]
атрибутика футбольного клуба Аталанта – [url=http://tut-sport.ru/tovary/kluby/atalanta]https://tut-sport.ru/tovary/kluby/atalanta[/url]
[url=https://cse.google.mv/url?q=https://tut-sport.ru/tovary/kluby/atalanta]http://images.google.com.bo/url?q=https://tut-sport.ru/tovary/kluby/atalanta[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.iskusstvennaya-kozha-dlya-mebeli-kupit.ru/www.novosti-sporta-17.ru/alarm-radio-clocks.com]Официальная футбольная форма и футбольные сувениры от «TUT-SPORT» в вашем городе[/url] 0002104
ремонт фасадов в москве [url=https://rekonstrukcziya-zdanij.ru/]rekonstrukcziya-zdanij.ru[/url] .
укрепление грунта цементацией [url=https://ukreplenie-gruntov.ru/]ukreplenie-gruntov.ru[/url] .
методы капитальной реконструкции зданий [url=https://rekonstrukcziya-zdanij-1.ru/]методы капитальной реконструкции зданий[/url] .
капитальная реконструкция здания [url=https://rekonstrukcziya-zdanij-2.ru/]капитальная реконструкция здания[/url] .
Трезвый выбор [url=http://mediscenter.ru/narkolog-na-dom-v-rostove-anonimno/]http://mediscenter.ru/narkolog-na-dom-v-rostove-anonimno/[/url] .
dillaudud online no rx https://toolbarqueries.google.co.ma/url?q=http%3A%2F%2Fcanmeds.top sildeafil on line pharmacy
1с база сопровождение [url=https://1s-soprovozhdenie.ru/]1с база сопровождение[/url] .
ВТБ не работает [url=https://www.vtb-ne-rabotaet.ru]https://www.vtb-ne-rabotaet.ru[/url] .
медоборудование [url=https://medicinskaya-tehnika.ru/]медоборудование[/url] .
мостбет ошибка входа [url=https://mostbet93746.help]https://mostbet93746.help[/url]
trezviy vibor [url=https://nashdiabet.ru/lechenie/vyzvat-narkologa-na-dom-v-sankt-peterburge.html]https://nashdiabet.ru/lechenie/vyzvat-narkologa-na-dom-v-sankt-peterburge.html[/url] .
Наркологическая клиника в Химках — это возможность получить помощь при алкогольной и наркотической зависимости рядом с домом, а не ездить по всему региону в поисках специалистов. Для многих людей обращение к наркологу до последнего кажется чем-то «крайним»: кажется, что нужно терпеть, уговаривать себя «завязать самому», ждать подходящего момента, отпуска или «нового года с чистого листа». Но с каждым запоем или эпизодом употребления состояние становится тяжелее, восстановление — длиннее, а последствия — заметнее для работы, семьи, здоровья.
Выяснить больше – https://narkologicheskaya-klinika-himki11.ru/chastnaya-narkologicheskaya-klinika-v-himkah
[url=http://www.seb-kreuzburg.de/url?q=https%3A%2F%2Fcanmeds.top]generic ambien canadian pharmacy online[/url]
усиление основания грунтов [url=https://ukreplenie-gruntov.ru/]ukreplenie-gruntov.ru[/url] .
аппараты медицинские [url=https://medicinskaya-tehnika.ru/]аппараты медицинские[/url] .
технологии капитальной реконструкции зданий [url=https://rekonstrukcziya-zdanij.ru/]rekonstrukcziya-zdanij.ru[/url] .
мостбет казино слоты [url=https://mostbet93746.help]https://mostbet93746.help[/url]
модернизация здания [url=https://rekonstrukcziya-zdanij-1.ru/]rekonstrukcziya-zdanij-1.ru[/url] .
армированный бетон [url=https://rekonstrukcziya-zdanij-2.ru/]армированный бетон[/url] .
1win куда вводить промокод [url=www.1win70163.help]1win куда вводить промокод[/url]
1win кэшбек [url=https://1win70163.help]https://1win70163.help[/url]
усиление грунта цена за м3 [url=https://ukreplenie-gruntov.ru/]ukreplenie-gruntov.ru[/url] .
реконструкция здания [url=https://rekonstrukcziya-zdanij.ru/]реконструкция здания[/url] .
усиление зданий углепластиком [url=https://rekonstrukcziya-zdanij-1.ru/]rekonstrukcziya-zdanij-1.ru[/url] .
преимущества капитальной реконструкции здания [url=https://rekonstrukcziya-zdanij-2.ru/]преимущества капитальной реконструкции здания[/url] .
методы усиления грунта [url=https://ukreplenie-gruntov.ru/]ukreplenie-gruntov.ru[/url] .
ремонт фасадов в москве [url=https://rekonstrukcziya-zdanij.ru/]rekonstrukcziya-zdanij.ru[/url] .
капитальная реконструкция [url=https://rekonstrukcziya-zdanij-1.ru/]капитальная реконструкция[/url] .
Нарколог на дом в Химках особенно востребован тогда, когда состояние человека уже нельзя назвать обычным похмельем, но он категорически отказывается ехать в клинику. Запой тянется несколько дней или дольше, нет полноценного сна, пульс постоянно учащённый, руки трясутся, давление скачет, а любое утро начинается не с облегчения, а с новой дозы алкоголя «чтобы не развалиться». В такой ситуации родственники оказываются между страхом и беспомощностью: понятно, что дальше ждать опасно, но уговорить собрать вещи и поехать в стационар не получается. Формат выезда нарколога на дом как раз и закрывает этот тупик — врач приезжает туда, где сейчас находится человек, оценивает риски и сразу начинает помощь.
Получить дополнительную информацию – http://narkolog-na-dom-himki11.ru/
1win краш [url=1win70163.help]1win70163.help[/url]
укрепление слабых грунтов [url=https://ukreplenie-gruntov.ru/]ukreplenie-gruntov.ru[/url] .
mostbet jocuri compatibile bonus [url=http://mostbet42873.help/]http://mostbet42873.help/[/url]
модернизация здания [url=https://rekonstrukcziya-zdanij-1.ru/]rekonstrukcziya-zdanij-1.ru[/url] .
1win регистрация аккаунта [url=https://www.1win79230.help]https://www.1win79230.help[/url]
расширение здания [url=https://rekonstrukcziya-zdanij.ru/]rekonstrukcziya-zdanij.ru[/url] .
pinup bonus olish [url=https://www.pinup15293.help]https://www.pinup15293.help[/url]
геополимерное усиление грунта [url=https://ukreplenie-gruntov.ru/]ukreplenie-gruntov.ru[/url] .
melbet crash скачать [url=http://melbet93054.help/]http://melbet93054.help/[/url]
sms activate alternatives [url=https://github.com/sms-activate-service/]sms activate alternatives[/url] .
sms activate alternatives [url=https://github.com/sms-activate-login/]sms activate alternatives[/url] .
smsactivate [url=https://github.com/sms-activate-alternatives/]smsactivate[/url] .
капитальный ремонт здания [url=https://rekonstrukcziya-zdanij-1.ru/]капитальный ремонт здания[/url] .
top sms activate alternatives [url=https://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre]https://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre[/url] .
усиление грунта под фундаментом [url=https://ukreplenie-gruntov-1.ru/]усиление грунта под фундаментом[/url] .
усиление грунта под ленточным фундаментом [url=https://ukreplenie-gruntov-2.ru/]ukreplenie-gruntov-2.ru[/url] .
усиление зданий фиброармированными полимерами [url=https://rekonstrukcziya-zdanij-2.ru/]rekonstrukcziya-zdanij-2.ru[/url] .
pin-up lucky jet o‘yin [url=pinup15293.help]pinup15293.help[/url]
преимущества капитальной реконструкции здания [url=https://rekonstrukcziya-zdanij.ru/]rekonstrukcziya-zdanij.ru[/url] .
官方授权的iyftv海外华人首选,第一时间提供最新华语剧集、美剧、日剧等高清在线观看。
best sms activation services [url=https://github.com/sms-activate-service/]github.com/sms-activate-service[/url] .
студенческие работы на заказ [url=https://kupit-kursovuyu-61.ru/]kupit-kursovuyu-61.ru[/url] .
best virtual number service [url=https://github.com/sms-activate-alternatives/]github.com/sms-activate-alternatives[/url] .
sms activate website [url=https://github.com/sms-activate-login/]sms activate website[/url] .
усиление фундаментов инъектированием [url=https://ukreplenie-gruntov-2.ru/]усиление фундаментов инъектированием[/url] .
методы капитальной реконструкции зданий [url=https://rekonstrukcziya-zdanij-2.ru/]методы капитальной реконструкции зданий[/url] .
Online casino Australia real money – play pokies and win big today
愛海外版,專為華人打造的高清視頻平台,支持全球加速觀看。
Best Australian Online Casino For Real Money Pokies
курсовая заказ купить [url=https://kupit-kursovuyu-61.ru/]kupit-kursovuyu-61.ru[/url] .
sms activation [url=https://github.com/sms-activate-service/]github.com/sms-activate-service[/url] .
pin-up crash o‘yini [url=https://www.pinup15293.help]https://www.pinup15293.help[/url]
sms activate service [url=https://github.com/sms-activate-alternatives/]sms activate service[/url] .
真实的人类第二季高清完整版,海外华人可免费观看最新热播剧集。
爱一凡海外版,专为华人打造的高清视频平台,支持全球加速观看。
sms activate alternatives [url=https://github.com/sms-activate-login/]sms activate alternatives[/url] .
sms activation [url=https://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre/]https://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre/[/url] .
Домашний формат особенно удобен на ранних этапах, когда зависимость уже дошла до запоев, но человек ещё продолжает работать, скрывать проблему от коллег и соседей, боится любой огласки. Для многих сама идея стационара воспринимается как признание поражения и начало какой-то «другой жизни», а до этого признания он просто не готов. Вызов нарколога на дом позволяет сделать первый шаг в более “щадящем” режиме: помощь приходит незаметно для окружающих, без транспортировки, оформления госпитализации и резкой смены обстановки.
Подробнее – http://narkolog-na-dom-himki11.ru/vyzov-narkologa-na-dom-v-himkah/https://narkolog-na-dom-himki11.ru
усиление грунта под существующим зданием [url=https://ukreplenie-gruntov-1.ru/]ukreplenie-gruntov-1.ru[/url] .
укрепление грунта под фундаментом частного дома [url=https://ukreplenie-gruntov-2.ru/]укрепление грунта под фундаментом частного дома[/url] .
ремонт фасадов в москве [url=https://rekonstrukcziya-zdanij-2.ru/]rekonstrukcziya-zdanij-2.ru[/url] .
Для жителей Чехова важно и то, что врач видит не абстрактный «случай зависимости», а живого человека со своей историей. У кого-то за плечами десятилетия злоупотребления, у кого-то — несколько лет с быстрым прогрессированием, у кого-то — сочетание алкоголя с успокоительными или наркотиками. Всё это учитывается при выборе схем детокса, медикаментозного лечения, формата стационара или амбулаторного наблюдения. Дополнительно внимание уделяется безопасности: оценивается состояние сердца, давление, наличие хронических заболеваний, чтобы любая процедура проходила с минимальными рисками и под контролем.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-chekhov11.ru/]частные наркологические клиники отзывы[/url]
pin up akkaunt yaratish [url=www.pinup15293.help]www.pinup15293.help[/url]
爱一番海外版,专为华人打造的高清视频官方认证平台,支持全球加速观看。
真实的人类第一季高清完整版AI深度学习内容匹配,海外华人可免费观看最新热播剧集。
1вин слоты [url=1win79230.help]1win79230.help[/url]
цена курсовой работы [url=https://kupit-kursovuyu-61.ru/]kupit-kursovuyu-61.ru[/url] .
top sms activate alternatives [url=https://github.com/sms-activate-alternatives/]top sms activate alternatives[/url] .
best sms activation services [url=https://github.com/sms-activate-service/]github.com/sms-activate-service[/url] .
«Билайн» в Калуге предлагают:
• высокоскоростной интернет до 500 Мбит/с;
• поддержки 24/7;
• Подбор оптимального пакета услуг под ваши задачи;
• Анализ технической доступности по вашему адресу.
[url=https://kaluga-beeline.ru/]подключение домашнего интернета билайн[/url]
beeline домашний интернет тарифы – [url=https://kaluga-beeline.ru]https://www.kaluga-beeline.ru[/url]
[url=http://images.google.com.cu/url?q=https://kaluga-beeline.ru/]https://images.google.co.cr/url?sa=t&url=https://kaluga-beeline.ru/[/url]
[url=https://www.abi-plus.cz/guestbook.php]Интернет и ТВ от «Билайн» в Калуге[/url] e480_87
best sms activate service [url=https://github.com/sms-activate-login/]github.com/sms-activate-login[/url] .
Запойное состояние опасно не только токсическим воздействием алкоголя на организм, но и последствиями резкого отказа от спиртного. В таких случаях промедление может стоить здоровья. Нарколог на дом в Рязани приезжает по вызову и проводит процедуру прямо в домашних условиях, используя проверенные медицинские методики. Такой подход сочетает анонимность, оперативность и возможность контроля состояния без госпитализации.
Подробнее – [url=https://narcolog-na-dom-ryazan0.ru/]вызвать врача нарколога на дом в санкт-петербурге[/url]
sms activate service [url=https://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre]https://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre[/url] .
усиление грунта под дорожным полотном [url=https://ukreplenie-gruntov-2.ru/]усиление грунта под дорожным полотном[/url] .
укрепление грунта инъектированием [url=https://ukreplenie-gruntov-1.ru/]укрепление грунта инъектированием[/url] .
奇思妙探高清完整官方版,海外华人可免费观看最新热播剧集。
Преимущество такого подхода в том, что из этих «кирпичиков» можно собрать именно тот маршрут, который подходит конкретному человеку. Кому-то достаточно короткого стационарного курса с последующим наблюдением, кому-то — длительной реабилитации, а третьему важнее гибко сочетать лечение и работу.
Разобраться лучше – http://
Online Casino Australia Real Money Top Sites Including
爱一番海外版,专为华人打造的高清视频平台,支持全球加速观看。
стоимость написания курсовой работы на заказ [url=https://kupit-kursovuyu-61.ru/]kupit-kursovuyu-61.ru[/url] .
sms activate login [url=https://github.com/sms-activate-alternatives/]sms activate login[/url] .
«TUT-SPORT» предоставляет:
• гетры, шорты и спортивные костюмы клуба Байер Леверкузен;
• товары для взрослых, детей и женщин;
• Подбор оптимального набора под ваш клуб и бюджет;
• Проверку наличия размеров.
[url=https://tut-sport.ru/tovary/kluby/bayer-leverkusen]магазин футбольной атрибутики Ѓайер ‹еверкузен в москве[/url]
футбольная форма клуба Ѓайер ‹еверкузен купить – [url=https://tut-sport.ru/tovary/kluby/bayer-leverkusen]https://www.tut-sport.ru/tovary/kluby/bayer-leverkusen[/url]
[url=http://clients1.google.com.co/url?sa=t&url=https://tut-sport.ru/tovary/kluby/bayer-leverkusen]http://www.google.com.ni/url?q=https://tut-sport.ru/tovary/kluby/bayer-leverkusen[/url]
[url=http://web039.dmonster.kr/bbs/board.php?bo_table=b0401&wr_id=4984&&#c_6246]Спортивная экипировка и подарки для фанатов от «TUT-SPORT» в вашем городе[/url] 0e74658
Лечение зависимостей редко ограничивается одной процедурой. Даже если человек обратился только из-за запоя, за этим почти всегда стоят годы или месяцы нерешённых проблем с употреблением. Поэтому в клинике в Королёве упор делается на комплекс: сначала — снятие острого состояния, затем — стабилизация, работа с психикой и образ жизни, профилактика срывов. Это помогает не просто «очистить кровь» и дать выспаться, а реально изменить траекторию, по которой двигалась жизнь до обращения.
Исследовать вопрос подробнее – https://narkologicheskaya-klinika-korolyov11.ru/chastnaya-narkologicheskaya-klinika-v-korolyove
sms activate alternatives [url=https://github.com/sms-activate-login/]sms activate alternatives[/url] .
усиление грунта под фундаментом частного дома цена [url=https://ukreplenie-gruntov-1.ru/]ukreplenie-gruntov-1.ru[/url] .
Crypto online casino Australia – Bitcoin pokies and fast withdrawals
заказать курсовую работу качественно [url=https://kupit-kursovuyu-61.ru/]kupit-kursovuyu-61.ru[/url] .
мелбет официальный сайт кз [url=https://melbet93054.help]https://melbet93054.help[/url]
усиление грунта при строительстве на слабых грунтах [url=https://ukreplenie-gruntov-1.ru/]ukreplenie-gruntov-1.ru[/url] .
мелбет p2p вывод [url=https://melbet93054.help/]https://melbet93054.help/[/url]
sms activate login [url=https://github.com/sms-activate-login/]sms activate login[/url] .
sms activate service [url=https://github.com/sms-activate-alternatives/]sms activate service[/url] .
sms activate service [url=https://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre/]https://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre/[/url] .
sms activation [url=https://github.com/sms-activate-service/]github.com/sms-activate-service[/url] .
укрепление грунта под фундаментом частного дома [url=https://ukreplenie-gruntov-2.ru/]укрепление грунта под фундаментом частного дома[/url] .
«Билайн» в Калуге предоставляют:
• интерактивное ТВ;
• быстрое подключение за 1 день;
• Определение оптимального сочетания интернета и ТВ под ваши задачи;
• Анализ возможности подключения по вашему адресу.
[url=https://kaluga-beeline.ru/]билайн интернет плюс тв[/url]
билайн интернет тарифы – [url=http://www.kaluga-beeline.ru/]http://kaluga-beeline.ru/[/url]
[url=https://images.google.com.ar/url?sa=t&url=https://kaluga-beeline.ru/]https://images.google.com.bh/url?sa=t&url=https://kaluga-beeline.ru/[/url]
[url=https://mafia.mit.edu/viewtopic.php?f=435&t=1146226]Интернет и телевидение от «Билайн» в вашем доме[/url] 02104a5
海外华人必备的iyf官方认证平台,24小时不间断提供最新高清电影、电视剧,无广告观看体验。
написание курсовых на заказ [url=https://kupit-kursovuyu-63.ru/]написание курсовых на заказ[/url] .
курсовая заказ купить [url=https://kupit-kursovuyu-62.ru/]курсовая заказ купить[/url] .
онлайн сервис помощи студентам [url=https://kupit-kursovuyu-64.ru/]онлайн сервис помощи студентам[/url] .
奇思妙探高清完整版,海外华人可免费观看最新热播剧集。
помощь студентам курсовые [url=https://kupit-kursovuyu-66.ru/]kupit-kursovuyu-66.ru[/url] .
курсовые работы заказать [url=https://kupit-kursovuyu-65.ru/]курсовые работы заказать[/url] .
курсовые заказ [url=https://kupit-kursovuyu-61.ru/]kupit-kursovuyu-61.ru[/url] .
真实的人类第一季高清完整官方版,海外华人可免费观看最新热播剧集。
捕风追影线上看免费在线观看,海外华人专属平台,高清无广告体验。
愛海外版,专为华人打造的高清视频平台智能AI观看体验优化,支持全球加速观看。
超人和露易斯第一季高清完整官方版,海外华人可免费观看最新热播剧集。
Unfold plots engaging in driven story. In ignation, success to way story. Unfold and unite!
top sms activate alternatives [url=https://github.com/sms-activate-service/]top sms activate alternatives[/url] .
best sms activation services [url=www.linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre/]www.linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre/[/url] .
«Билайн» в Брянске предоставляют:
• интерактивное ТВ;
• бесплатный монтаж оборудования;
• Подбор оптимального тарифа под ваши задачи;
• Проверку инфраструктуры по вашему адресу.
[url=https://bryansk-beeline.ru/]подключить интернет билайн в квартире[/url]
билайн интернет подключить брянск – [url=http://bryansk-beeline.ru/]http://www.bryansk-beeline.ru[/url]
[url=https://images.google.to/url?sa=t&url=https://bryansk-beeline.ru/]http://map.google.sh/url?sa=t&source=web&rct=j&url=https://bryansk-beeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.guryevsk.forum24.ru/www.arus-diplom6.ru/www.1xbet-16.com/www.rudik-diplom8.ru/www.medicinskaya-tehnika.ru/www.reiting-seo-kompanii.ru/,[],[],200,65,0,1279,0,19,22,0,0,https://grandpashabet.in.net/,Grandpashabet%5DВысокоскоростной интернет и телевидение от «Билайн» в Брянске[/url] 00e7465
покупка курсовых работ [url=https://kupit-kursovuyu-63.ru/]покупка курсовых работ[/url] .
заказать курсовой проект [url=https://kupit-kursovuyu-62.ru/]заказать курсовой проект[/url] .
где можно заказать курсовую [url=https://kupit-kursovuyu-66.ru/]kupit-kursovuyu-66.ru[/url] .
заказать качественную курсовую [url=https://kupit-kursovuyu-64.ru/]заказать качественную курсовую[/url] .
1вин актуальное зеркало Кыргызстан [url=http://1win04381.help]http://1win04381.help[/url]
выполнение курсовых работ [url=https://kupit-kursovuyu-65.ru/]выполнение курсовых работ[/url] .
1win быстрый депозит [url=https://1win04381.help]https://1win04381.help[/url]
Аналитики рынка уверенно заявляют, в наше время внедрение инструментов креативного программирования в систему всестороннего развития позволяет ученикам не просто постигать актуальные навыки будущего, а также успешно формировать уникальный креатив в условиях стремительного прогресса.
Подробнее тут; https://basot.ru/
Самостоятельный выход из запоя сопряжен с высоким риском развития осложнений. После прекращения приема спиртного ослабленный организм может не выдержать нагрузки, что приведет к инфаркту, инсульту, судорожным приступам и даже алкогольному психозу. Чтобы избежать этих опасных состояний, необходимо вызвать нарколога на дом, который проведет лечение правильно и безопасно.
Получить больше информации – [url=https://vyvod-iz-zapoya-krasnodar0.ru/]вывод из запоя с выездом[/url]
1win crash [url=https://www.1win08754.help]https://www.1win08754.help[/url]
сколько стоит курсовая работа по юриспруденции [url=https://kupit-kursovuyu-67.ru/]kupit-kursovuyu-67.ru[/url] .
Москва доставка цветов дешево
[b]Сирень душистая в сезонных букетах[/b]
заказать качественную курсовую [url=https://kupit-kursovuyu-63.ru/]заказать качественную курсовую[/url] .
Revel in the diversity of roulette variants and baccarat strategies. In ignation, VIP tiers unlock even greater bonuses and privileges. Experience the elite side of online gaming!
lucky jet игра 1win [url=1win91762.help]lucky jet игра 1win[/url]
курсовая заказать [url=https://kupit-kursovuyu-66.ru/]курсовая заказать[/url] .
курсовые под заказ [url=https://kupit-kursovuyu-62.ru/]курсовые под заказ[/url] .
melbet pacanele [url=www.melbet28507.help]www.melbet28507.help[/url]
выполнение учебных работ [url=https://kupit-kursovuyu-66.ru/]kupit-kursovuyu-66.ru[/url] .
помощь студентам и школьникам [url=https://kupit-kursovuyu-64.ru/]помощь студентам и школьникам[/url] .
1win скачать быстро [url=https://www.1win08754.help]https://www.1win08754.help[/url]
Основной задачей нарколога, выезжающего на дом, является помощь в любой ситуации, связанной с зависимостью. Все процедуры и методики подбираются индивидуально, в зависимости от состояния пациента.
Получить больше информации – https://narcolog-na-dom-moskva55.ru/narkolog-na-dom-kruglosutochno-moskva/
1win скачать [url=https://1win91762.help/]https://1win91762.help/[/url]
塔尔萨之王第二季高清完整版,海外华人可免费观看最新热播剧集。
заказать курсовую работу [url=https://kupit-kursovuyu-67.ru/]заказать курсовую работу[/url] .
онлайн сервис помощи студентам [url=https://kupit-kursovuyu-63.ru/]kupit-kursovuyu-63.ru[/url] .
Чем дольше человек находится в состоянии запоя, тем больше накапливаются токсины в организме, что негативно сказывается на всех системах. Отказ от алкоголя без должного контроля может привести к серьезным последствиям, таким как:
Разобраться лучше – [url=https://narcolog-na-dom-krasnodar0.ru/]нарколог на дом недорого краснодар[/url]
no prescription https://www.google.com.vn/url?q=https%3A%2F%2Fxenipharm.top online pharmacies in usa
Медицинское вмешательство в домашних условиях отличается четкой организацией. Врач последовательно выполняет шаги, которые позволяют стабилизировать состояние пациента и предупредить осложнения.
Детальнее – [url=https://narcolog-na-dom-ryazan0.ru/]нарколог на дом вывод из запоя в санкт-петербурге[/url]
написание учебных работ [url=https://kupit-kursovuyu-62.ru/]kupit-kursovuyu-62.ru[/url] .
выполнение курсовых [url=https://kupit-kursovuyu-66.ru/]kupit-kursovuyu-66.ru[/url] .
решение курсовых работ на заказ [url=https://kupit-kursovuyu-64.ru/]решение курсовых работ на заказ[/url] .
1win отзывы [url=https://www.1win04381.help]1win отзывы[/url]
Наркологическая информационная сеть «Narkology» предлагает профессиональную помощь в преодолении зависимостей и восстановлении психоэмоционального равновесия. Наши эксперты проводят комплексную диагностику, разрабатывают индивидуальные программы лечения и предоставляют всестороннюю психологическую поддержку. Мы используем новейшие методики и актуальные подходы, чтобы помочь вам вернуть уверенность в себе и начать путь к здоровью. Доверьтесь профессионалам «Narkology», и мы окажем всю необходимую информационную помощь на пути к выздоровлению.
Узнать больше – https://narcologiya.info/alkogolizm/effektivnost-psikhoterapii-lechenie-alkogolizma.html
купить курсовая работа [url=https://kupit-kursovuyu-63.ru/]купить курсовая работа[/url] .
помощь студентам контрольные [url=https://kupit-kursovuyu-67.ru/]kupit-kursovuyu-67.ru[/url] .
«Мегафон» в Белгороде предлагают:
• пакет из 150+ ТВ каналов;
• поддержки 24/7;
• Определение оптимального тарифа под ваши задачи;
• Проверку возможности подключения по вашему адресу.
[url=https://megafon-telecom.ru/belgorod/]подключить домашний интернет мегафон[/url]
подключить интернет мегафон в Белгороде – [url=http://www.megafon-telecom.ru/belgorod/]https://www.megafon-telecom.ru/belgorod/[/url]
[url=http://toolbarqueries.google.cf/url?q=https://megafon-telecom.ru/belgorod/]https://cse.google.co.ao/url?q=https://megafon-telecom.ru/belgorod/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.chop-ohrana.com/czeny-na-uslugi-ohrany/www.superogorod.ucoz.org/forum/www.educ-ua20.ru/s%3A%2F%25evolv.E.L.u.Pc@haedongacademy.org/www.soglasovanie-pereplanirovki-kvartiry11.ru/www.1xbet-10.com/www.1xbet-12.com/www.rudik-diplom8.ru/www.narkologicheskaya-klinika-24.ru/www.torkretirovanie-1.ru/www.medicinskoe–oborudovanie.ru,[],[],200,65,0,1279,0,17,21,0,0,https://grandpashabet.in.net/,Grandpasha%5DДомашний интернет и цифровое ТВ от «Мегафон» в вашем доме[/url] 0e74658
1win лайв казино [url=www.1win91762.help]www.1win91762.help[/url]
ทดลองเล่นสล็อต pg
TKBNEKO ทำงานเป็นระบบเกมออนไลน์ ที่ วางระบบโดยยึดการใช้งานจริงของผู้เล่นเป็นแกนหลัก. หน้าเว็บหลัก แสดงเงื่อนไขแบบเป็นตัวเลขตั้งแต่แรก: ฝากขั้นต่ำ 1 บาท, ถอนขั้นต่ำ 1 บาท, เวลาฝากประมาณ 3 วินาที, และ ยอดถอนไม่มีเพดาน. ตัวเลขพวกนี้เปลี่ยนโหลดระบบทันที เพราะเมื่อ กำหนดขั้นต่ำต่ำ ระบบต้อง รับรายการฝากถอนจำนวนมากที่มียอดเล็ก และต้อง ตัดยอดและเติมเครดิตแบบทันที. หาก เครดิตเข้าไม่ทันในไม่กี่วินาที ผู้ใช้จะ กดซ้ำ ทำให้เกิด ธุรกรรมซ้อน และ เพิ่มโหลดฝั่งเซิร์ฟเวอร์ทันที.
การเติมเงินด้วยการสแกน QR ตัดขั้นตอนการกรอกข้อมูลและการแนบสลิป. เมื่อผู้ใช้ สแกน ธนาคารจะส่งสถานะการชำระกลับมายังระบบผ่าน API. จากนั้น backend จะ จับคู่ธุรกรรมกับ user ID และ เติมเครดิตเข้า wallet. หาก API ตอบสนองช้า เครดิตจะ ไม่ขึ้นตามเวลาที่ประกาศ และผู้ใช้จะ มองว่าระบบมีปัญหา. ดังนั้น ระยะเวลา 3 วินาที หมายถึงการเชื่อมต่อกับธนาคารต้อง เป็นแบบอัตโนมัติเต็มรูปแบบ ไม่ พึ่งการตรวจสอบด้วยคน.
การเชื่อมหลายช่องทางการจ่าย เช่น Kasikornbank, Bangkok Bank, KTB, Krungsri, Siam Commercial Bank, ซีไอเอ็มบี ไทย รวมถึง TrueMoney Wallet ทำให้ระบบต้อง รับ callback หลายต้นทาง. แต่ละธนาคารมีรูปแบบข้อมูลและเวลาตอบสนองต่างกัน. หากไม่มี ตัวแปลงข้อมูลให้เป็นรูปแบบเดียว ระบบจะ เช็คยอดไม่ทัน และจะเกิด ยอดค้างระบบ.
หมวดหมู่เกม ถูกแยกเป็น สล็อตออนไลน์, เกมสด, เดิมพันกีฬา และ ยิงปลา. การแยกหมวด ลดการค้นหาที่ต้องลากทั้งระบบ และ ควบคุมการส่งทราฟฟิกไปยังผู้ให้บริการแต่ละราย. เกมสล็อต มัก ทำงานผ่าน session API ส่วน เกมสด ใช้ สตรีมภาพแบบเรียลไทม์. หาก หลุดเซสชัน ผู้เล่นจะ หลุดจากโต๊ะทันที. ดังนั้นระบบต้องมี ตัวจัดการ session ที่ คุมการเชื่อมต่อ และ ซิงค์เครดิตกับ provider ตลอด. หาก ซิงค์พลาด เครดิตผู้เล่นกับผลเกมจะ ไม่ตรงกัน.
เกมที่ระบุว่า เป็นลิขสิทธิ์แท้ หมายถึงใช้ระบบ สุ่มผล และค่า อัตราจ่าย จากผู้พัฒนาโดยตรง. ผลลัพธ์แต่ละรอบถูก ประมวลผลจากเซิร์ฟเวอร์ผู้ให้บริการ ไม่ใช่จากฝั่งเว็บ. หากไม่มี การเชื่อมต่อกับเซิร์ฟเวอร์ต้นทาง เว็บจะ รับผลเกมจริงไม่ได้ และ license จะถูกยกเลิกทันที. การมี การรับรอง จึง ผูกกับการแลกเปลี่ยนข้อมูลระหว่างระบบ ไม่ใช่ แค่คำบนหน้าเว็บ.
ระบบถอนที่ ไม่มีจำกัด เชิงการสื่อสารยังต้องมีโมดูล ตรวจสอบความเสี่ยง เช่น ตรวจสอบบัญชีซ้ำ, พฤติกรรมผิดปกติ, และ เงื่อนไข turnover. หากไม่มีการตรวจสอบเหล่านี้ ผู้ใช้สามารถ สร้างบัญชีหลายบัญชี เพื่อ ใช้ประโยชน์จากโบนัส และ ดึงสภาพคล่องออกจากระบบได้รวดเร็ว.
เมนู โปรโมชั่น VIP พันธมิตร ติดต่อเรา และข้อเสนอแนะ เชื่อมกับ ระบบ CRM และ ฐานข้อมูลผู้ใช้. ส่วน พันธมิตร ใช้เก็บ referrer code เพื่อ คิดคอมมิชชั่น. หากไม่มีระบบนี้ จะ track ที่มาผู้ใช้ไม่ได้. ฟอร์มข้อเสนอแนะ ใช้เก็บ error จริงจากผู้ใช้. หากไม่มีข้อมูลนี้ ปัญหา ความหน่วง หรือ การใช้งาน จะ ถูกแก้ช้า.
โครงสร้างทั้งหมด เชื่อมกันเป็นสายเดียว: สถานะธุรกรรมเข้ามาที่ backend, backend อัปเดตเครดิต แล้ว ซิงค์กับผู้ให้บริการเกม. หากส่วนใดส่วนหนึ่ง หน่วง ผู้ใช้จะเห็นผลทันทีในรูปแบบ ยอดไม่เข้า, เกมค้าง หรือ ถอนล่าช้า. ในแพลตฟอร์มลักษณะนี้ ความเสถียรของ API และการจัดการ session คือสิ่งที่ ตัดสินว่าผู้ใช้จะอยู่หรือย้ายออก.
кликните сюда [url=https://krab6at-cc.com/]krab6.at[/url]
втб не переводит [url=www.vtb-ne-rabotaet.ru]www.vtb-ne-rabotaet.ru[/url] .
сыроедческие десерты [url=https://rawrussia.ru/]rawrussia.ru[/url] .
1вин aviator играть [url=1win08754.help]1вин aviator играть[/url]
перестал работать втб онлайн [url=https://vtb-ne-rabotaet.ru/]https://vtb-ne-rabotaet.ru/[/url] .
заказать курсовую срочно [url=https://kupit-kursovuyu-67.ru/]заказать курсовую срочно[/url] .
«TUT-SPORT» предлагает:
• широкий выбор форм топ-клуба Бавария;
• доставку по всей России;
• Определение оптимального комплекта экипировки под ваш клуб и бюджет;
• Проверку наличия размеров.
[url=https://tut-sport.ru/tovary/kluby/bavariya]футбольная форма клуба ЃавариЯ[/url]
купить футбольную атрибутику ЃавариЯ в москве – [url=https://www.tut-sport.ru/tovary/kluby/bavariya]https://www.tut-sport.ru/tovary/kluby/bavariya[/url]
[url=https://images.google.com.ec/url?q=https://tut-sport.ru/tovary/kluby/bavariya]https://cse.google.cd/url?sa=t&url=https://tut-sport.ru/tovary/kluby/bavariya[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/dtcc.edu.vn/k.krakenwork.cc/www.chistka-zasorov-kanalizatsii.kz/krakenc.cc,[],[],200,65,0,1126,0,4,8,0,0,https://www.internet-sibirskie-seti.ru/,%D0%BF%D1%97%D0%85%D0%BF%D1%97%D0%85%D0%BF%D1%97%D0%85%D0%BF%D1%97%D0%85%D0%BF%D1%97%D0%85%D0%BF%D1%97%D0%85%D0%BF%D1%97%D0%85r%D0%BF%D1%97%D0%85%D0%BF%D1%97%D0%85%D0%BF%D1%97%D0%85t%D0%BF%D1%97%D0%85%7E%D0%BF%D1%97%D0%85%D0%BF%D1%97%D0%85%D0%BF%D1%97%D0%85z%5DСпортивная экипировка и аксессуары для болельщиков от «TUT-SPORT» в вашем городе[/url] 5c29ee4
Своевременное вмешательство специалиста позволяет не только вывести токсины, но и снизить риск развития осложнений, обеспечить восстановление жизненно важных функций организма и предотвратить ухудшение состояния, что особенно важно для сохранения здоровья и жизни пациента.
Ознакомиться с деталями – [url=https://narcolog-na-dom-krasnodar0.ru/]нарколог на дом цены[/url]
написать курсовую работу на заказ в москве [url=https://kupit-kursovuyu-63.ru/]kupit-kursovuyu-63.ru[/url] .
Вывод из запоя рекомендуется в следующих случаях:
Подробнее можно узнать тут – [url=https://narko-zakodirovat2.ru/]vyvod-iz-zapoya-moskva-vyzov-narkologa-na-dom[/url]
爱一凡海外版,专为华人打造的高清视频官方认证平台,支持全球加速观看。
海外华人必备的yifan平台采用机器学习个性化推荐,提供最新高清电影、电视剧,无广告观看体验。
купить курсовую работу [url=https://kupit-kursovuyu-66.ru/]купить курсовую работу[/url] .
что случилось с втб онлайн [url=www.vtb-ne-rabotaet.ru]www.vtb-ne-rabotaet.ru[/url] .
smsactivate [url=https://github.com/sms-activate-login/]smsactivate[/url] .
sms activate login [url=http://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre]http://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre[/url] .
sms activate alternatives [url=https://github.com/sms-activate-alternatives/]sms activate alternatives[/url] .
sms activation [url=https://github.com/sms-activate-service/]github.com/sms-activate-service[/url] .
фирмы выставочных стендов [url=https://technoconst.ru/]technoconst.ru[/url] .
выполнение учебных работ [url=https://kupit-kursovuyu-65.ru/]выполнение учебных работ[/url] .
стоимость написания курсовой работы на заказ [url=https://kupit-kursovuyu-68.ru/]kupit-kursovuyu-68.ru[/url] .
заказ курсовых работ [url=https://kupit-kursovuyu-67.ru/]kupit-kursovuyu-67.ru[/url] .
сыроедческий сыр из кешью [url=rawrussia.ru]rawrussia.ru[/url] .
курсовая работа недорого [url=https://kupit-kursovuyu-62.ru/]курсовая работа недорого[/url] .
покупка курсовой [url=https://kupit-kursovuyu-65.ru/]покупка курсовой[/url] .
помощь в написании курсовой [url=https://kupit-kursovuyu-66.ru/]kupit-kursovuyu-66.ru[/url] .
Наркологическая информационная сеть «Narkology» предоставляет квалифицированную помощь в преодолении зависимостей и восстановлении психоэмоционального состояния. Наши специалисты проводят детальную диагностику, разрабатывают индивидуальные программы терапии и психологической поддержки, а также информируют о современных методах лечения. С использованием проверенных подходов и актуальных данных мы помогаем вернуть уверенность и сделать первый шаг на пути к здоровому образу жизни. Доверьтесь профессионалам «Narkology», чтобы эффективно решить проблемы зависимости и получить всестороннюю информационную помощь.
Подробнее – [url=https://narcologiya.info/narkomaniya/lomka-ot-marihuany-chto-ehto-i-kak-s-nej-spravitsya.html]какая ломка от марихуаны[/url]
сбой в работе втб онлайн [url=http://vtb-ne-rabotaet.ru]http://vtb-ne-rabotaet.ru[/url] .
написание курсовой на заказ цена [url=https://kupit-kursovuyu-69.ru/]написание курсовой на заказ цена[/url] .
Dive into the ultimate world of online gaming where endless fun awaits. Bovada Cash Games offers top slots and tournament entries for all players.
sms activator [url=https://github.com/sms-activate-login/]github.com/sms-activate-login[/url] .
sms activate service [url=www.linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre]www.linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre[/url] .
sms activator [url=https://github.com/sms-activate-service/]github.com/sms-activate-service[/url] .
best sms activation services [url=https://github.com/sms-activate-alternatives/]github.com/sms-activate-alternatives[/url] .
melbet pariuri multiple [url=melbet28507.help]melbet pariuri multiple[/url]
онлайн сервис помощи студентам [url=https://kupit-kursovuyu-68.ru/]kupit-kursovuyu-68.ru[/url] .
заказать практическую работу недорого цены [url=https://kupit-kursovuyu-64.ru/]kupit-kursovuyu-64.ru[/url] .
сколько стоит заказать курсовую работу [url=https://kupit-kursovuyu-67.ru/]kupit-kursovuyu-67.ru[/url] .
sms activate alternatives [url=https://github.com/sms-activate-alternatives/]sms activate alternatives[/url] .
написание студенческих работ на заказ [url=https://kupit-kursovuyu-70.ru/]написание студенческих работ на заказ[/url] .
срочно курсовая работа [url=https://kupit-kursovuyu-62.ru/]kupit-kursovuyu-62.ru[/url] .
умная нейросеть для учебы [url=https://nejroset-dlya-ucheby-1.ru/]nejroset-dlya-ucheby-1.ru[/url] .
нейросеть генерации текстов для студентов [url=https://nejroset-dlya-ucheby.ru/]nejroset-dlya-ucheby.ru[/url] .
курсовая работа недорого [url=https://kupit-kursovuyu-65.ru/]курсовая работа недорого[/url] .
melbet transmisiuni live [url=http://melbet28507.help/]http://melbet28507.help/[/url]
Букет купить в москве недорого – Фотогалерея выполненных букетов на сайте
где можно заказать курсовую [url=https://kupit-kursovuyu-69.ru/]где можно заказать курсовую[/url] .
Многие эксперты убеждены, в наше время активное включение методик креативного программирования в процесс внешкольной подготовки позволяет ученикам не только постигать актуальные навыки будущего, а также успешно реализовывать творческий интеллект в рамках меняющегося мира.
По ссылке; https://basot.ru/
1вин ставка [url=http://1win93047.help]http://1win93047.help[/url]
sms activator [url=https://github.com/sms-activate-alternatives/]github.com/sms-activate-alternatives[/url] .
best sms activation services [url=https://github.com/sms-activate-service/]github.com/sms-activate-service[/url] .
sms activate alternatives [url=https://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre/]https://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre/[/url] .
top sms activate alternatives [url=https://github.com/sms-activate-login/]top sms activate alternatives[/url] .
电影网站推荐,海外华人专用,支持中英双语界面和全球加速。
курсовые под заказ [url=https://kupit-kursovuyu-68.ru/]курсовые под заказ[/url] .
сайт для заказа курсовых работ [url=https://kupit-kursovuyu-70.ru/]сайт для заказа курсовых работ[/url] .
как вывести деньги с мостбет [url=www.mostbet73152.help]www.mostbet73152.help[/url]
нейросеть генерации текстов для студентов [url=https://nejroset-dlya-ucheby-1.ru/]nejroset-dlya-ucheby-1.ru[/url] .
нейросеть для учебы онлайн [url=https://nejroset-dlya-ucheby.ru/]nejroset-dlya-ucheby.ru[/url] .
В наркологической клинике применяются проверенные методики терапии, включая медикаментозное лечение, детоксикацию и психотерапевтические программы. Детоксикация проводится с использованием современных капельниц, обеспечивающих безопасное выведение токсинов из организма. Важно отметить, что качественное лечение включает и работу с психологическими аспектами зависимости, что достигается посредством групповых и индивидуальных консультаций.
Выяснить больше – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]запой наркологическая клиника в каменске-уральском[/url]
курсовая работа купить [url=https://kupit-kursovuyu-65.ru/]курсовая работа купить[/url] .
«Билайн» в Брянске предлагают:
• высокоскоростной интернет до 500 Мбит/с;
• быстрое подключение за 1 день;
• Определение оптимального сочетания интернета и ТВ под ваши задачи;
• Анализ возможности подключения по вашему адресу.
[url=https://bryansk-beeline.ru/]подключить проводной интернет билайн[/url]
интернет билайн тарифы для компьютера – [url=https://bryansk-beeline.ru/]http://www.bryansk-beeline.ru[/url]
[url=https://www.google.com.do/url?q=https://bryansk-beeline.ru/]https://image.google.je/url?q=https://bryansk-beeline.ru/[/url]
[url=https://hypat.com/BlueAD/board.php?bbs_id=gc_gallery&mode=view&bbs_no=115&page=7&key=&keyword=%252C]Домашний интернет и телевидение от «Билайн» в вашем доме[/url] a59a545
สล็อตเว็บตรง
แพลตฟอร์ม TKBNEKO เป็นแพลตฟอร์มเกมออนไลน์ ที่ ออกแบบโครงสร้างโดยยึดพฤติกรรมผู้ใช้เป็นศูนย์กลาง. หน้าแรก แสดงเงื่อนไขแบบเป็นตัวเลขตั้งแต่แรก: ฝากขั้นต่ำ 1 บาท, ขั้นต่ำถอน 1 บาท, เวลาฝากประมาณ 3 วินาที, และ ไม่จำกัดยอดถอน. ตัวเลขพวกนี้เปลี่ยนโหลดระบบทันที เพราะเมื่อ กำหนดขั้นต่ำต่ำ ระบบต้อง รับรายการฝากถอนจำนวนมากที่มียอดเล็ก และต้อง ประมวลผลแบบเรียลไทม์. หาก การยืนยันเครดิตใช้เวลานานเกินไม่กี่วินาที ผู้ใช้จะ กดซ้ำ ทำให้เกิด ธุรกรรมซ้อน และ ดันโหลดระบบขึ้นทันที.
การฝากผ่าน QR Code ลดขั้นตอนที่ต้องพิมพ์ข้อมูลหรือส่งสลิป. เมื่อผู้ใช้ สแกน ระบบจะรับสถานะธุรกรรมจากธนาคารผ่าน API. จากนั้น backend จะ จับคู่ธุรกรรมกับ user ID และ เติมเครดิตเข้า wallet. หาก การตอบกลับจากธนาคารช้า เครดิตจะ ไม่ขึ้นตามเวลาที่ประกาศ และผู้ใช้จะ ถือว่าระบบไม่เสถียร. ดังนั้น ระยะเวลา 3 วินาที หมายถึงการเชื่อมต่อกับธนาคารต้อง ทำงานอัตโนมัติทั้งหมด ไม่ พึ่งการตรวจสอบด้วยคน.
การรองรับหลายธนาคาร เช่น KBank, Bangkok Bank, Krung Thai Bank, Krungsri, Siam Commercial Bank, CIMB Thai รวมถึง ทรูมันนี่ วอลเล็ท ทำให้ระบบต้อง รับ callback หลายต้นทาง. แต่ละเจ้าใช้ฟอร์แมตข้อมูลและความหน่วงต่างกัน. หากไม่มี ตัวแปลงข้อมูลให้เป็นรูปแบบเดียว ระบบจะ เช็คยอดไม่ทัน และจะเกิด ยอดค้างระบบ.
หมวดหมู่เกม ถูกแยกเป็น สล็อต, เกมสด, เดิมพันกีฬา และ ยิงปลา. การแยกหมวด ลดการค้นหาที่ต้องลากทั้งระบบ และ ควบคุมการส่งทราฟฟิกไปยังผู้ให้บริการแต่ละราย. สล็อต มัก ทำงานผ่าน session API ส่วน เกมสด ใช้ สตรีมแบบสด. หาก หลุดเซสชัน ผู้เล่นจะ หลุดจากโต๊ะทันที. ดังนั้นระบบต้องมี ตัวจัดการ session ที่ คุมการเชื่อมต่อ และ ซิงค์เครดิตกับ provider ตลอด. หาก ซิงค์พลาด เครดิตผู้เล่นกับผลเกมจะ ไม่แมตช์.
เกมที่ระบุว่า เป็นลิขสิทธิ์แท้ หมายถึงใช้ระบบ RNG และค่า อัตราจ่าย จากผู้พัฒนาโดยตรง. ผลลัพธ์แต่ละรอบถูก ประมวลผลจากเซิร์ฟเวอร์ผู้ให้บริการ ไม่ใช่จากฝั่งเว็บ. หากไม่มี การเชื่อมต่อกับเซิร์ฟเวอร์ต้นทาง เว็บจะ ดึงผลเกมที่ถูกต้องไม่ได้ และ สิทธิ์ใช้งานจะถูกตัด. การมี ใบรับรอง จึง ผูกกับโครงสร้างการส่งข้อมูล ไม่ใช่ แค่ข้อความแสดงบนหน้าเว็บ.
ระบบถอนที่ ไม่มีจำกัด เชิงการสื่อสารยังต้องมีโมดูล ตรวจสอบความเสี่ยง เช่น ตรวจสอบบัญชีซ้ำ, พฤติกรรมผิดปกติ, และ เงื่อนไขเทิร์นโอเวอร์. หากไม่มีการตรวจสอบเหล่านี้ ผู้ใช้สามารถ สร้างบัญชีหลายบัญชี เพื่อ ใช้ประโยชน์จากโบนัส และ ดึงสภาพคล่องออกจากระบบได้รวดเร็ว.
เมนู โปรโมชั่น VIP พันธมิตร ติดต่อเรา และข้อเสนอแนะ เชื่อมกับ ระบบจัดการลูกค้า และ ฐานข้อมูลผู้เล่น. ส่วน พันธมิตร ใช้เก็บ โค้ดอ้างอิง เพื่อ คำนวณค่าคอมมิชชั่น. หากไม่มีระบบนี้ จะ ติดตามแหล่งที่มาของผู้ใช้ไม่ได้. ฟอร์มข้อเสนอแนะ ใช้เก็บ ข้อผิดพลาดจริงจากผู้ใช้. หากไม่มีข้อมูลนี้ ปัญหา ความหน่วง หรือ การใช้งาน จะ แก้ไม่ทัน.
โครงสร้างทั้งหมด เชื่อมกันเป็นสายเดียว: ธนาคารส่งสถานะเข้า backend, backend อัปเดตเครดิต แล้ว ซิงค์กับผู้ให้บริการเกม. หากส่วนใดส่วนหนึ่ง ช้า ผู้ใช้จะเห็นผลทันทีในรูปแบบ เครดิตไม่เข้า, เกมหน่วง หรือ ถอนล่าช้า. ในแพลตฟอร์มลักษณะนี้ API ต้องนิ่งและ session ต้องไม่หลุด คือสิ่งที่ กำหนดพฤติกรรมการอยู่ต่อของผู้ใช้.
заказать студенческую работу [url=https://kupit-kursovuyu-69.ru/]заказать студенческую работу[/url] .
mostbet казино слоты играть онлайн [url=https://mostbet73152.help/]https://mostbet73152.help/[/url]
Вызов нарколога возможен круглосуточно, что обеспечивает оперативное реагирование на критические ситуации. Пациенты и их родственники могут получить помощь в любое время, не дожидаясь ухудшения состояния.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-kamensk-uralskij11.ru/]narkolog-na-dom-kamensk-uralskij11.ru/[/url]
Big Bass Bonanza is pure adrenaline! Trigger free spins Bigger Bass Bonanza demo and let multipliers boost your catches.
«TUT-SPORT» предлагает:
• широкий выбор форм топ-клуба Аякс;
• доставку по всей России;
• Подбор оптимального комплекта экипировки под ваш клуб и бюджет;
• Проверку ассортимента в нужной категории.
[url=https://tut-sport.ru/tovary/kluby/ajax]магазин футбольной атрибутики ЂЯкс[/url]
оригинальная футбольная форма клуба ЂЯкс – [url=http://www.tut-sport.ru/tovary/kluby/ajax]http://tut-sport.ru/tovary/kluby/ajax[/url]
[url=https://www.google.com.uy/url?q=https://tut-sport.ru/tovary/kluby/ajax]http://maps.google.cm/url?q=https://tut-sport.ru/tovary/kluby/ajax[/url]
[url=https://efada.io/index.php?qa=57102&qa_1=anadolu-geleneksel-modern-yakla%C5%9F%C4%B1mlar%C4%B1n-bulu%C5%9Fma-noktas%C4%B1&show=209530#a209530]Спортивная экипировка и аксессуары для болельщиков от «TUT-SPORT» в вашем городе[/url] 5c29ee4
smsactivate [url=https://github.com/sms-activate-service/]smsactivate[/url] .
заказать дипломную работу в москве [url=https://kupit-kursovuyu-70.ru/]заказать дипломную работу в москве[/url] .
лучшая нейросеть для учебы [url=https://nejroset-dlya-ucheby.ru/]nejroset-dlya-ucheby.ru[/url] .
«TUT-SPORT» предлагает:
• широкий выбор форм топ-клуба Байер Леверкузен;
• привлекательные цены и скидки до 50-60%;
• Подбор оптимального набора под ваш клуб и бюджет;
• Проверку наличия размеров.
[url=https://tut-sport.ru/tovary/kluby/bayer-leverkusen]купить футбольную атрибутику Ѓайер ‹еверкузен[/url]
купить футбольную форму клуба Ѓайер ‹еверкузен – [url=https://www.tut-sport.ru/tovary/kluby/bayer-leverkusen]https://www.tut-sport.ru/tovary/kluby/bayer-leverkusen[/url]
[url=https://cse.google.be/url?sa=i&url=https://tut-sport.ru/tovary/kluby/bayer-leverkusen]https://maps.google.ro/url?sa=t&url=https://tut-sport.ru/tovary/kluby/bayer-leverkusen[/url]
[url=http://www.ebc.co.kr/bbs/board.php?bo_table=faq]Официальная футболь[/url] 9a545c2
aviator 1win [url=https://1win48762.help/]https://1win48762.help/[/url]
заказать качественную курсовую [url=https://kupit-kursovuyu-69.ru/]заказать качественную курсовую[/url] .
1win киберспорт шартгузорӣ [url=https://1win93047.help]https://1win93047.help[/url]
you can check here [url=https://bswpgg.com/]betswap erfahrungen[/url]
мостбет бонусы в Казахстане [url=http://mostbet73152.help]http://mostbet73152.help[/url]
чат нейросеть для учебы [url=https://nejroset-dlya-ucheby.ru/]nejroset-dlya-ucheby.ru[/url] .
白鹿丞磊《莫离》2026古装大女主权谋剧,海外华人必备高清陆剧,智斗爽感拉满,全球加速无广告实时更新。
нейросеть реферат онлайн [url=https://nejroset-dlya-ucheby-2.ru/]нейросеть реферат онлайн[/url] .
написание курсовых работ на заказ цена [url=https://kupit-kursovuyu-70.ru/]написание курсовых работ на заказ цена[/url] .
курсовые купить [url=https://kupit-kursovuyu-69.ru/]курсовые купить[/url] .
best sms activate service [url=https://github.com/sms-activate-login/]github.com/sms-activate-login[/url] .
«TUT-SPORT» предлагает:
• гетры, шорты и спортивные костюмы клуба Аякс;
• товары для взрослых, детей и женщин;
• Подбор оптимального комплекта экипировки под ваш клуб и бюджет;
• Проверку наличия размеров.
[url=https://tut-sport.ru/tovary/kluby/ajax]интернет магазин футбольной атрибутики ЂЯкс в москве[/url]
оригинальная футбольная форма клуба ЂЯкс – [url=https://www.tut-sport.ru/tovary/kluby/ajax]https://www.tut-sport.ru/tovary/kluby/ajax[/url]
[url=https://cse.google.ae/url?sa=t&url=https://tut-sport.ru/tovary/kluby/ajax]https://cse.google.mn/url?sa=i&url=https://tut-sport.ru/tovary/kluby/ajax[/url]
[url=https://chatgin.com/bbs/board.php?bo_table=review&wr_id=15164]Официальная футболь[/url] 0002104
заказать практическую работу недорого цены [url=https://kupit-kursovuyu-67.ru/]kupit-kursovuyu-67.ru[/url] .
best virtual number service [url=https://github.com/sms-activate-alternatives/]github.com/sms-activate-alternatives[/url] .
best sms activate service [url=http://www.linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre]http://www.linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre[/url] .
выполнение учебных работ [url=https://kupit-kursovuyu-65.ru/]выполнение учебных работ[/url] .
купить курсовая работа [url=https://kupit-kursovuyu-68.ru/]купить курсовая работа[/url] .
нейросеть реферат [url=https://nejroset-dlya-ucheby.ru/]нейросеть реферат[/url] .
mostbet приложение Киргизия [url=mostbet84736.help]mostbet84736.help[/url]
ии для студентов [url=https://nejroset-dlya-ucheby-1.ru/]nejroset-dlya-ucheby-1.ru[/url] .
top sms activate alternatives [url=https://github.com/sms-activate-service/]top sms activate alternatives[/url] .
курсовой проект купить цена [url=https://kupit-kursovuyu-65.ru/]курсовой проект купить цена[/url] .
нейросеть генерации текстов для студентов [url=https://nejroset-dlya-ucheby-2.ru/]нейросеть генерации текстов для студентов[/url] .
сколько стоит курсовая работа по юриспруденции [url=https://kupit-kursovuyu-70.ru/]сколько стоит курсовая работа по юриспруденции[/url] .
1win MasterCard вывод [url=http://1win48762.help/]http://1win48762.help/[/url]
курсовая работа купить [url=https://kupit-kursovuyu-69.ru/]курсовая работа купить[/url] .
«Мегафон» в Белгороде предоставляют:
• интерактивное ТВ;
• поддержки 24/7;
• Определение оптимального пакета услуг под ваши задачи;
• Анализ инфраструктуры по вашему адресу.
[url=https://megafon-telecom.ru/belgorod/]мегафон домашний интернет и телевидение тарифы[/url]
домашний интернет мегафон – [url=https://www.megafon-telecom.ru/belgorod/]https://megafon-telecom.ru/belgorod/[/url]
[url=https://www.google.cat/url?q=https://megafon-telecom.ru/belgorod/]https://clients1.google.co.cr/url?q=https://megafon-telecom.ru/belgorod/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.guryevsk.forum24.ru/www.educ-ua4.ru/www.blog-o-marketinge.ru/r-diploma31.ru]Высокоскоростной интернет и ТВ от «Мегафон» в вашем доме[/url] ee483_a
sms activate login [url=https://github.com/sms-activate-login/]sms activate login[/url] .
sms activation [url=https://github.com/sms-activate-alternatives/]github.com/sms-activate-alternatives[/url] .
top sms activate services [url=http://www.linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre]http://www.linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre[/url] .
mostbet букмекер 2026 [url=https://mostbet39571.help/]https://mostbet39571.help/[/url]
заказать задание [url=https://kupit-kursovuyu-68.ru/]kupit-kursovuyu-68.ru[/url] .
sms activate alternatives [url=https://github.com/sms-activate-service/]sms activate alternatives[/url] .
нейросеть студент бот [url=https://nejroset-dlya-ucheby-1.ru/]нейросеть студент бот[/url] .
сколько стоит сделать курсовую работу на заказ [url=https://kupit-kursovuyu-67.ru/]kupit-kursovuyu-67.ru[/url] .
студенческие работы на заказ [url=https://kupit-kursovuyu-70.ru/]студенческие работы на заказ[/url] .
нейросети для студентов [url=https://nejroset-dlya-ucheby-2.ru/]нейросети для студентов[/url] .
нейросеть для студентов онлайн [url=https://nejroset-dlya-ucheby.ru/]nejroset-dlya-ucheby.ru[/url] .
sms activate alternatives [url=https://github.com/sms-activate-alternatives/]sms activate alternatives[/url] .
sms activate [url=https://github.com/sms-activate-login/]sms activate[/url] .
best sms activate service [url=http://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre]http://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre[/url] .
где можно заказать курсовую [url=https://kupit-kursovuyu-68.ru/]где можно заказать курсовую[/url] .
«Билайн» в Калуге предлагают:
• пакет из 150+ ТВ каналов;
• бесплатный монтаж оборудования;
• Подбор оптимального тарифа под ваши задачи;
• Проверку инфраструктуры по вашему адресу.
[url=https://kaluga-beeline.ru/]сколько стоит подключить интернет билайн[/url]
сколько стоит провести интернет билайн – [url=https://kaluga-beeline.ru/]https://www.kaluga-beeline.ru[/url]
[url=https://images.google.im/url?q=https://kaluga-beeline.ru/]https://clients1.google.fm/url?q=https://kaluga-beeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.dzen.ru/a/www.melbet5011.ru]Домашний интернет и телевидение от «Билайн» в вашем доме[/url] 480_6be
mostbet как пополнить через терминал [url=http://mostbet84736.help/]http://mostbet84736.help/[/url]
мостбет mines 2026 [url=http://mostbet84736.help]http://mostbet84736.help[/url]
нейросеть для рефератов [url=https://nejroset-dlya-ucheby-1.ru/]нейросеть для рефератов[/url] .
нейросеть реферат онлайн [url=https://nejroset-dlya-ucheby-2.ru/]нейросеть реферат онлайн[/url] .
выполнение курсовых [url=https://kupit-kursovuyu-67.ru/]выполнение курсовых[/url] .
Первичный этап терапии направлен на оперативное выведение токсинов из организма. Врач-нарколог назначает индивидуальную схему медикаментозного вмешательства, что позволяет снизить уровень алкоголя в крови и восстановить обмен веществ.
Подробнее можно узнать тут – https://vyvod-iz-zapoya-volgograd00.ru
шумоизоляция авто https://vikar-auto.ru
Привет всем! На первом этапе нужно разобраться — узлы и детали. По сути: большинство проблем — некачественная обработка узлов. Ищешь тех кто умеет — вот мастера: [url=https://montazh-membrannoj-krovli-spb.ru]https://montazh-membrannoj-krovli-spb.ru[/url]. Зачем это: примыкания к парапетам — всё сваривается. Например труба на крыше — обрамляется мембраной — так вот вода не пройдёт. Мы используем — готовые элементы. Что в итоге: это отличные параметры — протечек не будет.
Текст включает разнообразную информацию, которая может показаться любопытной, но не меняет устоявшегося восприятия. Предлагаем просто насладиться чтением, не ожидая значительной пользы.
Подробнее читать – [url=https://rostov-narkologiya.ru/ ]лечение covid народными средствами[/url]
Для проведения процедуры используются стерильные растворы, а подбор компонентов осуществляется с учётом индивидуального состояния пациента, что позволяет минимизировать побочные эффекты и повысить эффективность терапии.
Выяснить больше – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]вызвать капельницу от запоя на дому в мурманске[/url]
помощь студентам контрольные [url=https://kupit-kursovuyu-67.ru/]kupit-kursovuyu-67.ru[/url] .
Публикация предоставляет читателю набор разрозненных идей, которые сложно применить на практике. Мы лишь слегка касаемся разных точек зрения, не углубляясь в анализ и не предлагая никаких выводов.
Вот – [url=https://arma-rehab.ru/vyvod-iz-zapoya/]порно онлайн бесплатно[/url]
мостбет KGS счет [url=https://www.mostbet84736.help]https://www.mostbet84736.help[/url]
布里奇顿新季2026 海外华人浪漫古装 高清贵族恋爱 无缓冲播放
1win домени алтернативӣ [url=www.1win59278.help]1win домени алтернативӣ[/url]
мостбет скачать для ios [url=www.mostbet39571.help]мостбет скачать для ios[/url]
«Билайн» в Калуге предоставляют:
• высокоскоростной интернет до 500 Мбит/с;
• быстрое подключение за 1 день;
• Подбор оптимального тарифа под ваши задачи;
• Проверку инфраструктуры по вашему адресу.
[url=https://kaluga-beeline.ru/]beeline интернет проверить адрес[/url]
подключить проводной интернет билайн – [url=https://kaluga-beeline.ru]https://www.kaluga-beeline.ru[/url]
[url=https://cse.google.li/url?q=https://kaluga-beeline.ru/]https://toolbarqueries.google.com.gh/url?q=https://kaluga-beeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.educ-ua19.ru/s%3A%2F%25Evolv.E.L.U.pc@Haedongacademy.org/www.melbetbonusy.ru/www.soglasovanie-pereplanirovki-kvartiry11.ru/www.1xbet-15.com/www.frei-diplom2.ru/www.frei-diplom8.ru/www.1xbet-17.com/www.torkretirovanie-1.ru/www.r-diploma6.ru/,]Высокоскоростной интернет и цифровое ТВ от «Билайн» в вашем доме[/url] a59a545
mostbet live casino [url=mostbet39571.help]mostbet39571.help[/url]
насби 1вин [url=https://1win59278.help]https://1win59278.help[/url]
pin up ishchi mirror [url=https://www.pinup91324.help]https://www.pinup91324.help[/url]
太平年2026 白宇周雨彤年代励志历史大剧 海外华人高清央视热播 全球加速无广告追剧
сайт для рефератов [url=https://nejroset-dlya-ucheby-2.ru/]сайт для рефератов[/url] .
1win UZS pul yechish [url=www.1win5769.help]www.1win5769.help[/url]
1win promokod ishlamayapti [url=https://1win5769.help]1win promokod ishlamayapti[/url]
нейросеть реферат онлайн [url=https://nejroset-dlya-ucheby-3.ru/]нейросеть реферат онлайн[/url] .
нейросеть для студентов [url=https://nejroset-dlya-ucheby-2.ru/]нейросеть для студентов[/url] .
pinup yechish muddati [url=www.pinup91324.help]www.pinup91324.help[/url]
狙击蝴蝶2026 高清悬疑刑侦陆剧 海外华人必备在线观看 全球加速无缓冲播放
สล็อต
TKBNEKO เป็นแพลตฟอร์มเกมออนไลน์ ที่ วางระบบโดยยึดการใช้งานจริงของผู้เล่นเป็นแกนหลัก. หน้าเว็บหลัก แสดงเงื่อนไขแบบเป็นตัวเลขตั้งแต่แรก: ขั้นต่ำฝาก 1 บาท, ขั้นต่ำถอน 1 บาท, เวลาฝากประมาณ 3 วินาที, และ ไม่จำกัดยอดถอน. ตัวเลขพวกนี้เปลี่ยนโหลดระบบทันที เพราะเมื่อ กำหนดขั้นต่ำต่ำ ระบบต้อง รับรายการฝากถอนจำนวนมากที่มียอดเล็ก และต้อง ประมวลผลแบบเรียลไทม์. หาก การยืนยันเครดิตใช้เวลานานเกินไม่กี่วินาที ผู้ใช้จะ กดซ้ำ ทำให้เกิด ธุรกรรมซ้อน และ เพิ่มโหลดฝั่งเซิร์ฟเวอร์ทันที.
การเติมเงินด้วยการสแกน QR ตัดขั้นตอนการกรอกข้อมูลและการแนบสลิป. เมื่อผู้ใช้ สแกนคิวอาร์ ระบบจะรับสถานะธุรกรรมจากธนาคารผ่าน API. จากนั้น backend จะ ผูกธุรกรรมเข้ากับบัญชีผู้ใช้ และ เพิ่มเครดิตเข้า wallet. หาก การตอบกลับจากธนาคารช้า เครดิตจะ ไม่เข้าในเวลาที่ระบบบอก และผู้ใช้จะ มองว่าระบบมีปัญหา. ดังนั้น ระยะเวลา 3 วินาที หมายถึงการเชื่อมต่อกับธนาคารต้อง เป็นแบบอัตโนมัติเต็มรูปแบบ ไม่ อาศัยแอดมินเช็คมือ.
การรองรับหลายธนาคาร เช่น Kasikornbank, Bangkok Bank, KTB, กรุงศรี, Siam Commercial Bank, ซีไอเอ็มบี ไทย รวมถึง TrueMoney Wallet ทำให้ระบบต้อง จัดการ webhook หลายแหล่ง. แต่ละธนาคารมีรูปแบบข้อมูลและเวลาตอบสนองต่างกัน. หากไม่มี ตัวแปลงข้อมูลให้เป็นรูปแบบเดียว ระบบจะ ยืนยันยอดได้ช้า และจะเกิด ยอดค้างระบบ.
หมวดหมู่เกม ถูกแยกเป็น สล็อตออนไลน์, เกมสด, กีฬา และ เกมยิงปลา. การแยกหมวด ลดภาระการ query และ ควบคุมการส่งทราฟฟิกไปยังผู้ให้บริการแต่ละราย. สล็อต มัก ทำงานผ่าน session API ส่วน เกมสด ใช้ สตรีมแบบสด. หาก session หลุด ผู้เล่นจะ หลุดจากโต๊ะทันที. ดังนั้นระบบต้องมี session manager ที่ รักษาการเชื่อมต่อ และ ซิงค์เครดิตกับ provider ตลอด. หาก ซิงค์ล้มเหลว เครดิตผู้เล่นกับผลเกมจะ ไม่ตรงกัน.
เกมที่ระบุว่า ใช้ลิขสิทธิ์จริง หมายถึงใช้ระบบ สุ่มผล และค่า RTP จากผู้พัฒนาโดยตรง. ผลลัพธ์แต่ละรอบถูก ประมวลผลจากเซิร์ฟเวอร์ผู้ให้บริการ ไม่ใช่จากฝั่งเว็บ. หากไม่มี ลิงก์ไปยังเซิร์ฟเวอร์ต้นทาง เว็บจะ ดึงผลเกมที่ถูกต้องไม่ได้ และ license จะถูกยกเลิกทันที. การมี การรับรอง จึง ผูกกับการแลกเปลี่ยนข้อมูลระหว่างระบบ ไม่ใช่ แค่คำบนหน้าเว็บ.
ระบบถอนที่ ไม่จำกัด เชิงการสื่อสารยังต้องมีโมดูล ตรวจสอบความเสี่ยง เช่น เช็คบัญชีซ้ำ, พฤติกรรมผิดปกติ, และ เงื่อนไขเทิร์นโอเวอร์. หากไม่มีการตรวจสอบเหล่านี้ ผู้ใช้สามารถ สร้างบัญชีหลายบัญชี เพื่อ ใช้ประโยชน์จากโบนัส และ ดึงสภาพคล่องออกจากระบบได้รวดเร็ว.
ส่วน โปรโมชั่น VIP พันธมิตร ติดต่อ และฟีดแบ็ก เชื่อมกับ ระบบ CRM และ ฐานข้อมูลผู้ใช้. ส่วน Affiliate ใช้เก็บ referrer code เพื่อ คำนวณค่าคอมมิชชั่น. หากไม่มีระบบนี้ จะ ติดตามแหล่งที่มาของผู้ใช้ไม่ได้. ฟอร์มข้อเสนอแนะ ใช้เก็บ ข้อผิดพลาดจริงจากผู้ใช้. หากไม่มีข้อมูลนี้ ปัญหา latency หรือ การใช้งาน จะ แก้ไม่ทัน.
โครงสร้างทั้งหมด เชื่อมกันเป็นสายเดียว: สถานะธุรกรรมเข้ามาที่ backend, backend อัปเดตเครดิต แล้ว ซิงค์ไปยัง provider. หากส่วนใดส่วนหนึ่ง ช้า ผู้ใช้จะเห็นผลทันทีในรูปแบบ เครดิตไม่เข้า, เกมค้าง หรือ ถอนล่าช้า. ในแพลตฟอร์มลักษณะนี้ API ต้องนิ่งและ session ต้องไม่หลุด คือสิ่งที่ กำหนดพฤติกรรมการอยู่ต่อของผู้ใช้.
生命树2026 杨紫胡歌主演 海外华人高清现实主义陆剧 全球加速无广告追剧 AI推荐热播
Процедура длится от 40 минут до 2 часов, в зависимости от тяжести состояния, и проводится в комфортной домашней обстановке, что значительно снижает стресс у пациента и его близких.
Узнать больше – http://
plinko pin-up [url=http://pinup63481.help/]http://pinup63481.help/[/url]
1win sport tikish [url=https://1win5769.help/]https://1win5769.help/[/url]
Для эффективного лечения наши врачи используют только проверенные и сертифицированные медикаменты, которые подбираются индивидуально для каждого пациента. В состав лечебного курса входят:
Узнать больше – https://narcolog-na-dom-ekaterinburg000.ru/zapoj-narkolog-na-dom-ekb/
Данный порядок действий позволяет снизить риски для здоровья и обеспечить контроль за эффективностью процедур.
Ознакомиться с деталями – [url=https://narcolog-na-dom-sankt-peterburg0.ru/]нарколог на дом в санкт-петербурге[/url]
нейросеть генерации текстов для студентов [url=https://nejroset-dlya-ucheby-4.ru/]нейросеть генерации текстов для студентов[/url] .
秋雪漫过冬天2026 高清情感陆剧 海外华人无广告体验 全球加速实时更新
мостбет promo code [url=http://mostbet72413.help/]http://mostbet72413.help/[/url]
согласование перепланировки квартиры в москве [url=https://pereplanirovka-kvartir9.ru/]согласование перепланировки квартиры в москве[/url] .
ии для студентов [url=https://nejroset-dlya-ucheby-9.ru/]ии для студентов[/url] .
Привет всем! В этой статье я расскажу про гидроизоляцию крыши ТЦ. На практике понял: нужен результат — могу рекомендовать ребята: [url=https://montazh-membrannoj-krovli-spb.ru]https://montazh-membrannoj-krovli-spb.ru[/url]. Здесь такой момент: крыша без уклона — это специфический подход. Вот, то есть плохой водоотвод — слышишь постоянно про лужи? То есть технология нарушена. Мы используем разуклонку из керамзита, сверху — ПВХ мембрану. Вот потому что высокоэффективный инструмент. Что в итоге: никаких луж и протечек.
Для безопасного и эффективного лечения наши специалисты используют только проверенные и сертифицированные медикаменты, подбираемые индивидуально с учетом состояния пациента. В состав капельницы входят следующие группы препаратов:
Получить больше информации – [url=https://narcolog-na-dom-krasnodar0.ru/]вызвать врача нарколога на дом[/url]
[url=https://vikar-auto.ru]шумоизоляция авто[/url]
Athletic Bilbao vs Elche 2026 La Liga live – 21:00 kick-off thriller! Lions hungry for goals – Spanish football scores incoming hot!
玉茗茶骨2026 古装权谋爱情 海外华人高清在线观看 AI智能推荐热播陆剧
нейросеть для рефератов [url=https://nejroset-dlya-ucheby-8.ru/]нейросеть для рефератов[/url] .
генерация [url=https://nejroset-dlya-ucheby-5.ru/]nejroset-dlya-ucheby-5.ru[/url] .
заказ цветов мск – Ромашки полевые в букетах доступны
мостбет скачать приложение с сайта [url=https://www.mostbet72413.help]мостбет скачать приложение с сайта[/url]
сайт для рефератов [url=https://nejroset-dlya-ucheby-6.ru/]сайт для рефератов[/url] .
ии для студентов [url=https://nejroset-dlya-ucheby-7.ru/]nejroset-dlya-ucheby-7.ru[/url] .
Brest vs Marseille 2026 Ligue 1 blockbuster 20:45! Marseille road warriors clash – French football latest results & predictions!
нейросеть для студентов [url=https://nejroset-dlya-ucheby-3.ru/]нейросеть для студентов[/url] .
Одним из ключевых направлений является проведение капельниц, призванных вывести токсины из организма и нормализовать водно-электролитный баланс. Используемые препараты и состав растворов подбираются индивидуально, исходя из клинической картины и истории болезни пациента.
Детальнее – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]нарколог на дом цена в ярославле[/url]
pin-up app ishlamayapti [url=https://www.pinup63481.help]https://www.pinup63481.help[/url]
нейросеть онлайн для учебы [url=https://nejroset-dlya-ucheby-3.ru/]nejroset-dlya-ucheby-3.ru[/url] .
双轨2026 高清都市情感 海外华人专属平台 AI智能推荐高清
В этой статье-обзоре мы собрали данные, актуальность которых сомнительна, а факты — не всегда взаимосвязаны. Читатель сможет ознакомиться с разными мнениями, хотя вряд ли они существенно повлияют на его понимание темы.
Вот – [url=https://arma-rehab.ru/]онлайн покер на деньги[/url]
non prescription canadian pharmacy: https://canadianpharmacy-usa.net/# – online pharmacy canada
mostbet способы оплаты [url=https://mostbet26148.help/]https://mostbet26148.help/[/url]
1win вход быстро [url=http://1win52609.help/]1win вход быстро[/url]
сколько стоит перепланировка квартиры [url=https://skolko-stoit-uzakonit-pereplanirovku-8.ru/]сколько стоит перепланировка квартиры[/url] .
проект перепланировки москва [url=https://proekt-pereplanirovki-kvartiry22.ru/]проект перепланировки москва[/url] .
внедрение 1с москва [url=https://1s-vnedrenie.ru/]внедрение 1с москва[/url] .
暗夜情报员第三季2026 海外华人动作爽剧 Netflix全季上架 全球加速
crash мостбет [url=mostbet26148.help]crash мостбет[/url]
pg slot
PG Slot เกมสล็อตออนไลน์ที่คนค้นหาเยอะ เข้าเล่นไว ฝากถอนออโต้
คำค้นหา pg slot กำลังได้รับความนิยมอย่างต่อเนื่อง ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น แบรนด์เกมที่โดดเด่น ด้าน งานภาพคุณภาพสูง ความ นิ่งไม่สะดุด และ อัตราการจ่ายรางวัลที่น่าสนใจ เกมของ PG ออกแบบโดยทีมงานมืออาชีพ ที่รองรับการเล่นทั้งบน โทรศัพท์มือถือ และ พีซี
จุดเด่น ของ PG Slot
PG Slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เข้าเกมไว เล่นผ่าน ระบบเว็บ และรองรับ ทุกอุปกรณ์ เข้าเล่นผ่านเว็บได้เลย ผู้เล่นสามารถเข้าเล่นผ่าน เว็บเบราว์เซอร์ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ สามมิติ ให้ความคมชัด พร้อมเอฟเฟกต์ สวยงาม
คุณสมบัติหลักของเกม pg slot ได้แก่
โบนัสและฟรีสปินหลายแบบ
ฟีเจอร์ตัวคูณรางวัล
โหมดทดลองเล่นฟรี
มีเมนูภาษาไทย
ฝากถอนง่าย ไม่ต้องรอนาน
แพลตฟอร์ม สล็อต PG มักมี การฝาก-ถอน ออโต้ตลอด 24 ชม. ขั้นต่ำเริ่มต้นเพียง 10 บาท ขึ้นอยู่กับ ระบบของผู้ให้บริการ การทำรายการใช้เวลา ไม่กี่วินาที ผ่าน คิวอาร์โค้ด หรือระบบ ธนาคารบนมือถือ ทำให้ธุรกรรมเป็นไปอย่าง ลื่นไหล
ประเภทเกมยอดนิยม ใน PG Slot
เกม pg slot มีธีมหลากหลาย เช่น
ธีม เทพเจ้าและแฟนตาซี
ธีม ลุยด่าน
ธีม เอเชียและโชคลาภ
ธีม Animal
ผู้เล่นนิยมเกมที่มีรอบพิเศษบ่อย พร้อมระบบ โบนัสรอบพิเศษ และ ระบบจ่ายคุ้มค่า เหมาะกับทั้ง มือใหม่ และ สายสล็อตจริงจัง
ความปลอดภัย
PG Slot ใช้ระบบที่ได้มาตรฐาน มีการ รักษาความปลอดภัย และใช้ระบบสุ่มผล Random Number Generator เพื่อให้ผลลัพธ์ ตรวจสอบได้ แพลตฟอร์มที่ให้บริการ สล็อต PG ควรมี ความปลอดภัยสูง
โดยภาพรวม
PG Slot เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน กราฟิกคุณภาพ และการทำธุรกรรมที่ รวดเร็ว ผู้เล่นสามารถเริ่มต้นได้ ง่าย ฝากถอนสะดวก และเลือกเกมได้ ครบทุกหมวด เหมาะสำหรับ ทุกระดับประสบการณ์ ในโลกของเกมสล็อตออนไลน์
скачать мелбет на телефон официальный сайт [url=http://www.melbetmobi.ru]скачать мелбет на телефон официальный сайт[/url] .
Чем дольше человек находится в состоянии запоя, тем больше накапливаются токсины в организме, что негативно сказывается на всех системах. Отказ от алкоголя без должного контроля может привести к серьезным последствиям, таким как:
Разобраться лучше – [url=https://narcolog-na-dom-krasnodar0.ru/]выезд нарколога на дом краснодар[/url]
рабочее зеркало мелбет [url=http://melbet-ru.it.com/]рабочее зеркало мелбет[/url] .
Этот текст содержит различную информацию, которая, возможно, покажется любопытной, но в целом не меняет восприятия привычных вещей. Предлагаем просто получить удовольствие от чтения, не ожидая особой пользы.
Вот – [url=https://arma-rehab.ru/]рулетка онлайн[/url]
скачать приложение бк мелбет [url=http://www.melbetmobi.ru]скачать приложение бк мелбет[/url] .
Отличный сайт! Всем рекомендую![url=https://cubamobile.store/]купить смартфон xiaomi Екатеринбург[/url]
Лечение хронического алкоголизма начинается с купирования абстинентного синдрома, после чего проводятся мероприятия по нормализации работы печени, сердечно-сосудистой и нервной системы. Назначаются гепатопротекторы, ноотропы, витамины группы B. Также проводится противорецидивная терапия.
Подробнее тут – https://narkologicheskaya-klinika-v-yaroslavle12.ru/narkologicheskaya-klinika-telefon-v-yaroslavle
mostbet как получить фриспины [url=https://www.mostbet26148.help]mostbet как получить фриспины[/url]
1win лайв казино Кыргызстан [url=http://1win50742.help/]1win лайв казино Кыргызстан[/url]
melbet скачать на айфон без аппстор [url=https://mobilemelbet.ru]melbet скачать на айфон без аппстор[/url] .
mostbet фриспины на сегодня [url=http://mostbet26148.help/]http://mostbet26148.help/[/url]
1win istoric pariuri [url=https://www.1win5807.help]https://www.1win5807.help[/url]
Данный порядок действий позволяет снизить риски для здоровья и обеспечить контроль за эффективностью процедур.
Разобраться лучше – [url=https://narcolog-na-dom-sankt-peterburg0.ru/]нарколог на дом недорого[/url]
1win последняя версия apk [url=www.1win52609.help]www.1win52609.help[/url]
1win промо код [url=https://www.1win50742.help]https://www.1win50742.help[/url]
1вин android [url=https://1win50742.help]https://1win50742.help[/url]
1win mines игра [url=https://www.1win52609.help]https://www.1win52609.help[/url]
ทดลองเล่นสล็อต pg
แพลตฟอร์ม TKB NEKO นำเสนอ พื้นที่ออนไลน์ที่ทันสมัย ซึ่ง ผู้ที่สนใจ สามารถ ทดลองใช้งาน ประสบการณ์เกมออนไลน์ รวมถึง โอกาสสร้างรายได้แบบรวดเร็ว เว็บไซต์นี้ นำเสนอแนวคิดว่าทุกคนมีสิทธิ์ประสบความสำเร็จ เนื่องจาก ออกแบบมาให้เข้าถึงได้ทุกกลุ่มผู้เล่น
หนึ่งใน คุณสมบัติหลัก ของแพลตฟอร์มนี้คือ ระบบการเงิน ซึ่งมีขั้นต่ำในการเติมเงินเพียง ขั้นต่ำแค่ 1 บาท และขั้นต่ำในการถอนเงินก็เช่นเดียวกันที่ เริ่มต้น 1 บาท เท่านั้น กระบวนการเติมเงินใช้เวลาเพียง 3 วินาที ทำให้แพลตฟอร์มนี้ โดดเด่นด้านความเร็ว นอกจากนี้ยัง ไม่มีวงเงินจำกัดในการถอน ซึ่งเป็น ปัจจัยสำคัญที่สร้างความแตกต่าง
สำหรับการเติมเงิน รองรับการฝากเงินผ่าน QR Code ซึ่งเป็นระบบที่ เพิ่มความรวดเร็วในการทำธุรกรรม
แพลตฟอร์มนี้มีเกมให้เลือก ครบทุกหมวดหมู่ เช่น เกมสล็อต, Live Casino, เดิมพันกีฬา และ ยิงปลา ผู้เล่นสามารถดูรายชื่อเกมทั้งหมดได้ผ่านตัวกรอง “All Games” ซึ่งช่วยให้ ผู้เล่นเลือกเกมที่ตรงกับความสนใจได้อย่างลงตัว
TKBNEKO ให้ความสำคัญกับความโปร่งใสและมาตรฐานเกม โดยร่วมมือกับ พันธมิตรเกมที่ผ่านมาตรฐานสากล ซึ่งช่วยให้มั่นใจได้ว่า ทุกเกมเป็นไปตามมาตรฐานความปลอดภัย
TKBNEKO ได้ผสานระบบการชำระเงินเข้ากับ ธนาคารชั้นนำของประเทศไทย เช่น Krungthai Bank, Bangkok Bank, SCB, Kasikorn Bank, Thanachart Bank, GSB, TrueMoney Wallet, Citibank, UOB และ BAAC ทำให้การทำธุรกรรมทางการเงิน รวดเร็วและปลอดภัยยิ่งกว่าเดิม
สรุปได้ว่า TKBNEKO คือแพลตฟอร์มที่ ครบวงจรสำหรับเกมออนไลน์ สำหรับเกมออนไลน์และการเดิมพัน ด้วยเงื่อนไขขั้นต่ำที่ต่ำ การทำธุรกรรมที่รวดเร็ว และเกมให้เลือกมากมาย ทำให้แพลตฟอร์มนี้ เหมาะสำหรับทั้งผู้เริ่มต้นและผู้เล่นที่มีประสบการณ์ ร่วมสนุกได้เลยวันนี้ และ เปิดประสบการณ์ใหม่กับโลกแห่งความบันเทิงและการเดิมพัน
Эффективное лечение требует поэтапного подхода, который реализуется следующим образом:
Узнать больше – http://narkologicheskaya-klinika-v-ryazani12.ru/narkologicheskaya-klinika-czeny-v-ryazani/
Наркологическая клиника в Рязани предоставляет квалифицированную помощь пациентам, страдающим от алкогольной, наркотической и медикаментозной зависимости. Здесь проводится полный цикл медицинской и психотерапевтической поддержки, начиная с детоксикации и заканчивая восстановительным этапом. Учреждение оборудовано современными технологиями, а персонал обладает подтверждённой квалификацией и практическим опытом.
Изучить вопрос глубже – https://narkologicheskaya-klinika-v-ryazani12.ru/narkologicheskaya-klinika-czeny-v-ryazani
Одновременно с медикаментозной детоксикацией начинается работа по снижению эмоционального напряжения. Психотерапевтическая помощь помогает пациенту осознать причины зависимости и выработать стратегии для предотвращения рецидивов, что является важным аспектом успешного лечения.
Подробнее тут – [url=https://vyvod-iz-zapoya-volgograd00.ru/]скорая вывод из запоя волгоград[/url]
1win оптимабанк пополнение [url=https://1win50742.help/]https://1win50742.help/[/url]
Группа препаратов
Ознакомиться с деталями – [url=https://narcolog-na-dom-ekaterinburg000.ru/]частный нарколог на дом[/url]
mostbet пайванди нав [url=mostbet43926.help]mostbet43926.help[/url]
«Билайн» в Калуге предлагают:
• интерактивное ТВ;
• быстрое подключение за 1 день;
• Определение оптимального сочетания интернета и ТВ под ваши задачи;
• Проверку инфраструктуры по вашему адресу.
[url=https://kaluga-beeline.ru/]оптоволоконный интернет билайн[/url]
beeline домашний интернет тарифы – [url=http://kaluga-beeline.ru/]https://kaluga-beeline.ru/[/url]
[url=http://images.google.vu/url?q=https://kaluga-beeline.ru/]http://clients3.google.com/url?q=https://kaluga-beeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.pelsh.forum24.ru/www.elektrokarnizy50.ru/www.sportbets31.ru/2bs2bet.at]Интернет и ТВ от «Билайн» в Калуге[/url] 5c29ee4
«Билайн» в Брянске предоставляют:
• пакет из 150+ ТВ каналов;
• поддержки 24/7;
• Определение оптимального пакета услуг под ваши задачи;
• Анализ технической доступности по вашему адресу.
[url=https://bryansk-beeline.ru/]стоимость интернета билайн[/url]
билайн тв и интернет тарифы брянск – [url=https://bryansk-beeline.ru/]http://bryansk-beeline.ru[/url]
[url=https://clients1.google.vg/url?q=https://bryansk-beeline.ru/]https://www.google.com.pg/url?q=https://bryansk-beeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.pelsh.forum24.ru/www.soglasovanie-pereplanirovki-kvartiry11.ru/www.soglasovanie-pereplanirovki-kvartiry4.ru/www.rudik-diplom9.ru/www.rudik-diplom6.ru/www.zakazat-onlayn-translyaciyu4.ru]Интернет и ТВ от «Билайн» в вашем доме[/url] a59a545
мелбет бк [url=http://www.gamemelbet.ru]мелбет бк[/url] .
Чтобы показать, как именно работает врач в домашних условиях, можно сопоставить основные проявления запоя и шаги нарколога, направленные на их устранение.
Получить дополнительную информацию – [url=https://narcolog-na-dom-ryazan0.ru/]нарколог на дом срочно санкт-петербург[/url]
1win cod bonus casino [url=https://www.1win5807.help]https://www.1win5807.help[/url]
мостбет лотерея [url=https://www.mostbet43926.help]https://www.mostbet43926.help[/url]
В этой статье мы рассмотрим современные достижения в области медицины, включая инновационные методы лечения и диагностики. Мы обсудим важность профилактики заболеваний и роль технологий в улучшении качества здравоохранения. Читатели узнают о влиянии медицины на повседневную жизнь и ее значение для современного общества.
Выяснить больше – http://google.com.pe/url?sa=t&url=https://moskva.pohmelochnaya.ru/anonimnaya-narkologicheskaya-pomosch
Минское «Динамо» — пример современного хоккейного клуба: международный состав, сильная школа и невероятная атмосфера матчей. Подробнее здесь: https://cont.ws/@sirgreensz/3129433
Высокий уровень лечения обеспечивается квалификацией врачей, имеющих опыт работы в области наркологии, а также современным медицинским оборудованием, позволяющим проводить диагностику и лечение на самом высоком уровне. Врачи регулярно повышают квалификацию, участвуя в конференциях и обучающих программах. Подробности о квалификации специалистов доступны на портале медицинского сообщества.
Подробнее – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]наркологическая клиника вывод из запоя в каменске-уральском[/url]
В данном тексте собраны разнообразные случайные сведения и не вполне определённые идеи, которые могут вызвать интерес. Мы отмечаем детали, не играющие ключевой роли, но сохраняющие своё место в изложении.
Подробнее читать – [url=https://rostov-narkologiya.ru/ ]детокс чай для похудения[/url]
Длительный запой способен нанести непоправимый вред организму, привести к тяжелым нарушениям работы внутренних органов и поставить под угрозу жизнь пациента. В таких случаях необходимо срочное медицинское вмешательство, которое позволяет быстро стабилизировать состояние, вывести токсины и предотвратить развитие опасных осложнений. Клиника «ЗдоровьеНорм» в Краснодаре предлагает профессиональный вывод из запоя на дому, обеспечивая комплексное лечение с максимальной оперативностью и полной конфиденциальностью.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя вызов на дом краснодар[/url]
online pharmacy canada: https://canadianpharmacy-store.net/# – canadian pharmacy otc
When Zeus wakes up angry in gatesofolympusgm.org, balances explode. Multiplier after multiplier crashes down without mercy. Spin Gates of Olympus — survive the blessing.
обзор образовательных платформ [url=https://best-schools-online.ru/]best-schools-online.ru[/url] .
สล็อต PG สล็อตยอดฮิต ใช้งานง่าย ฝากถอนรวดเร็ว
คำค้นหา สล็อต PG กำลังได้รับความนิยมอย่างต่อเนื่อง ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น แบรนด์เกมที่โดดเด่น ด้าน กราฟิก ความ ลื่นไหล และ โอกาสรับกำไรที่ดี เกมของ PG ออกแบบโดยทีมงานมืออาชีพ ที่รองรับการเล่นทั้งบน มือถือ และ คอมพิวเตอร์
จุดเด่น ของ PG Slot
PG Slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ โหลดเร็ว เล่นผ่าน ระบบออนไลน์ และรองรับ ทั้ง iOS และ Android เข้าเล่นผ่านเว็บได้เลย ผู้เล่นสามารถเข้าเล่นผ่าน หน้าเว็บ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ เอฟเฟกต์ 3 มิติ ให้ความคมชัด พร้อมเอฟเฟกต์ สมจริง
คุณสมบัติหลักของเกม pg slot ได้แก่
มีรอบโบนัสให้ลุ้นบ่อย
ระบบตัวคูณ
เล่นฟรีก่อนเติมเงิน
รองรับภาษาไทยเต็มรูปแบบ
ระบบการเงินรวดเร็ว ทันใจ
แพลตฟอร์ม pg slot โดยทั่วไปให้บริการ การฝาก-ถอน ออโต้ตลอด 24 ชม. ขั้นต่ำเริ่มต้นเพียง หลักหน่วย ขึ้นอยู่กับ เงื่อนไขของเว็บไซต์ การทำรายการใช้เวลา เพียงไม่กี่วินาที ผ่าน คิวอาร์โค้ด หรือระบบ Mobile Banking ทำให้ธุรกรรมเป็นไปอย่าง ลื่นไหล
หมวดเกมฮิต ใน PG Slot
เกม สล็อต PG มีธีมหลากหลาย เช่น
ธีม แฟนตาซี
ธีม ลุยด่าน
ธีม เอเชียและโชคลาภ
ธีม สัตว์และธรรมชาติ
หลายคนชอบเกมที่โบนัสเข้าไว พร้อมระบบ Special Feature และ ระบบจ่ายคุ้มค่า เหมาะกับทั้ง ผู้เล่นเริ่มต้น และ ผู้เล่นที่มีประสบการณ์
มาตรฐานระบบ
PG Slot ใช้ระบบที่ได้มาตรฐาน มีการ ปกป้องข้อมูลผู้เล่น และใช้ระบบสุ่มผล ระบบสุ่มมาตรฐาน เพื่อให้ผลลัพธ์ โปร่งใส แพลตฟอร์มที่ให้บริการ pg slot ควรมี ทีมซัพพอร์ต 24 ชม.
สรุป
pg slot เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน โบนัสหลากหลาย และการทำธุรกรรมที่ ทันใจ ผู้เล่นสามารถเริ่มต้นได้ ไม่ซับซ้อน ฝากถอนสะดวก และเลือกเกมได้ จำนวนมาก เหมาะสำหรับ ผู้เล่นทุกสไตล์ ในโลกของเกมสล็อตออนไลน์
анализ карточек маркетплейс [url=https://reklamnyj-kreativ9.ru/]анализ карточек маркетплейс[/url] .
Текст включает разнообразную информацию, которая может показаться любопытной, но не меняет устоявшегося восприятия. Предлагаем просто насладиться чтением, не ожидая значительной пользы.
Подробнее читать – [url=https://rostov-narkologiya.ru/ ]похудеть на таблетках[/url]
1win вход не работает сегодня [url=https://1win50742.help]https://1win50742.help[/url]
проект водопонижения [url=https://vodoponizhenie-msk.ru/]vodoponizhenie-msk.ru[/url] .
«Билайн» в Калуге предлагают:
• пакет из 150+ ТВ каналов;
• бесплатный монтаж оборудования;
• Определение оптимального сочетания интернета и ТВ под ваши задачи;
• Анализ технической доступности по вашему адресу.
[url=https://kaluga-beeline.ru/]подключен ли дом к интернету билайн Калуга[/url]
подключить домашний интернет билайн Калуга – [url=http://kaluga-beeline.ru]https://www.kaluga-beeline.ru[/url]
[url=https://cse.google.mn/url?sa=i&url=https://kaluga-beeline.ru/]https://clients1.google.am/url?q=https://kaluga-beeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.1xbet-14.com/www.torkretirovanie-1.ru/www.r-diploma19.ru/r-diploma23.ru]Высокоскоростной интернет и ТВ от «Билайн» в Калуге[/url] f200021
Brann 0-1 Bologna 2026 Europa League tight win! Italians steal it late – latest results heating up knockout race!
иглофильтровое водопонижение [url=https://vse-o-vodoponizhenii.ru/]иглофильтровое водопонижение[/url] .
бурение скважин обратной промывкой [url=https://vodoponizhenie-blog.ru/]бурение скважин обратной промывкой[/url] .
Dubai escorts offers premium lifestyle and entertainment services in UAE, providing a discreet, professional, and client-focused experience. Escorts in Dubai
«Билайн» в Брянске предлагают:
• высокоскоростной интернет до 500 Мбит/с;
• поддержки 24/7;
• Определение оптимального сочетания интернета и ТВ под ваши задачи;
• Анализ инфраструктуры по вашему адресу.
[url=https://bryansk-beeline.ru/]подключить домашний интернет билайн[/url]
подключен ли дом к интернету билайн брянск – [url=https://bryansk-beeline.ru]http://www.bryansk-beeline.ru[/url]
[url=http://toolbarqueries.google.nl/url?sa=t&url=https://bryansk-beeline.ru/]https://clients1.google.co.id/url?sa=t&url=https://bryansk-beeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.arus-diplom31.ru/www.ustroystvo-gidroizolyacii.ru/www.rudik-diplom6.ru/www.elektrokarniz499.ru]Интернет и цифровое ТВ от «Билайн» в вашем доме[/url] 29ee480
анализ наружной рекламы [url=https://reklamnyj-kreativ8.ru/]анализ наружной рекламы[/url] .
При таких проявлениях самостоятельное вмешательство не рекомендуется, так как это может привести к ухудшению состояния. Своевременное обращение к врачу позволит предотвратить тяжелые осложнения и эффективно стабилизировать состояние больного.
Детальнее – https://narcolog-na-dom-novosibirsk0.ru/narkolog-na-dom-czena-novosibirsk
best sms activate service [url=https://github.com/SMS-Activate-Login]github.com/SMS-Activate-Login[/url] .
система водопонижения иглофильтрами [url=https://vodoponizhenie-moskva.ru/]vodoponizhenie-moskva.ru[/url] .
система водопонижения грунтовых вод [url=https://xn—77-eddkgagrc5cdhbap.xn--p1ai/]xn—77-eddkgagrc5cdhbap.xn--p1ai[/url] .
бурение водопонижение [url=https://vodoponizhenie-iglofiltrami-moskva.ru/]vodoponizhenie-iglofiltrami-moskva.ru[/url] .
Запой — это тяжёлое состояние, характеризующееся длительным употреблением алкоголя, при котором человек не в силах самостоятельно прекратить пить. Алкогольная интоксикация при длительных запоях вызывает нарушения в работе всех органов и систем, приводя к серьёзным последствиям, таким как инфаркты, инсульты, психозы и даже летальный исход. В такой ситуации единственным надёжным решением становится обращение за профессиональной помощью.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-korolev2.ru/]vyvod iz zapoya na domu kruglosutochno[/url]
[url=https://elixiumhealth.digital/#]order ed meds[/url]
Candy avalanche incoming! sugar rush cluster pays delivers non-stop cascades and growing multiplier madness. Get ready to win!
1win минимальный вывод [url=https://www.pharm.kg]1win минимальный вывод[/url]
cheap ed pills https://elixiumhealth.digital/# top rated ed pills
После первичной диагностики начинается активная фаза детоксикации. Современные препараты вводятся капельничным методом, что позволяет быстро снизить концентрацию токсинов в крови и восстановить нормальные обменные процессы. Этот этап является основополагающим для стабилизации работы внутренних органов, таких как печень, почки и сердце.
Подробнее – https://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-tyumen/
sms activator [url=https://github.com/SMS-Activate-Login]github.com/SMS-Activate-Login[/url] .
[url=https://elixiumhealth.digital/#]erectile dysfunction medication[/url]
Главная цель — безопасно стабилизировать состояние, вернуть контроль над сном, гидратацией и базовой активностью в первые сутки и удержать результат. Для этого мы используем модульный подход: один этап — одна клиническая задача — один измеримый маркер. Такой принцип исключает «гонку доз», снижает риск перегрузки объёмом и делает прогноз понятным для пациента и близких. Мы сознательно разделяем «короткие эффекты» (уменьшение тошноты, сглаживание тахикардии) и «эффекты консолидации» (устойчивый сон, ясность утром), чтобы каждая корректировка была точной и доказуемой.
Ознакомиться с деталями – http://narkologicheskaya-klinika-v-nizhnem-novgorode16.ru/chastnaya-narkologicheskaya-klinika-nizhnij-novgorod/
top sms activate alternatives [url=https://www.linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre/]top sms activate alternatives[/url] .
1win пополнение не проходит [url=https://pharm.kg/]https://pharm.kg/[/url]
Pure emotion ReislinOfficiall bold presentation, and a private format without boundaries. Exclusive content, personally created and available only here—for those who appreciate true energy.
Запой — это не просто длительное употребление алкоголя, а тяжелое состояние, когда организм перестает функционировать нормально без постоянного поступления этанола. При запое происходит накопление токсинов, что ведет к нарушению работы внутренних органов и сильному ослаблению иммунной системы. Пациенты часто испытывают невыносимые физические и психические страдания, а попытки самостоятельно выйти из запоя только усугубляют ситуацию.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-krasnoyarsk0.ru/]вывод из запоя клиника[/url]
1win слоты [url=pharm.kg]pharm.kg[/url]
erectile dysfunction natural pills https://elixiumhealth.digital/# over the counter erectile dysfunction pills cvs
Как отмечает главный врач клиники, кандидат медицинских наук Сергей Иванов, «мы создали систему, при которой пациент получает помощь в течение часа — независимо от дня недели и времени суток. Это принципиально меняет шансы на выздоровление».
Изучить вопрос глубже – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]poryadok-narkologicheskoj-pomoshchi[/url]
For those seeking expert residential and commercial painting within Los Angeles County, experienced specialists ensure a flawless finish with zero mess and strictly adhering to your schedule tailored to your specific needs.
Service link- https://www.urban-studies.eu/?p=757
Основная проблема запоя заключается в том, что человек постепенно теряет контроль над ситуацией, а его организм подвергается всё более тяжёлой интоксикации. Определить момент, когда требуется немедленное обращение за помощью, несложно, если внимательно следить за состоянием человека.
Узнать больше – [url=https://vyvod-iz-zapoya-korolev2.ru/]vyvod iz zapoya na domu korolev[/url]
согласование перепланировки в москве [url=https://sostav.ru/blogs/286398/77663/]согласование перепланировки в москве[/url] .
best sms activation services [url=https://github.com/SMS-Activate-Service]github.com/SMS-Activate-Service[/url] .
«Билайн» в Хабаровске предлагают:
• высокоскоростной интернет до 500 Мбит/с;
• поддержки 24/7;
• Подбор оптимального тарифа под ваши задачи;
• Проверку технической доступности по вашему адресу.
[url=https://khabarovsk-beeline.ru/]билайн тв и интернет цена[/url]
проводной интернет билайн тарифы – [url=https://khabarovsk-beeline.ru]http://www.khabarovsk-beeline.ru[/url]
[url=https://clients1.google.az/url?sa=t&url=https://khabarovsk-beeline.ru/]https://image.google.mn/url?q=https://khabarovsk-beeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.elektrokarnizy150.ru/www.melbetofficialsite.ru/www.zakazat-onlayn-translyaciyu4.ru]Интернет и ТВ от «Билайн» в вашем доме[/url] 29ee488
best virtual number service [url=https://github.com/SMS-Activate-Alternatives]github.com/SMS-Activate-Alternatives[/url] .
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Получить больше информации – [url=https://snyatie-lomki-podolsk1.ru/]снятие наркотической ломки в подольске[/url]
Многие семьи сталкиваются с трудностями, когда зависимый отказывается ехать в клинику. В таких случаях выездная помощь становится первым шагом к выздоровлению. Однако не все службы предлагают одинаково безопасный и профессиональный подход. Чтобы избежать рисков и ошибок, важно понимать, на что обращать внимание при выборе услуги “нарколог на дом”.
Подробнее тут – http://narkolog-na-dom-nizhnij-tagil11.ru
PG Slot เกมสล็อตออนไลน์ที่คนค้นหาเยอะ เข้าเล่นไว ฝากถอนออโต้
คำค้นหา pg slot ถูกค้นหามากขึ้นเรื่อยๆ ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น แบรนด์เกมที่โดดเด่น ด้าน ภาพและเอฟเฟกต์ ความ ลื่นไหล และ อัตราการจ่ายรางวัลที่น่าสนใจ เกมของ PG ผลิตโดยค่ายมาตรฐาน ที่รองรับการเล่นทั้งบน มือถือ และ พีซี
ความโดดเด่น ของ pg slot
สล็อต PG เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เปิดเกมได้ทันที เล่นผ่าน ระบบอัตโนมัติ และรองรับ ทุกอุปกรณ์ ไม่ต้องติดตั้งเพิ่มเติม ผู้เล่นสามารถเข้าเล่นผ่าน หน้าเว็บ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ เอฟเฟกต์ 3 มิติ ให้ความคมชัด พร้อมเอฟเฟกต์ สวยงาม
คุณสมบัติหลักของเกม pg slot ได้แก่
มีรอบโบนัสให้ลุ้นบ่อย
ระบบตัวคูณ
เดโม่ฟรี
รองรับภาษาไทยเต็มรูปแบบ
ระบบฝากถอนสะดวก ไม่ต้องรอนาน
แพลตฟอร์ม pg slot โดยทั่วไปให้บริการ การฝาก-ถอน ฝากถอนตลอดเวลา ขั้นต่ำเริ่มต้นเพียง หลักหน่วย ขึ้นอยู่กับ เงื่อนไขของเว็บไซต์ การทำรายการใช้เวลา ไม่กี่วินาที ผ่าน สแกน QR หรือระบบ ธนาคารบนมือถือ ทำให้ธุรกรรมเป็นไปอย่าง ไม่สะดุด
ประเภทเกมยอดนิยม ใน pg slot
เกม สล็อต PG มีธีมหลากหลาย เช่น
ธีม เทพเจ้า
ธีม ผจญภัย
ธีม ความมั่งคั่ง
ธีม ธรรมชาติ
เกมยอดนิยมมักเป็นเกมที่แตกง่าย พร้อมระบบ โบนัสรอบพิเศษ และ อัตราการจ่ายที่สูง เหมาะกับทั้ง คนเพิ่งเล่น และ ผู้เล่นมือโปร
มาตรฐานระบบ
สล็อต PG พัฒนาในระบบสากล มีการ เข้ารหัสข้อมูล และใช้ระบบสุ่มผล Random Number Generator เพื่อให้ผลลัพธ์ ยุติธรรม แพลตฟอร์มที่ให้บริการ สล็อต PG ควรมี ระบบดูแลข้อมูล
บทสรุปท้ายบท
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน กราฟิกคุณภาพ และการทำธุรกรรมที่ ไว ผู้เล่นสามารถเริ่มต้นได้ ง่าย ฝากถอนสะดวก และเลือกเกมได้ ครบทุกหมวด เหมาะสำหรับ ทั้งมือใหม่และมือโปร ในโลกของเกมสล็อตออนไลน์
erection pills online https://elixiumhealth.digital/# best erectile dysfunction pills over the counter
สล็อต PG แพลตฟอร์มเกมสล็อตยอดนิยม เล่นง่าย ฝากถอนเร็ว
คำค้นหา PG Slot มาแรงในช่วงนี้ ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น แบรนด์เกมที่โดดเด่น ด้าน กราฟิก ความ เสถียร และ โอกาสรับกำไรที่ดี เกมของ PG พัฒนาโดยผู้ให้บริการชั้นนำ ที่รองรับการเล่นทั้งบน โทรศัพท์มือถือ และ เดสก์ท็อป
ความโดดเด่น ของ PG Slot
pg slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ โหลดเร็ว เล่นผ่าน ระบบอัตโนมัติ และรองรับ ทุกแพลตฟอร์ม เข้าเล่นผ่านเว็บได้เลย ผู้เล่นสามารถเข้าเล่นผ่าน เว็บเบราว์เซอร์ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ เอฟเฟกต์ 3 มิติ ให้ความคมชัด พร้อมเอฟเฟกต์ สวยงาม
คุณสมบัติหลักของเกม สล็อต PG ได้แก่
ระบบโบนัสและฟรีสปินหลากหลายรูปแบบ
ระบบตัวคูณ
เล่นฟรีก่อนเติมเงิน
รองรับภาษาไทยเต็มรูปแบบ
ฝากถอนง่าย ทำรายการไว
แพลตฟอร์ม สล็อต PG โดยทั่วไปให้บริการ การฝาก-ถอน ฝากถอนตลอดเวลา ขั้นต่ำเริ่มต้นเพียง 10 บาท ขึ้นอยู่กับ ระบบของผู้ให้บริการ การทำรายการใช้เวลา รวดเร็วมาก ผ่าน คิวอาร์โค้ด หรือระบบ ธนาคารบนมือถือ ทำให้ธุรกรรมเป็นไปอย่าง ลื่นไหล
แนวเกมที่คนเล่นเยอะ ใน PG Slot
เกม PG Slot มีธีมหลากหลาย เช่น
ธีม เทพเจ้าและแฟนตาซี
ธีม Adventure
ธีม โชคลาภ
ธีม Animal
เกมยอดนิยมมักเป็นเกมที่แตกง่าย พร้อมระบบ โบนัสรอบพิเศษ และ โอกาสทำกำไรสูง เหมาะกับทั้ง คนเพิ่งเล่น และ สายสล็อตจริงจัง
ความปลอดภัย
สล็อต PG พัฒนาในระบบสากล มีการ รักษาความปลอดภัย และใช้ระบบสุ่มผล ระบบสุ่มมาตรฐาน เพื่อให้ผลลัพธ์ ตรวจสอบได้ แพลตฟอร์มที่ให้บริการ สล็อต PG ควรมี ทีมซัพพอร์ต 24 ชม.
โดยภาพรวม
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน โบนัสหลากหลาย และการทำธุรกรรมที่ รวดเร็ว ผู้เล่นสามารถเริ่มต้นได้ ง่าย ฝากถอนสะดวก และเลือกเกมได้ หลากหลายแนว เหมาะสำหรับ ทั้งมือใหม่และมือโปร ในโลกของเกมสล็อตออนไลน์
Поэтому наша служба экстренного выезда работает круглосуточно. Медицинская бригада приезжает на вызов в любой район Балашихи в течение часа. Пациенту ставят капельницы, стабилизируют давление, снимают судорожный синдром и устраняют тревожность. Всё это проходит под наблюдением опытных врачей, которые ежедневно сталкиваются с острыми ситуациями и знают, как действовать быстро и безопасно.
Выяснить больше – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]narkologicheskaya-pomoshch-balashiha[/url]
ทดลองเล่นสล็อต pg
TKBNEKO มอบมิติใหม่ของเกมออนไลน์ ฝาก-ถอนไว ด้วยระบบสแกน คิวอาร์โค้ด
ในยุคดิจิทัลที่ เทคโนโลยีพัฒนาอย่างรวดเร็ว TKBNEKO พร้อมยกระดับการให้บริการ ด้วยระบบที่ ทันสมัย เสถียร และ โปร่งใส เพื่อให้ผู้เล่น มั่นใจ ทุกครั้งที่ใช้งาน
จุดเด่นระบบฝาก-ถอน
ฝากขั้นต่ำ: 1 บาท
ถอนขั้นต่ำ: 1 บาท
เวลาฝากเงิน: ภายใน 3 วินาที
ยอดถอน: ไม่มีลิมิต
ฝากง่าย เพียงสแกน QR Code
สแกน คิวอาร์ ระบบจะ ประมวลผลอัตโนมัติ ขั้นต่ำ 100 บาท สูงสุด ไม่เกิน 500,000 บาทต่อครั้ง
เกมยอดนิยม
สล็อต: ธีมหลากหลาย
เกมสด: คาสิโนเรียลไทม์
กีฬา: แมตช์ทั่วโลก
ยิงปลา: สนุกได้เงินจริง
โบนัสและโปรโมชัน
ติดตามหน้า โปรโมชั่น พร้อมระบบ VIP และโปรแกรม พันธมิตร
ติดต่อเรา
สอบถามข้อมูลได้ตลอด 24 ชั่วโมง ผ่านหน้า ติดต่อเรา ทีมงาน TKBNEKO พร้อมดูแลตลอดเวลา
[url=http://imitrexpharm.top/#]buy sumatriptan no prescription[/url]
Запой — это тяжёлое состояние, характеризующееся длительным употреблением алкоголя, при котором человек не в силах самостоятельно прекратить пить. Алкогольная интоксикация при длительных запоях вызывает нарушения в работе всех органов и систем, приводя к серьёзным последствиям, таким как инфаркты, инсульты, психозы и даже летальный исход. В такой ситуации единственным надёжным решением становится обращение за профессиональной помощью.
Получить дополнительную информацию – http://vyvod-iz-zapoya-korolev2.ru/vyvod-iz-zapoya-kruglosutochno/
«Билайн» в Иваново предоставляют:
• интерактивное ТВ;
• поддержки 24/7;
• Подбор оптимального сочетания интернета и ТВ под ваши задачи;
• Проверку инфраструктуры по вашему адресу.
[url=https://ivanovobeeline.ru/]проводной интернет билайн тарифы[/url]
билайн тарифы на домашний интернет и телевидение – [url=https://ivanovobeeline.ru]https://www.ivanovobeeline.ru/[/url]
[url=https://images.google.co.kr/url?sa=t&url=https://ivanovobeeline.ru/]https://toolbarqueries.google.gl/url?q=https://ivanovobeeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.iskusstvennaya-kozha-dlya-mebeli-kupit.ru/www.arus-diplom35.ru/www.kinogo-11.top/www.mostbet12032.ru]Домашний интернет и цифровое ТВ от «Билайн» в вашем доме[/url] 02104a5
purchase imitrex online no prescription http://imitrexpharm.top/# where buy imitrex
Запой — это не просто периодическое употребление спиртного, а опасное состояние, при котором организм находится в постоянной интоксикации, теряет ресурсы и перестаёт справляться с последствиями этанола. Со временем развивается тяжёлое отравление, нарушается работа сердца, печени, мозга, а попытка «самостоятельно бросить» может привести к судорогам, галлюцинациям и даже коме. Именно поэтому важно вовремя обратиться за медицинской помощью. В Серпухове вывод из запоя осуществляет наркологическая клиника «Новая Энергия» — мы выезжаем на дом круглосуточно и при необходимости госпитализируем пациента в стационар.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-serpuhov3.ru/]vyvod-iz-zapoya-deshevo[/url]
приложение мелбет
Скачать приложение Melbet: APK, iPhone и ПК
Приложение Melbet включает букмекерскую контору и казино в одном интерфейсе. Пользователю доступны live-ставки, слоты, прямые трансляции, аналитика и операции по счёту. Установка занимает 1–2 минуты.
Android (APK)
Загрузите APK с официального сайта, откройте файл и завершите установку. Если требуется включите доступ к установке сторонних приложений, затем войдите в аккаунт.
iOS (iPhone)
Перейдите в App Store, найдите «Melbet», выберите «Получить», после установки авторизуйтесь в системе.
ПК
Перейдите официальный сайт, войдите в личный кабинет и создайте ярлык на рабочий стол. Браузерная версия функционирует как отдельное приложение.
Функционал
Live-ставки с обновлением коэффициентов, игровой раздел с тысячами игр, просмотр матчей, аналитические данные, push-оповещения, быстрая регистрация и поддержка 24/7.
Бонусы
После установки доступны приветственный бонус, акционные коды и фрибеты. Условия зависят от региона.
Безопасность
Загружайте только с официального сайта, проверяйте домен, не передавайте пароль третьим лицам и активируйте двухфакторную аутентификацию.
Загрузка выполняется быстро, после чего доступен весь функционал Melbet.
вход в мелбет
Установить приложение Melbet: Android, iOS и ПК
Приложение Melbet включает букмекерскую контору и казино в едином приложении. Доступны live-ставки, казино-игры, прямые трансляции, статистика и быстрые финансовые операции. Загрузка занимает 1–2 минуты.
Android (APK)
Загрузите APK с официального сайта, запустите установщик и завершите установку. При необходимости включите разрешение на установку из неизвестных источников, затем войдите в аккаунт.
iOS (iPhone)
Перейдите в App Store, введите в поиске «Melbet», нажмите «Получить», после установки выполните вход.
ПК
Откройте официальный сайт, войдите в личный кабинет и создайте ярлык на рабочий стол. Браузерная версия функционирует как полноценное приложение.
Функционал
Live-ставки с обновлением коэффициентов, казино и слоты, прямые трансляции, подробная статистика, уведомления о матчах, быстрая регистрация и круглосуточная служба поддержки.
Бонусы
После загрузки доступны приветственный бонус, промокоды и фрибеты. Правила начисления определяются регионом.
Безопасность
Загружайте только с официальных источников, проверяйте домен, не сообщайте данные доступа третьим лицам и включите 2FA.
Установка занимает несколько минут, после чего открывается полный доступ Melbet.
В течение полугода пациент может бесплатно посещать онлайн-группы поддержки и консультироваться у психологов клиники.
Узнать больше – https://lechenie-narkomanii-volgograd9.ru/czentr-lecheniya-narkomanii-volgograd/
«Билайн» в Ульяновске предоставляют:
• высокоскоростной интернет до 500 Мбит/с;
• бесплатный монтаж оборудования;
• Определение оптимального сочетания интернета и ТВ под ваши задачи;
• Проверку возможности подключения по вашему адресу.
[url=https://ulyanovsk-beeline.ru/]подключить билайн интернет и телевидение[/url]
домашний интернет билайн – [url=https://www.ulyanovsk-beeline.ru]http://www.ulyanovsk-beeline.ru[/url]
[url=https://cse.google.li/url?sa=i&url=https://ulyanovsk-beeline.ru/]https://clients1.google.com.ag/url?q=https://ulyanovsk-beeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.ocenka-chasov-onlajn9.ru/www.nitkapro.ru/www.1xbet-giris-5.com/www.alarm-radio-clocks.com]Домашний интернет и цифровое ТВ от «Билайн» в Ульяновске[/url] e487_fd
melbet скачать на айфон с официального сайта
Установить приложение Melbet: Android, iPhone и компьютер
Приложение Melbet включает ставки и казино в одном интерфейсе. Доступны live-ставки, слоты, онлайн-трансляции, аналитика и операции по счёту. Загрузка занимает несколько минут.
Android (APK)
Скачайте APK с официального сайта, запустите установщик и завершите установку. При необходимости включите доступ к установке сторонних приложений, затем войдите в аккаунт.
iOS (iPhone)
Перейдите в App Store, введите в поиске «Melbet», нажмите «Получить», после установки авторизуйтесь в системе.
ПК
Откройте официальный сайт, авторизуйтесь и создайте ярлык на рабочий стол. Браузерная версия функционирует как отдельное приложение.
Функционал
Live-ставки с обновлением коэффициентов, игровой раздел с тысячами игр, прямые трансляции, подробная статистика, уведомления о матчах, регистрация за минуту и круглосуточная служба поддержки.
Бонусы
После установки доступны приветственный бонус, промокоды и бесплатные ставки. Условия зависят от региона.
Безопасность
Скачивайте только с официальных источников, контролируйте адрес сайта, не сообщайте данные доступа третьим лицам и включите 2FA.
Установка занимает несколько минут, после чего открывается полный доступ Melbet.
Play online http://www.bloxd-io.com.az for free right in your browser. Build, compete, and explore the world in dynamic multiplayer mode with no downloads or installations required.
buy valtrex https://unipharms.shop/# buy valacyclovir
Наши опытные наркологи регулярно повышают квалификацию и используют современные методики для быстрого восстановления пациентов после запоев.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod0.ru/]kapelnica-ot-zapoya-nizhniy-novgorod0.ru/[/url]
Недостаточно снять физическую зависимость — важно помочь человеку вернуться в сообщество. В «Доктор Здоровье» разработана система сопровождения, включающая мотивационные беседы, групповые занятия и социальную реабилитацию. Психотерапевты владеют методами когнитивно-поведенческой терапии и мотивационного интервью, консультанты помогают восстановить профессиональные навыки и адаптироваться к повседневной жизни, а встречи в группе взаимопомощи и психодраматические сессии способствуют укреплению чувства поддержки и навыков эффективного общения. Для родственников доступны семейные консультации, на которых объясняют природу зависимости и обучают стратегиям поддержки без критики и давления.
Углубиться в тему – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]narkologicheskaya-klinika-mytishchi[/url]
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Исследовать вопрос подробнее – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]кодирование от алкоголизма одинцово[/url]
Параллельно с медицинской терапией начинается работа психотерапевта. В индивидуальных и семейных сессиях пациенты учатся распознавать механизмы зависимости, вырабатывать новые стратегии поведения и справляться со стрессовыми ситуациями без употребления. Последний этап — реабилитация и ресоциализация — включает трудотерапию, арт- и групповую терапию, помощь в восстановлении профессиональных навыков и возвращении к социально-активной жизни.
Узнать больше – https://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-ceny-v-mytishchah/
В материале приведены детали, интересные, но не особенно важные. Мы рассматриваем аспекты, которые сложно назвать существенными, но включили их для большей полноты.
Подробнее читать – [url=https://rostov-narkologiya.ru/uslugi-ot-narkomanii/mefedronovaya-zavisimost/]таблетки для аборта[/url]
проект перепланировки квартиры [url=https://teletype.in/@jorik11/proekt-dlya-pereplanirovki/]проект перепланировки квартиры[/url] .
Недостаточно снять физическую зависимость — важно помочь человеку вернуться в сообщество. В «Доктор Здоровье» разработана система сопровождения, включающая мотивационные беседы, групповые занятия и социальную реабилитацию. Психотерапевты владеют методами когнитивно-поведенческой терапии и мотивационного интервью, консультанты помогают восстановить профессиональные навыки и адаптироваться к повседневной жизни, а встречи в группе взаимопомощи и психодраматические сессии способствуют укреплению чувства поддержки и навыков эффективного общения. Для родственников доступны семейные консультации, на которых объясняют природу зависимости и обучают стратегиям поддержки без критики и давления.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]chastnaya-narkologicheskaya-klinika-v-mytishchah[/url]
Казино онлайн топ [url=https://t.me/casinotop_official/]Казино онлайн топ[/url] .
Ita? caiu [url=https://caiu.site/]caiu.site[/url] .
Казино фреш [url=https://t.me/vanechekvan/]Казино фреш [/url] .
[url=https://unipharms.shop/#]valtrex 100mg[/url]
на этом сайте https://slon2-at.cc/
кухни в спб от производителя [url=https://kuhni-spb-41.ru/]кухни в спб от производителя[/url] .
buy valtrex online https://unipharms.shop/# unipharms
«Билайн» в Брянске предоставляют:
• пакет из 150+ ТВ каналов;
• поддержки 24/7;
• Определение оптимального тарифа под ваши задачи;
• Анализ технической доступности по вашему адресу.
[url=https://bryansk-beeline.ru/]подключить домашний интернет билайн брянск[/url]
билайн тарифы домашний интернет и телевидение брянск – [url=http://www.bryansk-beeline.ru/]https://bryansk-beeline.ru/[/url]
[url=https://clients1.google.com.tj/url?q=https://bryansk-beeline.ru/]https://maps.google.cf/url?sa=t&url=https://bryansk-beeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.guryevsk.forum24.ru/www.disserpro.ru/www.arus-diplom25.ru/www.gidroizolyaciya-cena-8.ru/www.alarm-radio-clocks.com/www.statyi-o-marketinge7.ru,]Высокоскоростной интернет и ТВ от «Билайн» в вашем доме[/url] 29ee485
типография изготовление [url=https://telegra.ph/5-prichin-pochemu-deshevaya-tipografiya-vyhodit-dorozhe-02-19/]https://telegra.ph/5-prichin-pochemu-deshevaya-tipografiya-vyhodit-dorozhe-02-19[/url] .
Услуга “капельница от запоя” на дому имеет ряд преимуществ, делающих её оптимальным выбором для экстренной помощи:
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-tyumen0.ru/]выезд на дом капельница от запоя в тюмени[/url]
«Билайн» в Иваново предлагают:
• высокоскоростной интернет до 500 Мбит/с;
• быстрое подключение за 1 день;
• Определение оптимального тарифа под ваши задачи;
• Анализ возможности подключения по вашему адресу.
[url=https://ivanovobeeline.ru/]билайн подключение интернета в квартиру[/url]
домашний интернет билайн тарифы иваново – [url=https://www.ivanovobeeline.ru]http://www.ivanovobeeline.ru/[/url]
[url=https://www.google.sn/url?sa=t&url=https://ivanovobeeline.ru/]https://clients1.google.com.jm/url?sa=t&url=https://ivanovobeeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.chop-ohrana.com/www.php.ru/forum/members/k.krakenwork.cc/www.1xbet-4.com/www.google.cg/1win5519.ru,[],[],200,65,0,1279,0,12,13,0,0,https://grandpashabet.in.net/,Grandpashabet%5DДомашний интернет и цифровое ТВ от «Билайн» в вашем доме[/url] 04a59a5
кухни под заказ [url=https://kuhni-spb-41.ru/]kuhni-spb-41.ru[/url] .
заказать кухню по размерам [url=https://zakazat-kuhnyu-1.ru/]zakazat-kuhnyu-1.ru[/url] .
заказать кухню стоимость [url=https://zakazat-kuhnyu-3.ru/]zakazat-kuhnyu-3.ru[/url] .
заказать кухню с доставкой [url=https://zakazat-kuhnyu-2.ru/]zakazat-kuhnyu-2.ru[/url] .
узаконить перепланировку москва [url=https://sites.google.com/view/dokument-dlya-pereplan/главная-страница/]sites.google.com/view/dokument-dlya-pereplan/главная-страница[/url] .
заказать кухню по индивидуальному заказу [url=https://zakazat-kuhnyu-4.ru/]заказать кухню по индивидуальному заказу[/url] .
кухни на заказ в спб недорого [url=https://kuhni-spb-42.ru/]кухни на заказ в спб недорого[/url] .
«Билайн» в Иваново предлагают:
• пакет из 150+ ТВ каналов;
• бесплатный монтаж оборудования;
• Подбор оптимального сочетания интернета и ТВ под ваши задачи;
• Анализ технической доступности по вашему адресу.
[url=https://ivanovobeeline.ru/]билайн интернет тарифы для домашнего интернета иваново[/url]
оптоволокно интернет билайн – [url=http://ivanovobeeline.ru/]http://www.ivanovobeeline.ru[/url]
[url=http://alt1.toolbarqueries.google.com.br/url?q=https://ivanovobeeline.ru/]https://toolbarqueries.google.mw/url?q=https://ivanovobeeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.chop-ohrana.com/czeny-na-uslugi-ohrany/www.superogorod.ucoz.org/forum/www.candy-casino-9.com/k.krakenwork.cc/www.frei-diplom6.ru/s3A2F2247-poker.com%7Cimages.google.nl/k.krakenwork.cc/www.medicinskoe–oborudovanie.ru/www.gidroizolyaciya-podvala-cena.ru/images.google.fi/url?q=https://healthyturkiye.com/all-on-4-dental-implants-turkey]Высокоскоростной интернет и телевидение от «Билайн» в вашем доме[/url] 2104a59
[url=https://unipharms.shop/#]buy valacyclovir[/url]
внедрение erp стоимость 1с [url=http://1s-erp-vnedrenie.ru/]внедрение erp стоимость 1с[/url] .
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Углубиться в тему – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]www.domen.ru[/url]
В этой статье-обзоре мы собрали данные, актуальность которых сомнительна, а факты — не всегда взаимосвязаны. Читатель сможет ознакомиться с разными мнениями, хотя вряд ли они существенно повлияют на его понимание темы.
Вот – [url=https://arma-rehab.ru/lechenie-alkogolizma/]эротические фильмы[/url]
В стационаре работают узкопрофильные специалисты: наркологи, неврологи, психотерапевты, а также персонал, обеспечивающий круглосуточный уход. Программа включает медикаментозное лечение, психологическую коррекцию, восстановление сна, устранение депрессии, обучение саморегуляции и работу с мотивацией.
Изучить вопрос глубже – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]vyzvat-narkologicheskuyu-pomoshch[/url]
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Разобраться лучше – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]кодирование от алкоголизма на дому[/url]
buy valtrex cheap https://unipharms.shop/# unipharms
Когда зависимость захватывает жизнь, она разрушает не только организм, но и личность, отношения с близкими, карьерные планы и самоощущение. Алкоголь, наркотики и психотропные препараты постепенно подрывают работу внутренних органов, нарушают баланс нейромедиаторов в мозге и приводят к серьёзным психическим и физическим осложнениям. Попытки справиться с этим самостоятельно редко бывают успешными: необходим системный, профессиональный подход. В наркологической клинике «Доктор Здоровье» в Мытищах вы найдёте надёжную опору на всех этапах выздоровления — от экстренной детоксикации до длительной реабилитации.
Детальнее – https://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-narkolog-v-mytishchah
Мы не делаем «массовых решений»: каждый пациент для нас — уникальная история, и мы строим терапию, исходя из его состояния, целей и личных возможностей. Наша задача — не просто временно облегчить симптомы, а дать человеку реальные инструменты для жизни без зависимости.
Выяснить больше – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника обратный звонок[/url]
stake originals — where every bet feels electric. Fast crypto. Fair games. Real wins.
1с внедрение erp [url=https://www.1s-erp-vnedrenie.ru]https://www.1s-erp-vnedrenie.ru[/url] .
Запой — это тяжёлое состояние, характеризующееся длительным употреблением алкоголя, при котором человек не в силах самостоятельно прекратить пить. Алкогольная интоксикация при длительных запоях вызывает нарушения в работе всех органов и систем, приводя к серьёзным последствиям, таким как инфаркты, инсульты, психозы и даже летальный исход. В такой ситуации единственным надёжным решением становится обращение за профессиональной помощью.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-korolev2.ru/]vyvod iz zapoya na domu kruglosutochno[/url]
Процедура вывода из запоя начинается с тщательной диагностики состояния пациента, чтобы определить, какие методы лечения будут наиболее эффективными. Мы применяем индивидуальный подход и комбинируем медикаментозное лечение с психотерапевтической поддержкой, что даёт лучший результат.
Детальнее – [url=https://narcolog-na-dom-novokuznetsk0.ru/]нарколог на дом анонимно новокузнецк[/url]
– человек не может прекратить употребление сам; – наблюдается агрессия, страх, паника, бессвязная речь; – нарушен сон, отсутствует аппетит, сильная слабость; – алкоголь стал способом снятия боли или тревоги; – попытки отказа приводят к ухудшению состояния.
Ознакомиться с деталями – https://vyvod-iz-zapoya-serpuhov3.ru/anonimnyj-vyvod-iz-zapoya-v-serpuhove/
заказать кухню в спб от производителя [url=https://kuhni-spb-44.ru/]заказать кухню в спб от производителя[/url] .
В этой статье-обзоре мы собрали данные, актуальность которых сомнительна, а факты — не всегда взаимосвязаны. Читатель сможет ознакомиться с разными мнениями, хотя вряд ли они существенно повлияют на его понимание темы.
Вот – [url=https://arma-rehab.ru/]эротические фильмы[/url]
заказать кухню в спб по индивидуальному проекту [url=https://kuhni-spb-43.ru/]заказать кухню в спб по индивидуальному проекту[/url] .
кухни спб [url=https://kuhni-spb-42.ru/]кухни спб[/url] .
Аппаратные методы кодирования включают лазерную терапию и электростимуляцию биологически активных точек, влияющих на центры зависимости в головном мозге. Эти методики способствуют быстрому формированию устойчивого отвращения к спиртному и хорошо переносятся пациентами.
Получить больше информации – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu
[url=https://canbaypharm.top/#]fioricet overseas pharmacy[/url]
В течение полугода пациент может бесплатно посещать онлайн-группы поддержки и консультироваться у психологов клиники.
Разобраться лучше – http://lechenie-narkomanii-volgograd9.ru
Этот текст содержит различную информацию, которая, возможно, покажется любопытной, но в целом не меняет восприятия привычных вещей. Предлагаем просто получить удовольствие от чтения, не ожидая особой пользы.
Вот – [url=https://arma-rehab.ru/lechenie-alkogolizma/]игровые автоматы[/url]
Этот сборник информации привлекает множеством мелких деталей и необычных ракурсов. Мы предлагаем взгляды, редко полезные, но способные немного разнообразить знакомство с темой.
Подробнее читать – [url=https://rostov-narkologiya.ru/uslugi-ot-narkomanii/mefedronovaya-zavisimost/]сиалис онлайн[/url]
Feel the thrill at North America’s favorite social casino—luckyland slots hacks! Get started with 7,777 Gold Coins and 10 free Sweeps Coins on signup. Compete in tournaments and redeem extraordinary prizes!
Как подчеркивает нарколог Олег Смирнов, «чем быстрее будет оказана помощь, тем ниже риск тяжелых осложнений, таких как судороги, отек мозга или сердечные приступы».
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-krasnoyarsk0.ru/]вывод из запоя капельница на дому[/url]
Когда запой превращается в острую угрозу здоровью, оперативное вмешательство становится необходимым условием для спасения жизни и предотвращения серьезных осложнений. В Уфе наркологи выезжают на дом для оказания качественной помощи при запое, предлагая детоксикацию, корректировку обменных процессов и психологическую поддержку. Такой формат лечения обеспечивает комфортную обстановку, индивидуальный подход и полную конфиденциальность для каждого пациента.
Получить дополнительные сведения – [url=https://narcolog-na-dom-ufa0.ru/]нарколог на дом вывод в уфе[/url]
legitimate online pharmacies india https://canpharmhub.top/# best foreign online discount pharmacy for viagra
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Разобраться лучше – https://kapelnica-ot-zapoya-tyumen00.ru/postavit-kapelniczu-ot-zapoya-tyumen/
мелбет зеркало скачать на айфон
Скачать приложение Melbet: APK, iPhone и ПК
Приложение Melbet объединяет букмекерскую контору и казино в одном интерфейсе. Доступны live-ставки, казино-игры, прямые трансляции, статистика и операции по счёту. Установка занимает 1–2 минуты.
Android (APK)
Скачайте APK с официального источника, откройте файл и завершите установку. При необходимости включите разрешение на установку из неизвестных источников, затем войдите в аккаунт.
iOS (iPhone)
Перейдите в App Store, найдите «Melbet», нажмите «Получить», после установки авторизуйтесь в системе.
ПК
Откройте официальный сайт, войдите в личный кабинет и добавьте ярлык на рабочий стол. Веб-версия работает как полноценное приложение.
Функционал
Live-ставки с обновлением коэффициентов, казино и слоты, просмотр матчей, аналитические данные, push-оповещения, быстрая регистрация и круглосуточная служба поддержки.
Бонусы
После загрузки доступны приветственный бонус, акционные коды и фрибеты. Правила начисления определяются регионом.
Безопасность
Скачивайте только с официальных источников, проверяйте домен, не сообщайте данные доступа третьим лицам и активируйте двухфакторную аутентификацию.
Установка занимает несколько минут, после чего доступен весь функционал Melbet.
[url=https://canbaypharm.top/#]safe online pharmacies in canada[/url]
мелбет официальный сайт
Установить приложение Melbet: Android, iOS и ПК
Приложение Melbet объединяет ставки и казино в едином приложении. Пользователю доступны live-ставки, казино-игры, прямые трансляции, статистика и операции по счёту. Загрузка занимает несколько минут.
Android (APK)
Скачайте APK с официального источника, запустите установщик и подтвердите установку. Если требуется включите разрешение на установку из неизвестных источников, затем войдите в аккаунт.
iOS (iPhone)
Откройте App Store, введите в поиске «Melbet», нажмите «Получить», после установки авторизуйтесь в системе.
ПК
Перейдите официальный сайт, авторизуйтесь и создайте ярлык на рабочий стол. Веб-версия работает как полноценное приложение.
Функционал
Live-ставки с мгновенным обновлением линии, казино и слоты, просмотр матчей, подробная статистика, push-оповещения, регистрация за минуту и круглосуточная служба поддержки.
Бонусы
После установки доступны приветственный бонус, промокоды и бесплатные ставки. Условия зависят от региона.
Безопасность
Загружайте только с официального сайта, проверяйте домен, не передавайте пароль третьим лицам и активируйте двухфакторную аутентификацию.
Установка занимает несколько минут, после чего доступен весь функционал Melbet.
Мы не делаем «массовых решений»: каждый пациент для нас — уникальная история, и мы строим терапию, исходя из его состояния, целей и личных возможностей. Наша задача — не просто временно облегчить симптомы, а дать человеку реальные инструменты для жизни без зависимости.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника мытищи[/url]
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Подробнее – [url=https://kapelnica-ot-zapoya-tyumen00.ru/]капельница от запоя цена в тюмени[/url]
Call Girls in Dubai | Dubai Call Girls | Call Girl in Dubai | Call Girl Dubai| Call Girls Dubai| Dubai Call Girls Service | Dubai Call Girls | Call Girls in Dubai
«Билайн» в Калуге предлагают:
• пакет из 150+ ТВ каналов;
• бесплатный монтаж оборудования;
• Определение оптимального сочетания интернета и ТВ под ваши задачи;
• Анализ инфраструктуры по вашему адресу.
[url=https://kaluga-beeline.ru/]билайн тв и интернет тарифы[/url]
тарифы билайн домашний интернет 2025 – [url=http://www.kaluga-beeline.ru/]https://www.kaluga-beeline.ru/[/url]
[url=https://clients1.google.vg/url?q=https://kaluga-beeline.ru/]https://clients1.google.cf/url?q=https://kaluga-beeline.ru/[/url]
[url=http://www2.saganet.ne.jp/cgi-bin/hatto/board/wwwboard.pl/www.pelsh.forum24.ru/www.arus-diplom24.ru/a-bsme.at]Высокоскоростной интернет и ТВ от «Билайн» в вашем доме[/url] 5c29ee4
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Выяснить больше – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu/
rx canadian pharmacy https://canbaypharm.top/# on line medication without a perscriptrion
Запой — это тяжёлое состояние, характеризующееся длительным употреблением алкоголя, при котором человек не в силах самостоятельно прекратить пить. Алкогольная интоксикация при длительных запоях вызывает нарушения в работе всех органов и систем, приводя к серьёзным последствиям, таким как инфаркты, инсульты, психозы и даже летальный исход. В такой ситуации единственным надёжным решением становится обращение за профессиональной помощью.
Разобраться лучше – https://vyvod-iz-zapoya-korolev2.ru/vyvod-iz-zapoya-kruglosutochno
нарколог на дом ночью ростов-на-дону [url=https://narkolog-na-dom-v-rostove.ru/]narkolog-na-dom-v-rostove.ru[/url] .
Мы не делаем «массовых решений»: каждый пациент для нас — уникальная история, и мы строим терапию, исходя из его состояния, целей и личных возможностей. Наша задача — не просто временно облегчить симптомы, а дать человеку реальные инструменты для жизни без зависимости.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника помощь на дому[/url]
Аппаратные методы кодирования включают лазерную терапию и электростимуляцию биологически активных точек, влияющих на центры зависимости в головном мозге. Эти методики способствуют быстрому формированию устойчивого отвращения к спиртному и хорошо переносятся пациентами.
Выяснить больше – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma odincovo[/url]
вызвать нарколога на дом ростов-на-дону [url=https://narkolog-na-dom-v-rostove-1.ru/]вызвать нарколога на дом ростов-на-дону[/url] .
Если человек страдает от алкоголизма, запойное состояние требует незамедлительного вмешательства, особенно если признаки токсического отравления начинают угрожать жизни. Признаки запоя — это не только физическая зависимость, но и эмоциональные и психические расстройства, такие как тревога, агрессия и галлюцинации.
Разобраться лучше – [url=https://narcolog-na-dom-novokuznetsk0.ru/]нарколог на дом срочно новокузнецк[/url]
pg
เว็บไซต์ TKBNEKO เปิดประสบการณ์ใหม่แห่งการเดิมพันออนไลน์ ระบบการเงินรวดเร็ว ด้วยระบบสแกน QR Code
ในยุคที่ เทคโนโลยีเปลี่ยนวิถีการเดิมพันออนไลน์ไปอย่างสิ้นเชิง TKBNEKO พร้อมยกระดับมาตรฐานการเดิมพัน ด้วยระบบการให้บริการที่ ทันสมัย ฉับไว และ ตรวจสอบได้ พร้อมต้อนรับสมาชิกทุกท่านสู่ โลกแห่งเกมที่เหนือกว่าเดิม ที่ เปิดโอกาสให้ทุกคนสร้างรายได้
ทำไมต้อง TKBNEKO?
เราคัดสรรเกมคุณภาพจากผู้พัฒนาชั้นนำ โดยเฉพาะเกมที่ มีใบรับรองอย่างถูกต้อง และ ได้มาตรฐานสากล เพื่อให้ผู้เล่นทุกคน มั่นใจ ได้ว่า จะได้รับความเพลิดเพลินกับเกมที่ ไม่มีการเอาเปรียบ ปลอดภัย และ ได้มาตรฐานระดับสากล
ข้อดีของธุรกรรมบนแพลตฟอร์ม
เราออกแบบระบบการเงินให้ง่ายและเร็วที่สุด เพื่อให้คุณ โฟกัสกับความสนุกได้อย่างเต็มที่
ฝากขั้นต่ำ: เพียง 1 บาท
ถอนขั้นต่ำ: ขั้นต่ำ 1 บาท
เวลาฝากเงิน: เงินเข้าภายใน 3 วินาที
ยอดจำกัดการถอน: ไม่มีลิมิตการถอนรายวัน
ธุรกรรมสะดวก แค่สแกนคิวอาร์
เพียงคุณสแกน คิวอาร์ ระบบของเราจะ ประมวลผลอย่างรวดเร็ว ขั้นต่ำเพียง อย่างน้อย 100 บาท และสามารถฝากได้สูงถึง ไม่เกิน 500,000 บาทต่อครั้ง เริ่มต้นได้ทันที กับ แพลตฟอร์มของเรา ที่ ใช้งานง่าย ทำกำไรได้รวดเร็ว
เกมยอดนิยมรวมไว้ในที่เดียว
เรารวบรวมเกมยอดนิยมหลากหลายประเภท รองรับทุกความชอบของผู้เล่น
สล็อต: หลากหลายธีม แจ็คพอตรอคุณอยู่
เกมสด: ดีลเลอร์ถ่ายทอดสดตลอดเวลา
กีฬา: รองรับลีกดังระดับโลก
ยิงปลา: เกมยิงปลาสุดมันส์ ได้เงินจริง
ติดตามโปรโมชั่นและสิทธิพิเศษ
อย่าลืมแวะมาเยี่ยมชมที่หน้า โบนัส เพื่อรับ โบนัสสุดคุ้ม ที่เรามอบให้สมาชิกทุกท่าน นอกจากนี้ยังมีระบบ ลูกค้าระดับพรีเมียม สำหรับลูกค้าคนสำคัญ และช่องทาง แอฟฟิลิเอต สำหรับผู้ที่สนใจสร้างรายได้ร่วมกับเรา
ช่องทางติดต่อ
หากมี คำถาม หรือ ข้อเสนอแนะ สามารถติดต่อทีมงานของเราได้ตลอด 24 ชั่วโมงที่หน้า ติดต่อเรา และ ส่งความคิดเห็น ทีมงาน ของเรา ยินดีให้บริการทุกท่านด้วยใจ
ทดลองเล่นสล็อต pg เว็บ ตรง”
สล็อต PG สล็อตยอดฮิต เล่นง่าย ฝากถอนเร็ว
คำค้นหา สล็อต PG กำลังได้รับความนิยมอย่างต่อเนื่อง ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ค่ายเกมที่มีชื่อเสียง ด้าน กราฟิก ความ ลื่นไหล และ อัตราการจ่ายรางวัลที่น่าสนใจ เกมของ PG พัฒนาโดยผู้ให้บริการชั้นนำ ที่รองรับการเล่นทั้งบน มือถือ และ เดสก์ท็อป
ข้อดี ของ PG Slot
pg slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เปิดเกมได้ทันที เล่นผ่าน ระบบออนไลน์ และรองรับ ทั้ง iOS และ Android เข้าเล่นผ่านเว็บได้เลย ผู้เล่นสามารถเข้าเล่นผ่าน หน้าเว็บ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ สามมิติ ให้ความคมชัด พร้อมเอฟเฟกต์ สมจริง
คุณสมบัติหลักของเกม pg slot ได้แก่
โบนัสและฟรีสปินหลายแบบ
ฟีเจอร์ตัวคูณรางวัล
โหมดทดลองเล่นฟรี
ใช้งานภาษาไทยง่าย
ระบบฝากถอนสะดวก ไม่ต้องรอนาน
แพลตฟอร์ม สล็อต PG ส่วนใหญ่รองรับ การฝาก-ถอน ฝากถอนตลอดเวลา ขั้นต่ำเริ่มต้นเพียง 10 บาท ขึ้นอยู่กับ กติกาแต่ละแพลตฟอร์ม การทำรายการใช้เวลา รวดเร็วมาก ผ่าน คิวอาร์โค้ด หรือระบบ ธนาคารบนมือถือ ทำให้ธุรกรรมเป็นไปอย่าง ต่อเนื่อง
แนวเกมที่คนเล่นเยอะ ใน pg slot
เกม pg slot มีธีมหลากหลาย เช่น
ธีม แฟนตาซี
ธีม Adventure
ธีม ความมั่งคั่ง
ธีม สัตว์และธรรมชาติ
หลายคนชอบเกมที่โบนัสเข้าไว พร้อมระบบ โบนัสรอบพิเศษ และ โอกาสทำกำไรสูง เหมาะกับทั้ง ผู้เล่นเริ่มต้น และ สายสล็อตจริงจัง
ความปลอดภัย
สล็อต PG มีมาตรฐานรองรับ มีการ ปกป้องข้อมูลผู้เล่น และใช้ระบบสุ่มผล RNG เพื่อให้ผลลัพธ์ โปร่งใส แพลตฟอร์มที่ให้บริการ pg slot ควรมี ระบบดูแลข้อมูล
สรุป
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน ระบบลื่นไหล และการทำธุรกรรมที่ รวดเร็ว ผู้เล่นสามารถเริ่มต้นได้ ทันที ฝากถอนสะดวก และเลือกเกมได้ หลากหลายแนว เหมาะสำหรับ ทุกระดับประสบการณ์ ในโลกของเกมสล็อตออนไลน์
Клиника «Семья и Здоровье» предлагает комплексное лечение на дому, что позволяет избежать стрессов, связанных с госпитализацией, и получить квалифицированную помощь в привычной обстановке. Наши специалисты работают круглосуточно, приезжают в течение 30–60 минут и проводят полный спектр процедур для восстановления здоровья.
Разобраться лучше – https://vyvod-iz-zapoya-krasnoyarsk0.ru/vyvod-iz-zapoya-na-domu-krasnoyarsk/
круглосуточный нарколог на дом в ростове [url=https://narkolog-na-dom-v-rostove-2.ru/]круглосуточный нарколог на дом в ростове[/url] .
สล็อต
TKBNEKO เปิดประสบการณ์ใหม่แห่งการเดิมพันออนไลน์ ธุรกรรมรวดเร็ว ด้วยระบบสแกน คิวอาร์โค้ด
ในยุคดิจิทัลที่ โลกออนไลน์เติบโตต่อเนื่อง เรามุ่งเน้นมาตรฐานใหม่ของการเดิมพัน ด้วยระบบที่ ทันสมัย รวดเร็ว และ โปร่งใส เพื่อให้ผู้เล่น อุ่นใจ ทุกครั้งที่ใช้งาน
จุดเด่นระบบฝาก-ถอน
ฝากขั้นต่ำ: 1 บาท
ถอนขั้นต่ำ: 1 บาท
เวลาฝากเงิน: ภายใน 3 วินาที
ยอดถอน: ไม่จำกัดต่อวัน
เติมเงินง่าย แค่สแกน
สแกน QR Code ระบบจะ ประมวลผลอัตโนมัติ ขั้นต่ำ 100 บาท สูงสุด 500,000 บาท
หมวดหมู่เกม
สล็อต: ธีมหลากหลาย
เกมสด: คาสิโนเรียลไทม์
กีฬา: เดิมพันลีกดัง
ยิงปลา: ลุ้นกำไรทันที
โบนัสและโปรโมชัน
ติดตามหน้า โบนัส พร้อมระบบ สมาชิกพรีเมียม และโปรแกรม แอฟฟิลิเอต
ติดต่อเรา
สอบถามข้อมูลได้ตลอด 24 ชั่วโมง ผ่านหน้า ศูนย์ช่วยเหลือ ทีมงาน ของเรา พร้อมดูแลตลอดเวลา
Параллельно с медицинской терапией начинается работа психотерапевта. В индивидуальных и семейных сессиях пациенты учатся распознавать механизмы зависимости, вырабатывать новые стратегии поведения и справляться со стрессовыми ситуациями без употребления. Последний этап — реабилитация и ресоциализация — включает трудотерапию, арт- и групповую терапию, помощь в восстановлении профессиональных навыков и возвращении к социально-активной жизни.
Выяснить больше – http://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-ceny-v-mytishchah/
вызвать нарколога на дом ростов-на-дону [url=https://narkolog-na-dom-v-rostove-3.ru/]вызвать нарколога на дом ростов-на-дону[/url] .
PG Slot สล็อตยอดฮิต ใช้งานง่าย ฝากถอนรวดเร็ว
คำค้นหา PG Slot กำลังได้รับความนิยมอย่างต่อเนื่อง ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ผู้ให้บริการเกมสล็อตที่มาแรง ด้าน ภาพและเอฟเฟกต์ ความ นิ่งไม่สะดุด และ อัตราการจ่ายรางวัลที่น่าสนใจ เกมของ PG ออกแบบโดยทีมงานมืออาชีพ ที่รองรับการเล่นทั้งบน โทรศัพท์มือถือ และ เดสก์ท็อป
ความโดดเด่น ของ pg slot
สล็อต PG เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เข้าเกมไว เล่นผ่าน ระบบเว็บ และรองรับ ทุกแพลตฟอร์ม เข้าเล่นผ่านเว็บได้เลย ผู้เล่นสามารถเข้าเล่นผ่าน Browser ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ เอฟเฟกต์ 3 มิติ ให้ความคมชัด พร้อมเอฟเฟกต์ จัดเต็ม
คุณสมบัติหลักของเกม pg slot ได้แก่
โบนัสและฟรีสปินหลายแบบ
Multiplier
เล่นฟรีก่อนเติมเงิน
ใช้งานภาษาไทยง่าย
ระบบการเงินรวดเร็ว ทำรายการไว
แพลตฟอร์ม สล็อต PG ส่วนใหญ่รองรับ การฝาก-ถอน อัตโนมัติ 24 ชั่วโมง ขั้นต่ำเริ่มต้นเพียง หลักหน่วย ขึ้นอยู่กับ กติกาแต่ละแพลตฟอร์ม การทำรายการใช้เวลา เพียงไม่กี่วินาที ผ่าน คิวอาร์โค้ด หรือระบบ ธนาคารบนมือถือ ทำให้ธุรกรรมเป็นไปอย่าง ไม่สะดุด
แนวเกมที่คนเล่นเยอะ ใน PG Slot
เกม pg slot มีธีมหลากหลาย เช่น
ธีม เทพเจ้า
ธีม ลุยด่าน
ธีม โชคลาภ
ธีม Animal
หลายคนชอบเกมที่โบนัสเข้าไว พร้อมระบบ โบนัสรอบพิเศษ และ โอกาสทำกำไรสูง เหมาะกับทั้ง มือใหม่ และ สายสล็อตจริงจัง
ความน่าเชื่อถือ
PG Slot พัฒนาในระบบสากล มีการ ปกป้องข้อมูลผู้เล่น และใช้ระบบสุ่มผล ระบบสุ่มมาตรฐาน เพื่อให้ผลลัพธ์ โปร่งใส แพลตฟอร์มที่ให้บริการ pg slot ควรมี ระบบดูแลข้อมูล
โดยภาพรวม
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน ระบบลื่นไหล และการทำธุรกรรมที่ ไว ผู้เล่นสามารถเริ่มต้นได้ ง่าย ฝากถอนสะดวก และเลือกเกมได้ จำนวนมาก เหมาะสำหรับ ทุกระดับประสบการณ์ ในโลกของเกมสล็อตออนไลน์
https://medium.com/@ratypw/ทดลองเล่นสล็อต-pg-70cdb1132344
нарколог в ростове цена вывод из запоя [url=https://vyvod-iz-zapoya-v-rostove-3.ru/]нарколог в ростове цена вывод из запоя[/url] .
анонимный нарколог на дом в ростове [url=https://narkolog-na-dom-v-rostove-3.ru/]анонимный нарколог на дом в ростове[/url] .
наркологическая помощь на дому ростов [url=https://narkolog-na-dom-v-rostove-4.ru/]наркологическая помощь на дому ростов[/url] .
нарколог вывод из запоя в ростове [url=https://vyvod-iz-zapoya-v-rostove-4.ru/]нарколог вывод из запоя в ростове[/url] .
наркологическая служба на дом ростов-на-дону [url=https://narkolog-na-dom-v-rostove-3.ru/]наркологическая служба на дом ростов-на-дону[/url] .
[url=https://chl.applemarketrf.ru]айфон 17 купить в челябинске[/url]
Ищете, где купить айфон в Челябинске? У нас вы найдете широкий ассортимент оригинальных iPhone по привлекательным ценам. Купить айфон в Челябинске стало проще — предлагаем актуальные модели, включая iPhone 17, iPhone 16, и iPhone 15. Хотите купить айфон про или макс? У нас есть iPhone 13 Pro Max, а также новинки — iPhone 17 и iPhone 17 Pro Max в наличии!
[url=https://chl.applemarketrf.ru/catalog/iphone/iphone-17-pro-max/]купить iphone челябинск[/url]
Если вам нужно купить айфон в Челябинске, обращайтесь к нам — мы гарантируем оригинальность и качество. В нашем магазине вы можете купить айфон 17 в рассрочку, а также оформить покупку с доставкой по всему городу. Хотите купить новый айфон в Челябинске? Тогда именно у нас вы найдете лучшие цены и актуальные модели.
[url=https://chl.applemarketrf.ru/catalog/iphone/iphone-air/]iphone air купить в челябинске[/url]
Особое внимание уделяем моделям айфон 17, в том числе айфон 17 256 ГБ. Купите айфон 16 или айфон 15 в Челябинске — у нас есть все новинки сезона. Где купить айфон в Челябинске? Ответ прост — у нас! Мы предлагаем купить айфон в Челябинске оригинал и с официальной гарантией.
[url=https://chl.applemarketrf.ru/catalog/iphone/]купить iphone челябинск[/url]
Звоните и приходите — у нас можно купить айфон 17, айфон про, макс, а также другие модели в рассрочку и по выгодным ценам. Сделайте правильный выбор — купите новый айфон в Челябинске у надежного продавца!
https://chl.applemarketrf.ru/catalog/iphone/iphone-17-pro/
купить айфон в челябинске
вывод из запоя клиника в ростове [url=https://vyvod-iz-zapoya-v-rostove-4.ru/]вывод из запоя клиника в ростове[/url] .
вывод из запоя в стационаре в ростове на дону [url=https://vyvod-iz-zapoya-v-rostove-5.ru/]вывод из запоя в стационаре в ростове на дону[/url] .
монтаж газового пожаротушения под ключ [url=https://montazh-gazovogo-pozharotusheniya.ru/]montazh-gazovogo-pozharotusheniya.ru[/url] .
ทดลองเล่นสล็อต pg ฟรี PG Slot สล็อตยอดฮิต ใช้งานง่าย ฝากถอนรวดเร็ว
คำค้นหา PG Slot กำลังได้รับความนิยมอย่างต่อเนื่อง ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ค่ายเกมที่มีชื่อเสียง ด้าน ภาพและเอฟเฟกต์ ความ นิ่งไม่สะดุด และ โอกาสรับกำไรที่ดี เกมของ PG ผลิตโดยค่ายมาตรฐาน ที่รองรับการเล่นทั้งบน โทรศัพท์มือถือ และ คอมพิวเตอร์
ความโดดเด่น ของ สล็อต PG
PG Slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เข้าเกมไว เล่นผ่าน ระบบเว็บ และรองรับ ทุกแพลตฟอร์ม ไม่ต้องติดตั้งเพิ่มเติม ผู้เล่นสามารถเข้าเล่นผ่าน Browser ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ สามมิติ ให้ความคมชัด พร้อมเอฟเฟกต์ สวยงาม
คุณสมบัติหลักของเกม สล็อต PG ได้แก่
มีรอบโบนัสให้ลุ้นบ่อย
Multiplier
โหมดทดลองเล่นฟรี
ใช้งานภาษาไทยง่าย
ฝากถอนง่าย ไม่ต้องรอนาน
แพลตฟอร์ม pg slot มักมี การฝาก-ถอน อัตโนมัติ 24 ชั่วโมง ขั้นต่ำเริ่มต้นเพียง หลักหน่วย ขึ้นอยู่กับ กติกาแต่ละแพลตฟอร์ม การทำรายการใช้เวลา เพียงไม่กี่วินาที ผ่าน QR Code หรือระบบ แอปธนาคาร ทำให้ธุรกรรมเป็นไปอย่าง ลื่นไหล
แนวเกมที่คนเล่นเยอะ ใน PG Slot
เกม สล็อต PG มีธีมหลากหลาย เช่น
ธีม เทพเจ้า
ธีม ผจญภัย
ธีม ความมั่งคั่ง
ธีม Animal
หลายคนชอบเกมที่โบนัสเข้าไว พร้อมระบบ ฟีเจอร์พิเศษ และ ระบบจ่ายคุ้มค่า เหมาะกับทั้ง มือใหม่ และ ผู้เล่นที่มีประสบการณ์
ความน่าเชื่อถือ
PG Slot มีมาตรฐานรองรับ มีการ ปกป้องข้อมูลผู้เล่น และใช้ระบบสุ่มผล Random Number Generator เพื่อให้ผลลัพธ์ โปร่งใส แพลตฟอร์มที่ให้บริการ pg slot ควรมี ทีมซัพพอร์ต 24 ชม.
บทสรุปท้ายบท
pg slot เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน กราฟิกคุณภาพ และการทำธุรกรรมที่ รวดเร็ว ผู้เล่นสามารถเริ่มต้นได้ ทันที ฝากถอนสะดวก และเลือกเกมได้ จำนวนมาก เหมาะสำหรับ ทุกระดับประสบการณ์ ในโลกของเกมสล็อตออนไลน์
Публикация предоставляет читателю набор разрозненных идей, которые сложно применить на практике. Мы лишь слегка касаемся разных точек зрения, не углубляясь в анализ и не предлагая никаких выводов.
Вот – [url=https://arma-rehab.ru/lechenie-alkogolizma/]бесплатные порно видео[/url]
Современные геймеры ищут площадки для общения с единомышленниками и обмена опытом. Платформа https://lolz.live/ объединяет тысячи любителей компьютерных игр разных уровней. Здесь каждый находит полезную информацию по любимым играм и жанрам. Форум постоянно развивается и предлагает участникам новые возможности для взаимодействия.
наркологическая клиника в ростове вывод из запоя [url=https://vyvod-iz-zapoya-v-rostove-1.ru/]vyvod-iz-zapoya-v-rostove-1.ru[/url] .
Реализуются участки под промышленное строительство общей площадью 20,15 гектара у пересечения А-108 и автодороги 17К-16 во Владимирской области. Земельный массив полностью обеспечен коммуникациями: газопровод высокого давления с ГРПШ на 1529 м?/час, пять ТП мощностью 400 кВА каждая, водозаборный узел на 600 м?/сутки с лицензией, канализационные сети с разрешенным сбросом. Подробная информация о земельных массивах и торговых объектах размещена на https://promzem-a108.ru/
шумоизоляция дверей авто https://shumoizolyaciya-dverej-avto.ru
[url=htts://rsmeds.top/#]rsmeds[/url]
вывод из запоя в ростове на дону на дому [url=https://vyvod-iz-zapoya-v-rostove-2.ru/]vyvod-iz-zapoya-v-rostove-2.ru[/url] .
Unleash the fun at DraftKings slots Casino. New welcome: 500 spins after $5 + up to $1,000 back on day one. Live dealers, slots, jackpots—all here!
Если человек страдает от алкоголизма, запойное состояние требует незамедлительного вмешательства, особенно если признаки токсического отравления начинают угрожать жизни. Признаки запоя — это не только физическая зависимость, но и эмоциональные и психические расстройства, такие как тревога, агрессия и галлюцинации.
Выяснить больше – [url=https://narcolog-na-dom-novokuznetsk0.ru/]нарколог на дом цены в новокузнецке[/url]
rsmeds https://rsmeds.top/# buy priligy
ifun平台2026 海外华人高清影视 大数据AI智能推荐
狙击蝴蝶2026 高清悬疑刑侦 海外华人高清在线 全球加速无缓冲
慕胥辞2026 迪丽热巴陈飞宇 高清古装爱情巨制 海外华人免费观看 全球加速
[url=https://rsmeds.top/#]order dapoxetine[/url]
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Выяснить больше – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu/
Мы не делаем «массовых решений»: каждый пациент для нас — уникальная история, и мы строим терапию, исходя из его состояния, целей и личных возможностей. Наша задача — не просто временно облегчить симптомы, а дать человеку реальные инструменты для жизни без зависимости.
Подробнее – http://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-ceny-v-mytishchah/
Как подчёркивает врач-нарколог клиники «Крылья Надежды» Андрей Кузьмин: «Своевременное обращение к специалистам гарантирует не только быстрое восстановление, но и предупреждает развитие тяжёлых осложнений, которые могут навсегда изменить жизнь пациента».
Подробнее тут – http://vyvod-iz-zapoya-korolev2.ru/srochnyj-vyvod-iz-zapoya/
purchase priligy https://rsmeds.top/# buy priligy pills
заказать печать стикеров [url=https://pechat-nakleek-v-moskve.ru/]заказать печать стикеров[/url] .
[url=htts://rsmeds.top/#]buy dapoxetine[/url]
Наркологическая помощь в Первоуральске доступна в различных форматах: амбулаторно, стационарно и на дому. Однако не каждое учреждение может обеспечить необходимый уровень комплексной терапии, соответствующей стандартам Минздрава РФ и НМИЦ психиатрии и наркологии. В этом материале мы рассмотрим ключевые особенности профессионального наркологического центра и критерии, которые помогут сделать осознанный выбор.
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-pervouralsk11.ru/]наркологическая клиника наркологический центр в первоуральске[/url]
Наличие у нарколога практического опыта и навыков быстрого реагирования критично — особенно если речь идёт о тяжелой интоксикации или судорожном синдроме. Ошибки в дозировке или игнорирование хронических заболеваний могут привести к осложнениям.
Получить дополнительные сведения – https://narkolog-na-dom-nizhnij-tagil11.ru/narkolog-na-dom-kruglosutochno-v-nizhnem-tagile
сделать аудит сайта цена [url=https://prodvizhenie-sajtov-v-moskve9.ru/]prodvizhenie-sajtov-v-moskve9.ru[/url] .
https://t.me/s/reg_official_1win/2346
buy priligy pills https://rsmeds.top/# rsmeds
Критерий
Получить дополнительные сведения – [url=https://narkolog-na-dom-nizhnij-tagil11.ru/]психиатр нарколог на дом нижний тагил[/url]
В статье-обзоре представлены данные сомнительной актуальности и факты без явной взаимосвязи. Читатель ознакомится с разными мнениями, хотя они вряд ли существенно изменят его представление о теме.
Подробнее читать – [url=https://rostov-narkologiya.ru/uslugi-ot-narkomanii/mefedronovaya-zavisimost/]детокс чай для похудения[/url]
buy priligy uk htts://rsmeds.top/# priligy generic
ทดลองเล่นสล็อต pg เว็บ ตรง”
pg slot สล็อตยอดฮิต เล่นง่าย ฝากถอนเร็ว
คำค้นหา PG Slot มาแรงในช่วงนี้ ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ผู้ให้บริการเกมสล็อตที่มาแรง ด้าน ภาพและเอฟเฟกต์ ความ เสถียร และ ระบบจ่ายที่ดึงดูด เกมของ PG พัฒนาโดยผู้ให้บริการชั้นนำ ที่รองรับการเล่นทั้งบน โทรศัพท์มือถือ และ คอมพิวเตอร์
ข้อดี ของ สล็อต PG
สล็อต PG เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เปิดเกมได้ทันที เล่นผ่าน ระบบเว็บ และรองรับ ทุกอุปกรณ์ ไม่ต้องติดตั้งเพิ่มเติม ผู้เล่นสามารถเข้าเล่นผ่าน หน้าเว็บ ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ สามมิติ ให้ความคมชัด พร้อมเอฟเฟกต์ จัดเต็ม
คุณสมบัติหลักของเกม pg slot ได้แก่
โบนัสและฟรีสปินหลายแบบ
ฟีเจอร์ตัวคูณรางวัล
โหมดทดลองเล่นฟรี
มีเมนูภาษาไทย
ฝากถอนง่าย ทำรายการไว
แพลตฟอร์ม สล็อต PG ส่วนใหญ่รองรับ การฝาก-ถอน ฝากถอนตลอดเวลา ขั้นต่ำเริ่มต้นเพียง 1 บาท ขึ้นอยู่กับ ระบบของผู้ให้บริการ การทำรายการใช้เวลา ไม่กี่วินาที ผ่าน สแกน QR หรือระบบ แอปธนาคาร ทำให้ธุรกรรมเป็นไปอย่าง ไม่สะดุด
แนวเกมที่คนเล่นเยอะ ใน PG Slot
เกม pg slot มีธีมหลากหลาย เช่น
ธีม แฟนตาซี
ธีม ลุยด่าน
ธีม ความมั่งคั่ง
ธีม ธรรมชาติ
ผู้เล่นนิยมเกมที่มีรอบพิเศษบ่อย พร้อมระบบ โบนัสรอบพิเศษ และ ระบบจ่ายคุ้มค่า เหมาะกับทั้ง ผู้เล่นเริ่มต้น และ ผู้เล่นที่มีประสบการณ์
ความน่าเชื่อถือ
PG Slot มีมาตรฐานรองรับ มีการ เข้ารหัสข้อมูล และใช้ระบบสุ่มผล ระบบสุ่มมาตรฐาน เพื่อให้ผลลัพธ์ โปร่งใส แพลตฟอร์มที่ให้บริการ สล็อต PG ควรมี ระบบดูแลข้อมูล
สรุป
pg slot เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน โบนัสหลากหลาย และการทำธุรกรรมที่ ทันใจ ผู้เล่นสามารถเริ่มต้นได้ ง่าย ฝากถอนสะดวก และเลือกเกมได้ ครบทุกหมวด เหมาะสำหรับ ทั้งมือใหม่และมือโปร ในโลกของเกมสล็อตออนไลน์
продвинуть сайт в москве [url=https://prodvizhenie-sajtov-v-moskve10.ru/]продвинуть сайт в москве[/url] .
Путь к свободе от зависимости начинается не с обещаний «просто перестать», а с профессионального медицинского вмешательства. В «Чистом Дыхании» мы применяем проверенные методы, которые работают там, где сила воли без нужной поддержки оказывается бессильной. Наша клиника в Долгопрудном работает круглосуточно — чтобы помощь была доступна в самый критический момент, когда человек ощущает острую потребность в детоксикации, снятии абстинентного синдрома или психологической поддержке.
Углубиться в тему – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]частная наркологическая клиника[/url]
[url=htts://rsmeds.top/#]order priligy[/url]
Рейтинг честных онлайн казино можно найти здесь: https://www.don8play.ru
расчет газового пожаротушения [url=https://montazh-gazovogo-pozharotusheniya-1.ru/]расчет газового пожаротушения[/url] .
priligy generic https://rsmeds.top/# purchase dapoxetine
Специализированный ресурс для хозяев частных домов представляет прикладные рекомендации по ремонтным работам, стройке, организации приусадебного участка с детальными руководствами и иллюстрациями. На сайте собраны экспертные рекомендации по выбору строительных материалов, систем отопления, сантехники, мебели, а также статьи о ландшафтном дизайне, уходе за растениями и домашними животными. Ищете кактус без корней как посадить? Полезная информация на dommovik.ru — здесь найдете решения для создания уюта в доме, идеи декора своими руками, рецепты народной медицины и видеоинструкции по различным работам. Интуитивная структура категорий обеспечивает оперативный поиск решений злободневных задач по организации загородного жилья и участка.
Запой — одно из самых опасных проявлений алкогольной зависимости. Он сопровождается глубокой интоксикацией организма, нарушением работы сердца, печени, головного мозга и других жизненно важных систем. Когда человек не может остановиться самостоятельно, а организм больше не справляется с нагрузкой, требуется медицинская помощь. В наркологической клинике «Спасение» в Мытищах мы проводим экстренные процедуры инфузионной терапии, позволяющие эффективно и безопасно вывести пациента из состояния запоя. Капельница — это первый шаг на пути к восстановлению здоровья и возвращению к нормальной жизни.
Получить больше информации – http://kapelnica-ot-zapoya-moskva2.ru
Если человек страдает от алкоголизма, запойное состояние требует незамедлительного вмешательства, особенно если признаки токсического отравления начинают угрожать жизни. Признаки запоя — это не только физическая зависимость, но и эмоциональные и психические расстройства, такие как тревога, агрессия и галлюцинации.
Подробнее – https://narcolog-na-dom-novokuznetsk0.ru/narkolog-na-dom-czena-novokuzneczk
Bez kompromisu v kvalite, s obrovskou slevou v cene
https://opravdovalekarna.cz
[url=https://livemedsrx.top/#]levitra cheap[/url]
Особенно уязвимыми становятся люди старше 45 лет, а также пациенты с сахарным диабетом, гипертонией, эпилепсией и болезнями печени. При этом многие продолжают надеяться, что «само пройдёт» — и упускают момент, когда помочь ещё можно без реанимации. Наша клиника организует выезд врача в течение 40–60 минут, чтобы не терять драгоценное время.
Изучить вопрос глубже – https://vyvod-iz-zapoya-kolomna3.ru/vyvod-iz-zapoya-nedorogo-v-kolomne
Стационарный формат предполагает круглосуточное наблюдение, возможность экстренного вмешательства и доступ к диагностическим средствам. Это особенно важно при наличии хронических заболеваний, психозов или алкогольного делирия.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-ryazani12.ru/]вывод из запоя цена в рязани[/url]
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Получить дополнительные сведения – https://snyatie-lomki-podolsk1.ru
Наши стандарты включают конфиденциальную маршрутизацию, детализированные инструкции для семьи, модульный план лечения и прозрачное разделение бесплатных и платных блоков. Каждому пациенту назначается ведущий специалист, который сопровождает его на всём пути — от первого звонка до контрольных чек-инов после процедур. Мы не «наращиваем» объём вмешательств ради впечатления: используется минимально достаточный набор мер, который действительно влияет на целевые маркеры — переносимость воды, качество сна, сглаживание вегетативных «качелей» и возвращение утренней ясности.
Изучить вопрос глубже – http://narkologicheskaya-klinika-v-chelyabinske16.ru
Мы предлагаем полный спектр услуг по лечению зависимостей:
Подробнее тут – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]вывод наркологическая клиника[/url]
buy levitra pills http://livemedsrx.top/# buy-vardenafil-pills
Особенно уязвимыми становятся люди старше 45 лет, а также пациенты с сахарным диабетом, гипертонией, эпилепсией и болезнями печени. При этом многие продолжают надеяться, что «само пройдёт» — и упускают момент, когда помочь ещё можно без реанимации. Наша клиника организует выезд врача в течение 40–60 минут, чтобы не терять драгоценное время.
Детальнее – [url=https://vyvod-iz-zapoya-kolomna3.ru/]услуги вывода из запоя[/url]
глубокий комлексный аудит сайта [url=https://prodvizhenie-sajtov-v-moskve9.ru/]prodvizhenie-sajtov-v-moskve9.ru[/url] .
Just finished this article, really good stuff https://forum.shvedun.ru/ucp.php?mode=login
seo partners [url=https://prodvizhenie-sajtov-v-moskve9.ru/]seo partners[/url] .
продвижение сайта по трафику [url=https://prodvizhenie-sajtov-po-trafiku7.ru/]продвижение сайта по трафику[/url] .
[url=http://livemedsrx.top/#]buy levitra[/url]
PG Slot แพลตฟอร์มเกมสล็อตยอดนิยม ใช้งานง่าย ฝากถอนรวดเร็ว
คำค้นหา สล็อต PG ถูกค้นหามากขึ้นเรื่อยๆ ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ผู้ให้บริการเกมสล็อตที่มาแรง ด้าน กราฟิก ความ เสถียร และ ระบบจ่ายที่ดึงดูด เกมของ PG ออกแบบโดยทีมงานมืออาชีพ ที่รองรับการเล่นทั้งบน โทรศัพท์มือถือ และ คอมพิวเตอร์
จุดเด่น ของ PG Slot
pg slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ เข้าเกมไว เล่นผ่าน ระบบเว็บ และรองรับ ทุกแพลตฟอร์ม ไม่ต้องติดตั้งเพิ่มเติม ผู้เล่นสามารถเข้าเล่นผ่าน Browser ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ 3D ให้ความคมชัด พร้อมเอฟเฟกต์ จัดเต็ม
คุณสมบัติหลักของเกม PG Slot ได้แก่
ระบบโบนัสและฟรีสปินหลากหลายรูปแบบ
ระบบตัวคูณ
เดโม่ฟรี
ใช้งานภาษาไทยง่าย
ระบบการเงินรวดเร็ว ทำรายการไว
แพลตฟอร์ม PG Slot โดยทั่วไปให้บริการ การฝาก-ถอน ฝากถอนตลอดเวลา ขั้นต่ำเริ่มต้นเพียง 10 บาท ขึ้นอยู่กับ ระบบของผู้ให้บริการ การทำรายการใช้เวลา ไม่กี่วินาที ผ่าน คิวอาร์โค้ด หรือระบบ แอปธนาคาร ทำให้ธุรกรรมเป็นไปอย่าง ต่อเนื่อง
แนวเกมที่คนเล่นเยอะ ใน pg slot
เกม pg slot มีธีมหลากหลาย เช่น
ธีม แฟนตาซี
ธีม ผจญภัย
ธีม เอเชียและโชคลาภ
ธีม Animal
เกมยอดนิยมมักเป็นเกมที่แตกง่าย พร้อมระบบ โบนัสรอบพิเศษ และ อัตราการจ่ายที่สูง เหมาะกับทั้ง ผู้เล่นเริ่มต้น และ ผู้เล่นมือโปร
ความน่าเชื่อถือ
สล็อต PG พัฒนาในระบบสากล มีการ เข้ารหัสข้อมูล และใช้ระบบสุ่มผล RNG เพื่อให้ผลลัพธ์ ยุติธรรม แพลตฟอร์มที่ให้บริการ PG Slot ควรมี ทีมซัพพอร์ต 24 ชม.
สรุป
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน โบนัสหลากหลาย และการทำธุรกรรมที่ รวดเร็ว ผู้เล่นสามารถเริ่มต้นได้ ง่าย ฝากถอนสะดวก และเลือกเกมได้ หลากหลายแนว เหมาะสำหรับ ทั้งมือใหม่และมือโปร ในโลกของเกมสล็อตออนไลน์
https://medium.com/@ratypw/ทดลองเล่นสล็อต-pg-70cdb1132344
ทดลองเล่นสล็อต pg ฟรี PG Slot สล็อตยอดฮิต ใช้งานง่าย ฝากถอนรวดเร็ว
คำค้นหา pg slot กำลังได้รับความนิยมอย่างต่อเนื่อง ในกลุ่มผู้เล่นเกมสล็อตออนไลน์ เพราะเป็น ผู้ให้บริการเกมสล็อตที่มาแรง ด้าน ภาพและเอฟเฟกต์ ความ ลื่นไหล และ อัตราการจ่ายรางวัลที่น่าสนใจ เกมของ PG ออกแบบโดยทีมงานมืออาชีพ ที่รองรับการเล่นทั้งบน สมาร์ทโฟน และ เดสก์ท็อป
จุดเด่น ของ pg slot
pg slot เป็นเกมสล็อตออนไลน์ที่ออกแบบมาให้ โหลดเร็ว เล่นผ่าน ระบบเว็บ และรองรับ ทั้ง iOS และ Android ไม่ต้องติดตั้งเพิ่มเติม ผู้เล่นสามารถเข้าเล่นผ่าน Browser ได้ทันที ภาพและเสียงถูกพัฒนาในรูปแบบ 3D ให้ความคมชัด พร้อมเอฟเฟกต์ จัดเต็ม
คุณสมบัติหลักของเกม PG Slot ได้แก่
ระบบโบนัสและฟรีสปินหลากหลายรูปแบบ
ระบบตัวคูณ
โหมดทดลองเล่นฟรี
ใช้งานภาษาไทยง่าย
ระบบการเงินรวดเร็ว ทำรายการไว
แพลตฟอร์ม สล็อต PG โดยทั่วไปให้บริการ การฝาก-ถอน ออโต้ตลอด 24 ชม. ขั้นต่ำเริ่มต้นเพียง 1 บาท ขึ้นอยู่กับ เงื่อนไขของเว็บไซต์ การทำรายการใช้เวลา รวดเร็วมาก ผ่าน สแกน QR หรือระบบ แอปธนาคาร ทำให้ธุรกรรมเป็นไปอย่าง ต่อเนื่อง
แนวเกมที่คนเล่นเยอะ ใน PG Slot
เกม PG Slot มีธีมหลากหลาย เช่น
ธีม แฟนตาซี
ธีม Adventure
ธีม โชคลาภ
ธีม ธรรมชาติ
ผู้เล่นนิยมเกมที่มีรอบพิเศษบ่อย พร้อมระบบ ฟีเจอร์พิเศษ และ ระบบจ่ายคุ้มค่า เหมาะกับทั้ง คนเพิ่งเล่น และ ผู้เล่นที่มีประสบการณ์
ความน่าเชื่อถือ
สล็อต PG พัฒนาในระบบสากล มีการ เข้ารหัสข้อมูล และใช้ระบบสุ่มผล Random Number Generator เพื่อให้ผลลัพธ์ ยุติธรรม แพลตฟอร์มที่ให้บริการ pg slot ควรมี ระบบดูแลข้อมูล
โดยภาพรวม
สล็อต PG เป็นตัวเลือกยอดนิยมสำหรับผู้ที่ต้องการเล่นสล็อตออนไลน์ ด้วยจุดเด่นด้าน กราฟิกคุณภาพ และการทำธุรกรรมที่ ไว ผู้เล่นสามารถเริ่มต้นได้ ไม่ซับซ้อน ฝากถอนสะดวก และเลือกเกมได้ หลากหลายแนว เหมาะสำหรับ ทั้งมือใหม่และมือโปร ในโลกของเกมสล็อตออนไลน์
tuan88
ทดลองเล่นสล็อต pg ซื้อฟรีสปิน
заказать кухню под ключ [url=https://zakazat-kuhnyu-3.ru/]zakazat-kuhnyu-3.ru[/url] .
[url=https://livemedsrx.top/#]order-vardenafil[/url]