
DARTS: DIFFERENTIABLE ARCHITECTURE SEARCH
摘要
本文通过以可微分的方式解决架构搜索的可扩展性挑战。 与在离散和不可微搜索空间上应用进化算法或强化学习的传统方法不同,作者的方法是基于架构表示的连续松弛,能够使用梯度下降对架构进行有效搜索。 在 CIFAR-10、ImageNet、Penn Treebank 和 WikiText-2 上进行的大量实验表明,该算法在发现用于图像分类的高性能卷积架构和用于语言建模的循环架构方面表现出色,同时比现有的不可微分方法快几个数量级。下面,简单介绍下Darts对网络架构搜索的建模以及具体的松弛方法。
搜索空间
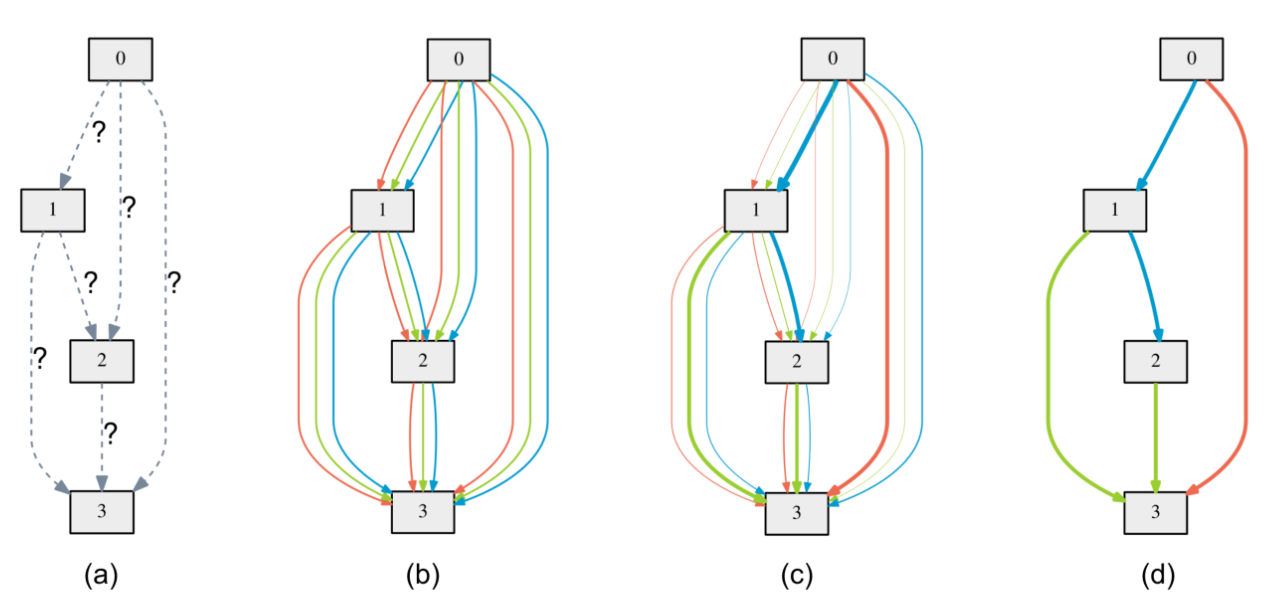
搜索空间被建模成如图所示的超网络。图中的方块表示的是featuremap,有向边表示连接两个featuremap的所有可能操作,且每条边只对应一个操作。(a) 边上的操作最初是未知的。(b) 通过在每条边上放置候选混合操作建立搜索空间。(c) 通过求解双层优化问题联合优化混合概率和网络权重。(d) 从学习到的混合概率中归纳最终架构。注意这里说的混合跟集成学习或者是注意力的意思有点像。也就是在超网络的训练中,两个featuremap之间的所有操作都是要参与到前向传播的,不同操作输出的featuremap被加权求和后作为新的featuremap。
Darts的重点是每个候选操作的权重如何构建,以及如何松弛。
松弛方法
\bar{o}^{(i, j)}(x)=\sum_{o \in \mathcal{O}} \frac{\exp \left(\alpha_o^{(i, j)}\right)}{\sum_{o^{\prime} \in \mathcal{O}} \exp \left(\alpha_{o^{\prime}}^{(i, j)}\right)} o(x) 将上图中的有向边对应到操作的表示符号 o(x),每个操作的权重则是
\frac{\exp \left(\alpha_o^{(i, j)}\right)}{\sum_{o^{\prime} \in \mathcal{O}} \exp \left(\alpha_{o^{\prime}}^{(i, j)}\right)}.其中,\alpha 是可训练的参数。如此,该权重具有以下特点:
- 可微分,权重具有自适应能力。
- 和为1,确保输出的featuremap在正常范围内。
- 权重越大,相应的候选操作在输出的featuremap中的贡献越大。
基于上述特点,在训练完成后,选择权重最大的候选即可。
训练算法

在训练的过程中,架构参数与模型参数被视作两组独立的参数交替使用梯度下降进行优化。参数收敛后,根据架构参数的最大值确定每两个featuremap之间的操作,从而生成最终架构。
Incredible insights! Sprunki transforms how we think about musical creativity. Sprunki offers unprecedented creative potential in composition. The way Sprunki empowers creative expression is truly remarkable.
Innovative breakdown! FNAF Games audio design deserves awards – that distant clanging could be Chica or your doom! 2AM pro tip: Headphones on!
I’m really impressed along with your writing skills as smartly as with the structure to your blog. Is this a paid subject or did you modify it your self? Either way keep up the nice quality writing, it’s rare to look a great blog like this one today!
Great breakdown on roulette strategies – it’s fascinating how math shapes outcomes. For those interested in AI-driven productivity, check out the AI Twitter Assistant for smart automation.
SuperPH22 offers a great mix of luck and strategy with its 1024 ways to win. The Jocker Card wilds and free spins really boost the fun. Check out SuperPH for a daily gaming hit!
I love how AI makes Ghibli magic accessible! 지브리 AI lets you turn simple ideas into stunning visuals. It’s like having Hayao Miyazaki in your pocket!
Do you have a spam issue on this blog; I also am a blogger, and I was curious about your situation; we have created some nice methods and we are looking to trade methods with others, be sure to shoot me an e-mail if interested.
George St-Pyer
What’s up i am kavin, its my first time to commenting anyplace, when i read this article i thought i could also make comment due to this good post.
melbet apps
What’s up, the whole thing is going perfectly here and ofcourse every one is sharing data, that’s actually excellent, keep up writing.
hafilat card recharge online
This is the perfect website for anybody who really wants to find out about this topic. You know so much its almost hard to argue with you (not that I actually will need to…HaHa). You certainly put a new spin on a topic that has been discussed for ages. Wonderful stuff, just great!
www zain com kuwait
Do you have a spam issue on this site; I also am a blogger, and I was curious about your situation; we have created some nice procedures and we are looking to swap methods with others, be sure to shoot me an e-mail if interested.
bus travel Abu Dhabi
кайт хургада
Hi there it’s me, I am also visiting this site on a regular basis, this web page is truly good and the users are genuinely sharing good thoughts.
https://hughes-mcgee-4.thoughtlanes.net/henry-uz-com-t-erri-daniel-anri-kh-ak-ik-ii-merosi-zhamlangan-manba
Jili77 stands out with its AI-driven approach, making it a smart pick for serious players. The platform’s variety and security really shine, especially for those diving into slots or live games.
Excellent article. Keep posting such kind of information on your page. Im really impressed by it.
Hi there, You have done an excellent job. I will definitely digg it and personally recommend to my friends. I’m confident they’ll be benefited from this website.
https://www.dermandar.com/user/airbusegg35/
I blog quite often and I genuinely thank you for your information. This great article has truly peaked my interest. I am going to take a note of your site and keep checking for new details about once per week. I opted in for your RSS feed too.
https://ital-parts.com.ua/gde-kupit-nadezhnyy-shoker-dlya-samooborony-luchshie-magaziny-shokeru-com-ua
cialis da 5 mg prezzo : an effective drug containing tadalafil, treats erectile dysfunction and benign prostatic hyperplasia. In Italy, 28 tablets of Cialis 5 mg is priced at approximately €165.26, though prices vary by pharmacy and discounts. Generic alternatives, like Tadalafil DOC Generici, cost €0.8–€2.6 per tablet, offering a budget-friendly option. Always consult a doctor, as a prescription is needed.
Baccarat strategies work best with discipline. I always check out the live dealer games at JLJL PH for a real casino feel-great mix of tech and tradition.
«Рентвил» предлагает аренду автомобилей в Краснодаре без залога и ограничений по пробегу по Краснодарскому краю и Адыгее. Требуется стаж от 3 лет и возраст от 23 лет. Оформление за 5 минут онлайн: нужны только фото паспорта и прав. Подача авто на жд вокзал и аэропорт Краснодар Мин-воды Сочи . Компания работает 10 лет , автомобили проходят своевременное ТО. Доступны детские кресла. Бронируйте через сайт машина в аренду краснодар
What a material of un-ambiguity and preserveness of precious know-how regarding unexpected feelings.
https://ital-parts.com.ua/gde-kupit-nadezhnyy-shoker-dlya-samooborony-luchshie-magaziny-shokeru-com-ua
http://pravo-med.ru/articles/18547/
kitesurfing это
кайт школа хургада
https://oboronspecsplav.ru/
Пассажирские перевозки Караганда – Новосибирск Пассажирские перевозки Новосибирск – Астана Отправляйтесь в комфортное путешествие из Новосибирска в Астану с нашими надежными пассажирскими перевозками. Мы предлагаем регулярные рейсы, обеспечивающие удобство и безопасность в пути. Пассажирские перевозки Астана – Новосибирск Планируете поездку из Астаны в Новосибирск? Наши пассажирские перевозки – это ваш лучший выбор. Наслаждайтесь комфортом и безопасностью в течение всего путешествия. Пассажирские перевозки Новосибирск – Павлодар Совершите увлекательное путешествие из Новосибирска в Павлодар с нашими пассажирскими перевозками. Мы гарантируем приятную поездку и своевременное прибытие. Пассажирские перевозки Павлодар – Новосибирск Наши пассажирские перевозки из Павлодара в Новосибирск – это ваш шанс насладиться комфортным и безопасным путешествием. Доверьте нам свою поездку и оцените высокий уровень сервиса.
Hi friends, its wonderful post on the topic of cultureand fully defined, keep it up all the time.
https://bestpeople.com.ua//krashchi-hermetyky-fary-auto
Пассажирские перевозки Новосибирск – Астана Развитая сеть пассажирских перевозок играет ключевую роль в обеспечении мобильности населения и укреплении экономических связей между регионами. Наша компания специализируется на организации регулярных и безопасных поездок между городами Сибири и Казахстана, предлагая комфортные условия и доступные цены.
Admiring the hard work you put into your blog and in depth information you present. It’s nice to come across a blog every once in a while that isn’t the same outdated rehashed material. Great read! I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
https://forthouse.com.ua/sklo-ta-korpusy-dlya-far-3er-bmw-vse-scho-potribno-znaty
«Рентвил» предлагает аренду автомобилей в Краснодаре без залога и ограничений по пробегу по Краснодарскому краю и Адыгее. Требуется стаж от 3 лет и возраст от 23 лет. Оформление за 5 минут онлайн: нужны только фото паспорта и прав. Подача авто на жд вокзал и аэропорт Краснодар Мин-воды Сочи . Компания работает 10 лет , автомобили проходят своевременное ТО. Доступны детские кресла. Бронируйте через сайт аренда машины в краснодаре
Запчасти для станков Bison Bial Токарные патроны Bison Запчасти для станков Bison Bial В мире металлообработки, где точность и надежность играют ключевую роль, токарные патроны Bison занимают особое место. Эти инструменты, производимые известной польской компанией Bison Bial, зарекомендовали себя как высококачественные и долговечные компоненты для токарных станков. Они обеспечивают надежный зажим заготовок, что напрямую влияет на качество и скорость обработки.
Hi are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started and set up my own. Do you need any coding expertise to make your own blog? Any help would be greatly appreciated!
Myzain
Опт из Китая В эпоху глобализации и стремительного развития мировой экономики, Китай занимает ключевую позицию в качестве крупнейшего производственного центра. Организация эффективных и надежных поставок товаров из Китая становится стратегически важной задачей для предприятий, стремящихся к оптимизации затрат и расширению ассортимента. Наша компания предлагает комплексные решения для вашего бизнеса, обеспечивая бесперебойные и выгодные поставки товаров напрямую из Китая.
Good day! Do you use Twitter? I’d like to follow you if that would be ok. I’m absolutely enjoying your blog and look forward to new updates.
my Zain
Hello! This post could not be written any better! Reading through this post reminds me of my previous room mate! He always kept talking about this. I will forward this post to him. Fairly certain he will have a good read. Thanks for sharing!
my Zain
Nice share!
A unique view on [url=https://winb.lt/vavada-casino-supporting-women-in-stem-through-digital-innovation/]vavada casino[/url] mixed with future-focused design and accessibility.
Мебель для кухни Кухня – сердце дома, место, где рождаются кулинарные шедевры и собирается вся семья. Именно поэтому выбор мебели для кухни – задача ответственная и требующая особого подхода. Мебель на заказ в Краснодаре – это возможность создать уникальное пространство, идеально отвечающее вашим потребностям и предпочтениям.
Understanding gambling psychology is key to responsible play. Platforms like Super PH offer immersive experiences, but balance is essential for long-term enjoyment.
What’s up to every one, the contents existing at this site are in fact awesome for people knowledge, well, keep up the nice work fellows.
hafilat recharge
Hi Dear, are you actually visiting this web site regularly, if so afterward you will without doubt take pleasant experience.
hafilat
В динамичном мире Санкт-Петербурга, где каждый день кипит жизнь и совершаются тысячи сделок, актуальная и удобная доска объявлений становится незаменимым инструментом как для частных лиц, так и для предпринимателей. Наша платформа – это ваш надежный партнер в поиске и предложении товаров и услуг в Северной столице. Подать объявление в СПб
аккаунты варфейс купить В мире онлайн-шутеров Warface занимает особое место, привлекая миллионы игроков своей динамикой, разнообразием режимов и возможностью совершенствования персонажа. Однако, не каждый готов потратить месяцы на прокачку аккаунта, чтобы получить желаемое оружие и экипировку. В этом случае, покупка аккаунта Warface становится привлекательным решением, открывающим двери к новым возможностям и впечатлениям.
Узи беременность В ритме современного мегаполиса, такого как Санкт-Петербург, забота о женском здоровье становится приоритетной задачей. Регулярные консультации с гинекологом, профилактические осмотры и своевременная диагностика – залог долголетия и благополучия каждой женщины.
Heya just wanted to give you a brief heads up and let you know a few of the images aren’t loading properly. I’m not sure why but I think its a linking issue. I’ve tried it in two different web browsers and both show the same results.
hafilat card balance check
Hello there I am so delighted I found your blog page, I really found you by error, while I was searching on Bing for something else, Nonetheless I am here now and would just like to say thanks for a fantastic post and a all round entertaining blog (I also love the theme/design), I don’t have time to browse it all at the moment but I have saved it and also included your RSS feeds, so when I have time I will be back to read much more, Please do keep up the superb work.
hafilat card
Hi there, the whole thing is going well here and ofcourse every one is sharing information, that’s really excellent, keep up writing.
hafilat card
музыкальные новинки Роп – Русский роп – это больше, чем просто музыка. Это зеркало современной российской души, отражающее её надежды, страхи и мечты. В 2025 году жанр переживает новый виток развития, впитывая в себя элементы других стилей и направлений, становясь всё более разнообразным и эклектичным. Популярная музыка сейчас – это калейдоскоп звуков и образов. Хиты месяца мгновенно взлетают на вершины чартов, но так же быстро и забываются, уступая место новым музыкальным новинкам. 2025 год дарит нам множество талантливых российских исполнителей, каждый из которых вносит свой неповторимый вклад в развитие жанра.
Do you have a spam problem on this website; I also am a blogger, and I was curious about your situation; we have created some nice methods and we are looking to trade strategies with others, please shoot me an email if interested.
http://daicond.com.ua/yak-doglyadaty-za-sklom-dlya-far-porady-ta-sekrety
красное море температура воды
Сергей Бидус кинул на деньги
Really insightful article! It’s great to see platforms focusing on service alongside the games themselves. I checked out game ph login & their support seems top-notch – crucial for a smooth experience, right? Definitely a step up!
That is very fascinating, You are an overly professional blogger. I have joined your feed and look ahead to in quest of more of your fantastic post. Additionally, I have shared your site in my social networks
porno izle
Творчество своими руками Самоделки своими руками – это не просто хобби, это целая философия, позволяющая взглянуть на окружающий мир под новым углом, увидеть потенциал в обыденных вещах и дать им новую жизнь. Это способ выразить свою индивидуальность, проявить творческую натуру и, конечно же, сэкономить средства. Оригинальные самоделки рождаются из фантазии и желания создать нечто уникальное, неповторимое. Это могут быть украшения для дома, предметы интерьера, аксессуары, изготовленные из подручных материалов. Главное – это идея и вдохновение.
пауэрлифтинг Гармония силы: Путь к совершенству через спорт и правильное питание Спорт, особенно силовой, – это не просто поднятие тяжестей. Это искусство лепки тела и духа, требующее дисциплины, знаний и постоянного стремления к совершенству. В основе этого искусства лежит три кита: жим, присед и становая тяга. Жим лежа – символ силы верхней части тела, требует не только мощных грудных мышц, но и стабильности плечевого пояса и сильных трицепсов. Правильная техника – ключ к прогрессу и предотвращению травм. Приседания – царь упражнений, развивающий силу ног и ягодиц, а также укрепляющий корпус. Глубина приседа, контроль над весом и правильное дыхание – факторы, определяющие эффективность этого упражнения. Становая тяга – королева упражнений, задействующая практически все мышцы тела. Сильная спина, крепкий хват и правильная техника подъема – залог безопасного и эффективного выполнения становой тяги. Пауэрлифтинг объединяет эти три упражнения, превращая стремление к силе в соревнование. Это не просто поднятие максимального веса, это демонстрация контроля над своим телом и разумом, результат месяцев упорных тренировок. Однако, сила без здоровья – ничто. Правильное питание – неотъемлемая часть спортивного успеха. Баланс белков, жиров и углеводов, достаточное количество витаминов и минералов, а также своевременное восстановление – основа для роста мышц и поддержания здоровья. Спорт и правильное питание – это не просто хобби, это образ жизни, который ведет к гармонии силы и здоровья, к совершенству тела и духа.
Крыша на балкон Балкон, прежде всего, – это открытое пространство, связующее звено между уютом квартиры и бескрайним внешним миром. Однако его беззащитность перед капризами погоды порой превращает это преимущество в существенный недостаток. Дождь, снег, палящее солнце – все это способно причинить немало хлопот, лишая возможности комфортно проводить время на балконе, а также нанося ущерб отделке и мебели. Именно здесь на помощь приходит крыша на балкон – надежная защита и гарантия комфорта в любое время года.
roobet redeem code WEB3 В мире онлайн-казино инновации не стоят на месте, и Roobet находится в авангарде этих перемен. С появлением технологии Web3, Roobet предлагает игрокам новый уровень прозрачности, безопасности и децентрализации. Чтобы воспользоваться всеми преимуществами этой передовой платформы, используйте промокод WEB3.
«Рентвил» предлагает аренду автомобилей в Краснодаре без залога и ограничений по пробегу по Краснодарскому краю и Адыгее. Требуется стаж от 3 лет и возраст от 23 лет. Оформление за 5 минут онлайн: нужны только фото паспорта и прав. Подача авто на жд вокзал и аэропорт Краснодар Мин-воды Сочи . Компания работает 10 лет , автомобили проходят своевременное ТО. Доступны детские кресла. Бронируйте через авто в аренду краснодар
Hi, I think your website might be having browser compatibility issues. When I look at your blog in Opera, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, wonderful blog!
hafilat balance check
chicken road demo Chicken Road: Взлеты и Падения на Пути к Успеху Chicken Road – это не просто развлечение, это обширный мир возможностей и тактики, где каждое решение может привести к невероятному взлету или полному краху. Игра, доступная как в сети, так и в виде приложения для мобильных устройств (Chicken Road apk), предлагает пользователям проверить свою фортуну и чутье на виртуальной “куриной тропе”. Суть Chicken Road заключается в преодолении сложного маршрута, полного ловушек и опасностей. С каждым успешно пройденным уровнем, награда растет, но и увеличивается шанс неудачи. Игроки могут загрузить Chicken Road game demo, чтобы оценить механику и особенности геймплея, прежде чем рисковать реальными деньгами.
Generate custom ai hentai generator. Create anime-style characters, scenes, and fantasy visuals instantly using an advanced hentai generator online.
Rainbet code ILBET В мире онлайн-гемблинга Rainbet сияет как яркая звезда, привлекая игроков своими щедрыми предложениями и захватывающими играми. Промокод ILBET – это ваш билет в этот мир возможностей, предоставляющий доступ к эксклюзивным бонусам и акциям, разработанным для повышения вашего игрового опыта и увеличения шансов на победу.
Baccarat patterns are fascinating – truly understanding them elevates your game. Seeing platforms like game ph login prioritize mobile UX is smart; seamless access is key for tracking trends on the go! It’s about convenience & insight.
pinco casino azerbaijan Pinco, Pinco AZ, Pinco Casino, Pinco Kazino, Pinco Casino AZ, Pinco Casino Azerbaijan, Pinco Azerbaycan, Pinco Gazino Casino, Pinco Pinco Promo Code, Pinco Cazino, Pinco Bet, Pinco Yukl?, Pinco Az?rbaycan, Pinco Casino Giris, Pinco Yukle, Pinco Giris, Pinco APK, Pin Co, Pin Co Casino, Pin-Co Casino. Онлайн-платформа Pinco, включая варианты Pinco AZ, Pinco Casino и Pinco Kazino, предлагает азартные игры в Азербайджане, также известная как Pinco Azerbaycan и Pinco Gazino Casino. Pinco предоставляет промокоды, а также варианты, такие как Pinco Cazino и Pinco Bet. Пользователи могут загрузить приложение Pinco (Pinco Yukl?, Pinco Yukle) для доступа к Pinco Az?rbaycan и Pinco Casino Giris. Pinco Giris доступен через Pinco APK. Pin Co и Pin-Co Casino — это связанные термины.
Скачать тик ток мод Тикток мод, словно цифровой феникс, возрождается на просторах Android, предлагая пользователям расширенные возможности и свободу самовыражения. Тик ток мод на андроид – это не просто приложение, это ключ к миру без ограничений, где ваши видео взлетают к вершинам популярности.
Найти мастера по ремонту холодильников в Виннице можно по ссылке
личные дебетовые карты Путеводитель по миру удобных банковских карт. Оформить современную дебетовую карту стало просто и удобно благодаря нашей поддержке. Выберите карту, которая идеально вам подходит, и наслаждайтесь всеми преимуществами современного финансового сервиса. Что мы предлагаем? Практические советы: Полезные лайфхаки и рекомендации для эффективного использования вашей карты. Свежие акции: Будьте в курсе всех актуальных предложений и специальных условий от наших банков-партнеров. Преимущества нашего сообщества. Полная информация о различных видах карт, особенностях тарифов и комиссий. Регулярно обновляемые материалы с актуальными данными и последними новостями о продуктах российских банков. Присоединяйтесь к нашему сообществу, чтобы сделать ваши финансовые решения простыми, быстрыми и безопасными. Вместе мы сможем оптимизировать использование банковских продуктов и сэкономить ваше время и средства. Наша цель — помочь вам эффективно управлять своими финансами и получать максимальную выгоду от каждого взаимодействия с банком.
тик ток мод русский скачать последняя Мир мобильных приложений не стоит на месте, и Тик Ток продолжает оставаться одной из самых популярных платформ для создания и обмена короткими видео. Но что, если стандартной функциональности вам недостаточно? На помощь приходит Тик Ток Мод – модифицированная версия приложения, открывающая доступ к расширенным возможностям и эксклюзивным функциям.
Ментор Стратегическое планирование: создайте будущее своей компании. Многие бизнесы борются с размытыми целями и отсутствием четкого плана. Настоящий успех достигается через стратегическое планирование — системный подход к развитию. Ментор поможет вам определить ключевые цели, разработать реалистичные стратегии и создать дорожную карту роста. Вместе вы сможете предвидеть вызовы, использовать возможности и избегать ошибок. Не откладывайте развитие на потом — инвестируйте в профессиональную поддержку и создайте прочный фундамент для долгосрочного успеха. Закажите консультацию и начните строить будущее уже сегодня.
Мир полон тайн https://phenoma.ru читайте статьи о малоизученных феноменах, которые ставят науку в тупик. Аномальные явления, редкие болезни, загадки космоса и сознания. Доступно, интересно, с научным подходом.
бесплатные общие аккаунты стим бесплатные общие аккаунты стим
тикток мод бесплатно
бесплатный мод на тик ток айфон Улучшенная версия TikTok для iPhone: загрузка, модификации и последние обновления. Как установить модифицированный TikTok на iPhone? Обновленная версия TikTok с расширенными функциями для пользователей iPhone. Где скачать последнюю версию модифицированного TikTok для iOS? Бесплатные моды TikTok для iPhone, включая версию 2025 года. Ищете способ улучшить свой опыт использования TikTok на iPhone? Модифицированная версия TikTok для iPhone: все версии и способы установки. Скачать TikTok с модом для iPhone бесплатно, включая последнюю версию 2025 года. Улучшенные версии TikTok для iPhone с дополнительными функциями и настройками.
раздача стим аккаунтов бесплатно t.me/Burger_Game/
оформить дебетовую карту Откройте для себя мир удобных банковских карт с нашей помощью. Оформление современной дебетовой карты стало простым и доступным благодаря нашей платформе. Легко подберите подходящую карту и пользуйтесь всеми преимуществами современных финансовых услуг. Что мы предлагаем? Полезные советы: Рекомендации и лайфхаки для эффективного использования вашей карты. Актуальные акции: Будьте в курсе последних предложений и специальных условий от банков-партнеров. Преимущества нашего сообщества. Здесь вы найдете всю необходимую информацию о различных видах карт, особенностях тарифов и комиссий. Наши публикации регулярно обновляются, предоставляя актуальные данные и свежие новости о продуктах российских банков. Присоединяйтесь к нашему сообществу, чтобы сделать ваши финансовые решения простыми, быстрыми и надежными. Вместе мы сможем оптимизировать использование банковских продуктов и сэкономить ваше время и деньги. Ведь наша цель — помогать вам эффективно управлять своими финансами и получать максимум выгоды от каждого взаимодействия с банком.
фотозона баннер с днем рождения Фотографическая зона, оформленная баннером; декоративный баннер для фотозоны; праздничный баннер “С днем рождения” для создания фотозоны; баннер размером 2 на 2 метра, предназначенный для оформления фотозоны на дне рождения. Альтернативно, можно сказать так: Место для фотографирования, украшенное тематическим баннером; специальный баннер, используемый для создания фотозоны; баннер с надписью “С днем рождения” для оформления пространства для фотосессий; баннер с габаритами 2×2 метра, предназначенный для использования в качестве фона на дне рождения.
робота вебкам моделлю в Польщі Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
легальна онлайн робота для дівчат Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
Научно-популярный сайт https://phenoma.ru — малоизвестные факты, редкие феномены, тайны природы и сознания. Гипотезы, наблюдения и исследования — всё, что будоражит воображение и вдохновляет на поиски ответов.
praca webcam Polska Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
steam account authenticator it is a desktop emulator of the Steam authentication mobile application. This desktop application allows users to manage their two-factor authentication easily, ensuring that only you can access your account.
тик ток без Тик ток нова – это уже не просто название, это эра. Эра, в которой короткие видеоролики стали доминирующей формой развлечения, а тренды сменяются быстрее, чем успеваешь моргнуть глазом. “Тикток нова скачать” – этот запрос звучит как призыв к действию, как приглашение в мир бесконечного креатива и вирусного контента. Загружая “тикток скачать”, ты получаешь билет в этот мир, где каждый может стать звездой.
сборка компьютера под ключ Компьютер для стрима: Высокое качество трансляций Компьютер для стрима должен обеспечивать стабильную работу во время трансляций, высокое качество изображения и звука. Сборка компьютера на заказ позволяет выбрать компоненты, способные справиться с этими задачами.
This article brilliantly simplifies blackjack basics-just like how Sprunki Incredibox makes music creation accessible yet deep. Both are perfect for beginners and pros alike.
сборка компьютеров для игр
It’s fascinating how casino tech is evolving – predictive analytics to personalize experiences is a game changer! Thinking about future gaming, platforms like ph567 Casino seem to be leading the charge with innovative approaches. Exciting times!
sda steam it is a desktop emulator of the Steam authentication mobile application. This desktop application allows users to manage their two-factor authentication easily, ensuring that only you can access your account.
download steam desktop authenticator it is a desktop emulator of the Steam authentication mobile application. This desktop application allows users to manage their two-factor authentication easily, ensuring that only you can access your account.
Hi Dear, are you really visiting this website daily, if so afterward you will absolutely obtain fastidious experience.
https://studioline-interior.com/led-lampy-avto-yak-zrobyty-pokupku-yaka-prosluzhyt.html
Готовьте вкусно рецепт приготовления у нас — рецепты на любой вкус: мясные, вегетарианские, диетические, сладкие и острые. Пошаговые фото, время приготовления и секреты идеального блюда.
Experience https://llmbrowser.net, a specialized cloud agentic browser, delivering seamless integration for AI agents. This platform includes cloud synchronization, making it an ideal agentic antidetect browser. Upgrade your AI toolkit with a better agentic browser. Start now.
Юрист Онлайн https://juristonline.com квалифицированная юридическая помощь и консультации 24/7. Решение правовых вопросов любой сложности: семейные, жилищные, трудовые, гражданские дела. Бесплатная первичная консультация.
Exploring roulette strategies adds depth to gameplay. It’s interesting how platforms like Jili App blend math and entertainment for engaging casino experiences.
Дом из контейнера https://russiahelp.com под ключ — мобильное, экологичное и бюджетное жильё. Индивидуальные проекты, внутренняя отделка, электрика, сантехника и монтаж
Сайт знакомств https://rutiti.ru для серьёзных отношений, дружбы и общения. Реальные анкеты, удобный поиск, быстрый старт. Встречайте новых людей, находите свою любовь и начинайте общение уже сегодня.
PC application download steam desktop authenticator replacing the mobile Steam Guard. Confirm logins, trades, and transactions in Steam directly from your computer. Support for multiple accounts, security, and backup.
No more phone needed! https://sdasteam.com lets you use Steam Guard right on your computer. Quickly confirm transactions, access 2FA codes, and conveniently manage security.
Агентство недвижимости https://metropolis-estate.ru покупка, продажа и аренда квартир, домов, коммерческих объектов. Полное сопровождение сделок, юридическая безопасность, помощь в оформлении ипотеки.
Квартиры посуточно https://kvartiry-posutochno19.ru в Абакане — от эконом до комфорт-класса. Уютное жильё в центре и районах города. Чистота, удобства, всё для комфортного проживания.
хэллоуин маникюр алматы Наращивание ногтей Алматы – это возможность создать идеальную длину и форму ногтей, о которой вы всегда мечтали. Наращивание на типсы Алматы, наращивание на верхние формы Алматы, наращивание гелем Алматы – выбор за вами.
kitesurfing
погода в хургаде в апреле 2023
СРО УН «КИТ» https://sro-kit.ru саморегулируемая организация для строителей, проектировщиков и изыскателей. Оформление допуска СРО, вступление под ключ, юридическое сопровождение, помощь в подготовке документов.
Ремонт квартир https://remont-kvartir-novo.ru под ключ в новостройках — от черновой отделки до полной готовности. Дизайн, материалы, инженерия, меблировка.
sitio web tavoq.es es tu aliado en el crecimiento profesional. Ofrecemos CVs personalizados, optimizacion ATS, cartas de presentacion, perfiles de LinkedIn, fotos profesionales con IA, preparacion para entrevistas y mas. Impulsa tu carrera con soluciones adaptadas a ti.
Webseite cvzen.de ist Ihr Partner fur professionelle Karriereunterstutzung – mit ma?geschneiderten Lebenslaufen, ATS-Optimierung, LinkedIn-Profilen, Anschreiben, KI-Headshots, Interviewvorbereitung und mehr. Starten Sie Ihre Karriere neu – gezielt, individuell und erfolgreich.
Interesting read! Seeing how platforms like sz777 log in focus on user engagement-it’s not just about the games, right? Psychological principles really do shape the experience. Smart stuff for retention!
Greate post. Keep posting such kind of info on your site. Im really impressed by it.
Hi there, You have performed a great job. I will definitely digg it and in my opinion suggest to my friends. I’m confident they’ll be benefited from this site.
bus card renewal
Hey there, You’ve done a great job. I will certainly digg it and personally recommend to my friends. I’m sure they’ll be benefited from this site.
buy bus card abu dhabi
Диагностика бесплатна при последующем ремонте Apple-устройства.
sitio web tavoq.es es tu aliado en el crecimiento profesional. Ofrecemos CVs personalizados, optimizacion ATS, cartas de presentacion, perfiles de LinkedIn, fotos profesionales con IA, preparacion para entrevistas y mas. Impulsa tu carrera con soluciones adaptadas a ti.
еайт школа в анапе Кайтсерфинг в Анапе – это больше, чем просто спорт, это философия жизни.
снять квартиру в ташкенте Снять квартиру в Ташкенте на длительный срок: Рассматривая аренду на длительный срок, тщательно изучайте договор аренды. Убедитесь, что в нем четко прописаны все условия, включая размер арендной платы, порядок ее внесения, условия расторжения договора и ответственность сторон.
kraken onion Кракен онино
Professional concrete driveways in seattle — high-quality installation, durable materials and strict adherence to deadlines. We work under a contract, provide a guarantee, and visit the site. Your reliable choice in Seattle.
Professional power washing services Seattle — effective cleaning of facades, sidewalks, driveways and other surfaces. Modern equipment, affordable prices, travel throughout Seattle. Cleanliness that is visible at first glance.
Нужна камера? камера удаленного видеонаблюдения для дома, офиса и улицы. Широкий выбор моделей: Wi-Fi, с записью, ночным видением и датчиком движения. Гарантия, быстрая доставка, помощь в подборе и установке.
Interesting analysis! Seeing platforms like Plus777 really push for data-driven play is smart. Understanding game mechanics does elevate the experience – beyond just luck, right? Good insights!
Need transportation? car carriers car transportation company services — from one car to large lots. Delivery to new owners, between cities. Safety, accuracy, licenses and experience over 10 years.
Thank you for the auspicious writeup. It in truth used to be a amusement account it. Glance complex to far introduced agreeable from you! By the way, how can we keep in touch?
balance check hafilat
Hi, this weekend is fastidious for me, because this occasion i am reading this enormous informative paragraph here at my house.
hafilat card recharge
vehicle freight auto shipping quotes
Sprunki Incredibox brings fresh beats and visuals to the beloved Incredibox formula, making creativity even more fun. Check out the innovation at Spunky Games!
telegram crypto channel Крипто Биржи и Telegram Каналы: Ваш Источник Информации Выбор надежной крипто биржи и подписка на проверенные crypto exchange telegram crypto channel, crypto telegram channel и best crypto telegram – залог вашей информированности. Crypto telegram news – это быстрый способ получать актуальные новости и аналитику.
Thanks for every other excellent post. Where else could anybody get that type of info in such an ideal method of writing? I have a presentation subsequent week, and I’m at the look for such info.
hafilat card balance check
купить диплом о среднем образовании Диплом о высшем образовании с занесением в реестр: Для тех, кто ценит надежность и уверенность, мы предлагаем дипломы с занесением в реестр. Это гарантирует подлинность документа и исключает любые сомнения в его легитимности.
Постеры, трейлеры, тизеры и арты Смотреть аниме сериалы онгоинги онлайн бесплатно в русской озвучке – это возможность погрузиться в захватывающий мир японской анимации, не пропустив ни одной новой серии. Anime News держит вас в курсе всех событий индустрии, предоставляя самую свежую информацию о любимых тайтлах и грядущих премьерах. Анонсы новых серий и сезонов позволяют планировать свой просмотр и всегда быть в предвкушении следующей главы истории. Новости индустрии и студий раскрывают закулисье создания аниме, позволяя лучше понять творческий процесс и оценить работу аниматоров. Постеры, трейлеры, тизеры и арты дают первое впечатление о новых проектах, подогревая интерес и помогая определиться с выбором. Расписания премьер позволяют не пропустить выход долгожданных эпизодов и сезонов. Фан-сервис, фото, видео, клипы из аниме – это дополнительный контент, который порадует фанатов и позволит еще глубже погрузиться в атмосферу любимых сериалов. Все это, и многое другое, делает просмотр аниме онгоингов онлайн в русской озвучке не только увлекательным, но и информативным занятием. Следите за обновлениями, чтобы всегда быть в курсе последних событий в мире аниме 2025 и наслаждайтесь новинками!
металлопрокат купить в москве цена Металлопрокат купить в Москве: цена, опт и разнообразие выбора Москва – огромный мегаполис с постоянно растущими потребностями в строительных материалах. Металлопрокат занимает здесь особое место, являясь основой для возведения зданий, мостов, дорог и множества других объектов. Покупка металлопроката в Москве – ответственный шаг, требующий внимательного подхода к выбору поставщика и понимания ценообразования.
auto transport Navigating the World of Automobile Transport Services: A Comprehensive Guide In today’s interconnected world, automobile transport services have become indispensable for individuals and businesses alike. Whether you’re relocating across the country, purchasing a vehicle online, or managing a dealership’s inventory, understanding the intricacies of car shipping is crucial. This guide delves into the various facets of auto transport, providing insights into car shipping companies, auto transport companies, vehicle shipping companies, and the critical factors to consider when selecting the best service.
Вова Чернышев
Строительство дома бани из клееного бруса Строительство дома, бани из клееного бруса: Мы используем только высококачественные материалы и современное оборудование. Наши специалисты – это команда профессионалов с многолетним опытом работы. Мы гарантируем индивидуальный подход к каждому клиенту и высокое качество строительства. Позвольте нам воплотить вашу мечту о загородной жизни в реальность!
варфейс акк Warface: Твой путь к вершинам Независимо от того, выбираете ли вы купить аккаунт Warface, приобрести мощное оружие или воспользоваться пин-кодами, важно помнить, что главное – это удовольствие от игры. Warface – это мир, полный возможностей, и каждый игрок может найти свой путь к победе.
керамогранит 120 60 керамическая плитка 1200х600 на стену
Great read! As a blackjack newbie, it’s helpful to break down strategies step by step. Platforms like JLJL PH offer immersive live dealer games that let you practice real-time decision-making-definitely a useful tool for learning the ropes.
Dice games are surprisingly mathematical! Thinking about probability & strategy really elevates the fun. It’s cool how platforms like PH222 focus on smooth access & a great user experience – essential for enjoying any game! 👍
ultimate createporn generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
ultimate createporn generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
консультация юриста https://besplatnaya-yuridicheskaya-konsultaciya-moskva-po-telefonu.ru
Профессиональное косметологическое оборудование для салонов красоты для салонов красоты, клиник и частных мастеров. Аппараты для чистки, омоложения, лазерной эпиляции, лифтинга и ухода за кожей.
Interesting analysis! Seeing platforms like 789bet99 really adapt to local preferences-easy account setup & payments-is key for growth. It’s smart to empower both new & seasoned players! What trends are you seeing in Vietnamese gaming specifically?
Hello are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and create my own. Do you need any coding knowledge to make your own blog? Any help would be greatly appreciated!
hafilat balance checking
вскрыть замок москва Вскрытие замков – деликатная проблема, требующая оперативного решения. Ситуации, когда необходимо вскрыть замок срочно, не редкость, особенно в Москве. Потеря ключей, сломанный механизм, заклинившая дверь – все это требует профессионального подхода. Вскрытие замков в Москве – востребованная услуга. Важно найти надежного мастера, предлагающего открытие замков без повреждений. Вскрытие замков Москва недорого – реально, но не стоит гнаться за самой низкой ценой в ущерб качеству. Вскрыть дверной замок – задача для специалиста. Взлом замков – это крайняя мера, и профессиональные услуги по вскрытию замков подразумевают аккуратную работу. Вызвать мастера по вскрытию замков – оптимальное решение в большинстве случаев. Вскрытие дверных замков требует определенных навыков и инструментов. Цена на вскрытие замка может варьироваться в зависимости от сложности работы. Вскрыть замок мастер должен быстро и эффективно.
https://plombi.ru/product/nabor-dlya-opechatyvaniya-dverey/
Pharmaceuticals Bazaar Drugs Marketplace: A New Darknet Platform with Dual Access Bazaar Drugs Marketplace is a new darknet marketplace rapidly gaining popularity among users interested in purchasing pharmaceuticals. Trading is conducted via the Tor Network, ensuring a high level of privacy and data protection. However, what sets this platform apart is its dual access: it is available both through an onion domain and a standard clearnet website, making it more convenient and visible compared to competitors. The marketplace offers a wide range of pharmaceuticals, including amphetamines, ketamine, cannabis, as well as prescription drugs such as alprazolam and diazepam. This variety appeals to both beginners and experienced buyers. All transactions on the platform are carried out using cryptocurrency payments, ensuring anonymity and security. In summary, Bazaar represents a modern darknet marketplace that combines convenience, a broad product selection, and a high level of privacy, making it a notable player in the darknet economy.
Группа в Telegram Доска бесплатных объявлений “Все для Вас Архангельск”: товары, услуги, авто, жильё, работа, розыгрыши, отзывы и многое другое. Архангельск, Северодвинск, Новодвинск, Катунино, Березник, Рикасиха, Холмогоры, Мезень, Карпогоры архангельск время
продать лекарственный препарат где
уроки кайтсёрфинга Обучение кайтсерфингу Если вы хотите научиться кайтсерфингу, в Хургаде есть множество школ и опытных инструкторов. Профессиональный кайтсерфинг тренер поможет вам освоить азы управления кайтом, технику скольжения по воде и правила безопасности. Обучение кайтсёрфингу обычно включает в себя теоретические занятия, практику на берегу и на воде.
сервис знай своего клиента
профнастил оцинкованный Продажа в Алматы Шымкенте и Астане Продажа металлопроката в Алматы, Шымкенте, Астане. Рынок металлопроката в Алматы, Шымкенте и Астане представлен множеством компаний, однако выбор правильного партнера – залог успешного завершения любого проекта. Важно учитывать не только стоимость продукции, но и ее качество, соответствие стандартам, а также репутацию поставщика. Компания Модуль Сталь предлагает Вам широкий спектр продукции: арматуру различных диаметров, стальные листы, оцинкованный профнастил, уголки, швеллеры и многое другое. Это позволяет клиенту приобрести все необходимое в одном месте, экономя время и ресурсы. Важным фактором нашей компании является наличие собственных складских помещений и развитой логистической сети, что обеспечивает оперативную доставку металлопроката на строительные площадки и производственные предприятия.
вопросы про катэг
ultimate AI porn maker generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
гарантийный ремонт стиральных машин алматы Ремонт платы стиральной машины в Алматы – мы производим ремонт плат любой сложности.
проверка стиральной машины алматы Телефон мастера стиральных машин Алматы. Звоните прямо сейчас для вызова специалиста.
демонтаж в выходные стоимость Демонтаж компьютерных сетей – необходимо при переезде или обновлении офиса.
честные весы металлолом Утилизация сканеров в Алматы: утилизация сканеров и другой офисной техники.
Бездепозитный бонус
This page definitely has all of the info I wanted about this subject and didn’t know who to ask.
Play daily on 88fb bet and win real money
It’s great to see platforms focusing on responsible gaming! Understanding game mechanics, like those at phlwin com login, can really enhance enjoyment. Remember to set limits & play for fun! It’s all about balance, right? 😊
гибкая керамика цена за 1 м2 Гибкая керамика для фасадов дома внутренней отделки Москва phomi купить цена фоми монтаж за 1 м2 отзывы divu
vavada casino бонусы Vavada Casino Отзывы: Узнайте, что говорят другие игроки о Vavada Casino, и сформируйте свое мнение об этом популярном онлайн-казино.
I appreciate, lead to I discovered just what I was having a look for. You have ended my four day long hunt! God Bless you man. Have a great day. Bye
Try the best slots and live tables on 88fb login
сборка алматы Нанять разнорабочих в Алматы можно как на краткосрочные, так и на долгосрочные проекты. Важно учитывать квалификацию, опыт и отзывы предыдущих клиентов.
a-p-s эвакуатор Сравнить эвакуаторы алматы – сравнение компаний, предоставляющих услуги эвакуатора в Алматы.
Бездепозитный бонус
Лучшие юристы Екатеринбурга http://yuristy-ekaterinburga.ru
Шиномонтаж Краснодар 24 https://shinomontazh-vyezdnoj.ru/
Сукааа казино официальный сайт казино Сукааа казино официальный сайт скачать на андроид мобильная версия бесплатно позволяет играть в любимые игры прямо на своем смартфоне или планшете.
Бездепозитные бонусы
Сукааа казино официальный рабочее зеркало на сегодняшний день Сукааа казино официальный сайт скачать на андроид мобильная версия бесплатно позволяет играть в любимые игры прямо на своем смартфоне или планшете.
Really insightful article! Thinking about user journeys & conversion is key. Seeing platforms like sz7777 login focus on that – reducing friction & building engagement – is smart. Great points on behavioral analytics too!
Бездепозитные бонусы
вавада казино официальный сайт Вавада Казино Официальный Сайт Скачать на Андроид Мобильная Версия Бесплатно: Скачайте мобильную версию Вавада Казино на свое устройство Android и наслаждайтесь игрой в любом месте и в любое время.
блокчейн проверка транзакции по кошельку
Защитные кейсы plastcase.ru в Санкт-Петербурге — надежная защита оборудования от влаги, пыли и ударов. Большой выбор размеров и форматов, ударопрочные материалы, индивидуальный подбор.
Бездепозитные бонусы в казино
Защитные кейсы plastcase.ru/ в Санкт-Петербурге — надежная защита оборудования от влаги, пыли и ударов. Большой выбор размеров и форматов, ударопрочные материалы, индивидуальный подбор.
Сукааа казино официальный сайт скачать на андроид мобильная версия бесплатно Сукааа казино официальный сайт вход бесплатный играть – это возможность попробовать свои силы в демо-режиме без внесения депозита.
онлайн займы на карту без отказа https://zajmy-onlajn.ru
Бездепозитный бонус в казино
займы онлайн на карту по паспорту займы онлайн без проверок срочно
вавада казино официальный сайт Вавада Казино Официальный Рабочее Зеркало на Сегодняшний День: Всегда имейте доступ к Вавада Казино через рабочее зеркало, актуальное на сегодняшний день, и не упустите возможность испытать удачу.
Портал о строительстве https://buildportal.kyiv.ua и ремонте: лучшие решения для дома, дачи и бизнеса. Инструменты, сметы, калькуляторы, обучающие статьи и база подрядчиков.
Бездепозитные бонусы в казино Бездепозитные бонусы в казино: Что это такое? Бездепозитный бонус в казино – это денежная сумма или бесплатные вращения, которые казино предоставляет новым игрокам в качестве приветственного подарка. Главное преимущество этого бонуса заключается в том, что для его получения не требуется внесение депозита. Игрок может просто зарегистрироваться на сайте казино и получить бонус на свой счет.
Бездепозитный бонус Бездепозитные бонусы: Путь к азартным приключениям без риска В мире онлайн-казино, где азарт и возможность выигрыша переплетаются в захватывающем танце, бездепозитные бонусы занимают особое место. Эти щедрые предложения служат своеобразным ключом, открывающим двери в мир азартных развлечений без необходимости вкладывать собственные средства.
лечение алкогольной зависимости https://alko-info.ru
вывод из запоя на дом цена вывод из запоя срочно круглосуточно
Бездепозитные бонусы в казино
Бездепозитные бонусы Бездепозитный бонус в казино: Как его получить? Получить бездепозитный бонус в казино, как правило, довольно просто. Обычно требуется пройти процедуру регистрации на сайте казино и подтвердить свою учетную запись. В некоторых случаях может потребоваться ввести специальный промокод. После выполнения всех условий бонус будет автоматически зачислен на ваш счет. Бездепозитные бонусы – это отличная возможность начать свой путь в мире онлайн-казино с минимальным риском и максимальным удовольствием. Однако, прежде чем принимать бонус, всегда внимательно ознакомьтесь с условиями его использования, чтобы избежать недоразумений в будущем.
Сукааа казино официальный сайт скачать на андроид мобильная версия бесплатно Сукааа казино официальный сайт – ваш надежный партнер в мире азартных игр.
Праздничная продукция https://prazdnik-x.ru для любого повода: шары, гирлянды, декор, упаковка, сувениры. Всё для дня рождения, свадьбы, выпускного и корпоративов.
оценка нма услуги по оценке стоимости недвижимости
Бездепозитные бонусы Бездепозитные бонусы в казино: Что это такое? Бездепозитный бонус в казино – это денежная сумма или бесплатные вращения, которые казино предоставляет новым игрокам в качестве приветственного подарка. Главное преимущество этого бонуса заключается в том, что для его получения не требуется внесение депозита. Игрок может просто зарегистрироваться на сайте казино и получить бонус на свой счет.
Строительный журнал https://garant-jitlo.com.ua всё о технологиях, материалах, архитектуре, ремонте и дизайне. Интервью с экспертами, кейсы, тренды рынка.
Онлайн-журнал https://inox.com.ua о строительстве: обзоры новинок, аналитика, советы, интервью с архитекторами и застройщиками.
Бездепозитные бонусы в казино Бездепозитные бонусы в казино: Что это такое? Бездепозитный бонус в казино – это денежная сумма или бесплатные вращения, которые казино предоставляет новым игрокам в качестве приветственного подарка. Главное преимущество этого бонуса заключается в том, что для его получения не требуется внесение депозита. Игрок может просто зарегистрироваться на сайте казино и получить бонус на свой счет.
Бездепозитные бонусы
Sykaaa casino официальный сайт вход Сукааа казино официальный сайт казино предлагает широкий выбор игр, включая слоты, рулетку и блэкджек.
Бездепозитные бонусы в казино Бездепозитный бонус в казино: Как его получить? Получить бездепозитный бонус в казино, как правило, довольно просто. Обычно требуется пройти процедуру регистрации на сайте казино и подтвердить свою учетную запись. В некоторых случаях может потребоваться ввести специальный промокод. После выполнения всех условий бонус будет автоматически зачислен на ваш счет. Бездепозитные бонусы – это отличная возможность начать свой путь в мире онлайн-казино с минимальным риском и максимальным удовольствием. Однако, прежде чем принимать бонус, всегда внимательно ознакомьтесь с условиями его использования, чтобы избежать недоразумений в будущем.
Всё о строительстве https://stroyportal.kyiv.ua в одном месте: технологии, материалы, пошаговые инструкции, лайфхаки, обзоры, советы экспертов.
Полезный сайт https://vasha-opora.com.ua для тех, кто строит: от фундамента до крыши. Советы, инструкции, сравнение материалов, идеи для ремонта и дизайна.
Владивосток работа Владивосток: работа для женщин и мужчин
1000 рублей за регистрацию с выводом
DeFi стратегии 2025 Актуальные листинги бирж предлагают новые возможности для инвестиций в перспективные проекты на ранних стадиях.
Игорь Стоунберг экстрасенс отзывы Я в шоке от точности его предсказаний. Он помогает людям в трудных ситуациях. | Рада, что обратилась. |
вавада Вабанк Казино Официальный Сайт: Посетите официальный сайт Вабанк Казино и окунитесь в мир азартных игр с широким выбором развлечений и возможностью крупных выигрышей.
kait travelling Сила ветра лазера в Египте: Вероятно, опечатка, имеется в виду “сила ветра для кайтсёрфинга в Египте”.
Since the admin of this website is working, no uncertainty very soon it will be well-known, due to its feature contents.
https://777-gaming.com/top-brands-for-plinko-boards.html
Журнал для мужчин https://swiss-watches.com.ua которые ценят успех, свободу и стиль. Практичные советы, мотивация, интервью, спорт, отношения, технологии.
Мужской журнал https://hand-spin.com.ua о стиле, спорте, отношениях, здоровье, технике и бизнесе. Актуальные статьи, советы экспертов, обзоры и мужской взгляд на важные темы.
Игорь Стоунберг экстрасенс Игорь Стоунберг – настоящий профессионал своего дела. Он помог мне принять важное решение, которое изменило мою жизнь к лучшему.
школы в хургаде кайт Обучение кайтсёрфингу Обучение кайтсёрфингу – это следующий шаг после освоения базовых навыков управления кайтом. На этом этапе учатся вставать на доску, контролировать скорость и направление движения, а также выполнять простые трюки. Важно выбирать опытного инструктора и комфортные условия для обучения.
Бездепозитные бонусы
Все новинки https://helikon.com.ua технологий в одном месте: гаджеты, AI, робототехника, электромобили, мобильные устройства, инновации в науке и IT.
1000 рублей за регистрацию вывод сразу без вложений в казино адмирал
Ремонт без стресса https://odessajs.org.ua вместе с нами! Полезные статьи, лайфхаки, дизайн-проекты, калькуляторы и обзоры.
кайтсерфинг в египте сезон Кайтсёрфинг Кайтсёрфинг – это сплав ветра, воды и мастерства. Этот вид спорта позволяет скользить по водной глади, используя силу ветра, пойманную кайтом. Это динамичный и захватывающий способ провести время на открытом воздухе, требующий определенной физической подготовки и навыков управления кайтом и доской.
стоимость сертификата кайтсерфинга iko Кайт школа Кайт школа – это место, где мечты о покорении волн с помощью кайта становятся реальностью. Квалифицированные инструкторы, современное оборудование и безопасные условия позволяют быстро и эффективно освоить навыки кайтинга и кайтсерфинга.
кайт школа унесенные ветром Кайт школа Кайт школа – это место, где мечты о покорении волн с помощью кайта становятся реальностью. Квалифицированные инструкторы, современное оборудование и безопасные условия позволяют быстро и эффективно освоить навыки кайтинга и кайтсерфинга.
Sykaaa casino бонусы Sykaaa casino бонусы порадуют как новичков, так и опытных игроков. Увеличьте свои шансы на выигрыш с помощью щедрых предложений!
1000 рублей за регистрацию вывод сразу без вложений в казино адмирал
vingfoil Обучение кайтсёрфингу Обучение кайтсёрфингу – это следующий шаг после освоения базовых навыков управления кайтом. На этом этапе учатся вставать на доску, контролировать скорость и направление движения, а также выполнять простые трюки. Важно выбирать опытного инструктора и комфортные условия для обучения.
Understanding game dynamics is crucial in betting, and platforms like Jili No1 offer great insights through diverse gameplay options that mirror real-time betting scenarios.
Работа для школьников во Владивостоке Подработка во Владивостоке для студентов: совмещение учебы и заработка Студенты Владивостока могут найти множество вариантов подработки, позволяющих совмещать учебу и работу. Гибкий график и неполная занятость делают подработку идеальным способом заработать деньги и получить ценный опыт. Популярные варианты включают работу в сфере обслуживания, курьерскую доставку и помощь в проведении мероприятий.
цельнозерновой хлеб ташкент ПП хлеб Ташкент: для тех, кто следит за фигурой
Читайте авто блог https://autoblog.kyiv.ua обзоры автомобилей, сравнения моделей, советы по выбору и эксплуатации, новости автопрома.
Авто портал https://real-voice.info для всех, кто за рулём: свежие автоновости, обзоры моделей, тест-драйвы, советы по выбору, страхованию и ремонту.
A full explanation of diagnostics, parts, and timing: https://teremok.org.ua/ipgeo/inc/vse_chto_nuzghno_znat_o_remonte_noutbukov_acer__ot_diagnostiki_do_garantii.html
можно ли встретить акулу осенью в египте Кайт египет: Открой для себя лучшие кайт-споты Египта
как не попасть в зубы акулы в египте Кайт – это не просто спортивный снаряд, а символ свободы и единения с природой, позволяющий ощутить мощь ветра и скольжение по волнам.
Портал о строительстве https://start.net.ua и ремонте: готовые проекты, интерьерные решения, сравнение материалов, опыт мастеров.
Сукааа казино официальный сайт Sykaaa casino скачать стоит для тех, кто ценит мобильность. Приложение обеспечивает бесперебойный доступ к любимым играм в любом месте.
Строительный портал https://apis-togo.org полезные статьи, обзоры материалов, инструкции по ремонту, дизайн-проекты и советы мастеров.
кайтинг в хургаде в июле Кайт Хургада: Лучшие кайт-споты Египта ждут вас!
1000 рублей за регистрацию вывод сразу
Портал для женщин https://olive.kiev.ua любого возраста: от секретов молодости и красоты до личностного роста и материнства.
Современный женский https://prowoman.kyiv.ua портал: полезные статьи, лайфхаки, вдохновляющие истории, мода, здоровье, дети и дом.
кайт сафари хургада Кайт станция египет: Комфорт и безопасность на кайт-станции
What’s up, everything is going sound here and ofcourse every one is sharing data, that’s genuinely fine, keep up writing.
https://dnmagazine.com.ua/kupyty-korpus-far-dlya-avtomobilya-shcho-potribno-.html
кайт школа в хургаде Кайт школа дети ветра: Мы предлагаем безопасное и эффективное обучение кайтингу для всех уровней подготовки. Наши опытные инструкторы помогут вам освоить этот захватывающий вид спорта и достичь новых высот.
Семейный портал https://stepandstep.com.ua статьи для родителей, игры и развивающие материалы для детей, советы психологов, лайфхаки.
Туристический портал https://aliana.com.ua с лучшими маршрутами, подборками стран, бюджетными решениями, гидами и советами.
кайт центр в хургаде Кайтсёрфинг: Энергия ветра в ваших руках, свобода движения по воде, адреналин и восторг – все это кайтсерфинг. Откройте для себя этот захватывающий вид спорта и ощутите, как ветер наполняет вашу жизнь новыми красками.
Бездепозитные бонусы в казино
I love how tech is making design more accessible! Tools like Lovart AI Agent turn ideas into visuals effortlessly-especially the pixel art conversion. Fun stuff!
1000 рублей за регистрацию с выводом
кайт кемп Кайт школа хургада: Обучение кайтсерфингу в лучших кайт-спотах Хургады. Откройте для себя новые горизонты!
Exploring keno strategies can be thrilling, especially with platforms like Jili OK offering AI-driven insights. It’s a great tool for players looking to sharpen their approach while enjoying a wide range of games.
кайт школа : Сертификат кайтсерфинг: Подтверди свои навыки!
I delight in, cause I found exactly what I was taking a look for. You have ended my four day long hunt! God Bless you man. Have a great day. Bye
https://dvernoyolimp.org.ua/yak-znajty-najbilsh-ekonomichne-rishennya-dlya-pok.html
Новости Украины https://useti.org.ua в реальном времени. Всё важное — от официальных заявлений до мнений экспертов.
Архитектурный портал https://skol.if.ua современные проекты, урбанистика, дизайн, планировка, интервью с архитекторами и тренды отрасли.
кайтсёрфинг в хургаде Кайт хургада: Идеальное место для кайтсерфинга круглый год. Теплая вода, стабильный ветер, песчаные пляжи.
Бездепозитный бонус
Всё об автомобилях https://autoclub.kyiv.ua в одном месте. Обзоры, новости, инструкции по уходу, автоистории и реальные тесты.
Новости Украины https://hansaray.org.ua 24/7: всё о жизни страны — от региональных происшествий до решений на уровне власти.
1000 рублей за регистрацию вывод сразу
кайтсерфинг в египте Кайт дети ветра: Открой мир кайтсерфинга с профессионалами. Почувствуй свободу, адреналин и единение с природой. Мы поможем тебе освоить этот захватывающий вид спорта безопасно и эффективно.
Do you have any video of that? I’d want to find out some additional information.
https://sinyak.com.ua/chy-pidkhodyt-butylovyj-hermetyk-dlya-zadnikh.html
египет русская кайт школа Кайт школа дети ветра: Безопасное и эффективное обучение кайтингу
кайт египте Кайтсерфинг в хургаде: Почувствуйте адреналин и свободу кайтсерфинга в Хургаде. Незабываемые впечатления гарантированы.
Новостной портал https://news24.in.ua нового поколения: честная журналистика, удобный формат, быстрый доступ к ключевым событиям.
Информационный портал https://dailynews.kyiv.ua актуальные новости, аналитика, интервью и спецтемы.
Бездепозитный бонус
1000 рублей за регистрацию
Мировые новости https://ua-novosti.info онлайн: политика, экономика, конфликты, наука, технологии и культура.
кайт в хургаде Кайт хургада: Хургада – один из лучших кайт-спотов в мире, с идеальными условиями для обучения и катания круглый год. Стабильный ветер, теплая вода и песчаные пляжи делают Хургаду настоящим раем для кайтсерферов.
Офисная мебель https://officepro54.ru в Новосибирске купить недорого от производителя
hawaii riviera aqua park hurghada кайт станция : Кайт школа дети ветра: Открой мир кайтсерфинга вместе с нами!
область туризма Кайтсерфинг в Хургаде — это популярный вид активного отдыха, который привлекает множество туристов. Хургада славится своими пляжами и стабильными ветрами, что делает ее идеальным местом для кайтеров.
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Подробнее можно узнать тут – https://nakroklinikatest.ru/
Бездепозитные бонусы
египет кайтинг : detivetra: Одно слово, эхо юности, когда мир казался безграничным, как морской горизонт.
1000 рублей за регистрацию в казино без депозита вывод сразу
кейс защитный 1100 1000 410 http://plastcase.ru
кайт школа windfamily : Сертификат кайтсерфинг: Подтверди свои навыки!
I’m not sure exactly why but this weblog is loading very slow for me. Is anyone else having this issue or is it a problem on my end? I’ll check back later on and see if the problem still exists.
betwinner
защитный кейс купить https://plastcase.ru
кайт станции египет : Кайт школа в хургаде египет: Твой ключ к миру кайтсерфинга!
An outstanding share! I have just forwarded this onto a co-worker who was doing a little homework on this. And he in fact ordered me breakfast because I stumbled upon it for him… lol. So allow me to reword this…. Thank YOU for the meal!! But yeah, thanx for spending some time to talk about this issue here on your internet site.
бетвинер зеркало
Бездепозитные бонусы в казино
1000 рублей за регистрацию с выводом
сертификат кайтсерфинг : Кайт лагерь анапа: Отдых и обучение в одном флаконе!
сертификат кайтсерфинг iko : Кайт школа дети ветра: Открой мир кайтсерфинга вместе с нами!
Keep on writing, great job!
tadalafil aurobindo 5 mg
That’s a fascinating point about game volatility! Seeing how skill & luck blend in titles like Happy Fishing is really interesting – a unique take on the usual slot experience in Vietnam. Definitely worth checking out!
кайт школа спб : Кайт серфинг в египте: Насладись идеальными условиями для кайтсерфинга круглый год!
Бездепозитный бонус
получить 1000 рублей за регистрацию
купить отчет о практике стоимость отчета по практике
есть ли акулы в египте в октябре : Кайт сафари: Приключение, которое запомнится навсегда!
заказать отчет по учебной практике https://otchetbuhgalter.ru
карточка iko это : Кайт кемп: Интенсивное обучение для быстрого прогресса!
кайт школа windfamily Кайт школа в Хургаде: Профессиональное обучение кайтингу в Хургаде.
Бездепозитные бонусы в казино
фонтан казино бездепозитный бонус 1000 рублей за регистрацию без депозита с выводом денег
оформить микрозаем http://zajmy-onlajn.ru
кайт Кайт серфинг в Египте: Насладитесь кайтсерфингом в кристально чистых водах Красного моря.
займ онлайн мгновенно https://zajmy-onlajn.ru
Hi Dear, are you actually visiting this website daily, if so after that you will without doubt take good knowledge.
punta cana airport to hard rock hotel
лучший хлеб ташкент Хлеб на Закваске: Возрождение Традиций Хлеб на закваске – это древний способ приготовления хлеба, который в последние годы переживает возрождение.
газель с пирамидой алматы Грузоперевозки в Алматы – это качественный и оперативный сервис, который предлагает широкий выбор автомобилей, в том числе и газелей, для решения различных задач. Если вам необходимо перевезти мебель, бытовую технику или строительные материалы, наши услуги газели в Алматы помогут вам осуществить это быстро и надежно. Мы предлагаем аренду газелей различной грузоподъемности, включая короткие и длинные модели, а также специальное оборудование, например, термобудки и рефрижераторы для транспортировки чувствительных грузов. Вы можете заказать газель с грузчиками для удобного переезда, будь то офисный или квартирный. Наша команда профессиональных грузчиков обеспечит аккуратную упаковку, разборку и сборку мебели, а также позаботится о безопасной перевозке ваших вещей. В Алматы мы работаем круглосуточно, предоставляя возможность вызвать газель в любое время суток. Цены на грузоперевозки в Алматыvarьируются в зависимости от расстояния и объема работ, но мы всегда готовы предложить конкурентные расценки и специальные скидки для постоянных клиентов. Для срочных заказов мы предоставляем услуги быстрого реагирования, чтобы вы не переживали о задержках. Не упустите возможность воспользоваться самым удобным и экономичным способом перевозки в Алматы. Свяжитесь с нами по телефону или через WhatsApp, чтобы обсудить детали вашего заказа. Обращайтесь за надежной газелью в Алматы и убедитесь сами в качестве наших услуг!
Новинки кино 2025 бесплатно Фильмы без рекламы бесплатно: Способы смотреть любимое кино, не платя за отсутствие рекламы.
уплотнитель двери посудомоечной машины алматы Квалифицированный мастер обладает необходимыми знаниями и опытом для диагностики и устранения любых неисправностей посудомоечных машин. Он оперативно определит причину поломки и предложит оптимальное решение. Сервис посудомоечных машин Алматы
ремонт холодильников самал алматы : Починка морозилки – это быстрое и эффективное устранение поломки, которое позволяет избежать порчи продуктов. ремонт морозильного ларя алматы
Бездепозитный бонус в казино
люкс детская одежда Рынок Садовод является одним из крупнейших оптовых рынков в России, где можно найти широкий ассортимент детской одежды, в том числе и реплики Zara Kids. Однако, при покупке на Садоводе важно быть внимательным и выбирать проверенных поставщиков. Опт Zara
плотник алатауский район Стоимость услуг электрика в Алматы варьируется в зависимости от сложности работ, используемых материалов и квалификации мастера. Перед вызовом специалиста рекомендуется уточнить расценки и сравнить предложения нескольких компаний. Электрик Алматы Недорого
варфейс акк Магазин аккаунтов Warface предлагает широкий выбор аккаунтов различных уровней и с различной экипировкой.
mines game strategy
шторы ночь Карниз для штор – это надежная опора, на которой держится вся шторная композиция. Важно выбрать карниз, который будет соответствовать стилю штор и выдерживать их вес. Римские шторы
Маска для снорклинга Существует множество видов акул, отличающихся по размеру, форме и образу жизни. Нападение акулы на человека
Чек стоп Дайвинг в Москве – это возможность заниматься дайвингом в бассейнах и озерах, не выезжая из города. Дайвер спасатель
Жак Ив Кусто Реестр нападения акул на человека – это база данных, содержащая информацию о зарегистрированных случаях нападения акул на людей. Дайвинг в Москве
For most recent news you have to pay a quick visit world wide web and on web I found this web page as a best web page for most up-to-date updates.
tadalafil pensa 5 mg
заказать отчет по практике срочно сделать отчет по практике на заказ
личный займ онлайн zajmy-onlajn.ru/
Маска для дайвинга Запуск маркерного буя – это навык, позволяющий дайверу обозначить свое местоположение на поверхности воды. Виды маркерных буев дайвера
шторы день ночь Потолочные шторы – это стильное и современное решение, которое визуально увеличивает высоту потолков. Как правильно шторы
warface аккаунт Приобретение нового оружия в Warface – это возможность расширить свой арсенал, улучшить свою статистику и адаптироваться к различным игровым ситуациям. Аккаунты Warface
ссылка на фишинговый сайт Определить, какой сайт фишинговый, можно путем внимательного анализа его URL-адреса, дизайна, контента и других характеристик, указывающих на его поддельность. Признаки фишинговых сайтов
Натяжные потолки Развилка Фото натяжных потолков – это отличный способ выбрать подходящий дизайн и оценить возможности этой технологии. Фотографии демонстрируют разнообразие цветов, фактур и конструкций натяжных потолков, позволяя подобрать оптимальное решение для любого интерьера. Натяжные потолки можно
фонтан казино бездепозитный бонус 1000 рублей за регистрацию без депозита с выводом денег Бездепозитный бонус в размере 1000 рублей с моментальным выводом – это редкая и ценная находка для азартных игроков. Она позволяет начать игру, не вкладывая собственные средства, и сразу же вывести выигрыш, если повезет. 1000 рублей за регистрацию вывод сразу без вложений
рулонные шторы купить Шторы своими руками – это возможность создать уникальный и неповторимый элемент интерьера. Установка штор
Какой натяжной потолок В Развилке натяжные потолки – это популярный выбор для тех, кто ценит качество и стиль. Натяжные потолки Островцы
аренда автомобилей краснодар аренда машины в краснодаре: Забудьте о пробках и общественном транспорте, арендуйте машину! Путешествуйте с комфортом и независимостью.
варфейс Акк Warface – это ваш цифровой идентификатор в мире Warface, отражающий ваш прогресс и достижения. Варфейс
Прокат авто без залога авто в аренду краснодар: Наслаждайтесь комфортом и свободой передвижения по Краснодару. Арендуйте автомобиль у нас и получите незабываемые впечатления от поездки!
Потолки помещений Жители Красково выбирают натяжные потолки за их практичность, долговечность и эстетичный внешний вид. Натяжные потолки Томилино
вавада казино официальный сайт рабочее зеркало на сегодня Вавада Казино Официальный Сайт Вход
Увлажнитель воздуха https://brand-climat.ru оптимальный уровень влажности для здоровья. Различные типы: ультразвуковые, паровые и др., фильтрация и защита. Подбор, доставка по России и официальная гарантия для вашего комфорта.
Ремонт бампера автомобиля — это популярная услуга, которая позволяет вернуть заводской вид транспортного средства после небольших повреждений. Новейшие технологии позволяют исправить сколы, трещины и вмятины без полной замены детали. При выборе между ремонтом или заменой бампера [url=https://telegra.ph/Remont-ili-zamena-bampera-05-22]https://telegra.ph/Remont-ili-zamena-bampera-05-22[/url] важно рассматривать уровень повреждений и экономическую целесообразность. Профессиональное восстановление включает подготовку, грунтовку и покраску.
Установка нового бампера требуется при значительных повреждениях, когда восстановление бамперов невыгоден или невозможен. Стоимость восстановления зависит от типа материала изделия, степени повреждений и марки автомобиля. Полимерные элементы допускают ремонту лучше металлических, а новые композитные материалы требуют специального оборудования. Качественный ремонт расширяет срок службы детали и сохраняет заводскую геометрию кузова.
Я с готовностью быть на подхвате по вопросам Ремонт бамперов в магнитогорске адреса и цены – обращайтесь в Телеграм sgf81
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this. Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
tadalafil pensa pharma 5 mg
Interesting read! The focus on culturally relevant tech, like what 68wim.tech is doing, is key for long-term player engagement. Seamless logins & a great 68win app download are huge wins for user experience, too. Solid platform!
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Детальнее – [url=https://narkologicheskaya-klinika-tyumen10.ru/]частная наркологическая клиника в тюмени[/url]
Школа Саморазвития https://bznaniy.ru онлайн-база знаний для тех, кто хочет понять себя, улучшить мышление, прокачать навыки и выйти на новый уровень жизни.
Бездепозитный бонус Казино, предлагающие бездепозитные бонусы, как гостеприимные хозяева, распахивают двери перед новичками и предлагают им оценить все прелести своего заведения. Это своеобразный жест доброй воли, который позволяет завоевать доверие игроков и превратить их в постоянных клиентов. Это умный маркетинговый ход, который работает в пользу обеих сторон. Бездепозитный бонус
На дом выезжает квалифицированный врач, который проводит процедуру детоксикации в комфортных условиях, позволяя пациенту избежать стресса и огласки. С помощью капельницы и медикаментов нормализуется состояние, восстанавливаются основные функции организма. Процедура длится несколько часов, после чего врач оставляет рекомендации по поддерживающему лечению.
Узнать больше – https://vyvod-iz-zapoya-lyubertsy2.ru
Для детоксикации и восстановления организма после запоя используются только сертифицированные лекарственные препараты с доказанной эффективностью и безопасностью:
Ознакомиться с деталями – http://narcolog-na-dom-sochi0.ru
Все вызовы фиксируются под кодовым номером без указания ФИО, что обеспечивает полную конфиденциальность каждого пациента.
Изучить вопрос глубже – https://narkologicheskaya-klinika-vladimir10.ru/chastnaya-narkologicheskaya-klinika-vladimir/
Репетитор по физике https://repetitor-po-fizike-spb.ru СПб: школьникам и студентам, с нуля и для олимпиад. Четкие объяснения, практика, реальные результаты.
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологическая клиника нарколог тюмень[/url]
Interesting points raised in this article! The convenience of mobile gaming is a huge draw, and platforms like phlwin app download apk are making it super accessible for Filipino players. Streamlined verification is key for trust!
бонусы в казино без депозита Принимая бездепозитный бонус, важно внимательно изучить условия его отыгрыша. Вейджер, сроки действия и ограничения по играм – все эти факторы могут существенно повлиять на возможность вывода выигрыша. Тщательное изучение правил поможет избежать разочарований и максимально эффективно использовать бонус. Бездепозитные бонусы казино без пополнения с отыгрышем
That’s a bold prediction – really interesting take on the potential upset! Seems like jlboss com understands entertainment, offering diverse games – a good distraction while waiting for results! 😉 Solid analysis overall.
вабанк казино официальный сайт Вавада казино открывает двери в мир азарта и возможностей, предлагая пользователям прямой доступ к обширной коллекции игр и захватывающим бонусам. Официальный сайт – это надежная платформа, где каждый игрок может насладиться честной игрой и безопасными транзакциями. Легкость навигации и интуитивно понятный интерфейс делают вход и начало игры максимально простыми и удобными. Vavada Casino Скачать
Борьба с наркотической зависимостью требует системного подхода и участия опытных специалистов. Важно понимать, что лечение наркомании — это не только снятие ломки, но и длительная психотерапия, обучение новым моделям поведения, работа с семьёй. Согласно рекомендациям Минздрава РФ, наиболее стабильные результаты достигаются при прохождении курса реабилитации под наблюдением профессиональной команды в специализированном центре.
Узнать больше – [url=https://lechenie-narkomanii-vladimir10.ru/]lechenie-narkomanii-vladimir10.ru/[/url]
I think that what you published made a lot of sense. But, think about this, suppose you added a little information? I mean, I don’t want to tell you how to run your website, however suppose you added something that grabbed people’s attention? I mean %BLOG_TITLE% is kinda boring. You ought to glance at Yahoo’s front page and see how they create news headlines to get viewers to click. You might add a related video or a related pic or two to grab people excited about what you’ve got to say. In my opinion, it would make your posts a little livelier.
cialis 5 mg generico prezzo
Кроме того, клиника «Новый шанс» уделяет особое внимание профилактике рецидивов. Мы обучаем пациентов навыкам управления стрессом, эмоциональной регуляции и прививаем навыки здорового образа жизни. Наша цель — обеспечить долгосрочное восстановление и снизить риск возврата к зависимости.
Детальнее – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-anonimno-v-rostove-na-donu.ru/]narkolog-vyvod-iz-zapoya rostov-na-donu[/url]
china to uae Shipping China to UAE: Ensuring Compliance with Environmental Regulations
Служба по контракту Вакансии Военная служба по контракту: Участие в учениях, тренировках и укреплении боевой готовности
доставка пионов в москве Букет пионов с доставкой в Москве: Совершенный подарок для тех, кто ценит прекрасное. Букет пионов – это не просто цветы, это символ внимания, заботы и любви. Мы создаем уникальные композиции, сочетая различные сорта и оттенки пионов, чтобы каждый букет был настоящим произведением искусства. Доставка букета пионов в Москве – это идеальный способ выразить свои чувства и подарить незабываемые эмоции близкому человеку.
1000 рублей за регистрацию в казино без депозита Многие казино, стремясь привлечь новых клиентов, предлагают 1000 рублей за регистрацию с моментальным выводом, не требующим никаких вложений. Это привлекательная возможность для тех, кто хочет испытать свою удачу без риска для собственного бюджета. 1000 рублей за регистрацию в казино без депозита вывод сразу
скачать игры по прямой ссылке Скачать игры без торрента: Откройте мир развлечений без ограничений. Забудьте о медленных загрузках и проблемах с сидированием. Теперь вы можете мгновенно погрузиться в захватывающие игровые миры, скачивая любимые игры напрямую, без использования торрент-клиентов. Наслаждайтесь быстрой и стабильной загрузкой, которая позволит вам не терять время на ожидание, а сразу окунуться в игровой процесс. Исследуйте обширную библиотеку игр различных жанров и найдите новые приключения, не утруждая себя поиском рабочих торрент-файлов.
Ремонт бампера автомобиля — это популярная услуга, которая позволяет восстановить заводской вид транспортного средства после незначительных повреждений. Современные технологии позволяют устранить сколы, трещины и вмятины без полной замены детали. При выборе между ремонтом или заменой бампера [url=https://telegra.ph/Remont-ili-zamena-bampera-05-22]https://telegra.ph/Remont-ili-zamena-bampera-05-22[/url] важно учитывать степень повреждений и экономическую рентабельность. Качественное восстановление включает шпатлевку, грунтовку и покраску.
Замена бампера требуется при серьезных повреждениях, когда реставрация бамперов нецелесообразен или невозможен. Расценки восстановления варьируется от состава изделия, масштаба повреждений и типа автомобиля. Пластиковые элементы поддаются ремонту лучше металлических, а инновационные композитные материалы требуют особого оборудования. Качественный ремонт продлевает срок службы детали и поддерживает заводскую геометрию кузова.
Готов прийти на помощь когда это необходимо по вопросам Ремонт крепления бампера тойота камри 50 – пишите в Телеграм ctu88
china to uae Shipping from China to UAE: The Benefits of Using a Logistics Platform
Наркомания — хроническое заболевание, требующее комплексного лечения и постоянной поддержки. В условиях Архангельска, где доступ к специализированной помощи может быть ограничен, клиника «АрктикМед» предлагает уникальную программу, основанную на мультидисциплинарном подходе и строгом соблюдении принципов анонимности. Ключевая цель — помочь каждому пациенту преодолеть зависимость, восстановить здоровье и вернуться к полноценной жизни.
Получить дополнительные сведения – https://lechenie-narkomanii-arkhangelsk0.ru/czentr-lecheniya-narkomanii-arkhangelsk/
Перевод документов https://medicaltranslate.ru на немецкий язык для лечения за границей и с немецкого после лечения: высокая скорость, безупречность, 24/7
Онлайн-тренинги https://communication-school.ru и курсы для личного роста, карьеры и новых навыков. Учитесь в удобное время из любой точки мира.
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Получить дополнительные сведения – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma odincovo[/url]
Можно ещё добавить Скачать игры без торрента: Откройте для себя мир мгновенного гейминга. Забудьте о бесконечных ожиданиях загрузки, запутанных настройках и риске подхватить вирус. Современные альтернативы торрентам предоставляют возможность окунуться в любимую игру практически сразу после нажатия кнопки “Скачать”. Насладитесь простотой и скоростью, выбирая из обширной библиотеки игр различных жанров.
Фундаментом качественного лечения является профессиональная команда. Только при участии врачей-наркологов, психиатров, клинических психологов, терапевтов и консультантов по зависимому поведению можно говорить о комплексной помощи. По словам специалистов ФГБУН «Национальный научный центр наркологии», именно междисциплинарный подход формирует устойчивую динамику на всех этапах терапии — от стабилизации состояния до ресоциализации пациента.
Получить больше информации – [url=https://narkologicheskaya-klinika-tula10.ru/]наркологическая клиника тула.[/url]
Interesting points! The tech behind online casinos is often overlooked, but crucial for a smooth experience. I’ve heard jljl55 game is really pushing boundaries with fast processing & secure verification – sounds like a game changer for Filipino players!
Запреты дня [url=https://inforigin.ru]https://inforigin.ru[/url] .
Гороскоп [url=http://istoriamashin.ru]http://istoriamashin.ru[/url] .
Гороскоп [url=https://topoland.ru/]topoland.ru[/url] .
Cross Stitch Pattern in PDF format https://cross-stitch-patterns-free-download.store/ a perfect choice for embroidery lovers! Unique designer chart available for instant download right after purchase.
Для эффективного лечения алкогольной интоксикации и восстановления организма врачи клиники «АлкоДоктор» используют комплекс препаратов, которые индивидуально подбираются с учетом состояния пациента.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-sochi0.ru/]kapelnicza-ot-zapoya sochi[/url]
Фурнитура для ПВХ-окон http://kupit-furnituru-dla-okon.ru оптом и в розницу: европейские бренды, доступные цены, доставка по РФ.
Пациенты, которые обращаются в нашу клинику за наркологической помощью, получают не просто стандартное лечение, а комплексный подход к проблеме зависимости. Наши врачи имеют большой практический опыт и высокую квалификацию, благодаря чему могут эффективно справляться даже с самыми сложными случаями. Мы используем только проверенные методики и сертифицированные препараты, гарантирующие безопасность и эффективность лечения.
Детальнее – http://narcolog-na-dom-sochi00.ru/narkolog-na-dom-czena-sochi/
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Углубиться в тему – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/
В нашей клинике работают врачи-наркологи, психологи и психиатры с многолетним опытом в лечении зависимостей. Все специалисты регулярно повышают свою квалификацию, участвуя в семинарах и конференциях, чтобы обеспечивать своим пациентам наиболее современное и качественное лечение.
Выяснить больше – http://быстро-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-volgograde.xn--p1ai/
Календарь огородника [url=https://www.pechory-online.ru]https://www.pechory-online.ru[/url] .
Календарь стрижек [url=www.novorjev.ru]www.novorjev.ru[/url] .
В этой статье мы рассматриваем разные способы борьбы с алкогольной зависимостью. Обсуждаются методы лечения, программы реабилитации и советы для поддержки близких. Читатели получат информацию о том, как преодолеть зависимость и добиться успешного выздоровления.
Детальнее – http://narkolog-na-dom-krasnodar16.ru/http://narkolog-na-dom-krasnodar16.ru
It’s so important to remember gambling should be fun, not a source of stress. Seeing platforms like boss jili prioritize convenience with their app is good, but always play responsibly! Setting limits is key for a healthy experience. ✨
ремонт редких моделей стиральных машин алматы Обслуживание холодильного оборудования Алматы: Полное обслуживание холодильного оборудования.
выездной бар с лицензией лофт в аренду СПБ: Лофт – это современное и стильное пространство для проведения мероприятий любого формата. Аренда лофта в Санкт-Петербурге позволит вам создать уникальную атмосферу для вашей свадьбы, вечеринки или корпоратива. Мы предлагаем широкий выбор лофтов различной площади и стилистики, оборудованных всем необходимым для проведения мероприятий.
термостат для холодильника алматы посудомойка не моет посуду алматы Плохое качество мытья посуды в посудомоечной машине может быть вызвано несколькими факторами. Засорение фильтров, неправильная загрузка посуды, использование некачественных моющих средств или неисправность разбрызгивателей – все это может повлиять на результат.
В этой публикации мы обсуждаем современные методы лечения различных заболеваний. Читатели узнают о новых медикаментах, терапиях и исследованиях, которые активно применяются для лечения. Мы нацелены на то, чтобы предоставить практические знания, которые могут помочь в борьбе с недугами.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-krasnodar17.ru/]нарколог на дом круглосуточно[/url]
Магазин строительной техники Магазин генераторов: Независимость от капризов электросети Перебои с электроснабжением могут стать серьезной проблемой для дома, бизнеса или загородного участка. Наш магазин предлагает широкий выбор генераторов различных типов и мощности, чтобы обеспечить бесперебойное питание в любой ситуации. От компактных инверторных моделей для небольших потребителей до мощных дизельных агрегатов для крупных объектов. Мы поможем вам выбрать оптимальный генератор, учитывая ваши потребности и бюджет, а также предоставим квалифицированную установку и сервисное обслуживание.
Драгон Мани Dragon Money: углубленный анализ Dragon Money – это многофункциональная платформа, предлагающая широкий спектр возможностей. От увлекательных игр до инвестиций в перспективные проекты – Dragon Money удовлетворяет самые разнообразные потребности. Удобный интерфейс позволяет даже новичкам быстро освоиться, а опытные пользователи оценят разнообразие функций. Честность и прозрачность – ключевые принципы Dragon Money. Все игры проходят строгую проверку на случайность, а финансовые операции защищены передовыми технологиями шифрования, создавая атмосферу доверия и безопасности. Dragon Money – это также активное сообщество, где пользователи могут общаться, делиться опытом и заводить новых друзей. Регулярные конкурсы, акции и розыгрыши поддерживают интерес и дарят положительные эмоции.
ремонт посудомоечных машин bosch алматы Заправка фреоном холодильника Алматы: Заправка холодильника фреоном на дому. Быстрый и безопасный способ восстановить работоспособность вашего холодильника.
Roulette’s probability is fascinating – seemingly random, yet governed by clear math! Seeing platforms like 68wim app streamline the experience for Vietnamese players with easy registration & secure payments is impressive. Quick access boosts the fun!
погода хургада апрель 2023 Кайт в Хургаде: Почувствуйте силу ветра Кайт в Хургаде – это возможность почувствовать силу ветра и насладиться красотой Красного моря.
Эта публикация исследует взаимосвязь зависимости и психологии. Мы обсудим, как психологические аспекты влияют на появление зависимостей и процесс выздоровления. Читатели смогут понять важность профессиональной поддержки и применения научных подходов в терапии.
Изучить вопрос глубже – [url=https://narkolog-na-dom-krasnodar12.ru/]вызов врача нарколога на дом[/url]
В этой заметке мы представляем шаги, которые помогут в процессе преодоления зависимостей. Рассматриваются стратегии поддержки и чек-листы для тех, кто хочет сделать первый шаг к выздоровлению. Наша цель — вдохновить читателей на положительные изменения и поддержать их в трудных моментах.
Подробнее тут – [url=https://narkolog-na-dom-krasnodar17.ru/]врач нарколог на дом[/url]
Если состояние слишком тяжёлое, или в анамнезе есть сердечно-сосудистые заболевания, может быть рекомендована госпитализация в стационар клиники «Светлый Мир». Там пациент находится под круглосуточным наблюдением и получает полный комплекс восстановительной терапии, включая психологическую поддержку и консультации психотерапевта.
Исследовать вопрос подробнее – http://vyvod-iz-zapoya-domodedovo3.ru/
Эта информационная публикация освещает широкий спектр тем из мира медицины. Мы предлагаем читателям ясные и понятные объяснения современных заболеваний, методов профилактики и лечения. Информация будет полезна как пациентам, так и медицинским работникам, желающим поддержать уровень своих знаний.
Выяснить больше – [url=https://narkolog-na-dom-krasnodar17.ru/]вызов нарколога на дом[/url]
В этой публикации мы обсуждаем современные методы лечения различных заболеваний. Читатели узнают о новых медикаментах, терапиях и исследованиях, которые активно применяются для лечения. Мы нацелены на то, чтобы предоставить практические знания, которые могут помочь в борьбе с недугами.
Углубиться в тему – [url=https://narkolog-na-dom-krasnodar17.ru/]нарколог на дом вывод из запоя[/url]
Домашний формат идеально подходит для тех, кто находится в удовлетворительном состоянии и не требует круглосуточного контроля.
Разобраться лучше – [url=https://vyvod-iz-zapoya-lyubertsy2.ru/]vyvod iz zapoya dzerzhinskij[/url]
Процедура выезда врача на дом в Краснодаре строго регламентирована и включает несколько последовательных этапов. После поступления звонка и уточнения подробностей состояния пациента врач выезжает на место в течение 30–60 минут. На месте проводится первичный осмотр с оценкой жизненно важных показателей: артериального давления, уровня кислорода в крови, сердечного ритма и степени общей интоксикации.
Получить дополнительную информацию – [url=https://narcolog-na-dom-krasnodar00.ru/]нарколог на дом клиника[/url]
температура красного моря Теория кайтсерфинга по IKO: основные принципы безопасности Теория кайтсерфинга по IKO включает в себя основные принципы безопасности, правила управления кайтом и информацию о ветровых условиях.
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Получить дополнительную информацию – http://kodirovanie-ot-alkogolizma-odintsovo2.ru
В этом исследовании рассмотрены методы лечения зависимостей и их эффективность. Мы проанализируем различные подходы, используемые в реабилитационных центрах, и представим данные о результативности программ. Читатели получат надежные и научно обоснованные сведения о данной проблеме.
Узнать больше – [url=https://narkolog-na-dom-krasnodar16.ru/]врач нарколог на дом[/url]
Этот информативный текст сочетает в себе темы здоровья и зависимости. Мы обсудим, как хронические заболевания могут усугубить зависимости и наоборот, как зависимость может влиять на общее состояние здоровья. Читатели получат представление о комплексном подходе к лечению как физического, так и психического состояния.
Получить больше информации – [url=https://narkolog-na-dom-krasnodar15.ru/]нарколог на дом круглосуточно[/url]
vavada casino официальный сайт вход Vavada Casino славится своей щедрой бонусной политикой. От приветственных бонусов для новичков до регулярных акций и промокодов для постоянных игроков – каждый пользователь найдет для себя выгодное предложение, увеличивающее шансы на выигрыш. Vavada Casino Скачать Бесплатно на Телефон
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Подробнее – https://clubsasayama-campfield.com/archives/1025
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Подробнее можно узнать тут – https://aoneemia.md/cause/donate-2
What’s up to every body, it’s my first visit of this blog; this website contains amazing and really fine material in favor of readers.
http://cheryclub.com.ua/linzy-dlya-far-yak-zrobyty-avtosvitlo-yaskravishym.html
Бездепозитные бонусы в казино Перед тем, как воспользоваться бездепозитным бонусом, стоит внимательно изучить условия его получения и отыгрыша. Важно понимать, какие игры доступны для игры на бонусные средства, какой вейджер необходимо выполнить, чтобы вывести выигрыш, и какие сроки установлены для отыгрыша бонуса. Тщательное изучение правил поможет избежать разочарований и получить максимальную выгоду от использования бонуса.
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Выяснить больше – https://www.renewcomb.com/iec2
Когда алкогольная интоксикация становится угрозой для здоровья, оперативное вмешательство и качественное лечение на дому играют ключевую роль в спасении жизни. В Калининграде опытные наркологи выезжают на дом, чтобы обеспечить своевременную детоксикацию, стабилизацию работы внутренних органов и оказание психологической поддержки. Такой подход позволяет пациентам получить квалифицированную помощь в комфортной и привычной обстановке, сохраняя конфиденциальность и избегая лишнего стресса, связанного с госпитализацией.
Ознакомиться с деталями – https://narcolog-na-dom-kaliningrad0.ru/narkolog-na-dom-kruglosutochno-kaliningrad
Срочная медицинская помощь поможет избежать тяжелых последствий и сократит время на восстановление после запоя.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-krasnodar0.ru/]вывод из запоя капельница в краснодаре[/url]
Метод лечения
Ознакомиться с деталями – [url=https://lechenie-narkomanii-vladimir10.ru/]лечение наркомании и алкоголизма в владимире[/url]
В нашем центре работают наркологи высшей категории с многолетним опытом лечения различных зависимостей. Они владеют современными методами детоксикации, купирования абстинентного синдрома, кодирования и фармакотерапии.
Получить дополнительные сведения – https://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-voronezhe.xn--p1ai
канал авто Купить Санта Фе: Практичный и надежный кроссовер Hyundai Santa Fe – это популярный кроссовер, предлагающий сбалансированное сочетание цены, качества и функциональности.
kids puzzle with animals Bright and fun bird designs for kids! Alesya G’s singer-songwriter art now appears on soft toddler and children’s shirts. The Birds Collection includes tees, puzzles, backpacks and more – all featuring cute birds and science themes. Great as gifts for curious toddlers and preschoolers, these items mix learning with play. Shop kids’ bird t-shirts and accessories for your little explorer today!
В «Трезвом Истоке» мы понимаем: принять решение о вызове — это шаг, требующий смелости. Особенно если речь идёт о близком человеке, который отрицает наличие проблемы. Именно поэтому наши врачи умеют работать тактично, без давления. Мы не заставляем — мы объясняем. Спокойно, профессионально и по-человечески.
Подробнее тут – http://
dragonslot [url=https://dragonslotscasinos.net]https://dragonslotscasinos.net[/url] .
dragon casino [url=http://dragonslotscasinos.mobi]http://dragonslotscasinos.mobi[/url] .
https://1-bs2best.art/bs2best_at.html
автоподбор Купить машину: Советы начинающим автолюбителям При выборе первого автомобиля важно обратить внимание на его техническое состояние, стоимость обслуживания и страховки. Рекомендуется обратиться к специалистам для проведения диагностики перед покупкой.
В рамках реабилитации применяются когнитивно-поведенческие тренинги, арт-терапия и групповые занятия по развитию коммуникативных навыков. Это помогает пациентам осознать причины зависимости и выработать стратегии предотвращения рецидивов в будущем.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологическая клиника нарколог тюмень[/url]
soft toddler tee Bright and fun bird designs for kids! Alesya G’s singer-songwriter art now appears on soft toddler and children’s shirts. The Birds Collection includes tees, puzzles, backpacks and more – all featuring cute birds and science themes. Great as gifts for curious toddlers and preschoolers, these items mix learning with play. Shop kids’ bird t-shirts and accessories for your little explorer today!
хотите сделать утепление https://dv-zvezda.ru/126526-uteplenie-penopoliuretanom-v-raznyh-klimaticheskih-zonah.html
Зависимость — это коварное хроническое заболевание, затрагивающее как физическое, так и психическое здоровье человека. Она воздействует на волю и разум, искажает восприятие реальности и разрушает жизни, семьи и судьбы. Алкоголизм, наркомания и игровая зависимость — все это проявления одной и той же проблемы, требующей комплексного и профессионального подхода.
Выяснить больше – http://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-anonimno-v-voronezhe.xn--p1ai/
Наша миссия заключается в предоставлении качественной помощи людям, страдающим от зависимостей. Мы стремимся создать безопасную и поддерживающую атмосферу, где каждый сможет получить необходимую помощь. Основная цель — восстановление здоровья, психоэмоционального состояния и социальной адаптации.
Выяснить больше – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-omske.ru/]наркологический вывод из запоя омск[/url]
Команда клиники “Аура Здоровья” состоит из опытных и квалифицированных врачей-наркологов, обладающих глубокими знаниями фармакологии и психотерапии. Они регулярно повышают свою квалификацию, участвуя в профессиональных конференциях и семинарах, чтобы применять самые эффективные методы лечения.
Выяснить больше – https://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-rostove-na-donu.xn--p1ai/
Перед началом терапии врач проводит предварительный осмотр: измеряет давление, пульс, оценивает общее состояние пациента, наличие сопутствующих хронических заболеваний и признаков тяжёлой интоксикации. После этого разрабатывается индивидуальная схема лечения. В большинстве случаев она включает внутривенное введение растворов, улучшающих водно-солевой баланс, а также медикаментов, направленных на снятие абстиненции, нормализацию сна и снижение тревожности.
Углубиться в тему – http://vyvod-iz-zapoya-domodedovo3.ru
Проблемы, связанные с употреблением алкоголя или наркотических веществ, могут застать человека врасплох и требовать немедленного медицинского вмешательства. В Туле предоставляется наркологическая помощь, направленная на купирование острых состояний и оказание поддержки пациентам в кризисной ситуации. В клинике «Здоровье+» используются современные методы лечения, основанные на отечественных клинических рекомендациях, с акцентом на безопасность и индивидуальный подход.
Подробнее тут – http://narkologicheskaya-pomoshh-tula10.ru/vyzov-narkologicheskoj-pomoshhi-tula/https://narkologicheskaya-pomoshh-tula10.ru
Врач индивидуально подбирает:
Узнать больше – [url=https://lechenie-alkogolizma-tyumen10.ru/]наркологическое лечение алкоголизма[/url]
vavada casino официальный сайт вход Вавада казино открывает двери в мир азарта и возможностей, предлагая пользователям прямой доступ к обширной коллекции игр и захватывающим бонусам. Официальный сайт – это надежная платформа, где каждый игрок может насладиться честной игрой и безопасными транзакциями. Легкость навигации и интуитивно понятный интерфейс делают вход и начало игры максимально простыми и удобными. Vavada Casino Скачать
Первый и самый важный момент — какие методики применяются в клинике. Качественное лечение наркозависимости включает несколько этапов: детоксикация, стабилизация состояния, психотерапия, ресоциализация. Одного лишь выведения токсинов из организма недостаточно — без проработки психологических причин употребления высокий риск рецидива.
Получить больше информации – [url=https://lechenie-narkomanii-vladimir10.ru/]центр лечения наркомании[/url]
thepokies net [url=http://thepokiesau.org]thepokies net[/url] .
dragon slots [url=www.casinosdragonslots.eu/]dragon slots[/url] .
the pokies net [url=https://www.thepokiesnet250.com]https://www.thepokiesnet250.com[/url] .
В «Трезвом Истоке» мы понимаем: принять решение о вызове — это шаг, требующий смелости. Особенно если речь идёт о близком человеке, который отрицает наличие проблемы. Именно поэтому наши врачи умеют работать тактично, без давления. Мы не заставляем — мы объясняем. Спокойно, профессионально и по-человечески.
Получить дополнительные сведения – http://vyvod-iz-zapoya-ehlektrostal3.ru/anonimnyj-vyvod-iz-zapoya-v-ehlektrostali/
pokies101 [url=https://thepokiesnet101.com/]pokies101[/url] .
mephedrone Ephedrine is often used to produce phenylacetone, a key intermediate in stimulant synthesis. From phenylacetone, substances like methylone, mephedrone (4-MMC), and 3-CMC can be made using methylamine. Phenylnitropropene, derived from nitroethane, is another precursor. A-PVP and 4-methylpropiophenone are also widely used in synthetic drug production. BMK glycidate is commonly used to synthesize controlled substances.
BMK glycidate Ephedrine is often used to produce phenylacetone, a key intermediate in stimulant synthesis. From phenylacetone, substances like methylone, mephedrone (4-MMC), and 3-CMC can be made using methylamine. Phenylnitropropene, derived from nitroethane, is another precursor. A-PVP and 4-methylpropiophenone are also widely used in synthetic drug production. BMK glycidate is commonly used to synthesize controlled substances.
Асфальтировка
Алкоголь и наркотики воздействуют на организм комплексно: нарушается работа сердца, сосудов, печени и почек, страдает нервная система. При запое или ломке без квалифицированной помощи возникают судороги, делирий, галлюцинации и серьёзные сбои в обмене веществ. Самостоятельные попытки «перетерпеть» или «отмотать» запой зачастую приводят к тяжёлым осложнениям, вплоть до комы и необратимых изменений в органах.
Детальнее – http://narkologicheskaya-klinika-dolgoprudnyj3.ru
Перед началом терапии врач проводит предварительный осмотр: измеряет давление, пульс, оценивает общее состояние пациента, наличие сопутствующих хронических заболеваний и признаков тяжёлой интоксикации. После этого разрабатывается индивидуальная схема лечения. В большинстве случаев она включает внутривенное введение растворов, улучшающих водно-солевой баланс, а также медикаментов, направленных на снятие абстиненции, нормализацию сна и снижение тревожности.
Разобраться лучше – https://vyvod-iz-zapoya-domodedovo3.ru/
https://2bs-2best.at/blaksprut_ssylka.html
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Выяснить больше – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологические клиники алкоголизм тюмень[/url]
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Разобраться лучше – http://narkologicheskaya-klinika-tyumen10.ru/narkologicheskaya-klinika-klinika-pomoshh-tyumen/
Команда врачей клиники “Чистый Путь” состоит из квалифицированных специалистов в области наркологии с обширным опытом работы. Каждый врач обладает глубокими знаниями в фармакологии, психофармакологии и психотерапии, регулярно повышает свою квалификацию на профильных конференциях и семинарах, чтобы использовать в своей практике самые современные и эффективные методы лечения.
Подробнее – http://срочно-вывод-из-запоя.рф
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Разобраться лучше – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологическая клиника тюмень[/url]
methylone Ephedrine is often used to produce phenylacetone, a key intermediate in stimulant synthesis. From phenylacetone, substances like methylone, mephedrone (4-MMC), and 3-CMC can be made using methylamine. Phenylnitropropene, derived from nitroethane, is another precursor. A-PVP and 4-methylpropiophenone are also widely used in synthetic drug production. BMK glycidate is commonly used to synthesize controlled substances.
бонусы в казино без депозита Казино, предлагающие бездепозитные бонусы, демонстрируют свою уверенность в качестве предоставляемых услуг. Это своего рода маркетинговый ход, направленный на привлечение новых игроков и формирование лояльности. Игроки, получившие положительный опыт, с большей вероятностью вернутся и станут постоянными клиентами. Бездепозитный бонус
the pokies [url=https://pokies11.com/]pokies11.com[/url] .
pokies net 106 [url=http://pokies106.com]pokies net 106[/url] .
карниз с приводом [url=http://elektrokarnizy50.ru]http://elektrokarnizy50.ru[/url] .
Мы активно используем методы, такие как когнитивно-поведенческая терапия, гештальт-терапия и арт-терапия, помогая пациентам преодолеть психологические травмы и внутренние конфликты, лежащие в основе аддиктивного поведения. Также наши консультанты по химической зависимости предоставляют информационную поддержку пациентам и их семьям, помогая разобраться в вопросах лечения, реабилитации и социальной адаптации.
Детальнее – https://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-voronezhe.xn--p1ai
https://b2tsite3.cc/bs2web_at.html
В городе Домодедово такую услугу оказывает наркологическая клиника «Светлый Мир». Здесь работают опытные врачи с круглосуточной готовностью выехать к пациенту домой или принять его в условиях стационара. Главное — не откладывать помощь, особенно если речь идёт о пожилом человеке, пациенте с хроническими заболеваниями или тех, у кого уже проявляются тревожные симптомы: дрожь в руках, панические атаки, скачки давления, бессонница и даже слуховые или зрительные галлюцинации.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]вывод из запоя цена[/url]
Запойное состояние — это не просто следствие злоупотребления спиртным, а серьёзное расстройство, которое требует немедленного медицинского вмешательства. При длительном употреблении алкоголя на протяжении нескольких суток или недель организм человека сталкивается с тяжёлой интоксикацией, нарушением работы внутренних органов и изменениями в психоэмоциональном состоянии. В такой ситуации необходим профессиональный вывод из запоя — грамотно организованный процесс детоксикации, способный предотвратить тяжёлые осложнения.
Получить дополнительные сведения – https://vyvod-iz-zapoya-domodedovo3.ru/vyvod-iz-zapoya-stacionar-v-domodedovo
Срочные микрозаймы https://stuff-money.ru с моментальным одобрением. Заполните заявку онлайн и получите деньги на карту уже сегодня. Надёжно, быстро, без лишней бюрократии.
Мы понимаем уникальность каждого пациента и проводим тщательную диагностику, анализируя его медицинскую историю, психологическое состояние и социальные факторы. На основе полученных данных создаем персональные планы лечения, включающие медикаментозные средства, психотерапию и социальные программы.
Получить дополнительную информацию – https://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-rostove-na-donu.xn--p1ai
https://bs2bet.at
Услуги массаж ивантеевка — для здоровья, красоты и расслабления. Опытный специалист, удобное расположение, доступные цены.
Алкогольная зависимость — сложное хроническое заболевание, требующее комплексного подхода и квалифицированной помощи. В клинике «Тюменьбезалко» в центре Тюмени разработаны эффективные программы реабилитации, сочетающие современные медицинские методы, психологическую поддержку и социальную адаптацию. Опытные врачи-наркологи и психотерапевты помогают пациентам преодолеть употребление алкоголя, восстановить физическое и эмоциональное здоровье и вернуться к полноценной жизни.
Детальнее – http://lechenie-alkogolizma-tyumen10.ru
https://1-bs2best.lat/bs2best.html
Алкоголь и наркотики воздействуют на организм комплексно: нарушается работа сердца, сосудов, печени и почек, страдает нервная система. При запое или ломке без квалифицированной помощи возникают судороги, делирий, галлюцинации и серьёзные сбои в обмене веществ. Самостоятельные попытки «перетерпеть» или «отмотать» запой зачастую приводят к тяжёлым осложнениям, вплоть до комы и необратимых изменений в органах.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]www.domen.ru[/url]
Самостоятельный выход из запоя сопряжен с высоким риском развития осложнений. После прекращения приема спиртного ослабленный организм может не выдержать нагрузки, что приведет к инфаркту, инсульту, судорожным приступам и даже алкогольному психозу. Чтобы избежать этих опасных состояний, необходимо вызвать нарколога на дом, который проведет лечение правильно и безопасно.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-krasnodar0.ru/]vyvod-iz-zapoya-krasnodar0.ru/[/url]
Многие думают, что запой — это просто привычка. На деле же это глубокий физиологический и психологический кризис. Он может привести к очень серьёзным осложнениям — от инфаркта до алкогольного делирия, сопровождающегося агрессией, страхами и бредовыми состояниями. Это не преувеличение. Алкоголь разрушает организм молча — и делает это быстрее, чем кажется.
Получить дополнительные сведения – https://vyvod-iz-zapoya-ehlektrostal3.ru/anonimnyj-vyvod-iz-zapoya-v-ehlektrostali/
AI generator nsfw ai generator of the new generation: artificial intelligence turns text into stylish and realistic pictures and videos.
1000 рублей за регистрацию вывод сразу Получить 1000 рублей за регистрацию с моментальным выводом, не требующим каких-либо вложений, – это мечта любого новичка онлайн-казино. Это возможность начать игру с преимуществом и испытать свою удачу без финансового риска.
Каждый пациент получает индивидуальный план лечения, основанный на клинических исследованиях, данных лабораторных анализов и психологических тестов.
Разобраться лучше – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]narkologicheskaya-klinika-v-oblasti[/url]
https://bs2bcst.at
Мы понимаем уникальность каждого пациента и проводим тщательную диагностику, анализируя его медицинскую историю, психологическое состояние и социальные факторы. На основе полученных данных создаем персональные планы лечения, включающие медикаментозные средства, психотерапию и социальные программы.
Выяснить больше – http://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-anonimno-v-rostove-na-donu.xn--p1ai/
Мы предлагаем полный спектр услуг по лечению зависимостей:
Подробнее тут – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]narkologicheskaya-klinika[/url]
Алкоголь и наркотики воздействуют на организм комплексно: нарушается работа сердца, сосудов, печени и почек, страдает нервная система. При запое или ломке без квалифицированной помощи возникают судороги, делирий, галлюцинации и серьёзные сбои в обмене веществ. Самостоятельные попытки «перетерпеть» или «отмотать» запой зачастую приводят к тяжёлым осложнениям, вплоть до комы и необратимых изменений в органах.
Получить дополнительную информацию – https://narkologicheskaya-klinika-dolgoprudnyj3.ru/anonimnaya-narkologicheskaya-klinika-v-dolgoprudnom/
https://2-bs2best.lat/blaksprut_ssylka.html
Офисная мебель https://mkoffice.ru в Новосибирске: готовые комплекты и отдельные элементы. Широкий ассортимент, современные дизайны, доставка по городу.
Smart bankroll management is key in any tournament, just like choosing the right games! Seeing platforms like bossjl legit offer diverse options – slots, live casino – gives players more control over their variance. Fun stuff!
Бездепозитные бонусы Перед тем, как воспользоваться бездепозитным бонусом, стоит внимательно изучить условия его получения и отыгрыша. Важно понимать, какие игры доступны для игры на бонусные средства, какой вейджер необходимо выполнить, чтобы вывести выигрыш, и какие сроки установлены для отыгрыша бонуса. Тщательное изучение правил поможет избежать разочарований и получить максимальную выгоду от использования бонуса.
Особое внимание в клинике уделяется профилактике рецидивов. Мы обучаем пациентов навыкам управления стрессом, контролю эмоций и принципам здорового образа жизни. Наша цель — обеспечить длительное восстановление и снизить риск возврата к зависимости.
Выяснить больше – http://срочно-вывод-из-запоя.рф
При поступлении или выезде на дом врач-нарколог собирает анамнез, оценивает степень зависимости, измеряет жизненные показатели и назначает необходимые анализы. Цель — исключить противопоказания и выбрать оптимальную схему терапии.
Подробнее – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]narkologicheskaya-klinika-zdorove[/url]
New AI generator free nsfw ai chat of the new generation: artificial intelligence turns text into stylish and realistic image and videos.
Hindi News https://tfipost.in latest news from India and the world. Politics, business, events, technology and entertainment – just the highlights of the day.
В условиях стационара или на дневном стационаре применяются сбалансированные инфузионные растворы, витамины, антиоксиданты и препараты для поддержки печени. Цель — минимизировать интоксикацию и предотвратить осложнения.
Углубиться в тему – [url=https://lechenie-alkogolizma-tyumen10.ru/]лечение алкоголизма цена[/url]
https://b2shop.gl/blacksprut_zerkalo.html
При поступлении или выезде на дом врач-нарколог собирает анамнез, оценивает степень зависимости, измеряет жизненные показатели и назначает необходимые анализы. Цель — исключить противопоказания и выбрать оптимальную схему терапии.
Углубиться в тему – http://narkologicheskaya-klinika-dolgoprudnyj3.ru
https://b2tsite4.io/bs2best.html
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Подробнее – https://www.mahour.ca/fa/eb/8ef8ecc614c82284c18cac8c0a758eb4
Hey! Do you use Twitter? I’d like to follow you if that would be okay. I’m undoubtedly enjoying your blog and look forward to new posts.
http://babyphotostar.com.ua/linzi-v-fari-vibir-kupivlya-i-vstanovlennya
https://2-bs2best.lat/blacksprut_zerkalo.html
бездепозитный бонус игровые автоматы с выводом денег Бездепозитный бонус – это шанс сорвать куш, не вкладывая ни копейки. Он позволяет испытать азарт, риск и радость победы, не испытывая страха потери собственных средств. Это особенно ценно для начинающих игроков, которые еще не готовы рисковать большими суммами. Бездепозитный бонус в казино
https://2bs-2best.at/bs2web_at.html
ремонт стиральных машин remont stiralok ремонт стиральных машин бош
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-sochi00.ru/]вызвать капельницу от запоя на дому в сочи[/url]
magyar nyelvu tamogatas
проститутки донецк Проститутки Горловка – такая же ситуация, как и в предыдущих случаях.
Основная миссия нашего учреждения заключается в комплексной помощи пациентам с зависимостями. Основные цели нашей работы включают:
Подробнее можно узнать тут – http://тайный-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-samare.xn--p1ai/
Вызов нарколога на дом становится необходимым при любых состояниях, когда отказ от алкоголя сопровождается выраженными симптомами интоксикации и абстиненции. Основные ситуации, в которых срочно требуется профессиональная помощь врача:
Подробнее тут – http://
Useful information. Lucky me I discovered your website by chance, and I am shocked why this coincidence didn’t took place earlier! I bookmarked it.
https://kidsvisitor.com.ua/universal-hermetyk-dlia-remontu-skla-far-perevahy-ta-rekomendatsii
бездепозитный бонус игровые автоматы с выводом денег Многие игроки ищут именно такие бонусы, которые позволяют сразу вывести выигранные деньги, не вкладывая свои. Но стоит помнить о лимитах и правилах казино.
Как оформить карту карта иностранного банка для россиян в 2025 году. Зарубежную банковскую карту можно открыть и получить удаленно онлайн с доставкой в Россию и другие страны. Карты подходят для оплаты за границей.
секс Донецк Секс ДНР: Интим в условиях конфликта Вооруженный конфликт в Донецкой Народной Республике (ДНР) оказал глубокое влияние на все аспекты жизни, включая сексуальные отношения. Несмотря на трудности, люди продолжают искать любовь и близость.
Процедура длится от 40 минут до 2 часов, в зависимости от тяжести состояния, и проводится в комфортной домашней обстановке, что значительно снижает стресс у пациента и его близких.
Узнать больше – [url=https://narcolog-na-dom-krasnodar0.ru/]нарколог на дом вывод в краснодаре[/url]
https://1-bs2best.lat/https_bs2best_at.html
megbizhato kaszino
При поступлении или выезде на дом врач-нарколог собирает анамнез, оценивает степень зависимости, измеряет жизненные показатели и назначает необходимые анализы. Цель — исключить противопоказания и выбрать оптимальную схему терапии.
Получить больше информации – http://narkologicheskaya-klinika-dolgoprudnyj3.ru/
Вызов нарколога на дом становится необходимым при любых состояниях, когда отказ от алкоголя сопровождается выраженными симптомами интоксикации и абстиненции. Основные ситуации, в которых срочно требуется профессиональная помощь врача:
Выяснить больше – http://narcolog-na-dom-sochi0.ru
Обращение за медицинской помощью становится необходимым, когда пациент пребывает в состоянии, требующем немедленного вмешательства, так как самостоятельное лечение может только усугубить ситуацию. Это происходит, если запой продолжается несколько дней, и организм не успевает справляться с накопившимися токсинами, что ведёт к нарушению работы внутренних органов. Если у пациента регулярно наблюдаются симптомы, такие как частая рвота, сильное головокружение, спутанность сознания, судороги или резкие колебания артериального давления, это является явным сигналом к вызову специалиста. Особенно важно обращаться за помощью при выраженных признаках абстинентного синдрома, когда сильная дрожь, панические атаки, бессонница, тревожность и даже галлюцинации свидетельствуют о том, что организм испытывает критическую нехватку поддержки. Наличие психических нарушений, таких как агрессивное поведение, спутанность сознания или признаки алкогольного психоза, также требует незамедлительного вмешательства. В таких ситуациях обращение за профессиональной помощью помогает быстро стабилизировать состояние пациента, предотвратить развитие тяжелых осложнений и сохранить жизнь.
Подробнее тут – http://narcolog-na-dom-ekaterinburg00.ru/vrach-narkolog-na-dom-ekb/
That analysis was spot on! Seeing platforms like JL Boss 2025 really elevate the PH online gaming scene – especially with easy GCash integration. Curious to try their slots – check out jl boss login for a quick start! Solid insights overall.
https://bs2bsme.at
Преимущество
Разобраться лучше – http://narcolog-na-dom-ekaterinburg0.ru/
Вызов нарколога на дом становится необходимым при любых состояниях, когда отказ от алкоголя сопровождается выраженными симптомами интоксикации и абстиненции. Основные ситуации, в которых срочно требуется профессиональная помощь врача:
Разобраться лучше – http://narcolog-na-dom-sochi0.ru
iflow камеры видеонаблюдения [url=http://citadel-trade.ru]http://citadel-trade.ru[/url] .
электрокарниз двухрядный цена [url=https://www.elektrokarniz90.ru]https://www.elektrokarniz90.ru[/url] .
автоматические карнизы для штор [url=https://karnizy-s-elektroprivodom77.ru/]https://karnizy-s-elektroprivodom77.ru/[/url] .
электрокарнизы москва [url=http://karniz-motorizovannyj77.ru/]http://karniz-motorizovannyj77.ru/[/url] .
готовые рулонные шторы купить в москве [url=elektricheskie-rulonnye-shtory77.ru]elektricheskie-rulonnye-shtory77.ru[/url] .
электропривод рулонных штор [url=www.elektricheskie-rulonnye-shtory99.ru]www.elektricheskie-rulonnye-shtory99.ru[/url] .
какие бывают рулонные шторы [url=rulonnye-shtory-s-elektroprivodom15.ru]rulonnye-shtory-s-elektroprivodom15.ru[/url] .
вавада казино официальный сайт казино Отзывы реальных игроков – это ценный источник информации о Vavada Casino. Изучение отзывов позволяет узнать о преимуществах и недостатках платформы, а также получить представление об игровом опыте других пользователей.
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Детальнее – https://sterlingrec.org/anna
https://b2tsite4.io/bs2web_at.html
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Углубиться в тему – http://www.osmoharvard.se/backgroundsnyggt-jpg
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Получить дополнительную информацию – https://boccato.travel/multi-day-vs-single-day-rafting-trips
https://b2shop.gl/index.html
sportbets [url=https://sportbets14.ru]https://sportbets14.ru[/url] .
бонусы в казино на день рождения Многие игроки ищут именно такие бонусы, которые позволяют сразу вывести выигранные деньги, не вкладывая свои. Но стоит помнить о лимитах и правилах казино.
Дополнительно, если у пациента отмечаются психические нарушения — галлюцинации, агрессия или спутанность сознания, это является прямым сигналом к срочному вмешательству. В этом случае своевременное лечение помогает предотвратить риск инсульта, инфаркта или других серьезных заболеваний.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя на дому[/url]
Зависимость от психоактивных веществ — серьёзная проблема, которая становится всё актуальнее в современном мире. Алкоголизм, наркомания и игромания представляют угрозу как для здоровья отдельного человека, так и для общества в целом. В условиях растущей нагрузки на систему здравоохранения Наркологическая клиника “Возрождение” предлагает комплексные решения для тех, кто страдает от различных видов зависимости. Мы придерживаемся индивидуального подхода, что позволяет достигать высоких результатов в лечении и реабилитации.
Разобраться лучше – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-nizhnem-novgoroge.xn--p1ai/
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя наркология в сочи[/url]
психиатрическая клиника Психиатрическая клиника. Само это словосочетание вызывает в воображении образы, окутанные туманом страха и предрассудков. Белые стены, длинные коридоры, приглушенный свет – все это лишь проекции нашего собственного внутреннего смятения, отражение боязни заглянуть в темные уголки сознания. Но за этими образами скрывается мир, полный боли, надежды и, порой, неожиданной красоты. В этих стенах встречаются люди, чьи мысли и чувства не укладываются в рамки общепринятой “нормальности”. Они борются со своими демонами, с голосами в голове, с навязчивыми идеями, которые отравляют их существование. Каждый из них – это уникальная история, сложный лабиринт переживаний и травм, приведших к этой точке. Здесь работают люди, посвятившие себя помощи тем, кто оказался на краю. Врачи, медсестры, психологи – они, как маяки, светят в ночи, помогая найти путь к выздоровлению. Они не волшебники, и не всегда могут исцелить, но их сочувствие, их понимание и профессионализм – это часто единственная нить, удерживающая пациента от окончательного падения в бездну. Жизнь в психиатрической клинике – это не заточение, а скорее передышка. Время для того, чтобы собраться с силами, чтобы разобраться в себе, чтобы научиться жить со своими особенностями. Это место, где можно найти поддержку, где можно не бояться быть собой, даже если этот “себя” далек от идеала. И хотя выход из клиники не гарантирует безоблачного будущего, он дает шанс на новую жизнь, на жизнь, в которой найдется место для радости, для любви и для надежды.
Продолжительное употребление алкоголя наносит сильный удар по организму и психике человека. Если запой длится более двух дней, состояние резко ухудшается, и самостоятельный выход может привести к серьезным последствиям. Обязательно следует вызывать врача в следующих случаях:
Получить больше информации – https://vyvod-iz-zapoya-krasnodar0.ru/
Причины разрушения подошвы обуви https://e-pochemuchka.ru/prichiny-razrusheniya-podoshvy-obuvi/
[url=https://shiba-akita.ru/]https://www.shiba-akita.ru/[/url] – статья о полезности дизельных моторов для автомобилистов
кредит под залог машины
zaimpod-pts90.ru
займ залог птс
sportbets [url=https://www.sportbets15.ru]https://www.sportbets15.ru[/url] .
Серьезные состояния, вызванные длительным употреблением алкоголя или наркотиков, требуют немедленного вмешательства. Если пациент испытывает ухудшение самочувствия вследствие продолжительного запоя, его организм начинает накапливать токсичные вещества, что ведёт к нарушению работы внутренних органов. При появлении таких симптомов, как сильная рвота, спутанность сознания, судороги, резкие скачки артериального давления, а также выраженные признаки абстинентного синдрома (сильная дрожь, панические атаки, бессонница, тревожность), вызов нарколога становится жизненно необходимым. Экстренное вмешательство позволяет стабилизировать состояние больного и предотвратить развитие серьёзных осложнений, включая сердечно-сосудистые нарушения, повреждение печени и развитие алкогольного психоза. В таких ситуациях профессиональное лечение на дому — лучший способ сохранить здоровье и жизнь пациента.
Выяснить больше – [url=https://narcolog-na-dom-ekaterinburg000.ru/]нарколог на дом вывод из запоя в екатеринбурге[/url]
Группа препаратов
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-sochi0.ru/]врача капельницу от запоя[/url]
Мы работаем без праздников и выходных, принимаем срочные обращения, выезжаем оперативно и оказываем помощь в полном соответствии с медицинскими стандартами. Главный принцип — безопасность, эффективность и деликатность. Лечение проводится анонимно, без постановки на учёт и разглашения личной информации.
Узнать больше – https://vyvod-iz-zapoya-serpuhov3.ru/vyvod-iz-zapoya-na-domu-v-serpuhove/
Для эффективного лечения наши врачи используют только проверенные и сертифицированные медикаменты, которые подбираются индивидуально для каждого пациента. В состав лечебного курса входят:
Углубиться в тему – http://narcolog-na-dom-ekaterinburg000.ru/
Дополнительно, если у пациента отмечаются психические нарушения — галлюцинации, агрессия или спутанность сознания, это является прямым сигналом к срочному вмешательству. В этом случае своевременное лечение помогает предотвратить риск инсульта, инфаркта или других серьезных заболеваний.
Исследовать вопрос подробнее – http://vyvod-iz-zapoya-krasnodar00.ru
Пожалуй, самый распространённый миф — что если просто не пить сутки-двое, то всё наладится. Но если человек длительное время находился в состоянии опьянения, его тело уже адаптировалось к токсичной среде. Резкий отказ без медицинской помощи может привести к судорогам, галлюцинациям, тяжёлой бессоннице, паническим атакам и скачкам давления. Человек буквально «сгорает» изнутри — от собственного обмена веществ, который не справляется с последствиями интоксикации.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ehlektrostal3.ru/]vyvod-iz-zapoya-na-domu-cena[/url]
Действие и назначение
Выяснить больше – [url=https://kapelnica-ot-zapoya-sochi0.ru/]капельница от запоя на дому сочи.[/url]
https://2bs-2best.at/darknetmarket.html
LMC Middle School https://lmc896.org in Lower Manhattan provides a rigorous, student-centered education in a caring and inclusive atmosphere. Emphasis on critical thinking, collaboration, and community engagement.
высокое кашпо для цветов напольное из пластика [url=kashpo-napolnoe-msk.ru]высокое кашпо для цветов напольное из пластика[/url] .
Возможные признаки
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-tula10.ru/]платная наркологическая клиника[/url]
вазы кашпо напольные [url=http://kashpo-napolnoe-spb.ru]вазы кашпо напольные[/url] .
Для детоксикации и восстановления организма после запоя используются только сертифицированные лекарственные препараты с доказанной эффективностью и безопасностью:
Узнать больше – [url=https://narcolog-na-dom-sochi0.ru/]narcolog-na-dom-sochi0.ru/[/url]
Особенно важны первые дни пребывания, когда проводится диагностика, назначается медикаментозная поддержка и формируется план лечения. Компетентные врачи способны адаптировать программу под физическое и психоэмоциональное состояние пациента, учитывая как длительность употребления, так и возможные сопутствующие диагнозы. На этом этапе важно исключить риски осложнений и создать условия для безопасного перехода к следующему этапу — психологической реабилитации.
Получить дополнительные сведения – https://narkologicheskaya-klinika-tula10.ru/chastnaya-narkologicheskaya-klinika-tula/
Чем раньше нарколог окажет помощь, тем выше шансы избежать осложнений и восстановиться без последствий для здоровья.
Разобраться лучше – [url=https://narcolog-na-dom-sochi0.ru/]нарколог на дом вывод из запоя в сочи[/url]
После приезда нарколог оценивает состояние пациента, проверяет давление, частоту пульса и насыщенность крови кислородом. Затем врач подбирает индивидуальный состав капельницы, включающий растворы для очистки организма, препараты для нормализации работы сердца, печени и нервной системы. Процедура длится около 1–2 часов и позволяет быстро:
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-krasnodar0.ru/]вывод из запоя на дому цена в краснодаре[/url]
Путь к свободе от зависимости начинается не с обещаний «просто перестать», а с профессионального медицинского вмешательства. В «Чистом Дыхании» мы применяем проверенные методы, которые работают там, где сила воли без нужной поддержки оказывается бессильной. Наша клиника в Долгопрудном работает круглосуточно — чтобы помощь была доступна в самый критический момент, когда человек ощущает острую потребность в детоксикации, снятии абстинентного синдрома или психологической поддержке.
Выяснить больше – https://narkologicheskaya-klinika-dolgoprudnyj3.ru/
Миссия клиники — оказание комплексной помощи людям с зависимостями. Основные задачи, которые мы ставим перед собой:
Подробнее – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-nizhnem-novgoroge.xn--p1ai
При поступлении вызова специалисты клиники «ЗдоровьеНорм» выезжают на дом в течение 30–60 минут. Врач проводит тщательную диагностику, измеряя артериальное давление, пульс, уровень кислорода в крови и оценивая общее состояние пациента. После этого осуществляется индивидуальный подбор лечебной схемы, основанной на объективных данных и анамнезе пациента.
Подробнее тут – http://vyvod-iz-zapoya-krasnodar00.ru
Sykaaa casino online casino официальный сайт Получите эксклюзивный бонус за регистрацию на официальном сайте Sykaaa Casino! Начните свою игру с дополнительными средствами и увеличьте свои шансы на крупный выигрыш. Sykaaa Casino 100 Бесплатных Вращений
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Подробнее тут – https://wgift.vn/cung-cap-bo-am-chen-qua-ta%CC%A3ng-in-logo-so-luo%CC%A3ng-lon-cho-doanh-nghiep
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Узнать больше – https://dabet1.online/rut-tien-good88-cuc-de
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Выяснить больше – https://subcarpathia.com.pl/last-day-in-vegas
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Получить дополнительные сведения – http://erogework.com/contents/780?variant=zh-hant
https://b2tsite4.io/darknetmarket.html
Бездепозитный бонус Бездепозитный бонус – это не просто подарок судьбы, а возможность испытать свои силы и понять, как работают различные игры. Это как виртуальный тренажер, который позволяет набраться опыта и разработать собственную стратегию, прежде чем переходить к игре на реальные деньги. Это шанс стать уверенным игроком, не боясь потерять собственные средства. Бездепозитный бонус в казино
Клиника “Обновление” также активно занимается просветительской деятельностью. Мы организуем семинары и лекции, которые помогают обществу лучше понять проблемы зависимостей, их последствия и пути решения. Повышение осведомленности является важным шагом на пути к улучшению ситуации в этой области.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-irkutsk.ru/]kapelnicza-ot-zapoya-na-domu irkutsk[/url]
888starz bet скачать на айфон [url=http://www.https://888starz888.website]888starz bet скачать на айфон[/url] .
ткань для штор Купить шторы в Москве можно в многочисленных салонах и магазинах, предлагающих широкий ассортимент тканей и фурнитуры. Важно выбрать проверенного продавца с хорошими отзывами и возможностью заказа по индивидуальным размерам.
гибкая керамика для внутренней Гибкая керамика для фасадов цена за 1 м2 сравнима с традиционной плиткой, но монтаж и вес материала значительно легче, что снижает общие затраты.
•очешь продать авто? продажа и выкуп авто
Поддержка — ключевой элемент на пути к выздоровлению. Мы предлагаем программы, которые продолжаются даже после завершения основного курса лечения. Пациенты имеют возможность участвовать в регулярных встречах с психологами и наркологами, где они могут делиться своими успехами и получать необходимую помощь.
Выяснить больше – http://kapelnica-ot-zapoya-irkutsk2.ru
куда сходить в питере Экскурсии по Петербургу – лучший способ познакомиться с городом и его богатым наследием. Выберите свой маршрут и отправляйтесь в увлекательное путешествие.
Спортивные новости Спортивные ставки – это не только способ заработать деньги, но и возможность добавить азарта в просмотр спортивных событий. Правильный подход и умение управлять рисками – залог успеха в этом увлекательном мире.
Капельница от запоя — это быстрый и безопасный способ вывести токсины, восстановить водно-солевой баланс и улучшить общее самочувствие. Наркологи клиники «ТрезвоКлиник» оказывают круглосуточную медицинскую помощь на дому, используя только сертифицированные препараты и проверенные методики детоксикации.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-moskva0.ru/]капельница от запоя анонимно в москве[/url]
«ВладимирМед» основана группой врачей-наркологов и психотерапевтов, объединивших опыт работы в государственных и частных учреждениях. Мы предлагаем не просто преодоление запоя, а глубокую комплексную реабилитацию, включающую медико-психологическую оценку и долгосрочное сопровождение. Наша цель — восстановление здоровья на физическом и эмоциональном уровнях, возвращение пациента к полноценной социальной жизни без рецидивов.
Углубиться в тему – [url=https://narkologicheskaya-klinika-vladimir10.ru/]наркологическая клиника цены[/url]
Подшипники от производителей Шариковый подшипник – это один из наиболее распространенных типов подшипников качения, в котором тела качения имеют форму шариков. Он отличается универсальностью и подходит для различных применений.
штора для ванны Выбор карниза для штор — важный момент в оформлении окон. Карниз должен быть прочным и соответствовать весу штор, а также гармонировать с интерьером комнаты. Современные модели могут иметь разнообразные дизайны и механизмы управления.
В зависимости от состояния пациента мы предлагаем два формата помощи: выезд нарколога на дом или госпитализацию в стационар. Оба варианта включают детоксикацию — выведение токсинов из организма с помощью инфузионной терапии (капельницы), а также медикаментозную поддержку: успокоительные, витамины, препараты для печени и сердца.
Выяснить больше – http://vyvod-iz-zapoya-serpuhov3.ru
Алкоголь и наркотики воздействуют на организм комплексно: нарушается работа сердца, сосудов, печени и почек, страдает нервная система. При запое или ломке без квалифицированной помощи возникают судороги, делирий, галлюцинации и серьёзные сбои в обмене веществ. Самостоятельные попытки «перетерпеть» или «отмотать» запой зачастую приводят к тяжёлым осложнениям, вплоть до комы и необратимых изменений в органах.
Изучить вопрос глубже – https://narkologicheskaya-klinika-dolgoprudnyj3.ru/anonimnaya-narkologicheskaya-klinika-v-dolgoprudnom
Серьезные состояния, вызванные длительным употреблением алкоголя или наркотиков, требуют немедленного вмешательства. Если пациент испытывает ухудшение самочувствия вследствие продолжительного запоя, его организм начинает накапливать токсичные вещества, что ведёт к нарушению работы внутренних органов. При появлении таких симптомов, как сильная рвота, спутанность сознания, судороги, резкие скачки артериального давления, а также выраженные признаки абстинентного синдрома (сильная дрожь, панические атаки, бессонница, тревожность), вызов нарколога становится жизненно необходимым. Экстренное вмешательство позволяет стабилизировать состояние больного и предотвратить развитие серьёзных осложнений, включая сердечно-сосудистые нарушения, повреждение печени и развитие алкогольного психоза. В таких ситуациях профессиональное лечение на дому — лучший способ сохранить здоровье и жизнь пациента.
Изучить вопрос глубже – [url=https://narcolog-na-dom-ekaterinburg000.ru/]вызов врача нарколога на дом[/url]
It’s great to see platforms like ph987 com prioritizing user experience and security – essential for responsible gaming! A smooth download process is a big plus, making access easier for everyone. Let’s keep the conversation going about healthy gaming habits!
Не можете добраться до клиники? Нарколог на дом в Иркутске – оптимальный выход при запое. Нарколог на дом – это удобно: обследование, лечение и детоксикация в комфортных условиях. Выезд нарколога в любое время, анонимность и безопасность – это «ТрезвоМед». Без медицинской помощи не обойтись? Звоните наркологу! Чем быстрее помощь, тем лучше прогноз, – нарколог Игорь Васильев.
Узнать больше – [url=https://narcolog-na-dom-v-irkutske0.ru/]выезд нарколога на дом цена иркутск[/url]
888starz скачать на андроид бесплатно с официального [url=www.https://888starz-skachat-na-android.com/]www.https://888starz-skachat-na-android.com/[/url] .
Все вызовы фиксируются под кодовым номером без указания ФИО, что обеспечивает полную конфиденциальность каждого пациента.
Узнать больше – https://narkologicheskaya-klinika-vladimir10.ru/anonimnaya-narkologicheskaya-klinika-vladimir
Наша команда врачей оперативно реагирует на каждый вызов, оказывая квалифицированную медицинскую помощь на дому. Специалисты проводят полный комплекс лечебных мероприятий, направленных на безопасное снятие интоксикации, детоксикацию и облегчение симптомов абстиненции.
Получить дополнительную информацию – [url=https://narcolog-na-dom-ekaterinburg0.ru/]вызов нарколога на дом екатеринбург.[/url]
Игнорирование состояния пациента или попытки самостоятельно справиться с запоем могут привести к опасным последствиям для жизни и здоровья. Поэтому важно своевременно обращаться за профессиональной медицинской помощью.
Подробнее – https://narcolog-na-dom-sankt-peterburg0.ru
Тип- бизнес Туры в Санкт-Петербург – отличный способ организовать свою поездку и увидеть самые интересные места, не тратя время на планирование.
Некоторые состояния требуют немедленного вмешательства нарколога, так как отказ от лечения может привести к тяжелым осложнениям и риску для жизни.
Детальнее – [url=https://narcolog-na-dom-novokuznetsk00.ru/]нарколог на дом вывод из запоя[/url]
Клиника «Нарколог-Профи» предлагает круглосуточную помощь на дому в Екатеринбурге и Свердловской области. Наши опытные специалисты готовы оперативно приехать по вашему вызову и оказать экстренную медицинскую поддержку при алкогольной или наркотической зависимости. Мы проводим детоксикацию организма, купируем абстинентный синдром и стабилизируем состояние пациента, обеспечивая при этом полную конфиденциальность и комфорт в домашних условиях.
Подробнее – [url=https://narcolog-na-dom-ekaterinburg00.ru/]вызов нарколога на дом[/url]
Фрибеты за регистрацию Спортивные новости – незаменимый источник информации для успешных ставок. Анализируйте последние события, травмы игроков и статистику команд.
Миссия клиники “Обновление” заключается в предоставлении качественной и всесторонней помощи людям, страдающим от различных форм зависимости. Мы понимаем, что успешное лечение невозможно без индивидуального подхода, поэтому каждый пациент проходит детальную диагностику, после которой разрабатывается персонализированный план терапии. В процессе работы мы акцентируем внимание на следующих аспектах:
Узнать больше – [url=https://kapelnica-ot-zapoya-irkutsk.ru/]капельница от запоя в иркутске[/url]
Агентство контекстной рекламы https://kontekst-dlya-prodazh.ru настройка Яндекс.Директ и Google Ads под ключ. Привлекаем клиентов, оптимизируем бюджеты, повышаем конверсии.
Продвижение сайтов https://optimizaciya-i-prodvizhenie.ru в Google и Яндекс — только «белое» SEO. Улучшаем видимость, позиции и трафик. Аудит, стратегия, тексты, ссылки.
Наша миссия заключается в предоставлении качественной помощи людям, страдающим от зависимостей. Мы стремимся создать безопасную и поддерживающую атмосферу, где каждый сможет получить необходимую помощь. Основная цель — восстановление здоровья, психоэмоционального состояния и социальной адаптации.
Детальнее – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-omske.ru/]наркология вывод из запоя в омске[/url]
экстренный вывод из запоя краснодар
narkolog-krasnodar001.ru
лечение запоя
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Детальнее – http://www.backupteleinformatica.com.br/?p=94
домашний интернет тарифы челябинск
domashij-internet-chelyabinsk004.ru
интернет домашний челябинск
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Детальнее – http://soldadurasazteca.com/index.php/component/k2/item/27-versions-have-evolved-over-the-years?start=4530
Шины и диски https://tssz.ru для любого авто: легковые, внедорожники, коммерческий транспорт. Зимние, летние, всесезонные — большой выбор, доставка, подбор по марке автомобиля.
Инженерная сантехника https://vodazone.ru в Москве — всё для отопления, водоснабжения и канализации. Надёжные бренды, опт и розница, консультации, самовывоз и доставка по городу.
Цены на услуги маркетолога Услуги маркетолога цена – стоимость работы специалиста, определяемая исходя из объема задач, сложности проекта и опыта маркетолога. Цена может быть фиксированной или почасовой.
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Получить больше информации – https://creemorganics.com/hello-world
hd видеоконференции Учебные кабинеты Актобе В Актобе ТОО «Astana IT Garant» реализует комплексные проекты по оснащению учебных кабинетов, способствуя развитию качественного образования в западном регионе Казахстана. Мы создаем современную образовательную инфраструктуру, которая соответствует потребностям развивающегося региона и готовит квалифицированные кадры для местной экономики. Наши специалисты в Актобе работают с школами различного профиля, уделяя особое внимание созданию кабинетов естественных наук, математики и технологий. Мы понимаем важность качественного образования для развития нефтегазовой отрасли региона и оснащаем школы соответствующим лабораторным оборудованием. Astana IT Garant адаптирует свои решения под климатические условия Актобе, обеспечивая надежную работу оборудования в условиях резко континентального климата. Все поставляемая техника проходит дополнительное тестирование на устойчивость к температурным колебаниям и пыли. Мы поддерживаем инициативы акимата Актобе по развитию цифрового образования и участвуем в региональных программах модернизации школ. Наши проекты включают не только поставку оборудования, но и обучение педагогического персонала современным методикам преподавания. Сервисная служба в Актобе обеспечивает быстрое реагирование на технические проблемы и регулярное профилактическое обслуживание. Мы гарантируем высокое качество технической поддержки и долгосрочное сотрудничество с образовательными учреждениями региона, способствуя устойчивому развитию образования в Актобе.
актеры турции Сиде, древний портовый город, славится своими историческими руинами, включая амфитеатр и храм Аполлона, а также песчаными пляжами.
Промышленные ворота https://efaflex.ru любых типов под заказ – секционные, откатные, рулонные, скоростные. Монтаж и обслуживание. Установка по ГОСТ.
Продажа и обслуживание https://kmural.ru копировальной техники для офиса и бизнеса. Новые и б/у аппараты. Быстрая доставка, настройка, ремонт, заправка.
экстренный вывод из запоя краснодар
narkolog-krasnodar002.ru
экстренный вывод из запоя
Клиника “Ренессанс” расположена по адресу: ул. Бородинская, д. 37, г. Пермь, Россия. Мы работаем ежедневно и также предоставляем онлайн-консультации, что позволяет получать помощь из любого места.
Разобраться лучше – https://качество-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-permi.xn--p1ai/
вывод из запоя круглосуточно
narkolog-krasnodar001.ru
экстренный вывод из запоя
подключение интернета челябинск
domashij-internet-chelyabinsk005.ru
домашний интернет подключить челябинск
Вызов врача-нарколога на дом актуален в ситуациях, когда пациенту требуется срочная медицинская помощь, но его состояние не позволяет самостоятельно обратиться в клинику. Основными причинами вызова нарколога на дом являются:
Подробнее – https://narcolog-na-dom-sankt-peterburg00.ru/vyzov-narkologa-na-dom-spb
Наши специалисты применяют только сертифицированные и проверенные препараты. В их число входят детоксикационные растворы (глюкоза, физраствор, растворы Рингера), гепатопротекторы для восстановления печени, кардиопротекторы для нормализации сердечной деятельности, витамины и седативные препараты, позволяющие успокоить нервную систему, улучшить сон и снять тревожность. Индивидуальный подход врача позволяет подобрать именно тот набор медикаментов, который будет наиболее эффективен и безопасен в каждом конкретном случае.
Подробнее – http://narcolog-na-dom-sankt-peterburg0.ru
создать сайт с помощью нейросети нейросеть создать сайт
В зависимости от состояния пациента, помощь может быть оказана в домашних условиях или в стационаре. Вызов нарколога на дом особенно актуален при абстинентном синдроме или тяжелом алкогольном опьянении. Как отмечается в материалах НМИЦ психиатрии и наркологии, в таких ситуациях крайне важно избежать самолечения и довериться врачам, способным правильно подобрать препараты и дозировки.
Разобраться лучше – https://narkologicheskaya-pomoshh-arkhangelsk0.ru/neotlozhnaya-narkologicheskaya-pomoshh-arkhangelsk/
Прежде всего необходимо убедиться, что учреждение официально зарегистрировано и обладает соответствующей лицензией на медицинскую деятельность. Этот документ выдается Минздравом и подтверждает соответствие установленным нормам.
Исследовать вопрос подробнее – https://lechenie-narkomanii-yaroslavl0.ru/czentr-lecheniya-narkomanii-yaroslavl/
Woodworking and construction https://www.woodsurfer.com forum. Ask questions, share projects, read reviews of materials and tools. Help from practitioners and experienced craftsmen.
экстренный вывод из запоя краснодар
narkolog-krasnodar002.ru
лечение запоя краснодар
гибкая керамика Москва Монтаж гибкой керамики для фасадов купить лучше у тех производителей, которые предлагают техническую поддержку и обучение монтажу.
провайдеры домашнего интернета челябинск
domashij-internet-chelyabinsk006.ru
подключить домашний интернет в челябинске
экстренный вывод из запоя
narkolog-krasnodar003.ru
вывод из запоя краснодар
Мы предлагаем полный спектр услуг по лечению зависимостей:
Детальнее – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]narkologicheskaya-klinika-v-oblasti[/url]
В сети «Narkology» вы получите всестороннюю поддержку на пути к полному освобождению от алкогольной и наркотической зависимости. Используем передовые методы дистанционного мониторинга состояния, информационно-просветительские программы и индивидуальные занятия с психологом. Экстренная консультация и круглосуточная связь с медицинскими специалистами помогут справиться с любыми сложностями и обрести новую активность без вредных привычек. Мы предоставляем актуальную информацию о методах детоксикации, замещающих терапий и профилактике срывов.
Подробнее тут – https://narcologiya.info/vliyanie-na-zdorove/protivopokazaniya-k-kodirovaniu.html
услуги pr сопровождения Стоимость услуг маркетолога определяется индивидуально после анализа бизнеса и определения целей продвижения.
888starz обзор [url=http://https://starz888starz.com/]888starz обзор[/url] .
светодиодный экран караганда Оснащение школьных кабинетов Профессиональное оснащение школьных кабинетов требует глубокого понимания современных педагогических подходов и технологических возможностей. ТОО «Astana IT Garant» предлагает комплексные решения для оснащения школьных кабинетов всех профилей с учетом специфики каждого предмета и возрастных особенностей учащихся. Мы специализируемся на создании интерактивной образовательной среды, которая стимулирует активное участие учащихся в учебном процессе. Наше оснащение включает современные интерактивные панели, мультимедийные проекторы, документ-камеры, системы голосования и беспроводные презентационные комплексы. Особое внимание уделяется оснащению специализированных кабинетов: лабораторий естественных наук, компьютерных классов, лингафонных кабинетов, мастерских технологии и изобразительного искусства. Каждое решение адаптируется под конкретные потребности предмета и методики преподавания. Astana IT Garant работает только с проверенными производителями образовательного оборудования, имеющими международные сертификаты качества. Мы гарантируем долговечность, безопасность и соответствие всех компонентов требованиям для использования в школьной среде. Наши специалисты постоянно изучают новые тенденции в области образовательных технологий и адаптируют их для казахстанских школ. Мы предлагаем не только поставку оборудования, но и консультации по его оптимальному использованию, методическую поддержку педагогов и техническое обслуживание на весь период эксплуатации.
Понимание того, какие учреждения действительно способны помочь, позволяет избежать ошибок и не тратить время на неэффективные попытки лечения. Ключевыми признаками являются наличие медицинской лицензии, опытные специалисты, прозрачные условия и отзывы пациентов.
Получить больше информации – http://narkologicheskaya-pomoshh-arkhangelsk0.ru
Каждый этап проводится квалифицированным специалистом, что позволяет достичь максимального терапевтического эффекта.
Выяснить больше – [url=https://narcolog-na-dom-ekaterinburg0.ru/]нарколог на дом свердловская область[/url]
При вызове нарколога на дом в клинике «МедТрезвость» пациент получает квалифицированную помощь, состоящую из нескольких этапов:
Разобраться лучше – [url=https://narcolog-na-dom-sankt-peterburg0.ru/]вызов врача нарколога на дом[/url]
экстренный вывод из запоя краснодар
narkolog-krasnodar003.ru
вывод из запоя круглосуточно краснодар
Пациенты клиники «НаркоМед» полностью застрахованы от утечки личной информации. Приём и лечение оформляются по псевдониму, документы не передаются в другие организации.
Разобраться лучше – https://narkologicheskaya-klinika-ekaterinburg0.ru/
Краны-манипуляторы с изолированной люлькой — особенности и преимущества
https://t.me/s/kupit_gruzoviki/139
В Екатеринбурге ассортимент Wi-Fi роутеров от различных интернет-провайдеров впечатляет. На сайте domashij-internet-ekaterinburg004.ru предоставлены отзывы о роутерах‚ которые способствуют определиться с покупкой. При анализе роутеров важно учитывать скорость интернета и качество связи‚ которые они предлагают. Некоторые пользователи сталкиваются с неприятностями с интернетом‚ поэтому проверка скорости и рекомендации по выбору роутера становятся актуальными. Также не забудьте обратить внимание на антенны для Wi-Fi‚ которые могут улучшить беспроводную сеть. Не забудьте изучить советы по оптимизации связи и настройку роутера. Это существенно повысит качество подключения к интернету и сделает использование сети более комфортным.
Во-вторых, реабилитация является неотъемлемой частью нашего подхода. Мы понимаем, что избавление от физической зависимости — это только первый шаг. Важной задачей является восстановление социального статуса, создание новых привычек и умение управлять своей жизнью без наркотиков или алкоголя. Наша клиника предлагает групповые и индивидуальные занятия, направленные на изменение поведения и мышления.
Подробнее можно узнать тут – https://kapelnica-ot-zapoya-irkutsk.ru/kapelnica-ot-zapoya-na-domu-v-irkutske
– человек не может прекратить употребление сам; – наблюдается агрессия, страх, паника, бессвязная речь; – нарушен сон, отсутствует аппетит, сильная слабость; – алкоголь стал способом снятия боли или тревоги; – попытки отказа приводят к ухудшению состояния.
Получить дополнительную информацию – http://vyvod-iz-zapoya-serpuhov3.ru/anonimnyj-vyvod-iz-zapoya-v-serpuhove/
It’s fascinating how gaming evolved from simple dice rolls to strategic “arenas” like ph987 download. The focus on intellect & security-that multi-stage onboarding-really elevates the experience beyond just luck! A clever approach.
экстренный вывод из запоя краснодар
narkolog-krasnodar004.ru
экстренный вывод из запоя краснодар
Футбол ставки Ставки на спорт – это азарт и возможность проверить свою интуицию. Анализируйте команды, изучайте статистику, но помните об умеренности.
В этой статье мы рассмотрим ключевые признаки эффективной наркологической помощи в Ярославле — от состава команды до подходов в работе с мотивацией пациента.
Подробнее тут – http://lechenie-narkomanii-yaroslavl0.ru
Наркологическая помощь на дому становится всё более востребованной благодаря своей доступности, конфиденциальности и эффективности. Клиника «МедТрезвость» предлагает пациентам целый ряд важных преимуществ:
Подробнее – http://narcolog-na-dom-sankt-peterburg0.ru
Согласно данным ФБУ «НМИЦ терапии и профилактической медицины» Минздрава РФ, стойкая ремиссия возможна только при системном подходе: от медицинской детоксикации до сопровождения в период адаптации. Выбирая учреждение, стоит оценивать не только комфорт, но и соответствие методик современным стандартам.
Детальнее – http://lechenie-narkomanii-yaroslavl0.ru
Первичный этап заключается в оценке состояния пациента и быстром подборе схемы инфузионной терапии. Врач фиксирует показания ЭКГ, сатурацию кислорода и биохимический параметр глюкозы в крови. После этого подключается капельница с раствором для выведения продуктов распада алкоголя и одновременной коррекции показателей обмена веществ. Последующие визиты врача позволяют скорректировать терапию и предотвратить развитие побочных реакций.
Разобраться лучше – https://narkologicheskaya-pomoshh-ekaterinburg0.ru/neotlozhnaya-narkologicheskaya-pomoshh-v-ekb/
Наша команда врачей оперативно реагирует на каждый вызов, оказывая квалифицированную медицинскую помощь на дому. Специалисты проводят полный комплекс лечебных мероприятий, направленных на безопасное снятие интоксикации, детоксикацию и облегчение симптомов абстиненции.
Ознакомиться с деталями – http://narcolog-na-dom-ekaterinburg0.ru/zapoj-narkolog-na-dom-ekb/
вывод из запоя круглосуточно краснодар
narkolog-krasnodar004.ru
вывод из запоя круглосуточно краснодар
Многие родственники надеются, что человек «проспится», что со временем ему станет легче. Но практика показывает: если запой длится более суток, а тем более — несколько дней, состояние будет только ухудшаться. Организм теряет воду, витамины, нарушаются обменные процессы, появляется тревожность, бессонница, тремор, скачки давления. В сложных случаях развиваются острые психозы (делирий), судороги и отказ внутренних органов.
Получить дополнительную информацию – http://vyvod-iz-zapoya-serpuhov3.ru/
Как отмечает руководитель клинико-диагностического отдела ФГБУ «Национальный центр наркологии», «участие в терапии нескольких специалистов разных направлений позволяет учитывать не только симптомы, но и глубинные причины зависимости». Именно такой подход снижает риск рецидивов и повышает эффективность лечения.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-yaroslavl0.ru/]наркологическая клиника на дом[/url]
ИНТЕРНЕТ В Екатеринбурге: УСТАНОВКА И НАСТРОЙКА ОБОРУДОВАНИЯ Сегодня доступ к интернету является важной частью нашей повседневной жизни. При поиске провайдера по адресу в Екатеринбурге стоит обратить внимание на большое количество провайдеров, предлагающих разные тарифные планы. При выборе провайдера учитывайте свои требования, такие как скорость интернет-соединения и предлагаемые услуги связи в Екатеринбурге. Правильная установка роутера и настройка Wi-Fi имеют ключевое значение при подключении к интернету. Хотя беспроводной интернет удобен, кабельный вариант может предоставить более надежное соединение. Важно учитывать оборудование для интернета, которое вы будете использовать, так как от него зависит качество сигнала. узнать провайдера по адресу Екатеринбург После установки роутера следует проверить скорость интернета, чтобы удостовериться, что вы получаете именно то, за что платите. Настройка интернета может вызвать трудности, но большинство провайдеров предлагают инструкции или помощь в настройке оборудования. Корректная настройка Wi-Fi обеспечит вам стабильный и бесперебойный доступ к интернету.
вывод из запоя цена
narkolog-krasnodar005.ru
вывод из запоя круглосуточно
вывод из запоя
narkolog-krasnodar005.ru
вывод из запоя краснодар
sportbets [url=www.sportbets16.ru/]www.sportbets16.ru/[/url] .
Подключение оптоволоконного интернета в Екатеринбурге — это выбор, которое приобретает все большую популярность среди жителей и бизнеса. Провайдеры Екатеринбурга предлагают множество тарифов на интернет, обеспечивая скоростное соединение и надежность интернета. Оптоволоконный интернет, благодаря новейшим технологиям, способен обеспечить значительно более высокую скорость по сравнению с традиционными методами подключения. Это особенно важно для коммерческого использования, где стабильность и высокая скорость являются основными требованиями. Выбирая провайдера, стоит учесть мнения пользователей о провайдерах и сравнение провайдеров по тарифам и услугам связи. Процесс установки интернета, как правило, происходит быстро и без проблем, что делает подключение комфортным. Преимущества оптоволокна очевидны: высокая скорость интернета, минимальные задержки и возможность подключения большого количества устройств. Если вы находитесь в поиске надежного интернет-провайдера, рекомендуем посетить сайт domashij-internet-ekaterinburg006.ru для получения дополнительной информации и подбора подходящего тарифа для вашей квартиры или компании.
значки пины на заказ [url=www.znacki-na-zakaz.ru]www.znacki-na-zakaz.ru[/url] .
ставки на хоккей прогнозы от профессионалов [url=www.prognoz-na-segodnya-na-sport.ru/]www.prognoz-na-segodnya-na-sport.ru/[/url] .
прогнозы на баскетбол го спорт [url=www.prognoz-na-segodnya-na-sport1.ru]www.prognoz-na-segodnya-na-sport1.ru[/url] .
Спортивные ставки Спортивные новости – ключ к успешным ставкам. Будьте в курсе травм, дисквалификаций и других факторов, влияющих на исход матчей.
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Детальнее – https://blog.doozypics.com/bring-your-photos-to-life-with-doozypics-digital-painting
ставки на хоккей прогнозы от профессионалов [url=https://prognoz-na-segodnya-na-sport3.ru]ставки на хоккей прогнозы от профессионалов[/url] .
ставки на хоккей сегодня прогнозы точные [url=https://kompyuternye-prognozy-na-futbol1.ru/]kompyuternye-prognozy-na-futbol1.ru[/url] .
прогнозы на теннис го спорт [url=https://www.prognoz-na-segodnya-na-sport2.ru]прогнозы на теннис го спорт[/url] .
прием вторсырья казань Прием вторсырья в Казани – это возможность заработать деньги и одновременно позаботиться об окружающей среде. Многие компании предлагают выгодные условия приема вторсырья, что делает этот процесс еще более привлекательным.
примеры применения ИИ Альтернативный интеллект: Исследование новых подходов к созданию ИИ, альтернативных нейронным сетям.
Капельница от похмелья на дому: эффективное лечение и восстановление здоровья
мобильные прокси 2025 Рейтинг лучших – это квинтэссенция выбора, демонстрирующая лидеров в определенной области. Он формируется на основе тщательного анализа множества факторов, таких как качество, надежность, инновационность и отзывы пользователей. Попадание в рейтинг лучших – это знак признания и свидетельство высокого уровня мастерства.
Эффективные методы лечения алкоголизма в Туле Алкоголизм – это огромная проблема‚ которая требует комплексного подхода. В Туле доступны различные наркологические услуги‚ включая возможность вызвать нарколога на дом. Это особенно существенно для людей‚ кто стесняется идти в клиники для лечения зависимости. Первым этапом является детоксикация тела‚ которая позволяет очистить организм от алкоголя и токсинов. После этого начинается терапия алкогольной зависимости. Лечение алкоголизма может включать медикаментозные препараты и психологическую поддержку. Консультация нарколога позволит подобрать оптимальный метод лечения. Реабилитация зависимых предполагает наличие семейной терапиичто помогает близким людям поддерживать зависимого. Важно помнить о профилактике рецидивов‚ который включает занятия в группах поддержки и индивидуальные сессии. Лечение алкоголизма анонимно позволяет пациентам быть уверенными в своей конфиденциальности. Важно помнить‚ что лечение зависимости от алкоголя – это долгий процесс‚ который требует настойчивости и усилий. Вызвать нарколога на дом – это начало новой жизни без алкоголя.
сдать макулатуру в казани Прием вторсырья Казань включает в себя не только макулатуру, но и другие виды отходов, такие как пластик, стекло и металл. Сдавая вторсырье, вы помогаете сократить количество мусора на полигонах и сэкономить ресурсы.
Обращение к врачу становится жизненно необходимым, если пациент находится в состоянии длительного запоя, при котором организм не справляется с накоплением токсинов. Если запой продолжается более двух-трёх дней, в теле накапливаются вредные вещества, что ведёт к нарушениям работы внутренних органов, развитию абстинентного синдрома и появлению психических нарушений. Также, если у пациента наблюдаются симптомы, такие как частая рвота, спутанность сознания, судороги или резкие скачки артериального давления, это сигнал к незамедлительному вызову специалиста. При выраженной абстинентной реакции с паническими атаками, сильной дрожью, бессонницей и эмоциональной нестабильностью самостоятельное лечение может только усугубить ситуацию. Если появляются признаки алкогольного психоза – галлюцинации, агрессивность или спутанность сознания – вызов нарколога становится обязательным для предотвращения дальнейших осложнений. Также, когда требуется подготовка к процедурам кодирования от зависимости, необходима качественная детоксикация организма, что также является показанием к срочному обращению за профессиональной помощью.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-ekaterinburg0.ru/]вызвать нарколога на дом в екатеринбурге[/url]
Нарколог на дому проводит тщательный осмотр, собирает анамнез и назначает необходимые лабораторные исследования. Это позволяет выявить сопутствующие патологии и скорректировать тактику лечения.
Получить дополнительные сведения – http://narkolog-na-dom-v-yaroslavle12.ru/narkolog-na-dom-kruglosutochno-v-yaroslavle/
заказать сборку компьютера Сборка компьютера под ключ – мы берем на себя все этапы сборки, от подбора комплектующих до настройки операционной системы.
конфигуратор игрового ПК Конфигуратор ПК онлайн – соберите свой идеальный ПК онлайн и оцените его стоимость.
*машинное обучение Тренды AI показывают направление развития искусственного интеллекта.
интернет домашний казань
domashij-internet-kazan004.ru
проверить интернет по адресу
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]наркологическая клиника[/url]
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Получить больше информации – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]narkologicheskaya klinika kamensk-ural’skij[/url]
В настоящее время проблемы с алкоголем становятся все более актуальными . Многие люди сталкиваются с зависимостью от алкоголя , которая нуждаеться в оперативном вмешательстве врачей. В таких ситуациях вызов нарколога на дом – это оптимальное решение . Услуги нарколога включают диагностику алкоголизма и медикаментозное лечение запоя. Это помогает быстро и эффективно помочь в выходе из запоя, минимизируя психологическое напряжение для пациента. Анонимное лечение алкоголизма – важный аспект , поскольку многие пациенты не хотят делиться своими проблемами . Помощь при алкогольной зависимости также включает помощь близким в борьбе с алкоголизмом. Нарколог на дом предлагает консультационные услуги, что позволяет семье разобраться, как правильно общаться с зависимым. Лечение зависимостей на дому даёт возможность пройти реабилитацию от алкоголя в комфортной обстановке . Сайт narkolog-tula002.ru предоставляет сведения о вызове врача на дом , чтобы оказать помощь тем, кто в ней нуждается.
адрес больницы больницы Бар
Лечение алкоголизма в Туле: современные методы Алкоголизм — серьезная проблема, требующая профессионального подхода. Тула предлагает широкий спектр наркологических услуг, включая возможность вызвать нарколога на дом для конфиденциального лечения. Современные методы лечения включают медикаментозную терапию и процедуры детоксикации организма. Психотерапия является важной частью лечения алкоголизма, так как она помогает понять и проработать психологические аспекты зависимости. Реабилитация людей с зависимостями осуществляется в специализированных центрах, где семья играет ключевую роль в процессе восстановления. Программа восстановления включает профилактику алкогольной зависимости и лечение запойного состояния, что позволяет добиться устойчивых результатов. заказать нарколога на дом
Tivat hospital orthopedic clinic near me
Наркологическая клиника в Ярославле представляет собой специализированное учреждение, оказывающее медицинскую помощь пациентам с алкогольной, наркотической и медикаментозной зависимостью. Ключевыми направлениями работы являются детоксикация, стабилизация состояния, последующее реабилитационное сопровождение и профилактика рецидивов. Комплексный подход к лечению обеспечивается взаимодействием специалистов различных профилей, включая наркологов, психиатров, психотерапевтов и медицинских сестёр.
Подробнее – [url=https://narkologicheskaya-klinika-v-yaroslavle12.ru/]частная наркологическая клиника ярославская область[/url]
купить игровой ПК Сборка компьютеров на заказ – это индивидуальный подход к созданию машины, отвечающей вашим уникальным требованиям. От выбора комплектующих до финальной сборки, каждый этап контролируется для достижения максимальной производительности.
Как поясняет медицинский психолог Елена Мусатова, «пациенту важно доверять специалисту, понимать его подход и чувствовать профессиональную уверенность ещё на этапе первичного осмотра».
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-pervouralsk11.ru/]наркологические клиники алкоголизм первоуральск[/url]
Капельница от запоя в Мурманске является одной из наиболее востребованных процедур для снятия острого состояния алкогольной интоксикации. Эта методика позволяет быстро вывести токсины из организма, нормализовать водно-солевой баланс и улучшить самочувствие пациента. Современная капельная терапия считается эффективным средством в лечении запоя, обеспечивая поддержку жизненно важных функций и минимизируя риски осложнений.
Получить больше информации – https://kapelnicza-ot-zapoya-v-murmanske12.ru/kapelniczy-ot-zapoya-na-domu-v-murmanske/
Наркологическая клиника в Ярославле представляет собой специализированное учреждение, оказывающее медицинскую помощь пациентам с алкогольной, наркотической и медикаментозной зависимостью. Ключевыми направлениями работы являются детоксикация, стабилизация состояния, последующее реабилитационное сопровождение и профилактика рецидивов. Комплексный подход к лечению обеспечивается взаимодействием специалистов различных профилей, включая наркологов, психиатров, психотерапевтов и медицинских сестёр.
Получить дополнительные сведения – https://narkologicheskaya-klinika-v-yaroslavle12.ru/narkologicheskaya-klinika-klinika-pomoshh-v-yaroslavle/
домашний интернет тарифы
domashij-internet-kazan005.ru
провайдеры по адресу казань
Услуга откапывания на дому в Туле – это популярная услуга‚ которая особенно актуальна при проведении земляных работ‚ ремонте и строительстве. Компании‚ специализирующиеся на этом‚ предлагают услуги по копке с помощью экскаватора на вашем участке. Лицензированные специалисты обеспечивают качественное выполнение заказа‚ включая обработку грунта и установку дренажей. Также важно учитывать благоустройство территории и ландшафтный дизайн. Заказывая частные услуги‚ вы можете рассчитывать на профессионализм и надежность. Чтобы узнать больше‚ посетите сайт narkolog-tula003.ru.
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Подробнее – http://narkologicheskaya-klinika-kamensk-uralskij11.ru
Наркологическая клиника в Каменске-Уральском разрабатывает программы лечения, учитывая особенности различных видов зависимости: алкогольной, наркотической, лекарственной. Каждая программа ориентирована на индивидуальные потребности пациента, что подтверждается опытом ведущих российских реабилитационных центров. Подробнее о лечении зависимости читайте на официальном сайте Минздрава.
Выяснить больше – http://narkologicheskaya-klinika-kamensk-uralskij11.ru
Помощь нужна, если:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-serpuhov3.ru/]срочный вывод из запоя[/url]
Капельница от запоя на дому – это популярная опция в Туле, которую предлагают специалистами в области наркологии. Удобное лечение даёт возможность пациентам не испытывать стресс, связанного с поездками в клинику. Отзывы пациентов подтверждают результативности детоксикации организма и оперативного выхода из запойного состояния. Врач нарколог на дом обеспечивает конфиденциальное лечение, что является важным для многих. Преодоление алкогольной зависимости становится доступным, а восстановление здоровья – приоритетом. Медицинские услуги, как капельница, помогают справиться с алкогольной зависимостью и возврату к привычному образу жизни.
Преимущества вызова нарколога на дом:
Подробнее тут – [url=https://vyvod-iz-zapoya-v-murmanske12.ru/]vyvod-iz-zapoya-klinika murmansk[/url]
подключить домашний интернет казань
domashij-internet-kazan006.ru
домашний интернет
Капельницы от алкоголизма в городе Туле – это важный шаг в борьбе с алкоголизма. Методы детоксикации способствуют справиться с симптомами абстиненции и избавиться от пьянства. Медицинская помощь в специализированных центрах включает не только капельницы‚ но и поддержку психолога‚ что способствует восстановлению после алкоголя. narkolog-tula004.ru Восстановление начинается с очистки организма‚ после которой инициируются реабилитационные программы. Поддержка родственников также имеет значимую роль в профилактике рецидивов. Группы поддержки и консультация специалиста вполне способны оказать помощь в процессе выздоровления. Не забудьте‚ что лечение алкоголизма требует комплексного подхода.
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Углубиться в тему – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]наркологическая клиника каменск-уральский.[/url]
Капельница от запоя – проверенное решение для лечения алкогольной зависимости. Она обеспечивает быстрое вливание жидкости‚ что приводит к детоксикации тела и улучшению состояния здоровья. В клиниках лечения зависимостей‚ таких как narkolog-tula005.ru‚ квалифицированные специалисты предлагают комплексную помощь‚ включая инъекции от алкоголизма. Лечение включает не только капельницы‚ но и реабилитацию‚ психологическую поддержку при алкоголизме‚ что помогает пациентам возвращаться к обычной жизни.
точные ставки на футбол [url=www.kompyuternye-prognozy-na-futbol2.ru/]точные ставки на футбол[/url] .
провайдеры по адресу красноярск
domashij-internet-krasnoyarsk004.ru
интернет по адресу
Капельница от алкоголя на дому в Туле — это оптимальный вариант помочь зависимым попавшим в зависимость. Борьба с алкоголизмом включает выведение из запоя в домашних условиях, что позволяет избежать стационарного лечения. Детоксикация может осуществляться с помощью специальных растворовкоторые обеспечивают организм необходимыми веществами. Квалифицированная помощь в таких случаях необходима: работа с врачами-наркологами помогут правильно подобрать антиалкогольную терапию. Психотерапия при алкоголизме также играет ключевую роль в восстановлении. Семейная терапия и возвращение к нормальной жизни помогают в процессе восстановления после зависимости. Профилактика алкоголизма и восстановление после запоя — важные этапы в путь к трезвости. Не забывайте, что здоровый образ жизни без алкоголя. На сайте narkolog-tula004.ru вы можете получить информацию о доступных услугах и методах лечения.
Как подчёркивает врач-нарколог клиники «Светлый Мир» Александр Павлович Ермаков, «на фоне резкого отказа от алкоголя могут возникнуть острые состояния, требующие реанимационной помощи — поэтому нельзя пытаться прервать запой без участия специалиста». В домашних условиях, под присмотром профессионала, лечение может быть начато уже в течение часа после вызова, без необходимости транспортировки пациента в критическом состоянии.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]vyvod-iz-zapoya-v-domodedovo[/url]
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Получить дополнительную информацию – http://
Капельница от запоя, это необходимый шаг в лечении алкоголизма. Обращение к наркологу на дом в Туле позволяет получить квалифицированную помощь. Если появляются симптомы запоя, таких как дрожь, потливость и тревожность, важно сразу обратиться за помощью. Наркологи проводят диагностику алкоголизма и разрабатывают план медикаментозной терапии, включая инфузии для детоксикации. вызов нарколога на дом тула Восстановление после запоя включает семейную поддержку, что значительно повышает шансы на успешное восстановление. Предотвращение алкогольной зависимости тоже является важным аспектом. Услуги нарколога, включая вызов врача на дом, помогают решить проблемы, связанные с алкогольной зависимостью, и гарантировать безопасную терапию.
провайдеры интернета в красноярске по адресу
domashij-internet-krasnoyarsk005.ru
какие провайдеры интернета есть по адресу красноярск
После поступления вызова на дом врачи клиники «Трезвый Путь» проводят лечение по четко разработанному алгоритму, обеспечивающему максимальную эффективность и безопасность:
Подробнее можно узнать тут – [url=https://narcolog-na-dom-ekaterinburg0.ru/]выезд нарколога на дом екатеринбург[/url]
Капельницы для лечения алкогольной зависимости на дому – это эффективный метод лечения алкогольной зависимости, который предоставляет возможность пройти детоксикацию без необходимости госпитализации. Услуги нарколога включают капельницу на дому, что способствует повышению качества жизни и уменьшению симптомов абстиненции. Капельницы помогают организму ускоряют вывод токсинов, а также обеспечивают восстановлению организма. Поддержка при отказе от алкоголя важна на всех этапах, включая реабилитацию алкоголиков. Профилактика осложнений также играет ключевую роль в процессе излечения. Лечение на дому может состоять не только из капельниц, но и консультации специалистов, что способствует успешному выходу из запоя и эффективному лечению. Обращаясь на narkolog-tula005.ru, вы сможете получить профессиональную поддержку и поддержку в сражении с алкогольной зависимостью.
комплект напольных кашпо [url=https://www.kashpo-napolnoe-msk.ru]https://www.kashpo-napolnoe-msk.ru[/url] .
Согласно данным НМИЦ психиатрии и наркологии Минздрава РФ, профессиональный вывод из запоя с применением капельниц снижает риск осложнений и сокращает период восстановления. Процедура проводится только под наблюдением квалифицированных специалистов и требует правильного подбора препаратов в зависимости от стадии опьянения и наличия сопутствующих заболеваний.
Выяснить больше – [url=https://kapelnicza-ot-zapoya-pervouralsk11.ru/]капельница от запоя на дому первоуральск.[/url]
ПРОКАПАТЬ ОТ АЛКОГОЛЯ: ВАЖНОСТЬ ДЕТОКСИКАЦИИ И ПОДДЕРЖКИ Вопрос алкогольной зависимости затрагивает многих людей. Лечение алкоголизма часто начинается с детоксикации, что включает прокапывание. Этот этап помогает вывести токсины из организма и облегчить абстинентный синдром.Капельницы от алкоголя содержат препараты для детоксикации, способствующие восстановлению организма. Они помогают восстановиться после запоя, предоставляя необходимую медицинскую помощь. Важно помнить, что поддержка зависимых в этот период крайне важна.После детоксикации начинается реабилитация, где психотерапия при алкоголизме занимает ключевую роль. Специалисты поддерживают разобраться в причинах зависимости и предоставляют советы по борьбе с зависимостями.На сайте narkolog-tula007.ru можно найти информацию о том, как правильно пройти лечение и получить поддержку. Здоровье является важный шаг к новой жизни без алкоголя.
В такой момент человеку нужна не просто поддержка — ему нужна медицинская помощь. В Электростали её оказывает наркологическая клиника «Трезвый Исток». Мы работаем круглосуточно, без праздников и выходных. И выезжаем сразу — без очередей, без лишней бюрократии. Только быстрый, грамотный и безопасный вывод из запоя — на дому или в стационаре, в зависимости от состояния пациента.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ehlektrostal3.ru/]vyvod-iz-zapoya-na-domu-cena[/url]
Стоимость услуг зависит от продолжительности терапии, сложности случая и выбранных процедур. Однако клиника предоставляет гибкую систему оплаты, включая рассрочку и страховое покрытие.
Углубиться в тему – https://narkologicheskaya-klinika-v-ryazani12.ru/narkologicheskaya-klinika-czeny-v-ryazani
Отзывы о целителях Обряд на любовь – комплекс магических действий, направленный на привлечение любви и улучшение отношений. Обряды на любовь могут включать в себя использование свечей, трав, заговоров и других атрибутов.
Купить подписчиков в Telegram https://vc.ru/smm-promotion лёгкий способ начать продвижение. Выберите нужный пакет: боты, офферы, живые. Подходит для личных, новостных и коммерческих каналов.
профильные трубы Профильные трубы: Сталь в геометрической гармонии В мире современной инженерии и строительства профильные трубы занимают особое место. Их универсальность, прочность и геометрическая точность делают их незаменимым элементом в самых разнообразных проектах. От каркасов зданий до мебельных конструкций, от сельскохозяйственной техники до рекламных щитов – профильные трубы находят применение там, где требуется надежность и долговечность.
Виртуальные номера для Telegram https://basolinovoip.com создавайте аккаунты без SIM-карты. Регистрация за минуту, широкий выбор стран, удобная оплата. Идеально для анонимности, работы и продвижения.
Куда сходить в Санкт-Петербурге Любовная магия – это область магии, направленная на привлечение любви, укрепление отношений и решение проблем в личной жизни. Важно помнить об этичности использования любовной магии.
Odjeca i aksesoari za hotele poplin tekstil po sistemu kljuc u ruke: uniforme za sobarice, recepcionere, SPA ogrtaci, papuce, peskiri. Isporuke direktno od proizvodaca, stampa logotipa, jedinstveni stil.
Запой представляет собой состояние‚ когда индивид не в состоянии прекратить употребление алкоголя‚ что ведет к серьезным последствиям для его здоровья. Вызов нарколога в Туле — первоначальный этап на пути к выздоровлению. Капельницы играют важную роль в детоксикации организма‚ устраняя симптомы похмелья и восстанавливая водно-электролитный баланс. вызов нарколога тула Наркологические клиники предлагают различные методы лечения алкоголизма‚ включая уколы для детоксикации. Срочная помощь при запое включает не только капельницы‚ но и комплексную поддержку пациента на всех этапах его восстановления. Реабилитация после запоя крайне важен для снижения риска рецидивов. Качественная медицинская помощь должна быть профессиональной и предоставляться своевременно‚ чтобы гарантировать восстановление организма и минимизировать риски для здоровья. Тула предлагает широкий спектр наркологических услуг‚ которые помогут в борьбе с алкогольной зависимостью.
Подробности о технологии и методах выезда нарколога можно найти на официальных медицинских порталах, таких как Российское общество наркологов и Минздрав РФ.
Выяснить больше – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]нарколог на дом круглосуточно в ярославле[/url]
пансионат для пожилых после инсульта
pansionat-msk001.ru
пансионат для пожилых с инсультом
Капельница от запоя в Мурманске является одной из наиболее востребованных процедур для снятия острого состояния алкогольной интоксикации. Эта методика позволяет быстро вывести токсины из организма, нормализовать водно-солевой баланс и улучшить самочувствие пациента. Современная капельная терапия считается эффективным средством в лечении запоя, обеспечивая поддержку жизненно важных функций и минимизируя риски осложнений.
Подробнее тут – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя[/url]
Капельница от запоя в Мурманске является одной из наиболее востребованных процедур для снятия острого состояния алкогольной интоксикации. Эта методика позволяет быстро вывести токсины из организма, нормализовать водно-солевой баланс и улучшить самочувствие пациента. Современная капельная терапия считается эффективным средством в лечении запоя, обеспечивая поддержку жизненно важных функций и минимизируя риски осложнений.
Детальнее – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя цена в мурманске[/url]
Капельница от запоя применяется для комплексного восстановления организма после длительного употребления алкоголя. Она включает в себя введение растворов, насыщенных витаминами, электролитами, глюкозой и лекарственными средствами, направленными на устранение симптомов интоксикации. Основные задачи процедуры:
Получить больше информации – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя на дому мурманск[/url]
какие провайдеры по адресу
domashij-internet-krasnodar004.ru
провайдер интернета по адресу краснодар
Пребывание в стационаре обеспечивает круглосуточный мониторинг состояния, своевременное введение лекарств и защиту пациента от внешних факторов, провоцирующих срыв. Все палаты оснащены необходимым оборудованием, соблюдаются санитарные нормы, а условия размещения соответствуют медицинским стандартам.
Выяснить больше – [url=https://narkologicheskaya-klinika-v-yaroslavle12.ru/]наркологическая клиника нарколог[/url]
Как подчёркивает заведующая отделением клинической психологии ФГБУН «НМИЦ психиатрии и наркологии» Минздрава России, наличие в команде специалистов с опытом работы в области зависимости — это основа качественной помощи.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-nizhnij-tagil11.ru/]наркологические клиники алкоголизм свердловская область[/url]
После поступления вызова на дом врачи клиники «Трезвый Путь» проводят лечение по четко разработанному алгоритму, обеспечивающему максимальную эффективность и безопасность:
Углубиться в тему – [url=https://narcolog-na-dom-ekaterinburg0.ru/]нарколог на дом клиника в екатеринбурге[/url]
Вывод из запоя показан при:
Детальнее – [url=https://vyvod-iz-zapoya-v-murmanske12.ru/]срочный вывод из запоя[/url]
Процедура капельного введения лекарственных растворов проводится в условиях клиники с соблюдением всех санитарных норм. Пациенту устанавливается капельница, через которую вводятся препараты под контролем медперсонала. В зависимости от состояния пациента и тяжести запоя длительность капельной терапии может варьироваться от 1 до 6 часов.
Изучить вопрос глубже – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]kapelnicza-ot-zapoya-czena murmansk[/url]
Очищение солью от негатива Приворот – магическое воздействие, направленное на вызов любовного влечения у определенного человека. Приворот является мощным и опасным инструментом, который может иметь непредсказуемые последствия.
металлообработка Металлообработка – это обширная сфера деятельности, охватывающая широкий спектр процессов, направленных на изменение формы, размеров и свойств металлов и сплавов. От простых ручных операций до высокотехнологичных автоматизированных производств, металлообработка играет ключевую роль во многих отраслях промышленности, обеспечивая создание деталей, инструментов и конструкций, необходимых для функционирования современного мира.
пансионат для пожилых в москве
pansionat-msk002.ru
пансионат для людей с деменцией в москве
Профилактика алкоголизма — существенная проблема, требующая внимания и усилий. Врач нарколог на дом способен оказать необходимую помощь, предлагая квалифицированные консультации и лечение. Симптомы алкоголизма включают частом употреблении алкоголя и изменениях в поведении. Психотерапевтическая поддержка и групповые терапии являются важными элементами в борьбе с зависимостями. Чтобы предотвратить запойные состояния, рекомендуется придерживаться ряда рекомендаций по отказу от спиртного. Поддержка семьи и близких способствует успешной реабилитации от алкогольной зависимости. Меры профилактики, такие как самопомощь при алкоголизме и участие в социальных программах, поддерживают социализацию и усиливают желание вести трезвый образ жизни.
Компоненты
Углубиться в тему – https://kapelnicza-ot-zapoya-pervouralsk11.ru/kapelnicza-ot-zapoya-na-domu-stoimost-v-pervouralske
провайдеры интернета по адресу
domashij-internet-krasnodar005.ru
провайдеры интернета по адресу
Преимущества вызова нарколога на дом:
Детальнее – https://vyvod-iz-zapoya-v-murmanske12.ru
Мы предлагаем полный спектр услуг по лечению зависимостей:
Подробнее – http://narkologicheskaya-klinika-dolgoprudnyj3.ru
mostbet az aviator strategiya [url=http://mostbet4042.ru/]mostbet az aviator strategiya[/url]
пансионаты для инвалидов в москве
pansionat-msk003.ru
частный пансионат для пожилых
Запой — это не просто бытовое пьянство, а одно из наиболее опасных проявлений алкогольной зависимости. Во время запоя организм перестаёт функционировать в нормальном режиме: сердечно-сосудистая система работает на износ, нервная система перегружена токсинами, а печень не справляется с нагрузкой. На этом фоне могут возникать тяжёлые осложнения — от судорог и гипогликемии до нарушения дыхания и алкогольного психоза. Чем дольше длится запой, тем глубже метаболические нарушения и выше риск серьёзных последствий.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-kolomna3.ru/]vyvod-iz-zapoya-cena[/url]
Медицинский вывод из запоя включает несколько обязательных этапов:
Подробнее – [url=https://vyvod-iz-zapoya-kolomna3.ru/]вывод из запоя круглосуточно[/url]
какие провайдеры на адресе в краснодаре
[url=https://domashij-internet-krasnodar006.ru]domashij-internet-krasnodar006.ru[/url]
узнать провайдера по адресу краснодар
пансионат для лежачих москва
pansionat-msk001.ru
пансионат для престарелых
Для успешной адаптации пациента в обществе клиника организует поддержку родственников и последующее наблюдение. Это снижает риск рецидива и помогает сохранить достигнутые результаты.
Узнать больше – http://narkologicheskaya-klinika-v-murmanske12.ru
Первое, на что стоит обратить внимание — это профессиональный уровень сотрудников. Без квалифицированных наркологов, клинических психологов и психиатров реабилитационный процесс становится формальным и неэффективным.
Подробнее – [url=https://narkologicheskaya-klinika-nizhnij-tagil11.ru/]наркологическая клиника в нижнем тагиле[/url]
Подробности о технологии и методах выезда нарколога можно найти на официальных медицинских порталах, таких как Российское общество наркологов и Минздрав РФ.
Подробнее – https://narkolog-na-dom-v-yaroslavle12.ru/
самые точные прогнозы на футбол [url=www.kompyuternye-prognozy-na-futbol3.ru]самые точные прогнозы на футбол[/url] .
прогнозы на хоккей сегодня [url=http://www.luchshie-prognozy-na-khokkej2.ru]http://www.luchshie-prognozy-na-khokkej2.ru[/url] .
евросан [url=https://internet-magazine-santehniki.ru/]https://internet-magazine-santehniki.ru/[/url] .
хоккейные прогнозы на сегодня [url=www.luchshie-prognozy-na-khokkej.ru]www.luchshie-prognozy-na-khokkej.ru[/url] .
современные горшки напольные [url=https://www.kashpo-napolnoe-spb.ru]https://www.kashpo-napolnoe-spb.ru[/url] .
spoofer hwid Hardware ID Spoofer: Hardware ID Spoofer для Path of Exile
пансионат для пожилых с инсультом
pansionat-tula001.ru
пансионат для лежачих после инсульта
суши роллы барнаул суши сайт барнаул
Хирургические услуги хирургия Котор: диагностика, операции, восстановление. Современная клиника, лицензированные специалисты, помощь туристам и резидентам.
aviator 1win download [url=1win1138.ru]aviator 1win download[/url]
В Москве доступен высокоскоростной интернет, который обеспечивает высокую скорость и стабильное соединение. Актуальные тарифы провайдеров, предлагающих услуги связи, можно найти на сайте domashij-internet-msk004.ru.Важно учитывать сравнение тарифов и скорость интернета при выборе провайдера; Среди интернет-провайдеров существуют компании, предлагающие доступ в интернет через оптоволоконные линии в Москве. Эти технологии гарантируют высокую скорость и надежность.При выборе провайдера стоит ознакомиться с отзывами о провайдерах. Это позволит понять, какие провайдеры предлагают наилучшие тарифы и уровень сервиса. Сравнение скорости различных тарифов позволит подобрать лучший вариант для вашего жилья. Учтите, что стоимость интернет-услуг может отличаться, поэтому важно тщательно выбирать. Если заранее ознакомиться с предложениями на рынке, подключение интернета пройдет без проблем.
Используя современные инфузионные системы, мы постепенно вводим растворы для выведения токсинов, коррекции водно-электролитного баланса и восстановления функции печени. Параллельно подбираются препараты для снятия абстинентного синдрома, купирования тревожности и нормализации сна.
Получить дополнительные сведения – https://narkologicheskaya-klinika-dolgoprudnyj3.ru/anonimnaya-narkologicheskaya-klinika-v-dolgoprudnom
частные пансионаты для пожилых в москве
pansionat-msk002.ru
частный пансионат для престарелых
hwid spoofer … (далее 145 аналогичных статей, варьирующихся по смыслу и раскрывающих различные аспекты темы HWID Spoofer)
При своевременном обращении к специалистам капельница позволяет значительно улучшить состояние пациента уже в первые часы после начала лечения. Медицинская помощь при запое должна оказываться квалифицированно и в комфортных условиях, что снижает риски осложнений и ускоряет восстановление.
Выяснить больше – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]поставить капельницу от запоя в мурманске[/url]
бк 888starz [url=www.888starz.com.ru]бк 888starz[/url] .
mostbet mobil qeydiyyat [url=https://mostbet3041.ru/]https://mostbet3041.ru/[/url]
пансионат для пожилых с инсультом
pansionat-tula002.ru
пансионат для лежачих после инсульта
mostbet baixar aplica??o para android [url=https://www.mostbetdownload-apk.com]mostbet baixar aplica??o para android[/url] .
Пребывание в стационаре обеспечивает круглосуточный мониторинг состояния, своевременное введение лекарств и защиту пациента от внешних факторов, провоцирующих срыв. Все палаты оснащены необходимым оборудованием, соблюдаются санитарные нормы, а условия размещения соответствуют медицинским стандартам.
Углубиться в тему – https://narkologicheskaya-klinika-v-yaroslavle12.ru/narkologicheskaya-klinika-klinika-pomoshh-v-yaroslavle/
Наша команда врачей оперативно реагирует на каждый вызов, оказывая квалифицированную медицинскую помощь на дому. Специалисты проводят полный комплекс лечебных мероприятий, направленных на безопасное снятие интоксикации, детоксикацию и облегчение симптомов абстиненции.
Узнать больше – http://narcolog-na-dom-ekaterinburg0.ru
Капельница от запоя применяется для комплексного восстановления организма после длительного употребления алкоголя. Она включает в себя введение растворов, насыщенных витаминами, электролитами, глюкозой и лекарственными средствами, направленными на устранение симптомов интоксикации. Основные задачи процедуры:
Подробнее – http://kapelnicza-ot-zapoya-v-murmanske12.ru/kapelniczy-ot-zapoya-na-domu-v-murmanske/
Подключение интернета в Москве требует осмотрительности при выборе провайдера. На рынке представлены различные интернет-провайдеры, предлагающих широкий спектр тарифов на интернет. При выборе стоит учитывать такие параметры, как скорость, цена подключения и условия.Сравнение предложений провайдеров поможет определить наиболее выгодный тариф. Многие провайдеры проводят акции и предлагают бесплатное подключение для новых клиентов. Важно также изучить отзывы о провайдерах, чтобы понять, насколько стабильно соединение и каковы услуги. провайдеры в москве Используя онлайн-сервисы, можно быстро найти и сравнить предложения от провайдеров, чтобы подобрать наилучшее решение для выхода в сеть. Обратите внимание на акции и специальные предложения провайдеров — они могут значительно уменьшить ваши расходы.
При лёгких и среднетяжёлых состояниях возможно проведение лечения на дому. Это удобно, комфортно и позволяет сохранить анонимность. Однако есть ситуации, в которых домашнее вмешательство нецелесообразно:
Подробнее тут – [url=https://vyvod-iz-zapoya-kolomna3.ru/]vyvod-iz-zapoya-na-domu[/url]
пансионат для престарелых
pansionat-msk003.ru
пансионат для пожилых людей
Магазин брендовых кроссовок https://kicksvibe.ru Nike, Adidas, New Balance, Puma и другие. 100% оригинал, новые коллекции, быстрая доставка, удобная оплата. Стильно, комфортно, доступно!
суши роллы барнаул https://sushi-barnaul.ru
пансионат для пожилых
pansionat-tula003.ru
пансионат для лежачих после инсульта
При своевременном обращении к специалистам капельница позволяет значительно улучшить состояние пациента уже в первые часы после начала лечения. Медицинская помощь при запое должна оказываться квалифицированно и в комфортных условиях, что снижает риски осложнений и ускоряет восстановление.
Углубиться в тему – https://kapelnicza-ot-zapoya-v-murmanske12.ru/postavit-kapelniczu-ot-zapoya-v-murmanske/
spoofer hwid Зачем нужен HWID Spoofer? Защита от блокировок и сохранение анонимности
Для эффективного вывода из запоя в Мурманске используются современные методы детоксикации, включающие внутривенное введение растворов, направленных на восстановление водно-солевого баланса, коррекцию электролитов и нормализацию работы почек и печени. Важным этапом является использование витаминных комплексов и препаратов, поддерживающих работу сердца и сосудов.
Выяснить больше – https://vyvod-iz-zapoya-v-murmanske12.ru/anonimnyj-vyvod-iz-zapoya-v-murmanske
вывод из запоя круглосуточно
[url=https://vivod-iz-zapoya-chelyabinsk001.ru]https://vivod-iz-zapoya-chelyabinsk001.ru[/url]
экстренный вывод из запоя челябинск
пансионат для пожилых людей
pansionat-tula001.ru
частный пансионат для пожилых
Как подчёркивает врач-нарколог И.В. Синицин, «современная наркология — это не только вывод из запоя, но и работа с глубинными причинами зависимости».
Углубиться в тему – https://narkologicheskaya-klinika-v-yaroslavle12.ru/narkologicheskaya-klinika-klinika-pomoshh-v-yaroslavle
лучший интернет провайдер нижний новгород
domashij-internet-nizhnij-novgorod004.ru
интернет провайдеры нижний новгород по адресу
mostbet poker otağı [url=mostbet4045.ru]mostbet4045.ru[/url]
вывод из запоя цена
vivod-iz-zapoya-chelyabinsk002.ru
экстренный вывод из запоя челябинск
пансионат для пожилых людей
pansionat-tula002.ru
пансионат после инсульта
домашний интернет нижний новгород
domashij-internet-nizhnij-novgorod005.ru
провайдеры интернета в нижнем новгороде
Pretty element of content. I just stumbled upon your web site and in accession capital to say that I acquire actually loved account your blog posts. Anyway I’ll be subscribing to your feeds or even I fulfillment you get admission to constantly fast.
https://eterna.in.ua/led-lampy-vs-halohen-u-skli-fary-testy-2025.html
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Подробнее можно узнать тут – https://laranca-limousin.com/events/this-is-a-test
экстренный вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk003.ru
лечение запоя челябинск
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее тут – https://japanstours.com/5-most-beautiful-islands-in-asia
ванная гидромассажная купить [url=https://hidromassazhnaya-vanna.ru/]ванная гидромассажная купить[/url] .
gessi каталог [url=https://www.gessi-santehnika-1.ru]https://www.gessi-santehnika-1.ru[/url] .
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Выяснить больше – https://www.lovero-koiji.jp/2019/05/15/%E3%80%90%E5%88%9D%E9%96%8B%E5%82%AC%EF%BC%81%E3%81%B6%E3%82%89%E3%82%8A%E9%85%92%E8%94%B5%E3%82%81%E3%81%90%E3%82%8A%E3%80%80%E5%BE%8C%E5%A4%9C%E7%A5%AD%E3%80%91%E3%81%93%E3%82%8C%E3%81%9E%E8%94%B5
букмекерские конторы со слотами [url=1win1139.ru]1win1139.ru[/url]
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Получить больше информации – https://cdn.feather.blog/?src=https://aokinaoki.com/2024/02/23/%E7%96%B2%E3%82%8C%E3%82%92%E7%99%92%E3%81%99%E5%AE%BF%E6%B3%8A%E6%96%BD%E8%A8%AD%EF%BC%81%E3%82%B9%E3%83%BC%E3%83%91%E3%83%BC%E3%83%9B%E3%83%86%E3%83%AB%E3%81%8A%E3%81%99%E3%81%99%E3%82%81/&optimizer=image
пансионат для пожилых
pansionat-tula003.ru
пансионат для пожилых
Критерии оценки профессионального уровня сотрудников:
Ознакомиться с деталями – [url=https://lechenie-alkogolizma-yaroslavl0.ru/]лечение алкоголизма цена[/url]
подключение интернета по адресу
domashij-internet-nizhnij-novgorod006.ru
провайдеры интернета по адресу
Даже телефонный разговор с клиникой может многое сказать о её подходе. Если вам предлагают типовое лечение без уточнения подробностей или избегают вопросов о составе команды, это тревожный сигнал. Серьёзные учреждения в Мурманске обязательно предложат предварительную консультацию, зададут уточняющие вопросы и расскажут, как строится программа помощи.
Подробнее можно узнать тут – http://lechenie-alkogolizma-murmansk0.ru/lechenie-khronicheskogo-alkogolizma-marmansk/https://lechenie-alkogolizma-murmansk0.ru
cours de theatre Cours de comedie a Paris
Музыкальные новости сегодня История создания культовых альбомов: Как рождались шедевры.
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-1.ru/
вывод из запоя
vivod-iz-zapoya-cherepovec004.ru
вывод из запоя череповец
Онлайн казино России Бонусы за пополнение счета в онлайн казино России
казино россии лучшие казино на деньги
экстренный вывод из запоя
[url=https://vivod-iz-zapoya-chelyabinsk001.ru]https://vivod-iz-zapoya-chelyabinsk001.ru[/url]
вывод из запоя челябинск
cours de theatre Carriere d’acteur
https://stroidom36.ru/catalog/proekty-domov-ot-150-kv-m/
В столице России существует множество интернет-провайдеров, которые предлагают разнообразные услуги. Ключевыми аспектами выбора являются скорость интернета, стабильное соединение и доступные тарифы. На сайте domashij-internet-novosibirsk004.ru можно найти отзывы о провайдерах, что поможет оценить качество связи и техническую поддержку. Список лучших интернет-провайдеров включает локальных провайдеров, предоставляющих как домашний интернет, так и мобильный интернет. Оптоволокно в новосибирске стало популярным благодаря высокой скорости и долговечности. Сравнение провайдеров поможет пользователям выбрать наилучший вариант. Необходимо принимать во внимание не только цену на тарифы, но и отзывы пользователей, чтобы обеспечить качественное подключение к интернету и Wi-Fi услуги.
Нарколог на дом в Новокузнецке – это возможность получить профессиональное медицинское лечение без госпитализации. Специалисты клиники «ЧистоЖизнь» приезжают в любое время суток, проводят детоксикацию, снимают абстинентный синдром и помогают пациенту стабилизировать состояние в комфортных домашних условиях.
Ознакомиться с деталями – http://narcolog-na-dom-novokuznetsk00.ru
В нашей клинике “Сила воли” в Иркутске вы можете получить помощь как в стационаре, так и на дому. Мы предлагаем два вида услуг:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-irkutsk3.ru/]капельница от запоя цена в иркутске[/url]
По информации ГБУЗ «Областной центр медицинской профилактики» Мурманской области, учреждения, ориентированные на результат, открыто информируют о применяемых методиках и допусках к лечению. Важно, чтобы уже на этапе первого контакта вы получили не только цену, но и понимание того, что вам предстоит.
Ознакомиться с деталями – http://lechenie-alkogolizma-murmansk0.ru/
экстренный вывод из запоя
vivod-iz-zapoya-cherepovec005.ru
вывод из запоя
Как распознать легальный центр:
Изучить вопрос глубже – http://lechenie-narkomanii-yaroslavl0.ru
стоимость проекта перепланировки квартиры [url=https://proekt-pereplanirovki-kvartiry.ru]стоимость проекта перепланировки квартиры[/url] .
работа военным Работа военным: служение Родине Работа военным – это не просто профессия, это призвание. Это служение Родине, защита ее интересов и обеспечение безопасности граждан. Военные – это люди, готовые рисковать своей жизнью ради мира и спокойствия в стране. Служба в армии – это школа жизни, которая закаляет характер, учит дисциплине и ответственности. Военные приобретают навыки, необходимые не только на поле боя, но и в обычной жизни. Они умеют работать в команде, быстро принимать решения в сложных ситуациях и нести ответственность за свои действия. Военная служба – это возможность получить образование и профессию. Армия предоставляет широкий выбор специальностей, от технических до гуманитарных. Военные могут получить высшее образование за счет государства и стать высококвалифицированными специалистами. Работа военным – это стабильность и социальные гарантии. Военнослужащие получают достойную зарплату, жилье, медицинское обслуживание и другие льготы. Они уверены в завтрашнем дне и могут планировать свое будущее. Служба в армии – это возможность проявить себя и сделать карьеру. Военные могут расти по служебной лестнице, занимать высокие должности и участвовать в принятии важных решений. Они вносят свой вклад в развитие страны и укрепление ее обороноспособности. Работа военным – это почет и уважение. Военные – это герои, которыми гордится страна. Их подвиги и заслуги отмечаются государственными наградами и званиями. Они являются примером для подражания и вдохновляют молодежь на служение Родине. Служба в армии – это нелегкий труд, требующий мужества, силы и выносливости. Но это также возможность реализовать себя, принести пользу обществу и оставить свой след в истории. Работа военным – это выбор сильных и ответственных людей, готовых посвятить свою жизнь защите Родины.
проект перепланировки цена [url=proekt-pereplanirovki-kvartiry1.ru]проект перепланировки цена[/url] .
перепланировка помещения [url=http://soglasowanie-pereplanirovki-kvartiry.ru]перепланировка помещения[/url] .
Sometimes image compatibility issues can disrupt a workflow. That’s where WEBPtoPNGHero com steps in. It transforms WebP images into PNG format while preserving sharpness, transparency, and original dimensions. The tool works entirely online — no plugins, no installations, and no registration. Its drag-and-drop interface allows fast single or batch uploads, with each file processed in real-time. Designed for convenience, it’s accessible from desktop or mobile devices alike. Upload your WebP, download your PNG, and move on with your project — that simple. Engineered for designers, developers, and anyone dealing with diverse file formats, this converter ensures images are ready for use on any platform. Your files are deleted automatically after conversion, providing both security and peace of mind.
WEBPtoPNGHero
That’s a great point about responsible gaming! Finding a platform that’s both fun and secure is key. I’ve heard good things about JILI PG – easy to use, and the jili pg app seems super convenient for quick play! Definitely checking them out. 👍
Ключевым фактором при выборе центра становится квалификация специалистов. Лечение алкоголизма — это не только выведение из запоя и купирование абстинентного синдрома. Оно включает работу с мотивацией, тревожными состояниями, семейными конфликтами, нарушением сна и другими последствиями зависимости. Только команда, включающая наркологов, психотерапевтов и консультантов по аддиктивному поведению, способна охватить все аспекты проблемы.
Подробнее – [url=https://lechenie-alkogolizma-murmansk0.ru/]lechenie alkogolizma murmansk[/url]
Нарколог измеряет пульс, артериальное давление, частоту дыхания, насыщение кислородом, а также уточняет историю употребления и наличие хронических заболеваний. Это позволяет оперативно скорректировать состав и скорость инфузии.
Детальнее – https://kapelnica-ot-zapoya-voronezh2.ru/vyezd-na-dom-kapelnicza-ot-zapoya-v-voronezhe/
— Растворы с глюкозой и витаминами для коррекции энергетического обмена. — Минеральные комплексы для нормализации электролитов. — Антиоксиданты и гепатопротекторы для защиты печени. — Спазмолитики для снятия болевого синдрома. — Противорвотные препараты при тошноте.
Получить дополнительную информацию – https://narkologicheskaya-klinika-arkhangelsk0.ru/platnaya-narkologicheskaya-klinika-arkhangelsk/
вывод из запоя круглосуточно челябинск
vivod-iz-zapoya-chelyabinsk002.ru
лечение запоя
https://stroidom36.ru/catalog/proekty-domov-ot-150-kv-m/ Внутренняя отделка – создание уютного интерьера. Обои, краска, плитка, ламинат – разнообразие материалов позволяет реализовать любые дизайнерские решения.
Бесплатный интернет в новосибирске: фантазия или истина? В последние годы новосибирск активно развивает информационную инфраструктуру, предлагая жителям и туристам безвозмездный Wi-Fi в публичных зонах. Сайты вроде site;com сообщают о множествах бесплатных точках доступа, которые обеспечивают интернет-соединение. Однако, насколько целесообразно полагаться на эти услуги? Одним из основных плюсов бесплатного интернета является возможность соединиться к общественным сетям без нужды использовать мобильный интернет. Но уровень связи и скорость соединения часто оставляют желать лучшего. Провайдеры, которые предлагают такие услуги, сталкиваются с большой нагрузкой, что может отразиться на ухудшении скорости. При этом необходимо учитывать безопасность данных. Бесплатные точки доступа могут подвергать пользователей рискам, связанным с компрометацией данных. Ограничения доступа к определенным сайтам также могут стать неожиданностью для пользователей. Городские инициативы по улучшению доступа к интернету подтверждают стремление новосибирска к совершенствованию, но необходимо помнить о возможных ограничениях и особенностях тарифов на интернет. В итоге, бесплатный интернет в новосибирске — это удобство, но с некоторыми подводными камнями.
вывод из запоя круглосуточно череповец
vivod-iz-zapoya-cherepovec006.ru
экстренный вывод из запоя
купить напольный горшок для цветов недорого [url=https://kashpo-napolnoe-rnd.ru/]https://kashpo-napolnoe-rnd.ru/[/url] .
работа военным Работа военным – это возможность получить ценный опыт, приобрести полезные навыки и найти настоящих друзей.
devenir acteur Etudes theatrales
В современном мире интернет с высокой скоростью превратился в неотъемлемой частью жизни. В столице множество интернет-провайдеров предоставляют интернет-услуги, гарантируя стабильный интернет без задержек. При выборе провайдера, стоит обратить внимание на стоимость и скорость подключения. Анализ тарифов позволит найти лучший вариант для вашего дома или офисного пространства. Множество операторов могут подключить интернет всего за один день, что будет удобно для клиентов, ценящих скорость. При подключении интернета можно обратиться к профессионалам, которые быстро и качественно проведут все необходимые работы. Не забудьте ознакомиться с отзывами о провайдерах, чтобы принимать взвешенное решение. Не следует жертвовать качеством: качественный интернет и высокая скорость подключения создадут комфортные условия для работы и отдыха. Используйте платформы, такие как domashij-internet-novosibirsk006.ru чтобы ознакомиться с актуальными данными и рекомендациями.
экстренный вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk003.ru
вывод из запоя
вывод из запоя иркутск
vivod-iz-zapoya-irkutsk001.ru
вывод из запоя цена
работа военным Работа военным сопряжена с риском и опасностью, но она также дает возможность проявить себя, реализовать свой потенциал и внести свой вклад в защиту мира и стабильности.
Как отмечает врач-нарколог Иванов И.И., «без своевременной медицинской помощи при запое повышается риск необратимых изменений в организме и летального исхода».
Узнать больше – [url=https://vyvod-iz-zapoya-nizhnij-tagil11.ru/]вывод из запоя свердловская область[/url]
iphone санкт петербург [url=www.kupit-ajfon-cs2.ru/]iphone санкт петербург[/url] .
айфон питер купить [url=http://kupit-ajfon-cs.ru]http://kupit-ajfon-cs.ru[/url] .
Отличная бонусная система: [url=https://ucla-free-speech.com/]вавада официальный сайт рабочее зеркало[/url]
Modern operations surgery innovative technologies, precision and safety. Minimal risk, short recovery period. Plastic surgery, ophthalmology, dermatology, vascular procedures.
вывод из запоя круглосуточно
vivod-iz-zapoya-cherepovec004.ru
вывод из запоя череповец
подключить домашний интернет в омске
domashij-internet-omsk004.ru
недорогой интернет омск
Профессиональное prp терапия обучение: PRP, Plasmolifting, протоколы и нюансы проведения процедур. Онлайн курс обучения плазмотерапии.
лечение запоя
vivod-iz-zapoya-irkutsk002.ru
лечение запоя иркутск
Как подчёркивает заведующий отделением наркологии Владимирского областного клинического диспансера, «только комплексная модель, включающая медикаментозную поддержку и психотерапию, даёт устойчивый эффект». Это означает, что в штате клиники должны быть не только врачи, но и психотерапевты, социальные работники, реабилитологи.
Узнать больше – https://lechenie-narkomanii-vladimir10.ru/lechenie-narkomanii-anonimno-vladimir/
купить кашпо комнатные напольные [url=www.kashpo-napolnoe-rnd.ru/]www.kashpo-napolnoe-rnd.ru/[/url] .
Онлайн-курсы prp терапия обучение: теория, видеоуроки, разбор техник. Обучение с нуля и для практикующих. Доступ к материалам 24/7, сертификат после прохождения, поддержка преподавателя.
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Подробнее можно узнать тут – https://praxis-schuemann.de/portfolio/classic-watch
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Получить дополнительные сведения – https://www.tsimpolis.gr/shortcode-ux-banner-grid
вибрационная настройка Психология души затрагивает глубинные аспекты человеческого бытия, духовность и смысл жизни.
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Получить больше информации – https://rikbeuselinck.be/2020/09/28/reportage
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Исследовать вопрос подробнее – https://exceedsound.com/what-is-the-difference-between-speakers-and-speakers
Негативное мышление Заговор на деньги: привлечение финансового благополучия. Заговор на деньги – это магический ритуал, направленный на привлечение финансового благополучия и удачи в делах.
вывод из запоя иркутск
vivod-iz-zapoya-irkutsk003.ru
экстренный вывод из запоя
дешевый интернет омск
domashij-internet-omsk005.ru
подключить проводной интернет омск
экстренный вывод из запоя
vivod-iz-zapoya-cherepovec005.ru
вывод из запоя круглосуточно
Первое, что необходимо уточнить перед вызовом — наличие у врача лицензии и профильного медицинского образования. Только сертифицированный нарколог может назначить препараты, поставить капельницу и провести детоксикацию без ущерба для здоровья пациента.
Получить дополнительную информацию – https://narkolog-na-dom-nizhnij-tagil11.ru/narkolog-na-dom-kruglosutochno-v-nizhnem-tagile/
Рейки и эфирные масла: гармония тела и духа Рейки и эфирные масла: гармония тела и духа: Углубите свою практику Рейки с помощью целебных ароматов эфирных масел. Узнайте, какие масла усиливают поток энергии, помогают снять блоки и способствуют духовному росту.
«ВоронежДоктор» сочетает в себе профессионализм, современное оборудование и заботу о приватности пациента. Ключевые преимущества:
Разобраться лучше – http://kapelnica-ot-zapoya-voronezh2.ru/vyezd-na-dom-kapelnicza-ot-zapoya-v-voronezhe/
Проблема зависимости от алкоголя, наркотиков и азартных игр остается одной из наиболее острых в современном обществе. Эти состояния оказывают значительное воздействие не только на здоровье самого человека, но и на его семью, друзей и общественные связи. Наркологическая клиника “Восстановление души” предлагает широкий спектр услуг для тех, кто борется с различными формами зависимости, такими как алкоголизм, наркомания и игромания. Наша цель — предоставить комплексный подход к лечению, что обеспечивает высокие показатели успешности среди наших пациентов.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-irkutsk2.ru/kapelnica-ot-zapoya-v-stacionare-v-irkutske/]капельница от запоя анонимно недорого иркутск[/url]
When it comes to traveling in the beautiful Dominican Republic, VIP Transfer Punta Cana is your go-to transportation company. With years of experience and a stellar reputation, we pride ourselves in providing a seamless and memorable VIP travel services in Punta Cana experience for all our customers.
One of the advantages of choosing VIP Transfers Punta Cana is our commitment to customer satisfaction. We understand that traveling can sometimes be stressful, especially when it comes to transportation logistics. That’s why we go above and beyond to ensure that your journey is smooth, comfortable, and hassle-free.
dominican vip transfer
душевная трансформация Женская энергия: Источник силы и вдохновения для женщин. Развитие и гармонизация женской энергии.
Преимущества капельницы от запоя на дому очевидны:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-irkutsk.ru/kapelnica-ot-zapoya-na-domu-v-irkutske/]капельница от запоя на дому цена в иркутске[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-kaluga004.ru
лечение запоя
домашний интернет в омске
domashij-internet-omsk006.ru
лучший интернет провайдер омск
Целительница Психолог онлайн
Дополнительно выясняются аллергические реакции, приём других препаратов и предпочтения пациента по времени визита врача.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-voronezh3.ru/]капельница от запоя выезд[/url]
Грузоперевозки Луганск Грузоперевозки Луганск: Офисный переезд под ключ. Минимизация простоев, бережное отношение к технике, опытные сотрудники.
вывод из запоя цена
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя цена
заказать напольные кашпо [url=https://www.kashpo-napolnoe-rnd.ru]заказать напольные кашпо[/url] .
Наркологическая информационная сеть «Narkology» предлагает высококвалифицированную помощь в преодолении зависимости и восстановлении психоэмоционального равновесия. Наши специалисты проводят индивидуальную диагностику состояния, разрабатывают комплексные программы терапии, психологической поддержки и информирования о современных методиках лечения. Используя проверенные подходы и актуальные данные, мы помогаем вернуть уверенность в себе и сделать первый шаг к здоровой жизни. Доверьтесь профессионалам «Narkology» для эффективного решения проблем зависимости и получения полной информационной поддержки.
Выяснить больше – https://narcologiya.info/sovmestimost-s-lekarstvami/
Выбор наркологической клиники — ключевой шаг на пути к выздоровлению, от которого зависит не только физическое и психическое состояние пациента, но и устойчивость достигнутых результатов. Современные учреждения предлагают широкий спектр услуг, однако уровень подготовки персонала, методики лечения и условия пребывания могут существенно отличаться.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-pervouralsk11.ru/]chastnaya narkologicheskaya klinika pervoural’sk[/url]
экстренный вывод из запоя
vivod-iz-zapoya-kaluga005.ru
лечение запоя
тёмная ночь души Психолог онлайн: Доступная поддержка в любое время и в любом месте. Обретите гармонию и понимание себя, не выходя из дома.
провайдеры интернета в перми
domashij-internet-perm004.ru
подключить интернет тарифы пермь
Наши врачи уделяют внимание не только медицинским аспектам, но также социальным и психологическим факторам. Мы помогаем пациентам находить новый смысл в жизни, формировать новые увлечения и восстанавливать старые связи с близкими.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-irkutsk.ru/kapelnica-ot-zapoya-v-stacionare-v-irkutske/]https://kapelnica-ot-zapoya-irkutsk.ru/kapelnica-ot-zapoya-v-stacionare-v-irkutske[/url]
Наша миссия заключается в предоставлении качественной помощи людям, страдающим от зависимостей. Мы стремимся создать безопасную и поддерживающую атмосферу, где каждый сможет получить необходимую помощь. Основная цель — восстановление здоровья, психоэмоционального состояния и социальной адаптации.
Изучить вопрос глубже – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-omske.ru/]вывод из запоя цена в омске[/url]
Immersive live dealer games are so much more than just playing – it’s the whole experience! Discovering platforms like jljl77 app com, with easy logins & bonuses, really elevates that feeling. Great article – thanks for the insights!
Эфирные масла для повышения энергии и настроения Рейки и эфирные масла: как они работают вместе: Узнайте, как синергия Рейки и эфирных масел может умножить целительную силу каждой практики. Откройте для себя специальные протоколы и комбинации масел для усиления потока энергии и достижения глубокого исцеления.
вывод из запоя цена
vivod-iz-zapoya-irkutsk001.ru
лечение запоя
Грузоперевозки Луганск Перевозка негабаритных грузов Луганск: Организация перевозки негабаритных и тяжеловесных грузов.
В статье рассмотрим ключевые моменты, которые помогут сориентироваться при выборе капельницы от запоя, понять механизм действия и особенности процедуры, а также избежать типичных ошибок при обращении за медицинской помощью.
Углубиться в тему – [url=https://kapelnicza-ot-zapoya-pervouralsk11.ru/]капельница от запоя первоуральск.[/url]
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Москве приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Подробнее тут – https://kapelnica-ot-zapoya-lyubercy11.ru
вывод из запоя калуга
vivod-iz-zapoya-kaluga006.ru
вывод из запоя круглосуточно
Зависимости часто сопровождаются физическими и психологическими нарушениями, требующими комплексного подхода. Мы убеждены, что успешное лечение невозможно без индивидуального подхода, что делает нашу клинику отличным местом для тех, кто нуждается в поддержке.
Подробнее можно узнать тут – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-omske.ru/]vyvod-iz-zapoya-klinika omsk[/url]
Работа клиники строится на принципах доказательной медицины и индивидуального подхода. При поступлении пациента осуществляется всесторонняя диагностика, включающая анализы крови, оценку психического состояния и анамнез. По результатам разрабатывается персонализированный курс терапии.
Подробнее – [url=https://narkologicheskaya-klinika-v-ryazani12.ru/]наркологическая клиника в рязани[/url]
домашний интернет тарифы пермь
domashij-internet-perm005.ru
подключить домашний интернет в перми
Нарколог на дому проводит тщательный осмотр, собирает анамнез и назначает необходимые лабораторные исследования. Это позволяет выявить сопутствующие патологии и скорректировать тактику лечения.
Получить больше информации – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]нарколог на дом ярославль[/url]
Hyvaa paivaa!!
Pelaajapalaute auttaa muita tekemään fiksuja valintoja casino sivustojen suhteen. Rehellinen pelaajapalaute on kullanarvoista tietoa. [url=https://reallivecasino.cfd/arvostelut-ja-luotettavuus.html]arvostelut ja luotettavuus[/url] Jaa omia kokemuksiasi ja hyödynnä muiden antamaa palautetta päätöksenteossa.
Lue linkki – https://www.reallivecasino.cfd/arvostelut-ja-luotettavuus.html
kasino korttipeli säännöt
åldersgräns casino cosmopol
Г¤r casino vinster skattefria
Onnea!
Грузоперевозки Луганск Грузоперевозки Луганск: Экспедирование грузов по Луганской области. Полный контроль над перемещением груза, оперативная информация о местонахождении, гарантия своевременной доставки.
лечение запоя иркутск
vivod-iz-zapoya-irkutsk002.ru
вывод из запоя
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Получить больше информации – https://humanitarianweb.org/programme-coordinator-programme-support-unit-psu
вывод из запоя круглосуточно краснодар
vivod-iz-zapoya-krasnodar001.ru
лечение запоя
электрокарниз купить в москве [url=https://elektrokarniz25.ru/]elektrokarniz25.ru[/url] .
iphone купить спб [url=kupit-ajfon-cs3.ru]iphone купить спб[/url] .
1win apk download for android [url=www.1win3027.com]1win apk download for android[/url]
гайнулин эмиль нилович Как начать зарабатывать в Telegram с нуля? Пошаговая инструкция от Эмиля Гайнулина: выбор ниши, создание контента, привлечение аудитории.
1win real or fake [url=www.1win3024.com]www.1win3024.com[/url]
the best and interesting https://edicionesdelau.com
interesting and new https://www.manaolahawaii.com
домашний интернет тарифы
domashij-internet-perm006.ru
подключить интернет тарифы пермь
best site online https://pvslabs.com
visit the site online https://justicelanow.org
лечение запоя краснодар
vivod-iz-zapoya-krasnodar002.ru
экстренный вывод из запоя
гайнулин эмиль нилович Telegram-боты для бизнеса: обзор полезных инструментов от Эмиля Гайнулина. Автоматизация процессов, улучшение коммуникации с клиентами и увеличение продаж.
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Ознакомиться с деталями – https://snhca.com/about-the-association/about1
вывод из запоя круглосуточно
vivod-iz-zapoya-irkutsk003.ru
экстренный вывод из запоя
обмен макросы на варфейс Превратитесь в легенду Warface с помощью макросы варфейс! Улучшите свою стрельбу, контролируйте отдачу и станьте непобедимым игроком. Покажите всем, кто здесь лучший! Начните свой путь к вершине!
Критерий
Подробнее можно узнать тут – http://narkolog-na-dom-nizhnij-tagil11.ru/vyzov-narkologa-na-dom-v-nizhnem-tagile/
похудение Сердце – главный орган кровеносной системы.
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Разобраться лучше – https://ponadschematami.org/osoby-neuroatypowe-sa-mniej-inteligentne-mit-czy-fakt
дешевый интернет ростов
domashij-internet-rostov004.ru
провайдеры интернета ростов
Установка и ремонт москитных сеток в Алматы Компания “Okna Service” в Алматы предлагает комплексные услуги по ремонту пластиковых окон, применяя исключительно материалы премиум-класса. В спектр услуг входит установка высококачественных уплотнителей, обеспечивающих идеальную герметичность и защиту от сквозняков, а также замена специализированной фурнитуры, такой как ручки и петли для различных систем открывания. Также осуществляется ремонт и замена москитных сеток, подверженных повреждениям и деформациям. Для повышения удобства эксплуатации окон специалисты “Okna Service” предлагают установку дополнительных устройств: доводчиков для дверей, ограничителей открывания (особенно актуально для семей с детьми) и монтаж пластиковых откосов внутри и снаружи помещения, улучшающих внешний вид окон. В сервисном центре в Алматы можно заказать и приобрести все необходимые комплектующие для ремонта окон, с их последующей доставкой и квалифицированной установкой. Подбор материалов осуществляется с учетом особенностей каждой оконной конструкции, что гарантирует надежность и долговечность ремонта. Замена изношенных элементов способствует восстановлению первоначальных характеристик окна, обеспечивая теплосбережение и комфорт в доме.
Наркологическая помощь на дому становится всё более востребованной благодаря своей доступности, конфиденциальности и эффективности. Клиника «МедТрезвость» предлагает пациентам целый ряд важных преимуществ:
Изучить вопрос глубже – [url=https://narcolog-na-dom-sankt-peterburg0.ru/]нарколог на дом в санкт-петербурге[/url]
http://888starz-downloads.com/ [url=https://888starz-downloads.com]http://888starz-downloads.com/[/url] .
Fantastic blog you have here but I was curious about if you knew of any community forums that cover the same topics discussed in this article? I’d really love to be a part of online community where I can get opinions from other experienced individuals that share the same interest. If you have any suggestions, please let me know. Thank you!
Best limo service near me
В рамках услуги вызова нарколога на дом используется современное оборудование и препараты, одобренные для амбулаторного применения.
Подробнее тут – [url=https://narkolog-na-dom-kamensk-uralskij11.ru/]нарколог на дом срочно в каменске-уральском[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar003.ru
экстренный вывод из запоя краснодар
Компоненты
Подробнее тут – http://kapelnicza-ot-zapoya-pervouralsk11.ru/
Пациенты, нуждающиеся в круглосуточном наблюдении, могут пройти курс терапии в стационаре. Обстановка клиники рассчитана на комфортное пребывание: палаты с индивидуальным санитарным блоком, охрана, контроль приёма препаратов, поддержка психологов.
Получить дополнительную информацию – https://narkologicheskaya-pomoshh-tula10.ru/neotlozhnaya-narkologicheskaya-pomoshh-tula/
Затяжной запой опасен для жизни. Врачи наркологической клиники в Москве проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lyubercy11.ru/]капельница от запоя наркология в Москве[/url]
вывод из запоя цена
vivod-iz-zapoya-kaluga004.ru
лечение запоя
Обеспечение своевременной наркологической помощи с выездом на дом в Каменске-Уральском — важный аспект комплексного лечения алкогольной и наркотической зависимости. Услуга вызова нарколога на дом позволяет получить квалифицированную медицинскую помощь в комфортных условиях, что снижает стресс и способствует более быстрому восстановлению.
Ознакомиться с деталями – http://narkolog-na-dom-kamensk-uralskij11.ru/chastnyj-narkolog-na-dom-v-kamensk-uralskom/
подключить интернет ростов
domashij-internet-rostov005.ru
лучший интернет провайдер ростов
visit the site https://lmc896.org
go to the site https://ibecensino.org.br
Запой – это не просто временное ухудшение самочувствия, а состояние, при котором организм подвергается значительному токсическому воздействию алкоголя. Длительное злоупотребление приводит к накоплению вредных веществ, что может вызвать:
Разобраться лучше – http://narcolog-na-dom-ryazan00.ru/vyzov-narkologa-na-dom-ryazan/
варфейс макросы мышки Поднимите свой скилл в Warface с помощью макросы варфейс! Забудьте о сложной отдаче, увеличьте точность стрельбы и доминируйте над противниками. Станьте настоящим профи и покажите свой скилл!
завьялов илья поинт пей Илья Завьялов о Будущем Криптовалют и Point Pay
После поступления вызова нарколог клиники «АльфаНаркология» оперативно выезжает по указанному адресу. На месте врач проводит первичную диагностику, оценивая степень интоксикации, физическое и психологическое состояние пациента. По результатам осмотра врач подбирает индивидуальный комплекс лечебных процедур, в который входит постановка капельницы с растворами для детоксикации, препараты для стабилизации работы органов и нормализации психического состояния.
Подробнее можно узнать тут – http://narcolog-na-dom-sankt-peterburg000.ru/
лечение запоя
vivod-iz-zapoya-krasnodar004.ru
вывод из запоя
Профессиональная анонимная наркологическая клиника. Лечение зависимостей, капельницы, вывод из запоя, реабилитация. Анонимно, круглосуточно, с поддержкой врачей и психологов.
Removing cloth remover from images is an advanced tool for creative tasks. Neural networks, accurate generation, confidentiality. For legal and professional use only.
Для успешного вывода из запоя используется комплексный подход с участием специалистов разных профилей. Более подробно об этом можно узнать на официальном портале наркологической службы.
Узнать больше – https://vyvod-iz-zapoya-nizhnij-tagil11.ru/
ручки для душевой кабины купить Ролики для душевых кабин купить в Екатеринбурге: широкий выбор роликов для дверей и шторок душевых кабин разных производителей.
вывод из запоя круглосуточно калуга
vivod-iz-zapoya-kaluga005.ru
вывод из запоя цена
Самостоятельно выйти из запоя — почти невозможно. В Москве врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-lyubercy11.ru/]капельница от запоя выезд Москва[/url]
Особенно важно на этапе поступления пройти полную психодиагностику и получить адаптированную под конкретного пациента программу. Это позволит учитывать возможные сопутствующие расстройства, включая тревожные, аффективные и когнитивные нарушения.
Детальнее – http://narkologicheskaya-klinika-nizhnij-tagil11.ru/narkologicheskaya-klinika-telefon-v-nizhnem-tagile/
Метод лечения
Разобраться лучше – [url=https://lechenie-narkomanii-vladimir10.ru/]центр лечения наркомании владимир.[/url]
интернет провайдер ростов
domashij-internet-rostov006.ru
домашний интернет
В Рязани возможен как стационарный, так и амбулаторный вывод из запоя. Выбор подхода зависит от состояния пациента, выраженности симптомов и наличия сопутствующих нарушений.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-ryazani12.ru/]вывод из запоя на дому рязань.[/url]
Многие семьи сталкиваются с трудностями, когда зависимый отказывается ехать в клинику. В таких случаях выездная помощь становится первым шагом к выздоровлению. Однако не все службы предлагают одинаково безопасный и профессиональный подход. Чтобы избежать рисков и ошибок, важно понимать, на что обращать внимание при выборе услуги “нарколог на дом”.
Получить дополнительные сведения – [url=https://narkolog-na-dom-nizhnij-tagil11.ru/]нарколог на дом анонимно нижний тагил[/url]
лечение запоя
vivod-iz-zapoya-krasnodar005.ru
вывод из запоя
шторы пятигорск кисловодское шоссе (Повтор) Пятигорск Где Купить Карнизы: Полезные Советы
завьялов илья поинт пей Илья Завьялов и PointPay: Создание сообщества активных крипто-инвесторов и трейдеров
Первый и самый важный момент — какие методики применяются в клинике. Качественное лечение наркозависимости включает несколько этапов: детоксикация, стабилизация состояния, психотерапия, ресоциализация. Одного лишь выведения токсинов из организма недостаточно — без проработки психологических причин употребления высокий риск рецидива.
Детальнее – https://lechenie-narkomanii-vladimir10.ru/lechenie-narkomanii-anonimno-vladimir/
В рамках услуги вызова нарколога на дом используется современное оборудование и препараты, одобренные для амбулаторного применения.
Углубиться в тему – [url=https://narkolog-na-dom-kamensk-uralskij11.ru/]нарколог на дом вывод[/url]
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Подробнее – [url=https://narkologicheskaya-klinika-tyumen10.ru/]narkologicheskaya-klinika-tyumen10.ru/[/url]
Как подчёркивает главный врач клинического отделения, «в условиях стационара мы можем оперативно реагировать на малейшие изменения в состоянии пациента, что критически важно при тяжёлых формах запоя».
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-v-ryazani12.ru/]наркологический вывод из запоя в рязани[/url]
гардина с электроприводом [url=https://www.elektrokarniz5.ru]https://www.elektrokarniz5.ru[/url] .
вывод из запоя
vivod-iz-zapoya-kaluga006.ru
вывод из запоя калуга
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-lyubercy11.ru/]капельница от запоя наркология[/url]
провайдер интернета по адресу самара
domashij-internet-samara004.ru
интернет по адресу
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Получить дополнительные сведения – https://desigheek.com/business-conference
Срочная наркологическая помощь в Красноярске доступна на сайте vivod-iz-zapoya-krasnoyarsk001.ru. Клиника наркологии предлагает помощь в лечении зависимостейвключая методы кодирования от алкоголизма и специализированные программы лечения. Здесь вы найдете поддержку при запойных состояниях и реабилитацию наркоманов. Услуги психотерапевта также доступны. Кризисные центры обеспечивают поддержку для родственников пациентов. Предотвращение зависимостей и восстановление после наркотиков, ключевые шаги к восстановлению здоровья. Гарантируем анонимность и конфиденциальность.
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Получить больше информации – https://tsukubathletics.com/archives/5268
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Ознакомиться с деталями – https://vistoweekly.com/beholderen
купить макрос варфейс Думаешь об обмен макросы на варфейс? Помни о рисках! Проверяй репутацию продавцов и будь осторожен с обменом аккаунтами. Лучше купить проверенный макрос.
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Узнать больше – https://vistoweekly.com/whispering-words-of-love-in-punjabi-shayari
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Ознакомиться с деталями – http://www.apzp.cz/dokumenty-ke-stazeni/hrda_osobni_asistence
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Узнать больше – https://www.ingridremvall.se/sample-page
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Выяснить больше – https://lalazada.es/contactar
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Разобраться лучше – https://desigheek.com/business-conference
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Получить больше информации – https://vistoweekly.com/dave-simmons-dahlgren-va
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Подробнее можно узнать тут – https://vistoweekly.com/spencer-bradley-make-him-jealous
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Подробнее можно узнать тут – https://www.mariannesoderberg.se/foto
завьялов илья поинт пей Point Pay: Платформа Возможностей благодаря Илье Завьялову
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Получить больше информации – https://www.mrpepe.com/daily-fx/currency-prices-usdgbpeur
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Детальнее – https://www.bestinksistemi.it/ciao-mondo
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Разобраться лучше – http://xamanoenergy.com/index.php/2024/02/18/consul-general-yu-peng-visits-the-city-of-campinas
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Ознакомиться с деталями – http://www.projectos.loneus.net/clsdois/2016/02/18/home-run-kitten-favored-in-competitive-san-simeon
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Детальнее – https://vistoweekly.com/trader-joes-dayforce
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Углубиться в тему – https://www.hydro-serve.in/hello-world
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Разобраться лучше – https://vistoweekly.com/mayo-group-wsj-crossword-clue
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее можно узнать тут – https://septfevrier.com/paris-mon-amour
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее – https://www.halaumohalailima.com/hidden-gems-of-oahu-7-local-secrets-beyond-waikiki
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Изучить вопрос глубже – https://thongkheng.org/level-1/level-2a
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее можно узнать тут – https://www.rechtsanwalt-erbrecht-in-essen.de/portfolio/berliner-testament/er-erbausschlagung
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Разобраться лучше – https://time2track.com/features-5
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Подробнее тут – https://fin-tokyo.com/2021/09/05/%E3%80%8E%E3%81%97%E3%82%83%E3%81%B6%E3%81%97%E3%82%83%E3%81%B6%E5%92%8C%E9%A3%9F%E3%80%80%E3%81%AB%E3%81%97%E5%B1%B1%E3%80%80%E5%B7%A3%E9%B4%A8%E5%BA%97%E3%80%8F10%E6%9C%88%E8%B1%9A%E3%82%AD%E3%83%A0
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Разобраться лучше – https://worldthreadstraveler.com/sustainable-fashion/fibers-that-bind
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Подробнее можно узнать тут – https://www.merceriapapillon.com/product/611282-carta-per-ricalco
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Узнать больше – http://auto-srnec.cz/sample-page
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Изучить вопрос глубже – https://blog.bunbusoft.com/?m=202403
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Детальнее – https://sumaanipharma.com/common-health-issues-in-dairy-cattle-and-how-to-address-them
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Подробнее можно узнать тут – http://mykinomir.ru/2017/12/13/dobropozalovat/%D0%BB%D0%B5%D0%BD%D1%82%D0%B0
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Выяснить больше – https://www.ccd.coop/link-post
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Разобраться лучше – https://bloc.xarxa-omnia.org/rierabonet/2014/05/21/que-es-per-a-mi-internet/internet5
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Углубиться в тему – https://www.sinapsystec.com.co/2013/12/30/just-a-cool-blog-post-with-images
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Выяснить больше – https://pelias.nl/how-to-pick-the-right-mutual-fund-for-you
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Разобраться лучше – https://cermam.com.br/como-se-preparar-para-a-residencia-medica
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Получить больше информации – https://tekintasmuhendislik.com/dogrusal-hareket-teknolojileri
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Получить дополнительные сведения – https://www.cristina-torrecilla.com/2023/11/16/elevador-global-360
смеситель врезной на борт ванной купить запчасти для душевой кабины
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее – https://softechts.com/line-icons-design
Рефрижераторные перевозки https://mybiysk.ru/business/ot-chego-zavisit-stoimost-refrizheratornyh-perevozok-i-kak-sekonomit-522146 по России и СНГ. Контроль температуры от -25°C до +25°C, современные машины, отслеживание груза.
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Выяснить больше – https://keesinha.com/2020-um-ano-de-muitos-desafios
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Подробнее тут – https://djro.nl/ronald-steenhouwer-2
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Подробнее тут – https://tmv-regental.de/beispiel-seite/tmv_image_01_18
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Ознакомиться с деталями – https://messiahmbc.org/product/smart-book-ichthys
провайдеры по адресу
domashij-internet-samara005.ru
узнать интернет по адресу
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Подробнее тут – https://vistoweekly.com/mastering-poptok-with-jonathan-worsley-to-elevate-your-tiktok-marketing
вывод из запоя краснодар
vivod-iz-zapoya-krasnodar001.ru
экстренный вывод из запоя краснодар
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Подробнее тут – https://korsellcorporateconsult.com/quia-sit-iusto-nihil-aliquam-sed
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Узнать больше – https://magneticafilms.com/cropped-favicon-magnetica-png
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Подробнее можно узнать тут – https://vistoweekly.com/vision-africa-roger-brugger
Прокапывание от алкоголя на дому — представляет собой эффективный метод помощи алкогольной зависимости, что даёт возможность быстро устранить признаки отмены и улучшить самочувствие пациента. Помощь нарколога на дому всё чаще востребованы, поскольку множество людей предпочитают не проходить лечение в стационаре. vivod-iz-zapoya-krasnoyarsk002.ru Эта процедура включает в себя домашнюю детоксикацию, где помощь специалиста при алкоголизме предоставляется в комфортной обстановке. Капельница для снятия похмелья содержит лекарственные средства для очищения организма, способствующие способствуют очистить организм от токсинов и восстановить водно-электролитный баланс. Важно помнить о симптомах алкогольного абстинентного синдрома, таких как тревога, потливость и тремор. Забота и поддержка со стороны близких играет ключевую роль в успешном лечении и реабилитации после длительного употребления алкоголя. Домашняя терапия может включать не только прокапывание, но и советы по предотвращению рецидивов алкогольной зависимости, что поможет предотвратить рецидивы и сохранить трезвый образ жизни.
https://пф-яндекс.рф/
Brazilian Ev!us: Эволюция стиля, балансирующая между минимализмом и дерзостью. Отличительные черты – чистые линии, приглушенные цвета, акцент на качестве материалов и кроя. Ev!us не кричит, а шепчет о безупречном вкусе.
Если человек страдает от алкоголизма, запойное состояние требует незамедлительного вмешательства, особенно если признаки токсического отравления начинают угрожать жизни. Признаки запоя — это не только физическая зависимость, но и эмоциональные и психические расстройства, такие как тревога, агрессия и галлюцинации.
Подробнее тут – [url=https://narcolog-na-dom-novokuznetsk0.ru/]вызов нарколога на дом кемеровская область[/url]
мистические детективы Мистическое читать – значит расширять свой кругозор, знакомиться с новыми идеями и концепциями, а также развивать свою фантазию и воображение.
Hi it’s me, I am also visiting this web site on a regular basis, this web site is in fact fastidious and the viewers are really sharing nice thoughts.
Best limo service near me
Limousine service offers luxurious, private transportation for various occasions. For Seattle visitors, consider the [url=https://taxi-prive.com/limo-service-seattle-airport-reviews/] Seattle Airport Chauffeur Service [/url] for seamless pick-up and drop-off at Sea-Tac International Airport. Professional chauffeurs ensure punctual and safe travel, providing assistance with luggage and navigation. The service caters to corporate travelers, weddings, proms, and special events, offering a fleet of high-end vehicles like sedans, SUVs, and stretch limousines. Amenities often include complimentary beverages, advanced sound systems, and climate control. Booking typically requires advance notice, with options for hourly or point-to-point pricing. Expect discretion, reliability, and comfort, making your journey stress-free and enjoyable. – https://taxi-prive.com/limo-service-seattle-airport-reviews/
Our [url=https://taxi-prive.com/] Seattle luxury transportation [/url] service offers an unparalleled experience in the Emerald City. We provide top-tier limousines, equipped with plush interiors, state-of-the-art amenities, and driven by professional chauffeurs. Perfect for weddings, corporate events, or a night out, our fleet includes sleek sedans, SUVs, and stretch limos. We prioritize punctuality, discretion, and safety, ensuring your journey is smooth and stress-free. Whether you’re traveling from Sea-Tac Airport or exploring downtown, our Seattle luxury transportation service sets the standard for elegance and reliability. – https://taxi-prive.com/
[url=https://taxi-prive.com/best-limo-service-seattle-airport/] Best Limo Service Seattle [/url] offers luxurious and reliable transportation for various occasions. With a fleet of top-notch vehicles, including sedans, SUVs, and stretch limousines, we cater to weddings, corporate events, airport transfers, and special nights out. Our professional chauffeurs ensure a smooth and comfortable ride, prioritizing safety and punctuality. Experience the best limo service Seattle has to offer, with amenities like complimentary beverages, advanced sound systems, and plush interiors. Whether you’re planning a grand entrance or a discreet arrival, our service guarantees elegance and convenience. Book with us for an unforgettable journey through Seattle. – https://taxi-prive.com/best-limo-service-seattle-airport/
перевод с английского языка нотариально заверенный перевод: Документ, имеющий полную юридическую силу и признаваемый в государственных учреждениях и международных организациях. Наша задача – обеспечить вам уверенность в каждом слове.
[url=https://taxi-prive.com/] Seattle limousine rental [/url] offers luxurious, reliable transportation for various occasions. Ideal for weddings, proms, corporate events, or airport transfers, our Seattle limousine rental service ensures comfort and style. Choose from a fleet of well-maintained vehicles, including sedans, SUVs, and stretch limousines. Professional chauffeurs guarantee a smooth, safe ride. Enjoy amenities like plush seating, climate control, and entertainment systems. Book your Seattle limousine rental for a memorable, stress-free experience. – https://taxi-prive.com/
провайдеры интернета по адресу
domashij-internet-samara006.ru
провайдер по адресу самара
1win ng [url=https://1win3026.com/]https://1win3026.com/[/url]
Запой — это критическое состояние, которое требует медицинского вмешательства. Нарколог на дом в Красноярске становится все более востребованным. Специалисты предлагают медикаментозное лечение, включая капельницы для оперативного выхода из запоя. Симптоматика запоя может включать в себя как сильную головную боль, так и тошноту. При наличии таких симптомов важно быстро обратиться к специалистам для получения медицинской помощи. Консультация нарколога поможет определить необходимый курс лечения. Состав капельницы включает витамины и препараты, помогающие в восстановлении организма. Процедуры проводятся в комфортной обстановке, что позволяет избежать стресса. Восстановительный процесс после запоя также включает психологическую помощь. нарколог на дом Красноярск Не забывайте, что лечение алкоголизма, это длительный процесс, который требует терпения и усилий. Нарколог на дом в Красноярске предоставляет не только услуги по выводу из запоя, но и дальнейшую реабилитацию. Выход из запоя возможен, и мы готовы поддержать вас на этом пути.
электрокарниз недорого [url=https://elektrokarnizy777.ru/]elektrokarnizy777.ru[/url] .
Наркологическая клиника в Ярославле представляет собой специализированное учреждение, оказывающее медицинскую помощь пациентам с алкогольной, наркотической и медикаментозной зависимостью. Ключевыми направлениями работы являются детоксикация, стабилизация состояния, последующее реабилитационное сопровождение и профилактика рецидивов. Комплексный подход к лечению обеспечивается взаимодействием специалистов различных профилей, включая наркологов, психиатров, психотерапевтов и медицинских сестёр.
Детальнее – http://narkologicheskaya-klinika-v-yaroslavle12.ru
автоматические карнизы для штор [url=elektrokarnizy10.ru]elektrokarnizy10.ru[/url] .
вывод из запоя
vivod-iz-zapoya-krasnodar002.ru
вывод из запоя
перевод документов для визы на английский [url=http://trs-center.ru]http://trs-center.ru[/url] .
https://x-vavada.ru Vavada – эксклюзивный обзор казино: честные отзывы о выплатах, секретные бонус-коды. Только проверенная информация о лицензии Кюрасао и слотах с высокой отдачей.
Напольное покрытие паркет [url=http://xn--1-7sba5anhi5b.xn--p1ai]http://xn--1-7sba5anhi5b.xn--p1ai[/url] .
Выбирайте казино https://casinopiastrix.ru с оплатой через Piastrix — это удобно, безопасно и быстро! Топ-игры, лицензия, круглосуточная поддержка.
http://www.1win bet.com login [url=http://1win3028.com]http://1win3028.com[/url]
Хотите купить контрактный двигатель ДВС с гарантией? Б большой выбор моторов из Японии, Европы и Кореи. Проверенные ДВС с небольшим пробегом. Подбор по VIN, доставка по РФ, помощь с установкой.
Ищете казино казино с СБП? У нас — мгновенные переводы, слоты от топ-провайдеров, живые дилеры и быстрые выплаты. Безопасность, анонимность и мобильный доступ!
Играйте в онлайн-покер https://droptopsite3.ru легальный с игроками со всего мира. МТТ, спины, VIP-программа, акции.
1win mobile app [url=https://www.1win-in1.com]1win mobile app[/url] .
Our [url=https://taxi-prive.com/limo-service-from-seattle-airport-to-cruise-terminal/] Seattle Airport Transportation [/url] limousine service offers luxurious, reliable rides. We specialize in Seattle Airport pick-ups/drop-offs, ensuring timely transit. Our fleet includes modern limos, sedans, SUVs. Professional chauffeurs prioritize safety, courtesy. Book online or call for Seattle Airport Transportation. Experience stress-free travel, style, comfort. Perfect for business, leisure travelers. Competitive rates, exceptional service guaranteed. Trust us for your Seattle Airport Transportation needs. – https://taxi-prive.com/limo-service-from-seattle-airport-to-cruise-terminal/
пополнить стим кошелек рубли Стим Баланс: Контролируйте свои расходы Управляйте своим игровым бюджетом! Мы научим вас, как эффективно использовать и пополнять свой Стим баланс, чтобы получать максимум удовольствия от игр.
Хирurgija u Crnoj Gori https://www.hirurgija-crna-gora.me savremena klinika, iskusni ljekari, evropski standardi. Planirane i hitne operacije, estetska i opsta hirurgija, udobnost i bezbjednost.
Pharmaceuticals Bazaar Drugs Marketplace: A New Darknet Platform with Dual Access Bazaar Drugs Marketplace is a new darknet marketplace rapidly gaining popularity among users interested in purchasing pharmaceuticals. Trading is conducted via the Tor Network, ensuring a high level of privacy and data protection. However, what sets this platform apart is its dual access: it is available both through an onion domain and a standard clearnet website, making it more convenient and visible compared to competitors. The marketplace offers a wide range of pharmaceuticals, including amphetamines, ketamine, cannabis, as well as prescription drugs such as alprazolam and diazepam. This variety appeals to both beginners and experienced buyers. All transactions on the platform are carried out using cryptocurrency payments, ensuring anonymity and security. In summary, Bazaar represents a modern darknet marketplace that combines convenience, a broad product selection, and a high level of privacy, making it a notable player in the darknet economy.
[url=https://taxi-prive.com/limo-service-seattle-airport/] Ideal Transportation Seattle Airport [/url] offers premier limousine services, focusing on luxury, comfort, and punctuality. Their fleet includes modern limousines, sedans, and SUVs, driven by professional chauffeurs. Services cover airport transfers, corporate travel, weddings, and special events. Booking is easy via their website or phone, with 24/7 customer support. They prioritize safety, reliability, and discretion, ensuring a seamless travel experience in the Seattle area. – https://taxi-prive.com/limo-service-seattle-airport/
1win apk download for android [url=http://1win3025.com/]http://1win3025.com/[/url]
Служба по контракту Служба по контракту: Стабильность, карьерный рост и социальные гарантии для военнослужащих. Это не просто работа, а возможность обрести уверенность в завтрашнем дне, обеспечить достойное будущее себе и своей семье.
Для успешного лечения зависимости необходима тщательная диагностика. В клинике проводят полное обследование пациента, включающее:
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-v-murmanske12.ru/]наркологическая клиника цены мурманск[/url]
Экстренный вызов нарколога на дом в Иркутске от «ТрезвоМед» при запое, интоксикации или кодировании – анонимно и удобно. Осмотр, детоксикация капельницей, индивидуальный план лечения – все это на дому! «ТрезвоМед» – круглосуточная помощь, анонимность и безопасность при отказе от алкоголя. Не можете бросить пить самостоятельно? Нужна помощь нарколога! Васильев: «Своевременная помощь при интоксикации – залог успешного выздоровления».
Подробнее можно узнать тут – [url=https://narcolog-na-dom-v-irkutske0.ru/]вызов нарколога на дом в иркутске[/url]
Клиника «АнтиАлко» предлагает экстренную медицинскую помощь на дому в Новосибирске и Новосибирской области для тех, кто столкнулся с запоем. Если вы или ваш близкий оказались в состоянии длительной алкогольной интоксикации, наши специалисты готовы оперативно приехать к вам, провести комплексную детоксикацию и купировать симптомы абстинентного синдрома. Мы гарантируем высокий уровень безопасности, полную анонимность и индивидуальный подход к каждому пациенту.
Подробнее – [url=https://vyvod-iz-zapoya-novosibirsk00.ru/]вывод из запоя клиника[/url]
A luxurious limousine service offers personalized transportation for various occasions. It provides a fleet of high-end vehicles, including sedans, SUVs, and stretch limousines, driven by professional chauffeurs. This service is popular for special events like weddings, corporate meetings, and airport transfers. One notable offering is [url=https://aolimo.com/wine-tours.html] Vancouver Island Wine Tours [/url], which takes passengers on a scenic journey through the region’s finest vineyards, offering a unique blend of luxury travel and wine tasting experiences. The service ensures comfort, safety, and punctuality, making every trip memorable and hassle-free. – https://aolimo.com/wine-tours.html
Особое внимание уделяется поддержке работы печени, сердца и почек, поскольку эти органы первыми страдают от токсического воздействия этанола. При необходимости подключаются дополнительные препараты — от седативных до противосудорожных. Все препараты подбираются с учётом возраста и общего состояния пациента.
Выяснить больше – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]вывод из запоя клиника[/url]
провайдеры интернета по адресу
domashij-internet-spb004.ru
домашний интернет тарифы
Our limousine service offers luxurious transportation for various occasions. We specialize in [url=https://aolimo.com/wine-tours.html] Corporate Wine Tour Packages [/url], providing a elegant and comfortable way to explore local vineyards with your team. Our fleet includes modern limousines equipped with premium amenities. We ensure professional chauffeurs, timely pickups, and safe journeys. Ideal for corporate outings, our Wine Tour Packages cater to groups seeking a refined experience. Enjoy scenic routes, visit renowned wineries, and indulge in wine tasting, all while traveling in style. Perfect for team building or entertaining clients, our service combines elegance with convenience. – https://aolimo.com/wine-tours.html
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом, что позволяет оперативно снизить концентрацию токсинов в крови и восстановить нормальные обменные процессы. Этот этап критически важен для стабилизации работы внутренних органов, таких как печень, почки и сердце.
Получить дополнительные сведения – [url=https://narcolog-na-dom-ryazan0.ru/]narkolog-na-dom-czena rjazan'[/url]
военная служба по контракту Контрактная служба: престижная работа, достойная оплата, уверенность в будущем
лечение запоя
vivod-iz-zapoya-minsk001.ru
вывод из запоя цена
В Москве решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-lyubercy13.ru/]врача капельницу от запоя Москва[/url]
The website tnschoolsonline.in is an official portal by the Tamil Nadu School Education Department. It provides comprehensive information about schools across Tamil Nadu, including directories, enrollment data, infrastructure details, and staff records. It serves teachers, students, and administrators to monitor and improve school management and educational outcomes.
вывод из запоя краснодар
vivod-iz-zapoya-krasnodar003.ru
лечение запоя
[url=https://aolimo.com/vehicles.html] Special Events Limousine Service [/url] offers luxurious transportation for weddings, proms, and other significant celebrations. With a fleet of high-end vehicles and professional chauffeurs, Special Events Limousine Service ensures a memorable and stress-free experience. – https://aolimo.com/vehicles.html
Пациенты, которые выбирают нашу клинику для лечения алкогольного запоя, получают качественную и оперативную помощь, обладающую следующими преимуществами:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod0.ru/]капельница от запоя клиника нижний новгород[/url]
смотреть онлайн бесплатно мистический Смотреть мистические фильмы онлайн: удобство и разнообразие
A limousine service offers luxurious transportation with [url=https://aolimo.com/] professional chauffeurs service [/url] for various events. It prioritizes comfort, style, and punctuality for clients. – https://aolimo.com/
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Узнать больше – http://narcolog-na-dom-novokuznetsk0.ru/narkolog-na-dom-klinika-novokuzneczk/https://narcolog-na-dom-novokuznetsk0.ru
Помощь нужна, если:
Детальнее – [url=https://vyvod-iz-zapoya-serpuhov3.ru/]vyvod-iz-zapoya-kruglosutochno[/url]
Служба по контракту Контрактная служба: Достойная оплата труда, жилищное обеспечение и медицинское обслуживание для военнослужащих и их семей. Государство заботится о своих защитниках, предоставляя им все необходимые условия для комфортной жизни и успешной службы.
mostbet kazinosu [url=http://mostbet4052.ru]http://mostbet4052.ru[/url]
Одним из ключевых направлений является проведение капельниц, призванных вывести токсины из организма и нормализовать водно-электролитный баланс. Используемые препараты и состав растворов подбираются индивидуально, исходя из клинической картины и истории болезни пациента.
Получить дополнительную информацию – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]нарколог на дом цена в ярославле[/url]
Также в расчет включается необходимость проведения дополнительных процедур (например, консультаций с психологом или кодирования) и географическая удаленность адреса вызова. Важно, что все эти параметры обсуждаются с пациентом заранее, что позволяет точно рассчитать расходы и избежать неожиданных доплат.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod000.ru/]капельница от запоя анонимно в нижний новгороде[/url]
Врачи клиники «ВитаЛайн» для снятия интоксикации и облегчения состояния пациента применяют исключительно качественные и проверенные лекарственные препараты, подбирая их в зависимости от особенностей ситуации и состояния здоровья пациента:
Подробнее – http://narcolog-na-dom-novosibirsk0.ru/narkolog-na-dom-kruglosutochno-novosibirsk/
Dual Access Bazaar Drugs Marketplace: A New Darknet Platform with Dual Access Bazaar Drugs Marketplace is a new darknet marketplace rapidly gaining popularity among users interested in purchasing pharmaceuticals. Trading is conducted via the Tor Network, ensuring a high level of privacy and data protection. However, what sets this platform apart is its dual access: it is available both through an onion domain and a standard clearnet website, making it more convenient and visible compared to competitors. The marketplace offers a wide range of pharmaceuticals, including amphetamines, ketamine, cannabis, as well as prescription drugs such as alprazolam and diazepam. This variety appeals to both beginners and experienced buyers. All transactions on the platform are carried out using cryptocurrency payments, ensuring anonymity and security. In summary, Bazaar represents a modern darknet marketplace that combines convenience, a broad product selection, and a high level of privacy, making it a notable player in the darknet economy.
Элитная недвижимость https://real-estate-rich.ru в России и за границей — квартиры, виллы, пентхаусы, дома. Где купить, как оформить, во что вложиться.
Наши врачи используют только проверенные и сертифицированные медикаменты, индивидуально подбираемые для каждого пациента. В состав лечебного курса входят:
Подробнее тут – [url=https://vyvod-iz-zapoya-novosibirsk00.ru/]вывод из запоя на дому цена[/url]
интернет по адресу дома
domashij-internet-spb005.ru
интернет по адресу санкт-петербург
вывод из запоя круглосуточно
vivod-iz-zapoya-minsk002.ru
вывод из запоя цена
военная служба по контракту Преимущества контрактной службы для молодого поколения Контрактная служба предоставляет молодым людям возможность получить стабильную работу, социальные гарантии, опыт и навыки, которые могут пригодиться в дальнейшей жизни.
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar004.ru
вывод из запоя цена
Эти данные являются основой для составления индивидуального плана лечения, позволяющего оперативно скорректировать терапевтические меры.
Получить больше информации – https://narcolog-na-dom-ryazan00.ru/narkolog-na-dom-kruglosutochno-ryazan/
mostbet promo kod az [url=www.mostbet4050.ru]www.mostbet4050.ru[/url]
Для оценки уровня учреждения важно понимать, какие конкретно методики в нём используются. Ниже приведён обобщённый обзор подходов в современных наркологических клиниках региона:
Углубиться в тему – [url=https://lechenie-narkomanii-vladimir10.ru/]лечение наркомании и алкоголизма владимир[/url]
провайдеры по адресу
domashij-internet-spb006.ru
провайдеры по адресу санкт-петербург
вывод из запоя цена
vivod-iz-zapoya-minsk003.ru
лечение запоя минск
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Узнать из первых рук – https://mybestbox.shop/index.php/2023/04/09/boost-your-online-presence-our-top-digital-marketing
военная служба по контракту Военный контракт: реальный шанс реализовать свой потенциал и добиться успеха в военной карьере
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Почему это важно? – https://hostingwebid.com/jasa-pembuatan-website-makassar
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Узнать напрямую – https://rbb.in.ua/stati-ofisnaya-bolezn2-html
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Узнать напрямую – https://kvinauto.com.ua/blog/podgotovka-peredney-podveski-3110-k-ustanovki-na-gaz-21
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также… – https://icouldeat.com/shop_item_06
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Получить полную информацию – https://www.coperura.com.br/avisos/614/aniversariantes-sorteados-em-janeiro-2018
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Выяснить больше – https://nysonline.org/2021/07/sdtk
мостбет официальный вход [url=https://www.mostbet4051.ru]https://www.mostbet4051.ru[/url]
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Заходи — там интересно – https://buyinsuranceplans.com/what-is-backup-health-policy
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Доступ к полной версии – https://www.pietrocarlopellegrini.it/memoriale-giuseppe-garibaldi/08-15
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Практические советы ждут тебя – https://kaganotokiralama.com/arac/citroen-c-elysee-gri
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Выяснить больше – https://depthfinder.click/%EB%9F%B0%EB%8D%98%EC%9D%98-%EC%9E%90%EC%A1%B4%EC%8B%AC-%EC%B2%BC%EC%8B%9C-fc
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Это ещё не всё… – https://qh88.repair/cuoc-the-thao-qh88
вывод из запоя краснодар
vivod-iz-zapoya-krasnodar005.ru
экстренный вывод из запоя
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Нажмите, чтобы узнать больше – http://mind-uk.org/environment-development
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Доступ к полной версии – https://tmsltd-x08c5pxewd.live-website.com/mastering-time-management-key-to-business-success
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Подробнее тут – https://f5fashion.vn/dac-san-hau-sua-thai-binh-duong-o-van-don
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Переходите по ссылке ниже – https://regionsliven.org/2024/05/23/%D0%B7%D0%B0%D0%BA%D0%BB%D1%8E%D1%87%D0%B8%D1%82%D0%B5%D0%BB%D0%BD%D0%B0-%D0%B4%D0%B5%D0%BA%D0%BB%D0%B0%D1%80%D0%B0%D1%86%D0%B8%D1%8F
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Почему это важно? – https://noodev.ca/2025/02/20/hello-world
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Получить дополнительные сведения – http://www.usdirectoryfinder.com/sheriff-in-maryland-pushes-for-day-reporting-center
Служба по контракту Контрактная служба: Это не только работа, но и образ жизни, требующий дисциплины, ответственности и преданности своему делу
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Смотрите также – http://starseniorcenter.org/star-senior-center-nov-2018-calendar
mostbet casino oyunları [url=http://mostbet4053.ru/]mostbet casino oyunları[/url]
Ламинат 33 класса для пола и стен. [url=https://laminat2.ru/]Ламинат 33 класса для пола и стен.[/url] .
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Нажмите, чтобы узнать больше – https://www.rovandesign.nl/purposecompany/2020/11/04/kerstidee
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Как достичь результата? – https://www.lifechange.at/meereswasser-im-kampf-gegen-klimawandel-einsetzen
Выбор застройщика https://spartak-realty.ru важный шаг при покупке квартиры. Расскажем, как проверить репутацию, сроки сдачи, проектную документацию и избежать проблем с новостройкой.
Смотреть фильмы kinobadi.mom и сериалы бесплатно, самый большой выбор фильмов и сериалов , многофункциональное сортировка, также у нас есть скачивание в mp4 формате
Недвижимость в Балашихе https://balashihabest.ru комфорт рядом с Москвой. Современные жилые комплексы, школы, парки, транспорт. Объекты в наличии, консультации, юридическое сопровождение сделки.
Поставка нерудных материалов https://sr-sb.ru песок, щебень, гравий, отсев. Прямые поставки на стройплощадки, карьерный материал, доставка самосвалами.
Лайфхаки для ремонта https://stroibud.ru квартиры и дома: нестандартные решения, экономия бюджета, удобные инструменты.
вывод из запоя круглосуточно
vivod-iz-zapoya-omsk001.ru
вывод из запоя круглосуточно омск
провайдеры по адресу уфа
domashij-internet-ufa004.ru
провайдер интернета по адресу уфа
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Обратитесь за информацией – https://mzs7krosno.pl/index.php/2015/09/01/rok-szkolny-201516-rozpoczety/poczatek_roku_2015_2016
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Читать дальше – https://brasilchat.net/2023/04/09/get-ahead-of-your-competition-our-proven-digital
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Изучить вопрос глубже – https://florence-neuberth.com/low3n0a0131-4
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Расширить кругозор по теме – https://www.ksiip.com/5a-sheep-milk-cheese
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Только для своих – https://www.wilsonmobilevet.com/services/kitty
Помощь родных является ключевой фактором в восстановлении после пьянки. Обсудите с ними о своих намерениях и позвольте о поддержке. Группы поддержки и обращение к специалистов представляют собой хорошим подспорьем. Не забывайте о профилактике срывов: советы по трезвости и самопомощь при зависимости от алкоголя помогут избежать соблазна вернуться к прежнему. вывод из запоя
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Полная информация здесь – https://liebeliebe.eu/seggs-school-2-6cm
Responsible gaming is key, and platforms like s5 casino com are gaining traction in the Philippines. Verification steps, like confirming age, are vital for a secure experience – good to see that focus! Remember to gamble within your limits.
Jogue o fortune tiger bet4 e divirta-se com segurança!
Участвуй в турнирах, активируй коды и начинай выигрывать прямо сейчас. [url=https://tcar.us/]500 р вавада[/url]
Женский журнал https://e-times.com.ua о красоте, моде, отношениях, здоровье и саморазвитии. Советы, тренды, рецепты, вдохновение на каждый день. Будь в курсе самого интересного!
Туристический портал https://atrium.if.ua всё для путешественников: путеводители, маршруты, советы, отели, билеты и отзывы. Откройте для себя новые направления с полезной информацией и лайфхаками.
Женский онлайн-журнал https://socvirus.com.ua мода, макияж, карьера, семья, тренды. Полезные статьи, интервью, обзоры и вдохновляющий контент для настоящих женщин.
Портал про ремонт https://prezent-house.com.ua полезные советы, инструкции, дизайн-идеи и лайфхаки. От черновой отделки до декора. Всё о ремонте квартир, домов и офисов — просто, понятно и по делу.
Всё о ремонте https://sevgr.org.ua на одном портале: полезные статьи, видеоуроки, проекты, ошибки и решения. Интерьерные идеи, советы мастеров, выбор стройматериалов.
mostbet mobil giriş [url=mostbet4048.ru]mostbet4048.ru[/url]
Нарколог на дому проводит тщательный осмотр, собирает анамнез и назначает необходимые лабораторные исследования. Это позволяет выявить сопутствующие патологии и скорректировать тактику лечения.
Подробнее – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]narkolog-na-dom-czena jaroslavl'[/url]
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Обратитесь за информацией – http://limit-solution.com/city-2278497_1920-2
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Обратитесь за информацией – https://saifulahi.com/2024/04/25/understanding-electrical-codes-a-guide-for-diy-enthusiasts
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Переходите по ссылке ниже – https://elastemgzn.com/flash-trash
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Смотрите также – https://metricco.es/premium-wordpress-themes-bursting-with-quality
экстренный вывод из запоя омск
vivod-iz-zapoya-omsk002.ru
экстренный вывод из запоя омск
Бюро дизайна https://sinega.com.ua интерьеров: функциональность, стиль и комфорт в каждой детали. Предлагаем современные решения, индивидуальный подход и поддержку на всех этапах проекта.
Портал про ремонт https://techproduct.com.ua для тех, кто строит, переделывает и обустраивает. Рекомендации, калькуляторы, фото до и после, инструкции по всем этапам ремонта.
провайдеры интернета по адресу уфа
domashij-internet-ufa005.ru
провайдеры по адресу уфа
Портал о строительстве https://bms-soft.com.ua от фундамента до кровли. Технологии, лайфхаки, выбор инструментов и материалов. Честные обзоры, проекты, сметы, помощь в выборе подрядчиков.
Всё о строительстве https://kinoranok.org.ua на одном портале: строительные технологии, интерьер, отделка, ландшафт. Советы экспертов, фото до и после, инструкции и реальные кейсы.
Ремонт и строительство https://mtbo.org.ua всё в одном месте. Сайт с советами, схемами, расчетами, обзорами и фотоидееями. Дом, дача, квартира — строй легко, качественно и с умом.
В Рязани возможен как стационарный, так и амбулаторный вывод из запоя. Выбор подхода зависит от состояния пациента, выраженности симптомов и наличия сопутствующих нарушений.
Углубиться в тему – https://vyvod-iz-zapoya-v-ryazani12.ru/
Капельница от запоя применяется для комплексного восстановления организма после длительного употребления алкоголя. Она включает в себя введение растворов, насыщенных витаминами, электролитами, глюкозой и лекарственными средствами, направленными на устранение симптомов интоксикации. Основные задачи процедуры:
Исследовать вопрос подробнее – https://kapelnicza-ot-zapoya-v-murmanske12.ru/
Лечение алкоголизма в домашних условиях — значимый этап для борьбы с алкогольной зависимостью . Лечение алкоголизма начинается с очищения организма, которая может быть проведена в домашних условиях . Основные подходы включают медицинскую помощь и препараты для детоксикации , что обеспечит безопасное прекращение употребления. vivod-iz-zapoya-krasnoyarsk002.ru Советы по трезвости и стратегии преодоления зависимости, такие как самообслуживание для людей с алкогольной зависимостью, имеют огромное значение в процессе восстановления. Отказ от алкоголя — это шаг к новой, трезвой жизни.
Сайт о ремонте https://sota-servis.com.ua и строительстве: от черновых работ до декора. Технологии, материалы, пошаговые инструкции и проекты.
Онлайн-журнал https://elektrod.com.ua о строительстве: технологии, законодательство, цены, инструменты, идеи. Для строителей, архитекторов, дизайнеров и владельцев недвижимости.
Полезный сайт https://quickstudio.com.ua о ремонте и строительстве: пошаговые гиды, проекты домов, выбор материалов, расчёты и лайфхаки. Для начинающих и профессионалов.
Журнал о строительстве https://tfsm.com.ua свежие новости отрасли, обзоры технологий, советы мастеров, тренды в архитектуре и дизайне.
Женский сайт https://7krasotok.com о моде, красоте, здоровье, отношениях и саморазвитии. Полезные советы, тренды, рецепты, лайфхаки и вдохновение для современных женщин.
вывод из запоя круглосуточно
vivod-iz-zapoya-omsk003.ru
вывод из запоя круглосуточно омск
провайдеры интернета по адресу уфа
domashij-internet-ufa006.ru
проверить провайдера по адресу
Женские новости https://biglib.com.ua каждый день: мода, красота, здоровье, отношения, семья, карьера. Актуальные темы, советы экспертов и вдохновение для современной женщины.
Все главные женские https://pic.lg.ua новости в одном месте! Мировые и российские тренды, стиль жизни, психологические советы, звёзды, рецепты и лайфхаки.
Сайт для женщин https://angela.org.ua любого возраста — статьи о жизни, любви, стиле, здоровье и успехе. Полезно, искренне и с заботой.
Женский онлайн-журнал https://bestwoman.kyiv.ua для тех, кто ценит себя. Мода, уход, питание, мотивация и женская энергия в каждой статье.
Путеводитель по Греции https://cpcfpu.org.ua города, курорты, пляжи, достопримечательности и кухня. Советы туристам, маршруты, лайфхаки и лучшие места для отдыха.
Зависимость от алкоголя у женщин является серьезной проблемой, которая требует внимательного подхода к лечению. В Красноярске наркологическая клиника предлагает экстренный вывод из запоя, что особенно важно для женщин, часто сталкивающихся с обществом, осуждающим их проблему. Зависимость от алкоголя у женщин может развиваться быстрее, чем у мужчин, и проявляется специфическими симптомами, такими как подавленное настроение и беспокойство.Лечение алкоголизма включает detox программу и медицинские методы лечения, а также психотерапию при алкоголизме. Важно обеспечить поддержку семьи и включение в группы взаимопомощи, что позволяет создать комфортные условия для выздоровления. Реабилитация алкоголиков в Красноярске акцентирует внимание на восстановлении социальной активности, что особенно важно для женщин, оказавшихся в такой ситуации. экстренный вывод из запоя Красноярск Предотвращение зависимости и обращение за экстренной помощью — основные элементы в борьбе с алкоголизмом. Комплексное лечение к процессу восстановления обеспечит успешное восстановление и возвращение к нормальной жизни.
Honestly, I wasn’t expecting this, but it really caught my attention. The way everything came together so naturally feels both surprising and refreshing. Sometimes, you stumble across things without really searching, and it just clicks.testinggoeshow It reminds me of how little moments can have an unexpected impact
Компоненты
Выяснить больше – [url=https://kapelnicza-ot-zapoya-pervouralsk11.ru/]капельница от запоя цена первоуральск.[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-orenburg001.ru
вывод из запоя круглосуточно
Пребывание в стационаре обеспечивает круглосуточный мониторинг состояния, своевременное введение лекарств и защиту пациента от внешних факторов, провоцирующих срыв. Все палаты оснащены необходимым оборудованием, соблюдаются санитарные нормы, а условия размещения соответствуют медицинским стандартам.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-v-yaroslavle12.ru/]частная наркологическая клиника[/url]
подключить проводной интернет омск
domashij-internet-volgograd004.ru
провайдеры интернета омск
лечение запоя
vivod-iz-zapoya-minsk001.ru
экстренный вывод из запоя минск
Канал с обзорами и сравнениями грузовой техники для выбора и покупки.
Публикуем новости, технические характеристики, рыночную аналитику, советы по выбору для бизнеса.
У нас всегда актуальные цены и тренды рынка СНГ! Подпишись:
[url=https://t.me/s/kupit_gruzoviki/263]Поведенческие факторы в кабине оператора: Почему эргономика (цветные сенсорные дисплеи, подогрев) снижает ошибки на 25% (анализ систем Liebherr 1025 LTM vs Челябинец КС-55732)[/url]
лечение запоя оренбург
vivod-iz-zapoya-orenburg002.ru
вывод из запоя круглосуточно
Основной этап в лечении — детоксикация организма от токсичных веществ, вызывающих интоксикацию. В клинике применяют современные методы капельниц и медикаментозной поддержки, включая препараты для снятия абстинентного синдрома.
Исследовать вопрос подробнее – https://narkologicheskaya-klinika-v-murmanske12.ru/chastnaya-narkologicheskaya-klinika-v-murmanske
Работа клиники строится на принципах доказательной медицины и индивидуального подхода. При поступлении пациента осуществляется всесторонняя диагностика, включающая анализы крови, оценку психического состояния и анамнез. По результатам разрабатывается персонализированный курс терапии.
Разобраться лучше – [url=https://narkologicheskaya-klinika-v-ryazani12.ru/]chastnaya narkologicheskaya klinika rjazan'[/url]
Клеевая пробка напольная [url=http://probkovoe-pokritie1.ru/]http://probkovoe-pokritie1.ru/[/url] .
Купить паркетную доску. [url=https://parketnay-doska2.ru/]parketnay-doska2.ru[/url] .
интернет тарифы омск
domashij-internet-volgograd005.ru
интернет тарифы омск
Вызов нарколога возможен круглосуточно, что обеспечивает оперативное реагирование на критические ситуации. Пациенты и их родственники могут получить помощь в любое время, не дожидаясь ухудшения состояния.
Узнать больше – [url=https://narkolog-na-dom-kamensk-uralskij11.ru/]нарколог на дом срочно в каменске-уральском[/url]
вывод из запоя минск
vivod-iz-zapoya-minsk002.ru
вывод из запоя круглосуточно
вывод из запоя цена
vivod-iz-zapoya-orenburg003.ru
вывод из запоя круглосуточно
подключить интернет в квартиру омск
domashij-internet-volgograd006.ru
лучший интернет провайдер омск
Портал о строительстве https://ateku.org.ua и ремонте: от фундамента до крыши. Пошаговые инструкции, лайфхаки, подбор материалов, идеи для интерьера.
Строительный портал https://avian.org.ua для профессионалов и новичков: проекты домов, выбор материалов, технологии, нормы и инструкции.
Туристический портал https://deluxtour.com.ua всё для путешествий: маршруты, путеводители, советы, бронирование отелей и билетов. Информация о странах, визах, отдыхе и достопримечательностях.
Открой мир https://hotel-atlantika.com.ua с нашим туристическим порталом! Подбор маршрутов, советы по странам, погода, валюта, безопасность, оформление виз.
Ваш онлайн-гид https://inhotel.com.ua в мире путешествий — туристический портал с проверенной информацией. Куда поехать, что посмотреть, где остановиться.
Особенно важны первые дни пребывания, когда проводится диагностика, назначается медикаментозная поддержка и формируется план лечения. Компетентные врачи способны адаптировать программу под физическое и психоэмоциональное состояние пациента, учитывая как длительность употребления, так и возможные сопутствующие диагнозы. На этом этапе важно исключить риски осложнений и создать условия для безопасного перехода к следующему этапу — психологической реабилитации.
Изучить вопрос глубже – http://narkologicheskaya-klinika-tula10.ru/
экстренный вывод из запоя
vivod-iz-zapoya-minsk003.ru
лечение запоя
вывод из запоя
vivod-iz-zapoya-smolensk004.ru
вывод из запоя цена
кайт египет Кайтсерфинг и реклама: Эффективные методы рекламы
I believe what you typed was very logical. However, think about this, what if you added a little content? I mean, I don’t wish to tell you how to run your website, however suppose you added something that grabbed folk’s attention? I mean %BLOG_TITLE% is a little vanilla. You could glance at Yahoo’s home page and note how they create post titles to grab people interested. You might add a related video or a picture or two to grab people interested about everything’ve written. Just my opinion, it might make your posts a little livelier.
Best limo service near me
Химчистка мебели ростов Удаление пятен с мебели Ростов – сложная задача, требующая профессионального подхода. Не рискуйте испортить обивку – доверьте это дело специалистам.
продать мекинист Продам лекарства России – объявления о продаже лекарств в России должны соответствовать действующему законодательству.
дешевый интернет воронеж
domashij-internet-voronezh004.ru
лучший интернет провайдер воронеж
Строительный сайт https://diasoft.kiev.ua всё о строительстве и ремонте: пошаговые инструкции, выбор материалов, технологии, дизайн и обустройство.
кайт школа хургада Кайт школа “Дети Ветра”: Преимущества обучения у нас
Журнал о строительстве https://kennan.kiev.ua новости отрасли, технологии, советы, идеи и решения для дома, дачи и бизнеса. Фото-проекты, сметы, лайфхаки, рекомендации специалистов.
Сайт о строительстве https://domtut.com.ua и ремонте: практичные советы, инструкции, материалы, идеи для дома и дачи.
Вывод из запоя в Мурманске представляет собой комплекс мероприятий, направленных на оказание медицинской помощи пациентам, находящимся в состоянии алкогольного отравления или длительного употребления спиртного. Процедура проводится с целью стабилизации состояния организма, предупреждения осложнений и минимизации риска развития тяжелых последствий алкоголизма.
Подробнее – [url=https://vyvod-iz-zapoya-v-murmanske12.ru/]вывод из запоя в стационаре в мурманске[/url]
На строительном сайте https://eeu-a.kiev.ua вы найдёте всё: от выбора кирпича до дизайна спальни. Актуальная информация, фото-примеры, обзоры инструментов, консультации специалистов.
Строительный журнал https://inter-biz.com.ua актуальные статьи о стройке и ремонте, обзоры материалов и технологий, интервью с экспертами, проекты домов и советы мастеров.
Журнал о строительстве https://kennan.kiev.ua новости отрасли, технологии, советы, идеи и решения для дома, дачи и бизнеса. Фото-проекты, сметы, лайфхаки, рекомендации специалистов.
вывод из запоя
vivod-iz-zapoya-smolensk005.ru
лечение запоя
вывод из запоя
vivod-iz-zapoya-omsk001.ru
вывод из запоя круглосуточно
Сайт о ремонте https://mia.km.ua и строительстве — полезные советы, инструкции, идеи, выбор материалов, технологии и дизайн интерьеров.
Сайт о ремонте https://rusproekt.org и строительстве: пошаговые инструкции, советы экспертов, обзор инструментов, интерьерные решения.
Всё для ремонта https://zip.org.ua и строительства — в одном месте! Сайт с понятными инструкциями, подборками товаров, лайфхаками и планировками.
Полезный сайт для ремонта https://rvps.kiev.ua и строительства: от черновых работ до отделки и декора. Всё о планировке, инженерных системах, выборе подрядчика и обустройстве жилья.
Автомобильный портал https://just-forum.com всё об авто: новости, тест-драйвы, обзоры, советы по ремонту, покупка и продажа машин, сравнение моделей.
Назначение
Узнать больше – http://kapelnicza-ot-zapoya-pervouralsk11.ru
mostbet aviator oyunu [url=http://mostbet4054.ru]http://mostbet4054.ru[/url]
приемка квартир от застройщика Прокат перфоратора – сверление отверстий в бетоне и кирпиче без лишних усилий.
кайт хургада Кайт Хургада: Отдохните и покатайтесь! Хургада – это не только кайтсерфинг, но и отличный пляжный отдых.
подключить домашний интернет воронеж
domashij-internet-voronezh005.ru
интернет домашний воронеж
Современный женский журнал https://superwoman.kyiv.ua стиль, успех, любовь, уют. Новости, идеи, лайфхаки и мотивация для тех, кто ценит себя и своё время.
Онлайн-портал https://spkokna.com.ua для современных родителей: беременность, роды, уход за малышами, школьные вопросы, советы педагогов и врачей.
Онлайн-журнал https://eternaltown.com.ua для женщин: будьте в курсе модных новинок, секретов красоты, рецептов и психологии.
Сайт для женщин https://ww2planes.com.ua идеи для красоты, здоровья, быта и отдыха. Тренды, рецепты, уход за собой, отношения и стиль.
Сайт для женщин https://womanfashion.com.ua которые ценят себя и своё время. Мода, косметика, вдохновение, мотивация, здоровье и гармония.
Играть в онлайн казино Нью Ретро
Казино Нью Ретро (Ньюретро) предлагает игрокам увлекательные азартные развлечения в современном формате. Здесь собраны сотни игр от ведущих провайдеров, включая слоты, рулетку, блэкджек и живые дилеры. Играть можно как на реальные деньги, так и бесплатно в демо-режиме.
Обзор официального сайта Нью Ретро
Официальный сайт Нью Ретро выполнен в стиле ретро с элементами современного дизайна. Интерфейс интуитивно понятен: главная страница содержит разделы с играми, акциями, турнирами и поддержкой. Сайт адаптирован под ПК и мобильные устройства, что делает игру комфортной в любом месте.
Лицензия онлайн-заведения
Нью Ретро работает на основании международной лицензии, выданной авторитетным регулятором (например, Кюрасао или Мальта). Это гарантирует честность игр и защиту данных игроков. Лицензионную информацию можно найти в подвале сайта.
Бонусы для постоянных клиентов и новых игроков
Казино предлагает щедрые бонусы:
• Приветственный пакет – бонус за первые депозиты (например, 100% + фриспины).
• Кешбэк – возврат части проигранных средств.
• VIP-программа – эксклюзивные подарки для постоянных игроков.
Бесплатная игра в демо-режиме
Перед ставками на деньги можно попробовать игры бесплатно в демо-режиме. Это отличный способ изучить правила и стратегии без риска.
Провайдеры
В Нью Ретро представлены игры от топовых разработчиков: NetEnt, Pragmatic Play, Play’n GO, Push Gaming, Novomatic и других.
Играть в слоты бесплатно в демо-режиме
Демо-версии слотов доступны без регистрации. Популярные игры: Book of Dead, Gates of Olympus, Starburst, Mega Moolah.
Способы регистрации и входа на сайт Нью Ретро
Зарегистрироваться можно:
• Через email и пароль.
• Через соцсети (Google, Telegram).
• По номеру телефона (SMS-подтверждение).
Верификация на сайте
Для вывода средств требуется верификация:
1. Подтверждение email/телефона.
2. Загрузка документов (паспорт, платежная карта).
3. Проверка занимает до 24 часов.
Другие игры в казино Нью Ретро
Помимо слотов, доступны:
• Рулетка, блэкджек, покер.
• Игры с живыми дилерами.
• Викторины и квизы.
Турниры и лотереи на Ньюретро
Казино регулярно проводит турниры с призовыми фондами и лотереи с розыгрышем денег и гаджетов. Условия участия – активная игра и выполнение заданий.
Мобильные приложения
Нью Ретро предлагает мобильное приложение для iOS и Android, где доступны все функции сайта.
Минимальный депозит
От 50-100 рублей (зависит от платежной системы).
Максимальные лимиты
Лимиты на вывод зависят от статуса игрока (обычно до 1 000 000 рублей в месяц).
Способы пополнения игрового счета
Доступные методы:
• Банковские карты (Visa/Mastercard).
• Электронные кошельки (Qiwi, WebMoney, Skrill).
• Криптовалюты (Bitcoin, Ethereum).
Вывод средств из заведения казино Ньюретро
Вывод занимает от 1 часа до 3 дней. Минимальная сумма – 500 рублей.
Служба поддержки игроков 24/7
Поддержка работает круглосуточно через:
• Онлайн-чат.
• Email.
• Telegram-бот.
Плюсы и минусы игры в казино для игроков
Плюсы:
? Много бонусов.
? Демо-режим.
? Быстрые выплаты.
Минусы:
? Ограниченные страны для регистрации.
? Долгая верификация.
Часто задаваемые вопросы
1. Как вывести деньги?
– Через тот же метод, которым делали пополнение.
2. Есть ли мобильное приложение?
– Да, для iOS и Android.
Последние отзывы о Нью Ретро
? Алексей, 28 лет: “Быстрые выплаты, но верификация затянулась”.
? Мария, 35 лет: “Нравится выбор слотов и турниры”.
Вывод
Нью Ретро https://newretrocasinow.com – надежное казино с богатой игровой коллекцией и бонусами. Подходит для новичков и опытных игроков.
Первое, что необходимо уточнить перед вызовом — наличие у врача лицензии и профильного медицинского образования. Только сертифицированный нарколог может назначить препараты, поставить капельницу и провести детоксикацию без ущерба для здоровья пациента.
Изучить вопрос глубже – http://narkolog-na-dom-nizhnij-tagil11.ru
Honestly, I wasn’t expecting this, but it really caught my
attention. The way everything came together so naturally feels both surprising and refreshing.
Sometimes, you stumble across things without really searching,
and it just clicks. It reminds me of how little moments can have an unexpected impact
вывод из запоя круглосуточно смоленск
vivod-iz-zapoya-smolensk006.ru
экстренный вывод из запоя
Капельница от запоя в Мурманске является одной из наиболее востребованных процедур для снятия острого состояния алкогольной интоксикации. Эта методика позволяет быстро вывести токсины из организма, нормализовать водно-солевой баланс и улучшить самочувствие пациента. Современная капельная терапия считается эффективным средством в лечении запоя, обеспечивая поддержку жизненно важных функций и минимизируя риски осложнений.
Подробнее можно узнать тут – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя на дому мурманск.[/url]
лечение запоя омск
vivod-iz-zapoya-omsk002.ru
вывод из запоя омск
Замковая инженерная доска Дуб в Декор Экспо. [url=http://inzenernay-doska1.ru/]http://inzenernay-doska1.ru/[/url] .
Женский онлайн-журнал https://abuki.info мода, красота, здоровье, психология, отношения и вдохновение. Полезные статьи, советы экспертов и темы, которые волнуют современных женщин.
Современный авто портал https://simpsonsua.com.ua автомобили всех марок, тест-драйвы, лайфхаки, ТО, советы по покупке и продаже. Для тех, кто водит, ремонтирует и просто любит машины.
Актуальные новости https://uapress.kyiv.ua на одном портале: события России и мира, интервью, обзоры, репортажи. Объективно, оперативно, профессионально. Будьте в курсе главного!
Онлайн авто портал https://sedan.kyiv.ua для автолюбителей и профессионалов. Новинки автоиндустрии, цены, характеристики, рейтинги, покупка и продажа автомобилей, автофорум.
Информационный портал https://mediateam.com.ua актуальные новости, аналитика, статьи, интервью и обзоры. Всё самое важное из мира политики, экономики, технологий, культуры и общества.
Химчистка мебели ростов Химчистка штор Ростов – удаление пыли и освежение внешнего вида.
Запой – это крайняя степень алкоголизма, требующая профессионального вмешательства. Нарколог на дом в Волгограде – ваш выбор. Лечение на дому помогает избежать стресса и сохранить анонимность, получив необходимую помощь. Важно как можно быстрее начать лечение, чтобы избежать токсического воздействия алкоголя на организм. Лечение на дому направлено на очищение организма, восстановление баланса и нормальную работу органов. Для достижения долгосрочного результата важно сочетать медикаментозную терапию и психологическую поддержку. Начинаем с детоксикации, используя капельницы и современные препараты.
Подробнее тут – [url=https://vyvod-iz-zapoya-volgograd0.ru/]вывод. из. запоя. волгоград.[/url]
Точная диагностика позволяет подобрать индивидуальную программу лечения, что значительно повышает шансы на успешное выздоровление.
Получить больше информации – [url=https://narkologicheskaya-klinika-v-murmanske12.ru/]наркологические клиники алкоголизм мурманская область[/url]
домашний интернет воронеж
domashij-internet-voronezh006.ru
подключить интернет тарифы воронеж
продать лекарства Беларусь Как продать препараты: Правовые аспекты и безопасность Продажа лекарственных препаратов – это сфера, строго регулируемая законодательством. Несоблюдение установленных правил может привести к административной и уголовной ответственности. Поэтому, прежде чем задумываться о продаже препаратов, необходимо четко понимать правовые аспекты и возможные риски. Законные способы продажи препаратов: Аптеки и аптечные пункты: Единственным законным способом продажи лекарственных препаратов является реализация через аптеки и аптечные пункты, имеющие соответствующую лицензию на фармацевтическую деятельность. Интернет-аптеки: Некоторые аптеки имеют право осуществлять продажу препаратов через интернет, при условии соблюдения всех требований законодательства, включая наличие лицензии и обеспечение надлежащих условий хранения и доставки препаратов. Незаконные способы продажи препаратов: Продажа с рук: Категорически запрещается продажа лекарственных препаратов с рук, через объявления в интернете или другие неофициальные каналы. Перепродажа рецептурных препаратов: Продажа лекарственных препаратов, отпускаемых по рецепту врача, лицам, не имеющим соответствующего рецепта, является незаконной. Продажа контрафактных препаратов: Продажа поддельных лекарственных препаратов является уголовным преступлением. Риски незаконной продажи препаратов: Уголовная ответственность: Незаконная продажа лекарственных препаратов может повлечь за собой уголовную ответственность в виде штрафа, исправительных работ или лишения свободы. Административная ответственность: Нарушение правил продажи лекарственных препаратов может привести к административному штрафу. Нанесение вреда здоровью: Продажа некачественных или поддельных препаратов может нанести серьезный вред здоровью покупателей. Альтернативные варианты: Возврат в аптеку: Если у вас остались неиспользованные препараты, узнайте в аптеке, принимают ли их обратно. Утилизация: Если препараты не подлежат возврату, их необходимо правильно утилизировать.
прокат строительных инструментов Тепловизионное обследование – обнаружение скрытых теплопотерь и дефектов изоляции.
mwq 1xbet [url=http://www.arabic1xbet.com]mwq 1xbet[/url] .
Выездной нарколог в Туле предоставляет профессиональную помощь тем, кто переживает проблемы с наркоманией и алкоголизмом. Лечение зависимости нуждается в персонализированном подходе, и вызов нарколога на дом – это практичное решение для пациентов. Центр реабилитации зависимостей в Туле предлагает конфиденциальное лечение и консультации нарколога. Домашняя реабилитация позволяет пройти курс психотерапии при зависимости в домашней обстановке. Выездная медицинская помощь включает в себя как телесное, так и психологическую поддержку. Профилактика зависимости также является ключевым моментом в противостоянии алкоголизму и наркомании. Помощь алкоголикам и их близким – это задача профессионалов, которые готовы протянуть руку помощи в трудную минуту. vivod-iz-zapoya-tula004.ru
Запой – критическая фаза зависимости, когда организм не может регулировать потребление алкоголя. Нарколог поможет провести детоксикацию и стабилизировать состояние в привычной обстановке, сохраняя конфиденциальность. Быстрое вмешательство при запое очень важно, чтобы избежать серьезных последствий для здоровья. Нарколог на дому поможет вывести токсины, восстановить водно-электролитный баланс и нормализовать работу органов. Вывод из запоя на дому включает медикаментозную терапию и психологическую поддержку для долгосрочной ремиссии. Сначала очищают организм от токсинов с помощью внутривенных инфузий и других современных препаратов.
Подробнее – https://vyvod-iz-zapoya-volgograd0.ru/vyvod-iz-zapoya-kruglosutochno-volgograd/
вывод из запоя круглосуточно омск
vivod-iz-zapoya-omsk003.ru
экстренный вывод из запоя омск
Нарколог на дому проводит тщательный осмотр, собирает анамнез и назначает необходимые лабораторные исследования. Это позволяет выявить сопутствующие патологии и скорректировать тактику лечения.
Выяснить больше – https://narkolog-na-dom-v-yaroslavle12.ru/vyzov-narkologa-na-dom-v-yaroslavle
приемка квартир от застройщика Прокат инструментов, прокат строительных инструментов, аренда инструментов, приемка квартир, приемка домов, приемка квартир от застройщика, тепловизионное обследование.
Online casinos are evolving so fast! It’s cool seeing platforms like phswerte app casino blend tradition with modern tech – a secure, curated experience seems key these days. Registration processes should prioritize trust & verification!
подключить интернет
domashij-internet-chelyabinsk004.ru
домашний интернет
Клиники предлагают реабилитацию зависимых, которая включает лечение зависимости и консультации психолога. Процедура кодирования также является популярной мерой, помогающей снизить тягу к алкоголю. Круглосуточные клиники обеспечивают конфиденциальное лечение и помощь специалистов, что позволяет пациентам ощущать комфортно и безопасно. вывод из запоя круглосуточно Социальная адаптация и поддержка после лечения — необходимые элементы, обеспечивающие успешной интеграции в общество. Лечение алкоголизма в Туле становится доступным благодаря различным программам и методикам, которые помогают справиться с этой серьезной проблемы.
1win pul çıxarma [url=1win3040.com]1win pul çıxarma[/url]
1win qeydiyyat zamanı bonus [url=https://1win3039.com/]https://1win3039.com/[/url]
вывод из запоя круглосуточно
vivod-iz-zapoya-orenburg001.ru
вывод из запоя круглосуточно оренбург
Нарколог на дому проводит тщательный осмотр, собирает анамнез и назначает необходимые лабораторные исследования. Это позволяет выявить сопутствующие патологии и скорректировать тактику лечения.
Получить больше информации – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]vyzov-narkologa-na-dom jaroslavl'[/url]
Новости Украины https://pto-kyiv.com.ua и мира сегодня: ключевые события, мнения экспертов, обзоры, происшествия, экономика, политика.
Современный мужской портал https://kompanion.com.ua полезный контент на каждый день. Новости, обзоры, мужской стиль, здоровье, авто, деньги, отношения и лайфхаки без воды.
Сайт для женщин https://storinka.com.ua всё о моде, красоте, здоровье, психологии, семье и саморазвитии. Полезные советы, вдохновляющие статьи и тренды для гармоничной жизни.
Новостной портал https://thingshistory.com для тех, кто хочет знать больше. Свежие публикации, горячие темы, авторские колонки, рейтинги и хроники. Удобный формат, только факты.
Следите за событиями https://kiev-pravda.kiev.ua дня на новостном портале: лента новостей, обзоры, прогнозы, мнения. Всё, что важно знать сегодня — быстро, чётко, объективно.
Борьба с наркотической зависимостью требует системного подхода и участия опытных специалистов. Важно понимать, что лечение наркомании — это не только снятие ломки, но и длительная психотерапия, обучение новым моделям поведения, работа с семьёй. Согласно рекомендациям Минздрава РФ, наиболее стабильные результаты достигаются при прохождении курса реабилитации под наблюдением профессиональной команды в специализированном центре.
Исследовать вопрос подробнее – [url=https://lechenie-narkomanii-vladimir10.ru/]наркологическое лечение наркомания в владимире[/url]
Terve!!
Pelisäännöt casino ympäristössä ovat selkeät ja kaikkien pelaajien noudatettavissa. Pelisäännöt casino toiminnassa varmistavat reilun pelaamisen. [url=https://www.reallivecasino.cfd/ikarajat-ja-saannot.html]casino neuvonta[/url] Tutustu sääntöihin etukäteen ja pelaa vastuullisesti sovittujen ohjeiden mukaan.
Lue linkki – https://www.reallivecasino.cfd/ikarajat-ja-saannot.html
casino savonlinna
casino ГҐrhus poker
kometa casino
Onnea!
Высокий уровень лечения обеспечивается квалификацией врачей, имеющих опыт работы в области наркологии, а также современным медицинским оборудованием, позволяющим проводить диагностику и лечение на самом высоком уровне. Врачи регулярно повышают квалификацию, участвуя в конференциях и обучающих программах. Подробности о квалификации специалистов доступны на портале медицинского сообщества.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]наркологическая клиника цены в каменске-уральском[/url]
Для успешного лечения зависимости необходима тщательная диагностика. В клинике проводят полное обследование пациента, включающее:
Получить дополнительные сведения – http://
интернет тарифы челябинск
domashij-internet-chelyabinsk005.ru
провайдеры интернета челябинск
Капельница для снятия запоя в Туле: стоимость и мнения В Туле услуги нарколога на дом становятся все более популярными. Множество людей нуждаются в помощи при алкогольной зависимости и ищут выход из сложной ситуации. Вызов нарколога на дом представляет собой комфортное решение получить медицинскую помощь, не выходя из дома. Капельница от запоя эффективно помогает в детоксикации организма и уменьшает проявления.Стоимость капельницы может различаться в зависимости от клиники, но в среднем составляет примерно 3000-6000 рублей. Отзывы о капельнице в основном положительные: пациенты отмечают быстрое улучшение состояния и уменьшение влечения к алкоголю. Экстренная помощь при запое способна сохранить здоровье.Лечение алкоголизма без лишних слов — ключевой фактор, так как многие чувствуют неловкость из-за своей зависимости. Услуги нарколога в Туле включают не только капельницы, но и реабилитацию после алкоголя. Помощь при запое доступна для всех, кто стремится к выздоровлению. нарколог на дом анонимно тула
проект перепланировки цена [url=http://belbeer.borda.ru/?1-6-0-00002270-000-0-0-1751553723/]проект перепланировки цена[/url] .
завинчивающиеся сваи [url=https://ostankino-svai.ru /]ostankino-svai.ru [/url] .
гастро-вечеринка Воронеж заказать кейтеринг
срок спирали мирена https://spiral-mirena1.ru
узи аппарат купить цена [url=http://kupit-uzi-apparat8.ru]http://kupit-uzi-apparat8.ru[/url] .
mostbet aviator [url=https://mostbet4049.ru/]https://mostbet4049.ru/[/url]
вывод из запоя цена
vivod-iz-zapoya-orenburg002.ru
лечение запоя
Video chat with girl – meet, chat, flirt! Private broadcasts, thousands of users online. No limits, free and no registration. Start a dialogue right now.
Эффективная накрутка ПФ https://nakrutka-pf-seo.ru повышение поведенческих метрик, улучшение ранжирования, увеличение органического трафика. Безопасно, анонимно, с гарантией результата.
аппарат узи стоимость оборудования [url=https://kupit-uzi-apparat9.ru/]https://kupit-uzi-apparat9.ru/[/url] .
ремонт замена стиральных машин ремонт стиральных машин beko
ремонт стиральных машин bosch ремонт двигателя стиральной машины
ремонт стиральной машины candy телефон мастера по ремонту стиральных машин
купить профилированную трубу Профнастил С8: экономичный и практичный материал для кровли и облицовки Профнастил С8 – это универсальное решение для кровли, облицовки стен и строительства заборов. Он отличается легкостью, прочностью, долговечностью и доступной ценой. Широкая цветовая гамма позволяет подобрать оптимальный вариант для любого архитектурного стиля.
При запое организм теряет контроль над употреблением алкоголя. В Волгограде вызов нарколога на дом поможет быстро стабилизировать состояние. На дому можно получить квалифицированную помощь, провести детоксикацию и сохранить анонимность. Не затягивайте с вызовом нарколога, чтобы избежать необратимых последствий для организма. Вывод токсинов, восстановление баланса и нормализация работы организма – задачи нарколога на дому. Медикаменты и психология – основа лечения запоя на дому. Детоксикация – первый этап лечения, который проводится с помощью современных препаратов.
Выяснить больше – [url=https://vyvod-iz-zapoya-volgograd0.ru/]вывод из запоя в волгограде[/url]
«ВладимирМед» основана группой врачей-наркологов и психотерапевтов, объединивших опыт работы в государственных и частных учреждениях. Мы предлагаем не просто преодоление запоя, а глубокую комплексную реабилитацию, включающую медико-психологическую оценку и долгосрочное сопровождение. Наша цель — восстановление здоровья на физическом и эмоциональном уровнях, возвращение пациента к полноценной социальной жизни без рецидивов.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-vladimir10.ru/]наркологическая клиника цены[/url]
провайдеры интернета челябинск
domashij-internet-chelyabinsk006.ru
подключить интернет в челябинске в квартире
Алкогольная зависимость серьезная проблема , требующая профессиональной помощи . В владимире работают специализированные центры по помощи алкоголикам, предлагающие экстренный вывод из запоя и лечение алкоголизма . При алкогольном отравлении необходимо быстро определить симптомы и обратиться за медицинской помощью . Квалифицированные наркологи в владимире предлагают консультации, обеспечивая безопасное восстановление после запоя и помощь при похмелье. Процесс реабилитации от алкоголизма включает программы реабилитации для зависимых , помогая не только пациентам , но и оказывая помощь родственникам алкоголиков. Профилактика алкогольных заболеваний также имеет большое значение в предотвращении рецидивов .
служба по контракту оренбург Финансовая поддержка контрактников: Контрактники в Оренбургской области получают достойную заработную плату, размер которой зависит от звания, должности и выслуги лет. Кроме того, предусмотрены различные надбавки и премии.
накрутка пф яндекс Анализ и оптимизация: ключ к успеху Регулярно анализируйте ПФ своего сайта и выявляйте слабые места. Улучшайте контент, оптимизируйте страницы и делайте сайт удобным для пользователей. Это – самый надежный путь к успеху в SEO.
экстренный вывод из запоя
vivod-iz-zapoya-orenburg003.ru
вывод из запоя оренбург
Возможные признаки
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-tula10.ru/]наркологическая клиника[/url]
mostbet az casino [url=https://mostbet4055.ru/]https://mostbet4055.ru/[/url]
Восстановление после запоя: шаги к нормальной жизни в владимире Проблема алкоголизма затрагивает множество людей, и восстановление после запоя является важным этапом на пути к трезвому образу жизни. В владимире доступны многообразные услуги в области наркологии, включая консультации у наркологов и выездные медицинские услуги. Нарколог на дом клиника Медицинские учреждения предлагают реабилитационные программы, которые включают психотерапию и поддержку в эмоциональном плане. Поддержка семьи также играет ключевую роль в процессе реабилитации. Группы поддержки и кризисные центры в владимире предоставляют помощь зависимым, способствуя их социальной адаптации. Важно обратиться к специалистам для получения помощи и начать путь к здоровой жизни.
1win az bank transfer [url=https://1win3037.com/]1win az bank transfer[/url]
Обширные исследования показывают, что качественная детоксикация снижает риск развития осложнений и способствует скорейшему восстановлению здоровья. Более подробная информация о методах детоксикации доступна на сайте Министерства здравоохранения РФ.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-nizhnij-tagil11.ru/]срочный вывод из запоя[/url]
culinary recipes https://retetesimple.com for every day: breakfasts, lunches, dinners, desserts and drinks. Step-by-step preparation, photos and tips.
downloading files https://all-downloaders.com from popular video services
Клиника располагает изолированными палатами с возможностью круглосуточного мониторинга состояния пациента. Оборудование соответствует гигиеническим требованиям и регулярно обновляется. В лечебный процесс включены:
Подробнее – [url=https://narkologicheskaya-klinika-v-ryazani12.ru/]наркологические клиники алкоголизм[/url]
Компоненты
Получить дополнительную информацию – https://kapelnicza-ot-zapoya-pervouralsk11.ru/kapelniczy-ot-zapoya-na-domu-v-pervouralske/
tahmil barnamaj 888starz [url=https://egypt888starz.net]tahmil barnamaj 888starz[/url] .
экстренный вывод из запоя
vivod-iz-zapoya-smolensk004.ru
лечение запоя смоленск
Для проведения процедуры используются стерильные растворы, а подбор компонентов осуществляется с учётом индивидуального состояния пациента, что позволяет минимизировать побочные эффекты и повысить эффективность терапии.
Получить больше информации – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя анонимно в мурманске[/url]
купить профилированную трубу Профилированная труба: универсальный материал для конструкций Профилированная труба – это универсальный строительный материал, который используется для создания каркасов, ограждений, навесов и других конструкций.
лазерная резка на металле нужна лазерная резка металла
После устранения острой зависимости важным этапом становится реабилитация. Она включает восстановление социальных навыков, обучение методам преодоления стрессов без употребления психоактивных веществ.
Получить больше информации – [url=https://narkologicheskaya-klinika-v-murmanske12.ru/]частная наркологическая клиника[/url]
типография напечатать типография печать
Для вашего удобства и прозрачности планирования лечения мы собрали ориентировочные цены на ключевые процедуры и форматы оказания помощи. Это позволит заранее оценить бюджет и подобрать оптимальный вариант терапии в зависимости от степени абстинентного синдрома и индивидуальных потребностей пациента.
Изучить вопрос глубже – http://narkolog-na-dom-ramenskoe4.ru
Специалист по наркологии — это медицинский работник, который обеспечивает поддержку людям, страдающим от зависимостей. Лечение зависимостей включает в себя детоксикацию, медикаменты и психотерапию. Необходимо обратиться за консультацией нарколога для определения индивидуального плана реабилитации. Семейная поддержка играет ключевую роль в выздоровлении, а группы взаимопомощи помогают адаптироваться в обществе. Профилактика зависимостей также важна, чтобы снизить риск рецидивов. Обращение к профессионалам на vivod-iz-zapoya-vladimir006.ru гарантирует качественную медицинскую помощь и поддержку на каждом этапе лечения.
накрутка пф яндекс “Белые” методы: фокус на пользователя Вместо того, чтобы пытаться обмануть поисковую систему, лучше сосредоточиться на улучшении пользовательского опыта. Создавайте качественный и полезный контент, оптимизируйте сайт под мобильные устройства, улучшайте скорость загрузки страниц и обеспечивайте удобную навигацию. Это – долгосрочная стратегия, которая принесет стабильные результаты.
служба по контракту оренбург Как поступить на службу по контракту в Оренбурге? Процесс поступления на службу по контракту включает в себя несколько этапов: подача заявления, прохождение медицинского освидетельствования и профессионального отбора, заключение контракта.
Одним из ключевых направлений является проведение капельниц, призванных вывести токсины из организма и нормализовать водно-электролитный баланс. Используемые препараты и состав растворов подбираются индивидуально, исходя из клинической картины и истории болезни пациента.
Разобраться лучше – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]нарколог на дом вывод из запоя в ярославле[/url]
Когда организм уже не может обходиться без алкоголя, возникает запой. Вызов нарколога на дом в Волгограде – это безопасно и эффективно. Нарколог приедет на дом, проведет детоксикацию и поможет стабилизировать состояние, не нарушая привычный ритм жизни. Своевременная помощь нарколога поможет избежать осложнений, вызванных запоем. Дома нарколог поможет очистить организм и восстановить его нормальную работу. Избавление от запоя на дому – это сочетание лекарств и психологической помощи. Сначала нужно очистить организм от токсинов, и в этом помогут специальные препараты.
Получить больше информации – [url=https://vyvod-iz-zapoya-volgograd0.ru/]вывод из запоя цены волгоград[/url]
Установка оптоволоконного интернета в Екатеринбурге — это выбор, которое приобретает все большую популярность среди населения и коммерческих организаций. Екатеринбургие провайдеры предлагают разнообразные тарифные планы на интернет, обеспечивая высокую скорость и стабильность соединения. Интернет на основе оптоволокна, благодаря современным технологиям, способен обеспечить значительно более высокую скорость по сравнению с традиционными методами подключения. Это особенно важно для интернета для бизнеса, где стабильность и высокая скорость являются основными требованиями. Выбирая провайдера, стоит обратить внимание на отзывы и изучить сравнение тарифов и предоставляемых услуг. Процесс установки интернета, как правило, происходит быстро и без проблем, что делает подключение удобным. Оптоволоконный интернет имеет множество преимуществ: высокая скорость интернета, низкие задержки и возможность подключения большого количества устройств. Если вы находитесь в поиске надежного интернет-провайдера, рекомендуем посетить сайт domashij-internet-ekaterinburg004.ru для получения более подробной информации и выбора лучшего тарифа для вашей квартиры или компании.
лечение запоя
vivod-iz-zapoya-smolensk005.ru
экстренный вывод из запоя
вывод из запоя круглосуточно
narkolog-krasnodar001.ru
лечение запоя краснодар
накрутка пф яндекс ПФ – это важно, но не все Яндекс действительно учитывает ПФ при ранжировании сайтов. Но это лишь один из множества факторов. Нельзя забывать о качестве контента, оптимизации, ссылочном профиле и других важных аспектах.
1win əlaqə [url=https://www.1win3042.com]1win əlaqə[/url]
BK
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Не упусти важное! – https://www.sm2itunisie.com/electrothermie-toutes-industries/electrothermie-2
медицинское оборудование узи [url=http://www.kupit-uzi-apparat10.ru]медицинское оборудование узи[/url] .
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Более подробно об этом – https://mevie-pro.com/mc7e77ybinmp312gewmal92yfhtf4e3qrc247cz7
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Подробная информация доступна по запросу – https://sabahi-sabahi.com/2021/01/05/%E2%98%86%E9%BB%92%E8%B1%86%E2%98%86
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Почему это важно? – https://www.consultrh.fr/project-details/campus-cafeteria
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Практические советы ждут тебя – https://www.bignewscentral.com/a-trip-to-legoland-california
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Изучить аспект более тщательно – https://lemondeinfos.com/sample-page
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Секреты успеха внутри – https://aocuoiduongthanh.com/chao-moi-nguoi
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Ссылка на источник – https://assuredsystech.com/eko-sapien-quis-porttitor-ipsum-etilk-3
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Все материалы собраны здесь – http://club-retraites.com/que-proposent-les-clubs-de-retraites-corses.php
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Читать дальше – https://axelzamudio.com/podcast/episode/como-se-vive-el-cancer-de-mama
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Узнай первым! – https://blog.kingwatcher.com/chess-power-rankings-april-2023-nakamura-enters-top-five
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Узнать напрямую – https://kalyankesari.com/?p=15453
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Смотрите также – https://catchii.com/catchii-magazine-c
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Получить полную информацию – https://aboutautomobile.ru/?paged=26