
AlphaGo其实很简单~
摘要
由于其巨大的搜索空间以及评估棋盘状态和落子的难度,围棋一直被认为是人工智能经典游戏中最具挑战性的游戏。在这篇文章里,作者介绍了一种新的AI围棋方法,它使用“价值网络”来评估棋盘位置和“策略网络”来选择落子。主模型以深度神经网络为主,训练由对人类专家的经验进行监督学习和自对弈的强化学习组成。研究者将训练成的价值网络、策略网络应用到蒙特卡洛搜索的过程中,从而增加了每个落子的价值。使用这种搜索算法,AlphaGo对其他围棋程序的胜率达到了99.8%,并以5比0击败了人类欧洲围棋冠军。
技术路线
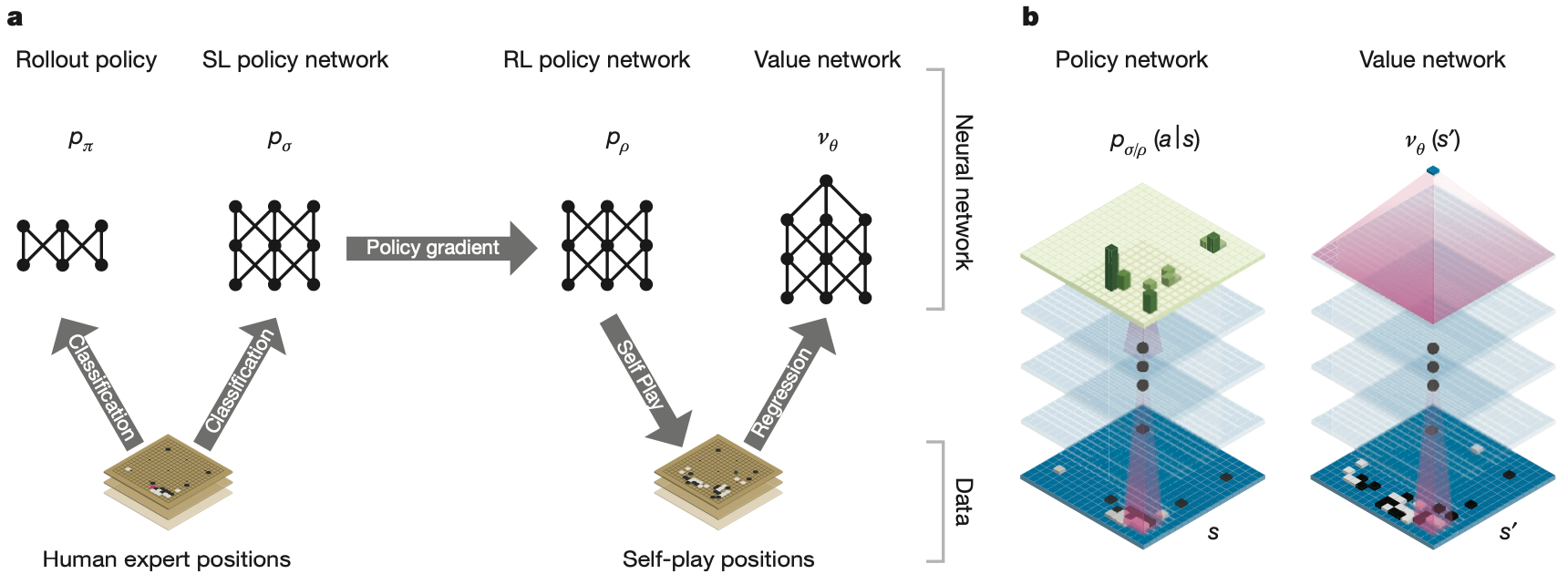
图a:p_{\pi} 和 p_{\sigma} 使用监督学习学习人类专家在不同棋盘状态下的落子,p_{\pi} 是一个更加轻量级的网络。p_{\rho} 的网络架构和 p_{\sigma} 想同,并且参数被初始化为训练好的p_{\sigma} 的参数,然后通过策略梯度强化学习自对弈进行改进,以最大化获胜的概率。通过使用强化学习策略网络 p_{\rho} 自对弈生成一个新的数据集。最后,回归训练一个价值网络 v_{\theta},以根据新数据集中的数据学习当前棋盘玩家获胜的期望。
图b:AlphaGo 中使用的神经网络架构的示意图。策略网络将棋盘状态 s 作为输入,通过参数为 \sigma 或 \rho的策略网络输出概率分布 p_{\sigma}(a|s) 或 p_{\rho}(a|s) 表示为了取胜当前棋盘每个合法位置的落子收益期望。价值网络类似地使用多个卷积层,参数为 \theta,输出一个标量值 v_{\theta}(s') 来预测当前棋盘状态的获胜期望。
策略网络的监督学习
训练的第一个阶段是使用监督学习学习人类专家的经验。SL 策略网络 p_{\sigma}(a|s) 在权重为 \sigma 的卷积层和非线性整流器之间交替,最终的 softmax 层输出所有合法落子位置的概率分布。策略网络的输入是棋盘状态的简单表示。策略网络在随机采样的状态-动作对上进行训练,使用随机梯度上升来最大化在状态 s 中选择的人类动作的可能性
\Delta\sigma\propto\frac{\partial p_{\sigma}(a|s)}{\partial\sigma} 作者从 KGS Go Server 的 3000 万个状态-动作训练了一个 13 层的策略网络,称为 SL(SupervisedLearning) 策略网络。该网络预测在测试集上的准确率为 57.0%,远远高于基准模型的 44.4%。然而,准确性的小幅提高会导致计算开销的增长,较大的网络可以获得更好的准确性,但在搜索过程中评估速度较慢。作者还训练了一个更快但不太准确的策略网络 p_{\pi}(a|s),使用更轻量级的特征的线性 softmax 达到了 24.2% 的准确率。p_{\pi}(a|s)选择一个动作只需要2 \mu s,比p_{\sigma}(a|s) 的3 ms要快得多。
策略网络的强化学习
训练的第二阶段旨在通过策略梯度强化学习 (RL) 改进策略网络。RL 策略网络 p_{\rho} 在结构上与 SL 策略网络相同,并且其权重 \rho 被初始化为相同的值,即 \rho = \sigma。使用随机化的动作采样策略放置过拟合,每个episode结束的时候设定胜方的reward为1,负方的reward为-1。然后在每个时间步 t,通过随机梯度上升最大化获胜的期望
\Delta\sigma\propto\frac{\partial p_{\rho}(a_t|s_t)}{\partial\sigma}z_t.值网络的强化学习
训练的最后一个阶段是评估每个棋盘状态获胜的期望,估计一个价值函数 v^p(s),训练时双方玩家都使用策略 p 预测的位置 s 的结果
v^p(s)=\mathbb{E}[z_t=z|s_t=s,a_{t\cdots T}\sim p]. RL价值网络与策略网络有相似的结构,参数为 \theta,使用策略梯度的MSE进行更新
\Delta\sigma\propto\frac{\partial v_{\theta}(s)}{\partial\theta}(z-v_{\theta}(s)).蒙特卡洛搜索
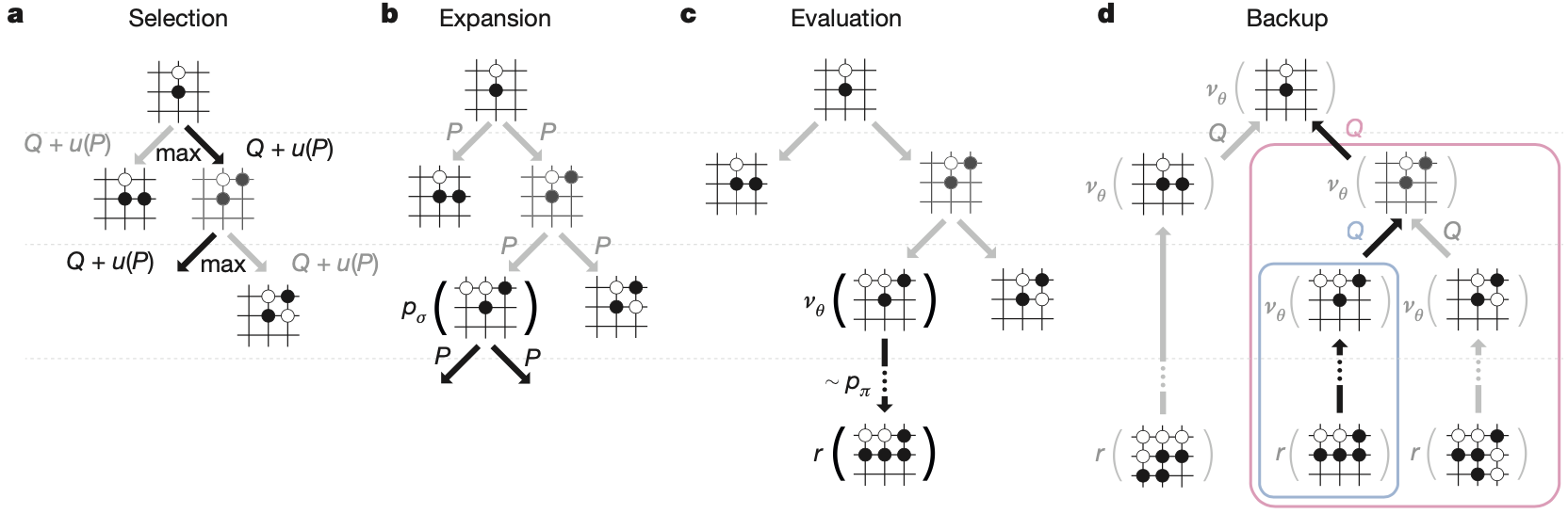
在对战中,AlphaGo 在 MCTS 算法中结合了策略和价值网络,该算法通过前瞻搜索来选择动作。搜索树的每条边 (s, a) 存储一个动作值 Q(s, a)、访问计数 N(s, a) 和先验概率 P(s, a)。从根状态开始模拟遍历可能的棋盘状态。 在每个模拟的每个时间步 t,从状态 s_t 中选择一个动作 a_t
a_t = \arg\max_a(Q(s_t,a)+u(s_t,a))来最大化价值+bonus
u(s,a) \propto \frac{P(s,a)}{1+N(s,a)}. Bonus 正比于先验概率,但是随着访问次数递减。当遍历在第L步到达叶节点 s_L 时,叶节点继续扩展,节点 s_L 仅由 SL 策略网络 p_\sigma 处理一次得到新的叶节点,输出概率存储为每个合法动作 a 的先验概率 P,p(s,a) = p_\sigma(a|s)。叶节点以两种不同的方式进行评估:首先是价值网络 v_\theta(s_L);其次,通过使用轻量级策略网络 \pi 随机出的从 L 直到最终步骤 T,使用混合参数 \lambda 将这些评估组合成叶节点的评估
V(s_L)=(1-\lambda)v_\theta(s_L)+\lambda z_L.在模拟结束时,更新所有遍历到的边的动作值和访问次数
N(s,a)=\sum_{i=1}^{n}1(s,a,i)\\
Q(s,a)=\frac{1}{N(s,a)}\sum_{i=1}^{n}1(s,a,i)V(s_L^i). 其中 s_i 是第 i 次模拟的叶节点,1(s, a, i) 表示在第 i 次模拟期间是否遍历了边 (s, a)。搜索完成后,算法从根位置选择访问次数最多的移动,因为这是根据概率分布采样的,被访问的次数阅读说明价值越大。
Thanks for the good writeup. It if truth be told was once a amusement account it. Look complex to far added agreeable from you! By the way, how can we be in contact?
https://postheaven.net/gumshape0/partying-the-legacy-associated-with-henry-thierry-also-referred-to-as
кайт египет
кайт школа египет
cialis 5 mg originale prezzo : an effective drug containing tadalafil, is used for erectile dysfunction and benign prostatic hyperplasia. In Italy, a 28-tablet pack of Cialis 5 mg is priced at around €165.26, though prices vary by pharmacy and discounts. Generic alternatives, like Tadalafil DOC Generici, cost €0.8–€2.6 per tablet, providing a budget-friendly option. Consult a doctor, as a prescription is needed.
погода хургада апрель 2023
https://med-express.spb.ru/kapelnicza-ot-pohmelya-effektivnyj-sposob-vosstanovleniya-organizma/
Hi there! I know this is kinda off topic nevertheless I’d figured I’d ask. Would you be interested in exchanging links or maybe guest writing a blog article or vice-versa? My site discusses a lot of the same subjects as yours and I feel we could greatly benefit from each other. If you might be interested feel free to shoot me an e-mail. I look forward to hearing from you! Fantastic blog by the way!
https://imperialgroup.com.ua/yak-vybraty-ta-vstanovyty-linzy-v-fary
https://oboronspecsplav.ru/
Nice post. I learn something new and challenging on blogs I stumbleupon on a daily basis. It’s always useful to read content from other writers and use something from other sites.
my Zain
«Рентвил» предлагает аренду автомобилей в Краснодаре без залога и ограничений по пробегу по Краснодарскому краю и Адыгее. Требуется стаж от 3 лет и возраст от 23 лет. Оформление за 5 минут онлайн: нужны только фото паспорта и прав. Подача авто на жд вокзал и аэропорт Краснодар Мин-воды Сочи . Компания работает 10 лет , автомобили проходят своевременное ТО. Доступны детские кресла. Бронируйте через сайт аренда авто краснодар
Howdy! This is my 1st comment here so I just wanted to give a quick shout out and tell you I really enjoy reading through your blog posts. Can you recommend any other blogs/websites/forums that deal with the same topics? Thank you so much!
Zain recharge
Thank you for sharing your info. I truly appreciate your efforts and I will be waiting for your next post thank you once again.
prepaid Zain
посредник в Китае В эпоху глобализации и стремительного развития мировой экономики, Китай занимает ключевую позицию в качестве крупнейшего производственного центра. Организация эффективных и надежных поставок товаров из Китая становится стратегически важной задачей для предприятий, стремящихся к оптимизации затрат и расширению ассортимента. Наша компания предлагает комплексные решения для вашего бизнеса, обеспечивая бесперебойные и выгодные поставки товаров напрямую из Китая.
May I just say what a comfort to discover someone who really knows what they are talking about online. You actually know how to bring an issue to light and make it important. More and more people should read this and understand this side of the story. I was surprised that you’re not more popular since you surely possess the gift.
zain kuwait recharge
Шкаф Кухня – сердце дома, место, где рождаются кулинарные шедевры и собирается вся семья. Именно поэтому выбор мебели для кухни – задача ответственная и требующая особого подхода. Мебель на заказ в Краснодаре – это возможность создать уникальное пространство, идеально отвечающее вашим потребностям и предпочтениям.
https://выкуп-авто-пермь.рф/kak-prodat-nasledstvo-avto
Attractive component of content. I just stumbled upon your site and in accession capital to say that I acquire actually loved account your blog posts. Any way I’ll be subscribing for your augment or even I achievement you get entry to consistently quickly.
hafilat recharge
В динамичном мире Санкт-Петербурга, где каждый день кипит жизнь и совершаются тысячи сделок, актуальная и удобная доска объявлений становится незаменимым инструментом как для частных лиц, так и для предпринимателей. Наша платформа – это ваш надежный партнер в поиске и предложении товаров и услуг в Северной столице. Объявления частных лиц
варфейс акк В мире онлайн-шутеров Warface занимает особое место, привлекая миллионы игроков своей динамикой, разнообразием режимов и возможностью совершенствования персонажа. Однако, не каждый готов потратить месяцы на прокачку аккаунта, чтобы получить желаемое оружие и экипировку. В этом случае, покупка аккаунта Warface становится привлекательным решением, открывающим двери к новым возможностям и впечатлениям.
What’s up to every body, it’s my first go to see of this web site; this web site includes awesome and in fact good data designed for readers.
https://mitsubishi-nikol-motors.com.ua/yak-vstanovyty-bi-led-linzy-porady-ta-rekomendatsii-dlya-avtolyubyteliv
роп Роп – Русский роп – это больше, чем просто музыка. Это зеркало современной российской души, отражающее её надежды, страхи и мечты. В 2025 году жанр переживает новый виток развития, впитывая в себя элементы других стилей и направлений, становясь всё более разнообразным и эклектичным. Популярная музыка сейчас – это калейдоскоп звуков и образов. Хиты месяца мгновенно взлетают на вершины чартов, но так же быстро и забываются, уступая место новым музыкальным новинкам. 2025 год дарит нам множество талантливых российских исполнителей, каждый из которых вносит свой неповторимый вклад в развитие жанра.
Поставки товаров из Китая – это сложный и многогранный процесс, который требует глубоких знаний логистики, таможенного законодательства и специфики китайского рынка. Когда речь идет об оптимизации этого процесса, на сцену выходит посредник в Китае. Этот специалист или компания берет на себя роль связующего звена между российским бизнесом и китайскими производителями, упрощая коммуникацию, контроль качества и организацию доставки. Выкуп товара из Китая – ключевой этап в импортных операциях. Особенно популярен выкуп с 1688 – крупнейшей оптовой онлайн-площадки Китая, предлагающей широкий ассортимент товаров по конкурентным ценам. Опт из Китая привлекает предпринимателей, стремящихся к масштабированию бизнеса и снижению закупочной стоимости. Важно понимать, что работа с оптовыми поставщиками требует внимательности и опыта, чтобы избежать недобросовестных поставщиков и получить качественный товар. Среди наиболее востребованных категорий товаров, импортируемых из Китая, выделяются оборудование и одежда. Оборудование из Китая часто отличается оптимальным соотношением цены и качества, что делает его привлекательным для производственных предприятий. Одежда из Китая продолжает оставаться популярной благодаря разнообразию моделей, материалов и ценовых категорий. Успешная организация поставок из Китая требует комплексного подхода, включающего выбор надежного посредника, тщательный отбор поставщиков, контроль качества продукции, оптимизацию логистических маршрутов и грамотное таможенное оформление. Только в этом случае бизнес сможет извлечь максимальную выгоду из сотрудничества с китайскими партнерами и укрепить свои позиции на рынке. выкуп товара из китая
Rainbet code ILBET В динамичном мире онлайн-развлечений Rainbet занимает особое место, предоставляя игрокам широкие возможности для азартных игр и спортивных ставок. Для максимального увеличения выгоды и усиления азарта используйте промокод ILBET при регистрации или внесении депозита. Этот код активирует эксклюзивные бонусы, акции и предложения, разработанные как для новичков, так и для опытных игроков.
красное море температура воды
chicken road 2025 Chicken Road: Взлеты и Падения на Пути к Успеху Chicken Road – это не просто развлечение, это обширный мир возможностей и тактики, где каждое решение может привести к невероятному взлету или полному краху. Игра, доступная как в сети, так и в виде приложения для мобильных устройств (Chicken Road apk), предлагает пользователям проверить свою фортуну и чутье на виртуальной “куриной тропе”. Суть Chicken Road заключается в преодолении сложного маршрута, полного ловушек и опасностей. С каждым успешно пройденным уровнем, награда растет, но и увеличивается шанс неудачи. Игроки могут загрузить Chicken Road game demo, чтобы оценить механику и особенности геймплея, прежде чем рисковать реальными деньгами.
Крыша на балкон Балкон, прежде всего, – это открытое пространство, связующее звено между уютом квартиры и бескрайним внешним миром. Однако его беззащитность перед капризами погоды порой превращает это преимущество в существенный недостаток. Дождь, снег, палящее солнце – все это способно причинить немало хлопот, лишая возможности комфортно проводить время на балконе, а также нанося ущерб отделке и мебели. Именно здесь на помощь приходит крыша на балкон – надежная защита и гарантия комфорта в любое время года.
roobet bonus WEB3 В мире онлайн-казино инновации не стоят на месте, и Roobet находится в авангарде этих перемен. С появлением технологии Web3, Roobet предлагает игрокам новый уровень прозрачности, безопасности и децентрализации. Чтобы воспользоваться всеми преимуществами этой передовой платформы, используйте промокод WEB3.
Бизнес-аналитика Бизнес-стратегия: создайте конкурентное преимущество. В условиях жесткой конкуренции важно иметь четкую и действенную бизнес-стратегию. Профессиональный ментор поможет вам определить уникальные преимущества, сформировать позиционирование, разработать план действий. Вместе вы создадите стратегию, которая выделит ваш бизнес и обеспечит долгосрочный рост. Не позволяйте конкуренции застать вас врасплох — инвестируйте в экспертную поддержку. Создайте рабочую стратегию. Закажите консультацию и начните строить стабильное будущее своей компании уже сегодня.
pinco Pinco, Pinco AZ, Pinco Casino, Pinco Kazino, Pinco Casino AZ, Pinco Casino Azerbaijan, Pinco Azerbaycan, Pinco Gazino Casino, Pinco Pinco Promo Code, Pinco Cazino, Pinco Bet, Pinco Yukl?, Pinco Az?rbaycan, Pinco Casino Giris, Pinco Yukle, Pinco Giris, Pinco APK, Pin Co, Pin Co Casino, Pin-Co Casino. Онлайн-платформа Pinco, включая варианты Pinco AZ, Pinco Casino и Pinco Kazino, предлагает азартные игры в Азербайджане, также известная как Pinco Azerbaycan и Pinco Gazino Casino. Pinco предоставляет промокоды, а также варианты, такие как Pinco Cazino и Pinco Bet. Пользователи могут загрузить приложение Pinco (Pinco Yukl?, Pinco Yukle) для доступа к Pinco Az?rbaycan и Pinco Casino Giris. Pinco Giris доступен через Pinco APK. Pin Co и Pin-Co Casino — это связанные термины.
мод на тик ток 2025 Мир мобильных приложений не стоит на месте, и Тик Ток продолжает оставаться одной из самых популярных платформ для создания и обмена короткими видео. Но что, если стандартной функциональности вам недостаточно? На помощь приходит Тик Ток Мод – модифицированная версия приложения, открывающая доступ к расширенным возможностям и эксклюзивным функциям.
Тик ток мод на андроид Тикток Мод: Откройте Новые Горизонты Видеоконтента на Вашем Android Мир социальных сетей постоянно эволюционирует, и TikTok занимает в нем лидирующие позиции. Но что, если я скажу вам, что можно расширить возможности этой платформы, получив доступ к функциям, недоступным в стандартной версии? Речь идет о ТикТок моде. ТикТок Мод: Что это такое? ТикТок мод – это модифицированная версия популярного приложения, предоставляющая расширенные возможности для пользователей Android. Скачать тик ток мод на андроид – значит открыть дверь в мир, где границы возможностей TikTok размываются.
легальная вебкам работа в Польше Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
дебетовая карта курьером Путеводитель по миру удобных банковских карт. Оформить современную дебетовую карту стало просто и удобно благодаря нашей поддержке. Выберите карту, которая идеально вам подходит, и наслаждайтесь всеми преимуществами современного финансового сервиса. Что мы предлагаем? Практические советы: Полезные лайфхаки и рекомендации для эффективного использования вашей карты. Свежие акции: Будьте в курсе всех актуальных предложений и специальных условий от наших банков-партнеров. Преимущества нашего сообщества. Полная информация о различных видах карт, особенностях тарифов и комиссий. Регулярно обновляемые материалы с актуальными данными и последними новостями о продуктах российских банков. Присоединяйтесь к нашему сообществу, чтобы сделать ваши финансовые решения простыми, быстрыми и безопасными. Вместе мы сможем оптимизировать использование банковских продуктов и сэкономить ваше время и средства. Наша цель — помочь вам эффективно управлять своими финансами и получать максимальную выгоду от каждого взаимодействия с банком.
https://amlkyc.tech/
вакансии для девушек в Польше Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
собрать компьютер онлайн Собрать компьютер онлайн: Удобство и контроль Онлайн сборка компьютера позволяет вам контролировать каждый этап процесса. Вы выбираете компоненты, следите за ценами и создаете машину, которая идеально соответствует вашему бюджету.
Дом на побережье Сочи – это не просто город, это мечта, воплощенная в реальность. Лазурное море, величественные горы, пышная зелень и мягкий климат делают его идеальным местом для жизни, отдыха и инвестиций. Если вы стремитесь к комфорту, красоте и перспективному будущему, то недвижимость в Сочи – это то, что вам нужно.
компьютер для стрима купить
кайтсерфинг
“Новости Новороссийска” – это не просто агрегатор информации, это платформа для диалога между горожанами и властью. Здесь можно задать вопрос чиновнику, оставить жалобу или просто выразить свое мнение по поводу той или иной городской проблемы. Благодаря оперативности и открытости, паблик стал незаменимым инструментом для тех, кто хочет быть в курсе всего, что происходит в Новороссийске. Новости Новороссийска Каждое утро начинается с просмотра ленты новостей, где местные жители делятся фотографиями рассветов над морем, а журналисты рассказывают о планах по развитию городской инфраструктуры. Вечером же паблик превращается в площадку для обсуждения насущных проблем: пробок на дорогах, благоустройства парков и скверов, качества жилищно-коммунальных услуг.
BestGold: Сияние золота и блеск бриллиантов в Краснодаре В сердце Краснодарского края, где солнце ласкает поля и виноградники, расцветает мир изысканных ювелирных украшений BestGold. Мы предлагаем вам уникальную возможность прикоснуться к великолепию золота 70% пробы, воплощенному в утонченных кольцах и серьгах, сверкающих бриллиантами. Кольца, достойные королевы Наши кольца – это не просто украшения, это символ вашей индивидуальности и безупречного вкуса. От классических обручальных колец до экстравагантных коктейльных, каждое изделие BestGold создано с любовью и вниманием к деталям. Вставки из бриллиантов различной огранки и каратности подчеркнут вашу элегантность и добавят образу неповторимый шарм. купить кольцо золото Серьги, подчеркивающие красоту Серьги BestGold – это идеальное дополнение к любому наряду. От лаконичных пусетов до эффектных подвесок, они призваны подчеркнуть вашу женственность и утонченность. Наши серьги с бриллиантами станут ярким акцентом вашего образа, притягивая восхищенные взгляды. Ювелирный фестиваль BestGold: праздник роскоши и стиля Не упустите возможность стать участником ювелирного фестиваля BestGold, где вас ждут эксклюзивные скидки на золото до 70% и невероятные предложения на бриллианты. Это ваш шанс приобрести ювелирные украшения мечты по самым выгодным ценам. BestGold: выбирайте лучшее, выбирайте золото! Погрузитесь в мир роскоши и блеска вместе с BestGold. Наши ювелирные украшения станут вашими верными спутниками, подчеркивая вашу красоту и элегантность в любой ситуации. Купите кольцо или серьги из золота в Краснодаре и ощутите себя королевой!
Аренда авто в Краснодаре Прокат авто Краснодар: Легкость и доступность Прокат авто в Краснодаре стал еще более легким и доступным благодаря онлайн-сервисам и удобным приложениям. Вы можете забронировать автомобиль заранее, выбрать удобное место получения и возврата, а также получить квалифицированную консультацию специалистов.
Wow, superb blog layout! How long have you been blogging for? you make blogging look easy. The overall look of your site is fantastic, as well as the content!
bus card balance check online
кайтсёрфинг анапа Рерайт текста о кайтсерфинге в Анапе (30 вариантов):
May I simply say what a comfort to discover an individual who genuinely understands what they’re talking about online. You definitely know how to bring an issue to light and make it important. A lot more people ought to look at this and understand this side of your story. It’s surprising you are not more popular because you definitely possess the gift.
hafilat bus card balance check
Balloons Dubai https://balloons-dubai1.com stunning balloon decorations for birthdays, weddings, baby showers, and corporate events. Custom designs, same-day delivery, premium quality.
ultimate AI porn maker generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
Профессиональное https://kosmetologicheskoe-oborudovanie-msk.ru для салонов красоты, клиник и частных мастеров. Аппараты для чистки, омоложения, лазерной эпиляции, лифтинга и ухода за кожей.
ultimate createporn AI generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
Защитные кейсы plastcase.ru в Санкт-Петербурге — надежная защита оборудования от влаги, пыли и ударов. Большой выбор размеров и форматов, ударопрочные материалы, индивидуальный подбор.
Защитные кейсы https://plastcase.ru в Санкт-Петербурге — надежная защита оборудования от влаги, пыли и ударов. Большой выбор размеров и форматов, ударопрочные материалы, индивидуальный подбор.
займ по паспорту онлайн https://zajmy-onlajn.ru
займ онлайн без истории быстрые онлайн займы без карты
официальный сайт ПокерОК
официальный сайт ПокерОК
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Ознакомиться с деталями – https://nakroklinikatest.ru/
кейс защитный fs купить http://plastcase.ru
кейс защитный сорокин plastcase
кайт сафари соловейкин Кайт Египет привлекает кайтеров со всего мира своими теплыми водами и благоприятным ветром.
помощь в написании отчета по практике отчет по практике сколько стоит
заказать отчет по практике купить отчет по учебной практике
микрозайм без процентов http://zajmy-onlajn.ru
получить займ онлайн https://zajmy-onlajn.ru
где взять займ без отказа [url=https://www.zajm-bez-otkaza-1.ru]где взять займ без отказа[/url] .
онлайн кредит без отказа бишкек [url=http://kredit-bez-otkaza-1.ru/]онлайн кредит без отказа бишкек[/url] .
I believe everything published made a bunch of sense. However, what about this? suppose you added a little content? I ain’t saying your content is not solid, but suppose you added a post title that makes people desire more? I mean %BLOG_TITLE% is a little vanilla. You could peek at Yahoo’s home page and see how they write article headlines to grab viewers to open the links. You might add a related video or a pic or two to grab readers interested about everything’ve written. Just my opinion, it might bring your blog a little livelier.
cialis 5 mg prezzo
шторы день ночь Рулонные шторы на пластиковых окнах – это современное и функциональное решение, которое идеально подходит для любого интерьера. Шторы Пятигорск
авто в аренду краснодар Аренда авто без залога: Экономьте свои средства и нервы! Наслаждайтесь поездкой без лишних финансовых обязательств.
Натяжные потолки Томилино Цена за метр натяжного потолка зависит от материала, фактуры и производителя. Натяжной потолок в зал
warface аккаунт Приобретение нового оружия в Warface – это отличный способ улучшить свою статистику, разнообразить игровой процесс и стать более эффективным в бою. Варфейс купить пин код
Thank you for the auspicious writeup. It in reality was once a enjoyment account it. Glance complicated to more brought agreeable from you! However, how could we communicate?
quanto dura l’effetto del tadalafil 5 mg?
Перед началом терапии врач собирает анамнез, оценивает состояние органов-мишеней (печень, почки, сердце), проводит лабораторные тесты на уровень электролитов и маркёры цирроза. Результаты обследования играют ключевую роль при выборе схемы инфузий и психотерапевтических методик.
Получить дополнительные сведения – [url=https://lechenie-alkogolizma-tyumen10.ru/]lechenie alkogolizma tjumen'[/url]
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Узнать больше – https://vyvod-iz-zapoya-1.ru/
При длительном запое или серьезной алкогольной интоксикации часто нет возможности или желания ехать в стационар. В таких ситуациях оптимальным решением становится вызов нарколога на дом в Сочи. Специалисты клиники «Жизнь без Запоя» круглосуточно приезжают к пациентам, оперативно оказывают медицинскую помощь и проводят профессиональную детоксикацию организма прямо в домашних условиях. Благодаря комфортному лечению на дому пациенты быстрее восстанавливаются, избегают дополнительного стресса и осложнений, связанных с госпитализацией.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-sochi0.ru/]нарколог на дом клиника сочи[/url]
1000 рублей за регистрацию вывод сразу без вложений в казино отзывы Многие казино, стремясь привлечь новых клиентов, предлагают 1000 рублей за регистрацию с моментальным выводом, не требующим никаких вложений. Это привлекательная возможность для тех, кто хочет испытать свою удачу без риска для собственного бюджета. 1000 рублей за регистрацию в казино без депозита вывод сразу
Как отмечают наркологи нашей клиники, чем раньше пациент получает необходимую помощь, тем меньше риск тяжелых последствий и тем быстрее восстанавливаются функции организма.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-sochi0.ru/]капельница от запоя выезд в сочи[/url]
Во Владимире и области работают десятки клиник, предлагающих помощь зависимым, но не все учреждения соответствуют современным медицинским и психологическим стандартам. Чтобы выбрать действительно эффективное лечение, нужно ориентироваться на проверенные критерии. В этом материале мы рассмотрим, на что стоит обратить внимание при выборе наркологического центра.
Подробнее – [url=https://lechenie-narkomanii-vladimir10.ru/]лечение наркомании нарколог[/url]
Наша наркологическая клиника предоставляет круглосуточную помощь, использует только сертифицированные медикаменты и строго соблюдает полную конфиденциальность лечения.
Детальнее – https://kapelnica-ot-zapoya-sochi0.ru/kapelnicza-ot-zapoya-na-domu-sochi
Для эффективного лечения алкогольной интоксикации и восстановления организма врачи клиники «АлкоДоктор» используют комплекс препаратов, которые индивидуально подбираются с учетом состояния пациента.
Выяснить больше – [url=https://kapelnica-ot-zapoya-sochi0.ru/]капельница от запоя вызов город[/url]
Группа препаратов
Ознакомиться с деталями – https://kapelnica-ot-zapoya-sochi0.ru/kapelnicza-ot-zapoya-na-domu-sochi
Перед началом терапии врач собирает анамнез, оценивает состояние органов-мишеней (печень, почки, сердце), проводит лабораторные тесты на уровень электролитов и маркёры цирроза. Результаты обследования играют ключевую роль при выборе схемы инфузий и психотерапевтических методик.
Детальнее – https://lechenie-alkogolizma-tyumen10.ru/klinika-lecheniya-alkogolizma-tyumen
В клинике «Горизонт Жизни» в Красногорске разработаны протоколы экстренного вывода из запоя, которые выполняются 24 часа в сутки, семь дней в неделю. Благодаря выезду бригады врачей-наркологов и оснащённости современным оборудованием мы оказываем помощь в кратчайшие сроки, обеспечивая максимальную безопасность и комфорт пациенту.
Узнать больше – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-cena/
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя на дому краснодарский край[/url]
Для эффективного лечения алкогольной интоксикации и восстановления организма врачи клиники «АлкоДоктор» используют комплекс препаратов, которые индивидуально подбираются с учетом состояния пациента.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-sochi0.ru/]поставить капельницу от запоя в сочи[/url]
Основная проблема запоя заключается в том, что человек постепенно теряет контроль над ситуацией, а его организм подвергается всё более тяжёлой интоксикации. Определить момент, когда требуется немедленное обращение за помощью, несложно, если внимательно следить за состоянием человека.
Подробнее тут – http://vyvod-iz-zapoya-korolev2.ru/vyvod-iz-zapoya-na-domu/https://vyvod-iz-zapoya-korolev2.ru
Наша наркологическая клиника предоставляет круглосуточную помощь, использует только сертифицированные медикаменты и строго соблюдает полную конфиденциальность лечения.
Детальнее – [url=https://kapelnica-ot-zapoya-sochi0.ru/]вызвать капельницу от запоя на дому сочи[/url]
Мы оказываем услуги 24 часа в сутки, 7 дней в неделю, без выходных и праздников. Это позволяет:
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-vladimir10.ru/]бесплатная наркологическая клиника владимир[/url]
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Получить дополнительную информацию – http://kodirovanie-ot-alkogolizma-odintsovo2.ru
Наша наркологическая клиника предоставляет круглосуточную помощь, использует только сертифицированные медикаменты и строго соблюдает полную конфиденциальность лечения.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-sochi0.ru/]kapelnicza-ot-zapoya-na-domu sochi[/url]
Наркологическая помощь в «Тюменьбезалко» основана на принципах доказательной медицины и индивидуального подхода. Каждый пациент проходит тщательное обследование и консультацию узких специалистов — кардиолога, гастроэнтеролога, невролога. Такой комплексный анализ позволяет не только вывести организм из интоксикации, но и скорректировать течение сопутствующих заболеваний, что повышает безопасность лечения.
Разобраться лучше – http://lechenie-alkogolizma-tyumen10.ru/klinika-lecheniya-alkogolizma-tyumen/https://lechenie-alkogolizma-tyumen10.ru
Капельница от запоя является неотъемлемой процедурой при острых и хронических отравлениях алкоголем. Она помогает стабилизировать состояние пациента, избежать тяжелых последствий и максимально быстро вернуться к нормальной жизни. Вызов врача для проведения процедуры рекомендуется в следующих ситуациях:
Подробнее тут – [url=https://kapelnica-ot-zapoya-sochi0.ru/]капельница от запоя на дому в сочи[/url]
Школа Саморазвития https://bznaniy.ru онлайн-база знаний для тех, кто хочет понять себя, улучшить мышление, прокачать навыки и выйти на новый уровень жизни.
Для каждого пациента используется индивидуальный монитор жизненно важных функций, передающий данные врачу в клинике через защищённый канал связи. Это обеспечивает безопасность при лечении как лёгких, так и тяжёлых форм интоксикации, снижая вероятность осложнений.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологическая клиника[/url]
Если состояние пациента не позволяет доставить его в стационар, на дом выезжает врач-нарколог с необходимым оборудованием. Применяются капельницы, дезинтоксикационная терапия, медикаментозная коррекция поведения и поддержка родственников.
Ознакомиться с деталями – [url=https://narkologicheskaya-pomoshh-tula10.ru/]narkologicheskaya pomoshch na domu tula[/url]
На базе частной клиники «Здоровье+» пациентам доступны как экстренные, так и плановые формы наркологической помощи. Все процедуры соответствуют стандартам Минздрава РФ и проводятся с соблюдением конфиденциальности.
Изучить вопрос глубже – [url=https://narkologicheskaya-pomoshh-tula10.ru/]срочная наркологическая помощь[/url]
Наша наркологическая клиника предоставляет круглосуточную помощь, использует только сертифицированные медикаменты и строго соблюдает полную конфиденциальность лечения.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-sochi0.ru/]posle-kapelniczy-ot-zapoya sochi[/url]
В условиях стационара или на дневном стационаре применяются сбалансированные инфузионные растворы, витамины, антиоксиданты и препараты для поддержки печени. Цель — минимизировать интоксикацию и предотвратить осложнения.
Подробнее тут – [url=https://lechenie-alkogolizma-tyumen10.ru/]лечение алкоголизма в тюмени[/url]
Наркологическая помощь «ТюменьМед» не ограничивается только физической детоксикацией. В состав команды входят психологи и социальные работники, которые проводят мотивационные беседы, обучают навыкам самоконтроля и оказывают помощь в планировании досуга и социальных активностей после детоксикации.
Получить больше информации – http://
Группа препаратов
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-sochi0.ru/]kapelnicza-ot-zapoya-na-domu sochi[/url]
Действие и назначение
Подробнее тут – https://kapelnica-ot-zapoya-sochi0.ru
Действие и назначение
Подробнее – http://kapelnica-ot-zapoya-sochi0.ru/kapelnicza-ot-zapoya-na-domu-sochi/
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Углубиться в тему – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]вывод из запоя на дому[/url]
Для эффективного лечения алкогольной интоксикации и восстановления организма врачи клиники «АлкоДоктор» используют комплекс препаратов, которые индивидуально подбираются с учетом состояния пациента.
Углубиться в тему – http://kapelnica-ot-zapoya-sochi0.ru/
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Узнать больше – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena/
Индивидуальный план включает детоксикацию, медикаментозную поддержку, психотерапию и реабилитацию. Специалисты учитывают:
Исследовать вопрос подробнее – [url=https://lechenie-alkogolizma-tyumen10.ru/]анонимное лечение алкоголизма тюмень[/url]
бездепозитный бонус игровые автоматы с выводом денег Бездепозитный бонус – это шанс сорвать куш, не вкладывая ни копейки. Он позволяет испытать азарт, риск и радость победы, не испытывая страха потери собственных средств. Это особенно ценно для начинающих игроков, которые еще не готовы рисковать большими суммами. Бездепозитный бонус в казино
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Выяснить больше – https://www.studioto.com/2022/03/11/dating-professional-review-of-shagle
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Выяснить больше – https://aata.mx/index.php/2024/02/29/hola-mundo
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Детальнее – https://www.nickatie.com/2020/12/12/233
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Получить дополнительную информацию – https://www.edmdjbookings.com/edmdjbookings-com-faceomslag
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Ознакомиться с деталями – https://mbale.mubs.ac.ug/hello-world
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Узнать больше – https://statuscaptions.com/rap-lyrics-captions.html
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Исследовать вопрос подробнее – https://meijerexclusiveline.nl/hallo-wereld
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Получить дополнительную информацию – https://statuscaptions.com/aai-birthday-wishes-in-marathi.html
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Детальнее – http://www.andyliffner.com/?attachment_id=99
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Ознакомиться с деталями – https://www.burtontownhall.co.uk/events/strikers-the-vale-rawlings-story
Для пациентов, требующих круглосуточного наблюдения, клиника «Полярис» предлагает стационар VIP-класса. Здесь созданы все условия для быстрого восстановления: удобные палаты, индивидуальное меню, зоны отдыха и консультации профильных специалистов.
Углубиться в тему – https://narkologicheskaya-klinika-arkhangelsk0.ru/platnaya-narkologicheskaya-klinika-arkhangelsk
Процесс терапии в клинике построен по поэтапной схеме, включающей:
Ознакомиться с деталями – [url=https://lechenie-alkogolizma-arkhangelsk0.ru/]наркология лечение алкоголизма[/url]
Алкоголизм — хроническое заболевание, требующее комплексного подхода и круглосуточного контроля. Клиника «УралМед» в Екатеринбурге предлагает полный спектр услуг для пациентов любого уровня зависимости: от экстренной детоксикации до долгосрочной реабилитации. Главные принципы работы — абсолютная анонимность, индивидуальный план лечения и постоянное сопровождение квалифицированной командой специалистов.
Получить дополнительную информацию – http://lechenie-alkogolizma-ekaterinburg0.ru/anonimnoe-lechenie-alkogolizma-v-ekb/
Понимание того, какие учреждения действительно способны помочь, позволяет избежать ошибок и не тратить время на неэффективные попытки лечения. Ключевыми признаками являются наличие медицинской лицензии, опытные специалисты, прозрачные условия и отзывы пациентов.
Получить больше информации – https://narkologicheskaya-pomoshh-arkhangelsk0.ru/anonimnaya-narkologicheskaya-pomoshh-arkhangelsk/
«В первые часы после окончания запоя организм наиболее уязвим, и своевременное вмешательство значительно снижает риски осложнений», — подчёркивает заведующая отделением наркологической реанимации Елена Морозова.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]vyvod iz zapoya krasnogorsk[/url]
Алкоголизм — хроническое заболевание, требующее комплексного подхода и круглосуточного контроля. Клиника «УралМед» в Екатеринбурге предлагает полный спектр услуг для пациентов любого уровня зависимости: от экстренной детоксикации до долгосрочной реабилитации. Главные принципы работы — абсолютная анонимность, индивидуальный план лечения и постоянное сопровождение квалифицированной командой специалистов.
Детальнее – [url=https://lechenie-alkogolizma-ekaterinburg0.ru/]лечение алкоголизма на дому[/url]
Чтобы обеспечить безопасное выведение психоактивных веществ и восстановление организма, применяется детоксикация под контролем врача-нарколога и анестезиолога-реаниматолога.
Подробнее можно узнать тут – https://lechenie-narkomanii-arkhangelsk0.ru
После диагностики выявленные нарушения восполняются посредством инфузий с витаминами группы B, C, магнием и элементами.
Углубиться в тему – [url=https://lechenie-alkogolizma-ekaterinburg0.ru/]центр лечения алкоголизма екатеринбург[/url]
В случаях, когда транспортировка в клинику затруднительна или пациент испытывает выраженный стресс, возможно выездное консультирование и начальная детоксикация на дому. Врач прибывает с портативным набором для инфузий, оперативно stabilizирует состояние и даёт рекомендации по дальнейшим действиям.
Подробнее можно узнать тут – [url=https://lechenie-alkogolizma-ekaterinburg0.ru/]принудительное лечение от алкоголизма[/url]
Как подчёркивает специалист ФГБУ «НМИЦ психиатрии и наркологии», «без участия квалифицированной команды невозможно обеспечить комплексный подход к пациенту, особенно если речь идёт о длительном стаже употребления и осложнённой картине заболевания». Отсюда следует — изучение состава персонала должно быть одним из первых шагов.
Получить больше информации – [url=https://lechenie-alkogolizma-murmansk0.ru/]lechenie-alkogolizma-murmansk0.ru/[/url]
Проблемы зависимости требуют оперативного вмешательства. Чем раньше начато лечение, тем выше вероятность полного восстановления. Наркологическая помощь в Архангельске представлена как государственными, так и частными клиниками, каждая из которых предлагает свой уровень сервиса и спектр услуг. Однако для получения эффективной и безопасной помощи важно понимать, какие критерии определяют качество наркологической поддержки.
Подробнее тут – [url=https://narkologicheskaya-pomoshh-arkhangelsk0.ru/]скорая наркологическая помощь архангельск[/url]
Если пациенту требуется постоянный мониторинг или комплексное лечение, мы обеспечиваем круглосуточное пребывание в стационаре. Здесь доступны углублённая диагностика — УЗИ органов брюшной полости, расширенные анализы крови, кардиомониторинг — и коррекция терапии в режиме реального времени. Комфортные палаты, ежедневное наблюдение медсестры и консультации психотерапевта создают условия для быстрого и безопасного выхода из зависимости.
Ознакомиться с деталями – https://narkologicheskaya-pomoshh-ekaterinburg0.ru/vyzvat-narkologicheskuyu-pomoshh-v-ekb
Согласно информации, опубликованной на сайте Минздрава РФ, успешная наркологическая помощь невозможна без своевременной диагностики, комплексного подхода и участия квалифицированных специалистов. Именно такие параметры становятся решающими при выборе учреждения, куда обратится пациент или его родственники.
Ознакомиться с деталями – [url=https://narkologicheskaya-pomoshh-arkhangelsk0.ru/]платная наркологическая помощь архангельск[/url]
В случаях, когда транспортировка в клинику затруднительна или пациент испытывает выраженный стресс, возможно выездное консультирование и начальная детоксикация на дому. Врач прибывает с портативным набором для инфузий, оперативно stabilizирует состояние и даёт рекомендации по дальнейшим действиям.
Ознакомиться с деталями – [url=https://lechenie-alkogolizma-ekaterinburg0.ru/]наркологическое лечение алкоголизма[/url]
Нередко пациенту требуется не только медикаментозная поддержка, но и психологическое сопровождение. Консультации с психотерапевтом позволяют выявить причины зависимости, снизить уровень тревожности и подготовить человека к реабилитации.
Подробнее можно узнать тут – [url=https://narkologicheskaya-pomoshh-arkhangelsk0.ru/]скорая наркологическая помощь архангельск.[/url]
Алкоголизм — хроническое заболевание, требующее комплексного подхода и круглосуточного контроля. Клиника «УралМед» в Екатеринбурге предлагает полный спектр услуг для пациентов любого уровня зависимости: от экстренной детоксикации до долгосрочной реабилитации. Главные принципы работы — абсолютная анонимность, индивидуальный план лечения и постоянное сопровождение квалифицированной командой специалистов.
Получить больше информации – [url=https://lechenie-alkogolizma-ekaterinburg0.ru/]лечение алкоголизма в екатеринбурге[/url]
В случаях, когда транспортировка в клинику затруднительна или пациент испытывает выраженный стресс, возможно выездное консультирование и начальная детоксикация на дому. Врач прибывает с портативным набором для инфузий, оперативно stabilizирует состояние и даёт рекомендации по дальнейшим действиям.
Узнать больше – [url=https://lechenie-alkogolizma-ekaterinburg0.ru/]лечение наркомании и алкоголизма в екатеринбурге[/url]
В случаях, когда транспортировка в клинику затруднительна или пациент испытывает выраженный стресс, возможно выездное консультирование и начальная детоксикация на дому. Врач прибывает с портативным набором для инфузий, оперативно stabilizирует состояние и даёт рекомендации по дальнейшим действиям.
Детальнее – [url=https://lechenie-alkogolizma-ekaterinburg0.ru/]клиника лечения алкоголизма екатеринбург.[/url]
Нередко пациенту требуется не только медикаментозная поддержка, но и психологическое сопровождение. Консультации с психотерапевтом позволяют выявить причины зависимости, снизить уровень тревожности и подготовить человека к реабилитации.
Ознакомиться с деталями – [url=https://narkologicheskaya-pomoshh-arkhangelsk0.ru/]скорая наркологическая помощь в архангельске[/url]
В программе используются когнитивно-поведенческая терапия, мотивационное интервьюирование, арт- и телесно-ориентированные практики. Занятия помогают пациенту осознать причины употребления, выработать навыки управления эмоциями и стрессом, сформировать устойчивую внутреннюю мотивацию к отказу от вещества.
Исследовать вопрос подробнее – https://lechenie-narkomanii-arkhangelsk0.ru/lechenie-narkomanii-anonimno-arkhangels
Борьба с наркотической зависимостью требует системного подхода и участия опытных специалистов. Важно понимать, что лечение наркомании — это не только снятие ломки, но и длительная психотерапия, обучение новым моделям поведения, работа с семьёй. Согласно рекомендациям Минздрава РФ, наиболее стабильные результаты достигаются при прохождении курса реабилитации под наблюдением профессиональной команды в специализированном центре.
Изучить вопрос глубже – http://
Наркологическая клиника «Ренессанс» в Екатеринбурге предоставляет полный спектр услуг по лечению зависимости от психоактивных веществ. В основе её работы лежит интеграция современных медицинских технологий, психологических методов и социальной реабилитации. Комплексный подход позволяет не только купировать острые симптомы интоксикации, но и формировать у пациента устойчивую мотивацию к трезвому образу жизни. Высокая квалификация врачей-наркологов, психотерапевтов и социальных педагогов гарантирует индивидуальный маршрут выздоровления для каждого обратившегося.
Детальнее – [url=https://lechenie-narkomanii-ekaterinburg0.ru/]лечение наркомании и алкоголизма свердловская область[/url]
Фундаментом качественного лечения является профессиональная команда. Только при участии врачей-наркологов, психиатров, клинических психологов, терапевтов и консультантов по зависимому поведению можно говорить о комплексной помощи. По словам специалистов ФГБУН «Национальный научный центр наркологии», именно междисциплинарный подход формирует устойчивую динамику на всех этапах терапии — от стабилизации состояния до ресоциализации пациента.
Изучить вопрос глубже – http://narkologicheskaya-klinika-tula10.ru/anonimnaya-narkologicheskaya-klinika-tula/
What a stuff of un-ambiguity and preserveness of precious experience about unexpected emotions.
tadalafil sandoz 5 mg
Выезд на дом подходит тем, кто не нуждается в круглосуточном наблюдении, но требует срочной детоксикации. Бригада врачей приезжает в течение 60 минут, проводит экспресс-диагностику (АД, пульс, сатурация и неврологический статус) и устанавливает внутривенную капельницу с индивидуально подобранным составом растворов. Уже через 1–2 часа пациенты отмечают существенное облегчение.
Детальнее – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]vyvod iz zapoya anonimno[/url]
Нередко пациенту требуется не только медикаментозная поддержка, но и психологическое сопровождение. Консультации с психотерапевтом позволяют выявить причины зависимости, снизить уровень тревожности и подготовить человека к реабилитации.
Получить больше информации – https://narkologicheskaya-pomoshh-arkhangelsk0.ru/neotlozhnaya-narkologicheskaya-pomoshh-arkhangelsk/
Чтобы обеспечить безопасное выведение психоактивных веществ и восстановление организма, применяется детоксикация под контролем врача-нарколога и анестезиолога-реаниматолога.
Получить дополнительную информацию – [url=https://lechenie-narkomanii-arkhangelsk0.ru/]центр лечения наркомании архангельск.[/url]
Понимание того, какие учреждения действительно способны помочь, позволяет избежать ошибок и не тратить время на неэффективные попытки лечения. Ключевыми признаками являются наличие медицинской лицензии, опытные специалисты, прозрачные условия и отзывы пациентов.
Ознакомиться с деталями – [url=https://narkologicheskaya-pomoshh-arkhangelsk0.ru/]скорая наркологическая помощь[/url]
Запой — тяжёлое состояние алкогольной зависимости, при котором организм постоянно подвергается токсическому воздействию алкоголя. Это не просто неприятное явление, а угрожающее жизни состояние, которое требует немедленного медицинского вмешательства. Наркологическая клиника «Воздух Свободы» в Люберцах предлагает профессиональный и эффективный вывод из запоя с индивидуальным подходом и максимальным уровнем конфиденциальности.
Получить больше информации – [url=https://vyvod-iz-zapoya-lyubertsy2.ru/]vyvod iz zapoya kruglosutochno[/url]
Современные клиники предоставляют широкий спектр услуг, начиная с первичной консультации и заканчивая долгосрочной поддержкой после прохождения курса лечения. Ключевым этапом является детоксикация — процедура, направленная на выведение токсинов и стабилизацию физического состояния пациента.
Подробнее – http://narkologicheskaya-pomoshh-arkhangelsk0.ru
Чтобы обеспечить безопасное выведение психоактивных веществ и восстановление организма, применяется детоксикация под контролем врача-нарколога и анестезиолога-реаниматолога.
Исследовать вопрос подробнее – [url=https://lechenie-narkomanii-arkhangelsk0.ru/]центр лечения наркомании в архангельске[/url]
После диагностики выявленные нарушения восполняются посредством инфузий с витаминами группы B, C, магнием и элементами.
Получить дополнительные сведения – [url=https://lechenie-alkogolizma-ekaterinburg0.ru/]lechenie-alkogolizma-ekaterinburg0.ru/[/url]
После диагностики выявленные нарушения восполняются посредством инфузий с витаминами группы B, C, магнием и элементами.
Углубиться в тему – [url=https://lechenie-alkogolizma-ekaterinburg0.ru/]лечение наркомании и алкоголизма[/url]
В случаях, когда транспортировка в клинику затруднительна или пациент испытывает выраженный стресс, возможно выездное консультирование и начальная детоксикация на дому. Врач прибывает с портативным набором для инфузий, оперативно stabilizирует состояние и даёт рекомендации по дальнейшим действиям.
Ознакомиться с деталями – https://lechenie-alkogolizma-ekaterinburg0.ru/
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Ознакомиться с деталями – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]клиника кодирования от алкоголизма[/url]
shipping from china to dubai China to UAE: Analyzing Trade Dynamics & Economic Partnerships
Клиника «УралМед» работает без выходных и праздников: прием пациентов — круглосуточно. Это позволяет оказывать экстренную помощь при острых состояниях, а также вести наблюдение за динамикой восстановления здоровья в ночные часы.
Ознакомиться с деталями – [url=https://lechenie-alkogolizma-ekaterinburg0.ru/]centr lecheniya alkogolizma ekaterinburg[/url]
Самолечение или игнорирование проблемы часто приводит к серьёзным осложнениям. Только профессиональная помощь гарантирует безопасный выход из алкогольного кризиса и минимизирует негативные последствия для организма.
Получить больше информации – [url=https://vyvod-iz-zapoya-lyubertsy2.ru/]vyvod iz zapoya lyubercy[/url]
Первое, на что стоит обратить внимание — медицинский состав клиники. Опытные врачи-наркологи, психотерапевты, специалисты по аддиктологии и социальные работники составляют основу эффективной терапии. Их взаимодействие позволяет точно определить стадию зависимости, выявить сопутствующие психические или соматические заболевания и выстроить логичную схему лечения.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-murmansk0.ru/]наркологическая клиника в мурманске[/url]
пионы москва Доставка пионов в Москве: Изысканное прикосновение к совершенству. Ощутите нежность шелковистых лепестков, представьте тонкий аромат, наполняющий пространство, и осознайте, что роскошь может быть доступной. Мы предлагаем не просто доставку цветов, а создание момента, который запомнится надолго. Наша коллекция включает в себя редкие сорта пионов, отобранные с особой тщательностью, чтобы удовлетворить даже самый изысканный вкус. От классических розовых букетов до смелых композиций с экзотическими оттенками – у нас вы найдете идеальный подарок для любого случая. Мы ценим ваше время, поэтому гарантируем быструю и надежную доставку по Москве.
Если пациенту требуется постоянный мониторинг или комплексное лечение, мы обеспечиваем круглосуточное пребывание в стационаре. Здесь доступны углублённая диагностика — УЗИ органов брюшной полости, расширенные анализы крови, кардиомониторинг — и коррекция терапии в режиме реального времени. Комфортные палаты, ежедневное наблюдение медсестры и консультации психотерапевта создают условия для быстрого и безопасного выхода из зависимости.
Разобраться лучше – https://narkologicheskaya-pomoshh-ekaterinburg0.ru/skoraya-narkologicheskaya-pomoshh-v-ekb
Первичный этап заключается в оценке состояния пациента и быстром подборе схемы инфузионной терапии. Врач фиксирует показания ЭКГ, сатурацию кислорода и биохимический параметр глюкозы в крови. После этого подключается капельница с раствором для выведения продуктов распада алкоголя и одновременной коррекции показателей обмена веществ. Последующие визиты врача позволяют скорректировать терапию и предотвратить развитие побочных реакций.
Подробнее – http://narkologicheskaya-pomoshh-ekaterinburg0.ru
скачать игры без торрента Скачать игры с облака Mail: Играйте где угодно, когда угодно. Облако Mail – это ваша мобильная библиотека игр, всегда под рукой. Загружайте, скачивайте и запускайте игры на любом устройстве, имеющем доступ к интернету. Насладитесь свободой и гибкостью, выбирая из постоянно пополняющегося каталога.
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Ознакомиться с деталями – http://androp-rono.ru/%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F-%D0%B3%D1%80%D0%B0%D0%BC%D0%BE%D1%82%D0%BD%D0%BE%D1%81%D1%82%D1%8C/item/2650-%D0%B0%D0%BD%D0%B4%D1%80%D0%BE%D0%BF%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D1%86%D0%B8%D1%84%D1%80%D0%B0?start=210
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Подробнее можно узнать тут – https://www.knowledgequran.com/our-nearness-to-day-of-judgement
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Разобраться лучше – https://www.meincreative.at/example-post-3
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Подробнее – https://diamondrvpark.com/hello-world
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Выяснить больше – https://kendrasmiley.com/cropped-042-jpg/?thc-month=202904
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Углубиться в тему – https://gulfcoastpwr.com/2024/04/02/hello-world
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Подробнее – https://avtox.net
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Изучить вопрос глубже – https://vickys.com.br/2024/05/19/prefeitura-inicia-projeto-jovem-empreendedor-com-acao-do-cras-vitoria-regia-voltado-a-estudantes-agencia-de-noticias
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Получить дополнительную информацию – https://statuscaptions.com/wedding-captions.html
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Изучить вопрос глубже – http://domainedebokassa.com/img_20171017_094630
В этом исследовании рассмотрены методы лечения зависимостей и их эффективность. Мы проанализируем различные подходы, используемые в реабилитационных центрах, и представим данные о результативности программ. Читатели получат надежные и научно обоснованные сведения о данной проблеме.
Подробнее тут – [url=https://narkolog-na-dom-krasnodar15.ru/]врач нарколог на дом[/url]
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Подробнее можно узнать тут – https://softtech-engr.com/icon-1
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Углубиться в тему – https://statuscaptions.com/corporate-event-planner-in-nyc-can-transform-your-event.html
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Подробнее можно узнать тут – https://ap35.de/it/architekturgespraeche-4
В этой публикации мы рассматриваем важную тему борьбы с зависимостями, включая алкогольную и наркотическую зависимости. Мы обсудим методы лечения, реабилитации и поддержку, которые могут помочь людям, столкнувшимся с этой проблемой. Читатели узнают о перспективах выздоровления и важности комплексного подхода.
Выяснить больше – [url=https://narkolog-na-dom-krasnodar16.ru/]vyzvat-narkologa-na-dom[/url]
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Разобраться лучше – https://profinderinternational.com/blog/navigating-remote-staff-success-key-metrics-and-strategies-for-law-firms
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Получить дополнительную информацию – http://kendrasmiley.com/cropped-042-jpg/?thc-month=203610
Наркологическая клиника “Аура Здоровья” — специализированное учреждение, предоставляющее профессиональную помощь людям, страдающим алкогольной и наркотической зависимостью. Мы стремимся помочь пациентам преодолеть зависимости и обрести контроль над своей жизнью, используя современные методики лечения и поддержки.
Подробнее тут – https://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-rostove-na-donu.xn--p1ai/
Мы понимаем, что каждая минута имеет решающее значение, поэтому наши специалисты готовы выехать на дом в кратчайшие сроки и провести все необходимые процедуры по детоксикации организма. Наша цель — помочь пациенту вернуться к нормальной жизни без лишних стрессов и рискованных попыток самостоятельного лечения.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя на дому[/url]
Наши специалисты всегда относятся к пациентам с уважением и вниманием, создавая атмосферу доверия и поддержки. Они проводят всестороннее обследование, выявляют причины зависимости и разрабатывают индивидуальные стратегии лечения. Профессионализм и компетентность врачей являются основой успешного восстановления наших пациентов.
Получить дополнительную информацию – http://срочно-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-chelyabinske.xn--p1ai/
В клинике «Горизонт Жизни» в Красногорске разработаны протоколы экстренного вывода из запоя, которые выполняются 24 часа в сутки, семь дней в неделю. Благодаря выезду бригады врачей-наркологов и оснащённости современным оборудованием мы оказываем помощь в кратчайшие сроки, обеспечивая максимальную безопасность и комфорт пациенту.
Разобраться лучше – http://vyvod-iz-zapoya-krasnogorsk2.ru/
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя анонимно в сочи[/url]
Запой — это тяжёлое состояние, характеризующееся длительным употреблением алкоголя, при котором человек не в силах самостоятельно прекратить пить. Алкогольная интоксикация при длительных запоях вызывает нарушения в работе всех органов и систем, приводя к серьёзным последствиям, таким как инфаркты, инсульты, психозы и даже летальный исход. В такой ситуации единственным надёжным решением становится обращение за профессиональной помощью.
Исследовать вопрос подробнее – http://vyvod-iz-zapoya-korolev2.ru/srochnyj-vyvod-iz-zapoya/
Наши специалисты всегда относятся к пациентам с уважением и вниманием, создавая атмосферу доверия и поддержки. Они проводят всестороннее обследование, выявляют причины зависимости и разрабатывают индивидуальные стратегии лечения. Профессионализм и компетентность врачей являются основой успешного восстановления наших пациентов.
Ознакомиться с деталями – http://срочно-вывод-из-запоя.рф/
Команда врачей клиники “Чистый Путь” состоит из квалифицированных специалистов в области наркологии с обширным опытом работы. Каждый врач обладает глубокими знаниями в фармакологии, психофармакологии и психотерапии, регулярно повышает свою квалификацию на профильных конференциях и семинарах, чтобы использовать в своей практике самые современные и эффективные методы лечения.
Разобраться лучше – https://срочно-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-chelyabinske.xn--p1ai
После окончания врач дает консультации и рекомендации по восстановлению организма и профилактике повторных запоев.
Разобраться лучше – [url=https://vyvod-iz-zapoya-krasnodar0.ru/]вывод из запоя на дому цена[/url]
Миссия клиники “Чистый Путь” — способствовать выздоровлению и реабилитации людей, оказавшихся в плену зависимости. Мы обеспечиваем комплексный подход, включающий медицинское лечение, психологическую помощь и социальную адаптацию. Наша задача — не только устранить физическую зависимость, но и восстановить психологическое здоровье пациента, чтобы он смог вернуться к полноценной жизни в обществе.
Разобраться лучше – https://срочно-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-chelyabinske.xn--p1ai/
Группа препаратов
Узнать больше – [url=https://kapelnica-ot-zapoya-sochi0.ru/]капельница от запоя выезд сочи[/url]
Чем дольше человек находится в состоянии запоя, тем больше накапливаются токсины в организме, что негативно сказывается на всех системах. Отказ от алкоголя без должного контроля может привести к серьезным последствиям, таким как:
Подробнее тут – [url=https://narcolog-na-dom-krasnodar0.ru/]выезд нарколога на дом краснодар[/url]
Для детоксикации и восстановления организма после запоя используются только сертифицированные лекарственные препараты с доказанной эффективностью и безопасностью:
Ознакомиться с деталями – https://narcolog-na-dom-sochi0.ru/narkolog-na-dom-czena-sochi/
Мы также уделяем большое внимание социальной адаптации. Пациенты учатся восстанавливать навыки общения и обретать уверенность в себе, что помогает в будущем избежать рецидивов и успешно вернуться к полноценной жизни, будь то работа или учеба.
Выяснить больше – http://быстро-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-volgograde.xn--p1ai/
Миссия клиники “Чистый Путь” — способствовать выздоровлению и реабилитации людей, оказавшихся в плену зависимости. Мы обеспечиваем комплексный подход, включающий медицинское лечение, психологическую помощь и социальную адаптацию. Наша задача — не только устранить физическую зависимость, но и восстановить психологическое здоровье пациента, чтобы он смог вернуться к полноценной жизни в обществе.
Детальнее – http://срочно-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-chelyabinske.xn--p1ai/https://срочно-вывод-из-запоя.рф
Мы понимаем, что каждая минута имеет решающее значение, поэтому наши специалисты готовы выехать на дом в кратчайшие сроки и провести все необходимые процедуры по детоксикации организма. Наша цель — помочь пациенту вернуться к нормальной жизни без лишних стрессов и рискованных попыток самостоятельного лечения.
Углубиться в тему – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя клиника краснодар[/url]
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Подробнее можно узнать тут – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]кодирование от алкоголизма гипнозом[/url]
Миссия клиники “Чистый Путь” — способствовать выздоровлению и реабилитации людей, оказавшихся в плену зависимости. Мы обеспечиваем комплексный подход, включающий медицинское лечение, психологическую помощь и социальную адаптацию. Наша задача — не только устранить физическую зависимость, но и восстановить психологическое здоровье пациента, чтобы он смог вернуться к полноценной жизни в обществе.
Ознакомиться с деталями – http://срочно-вывод-из-запоя.рф
Миссия клиники “Чистый Путь” — способствовать выздоровлению и реабилитации людей, оказавшихся в плену зависимости. Мы обеспечиваем комплексный подход, включающий медицинское лечение, психологическую помощь и социальную адаптацию. Наша задача — не только устранить физическую зависимость, но и восстановить психологическое здоровье пациента, чтобы он смог вернуться к полноценной жизни в обществе.
Получить дополнительную информацию – http://срочно-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-chelyabinske.xn--p1ai/https://срочно-вывод-из-запоя.рф
Наркологическая клиника “Чистый Путь” находится по адресу: г. Челябинск, ул. Пушкина, д. 68, корп. 1. Мы работаем ежедневно с 9:00 до 21:00 без выходных. Наши специалисты всегда готовы проконсультировать вас и ответить на все вопросы, касающиеся лечения зависимостей. Мы гарантируем конфиденциальность и индивидуальный подход к каждому пациенту.
Выяснить больше – http://срочно-вывод-из-запоя.рф
Чем дольше человек находится в состоянии запоя, тем больше накапливаются токсины в организме, что негативно сказывается на всех системах. Отказ от алкоголя без должного контроля может привести к серьезным последствиям, таким как:
Углубиться в тему – [url=https://narcolog-na-dom-krasnodar0.ru/]нарколог на дом вывод краснодар[/url]
В этой статье мы подробно рассматриваем проверенные методы борьбы с зависимостями, включая психотерапию, медикаментозное лечение и поддержку со стороны общества. Мы акцентируем внимание на важности комплексного подхода и возможности успешного восстановления для людей, столкнувшихся с этой проблемой.
Получить дополнительные сведения – [url=https://narkolog-na-dom-krasnodar15.ru/]narkolog-na-dom-krasnodar15.ru[/url]
В клинике «Горизонт Жизни» в Красногорске разработаны протоколы экстренного вывода из запоя, которые выполняются 24 часа в сутки, семь дней в неделю. Благодаря выезду бригады врачей-наркологов и оснащённости современным оборудованием мы оказываем помощь в кратчайшие сроки, обеспечивая максимальную безопасность и комфорт пациенту.
Подробнее тут – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]narkolog vyvod iz zapoya[/url]
Дополнительно, если у пациента отмечаются психические нарушения — галлюцинации, агрессия или спутанность сознания, это является прямым сигналом к срочному вмешательству. В этом случае своевременное лечение помогает предотвратить риск инсульта, инфаркта или других серьезных заболеваний.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]наркологический вывод из запоя в краснодаре[/url]
На дом выезжает квалифицированный врач, который проводит процедуру детоксикации в комфортных условиях, позволяя пациенту избежать стресса и огласки. С помощью капельницы и медикаментов нормализуется состояние, восстанавливаются основные функции организма. Процедура длится несколько часов, после чего врач оставляет рекомендации по поддерживающему лечению.
Получить больше информации – [url=https://vyvod-iz-zapoya-lyubertsy2.ru/]vyvod iz zapoya kapelnica[/url]
После поступления вызова клиника «ЗдоровьеНорм» отправляет к пациенту опытного нарколога, который прибывает на дом в течение 30–60 минут. По приезду врач проводит комплексную диагностику, включающую измерение артериального давления, пульса, уровня кислорода в крови и тщательную оценку общего состояния пациента. На основе полученных данных специалист подбирает индивидуальную схему лечения.
Получить дополнительные сведения – [url=https://narcolog-na-dom-krasnodar0.ru/]нарколог на дом вывод из запоя[/url]
Команда врачей клиники “Чистый Путь” состоит из квалифицированных специалистов в области наркологии с обширным опытом работы. Каждый врач обладает глубокими знаниями в фармакологии, психофармакологии и психотерапии, регулярно повышает свою квалификацию на профильных конференциях и семинарах, чтобы использовать в своей практике самые современные и эффективные методы лечения.
Исследовать вопрос подробнее – http://срочно-вывод-из-запоя.рф
После поступления вызова клиника «ЗдоровьеНорм» отправляет к пациенту опытного нарколога, который прибывает на дом в течение 30–60 минут. По приезду врач проводит комплексную диагностику, включающую измерение артериального давления, пульса, уровня кислорода в крови и тщательную оценку общего состояния пациента. На основе полученных данных специалист подбирает индивидуальную схему лечения.
Подробнее можно узнать тут – https://narcolog-na-dom-krasnodar0.ru/narkolog-na-dom-czena-krasnodar/
Домашний формат идеально подходит для тех, кто находится в удовлетворительном состоянии и не требует круглосуточного контроля.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-lyubertsy2.ru/]вывод из запоя[/url]
Медицинская публикация представляет собой свод актуальных исследований, экспертных мнений и новейших достижений в сфере здравоохранения. Здесь вы найдете информацию о новых методах лечения, прорывных технологиях и их практическом применении. Мы стремимся сделать актуальные медицинские исследования доступными и понятными для широкой аудитории.
Ознакомиться с деталями – [url=https://narkolog-na-dom-krasnodar17.ru/]нарколог на дом[/url]
Длительный запой способен нанести непоправимый вред организму, привести к тяжелым нарушениям работы внутренних органов и поставить под угрозу жизнь пациента. В таких случаях необходимо срочное медицинское вмешательство, которое позволяет быстро стабилизировать состояние, вывести токсины и предотвратить развитие опасных осложнений. Клиника «ЗдоровьеНорм» в Краснодаре предлагает профессиональный вывод из запоя на дому, обеспечивая комплексное лечение с максимальной оперативностью и полной конфиденциальностью.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя недорого краснодар[/url]
В клинике «Воздух Свободы» процедура вывода из запоя в Люберцах начинается с комплексной диагностики. Врач проводит первичный осмотр, измеряет жизненные показатели и подбирает препараты, которые быстро снимают симптомы интоксикации. В зависимости от состояния пациента, лечение может проходить дома или в стационаре клиники.
Выяснить больше – https://vyvod-iz-zapoya-lyubertsy2.ru/vyvod-iz-zapoya-anonimno
Миссия клиники “Чистый Путь” — способствовать выздоровлению и реабилитации людей, оказавшихся в плену зависимости. Мы обеспечиваем комплексный подход, включающий медицинское лечение, психологическую помощь и социальную адаптацию. Наша задача — не только устранить физическую зависимость, но и восстановить психологическое здоровье пациента, чтобы он смог вернуться к полноценной жизни в обществе.
Ознакомиться с деталями – https://срочно-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-chelyabinske.xn--p1ai
Команда врачей клиники “Чистый Путь” состоит из квалифицированных специалистов в области наркологии с обширным опытом работы. Каждый врач обладает глубокими знаниями в фармакологии, психофармакологии и психотерапии, регулярно повышает свою квалификацию на профильных конференциях и семинарах, чтобы использовать в своей практике самые современные и эффективные методы лечения.
Углубиться в тему – https://срочно-вывод-из-запоя.рф/vyvod-iz-zapoya-anonimno-v-chelyabinske.xn--p1ai
Наркологическая клиника “Чистый Путь” — это специализированное медицинское учреждение, предоставляющее помощь людям, страдающим от алкогольной и наркотической зависимости. Наша цель — помочь пациентам справиться с зависимостью, вернуться к здоровой и полноценной жизни, используя эффективные методы лечения и всестороннюю поддержку.
Получить больше информации – http://срочно-вывод-из-запоя.рф/vyvod-iz-zapoya-anonimno-v-chelyabinske.xn--p1ai/
Вызов нарколога на дом становится необходимым при любых состояниях, когда отказ от алкоголя сопровождается выраженными симптомами интоксикации и абстиненции. Основные ситуации, в которых срочно требуется профессиональная помощь врача:
Детальнее – [url=https://narcolog-na-dom-sochi0.ru/]нарколог на дом сочи[/url]
Наркологическая клиника “Чистый Путь” — это специализированное медицинское учреждение, предоставляющее помощь людям, страдающим от алкогольной и наркотической зависимости. Наша цель — помочь пациентам справиться с зависимостью, вернуться к здоровой и полноценной жизни, используя эффективные методы лечения и всестороннюю поддержку.
Разобраться лучше – https://срочно-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-chelyabinske.xn--p1ai
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Исследовать вопрос подробнее – https://gyalsung.bt/upcoming-medical-screening
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Получить дополнительные сведения – https://passionpassport.com/?attachment_id=48
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее – https://www.jandtdesigns.co.uk/imac
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Узнать больше – https://www.farsrls.com/prodotti/nozzzal
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Узнать больше – https://awanderingsteeper.com/9-most-beautiful-places-to-stay-in-spain
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Выяснить больше – https://gyalsung.bt/upcoming-medical-screening
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Ознакомиться с деталями – https://aacsatlanta.com/product/multiple-dui-evaluation-2
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Исследовать вопрос подробнее – https://surgevibex.com/indian-visa-for-belize-citizens-a-comprehensive-guide-to-application-and-requirements
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Углубиться в тему – https://clemensrofner.com/2015-10-23_hi5-josef-leitner-20
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Выяснить больше – https://perrosactorescine.com/citroen_dogs_08/citroen_dogs_08-vignette
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Получить больше информации – https://billviolajr.com/parkinsons/kick-parkinsons-disease
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Получить дополнительные сведения – https://3umf.in/teatr_kvn_dgu_u_nas_strana_takaya
купить напольное кашпо для комнатных растений [url=http://www.kashpo-napolnoe-spb.ru]купить напольное кашпо для комнатных растений[/url] .
В этой статье рассматриваются различные аспекты избавления от зависимости, включая физические и психологические методы. Мы обсудим поддержку, мотивацию и стратегии, которые помогут в процессе выздоровления. Читатели узнают, как преодолеть трудности и двигаться к новой жизни без зависимости.
Выяснить больше – [url=https://narkolog-na-dom-krasnodar11.ru/]нарколог на дом вывод[/url]
Индивидуальный план включает детоксикацию, медикаментозную поддержку, психотерапию и реабилитацию. Специалисты учитывают:
Ознакомиться с деталями – [url=https://lechenie-alkogolizma-tyumen10.ru/]лечение алкоголизма тюменская область[/url]
В «Горизонте Жизни» доступны два основных формата экстренной помощи: выездная служба на дому и лечение в условиях стационара.
Узнать больше – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-anonimno
Этот информационный материал подробно освещает проблему наркозависимости, ее причины и последствия. Мы предлагаем информацию о методах лечения, профилактики и поддерживающих программах. Цель статьи — повысить осведомленность и продвигать идеи о необходимости борьбы с зависимостями.
Подробнее тут – [url=https://narkolog-na-dom-krasnodar15.ru/]врач нарколог на дом[/url]
Алкогольная и наркотическая зависимость являются серьёзными заболеваниями, требующими оперативного и квалифицированного вмешательства. Когда речь идёт о критическом состоянии пациента, особенно после длительного употребления алкоголя или наркотических веществ, время играет ключевую роль. Клиника «РеабилитАльянс» в Краснодаре предлагает услугу нарколога на дом, обеспечивая пациентам необходимую помощь в любой момент дня и ночи. Наши специалисты готовы оперативно выехать по указанному адресу и предоставить все необходимые медицинские процедуры на месте.
Углубиться в тему – [url=https://narcolog-na-dom-krasnodar00.ru/]вызвать нарколога на дом[/url]
горшки для напольных цветов магазин [url=www.kashpo-napolnoe-spb.ru/]www.kashpo-napolnoe-spb.ru/[/url] .
Эта публикация исследует взаимосвязь зависимости и психологии. Мы обсудим, как психологические аспекты влияют на появление зависимостей и процесс выздоровления. Читатели смогут понять важность профессиональной поддержки и применения научных подходов в терапии.
Выяснить больше – [url=https://narkolog-na-dom-krasnodar17.ru/]запой нарколог на дом[/url]
Эта публикация исследует взаимосвязь зависимости и психологии. Мы обсудим, как психологические аспекты влияют на появление зависимостей и процесс выздоровления. Читатели смогут понять важность профессиональной поддержки и применения научных подходов в терапии.
Подробнее тут – [url=https://narkolog-na-dom-krasnodar11.ru/]запой нарколог на дом[/url]
Алкогольный запой — это не просто многодневное пьянство, а проявление зависимости, при котором каждое утро начинается с новой дозы спиртного. Организм человека уже не способен самостоятельно справляться с последствиями переработки этанола, и любое промедление ведёт к нарастанию тяжёлой интоксикации. Даже при резком прекращении употребления алкоголя последствия могут быть непредсказуемыми: от судорожных припадков до алкогольного психоза.
Углубиться в тему – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]наркология вывод из запоя[/url]
В данном обзоре представлены основные направления и тренды в области медицины. Мы обсудим актуальные проблемы здравоохранения, свежие открытия и новые подходы, которые меняют представление о лечении и профилактике заболеваний. Эта информация будет полезна как специалистам, так и широкой публике.
Подробнее тут – [url=https://narkolog-na-dom-krasnodar11.ru/]вызвать нарколога на дом[/url]
В данной статье рассматриваются проблемы общественного здоровья и социальные факторы, влияющие на него. Мы акцентируем внимание на значении профилактики и осведомленности в защите здоровья на уровне общества. Читатели смогут узнать о новых инициативах и программах, направленных на улучшение здоровья населения.
Подробнее тут – https://narkolog-na-dom-krasnodar11.ru/
«ВладимирМед» основана группой врачей-наркологов и психотерапевтов, объединивших опыт работы в государственных и частных учреждениях. Мы предлагаем не просто преодоление запоя, а глубокую комплексную реабилитацию, включающую медико-психологическую оценку и долгосрочное сопровождение. Наша цель — восстановление здоровья на физическом и эмоциональном уровнях, возвращение пациента к полноценной социальной жизни без рецидивов.
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-vladimir10.ru/]chastnaya narkologicheskaya klinika vladimir[/url]
Эта публикация обращает внимание на важность профилактики зависимостей. Мы обсудим, как осведомленность и образование могут помочь в предотвращении возникновения зависимости. Читатели смогут ознакомиться с полезными советами и ресурсами, которые способствуют здоровому образу жизни.
Подробнее можно узнать тут – [url=https://narkolog-na-dom-krasnodar17.ru/]вызов нарколога на дом[/url]
В этой статье мы рассмотрим современные достижения в области медицины, включая инновационные методы лечения и диагностики. Мы обсудим важность профилактики заболеваний и роль технологий в улучшении качества здравоохранения. Читатели узнают о влиянии медицины на повседневную жизнь и ее значение для современного общества.
Ознакомиться с деталями – [url=https://narkolog-na-dom-krasnodar11.ru/]нарколог на дом срочно[/url]
Наркологическая помощь в «Тюменьбезалко» основана на принципах доказательной медицины и индивидуального подхода. Каждый пациент проходит тщательное обследование и консультацию узких специалистов — кардиолога, гастроэнтеролога, невролога. Такой комплексный анализ позволяет не только вывести организм из интоксикации, но и скорректировать течение сопутствующих заболеваний, что повышает безопасность лечения.
Подробнее можно узнать тут – http://
В этой публикации мы обсуждаем современные методы лечения различных заболеваний. Читатели узнают о новых медикаментах, терапиях и исследованиях, которые активно применяются для лечения. Мы нацелены на то, чтобы предоставить практические знания, которые могут помочь в борьбе с недугами.
Получить дополнительные сведения – [url=https://narkolog-na-dom-krasnodar11.ru/]нарколог на дом срочно[/url]
Эта статья освещает различные аспекты освобождения от зависимости и пути к выздоровлению. Мы обсуждаем важность осознания своей проблемы и обращения за помощью. Читатели получат практические советы о том, как преодолевать трудности и строить новую жизнь без зависимости.
Подробнее можно узнать тут – [url=https://narkolog-na-dom-krasnodar11.ru/]нарколог на дом недорого[/url]
В этой статье мы рассмотрим современные достижения в области медицины, включая инновационные методы лечения и диагностики. Мы обсудим важность профилактики заболеваний и роль технологий в улучшении качества здравоохранения. Читатели узнают о влиянии медицины на повседневную жизнь и ее значение для современного общества.
Углубиться в тему – [url=https://narkolog-na-dom-krasnodar11.ru/]нарколог на дом срочно[/url]
Sykaaa casino официальный сайт бонус за регистрацию Sykaaa Casino – это надежное и проверенное онлайн-казино с широким выбором игр, щедрыми бонусами и высоким уровнем безопасности. Sykaaa Casino Официальный Сайт Рабочее
Все вызовы фиксируются под кодовым номером без указания ФИО, что обеспечивает полную конфиденциальность каждого пациента.
Получить дополнительные сведения – https://narkologicheskaya-klinika-vladimir10.ru/
В «Горизонте Жизни» доступны два основных формата экстренной помощи: выездная служба на дому и лечение в условиях стационара.
Выяснить больше – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-cena/
Основу терапии составляют современные методы детоксикации и восстановления функций организма. Клиника предлагает амбулаторные и стационарные программы, адаптированные под состояние пациента и пожелания семьи.
Детальнее – http://lechenie-alkogolizma-tyumen10.ru/klinika-lecheniya-alkogolizma-tyumen/https://lechenie-alkogolizma-tyumen10.ru
Этот краткий обзор предлагает сжатую информацию из области медицины, включая ключевые факты и последние новости. Мы стремимся сделать информацию доступной и понятной для широкой аудитории, что позволит читателям оставаться в курсе актуальных событий в здравоохранении.
Выяснить больше – [url=https://narkolog-na-dom-krasnodar17.ru/]vyzvat-narkologa-na-dom[/url]
Медицинская публикация представляет собой свод актуальных исследований, экспертных мнений и новейших достижений в сфере здравоохранения. Здесь вы найдете информацию о новых методах лечения, прорывных технологиях и их практическом применении. Мы стремимся сделать актуальные медицинские исследования доступными и понятными для широкой аудитории.
Разобраться лучше – [url=https://narkolog-na-dom-krasnodar11.ru/]нарколог на дом круглосуточно[/url]
Клиника «ВладимирМед» предоставляет круглосуточную анонимную помощь при алкогольной зависимости с возможностью выезда врача на дом. Мы объединяем профессиональную наркологию, психологическую поддержку и современные технологии детоксикации, чтобы каждый пациент мог получить комплексное лечение в безопасной и комфортной обстановке. Конфиденциальность и оперативность — ключевые принципы нашей работы, помогающие начать новый этап жизни без страха осуждения и лишних процедур.
Подробнее – [url=https://narkologicheskaya-klinika-vladimir10.ru/]частная наркологическая клиника[/url]
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Выяснить больше – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]www.domen.ru[/url]
Все вызовы фиксируются под кодовым номером без указания ФИО, что обеспечивает полную конфиденциальность каждого пациента.
Подробнее – http://narkologicheskaya-klinika-vladimir10.ru
В этой статье мы подробно рассматриваем проверенные методы борьбы с зависимостями, включая психотерапию, медикаментозное лечение и поддержку со стороны общества. Мы акцентируем внимание на важности комплексного подхода и возможности успешного восстановления для людей, столкнувшихся с этой проблемой.
Ознакомиться с деталями – [url=https://narkolog-na-dom-krasnodar15.ru/]врач нарколог на дом[/url]
Этот информационный материал подробно освещает проблему наркозависимости, ее причины и последствия. Мы предлагаем информацию о методах лечения, профилактики и поддерживающих программах. Цель статьи — повысить осведомленность и продвигать идеи о необходимости борьбы с зависимостями.
Выяснить больше – [url=https://narkolog-na-dom-krasnodar11.ru/]нарколог на дом вывод[/url]
Медицинская публикация представляет собой свод актуальных исследований, экспертных мнений и новейших достижений в сфере здравоохранения. Здесь вы найдете информацию о новых методах лечения, прорывных технологиях и их практическом применении. Мы стремимся сделать актуальные медицинские исследования доступными и понятными для широкой аудитории.
Разобраться лучше – [url=https://narkolog-na-dom-krasnodar11.ru/]вызов нарколога на дом[/url]
В этой публикации мы обсуждаем современные методы лечения различных заболеваний. Читатели узнают о новых медикаментах, терапиях и исследованиях, которые активно применяются для лечения. Мы нацелены на то, чтобы предоставить практические знания, которые могут помочь в борьбе с недугами.
Разобраться лучше – [url=https://narkolog-na-dom-krasnodar11.ru/]нарколог на дом круглосуточно[/url]
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Подробнее – http://kodirovanie-ot-alkogolizma-odintsovo2.ru
Индивидуальный план включает детоксикацию, медикаментозную поддержку, психотерапию и реабилитацию. Специалисты учитывают:
Подробнее тут – https://lechenie-alkogolizma-tyumen10.ru/
Эта статья подробно расскажет о процессе выздоровления, который включает в себя эмоциональную, физическую и психологическую реабилитацию. Мы обсуждаем значимость поддержки и наличие профессиональных программ. Читатели узнают, как строить новую жизнь и не возвращаться к старым привычкам.
Подробнее – [url=https://narkolog-na-dom-krasnodar16.ru/]врач нарколог на дом[/url]
кайт школа Вингфойлинг: новый горизонт водных видов спорта: Вингфойлинг – это захватывающий вид спорта, сочетающий в себе элементы виндсерфинга и кайтсерфинга. Спортсмен использует крыло (винг), которое держит в руках, и гидрофойл, прикрепленный к доске, чтобы парить над водой.
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Получить больше информации – https://liberezlepresidentbazoum.com/index.php/2024/09/16/liberez-le-president-bazoum-symbole-dun-combat-courageux-pour-la-democratie
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Узнать больше – https://observatoriorrhh.com/implementacion-de-la-ley-de-40-horas-desafios-y-perspectivas-desde-la-direccion-del-trabajo
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Изучить вопрос глубже – https://bhxhtphcm.com/chua-nhan-tien-thai-san-thi-phai-lam-the-nao
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Детальнее – https://becomepersoneindivenire.it/metodologie-trasformative
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Узнать больше – https://beautyloungesanmarcos.com/new-year-new-you-what-to-know-about-body-contouring
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Получить больше информации – https://kosma.pl/stereotyp/2019/03/30/zapros-sobie-samorzecznika
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Разобраться лучше – https://www.bergon-nature-jardin.com/jeffrey-veen-quote
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Получить больше информации – https://kaladarshancraftsbazaar.com/fashion-2/blog-image-post
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Подробнее – https://mgrd.site/index.php/2024/10/01/slogans
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Получить дополнительные сведения – https://zurico.sg/product/japan-2-5kg-sealed-moisture-proof-rice-barrel-storage-box-rice-barrel-insect-proof-rice-cylinder-miscellaneous-grain-storage-box
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Ознакомиться с деталями – https://www.johnrodgers.co.uk/painting-decorating
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Изучить вопрос глубже – https://sagotech.com.vn/tin-tuc/nhung-luu-y-ve-trang-thiet-bi-phong-hoi-thao
Основные случаи, когда следует незамедлительно вызвать нарколога:
Получить дополнительные сведения – http://narkologicheskaya-pomoshh-tula10.ru/vyzov-narkologicheskoj-pomoshhi-tula/
Зависимости часто сопровождаются физическими и психологическими нарушениями, требующими комплексного подхода. Мы убеждены, что успешное лечение невозможно без индивидуального подхода, что делает нашу клинику отличным местом для тех, кто нуждается в поддержке.
Ознакомиться с деталями – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-cena-v-omske.ru/]вывод из запоя анонимно омск[/url]
Индивидуальный план включает детоксикацию, медикаментозную поддержку, психотерапию и реабилитацию. Специалисты учитывают:
Выяснить больше – [url=https://lechenie-alkogolizma-tyumen10.ru/]www.domen.ru[/url]
Фундаментом качественного лечения является профессиональная команда. Только при участии врачей-наркологов, психиатров, клинических психологов, терапевтов и консультантов по зависимому поведению можно говорить о комплексной помощи. По словам специалистов ФГБУН «Национальный научный центр наркологии», именно междисциплинарный подход формирует устойчивую динамику на всех этапах терапии — от стабилизации состояния до ресоциализации пациента.
Подробнее можно узнать тут – https://narkologicheskaya-klinika-tula10.ru/chastnaya-narkologicheskaya-klinika-tula/
официальный сайт ПокерОК
официальный сайт ПокерОК
ремонт холодильников liebherr алматы Праздничные скидки ремонт холодильников Алматы: Скидки на ремонт в праздничные дни.
«ВладимирМед» основана группой врачей-наркологов и психотерапевтов, объединивших опыт работы в государственных и частных учреждениях. Мы предлагаем не просто преодоление запоя, а глубокую комплексную реабилитацию, включающую медико-психологическую оценку и долгосрочное сопровождение. Наша цель — восстановление здоровья на физическом и эмоциональном уровнях, возвращение пациента к полноценной социальной жизни без рецидивов.
Детальнее – [url=https://narkologicheskaya-klinika-vladimir10.ru/]бесплатная наркологическая клиника владимир[/url]
В «Чистом Дыхании» вы встретите врачей-наркологов, психиатров и психологов с многолетним опытом, готовых приехать на дом для первичной детоксикации или принять в стационаре для углублённой терапии. Мы соблюдаем строгие медицинские протоколы и гарантируем безопасность даже в самых тяжёлых случаях.
Выяснить больше – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]www.domen.ru[/url]
Как подчёркивает психотерапевт наркологической клиники «Чистая Дорога» Игорь Алексеевич Кондратенко, «кодирование — это не запрет, а защита. Мы не наказываем организм, а даём ему возможность отдохнуть от постоянной борьбы и переключиться на восстановление».
Разобраться лучше – http://kodirovanie-ot-alkogolizma-shchelkovo3.ru
Во многих регионах, в том числе и в Тульской области, работают десятки учреждений, предоставляющих услуги по наркологической помощи. Однако далеко не каждое из них соответствует современным стандартам. Часть клиник работает без лицензии, другие используют устаревшие методики или предлагают исключительно детоксикацию, без последующей психотерапевтической поддержки. Чтобы не ошибиться, важно заранее проанализировать основные характеристики надёжного медицинского учреждения.
Узнать больше – http://narkologicheskaya-klinika-tula10.ru
Проблемы, связанные с употреблением алкоголя или наркотических веществ, могут застать человека врасплох и требовать немедленного медицинского вмешательства. В Туле предоставляется наркологическая помощь, направленная на купирование острых состояний и оказание поддержки пациентам в кризисной ситуации. В клинике «Здоровье+» используются современные методы лечения, основанные на отечественных клинических рекомендациях, с акцентом на безопасность и индивидуальный подход.
Ознакомиться с деталями – [url=https://narkologicheskaya-pomoshh-tula10.ru/]narkologicheskaya-pomoshh-tula10.ru/[/url]
– затяжной запой более 5–7 дней; – наличие галлюцинаций, судорог, бредовых состояний; – тяжёлое общее состояние (высокая температура, спутанность сознания, обезвоживание); – хронические болезни в стадии обострения.
Углубиться в тему – https://vyvod-iz-zapoya-kolomna3.ru
кашпо под цветы напольные [url=http://kashpo-napolnoe-spb.ru]кашпо под цветы напольные[/url] .
Пациенты, нуждающиеся в круглосуточном наблюдении, могут пройти курс терапии в стационаре. Обстановка клиники рассчитана на комфортное пребывание: палаты с индивидуальным санитарным блоком, охрана, контроль приёма препаратов, поддержка психологов.
Узнать больше – [url=https://narkologicheskaya-pomoshh-tula10.ru/]срочная наркологическая помощь[/url]
Мы активно используем методы, такие как когнитивно-поведенческая терапия, гештальт-терапия и арт-терапия, помогая пациентам преодолеть психологические травмы и внутренние конфликты, лежащие в основе аддиктивного поведения. Также наши консультанты по химической зависимости предоставляют информационную поддержку пациентам и их семьям, помогая разобраться в вопросах лечения, реабилитации и социальной адаптации.
Изучить вопрос глубже – https://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-voronezhe.xn--p1ai/
Путь к свободе от зависимости начинается не с обещаний «просто перестать», а с профессионального медицинского вмешательства. В «Чистом Дыхании» мы применяем проверенные методы, которые работают там, где сила воли без нужной поддержки оказывается бессильной. Наша клиника в Долгопрудном работает круглосуточно — чтобы помощь была доступна в самый критический момент, когда человек ощущает острую потребность в детоксикации, снятии абстинентного синдрома или психологической поддержке.
Разобраться лучше – http://narkologicheskaya-klinika-dolgoprudnyj3.ru/
Перед началом терапии врач собирает анамнез, оценивает состояние органов-мишеней (печень, почки, сердце), проводит лабораторные тесты на уровень электролитов и маркёры цирроза. Результаты обследования играют ключевую роль при выборе схемы инфузий и психотерапевтических методик.
Выяснить больше – https://lechenie-alkogolizma-tyumen10.ru/klinika-lecheniya-alkogolizma-tyumen/
Успех наркологического центра “Здоровая Жизнь” обеспечивается командой высококвалифицированных специалистов, которые объединены не только профессионализмом, но и искренним желанием помочь людям в трудной ситуации.
Изучить вопрос глубже – http://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-voronezhe.xn--p1ai/https://надежный-вывод-из-запоя.рф
Во Владимире и области работают десятки клиник, предлагающих помощь зависимым, но не все учреждения соответствуют современным медицинским и психологическим стандартам. Чтобы выбрать действительно эффективное лечение, нужно ориентироваться на проверенные критерии. В этом материале мы рассмотрим, на что стоит обратить внимание при выборе наркологического центра.
Получить дополнительные сведения – https://lechenie-narkomanii-vladimir10.ru/lechenie-narkomanii-anonimno-vladimir
Все вызовы фиксируются под кодовым номером без указания ФИО, что обеспечивает полную конфиденциальность каждого пациента.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-vladimir10.ru/]бесплатная наркологическая клиника в владимире[/url]
Пациенты, нуждающиеся в круглосуточном наблюдении, могут пройти курс терапии в стационаре. Обстановка клиники рассчитана на комфортное пребывание: палаты с индивидуальным санитарным блоком, охрана, контроль приёма препаратов, поддержка психологов.
Детальнее – [url=https://narkologicheskaya-pomoshh-tula10.ru/]наркологическая клиника клиника помощь[/url]
Бездепозитный бонус Бездепозитные бонусы
Все вызовы фиксируются под кодовым номером без указания ФИО, что обеспечивает полную конфиденциальность каждого пациента.
Подробнее – [url=https://narkologicheskaya-klinika-vladimir10.ru/]наркологическая клиника нарколог владимир[/url]
Медицинский вывод из запоя включает несколько обязательных этапов:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-kolomna3.ru/]вывод из запоя цена[/url]
В рамках реабилитации применяются когнитивно-поведенческие тренинги, арт-терапия и групповые занятия по развитию коммуникативных навыков. Это помогает пациентам осознать причины зависимости и выработать стратегии предотвращения рецидивов в будущем.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологическая клиника тюмень.[/url]
Клиника «ВладимирМед» предоставляет круглосуточную анонимную помощь при алкогольной зависимости с возможностью выезда врача на дом. Мы объединяем профессиональную наркологию, психологическую поддержку и современные технологии детоксикации, чтобы каждый пациент мог получить комплексное лечение в безопасной и комфортной обстановке. Конфиденциальность и оперативность — ключевые принципы нашей работы, помогающие начать новый этап жизни без страха осуждения и лишних процедур.
Детальнее – [url=https://narkologicheskaya-klinika-vladimir10.ru/]наркологические клиники алкоголизм[/url]
сколько стоит машина Купить Ауди: Современные технологии и изысканный дизайн Audi – это бренд, известный своими современными технологиями, изысканным дизайном и высоким уровнем комфорта.
Как подчёркивает психотерапевт наркологической клиники «Чистая Дорога» Игорь Алексеевич Кондратенко, «кодирование — это не запрет, а защита. Мы не наказываем организм, а даём ему возможность отдохнуть от постоянной борьбы и переключиться на восстановление».
Выяснить больше – [url=https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/]кодирование от алкоголизма[/url]
Если состояние пациента не позволяет доставить его в стационар, на дом выезжает врач-нарколог с необходимым оборудованием. Применяются капельницы, дезинтоксикационная терапия, медикаментозная коррекция поведения и поддержка родственников.
Подробнее тут – [url=https://narkologicheskaya-pomoshh-tula10.ru/]наркологическая помощь на дому тула[/url]
При лёгких и среднетяжёлых состояниях возможно проведение лечения на дому. Это удобно, комфортно и позволяет сохранить анонимность. Однако есть ситуации, в которых домашнее вмешательство нецелесообразно:
Детальнее – [url=https://vyvod-iz-zapoya-kolomna3.ru/]vyvod-iz-zapoya-klinika[/url]
В городе Домодедово такую услугу оказывает наркологическая клиника «Светлый Мир». Здесь работают опытные врачи с круглосуточной готовностью выехать к пациенту домой или принять его в условиях стационара. Главное — не откладывать помощь, особенно если речь идёт о пожилом человеке, пациенте с хроническими заболеваниями или тех, у кого уже проявляются тревожные симптомы: дрожь в руках, панические атаки, скачки давления, бессонница и даже слуховые или зрительные галлюцинации.
Изучить вопрос глубже – https://vyvod-iz-zapoya-domodedovo3.ru/vyvod-iz-zapoya-na-domu-v-domodedovo
Запой — это не просто бытовое пьянство, а одно из наиболее опасных проявлений алкогольной зависимости. Во время запоя организм перестаёт функционировать в нормальном режиме: сердечно-сосудистая система работает на износ, нервная система перегружена токсинами, а печень не справляется с нагрузкой. На этом фоне могут возникать тяжёлые осложнения — от судорог и гипогликемии до нарушения дыхания и алкогольного психоза. Чем дольше длится запой, тем глубже метаболические нарушения и выше риск серьёзных последствий.
Разобраться лучше – https://vyvod-iz-zapoya-kolomna3.ru/vyvod-iz-zapoya-nedorogo-v-kolomne/
Наркологическая клиника “Чистый Путь” находится по адресу: г. Челябинск, ул. Пушкина, д. 68, корп. 1. Мы работаем ежедневно с 9:00 до 21:00 без выходных. Наши специалисты всегда готовы проконсультировать вас и ответить на все вопросы, касающиеся лечения зависимостей. Мы гарантируем конфиденциальность и индивидуальный подход к каждому пациенту.
Изучить вопрос глубже – https://срочно-вывод-из-запоя.рф/
Фундаментом качественного лечения является профессиональная команда. Только при участии врачей-наркологов, психиатров, клинических психологов, терапевтов и консультантов по зависимому поведению можно говорить о комплексной помощи. По словам специалистов ФГБУН «Национальный научный центр наркологии», именно междисциплинарный подход формирует устойчивую динамику на всех этапах терапии — от стабилизации состояния до ресоциализации пациента.
Детальнее – http://narkologicheskaya-klinika-tula10.ru
Если состояние пациента не позволяет доставить его в стационар, на дом выезжает врач-нарколог с необходимым оборудованием. Применяются капельницы, дезинтоксикационная терапия, медикаментозная коррекция поведения и поддержка родственников.
Подробнее можно узнать тут – [url=https://narkologicheskaya-pomoshh-tula10.ru/]наркологическая помощь на дому в туле[/url]
https://bs2bcst.at
Мы активно используем методы, такие как когнитивно-поведенческая терапия, гештальт-терапия и арт-терапия, помогая пациентам преодолеть психологические травмы и внутренние конфликты, лежащие в основе аддиктивного поведения. Также наши консультанты по химической зависимости предоставляют информационную поддержку пациентам и их семьям, помогая разобраться в вопросах лечения, реабилитации и социальной адаптации.
Ознакомиться с деталями – https://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-voronezhe.xn--p1ai/
Запойное состояние — это не просто следствие злоупотребления спиртным, а серьёзное расстройство, которое требует немедленного медицинского вмешательства. При длительном употреблении алкоголя на протяжении нескольких суток или недель организм человека сталкивается с тяжёлой интоксикацией, нарушением работы внутренних органов и изменениями в психоэмоциональном состоянии. В такой ситуации необходим профессиональный вывод из запоя — грамотно организованный процесс детоксикации, способный предотвратить тяжёлые осложнения.
Подробнее – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]vyvod-iz-zapoya-na-domu[/url]
school gift for boy Bright and fun bird designs for kids! Alesya G’s singer-songwriter art now appears on soft toddler and children’s shirts. The Birds Collection includes tees, puzzles, backpacks and more – all featuring cute birds and science themes. Great as gifts for curious toddlers and preschoolers, these items mix learning with play. Shop kids’ bird t-shirts and accessories for your little explorer today!
Клиника «ВладимирМед» предоставляет круглосуточную анонимную помощь при алкогольной зависимости с возможностью выезда врача на дом. Мы объединяем профессиональную наркологию, психологическую поддержку и современные технологии детоксикации, чтобы каждый пациент мог получить комплексное лечение в безопасной и комфортной обстановке. Конфиденциальность и оперативность — ключевые принципы нашей работы, помогающие начать новый этап жизни без страха осуждения и лишних процедур.
Исследовать вопрос подробнее – http://narkologicheskaya-klinika-vladimir10.ru/anonimnaya-narkologicheskaya-klinika-vladimir/
Наркологическая помощь может понадобиться в разных ситуациях — от тяжёлой алкогольной интоксикации до абстинентного синдрома при отказе от наркотиков. Своевременное обращение за помощью снижает риски для жизни и здоровья, а также упрощает последующую терапию.
Разобраться лучше – http://narkologicheskaya-pomoshh-tula10.ru/neotlozhnaya-narkologicheskaya-pomoshh-tula/
Медицинский вывод из запоя включает несколько обязательных этапов:
Детальнее – https://vyvod-iz-zapoya-kolomna3.ru/vyvod-iz-zapoya-stacionar-v-kolomne/
Алкогольная зависимость — это хроническое заболевание, которое со временем разрушает здоровье, отношения, профессиональную сферу и личную идентичность человека. Многие сталкиваются с этим не сразу: поначалу кажется, что всё под контролем, но с каждым срывом становится всё труднее остановиться. Постепенно алкоголь перестаёт быть выбором и превращается в навязчивую необходимость.
Получить дополнительную информацию – http://kodirovanie-ot-alkogolizma-shchelkovo3.ru
напольные кашпо ящики [url=http://kashpo-napolnoe-spb.ru/]http://kashpo-napolnoe-spb.ru/[/url] .
Наши наркологи проводят профессиональную инфузионную детоксикацию, направленную на:
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-vladimir10.ru/]www.domen.ru[/url]
Каждый курс инфузий разрабатывается с учётом возраста пациента, сопутствующих заболеваний и длительности запоя, что повышает безопасность и эффективность лечения.
Детальнее – [url=https://narkologicheskaya-klinika-vladimir10.ru/]частная наркологическая клиника в владимире[/url]
– затяжной запой более 5–7 дней; – наличие галлюцинаций, судорог, бредовых состояний; – тяжёлое общее состояние (высокая температура, спутанность сознания, обезвоживание); – хронические болезни в стадии обострения.
Детальнее – https://vyvod-iz-zapoya-kolomna3.ru/vyvod-iz-zapoya-na-domu-v-kolomne
«ВладимирМед» основана группой врачей-наркологов и психотерапевтов, объединивших опыт работы в государственных и частных учреждениях. Мы предлагаем не просто преодоление запоя, а глубокую комплексную реабилитацию, включающую медико-психологическую оценку и долгосрочное сопровождение. Наша цель — восстановление здоровья на физическом и эмоциональном уровнях, возвращение пациента к полноценной социальной жизни без рецидивов.
Подробнее можно узнать тут – https://narkologicheskaya-klinika-vladimir10.ru/chastnaya-narkologicheskaya-klinika-vladimir/
центр психиатрической помощи [url=psihiatry-nn-1.ru]центр психиатрической помощи[/url] .
Врач индивидуально подбирает:
Выяснить больше – [url=https://lechenie-alkogolizma-tyumen10.ru/]анонимное лечение алкоголизма тюмень[/url]
Если состояние пациента не позволяет доставить его в стационар, на дом выезжает врач-нарколог с необходимым оборудованием. Применяются капельницы, дезинтоксикационная терапия, медикаментозная коррекция поведения и поддержка родственников.
Получить дополнительные сведения – [url=https://narkologicheskaya-pomoshh-tula10.ru/]наркологическая помощь в туле[/url]
Особенно важны первые дни пребывания, когда проводится диагностика, назначается медикаментозная поддержка и формируется план лечения. Компетентные врачи способны адаптировать программу под физическое и психоэмоциональное состояние пациента, учитывая как длительность употребления, так и возможные сопутствующие диагнозы. На этом этапе важно исключить риски осложнений и создать условия для безопасного перехода к следующему этапу — психологической реабилитации.
Подробнее тут – [url=https://narkologicheskaya-klinika-tula10.ru/]narkologicheskie kliniki alkogolizm tula[/url]
Кодирование может быть проведено сразу после очистки организма. В зависимости от состояния человека и выбранного метода, процедура занимает от 30 минут до полутора часов. Медикаментозные способы предполагают введение препаратов внутримышечно, внутривенно или подкожно. Психотерапевтические методы включают беседу, работу с убеждениями, возможно использование элементов гипноза или суггестивных техник.
Выяснить больше – [url=https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/]www.domen.ru[/url]
Врач индивидуально подбирает:
Выяснить больше – https://lechenie-alkogolizma-tyumen10.ru/anonimnoe-lechenie-alkogolizma-tyumen/
На базе частной клиники «Здоровье+» пациентам доступны как экстренные, так и плановые формы наркологической помощи. Все процедуры соответствуют стандартам Минздрава РФ и проводятся с соблюдением конфиденциальности.
Разобраться лучше – [url=https://narkologicheskaya-pomoshh-tula10.ru/]наркологическая помощь тула.[/url]
Используя современные инфузионные системы, мы постепенно вводим растворы для выведения токсинов, коррекции водно-электролитного баланса и восстановления функции печени. Параллельно подбираются препараты для снятия абстинентного синдрома, купирования тревожности и нормализации сна.
Углубиться в тему – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]chastnaya-narkologicheskaya-klinika[/url]
Миссия наркологического центра “Здоровая Жизнь” заключается в том, чтобы быть надежным проводником для людей, страдающих зависимостями, на пути к выздоровлению. Мы не только лечим, но и занимаемся профилактикой рецидивов, социальной адаптацией пациентов, помогая им вернуться к полноценной жизни без психоактивных веществ.
Выяснить больше – http://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-voronezhe.xn--p1ai/
В городе Домодедово такую услугу оказывает наркологическая клиника «Светлый Мир». Здесь работают опытные врачи с круглосуточной готовностью выехать к пациенту домой или принять его в условиях стационара. Главное — не откладывать помощь, особенно если речь идёт о пожилом человеке, пациенте с хроническими заболеваниями или тех, у кого уже проявляются тревожные симптомы: дрожь в руках, панические атаки, скачки давления, бессонница и даже слуховые или зрительные галлюцинации.
Детальнее – http://vyvod-iz-zapoya-domodedovo3.ru/
Пациенты, нуждающиеся в круглосуточном наблюдении, могут пройти курс терапии в стационаре. Обстановка клиники рассчитана на комфортное пребывание: палаты с индивидуальным санитарным блоком, охрана, контроль приёма препаратов, поддержка психологов.
Изучить вопрос глубже – [url=https://narkologicheskaya-pomoshh-tula10.ru/]скорая наркологическая помощь в туле[/url]
Особенно важны первые дни пребывания, когда проводится диагностика, назначается медикаментозная поддержка и формируется план лечения. Компетентные врачи способны адаптировать программу под физическое и психоэмоциональное состояние пациента, учитывая как длительность употребления, так и возможные сопутствующие диагнозы. На этом этапе важно исключить риски осложнений и создать условия для безопасного перехода к следующему этапу — психологической реабилитации.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-tula10.ru/]наркологическая клиника[/url]
Если состояние пациента не позволяет доставить его в стационар, на дом выезжает врач-нарколог с необходимым оборудованием. Применяются капельницы, дезинтоксикационная терапия, медикаментозная коррекция поведения и поддержка родственников.
Подробнее можно узнать тут – [url=https://narkologicheskaya-pomoshh-tula10.ru/]неотложная наркологическая помощь тула[/url]
На базе частной клиники «Здоровье+» пациентам доступны как экстренные, так и плановые формы наркологической помощи. Все процедуры соответствуют стандартам Минздрава РФ и проводятся с соблюдением конфиденциальности.
Подробнее – https://narkologicheskaya-pomoshh-tula10.ru
Наркологическая помощь в «Тюменьбезалко» основана на принципах доказательной медицины и индивидуального подхода. Каждый пациент проходит тщательное обследование и консультацию узких специалистов — кардиолога, гастроэнтеролога, невролога. Такой комплексный анализ позволяет не только вывести организм из интоксикации, но и скорректировать течение сопутствующих заболеваний, что повышает безопасность лечения.
Подробнее можно узнать тут – [url=https://lechenie-alkogolizma-tyumen10.ru/]лечение наркомании и алкоголизма тюмень[/url]
4-methylpropiophenone Ephedrine is often used to produce phenylacetone, a key intermediate in stimulant synthesis. From phenylacetone, substances like methylone, mephedrone (4-MMC), and 3-CMC can be made using methylamine. Phenylnitropropene, derived from nitroethane, is another precursor. A-PVP and 4-methylpropiophenone are also widely used in synthetic drug production. BMK glycidate is commonly used to synthesize controlled substances.
Метод лечения
Выяснить больше – http://lechenie-narkomanii-vladimir10.ru/lechenie-narkomanii-anonimno-vladimir/
Каждый курс инфузий разрабатывается с учётом возраста пациента, сопутствующих заболеваний и длительности запоя, что повышает безопасность и эффективность лечения.
Подробнее – [url=https://narkologicheskaya-klinika-vladimir10.ru/]наркологическая клиника цены владимир[/url]
Если состояние пациента не позволяет доставить его в стационар, на дом выезжает врач-нарколог с необходимым оборудованием. Применяются капельницы, дезинтоксикационная терапия, медикаментозная коррекция поведения и поддержка родственников.
Выяснить больше – https://narkologicheskaya-pomoshh-tula10.ru/neotlozhnaya-narkologicheskaya-pomoshh-tula/
Благоустройство территории
https://b2tsite4.io/bs2web_at.html
Мы создаем благоприятные условия для полного выздоровления и восстановления личности каждого пациента. Наша команда разрабатывает индивидуальные программы терапии, учитывая особенности здоровья и психического состояния человека. Лечение строится на научно обоснованных методах, что позволяет нам добиваться высоких результатов.
Углубиться в тему – http://быстро-вывод-из-запоя.рф
Возможные признаки
Выяснить больше – http://narkologicheskaya-klinika-tula10.ru
Показатель
Узнать больше – [url=https://narkologicheskaya-klinika-tula10.ru/]наркологическая клиника цены[/url]
methylone Ephedrine is often used to produce phenylacetone, a key intermediate in stimulant synthesis. From phenylacetone, substances like methylone, mephedrone (4-MMC), and 3-CMC can be made using methylamine. Phenylnitropropene, derived from nitroethane, is another precursor. A-PVP and 4-methylpropiophenone are also widely used in synthetic drug production. BMK glycidate is commonly used to synthesize controlled substances.
Мы рекомендуем рассмотреть кодирование, если:
Выяснить больше – http://kodirovanie-ot-alkogolizma-shchelkovo3.ru
В условиях стационара или на дневном стационаре применяются сбалансированные инфузионные растворы, витамины, антиоксиданты и препараты для поддержки печени. Цель — минимизировать интоксикацию и предотвратить осложнения.
Изучить вопрос глубже – http://lechenie-alkogolizma-tyumen10.ru/anonimnoe-lechenie-alkogolizma-tyumen/
1000 рублей за регистрацию вывод сразу без вложений в казино Тысяча рублей, словно луч надежды, маячит перед новичками онлайн-казино, предлагая начать свой путь в мир азарта без каких-либо финансовых вложений. Это возможность испытать удачу, не рискуя собственными средствами, и почувствовать вкус победы, не расставаясь с кровно заработанными. 1000 рублей за регистрацию вывод сразу без вложений в казино адмирал
В нашем центре работают наркологи высшей категории с многолетним опытом лечения различных зависимостей. Они владеют современными методами детоксикации, купирования абстинентного синдрома, кодирования и фармакотерапии.
Разобраться лучше – https://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-anonimno-v-voronezhe.xn--p1ai/
Все вызовы фиксируются под кодовым номером без указания ФИО, что обеспечивает полную конфиденциальность каждого пациента.
Получить дополнительные сведения – http://narkologicheskaya-klinika-vladimir10.ru/
Перед началом терапии врач собирает анамнез, оценивает состояние органов-мишеней (печень, почки, сердце), проводит лабораторные тесты на уровень электролитов и маркёры цирроза. Результаты обследования играют ключевую роль при выборе схемы инфузий и психотерапевтических методик.
Изучить вопрос глубже – http://lechenie-alkogolizma-tyumen10.ru
Мы оказываем услуги 24 часа в сутки, 7 дней в неделю, без выходных и праздников. Это позволяет:
Получить больше информации – [url=https://narkologicheskaya-klinika-vladimir10.ru/]наркологическая клиника[/url]
Каждый курс инфузий разрабатывается с учётом возраста пациента, сопутствующих заболеваний и длительности запоя, что повышает безопасность и эффективность лечения.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-vladimir10.ru/]наркологическая клиника цены владимир[/url]
напольный пластиковый горшок [url=http://kashpo-napolnoe-msk.ru]напольный пластиковый горшок[/url] .
напольное кашпо для цветов высокое пластик [url=http://kashpo-napolnoe-msk.ru]напольное кашпо для цветов высокое пластик[/url] .
Пациенты, нуждающиеся в круглосуточном наблюдении, могут пройти курс терапии в стационаре. Обстановка клиники рассчитана на комфортное пребывание: палаты с индивидуальным санитарным блоком, охрана, контроль приёма препаратов, поддержка психологов.
Узнать больше – http://narkologicheskaya-pomoshh-tula10.ru/
Наркологическая клиника “Аура Здоровья” — специализированное учреждение, предоставляющее профессиональную помощь людям, страдающим алкогольной и наркотической зависимостью. Мы стремимся помочь пациентам преодолеть зависимости и обрести контроль над своей жизнью, используя современные методики лечения и поддержки.
Ознакомиться с деталями – https://медицинский-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-rostove-na-donu.xn--p1ai/
Наркологический центр “Здоровая Жизнь” — это надежный оплот для тех, кто оказался в плену зависимости. Наша команда опытных наркологов, психологов и психотерапевтов применяет современные методы лечения и реабилитации, чтобы помочь пациентам вернуться к трезвой и полноценной жизни. Мы стремимся не только устранить симптомы, но и выявить и устранить коренные причины заболевания, предоставляя пациентам инструменты для преодоления тяги к психоактивным веществам и формирования здоровых жизненных установок.
Углубиться в тему – http://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-voronezhe.xn--p1ai/
https://1-bs2best.lat/bs2_best_at.html
Перед началом терапии врач проводит предварительный осмотр: измеряет давление, пульс, оценивает общее состояние пациента, наличие сопутствующих хронических заболеваний и признаков тяжёлой интоксикации. После этого разрабатывается индивидуальная схема лечения. В большинстве случаев она включает внутривенное введение растворов, улучшающих водно-солевой баланс, а также медикаментов, направленных на снятие абстиненции, нормализацию сна и снижение тревожности.
Разобраться лучше – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]вывод из запоя с выездом[/url]
Возможные признаки
Узнать больше – [url=https://narkologicheskaya-klinika-tula10.ru/]наркологическая клиника цены в туле[/url]
Врач индивидуально подбирает:
Получить дополнительные сведения – [url=https://lechenie-alkogolizma-tyumen10.ru/]лечение алкоголизма тюмень[/url]
AI generator character ai nsfw of the new generation: artificial intelligence turns text into stylish and realistic pictures and videos.
Врач индивидуально подбирает:
Углубиться в тему – [url=https://lechenie-alkogolizma-tyumen10.ru/]лечение алкоголизма в тюмени[/url]
Мы оказываем услуги 24 часа в сутки, 7 дней в неделю, без выходных и праздников. Это позволяет:
Выяснить больше – https://narkologicheskaya-klinika-vladimir10.ru/chastnaya-narkologicheskaya-klinika-vladimir/
Алкоголь и наркотики воздействуют на организм комплексно: нарушается работа сердца, сосудов, печени и почек, страдает нервная система. При запое или ломке без квалифицированной помощи возникают судороги, делирий, галлюцинации и серьёзные сбои в обмене веществ. Самостоятельные попытки «перетерпеть» или «отмотать» запой зачастую приводят к тяжёлым осложнениям, вплоть до комы и необратимых изменений в органах.
Узнать больше – https://narkologicheskaya-klinika-dolgoprudnyj3.ru/chastnaya-narkologicheskaya-klinika-v-dolgoprudnom/
Наркологическая помощь может понадобиться в разных ситуациях — от тяжёлой алкогольной интоксикации до абстинентного синдрома при отказе от наркотиков. Своевременное обращение за помощью снижает риски для жизни и здоровья, а также упрощает последующую терапию.
Углубиться в тему – [url=https://narkologicheskaya-pomoshh-tula10.ru/]скорая наркологическая помощь тульская область[/url]
На базе частной клиники «Здоровье+» пациентам доступны как экстренные, так и плановые формы наркологической помощи. Все процедуры соответствуют стандартам Минздрава РФ и проводятся с соблюдением конфиденциальности.
Получить дополнительные сведения – [url=https://narkologicheskaya-pomoshh-tula10.ru/]круглосуточная наркологическая помощь в туле[/url]
В условиях стационара или на дневном стационаре применяются сбалансированные инфузионные растворы, витамины, антиоксиданты и препараты для поддержки печени. Цель — минимизировать интоксикацию и предотвратить осложнения.
Получить дополнительные сведения – [url=https://lechenie-alkogolizma-tyumen10.ru/]лечение наркомании и алкоголизма[/url]
Основу терапии составляют современные методы детоксикации и восстановления функций организма. Клиника предлагает амбулаторные и стационарные программы, адаптированные под состояние пациента и пожелания семьи.
Узнать больше – http://lechenie-alkogolizma-tyumen10.ru
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Разобраться лучше – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологическая клиника цены в тюмени[/url]
Первый и самый важный момент — какие методики применяются в клинике. Качественное лечение наркозависимости включает несколько этапов: детоксикация, стабилизация состояния, психотерапия, ресоциализация. Одного лишь выведения токсинов из организма недостаточно — без проработки психологических причин употребления высокий риск рецидива.
Исследовать вопрос подробнее – https://lechenie-narkomanii-vladimir10.ru/
Наркологический центр “Здоровая Жизнь” — это надежный оплот для тех, кто оказался в плену зависимости. Наша команда опытных наркологов, психологов и психотерапевтов применяет современные методы лечения и реабилитации, чтобы помочь пациентам вернуться к трезвой и полноценной жизни. Мы стремимся не только устранить симптомы, но и выявить и устранить коренные причины заболевания, предоставляя пациентам инструменты для преодоления тяги к психоактивным веществам и формирования здоровых жизненных установок.
Выяснить больше – http://надежный-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-voronezhe.xn--p1ai/https://надежный-вывод-из-запоя.рф
Метод лечения
Углубиться в тему – https://lechenie-narkomanii-vladimir10.ru/lechenie-narkomanii-czena-vladimir
Метод лечения
Углубиться в тему – [url=https://lechenie-narkomanii-vladimir10.ru/]лечение наркомании и алкоголизма владимирская область[/url]
Возможные признаки
Разобраться лучше – [url=https://narkologicheskaya-klinika-tula10.ru/]наркологические клиники алкоголизм[/url]
Перед началом кодирования важно провести комплексную диагностику. Врачи клиники оценивают общее состояние пациента, определяют степень зависимости, выявляют противопоказания к медикаментозным препаратам, уточняют психоэмоциональный фон. На этом этапе важно, чтобы пациент был трезв — либо как минимум 2–3 дня без алкоголя, либо прошёл процедуру детоксикации в нашей клинике или дома под наблюдением.
Выяснить больше – [url=https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/]metody-kodirovaniya-ot-alkogolizma[/url]
Если состояние пациента не позволяет доставить его в стационар, на дом выезжает врач-нарколог с необходимым оборудованием. Применяются капельницы, дезинтоксикационная терапия, медикаментозная коррекция поведения и поддержка родственников.
Подробнее тут – http://narkologicheskaya-pomoshh-tula10.ru/
New AI generator nsfw ai image generator of the new generation: artificial intelligence turns text into stylish and realistic image and videos.
Как подчёркивает врач-нарколог клиники «Светлый Мир» Александр Павлович Ермаков, «на фоне резкого отказа от алкоголя могут возникнуть острые состояния, требующие реанимационной помощи — поэтому нельзя пытаться прервать запой без участия специалиста». В домашних условиях, под присмотром профессионала, лечение может быть начато уже в течение часа после вызова, без необходимости транспортировки пациента в критическом состоянии.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]vyvod-iz-zapoya-vyzov-na-dom[/url]
В нашем центре работают наркологи высшей категории с многолетним опытом лечения различных зависимостей. Они владеют современными методами детоксикации, купирования абстинентного синдрома, кодирования и фармакотерапии.
Детальнее – http://надежный-вывод-из-запоя.рф/
Если состояние пациента не позволяет доставить его в стационар, на дом выезжает врач-нарколог с необходимым оборудованием. Применяются капельницы, дезинтоксикационная терапия, медикаментозная коррекция поведения и поддержка родственников.
Исследовать вопрос подробнее – https://narkologicheskaya-pomoshh-tula10.ru/neotlozhnaya-narkologicheskaya-pomoshh-tula/
Запойное состояние — это не просто следствие злоупотребления спиртным, а серьёзное расстройство, которое требует немедленного медицинского вмешательства. При длительном употреблении алкоголя на протяжении нескольких суток или недель организм человека сталкивается с тяжёлой интоксикацией, нарушением работы внутренних органов и изменениями в психоэмоциональном состоянии. В такой ситуации необходим профессиональный вывод из запоя — грамотно организованный процесс детоксикации, способный предотвратить тяжёлые осложнения.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]анонимный вывод из запоя[/url]
Наркологическая помощь может понадобиться в разных ситуациях — от тяжёлой алкогольной интоксикации до абстинентного синдрома при отказе от наркотиков. Своевременное обращение за помощью снижает риски для жизни и здоровья, а также упрощает последующую терапию.
Исследовать вопрос подробнее – http://narkologicheskaya-pomoshh-tula10.ru/vyzov-narkologicheskoj-pomoshhi-tula/
Пациенты, нуждающиеся в круглосуточном наблюдении, могут пройти курс терапии в стационаре. Обстановка клиники рассчитана на комфортное пребывание: палаты с индивидуальным санитарным блоком, охрана, контроль приёма препаратов, поддержка психологов.
Детальнее – [url=https://narkologicheskaya-pomoshh-tula10.ru/]наркологическая помощь тульская область[/url]
Во многих регионах, в том числе и в Тульской области, работают десятки учреждений, предоставляющих услуги по наркологической помощи. Однако далеко не каждое из них соответствует современным стандартам. Часть клиник работает без лицензии, другие используют устаревшие методики или предлагают исключительно детоксикацию, без последующей психотерапевтической поддержки. Чтобы не ошибиться, важно заранее проанализировать основные характеристики надёжного медицинского учреждения.
Подробнее – https://narkologicheskaya-klinika-tula10.ru/chastnaya-narkologicheskaya-klinika-tula/
Проблемы, связанные с употреблением алкоголя или наркотических веществ, могут застать человека врасплох и требовать немедленного медицинского вмешательства. В Туле предоставляется наркологическая помощь, направленная на купирование острых состояний и оказание поддержки пациентам в кризисной ситуации. В клинике «Здоровье+» используются современные методы лечения, основанные на отечественных клинических рекомендациях, с акцентом на безопасность и индивидуальный подход.
Подробнее можно узнать тут – [url=https://narkologicheskaya-pomoshh-tula10.ru/]наркологическая помощь на дому тула.[/url]
Наши специалисты всегда относятся к пациентам с уважением и вниманием, создавая атмосферу доверия и поддержки. Они проводят всестороннее обследование, выявляют причины зависимости и разрабатывают индивидуальные стратегии лечения. Профессионализм и компетентность врачей являются основой успешного восстановления наших пациентов.
Изучить вопрос глубже – https://срочно-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-chelyabinske.xn--p1ai
1000 рублей без депозита 1000 рублей без депозита
https://2-bs2best.art/blacksprut.html
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Подробнее – https://www.hotel-sugano.com/bbs/sugano.cgi/www.skitour.su/datasphere.ru/club/user/12/blog/2477/www.tovery.net/www.hip-hop.ru/forum
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Получить дополнительную информацию – https://www.breezeleeds.org/breeze
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Разобраться лучше – https://santongsuai.com/%E0%B9%82%E0%B8%9B%E0%B8%A3%E0%B9%82%E0%B8%A1%E0%B8%8A%E0%B8%B1%E0%B9%88%E0%B8%99%E0%B8%9B%E0%B8%A3%E0%B8%B0%E0%B8%88%E0%B8%B3%E0%B9%80%E0%B8%94%E0%B8%B7%E0%B8%AD%E0%B8%99%E0%B8%81%E0%B8%B8%E0%B8%A1
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Получить дополнительную информацию – https://piscinadiala.it/nuoto-master
Hey I am so glad I found your blog, I really found you by accident, while I was researching on Yahoo for something else, Nonetheless I am here now and would just like to say thank you for a incredible post and a all round enjoyable blog (I also love the theme/design), I don’t have time to read through it all at the minute but I have book-marked it and also added in your RSS feeds, so when I have time I will be back to read a lot more, Please do keep up the fantastic jo.
вход lee bet
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Получить дополнительные сведения – https://yinforchange.in/speed-up-our-destination-is-far
Все вызовы фиксируются под кодовым номером без указания ФИО, что обеспечивает полную конфиденциальность каждого пациента.
Получить дополнительную информацию – https://narkologicheskaya-klinika-vladimir10.ru/
For hottest information you have to visit world wide web and on web I found this site as a most excellent web site for latest updates.
сайт банда казино
Чем дольше человек находится в состоянии запоя, тем больше накапливаются токсины в организме, что негативно сказывается на всех системах. Отказ от алкоголя без должного контроля может привести к серьезным последствиям, таким как:
Получить дополнительные сведения – http://narcolog-na-dom-krasnodar0.ru
Алкогольная и наркотическая зависимость являются серьёзными заболеваниями, требующими оперативного и квалифицированного вмешательства. Когда речь идёт о критическом состоянии пациента, особенно после длительного употребления алкоголя или наркотических веществ, время играет ключевую роль. Клиника «РеабилитАльянс» в Краснодаре предлагает услугу нарколога на дом, обеспечивая пациентам необходимую помощь в любой момент дня и ночи. Наши специалисты готовы оперативно выехать по указанному адресу и предоставить все необходимые медицинские процедуры на месте.
Детальнее – [url=https://narcolog-na-dom-krasnodar00.ru/]нарколог на дом вывод краснодар[/url]
В этой статье мы рассматриваем разные способы борьбы с алкогольной зависимостью. Обсуждаются методы лечения, программы реабилитации и советы для поддержки близких. Читатели получат информацию о том, как преодолеть зависимость и добиться успешного выздоровления.
Изучить вопрос глубже – https://multinex.ru/narkologicheskaya-pomoshh-v-koroljove
Когда речь идет о запое, алкогольной интоксикации или абстинентном синдроме, промедление может привести к тяжелым последствиям для организма. Клиника «Реабилитация Плюс» в Сочи предлагает экстренную помощь нарколога на дому, благодаря которой пациенты могут быстро стабилизировать свое состояние и избежать опасных осложнений. Наши врачи работают круглосуточно, оперативно реагируют на вызовы и оказывают квалифицированную медицинскую поддержку прямо у вас дома.
Изучить вопрос глубже – [url=https://narcolog-na-dom-sochi00.ru/]нарколог на дом сочи[/url]
Врач индивидуально подбирает:
Получить дополнительные сведения – [url=https://lechenie-alkogolizma-tyumen10.ru/]клиника лечения алкоголизма[/url]
Клиника «Нарколог-Профи» предлагает круглосуточную помощь на дому в Екатеринбурге и Свердловской области. Наши опытные специалисты готовы оперативно приехать по вашему вызову и оказать экстренную медицинскую поддержку при алкогольной или наркотической зависимости. Мы проводим детоксикацию организма, купируем абстинентный синдром и стабилизируем состояние пациента, обеспечивая при этом полную конфиденциальность и комфорт в домашних условиях.
Выяснить больше – [url=https://narcolog-na-dom-ekaterinburg00.ru/]vyzov-narkologa-na-dom ekaterinburg[/url]
Запой — это не просто бытовое пьянство, а одно из наиболее опасных проявлений алкогольной зависимости. Во время запоя организм перестаёт функционировать в нормальном режиме: сердечно-сосудистая система работает на износ, нервная система перегружена токсинами, а печень не справляется с нагрузкой. На этом фоне могут возникать тяжёлые осложнения — от судорог и гипогликемии до нарушения дыхания и алкогольного психоза. Чем дольше длится запой, тем глубже метаболические нарушения и выше риск серьёзных последствий.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-kolomna3.ru/]вывод из запоя на дому недорого[/url]
“Обратился в ‘Ренессанс’ с алкоголизмом. Лечение было непростым, но врачи поддерживали меня на каждом шагу. Сейчас я живу трезво и очень благодарен за это.” — Дмитрий, 38 лет”Много лет боролась с зависимостью от марихуаны и наконец нашла помощь здесь. ‘Ренессанс’ предложила грамотный подход, и с их помощью я справилась.” — Екатерина, 25 лет”Страдал от лудомании и знал, что сам не справлюсь. Врачи предложили методы, которые помогли мне избавиться от зависимости. Теперь азартные игры — это прошлое.” — Алексей, 41 год
Исследовать вопрос подробнее – https://качество-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-permi.xn--p1ai/
Hi there, its pleasant piece of writing regarding media print, we all be familiar with media is a impressive source of data.
https://3dlevsha.com.ua/chomu-neyakisne-sklo-fary-nebezpechne-na-dorozi
При поступлении вызова специалисты клиники «ЗдоровьеНорм» выезжают на дом в течение 30–60 минут. Врач проводит тщательную диагностику, измеряя артериальное давление, пульс, уровень кислорода в крови и оценивая общее состояние пациента. После этого осуществляется индивидуальный подбор лечебной схемы, основанной на объективных данных и анамнезе пациента.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]vyvod-iz-zapoya krasnodar[/url]
Чем дольше человек находится в состоянии запоя, тем больше накапливаются токсины в организме, что негативно сказывается на всех системах. Отказ от алкоголя без должного контроля может привести к серьезным последствиям, таким как:
Выяснить больше – [url=https://narcolog-na-dom-krasnodar0.ru/]запой нарколог на дом[/url]
https://2-bs2best.lat/bs2best.html
Своевременное обращение к специалисту позволяет избежать опасных осложнений и облегчить процесс восстановления организма. Экстренный вызов врача-нарколога необходим в следующих случаях:
Ознакомиться с деталями – http://narcolog-na-dom-krasnodar00.ru
Мы рекомендуем рассмотреть кодирование, если:
Углубиться в тему – https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/kodirovanie-ot-alkogolizma-ceny-v-shchelkovo/
Используя современные инфузионные системы, мы постепенно вводим растворы для выведения токсинов, коррекции водно-электролитного баланса и восстановления функции печени. Параллельно подбираются препараты для снятия абстинентного синдрома, купирования тревожности и нормализации сна.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]наркологическая клиника в области[/url]
Why visitors still use to read news papers when in this technological world the whole thing is accessible on web?
https://warfare.com.ua/linzy-u-farah-osvitlennya
При длительном запое или серьезной алкогольной интоксикации часто нет возможности или желания ехать в стационар. В таких ситуациях оптимальным решением становится вызов нарколога на дом в Сочи. Специалисты клиники «Жизнь без Запоя» круглосуточно приезжают к пациентам, оперативно оказывают медицинскую помощь и проводят профессиональную детоксикацию организма прямо в домашних условиях. Благодаря комфортному лечению на дому пациенты быстрее восстанавливаются, избегают дополнительного стресса и осложнений, связанных с госпитализацией.
Исследовать вопрос подробнее – https://narcolog-na-dom-sochi0.ru/vyzov-narkologa-na-dom-sochi
Длительный запой способен нанести непоправимый вред организму, привести к тяжелым нарушениям работы внутренних органов и поставить под угрозу жизнь пациента. В таких случаях необходимо срочное медицинское вмешательство, которое позволяет быстро стабилизировать состояние, вывести токсины и предотвратить развитие опасных осложнений. Клиника «ЗдоровьеНорм» в Краснодаре предлагает профессиональный вывод из запоя на дому, обеспечивая комплексное лечение с максимальной оперативностью и полной конфиденциальностью.
Разобраться лучше – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя круглосуточно в краснодаре[/url]
Наркологическая помощь «ТюменьМед» не ограничивается только физической детоксикацией. В состав команды входят психологи и социальные работники, которые проводят мотивационные беседы, обучают навыкам самоконтроля и оказывают помощь в планировании досуга и социальных активностей после детоксикации.
Детальнее – [url=https://narkologicheskaya-klinika-tyumen10.ru/]частная наркологическая клиника[/url]
Основная процедура включает в себя:
Ознакомиться с деталями – [url=https://narcolog-na-dom-krasnodar0.ru/]вызов нарколога на дом[/url]
Наркологический центр “Новый Взгляд” расположен по адресу: г. Самара, ул. Ленина 9. Мы открыты для пациентов круглосуточно. Также доступны онлайн-консультации, что делает наши услуги более доступными для всех нуждающихся.
Исследовать вопрос подробнее – https://тайный-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-samare.xn--p1ai/
Процедура лечения начинается с установки внутривенной капельницы, через которую вводятся детоксикационные растворы, способствующие быстрому выведению токсинов и восстановлению водно-электролитного баланса. При необходимости врач назначает дополнительные препараты, такие как седативные средства для купирования симптомов абстинентного синдрома, гепатопротекторы для поддержки печени и кардиопротекторы для нормализации работы сердца.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя цена краснодарский край[/url]
В зависимости от состояния пациента мы предлагаем два формата помощи: выезд нарколога на дом или госпитализацию в стационар. Оба варианта включают детоксикацию — выведение токсинов из организма с помощью инфузионной терапии (капельницы), а также медикаментозную поддержку: успокоительные, витамины, препараты для печени и сердца.
Выяснить больше – https://vyvod-iz-zapoya-serpuhov3.ru/vyvod-iz-zapoya-na-domu-v-serpuhove/
Индивидуальный план включает детоксикацию, медикаментозную поддержку, психотерапию и реабилитацию. Специалисты учитывают:
Подробнее можно узнать тут – https://lechenie-alkogolizma-tyumen10.ru/anonimnoe-lechenie-alkogolizma-tyumen
Многие люди пытаются самостоятельно справиться с запоем или наркотической интоксикацией, однако это часто приводит к серьезным осложнениям и ухудшению состояния здоровья. Без квалифицированной медицинской помощи организм подвергается сильному токсическому воздействию, что негативно отражается на всех органах и системах. Особенно страдают сердечно-сосудистая, нервная и пищеварительная системы. Игнорирование проблемы может привести к хроническим заболеваниям, алкогольным психозам, поражениям печени и даже к летальному исходу.
Подробнее тут – [url=https://narcolog-na-dom-krasnodar00.ru/]нарколог на дом краснодар.[/url]
Вызов нарколога на дом становится необходимым при любых состояниях, когда отказ от алкоголя сопровождается выраженными симптомами интоксикации и абстиненции. Основные ситуации, в которых срочно требуется профессиональная помощь врача:
Получить дополнительную информацию – [url=https://narcolog-na-dom-sochi0.ru/]выезд нарколога на дом сочи[/url]
Для каждого пациента используется индивидуальный монитор жизненно важных функций, передающий данные врачу в клинике через защищённый канал связи. Это обеспечивает безопасность при лечении как лёгких, так и тяжёлых форм интоксикации, снижая вероятность осложнений.
Подробнее тут – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологическая клиника на дом[/url]
Каждый курс инфузий разрабатывается с учётом возраста пациента, сопутствующих заболеваний и длительности запоя, что повышает безопасность и эффективность лечения.
Выяснить больше – [url=https://narkologicheskaya-klinika-vladimir10.ru/]платная наркологическая клиника[/url]
секс знакомства макеевка Секс знакомства Донецк: Найди свою страсть онлайн В эпоху цифровых технологий, онлайн-знакомства стали популярным способом найти партнера для секса в Донецке. Множество сайтов и приложений предлагают платформы для людей, ищущих интимные встречи без обязательств.
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Подробнее – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологические клиники алкоголизм тюмень[/url]
Клиника также предлагает долгосрочные программы, которые включают как стационарное, так и амбулаторное лечение. Мы понимаем, что восстановление требует не только медицинской помощи, но и значительной психологической поддержки на каждом этапе.
Изучить вопрос глубже – http://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-nizhnem-novgoroge.xn--p1ai/
– затяжной запой более 5–7 дней; – наличие галлюцинаций, судорог, бредовых состояний; – тяжёлое общее состояние (высокая температура, спутанность сознания, обезвоживание); – хронические болезни в стадии обострения.
Исследовать вопрос подробнее – http://vyvod-iz-zapoya-kolomna3.ru/vyvod-iz-zapoya-na-domu-v-kolomne/
спины за регистрацию без депозита с выводом Бездепозитные бонусы – это как бесплатный билет в мир азарта, возможность испытать удачу, не рискуя собственными средствами. Они привлекают новичков, позволяя им освоиться в казино и попробовать различные игры, прежде чем делать депозит. Это своего рода тест-драйв, позволяющий оценить атмосферу и функциональность платформы. Бездепозитные бонусы в казино
Таким образом, наш подход охватывает все аспекты реабилитации, что позволяет пациентам успешно справляться с зависимостями и возвращаться к полноценной жизни.
Исследовать вопрос подробнее – https://тайный-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-samare.xn--p1ai
Своевременное обращение к специалисту позволяет избежать опасных осложнений и облегчить процесс восстановления организма. Экстренный вызов врача-нарколога необходим в следующих случаях:
Углубиться в тему – [url=https://narcolog-na-dom-krasnodar00.ru/]нарколог на дом краснодарский край[/url]
«ВладимирМед» основана группой врачей-наркологов и психотерапевтов, объединивших опыт работы в государственных и частных учреждениях. Мы предлагаем не просто преодоление запоя, а глубокую комплексную реабилитацию, включающую медико-психологическую оценку и долгосрочное сопровождение. Наша цель — восстановление здоровья на физическом и эмоциональном уровнях, возвращение пациента к полноценной социальной жизни без рецидивов.
Выяснить больше – [url=https://narkologicheskaya-klinika-vladimir10.ru/]наркологическая клиника на дом[/url]
Как подчёркивает психотерапевт наркологической клиники «Чистая Дорога» Игорь Алексеевич Кондратенко, «кодирование — это не запрет, а защита. Мы не наказываем организм, а даём ему возможность отдохнуть от постоянной борьбы и переключиться на восстановление».
Изучить вопрос глубже – [url=https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/]metody-kodirovaniya-ot-alkogolizma[/url]
В зависимости от состояния пациента мы предлагаем два формата помощи: выезд нарколога на дом или госпитализацию в стационар. Оба варианта включают детоксикацию — выведение токсинов из организма с помощью инфузионной терапии (капельницы), а также медикаментозную поддержку: успокоительные, витамины, препараты для печени и сердца.
Углубиться в тему – [url=https://vyvod-iz-zapoya-serpuhov3.ru/]вывод из запоя круглосуточно[/url]
Мы понимаем, что каждая минута имеет решающее значение, поэтому наши специалисты готовы выехать на дом в кратчайшие сроки и провести все необходимые процедуры по детоксикации организма. Наша цель — помочь пациенту вернуться к нормальной жизни без лишних стрессов и рискованных попыток самостоятельного лечения.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя клиника в краснодаре[/url]
Используя современные инфузионные системы, мы постепенно вводим растворы для выведения токсинов, коррекции водно-электролитного баланса и восстановления функции печени. Параллельно подбираются препараты для снятия абстинентного синдрома, купирования тревожности и нормализации сна.
Получить больше информации – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]www.domen.ru[/url]
https://b2tsite3.cc/darknetmarket.html
Good day! Would you mind if I share your blog with my myspace group? There’s a lot of people that I think would really enjoy your content. Please let me know. Thank you
https://renenergy.com.ua/innovatsiyni-tekhnologiyi-u-vyrobnytstvi-skla-dlya-far-shcho-varto-znaty
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Исследовать вопрос подробнее – https://www.iisertirupati.ac.in/demo-student
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Углубиться в тему – http://tokmaklasoch.minobr63.ru/cropped-image1-jpg
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Получить дополнительные сведения – https://www.himachallive.in/%E0%A4%B9%E0%A4%BF%E0%A4%AE%E0%A4%BE%E0%A4%9A%E0%A4%B2-%E0%A4%AA%E0%A5%8D%E0%A4%B0%E0%A4%A6%E0%A5%87%E0%A4%B6/%E0%A4%B8%E0%A4%AD%E0%A5%80-%E0%A4%AC%E0%A5%88%E0%A4%82%E0%A4%95-%E0%A4%A8%E0%A4%BF%E0%A4%B0%E0%A5%8D%E0%A4%A7%E0%A4%BE%E0%A4%B0%E0%A4%BF%E0%A4%A4-%E0%A4%B2%E0%A4%95%E0%A5%8D%E0%A4%B7%E0%A5%8D
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Изучить вопрос глубже – http://soraneko.net/blog/index.cgi/index.cgi?time=1097754268&id=kashiken&mode=disp&category=0&writer_all=&category_all=
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Подробнее можно узнать тут – http://soraneko.net/blog/index.cgi/index.cgi?time=1097754268&id=kashiken&mode=disp&category=&writer_all=&category_all=
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Детальнее – https://www.himachallive.in/%E0%A4%B9%E0%A4%BF%E0%A4%AE%E0%A4%BE%E0%A4%9A%E0%A4%B2-%E0%A4%AA%E0%A5%8D%E0%A4%B0%E0%A4%A6%E0%A5%87%E0%A4%B6/%E0%A4%B8%E0%A4%AD%E0%A5%80-%E0%A4%AC%E0%A5%88%E0%A4%82%E0%A4%95-%E0%A4%A8%E0%A4%BF%E0%A4%B0%E0%A5%8D%E0%A4%A7%E0%A4%BE%E0%A4%B0%E0%A4%BF%E0%A4%A4-%E0%A4%B2%E0%A4%95%E0%A5%8D%E0%A4%B7%E0%A5%8D
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Получить больше информации – https://kunsthandwerk-leutasch.com/hallo-welt
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Получить дополнительную информацию – https://vhwconsulting.be/component/k2/item/3-these-cases-are-perfectly-simple-and-easy-to-distinguish?start=73580
“Обратился в ‘Ренессанс’ с алкоголизмом. Лечение было непростым, но врачи поддерживали меня на каждом шагу. Сейчас я живу трезво и очень благодарен за это.” — Дмитрий, 38 лет”Много лет боролась с зависимостью от марихуаны и наконец нашла помощь здесь. ‘Ренессанс’ предложила грамотный подход, и с их помощью я справилась.” — Екатерина, 25 лет”Страдал от лудомании и знал, что сам не справлюсь. Врачи предложили методы, которые помогли мне избавиться от зависимости. Теперь азартные игры — это прошлое.” — Алексей, 41 год
Подробнее – https://качество-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-permi.xn--p1ai
напольные горшки для цветов купить цена [url=https://www.kashpo-napolnoe-spb.ru]напольные горшки для цветов купить цена[/url] .
Алкогольная зависимость — это хроническое заболевание, которое со временем разрушает здоровье, отношения, профессиональную сферу и личную идентичность человека. Многие сталкиваются с этим не сразу: поначалу кажется, что всё под контролем, но с каждым срывом становится всё труднее остановиться. Постепенно алкоголь перестаёт быть выбором и превращается в навязчивую необходимость.
Изучить вопрос глубже – http://kodirovanie-ot-alkogolizma-shchelkovo3.ru
Каждый пациент получает индивидуальный план лечения, основанный на клинических исследованиях, данных лабораторных анализов и психологических тестов.
Углубиться в тему – http://narkologicheskaya-klinika-dolgoprudnyj3.ru/
Каждый этап проводится квалифицированным специалистом, что позволяет достичь максимального терапевтического эффекта.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-ekaterinburg0.ru/]выезд нарколога на дом екатеринбург[/url]
В «Трезвом Истоке» мы понимаем: принять решение о вызове — это шаг, требующий смелости. Особенно если речь идёт о близком человеке, который отрицает наличие проблемы. Именно поэтому наши врачи умеют работать тактично, без давления. Мы не заставляем — мы объясняем. Спокойно, профессионально и по-человечески.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-ehlektrostal3.ru/]вывод из запоя недорого[/url]
Запой — это не просто бытовое пьянство, а одно из наиболее опасных проявлений алкогольной зависимости. Во время запоя организм перестаёт функционировать в нормальном режиме: сердечно-сосудистая система работает на износ, нервная система перегружена токсинами, а печень не справляется с нагрузкой. На этом фоне могут возникать тяжёлые осложнения — от судорог и гипогликемии до нарушения дыхания и алкогольного психоза. Чем дольше длится запой, тем глубже метаболические нарушения и выше риск серьёзных последствий.
Подробнее – [url=https://vyvod-iz-zapoya-kolomna3.ru/]vyvod-iz-zapoya-kruglosutochno[/url]
https://a-bsme.at/blacksprut.html
В зависимости от состояния пациента мы предлагаем два формата помощи: выезд нарколога на дом или госпитализацию в стационар. Оба варианта включают детоксикацию — выведение токсинов из организма с помощью инфузионной терапии (капельницы), а также медикаментозную поддержку: успокоительные, витамины, препараты для печени и сердца.
Детальнее – http://vyvod-iz-zapoya-serpuhov3.ru/vyvod-iz-zapoya-na-domu-v-serpuhove/https://vyvod-iz-zapoya-serpuhov3.ru
Группа препаратов
Получить дополнительную информацию – https://narcolog-na-dom-ekaterinburg000.ru/narkolog-na-dom-czena-ekb/
Группа препаратов
Подробнее – https://kapelnica-ot-zapoya-sochi0.ru/kapelnicza-ot-zapoya-czena-sochi/
высокие цветочные напольные кашпо [url=www.kashpo-napolnoe-spb.ru]www.kashpo-napolnoe-spb.ru[/url] .
Как подчёркивает врач-нарколог клиники «Светлый Мир» Александр Павлович Ермаков, «на фоне резкого отказа от алкоголя могут возникнуть острые состояния, требующие реанимационной помощи — поэтому нельзя пытаться прервать запой без участия специалиста». В домашних условиях, под присмотром профессионала, лечение может быть начато уже в течение часа после вызова, без необходимости транспортировки пациента в критическом состоянии.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-domodedovo3.ru/vyvod-iz-zapoya-stacionar-v-domodedovo/
Когда человек находится в состоянии запоя, это значит, что его организм уже не способен нормально функционировать без спиртного. Каждая новая доза становится не выбором, а необходимостью — чтобы унять дрожь, убрать головную боль, хоть как-то заснуть. Но облегчение временное. А вот последствия — нарастающие. На фоне постоянного потребления алкоголя развивается сильнейшее обезвоживание, страдают печень и сердечно-сосудистая система. Уровень сахара в крови нестабилен, мозг работает в режиме перегрузки.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ehlektrostal3.ru/]вывод из запоя с выездом цена[/url]
Когда человек находится в состоянии запоя, это значит, что его организм уже не способен нормально функционировать без спиртного. Каждая новая доза становится не выбором, а необходимостью — чтобы унять дрожь, убрать головную боль, хоть как-то заснуть. Но облегчение временное. А вот последствия — нарастающие. На фоне постоянного потребления алкоголя развивается сильнейшее обезвоживание, страдают печень и сердечно-сосудистая система. Уровень сахара в крови нестабилен, мозг работает в режиме перегрузки.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ehlektrostal3.ru/]vyvod-iz-zapoya-s-vyezdom-cena[/url]
Во Владимире и области работают десятки клиник, предлагающих помощь зависимым, но не все учреждения соответствуют современным медицинским и психологическим стандартам. Чтобы выбрать действительно эффективное лечение, нужно ориентироваться на проверенные критерии. В этом материале мы рассмотрим, на что стоит обратить внимание при выборе наркологического центра.
Ознакомиться с деталями – [url=https://lechenie-narkomanii-vladimir10.ru/]лечение наркомании реабилитация[/url]
Во многих регионах, в том числе и в Тульской области, работают десятки учреждений, предоставляющих услуги по наркологической помощи. Однако далеко не каждое из них соответствует современным стандартам. Часть клиник работает без лицензии, другие используют устаревшие методики или предлагают исключительно детоксикацию, без последующей психотерапевтической поддержки. Чтобы не ошибиться, важно заранее проанализировать основные характеристики надёжного медицинского учреждения.
Изучить вопрос глубже – http://narkologicheskaya-klinika-tula10.ru/chastnaya-narkologicheskaya-klinika-tula/
В современном обществе проблема зависимостей от психоактивных веществ становится всё более острой. Алкоголизм, наркомания и игромания представляют серьёзные угрозы для общественного здоровья и безопасности. На фоне растущей нагрузки на систему здравоохранения Наркологическая клиника “Новый Взгляд” предлагает комплексные решения для людей, страдающих от различных форм зависимости. Мы ориентируемся на индивидуальный подход к каждому пациенту, что позволяет достигать высоких результатов в лечении и реабилитации.
Разобраться лучше – https://тайный-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-samare.xn--p1ai/
Бездепозитный бонус в казино Бездепозитные бонусы
Когда абстиненция сменяется новым запоем, а самоконтроль ослабевает, наступает момент, когда усилий «просто не пить» уже недостаточно. Именно тогда на помощь приходит кодирование — действенный и проверенный метод, позволяющий прервать замкнутый круг зависимости и начать путь к устойчивой ремиссии. В клинике «Чистая Дорога» в Щелково мы подбираем индивидуальные методики кодирования, учитывая как физиологические, так и психологические особенности пациента. Работаем с мотивацией, устраняем страхи, поддерживаем на каждом этапе.
Получить дополнительные сведения – [url=https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/]кодирование от алкоголизма на дому[/url]
LMC Middle School https://lmc896.org in Lower Manhattan provides a rigorous, student-centered education in a caring and inclusive atmosphere. Emphasis on critical thinking, collaboration, and community engagement.
психиатрическая клиника Психиатрическая клиника. Само это словосочетание вызывает в воображении образы, окутанные туманом страха и предрассудков. Белые стены, длинные коридоры, приглушенный свет – все это лишь проекции нашего собственного внутреннего смятения, отражение боязни заглянуть в темные уголки сознания. Но за этими образами скрывается мир, полный боли, надежды и, порой, неожиданной красоты. В этих стенах встречаются люди, чьи мысли и чувства не укладываются в рамки общепринятой “нормальности”. Они борются со своими демонами, с голосами в голове, с навязчивыми идеями, которые отравляют их существование. Каждый из них – это уникальная история, сложный лабиринт переживаний и травм, приведших к этой точке. Здесь работают люди, посвятившие себя помощи тем, кто оказался на краю. Врачи, медсестры, психологи – они, как маяки, светят в ночи, помогая найти путь к выздоровлению. Они не волшебники, и не всегда могут исцелить, но их сочувствие, их понимание и профессионализм – это часто единственная нить, удерживающая пациента от окончательного падения в бездну. Жизнь в психиатрической клинике – это не заточение, а скорее передышка. Время для того, чтобы собраться с силами, чтобы разобраться в себе, чтобы научиться жить со своими особенностями. Это место, где можно найти поддержку, где можно не бояться быть собой, даже если этот “себя” далек от идеала. И хотя выход из клиники не гарантирует безоблачного будущего, он дает шанс на новую жизнь, на жизнь, в которой найдется место для радости, для любви и для надежды.
В «Трезвом Истоке» мы понимаем: принять решение о вызове — это шаг, требующий смелости. Особенно если речь идёт о близком человеке, который отрицает наличие проблемы. Именно поэтому наши врачи умеют работать тактично, без давления. Мы не заставляем — мы объясняем. Спокойно, профессионально и по-человечески.
Разобраться лучше – https://vyvod-iz-zapoya-ehlektrostal3.ru/
В такой момент человеку нужна не просто поддержка — ему нужна медицинская помощь. В Электростали её оказывает наркологическая клиника «Трезвый Исток». Мы работаем круглосуточно, без праздников и выходных. И выезжаем сразу — без очередей, без лишней бюрократии. Только быстрый, грамотный и безопасный вывод из запоя — на дому или в стационаре, в зависимости от состояния пациента.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ehlektrostal3.ru/]вывод из запоя клиника[/url]
При поступлении вызова специалисты клиники «СтопТокс» оперативно выезжают на дом в Екатеринбурге или по всей Свердловской области. По прибытии врач проводит всестороннюю диагностику, включая измерение артериального давления, пульса и уровня кислорода в крови, а также собирает анамнез и оценивает степень интоксикации. На основе полученной информации составляется индивидуальный план лечения, который включает следующие этапы:
Исследовать вопрос подробнее – http://narcolog-na-dom-ekaterinburg000.ru/vrach-narkolog-na-dom-ekb/
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-sochi00.ru/]вызвать капельницу от запоя в сочи[/url]
Лечение проводится в комфортных условиях дома, что позволяет избежать стресса, связанного с госпитализацией, и обеспечивает быстрое восстановление.
Разобраться лучше – [url=https://narcolog-na-dom-ekaterinburg000.ru/]вызов нарколога на дом свердловская область[/url]
Наша команда врачей оперативно реагирует на каждый вызов, оказывая квалифицированную медицинскую помощь на дому. Специалисты проводят полный комплекс лечебных мероприятий, направленных на безопасное снятие интоксикации, детоксикацию и облегчение симптомов абстиненции.
Ознакомиться с деталями – [url=https://narcolog-na-dom-ekaterinburg0.ru/]врач нарколог на дом в екатеринбурге[/url]
Пациенты, нуждающиеся в круглосуточном наблюдении, могут пройти курс терапии в стационаре. Обстановка клиники рассчитана на комфортное пребывание: палаты с индивидуальным санитарным блоком, охрана, контроль приёма препаратов, поддержка психологов.
Ознакомиться с деталями – https://narkologicheskaya-pomoshh-tula10.ru
Запойное состояние — это не просто следствие злоупотребления спиртным, а серьёзное расстройство, которое требует немедленного медицинского вмешательства. При длительном употреблении алкоголя на протяжении нескольких суток или недель организм человека сталкивается с тяжёлой интоксикацией, нарушением работы внутренних органов и изменениями в психоэмоциональном состоянии. В такой ситуации необходим профессиональный вывод из запоя — грамотно организованный процесс детоксикации, способный предотвратить тяжёлые осложнения.
Узнать больше – http://vyvod-iz-zapoya-domodedovo3.ru
Самостоятельный выход из запоя сопряжен с высоким риском развития осложнений. После прекращения приема спиртного ослабленный организм может не выдержать нагрузки, что приведет к инфаркту, инсульту, судорожным приступам и даже алкогольному психозу. Чтобы избежать этих опасных состояний, необходимо вызвать нарколога на дом, который проведет лечение правильно и безопасно.
Детальнее – [url=https://vyvod-iz-zapoya-krasnodar0.ru/]vyvod-iz-zapoya krasnodar[/url]
https://b2tor2.cc/bs2best.html
Клиника «ТюменьМед» специализируется на лечении алкогольной зависимости и вывода из запоя с 2010 года. За годы работы накоплен уникальный опыт в проведении комплексной детоксикации, реабилитации и последующего сопровождения пациентов. В основе методик лежат стандарты доказательной медицины, а команда состоит из наркологов, психотерапевтов, заведующих отделением интенсивной терапии и логистов для выездов.
Получить дополнительную информацию – http://narkologicheskaya-klinika-tyumen10.ru/narkologicheskaya-klinika-na-dom-tyumen/https://narkologicheskaya-klinika-tyumen10.ru
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Получить больше информации – https://www.wiseon.com.hk/312
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Получить дополнительную информацию – https://4pzs.cz/hello-world
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Изучить вопрос глубже – https://www.immoprobycaro.com/manhattan-apartments
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Подробнее тут – https://legalwisdom.com/25-unique-website-ideas-for-your-next-side-project
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Получить дополнительные сведения – https://anguil.com/news/staying-ahead-of-evolving-eto-regulations
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Подробнее можно узнать тут – http://graficosenrecorte.com/2017/01/25/a-day-alone-at-the-sea
Для снятия алкогольной интоксикации врач проводит детоксикационную терапию, которая включает внутривенные инфузии с растворами для выведения токсинов, поддерживающие препараты для печени, сердечно-сосудистой системы и нервной системы. В некоторых случаях назначаются седативные средства, нормализующие эмоциональное состояние пациента.
Подробнее тут – [url=https://narcolog-na-dom-v-irkutske00.ru/]платный нарколог на дом иркутск[/url]
Экстренный вызов нарколога на дом в Иркутске от «ТрезвоМед» при запое, интоксикации или кодировании – анонимно и удобно. Осмотр, детоксикация капельницей, индивидуальный план лечения – все это на дому! «ТрезвоМед» – круглосуточная помощь, анонимность и безопасность при отказе от алкоголя. Не можете бросить пить самостоятельно? Нужна помощь нарколога! Васильев: «Своевременная помощь при интоксикации – залог успешного выздоровления».
Детальнее – [url=https://narcolog-na-dom-v-irkutske0.ru/]нарколог на дом иркутск[/url]
Основная миссия нашего учреждения заключается в комплексной помощи пациентам с зависимостями. Основные цели нашей работы включают:
Ознакомиться с деталями – http://тайный-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-samare.xn--p1ai/https://тайный-вывод-из-запоя.рф
Наша команда врачей оперативно реагирует на каждый вызов, оказывая квалифицированную медицинскую помощь на дому. Специалисты проводят полный комплекс лечебных мероприятий, направленных на безопасное снятие интоксикации, детоксикацию и облегчение симптомов абстиненции.
Изучить вопрос глубже – [url=https://narcolog-na-dom-ekaterinburg0.ru/]нарколог на дом срочно[/url]
Обращение за медицинской помощью становится необходимым, когда пациент пребывает в состоянии, требующем немедленного вмешательства, так как самостоятельное лечение может только усугубить ситуацию. Это происходит, если запой продолжается несколько дней, и организм не успевает справляться с накопившимися токсинами, что ведёт к нарушению работы внутренних органов. Если у пациента регулярно наблюдаются симптомы, такие как частая рвота, сильное головокружение, спутанность сознания, судороги или резкие колебания артериального давления, это является явным сигналом к вызову специалиста. Особенно важно обращаться за помощью при выраженных признаках абстинентного синдрома, когда сильная дрожь, панические атаки, бессонница, тревожность и даже галлюцинации свидетельствуют о том, что организм испытывает критическую нехватку поддержки. Наличие психических нарушений, таких как агрессивное поведение, спутанность сознания или признаки алкогольного психоза, также требует незамедлительного вмешательства. В таких ситуациях обращение за профессиональной помощью помогает быстро стабилизировать состояние пациента, предотвратить развитие тяжелых осложнений и сохранить жизнь.
Углубиться в тему – [url=https://narcolog-na-dom-ekaterinburg00.ru/]нарколог на дом круглосуточно екатеринбург[/url]
При остром алкогольном отравлении появляются головокружение, рвота, сильная слабость, скачки давления, нарушение дыхания, обмороки и судороги. Это сигнал о том, что организм не справляется с интоксикацией, и без срочного медицинского вмешательства возможны опасные осложнения, вплоть до комы.
Исследовать вопрос подробнее – http://narcolog-na-dom-novokuznetsk00.ru/narkolog-na-dom-czena-novokuzneczk/
•очешь продать авто? мэджик авто продажа и выкуп авто
Перед началом кодирования важно провести комплексную диагностику. Врачи клиники оценивают общее состояние пациента, определяют степень зависимости, выявляют противопоказания к медикаментозным препаратам, уточняют психоэмоциональный фон. На этом этапе важно, чтобы пациент был трезв — либо как минимум 2–3 дня без алкоголя, либо прошёл процедуру детоксикации в нашей клинике или дома под наблюдением.
Детальнее – http://kodirovanie-ot-alkogolizma-shchelkovo3.ru
Вызов нарколога на дом от клиники «Трезвый Путь» имеет ряд неоспоримых преимуществ, которые высоко ценят наши пациенты:
Ознакомиться с деталями – [url=https://narcolog-na-dom-ekaterinburg0.ru/]vyzvat-narkologa-na-dom ekaterinburg[/url]
Пожалуй, самый распространённый миф — что если просто не пить сутки-двое, то всё наладится. Но если человек длительное время находился в состоянии опьянения, его тело уже адаптировалось к токсичной среде. Резкий отказ без медицинской помощи может привести к судорогам, галлюцинациям, тяжёлой бессоннице, паническим атакам и скачкам давления. Человек буквально «сгорает» изнутри — от собственного обмена веществ, который не справляется с последствиями интоксикации.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ehlektrostal3.ru/]vyvod-iz-zapoya-na-domu-cena[/url]
Как подчёркивает врач-нарколог клиники «Новая Энергия» Алексей Геннадьевич Лапшин, «запой — это не слабость, а болезнь. И чем быстрее начато лечение, тем меньше будет последствий. Не ждите осложнений — вызывайте врача».
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-serpuhov3.ru/]срочный вывод из запоя[/url]
Все вызовы фиксируются под кодовым номером без указания ФИО, что обеспечивает полную конфиденциальность каждого пациента.
Разобраться лучше – [url=https://narkologicheskaya-klinika-vladimir10.ru/]частная наркологическая клиника владимирская область[/url]
Современное общество сталкивается с серьёзными проблемами, связанными с зависимостями. Злоупотребление психоактивными веществами оказывает влияние не только на здоровье, но и на социальные отношения, а также на качество жизни. Наркологическая клиника “Новая Жизнь” предлагает широкий спектр услуг, направленных на восстановление и реабилитацию людей, которые сталкиваются с подобными трудностями.
Получить дополнительную информацию – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-omske.ru/]вывод из запоя капельница в омске[/url]
При поступлении вызова специалист прибывает по указанному адресу в течение 30–60 минут. На этом этапе врач проводит тщательный осмотр, измеряет артериальное давление, пульс и уровень кислорода в крови. Также собирается подробный анамнез: выясняется, сколько дней длился запой, какие напитки употреблялись, есть ли хронические заболевания, и были ли предыдущие эпизоды алкогольной интоксикации. Эти данные помогают составить оптимальный план лечения.
Разобраться лучше – [url=https://narcolog-na-dom-krasnoyarsk0.ru/]платный нарколог на дом красноярск[/url]
«ВладимирМед» основана группой врачей-наркологов и психотерапевтов, объединивших опыт работы в государственных и частных учреждениях. Мы предлагаем не просто преодоление запоя, а глубокую комплексную реабилитацию, включающую медико-психологическую оценку и долгосрочное сопровождение. Наша цель — восстановление здоровья на физическом и эмоциональном уровнях, возвращение пациента к полноценной социальной жизни без рецидивов.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-vladimir10.ru/]наркологическая клиника нарколог в владимире[/url]
Если в состоянии пациента наблюдаются такие признаки, как судороги, панические атаки, или гипертонический криз, необходимо немедленно вызвать врачей. Задержка может привести к необратимым последствиям.
Ознакомиться с деталями – http://narcolog-na-dom-novokuznetsk0.ru
Основные показания для вызова нарколога:
Получить дополнительную информацию – [url=https://narcolog-na-dom-v-irkutske00.ru/]вызов нарколога на дом цена иркутск[/url]
Купить подшипники оптом Куплю промышленные подшипники – запрос, который часто встречается у инженеров и закупщиков. Важно найти надежного поставщика, предлагающего широкий ассортимент и конкурентные цены. Правильный выбор подшипников обеспечит стабильную работу оборудования.
После поступления вызова на дом врачи клиники «Трезвый Путь» проводят лечение по четко разработанному алгоритму, обеспечивающему максимальную эффективность и безопасность:
Узнать больше – [url=https://narcolog-na-dom-ekaterinburg0.ru/]вызов нарколога на дом[/url]
Мы рекомендуем рассмотреть кодирование, если:
Углубиться в тему – http://kodirovanie-ot-alkogolizma-shchelkovo3.ru/
Запой – это состояние, когда организм требует постоянного поступления алкоголя для нормальной работы. Запой вызывает накопление вредных веществ, что негативно влияет на органы и иммунную систему. Не пытайтесь самостоятельно избавиться от запоя, это может навредить. Получите квалифицированную помощь на дому от клиники «Семья и Здоровье». Мы быстро приедем и окажем круглосуточную поддержку при запое. Длительное употребление алкоголя опасно для здоровья и жизни. Не ждите, пока станет слишком поздно, обратитесь за помощью при запое!
Узнать больше – [url=https://vyvod-iz-zapoya-krasnoyarsk0.ru/]вывод из запоя цены на дому красноярск[/url]
Как отмечают наркологи нашей клиники, чем раньше пациент получает необходимую помощь, тем меньше риск тяжелых последствий и тем быстрее восстанавливаются функции организма.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-sochi0.ru/]капельница от запоя в сочи[/url]
“Обратился в ‘Ренессанс’ с алкоголизмом. Лечение было непростым, но врачи поддерживали меня на каждом шагу. Сейчас я живу трезво и очень благодарен за это.” — Дмитрий, 38 лет”Много лет боролась с зависимостью от марихуаны и наконец нашла помощь здесь. ‘Ренессанс’ предложила грамотный подход, и с их помощью я справилась.” — Екатерина, 25 лет”Страдал от лудомании и знал, что сам не справлюсь. Врачи предложили методы, которые помогли мне избавиться от зависимости. Теперь азартные игры — это прошлое.” — Алексей, 41 год
Получить дополнительную информацию – https://качество-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-permi.xn--p1ai
Наша команда врачей оперативно реагирует на каждый вызов, оказывая квалифицированную медицинскую помощь на дому. Специалисты проводят полный комплекс лечебных мероприятий, направленных на безопасное снятие интоксикации, детоксикацию и облегчение симптомов абстиненции.
Ознакомиться с деталями – https://narcolog-na-dom-ekaterinburg0.ru/vrach-narkolog-na-dom-ekb
Перед началом кодирования важно провести комплексную диагностику. Врачи клиники оценивают общее состояние пациента, определяют степень зависимости, выявляют противопоказания к медикаментозным препаратам, уточняют психоэмоциональный фон. На этом этапе важно, чтобы пациент был трезв — либо как минимум 2–3 дня без алкоголя, либо прошёл процедуру детоксикации в нашей клинике или дома под наблюдением.
Разобраться лучше – https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/kodirovanie-ot-alkogolizma-ceny-v-shchelkovo/
Перед началом кодирования важно провести комплексную диагностику. Врачи клиники оценивают общее состояние пациента, определяют степень зависимости, выявляют противопоказания к медикаментозным препаратам, уточняют психоэмоциональный фон. На этом этапе важно, чтобы пациент был трезв — либо как минимум 2–3 дня без алкоголя, либо прошёл процедуру детоксикации в нашей клинике или дома под наблюдением.
Получить больше информации – [url=https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/]кодирование от алкоголизма стоимость[/url]
Клиника «Нарколог-Профи» предлагает круглосуточную помощь на дому в Екатеринбурге и Свердловской области. Наши опытные специалисты готовы оперативно приехать по вашему вызову и оказать экстренную медицинскую поддержку при алкогольной или наркотической зависимости. Мы проводим детоксикацию организма, купируем абстинентный синдром и стабилизируем состояние пациента, обеспечивая при этом полную конфиденциальность и комфорт в домашних условиях.
Углубиться в тему – [url=https://narcolog-na-dom-ekaterinburg00.ru/]vrach-narkolog-na-dom ekaterinburg[/url]
рулонные шторы на окна Как правильно шторы подобрать — учитывайте стиль комнаты, цветовую гамму и назначение помещения. Качественная ткань и правильный крой помогут создать гармоничный образ и обеспечить комфорт.
Мы работаем без праздников и выходных, принимаем срочные обращения, выезжаем оперативно и оказываем помощь в полном соответствии с медицинскими стандартами. Главный принцип — безопасность, эффективность и деликатность. Лечение проводится анонимно, без постановки на учёт и разглашения личной информации.
Детальнее – http://vyvod-iz-zapoya-serpuhov3.ru
Агентство контекстной рекламы https://kontekst-dlya-prodazh.ru настройка Яндекс.Директ и Google Ads под ключ. Привлекаем клиентов, оптимизируем бюджеты, повышаем конверсии.
Многие пациенты, обращаясь за помощью, уже имеют опыт самостоятельных попыток прекратить употребление, возможно — неоднократный вывод из запоя или даже амбулаторное лечение. Однако без поддержки со стороны специалистов и внутреннего «якоря» сохранить трезвость удаётся редко. Кодирование как раз и становится этим «якорем» — формирует в человеке стойкое отрицание алкоголя, как на физиологическом, так и на психологическом уровне.
Получить дополнительные сведения – [url=https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/]методы кодирования от алкоголизма[/url]
В городе Домодедово такую услугу оказывает наркологическая клиника «Светлый Мир». Здесь работают опытные врачи с круглосуточной готовностью выехать к пациенту домой или принять его в условиях стационара. Главное — не откладывать помощь, особенно если речь идёт о пожилом человеке, пациенте с хроническими заболеваниями или тех, у кого уже проявляются тревожные симптомы: дрожь в руках, панические атаки, скачки давления, бессонница и даже слуховые или зрительные галлюцинации.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]вывод из запоя на дому цена[/url]
В этой публикации мы рассматриваем важную тему борьбы с зависимостями, включая алкогольную и наркотическую зависимости. Мы обсудим методы лечения, реабилитации и поддержку, которые могут помочь людям, столкнувшимся с этой проблемой. Читатели узнают о перспективах выздоровления и важности комплексного подхода.
Получить дополнительные сведения – https://otravlenye.ru/vidy/alko-i-narko/programma-12-shagov-v-chyom-effektivnost-lecheniya-alko-i-narkozavisimosti.html
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Получить дополнительную информацию – https://kaosjapan.com/nitamago%E3%80%80%E7%85%AE%E7%8E%89%E5%AD%90-kaos-kitchen
Этот информационный материал подробно освещает проблему наркозависимости, ее причины и последствия. Мы предлагаем информацию о методах лечения, профилактики и поддерживающих программах. Цель статьи — повысить осведомленность и продвигать идеи о необходимости борьбы с зависимостями.
Углубиться в тему – https://sadovod69.ru/anonimnoe-kodirovanie-alkogolizma-sovremennye-podhody-i-effektivnost
Шины и диски https://tssz.ru для любого авто: легковые, внедорожники, коммерческий транспорт. Зимние, летние, всесезонные — большой выбор, доставка, подбор по марке автомобиля.
Инженерная сантехника https://vodazone.ru в Москве — всё для отопления, водоснабжения и канализации. Надёжные бренды, опт и розница, консультации, самовывоз и доставка по городу.
В этой заметке мы представляем шаги, которые помогут в процессе преодоления зависимостей. Рассматриваются стратегии поддержки и чек-листы для тех, кто хочет сделать первый шаг к выздоровлению. Наша цель — вдохновить читателей на положительные изменения и поддержать их в трудных моментах.
Получить дополнительную информацию – https://pharmio.ru/44186-platnaya-skoraya-pomosch-kogda-nuzhno-obratitsya-i-chto-ozhidat.html
Наркологический центр “Новый Взгляд” расположен по адресу: г. Самара, ул. Ленина 9. Мы открыты для пациентов круглосуточно. Также доступны онлайн-консультации, что делает наши услуги более доступными для всех нуждающихся.
Подробнее можно узнать тут – https://тайный-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-samare.xn--p1ai/
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Подробнее тут – https://www.mcyapandfries.com/13-ghosts
Этот информативный текст сочетает в себе темы здоровья и зависимости. Мы обсудим, как хронические заболевания могут усугубить зависимости и наоборот, как зависимость может влиять на общее состояние здоровья. Читатели получат представление о комплексном подходе к лечению как физического, так и психического состояния.
Детальнее – https://sopli.net/narkolog-na-dom-kachestvennaya-i-udobnaya-meditsinskaya-pomoshh
Наркологическая информационная сеть «Narkology» специализируется на оказании помощи при сложных стадиях зависимости, включая сопровождение после эпизодов передозировки. В комфортном режиме мы проводим удалённые консультации врачей-наркологов, психологов и социальные рекомендации по дальнейшей адаптации. Гарантируем полную анонимность, внимательное сопровождение и своевременное реагирование на любые запросы клиентов. Наша цель — обеспечить высокую эффективность информационной и психологической поддержки на всех этапах реабилитации.
Узнать больше – https://narcologiya.info/vliyanie-na-zdorove/kak-vybrat-alkotester.html
Первым этапом лечения является медицинская детоксикация, которая направлена на удаление токсинов из организма и стабилизацию физического состояния пациента. Мы используем современные методики, которые помогают минимизировать симптомы абстиненции, такие как головная боль, тошнота и слабость, обеспечивая комфортное пребывание в клинике.
Подробнее – https://kapelnica-ot-zapoya-irkutsk2.ru/kapelnica-ot-zapoya-cena-v-irkutske/
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Изучить вопрос глубже – https://seautomotriz.com/hello-world
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Получить дополнительные сведения – https://www.focuscontabil.com/decreto-no-66-de-24-de-marco-de-2022-da-prefeitura-de-parauna-go
LEBO Coffee https://lebo.ru натуральный кофе премиум-качества. Зерновой, молотый, в капсулах. Богатый вкус, аромат и свежая обжарка. Для дома, офиса и кофеен.
Gymnastics Hall of Fame https://usghof.org Biographies of Great Athletes Who Influenced the Sport. A detailed look at gymnastics equipment, from bars to mats.
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
Наши врачи уделяют внимание не только медицинским аспектам, но также социальным и психологическим факторам. Мы помогаем пациентам находить новый смысл в жизни, формировать новые увлечения и восстанавливать старые связи с близкими.
Исследовать вопрос подробнее – https://kapelnica-ot-zapoya-irkutsk.ru/kapelnica-ot-zapoya-anonimno-v-irkutske/
создать сайт с помощью нейросети нейросеть создать дизайн сайта
Выбор клиники — задача не только медицинская, но и стратегическая. Учитывать нужно не только наличие лицензии, но и содержание программ, их гибкость, участие родственников в процессе, а также прозрачность взаимодействия с пациентом. Именно эти аспекты позволяют отличить профессиональное учреждение от формального.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-yaroslavl0.ru/]наркологическая клиника нарколог ярославль[/url]
Woodworking and construction https://www.woodsurfer.com forum. Ask questions, share projects, read reviews of materials and tools. Help from practitioners and experienced craftsmen.
Фрибеты за регистрацию Фрибеты за регистрацию – отличный способ попробовать свои силы в ставках на спорт. Используйте их с умом и не рискуйте слишком многим.
Наркологическая информационная сеть «Narkology» специализируется на оказании помощи при сложных стадиях зависимости, включая сопровождение после эпизодов передозировки. В комфортном режиме мы проводим удалённые консультации врачей-наркологов, психологов и социальные рекомендации по дальнейшей адаптации. Гарантируем полную анонимность, внимательное сопровождение и своевременное реагирование на любые запросы клиентов. Наша цель — обеспечить высокую эффективность информационной и психологической поддержки на всех этапах реабилитации.
Получить больше информации – [url=https://narcologiya.info/sovmestimost-s-lekarstvami/fenazepam-i-alkogol.html]феназепам и алкоголь[/url]
Как подчёркивает психотерапевт наркологической клиники «Чистая Дорога» Игорь Алексеевич Кондратенко, «кодирование — это не запрет, а защита. Мы не наказываем организм, а даём ему возможность отдохнуть от постоянной борьбы и переключиться на восстановление».
Получить дополнительные сведения – [url=https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/]metody-kodirovaniya-ot-alkogolizma[/url]
Критерий
Получить больше информации – http://narkologicheskaya-pomoshh-arkhangelsk0.ru
Помощь нужна, если:
Углубиться в тему – https://vyvod-iz-zapoya-serpuhov3.ru/
Медицинский вывод из запоя включает несколько обязательных этапов:
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-kolomna3.ru/]вывод из запоя недорого[/url]
В современном обществе проблема зависимостей от психоактивных веществ становится всё более острой. Алкоголизм, наркомания и игромания представляют серьёзные угрозы для общественного здоровья и безопасности. На фоне растущей нагрузки на систему здравоохранения Наркологическая клиника “Новый Взгляд” предлагает комплексные решения для людей, страдающих от различных форм зависимости. Мы ориентируемся на индивидуальный подход к каждому пациенту, что позволяет достигать высоких результатов в лечении и реабилитации.
Углубиться в тему – http://тайный-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-samare.xn--p1ai/
Многие думают, что запой — это просто привычка. На деле же это глубокий физиологический и психологический кризис. Он может привести к очень серьёзным осложнениям — от инфаркта до алкогольного делирия, сопровождающегося агрессией, страхами и бредовыми состояниями. Это не преувеличение. Алкоголь разрушает организм молча — и делает это быстрее, чем кажется.
Узнать больше – https://vyvod-iz-zapoya-ehlektrostal3.ru/anonimnyj-vyvod-iz-zapoya-v-ehlektrostali/
Нередко пациенту требуется не только медикаментозная поддержка, но и психологическое сопровождение. Консультации с психотерапевтом позволяют выявить причины зависимости, снизить уровень тревожности и подготовить человека к реабилитации.
Детальнее – https://narkologicheskaya-pomoshh-arkhangelsk0.ru/neotlozhnaya-narkologicheskaya-pomoshh-arkhangelsk/
Как отмечает руководитель клинико-диагностического отдела ФГБУ «Национальный центр наркологии», «участие в терапии нескольких специалистов разных направлений позволяет учитывать не только симптомы, но и глубинные причины зависимости». Именно такой подход снижает риск рецидивов и повышает эффективность лечения.
Разобраться лучше – [url=https://narkologicheskaya-klinika-yaroslavl0.ru/]наркологические клиники алкоголизм[/url]
Круглосуточная клиника «НаркоЦентр» предлагает широкий спектр наркологических услуг в Екатеринбурге и области. В числе основных направлений — выезд врача на дом, проведение детоксикационных процедур, индивидуальные программы восстановления, врачебное сопровождение в стационаре, а также психологическая и физиотерапевтическая реабилитация. Мы опираемся на международные стандарты терапии и применяем только сертифицированные препараты, что гарантирует безопасность и эффективность лечения.
Ознакомиться с деталями – [url=https://narkologicheskaya-pomoshh-ekaterinburg0.ru/]наркологическая помощь на дому в екатеринбурге[/url]
“Обратился в ‘Ренессанс’ с алкоголизмом. Лечение было непростым, но врачи поддерживали меня на каждом шагу. Сейчас я живу трезво и очень благодарен за это.” — Дмитрий, 38 лет”Много лет боролась с зависимостью от марихуаны и наконец нашла помощь здесь. ‘Ренессанс’ предложила грамотный подход, и с их помощью я справилась.” — Екатерина, 25 лет”Страдал от лудомании и знал, что сам не справлюсь. Врачи предложили методы, которые помогли мне избавиться от зависимости. Теперь азартные игры — это прошлое.” — Алексей, 41 год
Получить больше информации – https://качество-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-permi.xn--p1ai/
Обращение к врачу становится жизненно необходимым, если пациент находится в состоянии длительного запоя, при котором организм не справляется с накоплением токсинов. Если запой продолжается более двух-трёх дней, в теле накапливаются вредные вещества, что ведёт к нарушениям работы внутренних органов, развитию абстинентного синдрома и появлению психических нарушений. Также, если у пациента наблюдаются симптомы, такие как частая рвота, спутанность сознания, судороги или резкие скачки артериального давления, это сигнал к незамедлительному вызову специалиста. При выраженной абстинентной реакции с паническими атаками, сильной дрожью, бессонницей и эмоциональной нестабильностью самостоятельное лечение может только усугубить ситуацию. Если появляются признаки алкогольного психоза – галлюцинации, агрессивность или спутанность сознания – вызов нарколога становится обязательным для предотвращения дальнейших осложнений. Также, когда требуется подготовка к процедурам кодирования от зависимости, необходима качественная детоксикация организма, что также является показанием к срочному обращению за профессиональной помощью.
Выяснить больше – [url=https://narcolog-na-dom-ekaterinburg0.ru/]вызвать нарколога на дом в екатеринбурге[/url]
Алкоголизм — хроническое заболевание, требующее комплексного подхода и круглосуточного контроля. Клиника «УралМед» в Екатеринбурге предлагает полный спектр услуг для пациентов любого уровня зависимости: от экстренной детоксикации до долгосрочной реабилитации. Главные принципы работы — абсолютная анонимность, индивидуальный план лечения и постоянное сопровождение квалифицированной командой специалистов.
Получить дополнительную информацию – http://
Проблема алкогольной зависимости требует срочного вмешательства, ведь чем дольше человек находится в запое, тем выше риск серьезных осложнений для его здоровья. Наркологическая клиника «Трезвый Путь» предоставляет услуги нарколога на дом в Екатеринбурге, гарантируя круглосуточную помощь и эффективное решение проблемы.
Выяснить больше – [url=https://narcolog-na-dom-ekaterinburg0.ru/]нарколог на дом срочно[/url]
В зависимости от состояния пациента мы предлагаем два формата помощи: выезд нарколога на дом или госпитализацию в стационар. Оба варианта включают детоксикацию — выведение токсинов из организма с помощью инфузионной терапии (капельницы), а также медикаментозную поддержку: успокоительные, витамины, препараты для печени и сердца.
Углубиться в тему – https://vyvod-iz-zapoya-serpuhov3.ru/anonimnyj-vyvod-iz-zapoya-v-serpuhove/
Наша команда врачей оперативно реагирует на каждый вызов, оказывая квалифицированную медицинскую помощь на дому. Специалисты проводят полный комплекс лечебных мероприятий, направленных на безопасное снятие интоксикации, детоксикацию и облегчение симптомов абстиненции.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-ekaterinburg0.ru/]вызов нарколога на дом свердловская область[/url]
Алкогольная и наркотическая зависимости требуют незамедлительного медицинского вмешательства. Длительные запои или острое отравление могут привести к тяжелым осложнениям и серьезным проблемам со здоровьем. Клиника «МедТрезвость» в Санкт-Петербурге предлагает квалифицированную наркологическую помощь прямо на дому, обеспечивая полную конфиденциальность и безопасность пациента. Наши специалисты оперативно выезжают по адресу, проводят все необходимые процедуры и помогают максимально быстро стабилизировать состояние пациента в комфортных домашних условиях.
Детальнее – [url=https://narcolog-na-dom-sankt-peterburg0.ru/]выезд нарколога на дом санкт-петербург[/url]
«Narkology» — ваш надёжный партнёр на пути к осознанному отказу от пагубных привычек. Мы предлагаем программы поддержки и консультирования при алкогольной, наркотической и медикаментозной зависимости. Комплекс услуг включает онлайн-консультации наркологов, психологические вебинары и круглосуточную информационную поддержку. Индивидуальный подход и забота о каждом клиенте помогут найти оптимальную стратегию отказа от вредных веществ.
Углубиться в тему – https://narcologiya.info/alkogolizm/problema-alkogolizma.html
Путь к свободе от зависимости начинается не с обещаний «просто перестать», а с профессионального медицинского вмешательства. В «Чистом Дыхании» мы применяем проверенные методы, которые работают там, где сила воли без нужной поддержки оказывается бессильной. Наша клиника в Долгопрудном работает круглосуточно — чтобы помощь была доступна в самый критический момент, когда человек ощущает острую потребность в детоксикации, снятии абстинентного синдрома или психологической поддержке.
Углубиться в тему – [url=https://narkologicheskaya-klinika-dolgoprudnyj3.ru/]narkologicheskaya-klinika-dolgoprudnyj3.ru/[/url]
Критерии оценки профессионального уровня сотрудников:
Углубиться в тему – https://lechenie-alkogolizma-yaroslavl0.ru
После диагностики выявленные нарушения восполняются посредством инфузий с витаминами группы B, C, магнием и элементами.
Получить дополнительную информацию – http://lechenie-alkogolizma-ekaterinburg0.ru
Понимание того, какие учреждения действительно способны помочь, позволяет избежать ошибок и не тратить время на неэффективные попытки лечения. Ключевыми признаками являются наличие медицинской лицензии, опытные специалисты, прозрачные условия и отзывы пациентов.
Подробнее тут – https://narkologicheskaya-pomoshh-arkhangelsk0.ru/vyzov-narkologicheskoj-pomoshhi-arkhangelsk
услуги pr менеджера Частный маркетолог услуги – это индивидуальный подход к решению задач клиента, разработка персонализированных стратегий и гибкость в работе, что позволяет достигать высоких результатов.
В зависимости от состояния пациента мы предлагаем два формата помощи: выезд нарколога на дом или госпитализацию в стационар. Оба варианта включают детоксикацию — выведение токсинов из организма с помощью инфузионной терапии (капельницы), а также медикаментозную поддержку: успокоительные, витамины, препараты для печени и сердца.
Углубиться в тему – https://vyvod-iz-zapoya-serpuhov3.ru/srochnyj-vyvod-iz-zapoya-v-serpuhove/
Критерий
Подробнее – http://narkologicheskaya-pomoshh-arkhangelsk0.ru
расширяемые системы персонализированное образование Персонализированное образование — это подход, который ставит в центр ученика, его интересы, цели и индивидуальные особенности. Технологии играют ключевую роль в реализации этой модели. Компания «Astana IT Garant» помогает учебным заведениям Казахстана делать шаги к настоящему персонализированному образованию. Мы предлагаем инструменты, которые делают персонализацию возможной. Это платформы для создания индивидуальных учебных планов, где ученик вместе с тьютором может выбирать курсы и проекты в соответствии со своими интересами. Это системы адаптивного обучения, которые подстраивают сложность заданий под уровень ученика. Это конструкторы курсов и цифровые портфолио, где ученики могут собирать свои достижения. Мы помогаем создавать гибкие учебные пространства с зонами для индивидуальной и групповой работы, которые ученики могут использовать для реализации своих проектов. «Astana IT Garant» понимает, что персонализация — это не только технологии, но и изменение педагогической культуры. Поэтому мы проводим для учителей тренинги по тьюторству, проектной деятельности и другим методикам, которые лежат в основе персонализированного подхода. Мы поможем вам создать среду, где каждый ученик сможет построить свой уникальный образовательный маршрут.
гибкая керамика для фасадов цена Гибкая керамика цена за м2 и отзывы покупателей свидетельствуют о том, что соотношение цены и качества является одним из лучших на рынке отделочных материалов.
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Получить больше информации – https://pratidinamarsangbad.com/%E0%A6%B8%E0%A6%B0%E0%A6%95%E0%A6%BE%E0%A6%B0-%E0%A6%A8%E0%A6%BF%E0%A6%B0%E0%A7%8D%E0%A6%A7%E0%A6%BE%E0%A6%B0%E0%A6%BF%E0%A6%A4-%E0%A6%A6%E0%A6%BE%E0%A6%AE%E0%A6%95%E0%A7%87-%E0%A6%AA%E0%A6%BE/%E0%A6%9C%E0%A6%BE%E0%A6%A4%E0%A7%80%E0%A6%AF%E0%A6%BC/newsdesk
В сети «Narkology» вы получите всестороннюю поддержку на пути к полному освобождению от алкогольной и наркотической зависимости. Используем передовые методы дистанционного мониторинга состояния, информационно-просветительские программы и индивидуальные занятия с психологом. Экстренная консультация и круглосуточная связь с медицинскими специалистами помогут справиться с любыми сложностями и обрести новую активность без вредных привычек. Мы предоставляем актуальную информацию о методах детоксикации, замещающих терапий и профилактике срывов.
Углубиться в тему – [url=https://narcologiya.info/sovmestimost-s-lekarstvami/]совместимость алкоголя с лекарствами проверить[/url]
В данной статье мы акцентируем внимание на важности поддержки в процессе выздоровления. Мы обсудим, как друзья, семья и профессионалы могут помочь тем, кто сталкивается с зависимостями. Читатели получат практические советы, как поддерживать близких на пути к новой жизни.
Получить больше информации – https://ketokotleta.ru/the_articles/kapelnitsa-ot-zapoya-2.html
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Разобраться лучше – https://akademik.upr.ac.id/pengumuman/pengumuman-pendaftaran-wisuda-universitas-palangka-raya-periode-bulan-maret-tahun-2024
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Углубиться в тему – https://vp-creations.gr/create-a-welcoming-beauty-shopping-experience-and-inspire
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Выяснить больше – https://cakeenciel.com/bonjour-tout-le-monde
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Изучить вопрос глубже – https://dh-electricalservices.co.uk/electrical-inspection-testing/how-often-should-you-rewire-a-house-in-the-uk
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Узнать больше – https://disparalor.com/padang-panjang
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Детальнее – https://apotheke-am-ukb.de/favicon
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Углубиться в тему – https://quentinschneider.fr/alterclub-w-orl-timid-records-fair-play-escalier-club-300814
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Разобраться лучше – https://lamoonalingerie.com/2019/04/21/feminism-and-femininity-are-not-mutually-exclusive
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Получить дополнительную информацию – https://erosta.me/%E7%AB%A5%E9%A1%94%E3%83%AD%E3%83%AA%E3%81%8A%E5%A7%89%E3%81%95%E3%82%93%E3%81%A8%E3%81%AE%E5%88%9D%E3%80%85%E3%81%97%E3%81%84%E3%82%BB%E3%83%83%E3%82%AF%E3%82%B9%E3%81%8C%E3%81%9F%E3%81%BE%E3%82%89
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Подробнее – https://massagekoeln.de/2024/07/hallo-welt
Оптимальный состав команды включает:
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-pervouralsk11.ru/]наркологическая клиника первоуральск[/url]
Как подчёркивает главный врач клинического отделения, «в условиях стационара мы можем оперативно реагировать на малейшие изменения в состоянии пациента, что критически важно при тяжёлых формах запоя».
Получить дополнительную информацию – http://vyvod-iz-zapoya-v-ryazani12.ru
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Подробнее – https://adefbahiablanca.org.ar/curso-en-gestion-de-farmacia-2020-inscribite
Наркологическая клиника в Каменске-Уральском разрабатывает программы лечения, учитывая особенности различных видов зависимости: алкогольной, наркотической, лекарственной. Каждая программа ориентирована на индивидуальные потребности пациента, что подтверждается опытом ведущих российских реабилитационных центров. Подробнее о лечении зависимости читайте на официальном сайте Минздрава.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]бесплатная наркологическая клиника[/url]
Многие семьи сталкиваются с трудностями, когда зависимый отказывается ехать в клинику. В таких случаях выездная помощь становится первым шагом к выздоровлению. Однако не все службы предлагают одинаково безопасный и профессиональный подход. Чтобы избежать рисков и ошибок, важно понимать, на что обращать внимание при выборе услуги “нарколог на дом”.
Получить больше информации – [url=https://narkolog-na-dom-nizhnij-tagil11.ru/]выезд нарколога на дом в нижнем тагиле[/url]
Вывод из запоя требует неотложного и профессионального подхода, поскольку состояние больного сопровождается нарушением работы внутренних органов, обезвоживанием и токсическим воздействием этанола на центральную нервную систему. В Мурманске, учитывая особенности региона и климата, особенно важно проводить процедуру с учётом возможных сопутствующих заболеваний и общего состояния здоровья пациента.
Выяснить больше – https://vyvod-iz-zapoya-v-murmanske12.ru/vyvod-iz-zapoya-na-domu-v-murmanske/
В ходе процедуры врач контролирует жизненные показатели пациента, корректирует состав раствора при необходимости и оказывает дополнительную поддержку. После завершения капельницы часто назначается курс восстановительной терапии, направленный на стабилизацию функций организма.
Получить дополнительные сведения – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]www.domen.ru[/url]
В сети «Narkology» вы получите всестороннюю поддержку на пути к полному освобождению от алкогольной и наркотической зависимости. Используем передовые методы дистанционного мониторинга состояния, информационно-просветительские программы и индивидуальные занятия с психологом. Экстренная консультация и круглосуточная связь с медицинскими специалистами помогут справиться с любыми сложностями и обрести новую активность без вредных привычек. Мы предоставляем актуальную информацию о методах детоксикации, замещающих терапий и профилактике срывов.
Получить дополнительные сведения – [url=https://narcologiya.info/vliyanie-na-zdorove/alkogol-pri-gastrite.html]при гастрите можно пить алкоголь[/url]
Мы рекомендуем рассмотреть кодирование, если:
Подробнее тут – [url=https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/]kodirovanie-ot-alkogolizma-na-domu[/url]
Вызов нарколога на дом в Каменске-Уральском обеспечивает безопасность пациента, исключая необходимость посещения медицинского учреждения, что особенно актуально при тяжелом состоянии или психологическом сопротивлении. Такая помощь включает в себя детоксикацию, купирование абстинентного синдрома и консультации по дальнейшему лечению.
Выяснить больше – http://narkolog-na-dom-kamensk-uralskij11.ru/narkolog-na-dom-kruglosutochno-v-kamensk-uralskom/https://narkolog-na-dom-kamensk-uralskij11.ru
аренда экскаватора цена за смену [url=www.arenda-ehkskavatora-1.ru/]аренда экскаватора цена за смену[/url] .
– затяжной запой более 5–7 дней; – наличие галлюцинаций, судорог, бредовых состояний; – тяжёлое общее состояние (высокая температура, спутанность сознания, обезвоживание); – хронические болезни в стадии обострения.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-kolomna3.ru/]uslugi-vyvoda-iz-zapoya[/url]
При своевременном обращении к специалистам капельница позволяет значительно улучшить состояние пациента уже в первые часы после начала лечения. Медицинская помощь при запое должна оказываться квалифицированно и в комфортных условиях, что снижает риски осложнений и ускоряет восстановление.
Углубиться в тему – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя вызов в мурманске[/url]
В нашей клинике используются только эффективные и безопасные препараты, что гарантирует вам быстрое восстановление и минимальные риски.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-irkutsk3.ru/]вызвать капельницу от запоя в иркутске[/url]
В клинике созданы комфортные условия для прохождения лечения. Пациенты получают не только медицинскую помощь, но и социальную поддержку, что способствует быстрому восстановлению и возвращению к нормальной жизни. Узнать больше о формате лечения и условиях можно на официальном сайте клиники.
Подробнее – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]наркологическая клиника[/url]
Вывод из запоя в Мурманске представляет собой комплекс мероприятий, направленных на оказание медицинской помощи пациентам, находящимся в состоянии алкогольного отравления или длительного употребления спиртного. Процедура проводится с целью стабилизации состояния организма, предупреждения осложнений и минимизации риска развития тяжелых последствий алкоголизма.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-murmanske12.ru/]вывод из запоя на дому мурманск[/url]
сборка компьютера под ключ Компьютер для работы на заказ – оптимальное решение для повышения продуктивности и эффективности работы.
Назначение
Углубиться в тему – http://kapelnicza-ot-zapoya-pervouralsk11.ru
При лёгких и среднетяжёлых состояниях возможно проведение лечения на дому. Это удобно, комфортно и позволяет сохранить анонимность. Однако есть ситуации, в которых домашнее вмешательство нецелесообразно:
Получить дополнительную информацию – http://vyvod-iz-zapoya-kolomna3.ru/
городская клиническая больница клиническая больница
medical centar clinic of neurology
В ходе процедуры врач контролирует жизненные показатели пациента, корректирует состав раствора при необходимости и оказывает дополнительную поддержку. После завершения капельницы часто назначается курс восстановительной терапии, направленный на стабилизацию функций организма.
Получить дополнительную информацию – http://kapelnicza-ot-zapoya-v-murmanske12.ru/
Вывод из запоя в Рязани — это комплексная медицинская услуга, направленная на устранение интоксикации, стабилизацию состояния пациента и предотвращение рецидива алкогольной зависимости. Методики подбираются индивидуально с учётом анамнеза, длительности запойного состояния, наличия сопутствующих заболеваний и психоэмоционального фона. Процедура осуществляется под контролем опытных врачей-наркологов с применением сертифицированных препаратов и оборудования.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-ryazani12.ru/]вывод из запоя на дому круглосуточно в рязани[/url]
Запой — это не просто бытовое пьянство, а одно из наиболее опасных проявлений алкогольной зависимости. Во время запоя организм перестаёт функционировать в нормальном режиме: сердечно-сосудистая система работает на износ, нервная система перегружена токсинами, а печень не справляется с нагрузкой. На этом фоне могут возникать тяжёлые осложнения — от судорог и гипогликемии до нарушения дыхания и алкогольного психоза. Чем дольше длится запой, тем глубже метаболические нарушения и выше риск серьёзных последствий.
Выяснить больше – [url=https://vyvod-iz-zapoya-kolomna3.ru/]вывод из запоя на дому недорого[/url]
Наркологическая клиника в Каменске-Уральском разрабатывает программы лечения, учитывая особенности различных видов зависимости: алкогольной, наркотической, лекарственной. Каждая программа ориентирована на индивидуальные потребности пациента, что подтверждается опытом ведущих российских реабилитационных центров. Подробнее о лечении зависимости читайте на официальном сайте Минздрава.
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]narkologicheskaya klinika kamensk-ural’skij[/url]
Лечение хронического алкоголизма начинается с купирования абстинентного синдрома, после чего проводятся мероприятия по нормализации работы печени, сердечно-сосудистой и нервной системы. Назначаются гепатопротекторы, ноотропы, витамины группы B. Также проводится противорецидивная терапия.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-v-yaroslavle12.ru/]www.domen.ru[/url]
«Narkology» — ваш надёжный партнёр на пути к осознанному отказу от пагубных привычек. Мы предлагаем программы поддержки и консультирования при алкогольной, наркотической и медикаментозной зависимости. Комплекс услуг включает онлайн-консультации наркологов, психологические вебинары и круглосуточную информационную поддержку. Индивидуальный подход и забота о каждом клиенте помогут найти оптимальную стратегию отказа от вредных веществ.
Получить больше информации – [url=https://narcologiya.info/]Сеть информационных статей[/url]
примеры применения ИИ Тренды AI показывают направление развития искусственного интеллекта.
В зависимости от состояния пациента мы предлагаем два формата помощи: выезд нарколога на дом или госпитализацию в стационар. Оба варианта включают детоксикацию — выведение токсинов из организма с помощью инфузионной терапии (капельницы), а также медикаментозную поддержку: успокоительные, витамины, препараты для печени и сердца.
Детальнее – http://vyvod-iz-zapoya-serpuhov3.ru/vyvod-iz-zapoya-na-domu-v-serpuhove/https://vyvod-iz-zapoya-serpuhov3.ru
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]частная наркологическая клиника[/url]
В нашей клинике используются только эффективные и безопасные препараты, что гарантирует вам быстрое восстановление и минимальные риски.
Исследовать вопрос подробнее – https://kapelnica-ot-zapoya-irkutsk3.ru/kapelnica-ot-zapoya-v-stacionare-v-irkutske/
«Narkology» — ваш надёжный партнёр на пути к осознанному отказу от пагубных привычек. Мы предлагаем программы поддержки и консультирования при алкогольной, наркотической и медикаментозной зависимости. Комплекс услуг включает онлайн-консультации наркологов, психологические вебинары и круглосуточную информационную поддержку. Индивидуальный подход и забота о каждом клиенте помогут найти оптимальную стратегию отказа от вредных веществ.
Выяснить больше – [url=https://narcologiya.info/vliyanie-na-zdorove/alkogol-pri-gastrite.html]при гастрите можно пить алкоголь[/url]
Обращение к врачу становится жизненно необходимым, если пациент находится в состоянии длительного запоя, при котором организм не справляется с накоплением токсинов. Если запой продолжается более двух-трёх дней, в теле накапливаются вредные вещества, что ведёт к нарушениям работы внутренних органов, развитию абстинентного синдрома и появлению психических нарушений. Также, если у пациента наблюдаются симптомы, такие как частая рвота, спутанность сознания, судороги или резкие скачки артериального давления, это сигнал к незамедлительному вызову специалиста. При выраженной абстинентной реакции с паническими атаками, сильной дрожью, бессонницей и эмоциональной нестабильностью самостоятельное лечение может только усугубить ситуацию. Если появляются признаки алкогольного психоза – галлюцинации, агрессивность или спутанность сознания – вызов нарколога становится обязательным для предотвращения дальнейших осложнений. Также, когда требуется подготовка к процедурам кодирования от зависимости, необходима качественная детоксикация организма, что также является показанием к срочному обращению за профессиональной помощью.
Выяснить больше – [url=https://narcolog-na-dom-ekaterinburg0.ru/]нарколог на дом анонимно в екатеринбурге[/url]
«Narkology» — ваш надёжный партнёр на пути к осознанному отказу от пагубных привычек. Мы предлагаем программы поддержки и консультирования при алкогольной, наркотической и медикаментозной зависимости. Комплекс услуг включает онлайн-консультации наркологов, психологические вебинары и круглосуточную информационную поддержку. Индивидуальный подход и забота о каждом клиенте помогут найти оптимальную стратегию отказа от вредных веществ.
Узнать больше – https://narcologiya.info/narkomaniya/ponyatie-narkomanii.html
– затяжной запой более 5–7 дней; – наличие галлюцинаций, судорог, бредовых состояний; – тяжёлое общее состояние (высокая температура, спутанность сознания, обезвоживание); – хронические болезни в стадии обострения.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-kolomna3.ru/]вывод из запоя стационар[/url]
Вывод из запоя в Мурманске представляет собой комплекс мероприятий, направленных на оказание медицинской помощи пациентам, находящимся в состоянии алкогольного отравления или длительного употребления спиртного. Процедура проводится с целью стабилизации состояния организма, предупреждения осложнений и минимизации риска развития тяжелых последствий алкоголизма.
Получить дополнительную информацию – https://vyvod-iz-zapoya-v-murmanske12.ru/vyvod-iz-zapoya-na-domu-v-murmanske
Перед началом кодирования важно провести комплексную диагностику. Врачи клиники оценивают общее состояние пациента, определяют степень зависимости, выявляют противопоказания к медикаментозным препаратам, уточняют психоэмоциональный фон. На этом этапе важно, чтобы пациент был трезв — либо как минимум 2–3 дня без алкоголя, либо прошёл процедуру детоксикации в нашей клинике или дома под наблюдением.
Получить дополнительные сведения – [url=https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/]anonimnoe-kodirovanie-ot-alkogolizma[/url]
Медицинский вывод из запоя включает несколько обязательных этапов:
Узнать больше – http://vyvod-iz-zapoya-kolomna3.ru/anonimnyj-vyvod-iz-zapoya-v-kolomne/
Проблема зависимости — это многогранная ситуация, которая требует комплексного подхода. Мы не ограничиваемся лишь лечением симптомов, а стремимся вернуть пациента к нормальной жизни. В клинике “Сила воли” используется индивидуальный подход к каждому пациенту, включающий как медицинские, так и психологические методы, направленные на полный восстановительный процесс. Одним из самых эффективных методов лечения при алкогольной зависимости является капельница от запоя — процедура, которая помогает снизить уровень токсинов в организме и нормализовать физическое состояние пациента.
Узнать больше – https://kapelnica-ot-zapoya-irkutsk3.ru/kapelnica-ot-zapoya-anonimno-v-irkutske/
В ходе процедуры врач контролирует жизненные показатели пациента, корректирует состав раствора при необходимости и оказывает дополнительную поддержку. После завершения капельницы часто назначается курс восстановительной терапии, направленный на стабилизацию функций организма.
Углубиться в тему – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]kapelnicza-ot-zapoya-czena murmansk[/url]
При необходимости применяется симптоматическое лечение для снижения болевого синдрома, устранения тошноты и рвоты, а также нормализации психоэмоционального состояния пациента. Врачи наркологи строго контролируют течение процедуры, что обеспечивает безопасность и снижает риски осложнений.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-murmanske12.ru/]вывод из запоя капельница в мурманске[/url]
Пребывание в стационаре обеспечивает круглосуточный мониторинг состояния, своевременное введение лекарств и защиту пациента от внешних факторов, провоцирующих срыв. Все палаты оснащены необходимым оборудованием, соблюдаются санитарные нормы, а условия размещения соответствуют медицинским стандартам.
Получить больше информации – [url=https://narkologicheskaya-klinika-v-yaroslavle12.ru/]наркологическая клиника цены в ярославле[/url]
Как поясняет врач-нарколог клиники «АлкоСтоп», «грамотно составленная инфузионная терапия не только устраняет последствия запоя, но и создаёт условия для дальнейшей мотивации пациента к лечению».
Детальнее – http://kapelnicza-ot-zapoya-pervouralsk11.ru/kapelniczy-ot-zapoya-na-domu-v-pervouralske/
Клинические протоколы стационарной терапии рекомендуют госпитализацию при средней и тяжёлой степени интоксикации.
Подробнее – https://vyvod-iz-zapoya-v-ryazani12.ru/vyvod-iz-zapoya-czena-v-ryazani/
Алкогольный запой — это не просто многодневное пьянство, а проявление зависимости, при котором каждое утро начинается с новой дозы спиртного. Организм человека уже не способен самостоятельно справляться с последствиями переработки этанола, и любое промедление ведёт к нарастанию тяжёлой интоксикации. Даже при резком прекращении употребления алкоголя последствия могут быть непредсказуемыми: от судорожных припадков до алкогольного психоза.
Подробнее – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]vyvod-iz-zapoya-cena[/url]
Особенно важно на этапе поступления пройти полную психодиагностику и получить адаптированную под конкретного пациента программу. Это позволит учитывать возможные сопутствующие расстройства, включая тревожные, аффективные и когнитивные нарушения.
Получить дополнительную информацию – https://narkologicheskaya-klinika-nizhnij-tagil11.ru/
Наша миссия заключается в предоставлении качественной помощи людям, страдающим от зависимостей. Мы стремимся создать безопасную и поддерживающую атмосферу, где каждый сможет получить необходимую помощь. Основная цель — восстановление здоровья, психоэмоционального состояния и социальной адаптации.
Выяснить больше – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-omske.ru/]вывод из запоя клиника[/url]
Как подчёркивает психотерапевт наркологической клиники «Чистая Дорога» Игорь Алексеевич Кондратенко, «кодирование — это не запрет, а защита. Мы не наказываем организм, а даём ему возможность отдохнуть от постоянной борьбы и переключиться на восстановление».
Подробнее можно узнать тут – https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/kodirovanie-ot-alkogolizma-na-domu-v-shchelkovo
Для успешной адаптации пациента в обществе клиника организует поддержку родственников и последующее наблюдение. Это снижает риск рецидива и помогает сохранить достигнутые результаты.
Подробнее тут – [url=https://narkologicheskaya-klinika-v-murmanske12.ru/]частная наркологическая клиника мурманск[/url]
Помощь нужна, если:
Получить больше информации – [url=https://vyvod-iz-zapoya-serpuhov3.ru/]вывод из запоя круглосуточно[/url]
Процедура капельного введения лекарственных растворов проводится в условиях клиники с соблюдением всех санитарных норм. Пациенту устанавливается капельница, через которую вводятся препараты под контролем медперсонала. В зависимости от состояния пациента и тяжести запоя длительность капельной терапии может варьироваться от 1 до 6 часов.
Изучить вопрос глубже – https://kapelnicza-ot-zapoya-v-murmanske12.ru/postavit-kapelniczu-ot-zapoya-v-murmanske
Лечение хронического алкоголизма начинается с купирования абстинентного синдрома, после чего проводятся мероприятия по нормализации работы печени, сердечно-сосудистой и нервной системы. Назначаются гепатопротекторы, ноотропы, витамины группы B. Также проводится противорецидивная терапия.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-v-yaroslavle12.ru/]наркологическая клиника цены в ярославле[/url]
В этой статье мы рассмотрим ключевые аспекты выбора надёжного специалиста, который приедет по вызову и сможет оказать квалифицированную помощь без промедлений.
Изучить вопрос глубже – http://narkolog-na-dom-nizhnij-tagil11.ru
Наши усилия направлены на то, чтобы вернуть пациентам уверенность в себе, здоровье и качество жизни.
Изучить вопрос глубже – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-omske.ru/]вывод из запоя в стационаре[/url]
Если состояние слишком тяжёлое, или в анамнезе есть сердечно-сосудистые заболевания, может быть рекомендована госпитализация в стационар клиники «Светлый Мир». Там пациент находится под круглосуточным наблюдением и получает полный комплекс восстановительной терапии, включая психологическую поддержку и консультации психотерапевта.
Узнать больше – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]вывод из запоя недорого[/url]
Виртуальные номера для Telegram https://basolinovoip.com создавайте аккаунты без SIM-карты. Регистрация за минуту, широкий выбор стран, удобная оплата. Идеально для анонимности, работы и продвижения.
Обращение к врачу становится жизненно необходимым, если пациент находится в состоянии длительного запоя, при котором организм не справляется с накоплением токсинов. Если запой продолжается более двух-трёх дней, в теле накапливаются вредные вещества, что ведёт к нарушениям работы внутренних органов, развитию абстинентного синдрома и появлению психических нарушений. Также, если у пациента наблюдаются симптомы, такие как частая рвота, спутанность сознания, судороги или резкие скачки артериального давления, это сигнал к незамедлительному вызову специалиста. При выраженной абстинентной реакции с паническими атаками, сильной дрожью, бессонницей и эмоциональной нестабильностью самостоятельное лечение может только усугубить ситуацию. Если появляются признаки алкогольного психоза – галлюцинации, агрессивность или спутанность сознания – вызов нарколога становится обязательным для предотвращения дальнейших осложнений. Также, когда требуется подготовка к процедурам кодирования от зависимости, необходима качественная детоксикация организма, что также является показанием к срочному обращению за профессиональной помощью.
Подробнее тут – [url=https://narcolog-na-dom-ekaterinburg0.ru/]выезд нарколога на дом в екатеринбурге[/url]
Odjeca i aksesoari za hotele poplin tekstil po sistemu kljuc u ruke: uniforme za sobarice, recepcionere, SPA ogrtaci, papuce, peskiri. Isporuke direktno od proizvodaca, stampa logotipa, jedinstveni stil.
При лёгких и среднетяжёлых состояниях возможно проведение лечения на дому. Это удобно, комфортно и позволяет сохранить анонимность. Однако есть ситуации, в которых домашнее вмешательство нецелесообразно:
Разобраться лучше – https://vyvod-iz-zapoya-kolomna3.ru/vyvod-iz-zapoya-stacionar-v-kolomne
Мы понимаем, что лечение от алкогольной зависимости — это только первый шаг на пути к восстановлению. Профилактика рецидивов — важная часть нашего подхода. Мы проводим тренинги и курсы, направленные на развитие навыков борьбы с соблазнами и стрессом. Психотерапевтическая поддержка помогает пациентам справиться с эмоциональными трудностями, а также укрепляет мотивацию для сохранения трезвости.
Получить больше информации – [url=https://kapelnica-ot-zapoya-irkutsk3.ru/]postavit-kapelniczu-ot-zapoya irkutsk[/url]
В нашей клинике “Сила воли” в Иркутске вы можете получить помощь как в стационаре, так и на дому. Мы предлагаем два вида услуг:
Выяснить больше – https://kapelnica-ot-zapoya-irkutsk3.ru/
Как разлюбить мужчину Как снять сглаз – вопрос, волнующий многих людей, верящих в существование негативного энергетического воздействия. Существуют различные способы снятия сглаза, такие как использование соли, воды, молитв и специальных ритуалов.
Многие пациенты, обращаясь за помощью, уже имеют опыт самостоятельных попыток прекратить употребление, возможно — неоднократный вывод из запоя или даже амбулаторное лечение. Однако без поддержки со стороны специалистов и внутреннего «якоря» сохранить трезвость удаётся редко. Кодирование как раз и становится этим «якорем» — формирует в человеке стойкое отрицание алкоголя, как на физиологическом, так и на психологическом уровне.
Разобраться лучше – https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/kodirovanie-ot-alkogolizma-na-domu-v-shchelkovo
Лечение хронического алкоголизма начинается с купирования абстинентного синдрома, после чего проводятся мероприятия по нормализации работы печени, сердечно-сосудистой и нервной системы. Назначаются гепатопротекторы, ноотропы, витамины группы B. Также проводится противорецидивная терапия.
Углубиться в тему – [url=https://narkologicheskaya-klinika-v-yaroslavle12.ru/]бесплатная наркологическая клиника[/url]
«Narkology» — это наркологическая информационная сеть, где каждому клиенту предлагают персонализированный план возвращения к здоровому образу жизни. Наши программы включают целевые консультации нарколога, психологическую реабилитацию, онлайн-группы поддержки и обучение навыкам саморегуляции. Круглосуточная информационная поддержка специалистов и современные технологии связи обеспечивают быстрое и комфортное возвращение к привычной жизни без зависимости.
Получить дополнительную информацию – https://narcologiya.info/alkogolizm/sozavisimost-pri-alkogolizme.html
Медицинский вывод из запоя включает несколько обязательных этапов:
Разобраться лучше – http://vyvod-iz-zapoya-kolomna3.ru
Для успешного лечения зависимости необходима тщательная диагностика. В клинике проводят полное обследование пациента, включающее:
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-v-murmanske12.ru/]наркологическая клиника[/url]
При лёгких и среднетяжёлых состояниях возможно проведение лечения на дому. Это удобно, комфортно и позволяет сохранить анонимность. Однако есть ситуации, в которых домашнее вмешательство нецелесообразно:
Разобраться лучше – [url=https://vyvod-iz-zapoya-kolomna3.ru/]vyvod-iz-alkogolnogo-zapoya[/url]
При своевременном обращении к специалистам капельница позволяет значительно улучшить состояние пациента уже в первые часы после начала лечения. Медицинская помощь при запое должна оказываться квалифицированно и в комфортных условиях, что снижает риски осложнений и ускоряет восстановление.
Подробнее тут – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя вызов в мурманске[/url]
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Подробнее тут – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]наркологическая клиника нарколог[/url]
При лёгких и среднетяжёлых состояниях возможно проведение лечения на дому. Это удобно, комфортно и позволяет сохранить анонимность. Однако есть ситуации, в которых домашнее вмешательство нецелесообразно:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-kolomna3.ru/]bystryj-vyvod-iz-zapoya-na-domu[/url]
Наркологическая клиника в Каменске-Уральском разрабатывает программы лечения, учитывая особенности различных видов зависимости: алкогольной, наркотической, лекарственной. Каждая программа ориентирована на индивидуальные потребности пациента, что подтверждается опытом ведущих российских реабилитационных центров. Подробнее о лечении зависимости читайте на официальном сайте Минздрава.
Исследовать вопрос подробнее – http://narkologicheskaya-klinika-kamensk-uralskij11.ru/
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]наркологические клиники алкоголизм в каменске-уральском[/url]
«Narkology» — это наркологическая информационная сеть, где каждому клиенту предлагают персонализированный план возвращения к здоровому образу жизни. Наши программы включают целевые консультации нарколога, психологическую реабилитацию, онлайн-группы поддержки и обучение навыкам саморегуляции. Круглосуточная информационная поддержка специалистов и современные технологии связи обеспечивают быстрое и комфортное возвращение к привычной жизни без зависимости.
Получить дополнительную информацию – [url=https://narcologiya.info/sovmestimost-s-lekarstvami/alkogol-i-disulfiram.html]дисульфирам и алкоголь[/url]
В городе Домодедово такую услугу оказывает наркологическая клиника «Светлый Мир». Здесь работают опытные врачи с круглосуточной готовностью выехать к пациенту домой или принять его в условиях стационара. Главное — не откладывать помощь, особенно если речь идёт о пожилом человеке, пациенте с хроническими заболеваниями или тех, у кого уже проявляются тревожные симптомы: дрожь в руках, панические атаки, скачки давления, бессонница и даже слуховые или зрительные галлюцинации.
Узнать больше – [url=https://vyvod-iz-zapoya-domodedovo3.ru/]vyvod-iz-zapoya-nedorogo[/url]
В клинике созданы комфортные условия для прохождения лечения. Пациенты получают не только медицинскую помощь, но и социальную поддержку, что способствует быстрому восстановлению и возвращению к нормальной жизни. Узнать больше о формате лечения и условиях можно на официальном сайте клиники.
Детальнее – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]наркологическая клиника[/url]
металлообработка Металлообработка – это обширная сфера деятельности, охватывающая широкий спектр процессов, направленных на изменение формы, размеров и свойств металлов и сплавов. От простых ручных операций до высокотехнологичных автоматизированных производств, металлообработка играет ключевую роль во многих отраслях промышленности, обеспечивая создание деталей, инструментов и конструкций, необходимых для функционирования современного мира.
– затяжной запой более 5–7 дней; – наличие галлюцинаций, судорог, бредовых состояний; – тяжёлое общее состояние (высокая температура, спутанность сознания, обезвоживание); – хронические болезни в стадии обострения.
Детальнее – https://vyvod-iz-zapoya-kolomna3.ru/vyvod-iz-zapoya-stacionar-v-kolomne
В Нижнем Тагиле действуют как частные, так и государственные учреждения, предоставляющие реабилитационные услуги. Однако подход, опыт специалистов и оснащение в них могут существенно различаться. Многие учреждения работают без лицензий, используют устаревшие методы или нанимают неквалифицированный персонал. Чтобы не столкнуться с такими рисками, необходимо тщательно проанализировать выбранный центр по нескольким ключевым направлениям.
Получить больше информации – https://narkologicheskaya-klinika-nizhnij-tagil11.ru/platnaya-narkologicheskaya-klinika-v-nizhnem-tagile/
суши барнаул каталог заказать доставку суши барнаул
Хирургические услуги хирургические операции в черногории: диагностика, операции, восстановление. Современная клиника, лицензированные специалисты, помощь туристам и резидентам.
Помощь нужна, если:
Разобраться лучше – https://vyvod-iz-zapoya-serpuhov3.ru/srochnyj-vyvod-iz-zapoya-v-serpuhove/
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]наркологические клиники алкоголизм каменск-уральский[/url]
Как подчёркивает врач-нарколог клиники «Новая Энергия» Алексей Геннадьевич Лапшин, «запой — это не слабость, а болезнь. И чем быстрее начато лечение, тем меньше будет последствий. Не ждите осложнений — вызывайте врача».
Выяснить больше – [url=https://vyvod-iz-zapoya-serpuhov3.ru/]срочный вывод из запоя[/url]
Как подчёркивает психотерапевт наркологической клиники «Чистая Дорога» Игорь Алексеевич Кондратенко, «кодирование — это не запрет, а защита. Мы не наказываем организм, а даём ему возможность отдохнуть от постоянной борьбы и переключиться на восстановление».
Выяснить больше – https://kodirovanie-ot-alkogolizma-shchelkovo3.ru/kodirovanie-ot-alkogolizma-na-domu-v-shchelkovo/
Медицинский вывод из запоя включает несколько обязательных этапов:
Узнать больше – https://vyvod-iz-zapoya-kolomna3.ru/anonimnyj-vyvod-iz-zapoya-v-kolomne/
Преимущество
Углубиться в тему – [url=https://narcolog-na-dom-ekaterinburg0.ru/]врач нарколог на дом в екатеринбурге[/url]
Brians club takes a proactive approach to help members align their entity setup with credit goals.
Adopting Russianmarket fosters trust among clients. When customers know their information is handled with care, they feel more confident engaging with your services.
hwid spoofer HWID Spoofer: Обход блокировок в играх и программах
Нарколог на дому проводит тщательный осмотр, собирает анамнез и назначает необходимые лабораторные исследования. Это позволяет выявить сопутствующие патологии и скорректировать тактику лечения.
Углубиться в тему – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]вызов врача нарколога на дом[/url]
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Узнать больше – http://narkologicheskaya-klinika-kamensk-uralskij11.ru/narkologicheskaya-klinika-telefon-v-kamensk-uralskom/https://narkologicheskaya-klinika-kamensk-uralskij11.ru
Многие родственники надеются, что человек «проспится», что со временем ему станет легче. Но практика показывает: если запой длится более суток, а тем более — несколько дней, состояние будет только ухудшаться. Организм теряет воду, витамины, нарушаются обменные процессы, появляется тревожность, бессонница, тремор, скачки давления. В сложных случаях развиваются острые психозы (делирий), судороги и отказ внутренних органов.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-serpuhov3.ru/]срочный вывод из запоя серпухов[/url]
Магазин брендовых кроссовок https://kicksvibe.ru Nike, Adidas, New Balance, Puma и другие. 100% оригинал, новые коллекции, быстрая доставка, удобная оплата. Стильно, комфортно, доступно!
ролик суши барнаул https://sushi-barnaul.ru
Наши усилия направлены на то, чтобы вернуть пациентам уверенность в себе, здоровье и качество жизни.
Выяснить больше – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-omske.ru/]вывод из запоя на дому в омске[/url]
The Impact of Russianmarket Credit Scores on Businesses Russianmarket credit scores are redefining how businesses assess potential clients. Traditional credit scoring can often overlook nuances in consumer behavior. Russianmarket brings a fresh perspective to the evaluation process.
Наркологическая информационная сеть «Narkology» специализируется на оказании помощи при сложных стадиях зависимости, включая сопровождение после эпизодов передозировки. В комфортном режиме мы проводим удалённые консультации врачей-наркологов, психологов и социальные рекомендации по дальнейшей адаптации. Гарантируем полную анонимность, внимательное сопровождение и своевременное реагирование на любые запросы клиентов. Наша цель — обеспечить высокую эффективность информационной и психологической поддержки на всех этапах реабилитации.
Ознакомиться с деталями – https://narcologiya.info/alkogolizm/
напольные вазоны [url=http://kashpo-napolnoe-msk.ru/]напольные вазоны[/url] .
Typically, the Stashpatrick minimum falls around 620 for most conventional loans. However, this can vary based on the type of loan you are seeking.
Капельница рекомендована при следующих состояниях:
Подробнее – [url=https://kapelnicza-ot-zapoya-v-murmanske12.ru/]капельница от запоя мурманск.[/url]
Запойное состояние — это не просто следствие злоупотребления спиртным, а серьёзное расстройство, которое требует немедленного медицинского вмешательства. При длительном употреблении алкоголя на протяжении нескольких суток или недель организм человека сталкивается с тяжёлой интоксикацией, нарушением работы внутренних органов и изменениями в психоэмоциональном состоянии. В такой ситуации необходим профессиональный вывод из запоя — грамотно организованный процесс детоксикации, способный предотвратить тяжёлые осложнения.
Подробнее – http://vyvod-iz-zapoya-domodedovo3.ru/vyvod-iz-zapoya-kruglosutochno-v-domodedovo/
Мы понимаем, что лечение от алкогольной зависимости — это только первый шаг на пути к восстановлению. Профилактика рецидивов — важная часть нашего подхода. Мы проводим тренинги и курсы, направленные на развитие навыков борьбы с соблазнами и стрессом. Психотерапевтическая поддержка помогает пациентам справиться с эмоциональными трудностями, а также укрепляет мотивацию для сохранения трезвости.
Подробнее – [url=https://kapelnica-ot-zapoya-irkutsk3.ru/]вызвать капельницу от запоя иркутск[/url]
Точная диагностика позволяет подобрать индивидуальную программу лечения, что значительно повышает шансы на успешное выздоровление.
Подробнее – [url=https://narkologicheskaya-klinika-v-murmanske12.ru/]наркологическая клиника цены мурманск[/url]
кашпо для цветов напольное магазин [url=www.kashpo-napolnoe-spb.ru]www.kashpo-napolnoe-spb.ru[/url] .
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Детальнее – https://emm.cv.ua/en/olympus-digital-camera-4-2
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Ознакомиться с деталями – https://bgcompanyinc.com/2024/07/28/hello-world
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Разобраться лучше – https://teepoem.com/product/my-gorgeous-soulmate-necklace-i-just-want-to-be-your-last-everything-sm-006-lk
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Углубиться в тему – https://pjcmediamagnet.com/the-dos-and-donts-of-seo-common-mistakes-to-avoid
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Выяснить больше – http://calmarsa.es/hola-mundo
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Подробнее можно узнать тут – https://gothamdoughnuts.com/post/doughnuts-delivery-melbourne-flavorful-delights-at-your-doorstep
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Углубиться в тему – https://worldtrackmag.com/reign-disick-justin-bieber-son
I’m not sure why but this site is loading very slow for me. Is anyone else having this problem or is it a issue on my end? I’ll check back later and see if the problem still exists.
https://mmartfashion.com/chy-mozhna-vstanovyty-sklo-fary-samomu-za-1-h.html
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Ознакомиться с деталями – https://www.servicioim.com/hello-world
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Ознакомиться с деталями – https://qaq.com.au/2014/09/02/name-the-screen
Все вызовы фиксируются под кодовым номером без указания ФИО, что обеспечивает полную конфиденциальность каждого пациента.
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-vladimir10.ru/]наркологическая клиника[/url]
В данной статье рассматриваются проблемы общественного здоровья и социальные факторы, влияющие на него. Мы акцентируем внимание на значении профилактики и осведомленности в защите здоровья на уровне общества. Читатели смогут узнать о новых инициативах и программах, направленных на улучшение здоровья населения.
Углубиться в тему – https://merkurii34.ru/znachimost-ekstrennoy-narkologicheskoy-pomoundefinedi-v-balashihe-ot-kliniki-detoks
Thank you for another informative site. The place else could I get that type of information written in such a perfect method? I have a mission that I’m simply now working on, and I’ve been at the glance out for such information.
http://respectstroy.com.ua/istoriya-vodiya-yak-ya-zekonomyv-na-zamini-sk.html
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Подробнее можно узнать тут – https://www.effie.com.mx/2013/02/15/ambrose-redmoon
На этом этапе нарколог выясняет, какие лекарства принимались ранее, есть ли аллергии, хронические заболевания, а также уточняет объём и длительность употребления алкоголя. Это позволяет скорректировать состав инфузионных растворов.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-voronezh.ru/]капельница от запоя цена[/url]
Дополнительно выясняются аллергические реакции, приём других препаратов и предпочтения пациента по времени визита врача.
Выяснить больше – [url=https://kapelnica-ot-zapoya-voronezh3.ru/]поставить капельницу от запоя воронеж[/url]
Нарколог измеряет пульс, артериальное давление, частоту дыхания, насыщение кислородом, а также уточняет историю употребления и наличие хронических заболеваний. Это позволяет оперативно скорректировать состав и скорость инфузии.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-voronezh2.ru/]после капельницы от запоя[/url]
Зависимости часто сопровождаются физическими и психологическими нарушениями, требующими комплексного подхода. Мы убеждены, что успешное лечение невозможно без индивидуального подхода, что делает нашу клинику отличным местом для тех, кто нуждается в поддержке.
Исследовать вопрос подробнее – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-omske.ru/]вывод из запоя цена в омске[/url]
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-1.ru/
прайс услуг косметолога [url=clinics-marbella-1.ru]прайс услуг косметолога[/url] .
русские казино онлайн список лицензионных казино
Вызов нарколога на дом в Ярославле — это удобный и эффективный способ начать лечение или оказать первую помощь при острых состояниях, связанных с алкоголизмом, наркотической зависимостью или другими психоактивными веществами. Основные преимущества такой услуги заключаются в следующем:
Узнать больше – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]запой нарколог на дом[/url]
При длительном запое в крови накапливаются ацетальдегид и другие токсичные метаболиты этанола, которые повреждают клетки печени, нарушают функцию почек и приводят к дисбалансу электролитов. Без своевременной детоксикации повышается риск острых состояний — судорог, инсультов, инфаркта, панкреатита и психоза. Чем раньше начато лечение, тем быстрее нормализуются показатели обмена веществ, возвращается водно-электролитный баланс и восстанавливается работа жизненно важных органов. Анонимный выезд нарколога помогает снять психологический барьер перед обращением за помощью.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-voronezh.ru/]капельница от запоя на дому цена воронеж[/url]
Первым этапом лечения является медицинская детоксикация, которая направлена на удаление токсинов из организма и стабилизацию физического состояния пациента. Мы используем современные методики, которые помогают минимизировать симптомы абстиненции, такие как головная боль, тошнота и слабость, обеспечивая комфортное пребывание в клинике.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-irkutsk2.ru/]капельница от запоя иркутск.[/url]
Как подчёркивает руководитель направления клинической токсикологии НМИЦ психиатрии и наркологии, «оказание помощи на дому требует не меньшего профессионализма, чем лечение в стационаре, ведь врач действует в ограниченных условиях».
Выяснить больше – [url=https://narkolog-na-dom-nizhnij-tagil11.ru/]нарколог на дом круглосуточно[/url]
Вызов нарколога возможен круглосуточно, что обеспечивает оперативное реагирование на критические ситуации. Пациенты и их родственники могут получить помощь в любое время, не дожидаясь ухудшения состояния.
Углубиться в тему – [url=https://narkolog-na-dom-kamensk-uralskij11.ru/]нарколог на дом анонимно каменск-уральский[/url]
Особую опасность представляет белая горячка (алкогольный психоз). У пациента возникают галлюцинации, приступы паники, агрессивное поведение, дезориентация во времени и пространстве. Это состояние требует незамедлительного вмешательства врача, так как человек может представлять опасность для себя и окружающих.
Подробнее – http://narcolog-na-dom-novokuznetsk00.ru/narkolog-na-dom-czena-novokuzneczk/
Перед оформлением вызова проводится предварительная телефонная консультация, позволяющая оценить тяжесть состояния и заранее подготовить необходимые препараты.
Углубиться в тему – http://kapelnica-ot-zapoya-voronezh.ru/
— Растворы с глюкозой и витаминами для коррекции энергетического обмена. — Минеральные комплексы для нормализации электролитов. — Антиоксиданты и гепатопротекторы для защиты печени. — Спазмолитики для снятия болевого синдрома. — Противорвотные препараты при тошноте.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-arkhangelsk0.ru/]наркологическая клиника на дом[/url]
Когда организм на пределе, важна срочная помощь в Москве — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-lyubercy13.ru/]капельница от запоя Московская область[/url]
Запой — опасное состояние, которое стремительно приводит к тяжелым последствиям для организма. Обычные домашние методы восстановления при алкогольной интоксикации не только малоэффективны, но и небезопасны. Для быстрого и безопасного выведения токсинов требуется профессиональная помощь нарколога с применением капельницы от запоя.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-moskva000.ru/]врача капельницу от запоя[/url]
Для пациентов, требующих круглосуточного наблюдения, клиника «Полярис» предлагает стационар VIP-класса. Здесь созданы все условия для быстрого восстановления: удобные палаты, индивидуальное меню, зоны отдыха и консультации профильных специалистов.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-arkhangelsk0.ru/]наркологические клиники алкоголизм[/url]
Вывод из запоя в Нижнем Тагиле представляет собой комплекс медицинских мероприятий, направленных на безопасное и эффективное прерывание состояния острого алкогольного отравления. Этот процесс требует профессионального подхода, так как самостоятельное прерывание запоя чревато серьезными осложнениями, включая судороги, инсульты и инфаркты. В медицинской практике используется комплекс мер, включающий детоксикацию организма, коррекцию водно-электролитного баланса и лечение симптомов абстиненции.
Выяснить больше – [url=https://vyvod-iz-zapoya-nizhnij-tagil11.ru/]вывод из запоя на дому свердловская область[/url]
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Москве приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-lyubercy12.ru/]врач на дом капельница от запоя Москва[/url]
ecole de theatre Interpreter dans des films
Клиника «ВоронежМед» обеспечивает выезд нарколога на дом в любое время суток, включая праздники и выходные. Анонимность достигается за счёт минимального контакта с персоналом клиники и отсутствия бумажной волокиты. Все этапы лечения согласовываются только с пациентом или доверенным лицом, а сведения о визите не передаются третьим лицам.
Узнать больше – http://kapelnica-ot-zapoya-voronezh.ru
работа военным Работа военным – призвание, требующее самоотдачи и готовности к риску. Это служение Родине, защита ее интересов и обеспечение безопасности граждан. Военные – это не просто люди в форме, это профессионалы, прошедшие серьезную подготовку и обладающие уникальными навыками. Их работа сопряжена с трудностями, лишениями и опасностью, но она также приносит чувство гордости и удовлетворения от выполнения долга. Военная служба – это возможность проявить свои лучшие качества, такие как мужество, дисциплина, ответственность и товарищество. Это шанс внести свой вклад в историю страны и оставить след в сердцах людей. Военные – это опора государства, гарант его стабильности и процветания. Они всегда на передовой, готовы защитить свою землю и свой народ от любых угроз. Служба в армии – это школа жизни, которая закаляет характер и учит ценить простые вещи. Это возможность получить образование, освоить новую профессию и построить карьеру. Военные – это люди, которые умеют работать в команде, принимать решения в сложных ситуациях и нести ответственность за свои действия. Их опыт и навыки востребованы не только в военной сфере, но и в гражданской жизни. Военная служба – это выбор сильных и смелых людей, готовых посвятить свою жизнь защите Родины. Это работа, которая требует полной отдачи и преданности своему делу. Военные – это гордость нации, пример для подражания и символ мужества и героизма.
Одним из ключевых направлений является проведение капельниц, призванных вывести токсины из организма и нормализовать водно-электролитный баланс. Используемые препараты и состав растворов подбираются индивидуально, исходя из клинической картины и истории болезни пациента.
Выяснить больше – [url=https://narkolog-na-dom-v-yaroslavle12.ru/]narkolog-na-dom-v-yaroslavle12.ru/[/url]
Вся процедура проходит под полным контролем врача и занимает от 40 минут до 2 часов. Пациенту и его родственникам даются рекомендации по дальнейшему лечению и профилактике повторных запоев.
Получить больше информации – [url=https://kapelnica-ot-zapoya-moskva00.ru/]врач на дом капельница от запоя москва[/url]
Наши специалисты выезжают в любой район Москвы и ближайшего Подмосковья, чтобы помочь пациентам избежать осложнений и быстро прийти в норму после длительного запоя.
Получить больше информации – [url=https://kapelnica-ot-zapoya-moskva0.ru/]поставить капельницу от запоя[/url]
Проблема алкоголизма в Ярославле, как и в других регионах России, остаётся одной из самых актуальных. По данным Минздрава РФ, количество людей, нуждающихся в медицинской помощи из-за злоупотребления спиртным, ежегодно растёт. При этом эффективное лечение возможно лишь при комплексном подходе, включающем как медицинскую, так и психологическую поддержку.
Детальнее – https://lechenie-alkogolizma-yaroslavl0.ru/lechenie-khronicheskogo-alkogolizma-yaroslavl
Наша миссия заключается в предоставлении качественной помощи людям, страдающим от зависимостей. Мы стремимся создать безопасную и поддерживающую атмосферу, где каждый сможет получить необходимую помощь. Основная цель — восстановление здоровья, психоэмоционального состояния и социальной адаптации.
Выяснить больше – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-omske.ru/]вывод из запоя на дому цена омск[/url]
При остром алкогольном отравлении появляются головокружение, рвота, сильная слабость, скачки давления, нарушение дыхания, обмороки и судороги. Это сигнал о том, что организм не справляется с интоксикацией, и без срочного медицинского вмешательства возможны опасные осложнения, вплоть до комы.
Детальнее – [url=https://narcolog-na-dom-novokuznetsk00.ru/]нарколог на дом цена в новокузнецке[/url]
Вызов нарколога возможен круглосуточно, что обеспечивает оперативное реагирование на критические ситуации. Пациенты и их родственники могут получить помощь в любое время, не дожидаясь ухудшения состояния.
Получить дополнительные сведения – https://narkolog-na-dom-kamensk-uralskij11.ru/chastnyj-narkolog-na-dom-v-kamensk-uralskom/
Согласно данным Федерального наркологического центра, своевременный выезд врача снижает риск осложнений и повторных госпитализаций.
Углубиться в тему – [url=https://narkolog-na-dom-kamensk-uralskij11.ru/]нарколог на дом срочно[/url]
Как подчёркивает специалист ФГБУ «НМИЦ психиатрии и наркологии», «без участия квалифицированной команды невозможно обеспечить комплексный подход к пациенту, особенно если речь идёт о длительном стаже употребления и осложнённой картине заболевания». Отсюда следует — изучение состава персонала должно быть одним из первых шагов.
Разобраться лучше – [url=https://lechenie-alkogolizma-murmansk0.ru/]центр лечения алкоголизма в мурманске[/url]
https://stroidom36.ru/catalog/doma-s-terrasoi/ Система отопления должна быть эффективной и экономичной. Газовый котел, электрический котел, твердотопливный котел – выбор зависит от доступности ресурсов.
В Москве решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-lyubercy11.ru/]врача капельницу от запоя[/url]
For most recent information you have to pay a quick visit web and on web I found this website as a best site for most recent updates.
https://ital-parts.com.ua/chy-varto-kupuvaty-sklo-fary-z-ruk.html
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Получить дополнительную информацию – https://stefactory.pro/block-quote-example
Modern operations laparoscopy innovative technologies, precision and safety. Minimal risk, short recovery period. Plastic surgery, ophthalmology, dermatology, vascular procedures.
Профессиональное прп терапия обучение: PRP, Plasmolifting, протоколы и нюансы проведения процедур. Онлайн курс обучения плазмотерапии.
работа военным Работа военным: защита Отечества Работа военным – это защита Отечества. Это священный долг каждого гражданина, готового встать на защиту своей Родины в трудную минуту. Военная служба – это не просто работа, это призвание, требующее мужества, отваги и самоотверженности. Военные – это люди, которые прошли специальную подготовку, владеют современным оружием и техникой, готовы выполнить любой приказ, защитить свою страну от внешних угроз. Они стоят на страже мира и спокойствия, обеспечивая безопасность граждан. Военная служба – это возможность получить уникальный опыт, развить свои физические и моральные качества, научиться преодолевать трудности и нести ответственность за свои действия. Военные – это сильные и уверенные в себе люди, способные принимать решения в сложных ситуациях. Армия – это школа жизни, которая воспитывает патриотизм, дисциплину и уважение к старшим. Военные – это пример для подражания, люди, которые своим примером вдохновляют молодежь на служение Родине. Государство заботится о своих защитниках, предоставляя им достойное денежное довольствие, жилье, медицинское обслуживание и другие социальные гарантии. Военная служба – это стабильность и уверенность в завтрашнем дне. Работа военным – это возможность внести свой вклад в развитие страны, в укрепление ее обороноспособности и международного авторитета. Военные участвуют в научных исследованиях, разрабатывают новые виды вооружения и техники, повышают боеготовность армии. Военная служба – это нелегкий труд, требующий постоянного совершенствования, физической и моральной подготовки. Но это также возможность почувствовать себя частью сильной и сплоченной команды, гордиться своей профессией и служением Родине. Работа военным – это выбор настоящих героев, готовых отдать свою жизнь за свободу и независимость своей страны.
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Подробнее можно узнать тут – http://www.6555555.com/1198.html?replyTo=40924
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Получить дополнительную информацию – https://aas-fanzine.co.uk/woocommerce-placeholder
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Выяснить больше – https://agriprime.pl/witaj-swiecie
Современное общество сталкивается с серьёзными проблемами, связанными с зависимостями. Злоупотребление психоактивными веществами оказывает влияние не только на здоровье, но и на социальные отношения, а также на качество жизни. Наркологическая клиника “Новая Жизнь” предлагает широкий спектр услуг, направленных на восстановление и реабилитацию людей, которые сталкиваются с подобными трудностями.
Получить дополнительную информацию – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-omske.ru/]вывод из запоя на дому омск[/url]
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Исследовать вопрос подробнее – https://www.mahaayush.in/climate-crisis-into-the-mainstream-and-engages
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее – http://www.enirys.fr/galerie/img_0719
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Получить дополнительные сведения – https://pilanatrireki.mk/2016/10/23/%D0%B3%D0%B0%D0%BB%D0%B5%D1%80%D0%B8%D1%98%D0%B0
Онлайн-курсы прп терапия обучение: теория, видеоуроки, разбор техник. Обучение с нуля и для практикующих. Доступ к материалам 24/7, сертификат после прохождения, поддержка преподавателя.
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Подробнее – https://singulartruffle.com/en/quality-black-truffles-are-no-coincidence
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Получить дополнительные сведения – https://med-advisor.ru/preimushhestva-vyzova-narkologa-na-dom
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Узнать больше – https://www.wif.malopolska.pl/info
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Подробнее тут – https://quackplex.com/livestock-management/care-and-feeding/duramycin-72-200-dosage-for-goats
Перед оформлением вызова проводится предварительная телефонная консультация, позволяющая оценить тяжесть состояния и заранее подготовить необходимые препараты.
Изучить вопрос глубже – https://kapelnica-ot-zapoya-voronezh.ru/kapelnicza-ot-zapoya-na-domu-v-voronezhe
Экстренная капельница от запоя необходима при первых же признаках тяжелого состояния после длительного употребления алкоголя. Не стоит дожидаться осложнений, вызов нарколога обязателен в таких ситуациях:
Получить больше информации – http://kapelnica-ot-zapoya-moskva000.ru
Профессиональная клиника никогда не скрывает информацию о своих сотрудниках. На официальных сайтах нередко размещены сканы дипломов, сведения о специализации и стаже, участие в отраслевых конференциях и проектах Минздрава.
Получить больше информации – [url=https://narkologicheskaya-klinika-pervouralsk11.ru/]наркологическая клиника нарколог первоуральск[/url]
Запой — это серьёзное состояние, при котором организм страдает от накопления токсинов, обезвоживания и нарушения обмена веществ. Клиника «ВоронежЛайф» предлагает услугу выездного инфузионного лечения от запоя с возможностью круглосуточного реагирования. Благодаря персонализированному подходу и использованию современных автоматизированных систем дозирования, наши специалисты обеспечивают безопасную и эффективную детоксикацию в условиях домашнего уюта.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-voronezh3.ru/]капельница от запоя вызов[/url]
Критерий
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-nizhnij-tagil11.ru/]наркологические клиники алкоголизм в нижнем тагиле[/url]
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Узнать больше – https://vyvod-iz-zapoya-1.ru/
Для успешного вывода из запоя используется комплексный подход с участием специалистов разных профилей. Более подробно об этом можно узнать на официальном портале наркологической службы.
Подробнее тут – [url=https://vyvod-iz-zapoya-nizhnij-tagil11.ru/]наркология вывод из запоя в нижнем тагиле[/url]
Наркологическая клиника в Ярославле представляет собой специализированное учреждение, оказывающее медицинскую помощь пациентам с алкогольной, наркотической и медикаментозной зависимостью. Ключевыми направлениями работы являются детоксикация, стабилизация состояния, последующее реабилитационное сопровождение и профилактика рецидивов. Комплексный подход к лечению обеспечивается взаимодействием специалистов различных профилей, включая наркологов, психиатров, психотерапевтов и медицинских сестёр.
Детальнее – [url=https://narkologicheskaya-klinika-v-yaroslavle12.ru/]наркологическая клиника ярославская область[/url]
В Москве решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-lyubercy11.ru/]капельница от запоя цена Москва[/url]
Как подчёркивает заведующая отделением клинической психологии ФГБУН «НМИЦ психиатрии и наркологии» Минздрава России, наличие в команде специалистов с опытом работы в области зависимости — это основа качественной помощи.
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-nizhnij-tagil11.ru/]наркологическая клиника цены[/url]
Как поясняет врач-нарколог клиники «АлкоСтоп», «грамотно составленная инфузионная терапия не только устраняет последствия запоя, но и создаёт условия для дальнейшей мотивации пациента к лечению».
Ознакомиться с деталями – [url=https://kapelnicza-ot-zapoya-pervouralsk11.ru/]капельница от запоя выезд[/url]
Как подчёркивает главный врач клинического отделения, «в условиях стационара мы можем оперативно реагировать на малейшие изменения в состоянии пациента, что критически важно при тяжёлых формах запоя».
Подробнее тут – http://vyvod-iz-zapoya-v-ryazani12.ru/
Эффективное лечение требует поэтапного подхода, который реализуется следующим образом:
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-v-ryazani12.ru/]narkologicheskie kliniki alkogolizm rjazan'[/url]
энергетическая психология Женская энергия: Раскрытие и развитие женской силы и потенциала. Гармония с собой и окружающим миром.
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Узнать больше – https://narkologicheskaya-klinika-kamensk-uralskij11.ru/anonimnaya-narkologicheskaya-klinika-v-kamensk-uralskom
Особенно важно на этапе поступления пройти полную психодиагностику и получить адаптированную под конкретного пациента программу. Это позволит учитывать возможные сопутствующие расстройства, включая тревожные, аффективные и когнитивные нарушения.
Получить дополнительную информацию – https://narkologicheskaya-klinika-nizhnij-tagil11.ru/
Современная наркологическая клиника в Каменске-Уральском предоставляет комплексные услуги по диагностике и лечению различных видов зависимостей. Заболевания, связанные с алкоголизмом и наркоманией, требуют индивидуального подхода и применения современных медицинских технологий. В условиях клиники обеспечивается полный медицинский контроль и психологическая поддержка, что способствует успешной реабилитации пациентов.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-kamensk-uralskij11.ru/]chastnaya narkologicheskaya klinika kamensk-ural’skij[/url]
Грузоперевозки Луганск Грузоперевозки Луганск: Экспедирование грузов по Луганской области. Полный контроль над перемещением груза, оперативная информация о местонахождении, гарантия своевременной доставки.
После поступления вызова врач наркологической клиники «МедАльянс» прибывает на дом в течение 30–60 минут. Сначала специалист оценивает общее состояние пациента, измеряет давление, уровень кислорода в крови и уточняет детали анамнеза.
Получить дополнительные сведения – https://kapelnica-ot-zapoya-moskva000.ru/kapelnicza-ot-zapoya-anonimno-msk
Затяжной запой опасен для жизни. Врачи наркологической клиники в Москве проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-lyubercy11.ru/]вызвать капельницу от запоя на дому[/url]
Вся процедура проходит под полным контролем врача и занимает от 40 минут до 2 часов. Пациенту и его родственникам даются рекомендации по дальнейшему лечению и профилактике повторных запоев.
Разобраться лучше – https://kapelnica-ot-zapoya-moskva00.ru/kapelnicza-ot-zapoya-czena-msk
Наркологическая помощь в Первоуральске доступна в различных форматах: амбулаторно, стационарно и на дому. Однако не каждое учреждение может обеспечить необходимый уровень комплексной терапии, соответствующей стандартам Минздрава РФ и НМИЦ психиатрии и наркологии. В этом материале мы рассмотрим ключевые особенности профессионального наркологического центра и критерии, которые помогут сделать осознанный выбор.
Подробнее тут – [url=https://narkologicheskaya-klinika-pervouralsk11.ru/]наркологическая клиника в первоуральске[/url]
Обряд на любовь Целитель – проводник энергии, помогающий восстановить гармонию тела и духа. Целители используют различные техники, от традиционных до современных, для запуска процессов самоисцеления.
Запой — опасное состояние, которое стремительно приводит к тяжелым последствиям для организма. Обычные домашние методы восстановления при алкогольной интоксикации не только малоэффективны, но и небезопасны. Для быстрого и безопасного выведения токсинов требуется профессиональная помощь нарколога с применением капельницы от запоя.
Узнать больше – [url=https://kapelnica-ot-zapoya-moskva000.ru/]posle-kapelniczy-ot-zapoya moskva[/url]
Moi!
Casino lisenssi on tärkein yksittäinen luotettavuuden mittari. Voimassa oleva casino lisenssi takaa toiminnan laillisuuden. [url=https://www.reallivecasino.cfd/arvostelut-ja-luotettavuus.html]casino testimonials[/url] Tarkista aina lisenssin voimassaolo ja myöntäjätaho ennen rekisteröitymistä.
Lue linkki – https://reallivecasino.cfd/arvostelut-ja-luotettavuus.html
casino ГҐrhus poker
casino savonlinna
casino adrenaline
Onnea!
This is the right blog for anyone who wants to understand this topic. You know so much its almost tough to argue with you (not that I really will need to…HaHa). You certainly put a fresh spin on a subject that has been discussed for ages. Excellent stuff, just great!
Stretch limo near me
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Ознакомиться с деталями – http://prometgrudziadz.pl/proin-sodales-quam-nec-ante-sollicits
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Разобраться лучше – https://financialstory.in/andhra-cement-secures-sebi-approval-for-inr-180-crore-rights-issue
the best and interesting https://hello-jobs.com
interesting and new https://www.manaolahawaii.com
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Изучить вопрос глубже – https://wellness350.com/daily-affirmations-for-women-in-recovery-life-changing
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Исследовать вопрос подробнее – https://www.gllogistics.eu/olympus-digital-camera-7
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Узнать больше – https://odontologiaeoc.cl/ortodonciainvisible
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Исследовать вопрос подробнее – https://manufacturingtradingbv.com/the-significance-of-the-sound-of-shofar
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Подробнее тут – https://colledellasinello.com/utilizing-mobile-technology-in-the-field
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Получить дополнительную информацию – https://trippy420.org/product/buy-gelatti-strain-weed-online
best site online https://playplayfun.com
visit the site online https://justicelanow.org
Грузоперевозки Луганск Грузоперевозки Луганск: Перевозка негабаритных грузов. Специальная техника, опытные специалисты, оформление разрешений.
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Подробнее тут – https://hugobikes.com/2024/06/07/3179
What’s up, this weekend is nice in support of me, for the reason that this point in time i am reading this impressive educational post here at my residence.
Chauffeur service near me
кашпо пластиковое напольное высокое [url=www.kashpo-napolnoe-rnd.ru]кашпо пластиковое напольное высокое[/url] .
Как подчёркивает руководитель направления клинической токсикологии НМИЦ психиатрии и наркологии, «оказание помощи на дому требует не меньшего профессионализма, чем лечение в стационаре, ведь врач действует в ограниченных условиях».
Получить дополнительные сведения – https://narkolog-na-dom-nizhnij-tagil11.ru/vyzov-narkologa-na-dom-v-nizhnem-tagile/
В Рязани возможен как стационарный, так и амбулаторный вывод из запоя. Выбор подхода зависит от состояния пациента, выраженности симптомов и наличия сопутствующих нарушений.
Выяснить больше – [url=https://vyvod-iz-zapoya-v-ryazani12.ru/]вывод из запоя[/url]
Why users still make use of to read news papers when in this technological world everything is presented on web?
Black car near me
Наличие у нарколога практического опыта и навыков быстрого реагирования критично — особенно если речь идёт о тяжелой интоксикации или судорожном синдроме. Ошибки в дозировке или игнорирование хронических заболеваний могут привести к осложнениям.
Изучить вопрос глубже – http://narkolog-na-dom-nizhnij-tagil11.ru
Наличие у нарколога практического опыта и навыков быстрого реагирования критично — особенно если речь идёт о тяжелой интоксикации или судорожном синдроме. Ошибки в дозировке или игнорирование хронических заболеваний могут привести к осложнениям.
Подробнее можно узнать тут – [url=https://narkolog-na-dom-nizhnij-tagil11.ru/]вызов врача нарколога на дом нижний тагил[/url]
visit the site https://www.hlsports.de
go to the site https://petitedanse.com.br
Клинические протоколы стационарной терапии рекомендуют госпитализацию при средней и тяжёлой степени интоксикации.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-ryazani12.ru/]наркологический вывод из запоя в рязани[/url]
напольное кашпо с внутренним горшком [url=www.kashpo-napolnoe-rnd.ru/]www.kashpo-napolnoe-rnd.ru/[/url] .
Профессиональная анонимная наркологическая клиника. Лечение зависимостей, капельницы, вывод из запоя, реабилитация. Анонимно, круглосуточно, с поддержкой врачей и психологов.
Removing cloth remover from images is an advanced tool for creative tasks. Neural networks, accurate generation, confidentiality. For legal and professional use only.
завьялов илья поинт пей Илья Завьялов: PointPay – платформа для безопасного и эффективного обмена криптовалют
В Рязани возможен как стационарный, так и амбулаторный вывод из запоя. Выбор подхода зависит от состояния пациента, выраженности симптомов и наличия сопутствующих нарушений.
Подробнее – https://vyvod-iz-zapoya-v-ryazani12.ru/vyvod-iz-zapoya-czena-v-ryazani
варфейс макрос бесплатно Устали от промахов в Warface? Макросы варфейс – ваш выход! Точность выстрелов возрастет, отдача больше не проблема. Доминируйте на поле боя и наслаждайтесь игрой! Рекомендую!
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Узнать больше – https://vistoweekly.com/celerite-du-son-terminal-s-physique-driss-el-fadil
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Детальнее – https://www.ochicochiya.com/%E5%86%99%E7%9C%9F-2024-08-11-%E5%A4%8F%E5%AD%A3%E4%BC%91%E6%A5%AD%E3%81%8A%E7%9F%A5%E3%82%89%E3%81%9B
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Ознакомиться с деталями – https://www.arthemia.sk/video2
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Узнать больше – https://vistoweekly.com/m4ufree-fun
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Ознакомиться с деталями – https://tekintasmuhendislik.com/dogrusal-hareket-teknolojileri
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Получить больше информации – https://www.bemindful-project.eu/2019/01/28/the-art-of-relationship-with-personal-boundaries
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Подробнее можно узнать тут – https://groeberhuette.com/it/2024/04/12/eventi
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Подробнее – https://vistoweekly.com/phillies-vs-cincinnati-reds-match-player-stats
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Получить больше информации – https://personaltrainerrockvillemd.com/2024/10/05/all-about-vitamins
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Узнать больше – https://bloggenmeister.com/die-grundlagen-des-bloggens-verstehen
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Детальнее – https://tmpsltd.co.uk/mastering-time-management-key-to-business-success
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Получить больше информации – https://almontag.com/%D8%A3%D9%81%D8%B6%D9%84-%D8%A3%D9%86%D9%88%D8%A7%D8%B9-%D8%B3%D9%85%D9%83-%D8%A7%D9%84%D8%AA%D9%88%D9%86%D8%A9-%D8%AD%D9%88%D9%84-%D8%A7%D9%84%D8%B9%D8%A7%D9%84%D9%85
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Углубиться в тему – https://kntech.net.vn/kntech-dien-thoai-phong-sach
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Получить больше информации – http://mirmarfatia.com/2023/05/01/hello-world
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Получить больше информации – https://vistoweekly.com/amzp22x
Рефрижераторные перевозки https://auto24-krd.ru/gruzoperevozki/6505-tehnicheskie-trebovaniya-i-osnaschenie-refrizheratorov-dlya-arendy-chto-nuzhno-znat.html по России и СНГ. Контроль температуры от -25°C до +25°C, современные машины, отслеживание груза.
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Детальнее – https://tec4.kiev.ua/logo
карниз для штор купить в пятигорске Рулонные шторы Пятигорск: Современное решение для вашего окна Рулонные шторы – это практичное и стильное решение для любого интерьера. Они легко регулируют уровень освещения, защищают от посторонних глаз и идеально подходят для современных квартир и офисов в Пятигорске.
Без воды — просто рабочие игровые советы: https://30fond.ru/wp-content/articles/kak_vuigrat_v_kazino_vavada_2.html
Brians club equips its members with strategies designed for long-term success in both business and personal finance realms.
Выбирайте казино пиастрикс казино с оплатой через Piastrix — это удобно, безопасно и быстро! Топ-игры, лицензия, круглосуточная поддержка.
Хотите купить контрактный двигатель ДВС с гарантией? Б большой выбор моторов из Японии, Европы и Кореи. Проверенные ДВС с небольшим пробегом. Подбор по VIN, доставка по РФ, помощь с установкой.
Ищете казино казино с СБП? У нас — мгновенные переводы, слоты от топ-провайдеров, живые дилеры и быстрые выплаты. Безопасность, анонимность и мобильный доступ!
Играйте в онлайн-покер покерок легальный с игроками со всего мира. МТТ, спины, VIP-программа, акции.
Хирurgija u Crnoj Gori https://www.hirurgija-crna-gora.me savremena klinika, iskusni ljekari, evropski standardi. Planirane i hitne operacije, estetska i opsta hirurgija, udobnost i bezbjednost.
Aligning your entity setup with Briansclub.bz credit goals unlocks numerous advantages for both personal and business finances.
военная служба по контракту Контрактная служба: социальная поддержка государства, льготы и преимущества для военнослужащих и их семей
Элитная недвижимость https://real-estate-rich.ru в России и за границей — квартиры, виллы, пентхаусы, дома. Где купить, как оформить, во что вложиться.
Служба по контракту Служба по контракту: Социальная защита и поддержка ветеранов военной службы, обеспечение достойной пенсии и льгот.
https://russiamarkets.to/
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Почему это важно? – https://aichi-gorin-abilym.jp/?p=1
https://russiamarkets.to/
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Лови подробности – https://topic.lk/952
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Ссылка на источник – https://daotaocntt.org/about-us/contact-us-02.html
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Доступ к полной версии – https://newdesignhomes.com/how-to-lower-the-cost-of-home-renovation
The Stashpatrick approach highlights the significance of understanding your creditworthiness and how it impacts your borrowing options.
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Обратитесь за информацией – https://foxy1069.com/2024/08/chloe-bailey-to-star-in-new-horror-movie-goons
https://savasatan0.at/
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Секреты успеха внутри – https://www.karolinloven.com/2022/12/12/hello-world
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Подробнее – https://abc1.com.br/servicos-bsb-ronda
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Изучить вопрос глубже – https://yoshihiroito.jp/solar-eclipse-152834_1280
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Почему это важно? – https://gmdatatrust.org.uk/bowdon-preparatory-school
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Перейти к статье – https://f5fashion.vn/tong-hop-hon-63-ve-hinh-nen-among-us-ngau-hay-nhat
Clearnet & Onion Bazaar Drugs Marketplace: A New Darknet Platform with Dual Access Bazaar Drugs Marketplace is a new darknet marketplace rapidly gaining popularity among users interested in purchasing pharmaceuticals. Trading is conducted via the Tor Network, ensuring a high level of privacy and data protection. However, what sets this platform apart is its dual access: it is available both through an onion domain and a standard clearnet website, making it more convenient and visible compared to competitors. The marketplace offers a wide range of pharmaceuticals, including amphetamines, ketamine, cannabis, as well as prescription drugs such as alprazolam and diazepam. This variety appeals to both beginners and experienced buyers. All transactions on the platform are carried out using cryptocurrency payments, ensuring anonymity and security. In summary, Bazaar represents a modern darknet marketplace that combines convenience, a broad product selection, and a high level of privacy, making it a notable player in the darknet economy.
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Нажми и узнай всё – https://newssamiksha.com/index.php/2023/06/20/bri-teresi-biography
Выбор застройщика https://spartak-realty.ru важный шаг при покупке квартиры. Расскажем, как проверить репутацию, сроки сдачи, проектную документацию и избежать проблем с новостройкой.
Смотреть фильмы kinobadi.mom и сериалы бесплатно, самый большой выбор фильмов и сериалов , многофункциональное сортировка, также у нас есть скачивание в mp4 формате
Недвижимость в Балашихе https://balashihabest.ru комфорт рядом с Москвой. Современные жилые комплексы, школы, парки, транспорт. Объекты в наличии, консультации, юридическое сопровождение сделки.
Поставка нерудных материалов https://sr-sb.ru песок, щебень, гравий, отсев. Прямые поставки на стройплощадки, карьерный материал, доставка самосвалами.
мистические сериалы Интернет стал настоящей сокровищницей для любителей мистики. Здесь можно найти мистические романы, рассказы, фильмы, сериалы и даже аудиокниги, позволяющие погрузиться в мир загадок и тайн.
Лайфхаки для ремонта https://stroibud.ru квартиры и дома: нестандартные решения, экономия бюджета, удобные инструменты.
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Лови подробности – https://purerinsurer.com/2022/11/26/simple-tips-to-save-on-car-insurance
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Все материалы собраны здесь – http://178evakuator178.ru
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Узнать напрямую – https://weihong.vn/?attachment_id=2298
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Обратиться к источнику – https://corpogift.bg/koleden-podarak
Женский журнал https://e-times.com.ua о красоте, моде, отношениях, здоровье и саморазвитии. Советы, тренды, рецепты, вдохновение на каждый день. Будь в курсе самого интересного!
Туристический портал https://atrium.if.ua всё для путешественников: путеводители, маршруты, советы, отели, билеты и отзывы. Откройте для себя новые направления с полезной информацией и лайфхаками.
Женский онлайн-журнал https://socvirus.com.ua мода, макияж, карьера, семья, тренды. Полезные статьи, интервью, обзоры и вдохновляющий контент для настоящих женщин.
Портал про ремонт https://prezent-house.com.ua полезные советы, инструкции, дизайн-идеи и лайфхаки. От черновой отделки до декора. Всё о ремонте квартир, домов и офисов — просто, понятно и по делу.
Всё о ремонте https://sevgr.org.ua на одном портале: полезные статьи, видеоуроки, проекты, ошибки и решения. Интерьерные идеи, советы мастеров, выбор стройматериалов.
O jogo do tigrinho fortune tiger é a febre do momento, venha jogar!
военная служба по контракту Военная служба по контракту: современные тенденции В этом разделе рассматриваются современные тенденции развития военной службы по контракту в России и за рубежом.
Бюро дизайна https://sinega.com.ua интерьеров: функциональность, стиль и комфорт в каждой детали. Предлагаем современные решения, индивидуальный подход и поддержку на всех этапах проекта.
Портал про ремонт https://techproduct.com.ua для тех, кто строит, переделывает и обустраивает. Рекомендации, калькуляторы, фото до и после, инструкции по всем этапам ремонта.
Портал о строительстве https://bms-soft.com.ua от фундамента до кровли. Технологии, лайфхаки, выбор инструментов и материалов. Честные обзоры, проекты, сметы, помощь в выборе подрядчиков.
Всё о строительстве https://kinoranok.org.ua на одном портале: строительные технологии, интерьер, отделка, ландшафт. Советы экспертов, фото до и после, инструкции и реальные кейсы.
Ремонт и строительство https://mtbo.org.ua всё в одном месте. Сайт с советами, схемами, расчетами, обзорами и фотоидееями. Дом, дача, квартира — строй легко, качественно и с умом.
Сайт о ремонте https://sota-servis.com.ua и строительстве: от черновых работ до декора. Технологии, материалы, пошаговые инструкции и проекты.
Онлайн-журнал https://elektrod.com.ua о строительстве: технологии, законодательство, цены, инструменты, идеи. Для строителей, архитекторов, дизайнеров и владельцев недвижимости.
Полезный сайт https://quickstudio.com.ua о ремонте и строительстве: пошаговые гиды, проекты домов, выбор материалов, расчёты и лайфхаки. Для начинающих и профессионалов.
Журнал о строительстве https://tfsm.com.ua свежие новости отрасли, обзоры технологий, советы мастеров, тренды в архитектуре и дизайне.
Женский сайт https://7krasotok.com о моде, красоте, здоровье, отношениях и саморазвитии. Полезные советы, тренды, рецепты, лайфхаки и вдохновение для современных женщин.
Женские новости https://biglib.com.ua каждый день: мода, красота, здоровье, отношения, семья, карьера. Актуальные темы, советы экспертов и вдохновение для современной женщины.
Все главные женские https://pic.lg.ua новости в одном месте! Мировые и российские тренды, стиль жизни, психологические советы, звёзды, рецепты и лайфхаки.
Сайт для женщин https://angela.org.ua любого возраста — статьи о жизни, любви, стиле, здоровье и успехе. Полезно, искренне и с заботой.
Женский онлайн-журнал https://bestwoman.kyiv.ua для тех, кто ценит себя. Мода, уход, питание, мотивация и женская энергия в каждой статье.
Путеводитель по Греции https://cpcfpu.org.ua города, курорты, пляжи, достопримечательности и кухня. Советы туристам, маршруты, лайфхаки и лучшие места для отдыха.
Стабильно работающая копия сайта — для доступа из любой точки мира. [url=https://shopgreydog.com/]скачать вавада — играть на деньги[/url]
Портал о строительстве https://ateku.org.ua и ремонте: от фундамента до крыши. Пошаговые инструкции, лайфхаки, подбор материалов, идеи для интерьера.
Строительный портал https://avian.org.ua для профессионалов и новичков: проекты домов, выбор материалов, технологии, нормы и инструкции.
Туристический портал https://deluxtour.com.ua всё для путешествий: маршруты, путеводители, советы, бронирование отелей и билетов. Информация о странах, визах, отдыхе и достопримечательностях.
Открой мир https://hotel-atlantika.com.ua с нашим туристическим порталом! Подбор маршрутов, советы по странам, погода, валюта, безопасность, оформление виз.
Ваш онлайн-гид https://inhotel.com.ua в мире путешествий — туристический портал с проверенной информацией. Куда поехать, что посмотреть, где остановиться.
Hyvää päivää!!
Bonus ehdot ilman kierrätystä ovat yksinkertaiset ja selkeät. Lue aina bonus ehdot ilman kierrätystä ennen tarjouksen hyväksymistä. [url=https://www.reallivecasino.cfd/bonukset-ilman-kierratysta.html]casino bonus hyödyt[/url] Näin vältät epämiellyttävät yllätykset ja nautit stressittömästä pelaamisesta.
Lue linkki – https://www.reallivecasino.cfd/bonukset-ilman-kierratysta.html
casino helsinki turnaukset
kulosaaren casino äitienpäivä
casino fuengirola
Onnea!
Строительный сайт https://diasoft.kiev.ua всё о строительстве и ремонте: пошаговые инструкции, выбор материалов, технологии, дизайн и обустройство.
Сайт о строительстве https://domtut.com.ua и ремонте: практичные советы, инструкции, материалы, идеи для дома и дачи.
На строительном сайте https://eeu-a.kiev.ua вы найдёте всё: от выбора кирпича до дизайна спальни. Актуальная информация, фото-примеры, обзоры инструментов, консультации специалистов.
Строительный журнал https://inter-biz.com.ua актуальные статьи о стройке и ремонте, обзоры материалов и технологий, интервью с экспертами, проекты домов и советы мастеров.
Сайт о ремонте https://mia.km.ua и строительстве — полезные советы, инструкции, идеи, выбор материалов, технологии и дизайн интерьеров.
Сайт о ремонте https://rusproekt.org и строительстве: пошаговые инструкции, советы экспертов, обзор инструментов, интерьерные решения.
кайт хургада Кайтсерфинг и успешный бизнес: Секреты успеха
Всё для ремонта https://zip.org.ua и строительства — в одном месте! Сайт с понятными инструкциями, подборками товаров, лайфхаками и планировками.
Полезный сайт для ремонта https://rvps.kiev.ua и строительства: от черновых работ до отделки и декора. Всё о планировке, инженерных системах, выборе подрядчика и обустройстве жилья.
Автомобильный портал https://just-forum.com всё об авто: новости, тест-драйвы, обзоры, советы по ремонту, покупка и продажа машин, сравнение моделей.
Современный женский журнал https://superwoman.kyiv.ua стиль, успех, любовь, уют. Новости, идеи, лайфхаки и мотивация для тех, кто ценит себя и своё время.
Онлайн-портал https://spkokna.com.ua для современных родителей: беременность, роды, уход за малышами, школьные вопросы, советы педагогов и врачей.
Сайт для женщин https://ww2planes.com.ua идеи для красоты, здоровья, быта и отдыха. Тренды, рецепты, уход за собой, отношения и стиль.
Онлайн-журнал https://eternaltown.com.ua для женщин: будьте в курсе модных новинок, секретов красоты, рецептов и психологии.
Сайт для женщин https://womanfashion.com.ua которые ценят себя и своё время. Мода, косметика, вдохновение, мотивация, здоровье и гармония.
Современный авто портал https://simpsonsua.com.ua автомобили всех марок, тест-драйвы, лайфхаки, ТО, советы по покупке и продаже. Для тех, кто водит, ремонтирует и просто любит машины.
Женский онлайн-журнал https://abuki.info мода, красота, здоровье, психология, отношения и вдохновение. Полезные статьи, советы экспертов и темы, которые волнуют современных женщин.
Актуальные новости https://uapress.kyiv.ua на одном портале: события России и мира, интервью, обзоры, репортажи. Объективно, оперативно, профессионально. Будьте в курсе главного!
Онлайн авто портал https://sedan.kyiv.ua для автолюбителей и профессионалов. Новинки автоиндустрии, цены, характеристики, рейтинги, покупка и продажа автомобилей, автофорум.
Информационный портал https://mediateam.com.ua актуальные новости, аналитика, статьи, интервью и обзоры. Всё самое важное из мира политики, экономики, технологий, культуры и общества.
Приемка квартир и ИЖС от застройщиков Приемка коммерческой недвижимости – защита ваших инвестиций и гарантия соответствия нормам.
Новости Украины https://pto-kyiv.com.ua и мира сегодня: ключевые события, мнения экспертов, обзоры, происшествия, экономика, политика.
Современный мужской портал https://kompanion.com.ua полезный контент на каждый день. Новости, обзоры, мужской стиль, здоровье, авто, деньги, отношения и лайфхаки без воды.
Сайт для женщин https://storinka.com.ua всё о моде, красоте, здоровье, психологии, семье и саморазвитии. Полезные советы, вдохновляющие статьи и тренды для гармоничной жизни.
Следите за событиями https://kiev-pravda.kiev.ua дня на новостном портале: лента новостей, обзоры, прогнозы, мнения. Всё, что важно знать сегодня — быстро, чётко, объективно.
Новостной портал https://thingshistory.com для тех, кто хочет знать больше. Свежие публикации, горячие темы, авторские колонки, рейтинги и хроники. Удобный формат, только факты.
приемка квартир от застройщика Доступные цены и гибкие условия аренды.
Hyvää päivää!!
Ongelmapelaamisen ehkäisy alkaa varhaisesta tunnistamisesta ja tietoisuudesta. Ongelmapelaamisen ehkäisy työkaluja on saatavilla kaikissa laillisissa kasinoissa. [url=https://www.reallivecasino.cfd/ikarajat-ja-saannot.html]casino rahanhallinnan rajat[/url] Käytä ehkäisevät työkalut hyväksesi ja pidä pelaaminen terveenä harrastuksena.
Lue linkki – https://www.reallivecasino.cfd/ikarajat-ja-saannot.html
casino arpa hinta
casino lounas helsinki
casino elokuva vuokraa
Onnea!
продать аптечные препараты Продам лекарства России – объявления о продаже лекарств в России должны соответствовать действующему законодательству.
гастро-вечеринка Воронеж кейтеринг Воронеж
спираль мирена показания https://spiral-mirena1.ru
ремонт стиральных машин сименс ремонт барабана стиральной машины
ремонт стиральных машин beko ремонт замка стиральной машины
ремонт блоков стиральных машин ремонт стиральных машин бош
Moi!
Suomalaiset kasinot ilman rekisteröitymistä hyödyntävät pankkien vahvaa tunnistautumista. Parhaat suomalaiset kasinot ilman rekisteröitymistä ovat täysin laillisia. [url=https://reallivecasino.cfd/kasinot-ilman-rekisteroitymista.html]casino anonyymi[/url] Pelaa turvallisesti kotimaisten pankkien luotettavan järjestelmän avulla.
Lue linkki – https://reallivecasino.cfd/kasinot-ilman-rekisteroitymista.html
casino jyväskylä
åldersgräns casino sverige
casino kokemuksia
Onnea!
Химчистка мебели ростов Подготовка мебели к химчистке в Ростове – простые шаги для лучшего результата.
Купить профилированный лист Профилированная труба: универсальный материал для конструкций Профилированная труба – это универсальный строительный материал, который используется для создания каркасов, ограждений, навесов и других конструкций. Она отличается высокой прочностью, устойчивостью к коррозии и доступной ценой, что делает ее оптимальным выбором для различных строительных задач.
накрутка пф яндекс Накрутка ПФ: взвешенное решение Накрутка ПФ – это инструмент, требующий осторожного и взвешенного подхода. Прежде чем прибегать к каким-либо методам, необходимо тщательно оценить риски и возможные последствия. В большинстве случаев, лучше сосредоточиться на создании качественного сайта, который будет интересен реальным пользователям.
лазерная резка москва металла резка металла лазером москва
типография санкт петербург типография спб дешево
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Провести детальное исследование – https://f5fashion.vn/chia-se-hon-52-ve-ao-so-mi-mau-kem
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Посмотреть подробности – https://www.nishio-seifun.co.jp/2025/01/06/marche-recrutment
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Провести детальное исследование – https://vitamagazine.com/2024/10/02/stardust-roller-rink-is-back-in-b-c-win
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Детальнее – https://peg-it.ie/product/comprehension-01
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Читать дальше – http://deepwebifsa.tk/post/34
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Узнать напрямую – http://sunset.jp/shopblog/index.php?itemid=160