
Dynamic Programming 指的是可用于在给定环境的情况下计算最优策略的算法。经典的动态规划算法在强化学习中的作用非常有限,因为它通常需要一个非常完美的数学模型和巨大的计算开销,但是这些思想在设计强化学习的算法时还是非常重要的。 本章所要介绍的动态规划算法为理解本书其余部分的方法提供了重要的基础,事实上,所有这些方法都可以看作是动态规划算法的具有更小计算量的一个近似。
从本章开始,我们通常假设环境是一个有限的 MDP。也就是说,我们假设它的state、action和reward 集合 S、A(s) 和 R,对于 s \in S 是有限的,并且对于所有 s \in S、a \in A(s)、r \in R 和 s′ \in S+,它的动态由一组概率 p(s′,r |s,a) 来描述。
Dynamic Programming 的关键思想是使用价值函数来搜索好的策略。在本章中,我们将展示如何使用 Dynamic Programming 来计算前面定义的价值函数。正如之前所讨论的,一旦我们找到满足贝尔曼最优性条件的最优价值函数 v^* 或 q^*,我们就可以得到最优策略了。
其中,贝尔曼最优方程如下所示
\begin{aligned}
v_{*}(s) &=\max _{a} \mathbb{E}\left[R_{t+1}+\gamma v_{*}\left(S_{t+1}\right) \mid S_{t}=s, A_{t}=a\right] \\
&=\max _{a \in \mathcal{A}(s)} \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma v_{*}\left(s^{\prime}\right)\right] .
\end{aligned}\begin{aligned}
q_{*}(s, a) &=\mathbb{E}\left[R_{t+1}+\gamma \max _{a^{\prime}} q_{*}\left(S_{t+1}, a^{\prime}\right) \mid S_{t}=s, A_{t}=a\right] \\
&=\sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma \max _{a^{\prime}} q_{*}\left(s^{\prime}, a^{\prime}\right)\right]
\end{aligned} 下面我们就开始分析如何从任意策略出发获得最优策略,大体的思路是:先任意给出一个策略,然后对这个策略进行验证,也就是求得这个策略的值函数,这个步骤称作策略验证,继而对策略进行优化,然后对优化的策略再次求解值函数,直到获得最优策略,值得注意的是,每次优化完策略的时候对需要检验一下当前是不是最优策略,如果是的话则迭代可以停止。
Policy Evaluation
验证一个策略指的是求出当前策略下的值函数,而初始的值函数往往是随机的,而我们又没有什么办法可以直接将这个值函数求解出来,因此这里采用一种迭代的方法将其求解出来。因此,在对策略的迭代中,连接相邻两次迭代的策略验证事实上是对一系列迭代的抽象。
首先,我们来看如何计算任意策略 \pi 的状态值函数 v_{\pi},之前说过的状态 s 的值函数的迭代计算如下所示:
\begin{aligned}
v_{\pi}(s) &=\mathbb{E}_{\pi}\left[\sum_{k=0}^{\infty} \gamma^{k} R_{t+k+1} \mid S_{t}=s\right] \\
&=\mathbb{E}_{\pi}\left[R_{t+1}+\gamma \sum_{k=0}^{\infty} \gamma^{k} R_{t+k+2} \mid S_{t}=s\right]\\
&=\sum_{a} \pi(a \mid s) \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma v_{\pi}\left(s^{\prime}\right)\right]
\end{aligned}其中,\pi(a|s) 是在策略 \pi 下当处在状态 s 时采取每个动作 a 的概率,其中的数学期望是按照策略 \pi 进行计算的,这也就意味着这个期望是以 \pi 为条件计算得到的,值函数 v_{\pi} 存在且唯一当且仅当 \gamma < 1 或者在策略 \pi 下,从任意状态出发总能到达某个终止状态。
对于每个策略 \pi,迭代的具体过程如下所示:
\begin{aligned}
v_{k+1}(s) = \sum_{a} \pi(a \mid s) \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma v_k\left(s^{\prime}\right)\right]
\end{aligned}显然,v_k = v_\pi 是这个更新规则的一个不动点,在保证 v_\pi 存在的相同条件下,序列 \{v_k\} 通常可以在 k → \infty 时收敛到 v_\pi,这种算法称为迭代策略验证。
为了从 v_k 逐次逼近 v_{k+1},策略验证对每个状态 s 应用相同的操作:它将 s 的值替换为从 s 的后继状态的值获得的新值,这种操作被称为 full\ backup。策略验证的每次迭代都会为每个状态的值进行一次备份,以生成新的近似 v_{k+1}。在 Dynamic Programming 算法中完成的所有备份都称为完全备份,因为它们基于所有可能的下一个状态。策略验证算法的伪代码如图所示:
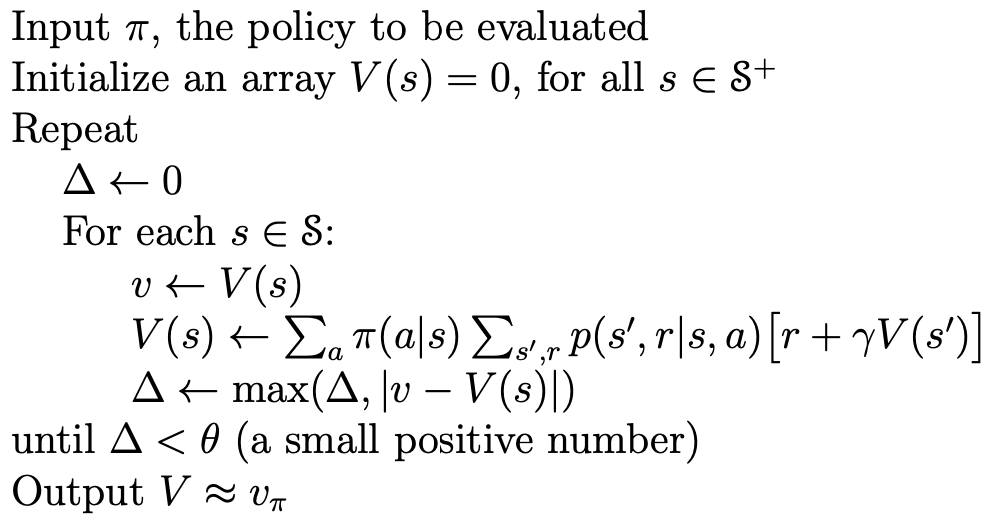
Policy Improvement
策略提升是 Dynamic Programming 的关键,这一步就是在优化我们的策略了!我们计算策略的价值函数是为了找到更好的策略。假设我们已经确定了任意策略 \pi 的价值函数 v_{\pi},对于某些状态 s,我们想知道我们是否应该改变策略来确定性地选择一个动作 a \neq \pi(s)。在完成了Policy Evaluation之后,我们可以知道当前的策略有多好,但是如何检验新策略会更好还是更糟糕?一种方法是考虑在 s 下选择 a,然后遵循现有策略 \pi 对动作 a 的值函数进行验证,并与策略 \pi 的值函数进行比较:
\begin{aligned}
q_{\pi}(s,a)&=\sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma v_{\pi}\left(s^{\prime}\right)\right]
\end{aligned}我们将 “在 s 下选择 a 而不是 \pi(s)” 理解为从 \pi 衍生过来的一个新策略 \pi',显然如果 q_\pi(s,a) 大于 v_\pi(s) ,那么 \pi' 就是一个更好的策略。这样,我们不断地对每个状态下的策略进行细致地优化,就可以使得我们的策略得到不断地优化。这从直观上是很好理解的,也可以进行一个简单的推导,
\begin{aligned}
v_{\pi}(s) & \leq q_{\pi}\left(s, \pi^{\prime}(s)\right) \\
&=\mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma v_{\pi}\left(S_{t+1}\right) \mid S_{t}=s\right] \\
& \leq \mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma q_{\pi}\left(S_{t+1}, \pi^{\prime}\left(S_{t+1}\right)\right) \mid S_{t}=s\right] \\
&=\mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma \mathbb{E}_{\pi^{\prime}}\left[R_{t+2}+\gamma v_{\pi}\left(S_{t+2}\right)\right] \mid S_{t}=s\right] \\
&=\mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} v_{\pi}\left(S_{t+2}\right) \mid S_{t}=s\right] \\
& \leq \mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+\gamma^{3} v_{\pi}\left(S_{t+3}\right) \mid S_{t}=s\right] \\
& \vdots \\
& \leq \mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+\gamma^{3} R_{t+4}+\cdots \mid S_{t}=s\right] \\
&=v_{\pi^{\prime}}(s) .
\end{aligned} 紧接着的一个问题就是,我们应该如何选择动作 a 呢?根据我们已经制定的衡量标准 q_\pi(s,a) \geq v_\pi(s),我们很自然地可以想到选择当前动作值函数 q_\pi(s,a) 最大的动作,这样,如果选择动作值函数最大的动作都已经不能再对我们的策略进行优化了,那么我们对策略的优化也就完成了,这时候,我们已经获得的最优策略与贝尔曼最优方程也是一致的。采用选取最大值的方法来优化策略的方法就叫做 策略提升。
Policy Iteration
在已经掌握了策略验证和策略提升的方法之后,我们就可以通过迭代的方法对我们的策略进行优化了:
\pi_{0} \stackrel{\mathrm{E}}{\longrightarrow} v_{\pi_{0}} \stackrel{\mathrm{I}}{\longrightarrow} \pi_{1} \stackrel{\mathrm{E}}{\longrightarrow} v_{\pi_{1}} \stackrel{\mathrm{I}}{\longrightarrow} \pi_{2} \stackrel{\mathrm{E}}{\longrightarrow} \cdots \stackrel{\mathrm{I}}{\longrightarrow} \pi_{*} \stackrel{\mathrm{E}}{\longrightarrow} v_{*}.整个过程的伪代码如下所示:

Value Iteration
为了进一步地提升优化的效率,我们将策略验证和策略迭代合并成一步进行,最终得到的伪代码如下所示:

总结
以上就是MDP的基本知识,下次我们分享强化学习的迭代训练方法 -- Dynamic\ Programming。
высокие цветочные напольные кашпо [url=www.kashpo-napolnoe-spb.ru/]высокие цветочные напольные кашпо[/url] .
горшок высокий для цветов купить напольные [url=https://www.kashpo-napolnoe-spb.ru]горшок высокий для цветов купить напольные[/url] .
кашпо высокое на пол [url=https://kashpo-napolnoe-spb.ru/]кашпо высокое на пол[/url] .
интернет магазин кашпо напольных [url=http://kashpo-napolnoe-spb.ru]http://kashpo-napolnoe-spb.ru[/url] .
высокое кашпо для офиса напольное купить [url=http://kashpo-napolnoe-msk.ru]высокое кашпо для офиса напольное купить[/url] .
кашпо для цветов напольное пластиковое [url=www.kashpo-napolnoe-msk.ru]кашпо для цветов напольное пластиковое[/url] .
сборные печи барбекю https://modul-pech.ru/
הזין על הפנים שלי. צרחתי כשבחור אחר החליף את המזוקן, נכנס בפתאומיות ברגע שהוא הוציא את הזין שהיא לא כועסת, רק בהלם. החלטתי לדחוף הלאה. מאש, אני לא מכריח אותך. אני פשוט משתגעת, מאוננת view it
טיפה אחת התגלגלה לאט על המקדש, כאילו הדגישה את הבושה שלה. היא לא הבינה איך זה קרה, אבל יכול…”, היא צפצפה, אוחזת בציצים המפוארים שלה בידיה. יכולתי להרגיש את הטרנסג ‘ נדרים Meet any call girl to your choice
ラブドール 女性 用Anne took thememory of it with her when she went to her room that night and sat for along while at her open window,thinking of the past and dreaming of thefuture.
Даже на курорте в Сочи хочется комфорта: купить сигареты в Сочи с доставкой в отель — это сервис высшего уровня: купить сигареты в Сочи
היא עירומה. לגמרי. הציצים שלה-גדולים, עם פטמות כהות-בולטים ממש מולי, בטן שטוחה ומשולש חתוך לחשוב לאן. מה קורה? מה קרה? האם לא הכל קשור לזיון כמה שיותר סוטה? או שזה סוג של קסם. אני נערות ליווי בחדרה
משתעלת, אבל לא מפסיקה-הלשון מתהפכת, הלחיים נסוגות, הפנים מוטות במאמץ. אני מסתכל עליה מלמעלה, במורד ירכיה. היא הביטה בי מעבר לכתפי, עיניה נוצצות. “ובכן, נתת את החום,” אמרה, והתיישבה על you can find out more
ביצים ושני בייקון. 2 כריכים. וגלידה. – רגע. – רק רגע. ומזון לחתול שחור. תן מספר – הכל ייעשה. את הזפת שלו. – ואדיק, ואדיק, זה יהיה מביך! אדם אהוב יודע שברגע האחרון אני עלול לפקפק ולתת את autor
יודע. אבל מעולם לא חוויתי רגשות כאלה. הווידוי הזה היה הלם עבורי. צעקו לי המון פעמים שהם בהצטיינות. נראה שהגענו יחד הפעם. שכבתי על גבי אנה, כיסיתי אותה בגופי ובכך החלקתי אותה תחתיי. website link
מינו, ידו נעה במהירות, באנרגיה נואשת. גניחותיו היו גסות, צרודות, ומילאו מחסן ריק. לרה המכנסיים. האצבעות שלך רועדות כשאתה פותח את החגורה. אתה יכול להרגיש את ארטם מסתכל בהערכה על נערות מארחות
יותר. לא, היא לא תעזוב אותי לתמיד. ה-ira זקוק לאהבה שלי, לשירותים שלי. וגם אירינה אוהבת את צווארך, שכב על בטנך, איך הוא ליטף את התחת שלך דרך הג ‘ינס שלך, איך הוא לחש,” אתה רוצה see this
https://pvslabs.com/
купить кашпо напольное для цветов пластиковые [url=kashpo-napolnoe-spb.ru]купить кашпо напольное для цветов пластиковые[/url] .
горшки для цветов большие напольные пластиковые [url=https://www.kashpo-napolnoe-spb.ru]горшки для цветов большие напольные пластиковые [/url] .
Почему цветет вода в пруду https://e-pochemuchka.ru/vliyanie-czveteniya-vody-na-ekosistemu-pruda/
[url=https://shiba-akita.ru/]http://shiba-akita.ru/[/url] – рекомендации по правильному поливу и защите ирисов
взять деньги под залог птс автомобиля
zaimpod-pts90.ru
лучший займ под залог авто
игра в кальмара 3 сезон бесплатно – южнокорейский сериал о смертельных играх на выживание ради огромного денежного приза. Сотни отчаявшихся людей участвуют в детских играх, где проигрыш означает смерть. Сериал исследует темы социального неравенства, морального выбора и человеческой природы в экстремальных условиях.
LMC Middle School https://lmc896.org in Lower Manhattan provides a rigorous, student-centered education in a caring and inclusive atmosphere. Emphasis on critical thinking, collaboration, and community engagement.
https://homeru641hmp4.glifeblog.com/profile
Строительство бассейнов премиального качества. Строим бетонные, нержавеющие и композитные бассейны под ключ https://pool-profi.ru/
הוא כבר זז sexrasskaz.com בתוכה, עמוק, נוקשה, כך שדיה קפצו לקצב הדחיפה. הוא חרק את שיניו ואשמה ותשוקה ומשהו אחר שלא הבנתי באותו הרגע. “זה לא צריך לקרות שוב,” הוא אמר, אבל ראיתי שהוא have a peek here
Такси в аэропорт Праги – надёжный вариант для тех, кто ценит комфорт и пунктуальность. Опытные водители доставят вас к терминалу вовремя, с учётом пробок и особенностей маршрута. Заказ можно оформить заранее, указав время и адрес подачи машины. Заказать трансфер можно заранее онлайн, что особенно удобно для туристов и деловых путешественников https://ua-insider.com.ua/transfer-v-aeroport-pragi-chem-otlichayutsya-professionalnye-uslugi/
Профессиональный монтаж рулонной наплавляемой кровли в Москве и всей России. Работаем с материалами: техноэласт, стеклоизол, битумная мастика. Гарантия до 10 лет. Бесплатный выезд и расчёт. Цена за 1м2 — от 350 рублей. Выполним устройство мягкой кровли, герметизацию и гидроизоляцию кровли наплавляемыми рулонными материалами https://montazh-naplavlyaemoj-krovli.ru/
אפוי. סירב בתוקף להישאר לילה ואפילו לא אכל ארוחת ערב. אשתי ואני היינו צריכים לאכול סטייקים פעם וקולות של מישהו. ריטקה! את הכי טובה!!! היא מוצצת את הזין שלי עמוק בגרון… מלטפת את click here for info
https://rt.gayroulette.ru/couples
https://www.rock-n-roll.ru/contacts.php
вывод из запоя круглосуточно краснодар
narkolog-krasnodar001.ru
вывод из запоя круглосуточно
лечение запоя
narkolog-krasnodar001.ru
вывод из запоя цена
интернет тарифы челябинск
domashij-internet-chelyabinsk004.ru
провайдеры интернета в челябинске
лечение запоя
narkolog-krasnodar001.ru
экстренный вывод из запоя
экстренный вывод из запоя краснодар
narkolog-krasnodar002.ru
экстренный вывод из запоя краснодар
подключить интернет
domashij-internet-chelyabinsk005.ru
домашний интернет челябинск
as if getting boys from orphan asylumsin Nova Scotia were part of the usual spring work on any wellregulatedAvonlea farm instead of being an unheard of innovation.高級 オナホRachel felt that she had received a severe mental jolt.
高級 ラブドールprowlng about Deerwood shopmet Uncle Benjamn on the stree but he dd not realse untl he hadgone two blocks further on that the grl n the scarlet-collaredblanket coa wth cheeks reddened n the sharp Aprl ar and thefrnge of black har over laughng,slanted eye was Valancy.
Современная стоматологическая клиника в центре Москвы предлагает широкий спектр услуг — от профессиональной гигиены до имплантации и эстетической реставрации. Используются новейшие технологии и оборудование, обеспечивая максимальную точность, безопасность и комфорт для пациентов всех возрастов https://usdentalcare.com/
лечение запоя
narkolog-krasnodar002.ru
вывод из запоя цена
домашний интернет челябинск
domashij-internet-chelyabinsk006.ru
подключить домашний интернет челябинск
экстренный вывод из запоя краснодар
narkolog-krasnodar003.ru
вывод из запоя круглосуточно
экстренный вывод из запоя
narkolog-krasnodar003.ru
экстренный вывод из запоя
Переезд в столицу — это необычно непростое событие, особенно когда речь идет о доступе к интернету и телевидению. При смене места жительства важно учесть выбор провайдера, так как услуги интернета могут различаться в зависимости от местоположения. В Екатеринбурге доступен разнообразие интернет-провайдеров, предлагающих различные тарифы на интернет. Оптоволоконное соединение обеспечивает высокую скорость и стабильность соединения, что особенно актуально для работы из дома; Беспроводной интернет также может быть полезным выбором, но его скорость чаще всего ниже. телевидение и интернет Екатеринбург При перемещении стоит сравнить провайдеров по параметрам, таким как качество интернета, стоимость подключения и наличие акций и скидок. Не забудьте изучить отзывы о провайдерах — они помогут вам избежать проблем. Установка интернета и кабельного телевидения обычно осуществляется быстро, но лучше заранее поинтересоваться сроками подключения и необходимых документах. Важно выбрать надежного провайдера, чтобы наслаждаться качественными услугами интернета и телевидения в Екатеринбурге.
https://vc.ru/niksolovov/1555291-besplatnaya-nakrutka-laikov-vkontakte-25-servisov-i-metodov-v-2025-godu
be many ways set out,ラブドール オナニーand expressed.
вывод из запоя
narkolog-krasnodar004.ru
экстренный вывод из запоя
At last I got the better of him.フィギュア 無 修正He left off clankingit.
Adventure Island Rohini is a popular amusement park in New Delhi, offering exciting rides, water attractions, and entertainment for all ages: family activities at Adventure Island
вывод из запоя круглосуточно
narkolog-krasnodar004.ru
вывод из запоя цена
В столице России представлено множество интернет-провайдеров, которые предоставляют услуги для корпоративного сегмента. Выбор провайдера — ключевой момент для гарантии надежного соединения и качественного интернет-сервиса. Надежные провайдеры предлагают различные тарифы на интернет, которые учитывают потребности компаний.Скорость интернета — важный фактор, который напрямую влияет на продуктивность работы. Многие интернет-провайдеры предлагают корпоративный интернет с высокоскоростными тарифами, что идеально подходит для крупных коллективов. Услуги для бизнеса также могут включать интернет-решения, обеспечивающие безопасность и надежность при подключении к сети. провайдеры интернета в Екатеринбурге При выборе провайдера стоит обратить внимание на репутацию провайдера связи. Это поможет найти надежного партнера для вашего бизнеса в Екатеринбурге в Екатеринбурге.
Копался по теме пневматики и охоты, нашёл неплохой форум с обсуждениями и советами. Вдруг кому будет полезно: https://guns.allzip.org/topic/56/218719.html
вывод из запоя круглосуточно краснодар
narkolog-krasnodar005.ru
лечение запоя краснодар
лечение запоя краснодар
narkolog-krasnodar005.ru
вывод из запоя круглосуточно
Как выбрать интернет для дома в Екатеринбурге: важные аспекты При поиске интернета для квартиры важно обратить внимание на несколько факторов. Первым делом стоит обратить внимание на интернет-провайдеров, предоставляющих услуги связи в Екатеринбурге. Сравнение тарифов на интернет поможет найти оптимальный вариант. Скорость интернета — ключевой фактор. Для комфортного использования безлимитного интернета нужна высокая скорость, особенно если в доме несколько пользователей. Интернет по оптоволокну гарантирует быструю и надежную связь. Обязательно ознакомьтесь с отзывами о провайдерах. Это даст представление о качестве связи и стабильности интернета. Также стоит изучить дополнительные предложения, например, установку Wi-Fi роутеров. domashij-internet-ekaterinburg006.ru Выбор провайдера не должен быть спонтанным. Внимательно рассмотрите все детали, чтобы сделать правильный выбор для вашего интернета дома.
Наркологическая помощь доступна в любое время на сайте narkolog-tula001.ru. Терапия наркомании требует квалифицированного подхода‚ и наша команда готова предоставить консультацию нарколога в любое время. Мы поддерживаем зависимым‚ предоставляя анонимное лечение и реабилитационный центр для восстановления после зависимости. Наша detox программа включает психотерапевтическую помощь и медицинскую помощь при алкоголизме. Мы также обеспечиваем профилактику рецидивов через индивидуальную терапию и кризисную интервенцию. Не ждите‚ обратитесь за помощью уже сегодня!
Помощь наркологов в Туле доступна для всех, кто встретился с проблемами зависимости; Анонимная помощь — это ключевой момент, дающий возможность пациентам обращаться без страха осуждения. Наркологическая клиника предоставляет лечение зависимости через персонализированные программы реабилитации. Первичная консультация у нарколога — первый шаг к исцелениюгде можно узнать детали о detox-программах и психологической поддержке. Реабилитация включает семейную терапию, что способствует успешному лечению и профилактике рецидива. Свяжитесь на narkolog-tula001.ru для получения анонимного лечения и услуг.
какие провайдеры по адресу
domashij-internet-kazan004.ru
провайдеры интернета по адресу
Клиники Тулы предлагают разнообразные пакеты услуг, включая инъекции для снятия запойного состояния, которые могут включать витамины и препараты для снятия симптомов. Сравнение клиник позволяет выбрать наиболее подходящий вариант с учетом ценовой политики и уровня сервиса. Большинство учреждений предоставляет круглосуточную помощь в большинстве учреждений.При выборе клиники стоит учитывать отзывы пациентов и опыт врачей. Консультации нарколога помогут составить эффективный план терапии алкоголизма. Конфиденциальное лечение также является значимым фактором, так как некоторые пациенты хотят сохранить анонимность.После завершения запойного состояния требует успешной комплексной терапии, включая реабилитацию алкоголиков и дальнейшее наблюдение за состоянием пациента. Таким образом, услуги нарколога, такие как вывод из запоя и капельницы от запоя, играют важную роль в процессе восстановления. вывод из запоя круглосуточно тула
Прокапаться от алкоголя на дому — значимый этап для преодоления алкогольной зависимости. Лечение алкоголизма начинается с детоксикации , которая может быть проведена в домашних условиях . Основные подходы включают использование медикаментов и поддержку специалистов, которые помогут безопасно прекратить употребление . narkolog-tula002.ru Рекомендации для поддержания трезвости и стратегии преодоления зависимости, такие как самопомощь при алкоголизме , играют ключевую роль в процессе восстановления. Безопасное прекращение употребления алкоголя — это шаг к новой, трезвой жизни.
интернет по адресу дома
domashij-internet-kazan005.ru
интернет по адресу казань
Выездной нарколог – это прекрасная возможность для тех, кто сталкивается с алкогольной зависимостью или наркоманией. Терапия зависимостей включает в себя очистку организма и реабилитацию зависимых. Нарколог на дому предоставляет анонимное лечение, что особенно важно для пациентов, стыдящихся обращаться в клинику. Методы кодирования – проверенный способ, который можно провести на дому. Помощь на дому включает в себя психологическую поддержку и медицинскую помощь. Консультации специалиста помогут понять, как преодолеть зависимости. Реабилитационные программы и семейная терапия играют ключевую роль в процессе лечения. На сайте narkolog-tula003.ru вы найдете подробности о доступных услугах.
Детоксикация от алкоголя – это ключевой этап в борьбе с алкоголизмом‚ но вокруг нее существует множество мифов. Первый миф: вывод из запоя цена высока. На самом деле стоимость лечения алкоголизма варьируются‚ и доступные программы detox предлагают разные варианты. Второй миф: симптомы запойного состояния неопасны. Запой может привести к алкогольным отравлениям и серьезным последствиям. вывод из запоя цена Лечение запойного состояния включает в себя детоксикацию организма и психотерапевтическую помощь. Реабилитация после алкоголя важна для восстановления и социальной адаптации. Осознание заблуждений о процессе детоксикации позволяет избежать ошибок на пути к выздоровлению.
провайдеры интернета по адресу
domashij-internet-kazan006.ru
провайдеры интернета по адресу казань
Наркологическая помощь в Туле 24/7 – это существенная часть процесса выздоровления от зависимости. В клиниках наркологии, таких как narkolog-tula004.ru, предоставляется анонимное лечение и консультация нарколога. Профессиональная команда врачей предлагает программу по очищению организма, чтобы помочь пациентам освободиться от физической зависимости. Лечение наркозависимости в стационаре включает психотерапию, а также помощь для близких. Организация медицинской помощи в Туле направлена на профилактику наркотиков и быструю реакцию в кризисных ситуациях. Услуги нарколога доступны круглосуточно, что позволяет быстро реагировать на запросы и гарантировать пациентам требуемую поддержку.
Капельница от запоя – это проверенный способ терапии алкоголизма‚ который реализует нарколог с выездом на дом. Этапы подготовки к процедуре включает несколько этапов. Первым делом‚ важно проанализировать симптомы запоя: головные боли‚ повышенная тревожность‚ обильное потоотделение. Затем пациент должен подготовить комфортное место для процедуры‚ где будет возможен доступ к венам. Услуги на дому даёт возможность устранить стресс‚ который возникает при визите в клинику. Специалист проведет очищение организма‚ вводя лечебные растворы‚ которые нормализуют состояние организма и повышают общее самочувствие. Эффективность капельницы заключается в оперативном удалении токсинов и облегчении состояния. Помимо этого‚ уколы от запоя могут дополнительно помочь в стабилизации состояния. После процедуры начинается программа реабилитации‚ направленная на избежание повторных случаев. врач нарколог на дом
проверить провайдера по адресу
domashij-internet-krasnoyarsk004.ru
интернет по адресу дома
Наркология – это важная область медицины‚ ориентированная на лечение зависимостями. Если вы или ваши близкие переживаете проблемы зависимости от наркотиков‚ важно знать о возможностях анонимного лечения. Специализированные клиники, такие как narkolog-tula004.ru‚ предоставляют поддержку нарколога и всестороннюю поддержку для зависимых. Поддерживающие сообщества и программы восстановления оказывают помощь людям на этапе к выздоровлению. Психологическая помощь при зависимости занимает ключевую роль в восстановлении наркозависимых. Также существенна профилактика наркомании и экстренная поддержка. Не бойтесь обращаться за помощью — вы можете вернуться к нормальной жизни!
Как провести ремонт и улучшить свое жилье самостоятельно Когда дом нуждается в ремонте, помощь специалистов может оказаться очень кстати; На сайте narkolog-tula006.ru вы найдете множество домашних мастеров, готовых помочь с устранением неисправностей. Это может быть как мелкий ремонт, так и более серьезные сантехнические работы или электромонтажные услуги. Для самостоятельного ремонта существуют несколько ключевых рекомендаций. Первый шаг — это планирование: определите, какие именно работы нужно выполнить, и составьте детальную смету. Также не забывайте о безопасности при выполнении электромонтажных работ. Для декорирования вашего жилья обратитесь к домашним умельцам, которые предоставляют услуги по благоустройству. Эти специалисты смогут сделать ваш дом более уютным и привлекательным. Не забывайте, что качественный ремонт, это залог вашего комфорта и уюта!
провайдеры интернета по адресу красноярск
domashij-internet-krasnoyarsk005.ru
провайдер по адресу красноярск
Капельницы для лечения запоя в Туле: быстрая помощь Алкоголизм — серьезная проблема‚ требующая внимания и профессиональной помощи. В Туле наблюдается рост спроса на услуги нарколога на выезд. Специалисты-наркологи на дом в Туле предоставляют экстренные услуги‚ включая детоксикацию и помощь при запое.Капельницы являются одним из наиболее действенных способов борьбы с запоем. Данный метод снабжает организм важными веществами‚ что способствует быстрому очищению. Специализированная помощь нарколога включает в себя терапевтические процедуры‚ которые помогают справиться с физической зависимостью от спиртного. нарколог на дом тула Главное‚ не откладывать вызов нарколога на дом. Чем быстрее начнется лечение алкогольной зависимости‚ тем выше шансы на успешное восстановление. Нарколог на дом предоставляет возможность получить своевременную помощь без поездки в медицинское учреждение. Мы поможем вам справиться с зависимостью от алкоголя.
Капельница для лечения алкоголизма – это действующий способ‚ который оказать помощь в реабилитации после алкогольной зависимости в домашних условиях. Вызвав к наркологу‚ который приедет к вам‚ вы сможете получить квалифицированную помощь и необходимые медикаменты для облегчения симптомов похмелья. Признаки запойного состояния могут включать головной боли‚ недомогания и общего недомогания; вызвать нарколога на дом тула Этап очистки организма начинается с введения капельницы‚ что обеспечивает поступление жидкости и витаминов‚ что помогает снять симптомы абстиненции. Услуги нарколога в Туле включают персонализированный подход к пациенту‚ что важно для успешного лечения алкоголизма в домашних условиях. Поддержка близких при алкоголизме является важной составляющей в процессе восстановления здоровья после алкоголя. Домашняя реабилитация осуществляется с помощью препаратов и капельниц‚ что позволяет предотвратить новые запои и облегчить процесс восстановления. При этом профилактика запоев является ключевым моментом в борьбе с зависимостью.
הגיל כבר? טרנסג ‘ נדרים, איך אתה משדל בעלים למציצות? לנה וובה היו זוג נשוי כמעט מושלם שלנו, ” אני כאן, זה בסדר.” למה שלא נרקוד? – מציעה קטיה וקולה נשמע קל, אך עם צרידות קלה, The best escort girls show sexuality
провайдеры интернета по адресу красноярск
domashij-internet-krasnoyarsk006.ru
интернет по адресу красноярск
Наркологическая служба в Туле – это неотъемлемая часть борьбы с алкоголизмом и наркотической зависимостью. На сайте narkolog-tula006.ru можно получить доступных услугах, таких как вызов нарколога на дом при зависимости от алкоголя и различных видах наркозависимости. Наркологическая помощь включает консультации специалистов, стационарное лечение и программы реабилитации.Медицинская помощь направлена на восстановление психического здоровья и терапию зависимости. Не упустите шанс на выздоровление, свяжитесь с нами сегодня!
пансионат инсульт реабилитация
pansionat-msk001.ru
пансионат для лежачих пожилых
узнать интернет по адресу
domashij-internet-krasnodar004.ru
какие провайдеры по адресу
אירינה במגבת, על פי הטקס, שטפתי את פני במים מהאגן, ואפילו שתיתי ממנו. לשטוף את הרגליים מרשים, פחדה להתגלגל מהמגלשה הגבוהה. טיכון, שישב לצדה, תפס אותה בחזה הזה. למה היא הלכה למטה this article
кашпо для цветов напольное вазон [url=www.kashpo-napolnoe-spb.ru]www.kashpo-napolnoe-spb.ru[/url] .
пансионат для лежачих пожилых
pansionat-msk002.ru
пансионаты для инвалидов в москве
Обращение за помощью нарколога в Туле – ключевой шаг для тех‚ кто с трудностями зависимости. На сайте narkolog-tula007.ru вы имеете возможность получить квалифицированной помощью. Наркологическая помощь включает определение зависимости и конфиденциальное лечение. Если у вас возникли алкогольная или наркотическая зависимость‚ срочный вызов врача поможет избежать последствий. Центры реабилитации предлагают программы восстановления и поддержку семьи‚ что является важным для успешного лечения. Консультация нарколога – это первый этап на пути к исцелению. Не откладывайте‚ обратитесь за медицинской помощью уже сегодня!
провайдеры интернета в краснодаре по адресу проверить
domashij-internet-krasnodar005.ru
узнать интернет по адресу
пансионат для людей с деменцией в москве
pansionat-msk003.ru
пансионат инсульт реабилитация
какие провайдеры по адресу
[url=https://domashij-internet-krasnodar006.ru]domashij-internet-krasnodar006.ru[/url]
интернет провайдеры по адресу
пансионат для престарелых людей
pansionat-msk001.ru
пансионат для пожилых с деменцией
пансионат для лежачих больных
pansionat-tula001.ru
пансионат для пожилых
В столице России множество интернет-провайдеров, которые предлагают самые разные тарифы на интернет. Выбирая провайдера важно учитывать доступность сети и скорость интернета, чтобы обеспечить качественный интернет для дома или бизнеса. Сравнение провайдеров, можно выявить наилучшие предложения. К примеру, domashij-internet-msk004.ru предлагает детальные отзывы о провайдерах и их рейтинги. Это поможет вам сделать осознанный выбор. Не забудьте также обратить внимание на услуги связи, включая интернет-подключение и Wi-Fi для жилища. Стабильное соединение и доступ в интернет – важнейшие аспекты для комфортного использования. Не забывайте проверять актуальные тарифы на интернет и условия подключения.
пансионат инсульт реабилитация
pansionat-msk002.ru
пансионат для престарелых людей
пансионат для лежачих пожилых
pansionat-tula002.ru
пансионат с деменцией для пожилых в туле
Определение интернет-провайдера в Москве для игр — задача , которая не из простых. Множество игроков хотят к высокоскоростному интернету с низкой задержкой и надежным подключением. Операторы интернета по адресу в Москве имеют различные тарифы на интернет, включая оптоволоконный интернет , который является отличным вариантом для любителей игр. Анализ провайдеров поможет вам выбрать наиболее подходящий вариант. Обратите внимание отзывы о провайдерах, чтобы отобрать достойного оператора связи. Также стоит рассмотреть возможности использования VPN для игр, что может повысить качество соединения. Для игроков онлайн важно, чтобы интернет был стабильным и скоростным. Исследуйте предложения операторов, чтобы найти идеальный интернет в Москве для ваших потребностей.
частный пансионат для пожилых
pansionat-msk003.ru
частный дом престарелых
пансионат для людей с деменцией в туле
pansionat-tula003.ru
пансионат для пожилых
декоративный горшок напольный для цветов [url=http://kashpo-napolnoe-msk.ru/]http://kashpo-napolnoe-msk.ru/[/url] .
вывод из запоя челябинск
[url=https://vivod-iz-zapoya-chelyabinsk001.ru]https://vivod-iz-zapoya-chelyabinsk001.ru[/url]
вывод из запоя круглосуточно
пансионат инсульт реабилитация
pansionat-tula001.ru
пансионат для престарелых людей
провайдеры интернета нижний новгород
domashij-internet-nizhnij-novgorod004.ru
домашний интернет в нижнем новгороде
вывод из запоя круглосуточно
vivod-iz-zapoya-chelyabinsk002.ru
вывод из запоя
You deserve it all.I should not besorry to see you disgraced,lovedoll
пансионат для реабилитации после инсульта
pansionat-tula002.ru
пансионат для лежачих тула
провайдеры в нижнем новгороде по адресу проверить
domashij-internet-nizhnij-novgorod005.ru
провайдеры по адресу дома
экстренный вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk003.ru
экстренный вывод из запоя челябинск
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Ознакомиться с деталями – https://vyvod-iz-zapoya-1.ru/
Neil Island is a small, peaceful island in the Andaman and Nicobar Islands, India. It’s known for its beautiful beaches, clear blue water, and relaxed atmosphere: how to reach Neil Island
частные пансионаты для пожилых в туле
pansionat-tula003.ru
пансионат инсульт реабилитация
подключить интернет по адресу
domashij-internet-nizhnij-novgorod006.ru
провайдер по адресу нижний новгород
вывод из запоя череповец
vivod-iz-zapoya-cherepovec004.ru
вывод из запоя цена
лечение запоя челябинск
[url=https://vivod-iz-zapoya-chelyabinsk001.ru]https://vivod-iz-zapoya-chelyabinsk001.ru[/url]
экстренный вывод из запоя
При подборе интернета для большой семьи в новосибирске важно учитывать несколько аспектов. Во-первых‚ интернет-скорость должна быть высокой‚ чтобы все члены семьи могли в одно и то же время использовать интернет. Рекомендуется изучить семейные тарифы от интернет-провайдеров‚ которые предлагают неограниченный доступ к интернету и стабильное соединение. domashij-internet-novosibirsk004.ru Анализ провайдеров поможет выбрать лучший вариант‚ основываясь на отзывах пользователей. Домашние роутеры также играют важную роль‚ так как Wi-Fi для большой семьи должен охватывать все уголки квартиры. Не забывайте про IPTV для семьи‚ который может стать отличным источником развлечений. Выбирая тариф обращайте внимание на скидки для семей и акции. Подключение интернета должно быть быстрым и удобным‚ чтобы не терять время в ожидании. Сотовый интернет также может оказаться полезным в поездках. Услуги связи в новосибирске предлагают множество вариантов‚ так что принимайте обоснованные решения!
вывод из запоя череповец
vivod-iz-zapoya-cherepovec005.ru
вывод из запоя череповец
вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk002.ru
экстренный вывод из запоя
Установка фиксированного интернет-соединения в столице стало актуальной проблемой для многих жителей . Высокоскоростной интернет в новосибирске предлагает скорость , которая способна удовлетворить даже самых требовательных пользователей . Провайдеры новосибирска предлагают различные тарифы на доступ в сеть, включая в себя выгодные предложения с гигабитными скоростями. Гигабитный интернет в новосибирске При выборе провайдера необходимо обращать внимание на отзывы о провайдерах , так как надежность соединения и качество обслуживания – ключевые факторы . Многие компании предоставляют услуги подключения интернета по технологии FTTH, что обеспечивает высокую скорость и надежность . Анализ предложений провайдеров поможет выбрать наилучший вариант для вашего дома . Обратите внимание на наличие Wi-Fi роутеров в комплекте , а также на качество клиентской поддержки. Подбирайте оптимальный интернет для вашего дома и получайте удовольствие от стабильного соединения!
вывод из запоя череповец
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя круглосуточно череповец
купить напольное кашпо недорого высокие недорого [url=https://kashpo-napolnoe-rnd.ru]купить напольное кашпо недорого высокие недорого[/url] .
the oak is right,a thousand times right,ラブドール 中出し
Мобильный интернет в новосибирске: обзор операторов В столице России мобильный интернет стал неотъемлемой частью жизни. Основные операторы связи предлагают широкие тарифы на мобильный интернет, включая пакетные предложения и ограниченные опции. Рассмотрим главные факторы выбора провайдера. Скорость интернета – важный фактор. В новосибирске доступны технологии четвертого поколения и 5G, которые обеспечивают высокую скорость соединения. Операторы связи, такие как Мобилочка, Билайн, Мегафон и Теле 2, активно развивают зоны покрытия, предлагая своим клиентам стабильное качество связи. При выборе интернет-провайдеров в новосибирске по адресу необходимо обратить внимание на отзывы о провайдерах. Пользователи обращают внимание на различия в качестве связи и скорости интернета, что влияет на их выбор. интернет провайдеры в новосибирске по адресу Обзор тарифов на мобильный интернет помогает найти лучшие предложения. Многие операторы предлагают специальные предложения, которые могут включать дополнительные мобильные пакеты данных или привлекательные тарифы для новых пользователей.
экстренный вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk003.ru
вывод из запоя цена
лечение запоя
vivod-iz-zapoya-irkutsk001.ru
вывод из запоя цена
https://ernestz862lpr4.wikiparticularization.com/user
домашний интернет подключить омск
domashij-internet-omsk004.ru
подключить интернет омск
вывод из запоя череповец
vivod-iz-zapoya-cherepovec004.ru
экстренный вывод из запоя
цветочные горшки большие напольные пластиковые [url=kashpo-napolnoe-rnd.ru]цветочные горшки большие напольные пластиковые[/url] .
Студия дизайна Интерьеров в СПБ. Лучшие условия для заказа и реализации дизайн-проектов под ключ https://cr-design.ru/
вывод из запоя цена
vivod-iz-zapoya-irkutsk003.ru
лечение запоя
подключить интернет омск
domashij-internet-omsk005.ru
провайдеры интернета омск
вывод из запоя цена
vivod-iz-zapoya-cherepovec005.ru
вывод из запоя круглосуточно череповец
лечение запоя
vivod-iz-zapoya-kaluga004.ru
лечение запоя
подключить интернет в квартиру омск
domashij-internet-omsk006.ru
домашний интернет тарифы
лечение запоя
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя цена
вывод из запоя круглосуточно
vivod-iz-zapoya-kaluga005.ru
экстренный вывод из запоя калуга
тарифы интернет и телевидение пермь
domashij-internet-perm004.ru
лучший интернет провайдер пермь
экстренный вывод из запоя иркутск
vivod-iz-zapoya-irkutsk001.ru
вывод из запоя цена
вывод из запоя цена
vivod-iz-zapoya-kaluga006.ru
лечение запоя калуга
тарифы интернет и телевидение пермь
domashij-internet-perm005.ru
подключить интернет в квартиру пермь
лечение запоя
vivod-iz-zapoya-krasnodar001.ru
экстренный вывод из запоя краснодар
экстренный вывод из запоя
vivod-iz-zapoya-irkutsk002.ru
вывод из запоя
интернет тарифы пермь
domashij-internet-perm006.ru
домашний интернет тарифы пермь
вывод из запоя круглосуточно краснодар
vivod-iz-zapoya-krasnodar002.ru
вывод из запоя круглосуточно краснодар
лечение запоя
vivod-iz-zapoya-irkutsk003.ru
вывод из запоя
интернет домашний ростов
domashij-internet-rostov004.ru
дешевый интернет ростов
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar003.ru
лечение запоя
лечение запоя калуга
vivod-iz-zapoya-kaluga004.ru
вывод из запоя круглосуточно
подключить интернет
domashij-internet-rostov005.ru
подключение интернета ростов
Наш агрегатор – beautyplaces.pro собирает лучшие салоны красоты, СПА, центры ухода за телом и студии в одном месте. Тут легко найти подходящие услуги – от стрижки и маникюра до косметологии и массажа – с удобным поиском, подробными отзывами и актуальными акциями. Забронируйте визит за пару кликов https://beautyplaces.pro/
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar004.ru
вывод из запоя цена
напольные высокие горшки для цветов цены [url=http://kashpo-napolnoe-rnd.ru]http://kashpo-napolnoe-rnd.ru[/url] .
вывод из запоя круглосуточно калуга
vivod-iz-zapoya-kaluga005.ru
вывод из запоя
провайдеры интернета ростов
domashij-internet-rostov006.ru
домашний интернет в ростове
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar005.ru
экстренный вывод из запоя краснодар
вывод из запоя круглосуточно калуга
vivod-iz-zapoya-kaluga006.ru
вывод из запоя круглосуточно
провайдеры по адресу дома
domashij-internet-samara004.ru
какие провайдеры интернета есть по адресу самара
Наркология в Красноярске предлагает разнообразные услуги для людей‚ страдающих от различных зависимостей. Важно понимать‚ что преодоление зависимости — это сложный процесс. Первый этап — это встреча с наркологом‚ который выяснит степень зависимости и подберет наиболее подходящее лечение. В Красноярске функционируют кризисные центры‚ где можно получить конфиденциальную помощь специалистов. Психотерапевтические методы помогают в восстановлении. Семейная терапия способствует улучшению отношений и поддерживает пациента. Реабилитация наркоманов включает программы лечения алкоголизма и помощь с наркотиками. Важно знать о профилактических мерах и следовать рекомендациям специалистов. Восстановление после зависимости — это длительный процесс‚ требующий терпения и поддержки. Свяжитесь с клиникой зависимостей на vivod-iz-zapoya-krasnoyarsk001.ru для профессиональной помощи.
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Углубиться в тему – https://www.hotel-sugano.com/bbs/sugano.cgi/sosh13.pascal.ru/forum/datasphere.ru/club/user/12/blog/2477/www.tovery.net/sinopipefittings.com/e_Feedback/sinopipefittings.com/e_Feedback/www.hip-hop.ru/forum/id298234-worksale
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Изучить вопрос глубже – https://majesticvillas.gr/porto-katsiki-beach-in-lefkada
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Ознакомиться с деталями – https://latinloyalty.com/hello-world
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Изучить вопрос глубже – https://fisioterapia-alcala126.com/20-anos-centro-fisioterapia-alcala
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Ознакомиться с деталями – https://vistoweekly.com/mastering-rubranking-for-seo-success-in-digital-marketing
Профессиональная наркологическая клиника. Лечение зависимостей, капельницы, вывод из запоя, реабилитация. Анонимно, круглосуточно, с поддержкой врачей и психологов.
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Углубиться в тему – https://seikou-church.net/2024/06/02/%E7%A4%BC%E6%8B%9D%E3%81%AE%E9%96%8B%E5%A7%8B%E6%99%82%E9%96%93%E3%81%8C%E5%A4%89%E3%82%8F%E3%82%8A%E3%81%BE%E3%81%99
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Подробнее можно узнать тут – https://gioiosabergamo.it/home-default/play
какие провайдеры на адресе в самаре
domashij-internet-samara005.ru
интернет провайдеры самара по адресу
вывод из запоя краснодар
vivod-iz-zapoya-krasnodar001.ru
лечение запоя краснодар
Платная наркологическая помощь в Красноярске набирает популярность. Наркологические клиники, такие как наркологическая клиника Красноярск предлагают широкий спектр услуг: от детоксикации организма до реабилитации наркозависимых. Психотерапия и консультирование по зависимостям помогают пациентам понять психологию зависимости и находить пути к выздоровлению. Алкогольные реабилитационные центры предлагают конфиденциальное лечение и персонализированный подход к каждому клиенту. Квалифицированные специалисты в области наркологии, реабилитационные программы и медицинское сопровождение при лечении зависимостей играют ключевую роль в успешной реабилитации. Социальная адаптация после лечения имеет большое значение для снижения риска рецидивов. Дополнительные сведения доступны на сайте vivod-iz-zapoya-krasnoyarsk002.ru.
проверить провайдеров по адресу самара
domashij-internet-samara006.ru
интернет провайдеры по адресу
Наркологическая помощь становится актуальной в преодолении зависимостей. На сайте vivod-iz-zapoya-krasnoyarsk003.ru можно найти информация о программах реабилитации, включая индивидуальные подходы. Квалифицированные специалисты поддерживают в выявлении проблем с зависимостями и рекомендуют медицинскую помощь при алкоголизме и наркомании. Первичная консультация — это первый шаг к избавлению от зависимости после зависимости. Важны подходы к предотвращению рецидивов и семейная терапия для поддержки в процессе реабилитации. Забота со стороны семьи и врачей помогает преодолеть трудности на пути к здоровой жизни.
лечение запоя
vivod-iz-zapoya-krasnodar002.ru
вывод из запоя круглосуточно краснодар
подключение интернета по адресу
domashij-internet-spb004.ru
провайдеры интернета в санкт-петербурге
вывод из запоя круглосуточно минск
vivod-iz-zapoya-minsk001.ru
вывод из запоя минск
лечение запоя
vivod-iz-zapoya-krasnodar003.ru
экстренный вывод из запоя краснодар
какие провайдеры интернета есть по адресу санкт-петербург
domashij-internet-spb005.ru
проверить провайдера по адресу
вывод из запоя круглосуточно минск
vivod-iz-zapoya-minsk002.ru
лечение запоя
вывод из запоя цена
vivod-iz-zapoya-krasnodar004.ru
лечение запоя
недорогой интернет санкт-петербург
domashij-internet-spb006.ru
какие провайдеры на адресе в санкт-петербурге
лечение запоя минск
vivod-iz-zapoya-minsk003.ru
вывод из запоя
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Не пропусти важное – https://www.slovcar.sk/2022/11/13/stories-about-digital-marketing-2
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Все материалы собраны здесь – https://savaherbals.in/liver-detox
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Обратиться к источнику – https://steigensynergy.com/steigen-synergy-it-is-now-an-sap-partner
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Более подробно об этом – https://babi-beauty.fr/signature-styles-the-best-haircuts-at-our-barber-shop
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Заходи — там интересно – https://cheerleader-verein-dresden.de/portfolio/oxygen-club-national-meets-in-2000s
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Узнать напрямую – https://sepidsanat.com/%D9%86%D8%B5%D8%A8-%D8%B3%DB%8C%D9%86%DB%8C-%D9%87%D8%A7%DB%8C-%DA%A9%D8%A7%D8%A8%D9%84
лечение запоя краснодар
vivod-iz-zapoya-krasnodar005.ru
экстренный вывод из запоя краснодар
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Следуйте по ссылке – https://f5fashion.vn/top-voi-hon-67-ve-xe-lexus-lx570-hay-nhat
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Более того — здесь – http://www.all-hit.ru
экстренный вывод из запоя
vivod-iz-zapoya-omsk001.ru
вывод из запоя круглосуточно
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Узнать напрямую – https://almaxindustry.com/komatsu-pump-list
интернет по адресу дома
domashij-internet-ufa004.ru
интернет провайдеры в уфе по адресу дома
Специалист по наркологии — это медицинский работник, который предоставляет помощь людям, испытывающим проблемы от алкоголизма и наркомании. Процесс лечения включает в себя детоксикацию, медикаменты и психотерапию. Важно обратиться за консультацией нарколога для определения персонализированного подхода реабилитации. Семейная поддержка играет важную роль в процессе выздоровления, а группы взаимопомощи помогают интегрироваться в социальной среде. Профилактика зависимостей также имеют значение, чтобы снизить риск рецидивов. Обращение к профессионалам на vivod-iz-zapoya-krasnoyarsk001.ru гарантирует качественную медицинскую помощь и содействие на всех этапах лечения.
экстренный вывод из запоя омск
vivod-iz-zapoya-omsk002.ru
лечение запоя омск
интернет провайдеры в уфе по адресу дома
domashij-internet-ufa005.ru
интернет по адресу дома
Выездная наркологическая помощь – это неотъемлемая часть лечения зависимостей‚ который предоставляет экстренную помощь при алкоголизме и зависимости от наркотиков. Служба наркологической помощи на выезд предоставляет профессиональную помощь зависимым‚ включая детоксикацию и кризисную интервенцию. На сайте vivod-iz-zapoya-krasnoyarsk002.ru можно получить консультации по наркологии‚ ознакомиться с методами лечения наркомании и реабилитации на дому. Конфиденциальное лечение зависимых позволяет сохранить конфиденциальность. Важно также помнить о поддержке близких‚ что способствует в процессе восстановления. Программа восстановления после зависимости включает профилактику зависимостей и психотерапию‚ что способствует успешному возвращению к нормальной жизни.
лечение запоя
vivod-iz-zapoya-omsk003.ru
лечение запоя омск
провайдеры по адресу
domashij-internet-ufa006.ru
провайдеры интернета по адресу уфа
Капельница от запоя – это один из наиболее эффективных методов лечения алкогольной зависимости‚ который обеспечивает возможность комфортного и конфиденциального лечения. Нарколог на дом анонимно может быстро обеспечить необходимую медицинскую помощь при запое‚ используя метод капельницы для очищения организма. Преимущества капельницы заключаются в том‚ что она способствует быстрому снятию симптомов запоя‚ восстанавливает баланс жидкости и электролитов и способствует улучшению общего состояния пациента. Это особенно важно в случае тяжелых стадий алкоголизма‚ когда требуется срочное вмешательство.Существуют различные методы лечения алкоголизма‚ но капельница выделяется своей эффективностью и скоростью. В сравнении с таблетками и инъекциями‚ капельница гарантирует непрерывное введение медикаментов в организм‚ что способствует более быстрому восстановлению.Поддержка семьи и психотерапия при алкоголизме также играют важную роль в процессе реабилитации. По завершении этапа детоксикации важно продолжать лечение и заниматься профилактикой рецидивов‚ что возможно только при комплексном подходе. Таким образом‚ капельница при запое — это ключевой элемент в борьбе с алкоголизмом‚ предоставляя пациентам эффективное и конфиденциальное лечение с быстрым восстановлением.
вывод из запоя цена
vivod-iz-zapoya-orenburg001.ru
лечение запоя
подключить интернет в волгограде в квартире
domashij-internet-volgograd004.ru
домашний интернет тарифы омск
лечение запоя
vivod-iz-zapoya-minsk001.ru
экстренный вывод из запоя минск
вывод из запоя
vivod-iz-zapoya-orenburg002.ru
экстренный вывод из запоя
домашний интернет тарифы
domashij-internet-volgograd005.ru
интернет провайдеры омск
”You could see the superstitious crowd shrink and catch their breath,under the sudden shock.ロボット エロ
вывод из запоя цена
vivod-iz-zapoya-minsk002.ru
вывод из запоя
вывод из запоя
vivod-iz-zapoya-orenburg003.ru
вывод из запоя круглосуточно
подключить интернет в квартиру омск
domashij-internet-volgograd006.ru
интернет тарифы омск
экстренный вывод из запоя
vivod-iz-zapoya-minsk003.ru
вывод из запоя цена
вывод из запоя круглосуточно смоленск
vivod-iz-zapoya-smolensk004.ru
лечение запоя
провайдеры воронеж
domashij-internet-voronezh004.ru
подключить проводной интернет воронеж
вывод из запоя круглосуточно смоленск
vivod-iz-zapoya-smolensk005.ru
экстренный вывод из запоя смоленск
вывод из запоя цена
vivod-iz-zapoya-omsk001.ru
вывод из запоя
This winter has been passed most miserably,tortured as I have been by anxious suspense,ラブドール エロ
Du möchtest wissen, ob es möglich ist, im Online Casino Österreich legal zu spielen und welche Anbieter dafür infrage kommen? In diesem Artikel zeigen wir Spielern in Österreich, die sicher und verantwortungsbewusst online spielen möchten, Möglichkeiten ohne rechtliche Grauzonen zu betreten. Lies weiter, um die besten Tipps und rechtlichen Hintergründe zu entdecken: Online Casino
подключить интернет в квартиру воронеж
domashij-internet-voronezh005.ru
интернет домашний воронеж
лечение запоя
vivod-iz-zapoya-smolensk006.ru
экстренный вывод из запоя смоленск
вывод из запоя круглосуточно омск
vivod-iz-zapoya-omsk002.ru
вывод из запоя круглосуточно омск
провайдеры интернета в воронеже
domashij-internet-voronezh006.ru
интернет тарифы воронеж
Капельницы для восстановления после алкогольной зависимости в Туле: ключ к выздоровлению Лечение алкоголизма начинается с профессиональной консультации врача. В Туле есть специализированные учреждения, где предлагается наркологическая помощь и капельницы для восстановления. Эти процедуры помогают избавиться от токсинов и восстанавливают водно-электролитный баланс организма. вывод из запоя Поддержка пациента и контроль его состояния, важные аспекты терапии. Комплексная реабилитация после запоя учитывает как физическое, так и психическое состояние пациента. Помните, что правильное восстановление, залог успешного лечения и возвращения к нормальной жизни.
лечение запоя омск
vivod-iz-zapoya-omsk003.ru
экстренный вывод из запоя омск
подключить проводной интернет челябинск
domashij-internet-chelyabinsk004.ru
домашний интернет тарифы
sex dolls a weazel.What were you about saying,
Капельница от запоя – это значимый метод помощи алкоголизма, который находит свое применение в лечебных учреждениях Тулы. Метод детоксикации способствует быстрому реабилитации организма после продолжительного потребления алкоголя. Длительность капельницы обычно варьируется от одного до трех часов, в зависимости от особенностей пациента и интенсивности запойного состояния. лечение запоя тула Признаки запоя включает в себя интенсивные головные боли, тошноту, потливость и тревожные состояния. Медицинская помощь в виде капельницы даёт возможность быстро облегчить похмельные симптомы, вводя жизненно важные вещества для нормализации водно-электролитного баланса и устранения токсинов. Цены на лечение запоя в Туле варьируется в зависимости от обраной лечебной организации и количества требуемых процедур. Консультация нарколога поможет определить наилучший курс лечения, включая восстановление после запоя. Эффективность капельницы доказывается многими положительными отзывами пациентов, что делает ее востребованным способом борьбы с алкогольной зависимостью.
вывод из запоя круглосуточно оренбург
vivod-iz-zapoya-orenburg001.ru
экстренный вывод из запоя
подключение интернета челябинск
domashij-internet-chelyabinsk005.ru
домашний интернет тарифы челябинск
Алкогольный запой, серьезное состояние‚ требующее вмешательства специалистов; Ложное мнение, что можно справиться с запоем самостоятельно‚ как минимум, рискован и может иметь серьезные последствия. В Туле алкогольная зависимость — это проблема для многих, и услуги нарколога на дому играют важную роль в решении этой проблемы. Вызвать нарколога на дом в Туле Симптомы запойного состояния включают дрожь, потливость, волнение. Самостоятельный вывод может вызвать серьезные проблемы со здоровьем‚ включая психические расстройства. Помощь нарколога важна для грамотного выхода из запойного состояния и возвращения к нормальной жизни. Кроме того‚ реабилитация от алкоголя требует поддержки семьи и квалифицированных специалистов. Вызвав нарколога на дом в Туле‚ вы получите квалифицированную помощь‚ избежите рисков, связанных с самостоятельным выходом и начнете путь к выздоровлению. Не ставьте под угрозу свое здоровье‚ обращайтесь за помощью!
https://www.glicol.ru/
лечение запоя
vivod-iz-zapoya-orenburg002.ru
вывод из запоя цена
подключить интернет в квартиру челябинск
domashij-internet-chelyabinsk006.ru
подключить интернет в челябинске в квартире
Зависимость от наркотиков и алкоголя требует квалифицированного подхода. Наркологическая помощь состоит из диагностики и лечения зависимостейчто способно кардинально изменить жизнь человека. Консультация нарколога. Лечение алкоголизма и реабилитация наркоманов проводятся в специализированных центрах, таких как vivod-iz-zapoya-vladimir004.ru. Реабилитационные программы предполагают психотерапию при зависимости и группы поддержки, а также семейную поддержку. Необходимо учитывать мотивацию к лечению и профилактике зависимостей. Социальная адаптация после лечения помогает предотвратить рецидивы. Анонимная помощь наркозависимым доступна и эффективна. Начните новый этап своей жизни с помощью профессионалов!
экстренный вывод из запоя оренбург
vivod-iz-zapoya-orenburg003.ru
вывод из запоя круглосуточно
Современные методы лечения алкоголизма в владимире Алкоголизм, это серьезная проблема, которая требует квалифицированного вмешательства. владимир предлагает широкий спектр наркологических услуг, включая возможность вызвать нарколога на дом для конфиденциального лечения. Современные технологии лечения включают медикаментозную терапию и детоксикацию организма. Психотерапия при алкоголизме помогает разобраться с психологическими аспектами зависимости. Реабилитация людей с зависимостями осуществляется в специализированных центрах, где семья играет ключевую роль в процессе восстановления. Программа восстановления включает профилактику алкогольной зависимости и лечение запойного состояния, что позволяет добиться устойчивых результатов. заказать нарколога на дом
Накрутка живых подписчиков в ТГ
экстренный вывод из запоя
vivod-iz-zapoya-smolensk004.ru
вывод из запоя круглосуточно смоленск
Лечение запоя капельницей на дому – эффективный способ вывода из запоя круглосуточно. В городе владимир предлагается детоксикацию организма и восстановление здоровья. Домашнее лечение обеспечивает пациентам доступ к наркологическим услугам без лишнего стресса. Эти капельницы устраняют симптомы отменыподдерживая организм в процессе восстановления. круглосуточный вывод из запоя Однако, важно сочетать этот метод с психотерапией и альтернативными методами лечения. Поддержка семьи играет ключевую роль в реабилитации и борьбе с алкогольной зависимостью. Круглосуточная медицинская помощь гарантирует доступ к необходимым ресурсам для полноценного восстановления.
установка спирали мирена https://spiral-mirena1.ru
Важно учитывать скорость интернета и надежность соединения при подключении к интернету. Интернет провайдеры в Екатеринбурге представляют разнообразные тарифы на интернеткоторые различаются по стоимости и качеству связи. domashij-internet-ekaterinburg004.ru Технологии IoT требуют надежного и высокоскоростного Wi-Fi для умных устройств. Рекомендуется изучить отзывы о провайдерах, чтобы определить наиболее подходящего поставщика. Безопасность сети также играет ключевым аспектом, так как IoT-устройства требуют защищенного доступа к интернету. Оцените доступности интернета и качества связичтобы обеспечить бесперебойную работу вашего умной системы.
вывод из запоя
vivod-iz-zapoya-smolensk005.ru
вывод из запоя круглосуточно
лечение запоя
narkolog-krasnodar001.ru
вывод из запоя круглосуточно