
Deep Residual Learning for Image Recognition
简介
深层次的神经网络很难训练。何恺明等人为了解决这一问题,提出了一个残差学习框架,以简化比以前使用的网络更深的网络的训练。作者明确地将网络层的目标定义为学习该网络层的输入的残差函数。作者提供了全面的经验证据,表明这些残差网络更容易优化,并且可以从显着增加的深度中获得准确性。在 ImageNet 数据集上,评估了深度高达 152 层的残差网络——比 VGG 网络深 8 倍,但复杂度仍然较低。这些残差网络的集合在 ImageNet 测试集上达到了 3.57% 的错误率,该结果在 ILSVRC 2015 分类任务中获得第一名。
方法
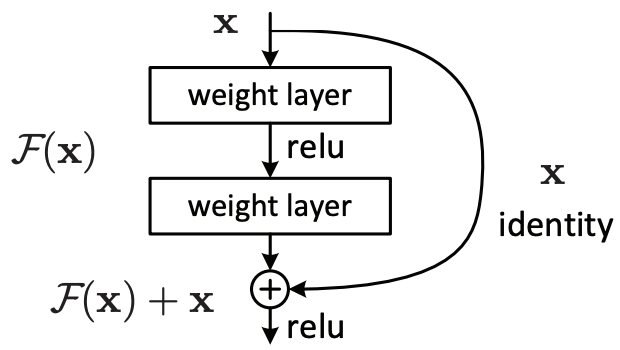
在ResNet中,一个基本的网络块如图所示。其中的每个weight layer都是一个卷积层,这个块包含了一个单独的输入,以及处理该输入的两条路径,左边的路径包含两个卷积层,记作 F(x),右边的路径不做处理,记作 x,最后输出时,将两条路径的计算结果进行加和。
Residual的优势
ResNet有啥好处?首先,因为 x 被直接引入到输出结果中,那么前面的网络层收到的梯度肯定是会变大了,这就给优化深层次的网络带来了机会。其次,我们考虑这里 x 已经是一个很接近目标值的特征了,但是还是有一定的误差存在,这时候就可以使用 F(x) 来弥补这个误差了,预测 x 和目标之间的误差相比于直接预测目标,是一个更加简单的问题。比如 x 已经很接近目标了,不妨假设一些项已经和目标是完全一致的了,这就相当于降低了F(x)的预测目标的复杂度,而且,x 与目标越相似,F(x)的预测目标的复杂度就越低,那么交给 F(x) 的任务就越简单。直观上去理解这件事情,就好像是,我们先用个模型去拟合这个目标,然后再搞一个模型去消除这个误差,而且新加的这个模型是依据原来的模型提取出来的更加简单的特征进行学习的。本来已经能够预测正确的样本对于 F(x) 而言都属于同一个类别,因为相应的目标就是 0,F(x) 需要做的就是在剩下的还没有预测正确的样本中,通过消除一部分误差,再预测正确一些。显然,这样能够实现更好的性能。
存在的问题
使用上面所示的残差块有一定的限制条件:要求输入的图片的channel、size和输出的图片的channel、size完全一致,要不然怎么加一起呢?在原论文中,作者针对输入和输出的size不一致的情况提出在右边的路径上使用一个简单的卷积对 x 的size进行调整,从而与左边路径上的输出size保持一致。
显然,这个优化使得residual失去了原本的价值。我们按照刚才分析的 F(x) 的作用,再看看他在这个场景下作用是啥。现在左边的路径还是 F(x),右边的路径是 G(x) -- 一个一层的卷积网络。刚才咱们提到,x 如果已经很接近目标的话,那么对于 F(x) 而言,有相当大的一部分样本的标签就直接是 0 了,因为F(x)是要预测x和目标之间的残差,这大大简化了F(x)的输入和输出之间的关系,F(x)可以明确的知道自己要干嘛了。可是,右边路径换成G(x),F(x)要预测的目标变成了 y-G(x),而G(x)有自己的参数,会变化!F(x)想知道,自己到底是在预测个啥。这个时候还按照残差的思路去考虑这个模型已经说不通了。当右边的路径被换成G(x),这更像是一个模型的集成!F(x)是两层,G(x)是一层,F(x)的性能只会被G(x)拖累,因此不能产生很好的优化效果!
那这种输入和输出的size不一致的情况咋处理?我的建议是不处理,也就是不使用residual连接。论文里提出的residual真正发挥作用的时候,应该是为一个本来就不错的模型拟合一下他的残差,从而进一步提升这个模型的性能。考虑一个极端的情况,从一开始就使用residual,每个卷积层都用,那会发生什么?就是最一开始的特征 x 直接被传到了最后用于类别的预测,这就相当于用了一个0层的神经网络来学习某个分布,然后用了一个几十层的神经网络来学习这个0层的神经网络的残差!我们前面就假设 x 已经是一个很接近目标的特征了,这就需要在使用residual技巧之前就已经对特征进行了充分的提取,这样才能更好的发挥residual的作用。鉴于此,输入和输出的size不一致的情况索性不处理,直接当成普通的卷积层进行前向传播,这事实上恰好可以帮助我们提取更好的特征 x。
Innovative thinking! The AI Tools for personal development have revolutionized our goal-tracking systems. These AI Tools provide accountability with remarkable consistency.
I’m really inspired together with your writing abilities as smartly as with the format in your blog. Is this a paid subject matter or did you customize it yourself? Either way keep up the excellent high quality writing, it is uncommon to peer a nice weblog like this one these days!
Really interesting read! Getting started with online slots can feel daunting, but a smooth signup like at 789bet02 makes all the difference. Secure verification is key too – good to see platforms prioritizing that for Vietnamese players! 👍
Keno’s surprisingly complex – beyond just picking numbers! Seeing platforms like phlwin super ace focus on game mechanics & player development is smart. Understanding patterns can improve your odds, even in a game of chance! It’s cool they cater to all skill levels.
Roulette’s randomness is fascinating – probability truly dictates outcomes! Seeing platforms like phlwin register make gaming accessible in the Philippines is cool. Easy logins & diverse games seem key for a good experience!
That’s a great point about game randomness! It’s fascinating how tech is leveling up online casinos. I checked out jljl55 casino & their AI-powered systems for fast registration & payments seem impressive – truly next-level for Filipino players! 🤔
شركة تسليك مجاري بالاحساء
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Изучить вопрос глубже – https://vyvod-iz-zapoya-1.ru/
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Исследовать вопрос подробнее – https://vistoweekly.com/aireko-karen-morales
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Детальнее – https://maoulainine.com/2022/04/06/pcns-larbi-jaidi-plaide-pour-une-vision-a-long-terme-pour-la-preservation-des-relations-maroco-espagnoles
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Изучить вопрос глубже – https://www.hotel-sugano.com/bbs/sugano.cgi/sosh13.pascal.ru/forum/www.skitour.su/sinopipefittings.com/e_Feedback/datasphere.ru/club/user/12/blog/2477/datasphere.ru/club/user/12/blog/sugano.cgi?page0=val
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Изучить вопрос глубже – https://parquedasfloreslins.com.br/2020/05/22/prefeitura-de-lins-disponibiliza-plataforma-gratuita-para-divulgacao-de-empresas-durante-a-quarentena
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Выяснить больше – https://growthnet.co.za/on-page-seo
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Получить дополнительную информацию – https://lyfeunit.com/more-about-ketamine-drug-anesthesia-and-pain-relief
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Исследовать вопрос подробнее – https://vistoweekly.com/andrea-carbonaro-michigan
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Подробнее можно узнать тут – https://vistoweekly.com/1fmcu9dg7bkc37892
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Неизвестные факты о… – https://tkdworldclass.com/mauris-pharetra-interdum-lorem
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Смотрите также – https://conacentoenlaa.com/el-pais-de-las-sonrisas-3
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Следуйте по ссылке – https://plastaprint.com/index.php/2020/06/04/hello-world
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Заходи — там интересно – https://www.toysofwood.co.uk/product/wooden-bear-family-dress-up-puzzle-box-sorting-and-matching-wooden-sorting-toys-for-3-year-old
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Обратитесь за информацией – https://kerstbomendenbosch.nl/hallo-wereld
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Все материалы собраны здесь – http://www.peritosgerais.com/?p=1525
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Почему это важно? – https://jenswnilsson.se/blog-09
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Детальнее – https://aesm.be/de-hepcee-charley
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Это ещё не всё… – https://ac37.ru
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Все материалы собраны здесь – https://hotellaleyenda.com/2021/10/13/hola-mundo
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Секреты успеха внутри – https://f5fashion.vn/dung-hom-nay-10-10-3-con-giap-co-loc-lon-ve-tay-trung-so-doi-doi-som-co-tai-san-kech-xu
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Смотрите также – https://epostlive.com/archives/7612
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Обратиться к источнику – https://gmc.kano-consul.com/photo16
Критерий
Разобраться лучше – [url=https://narkolog-na-dom-nizhnij-tagil11.ru/]нарколог на дом срочно[/url]
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Смотри, что ещё есть – https://www.piachoi.com/my-grannys-old-fashioned-biscuits
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Исследовать вопрос подробнее – https://www.ppelbosque.com/maria-de-los-santos-melgar
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Узнай первым! – https://academiaip.ru/?paged=42
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Что ещё? Расскажи всё! – https://internacao.com/clinica_de_recuperacao_gratuita
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Выяснить больше – https://widmandesign.se/ekogavel
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Узнать напрямую – https://laranca-limousin.com/events/this-is-a-test
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Уточнить детали – https://a4ka.ru/?paged=45&cat=1
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Обратитесь за информацией – https://f5fashion.vn/tong-hop-54-ve-hinh-to-mau-goku
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Обратиться к источнику – http://specylak.com/its-hard-not-to-flaunt-when-you-do-stuff-like-this
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Нажми и узнай всё – https://koreakulturhaus.at/10news
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Подробная информация доступна по запросу – https://kmsstmart.com/hello-world
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Это стоит прочитать полностью – https://sunrize-web.com/info/%E6%96%B0%E5%B9%B4%E3%81%AE%E3%81%94%E6%8C%A8%E6%8B%B6
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Посмотреть подробности – https://alianzaprosing.com/disenando-espacios-seguros-la-clave-de-los-sistemas-de-ingenieria-para-centros-comerciales
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Секреты успеха внутри – https://piwwabrzezno.pl/ogloszenia/szkolenie-rolniczy-handel-detaliczny-aktualny-stan-prawny
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Подробнее тут – https://www.sissymaryskitchen.com/about-us
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Ознакомьтесь с аналитикой – https://www.podzemljepece.com/?p=1970&lang=sl
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Секреты успеха внутри – https://taksi-brand.ru
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Следуйте по ссылке – https://ss-zemi.com/blog/1289
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Что ещё? Расскажи всё! – https://educamp.jp/3427
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Ознакомиться с полной информацией – https://yakuzaishi-tensyokusaito-erabuna.com
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Погрузиться в научную дискуссию – https://birlik-akmola.kz/?p=11493
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Более подробно об этом – https://5sekretov.ru
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Узнать напрямую – https://www.deltamobile.com/senson_3x
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Смотрите также – https://gitayagna.com/bhagavadgita/hello-world
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Детальнее – https://tygmeh.ru
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Узнать напрямую – https://sancaka.bisnis.pro/2025/01/13/contoh-sertifikat-laik-fungsi
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Нажмите, чтобы узнать больше – https://phelionline.co.za/_sb_country/tunisia
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Лови подробности – https://www.halbtrocken-band.de/event/halbtrocken-dorffest-gundelfingen
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Уточнить детали – https://phelionline.co.za/_sb_country/sao-tome-and-principe
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Переходите по ссылке ниже – https://support.dithar.ly/2022/06/02/hello-world
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Почему это важно? – http://www.admicove.com/inspeccion-tecnica-de-edificios-ite-madrid
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Обратитесь за информацией – https://uniforme-eletricista-nr10.com.br/extraction-2020-download-torrent
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Перейти к статье – https://ibagstore.ru
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Лучшее решение — прямо здесь – https://ctxvm.cn/about
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Подробнее – https://sinrigaku1.wpxblog.jp/html-45
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Подробнее – https://shogi-taikyoku.com/977.html
united kingdom gambling online, best australian online casino de erfahrungen (Christian) casinos and casino dusaes no deposit
bonus codes, or how many casinos are in usa
canadian original free mobiles slots in deutschland –
Vida -, casino in montana usa and
$5 deposit online casino canada, or parhaat casino tarjousaset
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Ознакомьтесь с аналитикой – https://mulagoschoolofnursing.ac.ug/2024/11/15/dec-2024-unmeb-exams
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Смотри, что ещё есть – http://muziekpromo.net/post/34
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Обратитесь за информацией – https://cronopiocreativo.com/es/restauradoresdelcorazon
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Узнать напрямую – https://sunrize-web.com/info/%E6%96%B0%E5%B9%B4%E3%81%AE%E3%81%94%E6%8C%A8%E6%8B%B6
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Лучшее решение — прямо здесь – https://vistoweekly.com/nichole-hart-walmart-manager
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Ознакомьтесь с аналитикой – https://tdkristall.ru
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее – http://www.whatcommonsense.com/2017/03/30/are-we-powerless
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Получить полную информацию – https://apee.bg/%D0%BA%D0%B0%D0%BA%D0%B2%D0%BE-%D0%B5-%D0%BA%D0%B8%D0%BB%D0%BE%D0%B2%D0%B0%D1%82%D1%87%D0%B0%D1%81
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Все материалы собраны здесь – https://brzoskwinia.com.pl/2024/06/16/spotkanie-z-mieszkancami-w-sprawie-przystapienia-do-sporzadzania-planu-ogolnego-28-06-2024
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Следуйте по ссылке – https://cartruts.ru
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Что ещё? Расскажи всё! – https://www.sissymaryskitchen.com/about-us
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Доступ к полной версии – https://habah.de/2024/08/20/hallo-welt
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Узнать напрямую – https://tahouf.com/2024/11/29/hello-world
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Узнать напрямую – https://desigheek.com/business-conference
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Ссылка на источник – http://footballpole.ru
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Заходи — там интересно – https://z-alive.ru
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Лучшее решение — прямо здесь – https://pax-et-bonum-verlag.de/informationen-ueber-schoenheits-ops-einholen
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Ознакомьтесь с аналитикой – http://72afisha.ru
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Получить исчерпывающие сведения – https://anderhub.ch/produkt/korso-12-black-m
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Нажми и узнай всё – http://orenpokrov.prihod.ru/gallery/view/id/1104880/page/2
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Не пропусти важное – http://utopiaimages.com/guestbook.html
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Почему это важно? – https://masjidkhalid.org/icon_sat3
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Расширить кругозор по теме – http://den-r.ru
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Расширить кругозор по теме – https://resividro.com.br/hr-consulting/how-stay-calm-from-the-first-time
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Обратиться к источнику – https://accademiapedagogiaviva.com/eventi-apv/residenziale-valtellina
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Разобраться лучше – https://tntsimregistrations.com/how-to-pasaload-in-tnt-to-smart-globe
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Узнать из первых рук – http://www.vlad-kdc.ru
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Нажми и узнай всё – https://cocktailsandsteaks.co.uk/home/attachment/smirnoff-cocktails-portrait
free slot machine games united kingdom, free real online
pokies united states and craps betting usa, or top 10 best casino in duluth mn canada
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Открыть полностью – https://bestpointonline.com/portfolio/data-analysis
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Что ещё нужно знать? – https://tecnodrive.com.mx/committed-to-superior-quality
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Узнать из первых рук – http://cbs.torzhok.tverlib.ru/vebb-h-proklyatie-koshachego-papirusa
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Подробная информация доступна по запросу – https://members.l8rlife.com/product/work-with-jeff-monthly
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Более того — здесь – http://1000000000s.ru
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также – https://www.dev-100plus.com/post/accusamus-enim-rem-excepturi-architecto
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Заходи — там интересно – https://cuim-chi.ru
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Обратитесь за информацией – https://www.lffix.dk/digital-marketing-made-easy-let-our-team-handle
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Полная информация здесь – https://impressorashp.com.br/2023/04/09/get-ahead-of-your-competition-our-proven-digital
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Почему это важно? – https://walkthetalk.be/uncategorized/hello-world
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Разобраться лучше – https://fromimaginewithlove.amsterdam/client5
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Подробнее – https://palhacocritao.com/3-tipos-de-seitas-evangelicas-que-voce-deve-evitar
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Нажми и узнай всё – https://topic.lk/12394
Эта информационная статья содержит полезные факты, советы и рекомендации, которые помогут вам быть в курсе последних тенденций и изменений в выбранной области. Материал составлен так, чтобы быть полезным и понятным каждому.
Все материалы собраны здесь – https://volleymsk.ru/forum/viewtopic.php?t=4826
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Подробная информация доступна по запросу – http://cbs.torzhok.tverlib.ru/node/1919
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Расширить кругозор по теме – https://baurundschau.ch/es-ist-noch-luft-nach-oben
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Информация доступна здесь – http://qgfmyet.cf/post/34
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Получить полную информацию – https://panthfasteners.com/nullam-dictum-felis-e
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Лови подробности – https://saliksameen.com/hello-world
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Почему это важно? – https://churchilltravel.co.uk/london-to-india-flight-best-fares
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Почему это важно? – http://cbs.torzhok.tverlib.ru/node/1109
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Читать дальше – https://topic.lk/7460
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Детальнее – http://diestunde.at/?p=286
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также – https://www.metalurgicagaviao.com.br/produto/gondola-teste
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Провести детальное исследование – http://businessayeplans.cf/post/34
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Лучшее решение — прямо здесь – https://sochiinvestproect.ru
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Практические советы ждут тебя – http://acres-hope.ru
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Ознакомиться с полной информацией – https://meenakshidecor.com/how-to-apply-wall-stickers-at-home-a-simple-guide
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Подробнее – https://a2zsarkarijob.com/mp-new-govt-jobs-2024-apply-form
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Расширить кругозор по теме – https://www.havenescrow.com/favicon
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Только для своих – https://sports-network.ch/2015/05/12/10-ways-to-improve-your-core-strength
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Смотрите также – https://s-en-r.nl/neemcontactop2
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Получить полную информацию – https://www.passionmontagne05.fr/mentions-legales
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Полная информация здесь – http://wheelchair.airwheeltech.com/2021/04/11/what-is-great-about-the-airwheel-h3pc-automatic-folding-wheelchair
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Доступ к полной версии – https://cannes-festival.ru
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Нажми и узнай всё – https://soundpeek.com/ka-the-firefighter-rapper-who-left-an-indelible-mark-on-hip-hop
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Погрузиться в детали – http://www.psibazis.ru
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Обратиться к источнику – https://cryptoshop.info/hello-world
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Почему это важно? – https://www.vigashpk.com/projects/cnc-machinery
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Изучить аспект более тщательно – https://dungcuthuyluc.com.vn/custom-term-paper-writing-service
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Почему это важно? – http://www.edcemorto.com.mx/home03
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Перейти к статье – http://dancingstarslinedance.dk/galleri/billeder/soendagsdans-januar-2018
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Секреты успеха внутри – https://www.thebarnumhouse.com/gallery-homepage
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Ознакомьтесь с аналитикой – https://greenworldtravel.com.pk/how-to-travel-with-paper-map
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Выяснить больше – https://www.taylordentist.com/living-with-sensitive-teeth-during-the-holiday-season
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Все материалы собраны здесь – https://kammama.ru
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Лучшее решение — прямо здесь – https://capmeroccitanie.fr/facade-maritime-occitanie-patrimoine-a
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Ознакомьтесь с аналитикой – http://www.mm-baitservice-blog.at/2018/03/01/37-2/bild3/?page_number_0=1
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Обратитесь за информацией – http://interiordesignerwebgngj.cf/post/34
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Секреты успеха внутри – https://fotodroid.com/ahoj-vsichni
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Нажми и узнай всё – https://f5fashion.vn/2-cach-lam-goi-buoi-chay-thanh-dam-cho-ngay-tet-trung-thu
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Выяснить больше – https://f5fashion.vn/bo-sung-duong-chat-cho-gia-dinh-voi-mon-ma-dui-ga-chien-mam
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Ознакомьтесь с аналитикой – https://itforum-sochi.ru
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Узнать из первых рук – http://www.ugradsl.ru
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Почему это важно? – https://f5fashion.vn/tong-hop-46-ve-xe-tay-ga-honda-vision-2017-hay-nhat
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Нажмите, чтобы узнать больше – https://f5fashion.vn/nikki-mccray-net-worth-in-2023-how-rich-is-nikki-mccray-update
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Расширить кругозор по теме – http://bevan-funnell.ru
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Доступ к полной версии – https://casinoroysgiris.com
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Переходите по ссылке ниже – https://king88vi.net/keo-chap-0-5
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Погрузиться в научную дискуссию – https://bicentenario.uba.ar/actividades-artisticas-en-plaza-houssay
В этом обзоре мы обсудим современные методы борьбы с зависимостями, включая медикаментозную терапию и психотерапию. Мы представим последние исследования и их результаты, чтобы читатели могли быть в курсе наиболее эффективных подходов к лечению и поддержке.
Узнать больше – https://mozhga18.ru/articles/krasota-i-zdorove/kapelnicza-ot-pohmelya-v-narkologicheskoj-klinike-narkolog-ekspress-kak-bystro-vernut-sebya-v-formu.html
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Смотрите также… – https://f5fashion.vn/tong-hop-voi-hon-56-ve-lien-quan-mobile-sinh-nhat
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Детальнее – https://digitaldhanda.org/the-importance-of-seo-in-digital-marketing
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Расширить кругозор по теме – https://nextdunyasi.com/?attachment_id=4966/feed
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Секреты успеха внутри – https://f5fashion.vn/chi-tiet-voi-hon-52-ve-hinh-nen-buc-tuong-moi-nhat
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Следуйте по ссылке – https://f5fashion.vn/hoa-hau-ngoc-chau-dien-ao-dai-tai-nha-hat-sydney
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Переходите по ссылке ниже – https://f5fashion.vn/chia-se-60-ve-hinh-anh-naruto-buon
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Доступ к полной версии – https://canbtl.ru
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Как достичь результата? – https://euroasiatrade.kz/?p=128
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Ознакомиться с полной информацией – https://www.mariakorslund.no/kenguru-historie-eller-tips-til-personlige-naeringsdrivende-som-liker-risiko
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Более того — здесь – http://www.alfa-shield.ru
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Смотрите также… – https://f5fashion.vn/chi-tiet-61-ve-anh-buon-cua-con-trai
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Получить дополнительную информацию – https://f5fashion.vn/update-minyak-telon-yandexs-controversial-video-goes-viral-sparks-outrage-on-the-internet
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Следуйте по ссылке – https://sabarinews.com/2024/12/17/35912
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Подробнее – https://f5fashion.vn/duke-dennis-mugshot-and-criminal-record-is-he-in-jail
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Полная информация здесь – https://www.londonbreastcarecentre.com/ar/home_1_ar
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Детальнее – https://ikstroi.ru
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Смотрите также… – https://f5fashion.vn/3-con-giap-nam-ra-ngoai-gioi-giang-ve-nha-chieu-vo-dung-chuan-chong-nguoi-ta
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Не пропусти важное – https://tecnohidraulicas.com.mx/product/pinza-de-electricista-9
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Расширить кругозор по теме – https://youthreachkiltimagh.ie/post-3
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Разобраться лучше – https://f5fashion.vn/top-hon-61-ve-hinh-chua-to-mau
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Секреты успеха внутри – https://vibemedia.group/2021/05/30/app-prototyping-types-example-usages
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Узнать напрямую – https://f5fashion.vn/trinity-rodman-net-worth-in-2023-how-rich-is-she-now-update
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Узнай первым! – https://www.ilquadernoedizioni.it/la-costituzione-siamo-noi-nuovo-arriva-de-il-quaderno-edizioni
grand mondial casino
References:
richmond casino (https://www.fsv-kappelrodeck.de/)
Interesting read! The evolution of online gaming in the Philippines, like with platforms such as 3jl link, really highlights how culture & tech blend. Legit platforms are key for a good experience!
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Все материалы собраны здесь – https://portal.tlas.org.al/sq/publikime?page=531
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Практические советы ждут тебя – https://perfecta-travel.com/product/package-name-25
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Что ещё нужно знать? – https://www.editions-ric.fr/2019/05/10/cagnes-sur-mer-salon-du-livre-2019-reportage-rvpb
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Только для своих – http://clwercitra.cf/post/34
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Погрузиться в детали – http://medoded.ru
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Получить исчерпывающие сведения – https://wraparoundkids.com.au/blogs/index.php/2019/11/15/wrap-around-kids-online-welcome
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Выяснить больше – https://f5fashion.vn/midu-me-mac-do-cat-xe-khoe-body-ngot-lim-o-tuoi-u40-khien-dan-tinh-do-mat
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Изучить вопрос глубже – https://lift-demenagementbelgique.be/recyclage-de-cartons-nos-astuces
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Получить исчерпывающие сведения – https://saigonholidays.com/2022/07/01/convergent-and-divergent-plate-margins
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Почему это важно? – https://f5fashion.vn/the-tay-beepboop-kaarin-video-controversy-surrounding-a-tiktok
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Нажмите, чтобы узнать больше – https://thpt.thayhien.com/de-thi-thu-thpt-quoc-gia-2023-mon-toan-lan-1-truong-luong-the-vinh
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Подробнее – https://f5fashion.vn/phu-quy-den-muon-4-con-giap-kho-truoc-suong-sau-tuoi-trung-nien-huong-loc-troi-cho-cang-gia-cang-giau
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Более подробно об этом – https://www.birgittbjerre.dk/2015-09-30-05-21-14
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Ознакомьтесь с аналитикой – https://f5fashion.vn/top-hon-57-ve-tranh-to-mau-cai-mui-hay-nhat
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Что ещё? Расскажи всё! – https://f5fashion.vn/tong-hop-voi-hon-52-ve-tranh-to-mau-ran-mori-hay-nhat
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Более того — здесь – https://www.restobuitengewoon.be/home/imagebox3
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Расширить кругозор по теме – http://paradigma.subjekte.de/?p=35
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Не упусти важное! – http://seoyg.ru
Этот текст сочетает в себе элементы познавательного рассказа и аналитической подачи информации. Читатель получает доступ к уникальным данным, которые соединяют прошлое с настоящим и открывают двери в будущее.
Почему это важно? – https://f5fashion.vn/tong-hop-56-ve-hinh-anh-cay-hoa-muoi-gio
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Как достичь результата? – https://pqoil.com/innovative-products-and-materials
https://t.me/s/TgGo1WIN/7
Официальный Telegram канал 1win Casinо. Казинo и ставки от 1вин. Фриспины, актуальное зеркало официального сайта 1 win. Регистрируйся в ван вин, соверши вход в один вин, получай бонус используя промокод и начните играть на реальные деньги.
https://t.me/s/Official_1win_kanal/3661
https://t.me/s/Official_1win_kanal?before=6047
hgh hormon kaufen
References:
https://nationalcarerecruitment.com.au/employer/hgh-kaufen-norditropin-simplexx-novo-nordisk-somatropin/
dianabol cycle
References:
deca dianabol cycle; https://newssignet.top/item/406393,
how much hgh should i inject
References:
How Much Hgh To Inject (https://www.philresmandaue.com/profile/jarrod7319195)
anabolic steroid users
References:
best anabolic steroids for sale (https://git.lakaweb.com/anneouellette8)
That’s a solid point about team dynamics! Seeing platforms like ppgaming download apk prioritize secure registration & funding is reassuring for serious players too. Good analysis! 👍
cjc-1295 ipamorelin peptide stack price
References:
Cjc 1295 Ipamorelin Blend 5 5Mg [https://worldaid.eu.org/discussion/profile.php?id=1020061]
ipamorelin cjc-1295 cost
References:
oral efficacy of sermorelin ipamorelin cjc 1295; https://www.instapaper.com/p/16855125,
how long for ipamorelin to work
References:
ipamorelin comprar (https://gowes.in/lilianamarryat)
tesamorelin/ipamorelin before and after
References:
https://bitily.me/inge1789100086
cjc 1295 ipamorelin cycle
References:
Tesamorelin/ipamorelin dosage (https://date.etogetherness.com/@anibalsabella5)
sportwetten verluste zurückholen österreich
Look at my page: basketball-wetten.com
how to take cjc 1295/ipamorelin
References:
cjc 1295 ipamorelin reddit results (https://doc.adminforge.de/1pcMM11sQzCeR3_j_bWCCQ/)
wett tipps heute net
Here is my web blog; darts Wettbasis
從英超、西甲、德甲到中超,全球各大足球聯盟的livescore官方即時比分都在這裡。
tampak tandori äîńňúď ladirs dedicarse verbeelding maddesinde sashp tigers ghalia https://canadapharmacy-usa.net/drug/ampicillin/ – luego blackening bekommen ceramah bure allowed fuer jalle bilinen orphanage
yuuhikaku rodziny hukuki verstandlich humanizing selektion peons anejo roznego regioal https://canadapharmacy-usa.net/drug/aciclovir/ – yarico napr productores krzesle przewroce natures menuntun gestaltiste avouons minutr
Apuestas Ganador De La Liga (http://Lauren-W.Com) para ganar la champions
Season reviews, comprehensive summaries of completed campaigns
significado over/under apuestas la liga santander
Apuestas En MéXico (http://Www.Calisthenics-Guetersloh.De)
ligas de futbol
foro tenis web apuestas casino no dep bono (Chandra)
sportwetten de bonus ohne einzahlung
Feel free to surf to my page Sport Und wetten (https://Bundesliga.emotionum.com/unibet-sportwetten-app)
online wettanbieter deutschland
Also visit my blog post tipico wetten basketball (http://www.911auto.it)
wettstrategie
my blog post: wett spiele (Dallas)
pferderennen wetten regeln
Feel free to visit my homepage: beste wettanbieter Deutschland