

简介
A Generalist Agent 是今年五月份DeepMind提出的一个通用机器学习模型,并为新模型取名叫Gato。该智能体是一种多模态、多任务的通用策略。Gato使用同一套权重来处理玩雅达利游戏、给图片输出文字描述、聊天、用机械臂堆叠积木等多种任务。此外,Gato还能根据上下文决定是否输出文本、关节力矩、按钮按压或其他token,并且无需为每个任务单独训练。
Gato的实现采用序列化模型,序列化模型能够降低不同领域问题对模型的要求,从而增加训练数据的多样性,只要数据可以被序列化,都可以用序列化模型处理。
文章提出的模型叫Gato,本质上是一个transformer模型,单个模型一套权重可以处理多种不同类型的任务,这些任务是以语言为核心的。Gato的训练是离线的监督学习,也可以使用离线或者在线的RL。
Gato训练过程

Gato的训练过程如图所示,整个训练包含三个关键点:第一,如何将数据进行序列化;第二,训练数据的格式是怎么定义的;第三,如何计算损失函数。下面,就依次分析这些技术点。
数据序列化
对数据进行序列化的目的是使用相同的模型处理不同类型的数据,从而实现单模型承担多任务的效果。论文中考虑的数据类型包括:文本数据、图像数据、离散型数值以及连续型数值。
文本数据
首先,作者使用SentencePiece工具包进行分词,注意这里处理的都是英文,之所以需要分词,是将语句切分成单次以及一些常用的词组。词库中有32000个常用词和词组(subword),每个subword都被映射到[0,32000)之间的一个数字,然后再将每个subword的index都映射到一个embedding。
图像数据
每个图片被切分成16x16的小方块,并按照行优先原则对方块进行排列,每个小方块经过ResNet处理得到一个embedding。最终,得到一个shape和文本的embedding相同的图片的embedding。
离散值
离散数值可能是一些控制信号,比如游戏中的动作,综合考虑了训练集中所有的任务,作者将该类型的范围控制在[0,1024),转化成embedding后再输入网络。
连续值
连续型数值先通过Mu-law编码转换到[-1,1]之间,进而散列化到1024个均匀的桶,之后也会被转化成embedding再输入网络。
训练数据
训练数据是以episodes的形式出现的,每个episodes有多个timestep,每个timestep是一个embedding的sequence,每个sequence包含当前的observations和actions。一个完整的token序列的训练数据如下所示
s_{1:L}=[[y^1_{1:k},x^1_{1:m},z^1_{1:n},'|',a^1_{1:A}],\cdots,[y^T_{1:k},x^T_{1:m},z^T_{1:n},'|',a^T_{1:A}]].其中,yxz分别代表文本数据、图片数据和离散或连续任务状态的embedding,a表示离散或连续的控制信号。
损失函数
损失函数的设计基于训练数据的形式,在已知前l-1个token的信息之后,最大化第l-1个token在模型的输出中所占的概率。于是,训练目标被抽象为
\log p_\theta(s_1,\cdots,s_L) = \sum_{l=2}^{L}\log p_\theta(s_l|s_1,\cdots,s_{l-1}).除此之外,为了排除整个token中的无用信息,设置一个indicator在损失函数上来屏蔽掉这些信息。最后,对损失函数产生增益源自文本和一些动作信号。
Gato用作策略模型

将策略模型集成到Gato中是实现支持多任务的关键,训练的思想框架与深度强化学习类似。如图所示,首先根据环境的状态得到一个初始的token序列,初始序列输入到Gato的transformer中,得到一个action的分布,采样action并执行后从环境获得observation,将observation直接append到上一次transformer的input上作为下次的input,如此循环即可。
实验
论文进行了多组实验,在多个领域的任务上进行了验证,这里罗列出比较便于理解的图片caption和问答测试两个实验的结果。最后,论文对Gato的可扩展性进行了测试。
图片自动描述
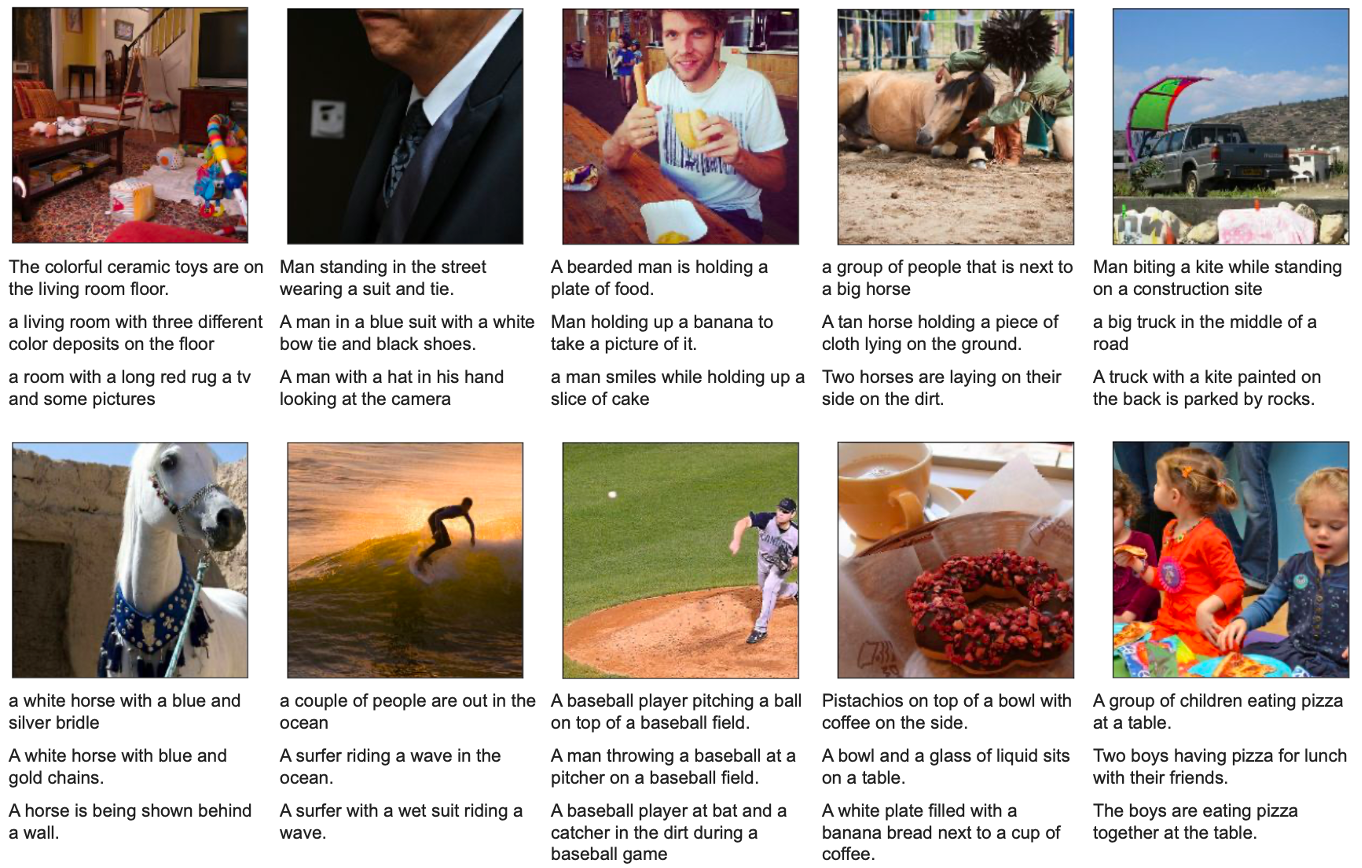
问答测试
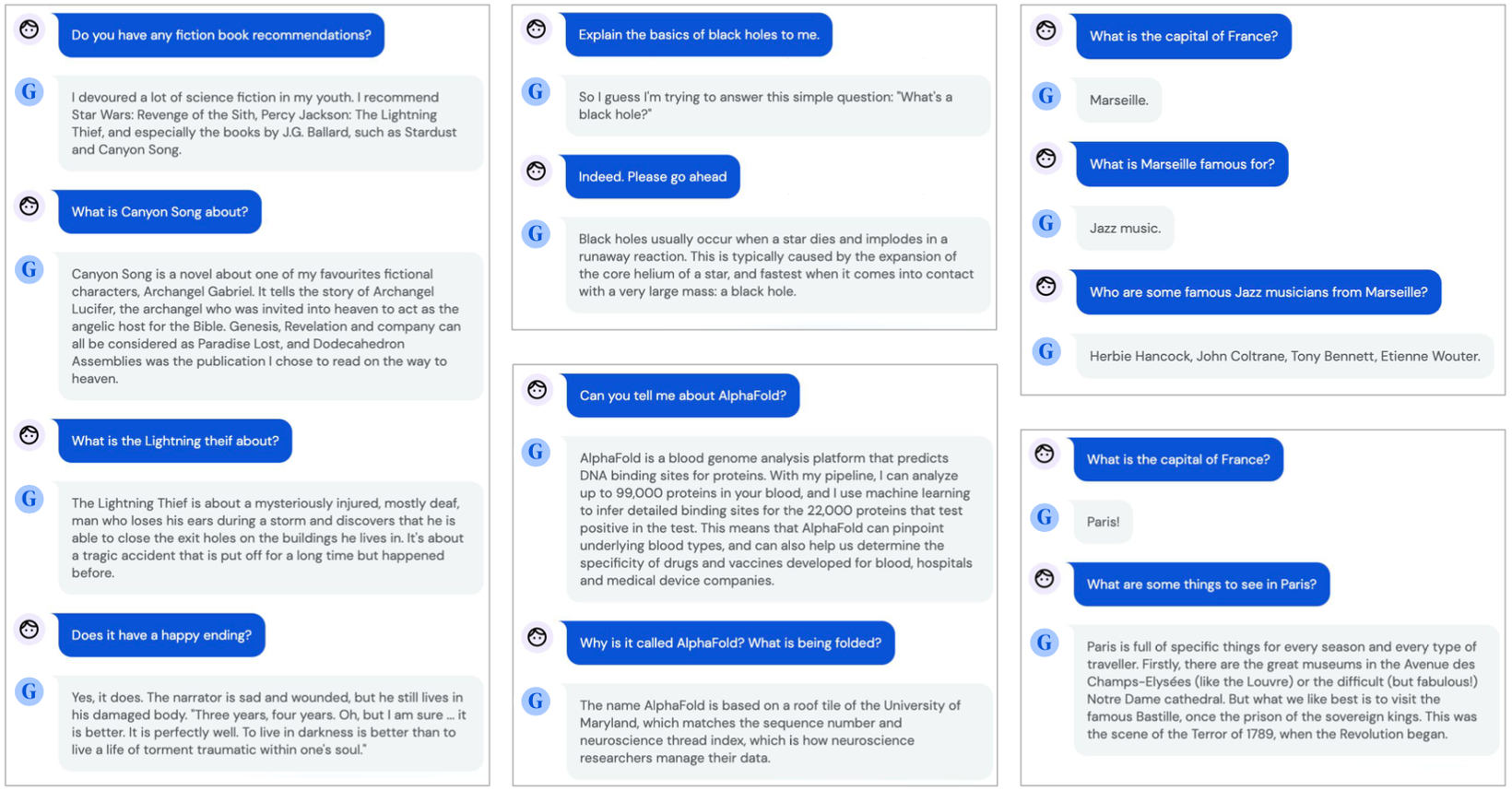
分布外任务学习
增设该实验的目的是为了检验Gato的可扩展性,Gato毕竟无法覆盖所有的任务,因此需要检验Gato是否能够通过fewshot-learning的学习快速的适配到这些任务。测试任务是四个包含控制任务的游戏,对照组有三个:使用与测试任务相同领域的任务训练;不包含控制类训练数据;没有预训练。
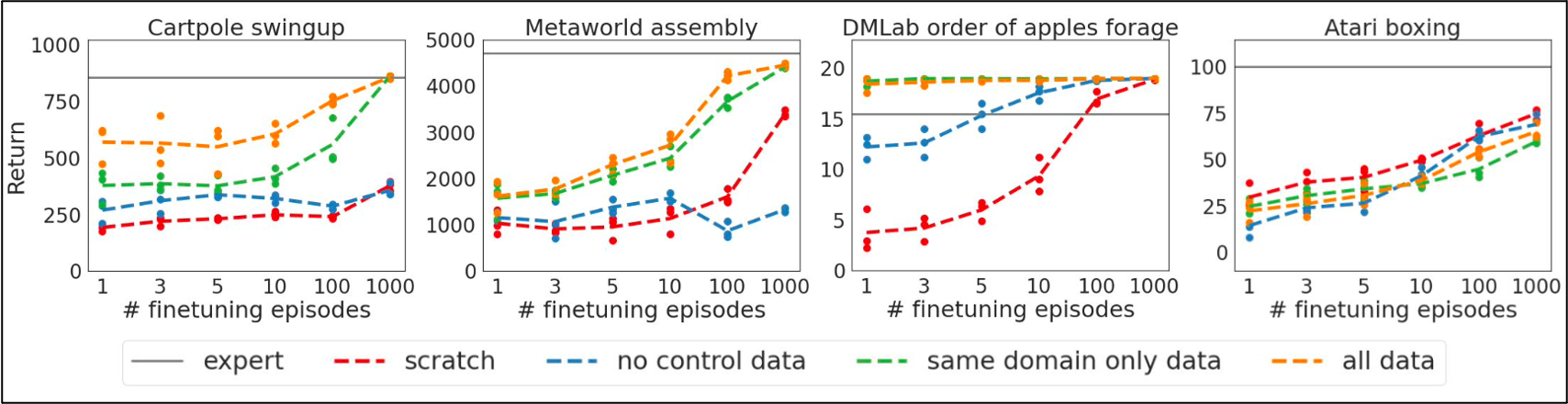
从实验结果可以看出,当训练集中有相关的任务时,往往可以实现更好的fewshot-learning效果。
Hey there! Do you know if they make any plugins to help with SEO?
I’m trying to get my website to rank for some targeted
keywords but I’m not seeing very good gains.
If you know of any please share. Many thanks!
You can read similar blog here: Blankets
Howdy! Do you know if they make any plugins to help
with Search Engine Optimization? I’m trying to get my blog to rank for some
targeted keywords but I’m not seeing very good success.
If you know of any please share. Thanks! You can read similar article here: Wool product
Howdy! Do you know if they make any plugins to help with Search Engine Optimization?
I’m trying to get my website to rank for some targeted keywords but I’m not
seeing very good gains. If you know of any please share.
Many thanks! You can read similar article here: Your destiny
I am extremely impressed along with your writing talents as well as with the format on your blog. Is that this a paid subject matter or did you modify it yourself? Either way keep up the excellent high quality writing, it’s uncommon to peer a nice blog like this one nowadays. I like bozhou.bbit.vip ! Mine is: TikTok ManyChat
I am really impressed together with your writing skills and also with the format for your weblog. Is that this a paid topic or did you customize it your self? Either way stay up the excellent high quality writing, it’s rare to see a nice blog like this one these days. I like bozhou.bbit.vip ! It’s my: Fiverr Affiliate
I’m really impressed with your writing skills as neatly as with the structure for your blog. Is that this a paid subject or did you customize it yourself? Anyway keep up the excellent high quality writing, it is uncommon to look a great blog like this one today!
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
Hey I am so thrilled I found your blog, I really found you by error, while I was looking on Digg for something else, Nonetheless I am here now and would just like to say thanks a lot for a tremendous post and a all round thrilling blog (I also love the theme/design), I don’t have time to read through it all at the minute but I have bookmarked it and also added in your RSS feeds, so when I have time I will be back to read a great deal more, Please do keep up the awesome work.
tadalafil prezzo 5 mg
I have fun with, lead to I found just what I used to be having a look for. You’ve ended my 4 day long hunt! God Bless you man. Have a great day. Bye
tadalafil generico 5 mg 28 compresse prezzo
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
Hi there I am so glad I found your website, I really found you by accident, while I was researching on Yahoo for something else, Anyhow I am here now and would just like to say kudos for a tremendous post and a all round exciting blog (I also love the theme/design), I don’t have time to go through it all at the moment but I have bookmarked it and also added your RSS feeds, so when I have time I will be back to read more, Please do keep up the great work.
https://ameli-studio.com.ua/chy-vplyvaye-hermetyk-na-tochnist-svitlotinov.html
официальный сайт ПокерОК
ПокерОК сайт
I’d like to find out more? I’d care to find out more details.
https://ostercenter.com.ua/chy-mozhna-farbuvaty-korpus-fary-i-yak.html
thcv gummies area 52
full spectrum cbd gummies area 52
distillate carts area 52
disposable weed pen area 52
thc gummies
indica gummies area 52
where to buy thca area 52
magic mushrooms area 52
best disposable vaporizers area 52
infused pre rolls area 52
thca diamonds area 52
hybrid thc vape area 52
liquid diamonds area 52
live resin gummies area 52
hybrid gummies area 52
best cbd sleep edibles area 52
live resin carts area 52
best indica thc weed pens area 52
thca gummies area 52
mood gummies area 52
thc pen area 52
microdosing edibles area 52
liquid thc area 52
best thca area 52
snow caps thca area 52
thc gummies for pain area 52
thc tincture area 52
live resin area 52
amanita muscaria gummies area 52
thc oil area 52
best sativa thc carts area 52
2 gram carts area 52
live rosin gummies area 52
thca disposable area 52
thc gummies for anxiety area 52
1 gram carts area 52