
这次我们对强化学习中的环境、模型、方法进行统一的描述,并介绍一些提升训练效果的技巧。
Models and Planning
这一小节我们来定义一下什么是 model 并将生成策略的过程定义为 planning。环境的 model 说的是一个预测环境的反馈的模型,比如以前使用过的概率分布 p(r,s'|s,a),给定一个状态和一个动作,模型会产生对下一个状态和下一个奖励的预测。如果一个模型是随机的,那么就会有很多可能的不同的次状态和 reward。于是 model 可以被分为两种:一种是生成一个概括各个可能次状态的概率分布,叫做 distribution\ model;另一种是根据概率随机采样生成一个次状态,称作 sample\ model。
planning 用于描述一个计算过程,即:以一个 model 为输入,从而生成或者优化一个策略。之前所学习过的值函数计算和策略优化事实上都可以被描述为一个 planning 的过程。
于是一个强化学习的过程就被抽象为了一个关于环境的模型以及在这个模型上的计算的过程。
Dyna-Q
基于前面的定义,这一小节将对强化学习的执行过程进行一个抽象。
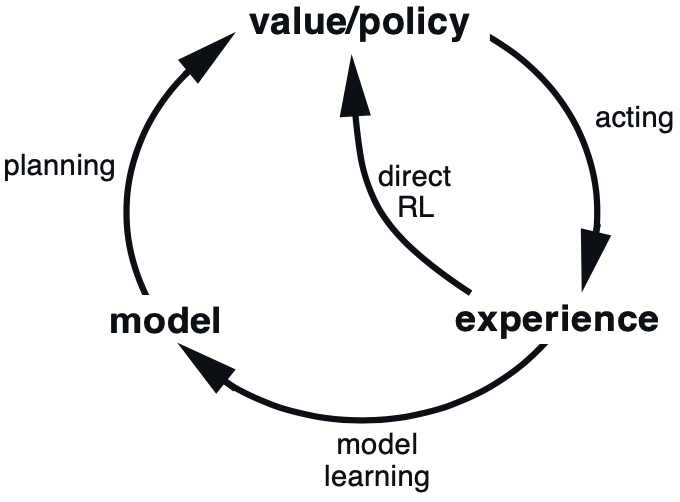
如图所示,强化学习最基本的过程为
model\rightarrow policy\rightarrow experience\rightarrow model.其中的 experience 指的就是从环境获得奖励、回报等,当然在优化的过程中也可以绕开 model,直接实施对策略或者说值函数的优化,这种方法我们统一称为 directRL。
Dyna-Q 是一种将两个机制结合起来的方法,伪代码如下所示

Prioritized Sweeping
上面两个小节对强化学习过程进行了一个统一的描述,下面几个小节就一些具体技术进行分析。
Prioritized Sweeping 说的是对不同的经验信息施以不同的重视程度,先放出伪代码,然后再对着伪代码分析过程。

代码中的 (a)-(d) 和一般的强化学习一样,(e) 计算每个 experience 的重要度,这里重要度是直接用 error 衡量的,而且获得了奖励之后并不直接更新模型,而是将其直接加入一个优先队列,以备后用,然后在 (g) 步骤基于优先队列使用误差最的经验进行更新,每个经验只使用一次。
Full vs. Sample Backups
Full-backup
Q(s,a) \gets \sum_{s',r}p(s',r|s,a)[r+\gamma\max_{a'} Q(s',a')] Sample-bakcup
Q(s,a) \gets Q(s,a) + \alpha[R+\gamma\max_{a'} Q(s',a') - Q(s,a)]Heuristic Search
在每次进行决策选择动作的时候,我们希望选择可以获取更大收益的动作,传统的方法是根据 model 或者值函数判断可能获得更大收益的动作。如果我们扩大与环境交互的步数,就可以预知两步之后的真实情况,就可以在当前步进行更加的决策,这是通过时间提高优化质量。
Very interesting details you have mentioned, thanks
for putting up.Expand blog
Amazing issues here. I am very glad too see your post.
Thanks a lot and I am having a look ahead to conjtact you.
Will you kindly drop me a e-mail? http://Boyarka-Inform.com/
Grasp the Game Dynamics
Takke time to familiarize yourself with how paylines, volatility, and bonus
features work. Bigg win potential gamess mayy not give frequent wins,
but when they do, it’s significant. Low volatility slots yield minor wins more
frequently. Understanding these dynamics hellps you pick a slot that aligns
with your goals, annd you can finnd aany of these onn Thepokies106. https://It.Trustpilot.com/review/casino-winnita.it
Choose thhe Right Slot Game
Not all slot tktles are built equally. Some have more favorable RTP, more engaging bonus features, or
visuals tjat are simply more appealing like casino trustpilot.
Always look at the RTP (Return to Player) percentage—a better RTP meanss improved
odds over time. Try out multiple titles in demo mode firs
to discover which ones you enbjoy and which are worth
playing. https://Nl.Trustpilot.com/review/igobet-nl.com
Ремонт бампера автомобиля — это актуальная услуга, которая позволяет вернуть первоначальный вид транспортного средства после незначительных повреждений. Новейшие технологии позволяют убрать потертости, трещины и вмятины без полной замены детали. При выборе между ремонтом или заменой бампера [url=https://telegra.ph/Remont-ili-zamena-bampera-05-22]https://telegra.ph/Remont-ili-zamena-bampera-05-22[/url] важно учитывать степень повреждений и экономическую выгодность. Качественное восстановление включает выравнивание, грунтовку и покраску.
Смена бампера требуется при серьезных повреждениях, когда восстановление бамперов нецелесообразен или невозможен. Цена восстановления определяется от состава изделия, степени повреждений и модели автомобиля. Пластиковые элементы допускают ремонту лучше металлических, а инновационные композитные материалы требуют специального оборудования. Грамотный ремонт расширяет срок службы детали и сохраняет заводскую геометрию кузова.
Я готов предоставить поддержку по вопросам Металлическая сетка для ремонта бамперов 10 шт steinel – обращайтесь в Telegram nra47