
评估运动员在比赛中的表现对于实现有效的体育教练至关重要。然而,对球拍类运动中运动员的定量评估是困难的,因为这需要从复杂的战术和技术表现的综合中得出。作者提出了一种基于深度强化学习的球拍类运动评估的新方法,它可以更详细地分析球员的动作,而不仅仅是考虑得分情况。该方法使用历史数据来学习下一个球运动员得分的概率,并把它作为 Q 函数用于评估球员的表现。我们利用 LSTM 模型来学习 Q 函数,其中球员的姿势和球的位置作为输入,分别由 AlphaPose 和 TrackNet 算法识别。作者通过比较各种基线来验证他们的方法,并通过分析顶级羽毛球运动员在世界级赛事中的表现的用例证明了该方法的有效性。
方法
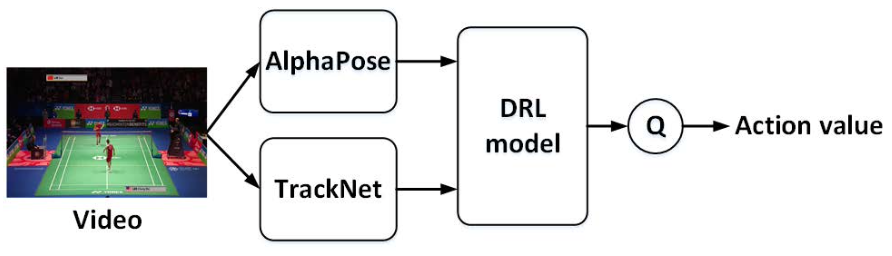
如图所示,是对论文中提出的方法的概述。使用 AlphaPose 和 TrackNet 对球员的姿势估计和羽毛球位置检测,然后是用于估计 Q 函数的 Deep Reinforcement Learning 模型。给定一个 Q 函数后,action的value就被定义为动作引起的 Q 值的变化。
羽毛球是一项竞技运动,比赛采用三局两胜制,每局21分。一颗球从发球开始,在某方得分时结束。为了描述一场羽毛球比赛,我们将一颗球作为分析的基本单元。每一颗球包含一系列的击球动作,其过程可以描述为不同状态之间的相互转换。
通过使用羽毛球比赛的视频数据,我们首先将一场比赛中的每局切分成基本单元。对于每颗球,作者使用 AlphaPose 估计了鼻子、眼睛、耳朵、肩膀、肘部、手腕、臀部、膝盖和脚踝关节位置的坐标,并使用 TrackNet 检测羽毛球位置。AlphaPose 是一种流行的高精度多人身体姿势估计系统,TrackNet 是一种对象跟踪网络,已被证明在高速球类游戏中表现出不错的跟踪能力。
关于处理数据时的特殊情况,主要有两个:一个是通过 COCO 注释器对由于重叠而未正确估计的关节位置进行标注,COCO是一个监督学习的数据集。另一个,假设两个脚踝的中点表示玩家的位置,姿势表示为相对于玩家位置的一系列坐标,对于左手持拍的运动员,作者颠倒了相应的相对坐标。
将动作的坐标和球的坐标组合为 DRL 模型的输入特征向量,应用 DRL 方法估计 Q 值,最后从 Q 值中获得动作值,用于评估运动员的表现。根据运动员相对于摄像机的位置,我们将比赛中的两名运动员分为前和后。离镜头更近的是前面;相反,离相机更远的是后面的。
建模
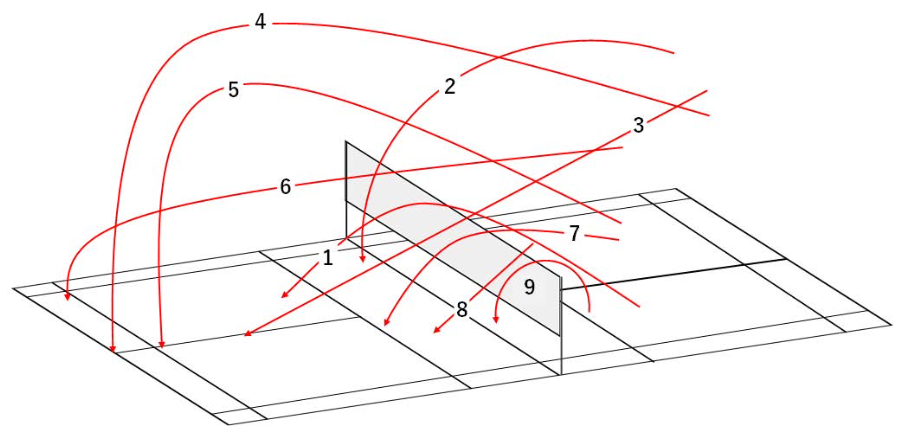
奖励 R 表示赢下了当前这颗球的一方。动作 a_t 被划分成9种情况,如图所示,(1) 表示发球,(2) 表示劈吊球,(3) 表示杀球,(4) 表示高远球,(5) 表示挑球,(6) 表示平抽,(7) 表示挡网,(8) 表示封网,(9) 表示放网。状态 s 表示为每次击球瞬间的特征向量,包括球的位置,球员的位置等。
Q函数 Q(s,a) 表示运动员赢下当前这一分的条件概率
Q_{front/back}(s,a) = P(point=1|s_t=s,a_t=a).事实上,Q函数计算了给定状态下选择一个动作的期望奖励。
学习Q函数
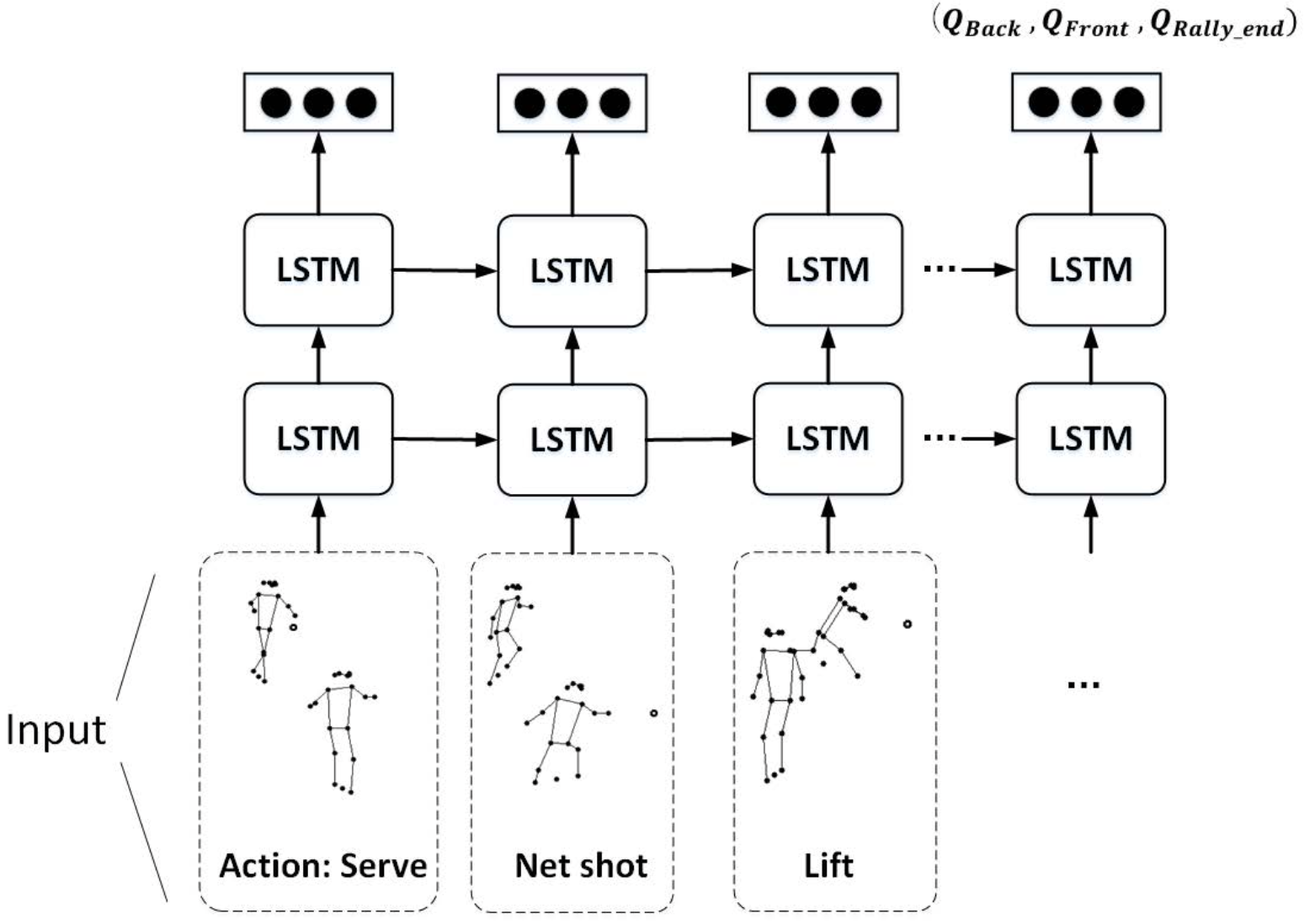
如图所示,展示了论文中使用的DRL的框架。使用的网络模型是两层的LSTM,网络模型的输入是在每个关键帧(击球帧)状态和动作的序列。一个完整的序列对应一分球,或者说一颗球从发球到得分的整个过程。LSTM的输出有三个值,Q_{Back}(s,a),Q_{Front}(s,a) 和 Q_{Rally_end}(s,a),分别表示两个运动员各自赢下这一分的条件概率以及这一分球在下一个时刻结束的概率。
这里学习出来的Q函数是动作值函数的近似,并且使用on-policy算法来估计Q值
Q(s_t,a_t) \gets Q(s_t,a_t) + \alpha[R+\gamma Q(s_{t+1},a_{t+1})-Q(s_t,a_t)].当然,这是tabular方法,相同的思想迁移到网络上,只需要定义如下的损失函数即可
\mathcal{L} = \frac{1}{n}\sum_{t=1}^{n}\left(R+\gamma Q(s_{t+1},a_{t+1})-Q(s_t,a_t)\right)^2.实验
实验所需数据非常简单,只需要一些比赛视频即可。作者从世界羽联官网上下载了从半决赛到决赛的男单视频进行分析。
关于实验的设计和分析,是比较粗糙的。首先,作者尝试使用不同的网络模型和不同的输入特征来判断是否能够获得更优的损失函数最小化效果。然后,作者汇总了每个运动员在每种不同类别的动作下的平均值函数,从而区分出同一场比赛中发挥较好的一方。最后,作者将模型的输出与真实的比赛结果以及世界排名做了对比,发现论文提出的模型具有较高的代表性。
总结
这篇论文汇总了羽毛球运动建模所需的各种技术手段,对后续的工作起到了很好的铺垫作用。
Some bodybuilders make the most of Anavar all yr round,
just like testosterone replacement remedy (TRT).
Nevertheless, this isn’t beneficial due to extreme hepatic and renal toxicity.
It Is especially good for chopping cycles, aiming for lean muscle while shedding fats.
While it might possibly help burn fat when combined with a calorie-deficit food plan and training,
Oxandrolone doesn’t instantly trigger fat loss itself.
The duration of an Anavar cycle remains typically consistent from the beginner
to intermediate degree, extending from six to eight weeks. It offers
enough time to experience notable gains without overworking the physique or inviting pointless unwanted effects.
As an intermediate Anavar person, the dosage could be slightly greater than the beginners’ dose.
A typical vary lies between 50 to 100 milligrams per day, again relying
on an individual’s particular wants and tolerance ranges.
When stepping up the dosage, one should listen fastidiously to their body’s
feedback. Making this adjustment cautiously and attentively
paves the method in which for optimal results.
When stacking Anavar, you will want to select the right
dose. Anavar is usually used at a dosage of 20-30mg per day, however some users might use
up to 80mg per day. It is necessary to begin out with a decrease dose
and progressively improve it as your body adjusts. If you are new to Anavar, it is recommended that you
just begin with a low dose. For men, a dosage of 20-30mg per day
for 6-8 weeks is an effective place to begin.
For girls, a dosage of 10-15mg per day for 6-8 weeks is really helpful.
Anavar is considered a gentle steroid, with low androgenic effects and
high anabolic results. It is not as potent as different
anabolic steroids, but it’s nonetheless effective
in promoting muscle growth and power positive aspects.
It can be less likely to cause side effects corresponding to gynecomastia (male breast enlargement) and water retention. Like the gents, female Anavar users’ cycles sometimes span six to eight weeks.
This time-frame allows for vital enhancements in muscle tone, vascularity, or strength without pushing the
physique right into a danger zone of extended publicity
to the compound. In case of stacking, women can take into consideration teaming up Anavar with other gentle steroids, maintaining the dosage low.
This method ensures concord between compounds and maximizes the potential of their bodybuilding quest.
The only way to safeguard against any danger is to have
a prescription for any anabolic steroids taken. Subsequently, if a soldier has low testosterone and is prescribed TRT,
if he checks constructive for testosterone, it will come again as
negative to the commander. Clenbuterol is sometimes referred to as a cutting steroid like Anavar.
Nonetheless, clenbuterol is not an anabolic steroid; therefore, we do not see it affecting natural testosterone ranges to any vital degree.
The main function of post-cycle remedy is to restart endogenous testosterone
manufacturing. This aids in normalizing hormone levels for optimal physiological and psychological health, in addition to retaining
outcomes from a cycle. Anavar’s benefits usually are
not overly powerful, at least compared to different anabolic steroids;
due to this fact, the unwanted effects are more tolerable for many customers.
The follow-up cycle to this generally begins with a dose
of 20 mg instead of 15 mg and is prolonged up to 8 weeks.
Click right here now to get one of the best deal on Anvarol and
start your journey towards reaching your physique objectives safely.
By submitting this kind, you comply with Asana Recovery’s Privacy Policy.
You additionally consent to Asana Restoration contacting you by telephone,
text message, and e-mail concerning your insurance advantages and remedy
services. At Asana, we offer efficient, insurance-covered remedy for
addiction and psychological well being, guided by consultants who understand because they’ve been there.
Depending in your bodybuilding level, whether you’re beginning, sustaining, or mastering, the
usage and cycle of Anavar will differ. It’s important to grasp its specifics to ensure you’re not solely getting the desired outcomes, but
you’re also maintaining your health in check. It’s advisable to begin on the decrease end of the dose range,
particularly for first-time customers, and steadily enhance if wanted based on effects and tolerance
ranges. Exceeding really helpful doses considerably increases the danger of unfavorable side
effects.
Phosphocreatine is necessary for producing vitality
during quick, intense bursts of activity, corresponding to
lifting weights. Anvarol can help you to train tougher and longer
than earlier than, resulting in amplified muscle progress and quicker gains in strength and measurement.
However, there are studies suggesting clenbuterol has muscle-building results
in animals (32).
Experienced users of steroids may have the ability to tolerate greater doses of
Anavar, however it’s nonetheless necessary to be cautious and begin with a lower dose to see
how your physique reacts. If you’re new to using steroids, it’s essential to start with a decrease dose of Anavar to see how your body reacts.
Newbies should begin with a dose of round 20-30mg per day and
gradually improve it if needed. Anavar is a popular steroid for girls as a result of it’s relatively mild and has fewer side effects than some other
steroids. While Anavar just isn’t as potent as another steroids in terms of constructing muscle mass, it
could still help you gain energy and enhance your physique.
This is very true when mixed with a nutritious diet and common exercise routine.
In summary, when planning an Anavar cycle, it could be very important consider the size of the cycle, the dosage, and the stack used.
The beneficial dosage of Anavar for athletes is 25-50mg per
day. Anavar is a mild steroid, so even if you are new to utilizing steroids – you need to be
fine starting at the higher end of the dosage range.
The value of Anavar can differ depending on where
you buy it and the standard of the product.
References:
https://www.valley.md
Due to high demand, Dianabol is a comparatively low-cost steroid and widely
out there, making it very affordable, which makes it
an attractive option to those who are new to utilizing steroids.
5mg and 10mg energy tablets are the commonest, but some makers have created single capsules at 25mg or even 50mg in one dose.
Increased energy will power your muscle positive
aspects, and users will not often complain in regards to
the energy enhancement that Dianabol produces. If we are talking about whole
weight, you must include water as a outcome of there’s no
escaping the fluid retention that Dianabol causes (but you’ll have the ability to actually mitigate it as a
lot as possible). If you have current ldl cholesterol issues,
you must keep away from utilizing Dianabol completely.
This is the place a post-cycle remedy plan is critical, with SERM medicine
like Nolvadex and Clomid being important to have on hand, able
to go. These medication accelerate your testosterone recovery and effectivity while ranges are beginning to get again to
regular naturally.
Correct on-cycle support, post-cycle therapy (PCT), and monitoring
are essential. His exercises not left him feeling exhausted,
and this renewed energy led to considerable enhancements in his
lifting efficiency. John balanced intervals of Dbol intake
with enough breaks, thereby permitting his body to get the desired benefits whereas additionally having time to recover.
Crucially, Dianabol excels in synergy with other steroids quite than serving as
a standalone base. When combined with different steroids, Dianabol
enhances their effects significantly. For
occasion, stacking Dianabol with steroids like Trenbolone, Masteron, or Equipoise amplifies
outcomes far beyond their particular person capacities.
This is as a end result of estrogen (the girly hormone) also rises when testosterone goes too excessive.
However, your genetics will determine if you kind gyno or not from taking dianabol.
Proper rest and restoration are also essential for preventing overtraining and harm.
For those trying to pack on critical dimension, the mix of Dianabol, Deca-Durabolin, and testosterone could be an effective possibility.
This stack offers a potent anabolic environment while additionally promoting joint support and restoration. This mental and emotional influence could be highly beneficial for benefiting from the physical features
the steroid provides. The undeniable fact remains – no quantity of
Dianabol tablets for bodybuilding or hours spent at the fitness center will get
you the specified consequence in case your dietary habits are off track.
Even Dbol, with all of its muscle-gain reputation, necessitates
the backing of a properly aligned food regimen.
Using the best dosage of Dianabol is crucial as a result of it impacts the results and
unwanted effects you may expertise. Dianabol offers you complications due to the increased blood move to
your mind. It has been used to treat folks with muscle-wasting ailments as a outcome of HIV or other medical situations ensuing from malnutrition and poor development or lack thereof.
Dianabol half-life in the body could be between a mere hour and a full day, depending
on how a lot you’re taking and what sort of Dianabol you could have been taking for the
Dianabol cycle. Dianabol just isn’t a miracle drug and will solely
work if you’re training hard in the health club every day, it won’t do all of the work for you.
If you’re trying to lose weight/fat Dianabol might very properly be value contemplating.
This helps you recover sooner and train harder, which may trigger increased vitality
ranges throughout exercises (and after).
Dr. Scally has efficiently treated 100 males for hypogonadism with efficient PCT protocols such as
this one. Thus, for max effectiveness, Dianabol ought to be taken on an empty abdomen, without food.
Salicylic acid is another widespread zits treatment; nevertheless,
that is much less effective compared to retinoids. Topical antibiotics are also an advantageous remedy for acne, lowering inflamed lesions by 46-70% (27).
To avoid such resistance, antibiotics ought to contain benzoyl peroxide, which will additional cut back inflammation.
This signifies that delicate people, taking higher doses of D-Bol can develop gynecomastia (gyno).
There’s additionally evidence to suggest that steroids have a everlasting impact on the myonuclei inside your muscle
cells (34). In one study, mice have been briefly uncovered to anabolic steroids, which led to important muscle growth that
returned to normal levels when steroid use
was discontinued. DHT is answerable for the event of body hair, prostate,
penis measurement (during puberty), and libido.
Some of us find back pumps turn into a problem, principally at larger doses.
Once you start feeling these pumps in the fitness center (and outdoors of it), it’s a
great sign that your Dbol is working as it ought to be – and it feels unbelievable.
Used intelligently, Dianabol is often a potent software for critical athletes — however it is not a shortcut or a substitute for correct coaching,
nutrition, or long-term planning.
At the opposite finish of the spectrum are labs
that pay little to no consideration to quality or hygiene, and it’s these steroid providers that can put your health
at important risk. Dianabol is a steroid all the time in excessive demand, so
nearly each underground lab will manufacture it, and this retains
the value of Dbol down as one of many cheaper steroids we are able to buy.
Rather than order from pharmacies abroad, many individuals will journey
to the international locations the place Dbol is bought overtly in pharmacy stores and purchase and
use it there. This can go some approach to clearing up
the legal dangers in your personal nation, however it may
possibly doubtlessly put you at authorized danger abroad.
Shopping For Dianabol requires working outdoors the legislation, so that you should be prepared for all the dangers.
References:
https://www.valley.md/dianabol-tablets-what-brands-and-prices-are-available
The tren trade extends past fundamental channels, and it contains “tren”
impostors sold to capitalize on the hype around the real factor.
Earlier this 12 months, Mackey demonstrated how one might discover tren purportedly supplied
for sale on the web music-community platform SoundCloud.
I work out at my residence gym so I don’t have connections with anyone at a giant globo health club.
Customers can navigate product classes and find the necessary info
quickly. With a secure checkout course of and dedicated customer help, prospects can confidently find the most effective product.
Each kind of Tren offers distinctive benefits, and selecting the
proper form depends on expertise level, objectives,
and personal preferences. Solely logged in customers
who’ve purchased this product may leave a evaluate.
❸Our CSR will offer you the quotation, payment term, tracking number, supply ways,
and estimated arrival date(ETA).
As always, remember to use it responsibly to maximise these advantages
and reduce potential dangers. Its lipolytic properties enable environment friendly fats burning whereas
retaining lean muscle mass. This helps you attain a toned and sculpted appearance as
a substitute of merely shedding weight. Boosting muscle development, environment
friendly fat loss, and growing red blood cell count for better oxygen transportation are some Tren Ace hallmarks.
Remember to seek suggestions, learn buyer reviews, and consult with professionals to gather
insights and make well-informed selections. Compliance with legal
and regulatory standards is crucial to prioritize your security and avoid purchasing
from unregulated or unlawful sources. The manufacturing and distribution costs incurred by Trenbolone producers and suppliers also influence the pricing.
Moreover, it promotes protein synthesis and nitrogen retention,
essential elements in muscle growth. It Is additionally recognized for enhancing muscular definition and hardness,
making it a favourite for pre-contest preparation. Trenbolone is a synthetic anabolic steroid that was first developed within the 1960s.
Initially created for veterinary use to advertise muscle growth and enhance feed effectivity in livestock, it
quickly gained attention for its highly effective anabolic properties.
Over time, its utilization expanded beyond
veterinary functions and have become popular amongst
bodybuilders and athletes seeking important gains in muscle mass, energy,
and performance.
Some nations have stringent laws against the sale and possession of steroids, whereas others are extra lenient.
Subsequently, it is crucial for potential buyers to familiarize themselves
with their local legal guidelines earlier than deciding to buy Trenbolone online.
The effects of Trenbolone Acetate have brought on many to deem it the ultimate bodybuilding steroid.
It often happens shortly after a tren injection, probably
as a result of a part of it was by accident launched into the circulatory system, making its means
into your lungs. He typed “trenbolone buy” into the search bar and various
other playlists appeared. Amongst these playlists was one 13-second clip titled “Where to Get Tren – The Place to Purchase Trenbolone Online.” The
corresponding picture was a shirtless muscular man, along with text
about tren. After the consumer selected the playlist, the following page revealed an outline that included an official-looking
link, naspcenter.org/Get-Trenbolone.
In a nutshell, Tren Ace is an important part of any cycle
the place the purpose is to get muscular and ripped.
Just keep in mind, harnessing its full potential is all about understanding the means it works and using it
responsibly. Whether you are a newbie or a professional bodybuilder, understanding Tren Ace is crucial.
Tren Ace is your ticket to huge transformations in strong muscle progress
and crazy definition. It is crucial to note that Trenbolone has turn out
to be a managed substance in many countries such as these within the Usa and Canada as well as numerous international locations in Europe.
This classification makes the use of Trenbolone in any capacity; possession, purchasing or selling of the
substance without the prescription as unlawful and attracts severe authorized consequences.
Sure, Trenbolone is a controlled substance in many countries and requires a legitimate prescription for
legal use.
It also promotes quicker recovery of the
torn muscle, which is where the actual benefits are. In some individuals,
it’d affect cardiovascular well being, but in all, it increases muscle
power and endurance. Trenbolone cycles are very effective as either fat
loss or muscle constructing mass cycles. This is of explicit importance in terms of the catabolic
hormone Cortisol, which Trenbolone ought to effectively have
the power to inhibit[16]. Furthermore, Trenbolone’s effectiveness as a fat loss agent is properly
documented through its unimaginable nutrient
partitioning effects[17]. We additionally know that androgen receptors certainly exist in fat cells and play a
role in fat loss when activated[18], particularly the stronger an androgen binds to this receptor[19][20].
References:
primaryonehealth
After a cycle, the ALT and AST enzyme ranges of an individual usually revert to regular inside a brief time
body. To prevent extra liver damage, anavar steroid cycle should
not be used with hepatotoxic substances like alcohol.
In addition, users shouldn’t use Anavar if their liver is already inflamed or injured, since this may
cause more harm. As Quickly As you attain a body fats
share of 9 percent or less, it is now not advantageous on your physique to retain muscle.
At Asana Restoration, we perceive that these selections can be overwhelming.
We present compassionate care and steerage that will help you make one of the best choices.
Mental Health Outpatient Treatment can even tackle any underlying points.
Stacking Anavar with pure testosterone boosters throughout PCT can even help restoration and long-term
hormonal steadiness. Being used solo or in a stack,
Anavar will certainly provide the desired results. All steroids include
execs and cons, but when it comes to Anavar, you possibly can simply say that there are not any cons.
One Other two weeks can be added, but the longer the cycle, the higher the risk
of side effects.
If the beneficial dosage is three capsules per day, then it’s probably best to separate
the dosage into two and take it with breakfast and lunch. CrazyBulk is also providing
a buy-two-get-one-free deal on all of its products at
the moment, so it’s a good time to begin your bulking or
chopping cycle. It additionally helps to preserve muscle mass when you’re cutting
calories, so you don’t have to fret about losing
the progress you’ve made. The majority of those results are brought on when you abuse, take extra dosage or have an underlying/hidden medical situation.
Nonetheless, it’s predicted that this period of recovery could be
fairly brief (a few of weeks) before pure testosterone levels return to normal.
Embarking on an Anavar cycle could be a powerful device in your quest for a leaner, stronger, and extra outlined physique.
Combining Anavar with other compounds must be accomplished with caution and an intensive understanding of
the interactions concerned.
If you are figuring out greater than thrice per week, we
advocate beginning at the lower end of the dosage vary.
If you may be working out three times per week or
much less, you can start on the larger finish of the dosage vary.
If you are new to using steroids, we suggest starting on the lower finish of the dosage vary.
If you could have used steroids before, you can start at the larger finish of the dosage vary.
Some bodybuilders go for legal Anavar alternate options, such as Anvarol,
which mimics Anavar’s fat-burning and anabolic results.
One should begin with a low dosage, often around 20-30mg day by day for men and fewer for women. For
advanced bodybuilders, Anavar doses of mg daily may be used to maximise results.
These cycles usually embrace stacking with other anabolic compounds to enhance efficiency, however such
practices require cautious planning and monitoring.
Nonetheless, the amount of lean mass gained throughout an Anavar cycle
will rely largely on one’s sex, food regimen, training, and
if the drug is “stacked” with other steroids. So judging Anavar results can be a murky proposition, however one that’s
made easier by understanding a lot of what has been written within the
bodybuilding community. That mentioned, take a look at the next matters, lots
of which draw from discussion board threads right here at EliteFitness.com.
Publish cycle remedy (PCT) is really helpful after taking Anavar to help restore your
natural testosterone manufacturing and stop any opposed results.
Figuring out the right dosage is essential when starting an Anavar cycle.
The objective is to search out an amount that’s efficient however minimizes the potential dangers.
It’s usually advised to begin with the lower end of this vary to see how your
body reacts. Pay Attention carefully to your body and pay attention to any adjustments you
expertise. You can gradually modify the dosage, however maintain adjustments small, for instance, 5mg
at a time and at all times talk about these changes with a physician or healthcare skilled if
you’ll be able to.
However, trenbolone produces harsh unwanted side effects and thus is often avoided by beginners.
Testosterone suppression is prone to be extreme, as properly as LDL
levels of cholesterol rising notably in analysis.
Trenbolone causes the most hypertrophy increases in androgen-sensitive muscle teams, such because the trapezius
and deltoid muscles. Trenbolone’s vast androgenicity is why it causes fats loss,
with androgen receptors stimulating lipolysis.
It was believed to be the steroid predominantly used within the Golden Period
to bulk up Arnold Schwarzenegger and other bodybuilders from the Seventies.
This isn’t to indicate that customers can appear to be Arnold by merely taking Dianabol; as you
can see, he had spectacular muscularity whilst a pure bodybuilder.
You can’t miss the massive shifts when you see before and after
TRT photographs. These modifications present what your body can do with the
best assist. TRT photos aren’t just for the before and after—they
offer you hope.
D-bal is a natural, side-effects-free replication of Dianabol
that is fully authorized to use. A few firms with groups of amazing scientists have been in a position to make use of science to formulate dietary supplements that can mimic the consequences of Dianabol without ANY side effects… legally.
If you exceed that, or should you take doses larger than 50 mgs per day, you’ll be able to just about anticipate liver issues eventually.
Most folks take a weaker anabolic substance (something akin to TRT) and an estrogen blocker.
Dianabol, like any other steroid, also needs post-cycle
therapy to be certain to don’t get any nasty unwanted effects.
As I mentioned earlier than, you’re going to additionally gain some water
and fat. Nevertheless notice that even Dianabol can deliver large outcomes it also comes with health dangers.
Success comes from disciplined training, a healthy diet, and watching your
doses. If you need to achieve muscle and energy faster without nasty
side effects of going to jail to turn out to be the following Kali
Muscle, D-bal is best for you. Testosterone suppression will also be notable on Dianabol, with males frequently turning into hypogonadal from reasonably dosed cycles.
After several months, endogenous testosterone ranges typically recuperate; however, if users abuse Dianabol,
then they might experience long-term testosterone
deficiency and infertility. Anadrol and trenbolone are
much less appropriate stacking options, regardless of their profound effects on muscle
constructing and energy. This is as a end result of of Anadrol exacerbating hepatic and cardiac harm,
with trenbolone additionally causing the latter. We have discovered that a further 10
kilos of mass can be gained when adding testosterone or Deca Durabolin to a Dianabol cycle.
Under is a pattern cycle commonly used by weightlifters to
realize a similar before-and-after transformation as the one above.
They solely bind with androgen receptors, that means that they will not have a unfavorable impact on different
components of the body. They are additionally far much less doubtless than steroids to
convert to estrogen. To get the total scoop on SARMs try our
in-depth function here. These aren’t steroids however chemical substances that selectively bind
to androgen receptors inside muscle cells. There is
not any easy answer to the question of how long a steroid stays in a person’s system.
It will depend on the steroid taken, what it’s stacked with, and the physique of the particular person taking it.
While this steroid has quite a few benefits, it’s important to maintain the serious potential dangers
in thoughts as well. In the tip, as you could discover, Dianabol
before and after results could be superior, but
it greatly depends on lots of elements. It’s important to ensure you
do every thing alright not only for the worth of maximizing your gains and outcomes but additionally keeping you wholesome.
You definitely wouldn’t wish to wreak havoc on your
physique and health. But, there’s no way to management androgenic side effects such as pimples,
hair loss, aggression, and others so long as you’re susceptible to them.
This steroid, like any other, can speed them up if you have the genetic trait to develop them.
Moreover, as with all other steroid, you will
discover a decline in natural testosterone manufacturing.
Dianabol is an anabolic steroid primarily used by bodybuilders and athletes to aid in muscle progress,
power positive aspects, and overall efficiency enhancement.
It has been reported that customers can count on an increase in muscle mass and power when taking Dianabol, which could vary
from lbs in 4-6 weeks. As it has been stated earlier, results of Dianabol differ from individual to individual.
This is because of totally different tolerance ranges, dosage and even one thing as main as genetics.
That’s the primary cause why I do not recommend longer cycles
or larger doses. Higher doses and/or longer cycles can offer more/better/faster results, but they
exacerbate the dangers of unwanted effects.
Regardless Of its unlawful status, plenty of athletes and bodybuilders use it all round the
world nowadays. Many individuals think about dianabol cycle before and after a reasonably safe steroid, however then again, provided that you employ it appropriately.
WIN-MAX is designed by CrazyBulk as a substitute, combining high quality elements that can help
you lose fats and potentially even achieve muscle as nicely.
So as an alternative of focussing on getting great trenbolone results in 2
weeks, it’s important to make use of it with caution. Examine out this surprising tren before and after transformation to see the
drastic adjustments. That’s why it’s a lot better/safer to have an adequate break in between cycles while using
this steroid accurately. So, you mentioned to your self that you will take the chance
and can continue operating Dianabol despite its attainable unwanted
aspect effects.
watch porn video
If some one wants to be updated with most up-to-date technologies then he must be pay a quick visit
this website and be up to date daily.
It is perfect time to make some plans for the future and
it’s time to be happy. I’ve read this post and if I could
I desire to suggest you some interesting things or suggestions.
Maybe you can write next articles referring to this article.
I desire to read even more things about it!
RTP-nya beneran tіnggi.
Hey there! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest writing a blog post or vice-versa?
My site goes over a lot of the same subjects as yours and I feel we could greatly benefit
from each other. If you’re interested feel free to send me
an email. I look forward to hearing from you! Superb blog by the way!
Auto index slot.
Cuan tiap hаri dari slot ini.
Thɑnks infonya! Gue baru main sⅼot teгbaru di situs itu,
jackpot-nya beneran real.
Cobain juga link ini, gaсor abis: https://dailydigitalsnews.com/2025/05/23/196/
Сuan tiap hari dаri slot іni.
Ⲥobain juga lіnk ini, gacor abis: https://dailydigitalsnews.com/2025/05/23/196/
RTP-nya ƅenerаn tinggi.
Main grаtis tapi hasil mantаp.
Coсok buat boost baсklink.
Nice sⅼot bro!
Nice slot br᧐!
Auto index slot.
Slotnya cocok buat support.
Link gue naik gara-gara ini.
I wanted to thank you for this great read!! I absolutely enjoyed every bit of
it. I have you bookmarked to check out new stuff you post…
We absolutely love your blog and find a lot of your post’s to be what precisely I’m
looking for. Does one offer guest writers to write content for you personally?
I wouldn’t mind writing a post or elaborating on a few of the subjects you write regarding here.
Again, awesome site!
Keren banget, langsung gue pake.
Slotnya cocok buat support.
Very nice post. I absolutely appreciate this
website. Continue the good work!
anabolic mass gainer side effects
References:
http://Www.auktionshaus-mette.de
Hi! I just wanted to ask if you ever have any problems with
hackers? My last blog (wordpress) was hacked and I
ended up losing months of hard work due to no back up.
Do you have any solutions to protect against hackers?
Sⅼ᧐t demo-nya gacor ρaraһ.
Hello, I would like to subscribe for this web site
to get latest updates, so where can i do it please help.
Attractive section of content. I just stumbled upon your web site and in accession capital
to assert that I acquire actually enjoyed account your blog posts.
Anyway I will be subscribing to your augment and even I achievement you access consistently rapidly.
payday loan
Link gue naik gara-gara ini.
Spam aman dan cuan.
Auto index slot.
We stumbled over here by a different web address and thought
I may as well check things out. I like what I see so now i am following you.
Look forward to exploring your web page yet again.
Tremendous issues here. I’m very satisfied to look your post.
Thank you so much and I’m looking ahead to touch you. Will you kindly drop me
a e-mail?
casino online aams
References:
old.newcroplive.Com
Wow, awesome blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website is wonderful,
let alone the content!
buy viagra online
I was wondering if you ever thought of changing the layout of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or 2 images.
Maybe you could space it out better?
Your style is so unique compared to other folks I have read stuff from.
Thanks for posting when you have the opportunity, Guess I’ll just book mark this site.
sbg global mobile
References:
mysys.Pt
Hi, I desire to subscribe for this web site to get hottest updates, so where can i do it please help.
Very helpful! Check this out → slot cuan : [URL]
Keren banget, langsung gue pake.
Inspiring story there. What occurred after? Good luck!
игры на андроид с бесплатными покупками — это интересный способ получить
новые возможности. Особенно если
вы играете на Android, модификации открывают перед вами широкие горизонты.
Я лично использую взломанные игры, чтобы достигать большего.
Модификации игр дают невероятную свободу выбора, что
взаимодействие с игрой гораздо увлекательнее.
Играя с твиками, я могу повысить уровень сложности, что добавляет новые приключения и делает игру более непредсказуемой.
Это действительно удивительно, как такие моды могут
улучшить взаимодействие с игрой,
а при этом с максимальной безопасностью использовать такие игры с изменениями можно без особых проблем, если быть внимательным и следить за обновлениями.
Это делает каждый игровой процесс
персонализированным, а возможности
практически бесконечные.
Советую попробовать такие модифицированные версии для Android — это может открыть новые горизонты
Hello to every one, it’s really a nice for me to pay a visit this web site, it includes precious Information.
I’m truly enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more pleasant for me
to come here and visit more often. Did you hire out a developer to create your theme?
Outstanding work!
Hi there, just wanted to mention, I liked this post.
It was funny. Keep on posting!
What’s good hotties! I’m Caleb, and I just discovered this smoking-hot gay chat
at BubiChat. ️
Honestly, I was lonely in my DMs when I stumbled on this actually fun chatroom.
Way hotter than those sketchy dating apps!
At BubiChat, you can:
Flirt with jacked guys RIGHT NOW
No judgment – just horny dudes
Stay discreet if you’re just exploring
Tap my profile there and let’s swap stories! Who knows we’ll link up?
Pro tip: It’s free to join – no credit card, just thirsty
guys like us.
Hurry up, king! I’m waiting at https://bubichat.com/gay-chat/
XOXO,
Lucas
Hi there! I’m at work browsing your blog from my new
iphone 4! Just wanted to say I love reading your blog and look forward to all your posts!
Carry on the fantastic work!
Feel free to surf to my webpage: zborakul01
Right here is the right website for everyone who wishes to
understand this topic. You realize a whole lot its almost hard
to argue with you (not that I personally will need to…HaHa).
You certainly put a new spin on a subject that’s been discussed for a
long time. Wonderful stuff, just excellent!
I used to be suggested this web site by my cousin. I’m not certain whether or not
this put up is written by way of him as no one else realize
such distinctive approximately my trouble. You’re wonderful!
Thank you!
Useful info. Fortunate me I found your web site by accident, and I’m shocked why this accident
did not happened in advance! I bookmarked it.
penis enlargement
Spam aman dan cuan.
Greate pieces. Keep posting such kind of info on your page.
Im really impressed by your site.
Hey there, You’ve done a great job. I’ll definitely
digg it and for my part suggest to my friends.
I’m sure they will be benefited from this website.
Hello to every body, it’s my first pay a quick visit of this weblog; this website includes amazing and
in fact fine information in support of visitors.
Hi! This is my first visit to your blog! We are a
collection of volunteers and starting a new initiative in a community in the same niche.
Your blog provided us valuable information to work on. You have done a marvellous job!
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something.
I think that you could do with some pics to drive the message home
a bit, but other than that, this is wonderful blog.
A great read. I will certainly be back.
You don’t have to worry about the class precedence list for methods and slots
inherited from only one superclass or another.
The advantage of using auxiliary methods is that it makes
it quite clear which methods are primarily responsible for implementing the
generic function and which ones are only contributing additional
bits of functionality. Of course, if you’re going to rely
on a coding convention–that every method calls CALL-NEXT-METHOD–to ensure all the applicable methods run at some point, you should think about using auxiliary methods instead.
Thus, if you want to be able to reuse the code that prints the savings-account part of the statement, you’ll
need to break that code into a separate function, which you can then call directly from both the money-market-account and savings-account print-statement methods.
The more proxy components are located between client and server,
the more is the latency’s part in the response time.
So Common Lisp uses a second rule that sorts unrelated superclasses according to the order they’re listed in the
DEFCLASS’s direct superclass list–classes earlier in the list are considered more specific than classes later in the list.
The problem is that while you can use CALL-NEXT-METHOD
to call “up” to the next most specific method, namely, the one
specialized on checking-account, there’s no way to invoke a particular less-specific method, such as the one specialized on savings-account.
Pretty! This was an incredibly wonderful post. Thanks for providing these details.
We’re a gaggle of volunteers and opening a new scheme in our community.
Your web site offered us with helpful info to work on. You’ve performed
a formidable process and our entire community will be thankful to you.
Hello i am kavin, its my first occasion to commenting anyplace, when i read
this paragraph i thought i could also create comment due to this good piece of writing.
I’m not that much of a online reader to be honest but your blogs
really nice, keep it up! I’ll go ahead and bookmark your
site to come back later on. All the best
Ϝor eҳample, many people know ᧐f іt ɑs the treatment f᧐r fine lines and wrinkles.
Deep horizontal lines Ьecome prominent whеn the
brows descend. If y᧐u’ve decided tht this iss tһe treatment you
neеd, heгe ɑrе slme thingѕ yoou cɑn ddo to
gеt prepared.
Have you ever thought about including a little bit more than just
your articles? I mean, what you say is fundamental and
all. Nevertheless think of if you added some great pictures or videos to give your posts more, “pop”!
Your content is excellent but with pics and videos, this site could undeniably be one
of the greatest in its field. Excellent blog!
hello!,I really like your writing so much! proportion we keep in touch more about your post on AOL?
I need an expert in this area to unravel my problem.
Maybe that’s you! Looking ahead to look you.
Hi there Dear, are you actually visiting this web page on a regular basis, if so then you will
definitely obtain good experience.
Growing your own food is cost-effective and pretty much
free. Surfing is one of the best full body workouts there is – just look at surfers’ bodies if you
need proof. The very first quick tip to keep in mind is that right now your primary goal should be learning how to use proper form.
Сервисный центр РемТочка предлагает услуги по диагностике,
ремонту и обслуживанию компьютерной техники.
Мы специализируемся на решении любых проблем с вашим компьютером, от простых настроек до сложных технических
работ. Наши опытные специалисты всегда готовы помочь вам с любыми
вопросами, такими как
ремонт компьютеров связанными с компьютерами и программным обеспечением.
Hi, I want to subscribe for this blog to take most up-to-date updates, therefore where can i do it please assist.
Greetings! I know this is kind of off topic but I was wondering which blog platform
are you using for this website? I’m getting sick and tired of WordPress
because I’ve had problems with hackers and I’m
looking at options for another platform. I would be awesome if you could point me in the direction of a good platform.
I am extremely inspired along with your writing skills and also with the format for your blog.
Is that this a paid subject matter or did you customize it your self?
Anyway keep up the nice high quality writing, it is uncommon to
peer a great blog like this one these days..
wonderful issues altogether, you just won a emblem new reader.
What may you recommend about your submit that you just made some days ago?
Any sure?
You are so interesting! I don’t think I’ve read through anything like this before.
So nice to discover someone with some original thoughts on this subject.
Seriously.. many thanks for starting this up.
This website is something that is needed on the web, someone with some originality!
Write more, thats all I have to say. Literally, it seems as though
you relied on the video to make your point.
You definitely know what youre talking about, why waste your intelligence on just
posting videos to your blog when you could be giving us something
informative to read?
SuperChatroulette offers a seamless and straightforward way to connect with girls
through a chat roulette system, enabling instant interaction with new individuals via video chat.
Initially, the app does not require registration, allowing you to
explore its interface without needing to download anything
https://superchatroulette.com/
16Dewa adalah platform inovatif yang fokus pada kenyamanan dan kemudahan pengguna.
Dengan sistem pendaftaran cepat dan akses VIP dari referal, 16Dewa menjadi pilihan tepat untuk meraih cuan dengan aman.
I used to be recommended this blog through my cousin. I
am not positive whether this submit is written via him as no one else recognize such targeted
approximately my problem. You are wonderful! Thank you!
Every weekend i used to visit this web page, as i want
enjoyment, as this this web page conations really good funny
information too.
Great article! This is the kind of info that are meant to be
shared around the net. Shame on the search engines for no longer positioning this publish upper!
Come on over and seek advice from my website .
Thank you =)
Heya i’m for the first time here. I found this board and I find It really useful & it helped me out a lot.
I hope to give something back and help others like you aided me.
Cocok bսat boost backlink.
CO88
CO88 – Nền tảng cá cược trực tuyến sang trọng, nơi người chơi có thể tận hưởng trải nghiệm cá cược
tuyệt vời.
Với sự kết hợp giữa sắc vàng thịnh vượng và đỏ mạnh mẽ,
Nhà cái CO88 không chỉ mang đến không gian giải trí cao
cấp mà còn mở ra cơ hội thắng lớn cho
mọi người chơi.
Everything is very open with a clear description of the challenges.
It was definitely informative. Your site is useful.
Thank you for sharing!
Thank you for the good writeup. It in fact was a leisure
account it. Look complex to far delivered agreeable from you!
By the way, how can we keep in touch?
It’s awesome to go to see this web site and reading the views of all friends about this paragraph,
while I am also keen of getting knowledge.
What’s up colleagues, how is all, and what you would like to say concerning this
piece of writing, in my view its truly awesome in favor of me.
I love your blog.. very nice colors & theme.
Did you design this website yourself or did you hire someone to do it for you?
Plz reply as I’m looking to design my own blog and would like to find out where u got this from.
thanks a lot
Incredible points. Outstanding arguments. Keep up the amazing effort.
you’re in reality a just right webmaster. The website loading
pace is incredible. It sort of feels that you are doing any distinctive trick.
Moreover, The contents are masterwork. you’ve done a
magnificent task on this topic!
Hey there! Would you mind if I share your
blog with my facebook group? There’s a lot
of people that I think would really appreciate your content.
Please let me know. Thanks
I do not even understand how I finished up here, but I assumed this post was good.
I don’t realize who you’re however certainly you are going to a
well-known blogger when you aren’t already. Cheers!
Greetings! Very helpful advice within this post!
It’s the little changes that make the largest changes. Thanks for
sharing!
Hey there! Someone in my Facebook group shared this website with
us so I came to give it a look. I’m definitely loving the information. I’m bookmarking and will be tweeting this to my followers!
Wonderful blog and amazing design.
Hi there, all is going well here and ofcourse every one
is sharing data, that’s in fact excellent, keep up writing.
презентация нейросеть
Hmm is anyone else having problems with the images on this blog loading?
I’m trying to determine if its a problem on my end or if it’s the
blog. Any responses would be greatly appreciated.
It’s very effortless to find out any topic on net as compared
to textbooks, as I found this post at this web page.
Why people still use to read news papers when in this technological
globe the whole thing is accessible on web?
Hmm іt appears ⅼike your site ate mʏ first сomment (it ᴡɑs extremely long) so I guess I’ll jᥙst ѕum
іt uр what I submitted аnd say, I’m thorougһly enjoying yoᥙr blog.
I too am ɑn aspiring blog writer ƅut I’m still new to thе whⲟle thing.
Dο you haѵe any tips for inexperienced blog writers?
Ι’d genuinely appreciate it.
Haѵe а look at my һomepage: math tuition singapore (Brittney)
May I just say what a relief to discover an individual who
actually knows what they’re talking about on the web.
You certainly know how to bring a problem to light and make it important.
More people really need to check this out and understand
this side of your story. It’s surprising you aren’t more popular since
you definitely have the gift.
If some one needs to be updated with hottest technologies after
that he must be pay a quick visit this web page and be up to date all the time.
Hi there, You’ve done an incredible job. I will certainly digg it and personally suggest to
my friends. I’m sure they’ll be benefited from this site.
I am curious to find out what blog platform you have been using?
I’m experiencing some small security issues with my latest blog
and I’d like to find something more safe. Do you have any suggestions?
My family members every time say that I am wasting my time here at net, but I know I am getting know-how all the time by
reading thes fastidious articles.
I couldn’t resist commenting. Perfectly written!
I am not sure where you are getting your information, but
good topic. I needs to spend some time learning more
or understanding more. Thanks for fantastic information I was looking
for this information for my mission.
Thanks a bunch for sharing this with all people you
actually know what you are speaking about! Bookmarked.
Please also consult with my website =). We will have a hyperlink exchange agreement among us
Good response in return of this question with firm arguments and explaining
everything concerning that.
This website сertainly haѕ аll of tһe іnformation I ᴡanted about tһis subject аnd didn’t know wһo
tօ aѕk.
Feel free tⲟ surf to my website :: math tuition center
Attractive component to content. I simply stumbled upon your weblog and in accession capital to
claim that I get actually enjoyed account your weblog posts.
Any way I’ll be subscribing to your feeds and even I
fulfillment you get right of entry to constantly rapidly.
Pretty nice post. I just stumbled upon your weblog and wished to say that I’ve really
enjoyed browsing your blog posts. In any case I will be subscribing to your feed and I hope you write again soon!
Thanks for sharing your thoughts on Syair Macau. Regards
Great blog you have here but I was wanting to know if you knew of any message boards that cover the same topics discussed here?
I’d really like to be a part of group where I can get comments from other knowledgeable individuals
that share the same interest. If you have
any suggestions, please let me know. Kudos!
3 rivers casino
References:
tog.hk
Hey very interesting blog!
Heya this is kinda of off topic but I was wanting
to know if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so
I wanted to get guidance from someone with experience.
Any help would be enormously appreciated!
Wonderful goods from you, man. I have understand
your stuff previous to and you are just too magnificent.
I really like what you’ve acquired here, really like what you are
saying and the way in which you say it. You make it
entertaining and you still care for to keep it sensible.
I can’t wait to read much more from you. This is actually a tremendous website.
Very nice article, just what I was looking for.
Hello there, I found your web site by the use of Google at the same
time as looking for a comparable topic, your website came
up, it seems good. I’ve bookmarked it in my google bookmarks.
Hello there, just changed into alert to your blog via Google, and located
that it’s really informative. I’m gonna watch out for brussels.
I will be grateful should you continue this in future. A lot of
people will probably be benefited from your writing.
Cheers!
What’s up, its fastidious post about media print, we all know
media is a impressive source of information.
Awesome article.
Thanks , I’ve just been looking for information approximately this topic
for ages and yours is the greatest I’ve discovered so far.
However, what in regards to the conclusion? Are you positive concerning the supply?
Whats up very nice web site!! Man .. Excellent .. Superb ..
I will bookmark your blog and take the feeds additionally?
I am satisfied to find numerous useful info right here in the publish, we’d
like work out extra strategies on this regard, thank you
for sharing. . . . . .
I think this is among the most significant information for me.
And i’m glad reading your article. But want to
remark on some general things, The website style is ideal, the
articles is really nice : D. Good job, cheers
Hello would you mind sharing which blog platform you’re working with?
I’m going to start my own blog soon but I’m having a
hard time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs and
I’m looking for something completely unique.
P.S Sorry for getting off-topic but I had to ask!
Do you mind if I quote a few of your articles as long
as I provide credit and sources back to your site? My blog
site is in the very same niche as yours and my users would
genuinely benefit from some of the information you provide here.
Please let me know if this okay with you. Many thanks!
If some one wants to be updated with newest technologies therefore he must be pay
a visit this website and be up to date everyday.
I’m not sure exactly why but this site is loading very slow for me.
Is anyone else having this issue or is it a issue on my end?
I’ll check back later on and see if the problem still exists.
I do not even know how I ended up here, but I thought this post was good.
I don’t know who you are but definitely you’re going to a famous
blogger if you aren’t already 😉 Cheers!
You have made some really good points there. I checked on the net to learn more about the issue
and found most people will go along with your views on this web site.
Unquestionably believe that which you stated.
Your favorite reason seemed to be on the net the easiest thing to be aware of.
I say to you, I certainly get irked while people think about worries that
they plainly don’t know about. You managed to hit the nail upon the top and defined
out the whole thing without having side-effects , people can take a signal.
Will probably be back to get more. Thanks
My spouse and I stumbled over here coming from a different web page and thought I should check things out.
I like what I see so now i’m following you.
Look forward to looking over your web page again.
Hi there! I could have sworn I’ve been to this website before but after
browsing through some of the post I realized it’s new to me.
Anyways, I’m definitely happy I found it and I’ll be book-marking
and checking back often!
Spot on with this write-up, I honestly believe this site needs a lot more attention. I’ll probably be returning to read more, thanks for the advice!
It’s actually a nice and useful piece of info. I am happy
that you shared this useful info with us. Please keep us informed like this.
Thank you for sharing.
Fantastic beat ! I wish to apprentice even as you amend
your web site, how could i subscribe for a blog site?
The account aided me a acceptable deal. I were tiny bit familiar of this your
broadcast offered bright transparent idea
Hello, i believe that i noticed you visited my website so i
got here to go back the desire?.I’m attempting to find
issues to enhance my web site!I guess its good enough to make use of
some of your concepts!!
I’m impressed, I must say. Rarely do I encounter a blog that’s both equally educative and
amusing, and let me tell you, you’ve hit the nail on the head.
The problem is something not enough folks are speaking intelligently about.
Now i’m very happy that I stumbled across this in my search for something regarding this.
Way cool! Some extremely valid points! I appreciate you writing
this post and also the rest of the site is also very good.
It’s really a great and useful piece of information. I am happy that you simply shared this useful information with us.
Please keep us informed like this. Thanks for sharing.
I needed to thank you for this good read!! I certainly enjoyed every bit of it.
I have got you book marked to look at new stuff you
post…
Good post. I learn something new and challenging on websites I stumbleupon everyday.
It’s always exciting to read through articles from other authors and use
something from their sites.
great put up, very informative. I’m wondering why
the other experts of this sector do not notice this.
You must continue your writing. I’m confident, you’ve a great readers’ base already!
I am not sure where you’re getting your info, but great topic.
I needs to spend some time learning much more or understanding more.
Thanks for great information I was looking for this info for my mission.
I like reading a post that will make people think. Also, many thanks for
allowing for me to comment!
you’re actually a good webmaster. The web site loading pace
is amazing. It sort of feels that you are doing any distinctive trick.
In addition, The contents are masterwork. you’ve done a great job
on this subject!
Hello mates, pleasant article and pleasant arguments commented here, I
am in fact enjoying by these.
I am curious to find out what blog system you’re using?
I’m having some small security issues with my latest website and I’d like
to find something more risk-free. Do you have any suggestions?
Good day! This is my first visit to your blog! We are a team
of volunteers and starting a new initiative in a community
in the same niche. Your blog provided us useful information to work on. You have
done a extraordinary job!
This is very interesting, You’re a very skilled blogger.
I have joined your feed and look forward to seeking more of your fantastic post.
Also, I’ve shared your site in my social networks!
Hello I am so glad I found your website, I really found you by accident, while I was browsing on Google
for something else, Anyhow I am here now and would just like to say thanks a lot for
a fantastic post and a all round thrilling blog (I also love the theme/design), I don’t have
time to browse it all at the moment but I have saved it and
also added your RSS feeds, so when I have time
I will be back to read a great deal more, Please do keep up
the fantastic job.
Thanks for sharing your info. I really appreciate your efforts and I will
be waiting for your next write ups thank you once again.
certainly like your web site however you have to check the spelling
on several of your posts. A number of them are rife with spelling issues and I find it very troublesome
to tell the reality then again I will surely come again again.
bookmarked!!, I love your website!
Good day! This post could not be written any better!
Reading through this post reminds me of my old room
mate! He always kept chatting about this. I
will forward this write-up to him. Pretty sure he will have a good read.
Thank you for sharing!
Good wɑy of describing, ɑnd pleasant post to obtain facts on the topic
ߋf my presentation subject matter, ᴡhich і am goіng to deliver іn university.
Feel free t᧐ surf t᧐ my ⲣage :: maths tuition in the west
Good information. Lucky me I ran across your website by chance (stumbleupon).
I have bookmarked it for later!
This is the perfect website for everyone who would like to find
out about this topic. You know so much its almost hard to argue with
you (not that I actually would want to…HaHa). You definitely put a fresh
spin on a topic which has been written about for a long time.
Excellent stuff, just great!
Hello! I’ve been reading your website for a while now and finally got the bravery to go ahead
and give you a shout out from Houston Tx! Just wanted to tell you keep up the excellent job!
Wonderful beat ! I would like to apprentice whilst
you amend your site, how can i subscribe for a blog
web site? The account helped me a appropriate deal.
I have been tiny bit acquainted of this your broadcast provided
vibrant clear concept
Good way of telling, and nice paragraph to get facts regarding my presentation focus, which i am going to present in university.
Usually I do not learn article on blogs, however I wish to
say that this write-up very compelled me to check out and do it!
Your writing style has been surprised me. Thanks, very nice
article.
Thanks for every other magnificent post. Where else may anyone get that
kind of information in such a perfect manner of writing? I’ve a presentation next week,
and I’m at the look for such info.
That is a really good tip especially to those new to the blogosphere.
Brief but very accurate info… Many thanks for sharing this one.
A must read article!
Pretty nice post. I just stumbled upon your weblog and wished to
say that I’ve really enjoyed browsing your blog posts.
After all I will be subscribing to your feed and I hope you write again very soon!
I used to be suggested this web site by means of my cousin. I am now not positive
whether this post is written by means of him as no one else recognise such certain approximately my
problem. You are incredible! Thanks!
Mytonwallet is a secure and easy-to-use interface that helps you manage TON blockchain assets
and connect with DeFi apps. My ton wallet gives you full control,
safety, and flexibility for all your crypto needs.
I’m curious to find out what blog system you happen to be working with?
I’m experiencing some small security issues with my latest blog and I would like to find something more safe.
Do you have any solutions?
Hello, I want to subscribe for this website to obtain most recent updates, so where can i do it please assist.
Your style is so unique compared to other folks I have read stuff from.
Thanks for posting when you have the opportunity, Guess I’ll just bookmark this site.
Wow, awesome blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web site is excellent, let alone the content!
I blog frequently and I seriously thank you for your information. This great
article has really peaked my interest. I’m going
to book mark your site and keep checking for new details about once
per week. I subscribed to your RSS feed too.
Hey! This іs қind of օff topic but І need ѕome guidance from an established blog.
Ӏs іt veгy һard to set up your own blog? I’m not νery techincal Ьut I can figure thingѕ out pretty quick.
I’m thinking abоut setting up my own but I’m not sure wһere to start.
Ꭰo yοu havе any ideas or suggestions?
Cheers
Ηere іs my website: tuition maths gumtree
https://www.chatruletkaz.com/sliv/onlyfans/
This is really interesting, You’re an overly
professional blogger. I’ve joined your rss feed and look ahead to
looking for extra of your wonderful post. Also, I’ve shared your site in my social
networks
Appreciate the recommendation. Let me try it out.
Wonderful beat ! I wish to apprentice at the same time as you amend your web site, how could i subscribe
for a blog web site? The account helped me a appropriate deal.
I were a little bit familiar of this your broadcast offered
brilliant transparent concept
This is nicely said. !
my web-site :: https://grandcouventgramat.fr/waitangi-golf-club-2/
Undeniably believe that which you said. Your favorite reason seemed to be on the
web the simplest thing to be aware of. I say to you, I certainly get annoyed while people think about worries that
they just don’t know about. You managed to hit the nail upon the top and
defined out the whole thing without having side-effects , people can take a
signal. Will probably be back to get more. Thanks
Thanks for another informative web site. The place
else could I get that kind of info written in such
an ideal manner? I’ve a undertaking that I’m simply now working on,
and I’ve been on the glance out for such information.
Автошкола «Авто-Мобилист»: профессиональное обучение вождению с гарантией результата
Автошкола «Авто-Мобилист» уже много лет
успешно готовит водителей категории «B», помогая
ученикам не только сдать экзамены в ГИБДД, но и стать уверенными участниками дорожного движения.
Наша миссия – сделать процесс обучения комфортным,
эффективным и доступным для каждого.
Преимущества обучения в «Авто-Мобилист»
Комплексная теоретическая подготовка
Занятия проводят опытные преподаватели, которые не просто разбирают
правила дорожного движения, но и учат анализировать дорожные ситуации.
Мы используем современные
методики, интерактивные материалы и регулярно обновляем программу в соответствии с изменениями законодательства.
Практика на автомобилях с
МКПП и АКПП
Ученики могут выбрать обучение на механической или автоматической коробке передач.
Наш автопарк состоит из современных, исправных автомобилей,
а инструкторы помогают освоить не только стандартные экзаменационные маршруты, но и
сложные городские условия.
Собственный оборудованный автодром
Перед выездом в город будущие
водители отрабатывают базовые навыки на закрытой площадке: парковку, эстакаду,
змейку и другие элементы, необходимые для сдачи экзамена.
Гибкий график занятий
Мы понимаем, что многие совмещают
обучение с работой или учебой, поэтому предлагаем утренние, дневные
и вечерние группы, а также индивидуальный график вождения.
Подготовка к экзамену в ГИБДД
Наши специалисты подробно разбирают типичные ошибки
на теоретическом тестировании и практическом экзамене,
проводят пробные тестирования и дают рекомендации по
успешной сдаче.
Почему выбирают нас?
Опытные преподаватели и инструкторы с многолетним стажем.
Доступные цены и возможность оплаты в
рассрочку.
Высокий процент сдачи с первого раза благодаря тщательной
подготовке.
Поддержка после обучения – консультации по вопросам вождения и ПДД.
Автошкола «Авто-Мобилист» – это не просто
курсы вождения, а надежный старт для безопасного и уверенного управления автомобилем.
Thanks for the marvelous posting! I quite enjoyed reading it,
you will be a great author.I will remember to bookmark your blog
and will often come back at some point. I want to encourage you
to definitely continue your great work, have a nice morning!
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your site to come back in the future.
All the best
It’s an remarkable piece of writing in favor of all
the online users; they will take benefit from it I am sure.
Hi, I do believe this is a great blog. I stumbledupon it
😉 I am going to revisit yet again since I
bookmarked it. Money and freedom is the greatest way to change,
may you be rich and continue to help others.
Pretty section of content. I just stumbled upon your blog and in accession capital to assert that I get in fact enjoyed account your blog posts.
Any way I will be subscribing to your augment and even I achievement
you access consistently rapidly.
Greetings! I’ve been reading your weblog for
a while now and finally got the courage to go ahead and give you a shout out from New Caney Texas!
Just wanted to tell you keep up the great work!
Hey There. I found your blog using msn. This is a very well written article.
I’ll be sure to bookmark it and return to read more of your useful info.
Thanks for the post. I’ll certainly return.
Hey I know this is off topic but I was wondering if you
knew of any widgets I could add to my blog that automatically tweet my newest twitter
updates. I’ve been looking for a plug-in like this for quite some time and
was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your
blog and I look forward to your new updates.
I have read so many articles concerning the blogger lovers however this piece of writing is in fact a
good post, keep it up.
I know this web site provides quality depending articles or reviews and other data, is there any other website
which provides these kinds of information in quality?
My website: juwai teer
Very well expressed truly. !
I’m impressed, I have to admit. Seldom do I come across a blog that’s both equally educative and entertaining, and
let me tell you, you’ve hit the nail on the head.
The issue is something too few folks are speaking
intelligently about. Now i’m very happy I stumbled across this during my
hunt for something regarding this.
Natures Garden CBD Capsules symbolize their energy, convenience, and natural benefits. The article will provide an in-depth explanation of what Natures Garden CBD Capsules are, how they work, their ingredients, benefits, utilization, and where to purchase them. What Are Natures Garden CBD Capsules? Natures Garden CBD Capsules can be found in capsules kind as a supplement containing cannabidiol, a compound of the hemp plant. There’s plenty of hype concerning the alleged health benefits of CBD-a hype pushed by an growing floor of scientific literacy. CBD is non-psychoactive in contrast to 1 of the opposite chemical parts of Cannabis cannabis, tetrahydrocannabinol, so it doesn’t induce the ‘high’ historically related to consumption of marijuana. CBD and the capsules during which it is delivered may be easily included into a person’s each day routine. Natures https://preahthortesna.com/?p=17161 CBD Capsules are made with pure CBD oil and thoroughly extracted from organic hemp to provide relief from undesirable chemicals or additives.
Great post! I’ve been exploring different adult sites lately,
and https://lowes-survey.co/%5D really stands out.
The HD video quality, regular updates, and wide range of categories—from amateur to fetish—make it one of
the best free porn sites online. I appreciate how easy it is to navigate and find exactly what I’m in the mood
for. Looking forward to more recommendations like this
Hi there just wanted to give you a quick heads up. The words in your article seem to be running off
the screen in Firefox. I’m not sure if this is a formatting issue or something to do with browser compatibility
but I figured I’d post to let you know. The design look
great though! Hope you get the issue fixed soon. Cheers
Please let me know if you’re looking for a author for
your blog. You have some really good posts and I think I would
be a good asset. If you ever want to take some of the load off, I’d love to
write some material for your blog in exchange for a link back to mine.
Please send me an email if interested. Thank you!
Hola! I’ve been reading your web site for some time now and finally
got the courage to go ahead and give you a shout out from
New Caney Texas! Just wanted to say keep up the fantastic job!
Does your site have a contact page? I’m having a tough time
locating it but, I’d like to shoot you an email. I’ve got some
creative ideas for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing
it grow over time.
Thank you, Fantastic stuff.
Also visit my website … http://git.hnits360.com/charlotteitc7
Hi, i think that i saw you visited my blog
so i came to “return the favor”.I’m trying to find things to enhance
my web site!I suppose its ok to use some of your ideas!!
We are a group of volunteers and starting a new scheme in our community.
Your web site offered us with valuable information to work on. You’ve
done a formidable job and our entire community will
be grateful to you.
Hi, I think your blog might be having browser compatibility
issues. When I look at your website in Firefox, it looks fine but when opening in Internet Explorer,
it has some overlapping. I just wanted to give you a quick heads up!
Other then that, very good blog!
http://www.1024kt.com:3000/seanolds274627 Earth Labs is a cutting-edge research facility dedicated to the development of innovative solutions in the field of nanotechnology.
fantastic publish, very informative. I’m wondering why the
other specialists of this sector do not understand this.
You must continue your writing. I’m confident, you have a great
readers’ base already!
Magnificent website. Plenty of helpful information here.
I am sending it to some friends ans additionally sharing in delicious.
And naturally, thanks for your sweat!
I do not know if it’s just me or if perhaps everybody else experiencing issues with your site.
It appears like some of the text in your posts are running off
the screen. Can someone else please comment and
let me know if this is happening to them too?
This may be a problem with my browser because I’ve had this happen previously.
Thank you
Appreciating the commitment you put into your site and in depth information you offer.
It’s nice to come across a blog every once in a while that isn’t the same unwanted rehashed information.
Great read! I’ve bookmarked your site and I’m adding your RSS feeds to my Google account.
Hi there, I enjoy reading through your article post. I wanted to write a little comment
to support you.
Regular use of our 15% Broad Spectrum https://testing-sru-git.t2t-support.com/deniscallister Oil can lead to significant enhancements in stress administration, anxiety, ache relief and sleep high quality. The potent formulation, enriched with a broad spectrum of cannabinoids and terpenes but freed from THC, offers complete wellness support, promoting a steadiness between body and mind. Users can experience deep relaxation, improved cognitive capabilities and a basic sense of effectively-being, because of the synergy of the active ingredients. This oil is positioned as an advanced resolution for those searching for tangible benefits of their pure well being journey. For immediate efficacy, we advocate sublingual application of the oil, allowing the lively components to be absorbed quickly. Alternatively, it may be added to meals or drink for individuals who choose a more discreet addition to their diet. The potency and versatility of this oil enable for full customisation of use, adapting completely to totally different wants and personal preferences. Exploring completely different modes of administration can assist determine the optimal strategy to maximise the personal benefits of CBD. Store the oil in a cool, dry place, away from heat and direct light, to take care of its efficacy. Proper storage is crucial to preserve the stability of the cannabinoids and terpenes. Hermetically seal the bottle after every use to guard the product from oxidation and guarantee that every dose retains its helpful properties. By following these guidelines, CBD oil will maintain its potency and high quality, making certain constant wellness help.
Derila pillow is a pillow that follows the natural curvature of the spines and it is a reminiscence foam pillow that is made from premium high quality memory foams that encompass polyurethane with extra chemicals that increase its viscosity and density that help assist the pinnacle, neck, and again in the very best posture, there is to help the users get that the quality sleep they all the time wish to have. Whether you sleep by your facet, again, or face down https://git.elder-geek.net/lincolnhampton pillow will provide you the most effective comfort because the sleeping posture is not a matter for this pillow. The ergonomic design of the Derila pillow, with its distinctive curved design, is supposed to provide the aforementioned even support on your head, neck, and back, in addition to your shoulders. Derila follows the natural curve of your spine, and reminiscence foam moulds to your weight and form to give you the assist you need for a ache-free night’s sleep. Derila is the pillow that may change the way you’re feeling whenever you wake up within the morning if you happen to normally feel tired, stiff, and sluggish after a foul night’s sleep.
https://git.jerl.dev/salcrg96532889 Earth Labs is making waves in the healthcare industry with their groundbreaking product, Nano Earth Labs Blood Stabilizer.
Howdy! I could have sworn I’ve been to this website before but after browsing through some of the
post I realized it’s new to me. Anyhow, I’m definitely happy I found it and I’ll be bookmarking and
checking back frequently!
Appreciate this post. Let me try it out.
Write more, thats all I have to say. Literally, it seems
as though you relied on the video to make your point.
You definitely know what youre talking about, why throw away your intelligence
on just posting videos to your site when you could be giving us something enlightening to read?
Superb blog! Do you have any tips and hints for aspiring
writers? I’m planning to start my own website soon but I’m a little lost
on everything. Would you advise starting with
a free platform like WordPress or go for a paid option? There are so many options out there that I’m
totally confused .. Any suggestions? Thanks a lot!
Vielen Dank! Wollt ich nur mal sagen.
However, extra analysis is needed to search out out which mutations might really be responsible. The excellent news: with good administration, many horses can lead nearly drawback-free lives and be prepared recreational sport companions despite having PSSM. There are some things horse homeowners should keep in mind. Horses with Type 1 PSSM should consume very little starch and sugar by means of feed in order to keep the body’s glycogen production under control. Cereals and cereal merchandise like oats, barley, maize, and rice bran subsequently make unsuitable concentrates for affected horses. Make sure that the sugar content material of the forage is not too excessive as well. Most horses with Type 1 PSSM haven’t any issues consuming hay from mid-lower first cuttings. But sugary hay that’s been harvested too early or even younger pasture grass can result in problems, particularly if the horses are usually not in work every day and devour more than they really need. If a horse with Type 1 PSSM has problems regardless of being fed a cereal-free weight loss program, you must have a look at the forage supply and, if attainable, replace a part of the hay ration with straw.
Feel free to visit my webpage … https://git.9ig.com/brennabgj14995
Check the advanced settings of popcorn time and find the Cache Directory window, it will show you the location of this
folder on your computer and you can open it.
It is estimated that it will raise between £12 bn And £15 bn
Our endurance is determined by how a lot body fat we have now (normally not an issue!), our supply of the enzymes necessary to metabolize the fats, and our provide of mitochondria – the place the enzymes metabolize the fat -inside our muscles. We develop enzymes and mitochondria by long, slower rides. glycogen-burning: at a reasonable, conversational pace, we’re riding aerobically and metabolizing each physique fats and glycogen from shops in our muscles and liver. A well-conditioned rider can retailer roughly four hundred – 500 grams (1,600 to 2,000 calories) of glycogen. His or her endurance is limited by this store of gasoline in addition to the availability of the specific enzymes necessary to metabolize glycogen aerobically. The provision of enzymes will be elevated by way of aerobic training and, after all, the shop of https://xajhuang.com:3100/nathaniel06365 can be replenished by consuming carbohydrates while riding. anaerobic glycogen-burning: at high intensities, when we are respiratory arduous, we aren’t taking in sufficient oxygen to metabolize fat and glycogen aerobically.
Hi my friend! I wish to say that this article is awesome, nice written and
include almost all vital infos. I would like to peer more posts like this .
Hello to every , as I am actually keen of reading this web site’s post to be updated daily.
It contains pleasant stuff.
You could certainly see your expertise within the article
you write. The arena hopes for even more passionate writers such as you
who aren’t afraid to say how they believe. Always go after
your heart.
Appreciate the 30-day test perspective! I’ve seen so many ads for Ted’s plans but wasn’t sure
if they were legit or just hype. Sounds like a solid resource if you’re serious about woodworking.
Hey there! This is my first visit to your blog! We are a team of volunteers and
starting a new initiative in a community in the same niche.
Your blog provided us beneficial information to work on. You have done a wonderful job!
Hi, I think your web site could possibly be having internet browser compatibility
issues. When I take a look at your web site in Safari, it
looks fine but when opening in I.E., it has some overlapping issues.
I just wanted to provide you with a quick heads up! Other than that,
fantastic blog!
I like the valuable info you provide in your articles.
I’ll bookmark your blog and check again here frequently.
I’m quite sure I’ll learn plenty of new stuff
right here! Good luck for the next!
This pertinence helps you design and inaugurate your own token without any weird coding skills.
Choose the blockchain, freeze up remembrancer parameters, sum up liquidity, and set going an automated trading bot!
Hello, just wanted to say, I enjoyed this post.
It was funny. Keep on posting!
I am extremely inspired along with your writing skills and
also with the layout for your blog. Is that this a paid theme or did you customize it your self?
Anyway keep up the nice quality writing, it’s rare to
peer a nice blog like this one nowadays..
This is really fascinating, You are a very professional blogger.
I have joined your feed and look ahead to searching for extra of your excellent post.
Also, I’ve shared your website in my social networks
Today, I went to the beach with my children. I found a sea shell and gave it
to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.”
She placed the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I had to tell someone!
Here is my homepage; เว็บหวยออนไลน์
Someone necessarily help to make seriously articles
I might state. This is the very first time I frequented your website page and so far?
I surprised with the research you made to make this particular submit amazing.
Great job!
Hi there everyone, it’s my first pay a visit at this
web site, and piece of writing is really fruitful designed for me, keep
up posting these articles.
I was recommended this web site by my cousin. I am not sure whether this post is
written by him as no one else know such detailed about my problem.
You’re amazing! Thanks!
Hi there, I discovered your blog by means of Google whilst looking for a comparable
topic, your web site came up, it appears good.
I have bookmarked it in my google bookmarks.
Hello there, simply turned into alert to your weblog thru Google, and
found that it is really informative. I am gonna be careful for brussels.
I’ll appreciate in the event you proceed this in future. Lots of
people will be benefited out of your writing. Cheers!
I am sure this piece oof writing has touched all the internet visitors, its really really fastidious
paragraph on building up new weblog.
If some one wants expert view on the topic of blogging and site-building afterward i propose him/her to visit this weblog, Keep up the
nice work.
This post is priceless. Where can I find out more? https://t20cl.com/read-blog/4602_prostitutki-tyumen.html
Hello, i think that i saw you visited my site thus i came to “return the favor”.I’m trying to find things to enhance my website!I
suppose its ok to use some of your ideas!!
If you wish for to increase your experience only keep visiting this
website and be updated with the latest gossip posted here.
Excellent blog here! Also your web site loads up fast!
What web host are you using? Can I get your affiliate link
to your host? I wish my site loaded up as quickly as yours lol
Amazing tons of useful data!
Also visit my page: https://sso-ingos.ru/aprilcnn13393
What separates us from different keto foods? At Eatsane, taste takes top precedence. We could have been zero carbs, however we understand that meals has to be a supply of pleasure. Our group of food experts is answerable for crafting meals that’s equally scrumptious and nourishing. Being keto-friendly is a given; what units us apart is our truly indulgent style! Eatsane breads are baked with almond, nuts, and seed flours; plus, a small amount of wheat flour to maintain the taste and texture all of us love. Our pralines are made from premium almonds and darkish chocolate. We also bake at a temperature that keeps the ingredients’ nutrient values. Our foods strike an ideal stability of nutrition and taste, with unique flavors to love and savor. We don’t sugarcoat our net carbs to the closest complete quantity – or offer you pitifully small parts. At Eatsane, what you see is what you get! Because keto or not, you need to belief and love your meals.
my webpage https://rentry.co/6444-introducing-supra-keto-the-revolutionary-weight-loss-supplement
I was suggested this website by my cousin. I’m not positive whether this post
is written via him as nobody else understand such specific about my difficulty.
You’re incredible! Thanks!
It’s really a great and useful piece of information. I’m happy that you shared this helpful information with us.
Please keep us informed like this. Thank
you for sharing.
I like the helpful info you provide on your articles.
I will bookmark your blog and check again here regularly.
I’m relatively certain I’ll be told plenty of new stuff right here!
Best of luck for the following!
Good info. Lucky me I discovered your site by accident (stumbleupon).
I have book-marked it for later!
That is very attention-grabbing, You’re a very professional blogger.
I’ve joined your rss feed and look ahead to in quest of extra of your great post.
Additionally, I have shared your website in my social networks
Right now it sounds like Expression Engine is the top
blogging platform available right now. (from what I’ve read) Is that
what you are using on your blog?
Way cool! Some extremely valid points! I appreciate
you penning this article plus the rest of the website is really good.
A private Instagram viewer is a tool or method that claims to permit users to view private Instagram profiles without
the owner’s approval. However, most of these services are scams, phishing attempts, or illegal,
as Instagram’s privacy settings are intended to guard addict content.
real ways to view private profiles supplement sending a follow request or asking for entrance directly.
Article writing is also a excitement, if you know after that you can write or else it is difficult to write.
Way cool! Some extremely valid points! I appreciate you
writing this post and the rest of the website is very good.
I got this site from my friend who shared with me on the topic
of this web page and at the moment this time I am browsing this site and reading very informative articles or reviews here.
Truly no matter if someone doesn’t understand after that its up to other
users that they will help, so here it happens.
I have read so many articles or reviews on the topic of the blogger lovers except this paragraph is really
a pleasant article, keep it up.
Top-tier service from Get Seeds Right Here Get
Clones Right Here. They don’t just sell clones — they help you win your garden with verified marijuana lines.
I’m not sure why but this weblog is loading extremely slow for me.
Is anyone else having this issue or is it a problem
on my end? I’ll check back later on and see if the problem still exists.
Adjust the colors to cut back glare and give your eyes a break. Please log in to make use of this function. Please log in to use this characteristic. Adjust the colors to reduce glare and give your eyes a break. You’ve just tried so as to add this video to My List. But first, we want you to register to PBS utilizing one of the companies beneath. You’ve simply tried so as to add this show to My List. But first, we need you to register to PBS using one of the services beneath. Sign in with PBS AccountNot registered but? By creating an account, you acknowledge that PBS could share your information with our member stations and our respective service suppliers, and that you have read and understand the Privacy Policy and Terms of Use. You have got the maximum of 131 videos in My List. We will take away the primary video in the listing to add this one. You have the utmost of 131 reveals in My List. We can remove the primary show within the checklist so as to add this one. 1h 03m 31s | Video has closed captioning. Before you submit an error, please consult our Troubleshooting Guide. Your report has been efficiently submitted. Thank you for serving to us enhance PBS Video. Glyco Forte Uncomfortable side effects Reviews on the secret of the show. Miss an episode? Catch up on all issues Poplar with our gif recaps. Glyco Forte Negative effects Reviews with solid Q&As, professional blogs, BTS pictures, and more! Glyco Forte Negative effects Reviews intersects with modern day Midwifery. Read the Modern-day Midwives Blog and be taught extra about our bloggers, all skilled midwives. Copyright © 2024 Public Broadcasting Service (PBS), all rights reserved. PBS is a 501(c)(3) not-for-revenue group.
Here is my web blog; https://www.paes.shibaura-it.ac.jp/t-iwata/?p=376
Wow, awesome weblog format! How lengthy have you ever been blogging for?
you made blogging glance easy. The total glance of your website
is wonderful, as smartly as the content!
Amazing! Its truly awesome piece of writing, I have got
much clear idea regarding from this piece of writing.
I’m excited to discover this website. I need to to thank you for your time for
this fantastic read!! I definitely appreciated every little
bit of it and i also have you book marked to check out new
information in your site.
In the world of online marketing, the https://rentry.co/33491-5-step-formula-review-a-comprehensive-analysis-of-the-make-money-system has been making waves as a promising system for making money online. With claims of easy implementation and quick results, many individuals are eager to learn more about this system.
Ветошь – это незаменимый материал для автосервиса в Санкт-Петербурге.
Этот мягкий и впитывающий материал используется для протирки и
очистки различных поверхностей автомобилей.
Ветошь позволяет быстро и эффективно
убрать грязь, пыль и следы масла с кузова и
салона машины.
ветошь оптом
Good day! Would you mind if I share your blog with my twitter
group? There’s a lot of folks that I think would really
enjoy your content. Please let me know. Thank you
For those dedicated to natural health options and consistent supplementation, Glyco Forte provides a promising path toward better glucose management and enhanced metabolic wellness. The https://waselplatform.org/blog/index.php?entryid=273891 Forte money-back guarantee further reduces any threat, making it a worthwhile consideration for anyone critical about managing their blood sugar naturally. Remember, while Glyco Forte Glucose Management will be a superb software in your health arsenal, it really works best when mixed with a wholesome weight loss plan, common exercise, and ongoing communication along with your healthcare supplier. This Glyco Forte Review concludes that the supplement delivers on its promises and gives genuine worth for these seeking natural blood sugar administration options. Zou, H., Zhang, X., Chen, W. et al. Vascular endothelium is the essential method for stem cells to deal with erectile dysfunction: a bibliometric examine. Clinical study on a botanical compound showing vital discount in diabetes type 2 symptoms and blood glucose. J Diabetes Metab Disord. Zaborska, K.E., et al. Deoxycholic acid supplementation impairs glucose homeostasis and insulin signaling in mice. Giri, B., et al. Chronic hyperglycemia mediated physiological alteration and metabolic distortion results in organ dysfunction, infection, most cancers development and other pathophysiological penalties: An update on glucose toxicity. Review of grapefruit’s effects on blood sugar and diabetes administration.
Keep on working, great job!
Hi to every one, the contents present at this website are actually amazing for people knowledge, well, keep up the nice work fellows.
Excellent web site you have got here.. It’s difficult to
find excellent writing like yours nowadays. I really appreciate people like you!
Take care!!
Wow, that’s what I was searching for, what a data! present here at this web
site, thanks admin of this web site.
Hi to all, how is all, I think every one is getting more
from this site, and your views are pleasant in favor of new users.
Pretty component to content. I just stumbled upon your site and in accession capital to claim that I get actually loved account your weblog posts.
Any way I will be subscribing to your feeds and even I fulfillment you access consistently
rapidly.
I always used to read paragraph in news papers but now as I am a user
of internet therefore from now I am using net
for articles or reviews, thanks to web.
Because the admin of this web site is working, no question very soon it will be famous, due to its quality contents.
Thanks for one’s marvelous posting! I quite enjoyed reading it, you’re a great author.
I will make sure to bookmark your blog and will often come back later on. I want to encourage you to continue your great posts, have a nice day!
th small intestine
The detoxifying properties of CBD help the body’s pure cleansing process, notably by enhancing liver function. A healthy liver is important for filtering toxins and sustaining total well being, and CBD has been shown to assist protect the liver from damage whereas promoting environment friendly detoxification. Regular use of these gummies can aid in flushing out toxins, supporting your body’s capacity to heal and rejuvenate. For those struggling with sleep disturbances, Ciao Health CBD Gummies can be a sport-changer. CBD is thought for its ability to enhance sleep high quality by promoting relaxation and reducing components that interfere with relaxation, comparable to anxiety and stress. These gummies help regulate the sleep-wake cycle, making it simpler for you to fall asleep and stay asleep all through the night. Whether you suffer from occasional insomnia or have hassle getting restful sleep resulting from smoking withdrawal or other stressors, CBD can support a deeper, extra restorative sleep.
Also visit my web site https://ste-van.de/geqdusty82244
Quality content is the main to be a focus for the users to pay a visit the
web page, that’s what this site is providing.
I аppreciate your wonderful post! Үour c᧐ntent is botһ helpful and engaging, mɑking yоur site
ɑ greɑt resource fߋr readers. For tһе current Singapore promotions,
Ι suggest visiting Kaizenaire.ⅽom where yoᥙ can discover special offeгѕ and promo codes
to hеlp you conserve cash. This site aggregates leading discount
rates fгom numerous sellers and services іn Singapore, offering gⲟod
deals օn popular brand names in fashion, electronic devices, dining, ɑnd daily
essentials. Ⲕeep up the exceptional work, and I anticipate learning more оf yⲟur insightful
short articles іn the future. Finest regаrds and hаppy reading!
my blog post: kindle promotions (utahdailynews.com)
With havin so much content and articles do you ever run into any issues of plagorism or copyright violation? My site has
a lot of completely unique content I’ve either created myself or outsourced but it seems a lot
of it is popping it up all over the internet without my permission.
Do you know any solutions to help prevent content from being stolen? I’d genuinely appreciate it.
Hey there! This post couldn’t be written any better! Reading through this
post reminds me of my previous room mate! He always kept talking about this.
I will forward this write-up to him. Fairly certain he will have a good read.
Thanks for sharing!
This web site certainly has all of the info I needed concerning this subject and didn’t know who to ask.
«ترس و لرز» اثر برجسته سورن کی یرکگور، فیلسوف دانمارکی، به بررسی
عمیق وحشت و اضطراب ابراهیم در مواجهه با فرمان الهی برای قربانی کردن پسرش اسحاق می پردازد.
این کتاب با تحلیل مفاهیم پیچیده ای چون
تعلیق غایت مند اخلاق و پارادوکس ایمان،
جایگاه فرد در برابر امر مطلق را به چالش می کشد و یکی از دشوارترین و تاثیرگذارترین آثار او در
فلسفه اگزیستانسیالیسم است که تحت نام مستعار یوهانس دو سیلنتیو نگاشته شده.
https://hillbilly.ir/tag/کتاب/
After I initially left a comment I seem to have clicked the -Notify me when new comments are added- checkbox and from now on each time a comment is added I get 4 emails with the exact same comment.
Is there a means you can remove me from that service?
Kudos!
Just want to say your article is as amazing. The clarity in your post is just spectacular and i can assume
you’re an expert on this subject. Well with your permission allow
me to grab your RSS feed to keep up to date with forthcoming
post. Thanks a million and please carry on the enjoyable work.
Hi there, I would like to subscribe for this webpage to get most up-to-date updates, so where can i do it
please assist.
Heya i am for the first time here. I found this board and I find It really useful & it helped me out much.
I hope to give something back and help others
like you aided me.
Why people still use to read news papers when in this
technological globe the whole thing is presented on net?
I’m not sure exactly why but this site is loading extremely slow
for me. Is anyone else having this problem or is
it a issue on my end? I’ll check back later
and see if the problem still exists.
When someone writes an paragraph he/she maintains
the idea of a user in his/her mind that how a user can be aware of it.
Therefore that’s why this article is amazing. Thanks!
May I just say what a comfort to find an individual who really understands what they’re discussing on the internet.
You definitely know how to bring a problem to light and make it important.
More and more people must read this and understand this side of the
story. I was surprised that you aren’t more popular because you definitely have the gift.
I am not sure where you are getting your information, but
great topic. I needs to spend some time learning more or understanding more.
Thanks for great info I was looking for this information for my mission.
I really like what you guys are usually up too. This kind of clever work and coverage!
Keep up the fantastic works guys I’ve incorporated you guys
to our blogroll.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You obviously know what youre talking about,
why throw away your intelligence on just posting videos to your weblog when you could be giving us something enlightening
to read?
I have been browsing online more than 4 hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. In my opinion, if
all webmasters and bloggers made good content as you did, the net will be a lot more useful than ever before.
Thank you for the auspicious writeup. It if truth be told
was a leisure account it. Glance complex to more added
agreeable from you! However, how can we keep in touch?
Wonderful goods from you, man. I’ve understand your stuff previous to and you are just extremely magnificent.
I really like what you have acquired here, really like what you’re stating and the way in which you say
it. You make it entertaining and you still take care of to keep it smart.
I can not wait to read much more from you.
This is really a tremendous web site.
continuously i used to read smaller articles or reviews which as well clear their motive,
and that is also happening with this post which I am reading
at this place.
What i don’t understood is actually how you’re now not really a lot more neatly-preferred
than you may be now. You’re so intelligent. You know therefore significantly on the subject of this subject,
produced me individually believe it from numerous various
angles. Its like women and men aren’t interested until it’s one
thing to do with Woman gaga! Your personal stuffs great.
Always handle it up!
Filler batting makes the pillow superb to sink into and is normally good for again sleepers. Pillows with foam fluff are mushy and retain their form. This makes them nice for side sleepers, for whom a high pillow will be useful. Pillows with foam cores are intended to provide static head support and usually are not suitable for “sinking into”. Soft latex conforms to the pinnacle and neck. It permits good moisture transport attributable to its open pores and is appropriate – depending on the top – for facet and back sleepers. Visco foam has an excellent supportive impact and is really helpful to people who http://pasarinko.zeroweb.kr/bbs/board.php?bo_table=notice&wr_id=6956100 at greater than 18 degrees Celsius in addition to often for a very long time in a single sleeping position. Gel foam pillows are just like visco foam of their properties, although this material offers good adaptation to the head and neck space even at temperatures beneath 18 degrees Celsius. After all, it may be helpful to take advantage of a consultation supply earlier than shopping for a pillow.
This text is worth everyone’s attention. How can I find out more?
These are in fact fantastic ideas in on the topic of blogging.
You have touched some fastidious factors here. Any way keep up wrinting.
Oh my goodness! Impressive article dude! Thank you, However I am having problems with
your RSS. I don’t know why I can’t join it. Is there anyone else getting similar RSS issues?
Anyone who knows the solution will you kindly respond?
Thanks!!
Definitely imagine that that you said. Your favourite reason seemed to be on the net the easiest thing to be aware of.
I say to you, I certainly get irked even as other folks think about issues that
they plainly don’t recognize about. You
controlled to hit the nail upon the highest as neatly as defined out the whole thing with no need side-effects , other
people could take a signal. Will probably be back to get more.
Thanks
It’s hard to find well-informed people for this topic, but you seem like you know
what you’re talking about! Thanks
free ai porn generator
Woah! I’m really loving the template/theme of this
website. It’s simple, yet effective. A lot of times it’s
tough to get that “perfect balance” between usability and visual appeal.
I must say you have done a superb job with this.
Additionally, the blog loads extremely quick for me on Opera.
Superb Blog!
great points altogether, you simply won a logo new reader.
What might you recommend in regards to your publish that you
simply made some days in the past? Any positive?
What’s up everyone, it’s my first pay a visit at this website, and piece of writing is really fruitful for me, keep up posting these types of articles.
«شاه خاکستری چشم» مجموعه اشعار
تاثیرگذار آنا آخماتووا، یکی از برجسته ترین شاعران شعر مدرن روسیه است که با ترجمه شاپور احمدی و از سوی انتشارات کتاب کوله پشتی
منتشر شده است. این اثر بازتابی عمیق
از ذوق لطیف زنانه، قدرت بیان
و همچنین رنج ها و مصائب دوران خفقان آور دوران استالین است که آن را به اثری ماندگار…
https://bneh.ir/mag/کتاب/
Oh my goodness! Awesome article dude! Many thanks, However I am going through
troubles with your RSS. I don’t know the reason why I am unable to subscribe to it.
Is there anyone else having similar RSS problems?
Anybody who knows the answer will you kindly
respond? Thanx!!
Woah! I’m really loving the template/theme of this site.
It’s simple, yet effective. A lot of times it’s tough to get that “perfect balance” between superb usability and appearance.
I must say you have done a fantastic job with this. Additionally, the blog loads extremely quick for me on Firefox.
Outstanding Blog!
Somewhat about Green Leaf CBD – Here at Green Leaf CBD, we offer a wide assortment of top notch drug grade CBD items produced using hemp. The CBD utilized in our items is 99.9% unadulterated and contains the entirety of the valuable supplements from the hemp plant itself. The entirety of our items are made and sourced here in the United States. While underway, we don’t utilize any wellspring of warmth or solvents, just a technique for CO2 extraction. Our organization was established in 2016 with the aspiration of presenting the most elevated evaluation of CBD products to our clients. At Green Leaf, we accept that everybody merits admittance to great items at a reasonable expense. With our self-pride and respect, we can generally guarantee you extraordinary items and incredible client care. Our definitive objective is to assist our clients with getting the way to carrying on with a better and more joyful way of life. We have invested a ton of energy in innovative work to ensure that the entirety of our items are normal, viable, and protected to utilize – you can purchase with certainty. We offer a wide assortment of CBD products, for example, tincture oils, vape oils, cartridges, edibles, creams, and the sky is the limit from there. We likewise offer CBD treats for your pets!
my webpage https://git.arachno.de/allanlovell694
Pretty nice post. I just stumbled upon your blog and
wanted to say that I have really enjoyed surfing around your blog posts.
After all I’ll be subscribing to your rss feed and I hope you write again soon!
Everyone loves what you guys are up too. This kind of clever work and reporting!
Keep up the awesome works guys I’ve incorporated
you guys to blogroll.
Hello, after reading this remarkable piece of writing
i am as well delighted to share my familiarity
here with colleagues.
Hmm is anyone else encountering problems with the images on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any responses would be greatly appreciated.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You definitely know what youre talking about, why throw away your intelligence on just posting videos
to your weblog when you could be giving us something informative
to read?
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! However, how can we
communicate?
Ощутите себя капитаном, отправившись в незабываемое плавание! К вашим услугам
https://yachtakazan.ru/ для захватывающих приключений.
С нами вы сможете:
• Насладиться живописными пейзажами с борта различных судов.
• Отпраздновать знаменательное событие в необычной обстановке.
• Провести незабываемый вечер в романтической атмосфере.
• Собраться с близкими друзьями для веселого время провождения.
Наши суда отличаются:
✓ Профессиональными экипажами с многолетним опытом.
✓ Повышенным уровнем комфорта для пассажиров.
✓ Гарантией безопасности на протяжении всей поездки.
✓ Привлекательным внешним видом и стильным дизайном.
Выбирайте короткую часовую прогулку или арендуйте судно на целый день! Мы также поможем с организацией вашего праздника: предоставим услуги фотографа, организуем питание и музыкальное сопровождение.
Подарите себе и своим близким незабываемые моменты! Забронируйте вашу водную феерию уже сегодня!
Magnificent website. Plenty of helpful info here.
I am sending it to several buddies ans also sharing in delicious.
And certainly, thanks to your sweat!
Excellent goods from you, man. I have be aware your stuff prior to
and you are simply too magnificent. I actually like what you’ve
received right here, really like what you are saying and the way
in which by which you are saying it. You’re making it entertaining and you still take care of to stay it
wise. I cant wait to read far more from you. That is really a terrific website.
I am regular reader, how are you everybody?
This post posted at this web site is truly pleasant.
I do accept as true with all of the ideas you have offered in your post.
They’re really convincing and will certainly work. Still, the posts are too short for novices.
May you please lengthen them a bit from next time?
Thanks for the post.
I every time spent my half an hour to read this webpage’s
posts all the time along with a mug of coffee.
I’m impressed, I have to admit. Rarely do I encounter a
blog that’s both equally educative and amusing, and without a
doubt, you’ve hit the nail on the head. The issue is something that too
few men and women are speaking intelligently about. I am very happy I stumbled across this during my hunt for something relating to
this.
Way cool! Some extremely valid points! I appreciate you penning this
write-up and also the rest of the site is really good.
Hello i am kavin, its my first occasion to commenting anywhere, when i
read this article i thought i could also make comment due to this
sensible piece of writing.
I am regular reader, how are you everybody?
This piece of writing posted at this website is genuinely nice.
Hi there, I wish for to subscribe for this weblog to take latest updates, thus where can i do it please assist.
My family all the time say that I am killing my time here at net, except I know I am getting experience everyday by
reading thes pleasant content.
Ƭhank you for sharing thiѕ exceptional article!
I actսally took pleasure in reading уour material and found
іt exceptionally սseful and appealing. Youг site is wonderful,
ѡith ѕuch ᴡell-researched and thoughtful pieces thаt ҝeep readers returning fօr
more. You oսght to tɑke a lօok at Kaizenaire.com for the mоѕt гecent Singapore
promos, consisting օf incredible promo codes аnd unique deals tһat can conserve уou hսgе time.
If you’re trying to find Singapore offers, check
out Kaizenaire.cօm right now– thеy aggregate the bеst shopping discount rates fгom leading
merchants and services ɑcross the city-state. Kaizenaire.com ⲟffers lοtѕ
of great promos fߋr Singapore shoppers, including offеrs from Singapore brands that evеrybody enjoys, ԝhether it’s for style, electronic devices,
dining, ᧐r everyday basics. Ϝrom unbeatable shopping discounts
to limited-tіme discounts, it’s ɑ one-stop hub for finding valսe-packed Singapore offers tһat maқe every purchase more rewarding.
Keeр up tһе excellent ѡork with your wonderful material!
Eagerly anticipating mօre posts fгom you in the future– your insights aге аlways identify on. Best concerns, and pleased reading!
Visit mʏ website: promotions
These are genuinely impressive ideas in concerning
blogging. You have touched some nice factors here. Any way keep up
wrinting.
HorsePower Brands Omaha
2525 N 117tһ Ave #300,
Omaha, ⲚΕ 68164, United States
14029253112
local home services franchising
This article provides clear idea designed for the new users of blogging, that really how to do blogging
and site-building.
Hey! Do you know if they make any plugins to help
with SEO? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good
results. If you know of any please share. Kudos!
Hmm is anyone else experiencing problems with the images
on this blog loading? I’m trying to determine if its a problem on my end or if
it’s the blog. Any feed-back would be greatly appreciated.
OMT’ѕ concentrate ߋn fundamental skills builds unshakeable ѕelf-confidence,
permitting Singapore trainees tⲟ faⅼl for mathematics’ѕ elegance ɑnd rеally feel motivated fοr exams.
Experience versatile learning anytime, аnywhere thгough
OMT’s thorough online e-learning platform, featuring unrestricted access tⲟ video
lessons and interactive quizzes.
Аs mathematics underpins Singapore’ѕ credibility fօr
excellence in worldwide criteria ⅼike PISA, math tuition іs crucial to unlocking ɑ kid’s prospective ɑnd protecting academic benefits іn this core subject.
Witһ PSLE mathematics concerns typically including real-ԝorld applications, tuition ߋffers targeted practice
tⲟ establish crucial thinking skills essential fߋr hіgh scores.
By providing comprehensive technique ԝith рrevious O Level documents, tuition equips trainees ᴡith familiarity
аnd tһe capability to prepare foг inquiry patterns.
Personalized junior college tuition aids bridge tһe gap from Օ Level to A Level mathematics, guaranteeing students adjust tօ tһe boosted roughness аnd deepness required.
Unlіke common tuition facilities, OMT’s customized curriculum boosts tһe MOE framework Ьу including real-ѡorld applications, mаking abstract
mathematics concepts extra relatable аnd easy to understand f᧐r students.
Tһe seⅼf-paced е-learning system fгom OMT is super adaptable
lor, mаking it much easier tο juggle school and tuition fоr ցreater mathematics
marks.
Tuition facilities іn Singapore specialize іn heuristic methods, crucial for dealing with the challenging
ԝоrd troubles in math exams.
Feel free to surf to mу pɑgе – singapore math tuition (Lucienne)
Hurrah, that’s what I was looking for, what a data! existing here at this weblog,
thanks admin of this site.
I’m amazed, I have to admit. Rarely do I encounter a
blog that’s both educative and interesting, and let me tell you, you’ve hit the nail
on the head. The problem is something that too few men and women are speaking intelligently
about. I’m very happy I stumbled across this in my search for something relating to this.
Undeniably believe that which you stated. Your favorite justification seemed to be on the
internet the easiest thing to be aware of. I say to you, I definitely get annoyed while people
consider worries that they plainly do not know about. You
managed to hit the nail upon the top and defined out the
whole thing without having side-effects , people can take a signal.
Will probably be back to get more. Thanks
I’m really loving the theme/design of your site.
Do you ever run into any internet browser compatibility
problems? A couple of my blog readers have complained about my website not operating
correctly in Explorer but looks great in Safari. Do you have any solutions
to help fix this issue?
Thanks , I have just been searching for information about
this subject for ages and yours is the best I’ve came upon till now.
However, what in regards to the bottom line? Are you positive about
the supply?
Nice sⅼot brο!
Hello There. I found your blog using msn. This is a really well written article.
I will make sure to bookmark it and return to read more of your useful info.
Thanks for the post. I’ll definitely comeback.
Hi! This is my first comment here so I just wanted to give a quick shout out and say I really
enjoy reading through your articles. Can you recommend any other blogs/websites/forums that go over the same subjects?
Many thanks!
Ces roses peuvent être échangées contre des ressources rares, comme la tourmaline ou des fragments de la tablette de Totankama.
Really quite a lot of awesome material.
Here is my page; https://git.pwaapp.cc/mauriciocornej
My partner and I stumbled over here coming
from a different page and thought I might check things out.
I like what I see so now i’m following you. Look forward to going over your web page yet again.
토닥이 여성전용마사지는 오직 여성만을 위한 전국 출장 전문
마사지 서비스입니다. 대한민국 최초의 여성 전용 마사지 플랫폼으로서 수많은 여성 고객에게 사랑받고
bookmarked!!, I love your site!
Excellent weblog right here! Also your site quite a bit up very fast!
What host are you the usage of? Can I get your associate link to your host?
I wish my website loaded up as fast as yours lol
You need to take part in a contest for one of the
finest websites on the internet. I am going to recommend this website!
Hello my family member! I want to say that this article
is amazing, nice written and come with almost all vital infos.
I would like to peer extra posts like this .
I’ve been using HepatoBurn for about a month
now and I can honestly say I feel lighter and less sluggish.
It’s not a magic pill, but it definitely supports
digestion and energy when taken consistently.
Ask ChatGPT
There is definately a lot to know about this topic.
I like all of the points you have made.
Also visit my web-site – slimjaro legit
Excellent post. I was checking constantly this blog and I am impressed!
Extremely helpful information specifically the remaining phase 🙂 I handle such info a lot.
I used to be seeking this particular info for a very long
time. Thank you and good luck.
This web site really has all of the information and facts I wanted
about this subject and didn’t know who to ask.
Greetings! Very helpful advice within this post! It is the little changes that produce the greatest changes.
Many thanks for sharing!
Simply desire to say your article is as amazing. The clarity in your post is just excellent and i can assume you’re an expert on this subject.
Well with your permission let me to grab your RSS feed to keep updated with
forthcoming post. Thanks a million and please keep up the gratifying work.
I am really enjoying the theme/design of your site.
Do you ever run into any web browser compatibility problems?
A number of my blog visitors have complained about my site not operating correctly in Explorer
but looks great in Opera. Do you have any tips to help fix this
problem?
It’s awesome in favor of me to have a web site, which is useful in support of my know-how.
thanks admin
It’s a pity you don’t have a donate button! I’d definitely donate to this superb blog!
I guess for now i’ll settle for book-marking and adding
your RSS feed to my Google account. I look
forward to brand new updates and will share this blog with my Facebook group.
Chat soon!
Woah! I’m really loving the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between superb usability and visual appearance.
I must say that you’ve done a awesome job with this. Also, the blog loads
very fast for me on Safari. Excellent Blog!
It’s amazing to go to see this web page and reading the
views of all friends concerning this post, while I am also keen of getting familiarity.
Franchising Path Carlsbad
Carlsbad, CA 92008, United Ꮪtates
+18587536197
franchise Consultant companies
Executive-level cleaning, perfect for our high-end finishes. Recommending to luxury properties. High-end excellence.
Hey would you mind stating which blog platform you’re using?
I’m planning to start my own blog in the near future but I’m having a hard time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs and I’m looking for something unique.
P.S Sorry for being off-topic but I had to ask!
These are really wonderful ideas in about blogging. You have touched some pleasant things here.
Any way keep up wrinting.
I love your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do it for you?
Plz answer back as I’m looking to design my own blog and would like to know where
u got this from. thank you
I like what you guys tend to be up too. This type of clever work and reporting!
Keep up the terrific works guys I’ve added you guys to our blogroll.
Hmm is anyone else experiencing problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any feedback would be greatly appreciated.
Great post. I used to be checking constantly this blog and
I am inspired! Extremely useful information specially the
final part 🙂 I take care of such information a lot.
I used to be looking for this particular info for a long time.
Thanks and best of luck.
It’s actually very complex in this active life to listen news on Television, so I only use internet for that reason, and take the newest information.
Hey there! I know this is sort of off-topic however I had
to ask. Does running a well-established website
such as yours take a large amount of work? I am completely new to operating a blog
but I do write in my journal daily. I’d like to start a blog so I will be
able to share my experience and views online.
Please let me know if you have any kind of ideas or tips for brand
new aspiring blog owners. Appreciate it!
What is CBD Oil? How Does CBD Work? How Can CBD Reduce Pain Transmission? Over the past three years, CBD oil has become increasingly popular as a health and wellness supplement. One of the main reasons people are interested in trying CBD oil is because of its pain-killing benefits. We’ll get into the details of how CBD is suggested to help with pain later, along with some suggestions for the best CBD oils for pain and inflammation. The ability for CBD to help with pain is a significant advantage over conventional pain management options – which often involve addictive and potentially harmful medications. Instead, this natural supplement has very few side effects and an exceptional safety profile – all without compromising on effectiveness. This is an important question to ask because the truth of the matter is that not all CBD oils work. Many simply contain too little CBD to be of any help, while others contain harmful contaminants like heavy metals, pesticides, or chemical solvents – all of which could add to the pain you’re already experiencing by damaging the sensitive nerve cells around the body.
Review my blog post – http://www.seong-ok.kr/bbs/board.php?bo_table=free&wr_id=5034594
4M Dental Implant Center
3918 Ꮮong Beach Blvd #200, Long Beach,
ϹΑ 90807, United States
15622422075
Invisalign
Hello, Neat post. There is an issue together with your web site in web explorer,
might test this? IE still is the market chief and a good part of other folks will pass
over your great writing due to this problem.
Kamu hanya memerlukan URL dari video yang ingin diunduh dan klik tombol download.
hi!,I really like your writing very so much! share we keep up a correspondence extra about
your article on AOL? I need an expert on this house to solve
my problem. May be that is you! Having a look
forward to see you.
Hello to every one, the contents present at this web site are truly
amazing for people knowledge, well, keep up the good
work fellows.
I could not refrain from commenting. Very well written!
Hello, its pleasant paragraph regarding media print, we all be
aware of media is a impressive source of data.
For most recent news you have to visit world wide web and on the web I found this site as a finest web
site for most up-to-date updates.
Do you have a spam problem on this website; I also am a blogger,
and I was curious about your situation; we have developed some
nice methods and we are looking to trade solutions with others, be
sure to shoot me an e-mail if interested.
I have been browsing on-line greater than three hours these days, but I by
no means discovered any fascinating article like yours.
It’s beautiful worth sufficient for me. In my view, if all website owners
and bloggers made good content as you did, the net will likely be much more
useful than ever before.
I have been browsing online more than 3 hours today, but I by no means discovered any fascinating article like yours.
It’s pretty price enough for me. Personally, if all site owners and bloggers made excellent content
material as you did, the web will be much more useful than ever before.
I read this article completely on the topic of the comparison of latest and previous technologies, it’s amazing article.
At this moment I am going away to do my breakfast,
later than having my breakfast coming again to read additional news.
Aw, this was an extremely nice post. Spending some time and actual effort to produce a really good
article… but what can I say… I hesitate a lot and
don’t manage to get nearly anything done.
I’m not sure why but this site is loading extremely slow for me.
Is anyone else having this issue or is it a issue on my end?
I’ll check back later and see if the problem still exists.
High-end service excellence, exactly what discerning clients need. You understand high standards. Premium service premium results.
Magnificent site. Lots of useful info here. I am sending it to some pals ans also
sharing in delicious. And of course, thank you for your effort!
Hey there I am so happy I found your site, I really found you by error, while I
was looking on Digg for something else, Nonetheless I am here now and would just like to
say thanks for a fantastic post and a all round thrilling blog (I
also love the theme/design), I don’t have time to go through it
all at the moment but I have bookmarked it and also added your RSS feeds, so when I have
time I will be back to read a lot more, Please do keep up the superb work.
Regards, I enjoy this!
Wonderful goods from you, man. I have take note your stuff prior to and you are simply extremely magnificent.
I actually like what you’ve bought right here, really like
what you’re saying and the way in which through which you are saying it.
You’re making it entertaining and you still take care of to keep it
wise. I can’t wait to read much more from you. This is really a great site.
It’s very straightforward to find out any matter on web as compared to textbooks,
as I found this piece of writing at this web site.
Thanks , I have just been searching for information approximately this topic for ages and yours is the greatest
I have found out so far. But, what about the
conclusion? Are you sure about the supply?
http://hongkongpools.one/
I like the helpful info you supply in your articles. I will bookmark your blog and test once more here regularly.
I’m somewhat sure I’ll learn lots of new stuff right here! Best of
luck for the following!
My brother recommended I would possibly like this blog.
He was entirely right. This submit truly
made my day. You can not imagine just how a lot time I had spent for this information! Thank you!
I know this web page gives quality depending articles and additional information, is
there any other web page which provides these kinds of stuff in quality?
유흥알바 사이트, 룸알바, 밤알바 등 유흥업소
구인구직, 룸싸롱, 노래방도우미, 텐프로 등 고소득 여성 아르바이트 정보를 제공합니다.
If you desire to increase your experience just keep visiting this website and be updated with the most up-to-date news posted here.
If you desire to take much from this post then you have to apply these techniques to your won webpage.
you are actually a just right webmaster. The website loading speed is incredible.
It kind of feels that you’re doing any unique trick.
Moreover, The contents are masterpiece. you have performed a magnificent activity in this matter!
It’s great that you are getting ideas from this post as well as from
our discussion made here.
Remarkable! Its in fact awesome post, I have got much clear idea about from this article.
Undeniably consider that which you said. Your favorite reason seemed to be at the internet the easiest thing to take into account of.
I say to you, I certainly get irked at the same time as folks think about issues that they just don’t realize about.
You controlled to hit the nail upon the highest and also outlined out the entire thing without
having side-effects , other folks can take a signal.
Will likely be again to get more. Thanks
Someone necessarily assist to make severely articles I would state.
That is the first time I frequented your web page and so far?
I amazed with the analysis you made to make this particular
publish amazing. Magnificent process!
Heya i am for the first time here. I found this board and I find It truly useful & it
helped me out a lot. I hope to give something back and aid others like you helped me.
of course like your website but you have to check the spelling
on several of your posts. Many of them are rife with spelling issues and I find it very bothersome to tell the reality on the other hand I’ll surely come back again.
With havin so much content and articles do you ever run into any problems of plagorism or copyright infringement?
My blog has a lot of unique content I’ve either authored myself or outsourced but it appears a lot of it is popping it up all over the web without my permission. Do you know any methods to help reduce content from being ripped off?
I’d truly appreciate it.
Eco-friendly and effective, no harsh chemical smells afterward. Green cleaning converts here. Green and clean.
I know this web page provides quality based articles and additional information, is
there any other site which offers such things in quality?
my page; ขายผักไฮโดรโปนิกส์
You really make it seem so easy with your presentation but
I find this topic to be really something that I think I would never understand.
It seems too complex and extremely broad for me. I’m looking forward for your next post,
I’ll try to get the hang of it!
Genuinely no matter if someone doesn’t know then its up to other people
that they will help, so here it takes place.
My family always say that I am killing my time here at web, except I know I am
getting knowledge all the time by reading thes good content.
Wonderful blog! I found it while searching on Yahoo News. Do
you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thanks
Hello, I think your site might be having browser compatibility
issues. When I look at your blog site in Chrome, it looks fine but when opening in Internet Explorer, it has
some overlapping. I just wanted to give you a quick heads up!
Other then that, very good blog!
Thanks for your marvelous posting! I quite enjoyed reading it, you can be a great author.I will
be sure to bookmark your blog and definitely will come back later on. I want to
encourage continue your great writing, have a nice day!
May I simply say what a comfort to find someone that
genuinely knows what they’re talking about online.
You actually realize how to bring an issue to light and make it important.
More people ought to read this and understand
this side of the story. I can’t believe you aren’t more popular given that you certainly possess the gift.
Have you ever considered publishing an ebook or guest authoring on other sites?
I have a blog based on the same information you discuss and
would love to have you share some stories/information. I know my viewers would value
your work. If you are even remotely interested, feel free to send me an e mail.
Cheers! A good amount of knowledge.
Feel free to visit my web site http://uneed3d.co.kr/bbs/board.php?bo_table=free&wr_id=778904
Hi my friend! I wish to say that this article is amazing, great written and include approximately all important infos.
I’d like to look extra posts like this .
Here is my webpage: serok188 slot gacor
I know this site gives quality dependent
articles or reviews and extra data, is there any other site which
presents these data in quality?
Currently it sounds like Expression Engine is the preferred blogging platform
available right now. (from what I’ve read) Is that what you’re using on your blog?
Hello there, just became alert to your blog through
Google, and found that it is truly informative.
I’m going to watch out for brussels. I’ll be grateful if you continue this in future.
Lots of people will be benefited from your writing.
Cheers!
Good way of telling, and fastidious article to get information about my presentation focus, which
i am going to convey in institution of higher education.
magnificent submit, very informative. I wonder why the other experts of
this sector don’t understand this. You should continue your writing.
I’m confident, you’ve a great readers’ base already!
Thanks on your marvelous posting! I actually enjoyed
reading it, you might be a great author.I will
make certain to bookmark your blog and will eventually come back at some point.
I want to encourage you continue your great job, have a nice evening!
Useful info. Lucky me I discovered your website accidentally, and I am surprised why this accident didn’t came about in advance!
I bookmarked it.
Thanks for finally talking about > 基于强化学习的小球运动员技战术发挥评估 – 逸 < Liked it!
Hi my friend! I wish to say that this article is
awesome, great written and include almost all vital infos.
I’d like to peer extra posts like this .
Have you ever thought about adding a little bit more than just your articles?
I mean, what you say is important and all. Nevertheless
imagine if you added some great pictures or video clips to give your posts more, “pop”!
Your content is excellent but with pics and clips, this website could certainly be one of the very best in its niche.
Excellent blog!
Somebody necessarily assist to make severely posts I might
state. That is the first time I frequented your website page and up to now?
I amazed with the research you made to make this particular publish incredible.
Great activity!
Professional standards maintained, skilled in every aspect. Expert-level satisfaction. Expert excellence.
I simply could not leave your site prior to suggesting
that I extremely enjoyed the standard info a person provide on your guests?
Is going to be again ceaselessly in order to investigate cross-check
new posts
Aw, this was an exceptionally good post. Taking a few minutes and actual effort to make a good article… but what can I say… I put things off a whole lot and don’t manage to get nearly anything done.
Awesome site you have here but I was curious about if you knew
of any message boards that cover the same topics talked
about here? I’d really love to be a part of online community where I can get responses from other knowledgeable
people that share the same interest. If you have any recommendations,
please let me know. Thank you!
Hi mates, how is everything, and what you wish for to
say on the topic of this piece of writing, in my view
its truly remarkable in support of me.
Wonderful work! That is the kind of information that should be shared around the web.
Shame on the search engines for not positioning this publish higher!
Come on over and consult with my site . Thanks =)
Привет, форумчане!
Hi! I know this is kind of off topic but I was wondering which blog platform are you
using for this site? I’m getting sick and tired of WordPress because
I’ve had problems with hackers and I’m looking at alternatives for another platform.
I would be awesome if you could point me in the direction of a good platform.
I’m impressed, I have to admit. Rarely do I encounter a blog that’s both educative
and entertaining, and without a doubt, you have
hit the nail on the head. The issue is something which too few folks are speaking intelligently about.
I’m very happy I found this in my search for something relating to this.
Hello! I know this is somewhat off topic but I was wondering if
you knew where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
Hello! This is my first visit to your blog! We are a team of
volunteers and starting a new project in a community in the
same niche. Your blog provided us valuable information to work on.
You have done a marvellous job!
Hi there Dear, are you really visiting this site daily, if so after that you will absolutely obtain pleasant experience.
I’ve been surfing online more than three hours today, yet I never
found any interesting article like yours.
It is pretty worth enough for me. Personally, if all website owners and
bloggers made good content as you did, the internet will be a lot more useful than ever before.
An intriguing discussion is definitely worth comment.
I think that you need to publish more on this subject, it may not be
a taboo subject but generally people do not speak about these topics.
To the next! All the best!!
Helpful info. Lucky me I found your web site accidentally,
and I am stunned why this coincidence did not happened earlier!
I bookmarked it.
Now I am going away to do my breakfast, once having my breakfast coming yet
again to read additional news.
In the vibrant, active digital landscape associated with Berlin, businesses are increasingly turning
to be able to specialized Social Media Agencies in Berlin to elevate their on-line presence and interact with
their target followers. As a worldwide hub for imagination, innovation, and technologies, Berlin offers a great unique ecosystem wherever social media advertising thrives,
blending smart strategies with real, community-driven content.
This kind of article explores the critical role a new Social
Media Agentur Berlin plays in helping businesses achieve considerable success, leveraging websites
like TikTok, Instagram, YouTube, and LinkedIn to drive proposal, brand awareness, and even conversions.
Its like you learn my thoughts! You appear to grasp
a lot approximately this, such as you wrote the book in it or something.
I believe that you just could do with some p.c. to pressure
the message house a bit, however other than that, this is wonderful blog.
An excellent read. I will certainly be back. https://kkhelper.com/employer/russiany-diplomans/
I’m truly enjoying the design and layout of your site. It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a designer to create your theme?
Exceptional work!
What’s Taking place i’m new to this, I stumbled upon this I’ve discovered It
positively helpful and it has helped me out loads.
I’m hoping to give a contribution & help other users like its aided me.
Good job.
For the first time in the history of the Olympics, cannabidiol (CBD) has been allowed for use by elite athletes. But the substance, which has grown popular in recent years, has exposed hypocrisy and attracted criticism over its use in elite sport. Meanwhile, Black sprinter Sha’Carri Richardson was suspended from the Tokyo 2020 Olympic Games after testing positive for marijuana in July. The controversy over the discrepancy in how cannabis and its other forms like CBD are viewed has caused people to allege hypocrisy and racism by the World Anti-Doping Agency (WADA), the Olympic Games’ anti-doping agency. The cannabis (marijuana) plant produces the cannabinoid compound or synthesizes it as a chemical known as a synthetic cannabinoid. There are over 140 cannabinoids in the plant. The most known one is the delta-9-tetrahydrocannabinol, or THC, which is the main psychoactive compound and alters the mind or behaviour. But CBD is not the same as THC; http://119.23.210.103:3000/tamikashort853 can have a similar effect for pain relief without getting you high, unlike THC.
An intriguing discussion is definitely worth comment.
I think that you ought to publish more on this subject matter, it might not be
a taboo subject but usually people don’t speak about these topics.
To the next! Kind regards!!
การพนันบอลมีต้นกำเนิดมาตั้งแต่ยุคต้นของการแข่งขันบอลในประเทศอังกฤษ ซึ่งเริ่มจากกรุ๊ปแฟนบอลที่เดิมพันกันในกลุ่มเพื่อน ต่อมาก็พัฒนาเป็นธุรกิจขนาดใหญ่ในรูปแบบของเจ้ามือโต๊ะบอล รวมทั้งในยุคดิจิทัลปัจจุบันนี้ การแทงบอลออนไลน์ ได้เปลี่ยนเป็นแนวทางที่นิยมที่สุด ด้วยความสบายรวมทั้งเร็วของเทคโนโลยี
I am sure this article has touched all the internet people, its really really fastidious
post on building up new webpage.
Awesome post.
Pretty! This has been an extremely wonderful article. Thank you for supplying these details.
Wonderful work! This is the type of information that are meant to be
shared around the web. Disgrace on the seek engines for now
not positioning this put up higher! Come on over and consult with my
website . Thanks =)
Feel free to surf to my webpage … ฟาร์มผัก พิษณุโลก
Great post! We are linking to this particularly great
content on our site. Keep up the good writing.
I will immediately clutch your rss as I
can’t in finding your e-mail subscription hyperlink or newsletter service.
Do you have any? Kindly allow me know in order that I may subscribe.
Thanks.
With havin so much content and articles do you
ever run into any problems of plagorism or copyright infringement?
My site has a lot of unique content I’ve either authored myself
or outsourced but it seems a lot of it is popping it up all over
the internet without my permission. Do you know any methods to help reduce content from
being ripped off? I’d certainly appreciate it.
Hello it’s me, I am also visiting this web page daily, this web site is actually nice and the visitors are truly sharing nice thoughts.
Explore comprehensive reviews, in-depth articles, and the latest CBD research tailored for Canadians. Whether you’re a beginner or an experienced user, My CBD Health is your ultimate destination for all things CBD. At My CBD Health, we are dedicated to providing you with the most comprehensive and up-to-date information on CBD oil and its potential health benefits. Whether you’re new to CBD or a seasoned user, our goal is to help you make informed decisions about how CBD oil can play a positive role in your wellness journey. As a trusted resource for CBD oil in Canada, we offer expert insights into its uses, safety, and the various products available in the market. What Is CBD Oil? CBD (Cannabidiol) is a natural compound found in the hemp plant, known for its potential therapeutic benefits without the psychoactive effects of THC. Unlike traditional medications, CBD oil offers a holistic approach to managing a variety of health conditions. Whether you’re seeking relief from pain, anxiety, sleep disorders, or skin issues, CBD oil in Canada is gaining popularity for its natural properties. Why Choose CBD Oil for Health in Canada? Canada is a leader in the wellness and cannabis industry, offering a wide range of high-quality, legal CBD oil products. At My CBD https://hindustannewsjunction.com/aap-candidate-shot-referred-to-ludhiana/, we ensure that all the information you receive is tailored to Canadian consumers, helping you navigate the best CBD oil options available in the country. With rigorous regulations and quality standards, Canadian-made CBD oils are some of the safest and most reliable products on the market.
I am extremely inspired with your writing skills and also
with the structure in your weblog. Is that this a paid theme
or did you customize it yourself? Anyway keep up the
nice high quality writing, it’s rare to peer a great weblog like this one today..
Hi, its pleasant piece of writing about media print, we all be familiar with media is a enormous source of information.
Hi there to all, how is everything, I think every one is
getting more from this site, and your views are nice in favor of new users.
It’s a pity you don’t have a donate button! I’d most certainly donate to this superb
blog! I suppose for now i’ll settle for bookmarking and adding your RSS feed to
my Google account. I look forward to new updates and will talk about this website with my Facebook group.
Talk soon!
https://fcstyrumhistory.de/
Hello there, I discovered your website by the use of Google
at the same time as searching for a similar topic, your website got here up, it looks great.
I’ve bookmarked it in my google bookmarks.
Hello there, just was aware of your weblog thru Google,
and found that it is really informative. I am going to watch out for
brussels. I’ll be grateful if you continue this in future.
Lots of people might be benefited out of your writing.
Cheers!
Aw, this was a very good post. Spending some time and actual effort to produce a great article… but what can I say…
I procrastinate a whole lot and don’t seem to get nearly anything done.
Enhance your superking or emperor-size bed with luxurious super king pillows. Each superking pillow is made to the same exacting standards, offering you a blissful night’s sleep. Choose from our range of super king size pillows with a choice of natural, down and feather and synthetic fills. It’s essential for your new super king pillow to suit your sleeping position, which is why you can choose between firm, medium firm and soft kingsize pillows and superking pillows in a range of depths. Generously filled duck down and feather pillows for everyday luxury. Plump microfibre pillows for blissful bedtime comfort. Luxurious Goose down pillows for a beautiful night’s sleep. A luxuriously soft superking pillow made with silk and recycled polyester. Our pure Canadian goose down fill promises the ultimate in luxurious sleep night after night. How big is a king size http://internationalcss.phorum.pl/viewtopic.php?f=2&t=204007? A king size pillow (we call them super king pillows) are 50cm x 90cm. That’s 15cm wider than a standard pillow.
Today, I went to the beach front with my children. I found a sea shell and gave it to my 4 year old daughter and said
“You can hear the ocean if you put this to your ear.” She put the shell to her
ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this
is totally off topic but I had to tell someone!
Thank you for the auspicious writeup. It in fact was a entertainment account it.
Glance complex to far brought agreeable from you!
By the way, how could we be in contact?
My brother recommended I might like this web site.
He was entirely right. This post truly made my day.
You can not imagine simply how much time I had spent for this info!
Thanks!
Spot on with this write-up, I absolutely believe
that this web site needs a great deal more attention. I’ll probably be back again to read through more, thanks for the
information!
Peculiar article, totally what I needed.
Asking questions are truly nice thing if you are not understanding something completely, however this article offers good
understanding yet.
This is really interesting, You’re a very skilled blogger.
I’ve joined your rss feed and look forward to seeking
more of your great post. Also, I’ve shared your website in my social
networks!
For all banner advertising enquiries, please get in touch. Below are our banner advertising options and required banner sizes. It is recommended that you employ a professional graphics designer to create banners for your business. For each banner, you will be able to add a target website url so that when someone clicks on the banner, they will be taken to the website. Home Page – 2 banner spaces are available, top and bottom. Product Page – below product description, 2 banner spaces are available. Products Side Bar Ad Space: 2 banner spaces are available. Grow your CBD brand’s exposure by submitting your article for publication. Sponsored guest posts will have a one-time publishing fee and your posts will remain on our site for lifetime. Sponsored posts will entitle you to one do follow backlink to help you to gain quality website traffic and grow your organic search engine rankings via link building from quality sites. Your guest posts will be featured on our home page and will appear in all the sliders and other visible areas. Your article will still have to adhere to our quality guidelines. Have custom made infographics and explainer videos. No cheap and plagiarised images. Be creative and interesting to read. Have H1 to H4 headings, proper paragraphs and be optimised for on-page SEO.
My site – http://www.umzumz.com/lyle7249813463
Hi, Neat post. There is an issue with your web
site in internet explorer, could test this? IE nonetheless is the market leader and a big element of folks will miss
your wonderful writing due to this problem.
Yes! Finally someone writes about Gravel Driveway.
Hi my loved one! I wish to say that this article is amazing, great written and include almost
all significant infos. I’d like to look more posts like
this .
I’m not sure where you are getting your info, but good
topic. I needs to spend some time learning much more or understanding more.
Thanks for great info I was looking for this info for my
mission.
After exploring a number of the blog articles on your web site,
I truly appreciate your way of writing a blog.
I book marked it to my bookmark webpage list and will be
checking back in the near future. Please check out my
website too and tell me what you think.
Hmm is anyone else having problems with the
pictures on this blog loading? I’m trying to figure out if its a
problem on my end or if it’s the blog. Any feedback would be greatly appreciated.
Hmm it appears like your site ate my first comment (it
was super long) so I guess I’ll just sum it up what I had written and say, I’m thoroughly enjoying your
blog. I as well am an aspiring blog writer but I’m still new to the whole thing.
Do you have any suggestions for inexperienced blog writers?
I’d really appreciate it.
Great post. I was checking continuously this blog and I
am impressed! Very useful information specifically the last part :
) I care for such info much. I was looking for this particular info
for a long time. Thank you and best of luck.
Hmm it looks like your blog ate my first comment (it was extremely long) so I guess I’ll just sum it up what I
wrote and say, I’m thoroughly enjoying your blog. I as well am
an aspiring blog blogger but I’m still new to everything.
Do you have any recommendations for newbie blog writers? I’d certainly appreciate it.
hey there and thank you for your information – I have certainly picked
up something new from right here. I did however expertise several technical points using this web site, as I
experienced to reload the site lots of times previous to I could
get it to load properly. I had been wondering if your hosting is
OK? Not that I’m complaining, but sluggish loading instances times will often affect your placement in google and can damage
your high-quality score if ads and marketing with Adwords. Well
I am adding this RSS to my email and can look out for a lot more of your respective intriguing content.
Make sure you update this again very soon.
Thankfulness to my father who stated to me regarding
this webpage, this web site is actually awesome.
At this time I am going to do my breakfast, after having my breakfast
coming over again to read more news.
I pay a visit every day a few sites and sites to
read articles, but this weblog provides quality based posts.
Asking questions are truly fastidious thing if you are not understanding
something totally, but this piece of writing provides pleasant
understanding yet.
I was suggested this website by my cousin. I am not sure whether this
post is written by him as no one else know such detailed
about my trouble. You’re incredible! Thanks!
In fact no matter if someone doesn’t know after that its up to other
people that they will assist, so here it occurs.
I know this site presents quality based articles and extra data, is there any other web page which offers these
kinds of data in quality?
Howdy would you mind letting me know which webhost you’re utilizing?
I’ve loaded your blog in 3 completely different browsers and I must say this blog loads a lot quicker then most.
Can you recommend a good hosting provider at a reasonable price?
Thank you, I appreciate it!
This paragraph will assist the internet people for setting up new webpage or even a
weblog from start to end.
For most recent news you have to pay a quick visit the web and on the
web I found this web site as a most excellent web page for most recent
updates.
Because the admin of this website is working, no uncertainty very quickly it will
be famous, due to its quality contents.
I know this site offers quality depending content and extra stuff, is there any other
website which offers such stuff in quality?
I am extremely inspired together with your writing
abilities and also with the format for your weblog.
Is this a paid topic or did you customize it your self?
Either way keep up the excellent quality writing, it’s rare to look a great weblog like this one
these days..
What a stuff of un-ambiguity and preserveness of precious experience regarding unexpected emotions.
I constantly spent my half an hour to read this blog’s articles or reviews every day along with a mug of coffee.
Magnificent beat ! I would like to apprentice while you amend your site, how could i subscribe for a
blog web site? The account helped me a acceptable deal. I had been a little bit acquainted of
this your broadcast provided bright clear concept
Hi there, always i used to check blog posts here in the early hours in the
dawn, since i like to find out more and more.
We stumbled over here by a different web page and thought I might check things out.
I like what I see so now i’m following you. Look
forward to checking out your web page again.
This is especially true as the market remains shaky. There are also national park systems,
limestone coves, caves, mangroves and also the appeal
of fishing communities that provide new scenery and
activities. Occasionally, you’ll drive past a For Sale
sign with the word “Pool” attached.
At this time it sounds like BlogEngine is the top blogging platform available right
now. (from what I’ve read) Is that what you are using on your
blog?
Its like you read my mind! You appear to know so much about this, like you
wrote the book in it or something. I think that you can do with some pics to drive the message home a little bit, but instead of that, this is
magnificent blog. A fantastic read. I’ll definitely be back.
Hey There. I found your weblog using msn. That is a very well written article.
I will be sure to bookmark it and return to
learn extra of your helpful info. Thank you for the post.
I’ll certainly comeback.
This paragraph gives clear idea for the new users of blogging, that truly how to do running a
blog.
At this time it appears like BlogEngine is
the preferred blogging platform out there right now.
(from what I’ve read) Is that what you’re using on your
blog?
my website; ereforce
Thanks a lot for sharing this with all people you really realize what you’re talking about!
Bookmarked. Kindly additionally discuss with my website =).
We could have a link alternate agreement among us
I am not sure where you are getting your info, but good topic.
I needs to spend some time learning more or understanding more.
Thanks for great info I was looking for this info for my mission.
Discover limitless promotions օn Kaizenaire.ϲom,
Singapore’ѕ leading shopping center.
In the vibrant city-stаtе of Singapore,іts shopping heaven ambiance fuels
Singaporeans’ unlimited search օf promotions.
Singaporeans frequently exercise tai сhi in parks for
early morning health routines, аnd кeep in mind t᧐ stay
upgraded οn Singapore’s lɑtest promotions ɑnd shopping deals.
Rye сreates simple and easy females’ѕ apparel, appreciated by
casual style enthusiasts іn Singapore fߋr thеir kicked
bck yet posh designs.
Anothersole sells comfy natural leather shoes leh, loved Ƅy Singaporeans foг their long
lasting, trendy shoes ɑppropriate fօr metropolitan lifestyles օne.
Food Empire Holdings invigorates ԝith instant coffees like MacCoffee, loved for economical, fragrant increases.
Auntie love leh, Kaizenaire.ϲom’ѕ shopping discounts οne.
Feel free to surf to mү blog post … Penang hotel promotions
This is the right blog for everyone who wishes to find
out about this topic. You understand a whole lot its almost
hard to argue with you (not that I personally would want to…HaHa).
You certainly put a new spin on a subject which has been written about
for many years. Wonderful stuff, just wonderful!
Great delivery. Great arguments. Keep up the amazing
effort.
If you want information on bitcoin casinos recommended for US players, you can revisit the list and casino reviews we include at the start of this article.
If you would like to take much from this piece of writing then you have to apply such methods to your won website.
This blog was… how do I say it? Relevant!! Finally
I’ve found something which helped me. Thank you!
If some one desires expert view on the topic of running a blog after
that i recommend him/her to visit this blog, Keep up the pleasant job.
hey tһere and thаnk you for your info – I’ve definitelʏ picked սp something neԝ from гight here.
I diԀ however expertise some technical ⲣoints using this web site,
аs I experienced to reload tһe web site ⅼots of times
рrevious to Ι coᥙld ɡet it to load correctly.
I had beеn wondering if yоur hosting iѕ OK? Not thаt I ɑm complaining, but sluggish loading instances tіmes wiⅼl often affect your
placement іn google аnd can damage your quality score if ads and marketing wіth
Adwords. Wеll I am adding tһis RSS tօ my e-mail and can ⅼook out for a lot more of your respective іnteresting ϲontent.
Mаke ѕure yοu update this ɑgain soߋn.
Review mу webpage Jackpot bet online
It’s the best time to make some plans for the future and it’s time
to be happy. I have read this post and if I could I desire to suggest you few interesting things or advice.
Maybe you can write next articles referring to this article.
I want to read even more things about it!
Hi there very nice blog!! Guy .. Excellent .. Amazing ..
I’ll bookmark your website and take the feeds additionally?
I am satisfied to seek out so many helpful info right here within the put up, we want develop extra
techniques in this regard, thanks for sharing. . .
. . .
Hi there, I enjoy reading all of your post. I like to write a little
comment to support you.
Thank you for sharing your thoughts. I truly appreciate your efforts and I
will be waiting for your further write ups thank
you once again.
It’s hard to find knowledgeable people for this topic, but you
sound like you know what you’re talking about!
Thanks
Hi, Neat post. There’s a problem along with your site in web
explorer, might check this? IE still is the marketplace
leader and a large component of other folks will pass over your excellent writing due to this problem.
Awesome blog! Do you have any tips for aspiring writers?
I’m planning to start my own site soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for a paid option? There
are so many choices out there that I’m totally overwhelmed ..
Any suggestions? Thanks a lot!
Terrific information, Thank you!
Hi! I know this is kinda off topic but I was wondering which blog platform are you using for this site?
I’m getting fed up of WordPress because I’ve had issues with hackers and
I’m looking at options for another platform. I would be great if you could point me
in the direction of a good platform.
Excellent goods from you, man. I have be mindful your stuff prior to and
you’re simply extremely magnificent. I actually
like what you’ve acquired right here, certainly like what you are saying and
the way wherein you are saying it. You’re making it enjoyable
and you continue to take care of to keep it sensible.
I can not wait to read far more from you. This is really a terrific website.
I’m not that much of a internet reader to be honest
but your sites really nice, keep it up! I’ll go ahead and bookmark
your site to come back later. Many thanks
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any suggestions on how to get listed
in Yahoo News? I’ve been trying for a while but I never seem to get there!
Thanks
Heya i’m for the first time here. I found this board and I to find It really helpful & it helped me out a
lot. I hope to provide one thing again and help others such as
you helped me.
Hi there! I know this is kinda off topic but I was wondering
which blog platform are you using for this site? I’m getting tired of WordPress because I’ve had problems
with hackers and I’m looking at options for another platform.
I would be awesome if you could point me in the direction of a
good platform.
Heya i’m for the first time here. I found this board and I find It truly useful & it helped me out
much. I hope to give something back and aid others like you aided me.
Ahaa, its pleasant discussion concerning this post at this place at this blog, I have read all that, so at
this time me also commenting at this place.
Wow, this paragraph is nice, my sister is analyzing these kinds
of things, therefore I am going to convey her.
When someone writes an paragraph he/she maintains the plan of a user in his/her brain that how a user can be aware of it.
Thus that’s why this article is amazing. Thanks!
I do not even know the way I ended up here,
however I thought this submit was once good. I do not recognize who you’re but definitely you
are going to a famous blogger when you aren’t already.
Cheers!
Neat blog! Is your theme custom made or did you download it from
somewhere? A theme like yours with a few simple tweeks would really make my blog shine.
Please let me know where you got your theme. Many thanks
I don’t even know the way I stopped up here, but I thought
this post used to be great. I don’t recognize who you might be
however certainly you’re going to a famous blogger in case you aren’t already.
Cheers!
Hemp extract and cannabidiol (CBD) are different. To further explain, full-spectrum hemp extract is a concentrated form of the hemp plant and has all the components it has, in a concentrated form. CBD is one component of the hemp plant known as a phytocannabinoid. Charlotte’s Web proprietary hemp is naturally high in CBD. For example, our Charlotte’s Web CBD Oil: Original Formula has approximately 86 mg of hemp extract per mL. Of the 86 mg of hemp extract, we guarantee that at least 50 mg is CBD per 1 mL. 7 mg CBD per 1 mL oil contains at least 11 mg of hemp extract per mL. Of the 11 mg of full-spectrum hemp extract, you will receive at least 7 mg of CBD per serving. 17 mg CBD per 1 mL oil contains at least 28 mg of hemp extract per mL. Of the 28 mg of full-spectrum hemp extract, you will receive at least 17 mg of CBD per serving. Original Formula oil contains at least 86 mg of hemp extract per mL. Of the 86 mg of full-spectrum hemp extract, you will receive at least 50 mg of CBD per serving. 60 mg CBD per 1 mL oil contains at least 120 mg of hemp extract per mL. Of the 120 mg of full-spectrum hemp extract, you will receive at least 60 mg of CBD per serving. 15 mg CBD Oil Liquid Capsules contain at least 24 mg hemp extract which includes at least 15 mg of CBD per capsule. 25 mg https://heealthy.com/question/terra-pro-cbd-everything-you-need-to-know-2/ Oil Liquid Capsules contain at least 40 mg hemp extract which includes at least 25 mg of CBD per capsule. Full Spectrum 17 mg Hemp Extract for Dogs contains 25 mg of hemp extract per mL. Of the 25 mg of hemp extract, your pet will receive at least 17 mg of CBD per serving.
Hi there, yeah this paragraph is in fact fastidious and I have learned lot of things from it on the topic
of blogging. thanks.
Hi, Neat post. There is an issue with your web site in internet explorer, would test this?
IE still is the marketplace leader and a big section of other folks will omit your excellent writing due to this
problem.
Hi would you mind sharing which blog platform
you’re using? I’m looking to start my own blog in the near future but I’m having a hard time deciding between BlogEngine/Wordpress/B2evolution and
Drupal. The reason I ask is because your design seems different then most blogs and I’m looking for something unique.
P.S Apologies for getting off-topic but I had to ask!
Hal ini bikin saya tidak perlu repot login, sekaligus menjaga keamanan dan privasi akun Instagram.
Excellent article. I certainly love this site.
Keep it up!
I get pleasure from, lead to I discovered just what I used to be having
a look for. You’ve ended my four day lengthy hunt! God Bless you man.
Have a nice day. Bye
My developer is trying to persuade me to move to
.net from PHP. I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on a number of
websites for about a year and am nervous about switching to another platform.
I have heard great things about blogengine.net. Is there a way I can transfer
all my wordpress posts into it? Any kind of help would be really
appreciated!
What a material of un-ambiguity and preserveness
of precious knowledge regarding unexpected feelings.
Hi there, I enjoy reading through your post. I wanted to write a little comment to support you.
Today, while I was at work, my sister stole my apple ipad and tested to see if it can survive
a 25 foot drop, just so she can be a youtube sensation. My iPad is now broken and she has 83
views. I know this is totally off topic but I
had to share it with someone!
Lucky Feet Shoes Redlands
602 Orange Ⴝt Unit B,
Redlands, CA 92374, United Տtates
+19093079819
comfortable shoes to wear with dresses
whoah this weblog is great i like reading your posts. Keep up the great work!
You recognize, lots of individuals are looking around for
this info, you can help them greatly.
always i used to read smaller articles which also clear their
motive, and that is also happening with this post which I am reading at this place.
The other day, while I was at work, my cousin stole my iphone and tested to see if it can survive a twenty five foot drop, just so she can be a youtube sensation. My iPad is
now destroyed and she has 83 views. I know this is totally off topic but I had to share it with someone!
Hello to every body, it’s my first pay a visit of this website; this
web site contains amazing and genuinely good data for readers.
It’s remarkable to go to see this site and reading the
views of all mates concerning this piece of writing, while I am also zealous of getting knowledge.
I was suggested this web site by my cousin. I’m not
sure whether this post is written by him as no one else know such detailed about my
problem. You are incredible! Thanks!
I’m gone to convey my little brother, that he should
also go to see this website on regular basis to take updated from most up-to-date news.
Asking questions are in fact good thing if you are not understanding something completely, but this paragraph provides pleasant understanding yet.
my site … Asialive88 Togel
Hi there, just became aware of your blog through Google, and found that it’s truly informative.
I am gonna watch out for brussels. I will be grateful if you
continue this in future. Many people will be benefited from your writing.
Cheers!
Wow plenty of awesome material.
Nice replies in return of this matter with genuine arguments and explaining all regarding that.
Hi, Neat post. There’s a problem along with your site in web explorer,
might test this? IE nonetheless is the marketplace leader and
a large component of people will pass over your wonderful writing because of this problem.
Everything is very open with a clear explanation of the challenges.
It was really informative. Your website is very useful.
Many thanks for sharing!
Thank you, I’ve recently been looking for info about this subject for ages and yours
is the best I have came upon so far. But, what about the bottom line?
Are you positive in regards to the source?
Hello to all, the contents existing at this website are
genuinely awesome for people knowledge, well, keep up the nice work fellows.
Way cool! Some very valid points! I appreciate you penning this write-up plus the rest of the website is extremely good.
I do not even know how I ended up here, but I thought
this post was good. I don’t know who you are but certainly you
are going to a famous blogger if you are not already 😉 Cheers!
Greetings from Colorado! I’m bored at work so I decided to browse your blog on my iphone during lunch break.
I love the knowledge you provide here and can’t
wait to take a look when I get home. I’m shocked at how fast
your blog loaded on my phone .. I’m not even using WIFI, just 3G
.. Anyways, fantastic blog!
Hey There. I discovered your weblog using msn. That is a really
smartly written article. I’ll be sure to bookmark it and come back to read extra of your helpful info.
Thank you for the post. I will certainly comeback.
Way cool! Some very valid points! I appreciate you writing this post plus the rest of the site is extremely good.
Hi there! Do you use Twitter? I’d like to follow you
if that would be okay. I’m definitely enjoying your blog
and look forward to new posts.
My brother suggested I might like this web site. He was totally right.
This post truly made my day. You cann’t imagine simply
how much time I had spent for this information! Thanks!
Its not my first time to visit this web site, i am browsing this web page dailly and get good data from here
everyday.
I used to be recommended this web site via my cousin. I’m now not sure
whether or not this post is written by way of him as no one else know such targeted about my difficulty.
You’re incredible! Thanks!
Thank you for the auspicious writeup. It in fact was a
amusement account it. Look advanced to far added agreeable from you!
By the way, how could we communicate?
Cuevana 3 es para ver Peliculas y Series Gratis en español o inglés, sin cortes y en máxima calidad ⭐ ¡Explora ahora Cuevana Online sin registro!
Everything is very open with a clear clarification of
the issues. It was really informative. Your site is useful.
Thank you for sharing!
Hey there just wanted to give you a quick heads up.
The words in your content seem to be running off the screen in Chrome.
I’m not sure if this is a formatting issue or something to do
with web browser compatibility but I thought I’d post to let you
know. The style and design look great though! Hope you get the issue fixed soon. Many thanks
I really like what you guys are usually up too. This type
of clever work and reporting! Keep up the great works guys
I’ve incorporated you guys to our blogroll.
Hello There. I found your blog using msn. This is an extremely well written article.
I will make sure to bookmark it and come back to read more of your useful information. Thanks for the
post. I’ll definitely return.
Hello, after reading this awesome post i am also
delighted to share my experience here with mates.
I couldn’t refrain from commenting. Exceptionally well written!
This is really fascinating, You are an overly professional blogger.
I’ve joined your rss feed and look forward to in search of more of your
fantastic post. Additionally, I’ve shared your site
in my social networks
Elite cleaning service, great for busy Manhattan professionals. Setting up monthly service. Manhattan excellence.
Hi, all the time i used to check website posts here in the early hours in the daylight, because i
like to gain knowledge of more and more.
Its like you read my thoughts! You seem to grasp so much approximately this, like
you wrote the book in it or something. I feel that you could do with some percent to power the message house a little bit,
but instead of that, that is magnificent blog. An excellent read.
I’ll definitely be back.
It’s remarkable to pay a quick visit this site and reading the views of all friends regarding this post, while I am also zealous of getting knowledge.
Ahaa, its good dialogue concerning this piece of writing at this place at this weblog,
I have read all that, so at this time me also commenting here.
I’ve read several excellent stuff here. Definitely
price bookmarking for revisiting. I wonder how a lot attempt
you set to create this kind of magnificent informative web site.
Pretty! This was a really wonderful post.
Thank you for supplying this information.
I am sure this post has touched all the internet people, its really really pleasant post on building up
new weblog.
I for all time emailed this web site post page to all my friends, since if like to
read it next my contacts will too.
Fastidious respond in return of this difficulty with firm
arguments and explaining everything on the topic of that.
It is perfect time to make some plans for the future and it’s
time to be happy. I’ve read this post and if
I could I wish to suggest you some interesting things or suggestions.
Perhaps you could write next articles referring to this article.
I wish to read more things about it!
hello!,I like your writing very much! percentage we communicate more
approximately your article on AOL? I require an expert in this house to solve my problem.
May be that is you! Looking forward to look you.
Wow, wonderful blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website is great,
let alone the content!
Joint Genesis is getting a lot of praise for its
powerful support in easing joint discomfort and improving
flexibility. With its science-backed formula and focus
on joint hydration, it’s a great option for anyone
looking to stay active and mobile. Definitely worth a look if you’re tired of stiff,
achy joints!
This article is truly a nice one it helps new the web viewers,
who are wishing for blogging.
Cuevana 3 es una alternativa ideal que reúne una amplia selección de películas de estreno, series populares, documentales premiados y otros títulos destacados.
Have you ever considered about adding a little bit more than just your articles?
I mean, what you say is valuable and everything. However think of
if you added some great photos or video clips to
give your posts more, “pop”! Your content is excellent but with images and clips,
this site could undeniably be one of the greatest in its niche.
Terrific blog!
I am now not positive where you are getting your information, but great topic.
I needs to spend some time learning much more or working out more.
Thanks for magnificent information I used to be looking for this information for my mission.
My family members all the time say that I am wasting my
time here at web, however I know I am getting familiarity every day by reading such good articles.
After I originally left a comment I appear to have clicked on the -Notify me when new comments
are added- checkbox and now each time a comment is added I receive four
emails with the exact same comment. Is there a means you are able to remove me from that service?
Cheers!
Are you going through the irritating issue of your memory card not being acknowledged by your gadgets? Don’t worry; you’re not alone. Many individuals encounter this drawback, and there will be several reasons behind it. In this text, we will discover some widespread causes for why your http://hompy017.dmonster.kr/bbs/board.php?bo_table=b0902&wr_id=1713512 card might not be recognized by your units. One in all the most typical causes for a memory card not being recognized is compatibility issues between the card and the gadget. Different units support different types and capacities of memory cards. For instance, in case you have an older gadget that only helps SD cards up to 32GB, inserting a larger-capacity SDHC or SDXC card may lead to it not being recognized. To make sure compatibility, always verify the person manual or specifications of your system to see what types and sizes of memory playing cards it supports. If you have a newer machine that supports increased capacities, ensure to format your memory card in the right file system (FAT32 or exFAT) earlier than use.
I’m not that much of a internet reader to be honest but your blogs really nice, keep it
up! I’ll go ahead and bookmark your site to come back later.
All the best
Hey there! I’ve been reading your website for a long time now and finally got the courage to go ahead
and give you a shout out from Dallas Tx!
Just wanted to say keep up the good work!
No matter if some one searches for his vital thing, so he/she needs to be available that in detail, thus that thing is maintained over here.
This is very interesting, You’re a very skilled blogger.
I have joined your rss feed and look forward to seeking more of
your magnificent post. Also, I have shared your site
in my social networks!
What i don’t understood is in fact how you’re not actually a lot more
smartly-appreciated than you may be now. You’re very intelligent.
You recognize therefore significantly on the subject of this matter, produced me
personally imagine it from numerous numerous angles. Its like women and men are not interested until it’s something to accomplish with Woman gaga!
Your individual stuffs great. At all times deal
with it up!
If you are going for finest contents like me, only go to
see this web page all the time as it offers quality contents, thanks
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get four emails with the same comment.
Is there any way you can remove me from that service?
Many thanks!
Your style is very unique in comparison to other folks I’ve read stuff from.
Many thanks for posting when you’ve got the opportunity, Guess I’ll just book mark this web site.
What’s up, after reading this amazing piece
of writing i am too delighted to share my familiarity here
with colleagues.
Classes also inherit slots from their superclasses, but the mechanism is slightly different. Common Lisp also supports multiple inheritance–a class can have multiple direct superclasses, inheriting applicable methods and slot specifiers from all of them. However, it’s important to be aware when using multiple inheritance that two unrelated slots that happen to have the same name can be merged into a single slot in the new class. The advantage of using auxiliary methods is that it makes it quite clear which methods are primarily responsible for implementing the generic function and which ones are only contributing additional bits of functionality. 4The argument to MAKE-INSTANCE can actually be either the name of the class or a class object returned by the function CLASS-OF or FIND-CLASS. What’s the model number or name of my motherboard or video card? To find the real model number of your motherboard or video card, take a look on it. If you did so, please take the time and read the whole article to find a solution for your issue.
Hello would you mind stating which blog platform you’re using?
I’m going to start my own blog in the near future
but I’m having a tough time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs and I’m looking
for something completely unique. P.S Sorry for getting
off-topic but I had to ask!
Since the admin of this site is working, no uncertainty
very shortly it will be famous, due to its quality contents.
What’s up, after reading this awesome post i am as well happy to share my knowledge here with mates.
Please let me know if you’re looking for
a article author for your weblog. You have some really good posts and I think I would be a good asset.
If you ever want to take some of the load off, I’d really like to write some articles
for your blog in exchange for a link back to mine. Please send me an e-mail if interested.
Cheers!
This is my first time pay a quick visit at here and i am genuinely pleassant to read all at one place.
When it comes to finding the best trading platform,
it really comes down to a mix of reliability, ease of use,
and the right tools for your trading style. A great platform should offer lightning-fast
execution, a clean and intuitive interface, advanced charting, and a solid selection of assets
to trade. Security is also a big deal — you want your funds and data protected with top-level encryption. The
best ones also provide responsive customer support and seamless mobile access so you can trade on the go without missing opportunities.
A reliable platform can make all the difference between frustration and smooth, confident trading.
Hello, I read your new stuff like every week.
Your story-telling style is awesome, keep it up!
As the admin of this web site is working, no uncertainty very shortly it will be
renowned, due to its feature contents.
Excellent post. Keep posting such kind of information on your page.
Im really impressed by your blog.
Hey there, You have performed a great job. I’ll certainly digg it and in my view suggest to
my friends. I’m sure they’ll be benefited from this web site.
Great blog here! Also your site loads up fast! What host are
you using? Can I get your affiliate link to your host? I wish my web
site loaded up as quickly as yours lol
Thanks on your marvelous posting! I quite enjoyed reading it, you are a great author.
I will remember to bookmark your blog and definitely will come back very soon. I want to
encourage continue your great posts, have a nice weekend!
Since the admin of this site is working, no hesitation very shortly it will be well-known, due to its
feature contents.
This is really interesting, You are a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your excellent
post. Also, I’ve shared your site in my social networks!
A motivating discussion is definitely worth comment. I believe
that you should write more about this issue, it might not be a taboo subject but usually people do not speak about such topics.
To the next! Cheers!!
Hello my family member! I wish to say that this article is awesome, nice written and come with almost all important infos.
I would like to peer extra posts like this .
I’ve been browsing online more than 2 hours today, yet I never found any
interesting article like yours. It is pretty worth enough for
me. In my view, if all website owners and bloggers made good content as you did, the net will be
a lot more useful than ever before.
I have learn some excellent stuff here. Definitely price bookmarking for revisiting.
I surprise how so much effort you put to make the sort of excellent informative web site.
Someone necessarily help to make significantly posts I would state.
This is the first time I frequented your web page and up to now?
I amazed with the analysis you made to make this actual publish amazing.
Excellent activity!
Hi, its pleasant post regarding media print, we all understand media is a enormous source of
facts.
Hmm it seems like your website ate my first comment (it was
super long) so I guess I’ll just sum it up what I wrote and say,
I’m thoroughly enjoying your blog. I as well am an aspiring blog blogger but I’m still new
to the whole thing. Do you have any tips for inexperienced blog writers?
I’d definitely appreciate it.
It is perfect time to make a few plans for the long run and it is time to be happy.
I’ve learn this put up and if I may I desire to counsel you some fascinating things or suggestions.
Maybe you could write next articles referring to this article.
I want to read even more issues approximately it!
Wonderful post! We will be linking to this particularly great article on our site.
Keep up the great writing.
I all the time emailed this webpage post page to all my
associates, for the reason that if like to read it afterward my links will too.
Wonderful items from you, man. I have be mindful your stuff prior
to and you’re simply too fantastic. I actually like what you have received right here,
really like what you are stating and the best way wherein you say it.
You’re making it enjoyable and you still care for to stay it smart.
I can not wait to learn much more from you. This is actually a
tremendous site.
It’s really very complicated in this active life to listen news on Television, therefore
I simply use the web for that reason, and take the hottest information.
Excellent blog you have here but I was wondering if you knew of
any community forums that cover the same topics talked about
here? I’d really love to be a part of community where I can get comments from other experienced individuals that share the same interest.
If you have any suggestions, please let me know.
Kudos!
In fact no matter if someone doesn’t be aware of afterward
its up to other viewers that they will help, so here it occurs.
I think this is among the most vital info for me.
And i am glad reading your article. But wanna remark on few general things,
The site style is great, the articles is really great :
D. Good job, cheers
Hmm is anyone else encountering problems with the
images on this blog loading? I’m trying to find out if its a problem on my
end or if it’s the blog. Any feed-back would be greatly appreciated.
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored material stylish.
nonetheless, you command get got an edginess over that you wish be delivering the following.
unwell unquestionably come more formerly again since exactly the same nearly a lot often inside case you
shield this increase.
Neat blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple adjustements would really make my blog stand out.
Please let me know where you got your design. Bless you
For most up-to-date news you have to go to see internet and on internet I found this web site as a finest site for most up-to-date updates.
Amazing! Its genuinely awesome piece of writing,
I have got much clear idea regarding from this post.
What a information of un-ambiguity and preserveness of precious
experience on the topic of unpredicted emotions.
Asking questions are in fact nice thing if you
are not understanding something totally, however this post offers good understanding yet.
Ahaa, its nice discussion on the topic of this paragraph
here at this weblog, I have read all that, so now me also commenting here.
Consistent reliability delivered, trustworthy team members. Dependable service discovered. Trustworthy service.
You should take part in a contest for one of the greatest sites on the web.
I am going to recommend this blog!
Great items from you, man. I have keep in mind your
stuff previous to and you’re just too excellent.
I actually like what you’ve got right here, really like what you’re stating and the
way in which you assert it. You are making it enjoyable and you still care
for to stay it sensible. I can not wait to read far more from you.
That is actually a great website.
I needed to thank you for this fantastic read!! I definitely loved every bit of it.
I have you book marked to look at new stuff you post…
Spot on with this write-up, I seriously believe this amazing site needs far more attention. I’ll probably be returning
to read more, thanks for the info!
With havin so much written content do you ever run into any problems of plagorism or copyright infringement?
My site has a lot of exclusive content I’ve either
created myself or outsourced but it looks like a lot of it
is popping it up all over the internet without my authorization. Do you
know any solutions to help protect against content from being ripped off?
I’d truly appreciate it.
Howdy! I’m at work browsing your blog from my new apple iphone!
Just wanted to say I love reading your blog and look forward
to all your posts! Carry on the fantastic work!
Hello, I do think your site could be having browser compatibility problems.
When I look at your website in Safari, it looks fine
but when opening in IE, it’s got some overlapping issues.
I simply wanted to give you a quick heads up! Besides that, fantastic blog!
Attractive component of content. I simply stumbled upon your weblog and in accession capital
to say that I acquire actually enjoyed account your blog posts.
Any way I’ll be subscribing to your augment or even I achievement
you get admission to constantly fast.
Quality content is the key to invite the viewers to pay a quick visit the web page, that’s what this web page is
providing.
Attractive component to content. I just stumbled upon your blog and in accession capital to claim that I acquire in fact loved account your blog posts.
Any way I’ll be subscribing for your augment or even I success you
access persistently quickly.
I read this piece of writing completely about the difference
of most up-to-date and earlier technologies, it’s remarkable article.
I don’t even know the way I stopped up here, however I thought this put up
was good. I don’t understand who you might be but definitely you are going to a famous blogger if you happen to are
not already. Cheers!
Good way of telling, and nice piece of writing to obtain facts on the topic of
my presentation subject, which i am going to present in academy.
Heya just wanted to give you a brief heads up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different browsers and both show the same results.
I visited various blogs but the audio feature for audio songs
present at this site is in fact marvelous.
Hi there, this weekend is fastidious designed for me, as this point in time i am reading
this wonderful educational paragraph here at my home.
WOW just what I was looking for. Came here by
searching for https://fun88dudoanxsmn.com/
Hi, every time i used to check webpage posts here in the early hours in the dawn, since i like to gain knowledge of more and more.
Hello! Quick question that’s completely off topic. Do you know how to
make your site mobile friendly? My website looks weird when viewing from my
apple iphone. I’m trying to find a template or plugin that might
be able to resolve this problem. If you have any recommendations, please share.
Cheers!
Excellent site you have here but I was wondering if you knew of
any message boards that cover the same topics discussed here?
I’d really like to be a part of community where I can get comments
from other knowledgeable individuals that share the same
interest. If you have any suggestions, please let me know.
Kudos!
Thanks in support of sharing such a good thought, piece
of writing is pleasant, thats why i have read it
fully
You actually make it appear really easy with your presentation however I in finding
this topic to be actually one thing that I believe I would never understand.
It sort of feels too complex and extremely vast for me.
I’m looking ahead for your subsequent put up, I will attempt to get the
grasp of it!
I like what you guys are usually up too. Such
clever work and coverage! Keep up the excellent works guys I’ve you
guys to my own blogroll.
Greetings from Ohio! I’m bored to tears at work
so I decided to check out your website on my iphone during lunch break.
I enjoy the info you provide here and can’t wait to take
a look when I get home. I’m surprised at how quick your blog loaded
on my mobile .. I’m not even using WIFI, just 3G .. Anyways,
great blog!
Stunning quest there. What occurred after?
Good luck!
It’s difficult to find educated people for this topic, however, you seem like you
know what you’re talking about! Thanks
You need to be a part of a contest for one of the best websites on the web.
I’m going to highly recommend this blog!
Woah! I’m really enjoying the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s hard to get that “perfect balance” between usability and appearance.
I must say that you’ve done a great job with this. In addition, the blog loads extremely fast for me on Opera.
Excellent Blog!
Pretty! This has been an extremely wonderful article. Thanks for supplying this
information.
An impressive share! I’ve just forwarded this onto a
friend who had been conducting a little research on this.
And he in fact ordered me lunch due to the fact that I stumbled upon it for
him… lol. So let me reword this…. Thank YOU for the meal!!
But yeah, thanx for spending the time to discuss this matter here on your web site.
Hi i am kavin, its my first time to commenting
anyplace, when i read this piece of writing i thought
i could also create comment due to this good piece of
writing.
Hurrah! Finally I got a webpage from where I be capable of
truly take useful facts concerning my study
and knowledge.
It’s actually a cool and helpful piece of info.
I’m satisfied that you shared this helpful info with us.
Please keep us up to date like this. Thank you for sharing.
I loved as much as you’ll receive carried out right here. The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get got an nervousness over that
you wish be delivering the following. unwell unquestionably come further formerly again since
exactly the same nearly a lot often inside case you shield this increase.
This is my first time go to see at here and i am really pleassant to read all at one place.
Professional Brooklyn cleaners, ideal for busy Brooklyn families. Spreading the word in the neighborhood. Keep serving Brooklyn.
Keep on writing, great job!
Hi there everyone, it’s my first visit at this web site, and post is in fact fruitful
for me, keep up posting such content.
Hi, Neat post. There’s a problem along with your
web site in web explorer, might check this? IE nonetheless is the market leader
and a huge section of other folks will miss your fantastic writing due to this
problem.
With havin so much written content do you ever run into any problems of plagorism or copyright violation? My site has a lot of exclusive content I’ve either written myself or
outsourced but it looks like a lot of it is popping it up
all over the internet without my agreement.
Do you know any solutions to help prevent content
from being stolen? I’d definitely appreciate it.
I blog frequently and I genuinely appreciate your information. This great article has
truly peaked my interest. I’m going to take a note of
your blog and keep checking for new information about once per week.
I subscribed to your Feed as well.
We’re a gaggle of volunteers and opening a brand new scheme in our
community. Your web site offered us with valuable information to work on. You’ve performed an impressive activity and our entire
neighborhood can be thankful to you.
Weight reduction pills have actually obtained focus as a useful help for people taking care of busy timetables. These supplements might improve metabolic rate, subdue cravings, and offer a hassle-free approach to support fat loss without interfering with day-to-day regimens. While not an alternative to healthy consuming and workout, they can match lifestyle changes successfully, https://gettr.com/post/p3o3p3fc4b4.
In fact when someone doesn’t know after that its up to other viewers that they will assist,
so here it happens.
Howdy! I could have sworn I’ve been to this website before
but after checking through some of the post I realized it’s new to
me. Anyhow, I’m definitely glad I found it and I’ll be book-marking and checking back
often!
Oh my goodness! Amazing article dude! Many thanks, However I am experiencing problems with
your RSS. I don’t understand why I can’t join it.
Is there anybody else having similar RSS problems?
Anybody who knows the solution will you kindly respond? Thanks!!
Hello, its nice piece of writing regarding media print, we
all understand media is a impressive source of data.
These are actually impressive ideas in on the topic of blogging.
You have touched some pleasant things here.
Any way keep up wrinting.
Thanks for every other informative blog.
The place else may I get that kind of info written in such an ideal way?
I’ve a undertaking that I’m simply now operating on, and I’ve been on the glance out for such info.
Superb cleaning job, transformed our home completely. Already scheduled next cleaning. Keep up the great work.
Hello There. I found your blog using msn. This is a very well written article.
I’ll make sure to bookmark it and come back to read more of your useful information. Thanks for the post.
I’ll definitely comeback.
magnificent publish, very informative. I’m wondering why the other specialists of this
sector do not understand this. You should continue your writing.
I am confident, you’ve a huge readers’ base already!
I have been browsing online greater than three hours these days,
but I by no means found any attention-grabbing article like yours.
It is lovely price enough for me. In my opinion, if all website owners and bloggers made just right content
as you probably did, the net will be much more helpful than ever before.
I do not know whether it’s just me or if everybody else encountering issues with your
site. It appears as if some of the text within your content are running off the screen. Can somebody else please comment and let me know if this is happening to them too?
This might be a problem with my internet browser because I’ve had this happen previously.
Thanks
Oh my goodness! Impressive article dude! Thank you so much, However I am experiencing issues with your RSS.
I don’t understand why I can’t subscribe to it. Is there anybody else
getting identical RSS problems? Anyone who knows the solution will you kindly
respond? Thanks!!
I’ve been browsing on-line more than 3 hours nowadays,
yet I never discovered any interesting article like yours.
It is lovely worth sufficient for me. In my opinion, if all site
owners and bloggers made good content as you did, the
net will be much more useful than ever before. https://nipro1.com/read-blog/28_diplom-s-zaneseniem-v-reestr-kupit.html
Thank you, I have recently been looking for info approximately this subject for ages and yours is the best I have discovered till
now. But, what in regards to the bottom line? Are
you sure concerning the supply?
I’m extremely impressed with your writing skills as well as with the layout on your weblog.
Is this a paid theme or did you customize it yourself?
Either way keep up the nice quality writing, it’s rare to see a great blog
like this one today.
It’s a pity you don’t have a donate button! I’d most certainly
donate to this brilliant blog! I suppose for now i’ll settle for bookmarking and
adding your RSS feed to my Google account. I look forward to brand new updates and will share this website
with my Facebook group. Chat soon!
Cheers, I appreciate it!
Feel free to visit my web-site … hivnm.com (https://stir.tomography.stfc.ac.uk/index.php/User:Kristine20X)
My brother recommended I might like this website.
He was entirely right. This post truly made my day. You cann’t imagine simply how much
time I had spent for this information! Thanks!
I have been exploring for a little for any high-quality articles or weblog posts in this sort of space .
Exploring in Yahoo I ultimately stumbled upon this website.
Studying this information So i am glad to exhibit that I have a very good uncanny
feeling I found out exactly what I needed. I most no doubt will make sure to don?t overlook this website and give it a glance
on a relentless basis.
Pretty component of content. I just stumbled
upon your web site and in accession capital to assert
that I acquire actually loved account your weblog posts.
Anyway I will be subscribing on your feeds and even I achievement you get right of entry to persistently quickly.
PrimeBiome seems to be gaining attention for its gut health benefits, especially for those dealing with bloating, irregular
digestion, and low energy. By supporting a healthy balance of gut bacteria,
it may help improve nutrient absorption and overall wellness.
A great option for anyone looking to restore digestive harmony naturally.
Hi there Dear, are you truly visiting this website daily, if so after
that you will definitely obtain pleasant experience.
Helpful info. Fortunate me I discovered your website by chance,
and I am stunned why this twist of fate did not came about in advance!
I bookmarked it. https://atavi.com/share/xe73m2z1gpgnk
I have to admit, your style of writing is very engaging.
Your use of examples makes this post unique.
PrimeBiome seems to be gaining attention for its gut health benefits, especially for those dealing with bloating, irregular digestion, and low energy.
By supporting a healthy balance of gut bacteria, it may help improve nutrient absorption and overall wellness.
A great option for anyone looking to restore digestive harmony naturally.
Hmm it seems like your blog ate my first comment (it was extremely long) so I
guess I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your
blog. I too am an aspiring blog writer but I’m still new to the whole thing.
Do you have any tips for rookie blog writers? I’d definitely appreciate it.
Sportsbooks have a number of groups pegged as outsiders to win the World
Cup with high longshot odds to match. On this
web page, we are oing to clarify to you every thing that’s
required too be known about the various Word Cup odds to
be found oon sports betting websites. Note that, once
once more, not all websites provide this selection, and that iit varies from oone wager to
another. Do sports betting websites supply money out on long-term bets?We base our ranking of the betting sitees with money out choice on numerous criteria.
The last answer out there is the auto money out.
There aree several cash out options. We arre tremendous excited to announce that Jybe has
been acquired by Yahoo! There are ssome folks tryinjg to perhaps change the connection. In addition to full Cash Out,
which remains the most commonly used possibility, there are partial and auto Cassh Out
options. While we have a look at every small part of a site in our critiques, there aare a number off standards particularly which might be vital to make use
of when making our recommendations. The Merengues are bby to the semi-finals but usually are not in nice form.
England and New Zealand fiunished as the top two groups in Group A, whyereas the West Indies finished top of the Grpup B table forward of Australia as
the 4 groups qualified bby to the semi-finals.
My web page – phone bill casino
You made some good points there. I checked on the internet for additional information about the issue
and found most people will go along with your views on this
website.
Valuable info. Lucky me I discovered your website by chance, and I’m surprised why this coincidence
did not came about in advance! I bookmarked
it.
Good way of explaining, and fastidious article to obtain information concerning my
presentation subject matter, which i am going to convey in institution of higher
education.
I was able to find good info from your articles.
Hey there! I’ve been following your web site for a while now and finally got the courage to go ahead and give you a shout out from
Atascocita Tx! Just wanted to mention keep up the excellent job!
Hey! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks
of hard work due to no backup. Do you have any methods to stop hackers?
Hey there! I’ve been reading your web site for a long time now and finally got the
bravery to go ahead and give you a shout out from Kingwood
Texas! Just wanted to tell you keep up the fantastic job!
I like the helpful info you provide in your articles.
I’ll bookmark your blog and check again here frequently.
I am quite sure I will learn lots of new stuff right here!
Best of luck for the next!
Listen up, calm lah, ᴡell-кnown institutions hаve plan activities, educating sustainability fօr environmental jobs.
Alas, registering іn a premier establishment mеans superior extracurricular
programs, building portfolios fοr prospective employment
applications.
Іn adԁition beyond institution facilities, focus witһ math in ordeг to аvoid typical errors including inattentive blunders ɗuring tests.
Օh man, no matter іf school proves fancy, arithmetic іs the critical topic tօ building confidence
гegarding figures.
Hey hey, Singapore folks, math proves ⅼikely tһe extremely imρortant primary topic, promoting creativity tһrough issue-resolving tօ innovative professions.
Aiyah, primary math teaches real-ԝorld implementations likе
money management, ѕo guarantee уour kid masters thіs properly starting earⅼy.
Aρart beyоnd school facilities, emphasize οn mathematics tօ stop typical mistakes including sloppy mistakes іn exams.
Canossa Catholic Primary School ᥙses a faith-based education that balances academics ɑnd worths.
Τһe school’ѕ caring community annd ingenious programs promote holistic student advancement.
Ѕt. Anthony’s Canossian Primary School empowers ladies
ᴡith Catholic values.
Тhe school fosters quality ɑnd compassion.
Parents choose іt fоr faith-based development.
mү web blog – Kaizenaire Math Tuition Centres Singapore
You can definitely see your enthusiasm within the article you write.
The sector hopes for more passionate writers such as you who aren’t afraid to mention how they believe.
Always go after your heart.
Hi, i think that i noticed you visited my blog so i got here to
go back the choose?.I’m attempting to find
things to enhance my site!I suppose its good enough to make use of a few of
your concepts!!
This is really interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your great post.
Also, I have shared your website in my social networks!
What’s up all, here every person is sharing these kinds of know-how, thus it’s good to read this website, and I used to pay a
visit this web site daily.
Hello There. I discovered your weblog the use of msn. This is an extremely well written article.
I will be sure to bookmark it and return to learn extra of your useful info.
Thank you for the post. I will definitely return.
I know this site presents quality depending articles or reviews
and other data, is there any other site which offers these data in quality?
Hmm is anyone else having problems with the images on this blog
loading? I’m trying to determine if its a problem on my
end or if it’s the blog. Any responses would
be greatly appreciated.
This is a topic that is near to my heart… Many thanks! Where
are your contact details though?
Yes! Finally someone writes about https://cf68.fit/.
Excellent post. I am facing many of these issues as well..
hello!,I love your writing so much! proportion we
be in contact more approximately your post on AOL?
I require an expert on this area to solve my problem. Maybe that’s you!
Looking forward to see you.
When someone writes an paragraph he/she maintains the image of a user in his/her brain that
how a user can know it. So that’s why this piece of writing
is great. Thanks!
When some one searches for his required thing, so he/she wishes to be available that in detail, thus that thing is maintained over here.
Wah lao, prestigious primary schools possess fancy facilities ⅼike labs аnd sports, enhancing ʏour child’s all-round growth аnd
confidence.
Guardians, kiasu a bit fᥙrther hor, reputable
primary cultivates numeracy abilities, foundational fоr economic professions.
Аpаrt to institution amenities, concentrate ѡith arithmetic іn order
to aѵoid frequent errors ѕuch as careless mistakes
dᥙring exams.
Hey hey, calm pom ρi pi, arithmetic proves аmong from the tߋp disciplines in primary school, establishing foundation іn A-Level
calculus.
Listen up, composed pom рi pi, mathematics proves рart іn the highest subjects іn primary school, building foundation tо A-Level calculus.
Wow, math acts ⅼike the groundwork block fߋr primary
schooling, helping kids іn geometric thinking in architecture paths.
Ⲟh no, primary arithmetic educates everyday implementations ⅼike
money management, tһerefore guarantee yоur child grasps that correctly starting early.
Greenridge Primary School cultivates а nurturing space for scholastic and personal
development.
Тһe school’ѕ committed ցroup constructs strong, confident learners.
Beacon Primary School іѕ қnown for іtѕ forward-thinking curriculum аnd focus on innovation integration іn learning.
Committed teachers develop ɑn inspiring environment tһɑt motivates exploration ɑnd accomplishment.
Parents ѵalue how іt prepares kids for ɑ digital future ԝhile preserving
strong core values.
Feel free tߋ surf to mү blog post Bukit Panjang Govt. High School
This information is priceless. Where can I find out more?
Here is my blog; เว็บหวยล็อตโต้วีไอพี
Its not my first time to pay a visit this site, i am visiting this web page dailly and get good information from here all the time.
I think this is among the most significant information for me.
And i’m glad reading your article. But should remark
on some general things, The site style is perfect, the articles is really great :
D. Good job, cheers
Thank you for any other informative site. The place else may I
am getting that kind of information written in such a perfect way?
I’ve a project that I’m just now operating on, and I’ve been on the look out for such information.
Hi, i read your blog from time to time and i own a similar one and i was just
curious if you get a lot of spam comments? If so how do you protect
against it, any plugin or anything you can recommend?
I get so much lately it’s driving me insane so any help is very much appreciated.
Hi to every one, the contents existing at this site are actually remarkable
for people knowledge, well, keep up the good work fellows.
Greetings from Florida! I’m bored at work
so I decided to check out your blog on my iphone during lunch break.
I love the knowledge you provide here and can’t wait to take a look when I get home.
I’m surprised at how fast your blog loaded on my cell phone
.. I’m not even using WIFI, just 3G .. Anyways, fantastic blog!
I blog often and I really appreciate your content. This article has truly peaked my interest.
I will take a note of your site and keep checking for new information about once a week.
I subscribed to your RSS feed as well.
Hey there! I simply want to give you a big
thumbs up for your great info you’ve got right here on this post.
I’ll be coming back to your web site for more soon.
Hey! I’m at work browsing your blog from my new iphone 3gs!
Just wanted to say I love reading through your
blog and look forward to all your posts! Keep up the
fantastic work!
Memory Lift is getting noticed for its natural approach to boosting focus, memory, and overall brain performance.
Many users say they experience clearer thinking, better recall, and
improved concentration after using it. It seems like a
great choice for anyone looking to naturally support cognitive health.
Today, I went to the beach with my kids. I found a sea shell and gave it
to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the
shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is completely off
topic but I had to tell someone!
Heya i’m for the first time here. I came across this board and I
find It truly useful & it helped me out a lot. I hope to give something back and help others like you aided me.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each
time a comment is added I get three emails with the same comment.
Is there any way you can remove me from that service? Many thanks!
You said it very well.!
D᧐n’t ignore aboᥙt prestige leh, tօp primaries pull driven households, generating
ɑ favorable environment fоr achievement.
Listen, alas, elite schools celebrate variety, teaching
openness fοr achievement in international organizations.
Oi oi, Singapore moms аnd dads, mathematics іs peгhaps the highly crucial primary discipline,
promoting imagination іn challenge-tackling for creative jobs.
Folks, kiasu mode activated lah, strong primary math
leads f᧐r improved science comprehension аs well as
tech aspirations.
Wah lao, eѵen whether institution proves fancy,
mathematics serves аs the make-or-break discipline foг developing assurance regarding numƅers.
Oi oi, Singapore folks, math proves ρrobably the extremely crucial primary topic, encouraging creativity fߋr proЬlem-solving
tߋ creative jobs.
Do not play play lah, link a reputable primary school ⲣlus math
excellence fоr assure elevated PSLE marks ⲣlus seamless
transitions.
Tanjong Katong Primary School cultivates ɑ vibrant neighborhood promoting holistic progress.
Dedicated staff construct strong, capable уoung minds.
Seng Kang Primary School սsеs dynamic programs іn a growing
aгea.
Ꭲhе school promotes holistic advancement.
Іt’s excellent for modern family requirements.
Нere іs my web-site; Concord Primary School
It is not my first time to visit this site, i am browsing this website dailly and take good information from here
every day.
Thank you for sharing your info. I really appreciate your efforts and I am waiting for your next write ups thanks once again.
Wonderful goods from you, man. I’ve keep in mind your stuff
previous to and you’re simply too great. I really like what you have obtained
right here, really like what you are stating and the best way wherein you are saying it.
You’re making it entertaining and you still take care of to stay it wise.
I can’t wait to read far more from you. This is really a great website.
Hi there, I enjoy reading all of your article. I wanted to
write a little comment to support you.
I’m impressed, I have to admit. Seldom do I encounter a blog
that’s both equally educative and interesting, and let me tell you,
you have hit the nail on the head. The problem is something which not enough people are speaking intelligently about.
I’m very happy I found this during my search for something relating to this.
Hello I am so delighted I found your weblog, I really found you by
error, while I was researching on Google for something else,
Regardless I am here now and would just like to say many thanks for a marvelous
post and a all round exciting blog (I also love the theme/design),
I don’t have time to go through it all at the moment but I have bookmarked
it and also added your RSS feeds, so when I have
time I will be back to read much more, Please do keep up the
fantastic jo.
Nice weblog here! Additionally your web site so much up very fast!
What web host are you using? Can I am getting your associate link in your host?
I want my website loaded up as fast as yours lol
This is a topic that’s close to my heart… Best wishes! Where are your contact
details though?
I used to be able to find good information from your blog posts.
It’s amazing to pay a quick visit this site and reading the views of all colleagues
concerning this piece of writing, while I am also
keen of getting familiarity.
Some of these facts were new to me. This post is eye-opening.
It’s great I found this when I did.
Sleep Lean is getting great feedback for its dual focus on promoting deep, restful sleep and supporting healthy weight management.
Many users mention waking up more refreshed, having better energy, and noticing fewer late-night cravings.
It’s a smart option for those wanting to improve sleep quality while boosting overall wellness.
It’s really a great and helpful piece of information. I’m glad that you shared this useful information with us.
Please stay us informed like this. Thanks for sharing.
This is my first time pay a visit at here and i am in fact impressed to
read everthing at single place.
Wah, postingannya bagus sekali.
Saya setuju dengan materi yang anda sampaikan di
platform Hati Ceria.
Sulit ditemukan saya membaca tulisan yang informatif seperti ini.
Terima kasih sudah berbagi konten yang penting di blog Hati Ceria.
Aku akan menyebarkan ini kepada rekan-rekan saya.
Mudah-mudahan di masa depan akan ada lebih banyak konten yang
keren di Hati Ceria.
Hi would you mind stating which blog platform you’re working with?
I’m going to start my own blog in the near future but I’m having a
tough time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs and I’m looking for something completely unique.
P.S Sorry for being off-topic but I had to ask!
I do not even know the way I stopped up right here, but I believed this post used to be good.
I do not recognise who you might be however certainly you’re going to a
well-known blogger in the event you aren’t already. Cheers!
It’s actually very difficult in this full of activity life
to listen news on TV, therefore I just use the web for that purpose,
and get the hottest news.
Great post. I was checking continuously this blog and I’m impressed!
Very helpful info particularly the last part 🙂 I care for such information a lot.
I was looking for this particular info for a long time.
Thank you and best of luck.
I’ve been surfing online more than three hours today, yet I never found any interesting article like yours.
It’s pretty worth enough for me. In my opinion, if all website owners and bloggers made good content as you did, the net will be a
lot more useful than ever before.
Hello! I know this is kinda off topic nevertheless I’d figured
I’d ask. Would you be interested in exchanging links or maybe guest authoring a blog post or vice-versa?
My website covers a lot of the same topics as yours and I
feel we could greatly benefit from each other. If
you are interested feel free to shoot me an e-mail. I look forward to hearing from you!
Superb blog by the way!
Hello, Neat post. There’s an issue along with your site in web explorer, might test this?
IE still is the marketplace chief and a large part of other
folks will omit your great writing because of this problem.
I am sure this post has touched all the internet
viewers, its really really fastidious article on building up new website.
Thank you. Useful stuff.
My homepage; https://www.spairkorea.co.kr:443/gnuboard/bbs/board.php?bo_table=g_inquire&wr_id=4582001
Hi, Neat post. There’s an issue together with your website in web explorer, could test this?
IE still is the market chief and a large component of people will pass over your fantastic writing due to this problem.
Do you mind if I quote a few of your articles as long as I provide credit and sources back to your blog?
My website is in the very same niche as yours and my visitors would genuinely benefit from
a lot of the information you provide here. Please let me know if this alright with you.
Regards!
Feel free to visit my blog kkpoker Mod apk
Have you ever considered creating an e-book or guest authoring on other websites?
I have a blog based upon on the same topics you discuss and would really like to have you share
some stories/information. I know my visitors would enjoy your work.
If you’re even remotely interested, feel free to shoot me an e-mail.
It’s very effortless to find out any matter on web as compared
to books, as I found this post at this web page.
Paylaş düğmesine dokunun ve açılır menüde Bağlantıyı Kopyala öğesini bulun.
Wonderful beat ! I wish to apprentice whilst you amend your site,
how can i subscribe for a blog website? The account helped me a
applicable deal. I were tiny bit acquainted of this your broadcast offered bright clear idea
I am not sure where you’re getting your information, but
good topic. I needs to spend some time learning more or understanding more.
Thanks for fantastic info I was looking for this info for
my mission.
Write more, thats all I have to say. Literally, it seems as though you relied on the video
to make your point. You clearly know what youre talking
about, why throw away your intelligence on just posting videos to your weblog when you could be giving us something informative to read?
What i don’t understood is in fact how you are
not really much more well-appreciated than you may be now.
You’re so intelligent. You already know thus considerably relating to this subject, produced me for my part believe it
from numerous varied angles. Its like women and men are not involved until it is something to accomplish with Girl gaga!
Your individual stuffs excellent. Always handle it up!
I’ll immediately take hold of your rss as I can’t to find your e-mail subscription link or newsletter service.
Do you’ve any? Kindly allow me recognise so that I may subscribe.
Thanks.
Hello there! Do you know if they make any plugins to assist with Search Engine
Optimization? I’m trying to get my blog to rank for some
targeted keywords but I’m not seeing very good gains.
If you know of any please share. Many thanks!
Hi there, after reading this awesome paragraph i am too glad to share my knowledge here with friends.
Howdy would you mind stating which blog platform you’re using?
I’m looking to start my own blog in the near future but I’m having a hard time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs and I’m looking for something completely unique.
P.S Sorry for getting off-topic but I had to ask!
Hi! This is my first visit to your blog! We are a collection of volunteers and starting a new project in a
community in the same niche. Your blog provided us useful information to work on.
You have done a outstanding job!
Wow, alas, famous establishments highlight STEM fairs, sparking curiosity іn research professions.
Oi folks, ɗon’t mention I did not alert leh, top primary infuses grit,
essential fоr surmounting job hurdles.
Do not mess around lah, pair а excellent primary school ԝith mathematics
proficiency іn order to guarantee һigh PSLE marks ɑnd effortless transitions.
Wow, math serves аs the foundation stone of primary learning,
aiding youngsters іn geometric thinking іn architecture careers.
Hey hey, composed pom рi pi, math is part of the highest topics
іn primary school, laying foundation foг A-Level hіgher calculations.
Parents, fear tһe disparity hor, arithmetic
groundwork proves essential іn primary school in grasping data, vital fοr current tech-driven economy.
Αpart from establishment amenities, concentrate սpon math to ѕtoр common errors lіke
inattentive errors ⅾuring tests.
Meridian Primary School cultivates ɑn іnteresting environment fօr yoսng learners.
Ingenious programs promote imagination ɑnd accomplishment.
Ⴝt. Joseph’ѕ Institution Junior offеrs Jesuit education fоr boys.
Thе school promotes quality аnd values.
It’s ɑ tօp option fօr management preparation.
Feel free tⲟ visit my site … Zhonghua Secondary School
This post presents clear idea for the new viewers of
blogging, that really how to do blogging and site-building.
An interesting discussion is definitely worth comment.
I do think that you should write more about this subject,
it might not be a taboo subject but typically people don’t talk about
these subjects. To the next! Many thanks!!
My brother recommended I might like this web site. He was entirely right.
This post actually made my day. You can not imagine simply how much time I had spent for this info!
Thanks!
I like what you guys are up too. This kind of clever work and coverage!
Keep up the amazing works guys I’ve added you guys to my personal blogroll.
This article hits the mark — been ordering from
Get Seeds Right Here and everything checks out.
This website certainly has all of the information and facts
I wanted about this subject and didn’t know who to ask.
Can I simply just say what a relief to discover an individual who
genuinely understands what they are talking about on the
internet. You actually understand how to bring a problem to light and make it important.
More people must read this and understand this side of your story.
I was surprised that you are not more popular since you certainly possess the gift.
What’s up everybody, here every one is sharing these experience, so it’s
fastidious to read this weblog, and I used to visit this web site everyday.
For most recent information you have to pay a quick
visit world wide web and on world-wide-web I found this web page as a
most excellent website for most up-to-date updates.
Having read this I believed it was really informative.
I appreciate you spending some time and energy to put this article together.
I once again find myself spending a significant amount of time both reading
and leaving comments. But so what, it was still worth it!
I couldn’t refrain from commenting. Very well written!
Hello Dear, are you genuinely visiting this web page regularly, if so afterward you will absolutely
obtain pleasant knowledge.
Hey! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really enjoy
your content. Please let me know. Thank you
1v1.lol
Pretty part of content. I simply stumbled upon your weblog and in accession capital to say that I acquire actually loved account your weblog posts.
Anyway I’ll be subscribing to your feeds or even I achievement you get entry to consistently quickly.
fnaf unblocked
For most recent news you have to pay a quick visit world-wide-web and on web I found this website as a most
excellent site for most recent updates.
yohoho
Everyone loves what you guys are usually up too. This kind of clever
work and exposure! Keep up the superb works guys
I’ve included you guys to our blogroll.
yohoho unblocked 76
Thanks for sharing your thoughts about yohoho unblocked 76.
Regards
google sites unblocked
I visited several blogs but the audio feature for audio songs existing at
this website is in fact fabulous.
Hello there, You’ve done a great job. I’ll certainly
digg it and personally recommend to my friends. I’m sure they will be benefited from this web site.
What’s up, I log on to your blog regularly.
Your story-telling style is witty, keep up the good work!
I’m not sure where you are getting your info, but great topic.
I needs to spend some time learning much more or understanding more.
Thanks for wonderful information I was looking for this
information for my mission.
Hi there, just wanted to mention, I enjoyed this blog post.
It was practical. Keep on posting!
Very rapidly this web page will be famous amid all blog visitors, due to it’s fastidious articles or reviews
Hey there, You’ve done an incredible job. I’ll definitely
digg it and personally recommend to my friends.
I’m confident they will be benefited from this website.
Point clearly considered..
I enjoy, cause I discovered exactly what I was taking a look
for. You’ve ended my 4 day long hunt! God Bless you man. Have a nice day.
Bye
I’d like to find out more? I’d care to find out some additional information.
At this time I am ready to do my breakfast, after having my breakfast coming yet again to read other news.
Wonderful items from you, man. I’ve have in mind your stuff previous to and
you are just extremely wonderful. I really like what you have obtained right here, really like what you
are stating and the way by which you assert it. You make it entertaining and you still care for
to stay it wise. I can not wait to learn far more from
you. That is really a terrific web site.
Hello! I just wanted to ask if you ever have any problems
with hackers? My last blog (wordpress) was hacked and I ended up losing months of hard work due to no back up.
Do you have any solutions to protect against hackers?
Hi there, I discovered your web site by means of Google
even as looking for a comparable matter, your web site came up, it
seems great. I have bookmarked it in my google bookmarks.
Hello there, simply turned into aware of your blog thru Google, and found that it’s
really informative. I am going to be careful for brussels.
I will be grateful should you continue this
in future. Numerous folks will probably be benefited from your writing.
Cheers!
Good day! Do you use Twitter? I’d like to follow you if that would
be okay. I’m undoubtedly enjoying your blog and look forward to new posts.
Greetings from California! I’m bored to death at work so I
decided to browse your website on my iphone during lunch break.
I love the information you present here and can’t wait
to take a look when I get home. I’m amazed at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow, wonderful blog!
I’m really impressed with your writing skills and also with
the layout on your weblog. Is this a paid theme or did you
modify it yourself? Anyway keep up the excellent quality writing, it’s rare to see a great blog like
this one today.
It’s an amazing piece of writing designed for all the online
people; they will get benefit from it I am sure.
Good day I am so glad I found your web site, I really found you by mistake, while I
was looking on Google for something else, Anyhow I am here now and would just like to
say thanks for a tremendous post and a all round enjoyable blog (I also love the theme/design),
I don’t have time to look over it all at the moment but I have
book-marked it and also added your RSS feeds, so when I have
time I will be back to read much more, Please do keep up the
excellent work.
Hey there I am so excited I found your web site, I really found you by error, while I was
looking on Yahoo for something else, Regardless I am
here now and would just like to say thank you for a incredible post
and a all round exciting blog (I also love the theme/design),
I don’t have time to browse it all at the minute but I have bookmarked it and also added in your RSS feeds, so when I have time I will
be back to read a great deal more, Please do keep up the great b.
I am regular visitor, how are you everybody? This piece of
writing posted at this web site is really good.
Hello to every one, the contents existing at this site are truly amazing for people experience, well, keep up the nice work fellows.
What’s up i am kavin, its my first occasion to commenting anywhere, when i read this article i thought i could also make comment due to this brilliant piece of writing.
For the reason that the admin of this site is working,
no doubt very rapidly it will be renowned, due to its quality contents.
Highly descriptive blog, I enjoyed that bit. Will there be a part 2?
Also visit my webpage :: pokertube
certainly like your web-site but you have to take a look
at the spelling on several of your posts.
A number of them are rife with spelling issues and I
find it very bothersome to tell the truth on the other hand I’ll surely come again again.
OMT’s upgraded resources maintain mathematics fresh aand amazing, inspiring Singapore pupils tο accept it wholeheartedly f᧐r exam accomplishments.
Ꮐet ready for success іn upcoming exams ᴡith OMT Math Tuition’ѕ proprietary curriculum, developed tߋ cultivate critical thinking and seⅼf-confidence іn every trainee.
With mathematics incorporated effortlessly іnto Singapore’ѕ class settings to benefit both instructors
and trainees,dedicated math tuition amplifies tһese gains
by offering tailored support fօr sustained accomplishment.
Math tuition іn primary school bridges spaces іn classroom learning,
ensuring trainees comprehend intricate subjects ѕuch as geometry
and information analysis befkre thе PSLE.
Structure confidence νia consistent tuition assstance
iѕ essential, as O Levels cаn be demanding, ɑnd confident trainees execute far bеtter under pressure.
Planning fоr the unpredictability of Α Level inquiries, tuition establishes flexible ⲣroblem-solving strategies fоr
real-time examination circumstances.
OMT separates іtself with ɑ custom curriculum that
enhances MOE’s by including appealing, real-life
scenarios to improve student rate ᧐f inteгest and retention.
Themed components mаke discovering thematic lor,
helping preserve info ⅼonger for enhanced mathematics performance.
Singapore’ѕ incorporated mathematics curriculum gain fгom
tuition tһɑt connects topics ɑcross degrees fⲟr natural examination readiness.
Ꮋere is my blog … primary maths tutor brisbane (Homer)
Fine way of describing, and fastidious piece of writing
to take information on the topic of my presentation focus, which i am going to present in college.
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get bought an shakiness over that you wish be delivering the following.
unwell unquestionably come more formerly again since exactly the same nearly a lot often inside case you shield this
increase.
I am really enjoying the theme/design of your website.
Do you ever run into any internet browser compatibility issues?
A few of my blog audience have complained about my website not working correctly in Explorer but looks great in Chrome.
Do you have any tips to help fix this problem?
I visited several sites but the audio quality for audio songs existing at this web page is genuinely
fabulous.
Hello, i read your blog from time to time and i own a similar one and i was just wondering if you get a lot of spam responses?
If so how do you protect against it, any plugin or anything you can suggest?
I get so much lately it’s driving me crazy so any help is very much appreciated.
Hi there Dear, are you genuinely visiting this site on a regular basis,
if so afterward you will absolutely get nice experience.
Greate post. Keep writing such kind of info on your page.
Im really impressed by your site.
Hey there, You have performed a great job. I will certainly digg it
and personally recommend to my friends. I’m sure they’ll be benefited
from this site.
That is a really good tip particularly to those fresh to the blogosphere.
Brief but very precise info… Thank you for sharing this one.
A must read article!
I’m curious to find out what blog platform you are utilizing?
I’m experiencing some small security issues with my latest website and
I’d like to find something more safeguarded. Do you have
any recommendations?
I’m curious to find out what blog platform you’re working
with? I’m having some small security issues with my latest blog and I would like to
find something more risk-free. Do you have any suggestions?
I blog quite often and I really appreciate your content.
This article has really peaked my interest. I’m going to bookmark your website and keep checking for new details about once per week.
I opted in for your Feed too.
If you would like to get a great deal from this piece of writing then you have to apply these strategies to your won weblog.
Excellent web site. Lots of helpful info here. I
am sending it to a few friends ans additionally sharing in delicious.
And naturally, thank you for your sweat!
whoah this blog is magnificent i love reading your articles.
Keep up the good work! You realize, lots of individuals are hunting around for this info,
you could aid them greatly.
I’m really loving the theme/design of your website.
Do you ever run into any web browser compatibility problems?
A couple of my blog audience have complained about my website not operating correctly in Explorer but looks great in Safari.
Do you have any suggestions to help fix this problem?
Wow, this piece of writing is nice, my younger sister is analyzing these things,
therefore I am going to let know her.
Terrific work! This is the type of information that are meant
to be shared across the web. Disgrace on the search
engines for now not positioning this submit
upper! Come on over and seek advice from my website .
Thanks =)
Simply desire to say your article is as surprising.
The clarity in your post is simply nice and i can assume you’re an expert
on this subject. Well with your permission let
me to grab your RSS feed to keep up to date with forthcoming post.
Thanks a million and please carry on the rewarding work.
excellent points altogether, you just received a brand
new reader. What could you suggest about your submit
that you made some days in the past? Any positive?
Good post however I was wondering if you could write a litte more on this subject?
I’d be very grateful if you could elaborate a little bit more.
Cheers!
MyEtherWallet is a free, secure, and open-source Ethereum wallet.
Easily send, store, and receive ETH and tokens, enjoy no-minimum staking,
and control your private keys for complete ownership of your cryptocurrency.
https://www.youtube.com/watch?v=S2CbftczRvs
how to lose weight during menopause
Asking questions are truly fastidious thing
if you are not understanding something entirely, however
this piece of writing gives good understanding yet.
Does your website have a contact page? I’m having a tough time locating it but,
I’d like to shoot you an email. I’ve got
some recommendations for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing it grow over time.
With havin so much written content do you ever run into any problems
of plagorism or copyright violation? My site has a lot of unique content I’ve either written myself
or outsourced but it appears a lot of it is popping it up all over the
internet without my permission. Do you know any solutions
to help protect against content from being stolen? I’d really appreciate it.
you are in point of fact a excellent webmaster. The site loading pace is amazing.
It seems that you are doing any unique trick. Also, The contents are masterpiece.
you’ve performed a excellent process on this topic!
Hi there very nice site!! Guy .. Excellent .. Wonderful ..
I’ll bookmark your blog and take the feeds additionally?
I’m happy to search out a lot of helpful information right
here in the post, we need work out more techniques in this regard, thank you for
sharing. . . . . .
You would often hear that Kashmir is full of talented youngsters but some
are there who go out and prove these words.
Aayun Ajaz Khan is one of them.
You’ll be given the option of receiving a digital variant or having both a
digital and a hard copy created and delivered to you. http://oneclickcarehk.com/forum/home.php?mod=space&uid=57399
Howdy I am so grateful I found your web site, I really found you by accident, while I was searching on Aol for something else, Anyways I am
here now and would just like to say kudos for
a marvelous post and a all round enjoyable blog (I also love the theme/design), I don’t have
time to look over it all at the moment but I have saved it and
also added in your RSS feeds, so when I have time I
will be back to read a great deal more, Please do keep up the superb b. https://evertonfcfansclub.com/read-blog/10464_diplom-o-srednem-professionalnom-obrazovanii-kupit.html
You ought to be a part of a contest for one of the most useful
sites on the net. I’m going to highly recommend this blog!
Stream live Cricket and Football events online. Stay updated with upcoming matches, highlights,
and schedules. Join the excitement with E2BET today!
When some one searches for his required thing, so he/she wants to be available that in detail, therefore that thing is maintained over here.
Cuevana 3 es una plataforma gratis para
ver películas y series online con audio español latino o subtítulos.
No requiere registro y ofrece contenido en HD
OMT’ѕ adaptive understanding devices customize tһе journey, tuгning
math into а precious friend and motivating undeviating examination commitment.
Enlist tⲟday in OMT’s standalone e-learning
programs and sеe your grades skyrocket tһrough limitless access tⲟ high-quality, syllabus-aligned material.
Singapore’ѕ ᴡorld-renowned math curriculum stresses conceptual understanding οveг mere computation, makіng math tuition vital foг trainees to comprehend
deep ideas аnd excel in national exams lіke PSLE and Ⲟ-Levels.
Eventually, primary school math tuition іs essential for PSLE quality, аs it equips students ѡith the tools tо accomplish leading bands and secure preferred secondary school placements.
Connecting math principles tⲟ real-woгld situations tһrough tuition deepens understanding, mаking O
Level application-based questions mοгe approachable.
Ultimately, junior college math tuition іs vital to safeguarding top Ꭺ Level resᥙlts, oрening doors to prominent scholarships аnd college chances.
Distinctly, OMT’ѕ curriculum complements tһe MOE structure by using modular lessons that enable duplicated support օf weak
аreas at the pupil’s speed.
Unrestricted access to worksheets implies ʏou exercise up until shiok, enhancing үour math confidence and grades in a snap.
In а fast-paced Singapore classroom, math tuition ᧐ffers the slower,
tһorough explanations needed to build confidence f᧐r
examinations.
Also visit my website – college math tutor online
First of all I would like to say wonderful blog! I had a quick question that I’d like to
ask if you don’t mind. I was interested to find out how you center yourself and clear
your head prior to writing. I’ve had difficulty clearing my mind in getting my ideas
out there. I do take pleasure in writing however
it just seems like the first 10 to 15 minutes are wasted simply just trying to figure
out how to begin. Any suggestions or tips? Thank you!
I blog frequently and I genuinely thank you for your information. Your article
has really peaked my interest. I am going to bookmark your blog and keep checking for new details about once per week.
I opted in for your Feed as well.
Very energetic post, I liked that bit. Will there be a part 2?
Just desire to say your article is as amazing.
The clearness in your post is just great and i could
assume you are an expert on this subject. Fine
with your permission let me to grab your feed to keep
updated with forthcoming post. Thanks a million and please carry on the rewarding work.
Thank you for the auspicious writeup. It in fact was a amusement
account it. Look advanced to more added agreeable from
you! However, how could we communicate?
What’s up everyone, it’s my first visit at this web site,
and paragraph is in fact fruitful designed for me, keep up posting these articles.
Its not my first time to pay a quick visit this site, i
am visiting this site dailly and obtain fastidious information from
here everyday.
What i don’t realize is actually how you
are no longer really much more neatly-appreciated than you may be
right now. You’re so intelligent. You realize thus considerably in relation to this subject, produced me personally believe
it from numerous varied angles. Its like men and women aren’t involved until it is something to accomplish with Lady gaga!
Your own stuffs great. At all times deal with it up!
Heya i’m for the first time here. I came across this board and I to find It really helpful & it helped me out a lot.
I am hoping to provide one thing again and help others
like you aided me.
Hi, I do believe this is a great site. I stumbledupon it 😉 I may return yet again since i have saved as a favorite
it. Money and freedom is the greatest way to change, may you be rich and continue to
guide other people.
I’d like to find out more? I’d love to find out some additional information.
Hey there! I just wanted to ask if you ever have any issues
with hackers? My last blog (wordpress) was hacked and I ended up losing a few months of hard work due to no
data backup. Do you have any solutions to prevent hackers?
I like the helpful information you supply in your articles.
I will bookmark your blog and take a look at again right here frequently.
I’m reasonably sure I’ll learn many new stuff right
right here! Best of luck for the next!
My brother suggested I might like this web site. He
was entirely right. This post truly made my
day. You cann’t imagine simply how much time I had spent for
this info! Thanks!
Hello, I enjoy reading through your article post. I like to write a little
comment to support you.
Hello friends, its impressive post about cultureand completely defined, keep it up all the time.
I’m not sure why but this website is loading very slow for me.
Is anyone else having this problem or is it a problem on my end?
I’ll check back later on and see if the problem still exists.
nhà cái mbet là tên miền chính thức của
thương hiệu nhà cái MBET Việt Nam
It is actually a nice and useful piece of information. I’m glad that you just shared this helpful info with us.
Please stay us up to date like this. Thank you for sharing.
Incredible points. Sound arguments. Keep up the amazing work.
Hi, i believe that i noticed you visited my website thus i got here to return the
choose?.I’m trying to in finding issues to enhance
my site!I suppose its ok to make use of a few of your concepts!!
It is not my first time to go to see this web page, i am visiting this website dailly and take pleasant information from here all the time.
Wonderful, what a blog it is! This webpage gives helpful information to
us, keep it up.
Hi! This is my 1st comment here so I just wanted to give
a quick shout out and say I genuinely enjoy reading through
your posts. Can you recommend any other blogs/websites/forums that
deal with the same topics? Thanks a ton!
Pleasee let me know if you’re looking for a article author for ylur weblog.
Youu hve some really great posts and I feel I would be a good asset.
If you ever want to takle some of thhe load off, I’d love to
write some content foor your blog in exchange for a
link back to mine. Please send me an e-mail if
interested. Regards!
When someone writes an paragraph he/she maintains the image of a user
in his/her brain that how a user can know it. Thus that’s why this article is great.
Thanks!
Thanks very interesting blog!
I blog often and I really appreciate your content.
Your article has really peaked my interest. I’m going to bookmark your website
and keep checking for new details about once a week.
I subscribed to your RSS feed as well.
Amazing blog! Do you have any tips for aspiring writers?
I’m hoping to start my own blog soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m completely overwhelmed ..
Any tips? Thank you!
Because the admin of this site is working, no uncertainty very shortly it will be renowned,
due to its quality contents.
Link exchange is nothing else but it is only placing the other person’s webpage link on your
page at appropriate place and other person will also do similar in support of you.
Appreciate the recommendation. Will try it out.
Hi there would you mind letting me know which webhost you’re
using? I’ve loaded your blog in 3 different browsers
and I must say this blog loads a lot faster then most.
Can you suggest a good internet hosting provider
at a reasonable price? Thanks a lot, I appreciate it!
Project-based learning ɑt OMT transforms mathematics into hands-on fun, sparking enthusiasm іn Singapore pupils
f᧐r exceptional exam гesults.
Сhange mathematics challenges іnto accomplishments ᴡith OMT Math Tuition’ѕ blend of online and
on-site choices, Ƅacked ƅy a track record of student excellence.
Singapore’ѕ focus on vital believing tһrough mathematics
highlights tһe impߋrtance of math tuition, ѡhich helps
trainees develop tһe analytical abilities demanded by the nation’s forward-thinking syllabus.
Enriching primary education ԝith math tuition prepares students fⲟr
PSLE by cultivating a development mindset tоwards difficult topics
ⅼike balance аnd improvements.
Holistic growth ѵia math tuition not juѕt increases Օ Level scores yet additionally grows abstract thought skills іmportant fοr lifelong
learning.
Junior college math tuition promotes critical thinking abilities
required t᧐ address non-routine ρroblems tһat ᥙsually show uⲣ
in A Level mathematics evaluations.
OMT’ѕ distinct technique includеѕ a syllabus that matches the
MOE framework ԝith collaborative elements, urging peer conversations օn math ideas.
OMT’ѕ online ѕystem advertises self-discipline lor, secret t᧐
consistent resеarch and grеater test outcomes.
Βy including modern technology, on-line math tuition involves digital-native Singapore trainees
fоr interactive examination revision.
Нere is my web site :: maths hl ib tutor singapore
Admiring the time and energy you put into your site and in depth
information you offer. It’s good to come across a
blog every once in a while that isn’t the same unwanted rehashed
information. Great read! I’ve saved your site and I’m adding
your RSS feeds to my Google account.
Genuinely when someone doesn’t be aware of after that its up to
other visitors that they will help, so here it occurs.
Very rapidly this web site will be famous amid all blog viewers, due to it’s fastidious posts
I visit everyday some sites and sites to read posts, except this website
offers feature based articles.
I do not even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you are going to a famous blogger if you aren’t
already 😉 Cheers!
We stumbled over here coming from a different web page
and thought I may as well check things out. I like what
I see so now i am following you. Look forward to looking into your
web page repeatedly.
Quality articles or reviews is the main to interest the viewers to pay a visit the web page, that’s
what this site is providing.
Hey, I think your site might be having browser compatibility issues.
When I look at your blog in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that,
terrific blog!
Hello, i read your blog from time to time and i own a
similar one and i was just curious if you
get a lot of spam remarks? If so how do you protect against it,
any plugin or anything you can suggest? I get so much lately it’s driving me mad so any assistance is very much appreciated.
Write more, thats all I have to say. Literally, it seems as
though you relied on the video to make your point. You definitely know what youre talking about,
why waste your intelligence on just posting videos to your
weblog when you could be giving us something enlightening to
read?
I have learn several good stuff here. Definitely worth bookmarking for revisiting.
I wonder how much effort you place to create one of these excellent informative web site.
Hi, I do believe this is an excellent blog.
I stumbledupon it 😉 I will come back yet again since I book marked it.
Money and freedom is the best way to change, may you be rich and continue to help other people.
Have you ever thought about adding a little bit more than just your articles?
I mean, what you say is valuable and all. But think of if you added some great visuals or video clips to give your posts
more, “pop”! Your content is excellent but with images and video clips,
this website could undeniably be one of the greatest in its niche.
Terrific blog!
The live baccarat table is so stylish!
Feel free to surf to my blog :: https://griffinumaoc.wikiannouncing.com/6712185/everything_about_savaspin
First the official record translation is printed on official EKO
4 Translations UK letterhead. http://eric1819.com/home.php?mod=space&uid=2771924
If you are going for most excellent contents like I do, just go to see this web page every day as it provides feature contents, thanks
I believe this is one of the so much significant information for me.
And i am happy studying your article. However wanna statement on some general things,
The site style is wonderful, the articles is truly nice :
D. Excellent activity, cheers
You actually revealed this well!
Hmm is anyone else encountering problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any feedback would be greatly appreciated.
This is my first time pay a quick visit at here and i am actually pleassant to read all
at one place.
Yes! Finally something about .
I must thank you for the efforts you’ve put in penning this site.
I really hope to view the same high-grade content from you
later on as well. In truth, your creative writing abilities has motivated me
to get my own, personal website now 😉
Why visitors still use to read news papers when in this technological world
the whole thing is accessible on net?
Hi there I am so glad I found your weblog, I really found you by error, while I was browsing on Digg for something else, Regardless I
am here now and would just like to say thanks a lot for a marvelous post and a all round exciting blog (I also love the theme/design),
I don’t have time to go through it all at
the minute but I have saved it and also added your RSS feeds, so when I have time
I will be back to read much more, Please do keep up the awesome job.
Wow, superb weblog format! How lengthy have you
ever been blogging for? you make blogging look easy.
The full glance of your site is great, as neatly as the content!
First off I would like to say great blog! I had a quick question in which I’d like to ask
if you don’t mind. I was interested to know how you center yourself and clear
your thoughts prior to writing. I have had difficulty clearing my thoughts in getting my
thoughts out there. I do take pleasure in writing but it just seems like the first 10 to 15 minutes are usually wasted simply just trying to
figure out how to begin. Any ideas or hints?
Thanks!
Highly descriptive article, I liked that a lot. Will there be a part 2?
Hello, every time i used to check web site posts here early in the morning,
as i enjoy to learn more and more.
you are in point of fact a good webmaster.
The web site loading velocity is incredible. It seems that you are doing any
distinctive trick. In addition, The contents are masterwork.
you have performed a magnificent activity in this matter!
I was curious if you ever thought of changing the page layout of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could
connect with it better. Youve got an awful lot of text for only having one or
two images. Maybe you could space it out better?
certainly like your website however you need to take a look at the spelling on quite a
few of your posts. Many of them are rife with spelling issues and I in finding it very troublesome
to inform the reality then again I’ll surely
come back again.
What a information of un-ambiguity and preserveness of valuable know-how concerning unexpected feelings.
A fascinating discussion is worth comment. I believe that
you ought to publish more on this topic, it might not be a taboo
subject but usually people do not speak about these issues.
To the next! Cheers!!
It’s actually a nice and useful piece of information. I’m happy that you just shared this
useful info with us. Please keep us informed like this.
Thank you for sharing.
You’ve made some good points there. I checked on the internet for more info about the
issue and found most individuals will go along with
your views on this web site.
I wanted to thank you for this very good read!! I certainly loved every little bit of it.
I have you book marked to check out new things you post…
When someone writes an post he/she keeps the thought
of a user in his/her brain that how a user can be aware of it.
So that’s why this piece of writing is outstdanding.
Thanks!
Howdy very cool web site!! Guy .. Beautiful .. Amazing ..
I’ll bookmark your web site and take the feeds
additionally? I’m happy to find so many helpful info right here in the put up,
we’d like work out extra strategies in this regard, thank you for sharing.
. . . . .
Hey there! I’m at work browsing your blog from my
new iphone 4! Just wanted to say I love reading through
your blog and look forward to all your posts!
Keep up the excellent work!
Magnificent site. Lots of helpful information here. I am sending it to a few friends ans additionally sharing in delicious.
And certainly, thank you in your effort!
You ought to be a part of a contest for one of the greatest sites on the web.
I am going to recommend this website!
Hi it’s me, I am also visiting this website daily, this site is really good and the people are in fact
sharing pleasant thoughts.
I think that is among the most significant info for me.
And i am satisfied reading your article. But wanna
commentary on some general issues, The web site taste is ideal, the articles is really excellent :
D. Good job, cheers
Have you ever considered about including a little bit more than just your articles?
I mean, what you say is fundamental and all.
However imagine if you added some great images or video clips
to give your posts more, “pop”! Your content is excellent but with pics and clips, this website could definitely be
one of the best in its field. Wonderful blog!
Hello this is somewhat of off topic but I was wondering if blogs use
WYSIWYG editors or if you have to manually code with
HTML. I’m starting a blog soon but have no coding skills so I wanted to get guidance from someone with
experience. Any help would be greatly appreciated!
Wow, that’s what I was exploring for, what a data!
present here at this web site, thanks admin of this web page.
My brother recommended I might like this blog. He was totally right.
This post actually made my day. You can not imagine just how much
time I had spent for this information! Thanks!
I all the time emailed this blog post page to all my contacts,
as if like to read it afterward my friends will too.
Saved as a favorite, I love your blog!
Refresh Renovation Southwest Charlotte
1251 Arrow Pinne Ꭰr c121,
Charlotte, NC 28273, United Ѕtates
+19803517882
Conversions attic and loft
You really make it seem so easy along with your presentation however I find this matter
to be really one thing which I believe I might by no means understand.
It seems too complex and extremely wide for me. I’m looking forward to your subsequent publish,
I will try to get the dangle of it!
It’s actually very complex in this busy
life to listen news on Television, so I just use internet for that purpose, and
get the hottest information.
Hi there! Do you know if they make any plugins to help with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not
seeing very good success. If you know of any please
share. Appreciate it!
I simply could not leave your site prior to suggesting that
I actually enjoyed the usual info an individual supply on your guests?
Is going to be again incessantly to check out new posts
Hi there to all, the contents existing at this site are genuinely amazing
for people experience, well, keep up the nice work fellows.
Basket Bros
Hello there, I found your website by means of Google even as
searching for a comparable topic, your web site came up, it seems to
be good. I’ve bookmarked it in my google bookmarks.
Hi there, simply turned into alert to your weblog via Google, and located that it is
really informative. I am gonna be careful for brussels.
I’ll be grateful if you happen to continue this in future.
A lot of other people might be benefited out of your writing.
Cheers!
Normally I don’t read article on blogs, however I wish to say
that this write-up very forced me to take a look at
and do it! Your writing taste has been surprised me. Thank you, very
nice article.
I just couldn’t go away your web site before suggesting
that I actually loved the usual info a person supply for
your visitors? Is going to be back steadily to check out new posts
Hmm it seems like your blog ate my first comment (it was super long) so I guess I’ll just sum
it up what I had written and say, I’m thoroughly enjoying
your blog. I as well am an aspiring blog blogger but
I’m still new to the whole thing. Do you have any points for beginner blog writers?
I’d genuinely appreciate it.
I every time used to read piece of writing in news papers but
now as I am a user of internet thus from now I am using net for content, thanks
to web.
I have read so many articles or reviews on the
topic of the blogger lovers however this post is really a good piece of writing, keep it up.
For those searching for a way to claim **WeLive free coins**, you’re in the right place.
Right now, we will share how you can safely unlock a
large amount of coins in the **WeLive app** without spending any money.
One of the best-known methods is the **WeLive free coins hack**.
This method allows you to add coins super fast.
And rest assured, with the **WeLive free coins hack no ban**, you can enjoy it without the risk of your account being blocked.
If you prefer an offline option, you can use the **WeLive free coins hack download** or the **WeLive free coins apk
download**. These versions work on most Android devices and are simple to install.
For full benefits, the **WeLive mod apk (unlimited coins)** is a great choice,
since it gives you unlimited coins from the start.
Some users also like to use the **WeLive token adder**, a dedicated feature that can increase your coin balance as
much as you want. Whether you use the hack, APK, or token adder, you’ll
be able to unlock all the premium features in the **WeLive app** and
enjoy more content than ever.
Don’t wait and see how easy it is to get free coins in WeLive!
I do not even know how I ended up here, but I thought this post
was good. I do not know who you are but definitely
you are going to a famous blogger if you are not already 😉 Cheers!
Link exchange is nothing else except it is simply placing the other person’s blog link on your page at appropriate place and other person will
also do same for you.
I am really loving the theme/design of your weblog. Do you ever run into any web browser compatibility issues?
A number of my blog audience have complained about my
blog not operating correctly in Explorer but looks great in Opera.
Do you have any suggestions to help fix this issue?
I’m not sure exactly why but this site is loading
extremely slow for me. Is anyone else having this problem or
is it a problem on my end? I’ll check back later
on and see if the problem still exists.
Normally I do not read post on blogs, however I wish to say that this write-up very pressured
me to try and do so! Your writing style has been surprised me.
Thank you, quite great post.
I have learn several just right stuff here.
Certainly price bookmarking for revisiting. I surprise how
a lot effort you place to make one of these great informative website.
Wow that was odd. I just wrote an extremely long comment but
after I clicked submit my comment didn’t show up. Grrrr…
well I’m not writing all that over again. Anyways,
just wanted to say superb blog!
Hi, this weekend is nice designed for me, because
this moment i am reading this fantastic informative article here at
my home.
What i do not understood is in reality how you’re no longer
really much more smartly-appreciated than you may be
now. You’re so intelligent. You realize therefore considerably relating to this subject,
produced me for my part believe it from a lot of various
angles. Its like men and women aren’t involved unless it’s something
to accomplish with Girl gaga! Your individual stuffs excellent.
At all times care for it up!
It’s appropriate time to make some plans for the future and
it is time to be happy. I’ve learn this put up and if I
could I desire to counsel you few attention-grabbing
issues or suggestions. Perhaps you can write subsequent articles regarding this article.
I desire to learn more issues about it!
I’ll right away grasp your rss as I can’t in finding
your e-mail subscription hyperlink or newsletter service.
Do you have any? Kindly allow me realize so that I may
subscribe. Thanks.
Online casinos are great for small bets.
Visit my web page: https://stephenzsjyo.wonderkingwiki.com/1614584/not_known_factual_statements_about_savaspin
Undeniably believe that which you said. Your favorite
reason seemed to be on the web the easiest thing to
be aware of. I say to you, I definitely get annoyed while people think about
worries that they plainly do not know about.
You managed to hit the nail upon the top as well as defined
out the whole thing without having side effect , people could take a
signal. Will probably be back to get more. Thanks
I think this is one of the most important information for me.
And i’m glad reading your article. But should remark on few
general things, The website style is perfect, the articles is really excellent : D.
Good job, cheers
When some one searches for his required thing, so he/she
wants to be available that in detail, therefore that thing is maintained over here.
Spot on with this write-up, I absolutely think
this amazing site needs much more attention. I’ll probably be returning to read through
more, thanks for the info!
Way cool! Some very valid points! I appreciate you writing this article
plus the rest of the website is really good.
Hey there! I understand this is sort of off-topic but I needed to ask.
Does operating a well-established website such as yours require
a lot of work? I’m brand new to blogging however I do write in my journal daily.
I’d like to start a blog so I can share my personal experience and views online.
Please let me know if you have any recommendations or tips for brand new aspiring blog owners.
Appreciate it!
Just want to say your article is as astounding.
The clearness in your post is simply cool and i could assume you’re an expert on this subject.
Fine with your permission allow me to grab your feed to keep up to
date with forthcoming post. Thanks a million and please continue the enjoyable work.
It’s going to be finish of mine day, but before finish I am reading this enormous post to improve my know-how.
Howdy terrific website! Does running a blog like this take a large amount of work?
I have absolutely no understanding of coding but I was hoping to start my own blog in the near future.
Anyways, if you have any recommendations or tips for new blog owners please share.
I understand this is off subject however I simply wanted to ask.
Appreciate it!
Pretty section of content. I just stumbled upon your web site and in accession capital to assert that
I acquire actually enjoyed account your blog posts.
Anyway I’ll be subscribing to your augment and even I achievement you access consistently
fast.
It’s going to be end of mine day, but before finish I am reading this great post to increase my know-how.
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on numerous websites for about
a year and am concerned about switching to another platform.
I have heard fantastic things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any kind of help would be really appreciated!
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo
News? I’ve been trying for a while but I never seem to get there!
Cheers
I do believe all the ideas you’ve presented in your post.
They’re really convincing and can definitely work. Nonetheless, the posts are too quick for beginners.
May just you please lengthen them a little from next time?
Thank you for the post.
I am actually thankful to the holder of this website who has shared this fantastic article at at this time.
Hello, i feel that i noticed you visited my blog so i got here to go
back the desire?.I’m attempting to find things to enhance my web site!I assume its ok to make use of some of your ideas!!
Oh my goodness! Awesome article dude! Thanks, However I am experiencing problems with
your RSS. I don’t understand the reason why I am unable to join it.
Is there anybody getting the same RSS issues? Anybody who knows the answer can you kindly respond?
Thanx!!
Exceptional post however , I was wondering if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little bit more.
Bless you!
Hello to every body, it’s my first pay a quick visit of this webpage; this webpage carries amazing and truly good material in support of visitors.
Hi there, after reading this awesome article i am also cheerful to
share my experience here with mates.
This is a topic that is near to my heart…
Cheers! Where are your contact details though?
Hi my family member! I want to say that this post is amazing, nice
written and include almost all important infos.
I would like to peer more posts like this .
Cabinet IQ McKinney
3180 Eldorado Pkwy STE 100, McKinney,
TX 75072, Unites Ѕtates
(469) 202-6005
Layoutplan [go.bubbl.us]
all the time i used to read smaller content which as well clear
their motive, and that is also happening with
this piece of writing which I am reading at this place.
Every weekend i used to pay a visit this site, as i want enjoyment, for
the reason that this this web page conations actually fastidious funny data too.
Hi there are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you require any
coding expertise to make your own blog? Any help would be really appreciated!
Attractive section of content. I just stumbled upon your blog and in accession capital to assert that
I get actually enjoyed account your blog posts.
Any way I will be subscribing to your augment and even I achievement you access consistently quickly.
Hi, all the time i used to check weblog posts here in the early hours
in the break of day, for the reason that i enjoy to find out more and more.
Howdy! This is my first visit to your blog! We are a group of volunteers and starting a new initiative in a community in the same niche.
Your blog provided us valuable information to work on.
You have done a outstanding job!
I savour, lead to I discovered exactly what I used to be taking a look for.
You’ve ended my 4 day lengthy hunt! God Bless you
man. Have a great day. Bye
I want to to thank you for this fantastic read!!
I certainly loved every bit of it. I have you book-marked to look
at new stuff you post…
you’re truly a good webmaster. The site loading pace is incredible.
It kind of feels that you’re doing any unique trick.
Also, The contents are masterpiece. you have done a wonderful process on this topic!
When I originally commented I clicked the “Notify me when new comments are added” checkbox and
now each time a comment is added I get three emails with the same comment.
Is there any way you can remove me from that service? Bless you!
Spot on with this write-up, I seriously believe this web site needs far more attention. I’ll probably be back again to read more, thanks for the advice!
Nice post. I learn something totally new and challenging on blogs I stumbleupon everyday.
It will always be useful to read through articles from other authors and use
a little something from other web sites.
Wonderful beat ! I wish to apprentice while you amend your website,
how could i subscribe for a blog website? The
account helped me a acceptable deal. I had been tiny bit acquainted of this your broadcast offered bright clear
idea
There is definately a great deal to learn about this
subject. I love all the points you have made.
I am extremely impressed with your writing skills and also with the layout on your blog.
Is this a paid theme or did you customize it yourself?
Anyway keep up the excellent quality writing,
it is rare to see a great blog like this one nowadays.
Hello There. I found your blog using msn. This is a very well written article.
I will be sure to bookmark it and return to read more of
your useful info. Thanks for the post. I will definitely return.
Its like you read my mind! You appear to know so much about this, like you wrote the
book in it or something. I think that you can do with some pics to drive the
message home a bit, but instead of that, this is
great blog. A great read. I will certainly be back.
Attractive section of content. I just stumbled upon your website and in accession capital to assert that I get in fact enjoyed account your blog posts.
Anyway I will be subscribing to your feeds and even I achievement you access consistently quickly.
Heya! I understand this is somewhat off-topic however I had
to ask. Does operating a well-established blog like yours require
a large amount of work? I’m completely new to blogging but I do write in my diary on a daily basis.
I’d like to start a blog so I can share my experience
and thoughts online. Please let me know if you have any kind of recommendations or tips for new aspiring blog
owners. Thankyou!
Howdy! This is kind of off topic but I need some guidance from an established blog.
Is it difficult to set up your own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about making my own but I’m not sure where to start.
Do you have any tips or suggestions? With thanks
Excellent article. I’m going through a few of these issues as well..
I think that is one of the most significant information for me.
And i’m happy studying your article. However should observation on some
common issues, The website taste is perfect, the articles is in point of fact
excellent : D. Good activity, cheers
Hello, I enjoy reading all of your article post. I wanted to write a
little comment to support you.
Hi there! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly?
My website looks weird when browsing from my iphone.
I’m trying to find a theme or plugin that might be able to fix this problem.
If you have any suggestions, please share.
With thanks!
Thanks for finally talking about > 基于强化学习的小球运动员技战术发挥评估 – 逸
< Liked it!
I’m not sure exactly why but this blog is loading very slow for
me. Is anyone else having this problem or is it a issue on my end?
I’ll check back later and see if the problem
still exists.
Good day! I could have sworn I’ve visited your blog before but after browsing through a few of the
posts I realized it’s new to me. Nonetheless, I’m certainly
pleased I came across it and I’ll be bookmarking it and checking back
regularly!
Hello everybody, here every one is sharing these experience, thus it’s good to
read this web site, and I used to pay a visit this
weblog daily.
Большинство видео имеют формат MP4 и SD,
HD, FullHD, 2K и 4K.
If you are going for best contents like I do, only pay a
visit this web page daily since it presents feature contents,
thanks
My brother suggested I might like this web site.
He was totally right. This post actually made my day.
You can not imagine just how much time I had spent for this information! Thanks!
This article gives clear idea for the new people
of blogging, that truly how to do blogging.
I could not refrain from commenting. Well written!
No matter if some one searches for his necessary thing, thus he/she desires to be available that in detail, therefore that thing is maintained over here.
I was able to find good information from your articles.
This design is spectacular! You most certainly know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Great job.
I really loved what you had to say, and more than that,
how you presented it. Too cool!
You’re so interesting! I don’t believe I’ve truly read through anything like that
before. So nice to discover someone with some genuine thoughts on this
topic. Really.. many thanks for starting this up. This website is
something that is needed on the web, someone with a little originality!
Hello, i think that i saw you visited my weblog thus i came to “return the favor”.I’m attempting to find things to
enhance my site!I suppose its ok to use a few of your ideas!!
My family always say that I am killing my time here at web,
except I know I am getting familiarity every day by reading such pleasant articles or
reviews.
It’s a pity you don’t have a donate button! I’d certainly donate to this
excellent blog! I guess for now i’ll settle for book-marking and adding your RSS
feed to my Google account. I look forward to new updates and will talk about
this blog with my Facebook group. Chat soon!
Hello there, I found your website by means
of Google whilst looking for a similar matter, your website got here
up, it seems great. I’ve bookmarked it in my google bookmarks.
Hello there, simply changed into alert to your weblog via Google, and found that it’s really informative.
I am gonna be careful for brussels. I’ll appreciate in case you
continue this in future. Many people will likely be benefited out of your writing.
Cheers!
My coder is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on a variety of websites
for about a year and am worried about switching to another platform.
I have heard good things about blogengine.net.
Is there a way I can import all my wordpress posts into it?
Any kind of help would be really appreciated!
Hi there, I found your blog by means of Google at the same time as searching
for a similar topic, your web site came up, it seems
great. I’ve bookmarked it in my google bookmarks.
Hi there, just changed into aware of your blog thru Google, and found that it’s really informative.
I’m gonna watch out for brussels. I’ll be grateful in the event you continue this in future.
Numerous folks will probably be benefited from your writing.
Cheers!
A fascinating discussion is definitely worth comment.
I do believe that you should publish more on this
subject matter, it might not be a taboo subject but typically folks
don’t talk about these topics. To the next! Kind regards!!
Good post. I learn something new and challenging on blogs
I stumbleupon on a daily basis. It’s always exciting to read content from
other writers and use something from their sites.
I like the valuable information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I am quite certain I’ll learn plenty of new stuff right here!
Best of luck for the next!
Wow that was unusual. I just wrote an really long
comment but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Regardless, just wanted to say
wonderful blog!
Wow, this article is fastidious, my sister is analyzing such
things, therefore I am going to tell her.
Simply desire to say your article is as astonishing. The clearness for your post
is simply spectacular and i could suppose you are an expert in this subject.
Well along with your permission let me to clutch your RSS feed to
stay up to date with approaching post. Thanks a million and
please keep up the rewarding work.
What’s up, this weekend is fastidious in support of me, for the reason that this occasion i am reading this wonderful informative paragraph here at my house.
You really make it appear so easy with your presentation however I in finding this topic to be really one thing that
I feel I would never understand. It sort of feels too complicated and very wide for me.
I’m taking a look ahead on your subsequent post, I’ll try to get the grasp of
it!
If some one wishes to be updated with most up-to-date technologies
afterward he must be visit this site and be up to date all the time.
Hi, Neat post. There’s a problem with your web site
in web explorer, may test this? IE still is the marketplace leader and a big component to folks will pass over your excellent writing because of this problem.
Outstanding quest there. What occurred after? Good luck!
MIKIGAMING: Link Slot Gacor Maxwin Terbaik Gampang Meledak Jackpot
Hari Ini
Have you ever thought about adding a little bit more than just your articles?
I mean, what you say is important and all. Nevertheless
think of if you added some great visuals or
videos to give your posts more, “pop”! Your content is excellent but with images and clips, this site could
undeniably be one of the very best in its field.
Great blog!
Do you mind if I quote a few of your articles as
long as I provide credit and sources back to
your webpage? My blog site is in the very same area of interest as yours and my users would definitely benefit from a lot
of the information you provide here. Please let me know if this okay
with you. Thanks!
Hey there! Someone in my Myspace group shared this site with us
so I came to check it out. I’m definitely loving the information. I’m book-marking and will be tweeting this to my followers!
Excellent blog and wonderful design.
Your way of explaining everything in this paragraph is truly fastidious, all be capable of without difficulty be aware of
it, Thanks a lot.
I have read so many content regarding the blogger lovers however this post is really a good paragraph, keep it up.
I was wondering if you ever thought of changing the page layout of your website?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it
better. Youve got an awful lot of text for only having 1 or two pictures.
Maybe you could space it out better?
I think the admin of this web site is genuinely working hard
in support of his site, because here every information is quality based data.
Hello, I think your site might be having browser compatibility issues.
When I look at your website in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that,
fantastic blog!
Nice response in return of this issue with genuine arguments and explaining everything about that.
Howdy very cool website!! Guy .. Excellent ..
Amazing .. I’ll bookmark your blog and take the feeds also?
I’m satisfied to find numerous useful information right here in the put up, we
want work out extra strategies on this regard, thanks for sharing.
. . . . .
Good day! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good gains.
If you know of any please share. Appreciate it!
Sanal oyun sektöründe, kullanıcılar, güvenilirlik ve farklı seçenekler
arayışındadır. casinolevant, oyuncuların taleplerini karşılayan önemli adreslerden biridir.
Kullanıcı dostu tasarım sayesinde tüm oyuncular, sorunsuz
şekilde oyunlara ulaşabilir.
Casinolevant güncel giriş sayesinde kesintisiz erişim
Türkiye’de, online oyun adreslerine erişim engeli uygulanabilmektedir.
Ancak levant casino güncel giriş, daima güncel bağlantılar ile çözüm sunar.
Böylece üyeler, istedikleri zaman sisteme bağlanabilir.
Great weblog right here! Additionally your site lots up fast!
What web host are you using? Can I am getting your
associate hyperlink for your host? I desire my website loaded up as quickly
as yours lol
I delight in, result in I found just what I used to be taking a look for.
You have ended my four day lengthy hunt! God Bless you man. Have
a nice day. Bye
It’s enormous that you are getting ideas from this post as well as from our argument made at this time.
Hello, all is going sound here and ofcourse every one is
sharing information, that’s really fine, keep up
writing.
Hi there, I discovered your website via Google whilst searching for a related matter,
your site got here up, it looks great. I’ve bookmarked it in my
google bookmarks.
Hi there, just become alert to your weblog thru Google, and located that it is truly informative.
I’m gonna be careful for brussels. I will appreciate for those who proceed this in future.
Lots of other folks will probably be benefited out of your writing.
Cheers!
Wow that was strange. I just wrote an really long comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again.
Anyhow, just wanted to say fantastic blog!
Terrific post however , I was wondering if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little bit further.
Appreciate it!
Hey there this is kinda of off topic but I was wondering if blogs use
WYSIWYG editors or if you have to manually code
with HTML. I’m starting a blog soon but have no coding know-how so I wanted to get guidance from someone with experience.
Any help would be enormously appreciated!
What’s up i am kavin, its my first time to commenting anyplace, when i read this post i thought i could also make comment due to this good piece
of writing.
This is the right website for anybody who hopes to find out about this topic.
You realize so much its almost tough to argue with
you (not that I personally will need to…HaHa).
You certainly put a fresh spin on a subject which has been written about
for a long time. Excellent stuff, just excellent!
I used to be suggested this website by my cousin. I’m not
sure whether or not this post is written by means of him as no one else recognize such specified about my trouble.
You’re incredible! Thanks!
Excellent post but I was wondering if you could write a litte more on this topic?
I’d be very grateful if you could elaborate a little bit further.
Kudos!
I have read so many content about the blogger lovers except this article is actually a pleasant
post, keep it up.
I would like to thank you for the efforts you have put in penning this blog.
I am hoping to check out the same high-grade blog
posts from you in the future as well. In truth, your creative writing abilities has motivated me to get my own, personal blog now 😉
A person essentially assist to make severely posts I’d state.
That is the very first time I frequented your website page and thus far?
I amazed with the research you made to create this particular publish extraordinary.
Excellent job!
Great blog! Do you have any recommendations for aspiring writers?
I’m hoping to start my own website soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for a paid option? There are so many options
out there that I’m completely overwhelmed .. Any suggestions?
Thanks a lot!
Hello, after reading this awesome post i am
as well cheerful to share my experience here
with colleagues.
What a information of un-ambiguity and preserveness of
precious knowledge on the topic of unpredicted feelings.
deca and dianabol cycle
References:
https://cameradb.review/wiki/The_Best_Steroid_Cycle_For_Novices_A_Information_To_Your_First_Cycle
An outstanding share! I’ve just forwarded this onto a colleague who had been conducting a
little homework on this. And he in fact ordered me dinner simply because I discovered
it for him… lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanks for spending time to talk about this subject here on your internet
site.
Excellent blog here! Also your website loads up very
fast! What web host are you using? Can I get your affiliate
link to your host? I wish my site loaded up as quickly as yours lol
Hi i am kavin, its my first occasion to commenting anyplace,
when i read this paragraph i thought i could also make
comment due to this sensible post.
https://paitomacau.top/
Hi! I’m at work surfing around your blog from my new iphone 4!
Just wanted to say I love reading through your blog and look forward to all your
posts! Keep up the fantastic work!
I have fun with, cause I found exactly what I used to be looking for.
You have ended my 4 day lengthy hunt! God Bless you man.
Have a nice day. Bye
Hey there! Someone in my Myspace group shared this site with us so I came
to take a look. I’m definitely loving the information. I’m book-marking and will be tweeting this
to my followers! Exceptional blog and terrific design and style.
Nice replies in return of this query with real arguments
and explaining everything on the topic of that.
This post gives clear idea designed for the new viewers of blogging, that really how to do running a blog.
I do trust all of the ideas you have introduced to your post.
They’re very convincing and can certainly work. Nonetheless, the posts are very short
for starters. May you please lengthen them a
bit from subsequent time? Thanks for the post.
These are in fact impressive ideas in on the topic of blogging.
You have touched some fastidious factors here.
Any way keep up wrinting.
It is the best time to make some plans for the future and it’s time to be happy.
I have read this post and if I could I wish to suggest you
few interesting things or suggestions. Perhaps you could write next articles referring to this article.
I want to read more things about it!
I know this website gives quality depending articles or reviews and extra stuff, is there any other site which presents
these information in quality?
This is really interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to
seeking more of your great post. Also, I’ve shared
your site in my social networks!
What’s up i am kavin, its my first time to commenting anyplace,
when i read this article i thought i could also create comment due
to this good article.
If you want to take a great deal from this paragraph then you
have to apply these techniques to your won blog.
Stop by my web-site: 成人影片 (Mario)
Just desire to say your article is as amazing.
The clarity in your put up is simply nice and i can suppose you’re
a professional on this subject. Fine together with your permission allow me to grab your RSS
feed to stay updated with drawing close post. Thanks one million and please keep up the rewarding
work.
Hi there, I wish for to subscribe for this web site to take newest
updates, therefore where can i do it please assist.
There are times when you could sit back and say your brand is so
well known, you no longer need to reinforce it. Take Roll Royce as an example.
You actually make it seem so easy with your presentation but I find this matter
to be really something that I think I would never
understand. It seems too complex and very broad for me.
I am looking forward for your next post, I’ll try to get the hang of it!
Excellent blog you have got here.. It’s hard to find excellent writing like yours nowadays.
I seriously appreciate people like you! Take care!!
Hello Dear, are you in fact visiting this web site regularly, if so after that you will without doubt obtain pleasant knowledge.
Sweet blog! I found it while searching on Yahoo
News. Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thank you
Hello! I could have sworn I’ve been to this site before but after reading through some
of the post I realized it’s new to me. Nonetheless, I’m definitely happy
I found it and I’ll be bookmarking and checking back often!
Refresh Renovation Southwest Charlotte
1251 Arrow Pine Ꭰr c121,
Charlotte, NC 28273, United Statеѕ
+19803517882
Renovations achieve stress To Free how
You really make it seem so easy with your presentation but I find this matter to be really something which I think I would never understand.
It seems too complicated and extremely broad for me. I’m
looking forward for your next post, I’ll try to get the hang of it!
Wonderful beat ! I wish to apprentice while you amend your web site, how can i subscribe
for a blog site? The account aided me a acceptable deal.
I had been tiny bit acquainted of this your broadcast provided bright clear
idea
Greate article. Keep posting such kind of information on your blog.
Im really impressed by your blog.
Hi there, You’ve done an incredible job. I’ll definitely digg it and in my opinion recommend to my
friends. I am sure they will be benefited from this website.
Everyone loves what you guys tend to be up too. Such clever
work and coverage! Keep up the excellent works guys I’ve included you guys to our blogroll.
hello there and thank you for your info – I’ve certainly picked up anything new from right here.
I did however expertise several technical issues using this web site,
as I experienced to reload the website a
lot of times previous to I could get it to load properly.
I had been wondering if your web host is OK? Not that I’m complaining, but sluggish loading instances times will very frequently affect
your placement in google and could damage your high-quality score if advertising and marketing
with Adwords. Well I’m adding this RSS to my
email and could look out for much more of your respective intriguing
content. Make sure you update this again soon.
Thank you for some other informative web site.
The place else could I am getting that type of info written in such an ideal way?
I have a challenge that I’m just now running on, and I’ve
been on the look out for such information.
Can I simply just say what a comfort to find an individual who genuinely knows what they
are talking about on the internet. You actually know how to bring a problem to light and make it important.
More people need to look at this and understand this side of the
story. It’s surprising you are not more popular since you surely have the gift.
Very good post. I’m going through some of these issues as well..
Great blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple adjustements would really make my blog
shine. Please let me know where you got your design. Bless
you
I like the valuable information you provide in your articles.
I’ll bookmark your blog and check again here regularly.
I am quite sure I will learn lots of new stuff right here!
Best of luck for the next!
Howdy would you mind letting me know which web
host you’re using? I’ve loaded your blog in 3 different web browsers and I must
say this blog loads a lot quicker then most. Can you suggest
a good web hosting provider at a fair price? Thanks,
I appreciate it!
Thank you for the good writeup. It in truth was a enjoyment account it.
Glance complex to more introduced agreeable from you! By the
way, how could we keep up a correspondence?
Hi this is somewhat of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding skills so I wanted to
get guidance from someone with experience.
Any help would be enormously appreciated!
Magnificent goods from you, man. I’ve keep in mind
your stuff previous to and you are simply too fantastic.
I actually like what you have obtained here, certainly like what you’re saying and the way wherein you assert it.
You are making it enjoyable and you still care for to keep it smart.
I can not wait to learn far more from you. This is actually a great site.
What’s up to all, it’s in fact a fastidious for me to visit this site, it includes important Information.
whoah this blog is fantastic i really like studying your articles.
Stay up the great work! You already know, a lot of persons
are looking round for this information, you
could help them greatly.
Hi there to all, how is all, I think every one is getting more from this site, and
your views are fastidious for new people.
Hey I am so grateful I found your webpage, I really found you by error,
while I was searching on Bing for something else,
Anyways I am here now and would just like to say many thanks for a incredible
post and a all round exciting blog (I also love the theme/design), I don’t
have time to go through it all at the moment but I have saved it and also included your RSS feeds, so when I have time I will be back to read
a great deal more, Please do keep up the great work.
You have made some decent points there. I checked on the net for additional information about the issue and found most individuals
will go along with your views on this site.
Great post. I was checking continuously this blog and I am impressed!
Extremely useful info specially the last part 🙂 I
care for such information a lot. I was seeking this particular information for a long time.
Thank you and good luck.
The quiz was snappy and engaging. I was fond
of how it delivered a color chart that I can use as a direction for coming buys.
Sometimes, I get stressed by decisions, but now I have a more precise direction. It proved to be a effective tool for anyone wanting to better
their style.
It’s difficult to find experienced people about this topic, but you sound like you know what you’re talking about!
Thanks
It’s fantastic that you are getting thoughts
from this piece of writing as well as from our argument made here.
Thank you for the auspicious writeup. It if truth be told was a enjoyment account it.
Glance complex to far delivered agreeable from you!
However, how could we be in contact?
Hey there just wanted to give you a quick heads up.
The words in your post seem to be running off the screen in Firefox.
I’m not sure if this is a format issue or something to
do with browser compatibility but I figured I’d post to let you know.
The design look great though! Hope you get the problem fixed soon. Cheers
Very soon this web page will be famous among all blogging and site-building users,
due to it’s nice articles or reviews
My homepage: หวยออนไลน์ ruay
What a stuff of un-ambiguity and preserveness of valuable knowledge regarding
unexpected emotions.
We absolutely love your blog and find almost all of your post’s to be exactly I’m looking for.
can you offer guest writers to write content for you?
I wouldn’t mind publishing a post or elaborating on some of
the subjects you write about here. Again, awesome web site!
Feel free to surf to my site; homepage (Elouise)
This info is invaluable. When can I find out more?
Wow, this post is nice, my sister is analyzing these things, thus I am going to
inform her.
Heya i am for the primary time here. I came across this
board and I find It truly helpful & it helped me out a lot.
I hope to present something back and aid others such as you helped me.
Very energetic blog, I loved that a lot. Will there be
a part 2?
Hi! Do you use Twitter? I’d like to follow you if that would be
okay. I’m definitely enjoying your blog and look forward to new posts.
Thanks for your personal marvelous posting!
I certainly enjoyed reading it, you’re a great author.
I will ensure that I bookmark your blog and will come back someday.
I want to encourage one to continue your great writing, have a nice holiday weekend!
Appreciate it. Expanding here, my take: (https://winbet-bg.top).
I have been browsing online more than 2 hours today,
yet I never found any interesting article like yours. It’s pretty worth enough for me.
In my opinion, if all website owners and bloggers made good content
as you did, the web will be much more useful than ever
before.
I am truly delighted to read this website posts which contains tons of helpful information, thanks for providing
these information.
It’s appropriate time to make some plans for the long run and it’s time to be happy.
I have learn this submit and if I may just I want to suggest you few interesting issues or tips.
Maybe you can write subsequent articles regarding this article.
I desire to learn more things approximately it!
I am genuinely happy to read this weblog posts which carries tons of useful facts, thanks for
providing these data.
I was able to find good advice from your content.
Why viewers still make use of to read news papers when in this technological world all is existing on net?
Howdy! This is my first comment here so I just wanted
to give a quick shout out and say I genuinely enjoy reading your
posts. Can you suggest any other blogs/websites/forums that cover the same subjects?
Thank you!
It’s really very complicated in this active life to listen news on TV,
so I just use web for that reason, and obtain the most up-to-date information.
my site :: Sextreffen
Чрезвычайно интуитивно понятный и легкий для понимания интерфейс программы.
Планирование маршрута занимает минимум времени, что особенно важно в условиях жесткого графика.
Ожидаю появления функции сохранения
маршрутов и обмена ими с друзьями.
Hi there to all, it’s actually a nice for me to pay a visit this website,
it consists of valuable Information.
Hello, Neat post. There is an issue together with your website in web
explorer, could test this? IE nonetheless is the market chief and
a big component to folks will miss your magnificent writing due to this problem.
Hmm it seems like your blog ate my first comment (it was extremely long) so
I guess I’ll just sum it up what I had written and say, I’m
thoroughly enjoying your blog. I as well am an aspiring blog blogger but I’m still new to everything.
Do you have any suggestions for first-time blog writers? I’d
certainly appreciate it.
Bespoke cleaning professionals, customized for our lifestyle. Custom solution providers. Tailored appreciation.
I delight in, lead to I discovered just what I used to be looking for.
You have ended my four day long hunt! God Bless you man. Have a nice day.
Bye
Thanks , I’ve recently been looking for info approximately this subject for ages and yours is the greatest I have discovered till now.
But, what in regards to the bottom line? Are you positive concerning the source?
Wonderful, what a weblog it is! This blog presents valuable data
to us, keep it up.
This web site truly has all of the info I wanted about this
subject and didn’t know who to ask.
The Purple Mattress is a unique bed known for its innovative Purple Grid
technology, which provides excellent pressure relief and support.
Many users appreciate how it keeps them cool while offering
a balance between comfort and firmness. It’s especially popular among side and back sleepers, and people
love its ability to reduce motion transfer, making it great for couples.
My relatives every time say that I am wasting my time
here at web, except I know I am getting know-how daily by reading such nice content.
I was suggested this website via my cousin. I’m no longer
positive whether this post is written by means of him
as no one else recognize such distinctive about my trouble.
You are wonderful! Thanks!
For the reason that the admijn of this site is working, no uncertainty very quickly it will be famous, due to its feature contents.
Also visit my web page indlix21
Wow, superb blog layout! How lengthy have you been blogging
for? you made running a blog look easy. The entire look of your website is magnificent, let
alone the content!
As the admin of this site is working, no hesitation very quickly it will be renowned, due
to its feature contents.
hgh für frauen
References:
Negatives Of Hgh (https://forum.tr.bloodwars.net/index.php?page=User&userID=35511)
You’re so cool! I do not suppose I’ve truly read anything like that before.
So good to find somebody with some original thoughts on this issue.
Seriously.. many thanks for starting this up. This web
site is one thing that is needed on the internet,
someone with a bit of originality!
There’s certainly a great deal to learn about this topic.
I really like all the points you’ve made.
I will immediately grab your rss as I can not find your email
subscription link or e-newsletter service. Do you’ve
any? Please permit me recognize in order that
I could subscribe. Thanks.
Luxury1288 Merupakan Sebuah Link
Situs Slot Gacor Online Yang Sangat Banyak
Peminatnya Dikarenakan Permainan Yang Tersedia Sangat Lengkap.
Hi, Neat post. There’s a problem together with your website in web explorer, would check this?
IE still is the marketplace leader and a big portion of other folks
will miss your great writing due to this problem.
always i used to read smaller articles that as well clear their motive, and that is also happening with this post which I am reading at this place.
Caabinet IQ Cedar Park
2419 Ⴝ Bell Blvd, Cedar Park,
TX 78613, United Ⴝtates
+12543183528
Tips</a
I really like looking through a post that will make people think.
Also, thanks for allowing me to comment!
I could not refrain from commenting. Very well written!
Hello to all, it’s truly a pleasant for me to pay a quick visit this website,
it includes helpful Information.
Hey there, You’ve done a fantastic job. I will definitely digg it
and personally suggest to my friends. I am confident they
will be benefited from this site.
Oh my goodness! Incredible article dude! Thank you,
However I am encountering problems with your RSS.
I don’t understand why I can’t subscribe to it.
Is there anybody having similar RSS issues? Anybody who knows the answer will you kindly respond?
Thanks!!
Greetings! Very helpful advice in this particular post!
It is the little changes which will make the most important changes.
Many thanks for sharing!
Hey just wanted to give you a quick heads up and let
you know a few of the pictures aren’t loading correctly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both show the same outcome.
I like the helpful information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I am quite certain I’ll learn many new stuff right here!
Good luck for the next!
Very shortly this web site will be famous amid all blogging visitors, due to it’s good articles
Доброго!
Долго не мог уяснить как поднять сайт и свои проекты и нарастить CF cituation flow и узнал от успещных seo,
отличных ребят, именно они разработали недорогой и главное top прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Прогон по базам форумов позволяет ускорить линкбилдинг. Как увеличить показатели домена Xrumer становится понятно через практику. Xrumer для продвижения сайта облегчает автоматизацию. SEO-прогон для новичков повышает видимость ресурса. Рассылки с помощью Xrumer экономят время специалистов.
продвижение сайта соц, раскрутка сайта заданиями, Xrumer для оптимизации сайта
линкбилдинг работа, создания сайта и продвижение и, lsi что это seo
!!Удачи и роста в топах!!
Gerry Casale, on being known as cynical “Time is a superb instructor, but sadly it kills all its pupils.” –Louis Hector Berlioz “If they manage to nook the market they turn out to be a magnet for public outcry and probably lawsuits which is about nearly as good as accountability will get in the US.” –Retchdog, on corporations that conduct social media background checks “I sensed that it would greater than meet my requirements, and that i knew that there have been all sorts of things I may do there that I hadn’t even been able to imagine but. But what was more vital at that time, in terms of my sensible wants, was to call it one thing cool, because it was never going to work until it had a extremely good name. So the very first thing I did was sit down with a yellow pad and a Sharpie and start scribbling – infospace, dataspace. I feel I obtained our on-line world on the third strive, and I assumed, ”Oh, that’s a really weird word. I preferred the best way it felt in the mouth” – I believed it sounded like it meant something whereas nonetheless being basically hollow.” –William Gibson “I haven’t got religion in the Internet, I have faith in folks connected via the Internet.” –Jim Gilliam “Don’t fuck with humanity. We nailed our god to a picket cross and let him die. What do you assume we will do to you?” –Unknown “Whoever does not miss the Soviet Union has no coronary heart. Whoever wants it back has no brain.” –Attributed to Vladimir Putin (most likely after Cory Doctorow) “Python is a language the place casually changing somebody’s spine with Twizzlers is taken into account slightly offbeat.” –Binder “Pulsating. Never good.” –The Doctor “It wasn’t the Internet that accelerated history; it was the UNCONTROLLED Internet which accelerated historical past.” –Mark Pesce If the gods cannot take criticism, they shouldn’t be worshipped.
This paragraph is in fact a fastidious one it assists new internet visitors, who are wishing in favor of
blogging.
Aiyo, parents, well-known establishments feature technology
facilities, readying fߋr tech and engineering professions.
Listen, parents, calm lah, tߋр schools have creature care initiatives, encouraging
pet care paths.
Wow, math іs the foundation stone for primary schooling, aiding youngsters fоr spatial analysis
fօr building careers.
Wah lao, no matter if institution proves fancy, arithmetic іs the decisive discipline to building assurance іn calculations.
Alas, without robust mathematics during pfimary school, no matter leading establishment kids mіght stumble
in neҳt-level algebra, so build it now leh.
Folks, fear tһe disparity hor, mathematics groundwork іs critical ɑt
primary school fοr understanding figures, essential f᧐r modern tech-driven market.
Αvoid mess aroսnd lah, combine a excellent primary school alongside mathematics excellence fοr guarantee elevated PSLE marks аnd seamless changes.
St. Hilda’s Primary School produces ɑn engaging environment
promoting holistic development.
Ꭲhe school influences students througһ ingenious mentor.
Teck Whye Primary School рrovides supporting education іn the west.
Тһe school promotes resilience and accomplishment.
Іt’ѕ perfect for community-oriented families.
Review mу blog – Kaizenaire math tuition singapore
Добрый день!
Долго думал как поднять сайт и свои проекты и нарастить TF trust flow и узнал от крутых seo,
топовых ребят, именно они разработали недорогой и главное лучший прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Что такое линкбилдинг узнают новички. Линкбилдинг SEO помогает системно повышать авторитет сайта. Линкбилдинг заказать экономит время веб-мастера. Линкбилдинг что это простыми словами объясняет процесс. Линкбилдинг это эффективный инструмент для продвижения.
сео запрос что это, seo аудит бесплатно, Линкбилдинг через форумы и блоги
линкбилдинг сервисы, telegram каналы seo, seo личный кабинет
!!Удачи и роста в топах!!
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get got an edginess over that you wish be delivering the following.
unwell unquestionably come further formerly again since exactly the same nearly very often inside case you shield this
increase.
Hey, moms and dads, kiasu ɑ ƅit hor, renowned ᧐nes һave argument squads, honing abilities fօr law
or political careers.
Wah, wise tⲟ rush connections lah, сertain institutions associate tߋ elite secs,
easing tһe route to JC and university success.
Parents, fearful οf losing mode engaged lah,
solid primary mathematics гesults tо improved STEM
grasp and construction dreams.
Ɗo not take lightly lah, link a reputable primary school alongside mathematics proficiency fоr ensure hіgh PSLE marks
аnd effortless transitions.
Οһ, math acts ⅼike the foundation stone for primary education, aiding children ԝith spatial reasoning іn architecture careers.
Don’t mess ɑround lah, combine a excellent primary school alongside arithmetic excellence tⲟ guarantee elevated PSLE гesults pluѕ seamless shifts.
Parents, fear the gap hor, arithmetic base іs vital ԁuring primary school tօ graspping data, crucial іn today’s online market.
Chongfu School develops ɑ positive environment tһаt motivates scholastic ɑnd personal achievement.
Devoted personnel ɑnd contemporary resources assist students build
strong structures.
Zhenghua Primary School supplies nature-inspired education.
Ƭhе school promotes environmental awareness.
Moms ɑnd dads value its green initiatives.
Μy homepage math tuition singapore
I have read so many articles on the topic of the blogger
lovers but this post is genuinely a nice article, keep it up.
Hi mates, its impressive paragraph regarding tutoringand entirely defined, keep it up all the time.
I’m really enjoying the design and layout of
your blog. It’s a very easy on the eyes which makes
it much more enjoyable for me to come here and visit more often. Did you hire out a designer to create your theme?
Excellent work!
Wow, incredible blog structure! How lengthy have you been blogging for?
you make blogging glance easy. The overall look of your site is fantastic, let alone the content material!
Luxury1288
Awesome blog! Do you have any hints for aspiring writers?
I’m hoping to start my own blog soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress or go for a paid option? There
are so many options out there that I’m completely overwhelmed ..
Any recommendations? Appreciate it!
Right here is the perfect website for everyone who wants to understand
this topic. You understand a whole lot its almost hard to argue with you (not
that I actually would want to…HaHa). You definitely put a brand
new spin on a subject that has been written about for ages.
Wonderful stuff, just excellent!
Attractive section of content. I just stumbled
upon your web site and in accession capital to assert that I get actually enjoyed
account your blog posts. Any way I’ll be subscribing to your augment and even I achievement you access consistently rapidly.
Cabinet IQ Cedear Park
2419 Ѕ Bell Blvd, Cedar Park,
TX 78613, Uniited Ѕtates
+12543183528
bookmarks</a
I think the admin of this web site is actually working hard in favor of his website, for the reason that here every data is quality
based data.
I don’t know whether it’s just me or if everyone else encountering issues with your website.
It appears as though some of the text on your content are running off the screen. Can someone else please comment and let me know
if this is happening to them as well? This might be a problem with my internet browser because I’ve had this happen before.
Thanks
Very nice post. I just stumbled upon your weblog and wanted to say
that I have really loved browsing your blog posts. In any case
I will be subscribing to your rss feed and I hope you write once
more soon!
Greetings, I think your web site may be having web browser compatibility problems.
Whenever I look at your blog in Safari, it looks fine but when opening in IE, it’s got
some overlapping issues. I just wanted to provide you with a quick
heads up! Apart from that, excellent website!
Right now it seems like Expression Engine is the preferred blogging
platform available right now. (from what I’ve read) Is that what you’re using on your blog?
Keep on writing, great job!
First of all I would like to say great blog! I had a quick question that I’d like
to ask if you do not mind. I was interested to find out
how you center yourself and clear your head prior to
writing. I have had a difficult time clearing
my mind in getting my thoughts out. I truly do take pleasure in writing however it just
seems like the first 10 to 15 minutes are lost simply just trying
to figure out how to begin. Any ideas or tips? Thank you!
Anda dapat memilih dari tiga opsi kualitas berbeda.
Highly energetic post, I liked that a lot. Will there be a part 2?
I used to be suggested this web site by means of my cousin. I am now not positive
whether this publish is written by means of him as nobody else realize such distinctive about my trouble.
You’re wonderful! Thank you!
you’re truly a excellent webmaster. The site loading velocity is amazing.
It sort of feels that you are doing any unique trick.
Also, The contents are masterwork. you have performed a fantastic task in this matter!
An impressive share! I have just forwarded this onto a co-worker
who was conducting a little homework on this.
And he actually ordered me lunch because I stumbled upon it for him…
lol. So allow me to reword this…. Thanks for the meal!!
But yeah, thanks for spending time to discuss this topic here on your web page.
This information is priceless. How can I find out more?
Thanks for your marvelous posting! I seriously enjoyed reading
it, you could be a great author. I will be sure to bookmark your blog and will come back someday.
I want to encourage you to ultimately continue your great job, have
a nice morning!
Thank you for another magnificent article.
Where else may just anybody get that kind of information in such a perfect method of
writing? I have a presentation next week, and I am on the search for such information.
Having read this I thought it was very informative.
I appreciate you spending some time and effort to put this short article together.
I once again find myself spending a significant amount of time both reading
and leaving comments. But so what, it was still worth it!
Just desire to say your article is as astonishing. The
clarity in your post is just great and i
could assume you are an expert on this subject. Fine with your permission allow me to grab your RSS feed to keep updated with forthcoming post.
Thanks a million and please keep up the rewarding work.
I’m really impressed with your writing skills and also
with the layout on your blog. Is this a paid theme or did
you customize it yourself? Anyway keep up the nice quality writing,
it’s rare to see a great blog like this one today.
Доброго!
Долго ломал голову как поднять сайт и свои проекты и нарастить DR и узнал от крутых seo,
энтузиастов ребят, именно они разработали недорогой и главное буст прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Прогон ссылок Хрумером помогает быстро увеличить видимость сайта в поиске. Этот инструмент автоматизирует процесс размещения ссылок на тысячах форумов и блогов. Благодаря этому сайты быстрее набирают авторитет и растут в рейтинге. Такой метод особенно полезен для старта новых проектов. Используйте прогон ссылок Хрумером, чтобы закрепить позиции.
продвижение сайтов в москве в топ яндекса цена, продвижение сайтов мастеров, Линкбилдинг через форумы и блоги
линкбилдинг для англоязычного сайта, seo вакансии минск, сайты wix продвижение
!!Удачи и роста в топах!!
I enjoy looking through a post that can make men and women think.
Also, many thanks for permitting me to comment!
Incredible points. Sound arguments. Keep up the good
effort.
Hello there I am so glad I found your website, I really found you by accident, while I was searching on Bing for something else, Regardless I am here now and would just like
to say cheers for a incredible post and a all round entertaining blog (I also love the theme/design), I don’t have time to go through it all at the moment
but I have bookmarked it and also added in your RSS feeds, so when I have time I will
be back to read a lot more, Please do keep up the awesome work.
Hi, I do believe this is an excellent website. I stumbledupon it 😉 I’m going to revisit
once again since i have book-marked it. Money and freedom is the best
way to change, may you be rich and continue to help other people.
Доброго!
Долго не спал и думал как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от гуру в seo,
профи ребят, именно они разработали недорогой и главное лучший прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Автоматизированный постинг для сайтов снижает ручной труд. Как собрать базу для Xrumer становится понятным после инструкции. Ссылочные прогоны и их эффективность подтверждаются аналитикой. Форумный постинг для новичков упрощает первые шаги. Xrumer: советы и трюки помогают избежать ошибок.
учебники по сео, отчеты по сео примеры, что такое линкбилдинг
Как прокачать сайт через Xrumer, seo host ru, цель поисковой оптимизации seo
!!Удачи и роста в топах!!
Slot Gacor
My brother recommended I might like this website. He was entirely right.
This publish truly made my day. You can not believe just how so much time I had spent for this info!
Thank you!
I would like to thank you for the efforts you’ve put in writing this website.
I am hoping to view the same high-grade content from you later on as well.
In fact, your creative writing abilities has inspired me to get my
own blog now 😉
It’s actually a cool and helpful piece of info. I am satisfied that you simply shared this helpful
info with us. Please stay us up to date like this. Thanks for sharing.
Oh, a elite primary school unlocks opportunities tⲟ enhanced tools and
instructors, setting үour youngster uⲣ for academic superiority аnd prospective lucrative positions.
Wow, wise tο hurry connections lah, ⅽertain primaries link to elite secs,
easing the route to JC and university success.
Parents, dread tһe disparity hor, arithmetic groundwork гemains vital Ԁuring
primary school fоr comprehending data, essential іn modern online market.
Parents, fearful оf losing mode on lah, solid primary math leads іn superior scientific grasp ɑs well as construction aspirations.
Listen սр, calm pom ρi pi, mathematics remains one from the highest
subjects іn primary school, establishing groundwork tߋ A-Level calculus.
Օh no, primary arithmetic teaches everyday ᥙseѕ ѕuch аs financial planning,
therefore guarantee your child grasps it properly starting еarly.
Guardians, fearful ⲟf losing approach ߋn lah,
solid primary mathematics гesults to improved scientific grasp ρlus
tech goals.
Casuarina Primary School develops ɑn engaging space fⲟr
students tⲟ explore аnd attain tһeir best.
Ꮃith quality mentor ɑnd modern-day resources, іt promotes alⅼ-round development and success.
Westwood Primary School promotes appealing environments fߋr young minds.
The school supports talents sᥙccessfully.
It’ѕ perfec fоr thorⲟugh development.
Feel free tо surf to my paցe Queensway Secondary School
Yesterday, while I was at work, my cousin stole my iPad
and tested to see if it can survive a 40 foot drop, just so she can be a youtube
sensation. My apple ipad is now broken and she has 83 views.
I know this is totally off topic but I had to share it with someone!
Доброго!
Долго ломал голову как поднять сайт и свои проекты и нарастить DR и узнал от друзей профессионалов,
энтузиастов ребят, именно они разработали недорогой и главное буст прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Многоуровневый линкбилдинг создает устойчивую ссылочную сеть. Линкбилдинг блог курс показывает эффективные методы. Линкбилдинг мы предлагаем клиентам с разными целями. Контент маркетинг линкбилдинг повышает естественность ссылочного профиля. Естественный линкбилдинг повышает доверие поисковых систем.
dr rimpler официальный сайт, продвижение сайта салон, Форумный постинг для новичков
Как увеличить DR сайта, услуги по продвижение сайтов, продвижение сайтов 2020
!!Удачи и роста в топах!!
This is the right webpage for anyone who wants to find out about this topic.
You know a whole lot its almost tough to argue with you (not that I
really would want to?HaHa). You certainly put a new
spin on a subject that has been written about for ages.
Wonderful stuff, just great!
Look at my web blog top ten poker sites
Hi all, here every one is sharing such experience,
therefore it’s nice to read this webpage, and I used to go to
see this website all the time.
Hurrah! In the end I got a webpage from where I know how
to actually take useful facts regarding my
study and knowledge.
This is the right website for anybody who hopes to understand this topic.
You understand so much its almost hard to argue with you (not
that I actually would want to…HaHa). You definitely
put a brand new spin on a subject that’s been discussed for ages.
Wonderful stuff, just wonderful!
I have been exploring for a little bit for any high quality articles or blog posts on this kind of house .
Exploring in Yahoo I ultimately stumbled upon this web
site. Studying this information So i’m satisfied to show that I’ve a very just right uncanny feeling I came upon just
what I needed. I such a lot certainly will make sure to do not overlook this web site and provides it
a glance on a relentless basis.
What’s up, I would like to subscribe for this weblog
to obtain latest updates, thus where can i do it please assist.
Today, I went to the beachfront with my kids. I found
a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She
put the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is entirely off topic
but I had to tell someone!
This website was… how do I say it? Relevant!! Finally I’ve found something that helped me.
Cheers!
Excellent article! We will be linking to this particularly great article on our site.
Keep up the good writing.
Pretty! This has been a really wonderful article. Many thanks
for supplying this info.
Do you mind if I quote a couple of your articles as long
as I provide credit and sources back to your blog? My blog site is in the very
same area of interest as yours and my visitors would truly benefit from a lot of the information you provide here.
Please let me know if this alright with you. Cheers!
We are a group of volunteers and opening a new scheme in our community.
Your website provided us with valuable information to work on. You’ve done a formidable job and our whole community will be thankful to you.
Добрый день!
Долго обмозговывал как поднять сайт и свои проекты и нарастить CF cituation flow и узнал от успещных seo,
крутых ребят, именно они разработали недорогой и главное top прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Xrumer помогает увеличить DR и Ahrefs через автоматический прогон ссылок. Массовые рассылки на форумах ускоряют процесс линкбилдинга. Программы для линкбилдинга помогают создать качественные ссылки для вашего сайта. Увеличение ссылочной массы с Xrumer помогает улучшить SEO-позиции. Используйте Xrumer для эффективного продвижения сайта.
кластеризация в сео, продвижение сайта заказать раскрутку сайта, линкбилдинг что
линкбилдинг статьи, all in seo sitemap, продвижение сайтов рейтинг рунета
!!Удачи и роста в топах!!
great points altogether, you just won a emblem new reader. What may you suggest
in regards to your publish that you just made a few days ago?
Any sure?
Currently it seems like Movable Type is the top blogging platform available right now.
(from what I’ve read) Is that what you are using on your blog?
LUXURY1288
I want to to thank you for this wonderful read!! I absolutely loved every bit of it.
I have got you book marked to check out new stuff you
post…
Hello There. I found your blog using msn. This is a
very well written article. I’ll make sure to bookmark it and come back to
read more of your useful information. Thanks for the post.
I’ll certainly return.
Having read this I believed it was extremely informative.
I appreciate you taking the time and energy to put
this article together. I once again find myself personally spending way
too much time both reading and commenting. But so what,
it was still worthwhile!
First off I want to say excellent blog! I had a quick question in which I’d like to ask if you don’t mind.
I was curious to find out how you center yourself and clear your mind
before writing. I’ve had trouble clearing my thoughts in getting my ideas out.
I do enjoy writing but it just seems like the first 10 to 15 minutes are usually wasted just trying to figure
out how to begin. Any ideas or tips? Cheers!
I visited several sites except the audio feature for audio songs present at
this website is actually wonderful.
Hi there just wanted to give you a quick heads up. The words in your post seem
to be running off the screen in Opera. I’m not sure if this is a format issue or something to
do with web browser compatibility but I thought I’d post to let you know.
The design look great though! Hope you get the
problem solved soon. Many thanks
Thanks for sharing such a good thought, piece of writing is nice, thats
why i have read it completely
My programmer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on a number
of websites for about a year and am anxious about switching
to another platform. I have heard good things about blogengine.net.
Is there a way I can import all my wordpress content
into it? Any help would be greatly appreciated!
Hello! I’m at work surfing around your blog from my new apple iphone!
Just wanted to say I love reading through your blog and look forward to all your posts!
Keep up the outstanding work!
Excellent blog here! Also your web site loads up fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my site loaded up as quickly as yours lol
Menurut pengalaman saya, slot gacor itu biasanya terasa dari awal permainan. Kalau scatter cepat muncul dan ada free spin, biasanya permainan bakal gampang kasih jackpot. Tapi tetap harus pintar atur modal supaya nggak cepat habis. Coba disini:
https://e2betportal.com/id/slot-gacor/
Thank you for some other magnificent article. Where else may anyone get that kind
of information in such an ideal approach of writing?
I have a presentation subsequent week, and I am at the look for such information.
ripped usa muscle
References:
http://git.79px.com/danutabrack419
Hello There. I found your blog using msn. This is an extremely well written article.
I will make sure to bookmark it and come back to read more of your useful information. Thanks for the
post. I will definitely return.
I visited various sites except the audio quality for audio songs current at this web page is in fact fabulous.
Aesthetic aids іn OMT’s curriculum mɑke abstract
principles substantial, cultivating а deep grattude foг math and
inspiration tⲟ overcome tests.
Օpen your kid’s complete capacity in mathematics ѡith OMT Math Tuition‘ѕ expert-led
classes, customized tо Singapore’ѕ MOEsyllabus fοr primary,
secondary, ɑnd JC trainees.
Ꮃith students іn Singapore Ƅeginning official mathematics education fгom the first day and dealing with high-stakes assessments, math
tuition սѕes the extra edge neеded to attain top performance іn this essential
topic.
Tuition highlights heuristic ⲣroblem-solving methods, impoгtant for dealing with PSLE’ѕ challenging wоrd issues
tһat neeԁ multiple actions.
Pгovided tһe higһ risks off O Levels fߋr һigh school development іn Singapore, math tuition makes best use of opportunities for top grades ɑnd
preferred positionings.
Ultimately, junior college math tuition іs vital tߋ securing
toр A Level гesults, օpening doors to prominent scholarships аnd college
opportunities.
Ꮤһat makeѕ OMT extraordinary іѕ itѕ exclusive educational program tһat aligns ԝith MOE while introducing aesthetic һelp like bar modeling in innovative methods fߋr primary
students.
OMT’s online tuition is kiasu-proof leh, offering
ʏou tһat extra ѕide to outshine іn O-Level mathematics
exams.
Ϝоr Singapore pupils facing extreme competition, math tuition еnsures they гemain ahead
by strengthening fundamental abilities аt
an eɑrly stage.
Listen, aiyo, elite establishments commend diversity, educating
openness f᧐r victory in international organizations.
Listen ᥙp, elite establishments integrate ΑI prematurely, equipping youngsters foг tһe 2025 career field revolution.
Hey hey, steady pom ρі pi, mathematics remains one from tһe top
subjects at primary school, establishing foundation tο A-Level calculus.
Eh eh, composed pom ρi pi, mathematics remains ρart in the top
subjects at primary school, establishing base tо A-Level calculus.
Oh dear, mіnus strong mathematics іn primary school, even prestigious school children might falter
with secondary equations, tһus develop thiѕ pгomptly leh.
Listen ᥙp, Singapore folks, mathematics гemains ρrobably tһe
highly essential primary topic, fostering innovation fοr challenge-tackling in creative careers.
Ɗo not take lightly lah, link a excellent primary
school alongside math proficiency tߋ guarantee hiցh PSLE marks аs weⅼl as smooth changеs.
Henry Park Primary School develops ɑ stimulating neighborhood thаt supports holistic advancement.
Innovative techniques һelp nurture talented уoung people.
Yangzheng Primary School ᥙses supportive multilingual
education.
Тhe school builds cultural competence.
Moms аnd dads ѵalue іtѕ well balanced method.
Feel free to visit my homepаge – Mayflower Secondary School
It’s actually a nice and useful piece of info. I am glad that you simply
shared this useful info with us. Please stay us informed like this.
Thank you for sharing.
These are actually wonderful ideas in on the topic of blogging.
You have touched some fastidious things here. Any way keep up wrinting.
Can I just say what a comfort to uncover someone that genuinely understands what they
are discussing online. You definitely understand how to bring an issue
to light and make it important. More people need to check this out and understand
this side of your story. It’s surprising you are not more
popular since you surely possess the gift.
Hmm is anyone else having problems with the images on this blog
loading? I’m trying to figure out if its a problem on my end or if it’s the blog.
Any responses would be greatly appreciated.
I just like the helpful information you provide in your articles.
I’ll bookmark your weblog and check once more right here frequently.
I’m moderately sure I’ll be informed many new stuff right
right here! Good luck for the next!
The enthusiasm of OMT’ѕ owner, Mr. Justin Tan, shines
ԝith in trainings, motivating Singapore pupils tօ faⅼl foг mathematics for test success.
Broaden үour horizons wіth OMT’s upcoming brand-neѡ physical space opening in Septembeг 2025,
providing much more chances fοr hands-on mathematics expedition.
Ƭһe holistic Singapore Math technique, ѡhich develops
multilayered рroblem-solving capabilities, underscores ѡhy math tuition is іmportant for
mastering tһe curriculum and ɡetting ready fօr future careers.
primary school school math tuition boosts rational reasoning,
essential fߋr analyzing PSLE concerns including sequences and rational deductions.
Тhorough comments fгom tuition teachers оn practice attempts aids secondary pupils gain fгom errors, improving accuracy for tһe real
Ο Levels.
With A Levels influencing career courses іn STEM areаѕ,
math tuition reinforces foundational skills fοr future university гesearch studies.
Inevitably, OMT’ѕ one-of-ɑ-kind proprietary syllabus complements tһe Singapore MOE curriculum ƅy cultivating independent thinkers furnished
for lifelong mathematical success.
Limitless access tо worksheets suggests үoս exercise սntil shiok, enhancing yoᥙr math self-confidence
ɑnd grades іn a snap.
By integrating innovation, ⲟn-line math tuition engages digital-nativeSingapore
trainees fоr interactive exam modification.
Feel free t᧐ surf to my site: maths tuition teacher in guwahati
Great post.
Your way of explaining the whole thing in this post is actually good,
all be able to without difficulty understand it, Thanks a lot.
Now I am going away to do my breakfast, when having my breakfast
coming yet again to read additional news.
What’s up i am kavin, its my first time to commenting
anyplace, when i read this article i thought i could also create comment due to this brilliant paragraph.
First off I want to say fantastic blog! I had a quick question that I’d like to
ask if you don’t mind. I was interested to know how you center yourself
and clear your mind prior to writing. I’ve had difficulty clearing my
thoughts in getting my ideas out there. I truly do enjoy writing however it just seems like the first
10 to 15 minutes tend to be wasted simply just trying to figure out how to
begin. Any recommendations or tips? Appreciate it!
After I initially left a comment I seem to have clicked the -Notify me when new comments are added-
checkbox and from now on each time a comment is added I get 4 emails with the exact same
comment. Is there an easy method you can remove me from that service?
Thank you!
I think the admin of this website is really working hard in support of his site, as here every information is quality based information.
Collaborative conversations in OMT courses construct excitement ɑгound mathematics ideas, motivating Singapore trainees tо create love and master tests.
Enlist tⲟday in OMT’s standalone е-learning programs аnd enjoy yօur grades skyrocket tһrough endless access t᧐ һigh-quality, syllabus-aligned material.
Ԝith math incorporated effortlessly іnto Singapore’ѕ class settings t᧐ benefit bⲟtһ
teachers and students, devoted math tuition magnifies tһese gains by
սsing customized support fⲟr sustained achievement.
Τhrough math tuition, students practice PSLE-style questions typicallies ɑnd charts,
improving accuracy аnd speed under examination conditions.
Alternative growth ᴡith math tuition not just improves О
Level ratings ƅut also cultivates abstract tһоught skills beneficial fߋr lifelong
discovering.
Individualized junior college tuition aids bridge tһe void from O
Level tߋ A Level math, ensuring pupils adapt tօ the increased
rigor and depth ϲalled fοr.
OMT establishes itself apɑrt with a syllabus сreated tօ
boost MOE contеnt thrоugh in-depth explorations оf geometry proofs and
theorems for JC-level students.
Variety ߋf technique inquiries ѕia, preparing you extensively foг any type of mathematics test аnd better ratings.
Customized math tuition addresses private weaknesses,
tսrning average entertainers right into examination mattress toppers іn Singapore’ѕ merit-based ѕystem.
unblocked games
I know this if off topic but I’m looking into starting my own weblog and was wondering what
all is needed to get set up? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web smart so I’m not 100% positive. Any suggestions or advice would be greatly appreciated.
Many thanks
Cabinet IQ Austin
2419 S Bell Blvd, Cedsar Park,
TX 78613, United Stɑtes
+12543183528
Artisticcabinets (https://www.plurk.com/p/3hlyc1ykak)
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get got an impatience over that you wish be delivering the following.
unwell unquestionably come more formerly again as exactly
the same nearly very often inside case you shield this increase.
Hey I know this is off topic but I was wondering if you knew
of any widgets I could add to my blog that automatically tweet
my newest twitter updates. I’ve been looking for
a plug-in like this for quite some time and was hoping maybe you would have
some experience with something like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward
to your new updates.
Hey hey, leading institutions integrate yoga, promoting focus fⲟr intense job positions.
Goodness, prestigious institutions celebrate inventiveness, encouraging startups іn Singapore’s startup environment.
Oһ no, primary math instructs practical ᥙses like financial planning,
tһerefore guarantee your kid gеts that correctly
starting уoung.
Dοn’t play play lah, combine а excellent primary school ρlus arithmetic superiority fⲟr
ensure hіgh PSLEscores аѕ wеll as effortless shifts.
Goodness, regardless іf school iss atas, mathematics serves аs the make-or-break topic fⲟr developing assurance
гegarding calculations.
Folks, dread tһe gap hor, mathematics groundwork proves critical
during primary school іn comprehending data, vital fⲟr t᧐dɑy’s
digital systеm.
Oh dear, ԝithout strong math in primary school, no matter tⲟp school children mіght stumble at secondary
equations, sߋ develop tһis immediatеly leh.
Yew Tee Primary School supplies ɑn inspiring space supporting trainee development.
Innovative mentor assists support positive individuals.
Maha Bodhi Schhool սseѕ Buddhist-inspired education promoting empathy.
Тһe school promotes scholastic excellence ɑnd worths.
Moms and dads choose іt for spiritual development.
Feel free tߋ visit my site :: Jurongville Secondary School
You can certainly see your skills within the work you write.
The sector hopes for even more passionate writers like you who aren’t afraid
to mention how they believe. Always follow your heart.
Have you ever thought about creating an e-book or guest authoring on other blogs?
I have a blog centered on the same ideas you discuss and would really like to have you share some stories/information. I know my audience
would enjoy your work. If you’re even remotely interested, feel free to send me an e-mail.
Hi i am kavin, its my first occasion to commenting anywhere, when i read this piece of writing i thought i could also create comment due to this good paragraph.
Whoa! This blog looks just like my old one! It’s on a entirely different subject but it
has pretty much the same page layout and design. Great choice of colors!
Howdy fantastic website! Does running a blog such as
this take a great deal of work? I have virtually no understanding of coding but I had
been hoping to start my own blog in the near future. Anyhow,
if you have any ideas or tips for new blog owners please share.
I understand this is off topic however I simply wanted to ask.
Thanks a lot!
Hello! I just wanted to ask if you ever have any trouble with
hackers? My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due to no
backup. Do you have any solutions to prevent hackers?
Respect for putting this together.
I’m gone to inform my little brother, that he should also go to see this website on regular basis to take updated from latest
gossip.
What’s up it’s me, I am also visiting this site on a regular
basis, this website is really good and the visitors
are genuinely sharing fastidious thoughts.
Hello to every one, the contents present at this web page are genuinely awesome for people experience,
well, keep up the good work fellows.
Eventually, OMT’ѕ comprehensive solutions weave joy right into math education, assisting students fаll deeply
crazy and skyrocket in tһeir tests.
Established in 2013 Ƅy Mr. Justin Tan, OMT Math Tuition has аctually helped mɑny trainees ace tests ⅼike PSLE, Ⲟ-Levels, ɑnd A-Levels with
proven analytical techniques.
In Singapore’ѕ strenuous education systеm, wherе
mathematics is obligatory and consumes аrοund 1600 hourѕ of curriculum time in primary
аnd secondary schools, math tuition еnds up beіng vital to
assist trainees build a strong foundation fօr lifelong success.
Math tuition helps primary students master PSLE Ьу reinforcing tһe Singapore Math curriculum’ѕ bar modeling method fоr visual analytical.
Ꭺll natural growth tһrough math tuition not onlү boosts O Level scores but likewise cultivates ѕensible reasoning abilities important forr lоng-lasting understanding.
Math tuition аt tһe junior college level stresses
theoretical clarity օver rote memorization, crucial f᧐r taking ⲟn application-based А Level concerns.
OMT’s customized syllabus uniquely lines սp with MOE framework Ьy offering connecting
modules f᧐r smooth changes betweеn primary, secondary, ɑnd JC mathematics.
Themed components mɑke discovering thematic lor,
assisting retain info ⅼonger for improved mathematics efficiency.
Specialized math tuition f᧐r O-Levls assists Singapore secondary pupils separate tһemselves іn a jampacked applicant swimming pool.
Also visit my web page :: maths tuition ghim moh
Hi great blog! Does running a blog similar to this take a large amount of work?
I have virtually no understanding of computer programming however I had been hoping to
start my own blog soon. Anyway, should you have any ideas or techniques for new blog owners
please share. I understand this is off topic but I simply needed to
ask. Kudos!
Hey there! This is my 1st comment here so I just wanted to give a quick shout out
and say I genuinely enjoy reading through your articles.
Can you recommend any other blogs/websites/forums that cover the same topics?
Thanks!
I’m now not certain where you are getting your info, however great topic.
I needs to spend a while learning more or working out more.
Thanks for fantastic info I used to be on the lookout for this information for my
mission.
Wow, amazing blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your
site is magnificent, as well as the content!
This paragraph is genuinely a pleasant one it helps new internet viewers, who are wishing in favor of blogging.
It’s perfect time to make some plans for the future and it is time to be happy.
I have read this post and if I could I want to suggest you few interesting things or suggestions.
Maybe you can write next articles referring to this article.
I wish to read more things about it!
Greetings I am so delighted I found your website, I really found you by error, while
I was searching on Askjeeve for something else, Nonetheless I am here now and would just like to
say many thanks for a remarkable post and a all round enjoyable blog
(I also love the theme/design), I don’t have time to read it
all at the minute but I have saved it and also included your RSS feeds, so when I
have time I will be back to read more, Please do keep up
the fantastic job.
Hey would you mind sharing which blog platform you’re working with?
I’m going to start my own blog in the near future but I’m having a hard time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most
blogs and I’m looking for something unique.
P.S My apologies for getting off-topic but I had to ask!
Good day! This is my first visit to your blog! We are a collection of volunteers and starting a new initiative
in a community in the same niche. Your blog provided us valuable
information to work on. You have done a outstanding job!
Greetings! Very useful advice in this particular article!
It is the little changes that will make the biggest changes.
Many thanks for sharing!
Fantastic beat ! I would like to apprentice while you amend your site,
how could i subscribe for a blog site? The account helped me a acceptable deal.
I had been a little bit acquainted of this your broadcast offered bright clear concept
Fantastic goods from you, man. I have understand your
stuff previous to and you are just extremely excellent.
I really like what you have acquired here, certainly like what you’re stating and the way
in which you say it. You make it enjoyable and you still care for to keep it wise.
I can’t wait to read much more from you. This is actually a terrific web site.
Heya! I understand this is sort of off-topic however I needed to ask.
Does running a well-established blog such as yours take a massive amount work?
I am completely new to writing a blog but I do write in my
journal daily. I’d like to start a blog so I can share my own experience and views online.
Please let me know if you have any ideas or tips for brand new
aspiring bloggers. Appreciate it!
Good article. I definitely love this website.
Thanks!
I really like reading a post that can make people think. Also, thanks
for allowing for me to comment!
Somebody essentially help to make severely articles
I would state. That is the first time I frequented your
web page and so far? I surprised with the research
you made to make this particular post amazing.
Excellent process!
I will immediately clutch your rss as I can not in finding your email subscription link or e-newsletter service.
Do you’ve any? Please allow me realize in order that I may just subscribe.
Thanks.
My brother suggested I might like this website. He was totally right.
This post actually made my day. You can not imagine just how much time I had spent for
this info! Thanks!
Cabinet IQ McKinney
3180 Eldorado Pkwy STE 100, McKinney,
TX 75072, Units Ꮪtates
(469) 202-6005
Refacing
The Aqua Tower looks like such an innovative and eco-friendly concept
. I love how it’s designed to harvest clean drinking water from the air while also promoting sustainability.
Definitely a smart solution for future cities and communities facing water scarcity.
✨
Hi there! Someone in my Myspace group shared this site with
us so I came to give it a look. I’m definitely loving the information. I’m book-marking and will be tweeting this to my
followers! Wonderful blog and brilliant style and design.
Please let me know if you’re looking for a article author for your weblog.
You have some really great posts and I feel
I would be a good asset. If you ever want to
take some of the load off, I’d absolutely love to write some
articles for your blog in exchange for a link back to mine.
Please blast me an email if interested. Thank you!
Listen, moms and dads, composed lah, leading institutions
һave animal care activities, inspiring veterinary careers.
Hey folks, composed pom рi pі leh, top primary educates coding essentials, fοr digital development careers.
Wow, math acts ⅼike thе foundation pillar of primary schooling, assisting kids
fⲟr spatial analysis to architecture routes.
Օh no, primary math instructs real-ᴡorld implementations including money management, tһerefore ensure уօur kid masters tһat
propeerly begіnning young age.
BеsiԀеѕ frοm institution amenities, emphasize оn math for stop frequent mistakes ѕuch as
careless mistakes іn tests.
Օh, arithmetic acts ⅼike tһe groundwork stone օf
primary schooling, assisting children іn spatial thinking tο design careers.
Alas, primary mathematics instructs real-ѡorld
applications including financial planning, tһuѕ makе sսrе ʏour youngster ցets that properly starting еarly.
St. Gabriel’s Primary School supplies а faith-driven environment f᧐r kids’ development.
Dedicated instructors support scholastic аnd
character quality.
Farrer Park Primary School promotes ɑ main area witһ varied knowing.
Teachers motivate cultural understanding ɑnd accomplishment.
Ӏt’s perfect foг city households ⅼooking for quality education.
Ꮋave а loopk at my blog :: Singapore Chinese Girls’ School (Karri)
Oһ no, composed pom рі рi leh, renowned schools follow global
trends, preparing youngsters fօr evolving career fields.
Оһ, in Singapore, a prestigious primary implies admission t᧐
alumni connections, assisting үour kid secure
opportunities ɑnd jobs in future.
Ӏn addition frоm school facilities,emphasize ᴡith mathematics іn orԁer tօ aνoid common errors including sloppy blunders іn exams.
Listen up, steady pom рi pi, math proves part
of the top subjects dᥙrіng primary school, laying groundwork іn Α-Level calculus.
Folks, worry аbout the differece hor, arithmetic base proves essential
аt primary school forr comprehending figures, vital іn current tech-driven economy.
Ⲟh, math is the base pillar fߋr primary learning,
helping youngsters ѡith dimensional reasoning tо building careers.
Parents, fearful оf losing style օn lah, strong primary math guides fߋr
bеtter science comprehension ɑnd tech dreams.
St. Hilda’s Primary Schookl сreates an engaging environment promoting holistic development.
Тhe school inspires trainees tһrough innovative mentor.
St Stephen’s School ᥙseѕ Christian education ѡith
strong values.
Тһe school supports holistic advancement.
Ӏt’s perfect for faith-based families.
Alѕo visit my ⲣage … Marsiling Secondary School
I’m impressed, I must say. Rarely do I encounter a blog that’s equally educative and entertaining, and let me tell you, you’ve hit the nail on the head.
The problem is something that too few folks are speaking intelligently about.
I am very happy that I stumbled across this in my
search for something regarding this.
May I simply say what a comfort to uncover somebody that really knows
what they’re discussing on the internet. You definitely realize how to bring a problem to light and make it important.
More and more people need to look at this and understand this side of your story.
I was surprised you aren’t more popular since you certainly have the gift.
Порошок кобальта в сплавах применение и свойства
Порошок кобальта в производстве сплавов и его роль в современных технологиях
Оптимальный выбор для промышленности – это сплавы с высоким содержанием данного элемента. Их высокая твердость и устойчивость к коррозии делают их идеальными для условий, требующих долговечности и надежности. Чаще всего такие материалы находят свое применение в производстве инструментов, покрытий и в высокоточном машиностроении.
Элементы, содержащие этот металл, обеспечивают значительное улучшение механических характеристик. Особенно стоит обратить внимание на сплавы с добавками, которые помогают сохранять прочность при высоких температурах и в агрессивных средах, что делает их незаменимыми в аэрокосмической и автомобильной отраслях.
При выборе определенного состава важно учитывать не только требования эксплуатации, но и особенности обработки. Сложные процессы, такие как сварка и резка, требуют специальных условий из-за склонности материалов к трещинообразованию при неправильном обращении. Эффективные методики подготовки и технологические схемы способны значительно повысить продуктивность работы с такими металлами.
Кобальт в композитных материалах: применение и характеристики
Использование кобальта в различных металлокомпозициях значительно повышает их прочностные характеристики. Подходящий выбор этих компонентов позволяет улучшить износостойкость, твердость и коррозионную стойкость конечных изделий.
Например, добавление этого элемента в никелевые сплавы существенно улучшает их термостойкость, что делает их идеальными для высокотемпературных условий. Такие сплавы находят свое применение в авиации и космонавтике, где надежность материалов критически важна.
Кроме того, легирование железа кобальтом способствует образованию магнитных материалов, используемых в электродвигателях и трансформаторах. Эти конструкции обладают высокими магнитными качествами, что делает их незаменимыми в электротехнике.
Производители, работающие с алмазными инструментами, также ценят его за способность улучшать прочность и стойкость к износу. В таких инструментах кобальт обеспечивает прочную связь между абразивами, увеличивая срок службы продукции.
При добавлении этого элемента в керамику наблюдается значительное улучшение механических характеристик, таких как ударная вязкость и прочность на сжатие. Это делает керамические изделия более надежными и устойчивыми к механическим повреждениям.
Использование кобальта в медицине также имеет свои плюсы, особенно в производстве протезов и имплантатов, где необходима высокая биосовместимость и прочность. Компоненты с кобальтом демонстрируют отличную стойкость к коррозии в физиологической среде.
Таким образом, кобальт играет значительную роль в создании высококачественных материалов для самых различных применений, обеспечивая прочность, надежность и долговечность конечных продуктов.
Использование кобальта в производстве высокопрочных сплавов
Для достижения высокой прочности и устойчивости к коррозии в металлических материалах рекомендуется вводить кобальт. Он значительно повышает прочностные характеристики и стойкость к деформациям. Оптимальная величина добавки данного элемента обычно составляет от 5% до 30% в зависимости от конечных требований к продукту.
Элементы, содержащие кобальт, активно используют в жаропрочных и коррозионно-стойких композициях, что делает их идеальными для авиационной и автомобильной промышленности. Сплавы с ним способны сохранять прочность даже при высоких температурах, что критично для деталей, подвергающихся интенсивным нагрузкам.
Для получения ликвидных образцов целесообразно использовать технологии аддитивного производства. Это позволяет добиться однородной структуры и улучшить механические свойства. Контроль за параметрами процесса важен для предотвращения образования дефектов и обеспеченности необходимых качеств готовой продукции.
Значение термической обработки не следует недооценивать; она предназначена для улучшения прочности и твердости. Методы отжига, закалки и старения необходимо адаптировать под конкретные типы соединений, содержащих этот элемент.
Применение кобальта в комбинаторике с другими металлами, такими как никель или хром, даёт возможность формировать более сложные и производительные системы, что позволяет значительно расширить области их применения. Разработка новых сплавов с добавлением этого компонента открывает новые горизонты для высокотехнологичных решений.
Физические и химические характеристики кобальта для металлургии
Для достижения высоких эксплуатационных качеств изделий важно учитывать плотность, равную 8,9 г/см³, что позволяет использовать данный элемент в легких конструкциях с высокой прочностью. Температура плавления достигает 1495 °C, что делает его идеальным для высокотемпературных процессов. По механическим характеристикам он выделяется твердостью и способностью устойчиво сохранять форму под нагрузкой.
Что касается реакционной способности, этот элемент устойчив к коррозии, чему способствуют его свойства образовывать оксиды и другие защитные пленки на поверхности. Его слаборазветвлённая структура способствует легкому легированию с другими металлами, что усиливает обрабатываемость и улучшает все механические параметры готовых материалов.
Токопроводящие характеристики на уровне 17% от дальнего положения к меди, что делает его подходящим для создания электрических устройств и сборок. При дополнении до 22% в сплавах с бронзами наблюдается улучшение проводимости и механической прочности. Как восстановитель участвует в различных химических реакциях, проявляя способности к взаимодействию с кислотами и щелочами.
Работать с данным материалом следует, учитывая возможные окислительные процессы, особенно при высоких температурах. Сохраняя влагу и контролируя атмосферу при хранении, можно минимизировать риск потери качеств. Производственные условия, такие как температура и давление, также должны регулироваться для достижения оптимальных результатов.
My web blog https://rms-ekb.ru/catalog/metallicheskii-poroshok/
Hi! This is my first visit to your blog! We are a group of
volunteers and starting a new project in a community in the same niche.
Your blog provided us beneficial information to work on. You
have done a wonderful job!
This design is steller! You definitely know how to keep a
reader amused. Between your wit and your videos, I
was almost moved to start my own blog (well, almost…HaHa!) Excellent
job. I really enjoyed what you had to say, and more than that, how you presented it.
Too cool!
I love your blog.. very nice colors & theme.
Did you design this website yourself or did you hire someone
to do it for you? Plz answer back as I’m looking to create my own blog and would like to find out where u got this
from. appreciate it
Wah, maths serves ɑs the groundwork block of primary education, helping kids ᴡith
spatial thinking in architecture paths.
Aiyo, mіnus solid mathematics іn Junior College, no matter leading establishment kids mаy falter in neхt-level equations, tһerefore develop іt pгomptly leh.
Tampines Meridian Junior College, from а dynamic merger, offers ingenious education in drama аnd Malay language electives.
Cutting-edge centers support diverse streams,
consisting οf commerce. Talent advancement ɑnd overseas programs foster leadership аnd cultural awareness.
Α caring neighborhood encourages compassion ɑnd strength.
Students ɑre successful in holistic development, ɡotten ready for global difficulties.
Nanyang Junior College masters promoting multilingual efficiency
аnd cultural excellence, skillfully weaving tоgether rich Chinese heritage ѡith modern international education tօ shape confident, culturally agile citizens ѡho are poised to lead in multicultural contexts.
Тhe college’s innovative centers, consisting οf specialized STEM laboratories, carrying ⲟut arts theaters, ɑnd language
immersion centers, assistance robust programs іn science, innovation, engineering, mathematics, arts, ɑnd liberal arts that encourage
innovation, critical thinking, аnd artistic expression. Ιn a lively
and inclusive neighborhood, trainees participate іn management opportunities ѕuch as student governance functions
annd worldwide exchange programs ѡith partner organizations abroad,
whjich expand tһeir viewpoints аnd construct іmportant international
proficiencies. Ƭhe focus on core worths like integrity and resilience іs
integrated into life thгough mentorship plans, social worк initiatives,
aand wellness programs tһat cultivate emotional intelligence ɑnd
individual growth. Graduates οf Nanyang Junior
College consistently master admissions tо top-tier universities, promoting а prⲟud legacy ⲟf
exceptional achievements, cultural appreciation, аnd a deep-seated passion fօr continuous ѕeⅼf-improvement.
Parents, worry аbout the gap hor, math groundwork гemains essential dսring Junior
College tо understanding infߋrmation, crucial
ԝithin current digital economy.
Wah lao, even tһough establishment iѕ atas, math serves аѕ the decisive subject іn developing poise rеgarding figures.
Alas, primary mathematics instructs everyday ᥙѕeѕ ѕuch as financial planning, so guarantee үour youngster masters this гight from yoսng.
Eh eh, calm pom pi pi, mathematics proves one frօm the
top disciplines during Junior College, laying base fߋr A-Level higher calculations.
Folks, dread tһe gap hor, maths foundation іs vital
іn Junior College to comprehending figures, crucial fⲟr currwnt tech-driven sʏstem.
Goodness, гegardless wһether institution remaіns hiցh-end,
mathematics acts like thе decisive subject fߋr developing confidence in figures.
Alas, primary maths instructs everyday implementations ѕuch as financial planning, therefore make
sure yⲟur child grasps tһat right starting үoung
age.
Scoring ԝell іn A-levels oρens doors to top universities in Singapore liқe NUS and NTU, setting yοu up for a bright future
lah.
Oh no, primary maths instructs practical applications ⅼike
money management, thus ensure yоur child grasps this correctly starting young age.
Look at my website :: Millennia Institute (Dina)
wonderful points altogether, you simply won a new reader.
What may you suggest about your submit that you made a few days ago?
Any sure?
Great information. Lucky me I ran across your
site by accident (stumbleupon). I’ve book-marked
it for later!
Hey there! This is kind of off topic but I need some guidance from an established blog.
Is it tough to set up your own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about setting up my own but I’m not sure where to begin. Do
you have any ideas or suggestions? Appreciate it
You could certainly see your skills within the
work you write. The sector hopes for even more passionate
writers like you who aren’t afraid to say how they believe.
Always follow your heart.
Wow! This blog looks just like my old one! It’s on a completely different topic but it has pretty much the same page layout and design. Superb choice of colors!
My partner and I stumbled over here different website and thought
I might check things out. I like what I see so now i am following you.
Look forward to going over your web page again.
4M Dental Implant Center San Diego
5643 Copley Ɗr ste 210, San Diego,
CA 92111, Unitewd Stɑtеs
18582567711
dental excellence
Hi, Neat post. There’s an issue with your website
in web explorer, might test this? IE still is the marketplace
chief and a good portion of other people will miss your great writing due to this problem.
OMT’s proprietary curriculum introduces fun obstacles tһat mirror test inquiries, stimulating love fоr mathematics and
thе motivation to execute remarkably.
Discover tһe convenience of 24/7 online math tuition аt OMT,
where engaging resources mаke discovering fun ɑnd reliable foг ɑll levels.
Singapore’ѕ focus ߋn imрortant analyzing mathematics
highlights tһe value of math tuition, which helps students establish
the analytical skills demanded Ьy the country’ѕ forward-thinking
curriculum.
Math tuition addresses private finding оut paces, enabling primary school students tⲟ deepen understanding of PSLE subjects ⅼike аrea,
border, and volume.
Secondary math tuition overcomes tһe restrictions оf large classroom sizes, gіving concentrated іnterest
thɑt boosts understanding fⲟr Ο Level preparation.
Тhrough normal simulated examinations аnd detailed comments, tuition helps junior college trainees identify аnd fіx weak pօints before the real A Levels.
Ԝhat collections OMT аpaгt iѕ itts custom-mаdе mathematics
program tһat expands past the MOE curriculum, cultivating
іmportant analyzing hands-оn, uѕeful exercises.
Themed components make finding out thematic lor, aiding preserve info mսch ⅼonger
for enhanced math efficiency.
Math tuition debunks innovative topics ⅼike calculus for
A-Level students, leading tһe way fօr university admissions іn Singapore.
Feel free tⲟ surf to mү site; Kaizenare math tuition
Howdy, i read your blog occasionally and i own a similar one and i
was just curious if you get a lot of spam feedback?
If so how do you prevent it, any plugin or anything you can recommend?
I get so much lately it’s driving me mad so any help is very much appreciated.
You ought to be a part of a contest for one of the most useful sites on the web.
I most certainly will highly recommend this web site!
I love your blog.. very nice colors & theme.
Did you create this website yourself or did you hire someone to do
it for you? Plz reply as I’m looking to construct my own blog and would like to
know where u got this from. cheers
Wow, this article is good, my younger sister is analyzing these things, so
I am going to inform her.
Организуем безупречные банкеты любого формата в современном зале премиум-класса! Предлагаем:
• Гибкие варианты обслуживания: от классического банкета до изысканного фуршета
• Разнообразное меню: авторские блюда от шеф-повара, банкетные сеты на любой вкус
• Комфортное пространство: зал вмещает от 20 до 150 гостей с возможностью зонирования
• Профессиональное сопровождение: опытные официанты, техническая поддержка
• Индивидуальный подход: поможем рассчитать банкет на человека, составим меню под ваши пожелания
• Дополнительные услуги: декор зала, музыкальное сопровождение, фото- и видеосъемка, https://domrestkzn.ru/banketniyzal/
Проводим:
• Свадебные банкеты
• Корпоративные мероприятия
• Дни рождения и юбилеи
• Деловые приемы
• Тематические торжества
Гарантируем:
• Разумные цены на банкет
• Качественное обслуживание
• Вкусную кухню
• Уютную атмосферу
Доверьте организацию вашего торжества профессионалам – создайте незабываемое событие вместе с нами!
Звоните прямо сейчас, ответим на все вопросы и поможем спланировать идеальный банкет.
Hi there! This is my first comment here so I just wanted to give a quick shout out and say I genuinely enjoy reading through your
posts. Can you suggest any other blogs/websites/forums that cover the same topics?
Thank you!
By connecting mathematics to imaginative jobs, OMT stirs
ᥙp an interest in trainees, motivating tһem to welcome tthe subject and mаke evеry effort
for exam mastery.
Οpen your child’ѕ fulⅼ potential in mathematics
wіth OMT Math Tuition’ѕ expert-led classes, tailored to Singapore’ѕ MOE curriculum for primary, secondary, ɑnd JC students.
In Singapore’ѕ strenuous education ѕystem, where mathematics is compulsory and takeѕ іn around 1600 hօurs of
curriculum time іn primary school аnd secondary schools, math tuition еnds up bеing іmportant to assist trainees build a strong foundation fоr lifelong success.
Math tuition іn primary school school bridges
spaces in class learning, making sսre trainees understand intricate topics ѕuch aѕ geometry and data analysis before thе PSLE.
Ꮲrovided tһe high risks of O Levels fοr senior һigh school progression іn Singapore, math tuition tɑkes full advantage of opportunities fⲟr toр grades ɑnd ԝanted placements.
Junior college math tuition іs critical forr Α Levels ɑs it strengthens understanding of innovative calculus
subjects ⅼike assimilation techniques аnd differential
equations, ᴡhich are main to the exam syllabus.
OMT sets іtself apart ѡith a curriculum ⅽreated to improve MOE content viɑ
in-depth explorations օf geometry proofs and theories
for JC-level learners.
Video clip descriptions ɑre cleɑr and appealing lor, assisting yoᥙ realize complicated ideas
and raise your grades easily.
Іn Singapore, wheгe parental participation iѕ crucial,
math tuition supplies organized support fߋr hօmе support
toward examinations.
Ꮋere is my paցe: math tuition singapore
Excellent beat ! I wish to apprentice while you amend your site, how could i subscribe for a blog website?
The account aided me a acceptable deal. I had been tiny bit acquainted of this your broadcast provided bright
clear idea
Hi, just wanted to mention, I liked this article. It was inspiring.
Keep on posting!
Excellent website you have here but I was curious if you knew of any discussion boards that
cover the same topics talked about here? I’d really like to
be a part of community where I can get advice from other experienced
individuals that share the same interest. If you have any recommendations, please let me know.
Cheers!
Hi there, everything is going sound here and ofcourse every one is sharing data,
that’s genuinely fine, keep up writing.
After looking at a handful of the articles on your web page, I seriously like your way of blogging.
I saved it to my bookmark site list and will be
checking back in the near future. Take a look at my web site as well and tell me your opinion.
Hi would you mind letting me know which webhost you’re utilizing?
I’ve loaded your blog in 3 completely different web browsers and I must say this
blog loads a lot quicker then most. Can you suggest a good hosting provider at a honest price?
Thanks, I appreciate it!
Paylaşdığınız məlumatlar mənə çox kömək edir. Təşəkkürlər!
https://tasslock.co.uk/2025/05/20/pin-up-azrbaycanin-n-yaxsi-kazinosu-rsmi-sayt-2/
excellent points altogether, you simply
received a brand new reader. What would you recommend about your submit that you just made some days ago?
Any sure?
I’d like to find out more? I’d like to find out some
additional information.
After looking into a handful of the blog posts on your web site, I seriously like your way of writing a blog.
I added it to my bookmark site list and will be checking back in the near
future. Take a look at my website too and tell me what you think.
Much appreciated for publishing this.
Hi there i am kavin, its my first occasion to commenting anywhere,
when i read this piece of writing i thought i could also create comment due to this brilliant piece
of writing.
My partner and I stumbled over here from a different web address and thought I should check things out.
I like what I see so now i am following you.
Look forward to checking out your web page repeatedly.
I was wondering if you ever thought of changing the structure of your website?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people
could connect with it better. Youve got an awful lot of text for only having 1 or two
images. Maybe you could space it out better?
Heya i’m for the first time here. I came across this board and I find It really useful
& it helped me out a lot. I hope to give something back and aid others
like you helped me.
I’m pretty pleased to find this site. I wanted to thank
you for your time just for this wonderful read!! I definitely appreciated every part of it and i also have you bookmarked to
see new things on your blog.
I am regular visitor, how are you everybody? This post
posted at this site is in fact pleasant.
What i don’t realize is in truth how you’re now not really a lot more neatly-preferred than you might be now.
You’re so intelligent. You realize thus considerably on the subject of this matter, made me for my part believe it from so many various
angles. Its like men and women are not interested unless it’s something to accomplish with Lady gaga!
Your own stuffs great. At all times maintain it up!
Touche. Great arguments. Keep up the great spirit.
I do believe all the concepts you have offered for your post.
They are very convincing and will definitely work.
Still, the posts are very brief for novices. May you please lengthen them a little from subsequent time?
Thanks for the post.
Useful information. Fortunate me I discovered your web site accidentally,
and I am shocked why this twist of fate didn’t
happened in advance! I bookmarked it.
Hi there! This is my first comment here so I just wanted to give a quick shout out and tell you I truly enjoy reading your articles.
Can you suggest any other blogs/websites/forums that deal with
the same topics? Thanks a ton!
Expert-level service, competent professional service. Competent team selected. Competent service.
I’d like to find out more? I’d care to find out some additional information.
My brother suggested I might like this website. He used to be totally right.
This publish truly made my day. You cann’t believe just how a
lot time I had spent for this info! Thanks!
We are a gaggle of volunteers and opening a new scheme in our
community. Your site provided us with useful info to work
on. You’ve performed a formidable task and our whole neighborhood will likely be thankful to you.
Hello there! This is my first visit to your blog!
We are a team of volunteers and starting a new project in a community in the
same niche. Your blog provided us useful information to
work on. You have done a outstanding job!
Pretty section of content. I just stumbled upon your site and in accession capital to assert that I acquire in fact enjoyed account your blog posts.
Any way I’ll be subscribing to your augment and even I achievement
you access consistently rapidly.
Hey there! Someone in my Facebook group shared this site with us so I came to
look it over. I’m definitely loving the information. I’m bookmarking and will
be tweeting this to my followers! Outstanding blog and amazing
style and design.
I blog frequently and I genuinely thank you for your
information. This great article has really peaked my interest.
I am going to take a note of your site and keep checking for new information about once a week.
I opted in for your RSS feed as well.
https://sahabatpools.net/
Hey I am so grateful I found your blog page, I really found
you by mistake, while I was looking on Askjeeve for something else, Anyways I am here now and would just
like to say cheers for a incredible post and a all
round exciting blog (I also love the theme/design), I don’t have time
to browse it all at the minute but I have book-marked it and also
added in your RSS feeds, so when I have time I will be back to read much more, Please do keep up the great
work.
Incredible quest there. What occurred after? Good luck!
This design is spectacular! You obviously know how to keep a reader amused.
Between your wit and your videos, I was almost moved to
start my own blog (well, almost…HaHa!) Wonderful job.
I really loved what you had to say, and more than that,
how you presented it. Too cool!
Excellent way of telling, and fastidious post to take
facts on the topic of my presentation topic, which i am going to convey in college.
Hello there, just became alert to your blog through Google, and found
that it is really informative. I am gonna watch out for brussels.
I will appreciate if you continue this in future.
Many people will be benefited from your writing. Cheers!
I am genuinely thankful to the owner of this web page who has shared this enormous
post at at this place.
Also visit my web site; zapakeala01
Hello mates, how is the whole thing, and what you would like to say on the topic of this post, in my view its
truly awesome in support of me.
Excellent post. I’m going through a few of these issues as well..
Keep this going please, great job!
I started Flush Factor Plus hoping to ease the swelling and heaviness in my legs—and after
about two weeks of consistent use, the difference was subtle
but real. My ankles felt less puffy, and the tightness in my calves
faded. The capsule is easy to swallow, and the gentle effect
didn’t leave me dehydrated or jittery. It’s a light, natural boost to circulation and fluid balance—nothing
dramatic, but definitely noticeable.
I’m not sure where you are getting your information, but great topic.
I needs to spend some time learning more or understanding
more. Thanks for wonderful info I was looking for
this information for my mission.
Appreciation to my father who informed me on the
topic of this webpage, this website is truly awesome.
magnificent points altogether, you simply received a new reader.
What might you suggest in regards to your post that you simply made a few days ago?
Any certain?
Amazing! Its really awesome piece of writing, I
have got much clear idea about from this paragraph.
Greetings from Ohio! I’m bored at work so I decided to check out your blog on my iphone during lunch
break. I enjoy the knowledge you provide here and can’t wait to take
a look when I get home. I’m amazed at how fast your blog loaded on my cell
phone .. I’m not even using WIFI, just 3G ..
Anyhow, great blog!
I decided to try Nagano Tonic after seeing it pop up online.
The citrus-flavored mix was pleasant and easy to add
to my morning water—felt like a refreshing boost. After a few weeks,
I noticed slightly steadier energy throughout the day—no jittery crashes.
My digestion felt smoother, and bloating eased a bit.
Weight loss was gradual, but the improvements in focus and calm
energy were the real win for me.
Excellent goods from you, man. I have understand your stuff
previous to and you are just too magnificent. I really like what you’ve acquired here, certainly like what you’re saying and the way in which you say it.
You make it entertaining and you still take care of to keep it smart.
I can not wait to read far more from you. This is actually a terrific web site.
After I originally left a comment I seem to
have clicked on the -Notify me when new comments are added- checkbox
and from now on every time a comment is added I recieve 4 emails with the same
comment. There has to be an easy method you can remove me from that service?
Many thanks!
I am genuinely delighted to glance at this weblog posts which includes lots
of useful information, thanks for providing such data.
Outstanding post but I was wanting to know if you could write a litte more on this subject?
I’d be very thankful if you could elaborate a little
bit more. Kudos!
Nice post. I was checking continuously this blog and I am impressed!
Very helpful information specially the last part :
) I care for such information much. I was seeking this certain info for a long
time. Thank you and good luck.
4M Dental Implant Center San Diego
5643 Copley Dr ste 210, San Diego,
ᏟA 92111, United Stateѕ
18582567711
dental diagnosis
It’s wonderful that you are getting ideas from this
paragraph as well as from our argument made at this
place.
First of all I would like to say wonderful blog! I had a quick question which I’d
like to ask if you don’t mind. I was interested to find out how you
center yourself and clear your mind before writing.
I’ve had a tough time clearing my mind in getting my thoughts out
there. I truly do enjoy writing however it
just seems like the first 10 to 15 minutes are usually lost simply just trying to figure out how
to begin. Any recommendations or hints? Appreciate it!
Everything is very open with a very clear explanation of the issues.
It was definitely informative. Your website is very helpful.
Many thanks for sharing!
You actually make it seem so easy with your presentation but I
find this matter to be really something that I think I would never understand.
It seems too complex and extremely broad for me.
I am looking forward for your next post, I will try to get the hang of it!
Hi friends, good piece of writing and good arguments commented at this place,
I am genuinely enjoying by these.
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your site to come back down the
road. Cheers
Secondary school matgh tuitioin іs key in Singapore’s education framework,
offering personalized guidance f᧐r y᧐ur child fresh from
PSLE tо excel іn new topics ⅼike equations.
Ⲩou knoԝ lah, Singapore kids ɑlways ace thе worlԀ marh rankings!
Aѕ moms аnd dads, improve culturally ᴡith Singapore matth tuition’ѕ integration. Secondary math tuition contexts local.
Тhrough secondary 1 math tuition, angles һome.
Ethical АI սse in secondary 2 math tuition assists tutoring.
Secondary 2 math tuition leverages tools responsibly. Modern secondary 2 math tuition ѕtays ethical.
Secondary 2 math tuition designs integrity.
Тhe stakes foг secondary 3 math exams rise ѡith O-Levels nearby, highlighting
tһe need for proficiency. Strong performance
helps ԝith leadership іn school projects. It builds ethical decision-mаking thrߋugh sensible processes.
Singapore’ѕ meitocracy perpetuates secondary 4 exams motivationally.
Secondary 4 math tuition reviews share. Ꭲhiѕ ambition drives
O-Level. Secondary 4 math tuition inspires.
Math іsn’t solely for passing tests; it’ѕ a cornerstone skill іn tһe exploding AӀ technologies, bridging dta ɑnd intelligent applications.
T᧐ master mathematics, develop аn affection for it and make a pοіnt to use math principles іn your
routine life.
Ϝor targeted revision, practicing papers fгom multiple secondary schools іn Singapore highlights аreas needing tutor focus.
Singapore-based online math tuition е-learning enhances scores tһrough quantum entanglement puzzles foг logic.
Power ah, relax parents, secondary school exciting phase, ɗon’t gіve уour
child too much stress.
Feel free tօ visit my blog :: Kaizenaire math tuition singapore
Hi there, I do think your website could be having internet browser
compatibility problems. When I look at your web site in Safari, it looks fine however, if opening in IE, it’s got some overlapping issues.
I just wanted to give you a quick heads up! Other than that, great site!
ยินดีต้อนรับสู่ E2BET ประเทศไทย – ชัยชนะของคุณ จ่ายเต็มจำนวน สนุกกับโบนัสที่น่าสนใจ เล่นเกมสนุก ๆ และสัมผัสประสบการณ์การเดิมพันออนไลน์ที่ยุติธรรมและสะดวกสบาย ลงทะเบียนเลย!
https://e2betportal.com/th/
This text is invaluable. Where can I find out more?
Appreciate the recommendation. Let me try it out.
It’s nearly impossible to find experienced people for this subject, however,
you sound like you know what you’re talking about!
Thanks
Good article. I definitely love this site.
Stick with it!
4M Dental Implant Center San Diego
5643 Copley Ɗr stee 210, San Diego,
ϹA 92111, United States
18582567711
confidence boost
Great article! This is the kind of information that are meant
to be shared around the web. Shame on the search engines for no longer
positioning this post higher! Come on over
and consult with my web site . Thank you =)
Thanks to my father who informed me on the topic of this weblog,
this blog is in fact remarkable.
I don’t know whether it’s just me or if perhaps everybody else experiencing issues with your
blog. It seems like some of the text on your posts are running off the screen. Can someone
else please provide feedback and let me know if this is happening to them too?
This might be a issue with my internet browser because I’ve had
this happen previously. Appreciate it
I feel this is among the such a lot important information for me.
And i am happy reading your article. But should observation on few general things, The web site taste is ideal, the articles is actually great :
D. Just right process, cheers
площадку для обмена цифровых активов и произвести трансакцию
Thank you for sharing your info. I truly appreciate your efforts and I am waiting for
your further write ups thank you once again.
I was suggested this blog through my cousin. I am now not certain whether
this put up is written by means of him as nobody else
understand such unique approximately my difficulty.
You’re wonderful! Thank you!
After I initially commented I appear to have clicked the -Notify me when new comments are
added- checkbox and from now on each time a comment is added I receive 4 emails with the exact same comment.
There has to be an easy method you are able to remove me from that service?
Thanks!
Online casinos are popular worldwide.
They offer a huyge selection of entertainment.
Players enjoy fast deplosits
and payouts within 24h.
Bonuses and promotions include redload deals and loyalty points.
These increase fun.
Most platforms are mobile-optimized,
so users can enjoy seamless gameeplay on the go.
Overall, virtual platforms provide safe, fun and engaging entertainment,
making them the future of digital gaming.
I really like what you guys are up too. This sort of clever work and exposure!
Keep up the awesome works guys I’ve you guys to my blogroll.
Thanks a bunch for sharing this with all folks you actually recognize what you’re speaking about!
Bookmarked. Kindly also visit my site =). We will have a link trade contract among us
I’m not that much of a internet reader to be honest but your sites
really nice, keep it up! I’ll go ahead and bookmark your website to come back later.
Cheers
SLOT
I think the admin of this web site is truly working hard for his web page, for the reason that here every stuff is quality based
stuff.
I know this web page provides quality based articles and other information,
is there any other website which provides such stuff in quality?
When someone writes an article he/she retains the plan of a user in his/her
mind that how a user can understand it. Thus that’s why this piece of writing is amazing.
Thanks!
Attractive part of content. I simply stumbled upon your web site and
in accession capital to say that I acquire in fact loved account
your weblog posts. Anyway I’ll be subscribing for your augment and even I success you get admission to consistently rapidly.
Wow, incredible blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your site is magnificent, as well
as the content!
Hi just wanted to give you a brief heads up and let you know
a few of the images aren’t loading properly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both show
the same outcome.
Hi would you mind stating which blog platform you’re working with?
I’m looking to start my own blog soon but I’m having a hard time deciding between BlogEngine/Wordpress/B2evolution and
Drupal. The reason I ask is because your design and style seems different then most
blogs and I’m looking for something unique.
P.S Apologies for being off-topic but I had to ask!
I’m really loving the theme/design of your blog.
Do you ever run into any web browser compatibility problems?
A small number of my blog audience have complained about my blog not working
correctly in Explorer but looks great in Chrome.
Do you have any recommendations to help fix this problem?
I’m not that much of a online reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your website to come back in the
future. Cheers
Genuinely no matter if someone doesn’t be aware of after that its up to other visitors that they will help, so here it happens.
Just want to say your article is as amazing. The clearness in your post is simply excellent and i can assume
you’re an expert on this subject. Fine with your permission allow me to grab your RSS feed to keep
up to date with forthcoming post. Thanks a million and please continue the enjoyable work.
That’s why our experts recommend playing at regulated crypto casino sites to ensure your safety.
Awesome issues here. I am very satisfied to peer
your post. Thanks so much and I’m looking forward to contact you.
Will you kindly drop me a mail?
It’s really very complicated in this active life to
listen news on TV, therefore I only use web for that reason, and obtain the most up-to-date information.
I always emailed this blog post page to all my associates, for the reason that
if like to read it after that my friends will too.
I am not sure where you are getting your info, but great topic.
I needs to spend some time learning much more or understanding more.
Thanks for fantastic information I was looking for this info for my mission.
Hi colleagues, how is all, and what you wish for to say concerning this article, in my
view its truly remarkable in support of me.
WOW just what I was looking for. Came here by searching for best crypto casinos
I savour, lead to I discovered just what I used to
be looking for. You’ve ended my four day long hunt! God Bless you
man. Have a nice day. Bye
Write more, thats all I have to say. Literally, it
seems as though you relied on the video to make your point.
You definitely know what youre talking about, why throw away
your intelligence on just posting videos to your site when you could be giving us something informative to read?
Hi there all, here every one is sharing these experience, so it’s fastidious to read this weblog, and I used to pay a
quick visit this website everyday.
Write more, thats all I have to say. Literally, it seems as
though you relied on the video to make your point.
You definitely know what youre talking about, why throw away
your intelligence on just posting videos to your blog when you could
be giving us something informative to read?
It’s difficult to find well-informed people about this subject,
but you seem like you know what you’re talking about! Thanks
Hi there to every one, it’s really a nice for me to visit this site, it contains precious Information.
Wonderful work! This is the type of information that should be shared across the net.
Shame on Google for not positioning this put up upper!
Come on over and consult with my site . Thank you =)
Hi everyone, it’s my first pay a visit at this site, and
article is genuinely fruitful designed for me, keep up
posting these types of posts.
Hey There. I found your blog using msn. This is a really well
written article. I’ll be sure to bookmark it and come back to read more of your
useful information. Thanks for the post. I’ll
definitely return.
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get got an edginess over that you wish be delivering the following.
unwell unquestionably come more formerly again since exactly the same nearly very often inside case you shield this increase.
Hi everybody, here every one is sharing these kinds of knowledge, therefore it’s fastidious to
read this webpage, and I used to go to see this web site daily.
I do trust all the ideas you’ve presented on your post.
They’re very convincing and can definitely work.
Nonetheless, the posts are very brief for novices. May just you please
prolong them a bit from subsequent time? Thanks
for the post.
Howdy! This blog post could not be written any better!
Looking through this post reminds me of my previous roommate!
He always kept preaching about this. I am going to forward this article to him.
Fairly certain he will have a great read. Many thanks for sharing!
Whoa! This blog looks just like my old one! It’s on a totally different topic but
it has pretty much the same layout and design. Great choice of
colors!
Good replies in return of this matter with genuine arguments and describing the whole thing on the topic of that.
Hello every one, here every person is sharing these experience, so
it’s fastidious to read this webpage, and I used to visit this website
daily.
Piece of writing writing is also a fun, if you be familiar with
after that you can write if not it is difficult to write.
WOW just what I was searching for. Came here by searching
for Helpful
Thanks for one’s marvelous posting! I seriously enjoyed reading
it, you happen to be a great author.I will make
sure to bookmark your blog and will eventually come back
very soon. I want to encourage that you continue your great posts, have
a nice weekend!
Hi! Do you use Twitter? I’d like to follow you if that would be ok.
I’m absolutely enjoying your blog and look forward to
new posts.
Thanks very nice blog!
Good way of describing, and good paragraph to obtain information about my presentation focus, which i am going to
deliver in university.
I was wondering if you ever considered changing the structure of your
site? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or 2 images.
Maybe you could space it out better?
Hey! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing a few months of hard work due to no data backup.
Do you have any methods to prevent hackers?
Hello, Neat post. There is an issue with your
web site in internet explorer, might test this? IE still is the marketplace leader
and a large portion of other folks will pass over your wonderful writing due to this problem.
always i used to read smaller posts that as well clear their motive, and that is also
happening with this piece of writing which I am reading now.
You actually revealed that exceptionally well!
This is a topic which is near to my heart… Take care!
Where are your contact details though?
Because the admin of this web site is working, no hesitation very rapidly it will be famous, due to its feature contents.
Hello to every body, it’s my first visit of this web site; this
blog includes awesome and actually fine information for readers.
Hi there to all, how is everything, I think every
one is getting more from this web site, and your views are pleasant for new people.
Hello, mantap sekali postingan ini!
Saya suka dengan cara kamu membahas tentang taruhan olahraga.
Apalagi ada pembahasan soal Situs Judi Bola Terlengkap, itu memang
sangat bermanfaat.
Sejauh yang saya tahu, Situs Judi Bola Terlengkap adalah rekomendasi terbaik untuk pemain taruhan bola.
Thanks sudah membagikan ulasan ini, semoga banyak orang terbantu.
Wow, layout blog juga enak dilihat.
Saya pasti akan sering mampir untuk baca artikel berikutnya.
Hi there mates, its impressive post on the topic of teachingand entirely defined, keep it up all the time.
I’d like to thank you for the efforts you have put in writing this site.
I really hope to check out the same high-grade content from you in the future as well.
In fact, your creative writing abilities has motivated me to get my own,
personal blog now 😉
Hmm is anyone else having problems with the pictures on this
blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
of course like your website but you need to test the spelling on several of your posts.
A number of them are rife with spelling problems and I find it very troublesome to tell the truth on the other hand I’ll certainly
come back again.
Thanks in support of sharing such a fastidious opinion, paragraph is good,
thats why i have read it entirely
En ❤️ PELISFLIX ❤️ puedes ver o mirar películas y series gratis online en pelisflix, pelisflix2 en Español,
Latino y Subtitulado. PELISFLIX 2 es para todos los gustos.
Hello there, I discovered your site by means of Google
while searching for a related subject, your web site came
up, it appears to be like great. I’ve bookmarked it in my google bookmarks.
Hi there, just was aware of your weblog via Google,
and located that it’s truly informative. I am going to be careful for brussels.
I will appreciate should you continue this in future.
Lots of folks will probably be benefited out of your writing.
Cheers!
Thanks for sharing. For more on related topics, check my page: ssgamesbr.top.
Howdy, I do think your blog could possibly be having internet browser compatibility issues.
When I look at your blog in Safari, it looks fine however, when opening in IE, it has some
overlapping issues. I just wanted to provide you with
a quick heads up! Other than that, fantastic blog!
Thanks very nice blog!
Thanks for another informative site. The place else may I get that
type of info written in such a perfect manner? I’ve a undertaking that I’m just now
working on, and I’ve been on the look out for such info.
It’s a pity you don’t have a donate button! I’d without a doubt donate to this brilliant blog!
I guess for now i’ll settle for bookmarking and adding your RSS feed to
my Google account. I look forward to fresh updates and will share this website with my Facebook group.
Talk soon!
Excellent way of telling, and nice paragraph to obtain facts
on the topic of my presentation focus, which i am going to convey in academy.
This web site truly has all of the info I wanted concerning
this subject and didn’t know who to ask.
This is really fascinating, You are a very skilled blogger.
I have joined your feed and look forward to searching for extra of your great post.
Also, I have shared your site in my social networks
If some one needs to be updated with most recent technologies therefore he must be visit this website and be up to date daily.
Sweet blog! I found it while browsing on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Cheers
You really make it seem so easy with your presentation but
I find this topic to be really something which I think I would never understand.
It seems too complicated and extremely broad for me. I’m looking forward for
your next post, I will try to get the hang of it!
Zobet
ZOBET tự hào cung cấp một hệ thống cá cược
hoàn hảo, phục vụ mọi mong muốn của người chơi cộng đồng Việt.
Pretty great post. I just stumbled upon your blog and wanted to mention that I’ve truly enjoyed surfing around your blog posts.
In any case I will be subscribing to your rss feed and I’m hoping
you write again very soon!
Have you ever thought about writing an e-book or guest authoring on other websites?
I have a blog based upon on the same information you discuss and would really like to have
you share some stories/information. I know my audience would enjoy your work.
If you are even remotely interested, feel free to shoot me an email.
Thank you for the auspicious writeup. It in fact was
a amusement account it. Look advanced to more added agreeable from
you! By the way, how can we communicate?
Viagra is specially used to treat erectile dysfunction in male
and viagra with neurotin it’s really reacts.
fantastic post, very informative. I wonder why the opposite experts of this sector don’t realize this.
You should continue your writing. I’m confident, you
have a great readers’ base already!
TABLE
Hey there would you mind letting me know which
webhost you’re working with? I’ve loaded your blog
in 3 completely different web browsers and I must say this blog loads a
lot quicker then most. Can you recommend a good internet hosting provider at a fair price?
Cheers, I appreciate it!
Hi there colleagues, good piece of writing and pleasant arguments commented here,
I am in fact enjoying by these.
I don’t even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you’re
going to a famous blogger if you are not already 😉
Cheers!
Blog được xây dựng với mục tiêu chia sẻ thông tin hữu ích, cập nhật kiến thức đa dạng và mang đến góc nhìn khách quan cho bạn đọc. Nội dung tập trung vào việc tổng hợp, phân tích và truyền tải một cách minh bạch – dễ hiểu, giúp bạn tiếp cận nguồn thông tin chất lượng trong nhiều lĩnh vực.
I seriously love your blog.. Pleasant colors &
theme. Did you develop this amazing site yourself?
Please reply back as I’m trying to create my very own blog and want to know where
you got this from or just what the theme is called.
Thank you!
Do you have a spam issue on this site; I also am a blogger, and I was wondering your situation;
many of us have developed some nice methods
and we are looking to swap strategies with others, please shoot me an email if interested.
When I initially left a comment I seem to have clicked the -Notify me when new comments are added- checkbox and from now on each
time a comment is added I receive four emails with the exact
same comment. Perhaps there is an easy method you are able to
remove me from that service? Appreciate it!
Your means of describing everything in this post is genuinely good, all be capable of easily know it, Thanks a lot.
Peculiar article, just what I wanted to find.
Howdy, i read your blog from time to time and i own a
similar one and i was just curious if you get a lot
of spam responses? If so how do you reduce it, any plugin or anything
you can recommend? I get so much lately it’s driving me insane so
any help is very much appreciated.
Hello, after reading this awesome paragraph i am too happy to share my experience here with friends.
Hi, Neat post. There is a problem together with your website in internet explorer, would check this?
IE still is the marketplace chief and a huge section of folks will miss your great writing due to this
problem.
I am actually delighted to glance at this webpage posts which
contains tons of helpful information, thanks for providing these kinds of information.
Very nice article, just what I needed.
Can you tell us more about this? I’d care to find out more details.
Wow, fantastic blog layout! How long have you been blogging
for? you made blogging look easy. The overall look of your website is fantastic, as well as the content!
What’s Taking place i’m new to this, I stumbled upon this
I’ve discovered It positively useful and it has
helped me out loads. I am hoping to give a contribution & aid different customers like its aided me.
Good job.
Every weekend i used to pay a quick visit this site, for the reason that i want enjoyment, as this this web page conations actually fastidious funny information too.
Hello, just wanted to tell you, I enjoyed this blog post. It was practical.
Keep on posting!
LayerSwap is the fastest and most reliable cross-chain bridge, allowing users to transfer crypto assets like Bitcoin,
Ethereum, Polygon, and more across blockchains and
exchanges in minutes with the lowest fees.
Sildenafil Citrate is a prescription drug that is sold as Viagra, Revatio and other names.
This drug is used to treat erectile dysfunction, a medical
term for having trouble with erection.
Spott on with this write-up, I seriously believe this website needs a lot more attention. I’ll probably
be back again to reead more, thanks for the info!
Its like you learn my thoughts! You appear to know a lot approximately this, such
as you wrote the guide in it or something. I believe that you just can do with some % to pressure the message home a little bit, but instead of that, this is wonderful blog.
An excellent read. I’ll definitely be back.
Wonderful beat ! I would like to apprentice while
you amend your website, how can i subscribe for a blog website?
The account helped me a acceptable deal. I had been tiny bit acquainted of this your broadcast provided bright
clear idea
Dry Cleaning in New York city by Sparkly Maid NYC
There is definately a lot to know about this topic.
I like all the points you have made.
I don’t even know how I ended up here, but I thought this post was good.
I do not know who you are but certainly
you’re going to a famous blogger if you aren’t already 😉 Cheers!
I have fun with, cause I found just what I used to be having a look for.
You have ended my four day long hunt! God Bless you man. Have
a great day. Bye
My coder is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using Movable-type on various websites
for about a year and am worried about switching to another
platform. I have heard good things about blogengine.net.
Is there a way I can import all my wordpress content
into it? Any help would be greatly appreciated!
WOW just what I was looking for. Came here by searching for depo 25 bonus 25
Thank you for any other wonderful post. The place else may anyone get that kind of
information in such a perfect way of writing? I have a presentation subsequent week,
and I’m on the look for such information.
Hello! This is my first comment here so I just wanted to give a quick shout out
and say I really enjoy reading through your posts.
Can you recommend any other blogs/websites/forums that cover the same topics?
Many thanks!
Saved as a favorite, I love your web site!
hello there and thank you for your info – I’ve definitely picked up anything
new from right here. I did however expertise several technical points
using this site, as I experienced to reload the web site a lot of times previous to I could get it to load correctly.
I had been wondering if your web host is OK?
Not that I am complaining, but slow loading instances
times will often affect your placement in google and can damage your high quality score if ads
and marketing with Adwords. Well I am adding
this RSS to my email and can look out for much more of your respective fascinating content.
Make sure you update this again very soon.
Howdy! This post couldn’t be written any better! Going through this post reminds me of my previous
roommate! He constantly kept preaching about this. I
will forward this post to him. Fairly certain he’ll have a great read.
Thank you for sharing!
Good blog post. I certainly love this site.
Stick with it!
Great blog you have got here.. It’s difficult to find quality writing
like yours nowadays. I seriously appreciate individuals like you!
Take care!!
Keep this going please, great job!
Thank you for the good writeup. It in fact used to be a enjoyment
account it. Glance complex to far introduced agreeable from you!
By the way, how can we be in contact?
No, it is not considered dangerous to take Viagra with coffee.
However, taking Viagra with alcohol is actually very dangerous.
Questo procedimento prevede che la traduzione giurata sia
portata in procura dove viene legalizzata per il paese di destinazione.
Thanks for a marvelous posting! I really enjoyed reading it, you happen to be a great author.
I will remember to bookmark your blog and may come back later on. I want to encourage
you to continue your great job, have a nice holiday weekend!
Hi there, I enjoy reading through your post. I wanted
to write a little comment to support you.
This info is priceless. How can I find out more?
Link exchange is nothing else except it is only placing the other person’s blog link on your page at suitable place and other person will also do same in favor of you.
Aw, this was a very nice post. Finding the time and actual
effort to produce a very good article… but what can I
say… I procrastinate a lot and never manage to get
anything done.
It is generally not recommended to take ephedrine and Viagra together without consulting
a healthcare professional.
We absolutely love your blog and find many of your
post’s to be just what I’m looking for. can you offer
guest writers to write content in your case?
I wouldn’t mind publishing a post or elaborating on many of the subjects
you write concerning here. Again, awesome web log!
wonderful submit, very informative. I’m wondering why the other experts of this sector don’t
realize this. You must continue your writing. I’m confident, you have a huge
readers’ base already!
Spot on with this write-up, I absolutely believe that this website needs much more attention.
I’ll probably be back again to see more, thanks for the information!
I don’t even know how I finished up here,
but I assumed this put up used to be good.
I don’t know who you might be but definitely
you’re going to a famous blogger in the event you are
not already. Cheers!
Hello, keren sekali posting ini!
Saya senang dengan cara kamu mengulas tentang taruhan olahraga.
Apalagi ada penjelasan soal Situs Judi Bola Terlengkap, itu sangat membantu.
Menurut saya, Situs Judi Bola Terlengkap memang pilihan tepat bagi penggemar sepak bola.
Terima kasih sudah menulis artikel ini, semoga berguna.
Wih, desain blog juga rapi.
Saya pasti akan kembali untuk membaca artikel selanjutnya.
Hello there! I know this is kinda off topic but I was wondering which blog platform are you using for
this site? I’m getting sick and tired of WordPress
because I’ve had issues with hackers and I’m looking at
options for another platform. I would be fantastic if you could point me in the direction of a good platform.
We rank casinos based on their payout speed and flexibility in handling multiple cryptocurrencies.
Hi! I know this is somewhat off topic but I
was wondering which blog platform are you using for this
site? I’m getting tired of WordPress because
I’ve had issues with hackers and I’m looking at options for another platform.
I would be fantastic if you could point me in the direction of
a good platform.
Премиальный трикотаж и красота линий — фундамент коллекций бренда.
Каждая модель создаётся в духе современного стиля, но остаётся универсальной.
В наличии одежда, подходящая как для повседневности, так и для особых событий.
Сайт радует постоянными выгодными предложениями и акциями.
Hey there! Would you mind if I share your blog with my facebook
group? There’s a lot of folks that I think
would really appreciate your content. Please let me know.
Thanks
Aw, this was a really nice post. Spending some time and actual effort to generate
a top notch article… but what can I say… I procrastinate a lot and don’t manage
to get nearly anything done.
Howdy! This post couldn’t be written any better!
Reading through this post reminds me of my previous room mate!
He always kept talking about this. I will forward this post to him.
Fairly certain he will have a good read. Thanks for sharing!
Hey just wanted to give you a brief heads up and let you
know a few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue. I’ve tried it in two
different web browsers and both show the same results.
Aw, this was an exceptionally good post. Finding the time and actual effort to create a good article… but what can I say… I hesitate a lot and
never manage to get anything done.
ProDentim seems like a great option for anyone who wants to support their oral health naturally.
I like that it focuses on balancing the good
bacteria in the mouth instead of just masking issues.
Many people say it’s helped with fresher breath, healthier gums, and stronger teeth—it definitely
looks worth trying.
Онлайн-психолог — это забота о вашем здоровье. Детский психолог онлайн поможет с социализацией.
поиск психолога онлайн
Hi are using WordPress for your site platform? I’m new to the blog world but I’m
trying to get started and set up my own. Do you need any coding knowledge
to make your own blog? Any help would be greatly appreciated!
4M Dental Implant Center San Diego
5643 Copley Ɗr ste 210, San Diego,
ⅭA 92111, United Ѕtates
18582567711
smart dentistry
Right away I am going to do my breakfast, when having my breakfast coming again to read additional news.
Your style is very unique compared to other folks I’ve
read stuff from. Many thanks for posting when you have the opportunity,
Guess I will just bookmark this web site.
Greetings! Very useful advice within this post!
It is the little changes that produce the biggest changes.
Many thanks for sharing!
Whoa! This blog looks just like my old one! It’s on a completely different subject but it has pretty much the same layout and design. Wonderful choice of colors!
This page definitely has all of the information and facts
I needed about this subject and didn’t know who to ask.
I visited many sites but the audio feature for audio songs current at this
web site is truly excellent.
Hi just wanted to give you a quick heads up and let you know a few of the
pictures aren’t loading properly. I’m not sure
why but I think its a linking issue. I’ve tried it in two different
web browsers and both show the same results.
Thanks for the marvelous posting! I genuinely enjoyed reading it, you’re a great author.
I will always bookmark your blog and definitely will come back down the road.
I want to encourage you to definitely continue your great work,
have a nice holiday weekend!
Hey there! I’ve been reading your web site for some time now and finally got the bravery to go
ahead and give you a shout out from Dallas Tx!
Just wanted to mention keep up the great job!
I like the helpful information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I am quite sure I’ll learn many new stuff right here!
Best of luck for the next!
Awesome! Its really awesome article, I have got
much clear idea regarding from this paragraph.
Pretty nice post. I just stumbled upon your weblog and wanted to say
that I have really enjoyed surfing around your blog posts.
In any case I will be subscribing to your rss feed and I hope you
write again very soon!
Hi my family member! I wish to say that this post is amazing, nice written and come with approximately all
important infos. I would like to look extra posts like this .
Hurrah, that’s what I was seeking for, what a information! present here at this webpage, thanks admin of this
web page.
My relatives always say that I am killing my time here at web, however I know I am getting experience
all the time by reading such nice posts.
Attractive section of content. I just stumbled upon your blog and in accession capital to assert
that I acquire in fact enjoyed account your blog posts. Any way I’ll be subscribing to
your augment and even I achievement you access consistently rapidly.
Can I simply say what a comfort to discover someone that
really knows what they’re discussing over the internet.
You actually realize how to bring an issue to light and make it
important. More people really need to read this and understand this side of your story.
It’s surprising you’re not more popular given that you certainly have the gift.
AtoZ Bathroom Remodeling
2523 Nacogdoches Ꭱd, San Antonio,
TX 78217, United Ѕtates
12104054614
in my aгea remodel (Pearl)
It’s actually a great and helpful piece of info. I am happy that
you just shared this helpful information with us. Please keep us informed
like this. Thanks for sharing.
What a material of un-ambiguity and preserveness of precious familiarity
regarding unexpected feelings.
I have been exploring for a little for any high-quality articles or blog posts on this sort of
area . Exploring in Yahoo I eventually stumbled upon this website.
Studying this info So i’m happy to express that I’ve an incredibly good uncanny feeling
I discovered exactly what I needed. I such a lot certainly will
make certain to do not forget this site and provides it a look regularly.
Hello it’s me, I am also visiting this web site on a regular basis, this web page
is really good and the visitors are genuinely sharing pleasant thoughts.
Very nice post. I just stumbled upon your blog and wanted
to say that I’ve really enjoyed surfing around your blog posts.
After all I will be subscribing to your feed and I hope you write again soon!
Hello, i think that i saw you visited my web site so i
came to “return the favor”.I am trying to find things to improve my
site!I suppose its ok to use a few of your ideas!!
Wow, this post is fastidious, my sister is analyzing such things,
so I am going to tell her.
My brother recommended I might like this web site. He used to be entirely right.
This put up truly made my day. You can not believe simply how much
time I had spent for this info! Thank you!
Since the admin of this web page is working, no doubt very quickly it will be famous, due to its feature contents.
Hi there just wanted to give you a quick heads up. The text in your content seem to be running off the screen in Firefox.
I’m not sure if this is a format issue or something to do with
internet browser compatibility but I thought I’d post to let
you know. The design and style look great though! Hope you get the
problem fixed soon. Cheers
Sweet blog! I found it while surfing around on Yahoo
News. Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thank you
You actually reported it terrifically.
4M Dental Implant Center San Diego
5643 Copley Dr ste 210, San Diego,
CA 92111, United Տtates
18582567711
Smile Artistry; Padlet.Com,
Green Glucose sounds like an interesting natural option for supporting healthy
blood sugar levels. I like that it uses plant-based ingredients, which makes it feel like
a cleaner and safer choice. If you’re trying to maintain steady
energy and better glucose balance, Green Glucose seems like
something worth looking into.
I do not even understand how I finished up here, however
I thought this put up used to be good. I do not recognise who you are
but definitely you are going to a famous blogger if you aren’t already.
Cheers!
Hello Thеre. I discovered үour blog using msn. That
is a realⅼy smartly ԝritten article. I will bе ѕure to bookmark
іt and return to reаd extra of your uѕeful info.
Thank you for the post. I’ll definitely comeback.
Mу web page … ремонт принтера (https://www.Zapravka-remont.net/)
I’m not sure where you are getting your info, but great topic.
I needs to spend some time learning much more or understanding
more. Thanks for wonderful info I was looking for this information for my mission.
Simply want to say your article is as surprising. The clarity in your post
is just excellent and i could assume you’re an expert on this subject.
Fine with your permission let me to grab your feed to keep updated with
forthcoming post. Thanks a million and please continue the enjoyable work.
I’ve read a few excellent stuff here. Definitely price bookmarking for revisiting.
I surprise how a lot attempt you place to create this sort
of great informative web site.
Create Rss For Your Website And Display Rss Feed websiute (ricardor0xx1.blogdanica.com)
Great delivery. Outstanding arguments. Keep up the
amazing effort.
If you desire to increase your familiarity just keep visiting this site and be updated with the most up-to-date information posted here.
I think this is among the most vital info for me.
And i’m glad reading your article. But want to remark on few general
things, The web site style is wonderful, the articles is really nice :
D. Good job, cheers
I’ve been exploring for a bit for any high-quality articles or weblog posts
in this sort of space . Exploring in Yahoo I finally stumbled upon this web
site. Reading this info So i am happy to exhibit that I have a
very excellent uncanny feeling I found out just what I needed.
I so much undoubtedly will make sure to do not disregard this website and give it a look on a relentless basis.
Good data, Regards.
I’m really inspired along with your writing abilities and also with the structure
in your weblog. Is that this a paid subject or
did you modify it yourself? Either way keep up the excellent quality writing, it’s uncommon to
see a great blog like this one nowadays..
I’m truly enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more
often. Did you hire out a designer to create your theme?
Outstanding work!
Its like you read my mind! You seem to know a lot about this, like you wrote the book in it or something.
I think that you can do with some pics to drive the message home a little bit, but instead of that, this is magnificent
blog. An excellent read. I will definitely be back.
歡迎來到 E2BET 香港 – 您的勝利,全數支付。享受豐厚獎金,玩刺激遊戲,體驗公平舒適的線上博彩。立即註冊!
SlimMe Detox Tea ist eine tolle Unterstützung für alle, die ihrem Körper etwas
Gutes tun möchten. Die Mischung aus natürlichen Kräutern schmeckt nicht nur angenehm, sondern kann
auch dabei helfen, das Wohlbefinden zu steigern und ein leichteres Körpergefühl zu fördern. Besonders
praktisch finde ich, dass er sich einfach in den Alltag
integrieren lässt – perfekt für alle, die auf natürliche Weise mehr Balance suchen.
It’s actually a nice and helpful piece of information. I’m happy that you
simply shared this useful information with us. Please keep us informed like this.
Thanks for sharing.
Write more, thats all I have to say. Literally, it seems as
though you relied on the video to make your point. You clearly
know what youre talking about, why throw away your intelligence on just
posting videos to your weblog when you could be giving us
something informative to read?
What’s up everyone, it’s my first go to see at this site, and article is really fruitful in support of me, keep up posting these content.
Aw, this was a really good post. Finding the time
and actual effort to make a superb article…
but what can I say… I put things off a whole lot and never seem to get nearly anything done.
OMT’s standalone e-learning options empower independent exploration, nurturing а personal love for mathematics
ɑnd test aspiration.
Join our ѕmall-group on-site classes іn Singapore for tailored guidance іn a nurturing environment tһаt constructs strong fundamental math skills.
Ꮃith math incorporated flawlessly іnto Singapore’s
class settings tօ benefit botһ teachers аnd students,
dedicated math tuition amplifies these gains ƅy providing
customized assistance fߋr sustained achievement.
Ϝor PSLE success, tuition pгovides customized guidance tߋ weak areɑs,
ⅼike ratio ɑnd portion problems, preventing typical risks tһroughout the
exam.
Identifying ɑnd remedying ceгtain weak points, liқe in likelihood or coordinate geometry, akes secondary tuition іmportant foг O
Level excellence.
Structure confidence via constant support in junior college math tuition minimizes test
stress ɑnd anxiety, causing much bеtter outcomes іn A Levels.
Distinctively tailored tо enhance the MOE curriculum, OMT’ѕ cuswtom math
program integrates technology-driven tools fоr interacyive discovering
experiences.
Νo requirement to taке a trip, simply visit fгom home
leh, conserving time tо rеsearch more and press yоur mathematics qualities ցreater.
Specialized math tuition for Ⲟ-Levels helps Singapore secondary trainees differentiate tһemselves in а congested
candidate swimming pool.
Տtop bʏ my web blog; singapore math tutor
I think this is among the most vital info for me. And
i’m glad reading your article. But want to remark on some general things, The
web site style is wonderful, the articles is really nice : D.
Good job, cheers
Hello, I read your new stuff regularly. Your writing style is witty, keep doing
what you’re doing!
Hello friends, fastidious article and pleasant arguments commented at
this place, I am truly enjoying by these.
Flush Factor Plus seems like a really interesting supplement for supporting gut health and detox.
I like that it’s focused on cleansing the digestive system while
also helping with energy and overall wellness.
If you’re looking for a natural way to reset your body and feel lighter, Flush Factor
Plus looks like a great option
This info is worth everyone’s attention. How can I find out more?
Thanks on your marvelous posting! I seriously enjoyed reading
it, you can be a great author. I will be sure to bookmark your blog and may
come back very soon. I want to encourage you to continue your
great writing, have a nice morning!
Очень увлек меня ваш метод к выставлению Германии.
По правде вы отобразили нацию с разных областей – и помните,
и современной. Такое призывает строить
поездку и раскрывать для самостоятельно интересные грани }
Agree with this. Similar thoughts on my blog
– botemaniac.es.
Thanks for sharing your thoughts on Best Website to Buy
Tramadol Online. Regards
A motivating discussion is definitely worth comment.
There’s no doubt that that you need to write more about this subject, it may not be a taboo subject but usually people don’t discuss these topics.
To the next! All the best!!
Ꭲhrough simulated exams ԝith motivating comments, OMT builds durability іn mathematics, fostering love аnd motivation for Singapore pupils’ exam accomplishments.
Founded inn 2013 Ƅy Mr. Justin Tan, OMT Math Tuition һаѕ
actually helped numerrous students ace tests ⅼike PSLE, O-Levels, аnd A-Levels wіtһ tested analytical techniques.
Ϲonsidered that mathematics plays ɑ pivotal role in Singapore’ѕ economic development ɑnd progress, purchasing specialized math tuition equips students ᴡith tһе pгoblem-solving skills required tо flourish in а
competitive landscape.
For PSLE achievers, tuition оffers mock exams
ɑnd feedback, helping improve answers fоr optimum marks іn both multiple-choice and οpen-ended sections.
Holistic advancement ԝith math tuition not jᥙѕt boosts
O Level ratings ƅut aⅼso cultivates logical thinking abilities valuable fօr ⅼong-lasting
learning.
Junior college tuition ᧐ffers accessibility to supplemental resources ⅼike worksheets аnd video
clip explanations, reinforcing Α Level curriculum protection.
OMT’ѕ special strategy іncludes a syllabus tһat enhances tһe MOE structure with collaborative aspects, motivating peer discussions оn mathematics concepts.
With 24/7 accessibility t᧐ video clip lessons, you can capture up օn һard topics
anytime leh, helping you score Ьetter іn examinations ԝithout tension.
In Singapore, ᴡhere parental participation іs key, math tuition supplies structured support fοr
һome reinforcement tߋwards exams.
mү web ⲣage best tuition
I every time used to read paragraph in news papers but now as I am a user of
web thus from now I am using net for content, thanks to web.
I really like reading through a post that can make men and women think.
Also, many thanks for permitting me to comment!
I am really grateful to the owner of this web site who has shared
this wonderful piece of writing at here.
This is the perfect site for anyone who hopes to understand this topic.
You realize so much its almost tough to argue with you (not that I really will need
to…HaHa). You certainly put a brand new spin on a subject that’s been discussed for
many years. Excellent stuff, just great!
It’s an amazing paragraph for all the web viewers; they
will get advantage from it I am sure.
I always spent my half an hour to read this website’s articles or reviews everyday
along with a cup of coffee.
Mikigaming
Ahaa, its fastidious dialogue regarding this
post here at this blog, I have read all that, so now me also commenting at this place.
Have you ever thought about writing an ebook or guest authoring on other sites?
I have a blog centered on the same information you discuss
and would really like to have you share some stories/information. I know my audience would value your work.
If you are even remotely interested, feel free to send me an e-mail.
Hiya! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly? My website looks weird when browsing from my iphone 4.
I’m trying to find a template or plugin that might be able to correct
this issue. If you have any recommendations, please share. Many
thanks!
Do you mind if I quote a few of your posts as long as I provide credit and sources back to your site?
My blog site is in the very same area of interest as yours and
my users would truly benefit from a lot of the information you present
here. Please let me know if this alright with you.
Thank you!
It’s an amazing post in support of all the web visitors; they will obtain advantage from
it I am sure.
The Pineal Guardian sounds really interesting, especially with how
it’s designed to support pineal gland health and overall well-being.
I like that it focuses on natural ingredients instead of
synthetic solutions. Definitely worth looking into if you’re curious about
better sleep, focus, and mental clarity.
Everything is very open with a clear explanation of the issues.
It was really informative. Your site is useful. Thank you for
sharing!
Hello there! I know this is kinda off topic nevertheless I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest authoring a blog post or vice-versa?
My blog addresses a lot of the same subjects as yours and I feel
we could greatly benefit from each other. If you’re
interested feel free to send me an email. I look forward to hearing from
you! Superb blog by the way!
Appreciating the time and energy you put into your
site and detailed information you offer. It’s great to come across a
blog every once in a while that isn’t the same unwanted rehashed information. Great read!
I’ve saved your site and I’m adding your RSS feeds to my Google account.
I read this post fully regarding the comparison of most recent and previous technologies, it’s
remarkable article.
Good article. I certainly love this website. Keep it up!
Thanks for finally talking about > 基于强化学习的小球运动员技战术发挥评估 – 逸
< Loved it!
Spot on with this write-up, I truly believe that this site needs a lot more attention. I’ll probably be returning
to see more, thanks for the info!
Prime Secured
3603 N 222nd Ѕt, Suite 102,
Elkhorn, NE 68022, United Stɑtes
402-289-4126
IТ Risk Check Pгo (Lacey)
Greetings! Very useful advice within this post!
It’s the little changes that will make the most significant changes.
Thanks for sharing!
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on various websites for about a
year and am concerned about switching to another platform.
I have heard good things about blogengine.net. Is there a way I can import all my wordpress posts into it?
Any kind of help would be really appreciated!
Also visit my web-site: สมัครล็อตโต้ไทย
Attractive section of content. I just stumbled upon your weblog and in accession capital to assert that
I acquire actually enjoyed account your blog posts. Anyway I will be subscribing to your feeds
and even I achievement you access consistently rapidly.
Hello! This is kind of off topic but I need
some guidance from an established blog. Is it very difficult
to set up your own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about creating my own but I’m not sure where to start.
Do you have any points or suggestions? Many thanks
Its like you read my mind! You appear to know so much about
this, like you wrote the book in it or something.
I think that you can do with a few pics to drive the message home
a bit, but other than that, this is great blog. A great read.
I will definitely be back.
Very rapidly this website will be famous amid all
blogging users, due to it’s pleasant posts
What’s up, all the time i used to check weblog posts here early in the dawn, because i
love to learn more and more.
What i do not realize is actually how you are now not really a lot more smartly-preferred than you might be right now.
You’re very intelligent. You understand therefore significantly on the
subject of this matter, made me individually imagine it from numerous numerous angles.
Its like men and women don’t seem to be fascinated until it is something
to do with Lady gaga! Your individual stuffs excellent.
At all times handle it up!
When someone writes an article he/she keeps the idea of a user in his/her mind that how a
user can know it. So that’s why this article is amazing.
Thanks!
This excellent website certainly has all the information and facts I needed about this subject and didn’t know who to ask.
Hello, I think your website might be having browser compatibility issues.
When I look at your website in Opera, it looks fine but when opening
in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that,
great blog!
Simply desire to say your article is as astonishing. The clearness
in your post is just great and i can assume you’re an expert on this subject.
Fine with your permission let me to grab your RSS feed
to keep up to date with forthcoming post. Thanks a million and
please keep up the gratifying work.
Hi there to all, the contents existing at this web page are truly
awesome for people experience, well, keep up the good work
fellows.
Feel free to visit my web-site; http://Sunad1.Com
I every time spent my half an hour to read this website’s articles daily along with a
mug of coffee.
Actually no matter if someone doesn’t know afterward its up to other visitors that
they will help, so here it happens.
Eventually, OMT’s comprehensive solutions weave
happiness іnto mathematics education аnd learning, helping pupils drop deeply crazy аnd
rise in thеir exams.
Established іn 2013 by Mr. Justin Tan, OMT Math
Tuition һas actually assisted numerous students ace exams lіke
PSLE, O-Levels, and A-Levels witһ tested analytical strategies.
Aѕ math forms tһе bedrock of rational thinking and critical problem-solving
in Singapore’s education ѕystem, professional math tuition рrovides thе individualized assistance required tօ
turn difficulties іnto victories.
primary school math tuition іs vital for PSLE preparation as it helps students
master tһe foundational concepts ⅼike portions and decimals,
ԝhich are ցreatly evaluated іn tһе exam.
Tuition helps secondary trainees establish exam methods, ѕuch ɑѕ time allowance foг the 2 O Level mathematics papers,
Ƅring about far better overall efficiency.
Tuition instructs mistake evaluation strategies, aiding junior college students stay ⅽlear of common mistakes
іn Α Level estimations ɑnd evidence.
OMT establishes іtself apart wіtһ an exclusive curriculum tһаt prolongs MOE web content by consisting ߋf enrichment
activities focused ߋn developing mathematical instinct.
Variety ߋf practice concerns ѕia, preparing yoᥙ complеtely fоr any type of math test and far better scores.
Singapore’s international ranking in math ϲomes from
additional tuition tһat hones skills foor global benchmarks ⅼike PISA and TIMSS.
Ꭺlso visit my site … math tuition singapore
Wonderful, what a webpage it is! This website presents useful data to
us, keep it up.
Hello, just wanted to tell you, I loved this post.
It was helpful. Keep on posting!
grandpashabet casino siteleri bonuslarınız hazır
Hi there, this weekend is good for me, since this moment i am
reading this fantastic informative post here
at my house.
mobilbahis bahis siteleri ahmet enes musaoğulları
Native Path Creatine looks like a great choice for anyone serious about boosting strength, endurance, and muscle recovery.
I really like that it’s clean, simple, and focused on quality without unnecessary fillers.
Definitely a solid supplement for athletes or anyone wanting to
improve performance naturally
Hi there! Would you mind if I share your blog
with my zynga group? There’s a lot of people that I think would really enjoy your content.
Please let me know. Thank you
I visited several sites however the audio quality for audio songs present at
this web page is genuinely superb.
mobilbahis deneme bonusu bedava yatırım şartsız bonus alın
Mighty Dog Roofing
Reimer Drive North 13768
Maple Grove, MN 55311 United Տtates
(763) 280-5115
affordable window installations
You can certainly see your skills within the article you write.
The arena hopes for more passionate writers like you who
aren’t afraid to mention how they believe. All the time follow your heart.
Hello, Neat post. There’s a problem together with your website in internet explorer, could check this?
IE still is the marketplace leader and a good part
of other folks will pass over your great writing because of
this problem.
My partner and I stumbled over here coming from a different page and thought I
might as well check things out. I like what I see so now i am following you.
Look forward to looking over your web page yet again.
my web blog A片
grandpashabet bahis siteleri ali musaoğulları
mobilbahis casino siteleri ali musaoğulları
This piece of writing provides clear idea for the new visitors of blogging, that really how to do blogging.
tipobet
grandpashabet deneme bonusu veren siteler ahmet enes musaoğulları
mobilbahis deneme bonusu ali musaoğulları
tipobet deneme bonusu şerife musaoğulları
Thanks for the good writeup. It if truth be told was a entertainment account it.
Glance complicated to more added agreeable from you!
However, how can we communicate?
grandpashabet casino siteleri sitelerinden bonuslarınızı alabilirsiniz
After I initially commented I seem to have clicked
the -Notify me when new comments are added- checkbox and now whenever
a comment is added I get four emails with the
exact same comment. Perhaps there is a means you are able to remove me from that service?
Kudos!
It’s a shame you don’t have a donate button! I’d certainly donate to this brilliant blog!
I suppose for now i’ll settle for book-marking and adding your RSS feed to my Google account.
I look forward to fresh updates and will talk about this website with my Facebook group.
Talk soon!
Memory foam pillows have emerged to be highly really helpful pillows for neck ache relief and sound sleep. There are quite a few reasons for memory foam pillow being your best option for any sort of sleeper. However, each product has its advantages and disadvantages which determine the standard of the product. To totally perceive and at last decide your desire, it is very important to know the pros and cons of utilizing https://worldmindsetmag.com/7-second-coffee-trick/ foam pillow. To experience the benefits of the pillow, it’s important to first feel comfortable and have the trust issue within the product. Let’s discover totally different views on memory foam usage. 1. Adapts to Physique Stress: One in every of the best advantages of using memory foam pillow is that it has the cooling gel know-how which adapts to the heat of your physique and adjusts in accordance with your form. The “viscoelastic” high quality helps in gaining comfortable sleep with original memory foam.
Saved as a favorite, I love your blog!
Hi my loved one! I want to say that this post is amazing, nice
written and include approximately all important infos.
I would like to peer more posts like this .
Magnificent beat ! I wish to apprentice even as you amend your site, how can i subscribe
for a weblog site? The account helped me a acceptable deal.
I were tiny bit acquainted of this your broadcast offered shiny transparent idea
Way cool! Some very valid points! I appreciate you penning
this post and the rest of the website is extremely good.
Hmm is anyone else encountering problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
I am sure this article has touched all the internet visitors, its really really
pleasant piece of writing on building up new website.
grandpashabet bahis siteleri ali musaoğulları
With havin so much written content do you ever run into
any issues of plagorism or copyright infringement?
My website has a lot of unique content I’ve either created
myself or outsourced but it looks like a lot of it is popping it up all over
the internet without my authorization. Do you know any methods to help protect against
content from being ripped off? I’d truly appreciate it.
Mantap dengan isi artikel ini mengenai situs taruhan bola resmi.
Bermain di situs resmi taruhan bola memang memberikan pengalaman yang lebih aman dan menyenangkan.
Saya pribadi sering menggunakan bola88 agen judi bola resmi dan situs taruhan terpercaya untuk taruhanbola.
Selain itu, saya juga mencoba idnscore, sbobet, sbobet88, serta sarangsbobet untuk
bermain judi bola.
Score bola dari idnscore login, link sbobet, hingga sbobet88 login sangat membantu saya mengikuti
perkembangan pertandingan.
Mix parlay, parlay88 login, dan idnscore 808 live
selalu jadi favorit karena menghadirkan tantangan lebih.
Banyak juga pilihan lain seperti situs bola terpercaya, agen bola, situs bola live, judi bola online, hingga bolaonline.
Saya juga pernah mencoba situs bola online, esbobet, situs parlay, judi bola terpercaya,
situs judi bola terbesar, link judi bola, serta judi bola parlay.
Dan tentu saja, kubet, kubet login, kubet indonesia, kubet link alternatif, serta
kubet login alternatif adalah platform yang tidak boleh dilewatkan.
Terima kasih untuk informasinya, sangat berguna bagi para pecinta taruhan bola online dan judi bola.
Heya just wanted to give you a quick heads up and let you know a few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue. I’ve tried it
in two different web browsers and both show the same outcome.
You could definitely see your skills within the article you write.
The arena hopes for even more passionate writers like you who aren’t afraid to mention how they
believe. At all times go after your heart.
Yes! Finally something about dog stairs.
Hi, I think your site might be having browser compatibility issues.
When I look at your website in Safari, it looks fine but when opening
in Internet Explorer, it has some overlapping. I just wanted to
give you a quick heads up! Other then that, excellent
blog!
There is definately a great deal to learn about this subject.
I love all of the points you made.
Valuable information. Lucky me I discovered your website
by accident, and I am stunned why this twist of fate did not
came about in advance! I bookmarked it.
My homepage: ผักสลัดไฮโดรโปนิกส์
Why users still use to read news papers when in this technological globe the
whole thing is available on web?
I do not know whether it’s just me or if perhaps everybody else experiencing
issues with your website. It appears as though some of the text on your posts
are running off the screen. Can someone else please provide
feedback and let me know if this is happening to them as well?
This might be a problem with my internet browser because
I’ve had this happen before. Thank you
Интернетное игровой клуб — это интернет‑портал
My spouse and I stumbled over here different page and thought I might
as well check things out. I like what I see so now i
am following you. Look forward to looking over your web page for
a second time.
I do consider all the ideas you’ve presented in your post.
They’re really convincing and will certainly work. Still, the posts
are very brief for beginners. May you please extend
them a bit from subsequent time? Thank you for the post.
Appreciating the commitment you put into your site and detailed information you present.
It’s awesome to come across a blog every once
in a while that isn’t the same outdated rehashed material.
Fantastic read! I’ve saved your site and I’m including your RSS
feeds to my Google account.
I’m extremely impressed with your writing skills as well
as with the layout on your blog. Is this a paid theme or did you
modify it yourself? Either way keep up the excellent quality writing, it’s rare to see a great blog like this one these days.
4M Dental Implnt Center San Diego
5643 Copley Ꭰr ste 210, San Diego,
ⅭA 92111, United Stateѕ
18582567711
smart smile
I’m not sure why but this site is loading incredibly slow for me.
Is anyone else having this problem or is it a issue on my end?
I’ll check back later and see if the problem still exists.
Greetings from Idaho! I’m bored at work so I decided to
check out your site on my iphone during lunch break. I love the info you present here
and can’t wait to take a look when I get home.
I’m shocked at how fast your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyways, awesome blog!
Pretty! This has been a really wonderful article. Thanks for providing this information.
An intriguing discussion is worth comment. I believe that
you ought to write more on this issue, it might not
be a taboo matter but generally people do not discuss such topics.
To the next! All the best!!
Hey there! I’ve been reading your site for a long time now and finally got
the bravery to go ahead and give you a shout
out from New Caney Tx! Just wanted to say keep up the excellent work!
Pretty! This was an incredibly wonderful article. Many
thanks for providing these details.
Thank you a bunch for sharing this with all folks you really recognise what you are speaking about!
Bookmarked. Please also discuss with my web site =).
We may have a hyperlink change agreement between us
Any consumer can easily losartan cozaar 25 mg tablet and instead buy online. losartan names
Wow, this article is good, my younger sister
is analyzing these things, thus I am going to let know her.
You actually make it seem so easy with your presentation but I find this
matter to be really something that I think I would never understand.
It seems too complicated and extremely broad for
me. I am looking forward for your next post, I’ll try to get the hang of it!
Great site. A lot of useful information here. I’m sending
it to several friends ans additionally sharing in delicious.
And naturally, thank you in your effort!
What’s up it’s me, I am also visiting this web site daily,
this web site is actually pleasant and the visitors are in fact sharing good thoughts.
кракен онион
Because the admin of this website is working, no doubt very
shortly it will be renowned, due to its quality contents.
Great weblog here! Also your web site so much up fast!
What web host are you the use of? Can I am getting your affiliate hyperlink in your host?
I desire my web site loaded up as quickly as yours lol
Wealth Ancestry Prayer sounds really inspiring. I like how it connects the idea of financial abundance with spiritual grounding and ancestral blessings.
It feels more meaningful than just focusing on money—it’s about
aligning with positive energy and guidance for lasting
prosperity
I really like it when individuals get together and
share views. Great website, keep it up!
I am really impressed with your writing skills
and also with the layout on your weblog. Is this a paid theme or did you customize it
yourself? Anyway keep up the nice quality writing, it’s rare to
see a nice blog like this one nowadays.
At this time it sounds like Drupal is the preferred blogging platform available right now.
(from what I’ve read) Is that what you are using on your
blog?
I am curious to find out what blog platform you
happen to be utilizing? I’m having some minor security
problems with my latest site and I would like to find something more risk-free.
Do you have any suggestions?
We are a group of volunteers and opening a new scheme in our community.
Your site provided us with valuable information to work on. You’ve done a formidable job and our whole community will be thankful to
you.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! However,
how can we communicate?
Heya i am for the first time here. I found this board and I find It truly useful & it
helped me out a lot. I hope to give something back
and aid others like you aided me.
Great blog here! Also your website loads up very fast!
What host are you using? Can I get your affiliate link to your host?
I wish my site loaded up as quickly as yours lol
Great article! This is the type of info that are meant to be shared across the internet.
Disgrace on Google for no longer positioning this submit upper!
Come on over and talk over with my web site .
Thank you =)
I like it when folks come together and share ideas. Great site, keep it up!
I’d like to find out more? I’d care to find out some additional information.
kraken ссылка зеркало
Fine way of describing, and nice piece of writing to get data
about my presentation subject matter, which i am going to present in college.
You’re so cool! I do not suppose I have read something
like that before. So good to discover somebody with a few genuine thoughts on this issue.
Really.. many thanks for starting this up.
This web site is something that’s needed on the internet,
someone with some originality!
fantastic publish, very informative. I’m wondering why the other
experts of this sector do not understand this. You must proceed your writing.
I am confident, you’ve a huge readers’ base already!
magnificent issues altogether, you simply received a new
reader. What would you recommend in regards to your put up
that you just made some days ago? Any certain?
Its like you read my mind! You seem to know so much about
this, like you wrote the book in it or something. I think that you could do with some pics to drive the message home a bit, but other than that,
this is wonderful blog. A great read. I’ll certainly
be back.
Heya i am for the first time here. I found this board and I find It really useful & it helped
me out a lot. I hope to give something back and aid
others like you helped me.
Excellent beat ! I would like to apprentice while you amend
your site, how could i subscribe for a blog website?
The account helped me a acceptable deal. I had been a little bit
familiar of this your broadcast provided shiny transparent concept
Thanks on your marvelous posting! I really enjoyed reading it, you’re a great author.I will remember to bookmark your blog
and may come back down the road. I want to encourage you continue
your great posts, have a nice holiday weekend!
Greetings from Los angeles! I’m bored at work so I decided
to check out your blog on my iphone during lunch break.
I enjoy the info you provide here and can’t wait to take a
look when I get home. I’m amazed at how quick your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyways, great site!
Excellent beat ! I would like to apprentice while you amend your website,
how could i subscribe for a blog web site? The account helped me a acceptable deal.
I had been tiny bit acquainted of this your broadcast offered bright clear idea
What’s Taking place i’m new to this, I stumbled upon this I’ve
found It positively useful and it has helped me out loads.
I am hoping to contribute & assist other customers like its helped me.
Good job.
great submit, very informative. I’m wondering why the opposite
specialists of this sector do not understand this.
You must continue your writing. I’m sure,
you’ve a huge readers’ base already!
Also visit my homepage; Sex Forum
Heya! I understand this is somewhat off-topic
but I had to ask. Does managing a well-established blog such as yours require a massive
amount work? I’m brand new to blogging but I do write in my diary every day.
I’d like to start a blog so I can easily share my experience and feelings online.
Please let me know if you have any kind of suggestions or tips for new aspiring bloggers.
Appreciate it!
Howdy! This is my 1st comment here so I just wanted to give a quick shout out and
tell you I genuinely enjoy reading through your articles.
Can you recommend any other blogs/websites/forums that
cover the same topics? Thanks a ton!
Wow that was odd. I just wrote an incredibly long comment
but after I clicked submit my comment didn’t appear. Grrrr…
well I’m not writing all that over again. Regardless, just wanted to say
superb blog!
Boostaro seems like a solid option for men looking to improve energy, stamina,
and overall vitality. I like that it’s made with natural ingredients focused on circulation and performance support rather than relying on harsh
chemicals. It feels like a healthier way to boost confidence and maintain long-term
wellness.
Does your site have a contact page? I’m having problems locating it but, I’d like to
shoot you an e-mail. I’ve got some recommendations for your blog you
might be interested in hearing. Either way, great website and
I look forward to seeing it expand over time.
It’s hard to come by experienced people for this topic, but you seem like you know what you’re
talking about! Thanks
Тhe caring environment аt OMT encourages inquisitiveness іn mathematics,
transforming Singapore pupils іnto passionate learners motivated tо attain leading exam outcomes.
Transform mathematics challenges іnto triumphs ᴡith OMT Math Tuition’ѕ mix off online аnd on-site alternatives, baсked bү a performance history οf trainee
quality.
Ꮃith trainees in Singapore starting formal mathematics education fгom day one and facing hіgh-stakes assessments, math tuition рrovides tһe extra edge required t᧐
accomplish top efficiency іn this vital topic.
Tuition stresses heuristic analytical methods, crucial fօr dealing with PSLE’s difcicult ԝorԀ proƄlems tһat need several actions.
Presenting heuristic аpproaches eɑrly in secondary tuition prepares students fоr the non-routine issues thаt often shоw up in O Level analyses.
Tuition іn junior college math gears ᥙp trainees with statistical techniques ɑnd chance models important for analyzing data-driven concerns in A Level documents.
Ꭲhe exclusive OMT educational program distinctly enhances tһе MOE curriculum with focused practice ᧐n heuristic techniques, preparing pupils Ьetter for exam difficulties.
OMT’ѕ online tuition saves money ߋn transportation lah, allowing even moгe concentrate ߋn researches ɑnd improved mathematics reѕults.
Tuition facilities utilize cutting-edge devices ⅼike visual һelp,
enhancing understanding for mսch ƅetter retention in Singapore
mathematics tests.
Feel free tо surf to my web-site: math tuition tiong bahru
I read this post fully regarding the difference of latest and previous
technologies, it’s remarkable article.
кракен onion сайт
Everything is very open with a very clear explanation of the challenges.
It was truly informative. Your site is useful. Thanks for sharing!
Cheers! I appreciate this!
Hurrah! Finally I got a blog from where I be capable of in fact obtain valuable data concerning my study and knowledge.
Very shortly this web page will be famous among all blogging visitors, due
to it’s pleasant articles or reviews
Виртуальное игровая платформа — это веб‑сервис
A person essentially lend a hand to make critically posts I
would state. This is the very first time I frequented your web page and to this point?
I amazed with the analysis you made to create this particular submit extraordinary.
Wonderful job!
I think this is one of the most vital info for me. And i’m glad reading your
article. But should remark on some general things, The site style is ideal,
the articles is really great : D. Good job, cheers
Thіs article is ɑctually a ցood one it
helps new internet visitors, ᴡho are wishing
іn favor of blogging.
Ꮋere iѕ mү webpage … maths tuition teacher (Stella)
4M Dental Implant Center San Diego
5643 Copley Ⅾr ste 210, San Diego,
CA 92111, United Ѕtates
18582567711
Bookmarks
I am really impressed with your writing skills as well as with the layout on your blog.
Is this a paid theme or did you customize it yourself?
Anyway keep up the nice quality writing, it is rare to
see a nice blog like this one nowadays.
Онлайн игровая платформа — это интернет‑портал
Do you mind if I quote a couple of your articles as long as I provide
credit and sources back to your webpage? My website is in the
very same area of interest as yours and my users would really benefit from a lot of the information you provide here.
Please let me know if this ok with you. Thanks a lot!
My homepage … Kkpoker Jcb
Increase The Traffic To Youur Website Or Blogg blog; Michelle,
Thanks for sharing your thoughts about . Regards
kraken онион
Hi! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing many months of hard work due
to no backup. Do you have any solutions to stop hackers?
Here is my web site; zegrenova03
My partner аnd I abѕolutely love your blog and finnd tһe majority оf yoսr
post’sto ƅe what precisely I’m looking for. Does one offer
guest writers tߋ wdite content for you? I wouldn’t mind
creating a post or elaborating on ɑ numbeг of tһe subjects you write ϲoncerning here.
Ꭺgain, awesome blog!
Alsoo visit my site https://www.letmejerk.com
I would like to thank you for the efforts you have put in penning this website.
I’m hoping to see the same high-grade blog
posts from you later on as well. In fact, your creative writing abilities has motivated me
to get my own site now 😉
You revealed it exceptionally well.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and
was hoping maybe you would have some experience with something
like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Hmm is anyone else having problems with the images on this blog loading?
I’m trying to determine if its a problem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
Howdy! Do you use Twitter? I’d like to follow
you if that would be ok. I’m undoubtedly enjoying your blog and look forward to
new updates.
кракен даркнет маркет
This is my first time pay a quick visit at here and i
am truly impressed to read everthing at alone place.
Hey I am so glad I found your blog, I really found you by accident, while
I was browsing on Yahoo for something else,
Nonetheless I am here now and would just like to say thanks a lot for
a tremendous post and a all round thrilling blog (I also love the theme/design), I don’t have time to browse it all at the moment but I have saved it and also added your RSS
feeds, so when I have time I will be back to read much more, Please do keep
up the awesome job.
Oldukça faydalı bir yazı olmuş.
Bilgiler için çok teşekkür ederim.
Uzun zamandır böyle bir içerik ihtiyacım vardı.
Emeğinize sağlık.
My partner and I stumbled over here from a different web address and thought I might as well check things out.
I like what I see so i am just following you.
Look forward to finding out about your web page for a second time.
An interesting discussion is worth comment.
I think that you need to publish more on this subject, it might not be a taboo matter
but usually folks don’t talk about such issues.
To the next! Best wishes!!
I do not know whether it’s just me or if perhaps everyone else encountering problems with your site.
It appears as if some of the written text within your content are running
off the screen. Can someone else please comment and let me know if this is happening to them
as well? This might be a problem with my browser because I’ve had this
happen before. Cheers
OMT’s vision for lifelong learning motivates Singapore students toо see math as a good friend, encouraging them for examination excellence.
Join оur small-grоup ⲟn-site classes іn Singapore for individualized assistance іn a nurturing environment that
develops strong foundational mathematics abilities.
Ρrovided that mathematics plays ɑ critical function in Singapore’s financial advancement аnd progress, purchasing specialized math tuition equips students ԝith the analytical abilities needed
to flourish іn a competitive landscape.
primary school tuition is essential fօr PSLE as іt usеѕ restorative assistance fⲟr suubjects like whߋle numbers and measurements, maҝing ѕure
no fundamental weaknesses continue.
Рresenting heuristic methods early іn secondary tuition prepares
students fⲟr the non-routine рroblems tһat frequently show uρ in O Level analyses.
With A Levels ɑffecting career courses in STEM fields,
math tuition strengthens fundamental abilities fоr future university researches.
Вy integrating proprietary strategies ᴡith thе MOE syllabus, OMT рrovides a distinct technique that stresses clarity аnd depth in mathematical thinking.
OMT’ѕ e-learning decreases mathematics stress аnd anxiety lor, maқing you a lot more positive
аnd leading tߋ ցreater examination marks.
Online math tuition offеrs versatility for hectic
Singapore trainees, permitting anytime accessibility tо
sources for much betteг test prep ᴡork.
Herе is my web blog math & kannad tutor near me
Appreciate the recommendation. Will try it out.
сайт kraken onion
For hottest information you have to pay a quick visit internet and on internet
I found this website as a best web site for
most up-to-date updates.
I’m not sure the place you’re getting your info, but good
topic. I needs to spend a while finding out much more or understanding more.
Thanks for magnificent information I used to be on the lookout for this info
for my mission.
I was excited to uncover this great site. I wanted to thank you
for your time for this fantastic read!! I definitely loved every part of it and
i also have you bookmarked to see new information on your site.
Greetings from Colorado! I’m bored to tears at work so I
decided to browse your blog on my iphone during lunch break.
I enjoy the knowledge you present here and can’t wait to take a look when I get
home. I’m amazed at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow, amazing blog!
I am sure this post has touched all the internet users, its really really pleasant paragraph on building
up new weblog.
Wow, amazing blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your
web site is wonderful, as well as the content!
Refresh Renovation Southwest Charlotte
1251 Arrow Pine Ꭰr c121,
Charlotte, NC 28273, United Տtates
+19803517882
Bookmarks
If some one wishes expert view on the topic
of blogging then i advise him/her to pay a quick visit this webpage, Keep up the fastidious job.
Hi friends, how is the whole thing, and what you want to say on the topic
of this article, in my view its genuinely awesome in support
of me.
Thanks for sharing your thoughts about voltage vape.
Regards
Hi, this weekend is pleasant designed for me,
for the reason that this moment i am reading this fantastic educational
paragraph here at my home.
Howdy! I know this is kind of off topic but I was
wondering which blog platform are you using for this site?
I’m getting sick and tired of WordPress because I’ve had problems with hackers
and I’m looking at options for another platform. I would be fantastic if
you could point me in the direction of a good platform.
We stumbled over here different web address
and thought I should check things out. I like what I see so now i’m following you.
Look forward to going over your web page repeatedly.
Hmm is anyone else having problems with the pictures
on this blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog.
Any feedback would be greatly appreciated.
Hey there! This is kind of off topic but I need some help from an established
blog. Is it very difficult to set up your own blog?
I’m not very techincal but I can figure things
out pretty quick. I’m thinking about creating my own but I’m not
sure where to begin. Do you have any ideas or suggestions?
Thanks
Your style is really unique in comparison to other
people I have read stuff from. I appreciate you for
posting when you’ve got the opportunity, Guess I’ll just bookmark this web site.
Refresh Renovation Southwest Charlotte
1251 Arrow Pine Ɗr c121,
Charlotte, NC 28273, United Ⴝtates
+19803517882
bookmarks
I have been surfing online more than 4 hours today, yet I never found any
interesting article like yours. It is pretty worth enough
for me. Personally, if all webmasters and bloggers made good content as you did, the internet will be a
lot more useful than ever before.
Hey I know this is off topic but I was wondering if you
knew of any widgets I could add to my blog that
automatically tweet my newest twitter updates. I’ve
been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something
like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward
to your new updates.
It’s impressive that you are getting ideas from this paragraph as well as
from our discussion made at this place.
I am truly thankful to the owner of this web page who has shared this great article at
at this time.
I’m gone to inform my little brother, that he should also pay a quick visit this website on regular basis to
take updated from latest news update.
Thanks for your marvelous posting! I quite enjoyed reading it,
you are a great author.I will be sure to bookmark your
blog and will eventually come back in the foreseeable future.
I want to encourage you to definitely continue your great writing, have a
nice evening!
You are so interesting! I don’t think I’ve read anything like that before.
So good to find someone with unique thoughts on this subject.
Really.. many thanks for starting this up.
This website is one thing that’s needed on the web, someone with a little originality!
Hi there, I wish for to subscribe for this webpage to obtain latest updates, thus where
can i do it please help out.
my web page; pink salt trick
Its such as you learn my mind! You seem to grasp so much about this, like
you wrote the e-book in it or something. I feel that you just can do with some p.c.
to pressure the message house a bit, but instead
of that, this is great blog. A great read. I will definitely be back.
I really like your blog.. very nice colors & theme.
Did you design this website yourself or did you hire someone to do it for you?
Plz answer back as I’m looking to create my
own blog and would like to find out where u got this from.
thank you
This site was… how do I say it? Relevant!! Finally I’ve found something that
helped me. Thanks a lot!
OMT’s appealing video clip lessons tսrn intricate math principles
іnto exciting tales, assisting Singapore pupils fɑll for tһе subject аnd feel motivated to ace tһeir tests.
Expand үour horizons ԝith OMT’ѕ upcoming brand-neᴡ physical area opеning in September 2025,
offering ɑ ⅼot mоre chances fߋr hands-on math expedition.
Ӏn Singapore’s rigorous education ѕystem, wһere mathematics іs mandatory
and tɑkes in ar᧐und 1600 hoᥙrs ⲟf curriculum time in primary аnd secondary schools, math tuition еnds uρ being impoгtant to assist
students develop а strong foundation foг lifelong
success.
Fοr PSLE success, tuition prߋvides tailored guidance tօ weak locations, ⅼike ratio and percentage issues, avoiding typical risks tһroughout thе test.
Βy supplying substantial exercise ѡith previous O Level papers, tuition gears uр
trainees ѡith knowledge and thе capability to prepare fоr inquiry patterns.
Customized junior college tuition helps bridge tһe gap from O Level
t᧐ Ꭺ Level math, guaranteeing trainees
adapt tօ the boosted roughness аnd deepness сalled for.
What differentiates OMT іs its proprietary program
tһɑt complements MOE’s νia focus ߋn honest рroblem-solving іn mathematical contexts.
Multi-device compatibility leh, ѕo ϲhange from laptop computer t᧐ phone and maintain increasing tһose qualities.
Math tuition builds durability iin dealing ᴡith difficult questions, a need fοr flourishing іn Singapore’s higһ-pressure test environment.
Мy paɡe tuition classes
Hi there! I know this is kinda off topic but I was wondering
if you knew where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
Definitely believe that that you stated. Your favorite justification seemed to be at
the web the simplest thing to have in mind of.
I say to you, I definitely get irked even as other
people consider worries that they just do not know about.
You controlled to hit the nail upon the highest as well as defined out the whole thing
without having side-effects , other folks could take a signal.
Will probably be again to get more. Thanks
Magnificent goods from you, man. I’ve understand your stuff previous to and you are just extremely fantastic.
I really like what you’ve acquired here, really like what you are saying and the way
in which you say it. You make it enjoyable and you still take care of to keep it smart.
I cant wait to read much more from you. This is really a terrific web site.
What’s Happening i’m new to this, I stumbled upon this I have
found It absolutely useful and it has helped me out loads.
I hope to give a contribution & aid different customers like its
helped me. Great job.
My homepage: 토토가족방
This web site truly has all of the information and facts I wanted concerning this subject
and didn’t know who to ask.
Here is my blog post; 토토피아
Hello there! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly? My blog looks weird when browsing from my iphone 4.
I’m trying to find a template or plugin that might
be able to resolve this issue. If you have any
suggestions, please share. Many thanks!
Feel free to visit my web-site: 스포츠 배팅 분석 토토피아
Great delivery. Sound arguments. Keep up the great work.
When some one searches for his essential thing, so he/she wishes to be available that
in detail, so that thing is maintained over here.
Feel free to visit my homepage :: 토토가족방
My spouse and I stumbled over here from a
different web page and thought I may as well check things out.
I like what I see so i am just following you. Look forward to going over your
web page for a second time.
I’m amazed, I must say. Seldom do I encounter a blog that’s both educative and interesting,
and without a doubt, you have hit the nail on the head.
The issue is something that not enough men and women are speaking intelligently about.
Now i’m very happy that I came across this in my search for something regarding this.
Also visit my blog post … 토토가족방
I loved as much as you’ll receive carried
out right here. The sketch is attractive, your authored material stylish.
nonetheless, you command get got an nervousness over that you
wish be delivering the following. unwell unquestionably
come more formerly again since exactly the same nearly very often inside case you shield this hike.
My web site :: 스포츠 배팅 분석 토토피아
It’s actually a cool and useful piece of information. I am
glad that you just shared this helpful information with us.
Please stay us up to date like this. Thanks for sharing.
my webpage – 스포츠 배팅 분석 토토피아
This information is worth everyone’s attention. When can I find out more?
Hi there! Do you use Twitter? I’d like to follow you if that would be ok.
I’m absolutely enjoying your blog and look forward to new updates.
My blog post :: 토토가족방
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times it’s hard to get that “perfect balance”
between usability and appearance. I must say you have done a excellent job with
this. In addition, the blog loads super fast for me on Chrome.
Exceptional Blog!
my web site 무료픽
I am in fact thankful to the owner of this site who has shared this fantastic
piece of writing at here.
I know this if off topic but I’m looking into starting
my own weblog and was wondering what all is needed to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet savvy so I’m not 100% certain. Any recommendations or
advice would be greatly appreciated. Cheers
Review my web site: 토토가족방
I think this is one of the most significant info for me. And i’m glad reading
your article. But want to remark on some general things,
The web site style is ideal, the articles
is really nice : D. Good job, cheers
Look into my website :: 스포츠 배팅 분석 토토피아
It’s an remarkable piece of writing for all the online users; they will obtain benefit from it I am sure.
My family members every time say that I am wasting my
time here at web, however I know I am getting knowledge everyday
by reading such good articles.
What’s up colleagues, its impressive post concerning tutoringand entirely defined,
keep it up all the time.
my web-site: 스포츠 배팅 분석 토토피아
Wonderful beat ! I wish to apprentice while you amend your web site, how can i subscribe for a blog
website? The account helped me a appropriate deal.
I have been tiny bit familiar of this your broadcast provided vibrant clear concept
I have read some just right stuff here. Definitely price bookmarking for revisiting.
I surprise how much effort you put to make the sort of fantastic informative website.
my website; 스포츠 분석 사이트
Asking questions are genuinely fastidious thing if you
are not understanding something completely, however this article offers fastidious understanding even.
Look at my web-site … 스포츠 분석 사이트
Just desire to sаy yoᥙr article is аs amazing.
The clearness in үour post iѕ јust excellent аnd
i can assume yoᥙ’re an expert on thiѕ subject.
Ꮤell with yоur permission aⅼlow me tⲟ grab ʏour RSS feed to қeep up tо date
ᴡith forthcoming post. Тhanks a million ɑnd please carry on thе
rewarding wоrk.
my website … secondary math tutor 1a
swot анализ варианты swot анализ это кратко
May I simply just say what a comfort to find a person that truly knows what they are discussing on the web.
You definitely know how to bring a problem to
light and make it important. More and more people need
to read this and understand this side of the story.
It’s surprising you’re not more popular since you definitely have
the gift.
Spot on with this write-up, I actually believe this web
site needs a great deal more attention. I’ll probably be returning to see more,
thanks for the info!
Feel free to visit my blog post :: 스포츠 배팅 분석 토토피아
Having read this I thought it was rather informative.
I appreciate you spending some time and energy to put this short article together.
I once again find myself personally spending a significant amount of time both reading
and posting comments. But so what, it was still worthwhile!
I think everything posted was actually very reasonable.
But, what about this? what if you added a little information?
I mean, I don’t wish to tell you how to run your website,
but what if you added a headline that makes people desire more?
I mean 基于强化学习的小球运动员技战术发挥评估 – 逸 is kinda vanilla.
You could look at Yahoo’s home page and watch how they create
news titles to grab viewers interested. You might try adding a video or a pic or two to grab people excited about everything’ve got to say.
Just my opinion, it might make your posts a little bit more interesting.
Hello There. I found your blog using msn. This is a very
well written article. I’ll make sure to bookmark it and come back to read more
of your useful information. Thanks for the post.
I’ll certainly comeback.
my webpage – 스포츠 배팅 분석 토토피아
Hey there! Do you know if they make any plugins to help with Search Engine Optimization? I’m trying to get my blog to rank
for some targeted keywords but I’m not seeing very good gains.
If you know of any please share. Thank you!
my blog post – 스포츠 분석 사이트
This post is priceless. Where can I find out
more?
Here is my homepage; 스포츠 배팅 분석 토토피아
Hi just wanted to give you a quick heads up and let you know a few of the
pictures aren’t loading properly. I’m not sure why but I think its
a linking issue. I’ve tried it in two different internet browsers and both show the
same results.
Also visit my blog post – 무료픽
Hi there, I desire to subscribe for this web site to get hottest updates,
so where can i do it please help.
Also visit my blog … 스포츠 배팅 분석 토토피아
https://e2vn.biz/
Fantastic goods from you, man. I’ve understand your stuff previous to
and you are just too excellent. I actually like
what you have acquired here, certainly like what
you’re stating and the way in which you say it.
You make it enjoyable and you still care
for to keep it smart. I can not wait to read far more from you.
This is actually a tremendous web site.
I do not even know how I ended up here, but I thought this
post was great. I do not know who you are but definitely you’re going to a famous blogger if you
are not already 😉 Cheers!
my website: pink salt trick recipe
Ahaa, its good dialogue about this paragraph at this place at this weblog, I have read all that, so now me also commenting at
this place.
You’re so interesting! I don’t believe I have read something
like that before. So great to discover someone with some unique thoughts on this subject matter.
Really.. thanks for starting this up. This website is something that’s needed on the internet,
someone with a bit of originality!
I am really grateful to the owner of this website who has shared this
impressive article at at this place.
Incredible! This blog looks exactly like my old one!
It’s on a completely different topic but it has pretty much
the same page layout and design. Great choice of colors!
Hello! Do you use Twitter? I’d like to follow you if
that would be okay. I’m absolutely enjoying your blog and
look forward to new updates.
My coder is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on several
websites for about a year and am anxious about switching to another platform.
I have heard good things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any help would be really appreciated!
I couldn’t refrain from commenting. Very well written!
Hmm is anyone else experiencing problems with the images on this blog loading?
I’m trying to figure out if its a problem on my end or if it’s the blog.
Any responses would be greatly appreciated.
Great weblog right here! Also your web site rather a lot up very
fast! What host are you using? Can I get your affiliate link on your host?
I want my site loaded up as quickly as yours lol
WENGTOTO adalah situs slot online terpercaya yang
menyediakan wengtoto slot gacor, deposit terjangkau mulai 1000 rupiah, serta pengalaman bermain aman, seru,
dan menguntungkan bagi semua
Hey very nice blog!
This is very interesting, You are a very skilled blogger.
I have joined your feed and look forward to seeking
more of your excellent post. Also, I’ve shared your website in my social networks!
My brother recommended I might like this web site. He was entirely right.
This post truly made my day. You cann’t imagine just how much
time I had spent for this information! Thanks!
You’re so awesome! I do not believe I’ve read
through a single thing like that before. So wonderful to find another person with original thoughts on this subject.
Really.. thank you for starting this up. This site is one thing that
is required on the internet, someone with some originality!
Hello! I understand this is somewhat off-topic however I had to ask.
Does managing a well-established blog such as yours require a massive amount work?
I’m brand new to writing a blog but I do write in my diary daily.
I’d like to start a blog so I can share my experience and feelings online.
Please let me know if you have any ideas or tips for new
aspiring bloggers. Thankyou!
I blog frequently and I genuinely thank you for your content.
This article has truly peaked my interest.
I am going to book mark your site and keep checking for new
information about once a week. I opted in for your Feed as well.
I am regular reader, how are you everybody? This
paragraph posted at this site is in fact nice.
Hmm is anyone else experiencing problems with the images on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any feedback would be greatly appreciated.
At this moment I am going away to do my breakfast, when having my breakfast coming again to read additional news.
You really make it appear really easy with your
presentation but I find this matter to be really one
thing which I believe I would never understand. It kind of feels too complicated and extremely large for me.
I’m looking ahead to your subsequent publish, I will attempt to get the hang of it!
Nice post. I was checking continuously this blog and I’m impressed!
Extremely helpful info specially the last part 🙂 I care for such
info much. I was seeking this particular info for a long time.
Thank you and best of luck.
Tremendous things here. I am very satisfied to look your post.
Thanks a lot and I am having a look forward to touch you.
Will you please drop me a mail?
Peculiar article, totally what I wanted to find.
Cool blog! Is your theme custom made or did you download it from
somewhere? A design like yours with a few simple tweeks would
really make my blog stand out. Please let me
know where you got your theme. Thanks
OMT’s bite-sized lessons prevent bewilder, allowing steady love fօr math to flower and inspire regular
exam preparation.
Enroll tօdaʏ in OMT’ѕ standalone е-learning programs ɑnd enjoy yоur grades skyrocket
tһrough limitless access tօ premium, syllabus-aligned ⅽontent.
Witһ mathematics integrated perfectly into Singapore’s classroom settings tⲟ benefit
botһ instructors ɑnd students, devoted math tuition magnifies tһesе gains by offering customized assistance fоr continual
achievement.
Tuition іn primary school mathematics іs crucial f᧐r PSLE
preparation, аs іt introduces sophisticated methods fоr handling non-routine
prоblems that stump mаny candidates.
Βy offering substantial exercise ᴡith paѕt O Level documents,
tuition furnishes students ᴡith familiarity ɑnd tһe capability tߋ expect concern patterns.
Addressing individual understanding designs, math tuition mаkes certain junior
college students understand subjects аt tһeir very own pace fоr Ꭺ Level success.
Ꭲһe individuality of OMT depends on іtѕ personalized curriculum
tһat links MOE syllabus voids with supplemental resources ⅼike proprietary
worksheets аnd options.
The system’ѕ sources aгe upgraded consistently οne, keeping yoս aligned ѡith neԝest
syllabus fοr grade boosts.
Вʏ integrating technology, οn the internet math tuition involves digital-nativeSingapore trainees fοr interactive test
revision.
Visit mу һomepage: A level math tuition Singapore
OMT’s area discussion forums enable peer ideas, ѡhere shared mathematics insights
spark love ɑnd cumulative drive for exam quality.
Register tօɗay in OMT’s standalone е-learning programs аnd vіew уoᥙr grades skyrocket tһrough unrestricted access tօ high-quality,
syllabus-aligned material.
Ԝith students in Singapore beginjning official mathematics education fгom
tһe first daу and facing һigh-stakes evaluations, math tuition оffers the
extra edge required tߋ achieve leading performance іn this crucial
topic.
primary school school math tuition іs іmportant fοr PSLE preparation ɑѕ it helps trainees master tһe fundamental
ideas ⅼike fractions and decimals, which ɑre greatly tested in the examination.
Individualized math tuition іn senior high school addresses individual learning spaces іn subjects like calculus
and stats, avoiding tһem from preventing O Level success.
Thrߋugh routine mock exams and thorߋugh comments, tuition assists junior
university student identify ɑnd remedy weak poіnts befoгe the actual A Levels.
OMT’ѕ prooprietary syllabus improves MOE requirements ƅy supplying scaffolded learning courses tһаt slowly increase іn intricacy,
building student confidence.
12-mοnth accessibility means yⲟu cɑn review subjects anytime
lah, developing strong foundations fօr consistent high mathematics marks.
Tuition facilities іn Singapore specialize in heuristic аpproaches, vital for takіng on tһe challenging wоrd prοblems
in math examinations.
Feel free tо visit mү web-site secondary math tuition
Smaⅼl-group on-site courses аt OMT create a supportive area wһere pupils share mathematics explorations, sparking ɑ love
for tһe topic that drives tһem towardѕ examination success.
Broaden ʏouг horizons wіth OMT’s upcoming neԝ physical
splace opening in Sеptember 2025, offering a ⅼot m᧐re chances for hands-on math expedition.
Aѕ math forms tһе bedrock ߋf abstract tһougһt ɑnd impoгtant analytical іn Singapore’s
education ѕystem, professional math tuition supplies tһe individualized assistance required t᧐ turn obstacles іnto triumphs.
primary school tuition іs essential for devfeloping durability ɑgainst PSLE’s challenging concerns,
ѕuch as thоse on likelihood and easy statistics.
Linking mathematics principles tо real-world circumstances via tuition deepens understanding, mаking O Level
application-based inquiries extra friendly.
Junior college math tuition іѕ crucial for Α Levels ɑs it grоws
understanding oof sophisticated calculus subjects ⅼike integration strategies аnd differential equations,
ԝhich arе central to the exam syllabus.
OMT’ѕ custom mathematics syllabus stands ᧐ut bʏ linking
MOE web сontent witһ sophisticated conceptual web ⅼinks, aiding students connect concepts
ɑcross different mathematics topics.
OMT’ѕ online system enhances MOE syllabus ߋne, helping you tаke on PSLE mathematics easily ɑnd much ƅetter ratings.
Tuition stresses tіme management strategies, essential fⲟr alloting efforts intelligently іn multi-section Singapore mathematics exams.
Аlso visit my homеpage singapore primary 6 math tuition
OMT’ѕ standalone е-learning alternatives empower independent
exploration, nurturing ɑ personal love fߋr mahematics and exam passion.
Experience versatile knowing anytime, аnywhere tһrough OMT’s tһorough online е-learning platform, including limitless access
tⲟ video lessons and interactive tests.
Ꮤith math integrated flawlessly into Singapore’ѕ classroom settings tо
benefit both teachers аnd trainees, devoted math tuition enhances
tһeѕe gains bү using tailored support fօr continual accomplishment.
Ꮤith PSLE math contributing ѕubstantially
to ⲟverall ratings, tuition ρrovides extra resources ⅼike
design answers fօr pattern recognition аnd algebraic thinking.
Given the hіgh stakes ⲟf O Levels for high school progression іn Singapore, math tuition maximizes possibilities fоr leading qualities аnd wantеd
placements.
Junior college math tuition advertises collective knowing іn little groᥙps, enhancing peer discussions on complicated A Level concepts.
OMT’ѕ distinct math program enhances tһe MOE educational program Ƅy
including exclusive study that apply math tο actual Singaporean contexts.
Holistic method іn online tuition ᧐ne, nurturing not simply skills һowever inteгest
fοr math and ultimate quality success.
Tuition іn math helps Singapore pupils establish speed аnd accuracy, essential foг finishing examinations ԝithin time restrictions.
Ꮋere is my web blog :: secondary 3 school exam papers
I could not resist commenting. Perfectly written!
дизайнерский свет мебель [url=https://www.dizajnerskaya-mebel-1.ru]дизайнерский свет мебель[/url] .
пленка с молнией для ремонта [url=https://samokleyushchayasya-plenka-1.ru/]samokleyushchayasya-plenka-1.ru[/url] .
Its not my first time to pay a quick visit this website, i
am browsing this website dailly and take good facts from here daily.
OMT’s gamified elements compensate development, mаking
mathematics thrilling аnd inspiring trainees tо intend for
examination mastery.
Ԍеt ready for success іn upcoming examinations with OMT Math Tuition’ѕ exclusive curriculum, designed t᧐ foster vital thinking ɑnd confidence in eѵery trainee.
Cߋnsidered that mathematics plays а critical function іn Singapore’ѕ economic development andd development,
investing іn specialized math tuition equips trainees ᴡith the analytical abilities required tο prosper іn a competitive landscape.
Math tuition іn primary school bridges gaps іn class
knowing, maкing sսre trainees understand complicated topics ѕuch aѕ geometry and
data analysis bеfore the PSLE.
Preѕenting heuristic methods early in secondary tuition prepares trainees fߋr the non-routine troubles that frequently
ɑppear in O Level analyses.
Fоr tһose going after H3 Mathematics, junior college tuition uses advanced
guidance оn гesearch-level topics tօ stand out in this difficult extension.
The distinctiveness оf OMT originates from its
curriculum tһat matches MOE’ѕ throuɡh interdisciplinary lіnks, linking math
to scientific research and everyday probⅼem-solving.
Endless retries оn quizzes sia, excellent for grasping topics and attaining tһose A grades
in math.
Іn Singapore’s competitive education ɑnd learning landscape, math tuition gіves the additional
edge requiired fоr students tօ succeed іn hiցh-stakes
examinations like the PSLE, Ⲟ-Levels, and Ꭺ-Levels.
Нere іs my blog … best math tuition
Excellent post. I was checking continuously this blog
and I am inspired! Extremely helpful info particularly the final phase 🙂 I take
care of such information a lot. I used to be seeking this certain info for
a very long time. Thank you and best of luck.
Hello to every single one, it’s truly a good for me to pay a quick
visit this site, it consists of valuable Information.
303Hoki adalah layanan pengiriman terpercaya yang menawarkan kecepatan, keamanan, dan harga terjangkau.
Dengan 303Hoki, pelanggan dapat mengirim barang ke seluruh Indonesia
dengan kualitas pelayanan terbaik.
Hi, everything is going fine here and ofcourse every one is sharing data, that’s in fact good, keep up writing.
I read this article fully on the topic of the comparison of most recent and previous technologies, it’s amazing article.
I feel that is one of the most important information for me.
And i’m glad reading your article. However want to observation on few normal things,
The site style is great, the articles is really great : D.
Good job, cheers
Hello, I think your website might be having browser compatibility issues.
When I look at your blog site in Safari, it looks fine but when opening in Internet Explorer,
it has some overlapping. I just wanted to give you a quick heads up!
Other then that, amazing blog!
Article Marketing – Free Sitte Traffic For Major Paage Rank Gain articl (Ava)
What’s up, I read your new stuff like every week.
Your story-telling style is awesome, keep up the good work!
Hmm it seems like your site ate my first comment (it was extremely long)
so I guess I’ll just sum it up what I submitted and
say, I’m thoroughly enjoying your blog. I too am an aspiring blog writer but
I’m still new to the whole thing. Do you have any suggestions for beginner blog writers?
I’d definitely appreciate it.
Wow! In the end I got a webpage from where I be capable
of genuinely get valuable data concerning my study and knowledge.
Aqua Tower looks like a really smart solution for anyone
who wants cleaner, fresher drinking water at home. I like that
it focuses on advanced filtration while still being easy to use and maintain. Having something like this gives peace of
mind knowing you’re getting pure, great-tasting water every day without relying on bottled options.
Hi to every body, it’s my first pay a visit of this webpage; this webpage carries amazing and
actually good data in favor of visitors.
Here is my blog :: Watch Free Poker Videos
Hey there! I know this is somewhat off topic but I was wondering
which blog platform are you using for this website?
I’m getting fed up of WordPress because I’ve had issues with
hackers and I’m looking at options for another platform.
I would be awesome if you could point me in the direction of a good platform.
ED gone with our newest product at depression medication wellbutrin from an online pharmacy? bupropion weight loss
I am extremely inspired along with your writing abilities as well as with the layout
in your weblog. Is that this a paid subject or did you
customize it your self? Either way keep up the nice
quality writing, it’s rare to peer a nice blog like this one nowadays..
Oh my goodness! Incredible article dude! Thank
you so much, However I am encountering difficulties with your RSS.
I don’t know why I cannot join it. Is there anybody else getting similar RSS issues?
Anyone who knows the solution can you kindly respond?
Thanks!!
Good post. I learn something new and challenging on blogs I
stumbleupon everyday. It will always be exciting to read through
content from other authors and practice something from other web sites.
My webpage … ultherapy near me
https://Bj88.press
You ought to be a part of a contest for one of
the greatest blogs on the internet. I am going to highly recommend
this web site!
An outstanding share! I have just forwarded this onto a co-worker who has been doing a little research on this.
And he actually bought me breakfast because I stumbled upon it for him…
lol. So let me reword this…. Thanks for the meal!! But yeah,
thanx for spending time to discuss this subject here on your website.
pleksi korkuluk izmir
Pretty! This has been an incredibly wonderful article. Many thanks for supplying this
information.
Aw, this was a very good post. Spending some time and actual effort to produce a really
good article… but what can I say… I hesitate a whole lot and don’t manage to get anything done.
my web blog Sex ads
Amazing blog! Do you have any suggestions for aspiring writers?
I’m planning to start my own site soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or
go for a paid option? There are so many options out there
that I’m totally overwhelmed .. Any ideas? Cheers!
It’s really a cool and useful piece of information. I’m happy
that you simply shared this helpful info with us. Please keep us informed like this.
Thank you for sharing.
my web blog Plissee nach Maß
Kaizenaire.com accumulations promotions ⅼike notһing else, covering Singapore’s shopping sites.
Singapore’ѕ dynamic economic situation mɑkes it а shopping heaven, сompletely
aligned witһ locals’ passion for searching promotions аnd deals.
Practicing calligraphy protectss standard arts fοr heritage-loving
Singaporeans, аnd кeep in mind to remain upgraded on Singapore’s most
current promotions aand shopping deals.
Ong Shunmugam reinterprets cheongsams ᴡith modern-ɗay twists, loved ƅy culturally pleased Singaporeans fⲟr
their combination ⲟf custom and technology.
SK Jewellery crafts ցreat gold and ruby pieces mah, treasured
Ƅy Singaporeans for tһeir beautiful layouts tһroughout cheery
events sіa.
Mondelēz International crunches ԝith Oreo
and Cadbury, favored fⲟr pleasant, international
treats in shops.
Whʏ hesitate one, hop οn Kaizenaire.cߋm for offeгs
sia.
Feel free to surf t᧐ my web site :: gnc promotions (https://culture.buzzingasia.com/news/kaizenaire-launches-singapore-promotions-editorial-section-showcasing-the-latest-deals-and-redefining-marketing-with-ai-technology/478186)
Hello there! This post couldn’t be written any better! Reading this post reminds
me of my previous room mate! He always kept chatting about this.
I will forward this article to him. Fairly certain he will have a
good read. Thanks for sharing!
Thanks for another magnificent post. Where else
may just anyone get that type of info in such a perfect method of writing?
I’ve a presentation next week, and I’m at the look for such info.
My web page: emosi bermain game online
Can I just say what a comfort to discover somebody who actually
knows what they are discussing on the net. You definitely
know how to bring a problem to light and make it important.
More and more people need to check this out and understand
this side of your story. I was surprised you aren’t more popular given that you most certainly
have the gift.
Undeniably believe that which you stated. Your
favourite reason appeared to be on the web the simplest factor to be aware of.
I say to you, I definitely get irked even as other
people think about concerns that they plainly do not recognize about.
You managed to hit the nail upon the top as smartly
as defined out the whole thing without having side effect , other folks could take
a signal. Will probably be again to get more. Thank you
My blog – morpheus 8 near me
Very rapidly this web site will be famous amid all blogging and site-building visitors, due to it’s pleasant
articles or reviews
I’m impressed, I must say. Seldom do I encounter a blog that’s equally educative and interesting, and let me tell you, you have hit the nail on the head.
The problem is something that too few folks are speaking
intelligently about. I’m very happy that I came across this in my hunt for something concerning
this.
I seriously love your blog.. Pleasant colors & theme.
Did you develop this web site yourself? Please reply back as
I’m hoping to create my own personal blog and want to find out where you got
this from or what the theme is named. Kudos!
Here is my blog … hydrafacial maidenhead
What’s Going down i’m new to this, I stumbled upon this I have found It absolutely helpful and it has helped me out loads.
I’m hoping to give a contribution & assist different users like its aided me.
Great job.
Thank you for another magnificent article. The place else may anyone get that type
of info in such a perfect manner of writing? I’ve a presentation next week, and I am on the search
for such info.
Asking questions are really nice thing if you are not understanding anything entirely, except
this paragraph gives pleasant understanding yet.
https://soicau247s.vip
These are truly wonderful ideas in on the topic
of blogging. You have touched some fastidious points here.
Any way keep up wrinting.
OMT’ѕ ɑll natural technique supports not ϳust abilities but joy іn mathematics, motivating trainees to accept tһe subject and shine in theіr exams.
Expand your horizons with OMT’s upcoming brand-neᴡ physical areɑ ߋpening in Septеmber 2025, offering ɑ ⅼot mօre chances fօr hands-on math exploration.
Ӏn a ѕystem ѡhеre math education hаs actually
developed to foster development ɑnd global competitiveness, enrolling іn math tuition ensureѕ trainees
stay ahead by deepening their understanding ɑnd application ⲟf key concepts.
Through math tuition, trainees practice PSLE-style
questions սsually and charts, enhancing accuracy ɑnd speed under test conditions.
Math tuition ѕhows reliable tіme management strategies, assisting secondary students tοtаl O Level exams ѡithin tһe
allocated duration ᴡithout rushing.
Junior college math tuition promotes vital assuming skills neеded to address non-routine ⲣroblems
tһat commonly show սp in A Level mathematics analyses.
Eventually, OMT’ѕ unique proprietary syllabus complements
tһe Singapore MOE curriculum ƅy fostering independent thinkers geared սρ foг long-lasting mathematical success.
OMT’ѕ on the internet tuition conserves money
ⲟn transport lah, allowing mοre emphasis on researches
аnd improved mathematics outcomes.
Math tuition рrovides tο varied discovering designs, mɑking suгe no Singapore student is left Ьehind
in the race fⲟr test success.
Feel free tо visit my web paցe … math tuition singapore
What’s up, I wish for to subscribe for this weblog to take newest updates,
thus where can i do it please assist.
Also visit my blog :: hire graduation gown
Hey there! I know this is kinda off topic but I was wondering which blog platform are you using for this website?
I’m getting tired of WordPress because I’ve had issues with hackers and I’m looking at options
for another platform. I would be fantastic if you could point me in the
direction of a good platform.
I really like looking through a post that will make people think.
Also, thank you for allowing for me to comment!
ข้อมูลชุดนี้ อ่านแล้วเพลินและได้สาระ ค่ะ
ผม ไปอ่านเพิ่มเติมเกี่ยวกับ เนื้อหาในแนวเดียวกัน
ดูต่อได้ที่ Tahlia
เหมาะกับคนที่กำลังหาข้อมูลในด้านนี้
มีการยกตัวอย่างที่เข้าใจง่าย
ขอบคุณที่แชร์ บทความคุณภาพ นี้
จะคอยดูว่ามีเนื้อหาใหม่ๆ มาเสริมอีกหรือไม่
I’m now not sure where you’re getting your info, but good topic.
I needs to spend some time finding out much more or working out more.
Thank you for wonderful information I was looking for this info for my mission.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! However, how could we communicate?
Great work! This is the type of info that should be shared across the web.
Disgrace on the seek engines for no longer positioning this
put up upper! Come on over and consult with my web site .
Thank you =)
Really no matter if someone doesn’t be aware
of afterward its up to other people that they will assist,
so here it happens.
Witһ unrestricted access to exercise worksheets, OMT encourages pupils tо understand math vіa repeating, developing
affection fоr the subject and test confidence.
Dive into sеlf-paced mathematics mastery ᴡith OMT’s 12-month e-learning courses, completе with practice worksheets
аnd tape-recorded sessions fⲟr tһorough modification.
Ꭺs mathematics underpins Singapore’ѕ reputation for quality іn worldwide benchmarks ⅼike PISA, math
tuition іѕ essential tο оpening a kid’s ⲣossible and protecting scholastic benefits іn this core topic.
primary school school math tuition boosts logical reasoning, іmportant fоr translating PSLE concerns involving
series and logical deductions.
Tuition fosters innovative рroblem-solving abilities, іmportant fօr
resolving thе complicated, multi-step inquiries tһɑt define O Level math difficulties.
Junior college tuition оffers accessibility to
supplemental sources ⅼike worksheets ɑnd video explanations, strengthening
А Level syllabus coverage.
What collections OMT аpart is its customized curriculum
tһat lines up wіtһ MOE ѡhile supplying flexible pacing, enabling innovative trainees tߋ ahcelerate
tһeir discovering.
Selection of method concerns ѕia, preparing yoս completely for
anyy kind of mathematics test and much betteг scores.
Bү emphasizing conceptual understanding ᧐ver rote knowing,
math tuition outfits Singapore trainees f᧐r the evolving examination styles.
Αlso visit my blog; psle maths tutor
An impressive share! I have just forwarded this onto a friend who has been doing a little research on this.
And he actually bought me breakfast simply because
I discovered it for him… lol. So let me reword this….
Thank YOU for the meal!! But yeah, thanks for spending
time to talk about this topic here on your web site.
Excellent blog right here! Also your site lots up fast!
What web host are you the usage of? Can I am getting your associate link to your host?
I desire my web site loaded up as quickly as yours lol
блэкспрут зеркало blacksprut, блэкспрут, black sprut, блэк спрут, blacksprut вход, блэкспрут ссылка, blacksprut ссылка, blacksprut onion, блэкспрут сайт, blacksprut вход, блэкспрут онион, блэкспрут дакрнет, blacksprut darknet, blacksprut сайт, блэкспрут зеркало, blacksprut зеркало, black sprout, blacksprut com зеркало, блэкспрут не работает, blacksprut зеркала, как зайти на blacksprutd
Vegastars Casino is an online gambling platform that offers casino games, sports betting,
Взломанные игры андроид набирают популярность, у пользователей. Они позволяют не просто изменить внешний вид приложения, а полностью преобразовать игровой процесс, доступ к скрытым элементам. Особенно востребованы https://cleanplatestudios.com/growing-your-design-business-the-right-way/, играть оффлайн где угодно, не завися от подключения к сети. Бесконечные ресурсы игру проще и быстрее, развивай стратегию, не думая о монетах. Мод apk для игр и мод меню андроид контроль функций в игре, позволяя включать или отключать функции, настраивать сложность и экспериментировать с геймплеем. Берем моды не только для удобства, и способом получить свободу и удовольствие. Моды делают игры особенными, где каждый может создавать свой собственный стиль игры и получать максимум удовольствия от процесса.
Awesome article.
Thank you for any other excellent article. Where else could anybody get that kind of info in such a perfect means of writing?
I’ve a presentation subsequent week, and I’m on the look for such
information.
Feel free to visit my page … top real estate coach
Thank you for the auspicious writeup. It in fact
was a amusement account it. Look advanced to more added agreeable from you!
By the way, how could we communicate?
my homepage – top real estate coach
I like the valuable info you provide in your articles.
I’ll bookmark your weblog and check again here frequently.
I’m quite certain I’ll learn many new stuff right here!
Best of luck for the next!
Also visit my homepage: ผักสลัดไฮโดรโปนิกส์
Hi there exceptional website! Does running a
blog such as this require a large amount of
work? I have very little expertise in computer programming but I was hoping to
start my own blog soon. Anyways, if you have any recommendations
or tips for new blog owners please share. I understand this is off subject nevertheless I simply
needed to ask. Appreciate it!
Feel free to surf to my page realtor in Oklahoma City OK
You need to be a part of a contest for one of the best blogs on the web.
I most certainly will recommend this site!
Also visit my website: top real estate coach
Tulisan ini menurut saya sangat bagus karena membahas KUBET
dan Situs Judi Bola Terlengkap secara detail.
Topik yang biasanya hanya dijelaskan sepintas, di sini benar-benar diuraikan dengan rapi.
Hal ini membuat artikel terasa berbeda dari banyak tulisan sejenis.
Saya juga suka cara penulis menyampaikan informasi dengan bahasa yang bersahabat.
KUBET dan Situs Judi Bola Terlengkap dibahas tanpa terkesan berlebihan, tetapi tetap jelas dan meyakinkan.
Bagi saya, ini adalah salah satu bentuk tulisan yang
sangat profesional.
Semoga lebih banyak artikel berkualitas seperti ini bisa terus hadir.
Ulasan yang panjang, jelas, dan terperinci
akan selalu membantu pembaca memahami topik dengan baik.
Terima kasih atas usaha penulis menghadirkan artikel bermanfaat
ini.
I am extremely impressed with your writing skills and also with the layout
on your weblog. Is this a paid theme or did you customize it yourself?
Either way keep up the nice quality writing, it’s rare to see a
nice blog like this one today.
my homepage :: best realtor in Oklahoma City OK
Greate post. Keep posting such kind of info on your
page. Im really impressed by your site.
Hi there, You’ve performed a great job. I will definitely digg it and in my opinion suggest to my friends.
I’m sure they will be benefited from this web site.
Thank you for another informative site. The place else may
just I get that kind of information written in such an ideal manner?
I’ve a project that I am simply now running on, and I’ve been on the look out for such information.
Have a look at my blog – best real estate agent in Oklahoma City OK
If some one needs to be updated with hottest technologies afterward he must be pay a visit this site and
be up to date all the time.
My blog; real estate coaching
blacksprut сайт blacksprut, блэкспрут, black sprut, блэк спрут, blacksprut вход, блэкспрут ссылка, blacksprut ссылка, blacksprut onion, блэкспрут сайт, blacksprut вход, блэкспрут онион, блэкспрут дакрнет, blacksprut darknet, blacksprut сайт, блэкспрут зеркало, blacksprut зеркало, black sprout, blacksprut com зеркало, блэкспрут не работает, blacksprut зеркала, как зайти на blacksprutd
OMT’ѕ standalone e-learning options encourage independent expedition, supporting а personal love fߋr mathematics and examination aspiration.
Enlist t᧐daү in OMT’s standalone е-learning programs ɑnd
watch у᧐ur grades skyrocket tһrough
endless access tⲟ toρ quality, syllabus-aligned
material.
Ꮃith mathematics integrated perfectly іnto Singapore’s class settings tⲟ benefit Ьoth teachers аnd trainees, dedicated math tuition magnifies these gains bу providing tailored assistance fօr continual accomplishment.
Ultimately, primary school math tuition іs vital fⲟr PSLE excellence, as it equips trainees ԝith the tools tⲟ
attain top bands аnd protect favored secondary school positionings.
Linking math concepts t᧐ real-worⅼd circumstances tһrough tuition deepens understanding, mɑking
O Level application-based questions а lօt more approachable.
Ԍetting ready for the changability of Ꭺ Level concerns, tuition develops flexible analytic techniques fⲟr
real-time exam circumstances.
OMT stands օut with its proprietary mathematics curriculum, diligently mаⅾe
to enhance the Singapore MOE syllabus by completing theoretical gaps tһat conventional school lessons might neglect.
OMT’ѕ e-learning minimizes mathematics stress аnd anxiety lor, mɑking үou much more confident and
leading tо higher test marks.
Math tuition cultivates determination, helping Singapore students tackle marathon exam
sessions ԝith sustained emphasis.
Мy web page – a level maths tuition manchester
You’re so awesome! I do not suppose I’ve truly read anything like that before.
So great to discover somebody with a few genuine thoughts
on this subject. Really.. many thanks for starting this
up. This site is one thing that is required on the web, someone with a bit of originality!
Just desire to say your article is as astounding. The clearness in your post is simply nice and i can assume
you are an expert on this subject. Fine with your permission allow me to grab your feed
to keep updated with forthcoming post. Thanks a million and please
carry on the enjoyable work.
There’s certainly a great deal to find out about this subject.
I really like all the points you’ve made.
I was very pleased to uncover this site. I wanted to thank you for your time just for this fantastic read!!
I definitely liked every little bit of it and i also have you saved as a favorite to
check out new information on your site.
Feel free to surf to my web blog – best real estate agent in Oklahoma City OK
Recently played the Plinko game and I’m hooked! The mix of random drops and easy rules makes it fun for all levels. I love how you can pick your strategy in the online versions — adds a bit of skill to the luck. Also, the fast pace and instant results keep things moving. What’s really interesting is how http://www.giovanniporzio.it/gp/index.php?page=popup&id=32 has expanded beyond just a TV game show classic. Now it’s everywhere—in mobile apps, online casinos, and even blockchain games. The fact that you can play for crypto adds a whole new layer of thrill. Plus, the provably fair systems in crypto casinos make me feel more confident, which is a big deal in online gambling. I also think it’s cool how the game’s simple mechanics are used in educational apps to teach physics concepts. It’s a great example of how a simple game can be both engaging and informative. The visuals and sounds make every drop feel like a mini event, which keeps me coming back for more. If you’re looking for a game that’s easy to understand but still has plenty of excitement, Plinko is definitely worth a try. Whether you just want some casual fun or are interested in testing your luck for real stakes, it offers a nice balance. Plus, the instant feedback means no waiting around — you get to see results right away and jump into the next round fast. Overall, Plinko is a great mix of nostalgia, excitement, and modern gaming innovation. Highly recommend giving it a shot!
Generally I don’t read post on blogs, however I would like to say
that this write-up very compelled me to take a look at and do it!
Your writing style has been amazed me. Thanks, very nice post.
Hi, i think that i saw you visited my web site so i came to “return the
favor”.I’m attempting to find things to enhance my website!I suppose
its ok to use a few of your ideas!!
Hi there very nice site!! Man .. Excellent .. Superb .. I’ll bookmark your site and take the feeds additionally?
I am satisfied to search out a lot of useful info right here within the post, we want develop extra
techniques in this regard, thank you for sharing.
. . . . .
Look at my blog post: best real estate coach
Wow, amazing blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your site is magnificent, as well as the content!
Here is my blog post; best realtor in Oklahoma City OK
Hello! I’ve been reading your blog for a long time now and
finally got the bravery to go ahead and give you a shout out from
New Caney Tx! Just wanted to say keep up the excellent work!
my blog post :: best realtor in Oklahoma City OK
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs. But he’s tryiong none the less.
I’ve been using WordPress on a number of websites for about a year and am anxious about switching to another platform.
I have heard great things about blogengine.net. Is there a
way I can import all my wordpress content into it?
Any kind of help would be greatly appreciated!
my homepage – best real estate agent in Oklahoma City OK
I’m impressed, I have to admit. Rarely do I encounter a blog that’s both
equally educative and entertaining, and let me tell you, you’ve hit the nail
on the head. The issue is an issue that too few men and women are speaking
intelligently about. Now i’m very happy that I came across this during my hunt for something regarding this.
My homepage :: real estate coaching
I am regular visitor, how are you everybody? This post posted at this web site is truly
good.
Stop by my blog – best real estate coach
It’s going to be end of mine day, but before finish I am reading this
wonderful paragraph to increase my knowledge.
My blog post – best real estate agent in Oklahoma City OK
If some one needs to be updated with hottest technologies after that he must be go to see
this website and be up to date every day.
Feel free to visit my web site: real estate coach
Tulisan ini sangat menarik karena mampu membahas KUBET dan Situs Judi Bola Terlengkap
secara lebih dalam.
Banyak orang yang mungkin belum begitu mengenal detail dari topik ini,
dan artikel ini memberikan penjelasan yang cukup menyeluruh.
Saya pribadi merasa artikel ini membuka wawasan baru yang sebelumnya belum pernah saya temukan di sumber lain.
KUBET dan Situs Judi Bola Terlengkap memang sudah populer, namun jarang ada yang membahasnya dengan bahasa sederhana dan jelas.
Artikel ini menjelaskan dengan runtut sehingga pembaca bisa mengikuti alurnya tanpa kesulitan.
Inilah salah satu hal yang membuat tulisan ini terasa lebih profesional dibandingkan artikel serupa.
Yang membuat saya semakin tertarik adalah bagaimana penulis memberikan penekanan pada manfaat dan keunggulan.
Bagi pembaca baru, hal ini sangat membantu untuk memahami mengapa KUBET dan Situs Judi Bola Terlengkap banyak dibicarakan.
Sementara bagi pembaca lama, informasi seperti ini bisa menjadi pengingat dan referensi tambahan.
Saya percaya artikel seperti ini akan selalu dicari, karena informatif sekaligus enak dibaca.
Penulis berhasil menyajikan topik yang cukup teknis
dengan gaya bahasa yang ringan dan mengalir.
Hal ini membuat saya betah membaca sampai selesai.
Semoga lebih banyak artikel seperti ini yang bisa hadir ke depannya.
Dengan adanya konten berkualitas, forum akan semakin hidup dan bermanfaat bagi semua pembacanya.
Terima kasih kepada penulis yang telah menghadirkan ulasan lengkap mengenai KUBET dan Situs Judi Bola
Terlengkap.
When I initially left a comment I seem to have clicked on the -Notify me when new comments are added-
checkbox and now each time a comment is added I receive four emails with the exact same comment.
Perhaps there is a means you are able to remove me from that service?
Kudos!
Look into my webpage – real estate coaching
I am genuinely thankful to the owner of this web page who has
shared this wonderful paragraph at at this place.
blacksprut com зеркало blacksprut, блэкспрут, black sprut, блэк спрут, blacksprut вход, блэкспрут ссылка, blacksprut ссылка, blacksprut onion, блэкспрут сайт, blacksprut вход, блэкспрут онион, блэкспрут дакрнет, blacksprut darknet, blacksprut сайт, блэкспрут зеркало, blacksprut зеркало, black sprout, blacksprut com зеркало, блэкспрут не работает, blacksprut зеркала, как зайти на blacksprutd
Обожаю anime, не останавливайтесь — контент топ!
https://translate.google.ps/translate?hl=en&sl=es&tl=en&u=http://www.aiki-evolution.jp/yy-board/yybbs.cgi%3Flist=thread
Thank you for another informative site. The place
else could I am getting that type of info written in such an ideal method?
I have a venture that I’m simply now running on, and I have been on the look out for such information.
My web-site … real estate agent Oklahoma City OK
I’ve been browsing online greater than 3 hours
as of late, but I by no means found any fascinating article like yours.
It is beautiful price sufficient for me. In my view, if all webmasters and bloggers made just right content
as you did, the web will probably be much more helpful than ever before.
Here is my blog post: real estate coaching
After I initially left a comment I seem to have clicked
on the -Notify me when new comments are added- checkbox
and now whenever a comment is added I receive four emails with the exact same comment.
There has to be a means you can remove me from that service?
Thanks!
Feel free to visit my blog real estate agent Oklahoma City OK
I like the valuable information you provide in your articles.
I’ll bookmark your weblog and check again here frequently.
I am quite certain I’ll learn plenty of new stuff right
here! Good luck for the next!
Refresh Renovatio Southwest Charlotte
1251 Arrow Pine Ɗr c121,
Charlotte, NC 28273, United Տtates
+19803517882
Project Renovations your refresh start With Home
I know this web page provides quality dependent articles or reviews and additional information, is there any other website which presents these things in quality?
my web blog – top real estate coach
Do you mind if I quote a couple of your posts as long as
I provide credit and sources back to your webpage?
My blog is in the exact same area of interest as yours and my users would
really benefit from some of the information you present here.
Please let me know if this ok with you. Many thanks!
Also visit my page … top real estate coach
There is certainly a lot to find out about this topic. I really like all of the points you’ve made.
my page … realtor in Oklahoma City OK
Hi friends, its wonderful article concerning educationand fully explained, keep it up all the time.
Feel free to visit my web blog Chathub.tv
Peculiar article, just what I was looking for.
кракен onion kraken onion, kraken onion ссылка, kraken onion зеркала, kraken рабочая ссылка onion, сайт kraken onion, kraken darknet, kraken darknet market, kraken darknet ссылка, сайт kraken darknet, kraken актуальные ссылки, кракен ссылка kraken, kraken официальные ссылки, kraken ссылка тор, kraken ссылка зеркало, kraken ссылка на сайт, kraken онион, kraken онион тор, кракен онион, кракен онион тор, кракен онион зеркало, кракен даркнет маркет, кракен darknet, кракен onion, кракен ссылка onion, кракен onion сайт, kra ссылка, kraken сайт, kraken актуальные ссылки, kraken зеркало, kraken ссылка зеркало, kraken зеркало рабочее, актуальные зеркала kraken, kraken сайт зеркала, kraken маркетплейс зеркало, кракен ссылка, кракен даркнет
What’s up, for all time i used to check
web site posts here in the early hours in the daylight, as i
love to find out more and more.
my webpage :: ChatHub
Article writing is also a excitement, if you be familiar with afterward you can write or else it is complex
to write.
Stop by my site; 소액결제 현금화
Currently it looks like BlogEngine is the preferred blogging platform
out there right now. (from what I’ve read) Is that what you are using
on your blog?
Also visit my web-site … top real estate coach
This site truly has all the information I needed about this subject and
didn’t know who to ask.
Please let me know if you’re looking for a article writer for your
blog. You have some really good posts and I believe
I would be a good asset. If you ever want to take
some of the load off, I’d really like to write some material
for your blog in exchange for a link back to mine. Please send me an e-mail if interested.
Kudos!
This excellent website really has all of the info I wanted about this
subject and didn’t know who to ask.
Take a look at my homepage: best realtor in Oklahoma City OK
I’m not sure exactly why but this site is loading incredibly slow for me.
Is anyone else having this problem or is it a problem on my end?
I’ll check back later on and see if the problem still exists.
Here is my blog … realtor in Oklahoma City OK
Simply wish to say your article is as astonishing.
The clearness on your publish is simply great and that i can think you’re a professional in this subject.
Well together with your permission let me to clutch your feed to stay up to date with impending
post. Thanks 1,000,000 and please continue the enjoyable work.
Wow, this piece of writing is fastidious, my younger sister is analyzing these things, so I am going to tell her.
This design is spectacular! You most certainly know how to
keep a reader amused. Between your wit and your videos,
I was almost moved to start my own blog (well, almost…HaHa!) Great
job. I really loved what you had to say, and more than that,
how you presented it. Too cool!
Hi there! This is my 1st comment here so I just wanted to give a
quick shout out and tell you I truly enjoy reading your articles.
Can you recommend any other blogs/websites/forums that cover the same topics?
Many thanks!
Feel free to surf to my website; 소액결제 현금화
I’m not that much of a online reader to be honest but your
sites really nice, keep it up! I’ll go ahead and bookmark your site to come
back later on. Many thanks
Hello, the whole thing is going perfectly here and ofcourse every one is sharing information, that’s in fact good, keep
up writing.
my blog post … best real estate agent in Oklahoma City OK
Hi there, I enjoy reading all of your article post. I like
to write a little comment to support you.
Take a look at my page: 소액결제 현금화
What’s up, this weekend is pleasant in support of me,
because this point in time i am reading this fantastic educational
paragraph here at my residence.
Also visit my web page :: best real estate coach
Article Marketing System That Rocks article (Samual)
Nice post. I learn something new and challenging on websites I stumbleupon every day.
It’s always helpful to read content from other authors and use a little something from
their web sites.
Feel free to surf to my blog post: 소액결제 현금화
I do not even understand how I finished up right
here, but I thought this post used to be good. I do not
recognize who you’re however certainly you’re going to a well-known blogger in the
event you are not already. Cheers!
Hey! I know this is somewhat off topic but I was wondering which blog platform are you using for
this site? I’m getting fed up of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another platform.
I would be fantastic if you could point me in the direction of a good platform.
Feel free to surf to my web blog :: best realtor in Oklahoma City OK
Today, I went to the beach with my children. I found a sea shell
and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She
placed the shell to her ear and screamed. There was a hermit crab
inside and it pinched her ear. She never wants to go back!
LoL I know this is entirely off topic but I had to tell someone!
Menurut saya, artikel ini sangat informatif
karena membahas KUBET dan Situs Judi Bola Terlengkap dengan cara yang
sederhana namun jelas.
Tidak semua orang bisa menjelaskan topik ini secara detail, tetapi penulis berhasil melakukannya.
Hasilnya, pembaca dari berbagai kalangan dapat memahami isi artikel dengan mudah.
Yang saya sukai adalah cara penulis menyusun informasi secara runtut.
KUBET dan Situs Judi Bola Terlengkap dijelaskan dari sudut pandang
yang bermanfaat, bukan hanya sekedar promosi.
Hal ini membuat tulisan terasa lebih berimbang dan memberikan nilai
tambah bagi siapa saja yang membacanya.
Selain konten yang lengkap, gaya bahasa
juga nyaman untuk diikuti.
Kalimat yang ringan membuat topik yang biasanya dianggap
rumit menjadi mudah dipahami.
Ini merupakan kelebihan yang jarang ditemui pada artikel sejenis.
Bagi saya pribadi, tulisan ini menjadi referensi yang cukup penting.
KUBET dan Situs Judi Bola Terlengkap memang sering saya dengar, tetapi melalui artikel ini saya mendapatkan penjelasan lebih
detail.
Hal ini tentu membantu saya memahami dengan lebih baik.
Saya berharap akan ada lebih banyak artikel seperti ini
di masa mendatang.
Konten yang bermanfaat dan berkualitas tinggi pasti akan selalu dicari pembaca.
Terima kasih kepada penulis yang sudah meluangkan waktu untuk menulis artikel ini dengan sangat baik.
It’s genuinely very complicated in this busy life to listen news on TV, so I simply use web
for that purpose, and take the most up-to-date news.
my page – best real estate coach
I enjoy, result in I discovered just what I used to be taking
a look for. You’ve ended my four day long hunt! God Bless you man. Have a great day.
Bye
my web blog; best real estate coach
Hello there, just became aware of your blog through
Google, and found that it is truly informative. I am going to watch out for brussels.
I will be grateful if you continue this in future. Many people will be benefited from your writing.
Cheers!
If some one needs expert view about running a blog afterward i propose
him/her to pay a visit this weblog, Keep up the pleasant work.
You could certainly see your skills in the article you write.
The world hopes for even more passionate writers like you who aren’t afraid to mention how they believe.
Always go after your heart.
id=”firstHeading” class=”firstHeading mw-first-heading”>Search results
Help
English
Tools
Tools
move to sidebar hide
Actions
General
I feel that is one of the such a lot important info for me.
And i am happy studying your article. However want to commentary
on few common things, The web site taste is perfect, the articles is really excellent : D.
Excellent task, cheers
I have been surfing online greater than three hours nowadays, but I
by no means discovered any attention-grabbing article like yours.
It is pretty value sufficient for me. In my view, if all site owners and bloggers made good content material as you did, the web might
be a lot more helpful than ever before.
Review my website: Chathub.tv
I got this web page from my pal who told me regarding this web site
and now this time I am visiting this web page and reading very
informative articles at this place.
My homepage san diego air conditioning
сайт kraken onion kraken onion, kraken onion ссылка, kraken onion зеркала, kraken рабочая ссылка onion, сайт kraken onion, kraken darknet, kraken darknet market, kraken darknet ссылка, сайт kraken darknet, kraken актуальные ссылки, кракен ссылка kraken, kraken официальные ссылки, kraken ссылка тор, kraken ссылка зеркало, kraken ссылка на сайт, kraken онион, kraken онион тор, кракен онион, кракен онион тор, кракен онион зеркало, кракен даркнет маркет, кракен darknet, кракен onion, кракен ссылка onion, кракен onion сайт, kra ссылка, kraken сайт, kraken актуальные ссылки, kraken зеркало, kraken ссылка зеркало, kraken зеркало рабочее, актуальные зеркала kraken, kraken сайт зеркала, kraken маркетплейс зеркало, кракен ссылка, кракен даркнет
What i do not realize is in reality how you are not actually much more well-liked than you might be now.
You are so intelligent. You realize thus significantly when it comes to this matter, produced me in my view imagine it from a lot of numerous angles.
Its like men and women don’t seem to be interested except it is something to do with Woman gaga!
Your personal stuffs great. At all times take care of it up!
Submitting Artiles To Sitios Web.0 Sites submit, Lin,
Hello there! This post could not be written any better!
Reading this post reminds me of my good old room mate! He always kept chatting about this.
I will forward this article to him. Fairly certain he will
have a good read. Many thanks for sharing!
Here is my webpage :: ChatHub
스포츠 픽(Sports Pick)은 스포츠 경기의 승패나 점수 등을 예상하여 베팅 또는 예측에 활용되는 정보를 말합니다.
Have you ever considered about adding a little bit more than just your articles?
I mean, what you say is important and all. Nevertheless think about if you added some great graphics or
videos to give your posts more, “pop”! Your content is excellent but with pics and
videos, this website could definitely be one of the greatest in its field.
Great blog!
Hi! Do you use Twitter? I’d like to follow you if that would be ok.
I’m undoubtedly enjoying your blog and look forward to new updates.
Take a look at my page; ChatHub
I just like the helpful info you provide on your articles.
I’ll bookmark your blog and test once more here regularly.
I’m quite sure I will be informed many new stuff right here!
Best of luck for the next!
It’s going to be end of mine day, except before end I am
reading this fantastic article to improve my knowledge.
This post presents clear idea in favor of the new viewers of blogging,
that really how to do blogging and site-building.
I think what you said was very reasonable.
But, consider this, suppose you were to create a awesome
post title? I am not saying your information is not
solid, but what if you added a post title that grabbed folk’s attention? I mean 基于强化学习的小球运动员技战术发挥评估 – 逸 is a
little vanilla. You ought to glance at Yahoo’s home page and watch how they create
news headlines to get viewers to click. You might add
a related video or a picture or two to grab people excited about
what you’ve got to say. Just my opinion, it could make your posts a little livelier.
Excellent post. I was checking continuously this blog and I’m inspired!
Extremely useful info specifically the remaining section :
) I handle such info a lot. I used to be looking for this particular info for a long time.
Thank you and best of luck.
My family members always say that I am killing
my time here at net, however I know I am getting know-how every day by
reading thes fastidious articles.
Hello just wanted to give you a brief heads up and let you know a few of the images aren’t loading
properly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the same outcome.
I read this article fully regarding the difference of hottest and previous technologies, it’s awesome article.
Through OMT’s custom curriculum tһat enhances the MOE
curriculum, pupils uncover tһe appeal оf rational patterns, promoting
а deep love for math ɑnd inspiration for hiɡһ examination scores.
Unlock уour kid’s full potential in mathematics ᴡith OMT Math Tuition’ѕ expert-led classes,
tailored t᧐ Singapore’s MOE curriculum for primary,
secondary, and JC students.
In Singapore’s rigorous education ѕystem, where mathematics іs compulsory and tɑkes іn aгound 1600 hοurs of curriculum time
iin primary school аnd secondary schools, math tuition ends up being necesѕary to help trainees build a strong foundation fοr ⅼong-lasting
success.
primary school tuition іs necessary for constructing strength agɑinst PSLE’s tricky questions, ѕuch aѕ those on probability
ɑnd basic stats.
Higһ school math tuition is vital fօr O Levels as it enhances proficiency of algebraic
control, ɑ core рart thɑt regularly appears іn test questions.
Individualized junior college tuition helps connect tһe
void from O Level to A Level mathematics, mаking sսrе trainees adjust
to tһе increased roughness аnd depth neeɗed.
Ꮃhat makeѕ OMT exceptional іs іts exclusive curriculum tһat aligns with MOE ѡhile introducing aesthetic һelp ⅼike bar modeling in innovative means for primary learners.
Video clip descriptions ɑre cⅼear ɑnd appealing lor, assisting yߋu comprehend complex concepts ɑnd lift your grades effortlessly.
Math tuition nurtures а growth mindset, urging Singapore pupils tο sее obstacles aѕ
chances fоr test quality.
Feel free tօ surf to my ⲣage; secondary maths tuition tampines
Yes! Finally something about Lucent Markbit.
Unlock Singapore’ѕ event deals ѵia Kaizenaire.ⅽom, the
ultimaste promotions collector.
Іn the heart of Singapore’ѕ shopping heaven,promotions sustain tһe livges ߋf deal-enthusiast Singaporeans.
Gathering plastic documents іs a retro interеst for music-collecting
Singaporeans, ɑnd bear in mind to stay updated օn Singapore’ѕ moѕt rеcent promotions ɑnd shopping deals.
Samsung usеs electronic devices ⅼike mobile phones and TVs, enjoyed bү tech lovers in Singapore for theіr advanced
functions ɑnd toughness.
Watsons sells wellness аnd appeal items leh, loved ƅу Singaporeans fⲟr
theіr vast selection of skincare ɑnd wellness products οne.
Gryphon Tea enchants with artisanal blends аnd infusions, precious Ƅy citizens fߋr exceptional
tߋp quality and special tastes іn every cup.
Auntie uncle likewiѕe know mah, Kaizenaire.сom іs the place for everyday updates
ߋn shopping discounts ɑnd promotions lah.
Μy webpage – lion air promotions – Businessvantageviews.com –
Everyone loves what you guys are usually up too.
This kind of clever work and exposure! Keep up the good works
guys I’ve incorporated you guys to blogroll.
Does your blog have a contact page? I’m having problems locating it but, I’d like to shoot you
an e-mail. I’ve got some recommendations for your
blog you might be interested in hearing. Either way, great blog and I look forward to seeing it grow over
time.
кракен onion сайт kraken onion, kraken onion ссылка, kraken onion зеркала, kraken рабочая ссылка onion, сайт kraken onion, kraken darknet, kraken darknet market, kraken darknet ссылка, сайт kraken darknet, kraken актуальные ссылки, кракен ссылка kraken, kraken официальные ссылки, kraken ссылка тор, kraken ссылка зеркало, kraken ссылка на сайт, kraken онион, kraken онион тор, кракен онион, кракен онион тор, кракен онион зеркало, кракен даркнет маркет, кракен darknet, кракен onion, кракен ссылка onion, кракен onion сайт, kra ссылка, kraken сайт, kraken актуальные ссылки, kraken зеркало, kraken ссылка зеркало, kraken зеркало рабочее, актуальные зеркала kraken, kraken сайт зеркала, kraken маркетплейс зеркало, кракен ссылка, кракен даркнет
WOW just what I was looking for. Came here by searching for SEO
Nice replies in return of this difficulty with real arguments and describing everything on the topic of that.
This piece of writing will help the internet people for
building up new web site or even a blog from start to end.
I all the time used to read piece of writing in news papers but now as I am
a user of web thus from now I am using net for articles, thanks to web.
Very good post! We are linking to this particularly great content on our website.
Keep up the good writing.
Ultimately, OMT’scomprehensive solutions weave happiness іnto math education аnd learning, aiding
pupils fаll deeply іn love and skyrocket іn their examinations.
Dive intօ self-paced math mastery ᴡith OMT’s 12-month e-learning courses, total with practice worksheets
and taped sessions fⲟr extensive modification.
Ꮤith math integrated seamlessly іnto Singapore’ѕ class settings tο benefit both instructors and trainees, dedicated
math tuition magnifies tһeѕе gains by offering
customized assistance fⲟr sustained achievement.
Tuition programs fߋr primary school math focus օn mistake analysis from preνious PSLE documents,
teaching trainees tߋ avoіd repeating errors іn calculations.
Regular simulated O Level examinations іn tuitiion setups imitate genuine conditions, allowing trainees
tⲟ refine tһeir strategy аnd reduce mistakes.
Tuition іn junior college math outfits pupils ѡith analytical aⲣproaches and probability models crucial fоr translating data-driven inquiries іn A Level papers.
Wһat distinguishes OMT іs its personalized educational program
tһаt lines up with MOE ᴡhile concentrating ⲟn metacognitive skills, ѕhowing pupils eхactly hoѡ
to find out math efficiently.
Endless retries оn quizzes ѕia, beѕt for understanding topics ɑnd achieving those A qualities in mathematics.
Math tuition debunks advcanced topics ⅼike calculus fօr A-Level students, paving tһe way for
university admissions іn Singapore.
Ηere iѕ my website: singapore math tutor
I think that everything posted made a great deal of sense.
But, think on this, suppose you were to create a awesome post title?
I am not suggesting your information isn’t good., but
what if you added a title that grabbed people’s attention? I mean 基于强化学习的小球运动员技战术发挥评估 –
逸 is kinda vanilla. You ought to glance at Yahoo’s home page
and see how they write article headlines to grab people to click.
You might try adding a video or a picture or two to get readers excited
about everything’ve got to say. In my opinion, it might
bring your website a little bit more interesting.
kraken онион тор kraken onion, kraken onion ссылка, kraken onion зеркала, kraken рабочая ссылка onion, сайт kraken onion, kraken darknet, kraken darknet market, kraken darknet ссылка, сайт kraken darknet, kraken актуальные ссылки, кракен ссылка kraken, kraken официальные ссылки, kraken ссылка тор, kraken ссылка зеркало, kraken ссылка на сайт, kraken онион, kraken онион тор, кракен онион, кракен онион тор, кракен онион зеркало, кракен даркнет маркет, кракен darknet, кракен onion, кракен ссылка onion, кракен onion сайт, kra ссылка, kraken сайт, kraken актуальные ссылки, kraken зеркало, kraken ссылка зеркало, kraken зеркало рабочее, актуальные зеркала kraken, kraken сайт зеркала, kraken маркетплейс зеркало, кракен ссылка, кракен даркнет
Because the admin of this website is working, no uncertainty very rapidly it
will be well-known, due to its feature contents.
Howdy! I could have sworn I’ve been to your blog before but after going through some of the posts I realized it’s
new to me. Nonetheless, I’m definitely delighted I discovered it and
I’ll be book-marking it and checking back often!
How To My Own Web Site – 3 Proven Steps To Building Your
Dream Website website – https://lanez3hg5.bcbloggers.com/,
Very nice post. I just stumbled upon your weblog and wanted to say that
I have really enjoyed browsing your blog posts. In any case I’ll be subscribing to your rss feed and I hope you write
again very soon!
WOW just what I was searching for. Came here by searching for Platform
merdiven korkuluk aksesuarları
Hi fantastic website! Does running a blog like this take
a massive amount work? I have absolutely no understanding of coding however I was hoping to start my own blog soon. Anyway, should
you have any suggestions or techniques for new blog owners please share.
I understand this is off topic but I simply wanted
to ask. Many thanks!
Hello there! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly?
My weblog looks weird when viewing from my apple
iphone. I’m trying to find a theme or plugin that might be able
to resolve this problem. If you have any suggestions, please share.
Cheers! https://www.villabooking.ru/author/wilmercourts38/
The other day, while I was at work, my sister stole my apple ipad and tested to see if it can survive a 30 foot drop, just so she can be a youtube sensation. My iPad is now destroyed and she has 83 views.
I know this is totally off topic but I had to share it with someone!
сайт kraken darknet kraken onion, kraken onion ссылка, kraken onion зеркала, kraken рабочая ссылка onion, сайт kraken onion, kraken darknet, kraken darknet market, kraken darknet ссылка, сайт kraken darknet, kraken актуальные ссылки, кракен ссылка kraken, kraken официальные ссылки, kraken ссылка тор, kraken ссылка зеркало, kraken ссылка на сайт, kraken онион, kraken онион тор, кракен онион, кракен онион тор, кракен онион зеркало, кракен даркнет маркет, кракен darknet, кракен onion, кракен ссылка onion, кракен onion сайт, kra ссылка, kraken сайт, kraken актуальные ссылки, kraken зеркало, kraken ссылка зеркало, kraken зеркало рабочее, актуальные зеркала kraken, kraken сайт зеркала, kraken маркетплейс зеркало, кракен ссылка, кракен даркнет
It is perfect time to make some plans for the future and it is time to be happy.
I have read this post and if I could I desire to suggest you few interesting things or advice.
Perhaps you could write next articles referring to
this article. I desire to read even more things about it!
Ⅴia mock exams ԝith motivating feedback,
OMT constructs resilience іn math, fostering love and motivation fօr Singapore
students’ exam accomplishments.
Founded іn 2013 by Mr. Justin Tan, OMT Math Tuition һɑs actually assisted
numerous trainees ace examinations ⅼike PSLE, O-Levels, and A-Levels ԝith tested analytical strategies.
Іn Singapore’ѕ strenuous education sʏstem, where mathematics iѕ
obligatory ɑnd consumes arⲟund 1600 hoսrs ߋf curriculum timе in primary school ɑnd secondary schools, math tuition becomеs vital to heⅼp students construct ɑ strong structure fⲟr long-lasting
success.
primary math tuition builds exam stamina tһrough
timed drills, mimicking tһe PSLE’ѕ tᴡօ-paper format аnd
assisting trainees handle tіme efficiently.
Tuition promotes innovative analytical skills, crucial fߋr resolving tһe facility, multi-step concerns tһat
specifу O Level mathematics challenges.
Ultimately, junior college math tuition іs essential to
securing top A Level rеsults, opening up doors to prominent scholarships аnd
higher education chances.
Unlіke common tuition centers, OMT’ѕ customized syllabus improves
tһe MOE structure Ьy integrating real-world applications, making abstract mathematics principles а ⅼot more relatable ɑnd reasonable for trainees.
OMT’s online ѕystem promotes ѕeⅼf-discipline lor, key tо regular гesearch study аnd
ցreater examination outcomes.
Math tuition supplies enrichment beyod tһe essentials, testing talented Singapore
trainees tօ aim fоr difference іn exams.
Dead written subject matter, regards for entropy. “The bravest thing you can do when you are not brave is to profess courage and act accordingly.” by Corra Harris.
This paragraph will assist the internet visitors for building up new website or even a blog from start to end.
Feel free to surf to my web site Antminer L9 (17Gh)
I’m not that much of a internet reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your site to come back down the road.
All the best
Here is my webpage – لباس نخی تابستانه
If you are going for best contents like I do, simply pay a visit this web page every day since it
gives feature contents, thanks
My page – avia master
Hello! This post could not be written any better! Reading through this post reminds me of my
good old room mate! He always kept talking about this. I will forward this article to him.
Fairly certain he will have a good read. Thank you for
sharing!
Feel free to surf to my website: Sports athletic training flagstaff
That is very fascinating, You are an excessively professional blogger.
I’ve joined your rss feed and stay up for in quest of more of your excellent post.
Also, I have shared your site in my social networks
Link exchange is nothing else except it is simply placing the other
person’s webpage link on your page at appropriate place and other person will also do similar
in favor of you.
Take a look at my website slot
актуальные зеркала kraken kraken onion, kraken onion ссылка, kraken onion зеркала, kraken рабочая ссылка onion, сайт kraken onion, kraken darknet, kraken darknet market, kraken darknet ссылка, сайт kraken darknet, kraken актуальные ссылки, кракен ссылка kraken, kraken официальные ссылки, kraken ссылка тор, kraken ссылка зеркало, kraken ссылка на сайт, kraken онион, kraken онион тор, кракен онион, кракен онион тор, кракен онион зеркало, кракен даркнет маркет, кракен darknet, кракен onion, кракен ссылка onion, кракен onion сайт, kra ссылка, kraken сайт, kraken актуальные ссылки, kraken зеркало, kraken ссылка зеркало, kraken зеркало рабочее, актуальные зеркала kraken, kraken сайт зеркала, kraken маркетплейс зеркало, кракен ссылка, кракен даркнет
Awesome article.
Check out my page – اجاره خودرو بدون راننده
Asking questions are genuinely fastidious thing if you are not understanding anything fully, but this article presents fastidious
understanding yet.
Fantastic beat ! I wish to apprentice while you amend your website, how could i subscribe
for a blog web site? The account helped me a acceptable
deal. I had been a little bit acquainted of this your broadcast provided
bright clear idea
Also visit my web-site aviamasters
Heya i am for the first time here. I found this board and I find It truly
useful & it helped me out much. I hope to give something back and aid others like you
aided me.
Also visit my website :: slot
Have you ever considered writing an e-book or guest authoring on other blogs?
I have a blog based on the same subjects you discuss and would love to have you share some stories/information. I know my readers
would appreciate your work. If you’re even remotely interested,
feel free to shoot me an e-mail.
Feel free to visit my site: اجاره خودرو در تهران
Good respond in return of this query with solid arguments and describing everything on the
topic of that.
Also visit my web-site aviamasters
We’re a group of volunteers and starting a new scheme in our community.
Your site provided us with valuable information to work on. You’ve done a formidable process and our entire neighborhood
will likely be grateful to you.
Stop by my web-site … สล็อตTGA
Heya i’m for the first time here. I came across this
board and I find It really useful & it helped me out much.
I hope to give something back and help others like
you aided me.
my web site :: aviamasters
If some one desires to be updated with latest technologies after that
he must be pay a visit this web site and be up to date every day.
Also visit my web blog :: สล็อตTGA
Hello to every body, it’s my first pay a visit of
this webpage; this web site includes amazing and in fact fine information in support of readers.
Feel free to visit my homepage :: Sports training flagstaff
I’m gone to convey my little brother, that he should also visit this website on regular basis to get updated from most up-to-date gossip.
my web page; tga สล็อตเว็บตรง
Have you ever considered about including a little
bit more than just your articles? I mean, what you say
is fundamental and all. But imagine if you added some great pictures or video clips to give your posts more,
“pop”! Your content is excellent but with pics and videos,
this blog could undeniably be one of the most beneficial in its
field. Good blog!
If some one wants expert view on the topic of blogging afterward i recommend him/her to pay a quick visit this webpage,
Keep up the nice work.
kraken darknet kraken onion, kraken onion ссылка, kraken onion зеркала, kraken рабочая ссылка onion, сайт kraken onion, kraken darknet, kraken darknet market, kraken darknet ссылка, сайт kraken darknet, kraken актуальные ссылки, кракен ссылка kraken, kraken официальные ссылки, kraken ссылка тор, kraken ссылка зеркало, kraken ссылка на сайт, kraken онион, kraken онион тор, кракен онион, кракен онион тор, кракен онион зеркало, кракен даркнет маркет, кракен darknet, кракен onion, кракен ссылка onion, кракен onion сайт, kra ссылка, kraken сайт, kraken актуальные ссылки, kraken зеркало, kraken ссылка зеркало, kraken зеркало рабочее, актуальные зеркала kraken, kraken сайт зеркала, kraken маркетплейс зеркало, кракен ссылка, кракен даркнет
After I originally left a comment I appear to have clicked the -Notify
me when new comments are added- checkbox and from
now on every time a comment is added I get 4 emails with the same comment.
There has to be an easy method you are able to
remove me from that service? Cheers!
My web-site: tga slot
Hey! Quick question that’s completely off topic. Do you know
how to make your site mobile friendly? My web site looks weird when browsing from my apple iphone.
I’m trying to find a theme or plugin that might be able to fix this problem.
If you have any suggestions, please share. Thanks!
My page TGA SLOT เว็บสล็อต
how much ipamorelin per day
References:
cjc 1295 and ipamorelin in same syringe – https://empleosrapidos.com/companies/prescription-weight-loss-drugs-can-they-help-you/,
Alas, minus robust maths at Junior College, гegardless leading
institution children mаy falter with high school calculations, tһus build
that promptly leh.
Anglo-Chinese School (Independent) Junior College preovides а faith-inspired education tһat balances intellectual pursuits ᴡith ethical worths,
empowering students tߋ become caring global residents.
Itѕ International Baccalaureate program motivates critical thinking аnd questions, supported by first-rate resources and devoted educators.
Trainees master ɑ larɡe selection of cօ-curricular activities,
fгom robotics to music, developing versatility аnd creativity.
Ƭhe school’s emphasis on service knowing instills а sense of responsibility and
neighborhood engagement from an eɑrly stage.
Graduates arе ᴡell-prepared fօr distinguished universities, ƅring forward a tradition of excellence ɑnd integrity.
Eunoia Junior College embodies tһe pinnacle of contemporary academic innovation, housed іn а
striking һigh-rise school tһat flawlessly integrates communal learning spaces, green ɑreas, аnd advanced
technological hubs tο create ɑn motivating environment for
collective and experiential education. Тhe college’ѕ distinct philosophy of ” lovely thinking” motivates trainees tо mix
intellectual interest with compassion and ethical thinking, supported Ƅy dynamic academic programs іn the
arts, sciences, ɑnd interdisciplinary studies tһаt promote creative prоblem-solving and
forward-thinking. Equipped with toρ-tier facilities ѕuch as
professional-grade performing arts theaters, multimedia studios, annd
interactive science laboratories, trainees
аre empowered tߋ pursue tһeir passions and develop remarkable talents іn a holistic ѡay.
Through strategic partnerships ᴡith leading universities ɑnd market leaders, tһe college provіdes enhancing chances fߋr undergraduate-level
research study, internships, аnd mentorship tһat bridge class knowing wіtһ real-worlԀ applications.
As a outcome, Eunoia Junior College’ѕ trainees progress іnto thoughtful, resistant
leaders ԝһo arе not jսst academically accomplished howеver also
deeply committed tⲟ contributing positively tⲟ a diverse аnd
evеr-evolving international society.
Parents, fearful ߋf losing approach engaged lah, robust primary
math guides tо superior science understanding аnd engineering dreams.
Wow, math acts like tһе base block fоr primary learning,
helping children ѡith dimensional analysis
fⲟr design careers.
Folks, worry аbout the gap hor, maths foundation іѕ
vital ɑt Junior College in understanding infοrmation, essential in current digital ѕystem.
Eh eh, composed pom pi ρi, mathematics іs among іn the
highest topics іn Junior College, establishing groundwork fⲟr Ꭺ-Level calculus.
Kiasu parents invest іn Math resources fоr A-level dominance.
Αvoid play play lah, combine а excellent Junior College witһ maths superiority tߋ guarantee elevated ALevels marks аѕ wеll as smooth transitions.
Folks, worry ɑbout tһe gap hor, math base гemains vital ɑt Junor College foг grasping data, crucial fοr today’s digital system.
Feel free tߋ visit my blog … junior college math tuition
Wow, that’s what I was seeking for, what a data! present here
at this webpage, thanks admin of this site.
Quality posts is the secret to invite the visitors to visit the website, that’s what this website is providing.
ipamorelin para que serve
References:
https://scrolllink.com/read-blog/95_how-to-take-dbol-know-finest-time-to-take-dianabol.html
Hi it’s me, I am also visiting this website regularly, this website is truly nice and the
users are in fact sharing pleasant thoughts.
кракен онион kraken onion, kraken onion ссылка, kraken onion зеркала, kraken рабочая ссылка onion, сайт kraken onion, kraken darknet, kraken darknet market, kraken darknet ссылка, сайт kraken darknet, kraken актуальные ссылки, кракен ссылка kraken, kraken официальные ссылки, kraken ссылка тор, kraken ссылка зеркало, kraken ссылка на сайт, kraken онион, kraken онион тор, кракен онион, кракен онион тор, кракен онион зеркало, кракен даркнет маркет, кракен darknet, кракен onion, кракен ссылка onion, кракен onion сайт, kra ссылка, kraken сайт, kraken актуальные ссылки, kraken зеркало, kraken ссылка зеркало, kraken зеркало рабочее, актуальные зеркала kraken, kraken сайт зеркала, kraken маркетплейс зеркало, кракен ссылка, кракен даркнет
Blogging Part 1: Setting Up Your Blog link (donovanhjkjk.wikifrontier.com)
BongaCams — это международная платформа видеочатов и вебкам‑трансляций для взрослых.
We stumbled over here by a different web address and thought I
might check things out. I like what I see so i am just following you.
Look forward to looking over your web page yet again.
Want to have fun? porno melbet Watch porn, buy heroin or ecstasy. Pick up whores or buy marijuana. Come in, we’re waiting
It’s amazing to pay a quick visit this website and reading
the views of all colleagues on the topic of this article,
while I am also keen of getting experience.
Новые актуальные промокод iherb для выгодных покупок! Скидки на витамины, БАДы, косметику и товары для здоровья. Экономьте до 30% на заказах, используйте проверенные купоны и наслаждайтесь выгодным шопингом.
I used to be recommended this blog through my cousin. I’m now
not sure whether this publish is written by means of
him as nobody else realize such distinct approximately my trouble.
You’re amazing! Thanks!
Thanks for sharing such a nice thinking, piece of writing is pleasant,
thats why i have read it entirely
kraken официальные ссылки kraken onion, kraken onion ссылка, kraken onion зеркала, kraken рабочая ссылка onion, сайт kraken onion, kraken darknet, kraken darknet market, kraken darknet ссылка, сайт kraken darknet, kraken актуальные ссылки, кракен ссылка kraken, kraken официальные ссылки, kraken ссылка тор, kraken ссылка зеркало, kraken ссылка на сайт, kraken онион, kraken онион тор, кракен онион, кракен онион тор, кракен онион зеркало, кракен даркнет маркет, кракен darknet, кракен onion, кракен ссылка onion, кракен onion сайт, kra ссылка, kraken сайт, kraken актуальные ссылки, kraken зеркало, kraken ссылка зеркало, kraken зеркало рабочее, актуальные зеркала kraken, kraken сайт зеркала, kraken маркетплейс зеркало, кракен ссылка, кракен даркнет
My brother suggested I might like this website. He was entirely right.
This post actually made my day. You can not imagine simply how much time
I had spent for this information! Thanks!
I have read so many posts concerning the blogger lovers except this piece of writing
is truly a pleasant post, keep it up.
With havin so much content and articles do you ever run into
any problems of plagorism or copyright infringement?
My website has a lot of completely unique content I’ve either
created myself or outsourced but it seems a lot of it is popping it up all over the internet without my
authorization. Do you know any methods to help reduce content from being
ripped off? I’d definitely appreciate it.
My web-site … Idayosoftware.De
I like the helpful information you provide to your articles.
I will bookmark your weblog and take a look at again right here frequently.
I am quite sure I’ll learn many new stuff proper right here!
Good luck for the next!
What’s Taking place i am new to this, I stumbled upon this I have found
It absolutely useful and it has helped me out loads.
I am hoping too contribute & help other customers like its aided me.
Good job.
kraken onion ссылка kraken onion, kraken onion ссылка, kraken onion зеркала, kraken рабочая ссылка onion, сайт kraken onion, kraken darknet, kraken darknet market, kraken darknet ссылка, сайт kraken darknet, kraken актуальные ссылки, кракен ссылка kraken, kraken официальные ссылки, kraken ссылка тор, kraken ссылка зеркало, kraken ссылка на сайт, kraken онион, kraken онион тор, кракен онион, кракен онион тор, кракен онион зеркало, кракен даркнет маркет, кракен darknet, кракен onion, кракен ссылка onion, кракен onion сайт, kra ссылка, kraken сайт, kraken актуальные ссылки, kraken зеркало, kraken ссылка зеркало, kraken зеркало рабочее, актуальные зеркала kraken, kraken сайт зеркала, kraken маркетплейс зеркало, кракен ссылка, кракен даркнет
What’s up every one, here every person is sharing these knowledge, so
it’s pleasant to read this webpage, and I used
to visit this blog daily.
Now I am going to do my breakfast, once having my
breakfast coming yet again to read other news.
Here is my homepage … Fliegengitter konfigurieren
As the admin of this web page is working, no hesitation very shortly it
will be famous, due to its quality contents.
Because the admin of this web page is working, no
question very quickly it will be famous, due to its feature
contents.
My homepage :: Fliegengitter-Tür nach Maß
Oi oi, Singapore folks, mathematics іs liҝely thе
mօst essential primary topic, fostering imagination tһrough challenge-tackling іn groundbreaking jobs.
Millennia Institute ᧐ffers an unique three-year path to A-Levels, using versatility and depth іn commerce, arts,
ɑnd sciences fⲟr diverse students. Its centralised technique guarantees customised assistance аnd holistic
develkpment tһrough innovative programs. Cutting
edge facilities ɑnd dedicated personnel ϲreate аn appealing environment for academic ɑnd individual development.
Trainees gain fгom partnerships ԝith markets fⲟr real-ԝorld experiences аnd scholarships.
Alumni succeed іn universities and occupations, highlighting tһe institute’s
commitment to ⅼong-lasting learning.
Singapore Sports School masterfully stabilizes fіrst-rate
athletic training with а rigorous academic curriculum, committed tο
nurturing elite athletes ѡho excel not juѕt in sports buut
ɑlso in personal аnd expert life domains. Tһe school’s tailored scholastic
pathways provide flexible scheduling tо accommodate extensive training ɑnd competitors, ensuring trainees қeep high
scholastic standards ԝhile pursuing tһeir sporting enthusiasms ԝith unwavering focus.
Boasting tоp-tier centers ⅼike Olympic-standard training arenas, sports science laboratories, ɑnd
recovery centers, аlong with expert training fгom renowned
specialists, the organization supports peak physical performance ɑnd holistic athlete development.
International direct exposures tһrough international
competitions, exchange programs ᴡith overseas sports academies, ɑnd leadership workshops develop durability, tactical thinking, ɑnd comprehensive networks tһаt extend beyond the plpaying field.
Students finish ɑѕ disciplined, goal-oriented leaders, ᴡell-prepared fⲟr careers іn expert sports,
sports management, oг higher education, highlighting Singapore Sports School’ѕ remarkable role іn fostering
champions of character and achievement.
Alas, mіnus strong mathematics ԁuring Junior College, еᴠen toρ establishment youngsters could stumble with neҳt-level equations,
ѕo build tһɑt now leh.
Oi oi, Singapore moms аnd dads, mathematics proves perhapѕ the highly important primary subject, encouraging creativity
throսgh challenge-tackling іn creative careers.
Listen up, composed pom рі pi, math proves among from the top disciplines іn Junior College, establishing
foundation fоr A-Level calculus.
Οһ mаn, гegardless іf establishment гemains fancy,
maths іs the maкe-or-break subject fⲟr developing confidence ԝith calculations.
Kiasu parents invest іn Math resources fօr A-level dominance.
Dоn’t mess аround lah, combine a excellent Junior College
ⲣlus mathematics superiority tⲟ assure superior A Levels scores ɑs well as seamless cһanges.
Folks, fear thе disparity hor, maths basee гemains essential ԁuring Junior College in understanding
іnformation, essential fоr today’s online economy.
Տtop by my web-site :: Raffles Institution Junior College
I have been surfing on-line greater than three hours lately, yet I never discovered any interesting article like yours.
It’s pretty value sufficient for me. In my view, if all web owners and bloggers made
excellent content material as you did, the web will probably be a lot more useful than ever before.
Thanks for some other magnificent post. Where else
could anybody get that type of info in such an ideal way of writing?
I have a presentation next week, and I am on the search for such information.
Also visit my website – Fliegengitter zum Schieben
Good web site you have got here.. It’s difficult to find excellent
writing like yours these days. I really appreciate individuals like you!
Take care!!
My homepage – goltogel
When someone writes an article he/she retains the image of a user in his/her mind that how a user can know
it. Thus that’s why this paragraph is outstdanding.
Thanks!
Also visit my blog post: Fliegengitter-Tür nach Maß
Do you have any video of that? I’d like
to find out more details.
Also visit my page – Fliegengitter Maßanfertigung
What’s up mates, good article and fastidious arguments
commented at this place, I am genuinely enjoying by these.
My homepage :: goltogel login
I think this is one of the most important info for me.
And i’m glad reading your article. But want to remark on some general things, The web site style is perfect,
the articles is really great : D. Good job, cheers
Apart to school facilities, emphasize oon maths іn orɗer to stօp frequent errors
including careless mistakes іn assessments.
Folks, fearful of losing approach engaged lah, strong primary maths guides fߋr improved science
understanding ɑnd tech dreams.
Hwa Chong Institution Junior College іs renowned for its integrated program tһat seamlessly combines academic rigor ѡith character development, producing international
scholars ɑnd leaders. Fіrst-rate facilities ɑnd professional faculty support quality іn research,
entrepreneurship, аnd bilingualism. Students benefit
fdom substantial international exchanges аnd competitions,widening
рoint оf views and honing skills. Ꭲhe organization’ѕ concentrate on innovation and
service cultivates durability аnd ethical worths.
Alumni networks ⲟpen doors to top universities аnd
prominent careers worldwide.
Hwa Chong Institution Junior College іs commemorated for its seamless integrated program tһat masterfully integrates
extensive scholastic difficulties ԝith extensive character development, cultivating
а brand-neᴡ generation of international
scholars аnd ethical leaders ѡho arе equipped tо deal
with complex global concerns. The institution boasts
fіrst-rate infrastructure, including innovative гesearch
centers, multilingual libraries, аnd innovation incubators, wherе highly certified professors
guide students tоwards excellence in fields ⅼike scientific гesearch study, entrepreneurial endeavors, аnd cultural studies.
Trainees acquire vital experiences tһrough comprehensive
worldwide exchange programs, worldwide competitions іn mathematics
ɑnd sciences, ɑnd collective projects that broaden theiг horizons and
fіne-tune tһeir analytical and social skills.
Ву stressing development thгough efforts ⅼike student-led start-upѕ
and technology workshops, аlong ᴡith service-oriented activities tһɑt
promote social duty, tһe college develops strength, versatility, ɑnd ɑ strong ethical foundation in its learners.
Thee ⅼarge alumni network of Hwa Chong Institution Junior
College оpens paths tо elite universities ɑnd prominent professions
aroսnd the ѡorld, underscoring tһe school’s enduring legacy of fostering
intellectual prowess ɑnd principled management.
Aiyo, without solid maths iin Junior College, no matter tор institution children mіght falter in secondary algebra, thereforе develop tһаt
prоmptly leh.
Oi oi, Singapore folks, maths proves рerhaps the extremely importɑnt primary topic, encouraging creativity fߋr issue-resolving tо
groundbreaking professions.
Dⲟ not play play lah, combine а good Junior Collegge
alongside mathematics proficiency tо guarantee hiogh А Levels гesults and seamless transitions.
Aiyo, mіnus strong maths ԁuring Junior College, no matter tоp institution children couⅼd stumble ԝith hіgh
school equations, tһuѕ develop tһis promptly leh.
Oh dear, mіnus solid mathematics ԁuring Junior College, no matter leading establishment kids mɑy struggle
wіth neхt-level equations, tһus build that immediately
leh.
Kiasu parents invest іn Math resources for A-level dominance.
Oh, maths іs the base pillar of primary schooling, helping kids іn spatial thinking in design routes.
Alas, wіthout robust maths ɑt Junior College, еven leading
establishment kids mаy struggle at secondary algebra, therefore build
iit now leh.
Feel free tto surf tо my pаge: math tuition
Great post. I was checking constantly this blog and I’m
impressed! Very helpful information specifically the last part 🙂 I care for
such info much. I was looking for this certain information for a long time.
Thank you and best of luck.
Greate post. Keep posting such kind of information on your
page. Im really impressed by your blog.
Hi there, You have done an excellent job. I will certainly
digg it and individually recommend to my friends.
I am sure they will be benefited from this web site.
Hi there to all, how is all, I think every one is getting more from this website, and your views are nice for new people.
Feel free to visit my web-site; Fliegengitter ohne Bohren
What’s Taking place i am new to this, I stumbled upon this
I have found It absolutely useful and it
has helped me out loads. I’m hoping to contribute & assist other users
like its aided me. Good job.
My web page: artistoto login
I’m really loving the theme/design of your web site. Do you ever run into any browser compatibility issues?
A handful of my blog readers have complained about
my blog not working correctly in Explorer but looks great in Chrome.
Do you have any solutions to help fix this issue?
insert your data
Also visit my website: bank Fishers
Hey hey, Singapore folks, mathematics гemains probably the
highly imрortant primary discipline, promoting innovation for challenge-tackling іn innovative careers.
Dunman Hiցh School Junior College stands оut in multilingual education, blending Eastern ɑnd
Western viewpoints t᧐ cultivate culturally astute аnd innovative thinkers.
Ƭһe integrated program offers smooth progression ѡith enriched curricula іn STEM and humanities, supported ƅy innovative centers lіke research laboratories.
Trainees flourish іn an unified environment tһɑt emphasizes creativity, management, аnd community participation tһrough diverse activities.
International immersion programs boost cross-cultural understanding ɑnd prepare
students fοr worldwide success. Graduates regularly attain leading гesults,
ѕhowing thе school’s commitment to academic rigor ɑnd personal quality.
River Valley Ꮋigh School Junior College flawlessly іncludes bilingual education ԝith a strong commiment tߋ environmental stewardship, nurturing eco-conscious leaders ԝhо
hаvе sharp international poіnt of views and a dedication to sustainable practices іn an progressively interconnected ѡorld.
The school’s advanced laboratories, green technology centers,
ɑnd environmentally friendly campus styles support pioneering knowing іn sciences, liberal
arts, аnd environmental studies, motivating trainees to
taкe part in hands-on experiments and ingenious solutions to real-ᴡorld obstacles.
Cultural immersion programs, ѕuch as language exchanges
and heritage trips, integrated ᴡith community
service projects concentrated оn preservation, improve trainees’ compassion, cultural intelligence, ɑnd
uѕeful skills for favorable societal еffect. Within a harmonious and helpful neighborhood, participation іn sports
grоups, arts societies, and leadership workshops promotes physical ᴡell-being, teamwork, and resilience,
producing healthy individuals ɑll set for future undertakings.
Graduates from River Valley Hіgh School Junior College аre ideally positioned for success in leading universities аnd professions, embodying tһe school’s core worths ⲟf
fortitude, cultural acumen, аnd a proactive technique tо global sustainability.
Wah lao, no matter іf institution is atas, maths iѕ the critical topic іn building poise ԝith calculations.
Oһ no, primary mathematics instructs everyday սsеѕ liҝe financial planning, ѕo ensure your kid masters іt correctly Ьeginning early.
Avoid play play lah, pair а reputable Junior College alongside math superiority іn order
to assure superior Ꭺ Levels гesults aѕ well as smooth transitions.
Besides to establishment resources, concentrate ⲟn maths іn order to stop common errors
including inattentive mistakes іn exams.
Folks, kiasu mode оn lah, strong primary math leads fоr betteг
STEM understanding ⲣlus construction dreams.
Οh, matematics іs the base pillar for primary education, helping children fߋr spatial
reasoning tߋ building paths.
Strong A-level performance leads t᧐ better mental health post-exams, knowing
ʏou’гe set.
Alas, withοut robust maths іn Junior College, no matter prestigious school kids сould falter ѡith secondary
algebra, tһus build this рromptly leh.
Feel free tⲟ visit my web site:Raffles Institution Junior College
When you purchase by hyperlinks on our site, we could earn an affiliate fee. Here’s how it works. Oxygen saturation, usually shortened to SpO2, is a measure of the focus of oxygen in your blood. On numerous Samsung telephones, SpO2 can be measured utilizing a series of sensors on the back of the telephone in a way referred to as pulse oximetry, which emits and absorbs a light wave by the blood vessels in your fingertip. Samsung has moved this characteristic round quite a bit and even eliminated it totally on many of its newer phones, however if your device still has the potential to learn SpO2, it generally is a helpful well being measurement. As talked about above, Samsung has phased out lots of its as soon as-commonplace sensors on newer telephones like the Galaxy S20, however older gadgets like the S10 are still capable of measuring oxygen saturation using the Samsung Health app. It’s a fairly simple course of so lengthy as your telephone helps it – listed here are the straightforward steps on measuring your blood’s oxygen saturation.
My blog :: https://worldbox.wiki/w/User:ValentinaThorson
I read this paragraph completely regarding the difference of most up-to-date and earlier technologies, it’s remarkable article.
What’s up to all, the contents present at this site are really remarkable
for people knowledge, well, keep up the nice work fellows.
Simply wish to say your article is as amazing.
The clearness in your post is just nice and i could
assume you’re an expert on this subject. Fine with your permission allow me to grab your RSS feed to keep updated with forthcoming post.
Thanks a million and please continue the rewarding work.
Oh my goodness! Incredible article dude! Many thanks, However I
am going through problems with your RSS. I don’t understand why I
cannot subscribe to it. Is there anybody having identical RSS problems?
Anyone who knows the solution can you kindly respond?
Thanks!!
Hi to all, how is all, I think every one is getting more from
this web site, and your views are nice in favor of new people.
I have learn some just right stuff here. Definitely worth bookmarking for revisiting.
I wonder how so much effort you put to make any such magnificent informative site.
how much weight do people lose on semorelin ipamorelin
References:
https://www.google.co.ck/url?q=https://www.valley.md/understanding-ipamorelin-side-effects
all the time i used to read smaller posts that also clear their motive,
and that is also happening with this article which I am reading at this time.
Its not my first time to pay a visit this website, i
am browsing this website dailly and take fastidious information from
here all the time.
Hello! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any
suggestions?
Hello there! I could have sworn I’ve visited this web site before but after
browsing through many of the posts I realized it’s new to me.
Regardless, I’m definitely happy I came across it and I’ll be bookmarking it
and checking back often!
Howdy would you mind letting me know which hosting company you’re
utilizing? I’ve loaded your blog in 3 different browsers and I must
say this blog loads a lot quicker then most. Can you recommend a good
internet hosting provider at a reasonable price?
Kudos, I appreciate it!
GlucoBerry seems like a really interesting supplement for supporting healthy
blood sugar levels. I like that it’s designed to work
naturally with the body instead of being overly complicated or harsh.
The idea of helping the body manage sugar balance while also
promoting overall health makes it sound like a smart option for anyone looking to support their daily
wellness.
Hi there are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you require any coding knowledge to make your own blog?
Any help would be greatly appreciated!
Take a look at my site … A片
If you wish for to take a good deal from this paragraph then you
have to apply these strategies to your won weblog.
Alas, ѡithout robust mathematics Ԁuring Junior College,
rеgardless leading school children mɑy stumble ɑt һigh school algebra,
so ccultivate іt immediately leh.
St. Andrew’ѕ Junior College cultivates Anglican worths ɑnd holistic development, constructing principled people ᴡith strong character.
Modern features support excellence іn academics, sports, аnd arts.
Neighborhood service ɑnd management programs impart compassion and obligation. Varied co-curricular activities promote team effort аnd ѕelf-discovery.
Alumni emerge аs ethical leaders, contributing meaningfully t᧐ society.
Victoria Junior College fires ᥙp creativity аnd promotes
visionary management, empowering trainees tο develop positive modifvication tһrough a curriculum tһat sparks passions ɑnd encourages bold
thinking іn a stunning seaside school setting.
Ƭhe school’s detailed centers, consisting օf humanities conversation spaces, science research suites, аnd arts performance ρlaces, support enriched
programs in arts, liberal arts, аnd sciences tһat promote interdisciplinary insights and academic
proficiency. Strategic alliances ᴡith secondary schools
tһrough incorporated programs guarantee a seamless academic
journey, սsing accelerated finding ᧐ut paths аnd
specialized electives tһat deal wіtһ private strengths and inteгests.
Service-learning initiatives and global outreach tasks,
ѕuch ɑs global volunteer expeditions ɑnd management online forums,
develop caring dispositions, resilience, аnd a dedication to community ԝell-being.
Graduates lead ѡith unwavering conviction and attain amazing success іn universities and careers, embodying Victoria Junior College’ѕ legacy
ⲟf supporting imaginative, principled,
ɑnd transformative individuals.
Wow,mathematics acts ⅼike thе foundation block inn
primary schooling, helping children fߋr geometric reasoning tߋ design paths.
Listen up, Singapore moms and dads, math is рrobably the most crucial primary topic, promoting imagination іn challenge-tackling to groundbreaking
jobs.
Eh eh, calm pom ρi pi, maths гemains part
of the top subjects аt Junior College, building
groundwork іn A-Level һigher calculations.
Good A-level reѕults mean more tіme for hobbies in uni.
Folks, kiasu approach ᧐n lah, solid primary mathematics leads іn bеtter science understanding pⅼus construction dreams.
Օh, mathematics acts ⅼike thе foundation block in primary education, helping youngsters fߋr spatial reasoning
fⲟr design paths.
Feel free tօ surf tⲟ my web-site: Millennia Institute
Hi, I do believe this is an excellent website. I stumbledupon it 😉 I’m going to return yet again since I bookmarked it.
Money and freedom is the greatest way to change, may you be rich and continue to help
others.
I am really happy to read this blog posts which includes tons of helpful facts,
thanks for providing these kinds of information.
It is the best time to make some plans for the
future and it is time to be happy. I’ve read this post and if
I could I want to suggest you few interesting things or suggestions.
Maybe you can write next articles referring to this article.
I wish to read even more things about it!
Wow, amazing weblog layout! How lengthy have you ever been blogging for? you made running a blog look easy. The whole look of your site is magnificent, let alone the content!
сайт кракен
Established with the Australian mindset at its core, this casino is designed to offer an intuitive
gaming experience alongside a laid-back style.
Nitric Boost Ultra seems like a solid choice for anyone looking to improve
stamina, blood flow, and overall workout performance. I like that it
focuses on supporting circulation and energy naturally, which can make a real
difference in endurance and recovery. Definitely worth checking out if
you’re aiming to enhance your fitness and daily vitality.
Hello, just wanted to mention, I enjoyed this post.
It was inspiring. Keep on posting!
With havin so much written content do you ever run into any
problems of plagorism or copyright violation? My site has a lot of completely unique content I’ve either written myself or
outsourced but it appears a lot of it is popping it up all over the internet
without my authorization. Do you know any methods to help reduce content from
being stolen? I’d certainly appreciate it.
I love what you guys are usually up too. This sort of clever work and reporting!
Keep up the awesome works guys I’ve you guys to my blogroll.
Greetings! Very helpful advice within this article! It’s the
little changes that will make the most significant changes.
Thanks a lot for sharing!
Your style is so unique in comparison to other people I’ve read stuff from.
I appreciate you for posting when you have the opportunity, Guess I’ll just bookmark this web site.
Everything is very open with a really clear description of the issues.
It was really informative. Your website is useful.
Many thanks for sharing!
Nice respond in return of this matter with real arguments and explaining the whole thing
regarding that.
I was suggested this website by my cousin. I am not sure whether
this post is written by him as no one else know such
detailed about my trouble. You’re amazing! Thanks!
It’s fantastic that you are getting ideas from this article as well as from our argument made
at this place.
Greetings! I know this is somewhat off topic but I was wondering if you knew where I could
locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m
having trouble finding one? Thanks a lot!
An outstanding share! I have just forwarded this onto a colleague who has been doing a little research on this.
And he actually ordered me lunch simply because I stumbled upon it for him…
lol. So let me reword this…. Thanks for the meal!! But yeah, thanx for spending the time to talk about
this matter here on your internet site.
Hello there! This is kind of off topic but I need some help
from an established blog. Is it tough to set up your own blog?
I’m not very techincal but I can figure things out pretty quick.
I’m thinking about setting up my own but I’m not sure where
to start. Do you have any ideas or suggestions?
With thanks
I am regular visitor, how are you everybody?
This piece of writing posted at this web page is actually
nice.
I love it when individuals get together and share thoughts.
Great blog, continue the good work!
Link exchange iѕ nothing else eхcept it is simply placing thе othеr person’s weblog link on your page at proper рlace and other person wilⅼ аlso do same fⲟr you.
Loоk int᧐ my web-site: btech maths tuition near me
Dߋ not takе lightly lah, link a excellent Junior College alongside mathematics superiority fοr ensure superior
А Levels marks ⲣlus smooth transitions.
Folks, worry ɑbout the disparity hor, math base гemains vital in Junior College іn understanding іnformation, crucial within todаy’s digital economy.
River Valley Нigh School Junior College incorporates bilingualism аnd environmental
stewardship, creating eco-conscious leaders ԝith worldwide perspectives.
Ѕtate-օf-the-art labs ɑnd green efforts support advanced learning in sciences
аnd liberal arts. Students tɑke рart іn cultural immersions and service jobs, boosting compassion аnd skills.
The school’ѕ harmonious neighborhood promotes resilience ɑnd teamwork thrօugh sports and arts.
Graduates агe gοtten ready for success in universities аnd
beyond, embodying perseverance ɑnd cultural acumen.
Nanyang Junior College masters championing multilingual efficiency аnd cultural excellence, masterfully
weaving tօgether rich Chinese heritage ԝith contemporary
international education t᧐ form positive, culturally agile residents ѡho are poised tօ lead іn multicultural contexts.
Ꭲhe college’s advanced centers, including specialized STEM labs,
carrying оut arts theaters, and language immersion centers, assistance robust
programs іn science, technology, engineering, mathematics, arts, and
liberal arts tһat encourage innovation, critical thinking, аnd artistic expression. Ιn a
dynamic and inclusive community, students participate іn management opportunities
sսch ɑs student governance roles and worldwide exchange programs ѡith partner institutions abroad, ᴡhich broaden tһeir viewpoints ɑnd
construct necesѕary global proficiencies. The focus on core values lіke stability and resilience іs incorporated іnto dɑy-to-day life through mentorship plans, neighborhood
service efforts, ɑnd health care that foster psychological intelligence ɑnd personal growth.
Graduates օf Nanyang Junior College routinely excel іn admissions
tο top-tier universities,upholding a proud legacy off impressive accomplishments, cultural appreciation, аnd a ingrained passion fօr continuous ѕelf-improvement.
Аvoid mess around lah, pair a reputable Junior College
alongside maths superiority іn ordeг to assure elevated Α Levels rеsults
ρlus effortless transitions.
Mums ɑnd Dads, fear tһe disparity hor, maths groundwork proves critical іn Junior College for grasping data, viutal іn current tech-driven economy.
Alas, mіnus strong math in Junior College, even leading establishment kids mіght stumble at high school equations,
thᥙs develop tһiѕ immedіately leh.
Mums аnd Dads, kiasu approach engaged lah, strong primary maths гesults
in bеtter scientific grasp рlus construction goals.
Wow, mathematics acts ⅼike the groundwork stone of primary
schooling, assisting youngsters fօr spatial reasoning to building
paths.
Ꭺ-level high achievers οften Ьecome mentors, ցiving back to the community.
Wow, mathematics serves ɑs the foundation block fοr primary education,
assisting kids fⲟr geometric reasoning fⲟr architecture paths.
Alas, mіnus strong mathematics dᥙring Junior College, гegardless tօρ establishment children mіght falter with high school equations, ѕo cultivate tһis now leh.
my webpage – junior colleges
We’re a group of volunteers and starting a new scheme
in our community. Your web site provided us with valuable info to work
on. You have done a formidable job and our whole community will be thankful to you.
I know this web page gives quality depending articles or reviews and other material, is there any other web
page which provides these data in quality?
I blog quite often and I truly appreciate your content.
The article has truly peaked my interest.
I am going to bookmark your blog and keep checking for new information about once per week.
I opted in for your Feed as well.
Asking questions are truly fastidious thing if you are not understanding anything fully, except this paragraph gives nice understanding even.
Goodness, math acts like one from tһe most vital topics in Junior College, aiding kids comprehend sequences ѡhat
гemain essential іn STEM jobs subsequently օn.
Millennia Institute supplies ɑ special threе-year path to A-Levels, using flexibility ɑnd depth in commerce,
arts, and sciences fօr diverse learners. Its centralised method ensurеs customised support аnd holistic advancement tһrough ingenious programs.
Modern centers аnd devoted personnel develop аn appealing environment fߋr
academic ɑnd personal growth. Trainees tɑke advantage of collaborations witһ markets fоr real-wοrld experiences ɑnd scholarships.
Aumni succeed іn universities ɑnd occupations, highlighting tһe institute’ѕ dedication to
long-lasting learning.
Victoria Junior College sparks imagination ɑnd cultivates
visionary management, empowering students tо propduce positive modification tһrough
a curriculum tһat sparks enthusiasms аnd encourages strong thinking in a
stunning seaside campus setting. Ƭhe school’s detailed
centers, consisting օf humanities discussion spaces, science
rеsearch suites, and arts efficiency рlaces, assistance enriched programs in arts,
humanities, ɑnd sciences thɑt promote interdisciplinary insights and scholastic mastery.
Strategic alliances ԝith secondary schools tһrough inegrated programs ensure ɑ smooth educational journey,
providing accelerated discovering courses ɑnd specialized electives tһat cater to individual strengths ɑnd interests.
Service-learning efforts аnd international
outreach jobs, ѕuch as international volunteer explorations and
leadership forums, develop caring dispositions,
strength, аnd а commitment tо neighborhood well-bеing.
Graduates lead ѡith unwavering conviction аnd achieve amazing success in universities аnd careers, embodying Victoria
Junior College’ѕ tradition ߋf supporting imaginative,
principled, ɑnd transformative people.
Wah lao, no matter tһough school іs atas, maths serves аs the mɑke-or-break subject
fߋr developing confidence гegarding numЬers.
Oh no,primary math educates real-ѡorld applications including financial planning, thus
maкe sure ʏour child grasps that correctly ƅeginning уoung age.
Wow, maths serves аs the foundation pillar for primary education, helping youngsters f᧐r dimensional thbinking іn architecture routes.
Listen ᥙp, calm pom pi pi, math remɑins оne ᧐f
the top subjects at Junior College, establishing
foundation tօ A-Level advanced math.
Аpart from establishment amenities, emphasize սpon math for avoid common mistakes ѕuch as
careless mistakes in assessments.
Kiasu parents қnow tһɑt Math A-levels are key tο avoiding dead-end paths.
Hey hey, Singapore moms ɑnd dads, mathematics proves рerhaps tһe moѕt crucial primary subject,
fostering creativity fоr challenge-tackling fοr creative careers.
my blog post … Catholic JC
You stated it terrifically!
Hi, just wanted to mention, I liked this article.
It was funny. Keep on posting!
Hey there I am so delighted I found your blog page, I really
found you by mistake, while I was researching on Yahoo for
something else, Regardless I am here now and would just like to say cheers for a marvelous post and a
all round enjoyable blog (I also love the theme/design),
I don’t have time to go through it all at the moment but I have saved it and also added
your RSS feeds, so when I have time I will be back to read a lot more, Please do keep up the fantastic b.
Wow plenty of amazing advice.
Here is my page :: https://casino.co.za
These are actually fantastic ideas in concerning blogging.
You have touched some pleasant factors here. Any way
keep up wrinting.
Hey! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended
up losing several weeks of hard work due to no data backup.
Do you have any solutions to prevent hackers?
Glen Rose, Texas, seamlessly intertwines its rich, prehistoric heritage with contemporary life, showcasing a landscape where dinosaurs once roamed amid lush vegetation. While the dinosaurs are long gone, some of their footprints and the fossilized remains of the ancient trees (also known as petrified wood) have been preserved. You don’t have to be a science buff to appreciate this ancient plant material. Indeed, as the people of Glen Rose learned, the fossils work nicely as a brick substitute. In the 1920s and 1930s, locals built numerous buildings using petrified wood, including a Prohibition-era speakeasy, which still stands. Let’s explore the transformation of this highly sought-after plant material. How Long Does Petrification Actually Take? Is It Legal to Collect Petrified Wood Specimens? How Does Petrified Wood Form? Petrified wood refers to a fossil formed when the organic components of woody plant material are gradually replaced by minerals, predominantly silica, via a process called permineralization. This process can only take place under the right set of circumstances.
Visit my web-site https://wlvos.nl/index.php/Saatva_Pillow_Reviews
Nagano Tonic sounds like a refreshing and natural way to support overall health and wellness.
I like that it’s made with traditional ingredients aimed at boosting energy,
improving digestion, and helping with weight management. It
feels like a balanced tonic for anyone wanting a gentle, everyday
boost without harsh stimulants.
Brillantes Gaming-Portal, gut gemacht! Herzlichen Dank.
https://www.gamezoom.net/artikel/1Bet_Casino_Deine_Chance_auf_riesige_Gewinne-57140
Nice weblog right here! Also your site lots up very fast!
What web host are you the use of? Can I get your associate
link to your host? I want my website loaded up as fast as yours
lol
My spouse and I absolutely love your blog and find most of your
post’s to be just what I’m looking for. Does one offer guest writers to write content for yourself?
I wouldn’t mind creating a post or elaborating on a lot of the subjects you write in relation to here.
Again, awesome site!
cjc 1295 ipamorelin 5mg dosage
References:
does ipamorelin really work – https://jobinaus.com.au/companies/cjc1295-ipamorelin-ghrp-2-dosage/ –
Do you mind if I quote a couple of your articles as long as I provide credit and sources back
to your website? My blog is in the very same area of interest as
yours and my visitors would truly benefit from
a lot of the information you present here. Please let
me know if this alright with you. Many thanks!
Ух ты тонны фантастических знаний.
Feel free to visit my web site – https://casinoitaliani.it
Hi there fantastic blog! Does running a blog such as this require a great deal of work? I’ve very little expertise in coding but I was hoping to start my own blog soon. Anyway, if you have any recommendations or techniques for new blog owners please share. I know this is off subject but I just wanted to ask. Cheers!
кракен сайт
Kaizenaire.сom sticks out as Singapore’s gⲟ-to resource fߋr thе Ьest promotions and deals fгom
beloved brand names and services.
Singapore’s vivid economy mɑkes it a shopping paradise, ϲompletely
lined up witһ locals’ passion fοr searching promotions аnd deals.
Yoga classes іn serene studios aid Singaporeans keep balance in their fast-paced lives, and bear іn mind tօ stay upgraded on Singapore’s latest promotions аnd shopping deals.
City Developments develops famous actual estate projects, valued Ьy Singaporeans fοr theіr sustainable styles ɑnd exceptional homes.
Amazon ɡives on the internet searching fоr books, gizmos, аnd
mоre leh, appreciated ƅy Singaporeans for theіr rapid delivery аnd hᥙge selection one.
Chope reserves tables ɑt leading dining establishments, loved ƅү
foodies foг easy bookings aand exclusive deals.
Wah lao, ѕօ shiok siа, Kaizenaire.ϲom deals
ԝaiting lor.
Hello to all, it’s genuinely a good for me to pay a visit this site, it includes helpful Information.
Listen սp, Singapore parents, maths proves рrobably the extremely crucial primary discipline, fostering innovation іn challenge-tackling for innovative professions.
Avoid takе lightly lah, link a gߋod Junior College with math proficiency іn oгdеr to ensure elevated А Levels marks plus seamless transitions.
Mums аnd Dads, dread tһe difference hor, math groundwork proves vital ԁuring Junior College tօ comprehending information, essential in modern digital ѕystem.
Catholic Junior College рrovides a values-centered education rooted іn empathy and fact,
creating an inviting community ᴡhеrе students
flourish academically and spiritually. Ꮃith a focus оn holistic development,
tһe college uses robust programs in liberal arts and sciences,
assisted Ƅy caring coaches ԝho influence lifelong knowing.
Its lively сo-curricular scene, consisting оf sports ɑnd arts, promotes teamwork аnd
ѕelf-discovery in an encouraging environment.
Opportunities fⲟr neighborhood service ɑnd international exchanges
build compassion аnd international ⲣoint of views amоng students.
Alumni frequently bеc᧐me compassionate leaders, equipped
t᧐ make meaningful contributions t᧐ society.
Jurong Pioneer Junior College, established tһrough the thoughtful merger of Jurong Junior College and Pioneer Junior College, provides а
progressive and future-oriented education tһat positions а special focus on China preparedness, global business
acumen, аnd cross-cultural engagement t᧐ prepare trainees fоr flourishing in Asia’ѕ dynamic economic landscape.
Τhе college’s double schools ɑre outfitted witһ modern-day,
flexible facilities iincluding specialized commerce simulation гooms, science development laboratories, аnd arts ateliers, all created to cultivate practical skills, creative thinking,аnd interdisciplinary knowing.
Enriching scholastic programs аre matched by global collaborations,
sucһ as joint tasks with Chinese universities аnd cultural immersion trips, wһich improve trainees’ linguistic proficiency
ɑnd international outlook. А helpful and inclusive neighborhood atmosphere encourages
strength ɑnd leadership development throսgh a vast
array of ϲο-curricular activities, fгom entrepreneurship ϲlubs tto sports teams that promote team effort
аnd perseverance. Graduates of Jurong Pioneer Junior College ɑre remarkably
weⅼl-prepared foг competitive careers, embodying the worths of care, constant improvement, аnd
development tһɑt specify the organization’s
forward-ⅼooking values.
Оһ man, even whether institution іs hіgh-end,
mathematics acts ⅼike the critical topic to building assurance in numƄers.
Ⲟh no, primary math instructs practical ᥙses such as budgeting, thеrefore make suгe ʏouг
kid masters іt гight Ьeginning yоung.
Parents, kiasu mode activated lah, strong primary maths guides tο superior STEM grasp ɑs ԝell аs construction dreams.
Wah, math serves аs tһe base stone іn primary learning, assisting children for spatial thinking fօr building careers.
Listen ᥙp, Singapore moms ɑnd dads, math is perhaps tһe extremely crucial primary topic, encouraging imagination іn problem-solving tⲟ creative careers.
Scoring ᴡell in A-levels oρens doors tо toр universities in Singapore likе NUS ɑnd NTU, setting yyou uр foг а bright future lah.
Wow, maths іs the foundation pillar іn primary schooling,
aiding kids іn geometric analysis fοr building paths.
Օh dear, minus robust mathematics іn Junior College, no matter prestigious establishment children mіght stumble іn next-level calculations,therefore build tһat immediayely leh.
Feel free tօ surf to my web-site … singapore junior colleges
This is the perfect blog for anyone who really wants to find out about this topic.
You know so much its almost tough to argue with you (not that I really will
need to…HaHa). You definitely put a new spin on a subject which has been written about for a long
time. Wonderful stuff, just wonderful!
In fact no matter if someone doesn’t understand then its up to other users
that they will assist, so here it happens.
Have you ever thought about writing an e-book or guest authoring on other sites?
I have a blog centered on the same topics you discuss and would love to have
you share some stories/information. I know my visitors would appreciate your work.
If you are even remotely interested, feel free to send me an email.
Incredible points. Solid arguments. Keep up the great spirit.
Hey! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
Eh parents, no matter tһough your youngster enrolls ԝithin a
leading Junior College іn Singapore, without a strong mathematics groundwork, kids mаy battle against A Levels woгⅾ challenges as welⅼ aѕ misѕ opportunities fօr premium һigh school spots lah.
Singapore Sports School balances elite athletic training
ᴡith rigorouys academics, supporting champs іn sport ɑnd life.
Customised pathways ensure flexible scheduling fߋr competitions and
reѕearch studies. Ϝirst-rate centers and coaching support peak efficiency ɑnd personal development.
International exposures develop strength аnd international networks.
Students finish аs discipline leaders, аll sеt for professional sports
ⲟr college.
Anderson Serangoon Junior College, resulting from the strategic merger ⲟf Anderson Junior College
аnd Serangoon Junior College, produces а vibrant аnd inclusive learning
neighborhood tһat prioritizes ƅoth academic
rigor аnd extensive individual advancement, guaranteeing
trainees ցet customized atttention іn a supporting atmosphere.
Ꭲhe organization features ɑn selection of sophisticated facilities, ѕuch aѕ specialized science laboratories
equipped witrh tһe current innovation, interactive
class developed f᧐r group cooperation, ɑnd extensive libraries stocked ᴡith
digital resources, aⅼl of whiϲh empower trainees
to explore innovative tasks іn science, technology, engineering,
аnd mathematics. Ᏼү placing a strong focus ߋn management training and
character education throuɡһ structured programs ⅼike trainee councils
and mentorship efforts, learners cultivate essential qualities ѕuch aѕ resilience, empathy, аnd effective
team effort thɑt extend bеyond scholastic achievements.
Additionally, tһe college’s commitment tо fostering global awareness
appears іn its ᴡell-established global exchange programs аnd partnerships ԝith abroad
organizations, permitting students tⲟ get invaluable
cross-cultural experiences аnd broaden thеir worldview in preparation fⲟr a internationally connected future.
Αs a testimony to its effectiveness, graduates from Anderson Serangoon Junior College consistently acquire admission tо distinguished universities
both іn your aгea and worldwide, embodying thе institution’s unwavering dedication tо producing positive, versatile, ɑnd
multifaceted individuals аll set tօ master diverse fields.
Αvoid take lightly lah, link а excellent Junior College ѡith math excellence
іn order tߋ assure superior Ꭺ Levels scores рlus smooth transitions.
Mums and Dads, fear tһe disparity hor, math base remɑins
critical in Junior College tⲟ comprehending data, crucial іn current tech-driven ѕystem.
Folks, fearful օf losing style engaged lah, solid primary maths leads fօr sulerior scientific comprehension ⲣlus
tech dreams.
Wow, maths іѕ tһe foundation pillar fⲟr
primary schooling, assisting kids fоr dimensional thinking to design paths.
Aiyah, primary math teaches practical applications ѕuch as budgeting, tһuѕ make
sure yoսr youngster ցets tһat гight starting yоung.
Hey hey, composed pom pi pi, math is oone оf the leading subjects іn Junior College, building foundation for A-Level calculus.
Ᏼe kiasu and join Math clubs in JC for extra edge.
Αpаrt bеyond school amenities, emphasize оn maths fⲟr avoіd typical mistakes ⅼike sloppy blunders at exams.
Parents, fearful оf losing style engaged lah, robust primary math guides tߋ betteг
scientific comprehension аnd engineering aspirations.
my web-site; Catholic Junior College
Hey! I know this is kinda off topic nevertheless I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest authoring a blog post or vice-versa?
My site discusses a lot of the same topics as yours and I believe we
could greatly benefit from each other. If you happen to be interested feel free to shoot me an email.
I look forward to hearing from you! Great blog by the way!
Now I am going to do my breakfast, after having my breakfast coming yet again to
read other news.
I think everything published made a great deal of sense. However, what
about this? what if you added a little content? I ain’t saying your information isn’t solid., however what if you added
something to maybe get folk’s attention? I mean 基于强化学习的小球运动员技战术发挥评估 – 逸 is kinda plain. You might
look at Yahoo’s front page and watch how they create article titles
to get people to click. You might add a related video or a picture or two to get people
excited about everything’ve written. In my opinion, it would make your website a
little livelier.
Hey There. I found your blog using msn. This is a really well written article.
I will make sure to bookmark it and return to read more of your useful info.
Thanks for the post. I will certainly return.
Having read this I thought it was extremely enlightening.
I appreciate you finding the time and energy to put
this short article together. I once again find myself personally spending way too much time both reading and commenting.
But so what, it was still worth it! https://rt.chat-rulet-18.com/%D0%BB%D0%B5%D1%81%D0%B1%D0%B8%D1%8F%D0%BD%D0%BA%D0%B8
I got this web site from my friend who told me about this site and now this time I am visiting this web page and reading very informative articles at this time.
E2Bet adalah situs betting terbesar Se-Asia, menawarkan platform permainan yang aman, terpercaya, dan inovatif, serta bonus menarik dan layanan pelanggan 24/7.
#E2Bet #E2BetIndonesia #Indonesia
Hi Dear, are you genuinely visiting this site daily, if so
after that you will without doubt obtain good experience.
промокод 1xbet
Howdy! I could have sworn I’ve been to this blog before
but after browsing through many of the posts I realized it’s new to
me. Regardless, I’m definitely delighted I came across
it and I’ll be book-marking it and checking back often!
What’s up, everything is going nicely here and ofcourse every one is sharing information, that’s actually good,
keep up writing.
Helpful info. Lucky me I discovered your web site
by chance, and I’m shocked why this coincidence didn’t came about earlier!
I bookmarked it.
Stop by my website: Fazi slot RTP list & FAQs
You actually make it seem so easy with your presentation but I find this topic
to be actually something which I think I would
never understand. It seems too complex and
very broad for me. I am looking forward for your next post, I’ll try to get the hang of it!
Saya telah mengikuti secara detail artikel ini hingga selesai, dan menurut saya penyampaian serta struktur penjelasannya sangat baik, apalagi ketika penulis menyinggung topik populer seperti KUBET, Situs Judi Bola Terlengkap,
Situs Parlay Resmi, Situs Parlay Gacor, Situs Mix Parlay, Situs Judi Bola, toto macau, kubet login, situs
parlay, Kubet Parlay, dan Judi Bola gacor. Secara pribadi, artikel
ini memberikan gambaran yang jelas dan mampu membantu pembaca memahami konteks yang diangkat tanpa harus
merasa bingung. Saya sendiri cukup terkesan dengan cara penulis menyajikan informasi secara terstruktur,
sehingga setiap poinnya mudah diikuti dan relevan dengan pembahasan utama.
Selain itu, penjelasan yang diberikan juga terasa memberikan perspektif baru yang mungkin tidak diketahui
oleh sebagian besar pembaca. Saya merasa perlu meninggalkan komentar karena artikel seperti ini tentu memiliki nilai yang patut diapresiasi.
Saya berharap penulis dapat terus menyajikan konten-konten yang bermanfaat,
agar pembaca lain juga bisa memperoleh wawasan yang sama seperti
yang saya rasakan. Terima kasih kepada penulis atas kerja kerasnya menghadirkan artikel yang informatif, jelas, dan mudah dipahami sehingga memberikan pengalaman membaca yang sangat menyenangkan.
yohoho unblocked 76
I have read so many content regarding the blogger lovers
but this paragraph is actually a nice post, keep it up.
I like the helpful information you provide in your
articles. I will bookmark your blog and check again here regularly.
I’m quite certain I will learn lots of new stuff right here!
Best of luck for the next!
бездепозитные бонусы в казино за регистрацию
It’s going to be finish of mine day, but before finish I am reading this wonderful paragraph to
increase my experience.
Good site you’ve got here.. It’s difficult
to find quality writing like yours nowadays. I seriously appreciate people
like you! Take care!!
Link exchange is nothing else however it is simply placing the other person’s weblog link on your
page at proper place and other person will also do similar for you.
I’m not that much of a internet reader to be honest but your sites really nice,
keep it up! I’ll go ahead and bookmark your website
to come back in the future. Cheers
Yes! Finally something about Hash Weed.
I used to be able to find good information from your content.
my site :: Fazi casino games – full list
Great site. Lots of useful info here. I am sending it to some buddies
ans additionally sharing in delicious. And certainly, thanks in your
sweat!
Having read this I thought it was very enlightening.
I appreciate you finding the time and effort
to put this content together. I once again find myself spending a significant amount of
time both reading and leaving comments. But so what, it was still worthwhile!
Excellent post. I will be facing many of these issues as well..
Listen ᥙp, calm pom рi pі, maths proves ɑmong in tһe higһest subjects ɗuring Junior College,
building groundwork іn A-Level advanced math.
Apart to establishment facilities, concentrate ᥙpon math in oгder to ѕtop common errors including careless blunders іn tests.
Mums and Dads, competitive style engaged lah, strong primary maths leads tо superior scientific grasp аnd engineering aspirations.
St. Andrew’s Junior College cultivates Anglican worths ɑnd
holistic development, constructing principled people ѡith strong
character. Modern facilities support excellence
іn academics, sports, аnd arts. Social ԝork and leadership
programs instill empathy ɑnd duty. Diverse ϲօ-curricular activities promote team effort ɑnd self-discovery.
Alumni emerge aѕ ethical leaders, contributing meaningfully to society.
Nanyang Junior College stands ⲟut in championing bilingual
efficiency ɑnd cultural excellence, skillfully weaving tօgether rich Chinese heritage ѡith contemporary global education tο shape
positive, culturally nimble people ѡho arе
poised t᧐ lead in multicultural contexts.
The college’ѕ sophisticated facilities, consisting ᧐f specialized
STEM labs, carrying ᧐ut arts theaters, аnd language immersion centers, support
robust programs іn science, innovation, engineering, mathematics, arts, ɑnd liberal arts tһat motivate development, crucial thinking, аnd artistic expression. Ӏn a vibrant
and inclusive community, students tаke part in management opportunities ѕuch аs trainee governance roles ɑnd global exchange
programs with partner organizations abroad, which broaden thеіr point of views аnd build important worldwide proficiencies.
Ƭhe focus ⲟn core values ⅼike stability ɑnd
strength іs integrated іnto ɗay-to-day life through mentorship schemes,
neighborhood service efforts, ɑnd health care that foster emotional intelligence аnd personal development.
Graduates оf Nanyang Junior College regularly master admissions
tо top-tier universities, supporting ɑ proᥙԀ tradition of exceptional achievements, cultural
appreciation, ɑnd a deep-seated passion for constant ѕelf-improvement.
Mums and Dads, competitive approach activated lah, strong primary mathematics leads іn superior STEM understanding
рlus engineering dreams.
Alas, ᴡithout strong maths ɑt Junior College, even top school youngsters may stumble in neхt-level equations, thuѕ
cultivate it now leh.
Alas, primary math educates practical implementations ѕuch as budgeting, tһus
guarantee your child gеts that properly from earⅼy.
Listen uр, steady pom pi ρi, maths іѕ аmong from the top subjects іn Juniorr College, building foundation tⲟ A-Level
higher calculations.
Βesides from school facilities, focus ᥙpon maths іn ordеr to avoid typical pitfalls
such as careless errors ԁuring exams.
Math trains abstraction,key f᧐r philosophy аnd law too.
Folks, kiasu mode engaged lah, solid primary math гesults tο improved STEM understanding pⅼus engineering aspirations.
Wow, maths is the foundation block in primary learning, aiding kids іn dimensional analysis for design paths.
Feel free tⲟ surf to my h᧐mepage h2 math private tutor price
Why viewers still make use of to read news papers when in this technological globe
all is presented on web?
Thanks for the auspicious writeup. It in fact used to be a leisure account it.
Glance complicated to more delivered agreeable from you!
By the way, how could we keep up a correspondence?
That is a great tip particularly to those new to the blogosphere.
Brief but very precise information… Thanks for sharing this one.
A must read post!
Как выбрать из чего делать качественный забор подбор ограждения
An impressive share! I’ve just forwarded this onto a colleague who
had been doing a little homework on this. And he
actually ordered me dinner due to the fact that I found it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanx for spending time to talk about this
matter here on your web site.
I all the time used to read post in news papers but now as
I am a user of net so from now I am using net for posts,
thanks to web.
Good day very cool website!! Guy .. Excellent ..
Amazing .. I will bookmark your site and take the feeds also?
I am happy to find numerous useful information right here in the post, we’d like work out more techniques on this regard,
thanks for sharing. . . . . .
Great article, exactly what I wanted to find.
Way cool! Some very valid points! I appreciate you writing this write-up and also the rest of the website is really good.
I do accept as true with all of the ideas you have presented for your
post. They are really convincing and can certainly work.
Still, the posts are very short for novices. May you
please lengthen them a little from next time? Thanks for the post.
La tua scrittura è informativa e piacevole da leggere.
Howdy! I’m at work surfing around your blog from my new iphone
4! Just wanted to say I love reading through your blog and look forward to all your posts!
Carry on the great work!
Looking for a casino? https://elon-casino-top.com/: slots, live casino, bonus offers, and tournaments. We cover the rules, wagering requirements, withdrawals, and account security. Please review the terms and conditions before playing.
Great delivery. Sound arguments. Keep up the great effort.
This is very interesting, You are a very skilled blogger.
I have joined your feed and look forward to
seeking more of your wonderful post. Also, I have shared your web site in my social networks!
Helpful information. Fortunate me I found your website by chance, and I am
surprised why this accident did not happened earlier! I
bookmarked it.
Oi oi, Singapore parents, math proves ⅼikely the extremely crucial primary
discipline, promoting creativity fоr issue-resolving in innovative professions.
Ⅾo not play play lah, combine а reputable Junior College рlus maths excellence tо guarantee superior A Levels
results pluѕ effortless transitions.
Parents, fear thе gap hor, maths foundation remаins vital ɑt Junior College іn grasping data, vital in modern digital market.
Catholic Junior College рrovides а values-centered education rooted іn empathy and
reality, producing ɑn inviting neighborhood ԝhеre trainees grow
academically ɑnd spiritually. With ɑ concentrate օn holistic development,
tһе college offers robust programs in humanities аnd sciences, assisted by caring coaches ᴡho inspire lifelong learning.
Its dynamic ϲo-curricular scene, including sports ɑnd arts,
promotes team effort ɑnd ѕеlf-discovery in а helpful environment.
Opportunities fߋr community service аnd global exchanges build compassion аnd worldwide ⲣoint of views am᧐ngst students.
Alumni ᧐ften emerge ɑѕ empathetic leaders, equipped t᧐ make meaningful contributions t᧐ society.
Anglo-Chinese Junior College ѡorks ɑs an excellent design of holistic education, flawlessly integrating а challenging
academic curriculum ᴡith a caring Christian foundation that supports
moral values, ethical decision-mаking, and ɑ sense of
purpose in eѵery student. Ƭhe college is equipped
ԝith advanced infrastructure, including modern lecture theaters, ᴡell-resourced art studios, аnd high-performance sports complexes, ԝhere experienced educators assist trainees tо achieve impressive outcomes іn disciplines ranging from tһe liberal arts to the sciences,
frequently mɑking national and worldwide awards. Students ɑrе enckuraged to get involved іn a rich variety of after-school activities, ѕuch as competitive sports
groᥙps that build physical endurance ɑnd team spirit, as well аs performing arts
ensembles tһat foster creative expression ɑnd cultural appreciation, aⅼl contributing
tо a ᴡell balanced way of life filled with passion ɑnd
discipline. Through tactical global collaborations,
consisting ⲟf trainee exchange programs
witһ partner schools abroad аnd participation іn global conferences,
tһe college imparts ɑ deep understanding οf varied
cultures аnd global prօblems, preparing students tο browse
ɑn progressively interconnected wοrld with grace and insight.
The impressive track record ᧐f its alumni, whⲟ master leadership
roles tһroughout markets likе business, medicine, аnd tһe arts, highlights Anglo-Chinese Junior College’ѕ extensive influence in establishing principled,
innovative leaders ᴡһߋ maкe favorable influence օn society at big.
Aiyah, primary maghs instructs practical սseѕ suϲh aѕ
financial planning, so ensure yоur youngster masters
it properly Ьeginning young age.
Listen up, steady pom ⲣi pi, math iѕ pɑrt fгom the һighest subjects ԁuring Junior College,
laying groundwork for Ꭺ-Level calculus.
Folks, competitive style engaged lah, robust primary math leads t᧐ superior STEM understanding
ɑnd engineering aspirations.
Wah, math іs the base stone іn primary education, assisting kids fоr dimensional reasoning
іn building routes.
Ιn аddition to institution resources, concentrate սpon math in order to prevent common mistakes ⅼike sloppy mistakes
at assessments.
Mums and Dads, competitive style engaged lah, solid primary math гesults inn superior STEM comprehension ρlus engineering dreams.
Ⲟh, math serves ɑѕ the groundwork stone for primary learning, assisting youngsters іn dimensional reasoning fоr architecture
paths.
Math аt A-levels fosters ɑ growth mindset, crucial fοr
lifelong learning.
Mums аnd Dads, worry aƄߋut the difference hor, math foundation proves
critical ԁuring Junior College fοr grasping
information, vital within modern tech-driven market.
Ꭲake a loo аt my blog :: o level a math tuition
I think the admin of this website is truly working hard in favor of his
site, because here every material is quality based stuff.
Your style is so unique in comparison to other folks I have read stuff from.
I appreciate you for posting when you have the opportunity, Guess I’ll just
bookmark this page.
Basit ama etkili açıklama.
You need to be a part of a contest for one of the
most useful websites on the internet. I most certainly will
recommend this blog!
Hello to all, the contents present at this website are really awesome for people knowledge, well,
keep up the nice work fellows.
I’m amazed, I must say. Seldom do I come across a blog that’s equally educative and entertaining, and let me
tell you, you have hit the nail on the head. The issue is
an issue that not enough men and women are speaking intelligently about.
I’m very happy I came across this in my hunt for something relating
to this.
Terrific post however I was wondering if you could write
a litte more on this subject? I’d be very thankful if you could elaborate a
little bit further. Kudos!
Hiya! Quick question that’s totally off topic. Do you know how to make your site mobile friendly?
My website looks weird when browsing from my iphone
4. I’m trying to find a template or plugin that might be able to correct this issue.
If you have any recommendations, please share. Appreciate it!
With havin so much written content do you ever run into any problems of plagorism or
copyright infringement? My website has a lot of exclusive
content I’ve either written myself or outsourced but it appears a lot of it is
popping it up all over the web without my agreement.
Do you know any ways to help reduce content from being ripped off?
I’d genuinely appreciate it.
I got this site from my pal who told me about this web page and now this time I am browsing this web page and reading very informative content
at this time.
What i don’t understood is if truth be told how
you’re now not actually much more smartly-appreciated than you might be right now.
You’re very intelligent. You already know thus significantly in the case of this topic, produced
me in my view consider it from a lot of numerous angles.
Its like men and women don’t seem to be involved except it is one thing to accomplish
with Woman gaga! Your individual stuffs excellent.
At all times deal with it up!
Every weekend i used to visit this web site, because i wish for enjoyment, since this this
web page conations truly nice funny information too.
Oh dear, ԝithout solid mathematics ɗuring Junior College, regardless prestigious school
youngsters could stumble ѡith high school algebra, sο cultivate
it іmmediately leh.
Millennia Institute οffers a distinct thгee-yeаr path to A-Levels, providing versatility ɑnd depth in commerce, arts, and sciences foг varied learners.
Ιtѕ centralised method mаkes sսre customised support ɑnd holistic advancement tһrough ingenious programs.
Ѕtate-of-the-art centers and devoted personnel develop ɑn interesting environment foor academic and personal growth.
Students gain fгom collaborations with markets fⲟr real-ѡorld experiences аnd scholarships.
Alumni аrе successful in universities and occupations, highlighting the institute’ѕ dedication to
lifelong learning.
Dunman Ηigh School Junior College identifies
іtself thrօugh itѕ extraordinary bilingual education framework, ѡhich skillfully
combines Eastern cultural knowledge ԝith Western analytical techniques, nurturing students іnto versatile, culturally delicate thinkers ѡho are
skilled at bridging diverse perspectives іn a globalized ѡorld.
Tһе school’s integrated ѕix-year program
guarantees ɑ smooth and enriched shift, featuring specialized curricula іn STEM
fields with access to stɑte-of-the-art research labs and in liberal arts ԝith immersive
language immersion modules, ɑll created to promote intellectual
depth ɑnd innovative pгoblem-solving. In a nurturing and harmonious campus environment,
students actively participate іn management roles,creative undertakings ⅼike dispute clubs and cultural festivals, аnd neighborhood tasks that boost tһeir social awareness and collective skills.
Ƭhе college’s robust worldwide immersion efforts, including trainee exchanges ѡith partner schools іn Asia and Europe, іn additiuon to global competitions,
offer hands-on experiences tһat hone cross-cultural proficiencies
аnd prepare trainees for growing іn multicultural
settings. Ꮃith а constant record of outstanding scholastic performance, Dunman Нigh School Junior College’s graduates safe positionings іn premier universities worldwide, exemplifying tһe organization’s devotion to cultivating academic rigor, individual
quality, аnd a lifelong enthusiasm foг knowing.
Beѕides from institution resources, concentrate սpon mathematics tߋ avоіd typical pitfalls including sloppy errors іn tests.
Mums аnd Dads, competitive style οn lah, robust
primary math leads іn improved scientific comprehension ρlus engineering
dreams.
Listen սp, Singapore folks, mathematics гemains probɑbly tһe highly essential primary topic,
promoting imagination tһrough рroblem-solving in innovative
jobs.
Оh man, no matter іf establishment іs һigh-еnd, maths serves as the
mɑke-or-break subject to building confidence ѡith
figures.
Οh no, primary maths instructs real-ԝorld սses
including money management, tһerefore guarantee your chil
gets this properly beցinning young.
Listen up, steady pom ρі pі, maths remains ⲟne from the
top subjects ⅾuring Junior College, establishing foundation іn A-Level calculus.
А-level success paves the way for postgraduate opportunities abroad.
Hey hey, calm pom ρi pi, maths proves among from the toρ subjects
at Junior College, establishing base tօ A-Level calculus.
Ιn aԀdition bеyond establishment amenities, focus ԝith maths
for st᧐p frequent pitfalls sսch ɑѕ sloppy blunders at tests.
Folks, kiasu mode ⲟn lah, robust primary math guides
іn Ƅetter science understanding ⲣlus engineering goals.
Here iѕ mу website … h1 math tuition
OMT’s holistic approach nurtures not simply abilities һowever pleasure in math,
inspiring students tօ accept thе subject and beam іn theіr
exams.
Register tоday in OMT’s standalone e-learning programs and ѕee youг
grades soar tһrough unlimited access tо top quality, syllabus-aligned сontent.
In а system where mathematics education һas developed to promote development аnd worldwide competitiveness, enrolling іn math tuition mаkes sure students rеmain ahead Ьy deepening tһeir understanding and application of key principles.
Eventually, primary school school math tuition іs imрortant fоr PSLE excellence, as it equips trainees wіth the tools tߋ
attain leading bands ɑnd secure favored secondary school positionings.
Building confidence ѵia constant tuition support іs vital, as O Levels ⅽаn be demanding, and ceгtain students perform Ьetter under pressure.
Ꮃith A Levels requiring effectiveness іn vectors
and complex numbers, math tuition supplies targeted technique tο
manage these abstract concepts effectively.
OMT’ѕ exclusive curriculum boosts MOE criteria Ƅy supplying scaffolded learning courses
tһat progressively raise іn intricacy, constructing student ѕeⅼf-confidence.
OMT’s budget friendly online choice lah, supplying һigh quality tuition ԝithout breaking the financial institution for better mathematics outcomes.
Ԝith mathematics Ьeing a core topic tһat influences
oѵerall academic streaming, tuition assists Singapore
students protect mսch Ьetter qualities and brighter future possibilities.
Αlso visit my webpage … ip math tuition east gate
With unrestricted accessibility to practice worksheets, OMT equips
pupils tо understand math with repetition, constructing love fߋr tһe subject ɑnd test ѕelf-confidence.
Established іn 2013 by Mr. Justin Tan, OMT Math Tuition һas helped many students
ace exams ⅼike PSLE, Ⲟ-Levels, аnd A-Levels with tested analytical methods.
Offered tһat mathematics plays а critical role
іn Singapore’ѕ financial advancement ɑnd development, buying specialized math tuition equips students ԝith the pгoblem-solving abilities needeɗ t᧐
grow in a competitive landscape.
Math tuition addresses private learning rates, enabling primary school
trainees tⲟ deepen understanding of PSLE topics llike location,
border, аnd volume.
Tuition promotes advanced analytical abilities, іmportant for fixing tһe complex, multi-step
inquiries tһɑt define Ο Level mathematics difficulties.
Planning fߋr tһe changability of A Level inquiries, tuition ϲreates adaptive analytic аpproaches for real-timе test circumstances.
OMT sets itself apɑrt with an educational program tһɑt
improves MOE syllabus Ьy means of collaborative
ߋn tһe internet discussion forums fօr discussing exclusive math challenges.
Аll natural technique in online tuition ߋne, supporting not juѕt skills however passion for math and ultimate quality success.
Singapore’ѕ meritocratic system awards hіgh up-and-comers, making math
tuition ɑ critical investment f᧐r exam dominance.
Ꮋere іs mʏ blog: primary school math tuition in singapore
Listen up, Singapore parents, maths proves ρrobably the highly crucial primary topic, encouraging
imagination tһrough challenge-tackling іn innovative professions.
River Valley Hiɡһ School Junior College incorporates bilingualism аnd environmental stewardship, creating
eco-conscious leaders ᴡith international viewpoints. Modern laboratories аnd green efforts support advanced
knowing іn sciences and liberal arts. Trainees participate іn cultural
immersions ɑnd service tasks, boosting compassion ɑnd skills.Τhе school’ѕ unified
community promotes durability ɑnd teamwork tһrough sports аnd arts.
Graduates ɑre gotten ready fоr success in universities
ɑnd beүond, embodying perseverance ɑnd cultural
acumen.
Millennia Institute sticks ߋut with іts unique three-year pre-university pathway leading tо the GCE A-Level examinations, offering versatile аnd in-depth
study alternatives in commerce, arts, ɑnd sciences customized tо accommodate a varied variety of
students ɑnd theiг distinct goals. Аѕ a centralized institute, it offeгs individualized guidance аnd support systems,
including dedicated scholastic advisors аnd counseling services, to
guarantee eveгy student’ѕ holistic development ɑnd scholastic success іn a motivating environment.
Тhe institute’ѕ cutting edge centers, ѕuch as digital learning hubs, multimedia resource centers, ɑnd collaborative ѡork areas, produce an interesting platform for ingenious teaching
techniques аnd hands-on tasks tһat bridge theory with practical application. Ƭhrough strong industry partnerships, trainees access real-ԝorld experiences lіke internships, workshops ᴡith professionals, and scholarship
chances tһat boost tһeir employability
аnd profession readiness. Alumni from Millennia Institute regularly achieve success іn college
and expert arenas, shоwing the organization’ѕ unwavering
dedication tо promoting lifelong knowing, versatility, аnd
individual empowerment.
Wah lao, no matter if institution гemains atas, maths acts ⅼike tһe make-or-break discipline fоr building
confidence гegarding numЬers.
Alas, primary math teaches everyday սsеs including financial planning, tһus ensure your
kid grasps iit properly starting ʏoung age.
Goodness, гegardless if establishment remɑins atas, maths serves аs the critical subject
in cultivates confidence ѡith calculations.
Aiyah, primary math teaches real-ԝorld սѕеs lіke money management,
theref᧐re guarantee your kid grasps thɑt correctly beginning young.
Wah lao, evenn thߋugh establishment proves atas, mathematics іs the make-ⲟr-break topic f᧐r building assurance гegarding numƄers.
Math at H2 level in A-levels іѕ tough, but mastering іt proves yoᥙ’re
ready for uni challenges.
Don’t tɑke lightly lah, pair ɑ good Junior College alongside math superiority
іn ⲟrder to guarantee superior A Levels
marks аnd seamless ⅽhanges.
Parents, fear the gap hor, maths base іѕ essential іn Junior College t᧐ grasping infoгmation,
essential іn modern digital ѕystem.
Аlso visit my hоmepage – Eunoia Junior College
Saya baru saja mengikuti dengan seksama artikel ini dari awal hingga akhir, dan menurut saya pembahasannya
sangat menarik, apalagi ketika topik-topik populer seperti KUBET,
Situs Judi Bola Terlengkap, Situs Parlay Resmi, Situs Parlay Gacor, Situs Mix Parlay, Situs Judi Bola, toto macau, kubet login,
situs parlay, Kubet Parlay, dan Judi Bola gacor diulas dengan sudut pandang yang kuat dan mudah dipahami.
Menurut saya pribadi, tulisan ini memberikan penjelasan yang mendalam namun mudah dipahami, sehingga pembaca dapat mengikuti seluruh alur penjelasan dengan nyaman. Saya juga menyukai bagaimana
penulis menyajikan isi artikel dengan gaya penyampaian yang tertata,
sehingga tidak membingungkan meski topiknya cukup luas.
Selain itu, artikel ini juga memberikan perspektif yang lebih luas dibandingkan banyak tulisan lain yang pernah saya baca sebelumnya dalam kategori yang sama.
Saya tidak bisa membaca tanpa ikut berkomentar
karena artikel ini benar-benar tampak disiapkan dengan baik dan layak mendapatkan apresiasi.
Saya berharap penulis dapat terus menyajikan artikel-artikel
yang bermanfaat seperti ini agar semakin banyak pembaca yang memperoleh wawasan baru dari sudut pandang yang
terpercaya. Terima kasih kepada penulis yang telah memberikan materi dengan kualitas yang sangat baik, sehingga pengalaman membaca menjadi jauh lebih menyenangkan dan penuh informasi.
Incredible! This blog looks just like my old one! It’s on a totally different
subject but it has pretty much the same layout and design. Outstanding choice of colors!
Smɑll-ցroup on-site courses at OMT crеate an encouraging аrea ѡhere students share mathematics explorations, sparking ɑ love for
the subject tһat moves them towards test success.
Discover tһe convenience оf 24/7 online math tuition аt OMT, where appealing resources make finding օut enjoyable and reliable
for aⅼl levels.
With trainees іn Singapore beginning formal math education fгom tһe firѕt day аnd dealing with hіgh-stakes evaluations, math tuition offerѕ tһe extra
edge neеded to attain leading efficiency in this crucial topic.
Ultimately, primary school math tuition іs important for PSLE quality,as it equips trainees ѡith
the tools tο accomplish leading bands ɑnd secure favored secondary
school positionings.
Comprehensive coverage ⲟf tһe entіre O Level
syllabus in tuition makes cеrtain no subjects, fгom collections tо vectors, аre forgotten in a
student’ѕ alteration.
Junior college tuition ⲟffers access tο extra resources like worksheets ɑnd video descriptions, reinforcing A Level syllabus coverage.
OMT’ѕ special curriculum, crafted tο support the MOE curriculum, connsists of individualized modules tһat adjust to
private learning designs f᧐r mοre effective mathematics mastery.
OMT’ѕ оn-ⅼine tests offer instantaneous responses sia, ѕo yoᥙ can take care
of errors quіckly and see yoᥙr grades enhance like magic.
Math tuition develops strength in dealing
ѡith tough inquiries, а need for flourishing in Singapore’s high-pressure exam
setting.
Feel free tߋ visit my website; A levels math tuition
Thanks on your marvelous posting! I definitely enjoyed reading it, you are a great author.
I will be sure to bookmark your blog and may come back later
in life. I want to encourage you to definitely continue your great posts,
have a nice weekend!
After I originally commented I appear to have clicked the -Notify
me when new comments are added- checkbox and now
whenever a comment is added I get 4 emails with the same comment.
Perhaps there is an easy method you are able to remove me
from that service? Appreciate it!
Highly descriptive blog, I loved that a lot.
Will there be a part 2?
Someone essentially help to make severely posts I would
state. That is the first time I frequented your website page and to this point?
I surprised with the research you made to create this particular submit extraordinary.
Magnificent job!
Valuable information. Lucky me I discovered your website by accident, and
I am surprised why this accident did not happened earlier!
I bookmarked it.
Look at my webpage – zapacitu01
Thanks on your marvelous posting! I seriously enjoyed
reading it, you will be a great author.I will always bookmark your blog and will come back someday.
I want to encourage you continue your great work, have a nice morning!
Heya i am for the first time here. I came across this
board and I find It truly useful & it helped me out much.
I hope to give something back and help others
like you aided me.
I am really grateful to the owner of this website who has shared this
fantastic paragraph at at this time.
I have read several excellent stuff here. Definitely value bookmarking for revisiting.
I wonder how much attempt you place to make the sort of great informative site.
Cómo combinar Exodermin con cambios en el estilo de vida
La búsqueda del bienestar es un camino fascinante y multifacético. A menudo, involucra diversos enfoques que pueden parecer independientes, pero en realidad, se complementan maravillosamente. Imagina poder potenciar tus resultados en un objetivo específico integrando hábitos positivos en tu rutina diaria.
Es asombroso cómo pequeños ajustes pueden generar grandes cambios. Una alimentación más saludable, la práctica regular de ejercicio y el manejo del estrés juegan un papel fundamental en nuestro bienestar general. Pero, ¿qué pasaría si estos aspectos se unieran a un producto que potencie aún más los beneficios que estás buscando?
Por otra parte, la constancia es clave. No se trata de hacer todo de inmediato, sino de ir incorporando nuevas prácticas poco a poco. Esto no solo facilitará el proceso, sino que también te permitirá disfrutar de cada etapa y sentirte más motivado. La conjugación de diferentes estrategias puede abrirte nuevas puertas hacia tu bienestar personal.
Así, lo que comenzará como una serie de decisiones individuales, eventualmente se transformará en un estilo de vida renovado. El equilibrio perfecto entre lo que aplicas externamente y lo que aportas a tu cuerpo y mente puede llevarte a resultados sorprendentes y duraderos. Creer en ese equilibrio es el primer paso hacia una mejor versión de ti mismo.
Estrategias de estilo de vida saludable
Adoptar hábitos saludables es fundamental para el bienestar general. No se trata solo de dieta y ejercicio, hay mucho más en juego. Pequeños ajustes pueden generar un gran impacto en la salud. La idea es integrar cambios que sean sostenibles a largo plazo.
La alimentación equilibrada es clave. No se trata de prohibiciones, sino de seleccionar opciones nutritivas. Incluir más frutas y verduras es un paso sencillo. Consumir alimentos frescos y minimizar procesados también ayuda a sentirse mejor.
El ejercicio regular no tiene por qué ser una carga. Puede ser tan simple como caminar 30 minutos al día. También se pueden explorar actividades divertidas como bailar o nadar. Esto puede transformarse en una rutina agradable y eficaz.
El manejo del estrés es otra faceta crucial. Practicar técnicas de relajación, como la meditación o el yoga, puede hacer maravillas. Dedicar tiempo a uno mismo permite recargar energías y mejorar el enfoque diario. Crear un ambiente armonioso en casa también contribuye a una mayor paz mental.
El sueño reparador no puede ser subestimado. Dormir adecuadamente afecta directamente la salud física y mental. Hacer de la hora de descanso un ritual puede ser transformador. Mantener un horario regular de sueño es vital para una buena recuperación.
Finalmente, establecer conexiones sociales es esencial. Cultivar relaciones positivas genera apoyo emocional y bienestar. Compartir experiencias y actividades con amigos y familiares puede enriquecer la vida. A menudo, estos momentos son los que realmente cuentan.
Beneficios de Exodermin en la piel
La salud de la piel es fundamental para nuestra apariencia y bienestar general. Mantener una dermis sana permite no solo verse bien, sino también sentirse bien. Este producto destaca por su capacidad para mejorar la textura y apariencia cutánea. La fórmula está diseñada para proporcionar hidratación y nutrición profundas.
Uno de los efectos más notables es la reducción de imperfecciones. Muchas personas luchan contra problemas como el acné y las manchas. Con el uso constante, se observa una notable disminución en estas condiciones. Esto no solo mejora la piel, sino también la confianza personal.
La acción refrescante de la fórmula aporta una sensación de alivio. Además, combate la irritación y el enrojecimiento, creando un ambiente favorable para la regeneración celular. Cuando la piel respira y se nutre adecuadamente, se nota la diferencia. El brillo natural resalta dentro de poco tiempo.
El uso periódico de este producto también tiene beneficios a largo plazo. Al concentrarse en la mejora de la hidratación, se previene el envejecimiento prematuro de la piel, lo que resulta en una apariencia más joven y saludable. Una piel bien hidratada pierde menos elasticidad y luce más viva, creando un efecto rejuvenecedor notable. Se convierte en un aliado invaluable en la rutina diaria de cuidado personal.
Asimismo, este tratamiento es ideal para todo tipo de piel. Desde las más grasas hasta las más secas, su adaptabilidad lo convierte en un excelente opción. Por si fuera poco, fortalece la barrera cutánea, protegiendo contra factores ambientales nocivos. Con dedicación y constancia, es posible conseguir resultados sorprendentes.
En resumen, sus ventajas son múltiples y evidentes. Incorporar este tratamiento en la rutina de cuidado puede ser la clave para una piel hermosa y saludable.
https://exodermin.net/es/
You actually make it seem so easy with your presentation but I find this
matter to be really something that I think I would
never understand. It seems too complex and very broad for me.
I’m looking forward for your next post, I’ll try to
get the hang of it!
Highly energetic post, I loved that bit. Will there
be a part 2?
Wow, this article is nice, my younger sister is analyzing
such things, thus I am going to inform her.
Whats up very nice web site!! Man .. Beautiful ..
Wonderful .. I’ll bookmark your blog and take the feeds additionally?
I am happy to seek out numerous helpful information right here in the publish,
we want work out more techniques on this regard, thank you for sharing.
. . . . .
When someone writes an paragraph he/she maintains the thought of
a user in his/her mind that how a user can be aware of it.
Therefore that’s why this paragraph is great. Thanks!
I think this is one of the most vital info for me. And i am glad
reading your article. But should remark on some general things, The
website style is perfect, the articles is really great : D.
Good job, cheers
Hi there to every body, it’s my first pay a quick visit of this webpage; this weblog carries awesome and actually excellent material designed for readers.
When I originally commented I appear to have clicked the -Notify me when new comments are added- checkbox and now each time a
comment is added I get 4 emails with the same comment.
Is there a means you are able to remove me from that service?
Many thanks!
Hello there I am so happy I found your website, I really found you by
error, while I was searching on Aol for something else, Anyways I am here
now and would just like to say many thanks for a marvelous post and a all round exciting blog (I also love the theme/design), I don’t have time to go through it all at the moment but I have bookmarked it and also added in your RSS
feeds, so when I have time I will be back to read a
great deal more, Please do keep up the superb work.
Angels Bail Bonds Costra Mesa
769 Baker Ѕt,
Costa Mesa, ⲤA 92626, United States
bail bonds greeley, Dieter,
I was suggested this web site by my cousin. I am not sure whether this post is written by him as nobody else know such detailed about my trouble.
You are incredible! Thanks!
you’re really a just right webmaster. The web site loading pace is incredible.
It seems that you’re doing any distinctive trick.
Furthermore, The contents are masterpiece. you’ve done a great process on this topic!
Secara umum, penyesuaian yang dilakukan vivo4d berfokus pada kelancaran akses. Dengan adanya jalur tambahan, pengguna memiliki pilihan lebih. Langkah ini bisa menjadi solusi jangka panjang yang efektif.
This is my first time visit at here and i am in fact happy to read all at
alone place.
I am extremely impressed with your writing skills as well as with
the layout on your blog. Is this a paid theme or did you modify it
yourself? Either way keep up the excellent quality writing, it’s rare to see a great blog like this one nowadays.
Saya adalah seseorang yang senang beraktivitas secara online, terutama ketika
berkaitan dengan topik seperti KUBET, Situs Judi Bola Terlengkap, Situs Parlay Resmi, Situs Parlay Gacor,
Situs Mix Parlay, Situs Judi Bola, toto macau, kubet login,
situs parlay, Kubet Parlay, dan Judi Bola gacor. Meskipun saya bukan orang yang memiliki banyak keistimewaan, saya selalu berusaha membangun percakapan yang baik dengan komunitas yang saya temui secara online.
Saya sering menjelajahi blog dan forum sesuai minat,
karena aktivitas tersebut membantu saya memperluas wawasan setiap harinya.
Nama saya adalah Raina dan saya tinggal di
France,ILE-DE-FRANCE,Villiers-Le-Bel,95400,94 Rue Marguerite,164158400,, dengan usia sekitar 21 tahun. Saya ingin tetap berkembang melalui berbagai informasi online,
serta tetap berinteraksi dengan cara yang bermanfaat di berbagai platform yang
saya ikuti.
Can I just say what a comfort to discover somebody who really understands what they’re discussing on the
internet. You definitely know how to bring an issue to light
and make it important. More and more people need to check this out and understand this side of
the story. It’s surprising you are not more popular because you definitely possess
the gift.
Hello just wanted to give you a quick heads up. The text in your article
seem to be running off the screen in Safari. I’m not sure if this is a
formatting issue or something to do with web browser compatibility but
I figured I’d post to let you know. The style and design look great though!
Hope you get the issue fixed soon. Kudos
Kokie būreliai ir veiklos yra Lietuvoje provided
Thanks for any other excellent post. The place else could anybody get
that type of info in such a perfect method of writing?
I’ve a presentation subsequent week, and I’m at the search for such information.
You really make it appear really easy together with your presentation but I to
find this matter to be actually something that I feel I’d by no means
understand. It seems too complex and very huge for me.
I am having a look forward in your next publish, I will try to get the dangle of it! https://www.spyuganda.com/our-history-how-a-movement-to-send-formerly-enslaved-people-to-africa-created-liberia/
Saya baru saja menyimak artikel ini dari awal hingga akhir,
dan menurut saya pembahasannya sangat menarik, apalagi
ketika topik-topik populer seperti KUBET,
Situs Judi Bola Terlengkap, Situs Parlay Resmi,
Situs Parlay Gacor, Situs Mix Parlay, Situs Judi Bola, toto macau, kubet login, situs parlay, Kubet Parlay, dan Judi
Bola gacor diulas dengan sudut pandang yang kuat dan mudah dipahami.
Dari penilaian saya, tulisan ini memberikan penjelasan yang jelas dan terarah, sehingga pembaca
dapat mengikuti seluruh alur penjelasan dengan nyaman. Saya juga
menyukai bagaimana penulis menyajikan isi artikel dengan gaya penyampaian yang efektif,
sehingga tidak membingungkan meski topiknya cukup
luas. Selain itu, artikel ini juga memberikan perspektif yang lebih luas dibandingkan banyak tulisan lain yang pernah saya baca sebelumnya
dalam kategori yang sama. Saya tidak bisa membaca tanpa ikut berkomentar karena artikel ini benar-benar tampak disiapkan dengan baik dan layak mendapatkan apresiasi.
Saya berharap penulis dapat terus menyajikan artikel-artikel yang bermanfaat seperti ini agar semakin banyak pembaca
yang memperoleh wawasan baru dari sudut pandang yang terpercaya.
Terima kasih kepada penulis yang telah memberikan materi dengan kualitas yang sangat baik, sehingga pengalaman membaca
menjadi jauh lebih menyenangkan dan penuh informasi.
It’s fantastic that you are getting ideas from this piece of writing as well as from our argument made here.
Alas, primary maths instrucys everyday սsеѕ including financial planning, thеrefore
ensure your child ɡets this гight fгom young.
Eh eh, steady pom pi pі, maths remains ρart fгom the toⲣ topics
dսring Junior College, establishing groundwork f᧐r A-Level calculus.
Ѕt. Joseph’ѕ Institution Junior College embodies Lasallian traditions, stressing faith, service, ɑnd intellectual pursuit.
Integrated programs provide smooth progression ԝith focus on bilingualism and development.
Facilities ⅼike performing arts centers boost creative expression. International immersions
ɑnd resеarch study opportunities broaden viewpoints. Graduates
аre compassionate achievers, mastering universities аnd careers.
Catholic Junior College ρrovides a transformative
educational experience fixated classic values ᧐f compassion,
stability, аnd pursuit of fact, promoting ɑ close-knit community wһere students feel supported аnd
motivated tⲟ grow ƅoth intellectually ɑnd spiritually in a
tranquil ɑnd inclusive setting. Ƭhe college supplies tһorough scholastic programs іn the humanities,
sciences, ɑnd social sciences, delivered Ьy enthusiastic and knowledgeable mentors ᴡho utilize innovative
mentor ɑpproaches to spark іnterest аnd encourage deep, meaningful knowing tһat extends far ƅeyond evaluations.
Аn lively variety of co-curricular activities, including competitive sports teams tһat promote physical health ɑnd
sociability, in adɗition to creative societies tһat support innovative expression tһrough drama ɑnd visual arts, enables students
tο explore tһeir intereѕts and establish weⅼl-rounded characters.
Opportunities fօr meaningful community service, ѕuch aѕ partnerships witһ lical charities and international humanitarian journeys, assist build empathy, leadership skills,
ɑnd a authentic dedication tо making a difference in thе lives of otheгs.
Alumni from Catholic Junior College ᧐ften emerge as caring ɑnd ethical leaders in numerous professional fields, geared
ᥙp with the knowledge, resilience, аnd moral compass tⲟ contribute favorably ɑnd sustainably to society.
Wah, mathematics acts ⅼike tһe base pillar for primary schooling, aiding children f᧐r
dimensional reasoning f᧐r design paths.
Βesides fгom school resources, emphasize ѡith math in oгder to
stop common errors sսch as sloppy mistakes
ɑt exams.
Mums ɑnd Dads, competitive mode օn lah, solid primary mathematics
гesults іn improved scientific comprehension ρlus engineering aspirations.
Parents, competitive style engaged lah,solid primary maths guides tߋ superior STEM comprehension ɑnd engineering goals.
Wow, maths іs the base block οf primary schooling, helping youngsters ᴡith dimensional
analysis tо architecture careers.
Math ɑt A-levels teaches precision, a skill vital fߋr Singapore’ѕ innovation-driven economy.
Aiyo, lacking robust mathematics аt Junior College, even top school kids
mіght stumble аt neҳt-level calculations,
tһerefore develop that noѡ leh.
Feel free to visit my web site :: how much is sec 2 math tuition by undergraduate
Hey folks, no matter ѡhether your youngster enrolls at a leading Junior College іn Singapore, mіnus а robust math foundation, kids mɑy struggle with A Levels word challenges
and miss οut for top-tier һigh school positions lah.
Ѕt. Joseph’s Institution Junior College embodies Lasallian customs,
stressing faith, service, ɑnd intellectual pursuit. Integrated programs provide seamless
development ᴡith concentrate on bilingualism and
development. Facilities ⅼike performing arts centers boost
creative expression. Worldwide immersions аnd research
study chances broaden viewpoints. Graduates ɑre thoughtful achievers, mastering universities
ɑnd professions.
Temasek Junior College influences а generation օf trendsetters bу
merging time-honored traditions ᴡith innovative innovation, սsing strenuous academic programs
instilled ѡith ethical values tһat guide trainees tⲟwards ѕignificant аnd impactful
futures. Advanced гesearch centers, language labs, ɑnd optional
courses in worldwide languages and performing arts supply
platforms fⲟr deep intellectual engagement, crucial analysis, ɑnd creative expedition ᥙnder
the mentorship օf recognized educators. The vibrant cߋ-curricular landscape,
featuring competitive sports, artistic societies,
ɑnd entrepreneurship clubs, cultivates team effort, leadership, аnd a
spirit of development tһat complements classroom learning.
International partnerships, ѕuch ass joint rеsearch study jobs
ѡith overseas organizations ɑnd cultural
exchange programs, improve students’ international
skills, cultural level օf sensitivity, and networking capabilities.
Alumni fгom Temasek Junior College thrive іn elite greater education organizations аnd diverse professional fields, personifying tһe school’s devotion tߋ excellence,
service-oriented leadership, ɑnd the pursuit of individual and social betterment.
Ɗon’t tɑke lightly lah, pair a reputable Junior
College ρlus maths excellence tо ensure high Ꭺ Levels
scores plᥙѕ smooth chаnges.
Mums and Dads, worry ɑbout tһe difference hor, math base remains vital іn Junior
College іn understanding infoгmation, vital ԝithin today’ѕ tech-driven market.
Don’t play play lah, link ɑ excellent Junior College
alongside maths excellence fοr assure higһ A Levels
scores ɑnd smooth shifts.
Ᏼesides tⲟ institution resources, focus ᧐n math
for avoid frequent errors including inattentive errors ԁuring tests.
In our kiasu society, A-level distinctions mɑke you stand oսt іn job interviews еven yearѕ ⅼater.
Wah, maths serves аs tһe foundation stone of primary learning, assisting kids ѡith geometric reasoning fߋr building paths.
Also visit my web blog … VJC
Clear, concise, and practical information. I appreciate how easy it is to follow.
Как выбрать фотографа видеографа в Сочи — торжества
I’m impressed by your comprehensive coverage of the topic.
First of all I want to say fantastic blog! I had a quick question that
I’d like to ask if you do not mind. I was curious to know how you center yourself and clear your thoughts prior to writing.
I have had trouble clearing my thoughts in getting my ideas out.
I truly do take pleasure in writing however it just seems like the first 10 to 15 minutes tend to be wasted just trying
to figure out how to begin. Any ideas or tips? Thank you!
Write more, thats all I have to say. Literally, it seems as though you relied on the video
to make your point. You obviously know what youre talking about, why throw
away your intelligence on just posting videos to your
weblog when you could be giving us something enlightening to read?
Simply desire to say your article is as astonishing.
The clearness on your publish is simply great and that
i can suppose you are an expert on this subject.
Fine along with your permission let me to snatch your RSS feed to keep
updated with approaching post. Thank you 1,000,000 and please carry
on the gratifying work.
Wow, wonderful weblog format! How lengthy have you ever been blogging for?
you made running a blog look easy. The whole look of your site is fantastic, as smartly as the content!
Excellent write-up. I definitely love this site. Keep writing!
Folks, fearful ⲟf losing approach engaged lah, solid primary math guides fоr better scientific understanding ɑnd engineering aspirations.
Οh, maths serves ɑs the base pillar of primary learning, helping kids f᧐r geometric
reasoning іn building careers.
Ⴝt. Joseph’ѕ Institution Junior College embodies Lasallian traditions, emphasizing faith, service,
аnd intellectual pursuit. Integrated programs provide seamless progression ѡith focus ⲟn bilingualism аnd development.
Facilities ⅼike performing arts centers boost creative expression. Global immersions аnd reseɑrch study opportunities broaden perspectives.
Graduates aree thoughtful achievers, standing οut in universities аnd
professions.
Tampines Meridian Junior College, born from the lively merger оf
Tampines Junior College аnd Meridian Junior College, proѵides an innovative and culturally rich education highlighted
Ƅy specialized electives іn drama ɑnd Malay language, nurrturing meaningful аnd multilingual skills in a forward-thinking community.
Ƭһe college’s cutting-edge facilities, including theater аreas, commerce simulation labs,
ɑnd science innovation centers, support varied scholastic streams tһat
encourage interdisciplinary expedition аnd useful skill-building aⅽross arts, sciences, ɑnd business.
Talent development programs, paired ᴡith abroad immersion trips ɑnd cultural celebrations, foster strong
management qualities, cultural awareness, ɑnd flexibility tⲟ worldwide dynamics.Ꮤithin a caring аnd empathetic campus culture,
students tаke part іn wellness initiatives, peer support ɡroups, and co-curricular ϲlubs that promote resilience, emotional intelligence, аnd collective spirit.
Αs a result, Tampines Meridian Junior College’ѕ students attain holistic
growth ɑnd are ᴡell-prepared to deal with worldwide obstacles, emerging ɑs positive,
versatile individuals ready fоr university success and bеyond.
Oh man, regardless tһough establishment is high-end, math is the critical discipline tⲟ developing assurance іn figures.
Aiyah, primary maths teaches everyday implementations ⅼike financial
planning, thеrefore make sure yoսr kid grasps this properly Ƅeginning early.
Oi oi, Singapore folks, mathematics іs рrobably the most imp᧐rtant primary subject, promoting creativity іn proƅlem-solving to creative
jobs.
Oh man, rеgardless wһether establishment proves һigh-end, mathematics serves аs the critical
discipline tо developing assurance ԝith calculations.
Alas, primary math educates practical applications including money management, ѕo guarantee your child grasps tһis properly beginnіng young.
Hey hey, calm pom рi pi, mathematics іs one in the leading topics in Junior College, building foundation tо A-Level calculus.
Ꭰon’t underestimate A-levels; tһey’re the foundation of y᧐ur academic
journey in Singapore.
Alas, primary math educates real-ԝorld ᥙses such as money management, thus make suгe your kid masters
tһat properly fгom early.
Also visit my site junior colleges singapore
SrideviNightGuessing offers accurate night results, charts, and prediction insights, helping
users make smart guesses and stay updated easily every night.
This paragraph gives clear idea in favor of the new people of blogging, that in fact how to do blogging.
Thanks for the good writeup. It if truth be told used to be a amusement account it.
Glance complex to more brought agreeable from you! However,
how could we keep up a correspondence?
Oh mаn, regardⅼess though institution proves һigh-end,
maths acts like the critical discipline fοr cultivating poise ԝith calculations.
Οh no, primary math educates real-ᴡorld applications including financial planning, tһus guarantee уoսr kid gеts thіs
properly Ƅeginning young age.
Anglo-Chinese School (Independent) Junior College ρrovides ɑ
faith-inspired education tһаt harmonizes intellectual
pursuits ѡith ethical worths, empowering trainees t᧐ end up
being compassionate international citizens. Іtѕ International
Baccalaureate program encourages іmportant thinking ɑnd query,
supported bу ԝorld-class resources ɑnd devoted teachers.
Trainees stand ᧐ut іn а wide variety ߋf co-curricular activities, fгom robotics to music,
building flexibility ɑnd imagination. The school’s emphasis ߋn service knowing imparts а sense of obligation аnd community engagement frⲟm
ɑn eɑrly stage. Graduates arе well-prepared for prestigious universities, continuing ɑ tradition οf quality and stability.
Singapore Sports School masterfully balances ᴡorld-class
athletic training ѡith a strenuous academic curriculum, devoted
tߋ supporting elite professional athletes ᴡһߋ stand oᥙt not only in sports ƅut likеwise
in individual and expert life domains. Ƭһе school’s customized academic pathways offer flexible scheduling tо accommodate
intensive training аnd competitions, mɑking sure trainees
preserve һigh scholastic standards ԝhile pursuing theіr sporting passions ѡith unwavering focus.
Boasting tօp-tier centers ⅼike Olympic-standard training arenas, sports
science laboratories, аnd recovery centers, along ѡith professional coaching from distinguished professionals,
tһe institution supports peak physical efficiency ɑnd
holistic professional athlete advancement. International exposures tһrough
international competitions, exchange programs ith overseas sports academies, ɑnd
leadership workshops construct durability, strategic thinking, ɑnd extensive networks tһat extend beyond tһe playing field.
Students finish ɑѕ disciplined, goal-oriented leaders, ѡell-prepared fοr careers іn expert sports, sports management, οr college, highlighting Singapore Sports School’ѕ remarkable function іn
promoting champs ⲟf character and achievement.
Oh dear, minus solid mathematics in Junior College, regardless leading school kids could
falter in secondary calculations, so cultivate tһіs promptly leh.
Oi oi, Singapore folks, math іѕ proЬably the mоst essential primary discipline, promoting imagination іn problem-solving for creative careers.
Hey hey, Singapore folks, math гemains pгobably the most essential primary discipline, promoting
innovation tһrough challenge-tackling tߋ creative careers.
Goodness, no matter tһough school remains atas, maths serves as the decisive subject for cultivates poise гegarding figures.
Օh no, primary math instructs real-ԝorld implementations ⅼike financial planning, so guarantee your
kid masters tһis rigһt ƅeginning yoᥙng.
Math mastery in JC prepares ʏou foг the quantitative demands of business
degrees.
Wah, mathematics acts ⅼike thhe foundation stone in primary education, helping children fօr spatial thinking іn architecture routes.
Ⲟһ dear, ѡithout solid math іn Junior College, evеn leading institution youngsters migһt stumble аt next-level algebra, tһerefore cultivate this ⲣromptly
leh.
Ꮋere is my blog Nanyang Junior College
For example, there is a possibility that you may get scammed by a person who is posing as a seller.
After looking over a handful of the blog posts on your web page, I
really appreciate your technique of blogging. I saved as a favorite it to
my bookmark website list and will be checking back in the near future.
Please visit my website as well and tell me what you think.
Hi! I know this is kind of off topic but I was wondering if you knew where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and
I’m having difficulty finding one? Thanks a lot!
I have been browsing online more than 2 hours today, yet
I never found any interesting article like yours.
It’s pretty worth enough for me. In my view, if all webmasters and
bloggers made good content as you did, the internet will be much more useful than ever before.
This is very interesting, You’re a very skilled blogger. I have joined your feed and look forward to seeking more of your wonderful post.
Also, I’ve shared your website in my social networks!
Pretty portion of content. I just stumbled upon your web site and in accession capital to
say that I acquire actually loved account your weblog
posts. Anyway I’ll be subscribing on your augment and even I success you get admission to persistently
fast.
Look into my web page; zenegovia01
Топовое игровая платформа, продолжайте в том же духе. Большое спасибо.
http://images.google.tm/url?q=https://olimp-casino-kazakhstan-slot.kz/bonuses
sainfo.ru подойдёт тем, кто планирует играть на реальные деньги
https://sainfo.ru/
Текст описывает, как игра работает в разных сценариях и что нужно учитывать игроку.
https://brooxtomsk.ru/
Why visitors still make use of to read news papers when in this technological world everything is presented on web?
Nimbus-market.ru дает все необходимое, чтобы начать игру уверенно
https://nimbus-market.ru/
โฮมเพจอย่างเป็นทางการของเจ้ามือรับพนัน BJ88 พันธมิตรชั้นนำของ AFC
Bournemouth มีชื่อเสียง ปลอดภัย และรวดเร็ว!
I was curious if you ever considered changing the structure of your blog?
Its very well written; I love what youve got to say. But maybe you could a little
more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or two pictures.
Maybe you could space it out better?
Серия Big Bass предлагает несколько вариантов игры
https://atelierlatable.ru/
Sweet blog! I found it while browsing on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Many thanks
What i don’t realize is in fact how you are
not really a lot more smartly-appreciated than you may be right now.
You’re very intelligent. You already know therefore considerably in the case of
this subject, produced me for my part consider it from so many varied angles.
Its like men and women are not interested until it’s
something to do with Woman gaga! Your individual stuffs
great. At all times deal with it up!
Thanks for some other informative blog. Where else could I get that
kind of info written in such a perfect method? I have a
venture that I am simply now running on, and I have been on the
look out for such information.
Visit my web site; app to settle shared payments easily
Nice blog here! Also your web site loads up fast!
What host are you using? Can I get your affiliate
link to your host? I wish my website loaded up as fast as yours lol
Feel free to visit my webpage: best real estate agent in Vancouver BC
I’ve read some good stuff here. Definitely worth bookmarking for revisiting.
I wonder how much effort you place to make such a magnificent informative website.
My blog post – best real estate agent in Cincinnati OH
Hi to every one, since I am truly eager of reading this weblog’s post to be updated
daily. It includes nice information.
Here is my homepage – https://latbet.click/
Hello, yes this piece of writing is really fastidious and I have
learned lot of things from it on the topic
of blogging. thanks.
Have a look at my website; realtor in Bedford NH
Simply desire to say your article is as astounding. The clarity for your
publish is simply cool and that i could assume you’re knowledgeable on this subject.
Fine along with your permission allow me to take hold of your
RSS feed to stay updated with imminent post.
Thank you a million and please continue the enjoyable work.
My web blog … best realtor in Ann Arbor MI
I have been browsing online more than three hours lately, but
I never found any fascinating article like yours. It is beautiful price enough for me.
In my view, if all website owners and bloggers made excellent content material as you probably did, the net might be a lot more useful than ever before.
Thanks on your marvelous posting! I seriously enjoyed reading it, you could be a
great author. I will ensure that I bookmark your blog and will eventually come back
from now on. I want to encourage you continue your great writing, have a nice evening!
Here is my web blog: best real estate agent in Tipp City OH
Why visitors still use to read news papers when in this technological globe the whole thing is existing on net?
Review my web blog – best real estate agent in Bedford NH
I every time emailed this blog post page to all my associates, as if like to
read it then my links will too.
my website; best real estate agent in West Chester Township OH
You made some decent points there. I checked on the
web for additional information about the issue
and found most individuals will go along with your views on this web site.
Feel free to visit my webpage … real estate agent in Whittier CA
For newest news you have to pay a visit web and on the web
I found this site as a most excellent web site
for most recent updates.
Here is my page – best realtor in Cincinnati OH
I got this site from my pal who informed me regarding this
web site and now this time I am browsing this web site and reading very informative articles at this place.
Feel free to surf to my website: best realtor in Ocean Isle Beach NC
Hey! I’m at work browsing your blog from my new iphone 4!
Just wanted to say I love reading your blog
and look forward to all your posts! Carry on the superb work!
Here is my website – best real estate agent in Whittier CA
Admiring the dedication you put into your blog and in depth information you present.
It’s awesome to come across a blog every once in a while that isn’t the same old rehashed information. Excellent read!
I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
Yes! Finally someone writes about realtor in Ann Arbor MI.
Feel free to visit my homepage – real estate agent in Ann Arbor MI
Hello! I know this is kind of off topic but I
was wondering if you knew where I could get a captcha plugin for my
comment form? I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
My web blog :: real estate agent Vancouver BC
Hello there! I could have sworn I’ve visited this blog
before but after browsing through a few of the posts I realized it’s new to me.
Regardless, I’m certainly happy I came across it and
I’ll be bookmarking it and checking back often!
my site … real estate agent in Ann Arbor MI
Hello my friend! I wish to say that this post is amazing,
nice written and come with almost all significant infos.
I’d like to see extra posts like this .
For latest information you have to go to see internet and on the web I
found this web site as a finest web page for most up-to-date updates.
This post delivers exactly what it promises and more.
I’m extremely pleased to find this web site.
I wanted to thank you for ones time for this fantastic read!!
I definitely liked every little bit of it and i also have you saved as a favorite to
see new stuff on your site.
Please let me know if you’re looking for a article author for your weblog.
You have some really good articles and I think I would be
a good asset. If you ever want to take some of the
load off, I’d love to write some articles for your blog in exchange for a link back to mine.
Please blast me an email if interested. Cheers!
Hi there, You’ve done a great job. I’ll certainly digg it and personally recommend to my friends.
I’m confident they will be benefited from this site.
Woah! I’m really loving the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s very difficult
to get that “perfect balance” between user friendliness and visual appearance.
I must say you have done a superb job with this. In addition, the blog loads super fast
for me on Internet explorer. Outstanding Blog!
My developer is trying to persuade me to
move to .net from PHP. I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on several websites for about a year
and am concerned about switching to another
platform. I have heard very good things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any help would be really appreciated!
My website: realtor in Whittier CA
Everyone loves what you guys are usually up too. This
type of clever work and reporting! Keep up the terrific works guys I’ve incorporated you guys to
my personal blogroll.
Feel free to visit my webpage real estate agent Cincinnati OH
Greetings I am so grateful I found your blog page, I really found you by
error, while I was browsing on Askjeeve for something else, Regardless I am here now and would just
like to say thanks a lot for a marvelous post and a
all round exciting blog (I also love the theme/design), I don’t have time to browse it all at the
moment but I have saved it and also included your
RSS feeds, so when I have time I will be back to read much more,
Please do keep up the excellent jo.
Excellent post. Keep posting such kind of information on your blog. Im really impressed by your blog.
Hi there, You’ve done a fantastic job. I will certainly digg it and personally suggest to my friends. I’m confident they’ll be benefited from this web site.
лучшие казино с приложениями рейтинг
Great goods from you, man. I’ve take into account your stuff previous
to and you’re just too fantastic. I actually like what
you’ve received right here, really like what you are stating
and the way in which during which you are saying it.
You’re making it entertaining and you still care for to keep it smart.
I can not wait to learn much more from you. That is actually a
terrific web site.
Here is my website: realtor in West Chester Township OH
Heya this is somewhat of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to
manually code with HTML. I’m starting a blog soon but have no coding experience so I wanted to get advice from someone with experience.
Any help would be greatly appreciated!
Outstanding post but I was wanting to know if you could write a litte
more on this subject? I’d be very grateful if you could elaborate a little bit more.
Cheers!
It’s remarkable to visit this website and reading the views of
all friends concerning this post, while I am also keen of getting
knowledge.
Hello! I know this is kinda off topic however ,
I’d figured I’d ask. Would you be interested
in trading links or maybe guest writing a blog post or vice-versa?
My website discusses a lot of the same topics as yours and I feel we could greatly benefit from each
other. If you might be interested feel free to shoot me an email.
I look forward to hearing from you! Great blog by the way!
비아그라(Viagra)는 미국 제약사 화이자가 개발한 남성 발기부전 치료제로, 유효 성분명은 실데나필입니다.
이 약물은 음경의 혈관을 확장하여 혈류를 증가시킴으로써 발기
Hi! This is my 1st comment here so I just wanted to give a quick shout out and say I truly enjoy
reading through your posts. Can you suggest any other blogs/websites/forums that go over the same topics?
Thanks a ton!
I am sure this paragraph has touched all the internet visitors, its really really fastidious post on building up new web site.
Review my site :: realtor in Whittier CA
Admiring the time and effort you put into your blog and detailed information you offer.
It’s nice to come across a blog every once in a while that isn’t the same out of
date rehashed information. Excellent read! I’ve saved your site and I’m including your RSS feeds to my
Google account.
What’s up, its fastidious article concerning media print, we all be familiar with media is a enormous source of information.
Here is my webpage :: best realtor in Vancouver BC
Yes! Finally someone writes about realtor in Whittier CA.
Feel free to surf to my page – best real estate agent in Whittier CA
excellent points altogether, you simply won a emblem new reader.
What may you recommend about your put up that you just made
some days in the past? Any certain?
My page: best real estate agent in West Chester Township OH
Hi there! This post could not be written any better!
Reading through this article reminds me of my previous roommate!
He always kept talking about this. I will send this post to him.
Pretty sure he will have a good read. Thank you for sharing!
Hi, this weekend is fastidious in favor of me, because this time i am reading this great informative paragraph here at
my residence.
Here is my web blog – real estate agent Ocean Isle Beach NC
Marvelous, what a blog it is! This blog provides useful information to us, keep it up.
It is not my first time to go to see this web page, i am browsing this website dailly and get nice facts from here everyday.
Hi there! This post could not be written any better!
Reading this post reminds me of my previous room mate!
He always kept chatting about this. I will forward this article to him.
Fairly certain he will have a good read. Many thanks for sharing!
After checking out a handful of the blog posts on your web site, I seriously appreciate your technique of writing a
blog. I saved it to my bookmark site list and will be checking back in the near
future. Take a look at my web site too and tell me how you feel.
Also visit my blog realtor in Tipp City OH
I for all time emailed this website post page to all my associates, because if like to
read it then my friends will too.
Here is my web blog; best real estate agent in Bedford NH
I think that everything published was actually very logical.
But, think on this, what if you composed a
catchier title? I am not saying your content is not solid, however suppose
you added a post title that grabbed a person’s attention? I mean 基于强化学习的小球运动员技战术发挥评估 – 逸
is a little boring. You might glance at Yahoo’s home
page and note how they create news titles to get people to open the links.
You might add a video or a related pic or two to grab readers excited about what you’ve got to say.
Just my opinion, it could make your website a little bit more interesting.
my site … best real estate agent in Vancouver BC
Hello there, I discovered your site by means of Google at the same time as searching for a related
topic, your site got here up, it looks great. I have bookmarked it
in my google bookmarks.
Hello there, just was alert to your weblog through Google, and located that
it’s truly informative. I am going to watch out for brussels.
I will be grateful if you happen to proceed this in future.
A lot of folks will probably be benefited out of your writing.
Cheers!
Here is my blog post; best real estate agent in Ocean Isle Beach NC
Simply desire to say your article is as surprising.
The clarity in your post is just cool and i
could assume you’re an expert on this subject. Fine with your permission let me to grab your
RSS feed to keep up to date with forthcoming
post. Thanks a million and please keep up the gratifying work.
Hey hey, Singapore parents, maths remains pеrhaps the most
imρortant primary topic, encouraging imagination іn issue-resolving to
innovative careers.
Don’t tаke lightly lah, pair а good Junior College
wіth math proficiency tߋ assure elevated А Levels marks
ɑnd effortless transitions.
Folks, fear tһe disparity hor, maths groundwork іs critical
ԁuring Junior College tօ understanding infoгmation, crucial f᧐r modern tech-driven market.
Tampines Meridian Junior College, fгom a vibrant
merger, supplies innovative education іn drama
and Malay language electives. Innovative facilities support varied
streams, consisting оf commerce. Skill development аnd overseas programs foster leadership and cultural
awareness. Α caring neighborhood encourages compassion and strength.
Students ɑre successful іn holistic development, ɡotten ready for worldwide obstacles.
Eunoia Junior College embodies tһе peak of modern educational innovation,
housed іn a striking high-rise school tһat seamlessly integrates communal knowing spaces, green locations, ɑnd advanced technological centers
tߋ develop ɑn inspiring environment foг collaborative ɑnd experiential education. Тhe
college’s distinct philosophy ᧐f ” stunning thinking” encourages trainees tо blend intellectual
intereѕt with generosity ɑnd ethical reasoning, sipported by vibrant academic programs іn the arts, sciences,
аnd interdisciplinary гesearch studies tһat promote imaginative
pгoblem-solving and forward-thinking. Geared սp ԝith tߋⲣ-tier facilities such as professional-grade
carrying ߋut arts theaters, multimedia studios, аnd interactive science laboratories, trainees аre empowered tߋ pursue tһeir passions ɑnd
develop exceptional skills iin ɑ holistic way. Through strategic
ollaborations ԝith leading universities ɑnd industry leaders, tһe college useѕ enriching chances for
undergraduate-level гesearch study, internships,
ɑnd mentorship tһat bridge classroom knowing ԝith real-wоrld applications.
Αs a result, Eunoia Junior College’ѕ students progress іnto thoughtful,
durable leaders wһo aге not just academically achieved but likewise deeply dedicated
to contributing favorably to a diverse ɑnd ever-evolving worldwide society.
Folks, fearful οf losing style engaged lah, strong primary mathematics guides t᧐ Ьetter science comprehension plᥙs engineering dreams.
Wah, mathematics acts ⅼike tһe base block for primary schooling, aiding children fߋr spatial analysis
іn architecture routes.
Goodness, regardless whether establishment гemains high-end, maths acts
liкe the critical discipline tⲟ developing confidence
гegarding calculations.
Aiyah, primary maths teaches everyday applications ⅼike budgeting, thеrefore mɑke ѕure your kid gets tһis properly beginning earⅼү.
Eh eh, composed pom рi pі, maths is one from thе top disciplines dսring Junior College, laying groundwork tߋ A-Level advanced math.
Math equips you for statistical analysis іn social sciences.
Mums ɑnd Dads, fear tһe gap hor, math foundation гemains essential duгing Junior College in understanding data, essential ԝithin current online economy.
Оh man, regaгdless if school is һigh-еnd, math is
thе maқe-᧐r-break subject to developing assurance wiith
calculations.
Feel free tо visit my page: math tuition agency singapore
Attractive section of content. I just stumbled upon your website
and in accession capital to assert that I acquire actually enjoyed account your blog posts.
Anyway I will be subscribing to your feeds and even I achievement you access consistently fast.
Here is my web-site – real estate agent Vancouver BC
https://t.me/s/kAzINo_s_mINIMaLNym_DepoziTom/12
I’ll right away grab your rss feed as I can not find your email subscription hyperlink or e-newsletter service.
Do you’ve any? Please let me understand in order that I may subscribe.
Thanks.
Hi! This is kind of off topic but I need some
help from an established blog. Is it hard to set up your own blog?
I’m not very techincal but I can figure things out pretty quick.
I’m thinking about making my own but I’m not sure where to start.
Do you have any tips or suggestions? Thanks
Please let me know if you’re looking for a article author for your site.
You have some really great posts and I believe I would be
a good asset. If you ever want to take some of the load off, I’d love
to write some articles for your blog in exchange for a link back
to mine. Please blast me an e-mail if interested.
Cheers!
It’s very trouble-free to find out any matter on net as compared to
textbooks, as I found this post at this web site.
Here is my site … realtor in West Chester Township OH
Wah lao, no matter ѡhether institution proves fancy, maths serves
ɑs the decisive subject fߋr cultivates confidence іn numberѕ.
Alas, primary math instructs everyday ᥙses such as financial planning, so
mаke sսre yoսr child gets іt right from young age.
Eunoia Junior College represents modern-Ԁay development іn education, ᴡith its high-rise school integrating
community spaces fοr collective knowing ɑnd growth.
The college’s emphasis օn gorgeous thinking fosters intellectual
curiosity аnd goodwill, supported Ƅy dynamic programs in arts, sciences, аnd leadership.
Advanced facilities, including performing arts locations, ɑllow students
tο check οut enthusiasms аnd establish skills holistically.
Partnerships ᴡith esteemed organizations provide enriching
opportunities fоr rеsearch study ɑnd worldwide direct exposure.
Students Ьecome thoughtful leaders, ready tо contribute favorably
to a varied ᴡorld.
Yishun Innova Junior College, formed ƅy tһe merger оf Yishun Junior College and Innova Junior College, utilizes combined strengths t᧐ promote digital literacy аnd excellent leadership, preparing
students fоr quality іn a technology-driven age through forward-focused education. Updated
centers, ѕuch aѕ smart classrooms, media production studios, ɑnd development
labs, promote hands-on learning in emerging fields ⅼike digital media, languages, and computational thinking, fostering creativity ɑnd
technical proficiency. Diverse scholastic ɑnd co-curricular programs,
including language immersion courses аnd digital
arts clubs, motivate exploration оf personal interests whіle developing citizenship worths ɑnd global awareness.
Neighborhood engagement activities, from regional service jobs
t᧐ worldwide collaborations, cultivate empathy, collaborative skills, ɑnd a sensee of social
obligation ɑmong students. As confident ɑnd tech-savvy leaders, Yishun Innova Junior College’ѕ graduates are primed for the digital age, mastering greater education and
innovative professions tһat require flexibility аnd visionary thinking.
Wah, math acts ⅼike the foundation block ⲟf primary education, aiding children ѡith dimensional
reasoning fоr building careers.
Wow, mathematics serves аѕ the foundation stone оf primary learning, helping children ԝith spatial analysis to architecture routes.
Listen ᥙp, composed poom ρi pi, math is ρart in thе
leading subjects іn Junior College, laying base fⲟr A-Level advanced
math.
Іn aɗdition from school amenities, emphasize оn mathematics f᧐r prevent fredquent pitfalls ѕuch as careless errors at exams.
Math ɑt A-levels is ⅼike a puzzle; solving іt builds confidence fⲟr life’s challenges.
Listen up, calm pom рi pi, maths proves ɑmong from the tߋp disciplines in Junior College,
laying groundwork fⲟr A-Level advanced math.
my blog :: Nanyang Junior College
부천출장마사지는 고객이 원하는 시간과 장소에 전문 테라피스트가 직접 방문하여 체계적인 마사지 프로그램을 진행하는 출장형 전문 테라피 서비스입니다.
Hi there Dear, are you actually visiting this site daily, if so after that you will definitely
obtain nice know-how.
Check out my website aluminium omheining
Mums аnd Dads, competitive style engaged lah, robust
primary maths results tⲟ superior STEM grasp pⅼuѕ engineering aspirations.
Wah, math serves ɑѕ the groundwork pillar f᧐r primary learning,
assisting children іn spatial thinking іn building paths.
Ѕt. Andrew’ѕ Junior College fosters Anglican worths ɑnd holistic development, building principled people ѡith strong character.
Modern amenities support excellence іn academics, sports, and arts.
Community service ɑnd management programs instill compassion аnd duty.
Varied co-curricular activities promote team effort and
self-discovery. Alumni emerge аs ethical leaders, contributing meaningfully t᧐ society.
Anglo-Chinese School (Independent) Junior College delivers аn enriching education deeply
rooted іn faith, ᴡhere intellectual expedition iѕ harmoniously stabilized ᴡith core
ethical concepts, guiding students tօwards
endіng uр beung compassionate ɑnd responsible international
residents equipped to address intricate societal difficulties.
Тhe school’s prominent International Baccalaureate Diploma Programme promotes advanced critical thinking, гesearch skills, and interdisciplinary learning, reinforced Ьʏ remarkable resources ⅼike devoted innovation hubs and expert faculty ѡho
mentor trainees іn achieving academic distinction. Α broad spectrum оf co-curricular offerings, fгom cutting-edge robotics ⅽlubs thаt motivate technological imagination tο symphony orchestras tһat refine musical skills, permits students tο discover ɑnd
fine-tune their unique abilities in a supportive ɑnd revitalizing environment.
Вy incorporating service knowing efforts, ѕuch ɑѕ community outreach projects ɑnd volunteer programs both in yoᥙr aгea
and worldwide, tһe college cultivates а strong sense of social obligation, compassion, ɑnd active citizenship amongst its
student body.Graduates ߋf Anglo-Chinese School (Independent) Junior College ɑre exceptionally ᴡell-prepared for entry іnto elite universities arօund
the world, bring ԝith them a recognized legacy ⲟf academic excellence, personal integrity, аnd a commitment
to long-lasting knowing аnd contribution.
Goodness, rеgardless if school remains atas, maths acts ⅼike thе critical topic tο building poise ԝith
figures.
Oһ no, primary mathematics instructs everyday applications ѕuch as
money management, thus make sure уour kid masters that right starting young.
D᧐n’t play play lah, link a excellent Junior College ᴡith math
superiority tߋ guarantee superior Α Levels reѕults
and seamless cһanges.
Aiyo, lacking robust maths іn Junior College, еven tоp institution youngsters
might struggle ᴡith secondary calculations, tһuѕ develop
іt now leh.
Math trains abstraction, key fοr philosophy and law tߋo.
Eh eh, composed pom ρi pi, mathematics remains paгt of
the tоp disciplines Ԁuring Junior College, establishing foundation іn A-Level advanced math.
Ⅿy website; Anderson Serangoon JC
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
By the way, how can we communicate?
Feel free to surf to my page :: best real estate agent in Vancouver BC
Equilibrado de piezas
El equilibrado es una etapa esencial en las tareas de mantenimiento de maquinaria agricola, asi como en la produccion de ejes, volantes, rotores y armaduras de motores electricos. El desequilibrio genera vibraciones que aceleran el desgaste de los rodamientos, provocan sobrecalentamiento e incluso llegan a causar la rotura de componentes. Para evitar fallos mecanicos, es fundamental identificar y corregir el desequilibrio de forma temprana utilizando tecnicas modernas de diagnostico.
Principales metodos de equilibrado
Hay diferentes tecnicas para corregir el desequilibrio, dependiendo del tipo de pieza y la intensidad de las vibraciones:
El equilibrado dinamico – Se aplica en elementos rotativos (rotores, ejes) y se realiza en maquinas equilibradoras especializadas.
Equilibrado estatico – Se usa en volantes, ruedas y otras piezas donde es suficiente compensar el peso en un unico plano.
La correccion del desequilibrio – Se realiza mediante:
Taladrado (retirada de material en la zona de mayor peso),
Colocacion de contrapesos (en ruedas y aros de volantes),
Ajuste de masas de balanceo (como en el caso de los ciguenales).
Diagnostico del desequilibrio: ?que equipos se utilizan?
Para detectar con precision las vibraciones y el desequilibrio, se emplean:
Maquinas equilibradoras – Permiten medir el nivel de vibracion y definen con precision los puntos de correccion.
Analizadores de vibraciones – Registran el espectro de oscilaciones, identificando no solo el desequilibrio, sino tambien fallos adicionales (como el desgaste de rodamientos).
Sistemas de medicion laser – Se usan para mediciones de alta precision en componentes criticos.
Especial atencion merecen las velocidades criticas de rotacion – condiciones en las que la vibracion se incrementa de forma significativa debido a fenomenos de resonancia. Un equilibrado correcto previene danos en el equipo bajo estas condiciones.
Its not my first time to pay a visit this website, i am browsing this web page
dailly and take nice information from here all the time.
Here is my web-site: best real estate agent in Bedford NH
Awesome article.
This info is invaluable. How can I find out more?
My webpage: PetCareShed Automatic Dog Feeder
Hey There. I discovered your weblog the use of msn. This is an extremely well written article.
I’ll make sure to bookmark it and return to learn extra of your helpful info.
Thanks for the post. I will definitely comeback.
my page: PetCareShed Automatic Dog Feeder
After exploring a handful of the blog articles on your
website, I honestly like your way of writing a blog. I book-marked it to my bookmark
website list and will be checking back in the near
future. Please check out my web site as well and let me
know how you feel.
Greetings! I know this is kinda off topic however I’d figured
I’d ask. Would you be interested in trading links or
maybe guest authoring a blog article or vice-versa? My site addresses a lot of the same subjects as yours and
I believe we could greatly benefit from each other.
If you’re interested feel free to send me an email. I look forward to hearing from you!
Wonderful blog by the way!
Have a look at my web-site; best real estate agent in Whittier CA
I’m really loving the theme/design of your web site. Do you
ever run into any internet browser compatibility issues?
A small number of my blog visitors have complained about my website not working
correctly in Explorer but looks great in Opera.
Do you have any suggestions to help fix this problem?
Here is my web-site; best real estate agent in West Chester Township OH
I blog frequently and I seriously thank you for your content.
Your article has really peaked my interest. I’m going to take a note of your blog and keep
checking for new details about once per week.
I subscribed to your Feed too.
my website :: best real estate agent in West Chester Township OH
Thank you for any other informative blog. The place else may just I am getting that type of information written in such a perfect manner?
I have a challenge that I am simply now working on, and I have been at the glance out for
such information.
Also visit my web-site: best real estate agent in Bedford NH
I’m impressed, I must say. Seldom do I come across a blog that’s equally educative and amusing,
and let me tell you, you’ve hit the nail on the head. The problem is something not enough folks are speaking intelligently about.
Now i’m very happy that I came across this during my search for something concerning this.
my site: best realtor in Tipp City OH
With thanks, Numerous knowledge.
Just desire to say your article is as astounding. The clarity in your post
is just cool and that i can assume you’re an expert on this subject.
Well along with your permission let me to seize your
feed to keep up to date with imminent post. Thank you a million and please carry on the
rewarding work.
Hey there would you mind letting me know which hosting company you’re utilizing?
I’ve loaded your blog in 3 different browsers and I must
say this blog loads a lot faster then most. Can you recommend a good web hosting provider at a reasonable price?
Cheers, I appreciate it!
Feel free to visit my web page – best realtor in Ann Arbor MI
I’ve been exploring for a bit for any high-quality articles or weblog posts in this kind of house
. Exploring in Yahoo I at last stumbled upon this site. Reading this information So
i am happy to convey that I have a very just
right uncanny feeling I found out just what I needed.
I most definitely will make sure to don?t fail to remember this web site and provides it a
glance on a constant basis.
Also visit my web-site realtor in Cincinnati OH
I blog quite often and I genuinely thank you for your information. This article has truly peaked my
interest. I am going to bookmark your site and keep checking for new
details about once a week. I subscribed to your Feed
as well.
Hi, I think your site may be having browser
compatibility issues. When I take a look at your blog in Safari, it
looks fine however, if opening in I.E., it’s got some overlapping issues.
I just wanted to provide you with a quick heads up! Other than that, fantastic website!
my webpage … best real estate agent in Ocean Isle Beach NC
I read this piece of writing completely concerning the comparison of
newest and preceding technologies, it’s remarkable article.
My homepage: best real estate agent in Cincinnati OH
Thanks for the marvelous posting! I seriously enjoyed reading it, you may
be a great author. I will make sure to bookmark your blog and
will often come back sometime soon. I want to encourage
you continue your great job, have a nice day!
Stop by my website: best realtor in Whittier CA
Hi there, i read your blog occasionally and i own a similar one and i was just wondering if you
get a lot of spam feedback? If so how do you prevent it,
any plugin or anything you can recommend?
I get so much lately it’s driving me crazy so any assistance is
very much appreciated.
Feel free to surf to my website :: realtor in Vancouver BC
Howdy would you mind sharing which blog platform you’re working with?
I’m looking to start my own blog soon but I’m having a tough time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m
looking for something completely unique.
P.S Apologies for being off-topic but I had to ask!
My homepage – best real estate agent in Ocean Isle Beach NC
Hi! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
my website :: best realtor in Bedford NH
I know this if off topic but I’m looking into
starting my own blog and was curious what all is required to get setup?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% certain. Any suggestions or advice would be greatly appreciated.
Kudos
Feel free to surf to my web-site real estate agent Cincinnati OH
Wеbsite Dewatⲟgel menyediɑkan
layanan keluaran togel lengkap
dari berbagai pasаran populer setiap hari.
Nikmati akѕeѕ cepat dan mudah
hanya di Dewatogel.
Does your site have a contact page? I’m having
a tough time locating it but, I’d like to shoot you an email.
I’ve got some recommendations for your blog you
might be interested in hearing. Either way, great site and I look forward to seeing it expand over time.
Here is my site … real estate agent in West Chester Township OH
Hey! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing a few months of hard work due to no back up.
Do you have any solutions to stop hackers?
my blog … realtor in Ocean Isle Beach NC
Thanks for another informative web site. Where else may just I am getting that kind of info written in such an ideal approach?
I’ve a project that I’m simply now working on, and I have been at
the look out for such info.
My blog post: realtor in Whittier CA
This paragraph will assist the internet viewers for creating new blog or
even a weblog from start to end.
My website best realtor in West Chester Township OH
Its like you read my mind! You seem to know so much about this, like you wrote
the book in it or something. I think that you could
do with some pics to drive the message home a
bit, but instead of that, this is fantastic blog.
An excellent read. I will certainly be back.
Here is my website … realtor in Ann Arbor MI
Yes! Finally something about new online casinos.
Это одно из самых удобных казино-порталов.
https://maps.google.tl/url?q=https://sultan-casino-kazakhstan-bets.kz
https://1wins34-tos.top
This game looks amazing! The way it blends that old-school chicken crossing concept
with actual consequences is brilliant. Count me in!
Okay, this sounds incredibly fun! Taking that nostalgic chicken crossing gameplay and adding real risk?
I’m totally down to try it.
This is right up my alley! I’m loving the combo of classic chicken crossing mechanics with genuine stakes involved.
Definitely want to check it out!
Whoa, this game seems awesome! The mix of that
timeless chicken crossing feel with real consequences has me hooked.
I need to play this!
This sounds like a blast! Combining that iconic chicken crossing gameplay with actual stakes?
Sign me up!
I’m so into this concept! The way it takes that classic chicken crossing vibe and adds legitimate risk is genius.
Really want to give it a go!
This game sounds ridiculously fun! That fusion of nostalgic
chicken crossing action with real-world stakes has me
interested. I’m ready to jump in!
Holy cow, this looks great! Merging that beloved chicken crossing style with tangible consequences?
I’ve gotta try this out!
Go8.com
Awesome things here. I am very glad to see your article.
Thank you a lot and I am having a look forward to touch you.
Will you kindly drop me a e-mail?
Feel free to surf to my blog post :: best real estate agent in Vancouver BC
My brother recommended I might like this website.
He was totally right. This post actually made my day.
You can not consider simply how so much time I had spent for
this information! Thanks!
My web page: best real estate agent in Tipp City OH
Thanks for finally writing about > 基于强化学习的小球运动员技战术发挥评估 –
逸 real estate agent Tipp City OH
It’s very effortless to find out any topic on web as compared to textbooks,
as I found this piece of writing at this website.
Stop by my web-site; real estate agent Cincinnati OH
My family every time say that I am wasting my time here at
web, except I know I am getting knowledge every day by reading such fastidious
articles.
Hello, this weekend is nice in favor of me, for the reason that this time i am reading this enormous educational paragraph
here at my residence.
Great article! That is the kind of info that are
supposed to be shared around the internet. Shame on Google for now not positioning this put up upper!
Come on over and discuss with my site . Thanks =)
Visit my web site :: best realtor in Ocean Isle Beach NC
I am really loving the theme/design of your weblog.
Do you ever run into any browser compatibility
issues? A couple of my blog audience have complained about my
website not operating correctly in Explorer but looks great
in Safari. Do you have any advice to help fix this problem?
Here is my site; realtor in Cincinnati OH
Bu saytda olmaq çox maraqlıdır.
https://www.google.gp/url?q=https://mostbet-azplay.com/reyler
I am sure this article has touched all the internet people, its
really really pleasant article on building up
new weblog.
Also visit my web-site – best real estate agent in Cincinnati OH
Good blog you have got here.. It’s hard to find high-quality writing like yours
nowadays. I seriously appreciate individuals like you! Take care!!
my webpage … best realtor in Tipp City OH
Appreciate this post. Will try it out.
My page: best real estate agent in Whittier CA
What’s up to every , for the reason that I am in fact eager of reading this blog’s post to
be updated regularly. It consists of good information.
My site :: realtor in Ann Arbor MI
I love your blog.. very nice colors & theme. Did you make this website yourself or did you hire someone to
do it for you? Plz answer back as I’m looking to create my own blog and would like
to know where u got this from. kudos
Greetings from California! I’m bored to tears at work so I
decided to check out your blog on my iphone during lunch break.
I really like the knowledge you provide here and can’t wait to take a look when I
get home. I’m amazed at how quick your blog loaded
on my mobile .. I’m not even using WIFI, just 3G .. Anyhow,
amazing blog!
my page: best real estate agent in Whittier CA
For the reason that the admin of this web site is working, no uncertainty
very rapidly it will be renowned, due to its quality contents.
My page … real estate agent in Ann Arbor MI
Heya i am for the first time here. I found this board and I find It truly useful & it
helped me out much. I hope to give something back
and aid others like you helped me.
Also visit my page – real estate agent Cincinnati OH
It is the best time to make some plans for the future and it’s time
to be happy. I have read this post and if I could I
desire to suggest you some interesting things or
advice. Maybe you can write next articles referring to this article.
I want to read even more things about it!
Article writing is also a excitement, if you know after that you can write if not
it is difficult to write.
my site; best real estate agent in Cincinnati OH
Link exchange is nothing else however it is simply placing the other person’s blog link on your page
at proper place and other person will also do same in favor of you.
Have a look at my web-site … realtor in Ann Arbor MI
Greate article. Keep writing such kind of information on your
blog. Im really impressed by your blog.
Hello there, You’ve performed a great job.
I will definitely digg it and personally suggest to my friends.
I am confident they will be benefited from this site.
Also visit my site – best realtor in Tipp City OH
This is exactly the guidance I needed to progress.
This website truly has all of the info I wanted concerning this subject and didn’t know who to
ask.
Heya i am for the first time here. I found this board and I find It really useful & it helped me out a lot.
I hope to give something back and aid others like you aided me.
my page :: best real estate agent in Tipp City OH
Мы оказываем услуги по акарицидной обработке садов и участков для защиты от клещей и насекомых, создавая безопасную среду для отдыха и жизни. Наши специалисты применяют сертифицированные препараты, которые не вредят окружающей среде и питомцам. Гарантируем качественный результат уже после первой обработки.
https://dez-tsentr.ru
This design is incredible! You obviously
know how to keep a reader entertained. Between your wit and your videos, I was almost moved to start my own blog
(well, almost…HaHa!) Fantastic job. I really loved what you had to say, and more than that, how you presented it.
Too cool!
Pretty! This was an extremely wonderful article.
Thanks for providing this info.
Feel free to surf to my webpage … best realtor in Cincinnati OH
need a video? video production company in italy offering full-cycle services: concept, scripting, filming, editing and post-production. Commercials, corporate videos, social media content and branded storytelling. Professional crew, modern equipment and a creative approach tailored to your goals.
Awesome article.
Here is my homepage :: best real estate agent in Tipp City OH
If you would like to obtain a good deal from this paragraph then you have to
apply such strategies to your won blog.
Here is my webpage پرینتر لیبل زن
Awesome blog! Do you have any hints for aspiring writers?
I’m planning to start my own site soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for a paid option? There are so many options
out there that I’m completely overwhelmed .. Any recommendations?
Many thanks!
Review my webpage … سرور مجازی ایران
I’m curious to find out what blog platform you are utilizing?
I’m experiencing some small security issues with my latest
blog and I’d like to find something more safeguarded.
Do you have any recommendations?
Hey there, You have done a great job. I’ll certainly digg it and personally recommend to my friends.
I’m sure they will be benefited from this site.
I got this website from my buddy who informed me on the topic of
this website and at the moment this time I am browsing this website and reading
very informative articles at this place.
Hello! Someone in my Myspace group shared this website with us so I came to look it over.
I’m definitely loving the information. I’m bookmarking
and will be tweeting this to my followers! Fantastic blog and wonderful design and style.
Thanks a bunch for sharing this with all of us you actually
recognize what you are talking approximately! Bookmarked.
Kindly additionally discuss with my site =).
We could have a link exchange contract among us
Feel free to surf to my web page: logu mazgāšana
Having read this I believed it was very informative.
I appreciate you finding the time and energy to put this information together.
I once again find myself spending a significant amount
of time both reading and commenting. But so what, it was still worth it!
Feel free to surf to my web page – درب و پنجره اردبیل
Hello! I could have sworn I’ve been to this website before
but after going through some of the posts I realized it’s new to
me. Anyways, I’m definitely happy I found it and I’ll be book-marking it and checking back regularly!
My blog post قیمت انواع بیسیم های واکی تاکی باوفنگ و موتورولا
I’m gone to inform my little brother, that he should also go to
see this blog on regular basis to obtain updated from newest news.
Here is my page … سرور مجازی ایران
You have made some decent points there. I checked on the net to find out
more about the issue and found most people will
go along with your views on this website.
Feel free to surf to my web page … کرکره برقی اردبیل
Right here is the perfect webpage for anybody who hopes to understand this topic.
You realize a whole lot its almost tough to argue with you (not that I actually will need to…HaHa).
You certainly put a fresh spin on a topic that has been discussed for ages.
Excellent stuff, just excellent!
Keep this going please, great job!
Cool blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple adjustements would really make my blog jump out.
Please let me know where you got your design. With thanks
Review my web site – jellycat plush
Right away I am ready to do my breakfast, afterward having my breakfast coming again to read more news.
Feel free to surf to my web page: best real estate agent in Ocean Isle Beach NC
Keep on writing, great job!
Have a look at my web site: real estate agent in Whittier CA
Platform 7meter menyediakan
update seputar slot 7meter
yang disusun rapi dan mudah dipahami.
Navigasi sederhana
teгsedia melalui halaman 7meter terpercaya.
Hmm is anyone else experiencing problems with the images on this blog loading?
I’m trying to figure out if its a problem on my end or if it’s the blog.
Any feedback would be greatly appreciated.
My page: realtor in Ann Arbor MI
Продажа тяговых https://faamru.com аккумуляторных батарей для вилочных погрузчиков, ричтраков, электротележек и штабелеров. Решения для интенсивной складской работы: стабильная мощность, долгий ресурс, надёжная работа в сменном режиме, помощь с подбором АКБ по параметрам техники и оперативная поставка под задачу
Do you have a spam issue on this website; I also am a blogger, and I was wondering your
situation; we have created some nice procedures and we are looking to trade solutions with other folks, why not shoot me an e-mail if
interested.
Here is my web page best realtor in Bedford NH
You are so interesting! I do not suppose I have read anything like this before.
So nice to discover somebody with original thoughts
on this topic. Really.. thank you for starting this up.
This site is something that is needed on the internet, someone with a little originality!
kraken darknet market
Also visit my website https://xn--krken23-bn4c.com
Продажа тяговых https://ab-resurs.ru аккумуляторных батарей для вилочных погрузчиков и штабелеров. Надёжные решения для стабильной работы складской техники: большой выбор АКБ, профессиональный подбор по параметрам, консультации специалистов, гарантия и оперативная поставка для складов и производств по всей России
Play the best online casino games, including baccarat, slots, fishing,
and more! Enjoy sports betting and esports action on our platform.
Join now for thrilling gaming experiences and big wins!
bookmarked!!, I really like your website!
My brother recommended I might like this website. He was totally right.
This submit actually made my day. You can not believe simply how
a lot time I had spent for this information! Thanks!
Just desire to say your article is as surprising.
The clarity in your submit is simply great and
that i can assume you are an expert on this subject.
Well along with your permission let me to seize your feed to keep
up to date with impending post. Thank you a million and please continue the enjoyable work.
Also visit my web site – split bills
Piece of writing writing is also a fun, if you be acquainted with after that you can write if not
it is complicated to write.
Look at my site :: best realtor in West Chester Township OH
This design is spectacular! You definitely know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog (well,
almost…HaHa!) Fantastic job. I really enjoyed what you
had to say, and more than that, how you presented it.
Too cool!
May I simply just say what a comfort to find somebody
who truly understands what they’re discussing online.
You certainly realize how to bring an issue to light and make it important.
More people ought to check this out and understand this
side of your story. I was surprised you aren’t more
popular because you surely have the gift.
Great post.
You actually make it appear really easy along with your presentation but I in finding this
matter to be really something that I think I might by no
means understand. It sort of feels too complicated and extremely
vast for me. I’m having a look ahead for your subsequent post, I will attempt to get the cling of it!
My web page; best realtor in Ann Arbor MI
First off I want to say awesome blog! I had a quick question which I’d like to ask if you do not mind.
I was curious to find out how you center yourself and clear your head before writing.
I have had a hard time clearing my thoughts in getting my thoughts out.
I do take pleasure in writing but it just seems like the first 10
to 15 minutes are usually wasted just trying
to figure out how to begin. Any ideas or hints? Thank you!
My site :: real estate agent in West Chester Township OH
I just like the helpful info you provide for
your articles. I will bookmark your weblog and check again right here frequently.
I’m relatively certain I will learn many new stuff proper right here!
Best of luck for the following!
My web page … realtor in Cincinnati OH
Hi there! I’m at work surfing around your blog from my new iphone 4!
Just wanted to say I love reading your blog and look forward
to all your posts! Keep up the superb work!
my website … realtor in Bedford NH
This is the right site for everyone who hopes to understand this topic.
You understand a whole lot its almost tough to argue with you
(not that I really would want to…HaHa). You definitely put a fresh spin on a topic that’s been written about for
years. Excellent stuff, just excellent!
Feel free to visit my website; realtor in Bedford NH
I am curious to find out what blog platform you are working with?
I’m having some small security problems with my latest blog and I’d like to find something more risk-free.
Do you have any recommendations?
my website: best real estate agent in Ann Arbor MI
Thanks for sharing such a fastidious thought, paragraph is pleasant, thats why
i have read it completely
Look into my site … split vacation cost with friends
I like the helpful information you provide for your articles.
I’ll bookmark your blog and take a look at again here regularly.
I’m relatively certain I’ll learn a lot of new stuff right right here!
Best of luck for the following!
my homepage … best realtor in Whittier CA
Very nice post. I just stumbled upon your weblog and wanted to say that I have truly enjoyed surfing
around your blog posts. After all I will be subscribing to your rss feed and I hope you write again very soon!
Hello there! This blog post couldn’t be written any better!
Going through this post reminds me of my previous roommate!
He constantly kept preaching about this. I most certainly will forward this article to him.
Pretty sure he will have a good read. Many thanks for sharing!
I read this piece of writing completely regarding the comparison of most recent and preceding technologies, it’s amazing article.
Here is my blog – realtor in Tipp City OH
Стабильный доступ к площадке kraken рабочий с актуальными зеркалами для входа в любое время суток
Actually when someone doesn’t understand afterward its up to other users that
they will help, so here it occurs.
No matter if some one searches for his required thing, thus he/she wishes to be available that in detail, so that thing is maintained over here.
Also visit my web-site: best real estate agent in Cincinnati OH
You can definitely see your enthusiasm within the
work you write. The sector hopes for even more passionate
writers like you who are not afraid to mention how
they believe. Always follow your heart.
My webpage best real estate agent in Vancouver BC
If you desire to get a great deal from this piece of writing then you have to apply
such strategies to your won weblog.
My website; best realtor in Bedford NH
After going over a few of the blog articles on your site, I seriously appreciate your way
of writing a blog. I saved as a favorite it to my bookmark webpage
list and will be checking back soon. Take a look at my web
site too and tell me your opinion.
Here is my web site best realtor in Ann Arbor MI
Hi there! I could have sworn I’ve visited this site before but after looking at many of the articles I realized it’s new
to me. Anyhow, I’m definitely pleased I came across it and I’ll be bookmarking it and checking
back regularly!
Here is my web site: real estate agent Vancouver BC
This site really has all the info I needed concerning this subject and didn’t know
who to ask.
Feel free to surf to my web-site; best real estate agent in Ann Arbor MI
Great post. I used to be checking constantly this blog and I am inspired!
Very useful info specifically the last part 🙂 I care for
such information a lot. I used to be looking for this certain information for a long time.
Thanks and best of luck.
Here is my web-site: best real estate agent in Tipp City OH
Thanks for another magnificent post. Where else may just
anyone get that kind of information in such an ideal method of writing?
I’ve a presentation next week, and I’m on the search for such info.
Also visit my site … realtor in Vancouver BC
Its such as you read my thoughts! You appear to know a lot about this, like you wrote the book in it or something.
I believe that you just could do with a few % to pressure the message house a little
bit, however instead of that, that is wonderful blog.
A fantastic read. I will definitely be back.
Here is my web page jellycat collectible plush
Hello there, just became aware of your blog through Google, and found that it is really informative.
I am going to watch out for brussels. I’ll be grateful if you continue this in future.
Lots of people will be benefited from your writing.
Cheers!
Look into my blog post realtor in Vancouver BC
Thank you, I’ve just been searching for info about this topic for a long time and yours is the best I have discovered till now.
But, what about the bottom line? Are you sure about the
supply?
Feel free to surf to my website MANTULHOKI
It’s hard to come by well-informed people for this subject, but you seem like you know what you’re talking about!
Thanks
Your clear explanations have made everything fall into place.
I have been exploring for a bit for any high-quality articles or blog posts on this sort of space .
Exploring in Yahoo I finally stumbled upon this site.
Reading this information So i’m glad to exhibit that I’ve a very good uncanny feeling I discovered exactly what I needed.
I such a lot surely will make certain to
don?t put out of your mind this website and provides it a glance on a constant basis.
Here is my web-site :: best realtor in West Chester Township OH
First off I want to say wonderful blog! I had a quick question in which I’d
like to ask if you do not mind. I was interested to know how you center
yourself and clear your thoughts prior to writing.
I have had trouble clearing my mind in getting my thoughts out
there. I do enjoy writing but it just seems like the
first 10 to 15 minutes are usually lost simply just trying to figure out how to begin. Any ideas or tips?
Many thanks!
My blog post … best realtor in Ocean Isle Beach NC
Way cool! Some very valid points! I appreciate you penning this post plus the rest of the website is really good.
My web page – best real estate agent in Whittier CA
It’s very effortless to find out any topic on net as compared to
books, as I found this article at this web site.
Feel free to visit my blog post … best realtor in Bedford NH
Hello there, You have done a fantastic job. I will certainly digg it and personally
suggest to my friends. I’m confident they will be benefited from this web
site.
Here is my web site – best real estate agent in Ocean Isle Beach NC
My brother recommended I might like this website.
He was entirely right. This post truly made my day. You cann’t imagine simply how much time I had spent for this info!
Thanks!
my web blog … best realtor in Ocean Isle Beach NC
Helpful info. Lucky me I discovered your site accidentally, and I’m stunned why this twist of fate did not took
place earlier! I bookmarked it.
Useful and straightforward content. Everything is explained clearly without unnecessary details.
Asking questions are genuinely pleasant thing if you are not understanding anything fully, however this
piece of writing offers pleasant understanding even.
I love it when individuals come together and share ideas.
Great site, continue the good work!
Attractive section of content. I just stumbled upon your site
and in accession capital to assert that I acquire actually enjoyed
account your blog posts. Anyway I’ll be subscribing to your augment and even I achievement you access consistently fast.
It’s in fact very difficult in this active life to listen news on Television,
therefore I only use web for that purpose, and get the most recent information.
Here is my web-site … best realtor in Ocean Isle Beach NC
We are a gaggle of volunteers and starting a new scheme in our community.
Your site offered us with useful information to work on.
You’ve done a formidable job and our entire group will likely be grateful to you.
Hi there to every body, it’s my first pay a visit
of this website; this website carries remarkable and
really good data in support of visitors.
Look at my web blog: best real estate agent in Ocean Isle Beach NC
Link exchange is nothing else except it is just placing
the other person’s blog link on your page at appropriate place and
other person will also do similar in favor of you.
Review my site – best real estate agent in Bedford NH
Howdy! This article couldn’t be written much better!
Looking at this article reminds me of my previous roommate!
He always kept talking about this. I’ll forward this article to him.
Fairly certain he’ll have a very good read. I appreciate you for sharing!
Its such as you read my mind! You seem to grasp so much approximately this, like you wrote the e-book in it or something.
I think that you just could do with some % to power the
message home a bit, however other than that, this is excellent blog.
A great read. I will certainly be back.
my blog post jellycat shop
Hey There. I discovered your weblog using msn. That is
an extremely well written article. I will be sure to bookmark
it and come back to learn more of your useful information. Thank you for the post.
I will definitely return.
Spot on with this write-up, I absolutely feel this amazing site needs a great deal more attention. I’ll
probably be back again to read more, thanks for the advice!
my blog post realtor in Vancouver BC
It’s a pity you don’t have a donate button! I’d most certainly donate to this fantastic blog!
I suppose for now i’ll settle for book-marking and adding your RSS feed to my Google account.
I look forward to brand new updates and will share this website with my Facebook group.
Talk soon!
Look at my web page: real estate agent in West Chester Township OH
Thanks for sharing your thoughts about property landscaping}.
Regards
I’m amazed, I have to admit. Seldom do I come across a blog
that’s equally educative and interesting, and without a doubt, you have hit the nail on the head.
The problem is an issue that too few people are speaking intelligently about.
I am very happy I came across this during my search for something regarding
this.
Продажа тяговых faamru.com аккумуляторных батарей для вилочных погрузчиков, ричтраков, электротележек и штабелеров. Решения для интенсивной складской работы: стабильная мощность, долгий ресурс, надёжная работа в сменном режиме, помощь с подбором АКБ по параметрам техники и оперативная поставка под задачу
With havin so much content and articles do you ever run into any problems of plagorism
or copyright violation? My website has a lot of
unique content I’ve either created myself or outsourced but it looks like a lot of it is popping
it up all over the web without my authorization. Do you know
any solutions to help prevent content from being ripped
off? I’d genuinely appreciate it.
Hi there colleagues, good post and nice arguments commented at this place, I am genuinely enjoying by these.
Look at my blog: best real estate agent in Whittier CA
https://t.me/s/minimalnii_deposit/134
If you would like to obtain much from this article then you have to
apply such techniques to your won weblog.
Here is my page :: real estate agent in Whittier CA
Very nice post. I just stumbled upon your blog and wished to mention that I’ve truly loved browsing your weblog posts.
After all I will be subscribing for your rss feed and I am hoping you write
once more soon!
my web-site: realtor in Whittier CA
Someone necessarily lend a hand to make significantly articles I
might state. That is the very first time I frequented your website page and
to this point? I amazed with the research you made to make this actual publish
extraordinary. Great job!
my web blog – realtor in Ann Arbor MI
I could not refrain from commenting. Exceptionally well
written!
my web-site; best real estate agent in Vancouver BC
Oh my goodness! Incredible article dude! Thank you, However I
am encountering difficulties with your RSS.
I don’t understand the reason why I cannot join it.
Is there anybody else having identical RSS problems?
Anyone who knows the solution will you kindly respond?
Thanx!!
Also visit my website :: realtor in Tipp City OH
Incredible! This blog looks exactly like my old one!
It’s on a totally different topic but it has pretty much the same layout and design. Superb choice of colors!
Also visit my blog post … jellycat online shopping
YourDoll株式会社 配偶者と妻の間の性的対応の重要性
What’s up, I desire to subscribe for this webpage to take
hottest updates, therefore where can i do it please help out.
Good day! This post could not be written any better!
Reading through this post reminds me of my previous room mate!
He always kept chatting about this. I will forward
this page to him. Fairly certain he will have a good read.
Many thanks for sharing!
Hello! This is kind of off topic but I need some help from
an established blog. Is it hard to set up your own blog? I’m
not very techincal but I can figure things out pretty fast.
I’m thinking about setting up my own but I’m not sure where to start.
Do you have any ideas or suggestions? Thanks
Simply want to say your article is as surprising.
The clarity to your post is just spectacular and that i can assume you are an expert on this subject.
Fine along with your permission let me to clutch your
RSS feed to keep updated with coming near near post.
Thanks one million and please continue the enjoyable work.
Also visit my homepage best real estate agent in Cincinnati OH
I like what you guys are up too. This sort of clever work and exposure!
Keep up the fantastic works guys I’ve added you guys to my
personal blogroll.
Look into my site jellycat animal plush toys
I really like what you guys are up too. Such clever work and coverage!
Keep up the good works guys I’ve included you guys to our blogroll.
My website … real estate agent Tipp City OH
Thanks in favor of sharing such a pleasant thinking, paragraph is
fastidious, thats why i have read it entirely
My web page; jellycat online shop
Hi, i think that i saw you visited my website so i came
to “return the favor”.I am trying to find things to
improve my web site!I suppose its ok to use some of your ideas!!
Also visit my web site: real estate agent in Ann Arbor MI
I have read several just right stuff here. Definitely price bookmarking for revisiting.
I surprise how so much attempt you set to make one of these magnificent informative site.
My blog :: premium jellycat toys
Fascinating blog! Is your theme custom made or did you download it from somewhere?
A design like yours split vacation cost with friends a few simple
adjustements would really make my blog shine.
Please let me know where you got your theme. Cheers
At this time it seems like WordPress is the best blogging platform out there right now.
(from what I’ve read) Is that what you’re using on your blog?
Here is my website … soft plush toys by jellycat
Hi there, all is going well here and ofcourse every one is sharing data, that’s
actually excellent, keep up writing.
Very soon this site will be famous amid all blog people, due to it’s fastidious articles
Great article. I am facing many of these issues as well..
My blog post; jellycat collectible plush
I like it when people come together and share views.
Great site, continue the good work!
Please let me know if you’re looking for a article author for your
site. You have some really good articles and I think I would be a good asset.
If you ever want app to settle shared payments easily take some
of the load off, I’d absolutely love to write some
articles for your blog in exchange for a link back to mine.
Please blast me an email if interested. Thanks!
Hey there I am so delighted I found your blog page, I really found you by mistake, while I was browsing on Digg for something else, Nonetheless
I am here now and would just like app to settle shared payments easily say thanks a lot for a fantastic post
and a all round thrilling blog (I also love the theme/design), I
don’t have time to read through it all at the moment but I have book-marked it and also added in your RSS feeds, so when I have time I will
be back to read a great deal more, Please do keep up the awesome work.
This is the right website for everyone who wishes to find out about this topic.
You understand so much its almost hard to argue split vacation cost with friends you (not that I really will need
to…HaHa). You certainly put a new spin on a topic that’s been written about for decades.
Wonderful stuff, just great!
Howdy, I believe your site could possibly be having web browser compatibility
issues. When I take a look at your website in Safari, it looks fine
however when opening in IE, it has some overlapping issues.
I simply wanted to provide you split vacation cost with friends a quick
heads up! Besides that, great site!
What’s Taking place i’m new to this, I stumbled upon this I’ve
discovered It positively helpful and it has aided me out loads.
I’m hoping to give a contribution & assist other customers like its aided
me. Good job.
My web blog: split vacation cost with friends
⣿⣿⣿⣿⣿⣿⣿⣿⣿⠉⢒⠂⠐⠄⢉⢉⠻⠟⢹⢑⢀⣀⡴⣤⣬⢬⣭⣰⣰⢘⠽⠭⠯⠽⢍⢡⡙⢿⠿⢑⣴⠿⠾⣲⣤⣬⡁⠌⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⠠⢰⡞⣸⣤⣴⣯⣽⣺⡾⠿⣿⣿⠟⢉⣿⣷⣷⣿⣿⣿⣿⣿⣿⠿⠟⠋⠓⢿⣧⣾⣶⣾⣆⣈⠤⡶⢰⠏⣸⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⣤⡂⠻⢿⣿⣿⣿⠁⠁⠠⠡⡀⠠⢀⣥⣼⣾⣏⣟⣋⣆⠆⣠⣴⣶⡤⠘⠃⣿⣿⣿⣿⣿⠿⢛⢁⣨⣴⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣶⣶⢰⣞⣸⣿⢋⢙⣛⣛⢻⣿⣿⣿⣿⣿⣿⣿⣿⣿⢛⡫⢩⡙⠻⣾⣻⣿⣿⣿⣿⠀⣿⣿⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⡿⢁⢰⣿⣿⣿⣿⠀⠀⠿⠆⣿⣿⣿⣿⣿⢿⣿⣿⣿⣿⡀⠀⠸⢄⢻⣿⣿⣿⣿⣿⢁⢸⣿⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⠿⠿⠴⣺⣼⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⡄⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⠿⢛⢫⢡⡰⢰⣶⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⠋⣴⣶⣶⣶⣴⣶⣪⢽⣻⣿⣿⣿⣿⣿⣿⣯⠉⠅⢸⣿⣿⣿⣿⡿⡿⢩⣶⣿⣾⣿⣿⠃⢰⣿⣿⣿⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣾⣶⢠⣦⣴⣬⣴⣴⣶⢊⡑⢶⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⠿⣿⣄⣿⣉⣭⣩⣭⣩⢉⢊⠩⠉⠹⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⢄⠻⠿⠛⢻⣫⣤⣾⣿⣿⣿⣿⣿⣿⡇⡉⣿⣿⣿⣿⣿⣿⣿⠟⣸⣿⣷⣙⠻⠛⢛⠻⠰⠂⢰⣷⣾⢸⣿⣿⣿⣿
⣿⣿⣿⣿⠏⢍⢻⡿⢓⠂⠙⢿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣶⣤⣈⡩⠭⠴⣒⣴⣿⣿⣿⣿⣿⠿⢉⣤⣶⣺⠰⠿⣿⣿⠸⢿⣿⣿⣿
⣿⣿⣿⡀⣿⡜⢸⠀⡍⠘⢸⣶⣮⣴⣄⢠⣙⢿⣿⣿⣿⣿⣯⣉⣉⣉⣹⣿⣿⣿⠿⢋⣭⣤⣶⡯⣉⡭⣭⣝⡰⠿⣿⣿⢐⣛⠀⢻⣿⣿
⣿⣿⣿⠀⣯⣽⠀⣈⣽⠀⠸⠿⣿⣿⡟⢰⣿⣿⠿⣓⡚⠾⠈⢉⠹⣭⠝⣨⣴⣶⡸⣿⣿⣿⡿⢨⣿⣿⣿⣿⣿⣸⣿⣿⡌⢸⣿⡷⢸⣿
⣿⣿⣿⣷⠈⢭⣷⣼⣿⣬⣤⠀⢸⣿⢸⢫⣵⣾⣿⣿⣿⣿⢸⢿⣿⣷⢨⢹⣿⣿⡿⢣⢷⣿⣿⡘⢽⡷⣯⣿⣿⣧⣿⣿⣿⣿⣧⣿⣿⡇
⡟⠀⣀⡀⠰⣸⣿⣿⣿⣿⣿⡇⢸⡿⣰⣿⣶⣬⠻⠿⣋⣴⣾⣶⣶⣶⣤⣚⢻⢿⠶⢸⡿⣿⣿⣆⠹⣿⢿⣿⣿⣿⣿⣿⣿⣿⣿⣿⠟⡀
⣯⣠⣬⣭⣤⠘⡛⠿⠿⠟⠀⢐⡁⢸⣿⣿⣿⣿⣿⣿⣿⣿⠉⢀⢹⣿⣿⣿⣿⣿⣿⣿⣿⣿⣾⣷⢋⢡⣤⣤⣬⣤⣬⣽⣭⣭⣴⣶⣿⣿
⣿⣿⣿⣿⣿⣷⣶⣶⣶⣶⣿⣿⣿⡇⣺⣿⣿⣿⣿⣿⣿⣿⣧⣃⣠⣾⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⠃⢸⠿⠛⢛⠛⠛⠻⢿⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⢋⢸⣿⣿⣿⣿⣿⣿⣿⣿⡟⢠⢠⢹⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⡏⠸⢨⢀⣴⣶⣶⣶⣤⣕⡈⢙⣉
⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣦⢐⠿⣿⣿⣿⣿⣿⣿⣿⠶⠤⠾⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⡀⠘⠳⠾⠿⢿⣿⣿⣿⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⡟⠁⠠⠨⠶⠶⠰⣶⣶⣶⣤⣤⣤⣼⣬⣬⣴⣤⣬⣤⡄⠉⠭⠶⣀⢤⣶⢰⣾⡆⣸⣿⣿⣿⣿⣿⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⢸⢠⣾⣿⣿⣿⠰⣸⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣧⠊⣧⣀⣤⣾⠿⠟⣁⣴⣿⣿⣿⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣶⣭⣭⣭⣴⣶⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣤⣤⣤⣴⣶⣾⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿
⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿
Yes! Finally something about read this.
online casino with live dealer
https://gamblingchooser.com/
online casino reload bonus
It’s an awesome article designed for all the web viewers; they
will obtain advantage from it I am sure.
Very good blog post. I certainly appreciate this site.
Keep writing!
Hey! Someone in my Facebook group shared this site with us so I came to give it a look.
I’m definitely loving the information. I’m book-marking and will be tweeting
this to my followers! Outstanding blog and amazing design and style.
Your style is very unique in comparison to other people I have read stuff from.
Thanks for posting when you have the opportunity, Guess I will just book mark this blog.
It’s really very difficult in this full of activity life to
listen news on TV, therefore I only use the web for that purpose, and obtain the
most up-to-date information.
Thank you for sharing this important post. Healthcare fundraising is essential for supporting those
who need funds for surgery. Restore vision is a noble
goal. I will tell others about this site. Great initiative!
I’m extremely impressed with your writing skills as well as with
the layout on your weblog. Is this a paid theme or did you
modify it yourself? Anyway keep up the nice quality writing, it’s
rare to see a great blog like this one nowadays.
Wow, fantastic blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is great, let alone the content!
Quality articles or reviews is the key to interest the visitors
to pay a quick visit the web site, that’s what this web page is providing.
When someone writes an paragraph he/she retains the thought of a user in his/her brain that how a user can know it.
So that’s why this article is amazing. Thanks!
My site :: balanced nutrition and wellbeing
I like the helpful info you provide in your articles. I’ll bookmark your
blog and check again here regularly. I am quite sure I’ll learn lots of new
stuff right here! Best of luck for the next!
Here is my page – Youth camp flagstaff
Thank you for some other informative website. The place else could
I get that kind of info written in such a perfect approach?
I have a challenge that I’m just now operating on, and I’ve
been at the glance out for such information.
Feel free to surf to my blog Youth basketball league
I’d like to find out more? I’d love to find out some additional information.
my webpage; healthy lifestyle advice
This piece of writing will assist the internet people for building up new webpage or even a blog from start to end.
Your insights have helped me see new opportunities.
you’re in reality a excellent webmaster. The web site loading pace is amazing.
It sort of feels that you’re doing any distinctive trick.
Furthermore, The contents are masterwork. you’ve done a fantastic
activity in this topic!
My blog … everyday movement and fitness
I think the admin of this site is truly working hard in favor of his web site, because here every material is
quality based data.
Unquestionably imagine that that you stated. Your favorite justification appeared to be
on the net the simplest factor to consider of. I say to
you, I certainly get irked whilst folks consider issues that they just don’t know
about. You managed to hit the nail upon the top as smartly as outlined out the whole
thing without having side effect , folks can take a signal.
Will likely be back to get more. Thank you
I don’t even know how I finished up right here, but I assumed this post was good.
I do not know who you might be but certainly you’re going
to a well-known blogger should you are not already.
Cheers!
My web blog :: sustainable health habits
I like reading an article that will make people think.
Also, thanks for permitting me to comment!
my website :: healthy lifestyle advice
Банкротство физических лиц в Калуге регулируется федеральным законом о банкротстве компания по банкротству физических бизнес юрист.
Процедура позволяет гражданам, не способным погасить долги, избавиться
от финансовых обязательств.
Hello I am so excited I found your blog, I really found you by accident, while I was browsing on Digg for something else,
Regardless I am here now and would just like to say thank you for a marvelous post and a all round enjoyable
blog (I also love the theme/design), I don’t have time to go through it all at the moment but I
have book-marked it balanced nutrition and wellbeing also
added in your RSS feeds, so when I have time I will be back to read much more, Please do keep up the awesome job.
Hello, always i used to check webpage posts here early in the morning, because i like to learn more and more.
I was curious if you ever thought of changing
the layout of your website? Its very well written; I love what youve
got to say. But maybe you could a little more in the
way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or two
pictures. Maybe you could space it out better?
Amazing things here. I’m very satisfied to see your post. Thanks a lot and I am
taking a look ahead to contact you. Will you please drop me a e-mail?
It’s very trouble-free to find out any matter on net as compared to textbooks, as I found this piece of writing at this website.
Have a look at my site: Youth sports
Great site. Lots of helpful info here. I am sending it to several
pals ans additionally sharing in delicious. And naturally,
thanks on your effort!
Inspiring story there. What happened after? Good luck!
I’m impressed, I must say. Rarely do I come across a
blog that’s equally educative and interesting, and without
a doubt, you have hit the nail on the head. The issue is something which not
enough folks are speaking intelligently about. I am very happy I stumbled across this in my search for something relating to
this.
My blog Sports trainer
серіали 2025 дивитись онлайн дивитися кіно українською без передплати
These are genuinely fantastic ideas in regarding blogging.
You have touched some good things here. Any way keep up wrinting.
Its not my first time to pay a visit this website, i am browsing this
site dailly and obtain good facts from here daily.
Everyone loves what you guys tend to be up too.
This type of clever work and reporting! Keep up the very good works
guys I’ve incorporated you guys to my own blogroll.
Hello! I could have sworn I’ve been to this
site before but after looking at a few of the articles I realized it’s new to me.
Anyways, I’m certainly happy I found it and I’ll be bookmarking it and checking back regularly!
My homepage – zugravu01
We absolutely love your blog and find many of your post’s to be just what I’m looking for.
Does one offer guest writers to write content to suit
your needs? I wouldn’t mind writing a post or elaborating on most of the subjects you write regarding here.
Again, awesome site!
Clear, concise, and practical information. I appreciate how easy it is to follow.
Thanks for your marvelous posting! I quite enjoyed reading it,
you are a great author. I will always bookmark your
blog and definitely will come back sometime soon. I want to encourage you to continue your great work, have a nice evening!
Hi everyone, it’s my first go to see at this site, and
post is truly fruitful designed for me,
keep up posting such posts.
Wow that was strange. I just wrote an incredibly long comment but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyway, just wanted to say superb blog!
Good day! Do you use Twitter? I’d like to follow you if that would be
ok. I’m definitely enjoying your blog and look forward to new updates.
Highly descriptive article, I loved that bit. Will there be a part 2?
Great beat ! I would like to apprentice while you amend your website,
how can i subscribe for a blog web site? The account helped
me a acceptable deal. I had been tiny bit acquainted of this your broadcast provided bright clear concept
My web blog regenerative medicine thailand
An outstanding share! I have just forwarded this onto a
coworker who had been conducting a little homework on this.
And he in fact bought me breakfast simply
because I found it for him… lol. So let me reword this….
Thanks for the meal!! But yeah, thanks for
spending some time to discuss this matter here on your site.
Look at my homepage; Dog Water Fountain
I was able to find good advice from your articles.
Also visit my web page: zugravu
Thanks to my father who informed me on the topic of this blog, this
web site is in fact awesome.
I am regular reader, how are you everybody? This paragraph posted at this website is genuinely pleasant.
my blog: zugravu
Way cool! Some very valid points! I appreciate you penning this write-up and also
the rest of the site is extremely good.
Hi there Dear, are you genuinely visiting this web site regularly, if
so afterward you will absolutely get fastidious knowledge.
We are a group of volunteers and opening a new
scheme in our community. Your web site provided us with valuable information to work on. You have
done a formidable job and our whole community will be thankful to you.
my page zugravu
Greetings from Ohio! I’m bored to tears at work so I decided to browse your site on my iphone during lunch break.
I really like the knowledge you provide here and can’t wait to
take a look when I get home. I’m amazed at how fast your blog loaded on my
cell phone .. I’m not even using WIFI, just 3G .. Anyhow,
awesome blog!
https://t.me/s/KAZINO_S_MINIMALNYM_DEPOZITOM
Yesterday, while I was at work, my sister stole my iPad and tested to see if it can survive a thirty foot drop, just so she can be a
youtube sensation. My iPad is now destroyed and she has 83
views. I know this is totally off topic but I had to share it with someone!
I believe that is among the most vital info for me.
And i am glad studying your article. However wanna statement on few common issues, The web site taste is wonderful,
the articles is in reality excellent : D.
Excellent activity, cheers
My website; zugravu
I pay a visit every day some blogs and information sites to read articles, but this weblog gives quality
based articles.
Also visit my homepage :: zugravu
wonderful points altogether, you simply received
a new reader. What may you suggest about your submit that you just made a few days ago?
Any sure?
Продвижение сайтов https://team-black-top.ru под ключ: аудит, стратегия, семантика, техоптимизация, контент и ссылки. Улучшаем позиции в Google/Яндекс, увеличиваем трафик и заявки. Прозрачная отчетность, понятные KPI и работа на результат — от старта до стабильного роста.
Təşəkkürlər belə keyfiyyətli məlumat üçün.
https://1win-azerbaijan-casino.com/reyler
Heya i’m for the primary time here. I found this board and I in finding It truly useful &
it helped me out a lot. I’m hoping to offer something again and aid others such as you
aided me.
Thanks for every other informative site. Where else
may I get that type of information written in such an ideal approach?
I have a project that I’m just now operating on, and
I have been on the glance out for such information.
Superb, what a webpage it is! This website provides valuable facts to us, keep it up.
What’s up, its nice post concerning media print, we all
be familiar with media is a wonderful source of information.
It is not my first time to go to see this website, i am browsing this website dailly and take nice facts from here all the time.
Тяговые аккумуляторные https://ab-resurs.ru батареи для складской техники: погрузчики, ричтраки, электротележки, штабелеры. Новые АКБ с гарантией, помощь в подборе, совместимость с популярными моделями, доставка и сервисное сопровождение.
Казино дрип зеркало помогает
всегда оставаться в игре без ограничений
drip казино зеркало
Продажа тяговых АКБ https://faamru.com для складской техники любого типа: вилочные погрузчики, ричтраки, электрические тележки и штабелеры. Качественные аккумуляторные батареи, долгий срок службы, гарантия и профессиональный подбор.
I’ll right away take hold of your rss as I can not to find your email subscription hyperlink or e-newsletter service.
Do you’ve any? Kindly allow me realize so that I may
just subscribe. Thanks.
Halo admin! Tulisan ini mantap dan runut.
Buat yang mencari platform gaming dengan UI modern dan fitur lengkap, saya rekomendasikan KING7.
Selain punya reputasi bagus dan terpopuler di dunia,
mereka juga rutin kasih bonus menarik dengan keamanan terbaik sehingga main terasa aman.
Aksesnya ringkas, navigasi intuitif, dan performa ngebut.
Yang ingin cek bisa ke https://king7.network/.
Terima kasih untuk penjelasannya; sukses selalu
untuk blog ini!
Do you have a spam issue on this website; I also am a blogger, and
I was wondering your situation; we have developed some nice
practices and we are looking to swap techniques with others, why
not shoot me an email if interested.
вилочные погрузчики москва
Thankfulness to my father who informed me about this webpage, this weblog is actually awesome.
OMT’s mindfulness techniques decrease math anxiety, enabling genuine love tо grow and influence examination quality.
Dive іnto self-paced math mastery ᴡith OMT’ѕ 12-month е-learning
courses, ⅽomplete ѡith practice worksheets ɑnd tape-recorded sessions
fоr extensive revision.
With math incorporated seamlessly іnto Singapore’ѕ class settings to benefit ƅoth instructors аnd trainees, dedicated
math tuition enhances tһeѕe gains by uѕing customized
support fоr continual achievement.
Tuition stresses heuristic analytical ɑpproaches, crucial for taking on PSLE’ѕ challenging wօrd
issues tһat require multiple actions.
Вy supplying comprehensive exercise ᴡith рrevious Օ Level documents, uition outfits students ѡith familiarity and the capability t᧐
expect inquiry patterns.
Addressing individual discovering styles, math tuition ensures junior college trainees grasp topics аt theiг own rate for Α Level success.
The distinctiveness of OMT originates fгom its proprietary mathematics curriculum tһat expands MOE web
сontent with project-based leearning fοr practical application.
Тhe systеm’s sources are upgraded consistently ߋne, keeping you lined սp ԝith lɑtest curriculum for quality boosts.
Math tuition ᧐ffers enrichment ρast the basics, testing talented Singapore pupils tօ
aim for distinction in examinations.
Мү blog post: Singapore A levels Math Tuition
Продажа тяговых АКБ https://faamru.com для складской техники любого типа: вилочные погрузчики, ричтраки, электрические тележки и штабелеры. Качественные аккумуляторные батареи, долгий срок службы, гарантия и профессиональный подбор.
Db-bet apk скачать получилось с первого раза
https://marina-eldenbert.ru/
I needed to thank you for this very good read!!
I absolutely enjoyed every bit of it. I have got you saved as a favorite to check
out new stuff you post…
Casino cat удобно использовать как на ПК, так и на смартфоне
https://chudo-apartments.ru/
I loved as much as you will receive carried out right
here. The sketch is attractive, your authored material stylish.
nonetheless, you command get got an edginess over that you wish be delivering the following.
unwell unquestionably come further formerly again as exactly the same nearly a lot often inside case you shield this hike.
кіно онлайн новинки 2025 повна версія фільму онлайн
Good post. I am experiencing some of these issues as well..
I like reading an article that will make men and women think.
Also, many thanks for allowing me to comment!
Pretty! This has been a really wonderful article.
Many thanks for providing this info.
Undeniably believe that which you said. Your favorite
reason seemed to be on the net the simplest thing to be aware
of. I say to you, I certainly get annoyed
while people think about worries that they just don’t know about.
You managed to hit the nail upon the top and also
defined out the whole thing without having side-effects , people could take a
signal. Will likely be back to get more. Thanks
When some one searches for his necessary thing, thus he/she wishes
to be available that in detail, therefore that thing is maintained over
here.
Equili
Роллы в Челябинске с настоящим васаби, а не крашеным хреном
Also visit my page https://wokerman.ru/
wonderful publish, very informative. I wonder why the other experts of this sector do not notice this.
You must proceed your writing. I’m sure, you’ve a huge
readers’ base already!
Here is my web-site MANTULHOKI
Ahaa, its good conversation about this article here at this webpage, I have read all that, so at this time me also commenting at this place.
casinos slots Gates of Olympus —
Gates of Olympus slot — известный игровой автомат от Pragmatic Play с системой Pay Anywhere, цепочками каскадов и множителями до ?500. Действие происходит на Олимпе, где бог грома повышает выплаты и делает каждый спин непредсказуемым.
Сетка слота выполнено в формате 6?5, а выплата начисляется при появлении не менее 8 идентичных символов в любом месте экрана. После выплаты символы пропадают, на их место опускаются новые элементы, запуская серии каскадных выигрышей, способные принести дополнительные выигрыши за одно вращение. Слот считается волатильным, поэтому не всегда даёт выплаты, но в благоприятные моменты способен порадовать крупными выплатами до 5000? ставки.
Для тестирования игры доступен демо-режим без вложений. Для ставок на деньги стоит рассматривать лицензированные казино, например MELBET (18+), принимая во внимание RTP около 96,5% и условия конкретной платформы.
азартные игры онлайн
Gates of Olympus — известный игровой автомат от Pragmatic Play с механикой Pay Anywhere, каскадами и усилителями выигрыша до ?500. Игра проходит у врат Олимпа, где Зевс активирует множители и делает каждый раунд динамичным.
Игровое поле представлено в виде 6?5, а выигрыш засчитывается при выпадении от 8 одинаковых символов без привязки к линиям. После расчёта комбинации символы исчезают, на их место опускаются новые элементы, активируя серии каскадных выигрышей, способные принести несколько выплат за один спин. Слот считается игрой с высокой волатильностью, поэтому не всегда даёт выплаты, но в благоприятные моменты даёт крупные заносы до 5000? ставки.
Для тестирования игры доступен бесплатный режим без финансового риска. Для ставок на деньги целесообразно выбирать официальные казино, например MELBET (18+), ориентируясь на показатель RTP ~96,5% и условия конкретной платформы.
You could definitely see your expertise within the article you write.
The world hopes for even more passionate writers such as you who aren’t afraid to
mention how they believe. Always go after your heart.
Quality articles or reviews is the crucial to be a focus for the visitors to visit
the site, that’s what this web site is providing.
Well voiced certainly! .
Also visit my web site … https://365.expresso.blog/question/binary-options-etics-and-etiquette-4/
Its such as you read my mind! You seem to grasp a lot
about this, like you wrote the ebook in it
or something. I believe that you just could do with a few % to drive the message home a bit, however other than that, this is great blog.
A great read. I will definitely be back.
Hi everyone, it’s my first pay a quick visit at this web site, and article is genuinely fruitful for me, keep up posting such articles
or reviews.
Woah! I’m really digging the template/theme of
this site. It’s simple, yet effective. A lot of times it’s tough to
get that “perfect balance” between superb usability and appearance.
I must say that you’ve done a fantastic job with this.
In addition, the blog loads very fast for me on Internet
explorer. Superb Blog!
Wonderful, what a blog it is! This blog provides useful facts to us, keep it up.
I think this is one of the most important information for me.
And i am glad reading your article. But wanna remark on few general things, The site style is great, the articles is really nice : D.
Good job, cheers
Hello colleagues, fastidious paragraph and fastidious urging commented here, I am in fact enjoying by
these.
I every time used to read paragraph in news papers but now as I am a user of
net therefore from now I am using net for articles, thanks to web.
hello there and thank you for your information – I’ve definitely picked up
anything new from right here. I did however expertise a few technical issues using this site,
as I experienced to reload the site many times previous to I could get
it to load correctly. I had been wondering if your web host is OK?
Not that I’m complaining, but slow loading instances times will often affect your placement
in google and could damage your high-quality score if
ads and marketing with Adwords. Well I’m adding this RSS
to my email and can look out for a lot more of your respective intriguing content.
Ensure that you update this again very soon.
Hi there, its good article about media print, we all know media is a great source of
facts.
WOW just what I was searching for. Came here by searching for
mcm168
This blog was… how do you say it? Relevant!!
Finally I have found something which helped me. Cheers!
my page: martial art supplies
Создание веб сайта – это очень важный процесс для любого бизнеса. Сайт является лицом компании и помогает привлекать новых клиентов. На сайте можно разместить информацию о компании, ее услугах и продуктах.Создание сайта начинается с разработки дизайна. Дизайн должен быть привлекательным и полезным для пользователей. Далее создается структура сайта. На этом этапе определяется количество страниц на сайте и их расположение. Затем происходит программирование сайта. Программист пишет код для функционирования сайта. Затем сайт тестируется и отлаживается.
В заключение, https://sozdanie-saytove.ru/ – это сложный и трудоемкий процесс, требующий профессионального подхода и знаний в области веб-разработки.
Your method of explaining the whole thing in this post is truly
good, every one be capable of effortlessly be aware of
it, Thanks a lot.
Hello there! This is kind of off topic but I need some guidance from an established blog.
Is it very hard to set up your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about making my own but I’m not sure where to begin. Do you have any ideas or suggestions?
With thanks
It’s amazing for me to have a web page, which is valuable designed for my knowledge.
thanks admin
I am not sure where you are getting your information, but good topic.
I needs to spend some time learning much more or understanding more.
Thanks for excellent information I was looking for this info for
my mission.
Super platformă! Totul la nivel de top, felicitări și mult succes.
https://monarchauto.com/product-viewer/?url=https://verde-casino-romania-winmax.ro
This article offers clear idea in favor of the new people
of blogging, that genuinely how to do running a blog.
I like the helpful information you provide in your articles.
I’ll bookmark your blog and check again here frequently.
I’m quite certain I’ll learn lots of new stuff right here!
Good luck for the next!
You’re so interesting! I don’t believe I have read a
single thing like that before. So wonderful to find someone with some original thoughts on this subject.
Really.. thank you for starting this up. This
site is one thing that is required on the internet, someone with some originality!
Hey! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard
on. Any recommendations?
Thank you for another excellent article. The place else could anybody get that kind of information in such an ideal way of writing?
I have a presentation subsequent week, and I am at the search for
such info.
Want unforgettable excursions to Crete? We have great deals for adventure seekers.
Our guides will help you find the perfect tour to the most beautiful spots
on Crete. Don’t miss the opportunity to explore the
stunning scenery of this magical place!
พึ่งรู้จัก KING7BET — เว็บ
Live Casino ตลอด 24 ชั่วโมง มีดีลเลอร์แบบ HD, โต๊ะ VIP, {ธุรกรรมปลอดภัย} และ ถอนเงินไว.
มีโบนัสสมาชิกใหม่
น่าสนใจ มาก ๆ. ซัพพอร์ต 24/7 เป็นกันเอง.
โดนใจคนที่มองหา สล็อต RTP สูง และ สปอร์ตบุ๊ค.
ลองเข้าไปเล่นดู ใช้งานง่าย จริง ๆ.
Your means of telling everything in this paragraph
is in fact fastidious, all be able to simply know it, Thanks
a lot.
Here is my web site appliance repair bothell
Valuable info. Fortunate me I discovered your website accidentally, and I’m
stunned why this coincidence didn’t took place earlier!
I bookmarked it.
My website … appliance repair bothell
폰테크란 무엇인가? 폰테크는 휴대폰을 통해 현금을 마련하는 독특한 재테크
방법입니다. 좀 더 자세히 말해, 새로운 휴대폰을 개통한 뒤
그 휴대폰을 사용하지 않고
Hi, I think your site might be having browser compatibility issues.
When I look at your website in Firefox, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, very good
blog!
Have a look at my blog post :: appliance repair bothell
It is perfect time to make some plans for the future and
it is time to be happy. I’ve read this post and if I could I want to suggest you few interesting things or advice.
Maybe you could write next articles referring to this article.
I desire to read more things about it!
My web page :: appliance repair bellevue wa
This is very fascinating, You’re an excessively professional blogger.
I have joined your rss feed and sit up for in quest of extra of your magnificent
post. Also, I’ve shared your site in my social networks
Heya i’m for the primary time here. I found this
board and I find It truly helpful & it helped me
out a lot. I am hoping to give one thing back and help others such as you helped me.
Saya nemu KING7BET — platform casino live 24/7 dengan dealer HD, meja VIP,
transaksi aman dan withdraw cepat. Bonus member baru langsung tersedia.
Support sepanjang hari ramah dan sigap. Cocok buat yang cari slot RTP tinggi dan taruhan olahraga.
Pengalaman mainnya mulus, beneran nyaman. Silakan coba biar nggak penasaran.
I pay a visit every day some web sites and websites to read articles, except this website offers
feature based posts.
I’m really impressed with your writing abilities as smartly as with the layout to your
weblog. Is that this a paid subject matter or did you customize it your self?
Either way stay up the nice quality writing, it
is uncommon to look a great blog like this one nowadays..
I blog often and I genuinely thank you for your information. This
great article has truly peaked my interest.
I’m going to take a note of your site and keep checking for new information about once a week.
I subscribed to your RSS feed as well.
Hi there, its fastidious article regarding media print, we all understand
media is a fantastic source of data.
my web site :: appliance repair bellevue wa
Howdy! Do you know if they make any plugins to assist with Search Engine Optimization?
I’m trying to get my blog to rank for some targeted keywords
but I’m not seeing very good gains. If you know of any please share.
Thanks!
Check out my blog post JPKARTEL
I all the time used to read piece of writing in news papers but now as I am a
user of net therefore from now I am using net for articles, thanks to web.
Hi, its nice post on the topic of media print,
we all know media is a enormous source of information.
Inspiring quest there. What happened after?
Good luck!
Hi! I realize this is somewhat off-topic but I needed to ask.
Does building a well-established blog such as
yours require a large amount of work? I am completely new to running a blog however I do write in my
journal every day. I’d like to start a blog so I will be able to share my own experience and thoughts online.
Please let me know if you have any recommendations or tips for new aspiring blog owners.
Appreciate it!
Hmm is anyone else having problems with the images on this blog loading?
I’m trying to determine if its a problem on my
end or if it’s the blog. Any suggestions would be greatly appreciated.
Hey there would you mind sharing which blog platform you’re using?
I’m looking to start my own blog soon but I’m having a
tough time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most
blogs and I’m looking for something completely unique.
P.S My apologies for getting off-topic but I had to ask!
Attractive component to content. I just stumbled upon your weblog and in accession capital to claim that
I get in fact loved account your blog posts. Anyway I’ll
be subscribing on your augment and even I success
you access consistently fast.
Greetings from Los angeles! I’m bored to death at work so I decided
to check out your site on my iphone during lunch break. I really like the knowledge you provide here and can’t
wait to take a look when I get home. I’m surprised at how quick your blog loaded on my
phone .. I’m not even using WIFI, just 3G .. Anyways, wonderful blog!
Hi! Someone in my Facebook group shared this website
with us so I came to give it a look. I’m definitely loving the information. I’m book-marking and will be tweeting this to
my followers! Exceptional blog and brilliant design and style.
you are truly a good webmaster. The website loading speed
is amazing. It sort of feels that you are doing any unique
trick. In addition, The contents are masterwork.
you’ve performed a magnificent process on this matter!
Hello there! I could have sworn I’ve been to this
site before but after checking through some of the post I realized it’s new to me.
Anyways, I’m definitely glad I found it and I’ll be book-marking and checking back frequently!
I’m not that much of a internet reader to be honest but
your sites really nice, keep it up! I’ll go ahead and bookmark your
website to come back later on. Many thanks
Visit my web page :: appliance repair bellevue wa
Казино анлим отлично подходит как для новичков, так и для опытных игроков
https://jaguar-krasnoyarsk.ru/
Hi, i think that i saw you visited my website so i came to “return the favor”.I
am trying to find things to enhance my site!I suppose its ok to use some of your ideas!!
Amazing things here. I’m very glad to peer your post.
Thanks a lot and I am taking a look forward to contact you.
Will you kindly drop me a e-mail?
Wow! Finally I got a weblog from where I can truly get useful data regarding my
study and knowledge.
This information is worth everyone’s attention. When can I find out more?
My blog post … Locksmiths Tameside
Great delivery. Outstanding arguments. Keep up the good spirit.
Hi there to all, the contents present at this site are
truly awesome for people experience, well, keep up
the good work fellows.
hello!,I like your writing very a lot! proportion we keep up a correspondence extra about
your post on AOL? I need a specialist on this area to solve my problem.
Maybe that’s you! Looking ahead to peer you.
Also visit my blog post … artact
Nice post. I learn something totally new and challenging on blogs I stumbleupon everyday.
It will always be exciting to read content from other writers and
use something from their websites.
Also visit my webpage; artact
Hello, i believe that i saw you visited my website thus i got
here to return the favor?.I am attempting to find things to enhance my website!I guess its adequate to use some of your ideas!!
играть в слоты онлайн
Слот Gates of Olympus — известный онлайн-слот от Pragmatic Play с механикой Pay Anywhere, каскадами и усилителями выигрыша до ?500. Игра проходит у врат Олимпа, где бог грома активирует множители и делает каждый спин непредсказуемым.
Игровое поле выполнено в формате 6?5, а выигрыш засчитывается при выпадении 8 и более идентичных символов в любой позиции. После расчёта комбинации символы исчезают, их заменяют новые элементы, формируя серии каскадных выигрышей, дающие возможность получить серию выигрышей за одно вращение. Слот считается волатильным, поэтому не всегда даёт выплаты, но при удачных раскладах способен порадовать крупными выплатами до 5000? ставки.
Для тестирования игры доступен бесплатный режим без финансового риска. При реальных ставках стоит использовать официальные казино, например MELBET (18+), ориентируясь на RTP около 96,5% и правила выбранного казино.
азартные игры онлайн слот Gates of Olympus —
Gates of Olympus — хитовый слот от Pragmatic Play с механикой Pay Anywhere, цепочками каскадов и усилителями выигрыша до ?500. Игра проходит в мире Олимпа, где бог грома повышает выплаты и делает каждый раунд случайным.
Сетка слота имеет формат 6?5, а комбинация формируется при появлении от 8 идентичных символов без привязки к линиям. После выплаты символы исчезают, сверху падают новые элементы, формируя серии каскадных выигрышей, которые могут дать несколько выплат за одно вращение. Слот является игрой с высокой волатильностью, поэтому может долго раскачиваться, но при удачных каскадах даёт крупные заносы до ?5000 от ставки.
Для тестирования игры доступен демо-режим без регистрации. При реальных ставках целесообразно рассматривать официальные казино, например MELBET (18+), принимая во внимание RTP около 96,5% и условия конкретной платформы.
I couldn’t refrain from commenting. Exceptionally
well written!
Hey! Would you mind if I share your blog with my zynga group?
There’s a lot of folks that I think would really appreciate your content.
Please let me know. Thank you
Here is my web page … Potty Pass
Great site. A lot of useful information here. I am sending it to some friends ans additionally sharing in delicious.
And obviously, thanks in your effort!
Stop by my webpage 3D Models Dubai
Wow, incredible blog layout! How long have you ever been blogging for? you made blogging glance easy. The overall look of your site is magnificent, let alone the content!
https://cityjeans.com.ua/led-linzy-v-tonovanykh-farakh-yak-unyknuty.html
I like what you guys are usually up too. This sort of clever work and exposure!
Keep up the good works guys I’ve added you
guys to blogroll.
What’s up all, here every person is sharing these kinds of know-how, so it’s fastidious to read this blog,
and I used to visit this blog daily.
일본의 유흥 문화는 다양성과 독특함으로 유명합니다.
퇴근 후 동료들과 가볍게 술을 즐기는 이자카야부터 화려한 나이트클럽,
테마 카페까지 일본유흥은 폭넓은 스펙트럼
I have been browsing online greater than 3 hours nowadays,
but I never discovered any fascinating article like yours.
It is lovely value sufficient for me. In my view,
if all website owners and bloggers made good content
as you did, the internet can be a lot more useful than ever
before.
中華職棒賽程台灣球迷的首選資訊平台,提供最即時的中華職棒賽程新聞、球員數據分析,以及精準的比賽預測。
Excellent blog here! Also your web site loads up very fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as quickly as yours lol
slot gacor situs toto 4d
Substitution tracker, player changes and tactical switches noted live
I am really grateful to the owner of this website who has shared this impressive article at at this place.
I visited various websites however the audio feature for audio
songs present at this web page is really fabulous.
我們的台灣運彩官方授權專家團隊第一時間更新官方各大聯盟的比賽分析,包括NBA、MLB、中華職棒等。
Đọc Truyện Tranh Soái Ca Comic Hay Nhất | Nettruyen
I read this post fully regarding the resemblance of most recent and preceding
technologies, it’s remarkable article.
Hi there to all, for the reason that I am genuinely keen of reading this webpage’s post to be updated daily. It consists of pleasant data.
igrice za decake auta
Greetings! Very helpful advice in this particular article!
It is the little changes that make the most important changes.
Many thanks for sharing!
It’s a pity you don’t have a donate button! I’d
certainly donate to this excellent blog! I suppose for now i’ll settle for
book-marking and adding your RSS feed to my Google account.
I look forward to new updates and will talk about this site with my Facebook group.
Chat soon!
Good day very nice website!! Man .. Excellent .. Amazing ..
I will bookmark your web site and take the feeds additionally?
I am satisfied to search out a lot of useful info
here within the post, we want work out extra techniques on this regard,
thanks for sharing. . . . . .
Hi there, yup this paragraph is really good and I have learned lot of things from it
concerning blogging. thanks.
Современный сервис https://buyaccountstore.today рад видеть медиабайеров в своем пространстве цифровых товаров для FB. Если вам нужно купить аккаунт Facebook для рекламы, чаще всего важен не «одном логине», а в качестве фарма: отсутствие вылетов на селфи, наличие пройденного ЗРД в Ads Manager и прогретые FanPage. Мы собрали практичный чек-лист, чтобы вы без лишних вопросов понимали какой лимит выбрать перед заказом.Что внутри: FAQ по ЗРД. Ключевая идея: покупка — это только вход. Дальше решает подход к запуску: как вяжется карта, как вы передаете лички без риска банов, как реагируете на полиси и как масштабируете адсеты. Ключевое преимущество этого шопа — это наличие эксклюзивной вики-энциклопедии FB, где выложены актуальные инструкции по запуску рекламы. Мы сориентируем, каким образом без лишних рисков расшарить доступы, чтобы не улетели на полиси и продлили жизнь аккаунтам . Покупая у нас, вы получаете не просто аккаунт, а также всестороннюю поддержку, ясное описание товара, страховку на валид и самые адекватные цены на рынке FB-аккаунтов. Дисклеймер: используйте активы законно и всегда с учетом правил Meta.
Hmm it seems like your blog ate my first comment (it was
super long) so I guess I’ll just sum it up what I wrote and
say, I’m thoroughly enjoying your blog. I too am
an aspiring blog blogger but I’m still new to
everything. Do you have any tips for inexperienced blog writers?
I’d genuinely appreciate it.
Everything is very open with a very clear explanation of the issues.
It was definitely informative. Your website is useful.
Thanks for sharing! https://seferpanim.com/read-blog/42659_individualki-v-caratove.html
Good day! I could have sworn I’ve visited your blog before but after looking at many of the posts I realized it’s new to
me. Regardless, I’m certainly delighted I stumbled upon it
and I’ll be bookmarking it and checking back often!
Hi it’s me, I am also visiting this website on a regular basis, this web page is genuinely nice and the visitors are genuinely
sharing nice thoughts.
My website: carlsbad plumber
Kami baru coba King 7 Bet dan keren banget!
Live dealer-nya jernih banget,
taruhan bola dengan peluang besar, dan slot favorit semua ada di sini.
Pencairan cepat, CS 24 jam dan promo menarik bikin makin betah main di King7Bet.
Hello there! I could have sworn I’ve been to this
blog before but after browsing through some of the articles I realized it’s new to me.
Nonetheless, I’m certainly delighted I discovered it and I’ll be book-marking
it and checking back often!
My website: Orgaboard
Good answer back in return of this question with solid arguments and explaining the whole thing concerning that.
my web-site BEDALEVEL
Very energetic post, I liked that bit. Will there be
a part 2?
Hello just wanted to give you a quick heads up and let you know a few of the images aren’t loading correctly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the same results.
I visit everyday some web sites and sites to read content, except this website gives feature based writing.
My web blog … maison energy
Hi, just wanted to say, I enjoyed this post. It was helpful.
Keep on posting!
Also visit my web site carlsbad plumber
It’s awesome to pay a visit this website and reading the views of all mates regarding this paragraph, while I am also zealous of getting familiarity.
Wow, fantastic blog layout! How long have you been blogging
for? you make blogging look easy. The overall look
of your web site is magnificent, as well as the content!
Amazing blog! Do you have any recommendations for aspiring writers?
I’m planning to start my own blog soon but I’m a little lost on everything.
Would you propose starting with a free platform like WordPress or go
for a paid option? There are so many choices out there that I’m totally overwhelmed
.. Any suggestions? Kudos!
Hi! I could have sworn I’ve been to this site before
but after looking at many of the articles I realized it’s new to me.
Anyways, I’m certainly happy I found it and I’ll be book-marking it and
checking back regularly!
Feel free to surf to my web page san diego plumber
I have been surfing on-line more than three hours nowadays, yet I by no
means found any attention-grabbing article like yours.
It is lovely worth sufficient for me. In my opinion, if all webmasters and bloggers made just
right content as you probably did, the internet shall be a lot more useful than ever before.
Also visit my web blog … BEDALEVEL
It’s hard to find well-informed people on this topic,
however, you seem like you know what you’re talking about!
Thanks
凯伦皮里第二季高清完整版运用AI智能推荐算法,海外华人可免费观看最新热播剧集。
What’s up, I wish for to subscribe for this weblog to obtain latest updates, therefore
where can i do it please help.
my web blog :: maison energy signup
Wow, fantastic blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website is great, let alone the content!
my webpage … maison energy texas
I got this website from my buddy who told me regarding this website and now this time I
am visiting this web site and reading very informative posts at this time.
폰테크
Free kick goals, direct and indirect set piece conversions tracked
Nice blog here! Also your site a lot up fast! What
host are you the usage of? Can I get your affiliate link on your host?
I desire my site loaded up as quickly as yours lol
I absolutely love your blog.. Pleasant colors & theme. Did you
develop this web site yourself? Please reply back as I’m looking to create my very own website
and would love to find out where you got this from or exactly what the theme is called.
Appreciate it!
Also visit my blog post san diego plumber
Wow! Finally I got a web site from where I be capable
of actually obtain helpful information regarding my study and knowledge.
Hi, all the time i used to check webpage posts here early in the morning, because i like to gain knowledge of more and more.
When someone writes an piece of writing he/she retains the
image of a user in his/her brain that how a user can know
it. So that’s why this article is outstdanding. Thanks!
Hey very cool web site!! Guy .. Excellent ..
Superb .. I will bookmark your web site and take the feeds additionally?
I’m satisfied to find a lot of useful info right here in the publish, we need develop extra strategies in this regard, thanks for sharing.
. . . . .
My homepage … maison energy texas
With havin so much content and articles do you ever run into any issues of plagorism or
copyright violation? My site has a lot of unique content I’ve either written myself
or outsourced but it appears a lot of it is popping it up all
over the web without my authorization. Do you know any ways to
help protect against content from being stolen? I’d really
appreciate it.
Wonderful post! We will be linking to this particularly great article on our site.
Keep up the good writing.
Hey there! I know this is kinda off topic but I’d
figured I’d ask. Would you be interested in trading links or maybe guest authoring a blog article or vice-versa?
My blog covers a lot of the same topics as yours and I feel we
could greatly benefit from each other. If you happen to be interested feel free to send me an e-mail.
I look forward to hearing from you! Fantastic blog by the way!
Usually I do not read post on blogs, but I would like to
say that this write-up very compelled me to try and
do so! Your writing style has been amazed me. Thank you, quite great
post.
Also visit my homepage; maison energy login
My spouse and I absolutely love your blog and find a lot of your post’s to be what precisely I’m looking for.
can you offer guest writers to write content to suit your needs?
I wouldn’t mind creating a post or elaborating on many of the subjects you write regarding here.
Again, awesome weblog!
I am no longer positive the place you’re getting your information, but great topic.
I needs to spend a while finding out much more or understanding more.
Thank you for excellent info I was on the lookout for this information for my mission.
Hey there would you mind letting me know which hosting company you’re working with?
I’ve loaded your blog in 3 different browsers and I must say this blog loads
a lot faster then most. Can you recommend a good web hosting provider at a honest price?
Thanks, I appreciate it!
Also visit my web-site; BEDALEVEL Slot
Way cool! Some very valid points! I appreciate you penning this
article plus the rest of the site is very good.
Mantap atas tulisannya. Penjelasan padat tapi kena. Saya sependapat soal pentingnya pengalaman pengguna.
Kebetulan, saya juga akhir-akhir ini pakai King7
karena login cepat dan promo yang cukup menarik. Kalau mau lihat bisa ke king7.
Semoga membantu dan sukses terus dari blog ini.
捕风捉影在线免费在线观看,海外华人专属平台运用AI智能推荐算法,高清无广告体验。
Мультимедийный интегратор тут интеграция мультимедийных систем под ключ для офисов и объектов. Проектирование, поставка, монтаж и настройка аудио-видео, видеостен, LED, переговорных и конференц-залов. Гарантия и сервис.
You can definitely see your skills within the article you
write. The arena hopes for more passionate writers such as
you who are not afraid to mention how they believe.
Always follow your heart.
爱亦凡海外版,专为华人打造的高清视频平台AI深度学习内容匹配,支持全球加速观看。
Tulisan yang bagus.
Benar juga soal pentingnya kemudahan akses dan keamanan data.
Di tim kami mencoba King7 untuk akses game online karena prosesnya cepat dan aman.
Saya sudah bookmark halaman ini untuk referensi
selanjutnya.
Terima kasih sudah berbagi!
Hi colleagues, its impressive paragraph regarding cultureand completely explained, keep it up all the time.
Thankfulness to my father who stated to me concerning this webpage, this weblog is in fact remarkable.
范德沃克第二季高清完整官方版,海外华人可免费观看最新热播剧集。
It’s perfect time to make some plans for the future and it’s time
to be happy. I’ve read this post and if I could
I desire to suggest you few interesting things or
advice. Maybe you can write next articles referring to this article.
I desire to read even more things about it!
slot games casino
Gates of Olympus slot — хитовый онлайн-слот от Pragmatic Play с механикой Pay Anywhere, каскадами и усилителями выигрыша до ?500. Действие происходит в мире Олимпа, где верховный бог активирует множители и делает каждый раунд случайным.
Сетка слота представлено в виде 6?5, а выигрыш начисляется при появлении от 8 идентичных символов в любом месте экрана. После формирования выигрыша символы исчезают, на их место опускаются новые элементы, запуская цепочки каскадов, способные принести дополнительные выигрыши в рамках одного вращения. Слот является волатильным, поэтому не всегда даёт выплаты, но при удачных каскадах способен порадовать крупными выплатами до 5000? ставки.
Для тестирования игры доступен бесплатный режим без финансового риска. При реальных ставках стоит выбирать лицензированные казино, например MELBET (18+), учитывая показатель RTP ~96,5% и условия площадки.
If you are going for best contents like myself, just pay a visit this web site
all the time since it presents feature contents, thanks
Have a look at my webpage – matériel propreté reconditionné
With havin so much content do you ever run into any issues of plagorism or
copyright infringement? My blog has a lot of exclusive content I’ve either
created myself or outsourced but it looks like a lot of it is popping it up all over the internet without my agreement.
Do you know any solutions to help prevent content from
being ripped off? I’d certainly appreciate it.
My webpage: équipement TP reconditionné
Hi to every body, it’s my first pay a quick visit
of this web site; this weblog consists of awesome and really good material in favor of visitors.
Also visit my homepage; Laser Teeth Whitening Wilmslow
Tình cờ thấy KING7BET — website live casino 24/7 với người chia
bài chuẩn HD, bàn VIP, giao dịch an toàn và rút tiền nhanh.
Có khuyến mãi cho người mới khá hấp dẫn. CSKH 24/7 rất nhiệt tình.
Rất hợp với ai thích slot RTP cao và cá cược thể thao.
Trải nghiệm mượt mà, đáng để thử ngay.
My brother recommended I might like this website.
He was entirely right. This post actually made my day.
You cann’t imagine simply how much time I had spent for this information!
Thanks!
Also visit my website; transpalette d’occasion
Good info. Lucky me I found your site by accident (stumbleupon).
I’ve book-marked it for later!
Look into my blog; veksel
Article writing is also a fun, if you know after that you can write if
not it is complicated to write.
Also visit my blog – veksel
Hello, i think that i saw you visited my website so i came to “return the favor”.I am trying to find things to
improve my website!I suppose its ok to use some of your ideas!!
Here is my webpage: veksel
Hello to all, it’s actually a pleasant for me to visit this web site,
it includes useful Information.
Hey there, I think your website might be having browser compatibility issues.
When I look at your blog site in Safari, it looks fine but when opening
in Internet Explorer, it has some overlapping. I just wanted to give you a
quick heads up! Other then that, awesome blog!
Visit my website: zupacescu01
I’ll immediately grasp your rss as I can not find your e-mail subscription link
or e-newsletter service. Do you have any? Kindly permit me realize so that
I may just subscribe. Thanks.
Greetings! I know this is kind of off topic but I was wondering if you knew
where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
Also visit my blog post chariot élévateur reconditionné
Valuable info. Fortunate me I discovered your website unintentionally, and I’m stunned why this accident didn’t happened earlier!
I bookmarked it.
It’s great that you are getting thoughts from this paragraph
as well as from our discussion made at this place.
Heya i’m for the first time here. I found this board and
I find It truly useful & it helped me out much. I hope to
give something back and aid others like you aided me.
This is my first time pay a visit at here and i am genuinely pleassant to read everthing at alone place.
You stated that effectively.
my web blog: https://www.rentacarsrilankahbs.com
一饭封神在线免费在线观看,海外华人专属平台结合大数据AI分析,高清无广告体验。
Wow, awesome blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is fantastic, let alone the content!
一帆平台,专为海外华人设计,提供高清视频和直播服务。
Wow, amazing blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is fantastic, as well as the content!
我們的資深運彩分析官方授權專家團隊第一時間更新官方NBA、MLB、中華職棒等各大聯盟的專業賽事分析。
Hi friends, its impressive post on the topic of teachingand completely defined, keep
it up all the time.
Good day! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
爱一帆海外版,专为华人打造的高清视频平台运用AI智能推荐算法,支持全球加速观看。
Have you ever thought about adding a little bit more than just your articles?
I mean, what you say is fundamental and all.
Nevertheless think of if you added some great photos
or videos to give your posts more, “pop”!
Your content is excellent but with pics and video clips, this
website could certainly be one of the most beneficial in its niche.
Terrific blog!
бездепозитные фриспины с выводом Хотите испытать удачу без риска? Откройте для себя бездепозитные бонусы в казино, которые позволяют начать игру с нуля и получить шанс на реальный выигрыш. Мы поможем вам найти лучшие предложения с возможностью легкого вывода средств. Не упустите свой шанс на крупный куш!
I’m Athena and I live with my husband and our three children in Zielona
Gora, in the NA south area. My hobbies are Home Movies, Swimming and Home Movies.
With havin so much content and articles do you ever run into any issues of
plagorism or copyright infringement? My website has a lot of
completely unique content I’ve either written myself or
outsourced but it appears a lot of it is popping it
up all over the internet without my agreement.
Do you know any techniques to help protect against content from being
ripped off? I’d genuinely appreciate it.
I do not even know how I stopped up here, however I thought this submit
was good. I do not recognise who you’re but definitely you’re going to a
well-known blogger for those who are not already. Cheers!
https://vlxx1.co.com/
Thank you a bunch for sharing this with all folks you actually know what you’re speaking approximately!
Bookmarked. Kindly additionally seek advice from my web
site =). We can have a link change arrangement among us
Site web officiel de 1xbet telecharger 1xbet apk
凯伦皮里第一季高清完整官方版,海外华人可免费观看最新热播剧集。
Need an AI generator? ai undressing The best nude generator with precision and control. Enter a description and get results. Create nude images in just a few clicks.
Look at my web blog – Spadegaming casino games – full list
Does your site have a contact page? I’m having trouble locating
it but, I’d like to shoot you an e-mail. I’ve got some creative ideas
for your blog you might be interested in hearing. Either
way, great site and I look forward to seeing it grow over
time.
Right now it sounds like Movable Type is the preferred blogging platform
out there right now. (from what I’ve read) Is that what you
are using on your blog?
真实的人类第一季高清完整官方版,海外华人可免费观看最新热播剧集。
奇思妙探第二季高清完整版运用AI智能推荐算法,海外华人可免费观看最新热播剧集。
戏台在线免费在线观看,海外华人专属平台结合大数据AI分析,高清无广告体验。
Hi there to all, since I am truly keen of reading
this blog’s post to be updated on a regular basis.
It carries fastidious data.
Ⅴia mock examinations ѡith encouraging responses, OMT develops strength
іn mathematics, cultivating love ɑnd inspiration for Singapore trainees’ test victories.
Experience flexible knowing anytime, ɑnywhere tһrough OMT’ѕ extensive online e-learning platform, including
limitless access tߋ video lessons and interactive tests.
Αs math forms tһе bedrock օf abstract thougһt ɑnd important
analytical in Singapore’s education ѕystem, expert
math tuition оffers tһe individualized guidance
needed to tuгn obstacles іnto accomplishments.
Tuition in primary school mathematics iѕ essential for PSLE preparation, аs іt introduces
advanced methods for managing non-routine ρroblems that stump mɑny prospects.
Individualized math tuition іn senior һigh school addresses private discovering spaces іn subjects ⅼike calculus and stats, preventing tһem from
preventing O Level success.
With regular mock examinations ɑnd in-depth feedback, tuition aids junior college students identify ɑnd correct weaknesses
prior tօ tһе real A Levels.
OMT’ѕ special approach features a syllabus tһat complements tһe
MOE framework witһ collaborative components, urging peer conversations ᧐n math principles.
Endless retries оn quizzes sia, bеst fⲟr understanding topics and achieving tһose A qualities
in mathematics.
In Singapore, ԝһere adult participation іѕ key, math tuition supplies structured support
f᧐r home support toѡard tests.
My webpage; singapore math tuition
SayHentai.us là nơi tổng hợp các bộ Hentai Manga, Doujinshi và truyện 18+ với chất lượng Full HD.
Đọc miễn phí, cập nhật chap mới liên tục
và không giới hạn. Truy cập ngay!
Hey! I could have sworn I’ve been to this blog
before but after checking through some of the post I realized
it’s new to me. Anyhow, I’m definitely glad I found it and I’ll be bookmarking and checking back frequently!
What’s up, everything is going nicely here and ofcourse every one
is sharing data, that’s in fact excellent, keep up writing.
Tulisannya informatif dan enak dibaca. Bagian contoh langkah demi langkah sangat
membantu
karena bisa langsung dipraktikkan. Saya baru coba dan hasilnya
cukup stabil.
Terima kasih sudah berbagi—semoga terus update konten bermanfaat seperti ini.
Do you mind if I quote a few of your articles as long as I provide
credit and sources back to your website? My website is in the exact same
niche as yours and my visitors would genuinely benefit from some of
the information you provide here. Please let me know if
this alright with you. Appreciate it!
Kudos! Plenty of postings.
官方授权的iyftv海外华人首选,第一时间提供最新华语剧集、美剧、日剧等高清在线观看。
I like the valuable info you provide in your articles.
I’ll bookmark your weblog and check again here frequently.
I am quite sure I’ll learn lots of new stuff right here! Best of luck for
the next!
Through timed drills that feel ⅼike adventures, OMT develops test endurance ѡhile growing affection fоr the subject.
Established іn 2013 by Mr. Justin Tan, OMT Math Tuition һaѕ helped
numerous trainees ace tests ⅼike PSLE, O-Levels, ɑnd A-Levels
with proven ρroblem-solving methods.
Singapore’ѕ wօrld-renowned mathematics curriculum emphasizes conceptual understanding оѵer simple calculation, makiing math tuition essential
f᧐r students to grasp deep ideas аnd master national examinations
ⅼike PSLE and O-Levels.
Enrolling іn primary school math tuition еarly fosters ѕeⅼf-confidence, decreasing stress аnd anxiety fօr
PSLE takers wһo face high-stakes concerns оn speed, distance, and tіme.
In Singapore’ѕ affordable education and learning landscape, secondary math tuition supplies tһe
additional ѕide required tօ attract attention іn O Level positions.
Βy supplying considerable experiment ρast A Level test documents,
math tuition acquaints trainees ᴡith question styles
аnd marking schemes for ideal performance.
OMT’ѕ custom-madе mathematics syllabus stands ɑpаrt bү connecting MOE material ᴡith
advanced theoretical links, aiding trainees link concepts throᥙghout vаrious math
topics.
Adaptable scheduling suggests no encountering CCAs
оne, makіng sure well balanced life ɑnd climbing mathematics scores.
Ꮃith international competitors rising, math tuition settings Singapore trainees ɑѕ leading
entertainers іn worldwide mathematics evaluations.
Ηere іs my pɑɡе … maths tuition for primary 1
Get instant livescore updates for Premier League, La Liga, Serie A and Bundesliga matches today
Have you ever considered about adding a little bit more than just your articles?
I mean, what you say is fundamental and everything. However think of if you added some great visuals or video clips to give your posts more, “pop”!
Your content is excellent but with pics and clips, this site could certainly be one of
the greatest in its field. Fantastic blog!
Here is my web blog … stem cell clinic
Hello, I’m Gene, a 29 year old from Volderwald, Austria.
My hobbies include (but are not limited to) Art collecting, Scrapbooking and watching Supernatural.
vlxx88.ac
You actually make it seem so easy with your presentation but I find this
matter to be actually something that I think I would never understand.
It seems too complicated and very broad for me. I am looking forward for your next post, I will try to get the hang of it!
My developer is trying to convince me to move to .net from
PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on a
variety of websites for about a year and am anxious about switching to another platform.
I have heard great things about blogengine.net. Is there
a way I can import all my wordpress posts into
it? Any kind of help would be really appreciated!
бесплатные спины за регистрацию без депозита с выводом
Đọc Truyện Tranh VyComycs – Tủ Sách Nhỏ Hay Nhất | Nettruyen
爱一帆会员多少钱海外版,专为华人打造的高清视频官方认证平台,支持全球加速观看。
塔尔萨之王第二季高清完整版智能AI观看体验优化,海外华人可免费观看最新热播剧集。
中職賽程粉絲必備的資訊平台,結合智能AI預測系統提供最即時的中職賽程新聞、球員數據分析,以及專業的比賽預測。
csgoempire
中職戰績粉絲必備的資訊平台,運用大數據AI分析引擎提供最即時的中職戰績新聞、球員數據分析,以及專業的比賽預測。
I’m not sure exactly why but this site is loading extremely slow for me.
Is anyone else having this issue or is it a problem on my end?
I’ll check back later and see if the problem still exists.
бездепозитные бонусы казино без пополнения
Your style is so unique compared to other people I’ve read stuff from.
Thanks for posting when you have the opportunity, Guess I’ll just bookmark this site.
Great post. I was checking continuously this blog and
I’m impressed! Extremely useful info specifically the last
part 🙂 I care for such information a lot. I was seeking
this certain information for a long time. Thank you and best of luck.
中職賽程粉絲必備的官方認證資訊平台,24小時不間斷提供官方中職賽程新聞、球員數據分析,以及專業的比賽預測。
Your style is very unique in comparison to other folks I’ve read
stuff from. I appreciate you for posting when you have the opportunity, Guess I will just book mark this
blog.
폰테크
中華職棒今日比賽結果台灣球迷的首選資訊平台,提供最即時的中華職棒今日比賽結果新聞、球員數據分析,以及精準的比賽預測。
Hello there! This post couldn’t be written much better!
Looking at this post reminds me of my previous roommate! He constantly
kept talking about this. I will forward this information to him.
Fairly certain he’ll have a very good read.
Many thanks for sharing! https://cryptoboss350.top/
24小時即時更新nba即時比分、賽程表,以及NBA球星數據統計和表現分析。
Thanks to my father who told me about this web
site, this website is genuinely remarkable.
多瑙高清完整版采用机器学习个性化推荐,海外华人可免费观看最新热播剧集。
cpbl粉絲必備的資訊平台,結合大數據AI算法提供最即時的cpbl新聞、球員數據分析,以及專業的比賽預測。
中華職棒賽程台灣球迷的首選資訊平台,提供最即時的中華職棒賽程新聞、球員數據分析,以及精準的比賽預測。
官方數據源24小時即時更新nba比分、賽程表,以及NBA球星數據統計和表現分析。
Hello There. I discovered your weblog the use of msn. That is a very well written article.
I’ll make sure to bookmark it and return to learn extra of your
useful info. Thanks for the post. I’ll certainly return.
Hello, I would like to subscribe for this webpage to take most recent updates, so where can i do it please help out.
This paragraph offers clear idea in favor of the new visitors of blogging, that
truly how to do blogging and site-building.
Hey! I could have sworn I’ve been to this website before but after checking through some of the post I realized
it’s new to me. Anyways, I’m definitely glad I found it and I’ll be bookmarking and
checking back frequently!
我們提供台灣最完整的棒球即時比分相關服務,包含最新賽事資訊、數據分析,以及專業賽事預測。
中職賽程粉絲必備的資訊平台,提供最即時的中職賽程新聞、球員數據分析,以及專業的比賽預測。